Submitted:
11 January 2024
Posted:
12 January 2024
You are already at the latest version
Abstract
In the industrial field, the 3D target detection algorithm PointPillars has gained popularity. Improving target detection accuracy while maintaining high efficiency has been a significant challenge. To address the issue of low target detection accuracy in the PointPillars 3D target detection algorithm, this paper proposes an algorithm based on feature enhancement to improve the backbone network. The algorithm enhances preliminary feature information of the Backbone network by modifying it based on PointPillars with the aid of channel attention and spatial attention mechanisms. To address the inefficiency caused by the excessive number of subsampled parameters in PointPillars, FasterNet (a lightweight and efficient feature extraction network) is utilized for downsampling and forming different scale feature maps. To prevent the loss and blurring of extracted features resulting from the use of inverse convolution, we utilize the lightweight and efficient up-sampling modules Carafe and Dysample for adjusting resolution. Experimental results indicate improved accuracy under all difficulties of the KITTI dataset, demonstrating the superiority of the algorithm over PointPillars.
Keywords:
Target Detection
; PointPillars
; FasterNet
; Upsampling
; Attention Mechanism
1. Introduction
With the ongoing advancements in automatic driving, virtual reality, and intelligent manufacturing, among other application scenarios, the detection of three-dimensional object targets has emerged as a favoured technique in the realm of computer vision [1]. The advancement in LIDAR manufacturing processes has lead to a gradual increase in the density of radar output point clouds, resulting in improved measurement accuracy. As a result, the point cloud 3D object detection algorithm which utilises point clouds as input, has become a mainstream technology in the field of vision.Currently, 3D target detection in point clouds relies primarily on point and voxel-based methods. While the PointNet [2]and VoxelNet [3] approaches have adequately prepared for feature extraction from point clouds, the data’s sparsity and complexity present difficulties in capturing the target, leading to poor detection accuracy [4,5].
The PointPIllars 3D target detection algorithm has gained immense popularity in the industry owing to its high efficiency and accuracy [6]. The algorithm converts three-dimensional point cloud voxel [3] features into two-dimensional images for detection, thereby greatly reducing operating costs. However, the main challenge presently is to enhance detection accuracy while maintaining efficiency. Several scholars from various countries have proposed different methods to address this issue. Ryota et al. suggest varying voxel sizes and carrying out feature fusion after extracting the features [7]. Li et al. recommend incorporating the attention mechanism within the voxel and introducing relationship features between diverse point clouds [8]. Konrad et al. [9] aim to replace the backbone network with alternative feature extraction networks. However, although these approaches have been attempted, they only result in marginal improvement of the detection accuracy. In light of this, he suggested that a considerable amount of parameters in PointPillars are concentrated in the backbone network. As a solution, novel backbone networks like MobileNet and DarkNet have been employed as substitutes to the original convolution.
The results showed that this modification greatly enhances detection efficiency. After a meticulous investigation, this study concludes that enhancing the Backbone network (2D CNN) is the most effective way to maximise detection accuracy and efficiency. Downsampling the model and implementing the attention mechanism, along with sampling the backbone network, can significantly enhance the detection precision and efficiency.Compared with the existing literatures, the major contributions of this work can be summarized as follows:
- Enhancing Features of Pseudo-Images generated through the algorithm via channel attention, spatial attention, and 1x1 2D convolution.
- FasterNet [10], a more lightweight network, replaces the feature extraction network resulting in a significant reduction in module parameters. This replacement not only enhances detection accuracy but also decreases the number of parameters required.
- Replacing the original model’s inverse convolution technique involves the implementation of two up-sampling methods and feature enhancement using proximity scale sampling methods.
2. Related Work
LiDAR data is commonly processed with Deep Convolutional Neural Networks (DCNNs), which integrate the entire processing flow, resulting in high computational and storage complexity. Target detection algorithms based on DCNNs outperform traditional methods in terms of detection accuracy and recognition rate [9]. Traditional 2D image detection algorithms, which utilise a camera as a data source, rely on an external light source and cannot precisely determine information such as distance, position, depth, and angle of targeted vehicles and individuals. In contrast, LiDAR generates three-dimensional point cloud data that provides details such as the object’s position, distance, depth, and angle, making the data representation more realistic. LIDAR provides the benefits of precise ranging and does not require visible light [11].
The unstructured and non-fixed-size characteristics of the point cloud hinder its direct processing by 3D target detectors, therefore, it necessitates transcription into a more condensed structure through some sort of expression form [12]. Currently, there are two primary expression forms: point-based and voxel-based procedures. The transcribed point cloud can undergo feature detection via convolutional or established backbone networks. Networks vary in their feature extraction capabilities and parametric quantities, thus network choice should be evaluated on a case-by-case basis.
2.1. Point-Based, Voxel-Based Approach to Target Detection
Qi et al. first extracts the PointNet network to derive features directly from the disordered point cloud. The T-Net network is then employed to predict the affine transformation matrix to align all the points with features. The symmetric function (MaxPooling) is utilized to address the disorderedness of the point cloud, while the multilayer perceptron resolves the problem of point cloud order invariance [2]. PointNet fails to address the issue of uncertain local feature extraction. To obtain more efficient features, PointNet++ [13] employs a Hierarchical Set Abstraction layer, with each module using several Set Abstraction modules to extract features. To enhance feature extraction capability, PointNet++ utilises Hierarchical Set Abstraction (HSA). HSA leverages various Set Abstraction modules for extracting features. Each module differs in the number of sampling points and the sampling radius. Consequently, this approach effectively improves local feature extraction. PointRCNN [14] utilizes PointNet++ for feature extraction, alongside foreground and background segmentation based on the aforementioned extracted features, 3D frame prediction on each foreground point, and ultimately further refinement on the object of interest.Whilst these approaches allow for maximization of geometric point cloud features and consequently improve detection performance, they do demand extensive time and computational resources during the feature extraction phase [15].
The process of transforming point clouds into voxels involves dividing the space occupied by the point cloud into blocks of a fixed size. The features of the point clouds within these voxel blocks are then extracted. VoxelNet algorithm utilises the Voxel Feature Encoder (VFE) to measure and standardise the features across voxels. Subsequently, a 3D convolutional neural network is employed to extract the features of the voxels, and finally, an RPN network is used to generate the detection frame. Because of the numerous voxels, feature extraction is sluggish. Yan et al. [16] proposed utilising 3D sparse convolution to conduct feature extraction of regulated voxels based on VoxelNet due to the rarity of the point cloud, which significantly improved the processing speed in contrast to VoxelNet. Lang et al. [17] et al. recommended PointPillars which effectively columnate the voxel points and change the height of the voxel to correspond to that of the point cloud space. A straightforward PointNet is applied to convert the voxel into a pseudo-image, allowing 2D convolution to extract features while maintaining 3D characteristics, thus significantly increasing the operational speed. PointPillars is the most prevalent 3D detection algorithm in the industry due to its rapid operation and exceptional accuracy. Voxel-based techniques have lower detection accuracy than point methods. How to ensure the detection efficiency on the basis of improving the detection accuracy has become a research hotspot.
2.2. Feature Extraction Networks
Different blocks and depths are employed by feature extraction networks to extract features. To prevent the issue of gradient explosion and gradient disappearance from more extensive models, He et al. [18] proposed ResNet, which uses residual networks that allow network layers to reach significant depth. The MobileNet [19] algorithm reduces the number of network parameters by using depth-separable convolution and introducing shrinkage hyperparameters. This approach provides excellent support for real-world scenarios in devices with limited computational power. DarkNet [20] employs a repeated stacked downsampled convolution and residual block architecture, renowned for its speed and efficiency, particularly in YOLO model series. This structure enables DarkNet to perform real-time or near real-time target detection, making it ideal for use on devices with limited computational power [21]. Extraction networks are progressing towards achieving greater accuracy with fewer parameters, and the utilization of appropriate feature extraction networks can significantly enhance target detection efficiency and accuracy.
3. Feature-Enhanced Backbone Network
This section will introduce the PointPillars model and how it can be improved for the Backbone network.
3.1. PointPillars
The PointPillars algorithm comprises three main parts: point cloud columnarisation, backbone feature extraction, and detection header output, as illustrated in Figure 1.
- Columnarisation of point cloud. a square box is created based on X-Y, with Z as the vertical dimension of point columns. Each column comprises multiple points, and a basic PointNet network is then employed to project the original point cloud onto a 2D plane, generating a sparse 2D pseudo-image that assists in subsequent feature learning. Technical abbreviations are explained when first employed [5].
- Feature extraction. a 2D convolutional neural network downsamples the pseudo-image several times, creating feature maps with varying resolutions and channels. The downsampling-generated feature maps are upsampled using inverse convolution to the same channel and resolution feature maps, and subsequently merged to form the final map.
- Detection head output. the feature map is fed to the SSD detection head to perform the target’s classification and the regression of the enclosing frame, obtaining the object’s position and type.
3.2. FasterNet Lightweight Feature Extraction Network
In the original version of the PointPillars network, most of the multiply-add operations (about 84%) are concentrated in the backbone,specifically in the "top-down" submodule. Thus, potentially, speeding up this part of the algorithm will have the greatest impact on the time results obtained [9].To create faster neural networks, researchers have concentrated on reducing FLOPs. However, it’s important to note that FLOPs and neural network latency don’t always have a direct correlation. To achieve greater speed, FasterNet utilises Partial Convolution (PConv), which improves the extraction of spatial features and reduces both redundant computation and memory access. As a result, FasterNet [10] is considerably quicker than other networks. To fully utilise all channel information, we have incorporated Point-Wise Convolution (PWConv) after PConv. This enhances the effective sensory field of input feature maps to resemble a T-shaped Conv, which focuses more on the central position than regular Conv.
Figure 2.
PointPillars Process.
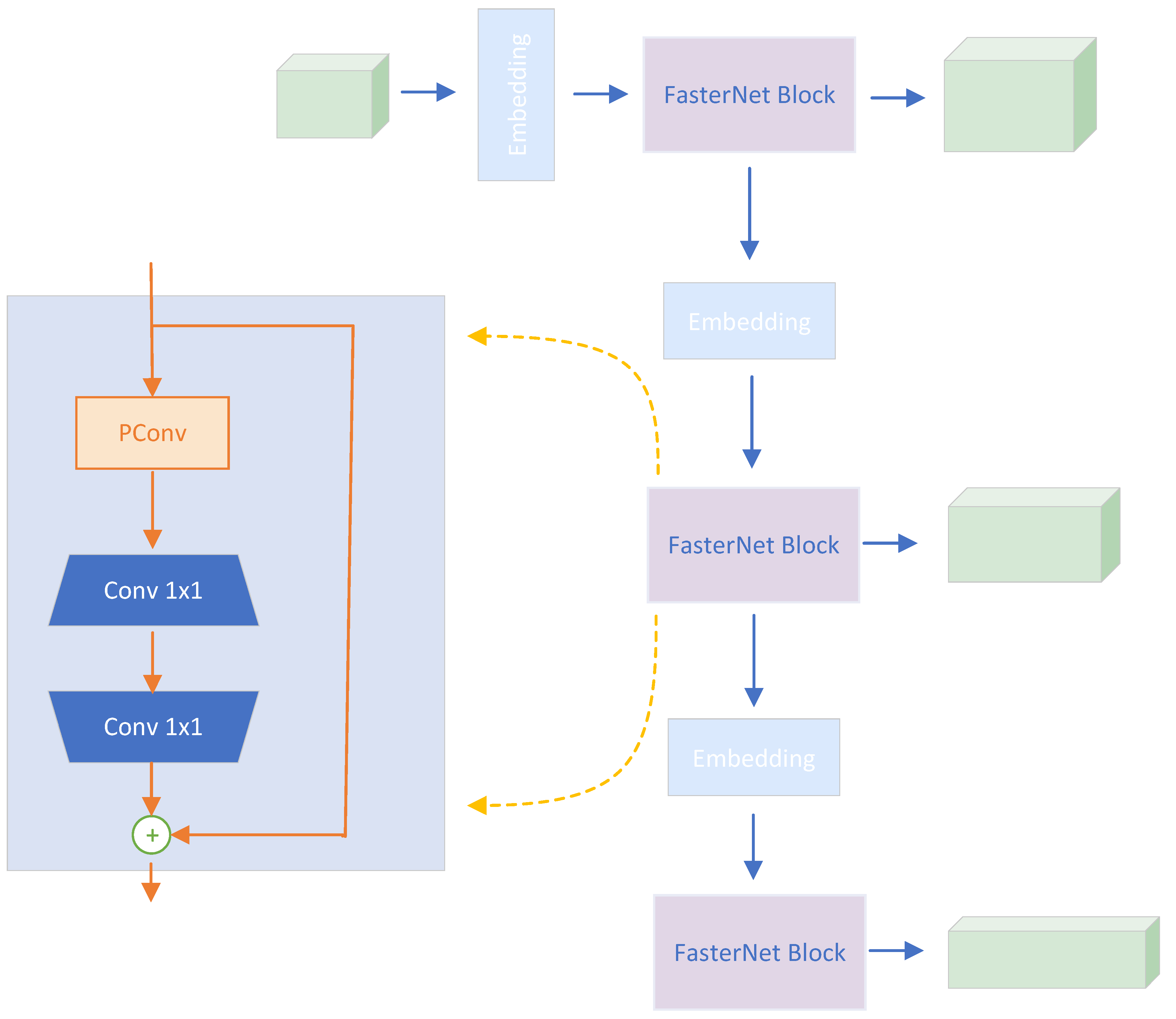
FasterNet is designed primarily as a combination of Stage and Embedding. Each Stage is subject to an Embedding or Merging layer for spatial downsampling and expansion of channel number. Each stage consists of a series of FasterNet Blocks comprised of PConv and PWConv. This paper presents the fine-tuning of the original FasterNet model to align with the PointPillars setup. The proceedings are elaborated as follows.
- Block depth settings correspond to PointPillars.
- Add Embedding before each Block for downsampling.
- The activation function uses GELU as suggested by FasterNet, and PointPIllars remains unchanged using RELU.
For the modifications in this paper, the parameters and other relevant data were calculated for PointPillars with FasterNet replacement.

Table 1.
Parameter characteristics.total params represent the overall number of trainable parameters in the downsampling process, such as weights and biases. The total mul-adds and pseudo-add operations executed during the propagation period is known as Total multiplicative addition, and it enables us to evaluate the procedure’s complexity. params size measures the amount of memory consumed by the parameters, with the estimated total size indicating the entire space occupied by the downsampling process. The estimated total size pertains to the memory that the downsampling process uses.
Table 1.
Parameter characteristics.total params represent the overall number of trainable parameters in the downsampling process, such as weights and biases. The total mul-adds and pseudo-add operations executed during the propagation period is known as Total multiplicative addition, and it enables us to evaluate the procedure’s complexity. params size measures the amount of memory consumed by the parameters, with the estimated total size indicating the entire space occupied by the downsampling process. The estimated total size pertains to the memory that the downsampling process uses.
| PointPillar | total params | total mult-adds(G) | params size(MB) | estimated size(MB) |
|---|---|---|---|---|
| PointPillars | 4,207,616 | 29.63 | 444.66 | 513.02 |
| OurFasterNet | 2,339,712 | 3.96 | 91.55 | 152.78 |
From the above table, it can be seen that by using FasterNet instead of downsampling, the total parameters are reduced by almost 50% and the multiply-add operation is reduced by about 9 times. The detection accuracy is improved after performing the substitution and we will give detailed results in the next section.
3.3. Attention-Based Feature Enhancement
The primary objective of attentional mechanisms is to suppress the influence of unimportant regions in an image through a heightened focus on regions of interest [22]. Attention mechanisms can be categorised into channel attention mechanisms, spatial attention mechanisms, and self-attention mechanisms. Some commonly used attention mechanism modules include ECA [23], CBAM [24], SENet [25], PAN, STN and PSA [26] et al.
The channel attention mechanism enhances the network’s expressiveness in the feature representation by evaluating the significance of each channel. This, in turn, advances the model’s performance. Each channel of the feature map acts as a feature detector that concentrates on the positional information within the image.
The spatial attention mechanism aims to facilitate the model’s adaptive learning of attention weights in various regions through the integration of an attention module. This allows the model to prioritize important image regions while ignoring those that are unimportant. To calculate spatial attention, the average pooling and maximum pooling are performed in the channel dimensions before concatenating the feature maps. Then, a convolution operation is applied to the spliced feature maps to generate the ultimate spatial attention feature maps.
The attention mechanism aims to highlight significant features of the image while minimizing irrelevant regional responses. Through analyzing research on channel and spatial dimensions, the CBAM (Convolutional Block Attention Module) has been developed and proven to enhance network performance by accurately directing attention and suppressing irrelevant noise information.
3.4. Carafe and Dysample Sampling on the Proximity Scale
The commonly used feature up-samplers are NN and bilinear interpolation. They apply fixed rules to interpolate the low-res feature, ignoring the semantic meaning in the feature map [27]. Max unpooling has been adopted in semantic segmentation by SegNet [28] to preserve the edge information, but the introduction of noise and zero filling destroy the semantic consistency in smooth areas. Similar to convolution, some learnable upsamplers introduce learnable parameters in upsampling. For example, deconvolution upsamples features in a reverse fashion of convolution. Pixel Shuffle [29] uses convolution to increase the channel number ahead and then reshapes the feature map to increase the resolution.
PointPillars utilizes the inverse convolution technique to up-sample, which can enhance image resolution, but disregards significant semantic content. To circumvent this limitation, this study replaces the original deconvolution with Carafe [30] and Dysample’s [27] light-weight up-sampling operators, respectively. Furthermore, an up-sampling approach involving an approximated scale fusion method is introduced to enrich the semantic relationship among various scales. Approximate scale fusion involves combining the current scale with the approximate scale post operator up-sampling. The resulting fused features will serve as current features, facilitating the incorporation of information from various scales. The module structure is shown in Figure 3.
X is the current scale feature and Y is the previous scale feature.
Content-aware reorganisation of features (Carafe) proposed by Wang et al. is a generic, lightweight and efficient component.Carafe reassembles features in a predefined region centred on each location by weighted combinations, where the weights are generated in a content-aware manner. In addition, each location has multiple sets of such up-sampling weights, and then feature up-sampling is achieved by rearranging the generated features as a spatial block.The advantages of Carafe are as follows:
- Large sensory field. Unlike previous approaches such as bilinear interpolation, Carafe can aggregate contextual information within a large receptive field.
- Content-aware: Instead of using a fixed kernel for all samples, Carafe supports instance-specific content-aware processing and can dynamically generate adaptive kernels.
- Lightweight and fast: Carafe has low computational overhead and can be easily integrated into existing framework networks.
Dysample is another ultra-lightweight, efficient dynamic upsampler. Unlike CARAFE, Dysample bypasses dynamic convolution and specifies upsampling from a point-sampling point of view, which is more resource efficient.Dysample does not require custom CUDA packages and has fewer parameters, FLOPs, GPU memory and latency.
4. Results
In this study, we conducted experimental evaluations utilizing the extensive KITTI dataset, which is publicly available. The dataset comprises 7481 training samples and 7518 test samples captured from autonomous driving scenarios. We partitioned the training data into a training set of 3712 frames and a validation set of 3796 frames using the PointPillars algorithm. The training set was utilized for testing, while the validation set was utilized for experimental studies. The KITTI dataset encompasses three classifications: Car, cyclist, and pedestrian are each classified into three levels of difficulty: easy, medium, and hard, which are determined by various factors such as 3D object size, occlusion level, and truncation level [31].
The experimental environment used in this study comprises Ubuntu 18.04 LTS, CUDA 11.4, python 3.8, and pytorch 1.13.1. To achieve end-to-end training, the Adam optimiser was applied, with a batch size of 8, a maximum of 100 iterations, and no ground truth frame. In the experiments, each Pillar was set to a size of [0.16, 0.16] in the X-Y dimensions, the maximum number of columns was 12000, and the global point cloud was randomly scaled in the range of [0.95, 1.05].
4.1. Experimental Results and Analysis
The algorithms in this paper were tested on the KITTI dataset and evaluated for accuracy (AP) using 40 predefined locations from the official KITTI test. The IOU threshold was set at 0.7 for cars and 0.5 for pedestrians and cyclists. Table 1, Table 2 and Table 3 compare the results of this paper with those of the PointPillars algorithm on the KITTI dataset for the car, pedestrian, and cyclist categories.
From the data in the above table, it is evident that up-sampling in Dysample or Carafe improves the detection of the Kitti dataset in any difficulty, although certain types of objects are biased towards improvement. Notably, Carafe up-sampling shows a more substantial improvement in object types. Specifically, in BEV, there is an improvement of Cyclist from 81.44 to 85.64 in Easy difficulty, and in 3D mode, there is a 6.51 improvement in Easy difficulty. In AOS mode, the most significant enhancement is observed for pedestrian, with a maximum improvement of 6.24 in Medium difficulty. The improvement effect is also more apparent in Easy and Hard modes. Dysample displays the most noticeable improvement in Pedestrian. On the other hand, the improvement of Dysample is less pronounced, which could be attributed to its lack of dynamic feature extraction.
Table 4.
RESULTS ON THE KITTI TEST AOS DETECTION BENCHMARK.
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| PointPillars | 94.75 | 91.27 | 88.29 | 46.34 | 42.96 | 39.68 | 86.15 | 70.35 | 65.98 |
| PP Carafe | 95.57 | 92.03 | 90.56 | 54.73 | 49.20 | 47.73 | 87.65 | 70.22 | 65.58 |
| PP Dysample | 95.47 | 91.79 | 88.90 | 53.98 | 48.42 | 45.44 | 86.40 | 70.08 | 66.01 |
It is apparent that the up-sampling techniques of Dysample and Carafe differ in their effect on target feature reconstruction. If detection accuracy is a priority, CARAFE upsampling is a suitable option. However, if detection efficiency is required, then Dysample may be more appropriate.
4.2. Ablation Experiments
In this section, we provide the results of ablation experiments to evaluate the key factors that affect the accuracy of the experiments.
Table 5.
ABLATION RESULTS ON THE KITTI TEST BEV MODE.
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| root | 90.74 | 86.57 | 84.05 | 55.89 | 48.86 | 44.42 | 81.44 | 63.63 | 59.29 |
| Attention | 91.67 | 87.75 | 85.18 | 56.19 | 49.89 | 46.16 | 85.05 | 65.91 | 61.41 |
| FasterNet | 92.63 | 88.32 | 86.91 | 56.19 | 49.95 | 45.82 | 88.09 | 67.98 | 63.46 |
| Carafe | 92.05 | 87.80 | 85.13 | 55.55 | 49.12 | 44.86 | 85.07 | 67.49 | 62.85 |
| Dysample | 91.78 | 87.79 | 85.08 | 59.28 | 51.76 | 47.28 | 84.74 | 66.01 | 61.79 |
Table 6.
ABLATION RESULTS ON THE KITTI TEST 3D MODE.
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| root | 85.40 | 75.14 | 72.71 | 48.16 | 41.58 | 37.07 | 76.76 | 59.74 | 55.53 |
| Attention | 86.52 | 76.24 | 73.09 | 49.81 | 43.13 | 39.13 | 79.88 | 60.48 | 56.57 |
| FasterNet | 88.73 | 78.76 | 75.58 | 50.69 | 43.98 | 39.25 | 83.41 | 61.94 | 57.69 |
| Carafe | 86.92 | 75.47 | 72.31 | 48.37 | 42.13 | 37.35 | 79.88 | 62.50 | 58.23 |
| Dysample | 87.89 | 78.13 | 73.44 | 50.72 | 43.28 | 39.01 | 81.69 | 63.46 | 58.96 |
The ablation experiments revealed that replacing each module separately resulted in an improvement outside the parameters. The replacement of the backbone network showed the most significant improvement, with FasterNet demonstrating the most noticeable increase in detection accuracy. The Attention Mechanism module showed an improvement of nearly 1 in detection at all difficulties. Both upsampling methods, Carafe and Dysample, demonstrated significant improvement. However, the improvement was more pronounced for Carafe upsampling.
4.3. Visualisation Analysis
To provide evidence of the method’s effectiveness in improving detection accuracy, this section presents visualised and analysed results of the algorithm. Due to the use of pure radar data in the algorithm, the relevant information cannot be visually represented. Therefore, the front-view camera image is referred to as a comparison for the radar detection results in the BEV view.
After analyzing the four scenes in Figure 4, it is evident that the PointPillars network misidentifies point cloud shapes reflected from objects such as tree trunks and line poles as cars or pedestrians. However, the model with the improved backbone network has a significantly lower misdetection and error detection rate. The improved backbone network strengthens the features of the point cloud pseudo-images, while the lightweight network and proximity scale sampling method retain more semantic information and improve the module’s ability to extract features. As a result, the improved PointPillars outperform the pre-improved version by reducing misdetection and omission, ultimately improving network detection performance.
- In the initial scene, PointPillars identifies the far-off iron house as a vehicle, which the algorithm in the optimization is able to avoid. Additionally, there are more trees on the left side, and PointPillars recognizes the number as people, which is significantly reduced compared to PointPillars in the optimized algorithm, although there is also a misdetection.
- In the second scenario, PointPillars made a mistake during multi-check by identifying the iron ladder near the car as a car. This error was avoided in the optimized scenario. Multi-checks occurred near the point in PointPillars and PP Carafe, mistaking the road sign for a person. The optimized scheme shows the direction of the two cars in the upper left at a more accurate angle. The three scenarios resulted in a false pickup on the right against the red streetlight army.
- The third scenario is straightforward. All three scenarios detected the bicycle following the car. PointPillars produced one multi-detection (a lateral car) for the car directly in front, and none in the optimized scenario. PointPillars is especially problematic for the false detection of trees on the left side. In the optimized scenario, PP Carafe produces only one multidetection, and PP Dysample identifies the number on the left side intact.
- The fourth scenario is complex, involving multiple object types. PointPillars still experiences significant multi-detection issues on the left side. In all three scenarios, there are missed detections directly in front. PP Dysample has more severe detection errors on the left side, and one vehicle lacks direction discrimination. For the nearby vehicles, the optimized scheme improves the vehicle facing angle significantly, resulting in much better direction prediction than PointPillars.
In summary, this paper’s optimization scheme produces a superior visualization effect compared to PointPillars. However, the scheme does have some limitations. For instance, it enhances near objects more than distant targets, possibly due to the limited number of point clouds for distant objects, resulting in errors. To address this, we suggest exploring the use of a multi-frame aggregation method to increase the number of radar point clouds for distant objects. The optimization scheme for enhancing small targets still has certain defects. After processing the point cloud into an image, it may ignore the connection between different voxels, resulting in a loss of contextual information. The next step of this paper will focus on studying point cloud coding.
5. Conclusions
In this paper, we present a 3D target detection algorithm with an enhanced backbone network based on PointPillars for object detection. Initially, we generate a point cloud pseudo-image, and subsequently employ channel spatial attention to consolidate contextual information, optimize image features, and establish connections across channels and locations. Additionally, a modified lightweight network, FasterNet, and proximity scale upsampling have been implemented to enhance the feature extraction capabilities of the convolutional neural network and maintain the integrity of deep point cloud features. The outcome shows significant improvement in comparison to the PointPillars algorithm. The comparison of the algorithm highlights that by introducing the attention mechanism, replacing the feature extraction network, and utilising a new up-sampling method, target detection accuracy can be significantly enhanced.
However, this experiment has a slight limitation. Despite the improved detection accuracy, it is unable to differentiate false detections and omissions at a glance. Additionally, in the presence of numerous pedestrians or bicycles, it may cause interference which can influence the results of the detection.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data generated or analyzed during this study are included in this published article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, F.; Jin, W.; Fan, C.; Zou, L.; Chen, Q.; Li, X.; Jiang, H.; Liu, Y. PSANet: Pyramid Splitting and Aggregation Network for 3D Object Detection in Point Cloud. Sensors 2020, 21, 136. [Google Scholar] [CrossRef] [PubMed]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. IEEE 2017. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2018. [Google Scholar] [CrossRef]
- Zhang, Q.; Che, H.; Liu, J.; Liu, R. Small object 3D detection algorithm based on lidar point cloud. In Proceedings of the 2023 IEEE 3rd International Conference on Information Technology, Big Data and Artificial Intelligence (ICIBA), May 2023. [Google Scholar] [CrossRef]
- LIDAR 3D target detection based on improved PointPillars. Advances in Lasers and Optoelectronics 2023, p. 15.
- Lee, M.; Kim, H.; Park, S.; Yoon, M.; Lee, J.; Choi, J.; Kang, M.; Choi, J. PillarAcc: Sparse PointPillars Accelerator for Real-Time Point Cloud 3D Object Detection on Edge Devices.
- Nakamura, R.; Enokida, S. Robust 3D Object Detection for Moving Objects Based on PointPillars. 2022 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW) 2022.
- Li, X.; Liang, B.; Huang, J.; Peng, Y.; Yan, Y.; Li, J.; Shang, W.; Wei, W. Pillar-Based 3D Object Detection from Point Cloud with Multiattention Mechanism. Wireless Communications and Mobile Computing 2023, 2023, 1–10. [Google Scholar] [CrossRef]
- Konrad Lis, T.K. Encyclopedia of Parallel Computing 2022.
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Wei-Qin, Z.; Ni, R.; Yang, B. PointPillars+3D Target Detection Based on Attention Mechanisms. Jiangsu University Journal: Natural Science Edition 2020, pp. 268–273.
- Zamanakos, G.; Tsochatzidis, L.; Amanatiadis, A.; Pratikakis, I. A comprehensive survey of LIDAR-based 3D object detection methods with deep learning for autonomous driving. Computers & graphics 2021, p. 99.
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space 2017.
- Shi, S.; Wang, X.; Li, H. PointRCNN: 3D Object Proposal Generation and Detection from Point Cloud 2018.
- Liu, W.; Zhu, D.; Luo, H.; Li, Y. 3D Target Detection by Fusing Point Attention Mechanisms in LiDAR Point Clouds. Journal of Photonics 2023, p. 11.
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds 2018. [CrossRef]
- Chapala, H.; Sujatha, B. ResNet: Detection of Invasive Ductal Carcinoma in Breast Histopathology Images Using Deep Learning. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Jul 2020. [Google Scholar] [CrossRef]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv: Computer Vision and Pattern Recognition,arXiv: Computer Vision and Pattern Recognition 2017. [CrossRef]
- Lasica, J. Darknet: La Guerra Contra La Generacion Digital Y El Futuro De Los Medios Audiovisuales / Hollywood and the War Against the Digital Generation (A Debate) 2006.
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv: Computer Vision and Pattern Recognition,arXiv: Computer Vision and Pattern Recognition 2018. [CrossRef]
- Tao, Z.; Su, J. Research on object detection algorithm of 3D point cloud PointPillar based on attention mechanism. [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2020. https://doi.org/10.1109/cvpr42600.2020.01155. Jun 2020. [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. , CBAM: Convolutional Block Attention Module. In Computer Vision – ECCV 2018,Lecture Notes in Computer Science; 2018; p. 3–19. [CrossRef]
- Cheng, D.; Meng, G.; Cheng, G.; Pan, C. SeNet: Structured Edge Network for Sea–Land Segmentation. IEEE Geoscience and Remote Sensing Letters 2017, 247–251. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. , PSANet: Point-wise Spatial Attention Network for Scene Parsing. In Computer Vision – ECCV 2018,Lecture Notes in Computer Science; 2018; p. 270–286. [CrossRef]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to Upsample by Learning to Sample.
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017; 2481–2495. [Google Scholar] [CrossRef]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2016. [Google Scholar] [CrossRef]
- Jee, A.; Ferguson, F. Carafe: an inductive fault analysis tool for CMOS VLSI circuits. In Proceedings of the Digest of Papers Eleventh Annual 1993 IEEE VLSI Test Symposium, Dec 2002. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. The International Journal of Robotics Research 2013, 1231–1237. [Google Scholar] [CrossRef]
Figure 1.
PointPillars Process.

Figure 3.
Approaching up-sampling fusion.
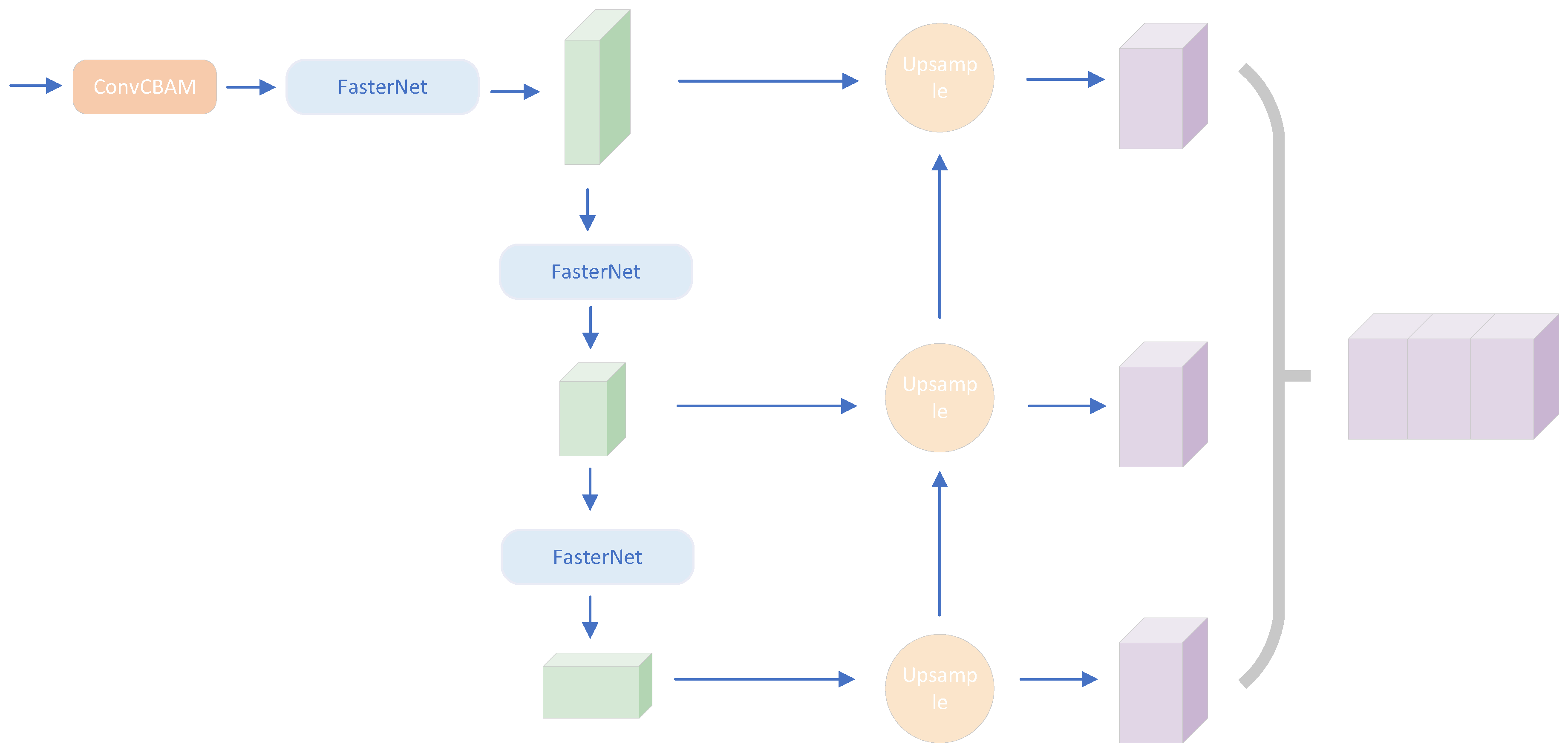
Figure 4.
Visualize the results. Different rows represent different scenarios. The columns represent the front camera, PointPillars results, PP Carafe upsampling results, and PP Dysample results one at a time.
Figure 4.
Visualize the results. Different rows represent different scenarios. The columns represent the front camera, PointPillars results, PP Carafe upsampling results, and PP Dysample results one at a time.


Table 2.
RESULTS ON THE KITTI TEST BEV DETECTION BENCHMARK.
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| PointPillars | 90.74 | 86.57 | 84.05 | 55.89 | 48.86 | 44.42 | 81.44 | 63.63 | 59.29 |
| PP Carafe | 91.55 | 87.76 | 85.04 | 58.97 | 51.88 | 48.47 | 85.64 | 66.15 | 61.59 |
| PP Dysample | 91.78 | 87.79 | 85.08 | 59.28 | 51.76 | 47.28 | 84.74 | 66.01 | 61.79 |
PP Carafe stands for downsampling using carafe. PP Dysample stands for downsampling using dysample, as do the tables that follow.
Table 3.
RESULTS ON THE KITTI TEST 3D DETECTION BENCHMARK.
| Car | Pedestrian | Cyclist | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Easy | Medium | Hard | Easy | Medium | Hard | Easy | Medium | Hard | |
| PointPillars | 85.40 | 75.14 | 72.71 | 48.16 | 41.58 | 37.07 | 76.76 | 59.74 | 55.53 |
| PP Carafe | 87.95 | 78.59 | 75.20 | 51.63 | 44.35 | 41.13 | 83.27 | 62.61 | 57.95 |
| PP Dysample | 87.89 | 78.13 | 73.44 | 50.62 | 43.28 | 39.01 | 81.69 | 63.46 | 58.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



