
Submitted:
09 July 2023
Posted:
10 July 2023
You are already at the latest version
Abstract
The escalating frequency and severity of global wildfires necessitate an in-depth understanding and monitoring of wildfire smoke impacts, specifically its contribution to fine particulate matter (PM2.5). We propose a data-fusion method to study wildfire contribution to PM2.5 using satellite-derived smoke plume indicators and PM2.5 monitoring data. Our study incorporates two types of monitoring data, the high-quality but sparse Air Quality System (AQS) stations and the abundant but less accurate PurpleAir (PA) sensors that are gaining popularity among citizen scientists. We propose a multi-resolution spatiotemporal model specified in the spectral domain to calibrate the PA sensors against accurate AQS measurements, and leverage the two networks to estimate wildfire contribution to PM2.5 in California in 2020 and 2021. A Bayesian approach is taken to incorporate all uncertainties and our prior intuition that the dependence between networks, as well as the accuracy of PA network, vary by frequency. We find that 1% to 3% increase in PM2.5 concentration due to wildfire smoke, and that leveraging PA sensors improves accuracy.
Keywords:
Bayesian analysis
; calibration
; citizen science
; spatiotemporal methods
; spectral analysis
1. Introduction
Airborne particles are a serious environmental health risk globally, contributing in excess of 7 million premature deaths each year [1]. Fine particulate matter (PM, particles with a diameter of less than 2.5 micrometers) has been causally linked to cardiovascular morbidity and mortality [2] and are therefore regulated under the provisions of the Clean Air Act [3] to protect human health and wellbeing. As a result, the emissions of PM from many antropogenic sources, such as transpiration and industry, have been on a steady decline [4] and wildfires have become the single largest source [5], potentially off setting reduction in emissions from other sources.
High concentrations of fine particles and gasses found in smoke have also produced alarming impacts on health [6,7]. During peak wildfire seasons, smoke exposure can exacerbate health problems, causing a spike in emergency department visits [8]. In an epidemiological study of health impacts, [9] estimated that 2.2 % of annual respiratory health burden, or 92 ED visits per 100,000 people, is attributed to ambient PM and that wildfire days account for over 15% of that burden. However, providing a definite answer as to how much of particle pollution can be attributed to wildfires remains a challenging problem because instruments measure a total ambient concentration which is composed of natural, anthropogenic, and wildfire sources.
Previous research has studied the contribution of wildfires on PM concentrations by integrating remote sensing data on the location and extend of smoke plumes and PM readings from Air Quality System (AQS) monitors deployed by the Environmental Protection Agency (EPA). These studies revealed that wildfires contribute to 40% of unhealthy days and substantially increase PM concentrations [10,11]. Wildfire smoke impacts are dynamic and often affect areas without a monitoring station, as AQS monitors have limited spatial coverage due to the high cost and difficulty in installation. It is important to make air quality information available to the public quickly during wildfires, therefore AQS alone provides insufficient data source for monitoring wildfire emissions.
The increased incidence of days with poor air quality due to wildfires has created a demand and public interest for monitoring particulate pollution. Perhaps the most prevalent sensors are PurpleAir (PA), which are installed by members of the public, providing a near real-time monitoring of PM with extensive spatial coverage [12]. However, it is known that PA sensors are less reliable compared to the AQS, and thus correction to the sensor readings is needed [13,14]. [15] developed a correction equation using meteorological conditions including relative humidity and temperature, as both measurements affect the accuracy of the instrument; however, this calibration is developed for a US-wide correction and without smoke impacts. Another simple linear correction model under smoke impacted conditions was proposed in [16]. As the sensor performance can be affected by geographic and environmental conditions, it is more reasonable to relax the assumption of a constant spatially varying bias, but rather capture the spatiotemporally varying bias.
Smoke impacts are dynamic and often affect areas without a monitoring station, as AQS monitors have limited spatial coverage. Previous studies have either separated anthropogenic PM from smoke emissions using chemical transport models or by subtracting out historically observed averages [17]. However, neither approach provides a definite answer as to how much of particle pollution can be attributed to wildfires. Data fusion is a widely used method that integrates information from different types of sensors to provide a robust and complete description of a process of interest [18,19]. It has been used extensively to estimate spatially and temporally resolved air quality surfaces. For example, [20,21,22,23] use data fusion method to study the complex relationship between monitoring data and outputs from Community Multi-Scale Air Quality (CMAQ), a deterministic chemical transport model. [24] combines observations from two noisy datasets to predict the true aerosol process. More recently, several researchers have exploited the usefulness of low-cost sensors such as Purple Air to map air quality and quantify the uncertainty of estimation [25,26,27]. Most similar to our approach is Stein et al (2005), who also use a spectral transformation in time and spatial processes to capture dependence between stations for a single fixed monitoring network [28]. We extend this approach to handle multiple data networks.
This study aims to provide an estimate of wildfire contribution on air quality by supplementing the remotely sensed smoke plume indicators with PurpleAir data. We propose a multi-resolution Bayesian approach fusing information from both AQS monitors and PA sensors to estimate the contribution to PM caused by wildfires. We apply a Discrete Fourier Transform (DFT) to account for temporal correlation, transforming the data from the time domain to the frequency domain, and model the spatial correlation in the frequency domain. To quantify the relative increase in PM concentrations due to wildfires, we propose regression and matching estimators, as discussed in Section 2.3. Our findings will not only enhance understanding of the relationship between wildfires and air pollution but also inform policy and decision-making related to wildfire management, public health, and climate change impacts.
The remainder of this paper is structured as follows: In Section 2, we present an overview of the Hazard Mapping System (HMS) and its smoke plume data. We also delve into the specifics of the AQS and PurpleAir sensors, contrasting their features and functionality. The latter part of Section 2 elucidates our use of the Discrete Fourier Transform (DFT) and the data fusion model, with detailed insights into our Markov Chain Monte Carlo (MCMC) approach. Section 3 presents our findings, including the estimated smoke plume parameters and the calculated contribution of wildfires to PM concentrations, as determined by both regression and matching estimators. We also offer a comparison of various models, illustrating the effectiveness of the PurpleAir sensors and the benefits of our proposed data fusion method. Finally, in Section 4, we discuss the implications of our findings, the limitations of our study, and potential directions for future research.
2. Materials and Methods
2.1. Data sources and exploratory analysis
Our analysis incorporates data from three distinct sources: satellite-derived smoke plume indicators obtained through the National Oceanic and Atmospheric Administration’s Hazard Mapping System (HMS), PM measurements from Air Quality System (AQS) monitoring stations, and PM readings from PurpleAir (PA) monitoring stations. We collect hourly data and average them to daily level from each source for 2020 and 2021 fire seasons, spanning July 1 to October 31. The original PM readings from both AQS and PA stations are right-skewed so we apply log-transformation to all PM readings.
2.1.1. Satellite-derived smoke plume indicators
Exposure to wildland fire smoke is assessed using smoke plume indicators supplied by the Hazard Mapping System (HMS) [29]. This automated data product integrates observations from multiple polar and geostationary satellites to generate daily polygons representing smoke plume extents in near-real time. Distinct polygons are provided for low-, medium-, and high-density plumes. Figure 1 shows the HMS smoke plumes for September 20, 2021. These smoke plume indicators tend to underestimate the actual intensity of smoke, as they primarily rely on satellite imagery with an approximate spatial resolution spanning several miles [30]. Additionally, smoke visibility is limited to daytime hours, resulting in a significant underestimation of smoke levels during the night.
2.1.2. AQS monitoring stations
The Air Quality System (AQS) monitoring stations, deployed by the US Environmental Protection Agency (EPA) and state, local, and tribal air pollution control agencies, provide precise PM measurements. However, their distribution is spatially sparse due to the high cost and complexity associated with their installation and maintenance. The black dots in Figure 1 depict the distribution of AQS monitoring sites across California in 2021. Figure 2 illustrates the distribution of PM levels, aggregated across stations, by smoke plume intensity.
2.1.3. PurpleAir sensors
PurpleAir (PA) sensors are low-cost monitoring devices deployed by individuals and organizations for continuous ambient air pollutant tracking. Despite their affordability and ease of installation, PA sensors offer less accurate PM readings and are significantly influenced by environmental factors, such as temperature and humidity [15]. We use bias corrected data for all analyses. However, this initial bias correction based on [15] may be insufficient because it only depends on a linear trend in temperature and humidity and is constant across space and time. Therefore, our Bayesian data fusion model adds a more flexible spatiotemporal bias correction term.
In 2021, more than 7,800 outdoor PA sensors were operational in California. The purple dots in Figure 1 represent the distribution of PA monitoring sites throughout the state. We have included only those PA stations that reported fewer than 18 missing days during the fire seasons, resulting in a total of 1,080 for 2020 and 712 PA stations for 2021. Figure 2 displays the distribution of PM, aggregated across stations for 2021, by smoke plume intensity. A similar pattern is observed in both PA stations and AQS stations where PM measurements escalate in the presence of a smoke plume.
Figure 3 investigates the relationship between AQS stations and their corresponding nearby PA sites. Each point in Figure 3 symbolizes one AQS station. For every AQS station, we pinpoint the closest PA station and calculate the sample correlation between the daily PM measurement series for these two locations. We can see that the correlation is generally high for nearby stations and decreases with distance, suggesting that PA data will be a useful supplement to the spatial model.
2.2. Statistical model
We propose a multi-resolution Bayesian model for modeling AQS and PA measurements jointly in the spectral domain. Let and be AQS and PA measurements, respectively, for spatial location at time (day) , and be a corresponding vector of covariates with for the intercept. The covariates are temperature, relative humidity and indicators of low, medium and high density smoke plumes at site S and day t. We note that temperature and relative humidity are standardized to have mean zero and variance one and that the AQS and PA measurements are not taken at the same spatial locations.
The observations are decomposed as for , where and are spatiotemporal processes, and is error. The time span of our data is relatively short, therefore, its reasonable to assume the spatiotemporal processes are stationary within the modeling period. We will apply Fourier transformation to the spatiotemporal processes with respect to time to remove the temporal dependence. The resulting spectral processes capture periodicity, are independent over frequency and spatially correlated. For time series observed at equal time intervals, we can apply the discrete Fourier transformation (DFT). The spectral processes at frequency is
and measures the variation in at frequency . Terms with small (low frequency) represent long-term trends such as month-to-month averages and terms with large (high frequency) represent short-term trends such as day-to-day variation. Let be the unique real components of the DFT of at frequencies with .
The spectral processes are dependent across , as they represent the two networks measuring the same underlying PM process. They are also spatially dependent processes as locations nearby may exhibit similar periodicity. We model the cross network dependence and spatial dependence for each as
where spatial process is the true PM concentration. The PA stations are assumed to be measuring a biased and noisy version of the true PM with discrepancy . The coefficient controls the dependence across networks. Both the bias and cross-dependence vary by to allow for a multi-resolution calibration of the two networks. We model linearly as , where and are unknown coefficients. This allows the correlation between the processes to vary stochastically with frequency. For example, if PA is more reliable for long-term trends than day-to-day variation, then we expect larger (smaller) correlation between networks for small (large) .
The true process and discrepancy term are both regressed onto the covariates. Since we are developing a model in the spectral domain, we will also apply DFT to each covariate in with respect to time and denote this as Define the covariates for the true process as , containing all five covariates, and define to include only temperature and relative humidity for bias correction [15]. We model and as independent (with each other and over l) Gaussian processes with means and , variances and , and spatial correlations and .
The regression coefficients control the effects of the covariates on the true PM process U. Although we specify the model in the spectral domain, the DFT is a linear operator and thus the covariates can be interpreted as usual in the spatial domain since the mean AQS response is
Therefore, is of primary interest. In particular, the components of that correspond to the smoke plume indicators are used to summarize the wildland fire contribution to PM.
The regression coefficients control the effect of the covariates on the discrepancy term V, and thus the contribution of the covariates to the PA bias. By allowing the covariance parameters and to vary by frequency (l), we allow for a different degree of dependence between the networks at different temporal scales, with
The prior for the variance components is
where the hyperparameters are modelled as log-linear in frequency, e.g., the prior captures the intuition that the variance is higher in month-to-month variation than day-to-day variation, and the correlation between two sources vary over frequencies.
2.3. Quantifying the wildland fire contribution
To estimate the PM contribution from wildfire, given the estimated parameters above, we consider two metrics based on either regression or matching. For the regression metric, let be the covariate vector with three plume indicators fixed at zero. For the matching estimator, define as the set of days for which site s is in a smoke plume (any density) and as the set of non-plume days. We match each plume day with a non-plume day with similar meteorology and time period. Let be the set of non-plume days within 30 days of plume day t. For each plume day, we selected the matching day as
where w above is a scaling factor adjusting the magnitude of humidity and temperature, we set so that the best matching station has equal weights on temperature and humidity. Then at site s the estimated contribution from wildland fires per day are
- Regression estimator:
- Matching estimator: for
In the matching estimator, is the true PM, the transformed pairs of in (2) obtained by inverse DFT, and thus this estimator accounts for spatiotemporal bias and correlation. Since the analysis is on the log-scale, we plot and which estimate the multiplicative effect, i.e., corresponds to a 5% increase in PM in the presence of a smoke plume.
2.4. Computational Algorithm
To complete the Bayesian model, we specify uninformative prior distributions for the model parameters. The regression coefficients have Gaussian priors . The variance parameters have conjugate priors . The hyperpameters have Gaussian priors . To give uninformative priors we set and . Due to poor convergence, the dependence parameters and were fixed based on cross-validation to minimize mean squared prediction error for AQS stations.
The main computational bottleneck of spatial modeling is manipulating spatial covariance matrices to estimate the range parameters and . Given the large size of the air pollution dataset, a reasonable simplification is to estimate the range parameters using variogram and then assume they are fixed for the purpose of fitting the final model. The estimated spatial range from variograms are and kilometers.
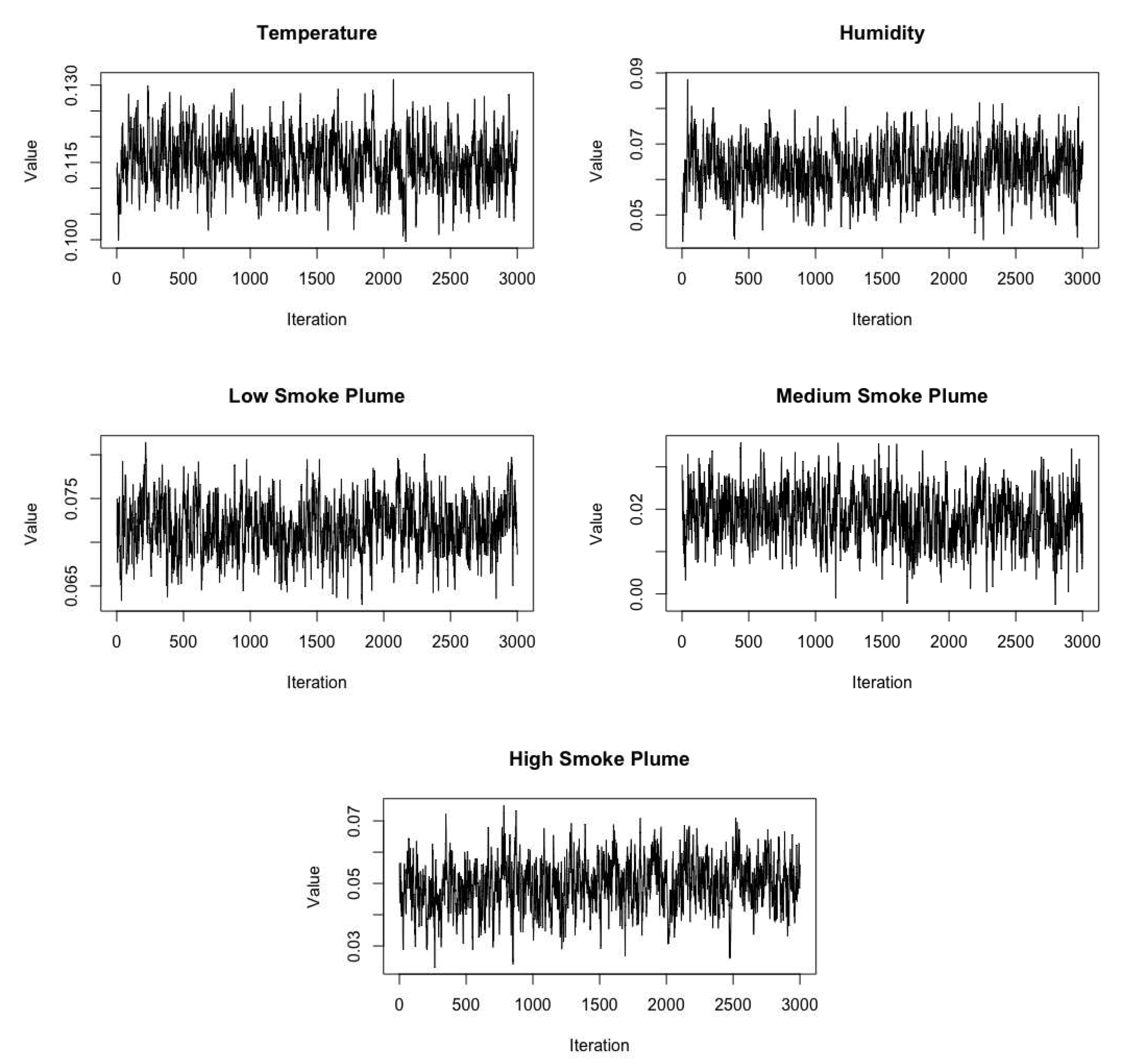
Given the range parameters are fixed, the remaining parameters are estimated using Markov Chain Monte Carlo (MCMC) methods. In particular, we perform Gibbs sampling steps for most parameters and Metropolis sampling for some hyperparameters. Missing values are addressed using Bayesian multiple imputation (refer to Appendix A for more information). We generate 8,000 posterior samples and discard the first 5,000 as burn-in. Convergence is monitored using trace plots. A simulation study is included in the Appendix to verify the algorithm produces reliable parameter estimates. Convergence plots for several representative parameters are shown in Figure A1 in the Appendix for the real data analysis.
3. Results
3.1. Summary of the fitted model
Table 1 gives the estimates of the regression coefficients for both the true process and bias correction term . All three smoke plume levels positively affect PM concentrations, with high smoke plumes having the greatest impact, followed by medium and low smoke plumes. These results are consistent between 2020 and 2021. The bias correction terms, however, are not significant. Given that PurpleAir readings have already been corrected as per [15] using temperature and relative humidity, it is reasonable that these variable do not explain trends in bias. We note that our model does include more general spatiotemporal bias correction in and including this bias term leads to improved results, as discussed below.
Figure 4 plots the estimated wildland fire contribution both years and both metrics. The estimated wildland fire contribution ranges from a 1-3% increase in PM, depending on the location. Both metrics yield similar estimates of contribution and spatial patterns. The impact of wildfires varies across the state and years. In 2020, both Northern and Central California experienced significant wildfire impacts, while only Northern California faced major effects in 2021. This is in line with the fact that 2020 had the highest frequency of wildfires across all states, whereas 2021 witnessed a single, massive wildfire in Northern California [31].
In addition to covariate effects, the data-fusion model provides an evaluation of the concordance between AQS and PA stations. Equation 3 defines the correlation between the two networks as a function of the spectral frequency, . Figure 5 plots the correlation between AQS and PA by period, i.e., . For example, period 7 (30) corresponds to variation that occurs on a weekly (monthly) scale. Figure 5 shows that the correlation between AQS and PA stations increases from short-term, such as day-to-day variation, to long-term, such as month-to-month variation. In the short-term, the correlation is lower since the readings are taken at different spatial locations and are subject to small scale variability. Over the long run, the correlation is higher as both sources estimate ambient unbiased PM readings.
3.2. Model Comparisons
To assess the effectiveness of integrating additional PurpleAir readings, we compared the proposed data-fusion model (“Data fusion”) with two simpler alternatives. The first uses only AQS data (“AQS only”) and discards the PA data (i.e., sets for all l). The second naively (“Naive”) combines AQS and PA data and treats them as a single source without spatiotemporal bias adjustment (i.e., sets and for all s, and includes an indicator variable in the regression term, , to distinguish two types of data).
The estimated parameters for each model, along with the corresponding posterior standard deviations, are presented in Table 2. Clearly, incorporating PurpleAir monitors significantly reduces the posterior standard deviation. For many of the parameters the reduction in uncertainty is striking, with the standard deviation being 2-4 times smaller for the data-fusion model. Also, with the AQS-only model, only high smoke plumes exhibit a significant contribution due to a higher standard deviation. In contrast, when merging AQS and PurpleAir data, both medium and high smoke plume levels show significant contributions.
Furthermore, to verify that our proposed methodologies not only improve parameter estimation but also lead to accurate PM predictions, we performed a 5-fold cross-validation for the three models. Their performance was compared based on three key metrics: Root mean squared error, 95% prediction coverage, and prediction variance. Detailed descriptions of the models and their results can be found in the Appendix. We find that the AQS-only and data fusion model produce fairly similar out-of-sample prediction accuracy, therefore the main benefit of including the PurpleAir data is reducing uncertainty in parameter estimates. Also, the Naive model gives a 50% largers RMSE and low coverage, emphasizing the need for a careful data fusion approach.
4. Discussion
In this study, we examine the impact of wildland fires on PM concentrations in California during the fire seasons of 2020 and 2021. To do this efficiently, we combine remotely-sensed smoke-plume indicators with AQS and PA measurement networks. To model the spatiotemporal correlation of PM concentration and relationship between AQS and PA monitors, we first transform the data from spatial domain to frequency domain, and then use a data-fusion approach to model spatial correlations while accounting for biases in the PA data. Furthermore, we use a Bayesian approach to compute posterior distributions of the quantities of interest to fully characterize uncertainty.
We find that including PurpleAir monitors significantly increases the precision of the estimated contribution of wildland fire smoke to total PM. Using only AQS data we find that medium and high smoke plume levels significantly contribute to PM concentration with standard deviations as large as 0.017, and the data fusion approach that supplements AQS with PA data gives similar parameter estimation, with standard deviation as small as 0.004. Moreover, the data fusion model also estimates a significant low smoke plume level contribution. However, since PM concentration is relatively smooth across space and AQS stations are evenly distributed across the state, incorporating PurpleAir readings does not improve prediction performance even for the data-fusion approach. Comparing prediction performance does reveal that simple data fusion model such as the model that ignores bias in the PA data gives inferior prediction results. With our model, all three smoke plume levels demonstrate a significant contribution to PM concentration, and the impact varies across different regions depending on the year. This study highlights the value of utilizing both AQS and PurpleAir data in understanding the impact of wildfires on air quality and informs future monitoring and management efforts.
There are some limitations of our current work. First, as mentioned above, the satellite-derived smoke plume levels might underestimate the actual smoke level, which may lead to underestimation of wildfires’ contribution to PM [30]. Second, due to computational limitations and poor MCMC convergence, we fixed the spatial correlation range parameters for both AQS and PA monitors and parameters that control the relationships between AQS and PA data. The analysis would more fully quantify uncertainty if we are able to implement a fully Bayesian analysis.
We have taken a purely statistical approach to estimating the contribution of wildland fires on ambient air pollution. An area of future work is to incorporate numerical models to simulate the process. Dispersion models, e.g., HySPLIT [32], combine the location and size of fires and meteorological conditions in a mathematical model to track particulate matter emanating from a fire. Of course, numerical models also have bias and other limitations [33], but combining their output within our statistical framework would likely further refine our estimates. Further, instead of using one range parameter for all frequencies, it is possible to get variogram estimates of ranges over frequencies. Also, to extend the current work, we can estimate the contribution over the entire U.S. continent, and investigate how different areas suffer from wildfires, although more computational efficient models are required to analyze all US data.
Author Contributions
Conceptualization, AR and BR; methodology, HY, YG, BR; validation, HY, SRS; formal analysis, HY; data curation, HY, SRS.; writing-original draft preparation, HY; writing—review and editing, SRS, BR, YG, AR. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Institutes of Health (R01ES031651-01) and the National Science Foundation (DMS2152887).
Data Availability Statement
AQS data is a publicly available dataset, which is part of this study. This data can be found on EPA website. Purple Air data is a 3rd party data and restrictions apply to the availability of these data. Data was obtained from Purple Air and are available from PurpleAir API with the permission of Purple Air. HMS smoke plume data is publicly available and can be downloaded at Office of Satellite and Product Operations website. The codes to download and analyze data in this paper is available at https://github.com/hyang199723/PAFusion.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Data Cleaning
Before the data was subjected to a statistical model, we implemented several pre-processing steps on the PurpleAir data and standardized certain covariates to meet the assumption of normality. PurpleAir stations feature two independent channels, Channel A and Channel B, both of which measure ambient PM independently. To achieve a more accurate estimation of the actual ambient PM concentration, we discarded readings where the measurement difference exceeded 200 and constant high PM readings over 2000 . Subsequently, the mean reading from Channel A and Channel B was considered as the PurpleAir measurement.
Most PurpleAir stations measure temperature (in Fahrenheit) and humidity (as a percentage). Given the spatially smooth changes in temperature and humidity, we employed a 10-nearest-neighbor approach to impute stations with missing temperature and humidity values. Both temperature and humidity were standardized before fitting the model as specified in the analysis.
Appendix B. MCMC algorithm
Assume the AQS monitors are at spatial locations and the PA monitors are located at for . The observations can be written as the vectors , and . Similarly, for frequency l let , and be vectors of length and , and be vectors of length , analogous to . The covariate matrices of size are denoted and is the matrix that stacks and . Then the model in the spectral domain is
where . Using this notation, the spatial models are defined by , , and . The full spatial correlation matrices are denoted and .
Each MCMC iteration we impute missing data and update the error variance parameters in the spatial domain, and then update all remaining parameters in the spectral domain. The missing values are simply drawn from the univariate normal distribution
independently over j and t. The error variances are drawn from full conditional distribution and .
After imputation in the spatial domain, the data are complete and can be projected into the spectral domain where they are independent over time. The spatial processes are updated as
where is diagonal with first elements equal one and the remaining elements equal , T is diagonal with first elements equal and the remaining elements equal , is the vector with zeros followed by , and .
The regression coefficients and bias parameters are updated as
where and . The remaining hyperparameters are updated as
Finally, , , and are updated using a Metropolis step with Gaussian candidate distribution tuned to give acceptance rate around 0.4.
Appendix C. Simulation Results
We conduct a simulation study to demonstrate the reliability of the MCMC algorithm. The regression parameters, and , are fixed at the mean of the 2021 model output in Table 1. We generate a total number of 80 AQS stations and 500 Purple Air stations with 60 time steps. The spatial locations are randomly sampled from the region . The data was generated in the frequency domain using the following equations:
The variables and are drawn from Gaussian processes as described in (2). The range parameters are set to and . The error variances of and are set to 1.6 and 3.6, respectively. The values of are fixed at the best selected from the real data which is .
To simulate realistic smoke plume frequencies, we assigned percentages to represent the occurrence of low, medium, and high smoke plume levels. Specifically, 20% of the days corresponded to low smoke plume levels, 15% to medium levels, and 10% to high levels. Temperature and humidity values were randomly generated from standard normal distributions.
The covariates were initially generated in the time domain and then transformed to the frequency domain. The values of form a decreasing sequence ranging from 50 to 10, with larger values assigned to lower frequencies. Similarly, follows a decreasing sequence from 40 to 10. Finally, the values of and are the mean values from Table 1.
We generate 50 datasets from this model. For each simulated dataset, we fit the model with , and fixed at the true values and generate 8000 MCMC iterations and discard the first 5000 as burn-in. Since our main interest is in the covariate effects, for each dataset we record the effective sample size of the MCMC algorithm [34] and the posterior mean estimator and 95% posterior interval.
For each dataset and each parameter, we compute the posterior mean, standard deviation and 95% interval and measure MCMC convergence using the effective sample size. The average of the posterior means, standard deviations and effective samples sizes, and the empirical coverage of 95% intervals are shown in Table A1. The posterior means show small bias, the coverage is near the nominal level and the effective sample size coefficients indicate reasonable convergence.

Table A1.
True value used for the fixed effects for the true PM () and bias () to simulate data and the average (SD) over the 50 datasets of the posterior mean estimators (“Ave post mean”), coverage of 95% posterior intervals and average (SD) effective sample size based on 3000 MCMC iterations.
Table A1.
True value used for the fixed effects for the true PM () and bias () to simulate data and the average (SD) over the 50 datasets of the posterior mean estimators (“Ave post mean”), coverage of 95% posterior intervals and average (SD) effective sample size based on 3000 MCMC iterations.
| Type | Covariate | True value | Average post mean | Coverage | ESS |
|---|---|---|---|---|---|
| PM | Temperature | 0.118 | 0.117 (0.013) | 100% | 420.23 (0.14) |
| Humidity | 0.064 | 0.069 (0.022) | 96% | 307.27 (0.10) | |
| Plume - Low | 0.007 | 0.006 (0.132) | 100% | 875.99 (0.29) | |
| Plume - Medium | 0.022 | 0.020 (0.037) | 98% | 376.91 (0.13) | |
| Plume - High | 0.049 | 0.050 (0.176) | 100% | 480.22 (0.16) | |
| Bias | Temperature | -0.002 | 0.003 (0.019) | 92% | 168.75 (0.06) |
| Humidity | 0.012 | 0.009 (0.041) | 96% | 176.97 (0.06) |
Appendix D. Cross-Validation Results
We compare methods using a 5-fold cross-validation using data from 2021. We randomly split the AQS stations into five folds. For each fold, we build predictive models based on the other AQS stations and all PA stations and make predictions at the test sites. We compare the proposed data-fusion model (“Data fusion”) with the AQS only and Naive models described in the main text. For all models, we fix the spatial range parameters ( and ) based on the variogram analysis of the full dataset. The cross-dependence parameter is fixed at 0.2.
The results in Table A2 show that the performance of the AQS-only analysis is fairly similar to the proposed data-fusion approach, with slightly smaller prediction mean squared error and larger average prediction variance. Therefore, carefully including the additional PA data mainly reduces the prediction variance. However, naively including the PA data gives much higher prediction errors and low coverage.
Table A2.
Root mean squared error (“RMSE”), coverage of 95% prediction intervals (“Coverage”) and average prediction variance (“Ave Var”) for the cross-validation study comparing the proposed data fusion model to models that ignore PA data (“AQS only”) and includes PA data without bias correction (“Naive”).
Table A2.
Root mean squared error (“RMSE”), coverage of 95% prediction intervals (“Coverage”) and average prediction variance (“Ave Var”) for the cross-validation study comparing the proposed data fusion model to models that ignore PA data (“AQS only”) and includes PA data without bias correction (“Naive”).
| Model | RMSE | Coverage | Ave Var |
|---|---|---|---|
| Data Fusion | 0.42 | 0.89 | 0.13 |
| AQS only | 0.40 | 0.91 | 0.16 |
| Naive | 0.66 | 0.73 | 0.18 |
Appendix E. Real Data Convergence
We display several representative trace plots of the data fusion model to verify the convergence of our MCMC algorithm for the 2021 CA analysis. After burn-in, the MCMC chains appear to have converged.
Figure A1.
Trace plots of parameters of interest () for the 2021 California data analysis.
References
- Dennekamp, M.; Abramson, M.J. The effects of bushfire smoke on respiratory health. Respirology 2011, 16, 198–209. [Google Scholar] [CrossRef]
- Dennekamp, M.; Straney, L.D.; Erbas, B.; Abramson, M.J.; Keywood, M.; Smith, K.; Sim, M.R.; Glass, D.C.; Del Monaco, A.; Haikerwal, A.; others. Forest fire smoke exposures and out-of-hospital cardiac arrests in Melbourne, Australia: a case-crossover study. Environmental Health Perspectives 2015, 123, 959–964. [Google Scholar] [CrossRef]
- Melnick, R.S. Regulation and the courts: The case of the Clean Air Act; Brookings Institution Press, 2010.
- Sager, L.; Singer, G. Clean identification? The effects of the Clean Air Act on air pollution, exposure disparities and house prices 2022.
- McClure, C.D.; Jaffe, D.A. US particulate matter air quality improves except in wildfire-prone areas. Proceedings of the National Academy of Sciences 2018, 115, 7901–7906. [Google Scholar] [CrossRef]
- Johnston, F.H.; Henderson, S.B.; Chen, Y.; Randerson, J.T.; Marlier, M.; DeFries, R.S.; Kinney, P.; Bowman, D.M.; Brauer, M. Estimated global mortality attributable to smoke from landscape fires. Environmental Health Perspectives 2012, 120, 695–701. [Google Scholar] [CrossRef]
- Rappold, A.G.; Stone, S.L.; Cascio, W.E.; Neas, L.M.; Kilaru, V.J.; Carraway, M.S.; Szykman, J.J.; Ising, A.; Cleve, W.E.; Meredith, J.T.; others. Peat bog wildfire smoke exposure in rural North Carolina is associated with cardiopulmonary emergency department visits assessed through syndromic surveillance. Environmental Health Perspectives 2011, 119, 1415–1420. [Google Scholar] [CrossRef]
- Haikerwal, A.; Akram, M.; Sim, M.R.; Meyer, M.; Abramson, M.J.; Dennekamp, M. Fine particulate matter (PM 2.5) exposure during a prolonged wildfire period and emergency department visits for asthma. Respirology 2016, 21, 88–94. [Google Scholar] [CrossRef]
- Thilakaratne, R.; Hoshiko, S.; Rosenberg, A.; Hayashi, T.; Buckman, J.R.; Rappold, A.G. Wildfires and the changing landscape of air pollution–related gealth burden in California. American Journal of Respiratory and Critical Care Medicine 2023, 207, 887–898. [Google Scholar] [CrossRef]
- Larsen, A.E.; Reich, B.J.; Ruminski, M.; Rappold, A.G. Impacts of fire smoke plumes on regional air quality, 2006–2013. Journal of Exposure Science & Environmental Epidemiology 2018, 28, 319–327. [Google Scholar]
- Matz, C.J.; Egyed, M.; Xi, G.; Racine, J.; Pavlovic, R.; Rittmaster, R.; Henderson, S.B.; Stieb, D.M. Health impact analysis of PM2. 5 from wildfire smoke in Canada (2013–2015, 2017–2018). Science of The Total Environment 2020, 725, 138506. [Google Scholar] [CrossRef]
- Barkjohn, K.K.; Gantt, B.; Clements, A.L. Development and application of a United States-wide correction for PM 2.5 data collected with the PurpleAir sensor. Atmospheric Measurement Techniques 2021, 14, 4617–4637. [Google Scholar] [CrossRef]
- Tryner, J.; L’Orange, C.; Mehaffy, J.; Miller-Lionberg, D.; Hofstetter, J.C.; Wilson, A.; Volckens, J. Laboratory evaluation of low-cost PurpleAir PM monitors and in-field correction using co-located portable filter samplers. Atmospheric Environment 2020, 220, 117067. [Google Scholar] [CrossRef]
- Wallace, L.; Bi, J.; Ott, W.R.; Sarnat, J.; Liu, Y. Calibration of low-cost PurpleAir outdoor monitors using an improved method of calculating PM2. 5. Atmospheric Environment 2021, 256, 118432. [Google Scholar] [CrossRef]
- Barkjohn, K.; Gantt, B.; Clements, A. Development and Application of a United States wide correction for PM2. 5 data collected with the PurpleAir sensor. Atmos. Meas. Tech. Discuss. 2020. [Google Scholar] [CrossRef]
- Holder, A.L.; Mebust, A.K.; Maghran, L.A.; McGown, M.R.; Stewart, K.E.; Vallano, D.M.; Elleman, R.A.; Baker, K.R. Field evaluation of low-cost particulate matter sensors for measuring wildfire smoke. Sensors 2020, 20. [Google Scholar] [CrossRef]
- Kosmopoulos, G.; Salamalikis, V.; Pandis, S.; Yannopoulos, P.; Bloutsos, A.; Kazantzidis, A. Low-cost sensors for measuring airborne particulate matter: Field evaluation and calibration at a South-Eastern European site. Science of The Total Environment 2020, 748, 141396. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Henderson, T.C. Multisensor data fusion. Springer Handbook of Robotics 2016, pp. 867–896.
- Luo, R.C.; Kay, M.G. A tutorial on multisensor integration and fusion. IECON’90: 16th Annual Conference of IEEE Industrial Electronics Society. IEEE, 1990, pp. 707–722.
- Reich, B.J.; Chang, H.H.; Foley, K.M. A spectral method for spatial downscaling. Biometrics 2014, 70, 932–942. [Google Scholar] [CrossRef]
- Warren, J.L.; Miranda, M.L.; Tootoo, J.L.; Osgood, C.E.; Bell, M.L. Spatial distributed lag data fusion for estimating ambient air pollution. The Annals of Applied Statistics 2021, 15, 323. [Google Scholar] [CrossRef]
- Friberg, M.D.; Zhai, X.; Holmes, H.A.; Chang, H.H.; Strickland, M.J.; Sarnat, S.E.; Tolbert, P.E.; Russell, A.G.; Mulholland, J.A. Method for fusing observational data and chemical transport model simulations to estimate spatiotemporally resolved ambient air pollution. Environmental Science & Technology 2016, 50, 3695–3705. [Google Scholar]
- Friberg, M.D.; Kahn, R.A.; Holmes, H.A.; Chang, H.H.; Sarnat, S.E.; Tolbert, P.E.; Russell, A.G.; Mulholland, J.A. Daily ambient air pollution metrics for five cities: Evaluation of data-fusion-based estimates and uncertainties. Atmospheric Environment 2017, 158, 36–50. [Google Scholar] [CrossRef]
- Nguyen, H.; Cressie, N.; Braverman, A. Spatial statistical data fusion for remote sensing applications. Journal of the American Statistical Association 2012, 107, 1004–1018. [Google Scholar] [CrossRef]
- Gressent, A.; Malherbe, L.; Colette, A.; Rollin, H.; Scimia, R. Data fusion for air quality mapping using low-cost sensor observations: Feasibility and added-value. Environment International 2020, 143, 105965. [Google Scholar] [CrossRef]
- Datta, A.; Saha, A.; Zamora, M.L.; Buehler, C.; Hao, L.; Xiong, F.; Gentner, D.R.; Koehler, K. Statistical field calibration of a low-cost PM2. 5 monitoring network in Baltimore. Atmospheric Environment 2020, 242, 117761. [Google Scholar] [CrossRef]
- Lin, Y.C.; Chi, W.J.; Lin, Y.Q. The improvement of spatial-temporal resolution of PM2. 5 estimation based on micro-air quality sensors by using data fusion technique. Environment International 2020, 134, 105305. [Google Scholar] [CrossRef]
- Stein, M.L. Statistical methods for regular monitoring data. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 2005, 67, 667–687. [Google Scholar] [CrossRef]
- National Oceanic and Atmospheric Administration. Hazard Mapping System Fire and Smoke Product. Available online: https://www.ospo.noaa.gov/Products/land/hms.html (accessed on 15 October 2022).
- O’Dell, K.; Ford, B.; Fischer, E.V.; Pierce, J.R. Contribution of wildland-fire smoke to US PM2. 5 and its influence on recent trends. Environmental Science & Technology 2019, 53, 1797–1804. [Google Scholar]
- California Department of Forestry and Fire Protection. Top 20 Largest California Wildfires. Available online: https://www.fire.ca.gov/our-impact/statistics.
- Draxler, R.; Rolph, G. HYSPLIT (HYbrid Single-Particle Lagrangian Integrated Trajectory) model access via NOAA ARL READY website (http://ready. arl. noaa. gov/HYSPLIT. php), NOAA Air Resources Laboratory. Silver Spring, MD 2010, 25. [Google Scholar]
- Su, L.; Yuan, Z.; Fung, J.C.; Lau, A.K. A comparison of HYSPLIT backward trajectories generated from two GDAS datasets. Science of the Total Environment 2015, 506, 527–537. [Google Scholar] [CrossRef] [PubMed]
- Geyer, C.J. Introduction to Markov Chain Monte Carlo. Handbook of Markov Chain Monte Carlo 2011, 20116022, 45. [Google Scholar]
Figure 1.
HMS smoke plume density on September 20, 2021 (shaded regions) the locations of PurpleAir (purple dots) and Air Quality System (black dots) monitoring stations.
Figure 1.
HMS smoke plume density on September 20, 2021 (shaded regions) the locations of PurpleAir (purple dots) and Air Quality System (black dots) monitoring stations.
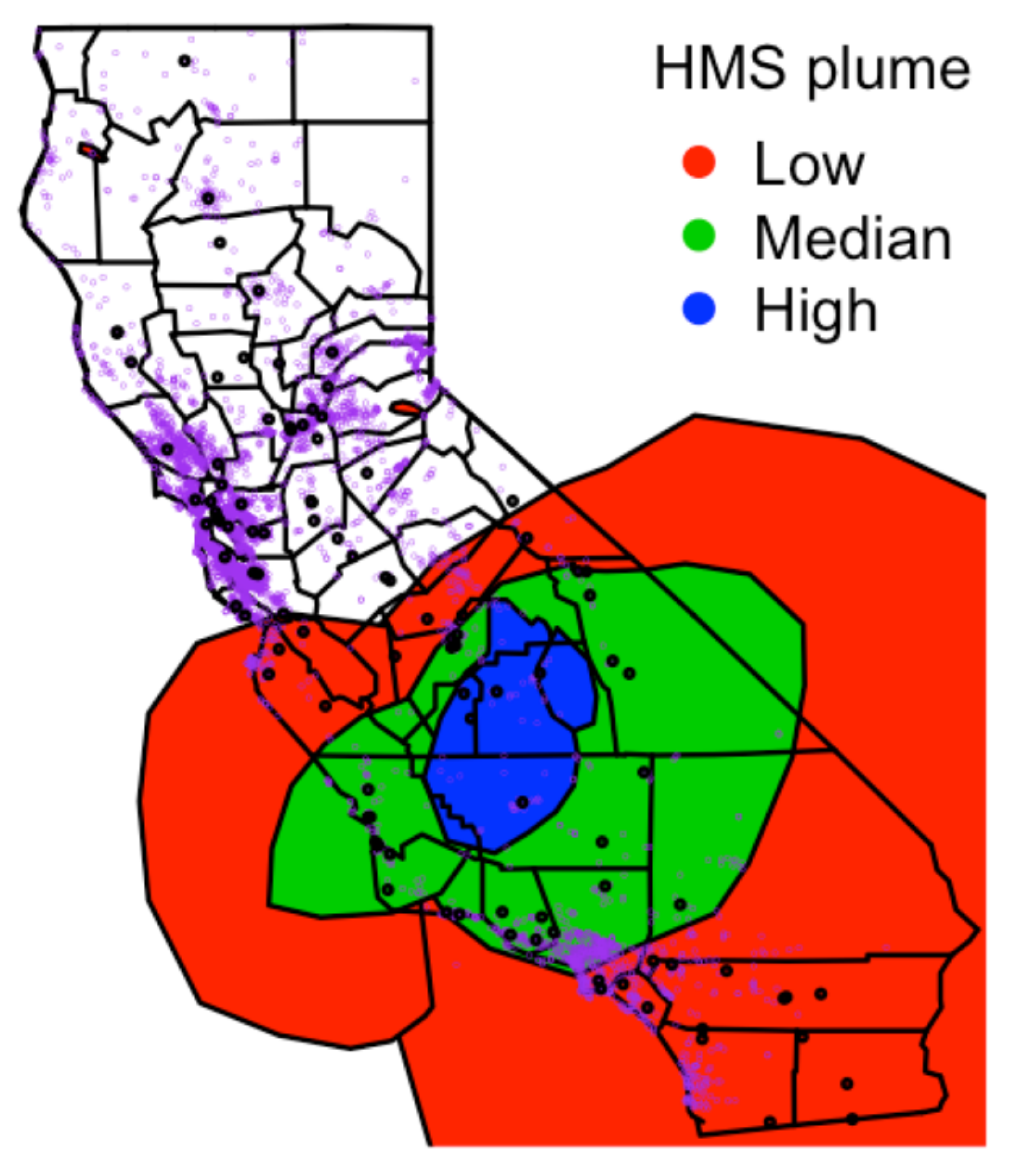
Figure 2.
Distribution of log PM () by smoke plume level for PurpleAir (PA) and Air Quality System (AQS) stations. Four smoke plume levels from left to right are: no smoke, low, medium, and high plume density.
Figure 2.
Distribution of log PM () by smoke plume level for PurpleAir (PA) and Air Quality System (AQS) stations. Four smoke plume levels from left to right are: no smoke, low, medium, and high plume density.
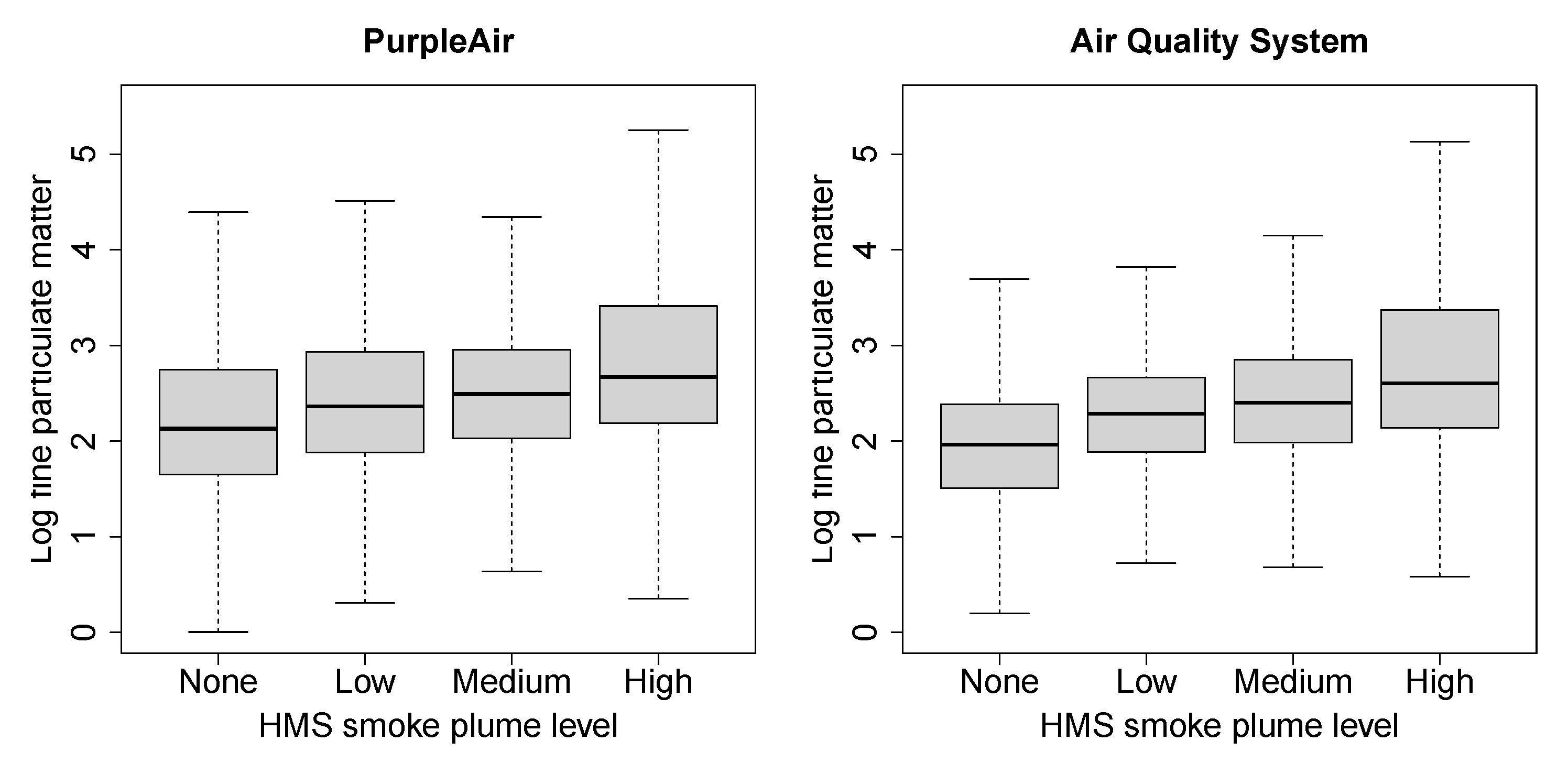
Figure 3.
Sample correlation between each AQS stations the nearest PA stations versus the distance (km) between the two stations.
Figure 3.
Sample correlation between each AQS stations the nearest PA stations versus the distance (km) between the two stations.
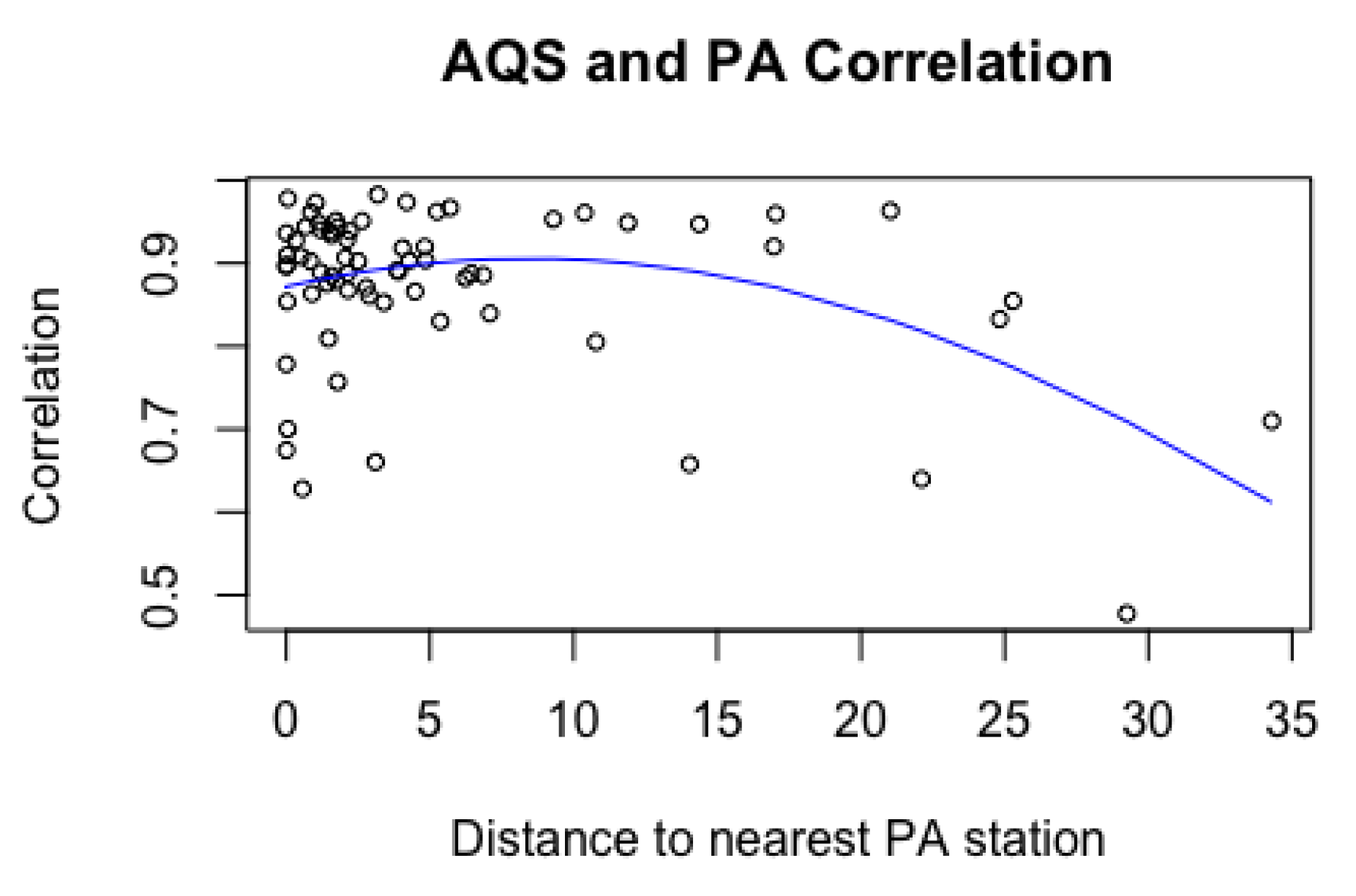
Figure 4.
Smoke contribution to PM2.5. Contributions are exponentiated to reflect actual percentage contribution. For example, a contribution of 1.02 means wildfire roughly contributes to 2% increase in PM.
Figure 4.
Smoke contribution to PM2.5. Contributions are exponentiated to reflect actual percentage contribution. For example, a contribution of 1.02 means wildfire roughly contributes to 2% increase in PM.
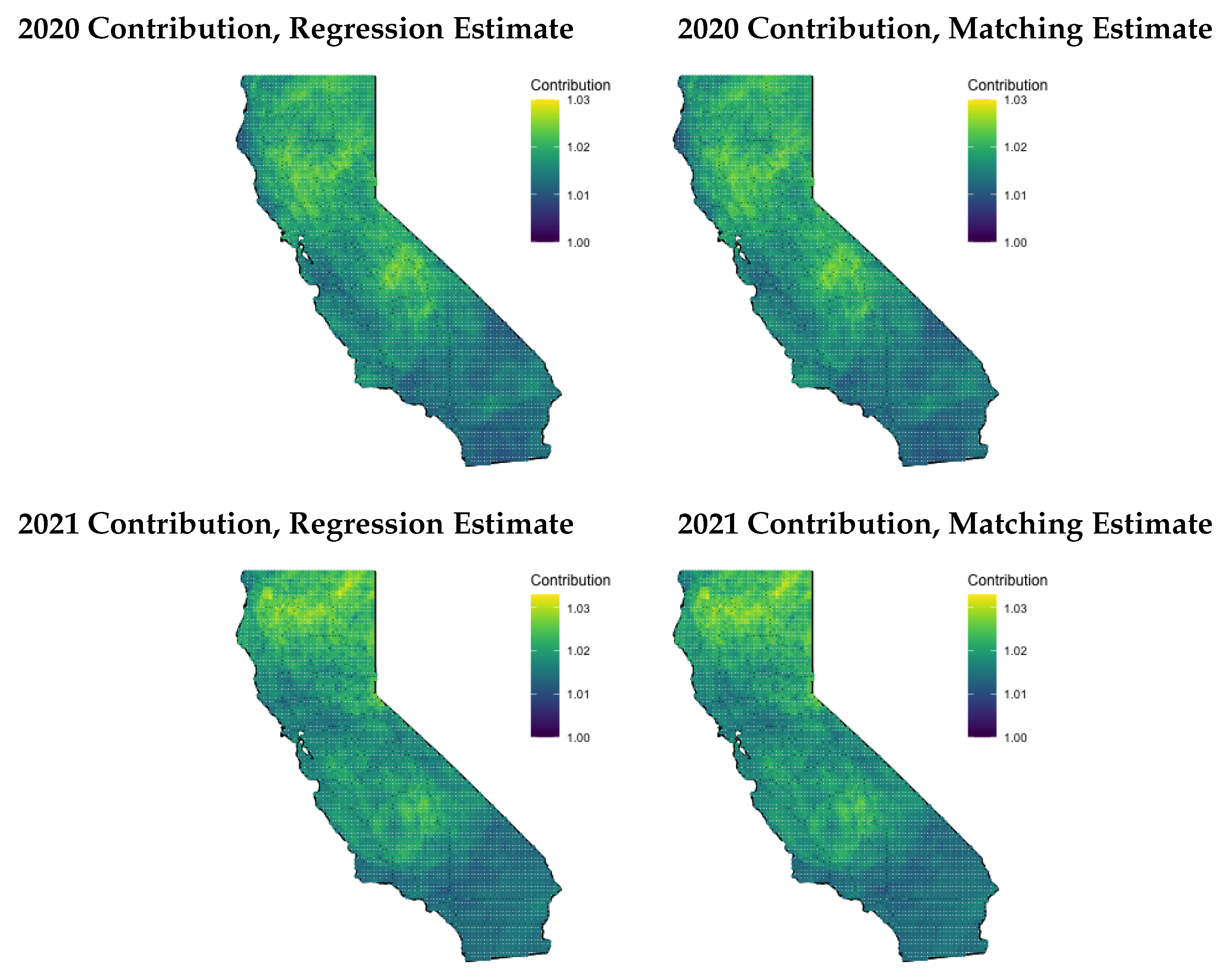
Figure 5.
Posterior distribution of the correlation between AQS and PA by period. Small periods capture short-term variation, such as day-to-day variation, while large periods capture long-term variation, such as monthly trends.
Figure 5.
Posterior distribution of the correlation between AQS and PA by period. Small periods capture short-term variation, such as day-to-day variation, while large periods capture long-term variation, such as monthly trends.
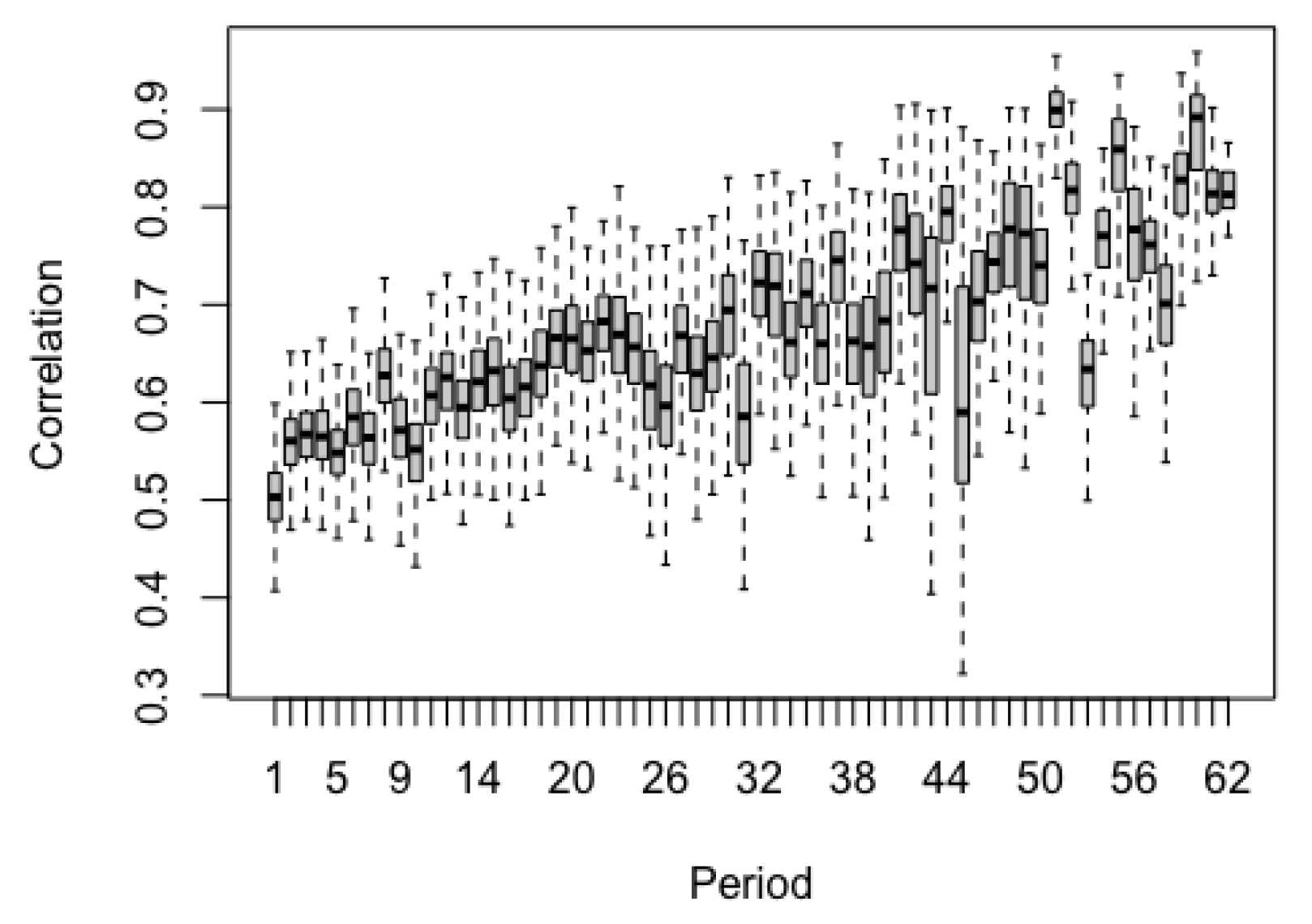
Table 1.
Posterior mean (95% interval) for the model parameters. The regression coefficients are given separately for the true PM process () and bias correction (). A “***” indicates that the 95% interval excludes zero.
Table 1.
Posterior mean (95% interval) for the model parameters. The regression coefficients are given separately for the true PM process () and bias correction (). A “***” indicates that the 95% interval excludes zero.
| 2020 fire season | ||
|---|---|---|
| Parameter | True PM | Bias correction |
| Temperature | 0.115 (0.106,0.125)*** | -0.002 (-0.009,0.005) |
| Humidity | 0.064 (0.048,0.080)*** | 0.012 (-0.002,0.035) |
| Plume – Low | 0.007 (0.003,0.011)*** | / |
| Plume – Medium | 0.022 (0.012,0.032)*** | / |
| Plume – High | 0.049 (0.033,0.065)*** | / |
| 2021 fire season | ||
| Parameter | True PM | Bias correction |
| Temperature | 0.006 (0.004,0.008)*** | 0.006 (-0.003,0.015) |
| Humidity | 0.000 (-0.001,0.001) | -0.011 (-0.026,0.003) |
| Plume – Low | 0.011 (0.001,0.021)*** | / |
| Plume – Medium | 0.018 (0.007,0.029)*** | / |
| Plume – High | 0.041 (0.031,0.051)*** | / |
Table 2.
Posterior mean (standard deviation) for the model parameters for the CA data using the proposed data fusion model, the model that uses only AQS data, and the naive data fusion model that ignores bias in the PA data. A “***” indicates that the 95% interval excludes zero.
Table 2.
Posterior mean (standard deviation) for the model parameters for the CA data using the proposed data fusion model, the model that uses only AQS data, and the naive data fusion model that ignores bias in the PA data. A “***” indicates that the 95% interval excludes zero.
| 2021 fire season | |||
|---|---|---|---|
| Parameter | Data fusion | AQS Only | Naive |
| Temperature | 0.115 (0.005)*** | 0.105 (0.024)*** | -0.418 (0.066)*** |
| Humidity | 0.064 (0.008)*** | 0.086 (0.022)*** | -1.125 (0.052)*** |
| Plume - Low | 0.007 (0.002)*** | 0.005 (0.012) | 0.107 (0.078) |
| Plume - Medium | 0.022 (0.005)*** | 0.020 (0.014) | 0.271 (0.052)*** |
| Plume - High | 0.049 (0.008)*** | 0.042 (0.016)*** | 0.637 (0.079)*** |
| 2021 fire season | |||
| Parameter | Data fusion | AQS Only | Naive |
| Temperature | 0.006 (0.001)*** | 0.015 (0.003)*** | -0.014 (0.006)*** |
| Humidity | 0.000 (0.000) | 0.008 (0.002)*** | -0.039 (0.003)*** |
| Plume - Low | 0.011 (0.004)*** | -0.001 (0.014) | -0.330 (0.032)*** |
| Plume - Medium | 0.018 (0.004)*** | 0.023 (0.016) | 0.230 (0.074)*** |
| Plume - High | 0.041 (0.005)*** | 0.054 (0.017)*** | 0.980 (0.071)*** |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



