Submitted:
10 January 2024
Posted:
10 January 2024
You are already at the latest version
Abstract
Electrolysis stands as a pivotal method for environmentally sustainable hydrogen production. However, the formation of gas bubbles during the electrolysis process poses significant challenges by impeding the electrochemical reactions, diminishing cell efficiency, and dramatically increasing energy consumption. Furthermore, the inherent difficulty in detecting these bubbles arises from the non-transparency of the wall of electrolysis cells. Additionally, these gas bubbles induce alterations in the conductivity of the electrolyte, leading to corresponding fluctuations in the magnetic flux density outside of the electrolysis cell, which can be measured by externally placed magnetic sensors. By solving the inverse problem of the Biot-Savart Law, we can estimate the conductivity distribution as well as the void fraction within the cell. In this work, we study different approaches to solve the inverse problem including Invertible Neural Networks (INNs) and Tikhonov regularization. Our experiments demonstrate that INNs are much more robust to solving the inverse problem than Tikhonov regularization when the level of noise in the magnetic flux density measurements is not known or changes over space and time.
Keywords:
Machine Learning
; Invertible Neural Networks
; Normalizing Flows
; Water Electrolysis
; Biot-Savart Law
; Inverse Problems
; Current Tomography
; Random Error Diffusion
1. Introduction
The surging demand for clean energy has led to extensive research into electrolysis as a viable method for greenhouse gas-free hydrogen production [70]. Harnessing excess renewable energy from sources like wind and sunlight enables us to power electrolysis that generates clean hydrogen gas. This hydrogen serves as a reliable energy reservoir, particularly during periods of limited renewable energy availability, thereby addressing the seasonal supply and demand gaps. Moreover, hydrogen exhibits benefits including extended storage capabilities, presenting a promising solution for reducing carbon footprints [1]. Hydrogen also finds diverse applications, ranging from usage as cryogenic liquid fuel and as a replacement for lithium batteries. However, the overall efficiency of electrolysis faces limitations due to the formation of gas bubbles which block electrodes’ reaction sites and obstruct electric current [2] like shown in Figure 1. Furthermore, the growth and detachment of bubbles are intricately governed by a complex interplay of forces, including buoyancy, hydrodynamic, and electrostatic forces [5,74,75]. Consequently, detecting both bubble sizes and the location of possible maldistribution of the gas fraction, along with the ability to control bubble formation is critical for ensuring the efficiency and sustainability of hydrogen production through electrolysis.
Detecting bubbles within electrolysis cells is a challenging problem, primarily due to the non-transparency of the electrolyzer structures. A viable and non-invasive solution involves utilizing externally positioned magnetic sensors to capture the bubble-induced fluctuations. However, the availability of only low-resolution magnetic flux density measurements outside the cell, coupled with the high-resolution current distribution inside the cell, necessary to provide accurate bubble information, creates an ill-posed inverse problem for precise bubble detection. To further add to the challenge, the measurement errors originating from sensor noise amplify the difficulty associated with bubble detection.
The Contactless Inductive Flow Tomography (CIFT), introduced by Stefani et al. [7], stands as a pioneering method for reconstructing flow fields within conducting fluids, an ill-posed linear inverse problem. This technique leverages Tikhonov regularization to estimate the fluid motion from the measured flow induced magnetic field under the influence of an applied magnetic field. The data for this reconstruction are obtained from magnetic sensors strategically positioned on the external walls of the fluid volume. However, the reconstruction of the conductivity distribution is an ill-posed non-linear inverse problem which do not induce current through an external magnetic field. Moreover, linear models, such as Tikhonov regularization, demonstrate high sensitivity to noise, particularly when there exists a significant disparity in the amplitude of noise between the data used for model fitting and testing. Also, the limited number of available sensors compounds the difficulty in achieving a satisfactory reconstruction of the high-dimensional current distribution.
Advanced machine learning (ML) techniques such as Deep Neural Networks (DNNs) offer a data-driven approach for reconstructing the current distribution within an electrolysis cell. By leveraging external magnetic flux density measurements, these techniques are capable of capturing relationships between the measured magnetic flux density and the internal current distribution of the cell. A method known as Network Tikhonov (NETT) [6] combines DNNs with Tikhonov regularization, where the regularization weightage parameter plays a crucial role in balancing data fidelity and regularization terms. However, the choice of the weightage parameter is based on some heuristic assumptions [4].
Given the limitations of the conventional approaches, we explored the feasibility of Invertible Neural Networks (INNs) to solve our ill-posed non-linear inverse problem. It was recently shown by Ardizzone et al. [3] that INNs are a good candidate for solving such tasks. INNs are marked by a bijective mapping and inherent invertibility between input and output spaces, which present a pragmatic solution for addressing the complexities in estimating the conductivity from relatively much lower resolution of magnetic flux density measurements. Therefore, we studied its performance in comparison to the Tikhonov regularization to estimate the binary conductivity distribution. The binary conductivity represent non-conducting void fraction as zeros, indicating the presence of bubbles. A cluster of zeros can indicate either the existence of large bubbles or a cluster of small bubbles, enabling us to estimate the void fraction. Our key contributions are:
- We introduce a novel method that uses INNs to reconstruct the spatial distribution of the void fraction from limited magnetic flux density measurements, thereby addressing the inverse problem of the Biot-Savart Equation in electrolysis.
- We show that INN is more accurate than the Tikhonov approach to reconstruct the distribution of the void fraction when the amplitude of the noise in the magnetic sensor measurements is not known or varies considerably in space and time.
- In scenarios where the number of sensors is further reduced, and the distance of the sensor placement from the region where the conductivity needs to be reconstructed is further increased, we show that our INN model is able to provide a good reconstruction of the void fraction distribution.
- We present a new evaluation metric named Random Error Diffusion that computes the likelihood that the predicted conductivity distribution resembles the ground truth. Based on Random Error Diffusion, we show that our INN-based approach is better than the Tikhonov regularization.
In Section 2, we review the related work, Section 3 details our simulation setup that mimics electrolysis, while Section 4 elaborates on our INN model and Random Error Diffusion metrics. Section 5 presents experimental results, while Section 6 summarizes our main contributions, and discusses the broader application of INNs in Process Tomography.
2. Related Work
This section presents an overview of the related works and is structured into four sub-sections. Section 2.1 delves into the works that discuss the bubble formation as a significant obstacle to efficient hydrogen production. Section 2.2 explores methods that provide analytical solutions for addressing the ill-posed inverse problem in process tomography, including setups that deal with Biot-Savart Law. Furthermore, Section 2.3 presents a review of conventional deep learning approaches for solving inverse problems, while Section 2.4 examines works that utilize INNs for tackling inverse problems.
2.1. Electrolysis for Clean Hydrogen: Notable Challenges
A recent study [19] discusses the challenge posed by the supply-demand mismatch in renewable energy sources such as solar and wind power to achieve a stable and sustainable energy grid. Another related work [20] explores the impact of fluctuations in energy production due to weather conditions and variables like climate change, emphasizing periods of excess energy or insufficient supply that can affect grid stability. Hydrogen production through electrolysis emerges as a promising solution to this issue, utilizing excess renewable energy during periods of abundance to power the electrolysis process. This allows for the generation and storage of hydrogen, which can then be converted back into electricity or used directly in various applications when the renewable energy supply is low [21]. Serving as an energy reservoir, hydrogen production through electrolysis effectively bridges the gap between fluctuating renewable energy production and consistent demand. Additionally, hydrogen’s versatility as a clean fuel makes it a valuable resource for transportation and chemical industry, thereby reducing dependence on fossil fuels and mitigating environmental impacts [21]. Consequently, hydrogen production through electrolysis represents a key strategy for achieving a reliable and sustainable energy system [21].
However, the formation of bubbles poses a significant challenge in the process of electrolysis. As an electrochemical reaction occurs at the electrodes, gas bubbles—typically hydrogen and oxygen are generated. These bubbles represent the desired product in many electrolytic processes, but they can also impede the efficiency of the reaction [2,22]. The accumulation of bubbles around the electrodes can obstruct the active sites, leading to increased resistance within the electrolysis cell [2,22]. This resistance necessitates higher energy input to sustain the desired current flow. Additionally, if left unmanaged, excessive bubble formation can result in operational issues and reduced efficiency [2,22]. Therefore, understanding and effectively managing bubble dynamics is crucial for optimizing the performance of electrolysis and ensuring the economical production of hydrogen.
Hence, bubble detection in electrolysis plays a critical role in optimizing the efficiency of the process. However, it is a challenging endeavor due to the complex dynamics within the electrolysis cell, and the non-transparent walls of the cell make direct visual observation impractical [23,24]. Instead, researchers often resort to indirect methods, such as utilizing magnetic sensors to detect the magnetic field disturbances caused by the movement of bubbles. These sensors are strategically placed outside the cell to minimize interference and provide reliable tracking of bubble behavior. Upon applying cell voltage to the electrolyzer, an electric current starts to flow. Consequently, this current induces a magnetic field in the vicinity of the electrolytic cell, governed by the Biot-Savart law. Therefore, such a setup may help in designing a more precise and efficient electrolysis system, which should ultimately contribute to advancements in clean and sustainable energy production.
2.2. Solving Inverse Problem of Biot-Savart Equation - Analytical Approaches
To the best of our knowledge, no prior research has addressed inverse problems within an electrolysis cell setup. However, works such as [72,73] have focused on solving inverse problems in the context of fuel cells. Wieser et al. [72] introduced a contactless magnetic loop array for estimating current distribution within fuel cells, while [73] designed a magnetic field analyzer with sensors associated with a ferromagnetic circuit that enhanced magnetic field variations, leading to more precise analysis of current distribution in fuel cells. The work by Roth et al. [11] proposed to reconstruct 2D current distribution using Fourier analysis in order to better interpret the magnetometer signals that may be useful in applications like in geophysical surveys. Similarly, [12] investigated the possibility of using magneto-optic imaging to directly observe current distributions in thin superconducting samples. Hauer et al. [25] presented Magnetotomography, a non-invasive method to visualize fuel cell current distribution by measuring magnetic flux with a 3D magnetic sensor and a four-axis positioning system. This method, enabled precise calculation of current flow within the cell since there was no feedback effect. In application of plasma physics, work such as [13] introduced the Bayesian modelling for inferring the current distribution from measurements of magnetic field and flux, where the plasma current is represented as a grid of toroidal current-carrying solid beams with rectangular cross sections.
2.3. Solving Inverse Problems using Deep Learning
With the advancement in machine learning algorithms, many deep learning approaches have been proposed to tackle inverse problems in medical imaging including Computed Tomography [6,14] and Magnetic Resonance Imaging [35]. Works such as [14] proposed a partially learned method by integrating prior information of the ill-posed inverse problem of 2D Tomography with a data-driven trainable neural network, while [53] explored deep image prior techniques in the context of ill-posed inverse problems. The work by [35] advocates for Convolutional Neural Networks (CNNs) as the choice for solving the inverse problem of medical image reconstruction and regularizing the network with a deep learned noise prior. Whereas [6] suggests using a neural network named Network Tikhonov (NETT) in conjunction with a Tikhonov regularizer to solve the inverse problem for medical imaging. Similarly, iNETT [26] is another recent method that combines Tikhonov regularization with Neural Networks, differing from [6] in that the non-stationary iterated Tikhonov method avoids exhaustive tuning of the regularization parameter. [44] developed a method for the fast convergence of neural networks used for solving inverse problems in imaging by reducing latency in calculating gradients. To explore more related works dealing with solving inverse problems in medical imaging or imaging in general via deep neural networks, readers are referred to [41,42,43,46,54]. Recent works such as [39] highlight that Deep Neural Networks (DNNs) trained to solve inverse problems are robust to noise and adversarial perturbations. Nevertheless, we believe that fine-tuning the regularization weightage when DNNs are trained with some regularization strategy is challenging, even though methods such as [40] learn such regularization weights.
Machine learning-based approaches have been proposed to solve ill-posed inverse problems in Electrical Capacitance Tomography (ECT) [27,28], Electrical Impedance Tomography (EIT) [29,30], Electrical Resistance Tomography (ERT) [31,32,33], Positron Emission Tomography [52], X-ray Tomography [49,50], and novel applications such as Electromagnetic Inverse Scattering using microwaves [45,51], generally via CNNs. A work by [48] explored the reason why CNNs are a good candidate for solving specific inverse problems, where they showed that the usage of convolution framelets represents the input data by convolving local and global information, aiding in learning underlying features in the data. Although CNNs show promise in solving inverse problems, their inherent non-invertibility may undermine their reliability. Other works to solve inverse problems via deep learning, especially Adversarial Networks [36,37,47], LSTM-based Autoencoder [38], face challenges in ensuring stable training due to their high complexity, making them less suitable for a wide variety of inverse problems.
Based on our survey on solving inverse problems via deep learning, we conclude that while significant progress has been made in developing such data-driven models, open questions persist regarding invertibility during training, scalability, and reliability of these deep learning-based approaches in applications of process tomography. Therefore, there is a need to explore novel network architectures and address challenges for the wider practical deployment of such machine learning models in scientific domains.
2.4. Invertible Neural Networks (INNs)
INNs are a promising new category of deep learning architectures that are inherently invertible in nature. Recently, Ardizzone et al. [3] showed the effectiveness of INNs for solving the inverse problem of predicting the level of oxygenation in tissues from endoscopic images. Even though there have been recent attempts to use INNs as surrogate models for solving inverse problems, such as [34] for inverse problem in physical systems governed by Partial Differential Equations (PDEs), [55] for inverse problem in morphology, [56] for inverse problem in medical imaging, or [57] for inverse design of optical lenses. However, INNs remain largely unexplored in the field of solving inverse problems in process tomography. INNs are popularly implemented based on Normalizing Flows (NFlows) that are suitable generative models due to their invertible architectural design, and accurate density estimation [64]. Additionally NFlows doesn’t suffer from posterior collapse, common in other generative models such as Variational Auto-Encoders (VAEs) and Generative Adversarial Networks (GANs). NFlows were popularized by [58] for density estimation. Since then, multiple novel NFlows have been proposed in the literature, such as RealNVP [8], Glow [9], FFJORD [59], NAF [60], SOS [61], Cubic Spline Flows [62], Neural Spline Flows [63]. Each of these prior works differs on the design of the NFlows that includes the design of the coupling function.
In summary, the section showcases the under-explored potential of INNs for addressing the inverse problem of the Biot-Savart Equation and other applications in the industrial process tomography domain in general.
3. Simulation Setup
The simulation setup mimics generic features of a water electrolyzer in a simplified model, as depicted in Figure 2 (top). In Section 3.1, we elaborate on the intricate design details related to the simulation. Moving to Section 3.2, we provide information on essential simulation parameters used for the experiment. Subsequently, in Section 3.3, we discuss the mesh transformation step to obtain the fine-grained mesh of the conductivity maps, which will be used as the input to the INN and other evaluated models. In Section 3.4, we formulate the forward physical process of the simulation based on the Biot-Savart Equation and finally, in Section 3.5, we give an overview of the data used to perform the experiments.
3.1. Simulation Design
The goal of our simulation setup, depicted in Figure 2 (top), is to investigate the feasibility of localizing and quantifying non-conducting bubbles by reconstructing the conductivity distribution from the observed induced magnetic flux density in the surrounding external region. To achieve this, the simulation setup simplifies the water electrolyzer to a quasi-two-dimensional configuration. The setup is filled with liquid as a substitute of water to avoid electrochemical reactions and the generation of additional bubbles. To represent non-conducting gas bubbles, Poly-methyl methacrylate (PMMA) cylinders with varying radii and locations are placed throughout the liquid. Hence, the setup incorporates materials with significant conductivity differences to simulate conducting water and low-conducting bubbles. We selected the dimensionality of the simulation setup based on the future experimental setup. The liquid channel’s configuration measures cm. The two electrodes (each measuring cm) facilitate the application of the electric current. The anode and cathode connections are established via wires, modeled with lengths of 50 cm and square cross-sections measuring cm on each side.
3.2. Simulation Parameters
To compute training data, diverse geometrical setups featuring regions of varying conductivity were compiled from a Java-class file in the finite element software COMSOL Multiphysics V6.0 (COMSOL Inc, Burlington, USA) [66]. This involves placing between 30 and 120 PMMA cylinders with radii ranging from 2 to mm within the liquid metal. The cylinder sizes are aligned with bubble agglomerates, and larger clusters are represented by merged cylinders. Since no electrochemical reactions occur in the liquid metal after the application of electric current, concentration-induced conductivity gradients are excluded. A low electrical conductivity of is employed to simulate the void fraction at PMMA cylinder positions [67]. For the wires and electrodes, values of are used, while the liquid metal is assigned a conductivity of [68]. A current density of 1 is applied at the electrode surface interfacing with the liquid metal, which falls within the typical range for alkaline and PEM electrolyzers. As the input current is conducted through the smaller cross-section copper wire, this necessitates an application of 14 , corresponding to a total current of 3.5 A.
3.3. Mesh Transformation
To facilitate automated grid generation for various bubble distributions, the geometry was discretized using finite tetrahedral elements, forming an unstructured mesh. Following a study to ensure grid independence, the mesh underwent refinement in regions exhibiting high current density gradients, notably at the interfaces between the wire and electrode, as well as within the volume containing liquid . For the liquid metal, the tetrahedral element size of 0.1 was set as the minimum, while the maximum was established at 5 . The computation of the current and the conductivity distribution for multiple geometries necessitates meshes with varying cell counts. As the INN and other evaluated models require fixed input array dimensions, the initial tetrahedral mesh is transformed into a grid of hexahedrons with a constant number of elements. The current density distribution within the structured mesh, consisting of one cell layer in height, can be treated as two-dimensional, given the negligible influence of the z-component and variations in the x and y components along the z-direction of the current. This grid comprises a total of 774 cells, with higher resolution allocated to the middle containing the liquid metal volume, comprising 510 nearly cubic cells, each with dimensions of . The current density and electrical conductivity within each hexahedron are determined through inverse distance-weighted interpolation [18] utilizing the 24 nearest tetrahedrons.
3.4. Solving Forward Process via Biot-Savart Equation
The current distribution was simulated using COMSOL for each bubble distribution, and the magnetic field exclusively at the positions of virtual sensors, was determined by Biot-Savart law given as,
where is the permeability of free space, i.e., vacuum given as , V is the volume with as infinitesimal volume element and is the magnetic flux density at point with as the integration variable and a location in V. Since only one spatial component of will be measurable in the planned experimental validation setup, we aim to reconstruct the conductivity distribution by using one spatial component of that is most informative about the magnetic flux density. Therefore, we selected the x-component of the magnetic flux density. The simulation of the current distribution typically requires 2.5 minutes. Additionally, the mesh transformation, along with calculating the magnetic field using Equation 1, requires around 3.5 minutes.
3.5. Simulation Data
To measure the magnetic flux density , we positioned an array of virtual sensors, i.e., , at a distance d below the liquid . In our future experimental setup, only one spatial component of the magnetic flux density, i.e., x-component is measurable. Thus, the conductivity distribution and one spatial component of the magnetic flux density serve as the ground truth for every geometrical configuration. We simulated the conductivity distribution for different geometrical configurations with a fixed applied current strength of 3.5 A. After transforming the tetrahedral mesh into a hexahedral mesh with fixed dimensions, the resulting conductivities were divided by , yielding relative conductivities between 0 and 1. Subsequently, were binarized by assigning values smaller than 0.25 as 0 and others as 1. Two examples of binary conductivity maps are shown in Figure 2 (bottom). We selected only those conductivity points directly above the sensor positions. Hence, out of the originally 774 simulated conductivity data points, only 510 data points were chosen for each simulated geometry. For each of the 10,000 configurations, the magnetic flux density was calculated at a distance and 25 mm for 50 and 100 sensor array (see Section 3.2).
4. Method
In this section, we provide details related to the INN model and present the developed metrics to evaluate the performance of the model. The section is organized into four main sub-sections. In Section 4.1, we delve into the architecture of the proposed INN framework for addressing the inverse problem of the Biot-Savart Equation. Additionally, Section 4.2 provides a detailed discussion of the loss function employed for training the INN. Following this, in the Section 4.3, we elucidate our Random Error Diffusion metric, which helps in assessing the quality of the conductivity reconstruction. To evaluate the robustness of the INN for reconstructing conductivity distribution when there is noise in sensor readings, Section 4.4 presents our algorithm for computing per-pixel bias and deviation maps.
4.1. INN Architecture
Let us reformulate the conductivity distribution as variable at discretized locations and the strongest spatial component of induced magnetic flux density as variable at distinct locations below the liquid metal. The setup for training the INN as shown in Figure 3, closely follows Ardizzone et al. [3]. Given the conductivity map is N-dimensional vector such that and the magnetic flux density measurements is M-dimensional such that where , the transformation is non-bijective and thus information loss occurs. We formulate an additional latent variable as such that for the INN shown in Figure 3, the dimensionality of is equal to the dimensionality of . It is to be noted that the conductivity distribution , the induced magnetic flux density and the latent dimension does not represent the Cartesian coordinates of three-dimensional space of the simulation setup in Figure 2.
The proposed INN model f is a series of k invertible mappings called coupling blocks with that predicts . The coupling blocks are learnable neural networks, i.e., scaling s and translation t, such that these functions need not be invertible and can be represented by any neural network [8]. The coupling block takes the input and splits it into two parts, which are transformed by s and t networks alternatively. The transformed parts are subsequently concatenated to produce the block’s output. The architecture allows for easy recovery of the block’s input from its output in the inverse direction, with minor architectural modifications ensuring invertibility. We follow [9] to perform a learned invertible convolution after every coupling block to reverse the ordering of the features, thereby ensuring each feature undergoes the transformation. Hence, the function f is a bijective mapping between and , leading to its invertibility which help it to associate the conductivity with unique pairs of magnetic flux density and latent space . We incorporate vector to address the information loss in the forward process i.e. and to capture the variance in mapping the inverse process i.e. .

4.2. INN Training and Testing Procedure
The algorithm for the training and testing of our proposed INN framework is shown in Algorithm 1. Given the INN as an invertible function f, its optimization via training explicitly calculates the inverse process, i.e., where are the INN parameters. We define the density of the latent variable as the multivariate standard Gaussian distribution. The desired posterior distribution can now be represented by the deterministic function f that pushes the known Gaussian prior distribution to -space, conditioned on . Note that the forward mapping through function , and the inverse mapping through function f, are both differentiable and efficiently computable for posterior probabilities. Therefore, we approximate the conditional probability by the inverse process of our tractable INN model which uses the training data with T samples from the forward simulation as discussed in Section 3. Hence, the objective is to deduce the high-dimensional conductivity distribution , from a sparse set of magnetic flux density measurements . Even though our INN can be trained in both directions with losses , and for variables , , respectively as performed in [3], we are only interested with reconstructing the conductivity variable , i.e., the inverse process. Given the training batch size as W, the loss minimizes the reconstruction error between the ground truth and predictions during training as follows:
4.3. Random Error Diffusion
The ground truth conductivity maps consist of binary values, , while the predictions are continuous-valued, . Therefore, it is crucial to define an appropriate metric to assess the performance of the model. In principle, image dithering approaches like Floyd-Steinberg Dithering [69] can be adopted for converting the continuous-valued pixels to binary pixels and then compare its similarity with the ground truth binary map. However, [69] disperses quantization errors into neighboring pixels with pre-defined fractions or a fixed dithering matrix, without adapting to the specific characteristics of the image. Therefore, we developed a novel algorithm named Random Error Diffusion [65] (see Algorithm 2) to assess the similarity between the continuous-valued conductivity predictions and the binary-valued ground truth maps. The algorithm utilizes four randomly sampled error fractions from Dirichlet distribution to diffuse quantization errors in the context of Floyd-Steinberg Dithering. The process is then repeated multiple times to create an ensemble of binary conductivity maps, whose density is estimated. Subsequently, the log-likelihood of the ground truth binary map is estimated with respect to the computed density.

4.3.1. Algorithm
To initiate the algorithm, four random error fractions, denoted as , are sampled from the Dirichlet distribution. Each fraction is a real number within the interval , and their sum is constrained to equal 1. Subsequently, these random error fractions are utilized to diffuse the quantization error to the neighboring pixels in order to obtain the binary conductivity map. This process is repeated n times for resampling the four error fractions, which is used to produce an ensemble of n binary conductivity maps , for each continuous valued conductivity prediction . We subsequently perform Kernel Density Estimation (KDE) on the ensembles for each conductivity prediction to obtain the density estimate , parameterized by the kernel bandwidth h. Finally, the log-likelihood of the ground truth binary map is computed from the density estimate . The Figure 15 shows the distribution of log-likelihoods for validation ground truth samples at ensemble count and 1000. The Table 3 shows the average of the log-likelihood scores from the validation ground truth samples for each evaluated models. The Section 5.5.2 discusses the results in Table 3 and the Figure 15.
4.4. Bias and Deviation
To comprehensively analyze the robustness of the INN and other evaluated models for reconstructing the conductivity distribution amid sensor noise, we introduce two additional evaluation metrics, namely the and maps. The motivation behind formulating these metrics lies in the observation that the reconstructed conductivity from different evaluated models as shown in Figure 4, do not reveal the model’s true robustness to noise. Therefore, a noise vector were sampled times from the uniform distribution in a pre-defined range. Subsequently, this sampled noise vector were added to the magnetic flux density measurements from the validation set . The models studied in this work were then utilized along with the noisy magnetic flux density to reconstruct conductivity maps, .
Bias: Our first metric, denoted as , is computed by first taking the per-pixel average of the conductivity maps. Then, the conductivity map predicted from the evaluated model when the sensor readings had no addition of noise is then subtracted from the averaged conductivity map. This results in the computation of the bias map given as:
where is the bias at pixel , is the number of iterations, is the predicted conductivity at pixel in the i-th iteration, is the predicted conductivity at pixel when no noise is added in . Thus, the bias map visualizes model’s tendency to deviate from accurate predictions under different noise conditions.
Deviation: We utilized the conductivity maps to compute per-pixel standard deviation values, resulting in the deviation map formulated as follows:
where is the deviation at pixel , and is the average predicted conductivity at pixel across all iterations. Hence, the per-pixel deviation map estimates the variability in the model’s conductivity predictions across multiple instances of sensor noise. It also elucidates the model’s sensitivity to noise in sensor readings. Together, the bias and deviation maps offer an effective way to analyze the specific strengths and weaknesses of a model to solve the inverse problem, enabling a deeper understanding of the model’s behavior under realistic noisy conditions.
4.4.1. Peak Signal-to-Noise Ratio (PSNR)
In our future experimental setup, a uniformly distributed noise may be present in the sensor readings. Our previous study [71] have shown that generally, up to ± noise is observed in similar settings. Therefore, we introduced uniform noise within the range of ±, , , , , , , and . We also evaluated our models on higher noise levels in order to analyze its robustness under atypical sensor anomalies. These noise levels were sampled times and was added to the validation set of magnetic flux density measurements, as discussed in Section 4.4. The distance of the sensors from the liquid metal was fixed at with sensors. To quantify the amount of noise added to the magnetic flux density measurements of the validation set, we computed the Peak Signal-to-Noise Ratio (PSNR), expressed in decibels (dB). PSNR measures the logarithmic ratio between the maximum power of the noise-free magnetic flux density measurement, and the mean of the squared noise as:
PSNR metric quantifies the relationship between the maximum possible signal power and the power of the noise in the signal. A higher PSNR value in this context implies better signal quality, indicating a reduced level of noise or distortion in the magnetic sensor readings. Table 1 presents the average PSNR scores obtained from samples within the validation set of magnetic sensor data. Notably, the noise level up to ± already results in a low PSNR score. Therefore, the insights from Table 1 prompt further study to visually and quantitatively assess the robustness of the INN model relative to other approaches when reconstructing the conductivity distribution under low PSNR settings.
5. Experiments and Results
In this section, we discuss our experimental setup and the obtained results. In Section 5.1, we explain the standardization of the training and test data. Section 5.2 details the meta-parameters defined for training the INN. Finally, we report qualitative results in Section 5.4 and quantitative results in Section 5.5.
5.1. Data Standardization
To create distinct training and validation sets, we shuffled the simulated geometries and allocated 80% of the 10,000 geometries for training and 20% for validation. Additionally, we conducted data standardization to facilitate the model’s learning process and enhance convergence efficiency. Standardizing the data ensures that all features share a similar scale, promoting faster convergence, numerical stability, and generalizability. Given the distinct units of measurement for magnetic flux density and conductivity distribution, standardization becomes particularly essential in our case. We specifically employ Z-score normalization as our standardization method, transforming the simulation data to have a per-feature mean value of 0 and a standard deviation of 1. We perform standardization procedure separately for magnetic flux density data and binary conductivity distribution.
5.2. INN Hyperparameters
The INN model underwent training on four NVIDIA A100 GPUs, utilizing Python 3.8.6 and PyTorch 1.9.0. We fixed the training meta-parameters such as the batch size at 100, optimizer as Adam with a learning rate of , the exponential decay rate for the first and second moment as and respectively, epsilon score at , and weight decay at . Concerning the INN architecture, we maintained three fully connected layers in s and t networks for each coupling block. Each layer has 128 neurons and activation function after the first and second layers, whereas there is no activation function in the output layer of the s and t networks. We studied the effect of the number of coupling blocks for validation loss convergence in Section 5.5.1.
5.3. Evaluated Methods
We implemented two distinct coupling block architectures, drawing inspiration from RealNVP [8] and Glow [9], as the backbone of our INN model. Each of these INN models was trained with the loss function described in Equation 2. We also trained the Glow based INN model with the mean squared error (MSE) as the objective function such that . The purpose was to assess its performance in terms of reconstructing the conductivity distribution. In addition, we explored three alternative approaches to address the inverse problem at hand, Tikhonov, Elastic Net and Convolutional Neural Network (CNN). The models, Tikhonov and Elastic Net, hinge on fitting a linear model regulated by a penalty term. The Tikhonov approach applies an -Norm penalty on the parameters of the linear model for regularization, while Elastic Net regularization employs a combination of -Norm and -Norm penalties on the model parameters. The weights of the regularization term for the Tikhonov and Elastic Net approaches were determined through cross-validation on the training set. To further diversify our evaluation, we introduced a CNN model designed for reconstructing the conductivity distribution. The loss function for the CNN was formulated similarly to Equation 2. For training the CNN model, we transformed the 100 sensor input data into a dimensional input, while the 510 conductivity points were transformed into a output 2D map. Further architectural details of the developed CNN model are provided in Table 2. In this paper, we will refer to the six models as INN-Glow, INN-RealNVP, INN-Glow (MSE), Tikhonov, Elastic Net, and CNN as needed.
5.4. Qualitative Results
In this section, we present a comprehensive visual comparison of the reconstructed conductivity distribution from several evaluated models. We also, report the results of the parameter studies and discuss the bias and deviation maps obtained from the INN-Glow and Tikhonov model under noisy sensor measurements.
5.4.1. Prediction of the Conductivity Maps: A Comparative Study
In Figure 4, we present the results of predicted conductivity maps by the INN-Glow, INN-RealNVP, Tikhonov, Elastic Net, and the CNN models. These predictions are based on the sensor configuration with and sensors. It can be observed that both INN-Glow and INN-RealNVP models provides a good approximation of the ground truth conductivity map. The reconstructions reveal pertinent details regarding the locations of non-conducting PMMA cylinder-induced void fraction. The visual outcomes of Tikhonov and Elastic Net regularization exhibit similarities to those of the INN models. In contrast, the CNN model yields a smoother prediction owing to the convolution operation inherent in its architecture. However, the CNN model wrongly predicts the presence of void fraction in regions characterized by high conductivity, as visible in the results of Sample 1. We believe that this occurs due to CNN’s inherent emphasis on learning the local patterns in the image. However, for our specific inverse problem, understanding the global relationship between the bubble distribution and conducting liquid using a fully connected network-based INN acts as a more suitable choice. Furthermore, CNNs are inherently tailored for image processing, while INNs are data agnostic and adaptable to diverse data types. Importantly, INNs are invertible in its design, a property that CNNs lack.
5.4.2. Effect of the Sensor Distance and Number of Sensors
We explored the impact of varying the distance of sensors from the liquid metal, d, and the number of sensors, M on the quality of the conductivity reconstruction using our INN-Glow model. In this experiment, we trained three separate instances of the INN-Glow model using simulation data which is based on varying the distance d and number of sensors M. The first setup is defined with , the second setup with and the third setup as . Figure 5 present the results obtained from the three example ground truths within the validation set. It shows that the region containing the void fraction is smoother as the distance of the sensors from the liquid metal is increased and the number of sensors is decreased. This outcome can be attributed to the increased difficulty for the model to solve the inverse problem with a lower number of sensors and a greater distance of the sensors from the liquid metal. Nevertheless, the model is effective in reconstructing the arrangement of PMMA cylinder-induced void fraction, also for the third setup with and .
5.4.3. Robustness to Noise: INN vs Tikhonov without Noisy Training Data
Based on the method in Section 4.4, we present the results for the reconstruction of the conductivity distribution, bias, and deviation maps after incorporating noise into the validation set of magnetic flux density data. The results are reported after fixing the parameter , for the INN-Glow model. We also report the results obtained after utilizing the Tikhonov model under the same experimental setup. Note the training data did not contain noise in the sensor readings.
Conductivity Maps: In Figure 6, the left column shows the INN-Glow model’s robustness in reconstructing the conductivity distribution, even with the presence of uniform noise up to ± in the magnetic flux density data. In contrast, the first column of Figure 7 conveys a noteworthy decline in Tikhonov’s performance to reconstruct conductivity distribution, evident even with ± noise in the sensor data. This discrepancy results from the Tikhonov model’s inherent linearity, making it highly susceptible to noise perturbations. In contrast, the INN-Glow, with its inherent non-linearity is resilient to noise, resulting in visually superior performance compared to Tikhonov.
Bias and Deviation Maps: The middle column in Figure 6 and Figure 7 illustrates bias maps for INN-Glow and Tikhonov, respectively. The results show that the Tikhonov model has a high bias, indicating a higher instability in its conductivity predictions when exposed to varying noise within the same noise value range. In contrast, the INN-Glow model exhibits minimal bias and has a high level of robustness for reconstructing conductivity maps with the presence of noise up to ± in the sensor readings. The right column in Figure 6 and Figure 7 shows the deviation maps for INN-Glow and Tikhonov, respectively. The per-pixel standard deviation of the conductivity maps obtained from the Tikhonov model (see color bars of the deviation maps) linearly increases from noise level ± to ± 1T. On the contrary, the INN-Glow model shows resilience with consistently low per-pixel deviation, that only rises after sensor readings are perturbed with ± 100nT noise level. These results convey that Tikhonov model, due to its linearity, is markedly more susceptible to noise than the INN-Glow model.
5.4.4. Robustness to Noise: INN vs Tikhonov with Noisy Training Data
In this section, we compare the results obtained from INN-Glow and Tikhonov models after the noise levels of ± and ± were added to the sensor measurements during training. The parameter is set at 100, and we show the reconstructed conductivity distribution, bias, and deviation maps at varying level of noise during testing.
Conductivity Maps: The left column of Figure 8 and Figure 10 shows the reconstruction of the conductivity maps obtained from the INN-Glow model trained with ± and ± noise in the training data, respectively. Additionally, the left column of Figure 9 and Figure 11 shows the reconstruction of the conductivity maps for the Tikhonov model at ± and ± noise in the training data, respectively. It is evident that for ± noise in training data, the INN-Glow model exhibit robustness to predict the void fraction up to ± noise in the validation example, while the Tikhonov model precisely reconstructs conductivity up to ± noise in the validation example. However with ± noise in training data, the reconstruction of the conductivity distribution from both the Tikhonov and INN-Glow model are robust until ± noise in the validation example.
Bias and Deviation Maps: The middle and right columns of Figure 8 and Figure 10 show the bias and deviation maps obtained from the INN-Glow model at ± and ± noise in the training data, respectively, while the middle and right columns in Figure 9 and Figure 11 display the bias and deviation maps for the Tikhonov model. The results for ± noise in the training data reveals that until ± noise in validation example, the Tikhonov model has lower bias and deviation than the INN-Glow model. With the presence of similar noise level in both training and validation data, a linear model like Tikhonov typically has a low bias while models like INN-Glow can produce higher bias due to its inherent non-linearity. However, both the INN-Glow and Tikhonov models exhibit high bias and deviation at ± 500nT and ± 1T noise levels in the validation example.
5.4.5. Robustness to Noise: Summary
To summarize, the results from Section 5.4.3 and Section 5.4.4 show that the INN-Glow model performs better than the Tikhonov model, if trained without noise and tested with noise in sensor measurements. This finding holds for a large range of noise levels. However, if the noise level is known during model training, Tikhonov model performs as good as our INN model for reconstructing conductivity maps with lower bias and deviation for the reconstruction. Therefore, for the future experimental setups, if the noise level is not known or if the noise is varying based on the properties of the sensor measurements or further external influences, we can perform INN-Glow training without incorporating noise and then utilize the trained INN-Glow model to precisely reconstruct the conductivity maps in the presence of noise in sensor readings, even if the noise level changes significantly.
5.4.6. Effect of Number of Uniform Noise Samples
We conducted a parameter study to analyze the significance of the number of uniform noise samples on the bias and deviation computation for reconstructing the conductivity maps. For this experiment, we fixed the noise level of ±, and the results are presented in Figure 12, for at 10, 100, and 1000 samples. It is apparent that has a pronounced effect on the Tikhonov model, reducing bias more significantly compared to the INN-Glow model when is higher. Furthermore, there is less effect of varying on the deviation maps for both models. The results affirm that an increase in the value tends to reduce bias, but fixing a very high value of may result in substantial computational requirements.
5.4.7. Random Sampling from Latent Space
We analyzed the influence of random sampling from the normally distributed latent space on the INN model’s robustness for reconstructing the conductivity distribution. We sampled the latent space multiple times, and alongside the magnetic flux density measurements , we passed to the INN-Glow model for the reconstruction of the conductivity distribution. This sampling procedure was repeated 100 times, and we computed bias and deviation maps following the similar protocol established in previous experiments. The results, illustrated in Figure 13 for the example validation ground truth show that random sampling from the latent space causes minimal bias and deviation on the quality of the reconstruction of the conductivity distribution. This observation is evident in the three examples of the predicted conductivity distributions as shown in Figure 13 d)-f) from three different latent vectors and low bias and deviation scores as shown in Figure 13 b)-c), respectively.
5.5. Quantitative Results
In this section, we provide quantitative results for a thorough evaluation of the proposed models for solving the inverse problem. We discuss key performance metrics, such as the Random Error Diffusion, average bias, and average deviation scores, to assess each of the evaluated model’s quality of the reconstructing conductivity distribution.
5.5.1. Effect of Number of Coupling Blocks on Validation Loss
Figure 14 illustrates the impact of the number of coupling blocks k of the INN-Glow model on the convergence of validation loss. We stop the model training when the validation loss begins to increase. The loss curves reveal that a single coupling block leads to underfitting, while higher number of blocks may result in overfitting without the stoppage of the training iterations. Figure 14 a)-c) show that the configuration and has higher validation loss compared to the setup with and due to reduced information in magnetic flux density measurements with a greater sensor distance from the liquid metal. Additionally, the configuration with and sensors further degrades information, leading to much higher loss while solving the inverse problem. Despite the inferior loss convergence, Figure 5 demonstrated the INN-Glow model’s ability to learn the location of void fraction for the configuration with and sensors. Notably, increasing the number of coupling blocks beyond does not substantially reduce validation loss, as the loss scores at the last epoch before the training stoppage as shown in Figure 14 d) reveals.
5.5.2. Random Error Diffusion
We compared the results obtained from the Random Error Diffusion metric presented in Section 4.3 for the six different models to solve the inverse problem. The results in Figure 15 shows the log-likelihood distribution of all the 2000 validation ground truth samples for varying counts of binary ensembles n. It can be seen that the log-likelihoods scores are centered near zero irrespective of the model, and the ensemble count n. This outcome can also be verified by the averaged log-likelihood scores in Table 3. Figure 15 and Table 3 shows that for both and 1000, the INN-Glow and INN-RealNVP models performs better than the linear models i.e., Tikhonov and Elastic Net as well as INN-Glow (MSE) as they achieve higher average log-likelihoods. However, the CNN model has a higher log-likelihood score than all other evaluated models. Due to the convolution operation, the CNN model predicts blurred images. The blurring obscures fine details and feature edges and makes the image appear more uniform and less detailed, similar to a binary map. Hence, Random Error Diffusion estimates higher likelihoods that these blurred images are being sampled from the density of binary ensembles.
5.5.3. Bias and Deviation
Table 4 presents quantitative results related to bias and deviation maps for INN-Glow and Tikhonov models. To compute the deviation score, we took the average of the deviation maps across all the 2000 validation samples for different noise levels. Additionally, for computing both bias (min) and bias (max), we determine the minimum and maximum bias scores from all the 2000 validation bias maps. The results in Table 4 indicate that the INN-Glow model consistently exhibits much lower deviation and bias scores compared to the Tikhonov model. This underscores the INN-Glow model’s stability and robustness in reconstructing conductivity maps in the presence of noise in sensor readings during testing, when there is no noise during training. Conversely, the Tikhonov model is less reliable, especially when subjected to noise beyond ± in sensor readings.
5.5.4. Number of Uniform Noise Samples
Table 5 displays the average deviation and bias scores for varying values of . The results indicate that a higher number of noise samplings lead to reduced bias, but a minimal change in the deviation scores, which is consistent with our findings in Figure 12. Notably, the Tikhonov model shows a significant reduction in bias scores, suggesting its sensitivity to the choice of . Similarly, the INN-Glow model’s sensitivity to is evident, although the impact is less pronounced given its already low bias scores. Given the results in Table 5, we fixed for our experiments as this value provides a good balance between the computational requirements and the model’s performance.
6. Conclusion
In this study, we introduced Invertible Neural Networks (INNs) for the reconstruction of conductivity distribution from external magnetic field measurements under simulation conditions similar to those encountered in a water electrolyzer. Our results highlight the robustness of the INN model, showcasing its ability to learn conductivity distributions in the face of the inherently ill-posed nature of the problem and the presence of noise in magnetic flux density measurements. In contrast, linear models like Tikhonov exhibit high susceptibility to noise, due to which the reconstructions from such models are unreliable beyond a certain noise level in sensor readings of the test data, especially when the model is fitted with sensor data containing no noise. The extensive evaluation, involving bias, deviation and random error diffusion metrics, underscore the superior performance of the INN model in approximating ground truth conductivity maps compared to the Tikhonov model. Additionally, our findings suggest that INNs can efficiently reconstruct conductivity maps even with limited number of sensors, positioned at distances exceeding 20 from the conducting plate. Our INN model’s real-time prediction capabilities have practical applications, especially in estimating the void fraction distributions within actual electrolysis cells. This positions INNs as a promising model for localizing and estimating bubble, respectively void fraction locations in current-conducting liquids. In future, we will focus on evaluating INNs for bubble and void fraction detection within experimental electrolysis setups and also test the findings from this work in other inverse problems of applied physics.
Author Contributions
Conceptualization, N.K., S.G.; simulation, L.K., T.W.; methodology, N.K., S.G.; software, N.K.; formal analysis, N.K.; investigation, N.K.; resources, N.K.; data curation, L.K.; writing—original draft preparation, N.K., L.K; writing—review and editing, N.K., L.K., T.W., S.E., K.E., S.G.; visualization, N.K.; supervision, S.G., T.W.; project administration, S.G., T.W.; funding acquisition, S.G., T.W. All authors have read and agreed to the published version of the manuscript.
Funding
Financial support by the School of Engineering of TU Dresden in the frame of the Hydrogen Lab and the German Helmholtz Association in the frame of the project "Securing raw materials supply through flexible and sustainable closure of material cycles" is gratefully acknowledged.
Data Availability Statement
Data can be provided upon the request to the authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Capurso, T.; Stefanizzi, M.; Torresi, M.; Camporeale, S.M. Perspective of the role of hydrogen in the 21st century energy transition. Energy Conversion and Management 2022, 251, 114898. [Google Scholar] [CrossRef]
- Angulo, A.; van der Linde, P.; Gardeniers, H.; Modestino, M.; Fernández Rivas, D. Influence of bubbles on the energy conversion efficiency of electrochemical reactors. Joule 2020, 4(3), 555–579. [Google Scholar] [CrossRef]
- Ardizzone, L.; Kruse, J.; Rother, C.; Köthe, U. Analyzing inverse Problems with invertible neural networks. In Proceedings of the International Conference on Learning Representations (ICLR) 2019. [Google Scholar]
- Hanke, M. Limitations of the L-curve method in ill-posed problems. BIT Numerical Mathematics 1996, 36(2), 287–301. [Google Scholar] [CrossRef]
- Hossain, S.S.; Mutschke, G.; Bashkatov, A.; Eckert, K. The thermocapillary effect on gas bubbles growing on electrodes of different sizes. Electrochimica Acta 2020, 353, 136461. [Google Scholar] [CrossRef]
- Li, H.; Schwab, J.; Antholzer, S.; Haltmeier, M. NETT: Solving inverse problems with deep neural networks. Inverse Problems 2020, 36(6), 065005. [Google Scholar] [CrossRef]
- Stefani, F.; Gundrum, T.; Gerbeth, G. Contactless inductive flow tomography. Physical Review E 2004, 70, 056306. [Google Scholar] [CrossRef] [PubMed]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density estimation using Real NVP. In Proceedings of the International Conference on Learning Representations (ICLR) 2017. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems 2018, 31. [Google Scholar]
- Amores, E.; Sánchez, M.; Rojas, N.; Sánchez-Molina, M. Renewable hydrogen production by water electrolysis. In Sustainable Fuel Technologies Handbook, 1st ed.; Dutta, S., Hussain, C.M., Eds.; Academic Press: London, UK, 2021; pp. 271–313. [Google Scholar]
- Roth, B.J.; Sepulveda, N.G.; Wikswo Jr, J.P. 1989. Using a magnetometer to image a two-dimensional current distribution. Journal of applied physics, 1989; 65, 1, 361–372. [Google Scholar]
- Johansen, T.H.; Baziljevich, M.; Bratsberg, H.; Galperin, Y.; Lindelof, P.E.; Shen, Y.; Vase, P. Direct observation of the current distribution in thin superconducting strips using magneto-optic imaging. Physical Review B 1996, 54(22), 16264. [Google Scholar] [CrossRef]
- Svensson, J.; Werner, A.; JET-EFDA Contributors. Current tomography for axisymmetric plasmas. Plasma Physics and Controlled Fusion 2008, 50(8), 085002. [Google Scholar] [CrossRef]
- Adler, J.; Öktem, O. Solving ill-posed inverse problems using iterative deep neural networks. Inverse Problems 2017, 33(12), 124007. [Google Scholar] [CrossRef]
- Hauer, K.H.; Potthast, R.; Wannert, M. Algorithms for magnetic tomography—on the role of a priori knowledge and constraints. Inverse Problems 2022, 24(4), 045008. [Google Scholar] [CrossRef]
- Larminie, J.; Dicks, A.; McDonald, M.S. Fuel cell systems explained. Chichester, UK: J. Wiley 2003, 2, 207–225. [Google Scholar]
- Molnarne, M.; Schroeder, V. Hazardous properties of hydrogen and hydrogen containing fuel gases. Process Safety and Environmental Protection 2019, 130, 1–5. [Google Scholar] [CrossRef]
- Shepard, D. A two-dimensional interpolation function for irregularly-spaced data. In Proceedings of the 1968 23rd ACM national conference 1968, 517–524. [Google Scholar]
- Gan, L.; Jiang, P.; Lev, B.; Zhou, X. Balancing of supply and demand of renewable energy power system: A review and bibliometric analysis. Sustainable Futures 2020, 2, 100013. [Google Scholar] [CrossRef]
- Iain Staffell, I.; Pfenninger, S. The increasing impact of weather on electricity supply and demand. Energy 2018, 145, 65–78. [Google Scholar] [CrossRef]
- Wang, M.; Wang, Z.; Gong, X.; Guo, Z. The intensification technologies to water electrolysis for hydrogen production—A Review. Renewable and Sustainable Energy Reviews 2014, 29, 573–588. [Google Scholar] [CrossRef]
- Zhao, X.; Ren, H.; Luo, L. Gas bubbles in electrochemical gas evolution reactions. Langmuir 2019, 35, 5392–5408. [Google Scholar] [CrossRef]
- Jeon, D.H.; Kim, S.; Kim, M.; Lee, C. , Cho, H. Oxygen bubble transport in a porous transport layer of polymer electrolyte water electrolyzer. Journal of Power Sources 2023, 553, 232322. [Google Scholar] [CrossRef]
- Mo, J.; Kang, Z.; Yang, G.; Li, Y.; Retterer, ST.; Cullen, DA.; Toops, TJ.; Bender, G.; Pivovar, BS.; Green Jr, JB.; Zhang, FY. In situ investigation on ultrafast oxygen evolution reactions of water splitting in proton exchange membrane electrolyzer cells. Journal of Materials Chemistry A 2017, 5(35), 18469–75. [Google Scholar] [CrossRef]
- Hauer, K.-H.; Potthast, R.; Wüster, T.; Stolten, D. Magnetotomography—a new method for analysing fuel cell performance and quality. Journal of Power Sources, 2005; 143, 1–2, 67–74. [Google Scholar]
- Bianchi, D.; Lai, G.; Li, W. Uniformly convex neural networks and non-stationary iterated network Tikhonov (iNETT) method. Inverse Problems 2023, 39(5), 055002. [Google Scholar] [CrossRef]
- Lei, J.; Liu, Q.; Wang, X. Deep learning-based inversion method for imaging problems in electrical capacitance tomography. IEEE Transactions on Instrumentation and Measurement 2018, 67(9), 2107–2118. [Google Scholar] [CrossRef]
- Zhu, H.; Sun, J.; Xu, L.; Tian, W.; Sun, S. Permittivity reconstruction in electrical capacitance tomography based on visual representation of deep neural network. IEEE Sensors Journal 2020, 20(9), 4803–15. [Google Scholar] [CrossRef]
- Smyl, D.; Liu, D. Optimizing electrode positions in 2-D electrical impedance tomography using deep learning. IEEE Transactions on Instrumentation and Measurement 2020, 69(9), 6030–44. [Google Scholar] [CrossRef]
- Fan, Y.; Ying, L. Solving electrical impedance tomography with deep learning. Journal of Computational Physics 2020, 404, 109119. [Google Scholar] [CrossRef]
- Tan, C.; Lv, S.; Dong, F.; Takei, M. Image reconstruction based on convolutional neural network for electrical resistance tomography. IEEE Sensors Journal 2018, 19(1), 196–204. [Google Scholar] [CrossRef]
- Li, F.; Tan, C.; Dong, F. Electrical resistance tomography image reconstruction with densely connected convolutional neural network. IEEE Transactions on Instrumentation and Measurement 2020, 70, 1. [Google Scholar] [CrossRef]
- Li, F.; Tan, C.; Dong, F.; Jia, J. V-net deep imaging method for electrical resistance tomography. IEEE Sensors Journal 2020, 20(12), 6460–9. [Google Scholar] [CrossRef]
- Padmanabha, GA.; Zabaras, N. Solving inverse problems using conditional invertible neural networks. Journal of Computational Physics 2021, 433, 110194. [Google Scholar] [CrossRef]
- Aggarwal, HK.; Mani, MP.; Jacob, M. MoDL: Model-based deep learning architecture for inverse problems. IEEE Transactions on Medical Imaging 2018, 38(2), 394–405. [Google Scholar] [CrossRef] [PubMed]
- Bao, G.; Ye, X.; Zang, Y.; Zhou, H. Numerical solution of inverse problems by weak adversarial networks. Inverse Problems 2020, 36(11), 115003. [Google Scholar] [CrossRef]
- Sim, B.; Oh, G.; Kim, J.; Jung, C.; Ye, JC. Optimal transport driven CycleGAN for unsupervised learning in inverse problems. SIAM Journal on Imaging Sciences 2020, 13(4), 2281–306. [Google Scholar] [CrossRef]
- Kłosowski, G.; Rymarczyk, T.; Wójcik, D. The use of an LSTM-based autoencoder for measurement denoising in process tomography. International Journal of Applied Electromagnetics and Mechanics 2023, 1–4. [Google Scholar] [CrossRef]
- Genzel, M.; Macdonald, J.; März, M. Solving inverse problems with deep neural networks–robustness included? IEEE Transactions on Pattern Analysis and Machine Intelligence 2022, 45(1), 1119–34. [Google Scholar] [CrossRef]
- Afkham, BM.; Chung, J.; Chung, M. Learning regularization parameters of inverse problems via deep neural networks. Inverse Problems 2021, 37(10), 105017. [Google Scholar] [CrossRef]
- McCann, MT.; Jin, KH.; Unser, M. Convolutional neural networks for inverse problems in imaging: A review. IEEE Signal Processing Magazine 2017, 34(6), 85–95. [Google Scholar] [CrossRef]
- Lucas, A.; Iliadis, M.; Molina, R.; Katsaggelos, AK. Using deep neural networks for inverse problems in imaging: beyond analytical methods. IEEE Signal Processing Magazine 2018, 35(1), 20–36. [Google Scholar] [CrossRef]
- Liang, D.; Cheng, J.; Ke, Z.; Ying, L. Deep magnetic resonance image reconstruction: Inverse problems meet neural networks. IEEE Signal Processing Magazine 2020, 37(1), 141–51. [Google Scholar] [CrossRef]
- Chun, IY.; Huang, Z.; Lim, H.; Fessler, J. Momentum-Net: Fast and convergent iterative neural network for inverse problems. IEEE transactions on pattern analysis and machine intelligence 2020. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Wang, LG.; Teixeira, FL.; Liu, C.; Nehorai, A.; Cui, TJ. DeepNIS: Deep neural network for nonlinear electromagnetic inverse scattering. IEEE Transactions on Antennas and Propagation 2018, 67(3), 1819–25. [Google Scholar] [CrossRef]
- Ongie, G.; Jalal, A.; Metzler, CA.; Baraniuk, RG.; Dimakis, AG.; Willett, R. Deep learning techniques for inverse problems in imaging. IEEE Journal on Selected Areas in Information Theory 2020, 1(1), 39–56. [Google Scholar] [CrossRef]
- Lunz, S.; Öktem, O.; Schönlieb, CB. Adversarial regularizers in inverse problems. NeurIPS 2018, 31. [Google Scholar]
- Ye, JC.; Han, Y.; Cha, E. Deep convolutional framelets: A general deep learning framework for inverse problems. SIAM Journal on Imaging Sciences 2018, 11(2), 991–1048. [Google Scholar] [CrossRef]
- Baguer, DO.; Leuschner, J.; Schmidt, M. Computed tomography reconstruction using deep image prior and learned reconstruction methods. Inverse Problems 2020, 36(9), 094004. [Google Scholar] [CrossRef]
- Bubba, TA.; Kutyniok, G.; Lassas, M.; März, M.; Samek, W.; Siltanen, S.; Srinivasan, V. Learning the invisible: A hybrid deep learning-shearlet framework for limited angle computed tomography. Inverse Problems 2019, 35(6), 064002. [Google Scholar] [CrossRef]
- Li, L.; Wang, LG.; Teixeira, FL. Performance analysis and dynamic evolution of deep convolutional neural network for electromagnetic inverse scattering. IEEE Antennas and Wireless Propagation Letters 2019, 18(11), 2259–63. [Google Scholar] [CrossRef]
- Gong, K.; Guan, J.; Kim, K.; Zhang, X.; Yang, J.; Seo, Y.; El Fakhri, G.; Qi, J.; Li, Q. Iterative PET image reconstruction using convolutional neural network representation. IEEE Transactions on Medical Imaging 2018, 38(3), 675–85. [Google Scholar] [CrossRef]
- Dittmer, S.; Kluth, T.; Maass, P.; Otero Baguer, D. Regularization by architecture: A deep prior approach for inverse problems. Journal of Mathematical Imaging and Vision 2020, 62, 456–70. [Google Scholar] [CrossRef]
- Arridge, S.; Maass, P.; Öktem, O.; Schönlieb, CB. Solving inverse problems using data-driven models. Acta Numerica 2019, 28, 1–74. [Google Scholar] [CrossRef]
- Şahin, GG.; Gurevych, I. Two birds with one stone: Investigating invertible neural networks for inverse problems in morphology. In: Proceedings of the AAAI Conference on Artificial Intelligence, 2020; 7814–7821. [Google Scholar]
- Denker, A.; Schmidt, M.; Leuschner, J.; Maass, P. Conditional invertible neural networks for medical imaging. Journal of Imaging 2021, 7(11), 243. [Google Scholar] [CrossRef]
- Luo, M.; Lee, S. Inverse design of optical lenses enabled by generative flow-based invertible neural networks. Scientific Reports 2023, 13(1), 16416. [Google Scholar] [CrossRef]
- Dinh, L.; Krueger, D.; Bengio, Y. NICE: Non-linear Independent Components Estimation. ICLR Workshop 2015. [Google Scholar]
- Grathwohl, W.; Chen, R.T.Q.; Bettencourt, J.; Sutskever, I.; Duvenaud, D. FFJORD: Free-form continuous dynamics for scalable reversible generative models. ICLR 2019. [Google Scholar]
- Huang, C.W.; Krueger, D.; Lacoste, A.; Courville, A. Neural Autoregressive Flows. ICML 2018. [Google Scholar]
- Jaini, P.; Selby, K.A.; Yu, Y. Sum-of-squares polynomial flow. Proceedings of the 36th International Conference on Machine Learning, ICML, 2019. [Google Scholar]
- Durkan, C.; Bekasov, A.; Murray, I.; Papamakarios, G. Cubic-spline flows. Workshop on Invertible Neural Networks and Normalizing Flows, ICML, 2019. [Google Scholar]
- Durkan, C.; Bekasov, A.; Murray, I.; Papamakarios, G. Neural Spline Flows. Advances in Neural Information Processing Systems 2019. [Google Scholar]
- Ivan, K.; Simon, J.D.P.; Marcus, A.B. Normalizing Flows: An introduction and review of current methods. IEEE Transactions on Pattern Analysis and Machine Intelligence 2020, 43(11), 3964–3979. [Google Scholar]
- Kumar, N.; Krause, L.; Wondrak, T.; Eckert, S.; Eckert, K.; Gumhold, S. Learning to reconstruct the bubble distribution with conductivity maps using Invertible Neural Networks and Error Diffusion. arXiv preprint arXiv:2307.02496, arXiv:2307.02496 2023.
- Krause, L.; Kumar, N.; Wondrak, T.; Gumhold, S.; Eckert, S.; Eckert, K. Current Tomography–Localization of void fractions in conducting liquids by measuring the induced magnetic flux density. arXiv preprint arXiv:2307.11540, arXiv:2307.11540 2023.
- Zhang, H.Q.; Jin, Y.; Qiu, Y. The optical and electrical characteristics of PMMA film prepared by spin coating method. IOP Conference Series: Materials Science and Engineering 2015, 87, 012032. [Google Scholar] [CrossRef]
- Plevachuk, Y.; Sklyarchuk, V.; Eckert, S.; Gerbeth, G.; Novakovic, R. Thermophysical properties of the liquid Ga–In–Sn eutectic alloy. Journal of Chemical & Engineering Data, 2014; 59, 3, 757–763. [Google Scholar]
- Floyd, R.W.; Steinberg, L. An adaptive algorithm for spatial grey scale. Proceedings of the Society of Information Display 1976, 17, 75–77. [Google Scholar]
- Ivanova, M. E; Peters, R.; Müller, M.; Haas, S.; Seidler, M. F.; Mutschke, G.; Eckert, K.; Röse, P.; Calnan, S.; Bagacki, R.; Schlatmann, R.; Grosselindemann, C.; Schäfer, L.-A.; Menzler, N. H.; Weber, A.; van de Krol, R.; Liang, F.; Abdi, F. F.; Brendelberger, S.; Neumann, N.; Grobbel, J.; Roeb, M.; Sattler, C.; Duran, I.; Dietrich, B.; Hofberger, M. E. C.; Stoppel, L.; Uhlenbruck, N.; Wetzel, T.; Rauner, D.; Hecimovic, A.; Fantz, U.; Kulyk, N.; Harting, J.; Guillon, O. Technological pathways to produce compressed and highly pure hydrogen from solar power. Angewandte Chemie International Edition 2023, 62, e202218850. [Google Scholar] [PubMed]
- Sieger, M.; Mitra, R.; Schindler, F.; Vogt, T.; Stefani, F.; Eckert, S.; Wondrak, T. Challenges in contactless inductive flow tomography for Rayleigh-Bénard convection cells. Magnetohydrodynamics 2022, 58, 25–32. [Google Scholar]
- Wieser, C.; Helmbold, A.; Gülzow, E. A new technique for two-dimensional current distribution measurements in electrochemical cells. Journal of Applied Electrochemistry 2000, 30, 803–807. [Google Scholar] [CrossRef]
- Plait, A.; Giurgea, S.; Hissel, D.; Espanet, C. New magnetic field analyzer device dedicated for polymer electrolyte fuel cells noninvasive diagnostic. International Journal of Hydrogen Energy 2020, 45(27), 14071–14082. [Google Scholar] [CrossRef]
- Bashkatov, A.; Hossain, S.S.; Yang, X.; Mutschke, G.; Eckert, K. Oscillating hydrogen bubbles at Pt microelectrodes. Physical Review Letters 2019, 123(21), 214503. [Google Scholar] [CrossRef]
- Bashkatov, A.; Hossain, S.S.; Mutschke, G.; Yang, X.; Rox, H.; Weidinger, I. M.; Eckert, K. On the growth regimes of hydrogen bubbles at microelectrodes. Physical Chemistry Chemical Physics 2022, 24(43), 26738–26752. [Google Scholar] [CrossRef]
Figure 1.
The illustration provides a visual representation of an electrolysis cell, elucidating the notable occurrence of bubble formation concentrated specifically at the electrode reaction sites.
Figure 1.
The illustration provides a visual representation of an electrolysis cell, elucidating the notable occurrence of bubble formation concentrated specifically at the electrode reaction sites.
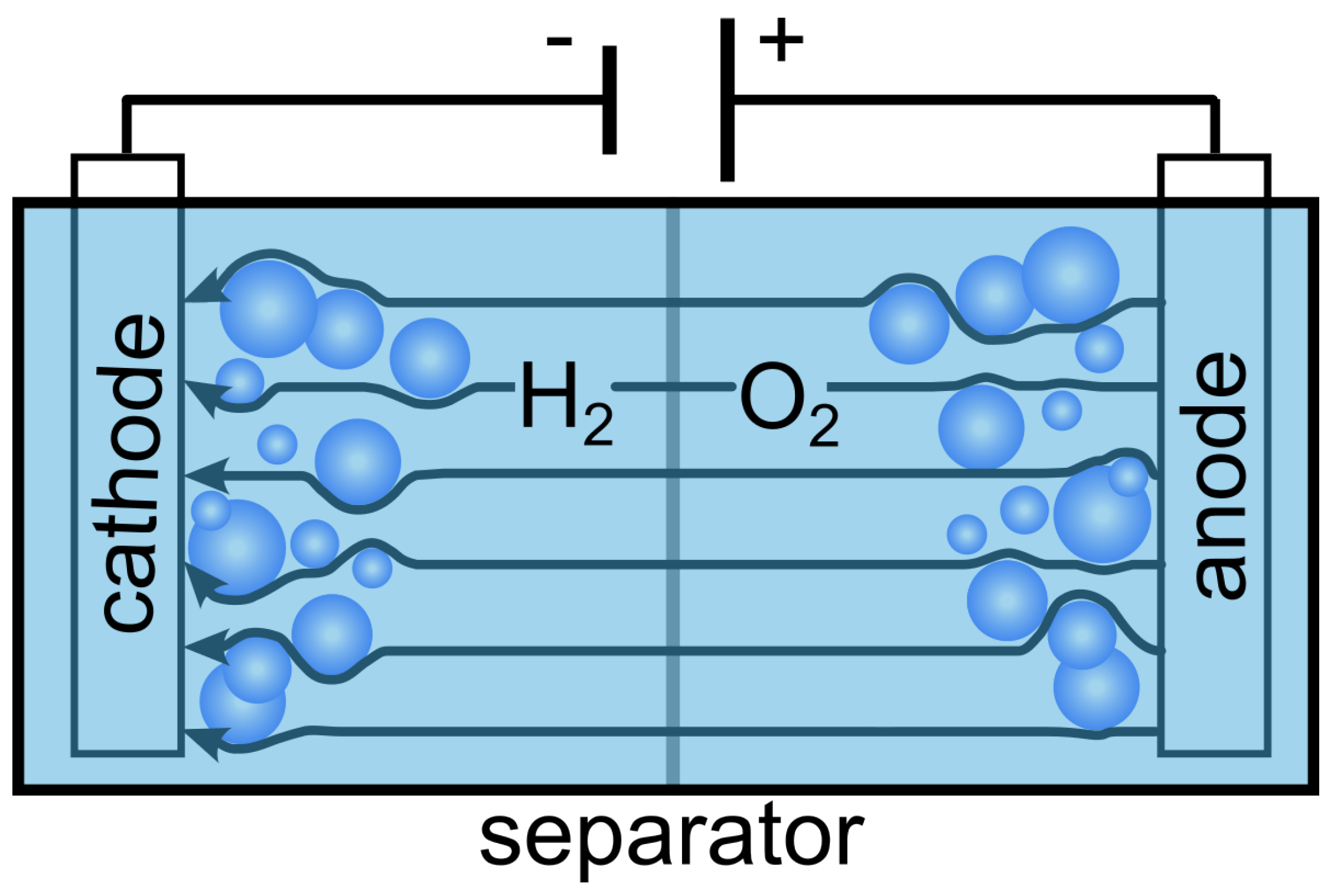
Figure 2.
The top figure shows the Proof-of-Concept (POC) model that contains a channel filled with liquid with PMMA cylinders normally distributed along the x-axis and randomly distributed along the y-axis in the channel. The top figure also shows the electrodes with wire to apply electric current to the plate, and the magnetic sensors on the bottom. The two bottom figures show examples of the binarized conductivity distribution of liquid metal-containing region in the cartesian plane. The dark pixels resembles low conductivity meaning the presence of void fraction clusters.
Figure 2.
The top figure shows the Proof-of-Concept (POC) model that contains a channel filled with liquid with PMMA cylinders normally distributed along the x-axis and randomly distributed along the y-axis in the channel. The top figure also shows the electrodes with wire to apply electric current to the plate, and the magnetic sensors on the bottom. The two bottom figures show examples of the binarized conductivity distribution of liquid metal-containing region in the cartesian plane. The dark pixels resembles low conductivity meaning the presence of void fraction clusters.
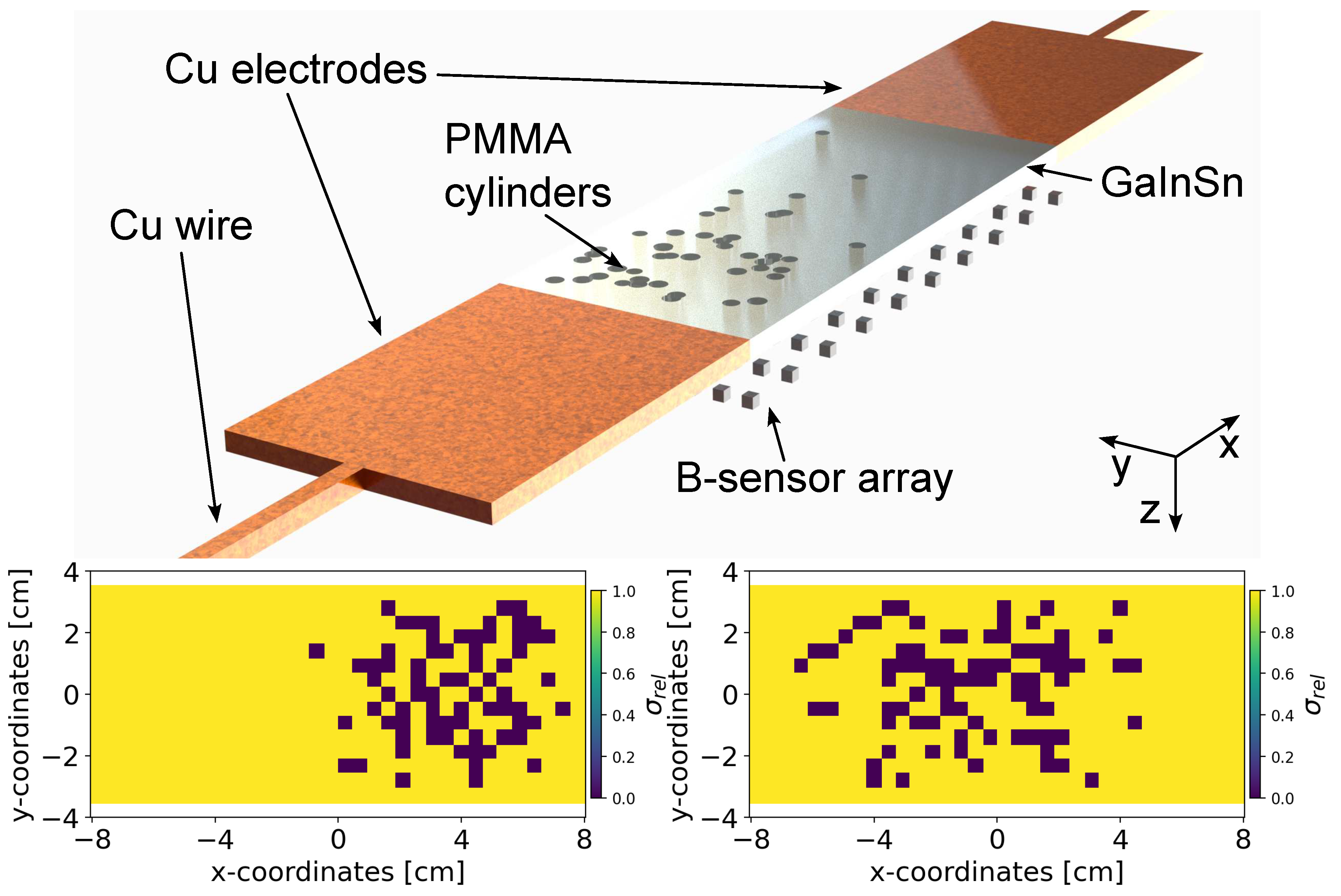
Figure 3.
An overview of our INN architecture. The conductivity map is positioned on the left side of the network. The INN architecture contains k coupling blocks. On the right side of the network are variables and , i.e., magnetic flux density and latent space, respectively. The INN is trainable in both directions, as shown with the bi-directional arrows in the figure.
Figure 3.
An overview of our INN architecture. The conductivity map is positioned on the left side of the network. The INN architecture contains k coupling blocks. On the right side of the network are variables and , i.e., magnetic flux density and latent space, respectively. The INN is trainable in both directions, as shown with the bi-directional arrows in the figure.
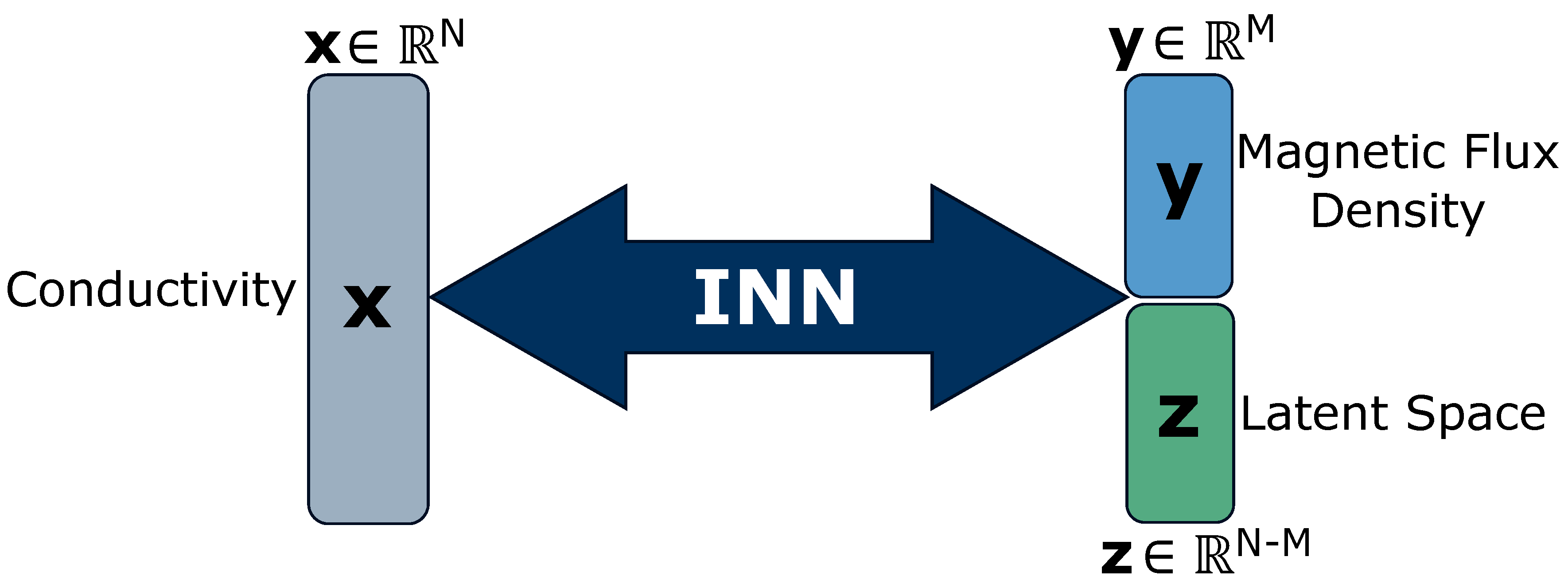
Figure 4.
Visual comparison of the quality of the reconstruction of conductivity distribution from example ground truths of the validation set on the evaluated models. We used the simulation configuration of with sensors.
Figure 4.
Visual comparison of the quality of the reconstruction of conductivity distribution from example ground truths of the validation set on the evaluated models. We used the simulation configuration of with sensors.
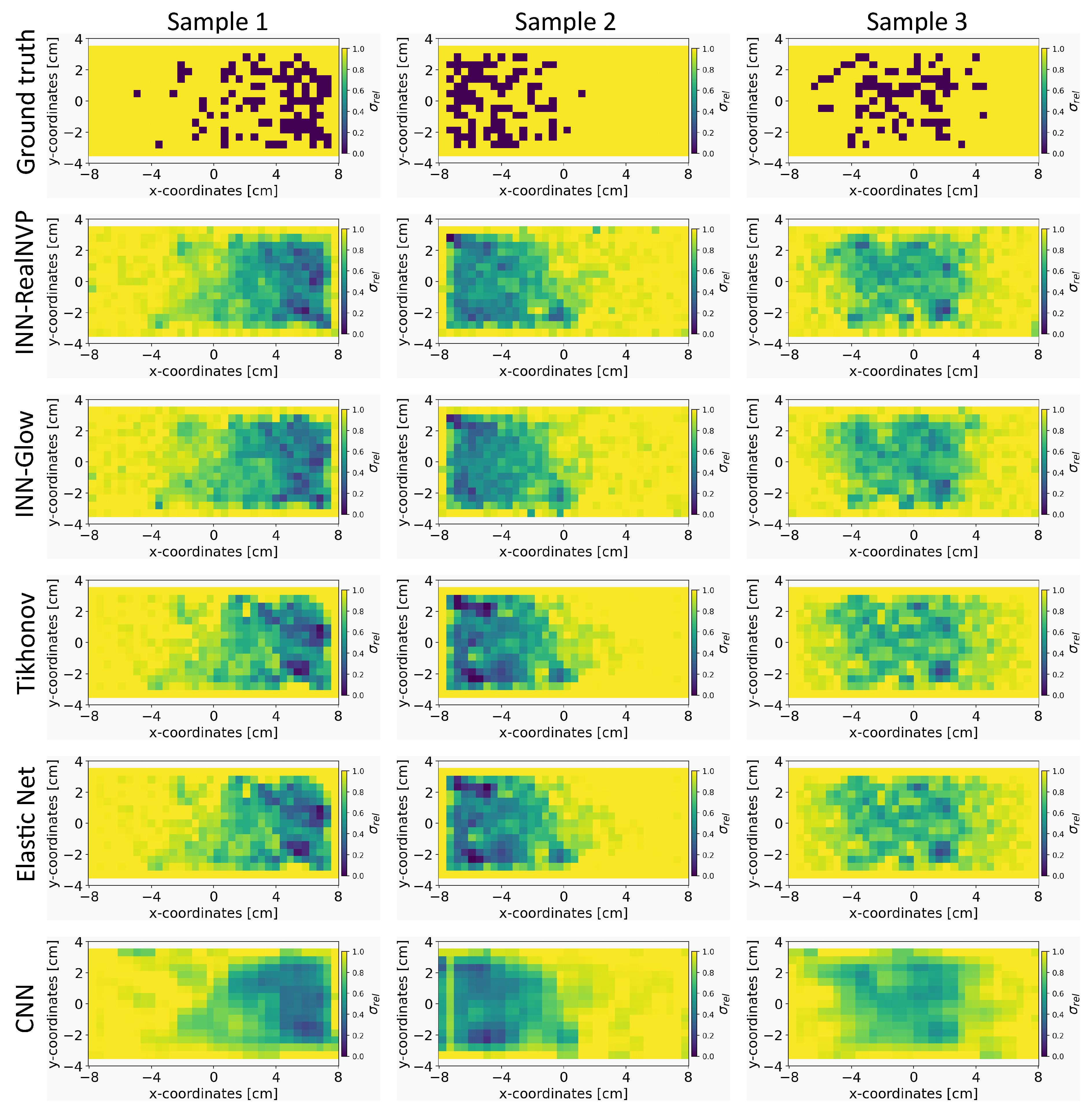
Figure 5.
Comparison of the reconstruction quality of the conductivity distribution for the INN-Glow model after varying the simulation parameters such as distance from the liquid metal d and the number of sensors M.
Figure 5.
Comparison of the reconstruction quality of the conductivity distribution for the INN-Glow model after varying the simulation parameters such as distance from the liquid metal d and the number of sensors M.
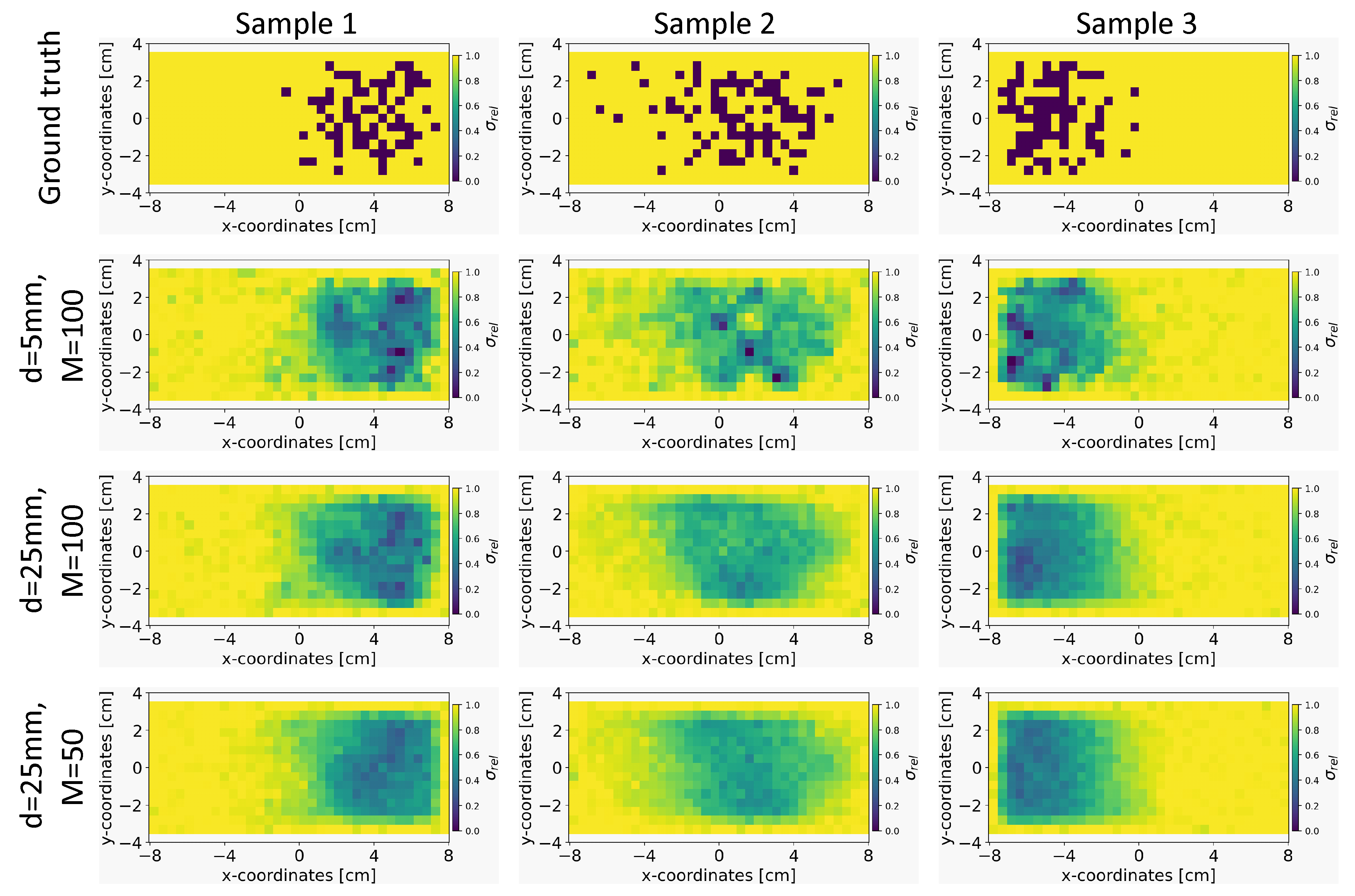
Figure 6.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the INN-Glow model at different noise levels with mm, sensors and . The INN-Glow model is trained with magnetic flux density measurements that have no noise in the sensor readings.
Figure 6.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the INN-Glow model at different noise levels with mm, sensors and . The INN-Glow model is trained with magnetic flux density measurements that have no noise in the sensor readings.
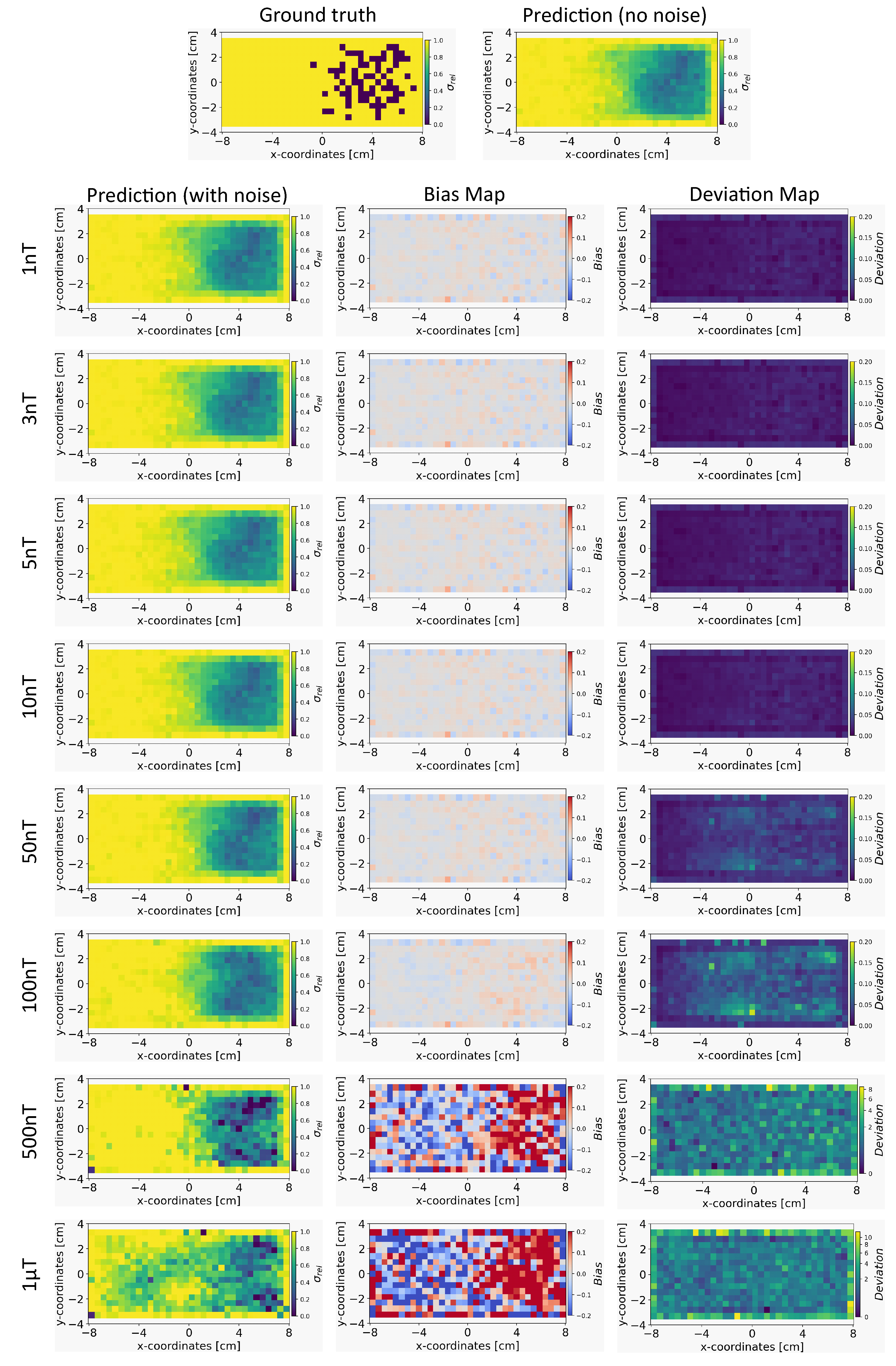
Figure 7.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the Tikhonov model at different noise levels with mm, sensors and . The Tikhonov model is fitted with magnetic flux density measurements that have no noise in the sensor readings.
Figure 7.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the Tikhonov model at different noise levels with mm, sensors and . The Tikhonov model is fitted with magnetic flux density measurements that have no noise in the sensor readings.
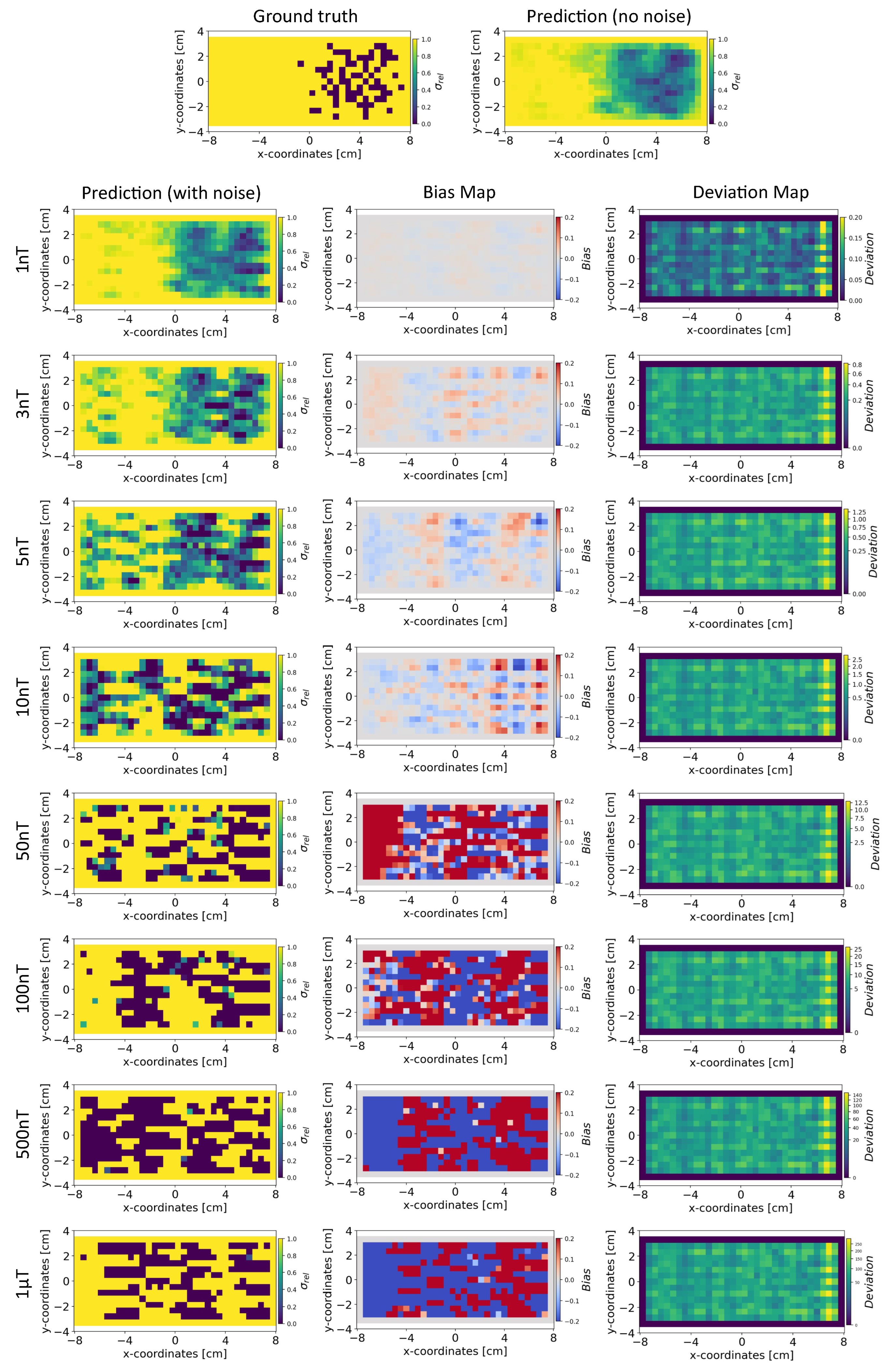
Figure 8.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the INN-Glow model at different noise levels with mm, sensors and . The INN-Glow model is trained with magnetic flux density measurements that have ± uniformly distributed noise in the sensor readings.
Figure 8.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the INN-Glow model at different noise levels with mm, sensors and . The INN-Glow model is trained with magnetic flux density measurements that have ± uniformly distributed noise in the sensor readings.
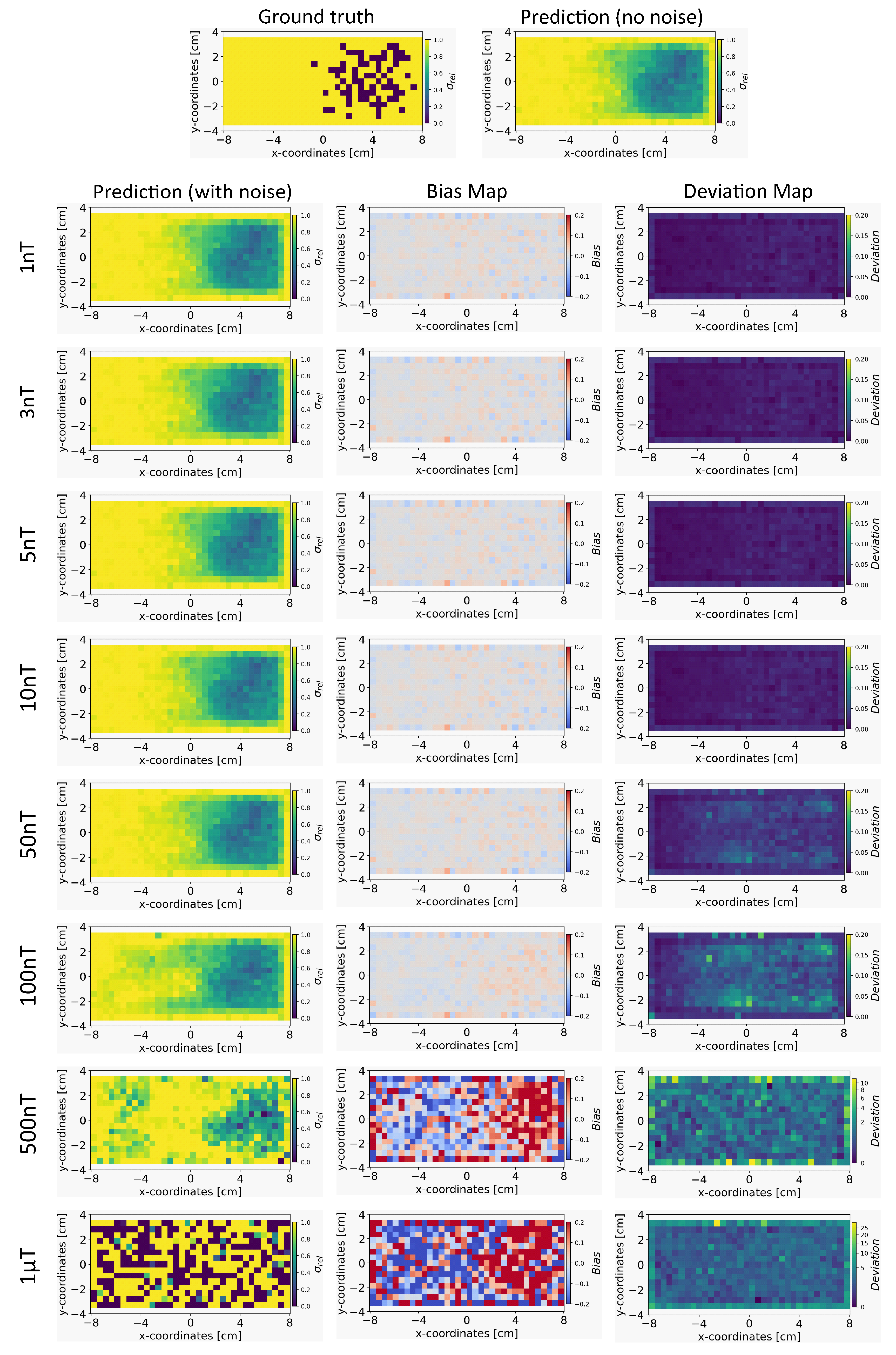
Figure 9.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the Tikhonov model at different noise levels with mm, sensors and . The Tikhonov model is fitted with magnetic flux density measurements that have ± uniformly distributed noise in the sensor readings.
Figure 9.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the Tikhonov model at different noise levels with mm, sensors and . The Tikhonov model is fitted with magnetic flux density measurements that have ± uniformly distributed noise in the sensor readings.
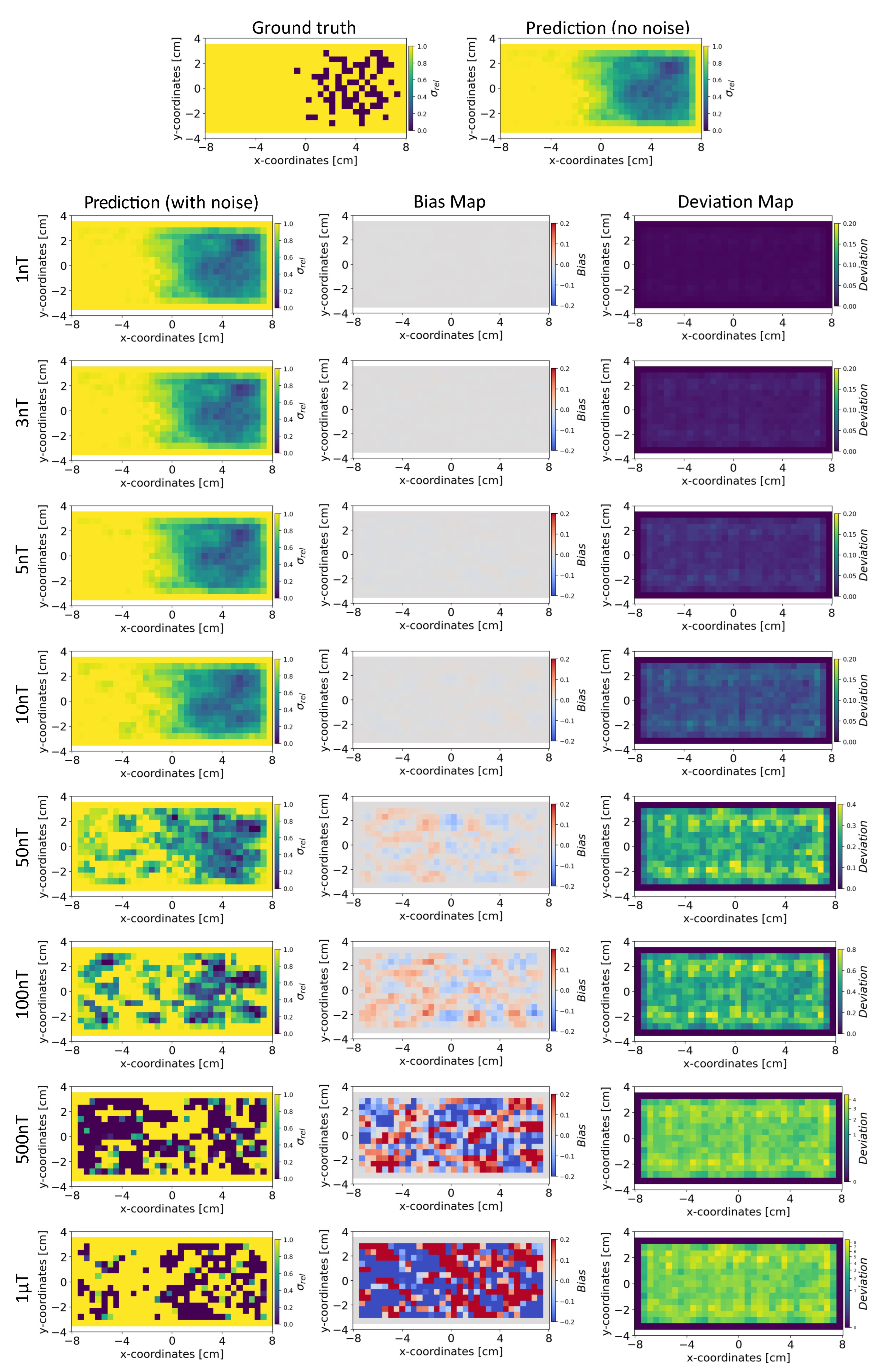
Figure 10.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the INN-Glow model at different noise levels with mm, sensors and . The INN-Glow model is trained with magnetic flux density measurements that have ± uniformly distributed noise in the sensor readings.
Figure 10.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation maps (right column) obtained from the INN-Glow model at different noise levels with mm, sensors and . The INN-Glow model is trained with magnetic flux density measurements that have ± uniformly distributed noise in the sensor readings.
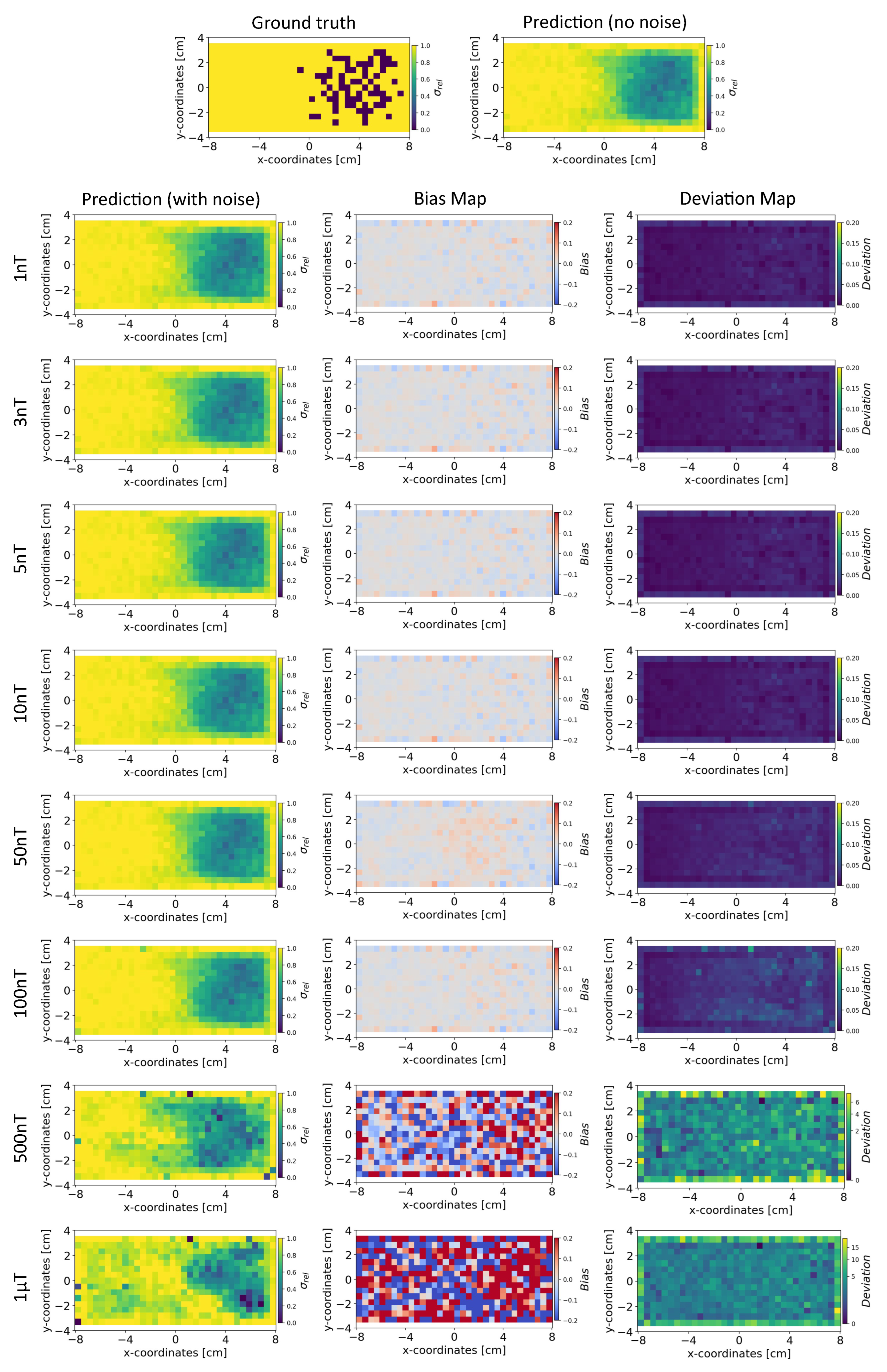
Figure 11.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation Maps (right column) obtained from the Tikhonov model at different noise levels with mm, sensors and . The Tikhonov model is fitted with magnetic flux density measurements that has ± uniformly distributed noise in the sensor readings.
Figure 11.
The figure shows the reconstruction of the conductivity maps (left column) and the corresponding bias (middle column) and deviation Maps (right column) obtained from the Tikhonov model at different noise levels with mm, sensors and . The Tikhonov model is fitted with magnetic flux density measurements that has ± uniformly distributed noise in the sensor readings.
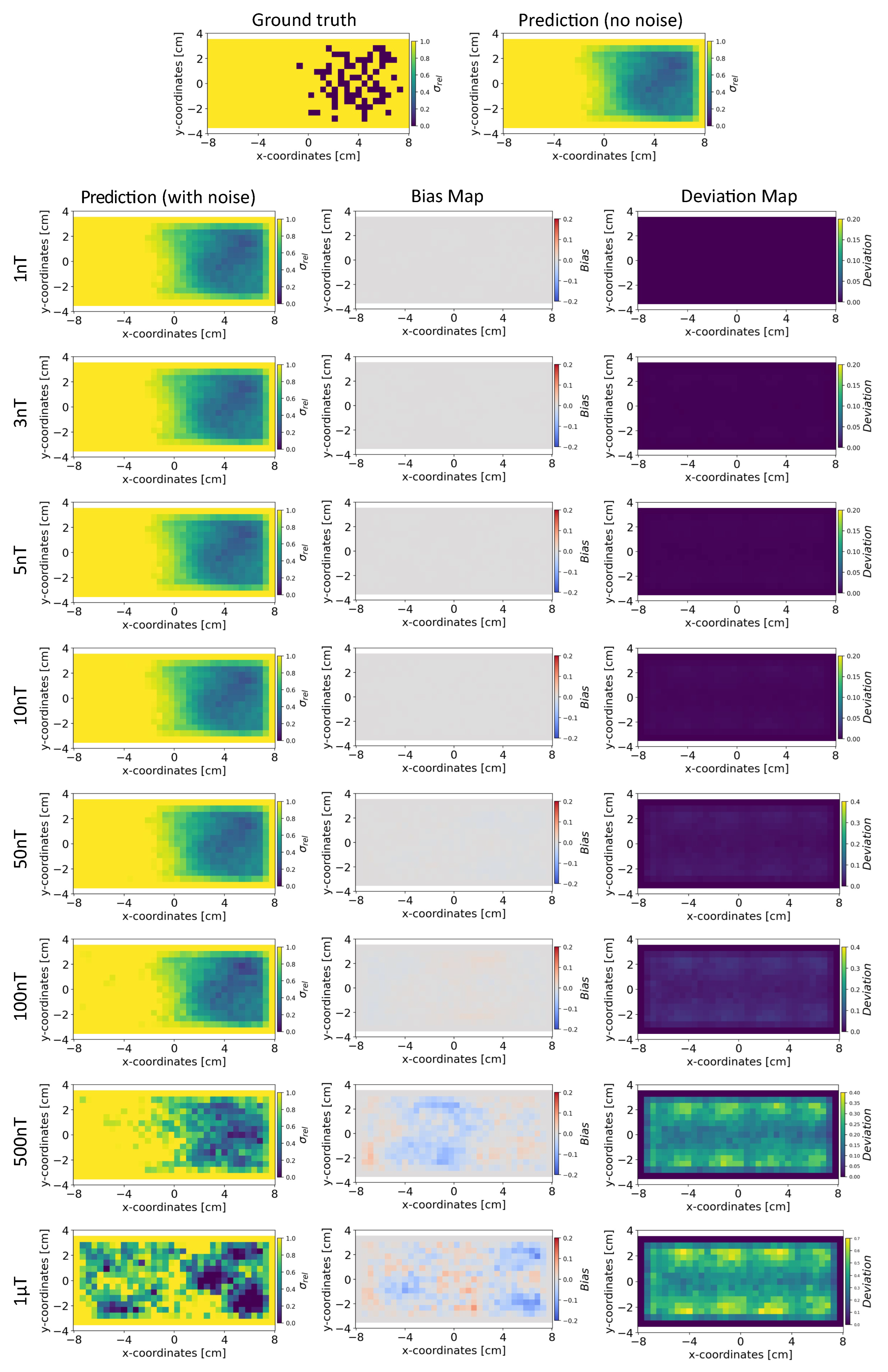
Figure 12.
The figure shows the bias and deviation maps for INN-Glow and Tikhonov models after varying the parameter . The results are for the validation ground truth example in Figure 6. We used the noise range ± in the sensor data, and no noise was added during the training.
Figure 12.
The figure shows the bias and deviation maps for INN-Glow and Tikhonov models after varying the parameter . The results are for the validation ground truth example in Figure 6. We used the noise range ± in the sensor data, and no noise was added during the training.
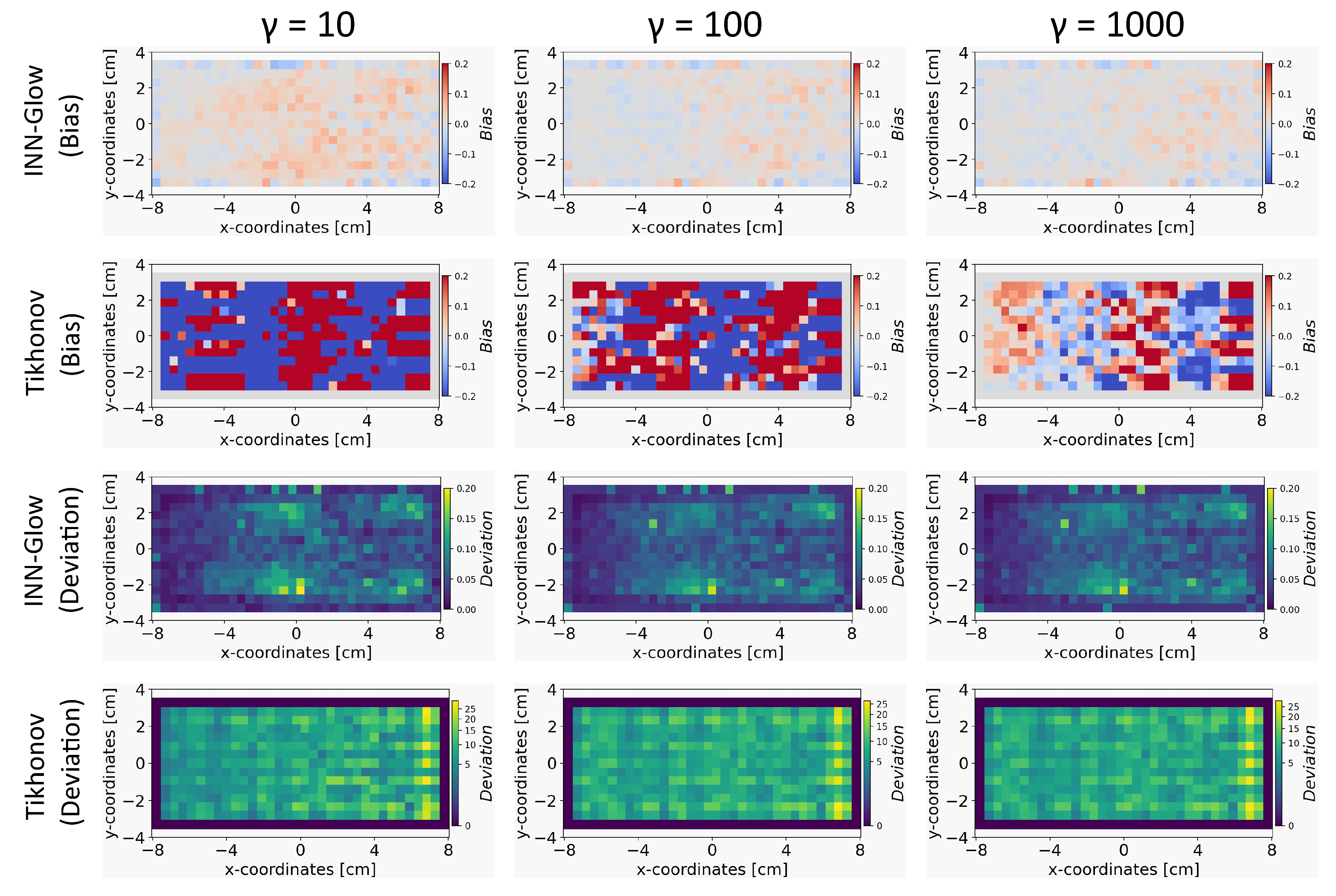
Figure 13.
The figure shows the results after random sampling from the latent space of the INN-Glow model. The bottom row shows examples of the reconstructed conductivity distribution after varying . The model is trained with the magnetic flux density measurements consisting of no noise in training and validation data and simulation parameters are , sensors.
Figure 13.
The figure shows the results after random sampling from the latent space of the INN-Glow model. The bottom row shows examples of the reconstructed conductivity distribution after varying . The model is trained with the magnetic flux density measurements consisting of no noise in training and validation data and simulation parameters are , sensors.
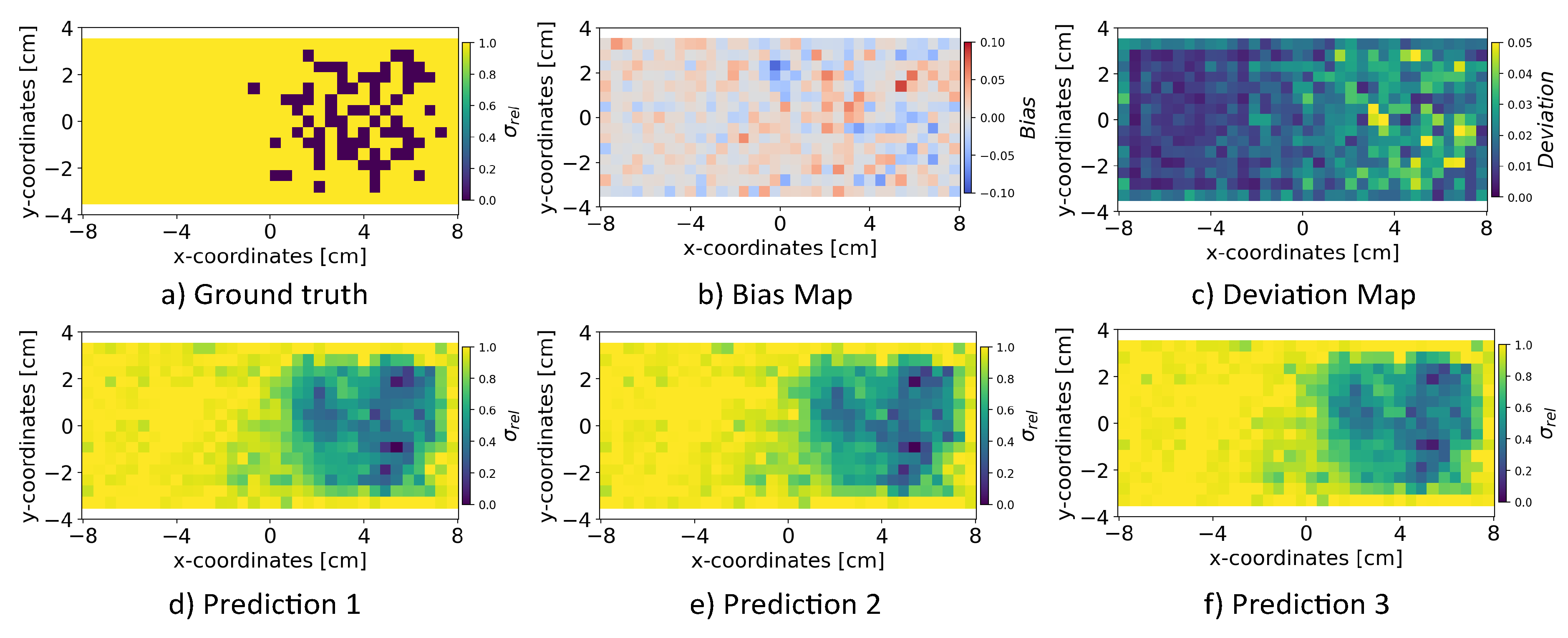
Figure 14.
The validation loss curves of multiple instances of the INN-Glow models with varying numbers of coupling blocks, denoted as k and under varying values of the parameters d and M.
Figure 14.
The validation loss curves of multiple instances of the INN-Glow models with varying numbers of coupling blocks, denoted as k and under varying values of the parameters d and M.
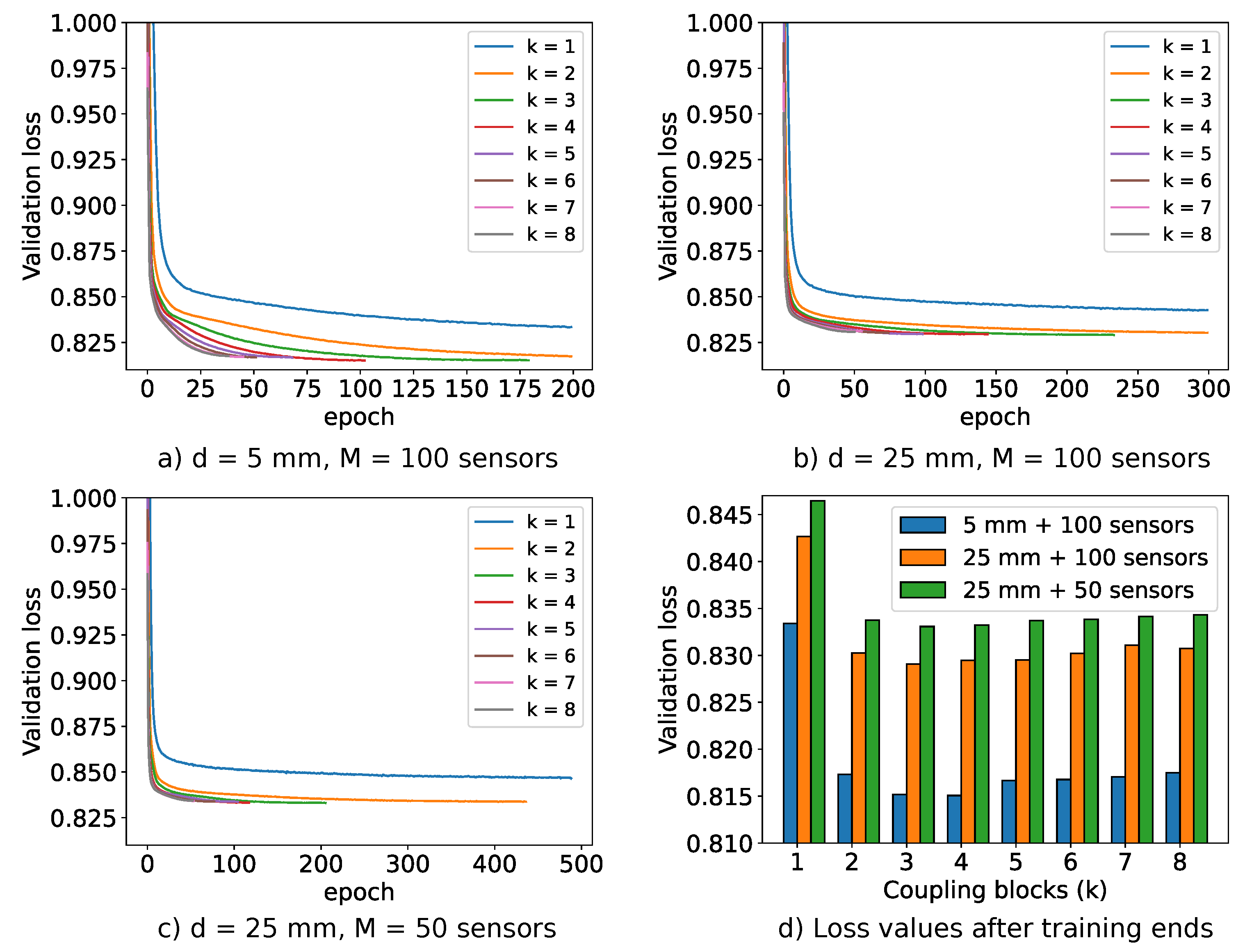
Figure 15.
The figure shows the distribution of log-likelihood scores for all the validation ground truth conductivity samples with respect to the probability distribution of binary ensemble maps via random error diffusion. The left and right figures are for ensemble count of 100 and 1000, respectively.
Figure 15.
The figure shows the distribution of log-likelihood scores for all the validation ground truth conductivity samples with respect to the probability distribution of binary ensemble maps via random error diffusion. The left and right figures are for ensemble count of 100 and 1000, respectively.
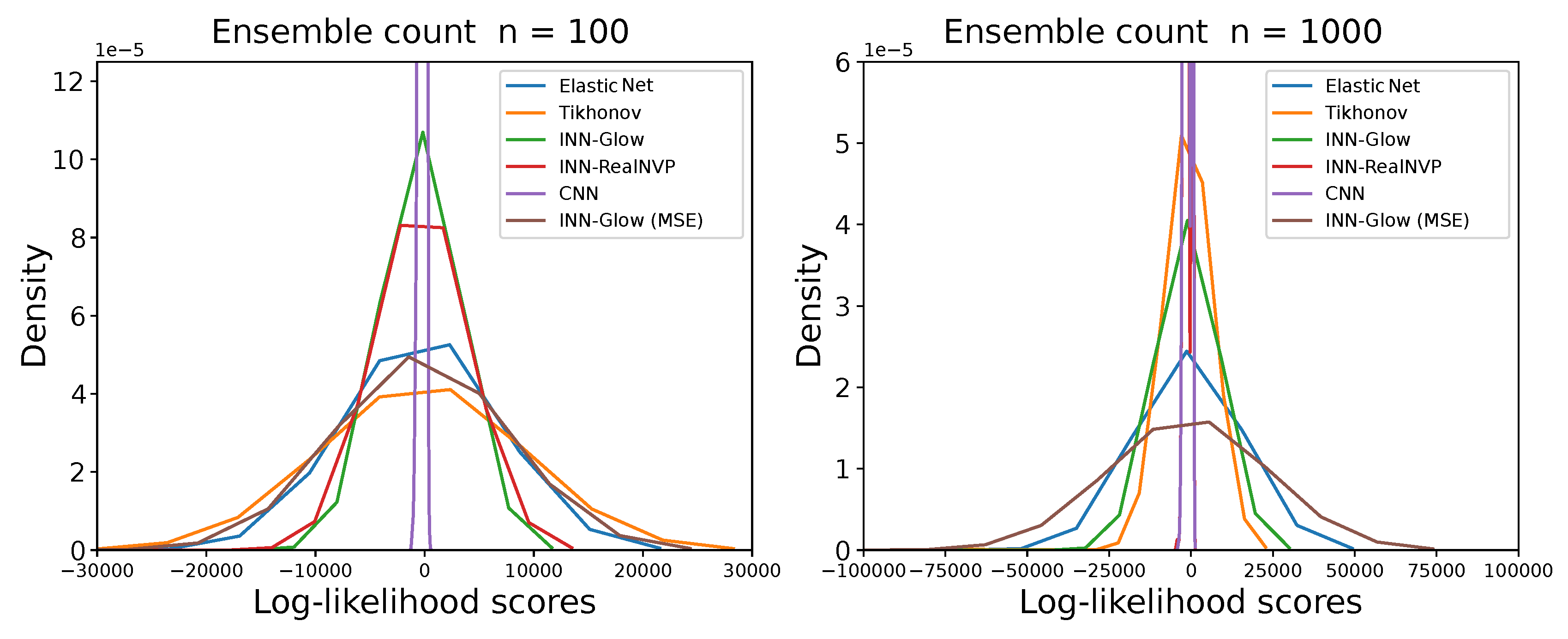

Table 1.
Average Peak Signal-to-Noise ratio for the validation set of the ground truth magnetic flux density data. The distance of the sensors from the liquid metal is with sensors.
Table 1.
Average Peak Signal-to-Noise ratio for the validation set of the ground truth magnetic flux density data. The distance of the sensors from the liquid metal is with sensors.
 |
Table 2.
Architecture of the developed Convolutional Neural Network (CNN) for the simulation configuration of sensors and the sensor distance of from the liquid metal.
Table 2.
Architecture of the developed Convolutional Neural Network (CNN) for the simulation configuration of sensors and the sensor distance of from the liquid metal.
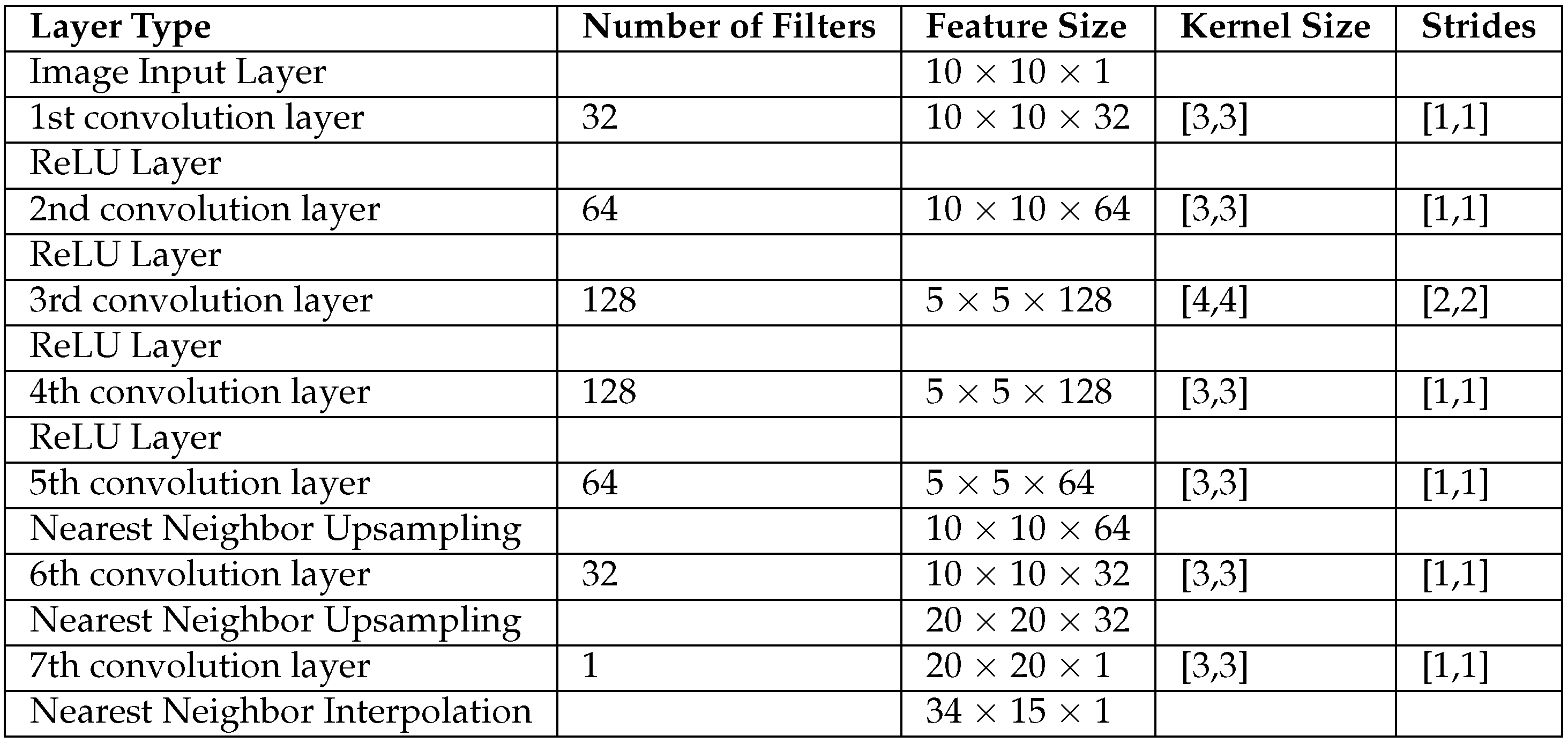 |
Table 3.
Averaged Log-Likelihood scores based on Random Error Diffusion from the validation ground truth samples. The simulation parameters are fixed at and sensors.
Table 3.
Averaged Log-Likelihood scores based on Random Error Diffusion from the validation ground truth samples. The simulation parameters are fixed at and sensors.
 |
Table 4.
Average bias and deviation scores with respect to all the validation ground truth at d = 25 , sensors and = 100 for different noise levels. The model is INN-Glow, and the training data is without the presence of noise in the sensor readings.
Table 4.
Average bias and deviation scores with respect to all the validation ground truth at d = 25 , sensors and = 100 for different noise levels. The model is INN-Glow, and the training data is without the presence of noise in the sensor readings.
 |
Table 5.
Average bias and deviation scores with respect to all the validation ground truth geometries at mm, sensors, noise level fixed at ± and varying . The results are from the INN-Glow model and the training data is without the presence of noise in the sensor readings.
Table 5.
Average bias and deviation scores with respect to all the validation ground truth geometries at mm, sensors, noise level fixed at ± and varying . The results are from the INN-Glow model and the training data is without the presence of noise in the sensor readings.
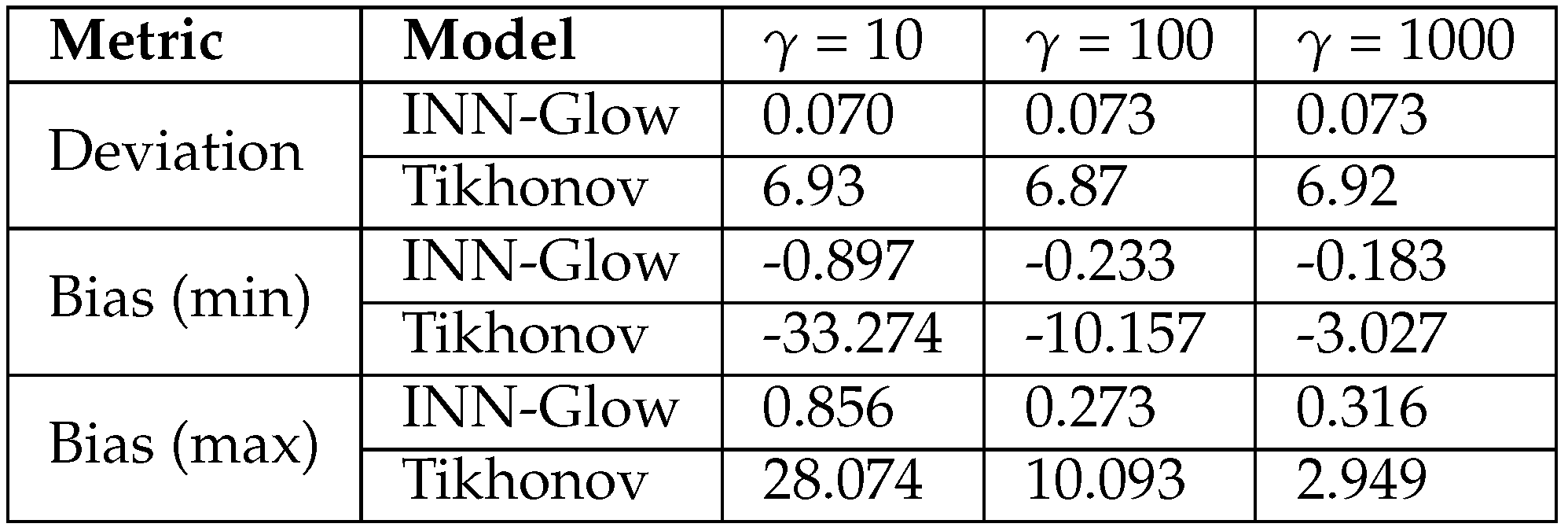 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



