
Submitted:
29 September 2023
Posted:
09 October 2023
Read the latest preprint version here
Abstract
Generative AI has gained enormous interest nowadays due to new applications like chatGPT, DALL E, Stable Difussion and Deep Fake. Particularly DALL E, Stable Difussion and others (Adobe Firefly, ImagineArt...) are able to create images from a text prompt and are also able to recreate real photographs. Due to this fact, intense research has arisen to create new image forensics applications able to distinguish between real captured images and videos and artificial ones. Detecting forgeries made with Deep Fake is one of the most researched issues. This paper is about another kind of forgery detection. The purpose of this research aims to detect photo realistic AI created images versus real photos coming from a physical camera. For this purpose, techniques that perform a pixel level feature extraction are used. First one is Photo Response Non-Uniformity (PRNU). PRNU is a special noise due to imperfections on the camera sensor that is used for source camera identification. The underlying idea is that AI images will have a different PRNU pattern. Second one is Error level analysis (ELA). This is other type of feature extraction traditionally used for detecting image editions. In fact, ELA is being used nowadays by photographers to detect manually AI created images. Both kinds of features are used to train Convolutional Neural Networks to differentiate between AI images and real photographs. Good results are obtained achieving accuracy rates over 95%. Both extraction methods are carefully assessed by computing precision/recall and F1-score measurements.
Keywords:
Artificial intelligence
; AI images
; photographs
; PRNU
; ELA
; CCN
; deep learning.
1. Introduction
Nowadays generative artificial intelligence is one of the top themes of computer engineering research. The emergence of transformers [1,2] as a key tool for generating content has opened a world of new applications where automated systems are able to create productions that, until now, were exclusive of human authorship. Transformers were first used for automated translation systems, where a first processing stage (the encoder) transforms the input text into a numerical representation of text meaning; then a second stage (the decoder) converts (like an inverse transform) those intermediate data into text in another language [3].
Besides neural machine translators, other impressive applications have arisen. Famous chatGPT is a conversational engine created with a decoder transformer [4,5]. Using also transformers, models for translating regular text into images have also been developed. Most known and documented examples of these last ones are DALL E [6,7] and Stable Diffusion [8]. But other examples have quickly been released like: OpenArt [9], ImagineArt [10], Adobe Firefly [11] and many others.
These artificial image generators have reached the point where they may create photo realistic images that can make humans to hesitate if a particular image is really coming from a camera or is an artificial creation. As an example, in Figure 1, three IA created images are presented. They have been created by three different engines: DALL E 2, Stable Diffusion and OpenArt (after testing many applications, these three were found the most appropriate for photorealistic images; other models are good on producing drawings or illustrations, not so much on imitating real photographs). Prompt was the same for the three images: “realistic photo, a portrait of a dog in a library, Sigma 85 mm f/1.4”. Note that details about lens have been added (85 mm focal lens, f/1.4 numeric aperture), this is a common trick used for getting more realistic results.
Other impressive AI application is Deep Fake [12,13]. Deep Fake is able to create photos and videos mixing plausibly information from previous photos and/or videos. For example, creating a video of a person mixing the body from one given individual and the face of another one. The potential danger of this technology being used for fraud or other illegal purposes (defamation, pornography…) has sparked much research on the field of detecting Deep Fake image creation [14]. For example, in [15], Rössler et al start by creating a large dataset of fake videos. In [16], authors exploit what it is, perhaps, the most intuitive method: finding image artifacts that can reveal synthetic content. In [17] a system called “FakeCatcher” is described; this system works relying on biological signals, like the small periodic color variations present in a real face video by cause of the person’s heart rate. Almost all publications in this field claim that direct use of neural networks does not produce good results in these kinds of applications. In [18], authors use detection of “convolutional traces”, basing themselves on the fact that AI generated images have passed several convolution stages.
The work described in this paper is similar to Deep Fake detection but with a different purpose. The Target is to automatically detect AI generated photo realistic images, id Est: distinguishing AI images from real photographs. This can be interesting for classifying images in photography websites and/or in social networks. Note that, in this case, the system is dealing with all kind of images: human faces, animals, still nature, landscapes… For this reason, it is not possible to rely on some of the “face related” characteristics. Relying on artifacts may work for some images but not for all. Artifacts are common in artificial images within some detailed parts (the fingers of a person’s hand, pedals of a bike), but in many images there are no visible errors. What’s more, there are some evident errors, like persons with three hands or even with two heads, which are evident for human view but not so easy to automate in an autonomous recognition system for any type of image.
For this particular application, there are much less references in the literature. In a recent preprint [19], authors propose a method for AI images detection using a complex feature extraction based on two parallel deep learning processes. Results are similar to the ones presented in this paper, but they are using a more complex method and their tests have been conducted on images of smaller resolution (maximum 256x256). Other references [20-22] focus on CG (Computer Generated) images, which is another type of problem as they are dealing with images that were created with intensive human intervention.
For this reason, the system has been designed based on methods from other image forensics applications. The main idea is extracting some relevant information from images before applying a convolutional neural network. Convolutional Neural Networks CCN’s are very useful in distinguishing between classes that are visually different for humans like digit classification [23,24], distinguishing objects relevant for taking driving decisions in real traffic and many other similar applications [25]. Nevertheless, in this case, classes are not visually different and that suggests that direct application of CNN’s could not be very useful (besides the experience from the Deep Fake case). For this reason, pixel wise feature extraction has been used. This means using processing stages that convert images into other images with the same size (it converts each pixel to a new pixel) but containing a reduced amount of information that should be relevant to the particular problem of distinguishing AI images.
Methods used for this issue are, up to date, two. First one is Photo Response Non-Uniformity (PRNU). PRNU is in fact a kind of noise used for source camera identification (distinguishing the camera that has taken a given image) [26]. The origin of PRNU is the slightly different sensitivity of individual pixels in a real image sensor. This effect is due to manufacturing imperfections and it is unavoidable. AI images should have no PRNU at all. Nevertheless PRNU computation methods always yield some nonzero result. PRNU has been extensively studied, including its limitations [27,28]. CNN is trained to infer special characteristics of AI images with false PRNU patterns. There exist applications designed for erasing or even forging PRNU patterns (embedding on an image the pattern of a given camera) [29]. So this is a method that can reveal images created by “not very expert” or “not very malicious” users.
The second feature extraction method used is Error Level Analysis (ELA). ELA is a special image (or pattern) that detects irregular errors in JPEG coded images. ELA has been successfully used to detect editions in images (thus to authenticate scanned or photographed images) [30,31]. ELA has also been applied for forged face detection [32]. Basically, ELA detects non uniformity in quantization errors due to JPEG compression. Applied to an AI generated image, ELA normally yields a strange result as if all pixels of the image would have been modified by edition. This could be due to the special nature of AI images coming from training with many JPEG coded photographs. So, ELA pattern is also a good choice for the application that this paper is addressing. It would seem that this method also has a limitation: all images, either coming from a real camera or from an AI engine, must be obtained in JPEG format. It would not be a great drawback as JPEG is the most frequent photography format. Nevertheless, as seen in the remainder of this paper, ELA has been successfully tested on AI images obtained in PNG format.
2. Materials and Methods
2.1. The Dataset
The dataset used in this work for training and testing is composed of a collection of images divided in two groups (or classes): AI generated and real camera photographs. First, AI generated images were created by authors using three different engines: DALL E, Stable Diffusion and OpenArt. These images were visually checked to discard those that were not photo-realistic. Second, real photos were selected randomly from image databases. There are images from Dresden Image Database [33], also from VISION dataset [34] and also from authors’ provided images that were already used in previous studies [28,35]. There are real photos from the following cameras: Canon Ixus 70 (two instances), Casio Ex Z150 (two instances), Canon PhotoSmart SX720, Canon EOS 1100D, Kodak M1063 (two instances) and Sony ILCE 5000. Photos from smartphones are also included: Huawei P20, Huawei P9, Samsung Galaxy S3 Mini, Apple Iphone 4s, Apple Iphone 5c, Apple Iphone 6 and LG D290.
Initially, the dataset was made up of 459 AI generated images and the same number of real photographs (a total of 918 images). Afterwards, an extended dataset of 1252 was tested. Both datasets are fully balanced (same number of samples on each class). On each test a percentage of dataset samples will be used for training, leaving the remainder for validation.
2.2. PRNU extraction
As the name: Photo Response Non-Uniformity, indicates PRNU comes from the different light sensitivity of the different pixels (elementary sensors). This is an unavoidable characteristic due to manufacturing imperfections and it is present on all image sensor chips. PRNU is seen as a multiplicative noise that responds to the following equation [22]:
where Imin is the “real” image presented to the camera (the incident light intensity), Iones is a matrix full of ones and Noisecam is the “sensor noise pattern” (PRNU pattern) and Imout is the final image surrendered by the camera. The symbol “.” means matrix point by point (pixel-wise) product and Noiseadd is additive noise from other sources.
PRNU is computed from an image (or from a collection of images coming from the same camera) performing a denoising process on Imout, and then computing a residual:
Neglecting the additive noise and assuming that Imin = denoise(Imout), given a collection of images from the same camera, the PRNU pattern (sometimes called camera fingerprint) can be estimated as:
Note that, in this application, we will always compute PRNU fingerprints with a single image (N=1) both for AI generated and for real images. In this case, F=W/Imin (pixel wise quotient) and it is clear that we will get some result, even for AI images.
Note that “denoising” is a noise reduction filter. For this problem, there are several options documented in the literature: median filter [32], Wiener filter [33], variations of Wiener filter. In this study, a Matlab [34] implementation from [35] is used, this software uses a Wavelet Transform [36] based Wiener filter.
From each image, a centered square 512x512 region is extracted to work with smaller images and to avoid logos or visible watermarks (that anyway are not present on the dataset images) and PRNU is computed from the sub-image.
The results of this process are noise like images very difficult to be interpreted visually (see Figure 2). Note that equation 2 can be seen as a high pass filter and so, the results contain part of image contours (a normal phenomenon when computing the pattern from a single image). There seems to be no visible difference between AI images: (a), (b) and (c) and real ones: (d), (e) and (f).
2.3. ELA Error Level Analysis
ELA pattern is computed to detect irregular distributions of quantization noise. This is a tool normally used to detect image editions. An ELA pattern is normally computed coding the whole image with JPEG standard at a known, constant, normally at a high-quality level (a typical value is 95%); then the decoded image from the JPEG bit stream is subtracted from the original image.
If we are facing an edited image, an irregular pattern with different intensities will appear. In Figure 3, ELA patterns for the same original images of Figure 2 are shown.
Note that, in this case, patterns are color images. For PRNU computation, images are converted to grayscale, prior to all processing. Images are again cropped to the central square sub-image of size 512x512.
Again, a “high pass filtering” effect is evident. Visual differences between AI images AI images: (a), (b) and (c) and real ones: (d), (e) and (f); are again not very remarkable. Perhaps, contours are more evident in the above part but it does not seem conclusive. Nevertheless, neural networks can be able to learn differences that are not perceived by humans.
2.4. CNN’s Convolutional Neural Networks
CNN’s are basically a cascade of convolutional (or linear filtering) stages accompanied by others of non-linear activation, normalization and decimation. These stages extract high level features from low level data (pixels) and so, CNN’s are able to process images directly with no need of feature extraction. The initial image is repeatedly filtered and decimated, creating a set of several small images that are finally processed by a classical perceptron (fully connected) stage to get the final result. This final result is a numerical vector of as many components as classes to be recognized. The Softmax normalization (the most frequently used at final stage of CNN’s) makes that vector components lie in the range 0.0-1.0 and besides, they always add up to 1.0. The maximum component defines which one is the recognized class.
Filter coefficients and perceptron weights are all optimized through the training process.
In this paper, a previous image to image transformation is done that acts as a pixel-wise feature extraction. This stage tries to search for relevant characteristics for distinguishing classes, removing unimportant information. As reported in the case of Deep Fake detection, direct CNN application is not good for this type of problem.
The dataset is divided randomly, selecting 85% images of each class for training and leaving the rest for validation. Note that the dataset is balanced (it has the same number of samples for each class). A validation stage is performed at each training epoch, adequately controlling the learning process. Each complete epoch (run of all training samples in random order) is divided into n iterations. Each of the iterations is a mini-batch, this is: a set of samples that is processed without updating weights (mini-batch size is DatasetSize/n). Testing values for n, optimum results were obtained for n=3.
CNN structure: the number of stages and filter configuration at each stage is shown in Figure 4. And it is the same for the two kinds of pattern extraction techniques tested.
At the end of training, a confusion matrix is computed for the validation set. This means, counting the number of True-Positive (AI images correctly detected), False-Negative (AI images not detected), False-Positive (real photographs detected as AI) and True-Negative (real photographs detected as real). The matrix is arranged in this manner:
From this matrix, several performance measurements can be computed:
Accuracy is simply the success rate. The other three parameters are very easy to interpret and are very typical in classification systems: P (Precision) would be the probability of true detection for true cases; R (recall) would be the probability for effective detection of true cases. F1-score is the harmonic mean of P & R. Obviously, the greater these quantities are, the better performance is achieved.
3. Results
CNN nets were trained and tested for both types of feature extraction. This process produces learning curves displayed in Figure 5 and Figure 6. In both cases, a good result is achieved: accuracy is 0.95 for PRNU and 0.98 for ELA. Both trainings have been done with 100 epochs. Training time is bigger for the ELA case (167 minutes versus 109), this is reasonable because ELA images are color ones with three times more information.
Blue curves in both figures are the accuracy values obtained for each iteration (measured on the training samples), black curves are accuracy values for the validation set at each epoch (an epoch is equal to n iterations, with n=3 in this case). The curves below (brown and black) are the mean square error (over training and validation set), this is other method for controlling learning.
In both cases, the fact that black curves follow the evolution of blue/brown curves demonstrates that neural net is generalizing. In the case of overfitting, the blue curve can go high but the black curve would remain low.
Comparing both trainings, ELA offers more stable results.
Final results for both methods (confusion matrices) are:
These matrices yield the following numbers in the P, R and F1 terms, see Table 1.
Results demonstrate again that both methods are good but ELA outperforms PRNU with a slight advantage. These results were obtained with a reduced dataset of 459 images per class. Afterwards, a new test was conducted using an extended version with 626 samples per class. This test was only done with the ELA extraction (the best option). Learning curve is presented in Figure 7. In this case the n parameter was set to 5 because with more samples, it is necessary to reduce batch size. Number of epochs is 75 because in previous tests, it was seen that learning for ELA features was already getting stable at that point.
New assessment data for ELA features improve slightly, accuracy is 0.99, Precision is 0.99, recall es 1.0 and F1 score is 0.99. Confusion matrix becomes:
4. Discussion
In this work, an automated system for detecting AI created images and distinguishing them from real camera photographs has been created.
Direct use of CNN’s over the images seemed not very recommendable, but extracting pattern-like (or pixel-wise) features like PRNU or ELA patterns yields good results. ELA patterns work slightly better.
As supplementary results:
- A new dataset on AI created images has been created. This set could be augmented and published as a separate result.
- A graphical demo application has been created, see Appendix A.
Author Contributions
Initial concept, AI images creation, software development: Fernando Martín-Rodríguez and Mónica Fernández-Barciela. CNN structure design: Rocío García-Mojón. Writing and revising: Fernando Martín-Rodríguez and Mónica Fernández-Barciela.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable (study not involving humans or animals).
Informed Consent Statement
Not applicable (study not involving humans or animals).
Data Availability Statement
Some data from public image databases: Dresden Image Database and Vision dataset. Other images were created by authors and are available upon request.
Acknowledgments
authors wish to thank all personnel in AtlantTIC research center for their support.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
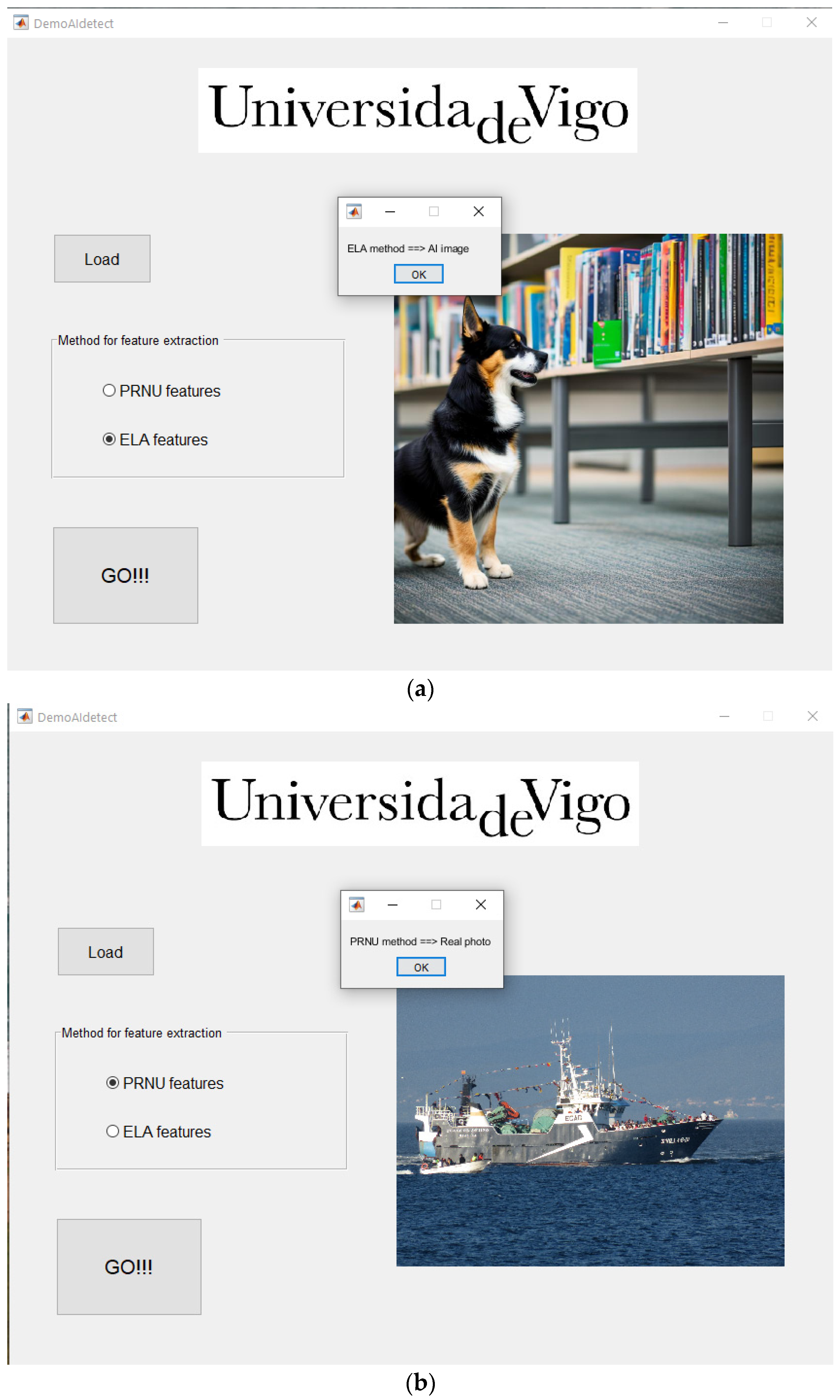
A demonstration application has been created using matlab GUI design tools. This app allows loading an image, choosing the preferred method (PRNU or ELA) and running the classifier. Result is output using a message box. See Figure A.1.
Figure A.1.
Graphical demo application. (a) Detection of AI image with ELA method. (b) Real photo detection with PRNU method.
Figure A.1.
Graphical demo application. (a) Detection of AI image with ELA method. (b) Real photo detection with PRNU method.
References
- Vaswani, A. et al. Attention is All You Need. In Proceedings of Neural Information Processing Systems (NIPS 2017), Long Beach (Ca, U.S.A.),December 2017.
- Vaswani, A. et al. Attention is All You Need. Preprint in arXiv (2017). [CrossRef]
- Tensor flow official tutorial, Neural machine translation with a Transformer and Keras. https://www.tensorflow.org/text/tutorials/transformer?hl=en, last access: September, 19th, 2023.
- Shahriar, S.; Hayawi, K. Let's have a chat! A Conversation with ChatGPT: Technology, Applications, and Limitations. Preprint in arXiv (2023). [CrossRef]
- Shahriar, S.; Hayawi, K. Let's have a chat! A Conversation with ChatGPT: Technology, Applications, and Limitations. Artificial Intelligence and Applications. Vol 1(1), January 2023. [CrossRef]
- Ramesh, A. et al, Hierarchical Text-Conditional Image Generation with CLIP Latents. Preprint in arXiv (2022). [CrossRef]
- Marcus, G., David E., Aaronson S., A very preliminary analysis of DALL-E 2. Preprint in arXiv (2022). [CrossRef]
- Ho, J., Jain A., Abbeel P., Denoising Diffusion Probabilistic Models. Preprint in arXiv (2020). [CrossRef]
- https://openart.ai/home , last access 21st-Sept-2023.
- https://www.imagine.art/, last access 21st-Sept-2023.
- https://www.adobe.com/es/sensei/generative-ai/firefly.html, last access 21st-Sept-2023.
- Massod M. et al, Deepfakes Generation and Detection: State-of-the-art, open challenges, countermeasures, and way forward. Preprint in arXiv (2021). [CrossRef]
- Nguyen T.T. et al. Deep learning for deepfakes creation and detection: A survey. In Computer Vision and Image Understanding, Vol 223, 103525 (2022). [CrossRef]
- Rana S. et al. Deepfake Detection: A Systematic Literature Review. In IEEE Access, Vol 10, pp 25494-25513 (2022). [CrossRef]
- Rössler et al. FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces. Preprint in arXiv (2018). [CrossRef]
- Matern, F., Riess C., Stamminger M. Exploiting Visual Artifacts to Expose Deepfakes and Face Manipulations. In 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW-2019), Waikoloa (Hi, USA), 2019. [CrossRef]
- Ciftci U.A., Demir I., Yin L. FakeCatcher: Detection of Synthetic Portrait Videos using Biological Signals. In IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol 42 (July), (2020). [CrossRef]
- Guarnera, L., Giudice O., Battiato S. Fighting Deepfake by Exposing the Convolutional Traces on Images. In IEEE Access, Vol 8, pp 165085-165098 (2020). [CrossRef]
- Xi Z. et al. AI-Generated Image Detection using a Cross-Attention Enhanced Dual-Stream Network. Preprint in arXiv (2023). [CrossRef]
- Cui, Q., McIntosh, S. Identifying materials of photographic images and photorealistic computer generated graphics based on deep CNNs. In Computer Materials and Continua, Vol 55(2), pp 229-241 (2018). [CrossRef]
- He, P. et al. Computer Graphics Identification Combining Convolutional and Recurrent Neural Networks. In IEEE Signal Processing Letters, Vol 25(9), (2018). [CrossRef]
- Wang K. Self-supervised learning for the distinction between computer-graphics images and natural images. In Applied Sciences, Vol. 13(3), pp 1887–1887 (2023). [CrossRef]
- Lecun Y. et al. Gradient-based learning applied to document recognition. In Proceedings of the IEEE, Vol 86(11), pp 2278-2324 (1998). [CrossRef]
- Ghouzam Y. Introduction to CCN Keras – 0.997. https://www.kaggle.com/code/yassineghouzam/introduction-to-cnn-keras-0-997-top-6, last access 21st-Sept-2023.
- Krizhevsky A., Sutskever I., Hinton G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25 (NIPS 2012). https://proceedings.neurips.cc/paper_files/paper/2012, last accessed 21st-Sept-2023.
- Lukas J., Fridrich J., Goljan M. Digital camera identification from sensor pattern noise. In IEEE Transactions on Information Forensics and Security (TIFS), 2006, Vol 1(2), pp 205-214. [CrossRef]
- Pérez-Gonzalez, F., Fernández-Menduiña, S. PRNU-leaks: Facts and remedies. In Proceedings of the 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021.
- Martín-Rodríguez F., Isasi-Vicente F., Fernández-Barciela M. A Stress Test for Robustness of Photo Response Nonuniformity (Camera Sensor Fingerprint) Identification on Smartphones. In Sensors, Vol 23(7), 3462, 2023. [CrossRef]
- https://sourceforge.net/projects/prnudecompare/, last accessed 21st-Sept-2023.
- Abd Warif N.B. et al. An evaluation of Error Level Analysis in image forensics. In 2015 5th IEEE International Conference on System Engineering and Technology (ICSET-2015). Shah Alam (Malaysia), 10-11 August 2015. [CrossRef]
- Gupta A., Joshi R., Laban R. Detection of Tool based Edited Images from Error Level Analysis and Convolutional Neural Network. Preprint in arXiv (2022). [CrossRef]
- Qurat-ul-ain et al. Forged Face Detection using ELA and Deep Learning Techniques. In 2021 International Bhurban Conference on Applied Sciences and Technologies (IBCAST-2021), Islamabad (Pakistan), 12-16 January 2021. [CrossRef]
- Gloe T., Böhme R. The ‘Dresden Image Database’ for Benchmarking Digital Image Forensics. In Proceedings of the 2010 ACM Symposium on Applied Computing, New York (NY, USA), 2010. [CrossRef]
- Shullani D. et al. VISION: a video and image dataset for source identification. In Eurasip Journal on Information Security, Vol 15 (2017). [CrossRef]
- Martín-Rodríguez F. Testing Robustness of Camera Fingerprint (PRNU) Detectors. Preprint in arXiv (2021). [CrossRef]
- G. J. Bloy. Blind camera fingerprinting and image clustering. In IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), Vol. 30(3), pp. 532-534 (2008). [CrossRef]
- H. Ogawa and E. Oja. Projection filter, Wiener filter, and Karhunen-Loève subspaces in digital image restoration. In Journal of Mathematical Analysis and Applications, Vol. 114(1), pp. 37-51 (1986). [CrossRef]
- https://www.mathworks.com/matlab, last accessed 21st-Sept-2023.
- Camera Fingerprint Homepage (from professor Goljan). http://dde.binghamton.edu/download/camera_fingerprint/, last accessed 21st-Sept-2023.
- C.K. Chui. An Introduction to Wavelets, Academic Press, San Diego (1992).
Figure 1.
(a) DALL E 2 image, (b) Stable Diffusion image, (c) OpenArt image.

Figure 2.
(a), (b) and (c), PRNU patterns computed for images of Figure 1. (d), (e) and (f) are examples of PRNU patterns for real images from different cameras.
Figure 2.
(a), (b) and (c), PRNU patterns computed for images of Figure 1. (d), (e) and (f) are examples of PRNU patterns for real images from different cameras.

Figure 3.
(a), (b) and (c), ELA patterns computed for images of Figure 1. (d), (e) and (f) are examples of ELA patterns for real images used to compute Figure 2.

Figure 4.
(a) CNN structure used. (b) Layers diagram. (c) Matlab code used to define net structure.
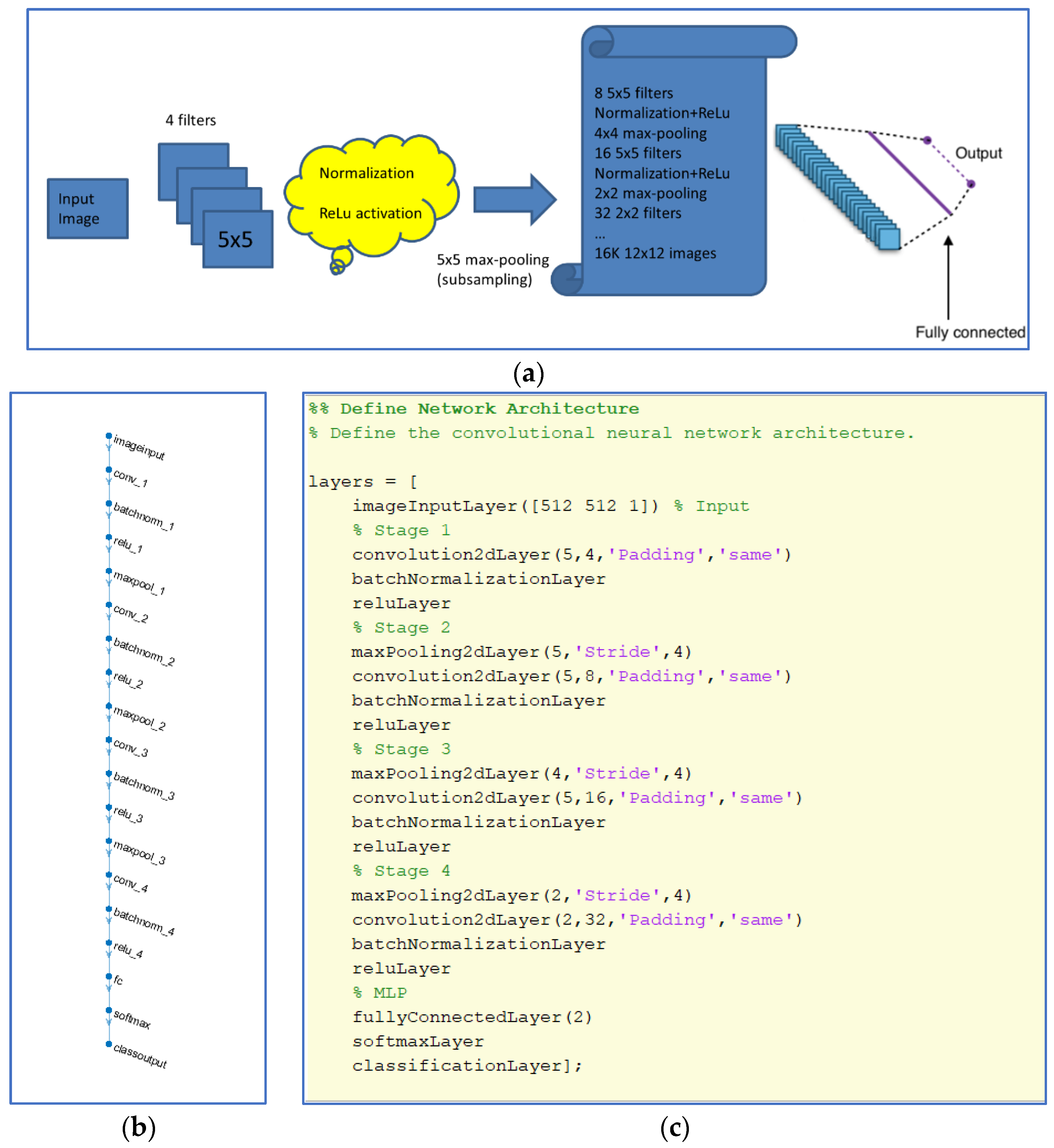
Figure 5.
CNN training for PRNU patterns.
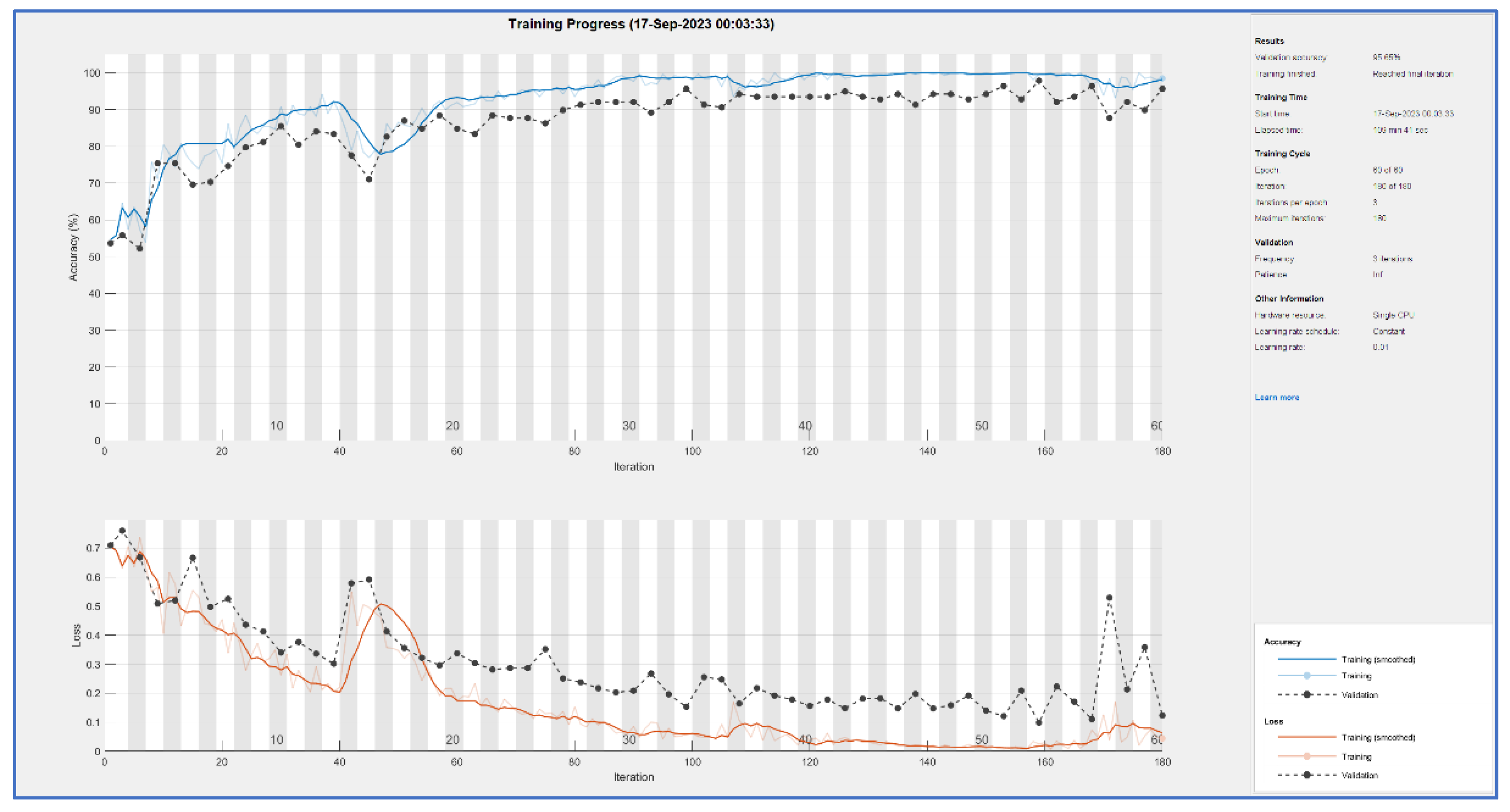
Figure 6.
CNN training for ELA patterns.
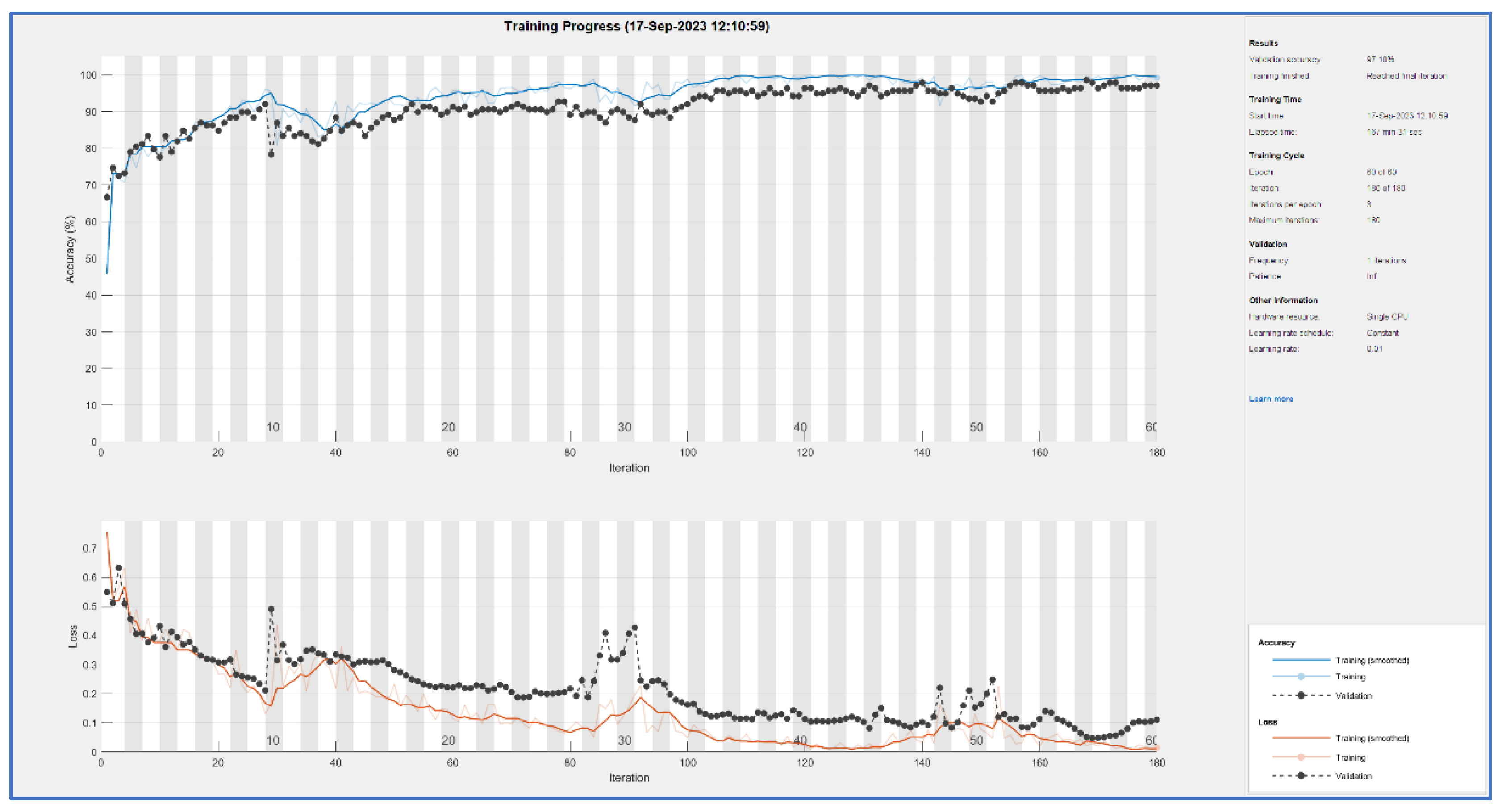
Figure 7.
CNN training for ELA patterns.
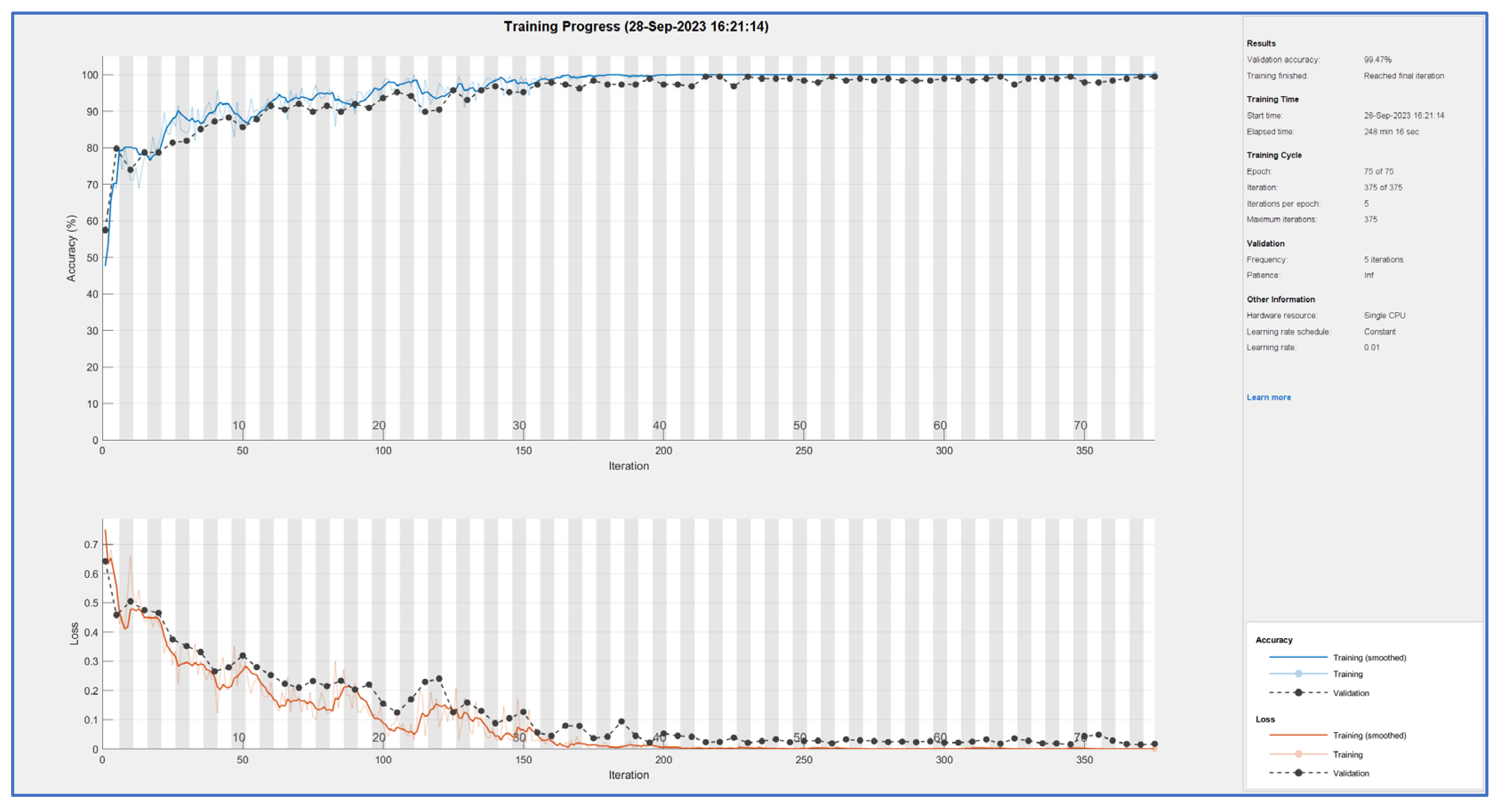

Table 1.
Numerical results for both methods.
| Method (pattern type) |
Accuracy | Precision | Recall | F1 score |
|---|---|---|---|---|
| PRNU | 0.95 | 0.93 | 0.97 | 0.95 |
| ELA | 0.98 | 0.97 | 0.99 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



