
Submitted:
15 June 2023
Posted:
16 June 2023
You are already at the latest version
Abstract
Digital images have become an important carrier for people to access information in the information age. However, with the development of the technology, digital images are vulnerable to illegal access and tampering, to the extent that they pose a serious threat to personal privacy, social order and national security. Therefore, image forensic techniques have become an important research topic in the field of multimedia information security. In recent years, deep learning technology has been widely applied in the field of image forensics and the performance achieved has significantly exceeded the conventional forensic algorithms. This survey compares the state-of-the-art image forensic techniques based on deep learning in recent years. The image forensic techniques are divided into passive and active forensics. In passive forensics, forgery detection techniques are reviewed, and the basic framework, evaluation metrics and commonly used datasets for forgery detection are presented. The performance, advantages and disadvantages of existing methods are also compared and analyzed according to different types of detection. In active forensics, robust image watermarking techniques are overviewed, the evaluation metrics and basic framework of robust watermarking techniques are presented. The technical characteristics and performance of existing methods are analyzed based on the different types of attacks on images. Finally, future research directions and conclusions are given to provide useful suggestions for people in image forensics and related research fields.
Keywords:
image forensics
; image forgery detection
; robust image watermarking
; deep learning
1. Introduction
Digital images are important information carriers in human life, and with the rapid development of the technology, digital images have gradually covered all aspects of life. However, data stored or transmitted in digital form is vulnerable to external attacks, and digital images are particularly susceptible to unauthorized access and illegal tampering. As a result, the credibility and security of digital images are under serious threat. If these illegally accessed and tampered images appear in the news media, academic research and judicial forensics, which require high originality of images, social stability and political security will be seriously threatened. To solve the above problems, digital image forensics has become a hot issue for research, and is the main method to identify whether the images are illegally acquired or tampered. Digital image forensic technology is a novel technique to determine the authenticity, integrity and originality of image content by analyzing the statistical characteristics of images, which is of great significance for securing cyberspace and maintaining the social order.
Digital image forensic techniques are mainly used to detect the authenticity of digital images, which can be divided into active forensics techniques and passive forensic techniques according to different detection methods, as shown in Figure 1. The active forensic techniques are used to embed prior information, and then extract the embedded information and compare it with the original information to identify whether the image is illegally obtained, such as digital watermark and digital signatures. The robust digital watermarking technique is to embed watermark information in the spatial or transform domain of the image in advance, then extract the watermark information of the image after transmission, and verify the copyright information of the image by judging the watermark information to determine whether the image is illegally acquired. Passive forensic techniques, which do not require prior information about the image, determine whether the image has been illegally tampered by analyzing the structure and statistical characteristics of the image. In passive forensic techniques, even if an image has been forged beyond recognition by the human eye, the statistical characteristics of the image will change, causing various inconsistencies in the image, and these inconsistencies are used to detect and locate tampered image. With the development of deep learning technology, deep learning technology has been widely applied in the field of image forensics, which has promoted the development of image forensics technology. In this survey, we focus on passive image forgery detection technology based on deep learning and robust image watermarking technology based on deep learning.
There have been many reviews of passive forgery detection techniques over the last few years. Kuar et al. [1] gave a detailed overview of the process of image tampering and the current problems of tampering detection, and sorted out the conventional algorithms in tampering detection from different aspects, without reviewing the techniques of deep learning. Zhang et al. [2] sorted out and compared the conventional copy-move tampering detection algorithms, giving the advantages and disadvantages of each conventional algorithm in detail, without reviewing the techniques related to deep learning. Zanardelli et al. [3] reviewed deep learning-based tampering algorithms and compared copy-move, splicing, and deep fake techniques. However, generic tampering detection algorithms was not provided in detail. Nabi et al. [4] reviewed image and video tampering detection algorithms, giving a detailed comparison of tampering detection datasets and algorithms, but did not summarize the evaluation metrics of tampering detection algorithms. This survey provides an overview of deep learning techniques and reviews the latest generic tamper detection algorithms. In this survey the evaluation metrics commonly used for tampering detection are summarized.
For active forensics, Rakhmawati et al. [5] analyzed a fragile watermarking model for tampering detection. Kumar et al. [6] summarized the existing work on watermarking from the perspective of blind and non-blind watermarking, robust and fragile watermarking, but it did not focus on the methods to improve the robustness. Menendez et al. [7] summarized the reversible watermarking model and analyzed its robustness. Agarwal et al. [8] reviewed the robustness and imperceptibility of the watermarking model from the spatial domain and transform domain perspectives. Amrit and Singh [9] analyzed the watermarking models based on deep watermarking in recent years, but it did not discuss the methods to improve the robustness of the models for different attacks. Wan et al. [10] analyzed robustness enhancement methods for geometric attacks in deep rendering images, motion images and screen content images. Evsutin and Dzhanashia [11] analyzed the characteristics of removal, geometric and statistical attacks and summarized the corresponding attack robustness enhancement methods, but there was less analysis of watermarking models based on deep learning. Compared to the existing active forensic reviews, we start from one of the fundamentals of model robustness enhancement (i.e., generating attack-specific adversarial samples). According to their compatibility with deep learning-based end-to-end watermarking models, the attacks are initially classified into differentiable attacks and non-differentiable attacks. According to their impact on the watermarking model, the network structure and training methods to improve the robustness of different attacks are further subdivided.
The rest of this survey is organized as follows: Section 2 gives the basic framework for tampering detection and robust watermarking based on deep learning, evaluation metrics, attack types and tampering datasets. Section 3 presents the state-of-the-art techniques of image forgery detection based on deep learning. Section 4 describes the state-of-the-art techniques of robust image watermark based on deep learning. Section 5 gives the conclusion and future work.
2. Image Forensic Techniques
2.1. Passive Forensics
Passive image forgery detection techniques can be classified as conventional manual feature-based and deep learning-based. The conventional detection algorithms for copy-move forgery detection (CMFD) are: discrete cosine transform (DCT) [12], discrete wavelet transform (DWT) [13], polar complex exponential transform (PCET) [14], scale invariant feature transform (SIFT) [15], speeded up robust feature (SURF) [16], etc. The conventional detection algorithms for splicing tamper detection are: inconsistency detection by color filter array (CFA) interpolation [17], inconsistency detection by noise features [18]. However, these conventional detection methods have the drawbacks of low generalization, poor robustness, and low detection accuracy. Deep learning-based detection algorithms, which take advantage of autonomous learning features, solve the above problems of conventional algorithms. In this survey, we mainly review the forgery detection algorithms based on deep learning.
2.1.1. Basic Framework of Image Forgery Detection
With the development of deep learning techniques, certain advantages have been achieved in areas such as image classification and segmentation. Deep learning is also increasingly being applied to image forgery detection. A basic framework of image forgery detection based on deep learning is shown in Figure 2. Firstly, the tamper detection network is built, feature extraction, feature classification and localization are performed by the network model. The weights of the network are saved by learning the parameters within the network through big data training to get the weights when optimal. The image to be detected is input to the network and tampering detection is performed using the saved network model.
2.1.2. Performance Evalution Metrics
The forgery detection task can be considered as a binary classification task of pixel, i.e., whether a pixel is tampered or not. Therefore, the evaluation metrics of the forgery detection algorithm needs to use the amount of categorization of the samples, including true positive, false positive, true negative, and false negative. The commonly used evaluation metrics for forgery detection are precision p, recall r, and score [2], which are expressed as Equations (1)–(3), respectively:
where denotes the number of tampered pixels detected as tampered; denotes the number of authentic pixels detected as tampered; denotes the number of tampered pixels detected as authentic. The values of p, r, and are in range [0, 1]. The larger p, r, and are, the higher the accuracy of detection results is.
Another important metric is the area under curve (AUC), which is defined as the area under the receiver operating characteristic (ROC) curve and can reflect the classification performance of a binary classifier. Like the score, AUC can evaluate the precision and recall together. Its value is generally between 0.5 and 1. The closer the value of AUC is to 1, the higher the performance of the algorithm. When it is equal to 0.5, the true value is the lowest and has no application value.
2.1.3. Datasets for Image Forgery Detection
Diverse datasets for forgery detection are described in this section. These datasets contain original images, tampered images, binary labels, and partially post-processed images. Different datasets are used depending on the problem being solved. In order to validate the results of tamper detection algorithms, different public tampered image datasets are used to test the performance of these algorithms. Table 1 describes the 14 public datasets for image forgery detection, presenting the type of forgery, number of forged images and authentic images, image format, and image resolution.
2.2. Active Forensics
Digital watermarking is one of the most effective active forensics methods to realize piracy tracking and copyright protection. It can be classified into conventional methods based on manually designed features and deep learning-based methods. Early digital watermarking was mostly embedded in the spatial domain, such as least significant bits (LSB) [30], but it lacked robustness and was easily detected by sample pair analysis [31]. To improve robustness, a series of transform domain-based methods were proposed, such as DWT [32], DCT [33], contourlet transform [34] and Hadamard transform [35]. In recent years, with the continuous update and progress of deep learning technology, deep learning has been widely used in image watermarking and achieved remarkable achievements. In this survey, we will focus on the analysis of deep learning-based robust watermarking.
2.2.1. Basic Framework of Robust Image Watermarking Algorithm
The main basic framework of deep learning-based end-to-end robust watermarking is shown in Figure 3. It is composed of three parts: embedding layer, attack simulation layer, and extraction layer. In the embedding layer, it can be subdivided into image feature extraction network, watermark feature enhancement network, and embedding network. The image feature extraction network is to extract more robust image feature space or feature points, so that the embedding network can embed the watermark more covertly and robustly in the original image. The watermark feature enhancement network is to enrich and redundantly diffuse watermark features so as to facilitate subsequent extraction. The attack simulation layer (ASL) is used to generate random attacked samples which can guide the parameters of the extracting network to improve extraction accuracy under different attack conditions. The extracting network is responsible for extracting the watermark from the attacked watermarked image or watermarked image.
2.2.2. Performance Evaluation Metrics
In digital image watermarking algorithm, the most important three evaluation indicators are robustness, imperceptibility, and capacity.
Robustness: Robustness is used to measure the ability of a watermark model to recover the original watermark after an image has been subjected to a series of intentional or unintentional image processing during electronic or non-electronic channel transmission. Bit error rate (BER) and normalized cross-correlation (NCC) are usually used as the objective evaluation metrics, which are expressed as Equations (4) and (5), respectively:
where , represents the ith bit of the original watermark and the mean value of the original watermark respectively; , represents the the i th bit of the extracted watermark and mean value of the extracted watermark; L represents the length of the watermark.
Imperceptibility: Imperceptibility is used to measure the sensory impact of the em-bedding point on the whole image after the model has completed watermark embedding (i.e., the watermarked image is guaranteed to be indistinguishable from the original image). Peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) are usually used as the objective evaluation metrics, which are expressed as Equations (6) and (7), respectively:
where W denotes the width of the original image; H denotes the length of the original image; denotes the maximum gray level of the original image; , denotes the mean value of the gray value of the original image and the watermarked image, respectively; , denotes the variance of the gray value of the original image and the watermarked image, respectively; , denotes the (i, j) original image and watermarked image; denotes the covariance of the original image and the watermark image; and are constant in range [, 9×].
Capacity: The capacity represents the maximum watermark embedding bits of the model while maintaining the established required imperceptibility and robustness metrics. It is mutually constrained with imperceptibility and robustness. Increasing the watermark embedding capacity, imperceptibility and robustness decrease, and vice versa. The number of embedded watermark bits per pixel (bpp) is usually used to measure the capacity metric of the model, which is expressed as Equation (8):
where denotes the number of watermark bits, and denotes the total number of original image pixels.
2.2.3. Attacks of Robust Watermarking
In the end-to-end watermarking framework, the attack simulation layer plays a decisive role in improving the robustness of the framework. However, when implementing backpropagation updates in parameters, it is necessary to ensure that each node is differentiable. For non-differentiable attacks, the model cannot perform parameter updates during backpropagation. Therefore, here comes a subdivision of whether the attack is differentiable or not.
Differentiable Attacks:
Noise and Filtering Attacks: Noise and filtering attacks refer to some intentional or unintentional attacks on the watermarked image in the electronic channel transmission, such as Gaussian noise, salt and pepper noise, Gaussian filtering, median filtering. Its robustness can usually be improved by generating the adversarial samples in the ASL layer.
Geometric Attacks: Applying geometric attacks to an image can break the synchronization between the watermark decoder and the watermarked image. Geometric attacks can be subdivided into rotation, scaling, translation and cropping, etc.
Non-differentiable Attacks:
Joint Photographic Experts Group (JPEG) Attacks: The JPEG standard has two basic compression methods: the DCT-based method and the lossless compression prediction method. In this survey, we focus on the DCT-based JPEG compression, which can consist of DCT, inverse DCT, quantization, inverse quantization, entropy coding and entropy decoding (i.e., color conversion and sampling), as shown in Figure 4. Quantization and dequantization are non-differentiable processes, leading to incompatibility of the model with simulated attacks.
Screen-shooting Attacks: In the process of watermarked images through the camera photo processing, it will undergo a series of analog-digital (A-D) conversion and digital-analog (D-A) conversion inevitably, which both affecting the extraction of the watermark seriously.
Agnostic Attacks: Agnostic attacks refer to attacks in which the model parameters are unknown to the attack prior information. For neural network models, it is difficult for the encoder and decoder to adapt to agnostic attacks without generating attack prior samples.
3. Image Forgery Detection Based on Deep Learning
Image passive forgery detection methods can be divided into the single type of forgery detection and generic forgery detection depending on the detection types. Single forgery detection methods can only detect specific type of tampered images, including image copy-move forgery detection and image splicing forgery detection. Generic forgery detection methods can be applied to different types of tampered images, including copy-move, splicing and removal. Diverse passive forgery detection methods are described in this section. A table is given to compare the performance of passive forgery detection methods form different aspects at the end of this section. An overview of image forgery detection based on deep learning, as shown in Figure 5.
3.1. Image Copy-Move Forgery Detection
The CMFD methods detect tampered images by extracting features associated with tampering. For an image, it is possible to globally capture the features either for the entire image or locally for regions. The choice of feature extraction methods affects the performance of CMFD methods greatly. The CMFD methods are divided into two categories, conventional manual feature-based methods and deep learning-based methods.
The conventional manual feature methods can be divided into block-based and keypoint-based CMFD methods. The block-based CMFD methods can locate tampered regions accurately, but there are main problems, such as high computational complexity and difficulty in resisting large scale rotation and scaling. To solve these problems, keypoint-based CMFD methods are proposed. The keypoint-based CMFD methods use the keypoint extraction techniques to extract keypoints of the images and find similar features using feature matching algorithms. The keypoint-based CMFD methods can accurately locate tampered regions of common tampered images, but it mainly suffers from problems, such as the small number of keypoints in smooth regions leading to undetectable and poor algorithm generalization ability. To solve these problems of conventional manual feature methods, deep learning-based CMFD methods are proposed.
With the rapid development of deep learning techniques, deep learning-based methods have been applied to the field of tampering detection. Deep learning-based CMFD methods have shown great performance improvements. Using a well-trained model can learn the latent features of images. The difference between the two types of images is found to discriminate the tampered image. Compared with conventional methods, deep learning-based CMFD can provide more accurate and comprehensive feature descriptors.
To detect whether an image was tampered, Rao and Ni [36] proposed a deep convolutional neural network (DCNN)-based model that used the spatial rich models (SRM) with 30 basic high-pass filters to initialize the weights of the first layer, which helped suppress the effects of image semantics and accelerated the network convergence. The image features were extracted by the convolutional layer and classified using support vector machine (SVM) to discern whether the image was tampered or not. Kumar and Gupta [37] proposed a convolutional neural network (CNN)-based model to automatically extract image features for image tampering classification with robust to image compression, scaling, rotation and blurring, but the method also required analysis at the pixel level to locate tampered regions. In [36,37], they only perform the detection of whether tampering has been performed, and cannot localize tampered regions, which has a limited application.
To further improve the application space of the algorithm and achieve the localization of copy and move regions, Li et al. [38] proposed a method combining image segmentation and DCNN, using Super-BPD [39] to segment the image to obtain the edge information of the image. VGG 16 and atrous spatial pyramid pooling (ASPP) [40] networks obtained the multi-scale features of the image to improve the accuracy of the algorithm. The feature matching module was introduced to achieve the localization of tampered regions. But segmentation module lead to high computational complexity. Liu et al. [41] designed a two-stage detection framework. The first stage introduced atrous convolution with autocorrelation matching based on spatial attention to improve similarity detection. In the second stage, the superglue method was proposed to eliminate false warning regions and repair incomplete regions, thus improving the detection accuracy of the algorithm. Zhong and Pun [42] gave an end-to-end deep neural network, referring to the Inception architecture fusing multi-scale convolution to extract multi-scale features. Kafali et al. [43] proposed a nonlinear inception module based on second-order Volterra kernel by considering the linear and nonlinear interactions among pixels. Nazir et al. [44] gave an improved mask region-based convolution network. The network used the DenseNet 41 model to extract deep features, which were classified using the Mask-RCNN [45] to locate tampered regions. Zhong et al. [46] proposed a coarse-fine spatial channel boundary attention network and designed the attention module for boundary refinement to obtain finer forgery details and improve the performance of detection. In [36,37,38,41,42,43], they improve the detection performance and robustness of the algorithm, but do not distinguish between source and target areas.
To correctly distinguish between source and target regions, some methods are proposed. Wu et al. [26] proposed the first parallel network for distinguishing between source and target. The manipulation detection branch located potential manipulation regions by visual artifacts, and the similarity detection branch located source and target regions by visual similarity. Chen et al. [47] used a serial structure and added the atrous convolutional attention module in the similarity detection phase to improve the detection accuracy. The network structure is shown in Figure 6. Aria et al. [48] proposed a quality-independent detection method, which used a generative adversarial network to enhance image quality and a two-branch convolutional network for tampering detection. The network could detect multiple tampered regions simultaneously and distinguish the source and target of tampering. It was resistant to various post-processing attacks and had good detection results in low quality tampered images. Barni et al. [49] proposed a multi-branch CNN network, which exploited the irreversibility caused by interpolation traces and the inconsistency of target region boundaries to distinguish source and target regions.
3.2. Image Splicing Forgery Detection
Image splicing forgery is also one of the most popular ways to manipulate the content of an image. The manipulation operation of splicing is copying an area from one image and pasting it to another image. The tampered images are a serious threat to the security of image information. It is crucial to develop suitable methods to detect image splicing forgery. Image splicing detection techniques are divided into manual feature-based methods and deep learning-based methods.
The current manual feature-based methods can be divided into three categories: textural feature-based techniques, noise-based techniques and other techniques. The textural feature-based techniques use the difference between the local frequency distribution in tampered image and the local frequency of the real image to detect image splicing. The commonly used textural feature descriptors are local binary pattern (LBP) [50], gray level co-occurrence matrices (GLCM) [51], local directional pattern (LDP) [52], etc. Since the splicing images come from two different images, the noise distribution of the tampered image is changed. Therefore, the noise-based techniques detect tamper by estimating the noise of the tampered image. The detection of splicing images can also be performed by fusing multiple features. Manual feature-based methods use different descriptors to obtain specific features, and the detection effect is various for different datasets. The generalization of manual feature-based techniques is poor. The deep learning-based methods can learn automatically a large number of features, which improve the accuracy and generalization ability performance of image splicing detection.
Deep learning-based methods can learn and optimize the feature representations for forgery forensics directly. This has inspired researchers to develop different techniques to detect image splicing. In recent years, U-Net structure is more widely used in splicing forgery detection. Wei et al. [53] proposed a tamper detection and localization network based on U-Net with multi-scale control. The network used a rotated residual structure to enhance the learning ability of features. Zeng et al. [54] proposed a multitask model for locating splicing tampering in an image, which fused attention mechanism, densely connected network, ASPP and U-Net. The model can capture more multi-scale features while expanding the receptive field and improve the detection accuracy of image splicing tampering. Zhang et al. [55] gave a multi-task squeeze and extraction network for splicing localization. The network consisted of label mask stream and edge-guided stream, which used U-Net architecture. Squeeze and excitation attention modules (SEAMs) were incorporated into the multi-task network to recalibrate the fused features and enhance the feature representation.
Many researchers have also used fully convolutional networks (FCN) commonly used in semantic segmentation for image splicing forgery detection. Chen et al. [56] proposed a residual-based fully convolutional network for image splicing localization. The residual blocks were added to FCN to make the network easier to optimize. Zhuang et al. [57] gave a dense fully convolutional network for image tampering localization. This structure comprised dense connections and dilated convolutions to capture subtle tampering traces and obtain finer feature maps for prediction. Liu et al. [58] proposed a fully convolutional network with noise feature. The network enhanced the generalization ability by extracting noise maps in the pre-processing stage to expose the subtle changes in the tampered images and improved the robustness by adding the region proposal network. The technique could accurately locate the tampered regions of images and improve generalization ability and robustness.
In recent years, attention mechanisms have been deeply developed and have gained a great advantage in the field of natural language processing. Many researchers have started to incorporate the attention mechanism in tampering detection. Ren et al. [59] proposed a multi-scale attention context-aware network and designed a multi-scale multi-level attention module, which not only effectively solved the inconsistency of features at different scales, but also automatically adjusted the coefficients of features to obtain a finer feature representation. To address the problem of poor accuracy of splicing boundary, Sun et al. [60] proposed an edge-enhanced transformer network. A two-branch edge-aware transformer was used to generate forgery features and edge features to improve the accuracy of tampering localization.
3.3. Image Generic Forgery Detection
To enable multiple types of tampering detection, the algorithm has been made more generalizable. Zhang et al. [61] proposed a two-branch noise and boundary network that used an improved constrained convolution to extract the noise map. It can effectively solve the problem of training instability. The edge prediction module was added to extract the tampered edge information to improve the accuracy of localization. But the detection performance was poor when the tampered image contained less tampered information. Dong et al. [62] designed a multi-view, multi-scale supervised image forgery detection model. The model combined the boundary and noise features of the tampered regions to learn semantic-independent features with stronger generalization, which improved detection accuracy and generalization. But the detection effect was poor when the tampered region was the background region. Chen et al. [63] proposed a network based on signal noise separation to improve the robustness. The signal noise separation module separated the tampered regions from the complex background regions with post-processing noise, reducing the negative impact of post-processing operations on the image and improving the robustness of the algorithm. Liu et al. [64] proposed a network for learning and enhancing multiple tamper traces, fusing multiple features of global noise, local noise and detail artifact features for forgery detection, which enabled the algorithm to have high generalization and detection accuracy. However, when the tampering artifacts are reduced, the lack of effective tampering traces results in tampered regions undetectable. Wang et al. [65] proposed a multimodal transformer framework, which consisted of three main modules: high frequency feature extraction, object encoder and image decoder, to address the difficulty of capturing invisible subtle tampering in the RGB domain. The frequency features of the image were first extracted, and the tampered regions were identified by combining RGB features and frequency features. The effectiveness of the method was shown on different datasets.
To achieve a more refined prediction of tampering mask, a progressive mask decoding approach is used. Liu et al. [66] proposed a progressive spatio-channel correlation network. The network used two paths, top-down path acquired local and global features of the image, and bottom-up path was used to predict the tampered mask. The spatio-channel correlation module was introduced to capture the spatial and channel correlation of features and extract features with global clues to enable the network to cope with various attacks and improve the robustness of the network. To solve the problem of irrelevant semantic information, Shi et al. [67] proposed a progressively-refined neural network. Tampered regions were localized progressively under a coarse-to-fine workflow and rotated residual structure was used to suppress the image content during the generation process. Finally, the refined mask was obtained.
To solve the existing problems of low detection accuracy and poor boundary localization, Gao et al. [68] proposed an end-to-end two-steam boundary-aware network for generic image forgery detection and localization. The network introduced an adaptive frequency selection module to adaptively select appropriate frequencies to mine inconsistent statistical information and eliminate the interference of redundant information. Meanwhile, a boundary artifact localization module was used to improve the boundary localization effect. To address the problem of poor generalization ability to invisible manipulation, Ganapathi et al. [69] proposed a channel attention-based image forgery detection framework. The network introduced a channel attention module to detect and localize forged regions using inter-channel interactions to focus more on tampered regions and achieve accurate localization. To identify forged regions by capturing the connection between foreground and background features, Xu et al. [70] proposed a mutually complementary forgery detection network, which consisted of two encoders for extracting foreground and background features, respectively. A mutual attention module was used to extract complementary information from the features, which consisted of self-feature attention and cross-feature attention. The network significantly improved the localization of forged regions using the complementary information between foreground and background.
To improve the generalization ability of the network model, Rao et al. [71] proposed a multi-semantic conditional random field model to distinguish the tampered boundary from the original boundary for localization of the forged regions. The attention blocks were used to guide the network to capture more intrinsic features of the boundary transition artifacts. The attention maps with multiple semantics were used to make full use of local and global information, thus improving the generalization ability of the algorithm. Li et al. [72] proposed an end-to-end attentional cross-domain network. The network consisted of three streams that extracted three types of features, including visual perception, resampling, and local inconsistency. The fusion of multiple features improved the generalization ability and localization accuracy of the algorithm effectively. Yin et al. [73] proposed a multi-task network based on contrast learning for the localization of multiple manipulation detection. Contrast learning was used to measure the consistency of statistical properties of different regions to enhance the feature representation and improved the performance of detection and localization.
To solve the problems of low accuracy and insufficient training data, Zhou et al. [74] gave a coarse-to-fine tampering detection network based on a self-adversarial training strategy. A self-adversarial training strategy was used to dynamically extend the training data to achieve higher accuracy. Meanwhile, to solve the problem of the insufficient dataset, Ren et al. [75] designed a novel dataset, called the multi-realistic scene manipulation dataset, which consisted of three kinds of tampering, including copy-move, splicing and removal, and covering 32 different tampering scenes in life. A general and efficient search and recognition network was proposed to reduce the computational complexity of forgery detection.
4. Robust Image Watermarking Based on Deep Learning
According to the gradient updating feature of the attack, robust watermarking can be classified into two categories: robust differentiable attack watermarking and robust non-differentiable attack watermarking. For differentiable attacks, the adversarial simulation layer (ASL) can be introduced into the model to generate attack counterexamples directly, while non-differentiable attacks require other means to improve their robustness, such as differentiable approximation, two-stage training, and network structure improvement, etc.
4.1. Robust Image Watermark against Differentiable Attack
As shown in Figure 7, differential attacks can be further categorized into noise and filtering attacks, as well as geometric attacks.
4.1.1. Robust Image Watermark against Noise and Filtering Attack
Noise and filtering attacks apply corresponding noise or filtering to the pixel from the spatial domain and transform domain directly, affecting the amplitude coefficient synchronization of the codec. There are three methods for recovering amplitude synchronization: zero-watermarking, generative adversarial network (GAN) [80]-based, and embedding coefficient optimization.
Zero-watermarking: The conventional zero-watermarking algorithm consists of three steps: original image robust feature extraction, zero-watermark generation, and zero-watermark verification. To extract noise-invariant feature, Fan et al. [81] used a pre-trained Inception V3 [82] network to extract the image feature tensor initially, and extracted its low-frequency subbands by DCT transform to generate a robust feature tensor. They dissociated the binary sequence generated by chaos mapping with the watermark information to obtain a noise-invariant zero-watermark.
GAN-based: In the watermarking model, GAN can generate high-quality images more efficiently by competing between the discriminator (i.e., watermarked image discriminator) and the generator (i.e., encoder) under adversarial loss supervision to continuously update each other’s parameters and improve the decoding accuracy by supervising the decoder through total loss function indirectly. Since the human visual system focuses more on the central region of the image, Wen and Aydore [83] introduced adversarial training into the watermarking algorithm where the distortion type and the distortion strength were adaptively selected thus minimizing the decoding error. Hao et al. [84] added a high-pass filter before the discriminator so that the watermark tended to be embedded in the mid-frequency region of the image, giving a higher weight to the middle region pixels in the computed loss function. However, it couldn’t resist geometric attacks effectively. Zhang et al. [85] proposed an embedding-guided end-to-end framework for robust watermarking. Using a prior knowledge extractor to obtain the chrominance and edge saliency of cover images for guiding the watermark embedding. However, it could not be applied to practical scenarios such as printing, camera photography and geometric attacks. Li et al. [86] designed a single-frame exposure optical image watermarking framework using conditional generative adversarial network (CGAN) [87]. Yu [88] introduced an attention mechanism to generate attention masks to guide the encoder to generate better target images without disturbing the spotlight, and improved the reliability of the model by combining GAN with a circular discriminant model and inconsistency loss. However, [83,84,85,86,88] did not effectively address the GAN network training instability problem, resulting in none of them being able to further improve the balance of robustness and imperceptibility.
Embedding Parameter Optimization: The position and strength of the embedding parameters determine the algorithm performance directly. Mun et al. [89] performed an iterative simulation of the attack on the watermarking system. But it can only get one bit of watermark information from a sub-block. Kang et al. [90] firstly subjected the host image to DCT transformation to extract human eye-insensitive LH sub-band and HL sub-band. Particle swarm optimization (PSO) was used to find the best DCT coefficients and the best embedding strength to improve the imperceptibility and robustness of the watermarking algorithm. However, due to the training overfitting of PSO [91], its model generalized and achieved good robust performance only on the experimental dataset badly. Rai and Goyal [92] combined fuzzy, backpropagation neural networks and shark optimization algorithms. However, [90,92] had the problem of training overfitting. To improve the training overfitting problem, Liu et al. [93] introduced a two-dimensional image information entropy loss to enhance the ability of the model to generate different watermarks, ensuring that the model was always able to assign enough information to a single host image for different watermark inputs and the extractor can extract the watermark information completely, therefore enhancing the dynamic randomness of the watermark embedding. Zhao et al. [94] introduced a spatial and channel attention mechanism that enabled the network to focus on low-sensitivity pixel during watermark embedding, but it had robustness to geometric attacks badly.
Deep learning-based image watermarking against noise and filtering attack algorithms and performance comparison are described in Table 3. Table 3 describes the methods from five aspects: watermark size (container size), category, method (effect), robustness, and dataset, where , , and represents the variance of Gaussian blur, Gaussian filtering, and Gaussian noise respectively.
4.1.2. Robust Image Watermark against Geometric Attacks
Geometric attacks mainly include rotation, cropping, and translation that change the spatial position relationship of pixel and affect the spatial synchronization of codecs. According to the method of recovering spatial synchronization, it can be divided into transform domain-based, zero-watermarking, and robust feature-based.
Transform Domain-based: The transform domain-based watermarking algorithm embeds the watermark into the transform domain coefficients, avoiding geometric attacks from corrupting the synchronization of the codec effectively. Ahmadi [100] implemented watermark embedding and extraction in the transform domain (such as DCT, DWT, Haar, etc.), and introduced circular convolution in the convolution layer used for feature extraction to make the watermark information diffuse in the transform domain, which effectively improved the robustness against cropping. Mei et al. [101] embedded watermark in the DCT domain and introduced the attention mechanism to calculate the confidence of each image block. In addition, joint source-channel coding was introduced to make the algorithm maintain good robustness and imperceptibility under the gray image watermarking with the background.
Zero-watermarking: The idea of the zero-watermarking is to obtain geometrically invariant feature from robust features in images and generate zero-watermark through zero-watermark generation by sequence synthesis operation such as dissimilar operation. Han et al. [102] used pre-trained VGG19 [103] network to extract original image features and selected DFT-transformed low-frequency sub-bands to construct a medical image feature matrix. Liu et al. [104] used neural style transfer (NST) [105] technique combined with pre-trained VGG19 network to extract the original image style features, fused the original image style with the original watermark content to obtain the style fusion image, and Arnold dislocation [106] to obtain the zero-watermark. Gong et al. [107] used the low-frequency features of the DCT of the original image as labels. Skip connection and loss function were applied to enhance and extract high-level semantic features. However, none of [102,104,107] could resist the robustness of multiple types of attacks effectively.
Robust Feature-based: Unlike the zero-watermarking, the idea of this method is to search for embedded feature coefficients or tensors in the image and embed the watermark in it robustly. Hu et al. [108] embedded the watermark in low-order Zernike moments with rotation and interpolation invariance. Mellimi et al. [109] proposed a robust image watermarking scheme based on lifting wavelet transform (LWT) and deep neural network (DNN). The DNN was trained to identify the changes caused by attacks in different frequency bands and select the best subbands for embedding. However, it was not robust to speckle noise. Fan et al. [110] combined the multiscale features in GAN and used pyramid filters and multiscale maximum pooling techniques to learn the watermark feature distribution and improve the geometric robustness of watermarking fully.
The state-of-the-art deep learning-based image watermarking against geometric attacks algorithms and performance comparison are described in Table 4. Table 4 describes the methods from five aspects: watermark size (container size), category, method (effect), robustness, and dataset, where represents the scaling factor for the scaling attack; represents the cropping ratio for cropping; represents the clockwise rotation of the rotation attack.
4.2. Robust Image Watermark against Non-differentiable Attack
As shown in Figure 8, non-differential attacks can be further categorized into JPEG attacks, screen-shooting attacks, agnostic attacks.
4.2.1. Robust Image Watermark against JPEG Attack
In recent years, end-to-end watermarking algorithms based on deep learning have been emerging, and thanks to the powerful feature extraction capabilities of CNN, watermarks can be covertly embedded in low-perception pixel regions of the human eye (such as diagonal line, textured complex regions, high-brightness slow-change regions, etc.) to obtain watermarked images that are very similar to the original images. In the end-to-end training, to improve the robustness of the watermarking algorithm, the watermarked image is added to the differentiable attack by introducing an attack simulation layer to generate the attacked counterexamples, and the decoder parameters are updated by decoding losses such as mean square error (MSE), binary cross entropy (BCE) of the original watermark and decoded watermark, etc. However, due to the introduction of the non-differentiable nature of real JPEG compression, it cannot be introduced into the end-to-end network to implement back-propagation updates of model parameters directly. To address this problem, relevant studies have been proposed recently, which can be subdivided into three directions according to the differences of the methods used to generate the JPEG counterexamples: differentiable approximation, specific decoder training, and network structure improvement.
Differentiable Approximation: Zhu et al. [113] proposed the JPEG-MASK approximation method firstly, which mainly set the high-frequency DCT coefficients to 0 and retained the 5 × 5 low-frequency coefficients of the Y channel and the 3 × 3 low-frequency coefficients in the U and V channels, which had some simulation effect on JPEG. Based on [113], Ahmadi et al. [100] added a residual network with adjustable weight factors to the watermark embedding network to achieve autonomous adjustment of imperceptibility and robustness. Meanwhile, unlike conventional convolution operation, circular convolution was introduced to achieve watermark information diffusion and redundancy. SSIM was used as the loss function of the encoder network to make the watermarked image more closely resemble the original image in terms of contrast, brightness, and structure. Although differentiable approximation methods effectively solve the back-propagation update problem for training parameters, [100,113] both suffered from bad simulation approximation, which led to a decoder that cannot perform robust parameter updates more efficiently against real JPEG in turn.
Specific Decoder Training: To avoid the introduction of non-differentiable components in the overall training process of the model. Liu et al. [114] proposed a two-stage separable training watermarking algorithm consisting of noise-free end-to-end adversarial training (FEAT) and a decoder only trained (ADOT) with attack simulation layer. In FEAT, the encoder and decoder were jointly trained to obtain a redundant encoder, and in ADOT, the encoder parameters were fixed and spectral regularization was used to effectively mitigate the training instability problem of GAN networks. At the same time, corresponding attacks were applied to the watermarked images to obtain the corresponding attack samples, which were then used as the training set to train the dedicated decoder. The disadvantages of the non-gradient nature of JPEG were solved, but the phased training suffered from the problem of training local optima.
Network Structure Improvement: Chen et al. [115] proposed a JPEG simulation network JSNet which could simulate JPEG lossy compression with any quality factors. The three processes of sampling, DCT and quantization in JPEG were simulated by a maximum pooling layer, a convolution layer and a 3D noise mask. However, it was found experimentally that the model was still less robust to JPEG compression after the introduction of JSNet (i.e., BER is greater than 30% under both ImageNet [116] and Boss Base [98] dataset tests). This was related to its use of random initialization of parameters in the maximum pooling, convolutional layer, and 3D noise layer during the simulation, which resulted in a poor simulation effect for JPEG compression.
Jia et al. [117] used mini-batch of real and simulated (MBRS) JPEG compression to improve the JPEG robustness. In the attack layer, one of several small mini-batches attack was selected randomly from the real, simulated, and equivalent sound layers as the noise layer. Thanks to the Adam momentum optimizer [118], even if the attack layer rotated to the non-differentiable real JPEG compression attack, the internal parameters of the codec network could still be updated by the accumulation of historical differentiable gradients, which avoided the problem of non-differentiable real JPEG compression and achieved a better simulation quality of JPEG compression effectively. However, the model ignored the feature tensor of the image in the spatial and channel directions for image feature extraction, which led to poor robustness in the face of high-intensity salt and pepper noise. Zhang et al. [119] proposed a pseudo-differentiable JPEG method. JPEG pseudo-noise was the difference between the compressed processed image and the original image. Since its backpropagation without going through the pseudo-noise sound path, there was no problem of non-differentiable. However, its robustness to conventional noise was poor due to the lack of noise prior when back propagating. Ma et al. [120] proposed a robust watermarking framework by combining reversible and irreversible mechanisms. In the reversible part, a diffusion extraction module (DEM) (consisting of a series of fully connected layers and a Haar transform) and a fusion separation module (FSM) were designed to implement watermark embedding and extraction in a reversible manner. For the irreversiable part, the irreversible attention model which was composed of a series of convolution layers including full-connected layer, squeeze and excitation block, and a dedicated noise selection module (NSM) were introduced to improve the JPEG compression robustness.
The state-of-the-art deep learning-based image watermarking against JPEG attack algorithms and performance comparison are described in Table 5. Table 5 describes the methods from five aspects: watermark size (container size), method, structure, robustness, and dataset, where represents the quality factor of the JPEG compression.
4.2.2. Robust Image Watermark against Screen-shooting Attack
Screen-shooting attacks mainly cause image transmission distortion, brightness distortion and Moiré distortion [121]. To improve robustness of the screen-shooting attacks, relevant studies have been proposed recently, which can be subdivided into template-based, distortion compensation-based, decoding based on attention mechanism, key point enhancement, transform domain and distortion simulation.
Template-based: Template-based watermarking algorithms have a high watermarking capacity. The templates characterizing the watermarking information are embedded in the image in a form similar to additive noise. To ensure robustness, templates usually carry special data distribution features, but conventional template-based watermarking algorithms [109,122,123,124] were designed with low complexity manually and thus could not cope with sophisticated attacks. Fang et al. [125] designed a template-based watermarking algorithm by exploiting the powerful feature learning capability of DNN. In the watermark embedding phase, the embedding template was designed based on the insensitivity of human eyes to the specific chromatic components, the proximity principle, and the tilt effect. In the watermark extraction phase, a two-stage DNN was designed, containing an auxiliary enhancement sub-network for enhancing the embedded watermark features and a classification of sub-network for extracting the internal information of the watermark.
Distortion Compensation-based: Fang et al. [126] used the method of swapping DCT coefficients to achieve watermark embedding and a distortion compensation extraction algorithm to achieve the robustness of the watermark to photographic processing. Specifically, a line spacing region and a symmetric embedding block were used to reduce the distortion generated by the text.
Decoding Based on Attention Mechanism: Fang et al. [127] designed a transparency, efficiency, robustness, and adaptability coding to effectively mitigate the conflict among transparency, efficiency, robustness, and adaptability. A color decomposition method was used to improve the visual quality of watermarked images, and a super-resolution scheme was used to ensure the embedding efficiency. Bose Chaudhuri Hocquenghem (BCH) coding [128] and an attention decoding network (ADN) were used to further ensure the robustness and adaptivity.
Key Point Enhancement: The feature enhanced keypoints are used to locate the watermark embedding region, but the existing keypoint enhancement methods [129,130] ignore the improvement of the overall algorithm by separating the two steps of keypoint enhancement and watermark embedding. Dong et al. [131] used a convex optimization framework to unify the two steps to improve the accuracy of watermark extraction and blind synchronization of embedding regions effectively.
Transform Domain: Bai et al. [132] introduced a separable noise layer over the DCT domain in the embedding and extraction layers to simulate screen-shooting attacks. SSIM-based loss functions was introduced to improve imperceptibility. Spatial transformation networks were used to correct the values of pixels on the image formed by the geometric attacks before extracting the watermark. Considering that conventional CNN-based algorithms introduce noise in the convolution operation, Lu et al. [133] used DWT and IDWT instead of down-sampling and up-sampling operations in CNN to enable the network to learn a more stable feature representation from the noisy samples and introduced a residual regularization loss containing the image texture to improve the image quality and watermark capacity. The Fourier transform is invariant to rotation and translation, Boujerfaoui et al. [134] improved the Fourier transform-based watermarking method by using a frame-based transmission correction of the captured image in the distortion correction process.
Distortion Simulation: Jia et al. [135] introduced a 3D rendering distortion network to improve the robustness of the model to camera photography and introduced an human visual system-based loss function to supervise the training of the encoder, which mainly contained the just notice difference (JND) loss and learned perceptual image patch similarity (LPIPS) loss of the original and watermarked images to improve the quality of the watermarked images. Fang et al. [136] modeled the three components of distortion with the greatest impacts: transmission distortion, luminance distortion, and Moiré distortion and further differentiated the operation so that the network can be trained end-to-end. The network was trained with end-to-end parameters and the residual noise was simply simulated with Gaussian noise. For imperceptibility, a mask-based edge loss was proposed to limit the embedding region which improved the watermarked image quality. To address the difficulty of conventional 3D watermarking algorithms to achieve watermark extraction from 2D meshes. Yoo et al. [137] proposed an end-to-end framework containing an encoder, a distortion simulator (i.e., a differentiable rendering layer that simulated the results of a 3D watermarked target after different camera angles), and a decoder to decode from 2D meshes. Tancik et al. [138] proposed the stegastamp steganography model to implement encoding and decoding of hyperlinks. The encoder used a U-Net-like [139] structure to transform a 400×400 tensor with 4 channels (including the input RGB image and watermark information) into a tensor of residual image features. However, the algorithm had a small embedding capacity.
The state-of-the-art deep learning-based image watermarking against screen-shooting attack algorithms and performance comparison are described in Table 6 and Table 7. Table 6 describes the methods from four aspects: watermark size (container size), category, robustness with BER metrics, and dataset. Table 7 describes the methods from four aspects: watermark size (container size), category, robustness with other metrics, and dataset.
4.2.3. Robust Image Watermark against Agnostic Attack
Agnostic attacks refer to attacks where the attack model cannot access prior information about the attack (i.e., the model cannot generate corresponding adversarial examples precisely to guide the decoder to improve its robustness). To address these problems, relevant studies have been proposed recently, which can be subdivided into two-stage separable training, no attack training, one-stage end-to-end.
Two-stage Separable Training: Zhang et al. [122] proposed a two-stage separable watermark training model. The first stage jointly trained the codec as well as an attack classification discriminator which used multivariate cross-entropy loss for convergence to obtain encoder parameters that generated stable image quality and an attack classification discriminator that can accurately classified the type of attacks on the image. In the second stage, a fixed encoder, a multiple classification discriminator, and an attack layer were set up by using the obtained watermarked image and attacked image as a prior to train a specific decoder. However, it still did not solve the local optimal solution of the two-stage separable training.
No Attack Training: Zhong et al. [123] introduced a multiscale fusion convolution module, avoiding the loss of image detail feature information as the number of layers of the network deepens, which triggered the inability of the encoder to find an effective hidden embedding point. The invariance layer was set in the encoder and decoder to reproject the most important information and to disable the neural connections in the independent regions of the watermark. Chen et al. [142] proposed a watermark classification network for implementing copyright authentication of attacked watermarks. In the training phase, the training set was generated by calculating the NC value of each watermarked image and classifying its labels into forged and genuine images according to the set threshold. The training set was fed into the model and supervised by the BCE loss function to obtain the model parameters which can accurately classify the authenticity of the watermark. Under high-intensity attacks, the model can still distinguish the real watermark effectively. However, the classification accuracy was affected by the NC threshold setting of the model itself. Xu et al. [143] proposed a blockchain-based zero-watermarking approach, which alleviates the pressure of authenticating zero-watermarks through third parties effectively.
One-stage End-to-end Training: The encoder trained on a fixed attack layer are prone to model overfitting, which is clearly not applicable to realistic watermarking algorithms that need to resist many different types of attacks, and Luo et al. [144] proposed the use of CNN-based adversarial training and channel encoding which can add redundant information to the encoded watermark to improve the algorithm robustness. Zhang et al. [145] proposed the reverse ASL end-to-end model (i.e., the gradient propagation update of parameters was involved in the forward propagation ASL layer, and the gradient does not pass through the ASL layer in the reverse propagation). Reverse ASL can effectively mitigate model overfitting and improve the robustness against agnostic attacks. Zheng et al. [146] proposed a new Byzantine-robust algorithm WMDefence which detected Byzantine malicious clients by embedding the degree of degradation of the model watermark.
The state-of-the-art deep learning-based image watermarking against agnostic attack algorithms and performance comparison are described in Table 8. Table 8 describes the methods from five aspects: watermark size (container size), category, structure, robustness, and dataset, where represents the ratio of salt and pepper in salt and pepper noise.
5. Conclusions
In this review, we synthesize existing research on deep learning-based image forensics from both passive forensics (i.e., tampering detection) and active forensics (i.e., digital watermarking), respectively.
For passive image forensics, tampered areas of images are detected and located by analyzing the traces left by image tampering. In this survey, we analyze and review the state-of-the-art techniques for deep learning-based image copy-move, splicing and generic forgery detection. Firstly, we introduce a framework of image forgery detection based on deep learning, evaluation metrics, and commonly used datasets. Then the state-of-the-art algorithms for image copy-move, splicing and generic forgery detection are reviewed from different aspects and the comparative analysis of the different algorithms is presented. Although tampering detection algorithm techniques have been developed to some extent, there are still some problems of low generalization ability and poor robustness. Because the performance of deep learning-based tampering localization models depends on the training dataset heavily , the performance usually degrades significantly for the test samples from different datasets. It requires us to analyze the intrinsic relationship between images from different sources more deeply and improve the network architecture to learn more effective features. The network model performance also degrades when the images are subjected to certain post-processing attacks, such as scaling, rotation and JPEG compression. It requires us to perform data augmentation on the data during training to improve the robustness of the model and push the algorithm into practical applications. The current problem of insufficient tampering and low quality of tampering detection datasets seriously affects the development of deep learning-based tampering detection techniques. It is also very important to construct a dataset that meets the actual forensic requirement. Deep learning techniques continue to evolve, bringing many opportunities and challenges to passive image forensics. We should continuously update tampering detection techniques and use more effective network models and learning strategies to improve the accuracy and robustness of algorithms.
For active forensics, we focus on the robustness of the digital watermarking. At the beginning, we introduce a classical end-to-end watermarking model. According to whether the attack type is differentiable attack or not, we subdivide it into five attacks: noise and filtering attack, geometric attacks, JPEG attack, screen-shooting attack, and agnostic attack. For noise and filtering attack. Most studies introduce attack simulation layer in the codec to generate attack counterexamples are to improve its robustness, but the joint codec training leads to the degradation of the watermarked image generated by the encoder. GAN is one of the methods to improve the watermarked image quality, but it has the disadvantage of training instability. In my opinion, a more stable encoder backbone, such as diffusion generation model [147,148,149] can be chosen to achieve imperceptibility and robustness improvement. For geometric attacks, the construction of geometric invariant features from two perspectives, frequency domain coefficients and zero-watermark, ensures the spatial synchronization of the codec to a certain extent, but it does not combine with the robustness of the other attacks. Differentiable approximation processing and phased training can improve the robustness significantly when the JPEG compression quality factor is high. However, the robustness for JPEG with low quality factor still needs to be improved. Distortion simulation is the most commonly used method to enhance screen-shooting attacks in existing studies, but it suffers from the complex composition of actual distortion and low simulation accuracy. For agnostic attacks, the reverse ASL model and the label classification of watermarks are worth continuing to search and develop in the future.
Author Contributions
C.S., L.C., and C.W. chose the topic and designed the structure of the paper. C.S. and C.W. sorted out and analyzed passive forensic techniques. L.C. and C.W. reviewed the robust image watermarking algorithms. C.S., L.C., X.Z., and Z.Q. classified the involved algorithms and analyzed the data. C.W., X.Z., and Z.Q. revised the manuscript. C.W. performed the project administration. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Shandong Provincial Natural Science Foundation (No. ZR2021MF060), in part by the Joint Fund of Shandong Provincial Natural Science Foundation (No. ZR2021LZH003), in part by the National Natural Science Foundation of China (No. 61702303), in part by the Scientific Research Project of Shandong University–Weihai Research Institute of Industry Technology (No. 0006202210020011), in part by the Science and Technology Development Plan Project of Weihai Municipality (No. 2022DXGJ13), in part by the Shandong University Graduate Education Quality Curriculum Construction Project (No. 202238), in part by the 17th Student Research Training Program (SRTP) at Shandong University, Weihai (Nos. A22293, A22299, A22086), and in part by the 18th Student Research Training Program (SRTP) at Shandong University, Weihai (Nos. A23246, A23248).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declare no conflict of interest.
References
- Kaur, G.; Singh, N.; Kumar, M. Image forgery techniques: A review. Artif. Intell. Rev. 2023, 56, 1577–1625. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, C.; Zhou, X. A survey on passive image copy-move forgery detection. Journal of Information Processing Systems 2018, 14, 6–31. [Google Scholar] [CrossRef]
- Zanardelli, M.; Guerrini, F.; Leonardi, R.; Adami, N. Image forgery detection: A survey of recent deep-learning approaches. Multimed. Tools Appl. 2023, 82, 17521–17566. [Google Scholar] [CrossRef]
- Nabi, S.T.; Kumar, M.; Singh, P.; Aggarwal, N.; Kumar, K. A comprehensive survey of image and video forgery techniques: Variants, challenges, and future directions. Multimedia Syst. 2022, 28, 939–992. [Google Scholar] [CrossRef]
- Rakhmawati, L.; Wirawan, W.; Suwadi, S. A recent survey of self-embedding fragile watermarking scheme for image authentication with recovery capability. EURASIP J. Image Video Process. 2019, 2019, 1–22. [Google Scholar] [CrossRef]
- Kumar, C.; Singh, A.K.; Kumar, P. A recent survey on image watermarking techniques and its application in e-governance. Multimed. Tools Appl. 2018, 77, 3597–3622. [Google Scholar] [CrossRef]
- Menendez-Ortiz, A.; Feregrino-Uribe, C.; Hasimoto-Beltran, R.; Garcia-Hernandez, J.J. A survey on reversible watermarking for multimedia content: A robustness overview. IEEE Access 2019, 7, 132662–132681. [Google Scholar] [CrossRef]
- Agarwal, N.; Singh, A.K.; Singh, P.K. Survey of robust and imperceptible watermarking. Multimed. Tools Appl. 2019, 78, 8603–8633. [Google Scholar] [CrossRef]
- Amrit, P.; Singh, A.K. Survey on watermarking methods in the artificial intelligence domain and beyond. Comput. Commun. 2022, 188, 52–65. [Google Scholar] [CrossRef]
- Wan, W.; Wang, J.; Zhang, Y.; Li, J.; Yu, H.; Sun, J. A comprehensive survey on robust image watermarking. Neurocomputing 2022, 488, 226–247. [Google Scholar] [CrossRef]
- Evsutin, O.; Dzhanashia, K. Watermarking schemes for digital images: Robustness overview. Signal Process. Image Commun. 2022, 100, 116523. [Google Scholar] [CrossRef]
- Mahmood, T.; Mehmood, Z.; Shah, M.; Saba, T. A robust technique for copy-move forgery detection and localization in digital images via stationary wavelet and discrete cosine transform. J. Vis. Commun. Image Represent. 2018, 53, 202–214. [Google Scholar] [CrossRef]
- Jaiprakash, S.P.; Desai, M.B.; Prakash, C.S.; Mistry, V.H.; Radadiya, K.L. Low dimensional DCT and DWT feature based model for detection of image splicing and copy-move forgery. Multimed. Tools Appl. 2020, 79, 29977–30005. [Google Scholar] [CrossRef]
- Wo, Y.; Yang, K.; Han, G.; Chen, H.; Wu, W. Copy-move forgery detection based on multi-radius PCET. IET Image Process. 2017, 11, 99–108. [Google Scholar] [CrossRef]
- Park, J.Y.; Kang, T.A.; Moon, Y.H.; Eom, I.K. Copy-move forgery detection using scale invariant feature and reduced local binary pattern histogram. Symmetry-Basel. 2020, 12, 492. [Google Scholar] [CrossRef]
- Rani, A.; Jain, A.; Kumar, M. Identification of copy-move and splicing based forgeries using advanced SURF and revised template matching. Multimed. Tools Appl. 2021, 80, 23877–23898. [Google Scholar] [CrossRef]
- Singh, G.; Singh, K. Digital image forensic approach based on the second-order statistical analysis of CFA artifacts. Forens. Sci. Int. Digit. Investig. 2020, 32, 200899. [Google Scholar] [CrossRef]
- Zeng, H.; Peng, A.; Lin, X. Exposing image splicing with inconsistent sensor noise levels. Multimed. Tools Appl. 2020, 79, 26139–26154. [Google Scholar] [CrossRef]
- Hsu, Y.F.; Chang, S.F. Detecting image splicing using geometry invariants and camera characteristics consistency. In Proceedings of the IEEE International Conference on Multimedia and Expo. IEEE: Toronto, ON, Canada; 2006; pp. 549–552. [Google Scholar] [CrossRef]
- Amerini, I.; Ballan, L.; Caldelli, R.; Del Bimbo, A.; Serra, G. A SIFT-based forensic method for copy-move attack detection and transformation recovery. IEEE Trans. Inf. Forensic Secur. 2011, 6, 1099–1110. [Google Scholar] [CrossRef]
- Dong, J.; Wang, W.; Tan, T. Casia image tampering detection evaluation database. In Proceedings of the IEEE China Summit and International Conference on Signal and Information Processing. IEEE: Beijing, China; 2013; pp. 422–426. [Google Scholar] [CrossRef]
- De Carvalho, T.J.; Riess, C.; Angelopoulou, E.; Pedrini, H.; de Rezende Rocha, A. Exposing digital image forgeries by illumination color classification. IEEE Trans. Inf. Forensic Secur. 2013, 8, 1182–1194. [Google Scholar] [CrossRef]
- Tralic, D.; Zupancic, I.; Grgic, S.; Grgic, M. CoMoFoD–New database for copy-move forgery detection. In Proceedings of the International Symposium Electronics in Marine. IEEE: Zadar, Croatia; 2013; pp. 49–54. [Google Scholar]
- Wen, B.; Zhu, Y.; Subramanian, R.; Ng, T.T.; Shen, X.; Winkler, S. COVERAGE–A novel database for copy-move forgery detection. In Proceedings of the IEEE International Conference on Image Processing. IEEE: Phoenix, AZ, USA; 2016; pp. 161–165. [Google Scholar] [CrossRef]
- Korus, P. Digital image integrity–A survey of protection and verification techniques. Digit. Signal Process. 2017, 71, 1–26. [Google Scholar] [CrossRef]
- Wu, Y.; Abd-Almageed, W.; Natarajan, P. Busternet: Detecting copy-move image forgery with source/target localization. In Proceedings of the European Conference on Computer Vision, Munich, Berlin; 2018; pp. 168–184. [Google Scholar]
- Guan, H.; Kozak, M.; Robertson, E.; Lee, Y.; Yates, A.N.; Delgado, A.; Zhou, D.; Kheyrkhah, T.; Smith, J.; Fiscus, J. MFC datasets: Large-scale benchmark datasets for media forensic challenge evaluation. In Proceedings of the IEEE Winter Applications of Computer Vision Workshops. IEEE: Waikoloa, HI, USA; 2019; pp. 63–72. [Google Scholar] [CrossRef]
- Mahfoudi, G.; Tajini, B.; Retraint, F.; Morain-Nicolier, F.; Dugelay, J.L.; Marc, P. DEFACTO: Image and face manipulation dataset. In Proceedings of the 27th European Signal Processing Conference. IEEE: A Coruna, Spain; 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Novozamsky, A.; Mahdian, B.; Saic, S. IMD2020: A large-scale annotated dataset tailored for detecting manipulated images. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision Workshops. IEEE: Snowmass, CO, USA; 2020; pp. 71–80. [Google Scholar] [CrossRef]
- Van Schyndel, R.G.; Tirkel, A.Z.; Osborne, C.F. A digital watermark. In Proceedings of the 1st International Conference on Image Processing; IEEE: Austin, TX, USA, 1994; Vol. 2, pp. 86–90. [Google Scholar] [CrossRef]
- Dumitrescu, S.; Wu, X.; Wang, Z. Detection of LSB steganography via sample pair analysis. IEEE Trans. Signal Process. 2003, 51, 1995–2007. [Google Scholar] [CrossRef]
- Guo, H.; Georganas, N.D. Digital image watermarking for joint ownership verification without a trusted dealer. In Proceedings of the International Conference on Multimedia and Expo; IEEE: Baltimore, MD, USA, 2003; Vol. 2, pp. 497–500. [Google Scholar] [CrossRef]
- Parah, S.A.; Sheikh, J.A.; Loan, N.A.; Bhat, G.M. Robust and blind watermarking technique in DCT domain using inter-block coefficient differencing. Digit. Signal Process. 2016, 53, 11–24. [Google Scholar] [CrossRef]
- Etemad, S.; Amirmazlaghani, M. A new multiplicative watermark detector in the contourlet domain using t location-scale distribution. Pattern Recognit. 2018, 77, 99–112. [Google Scholar] [CrossRef]
- Etemad, E.; Samavi, S.; Reza Soroushmehr, S.; Karimi, N.; Etemad, M.; Shirani, S.; Najarian, K. Robust image watermarking scheme using bit-plane of Hadamard coefficients. Multimed. Tools Appl. 2018, 77, 2033–2055. [Google Scholar] [CrossRef]
- Rao, Y.; Ni, J. A deep learning approach to detection of splicing and copy-move forgeries in images. In Proceedings of the IEEE International Workshop on Information Forensics and Security. IEEE: Abu Dhabi, United Arab Emirates; 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Kumar, S.; Gupta, S.K. A robust copy move forgery classification using end to end convolution neural network. In Proceedings of the 8th International Conference on Reliability, Infocom Technologies and Optimization. IEEE: Noida, India; 2020; pp. 253–258. [Google Scholar] [CrossRef]
- Li, Q.; Wang, C.; Zhou, X.; Qin, Z. Image copy-move forgery detection and localization based on super-BPD segmentation and DCNN. Sci Rep. 2022, 12, 14987. [Google Scholar] [CrossRef]
- Wan, J.; Liu, Y.; Wei, D.; Bai, X.; Xu, Y. Super-BPD: Super boundary-to-pixel direction for fast image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE: Seattle, WA, USA; 2020; pp. 9253–9262. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Liu, Y.; Xia, C.; Zhu, X.; Xu, S. Two-stage copy-move forgery detection with self deep matching and proposal superglue. IEEE Trans. Image Process. 2021, 31, 541–555. [Google Scholar] [CrossRef]
- Zhong, J.L.; Pun, C.M. An end-to-end dense-inceptionnet for image copy-move forgery detection. IEEE Trans. Inf. Forensic Secur. 2019, 15, 2134–2146. [Google Scholar] [CrossRef]
- Kafali, E.; Vretos, N.; Semertzidis, T.; Daras, P. RobusterNet: Improving copy-move forgery detection with Volterra-based convolutions. In Proceedings of the 25th International Conference on Pattern Recognition. IEEE: Milan, Italy; 2020; pp. 1160–1165. [Google Scholar] [CrossRef]
- Nazir, T.; Nawaz, M.; Masood, M.; Javed, A. Copy move forgery detection and segmentation using improved mask region-based convolution network (RCNN). Appl. Soft. Comput. 2022, 131, 109778. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision. IEEE: Venice, Italy; 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Zhong, J.L.; Yang, J.X.; Gan, Y.F.; Huang, L.; Zeng, H. Coarse-to-fine spatial-channel-boundary attention network for image copy-move forgery detection. Soft Comput. 2022, 26, 11461–11478. [Google Scholar] [CrossRef]
- Chen, B.; Tan, W.; Coatrieux, G.; Zheng, Y.; Shi, Y.Q. A serial image copy-move forgery localization scheme with source/target distinguishment. IEEE Trans. Multimedia. 2020, 23, 3506–3517. [Google Scholar] [CrossRef]
- Aria, M.; Hashemzadeh, M.; Farajzadeh, N. QDL-CMFD: A quality-independent and deep learning-based copy-move image forgery detection method. Neurocomputing 2022, 511, 213–236. [Google Scholar] [CrossRef]
- Barni, M.; Phan, Q.T.; Tondi, B. Copy move source-target disambiguation through multi-branch CNNs. IEEE Trans. Inf. Forensic Secur. 2020, 16, 1825–1840. [Google Scholar] [CrossRef]
- Niyishaka, P.; Bhagvati, C. Image splicing detection technique based on illumination-reflectance model and LBP. Multimed. Tools Appl. 2021, 80, 2161–2175. [Google Scholar] [CrossRef]
- Shen, X.; Shi, Z.; Chen, H. Splicing image forgery detection using textural features based on the grey level co-occurrence matrices. IET Image Process. 2017, 11, 44–53. [Google Scholar] [CrossRef]
- Sharma, S.; Ghanekar, U. Spliced image classification and tampered region localization using local directional pattern. International Journal of Image, Graphics and Signal Processing 2019, 11, 35–42. [Google Scholar]
- Wei, Y.; Wang, Z.; Xiao, B.; Liu, X.; Yan, Z.; Ma, J. Controlling neural learning network with multiple scales for image splicing forgery detection. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–22. [Google Scholar] [CrossRef]
- Zeng, P.; Tong, L.; Liang, Y.; Zhou, N.; Wu, J. Multitask image splicing tampering detection based on attention mechanism. Mathematics 2022, 10, 3852. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, G.; Wu, L.; Kwong, S.; Zhang, H.; Zhou, Y. Multi-task SE-network for image splicing localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4828–4840. [Google Scholar] [CrossRef]
- Chen, B.; Qi, X.; Zhou, Y.; Yang, G.; Zheng, Y.; Xiao, B. Image splicing localization using residual image and residual-based fully convolutional network. J. Vis. Commun. Image Represent. 2020, 73, 102967. [Google Scholar] [CrossRef]
- Zhuang, P.; Li, H.; Tan, S.; Li, B.; Huang, J. Image tampering localization using a dense fully convolutional network. IEEE Trans. Inf. Forensic Secur. 2021, 16, 2986–2999. [Google Scholar] [CrossRef]
- Liu, Q.; Li, H.; Liu, Z. Image forgery localization based on fully convolutional network with noise feature. Multimed. Tools Appl. 2022, 81, 17919–17935. [Google Scholar] [CrossRef]
- Ren, R.; Niu, S.; Jin, J.; Zhang, J.; Ren, H.; Zhao, X. Multi-scale attention context-aware network for detection and localization of image splicing. Appl. Intell. 2023, 1–20. [Google Scholar] [CrossRef]
- Sun, Y.; Ni, R.; Zhao, Y. ET: Edge-enhanced transformer for image splicing detection. IEEE Signal Process. Lett. 2022, 29, 1232–1236. [Google Scholar] [CrossRef]
- Zhang, Z.; Qian, Y.; Zhao, Y.; Zhu, L.; Wang, J. Noise and edge based dual branch image manipulation detection. arXiv preprint 2022, arXiv:2207.00724. [Google Scholar]
- Dong, C.; Chen, X.; Hu, R.; Cao, J.; Li, X. MVSS-Net: Multi-view multi-scale supervised networks for image manipulation detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3539–3553. [Google Scholar] [CrossRef]
- Chen, J.; Liao, X.; Wang, W.; Qian, Z.; Qin, Z.; Wang, Y. SNIS: A signal noise separation-based network for post-processed image forgery detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 935–951. [Google Scholar] [CrossRef]
- Lin, X.; Wang, S.; Deng, J.; Fu, Y.; Bai, X.; Chen, X.; Qu, X.; Tang, W. Image manipulation detection by multiple tampering traces and edge artifact enhancement. Pattern Recognit. 2023, 133, 109026. [Google Scholar] [CrossRef]
- Wang, J.; Wu, Z.; Chen, J.; Han, X.; Shrivastava, A.; Lim, S.N.; Jiang, Y.G. Objectformer for image manipulation detection and localization. In Proceedings of the Conference on Computer Vision and Pattern Recognition. IEEE: New Orleans, LA, USA; 2022; pp. 2364–2373. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Chen, J.; Liu, X. PSCC-Net: Progressive spatio-channel correlation network for image manipulation detection and localization. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7505–7517. [Google Scholar] [CrossRef]
- Shi, Z.; Chang, C.; Chen, H.; Du, X.; Zhang, H. PR-Net: Progressively-refined neural network for image manipulation localization. Int. J. Intell. Syst. 2022, 37, 3166–3188. [Google Scholar] [CrossRef]
- Gao, Z.; Sun, C.; Cheng, Z.; Guan, W.; Liu, A.; Wang, M. TBNet: A two-stream boundary-aware network for generic image manipulation localization. IEEE Trans. Knowl. Data Eng. 2022, 1–16. [Google Scholar] [CrossRef]
- Ganapathi, I.I.; Javed, S.; Ali, S.S.; Mahmood, A.; Vu, N.S.; Werghi, N. Learning to localize image forgery using end-to-end attention network. Neurocomputing 2022, 512, 25–39. [Google Scholar] [CrossRef]
- Xu, D.; Shen, X.; Lyu, Y.; Du, X.; Feng, F. MC-Net: Learning mutually-complementary features for image manipulation localization. Int. J. Intell. Syst. 2022, 37, 3072–3089. [Google Scholar] [CrossRef]
- Rao, Y.; Ni, J.; Xie, H. Multi-semantic CRF-based attention model for image forgery detection and localization. Signal Process. 2021, 183, 108051. [Google Scholar] [CrossRef]
- Li, S.; Xu, S.; Ma, W.; Zong, Q. Image manipulation localization using attentional cross-domain CNN features. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Yin, Q.; Wang, J.; Lu, W.; Luo, X. Contrastive learning based multi-task network for image manipulation detection. Signal Process. 2022, 201, 108709. [Google Scholar] [CrossRef]
- Zhuo, L.; Tan, S.; Li, B.; Huang, J. Self-adversarial training incorporating forgery attention for image forgery localization. IEEE Trans. Inf. Forensic Secur. 2022, 17, 819–834. [Google Scholar] [CrossRef]
- Ren, R.; Niu, S.; Ren, H.; Zhang, S.; Han, T.; Tong, X. ESRNet: Efficient search and recognition network for image manipulation detection. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–23. [Google Scholar] [CrossRef]
- Silva, E.; Carvalho, T.; Ferreira, A.; Rocha, A. Going deeper into copy-move forgery detection: Exploring image telltales via multi-scale analysis and voting processes. J. Vis. Commun. Image Represent. 2015, 29, 16–32. [Google Scholar] [CrossRef]
- Cozzolino, D.; Poggi, G.; Verdoliva, L. Copy-move forgery detection based on patchmatch. In Proceedings of the IEEE International Conference on Image Processing. IEEE: Paris, France; 2014; pp. 5312–5316. [Google Scholar] [CrossRef]
- Ng, T.T.; Chang, S.F.; Sun, Q. A data set of authentic and spliced image blocks. Columbia University, ADVENT Technical Report 2004, 4, 1–9. [Google Scholar]
- Shi, Z.; Shen, X.; Chen, H.; Lyu, Y. Global semantic consistency network for image manipulation detection. IEEE Signal Process. Lett. 2020, 27, 1755–1759. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Communications of the ACM 2020, 63, 139–144. [Google Scholar]
- Fan, Y.; Li, J.; Bhatti, U.A.; Shao, C.; Gong, C.; Cheng, J.; Chen, Y. A multi-watermarking algorithm for medical images using Inception V3 and DCT. CMC-Comput. Mat. Contin. 2023, 74, 1279–1302. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE: Las Vegas, NV, USA; 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Wen, B.; Aydore, S. Romark: A robust watermarking system using adversarial training. arXiv preprint 2019, arXiv:1910.01221. [Google Scholar]
- Hao, K.; Feng, G.; Zhang, X. Robust image watermarking based on generative adversarial network. China Commun. 2020, 17, 131–140. [Google Scholar] [CrossRef]
- Zhang, B.; Wu, Y.; Chen, B. Embedding guided end-to-end framework for robust image watermarking. Secur. Commun. Netw. 2022, 2022, 1–11. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Li, J.; Zhang, Q.; Yang, G.; Chen, S.; Wang, C.; Li, J. Single exposure optical image watermarking using a cGAN network. IEEE Photonics J. 2021, 13, 1–11. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv preprint 2014, arXiv:1411.1784. [Google Scholar]
- Yu, C. Attention based data hiding with generative adversarial networks. In Proceedings of the AAAI Conference on Artificial Intelligence. AAAI: New York, NY, USA; 2020; Vol. 34, pp. 1120–1128. [Google Scholar] [CrossRef]
- Mun, S.M.; Nam, S.H.; Jang, H.U.; Kim, D.; Lee, H.K. A robust blind watermarking using convolutional neural network. arXiv preprint 2017, arXiv:1704.03248. [Google Scholar]
- Kang, X.; Chen, Y.; Zhao, F.; Lin, G. Multi-dimensional particle swarm optimization for robust blind image watermarking using intertwining logistic map and hybrid domain. Soft Comput. 2020, 24, 10561–10584. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks; IEEE: Perth, WA, Australia, 1995; Vol. 4, pp. 1942–1948. [Google Scholar]
- Rai, M.; Goyal, S. A hybrid digital image watermarking technique based on fuzzy-BPNN and shark smell optimization. Multimed. Tools Appl. 2022, 81, 39471–39489. [Google Scholar] [CrossRef]
- Liu, C.; Zhong, D.; Shao, H. Data protection in palmprint recognition via dynamic random invisible watermark embedding. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6927–6940. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, C.; Zhou, X.; Qin, Z. DARI-Mark: Deep learning and attention network for robust image watermarking. Mathematics 2022, 11, 209. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the 13th European Conference on Computer Vision. Springer: Zurich, Switzerland; 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Latecki, L. Shape data for the MPEG-7 core experiment ce-shape-1. Web Page: http://www.cis.temple.edu/latecki/TestData/mpeg7shapeB. tar. gz 2002, 7. [Google Scholar]
- Weber, A.G. The USC-SIPI image database: Version 5. http://sipi.usc.edu/database/ 2006.
- Bas, P.; Filler, T.; Pevnỳ, T. Break our steganographic system: The ins and outs of organizing BOSS. In Proceedings of the 13th International Conference on Information Hiding, Prague, Czech Republic; Springer: Berlin, Heidelberg, 2011; pp. 59–70. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Nair, V.; Hinton, G. Cifar-10 and cifar-100 datasets. URl: https://www.cs.toronto.edu/kriz/cifar.html 2009, 6, 1. [Google Scholar]
- Ahmadi, M.; Norouzi, A.; Karimi, N.; Samavi, S.; Emami, A. ReDMark: Framework for residual diffusion watermarking based on deep networks. Expert Syst. Appl. 2020, 146, 113157. [Google Scholar] [CrossRef]
- Mei, Y.; Wu, G.; Yu, X.; Liu, B. A robust blind watermarking scheme based on attention mechanism and neural joint source-channel coding. In Proceedings of the IEEE 24th International Workshop on Multimedia Signal Processing. IEEE: Shanghai, China; 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Han, B.; Du, J.; Jia, Y.; Zhu, H. Zero-watermarking algorithm for medical image based on VGG19 deep convolution neural network. J. Healthc. Eng. 2021, 2021, 1–12. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv preprint 2014, arXiv:1409.1556. [Google Scholar]
- Liu, G.; Xiang, R.; Liu, J.; Pan, R.; Zhang, Z. An invisible and robust watermarking scheme using convolutional neural networks. Expert Syst. Appl. 2022, 210, 118529. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE: Las Vegas, NV, USA; 2016; pp. 2414–2423. [Google Scholar] [CrossRef]
- Sun, L.; Xu, J.; Zhang, X.; Dong, W.; Tian, Y. A novel generalized Arnold transform-based zero-watermarking scheme. Appl. Math. Inf. Sci. 2015, 4, 2023–2035. [Google Scholar]
- Gong, C.; Liu, J.; Gong, M.; Li, J.; Bhatti, U.A.; Ma, J. Robust medical zero-watermarking algorithm based on residual-DenseNet. IET Biom. 2022, 11, 547–556. [Google Scholar] [CrossRef]
- Hu, R.; Xiang, S. Cover-lossless robust image watermarking against geometric deformations. IEEE Trans. Image Process. 2020, 30, 318–331. [Google Scholar] [CrossRef]
- Mellimi, S.; Rajput, V.; Ansari, I.A.; Ahn, C.W. A fast and efficient image watermarking scheme based on deep neural network. Pattern Recognit. Lett. 2021, 151, 222–228. [Google Scholar] [CrossRef]
- Fan, B.; Li, Z.; Gao, J. DwiMark: A multiscale robust deep watermarking framework for diffusion-weighted imaging images. Multimedia Syst. 2022, 28, 295–310. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Ma, K.; Duanmu, Z.; Wu, Q.; Wang, Z.; Yong, H.; Li, H.; Zhang, L. Waterloo exploration database: New challenges for image quality assessment models. IEEE Trans. Image Process. 2016, 26, 1004–1016. [Google Scholar] [CrossRef]
- Zhu, J.; Kaplan, R.; Johnson, J.; Fei-Fei, L. Hidden: Hiding data with deep networks. In Proceedings of the European Conference on Computer Vision. Springer: Munich, Germany; 2018; pp. 657–672. [Google Scholar] [CrossRef]
- Liu, Y.; Guo, M.; Zhang, J.; Zhu, Y.; Xie, X. A novel two-stage separable deep learning framework for practical blind watermarking. In Proceedings of the 27th ACM International Conference on Multimedia. ACM: New York, NY, USA; 2019; pp. 1509–1517. [Google Scholar] [CrossRef]
- Chen, B.; Wu, Y.; Coatrieux, G.; Chen, X.; Zheng, Y. JSNet: A simulation network of JPEG lossy compression and restoration for robust image watermarking against JPEG attack. Comput. Vis. Image Underst. 2020, 197, 103015. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE: Miami, FL, USA; 2009; pp. 248–255. [Google Scholar]
- Jia, Z.; Fang, H.; Zhang, W. MBRS: Enhancing robustness of DNN-based watermarking by mini-batch of real and simulated JPEG compression. In Proceedings of the 29th ACM International Conference on Multimedia. ACM: New York, NY, USA; 2021; pp. 41–49. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv preprint 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, C.; Karjauv, A.; Benz, P.; Kweon, I.S. Towards robust data hiding against (JPEG) compression: A pseudo-differentiable deep learning approach. arXiv preprint 2020, arXiv:2101.00973. [Google Scholar]
- Ma, R.; Guo, M.; Hou, Y.; Yang, F.; Li, Y.; Jia, H.; Xie, X. Towards blind watermarking: Combining invertible and non-invertible mechanisms. In Proceedings of the 30th ACM International Conference on Multimedia. ACM: New York, NY, USA; 2022; pp. 1532–1542. [Google Scholar] [CrossRef]
- Tsai, P.H.; Chuang, Y.Y. Target-driven moire pattern synthesis by phase modulation. In Proceedings of the IEEE International Conference on Computer Vision. IEEE: Sydney, NSW, Australia; 2013; pp. 1912–1919. [Google Scholar] [CrossRef]
- Zhang, L.; Li, W.; Ye, H. A blind watermarking system based on deep learning model. In Proceedings of the IEEE 20th International Conference on Trust, Security and Privacy in Computing and Communications. IEEE: Shenyang, China; 2021; pp. 1208–1213. [Google Scholar] [CrossRef]
- Zhong, X.; Huang, P.C.; Mastorakis, S.; Shih, F.Y. An automated and robust image watermarking scheme based on deep neural networks. IEEE Trans. Multimedia 2020, 23, 1951–1961. [Google Scholar] [CrossRef]
- Wang, R.; Lin, C.; Zhao, Q.; Zhu, F. Watermark faker: Towards forgery of digital image watermarking. In Proceedings of the IEEE International Conference on Multimedia and Expo. IEEE: Shenyang, China; 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Fang, H.; Chen, D.; Huang, Q.; Zhang, J.; Ma, Z.; Zhang, W.; Yu, N. Deep template-based watermarking. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1436–1451. [Google Scholar] [CrossRef]
- Fang, H.; Zhang, W.; Ma, Z.; Zhou, H.; Sun, S.; Cui, H.; Yu, N. A camera shooting resilient watermarking scheme for underpainting documents. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4075–4089. [Google Scholar] [CrossRef]
- Fang, H.; Chen, D.; Wang, F.; Ma, Z.; Liu, H.; Zhou, W.; Zhang, W.; Yu, N. Tera: Screen-to-camera image code with transparency, efficiency, robustness and adaptability. IEEE Trans. Multimedia 2021, 24, 955–967. [Google Scholar] [CrossRef]
- Bose, R.C.; Ray-Chaudhuri, D.K. On a class of error correcting binary group codes. Information and Control 1960, 3, 68–79. [Google Scholar] [CrossRef]
- Pramila, A.; Keskinarkaus, A.; Seppänen, T. Toward an interactive poster using digital watermarking and a mobile phone camera. Signal, Image and Video Processing 2012, 6, 211–222. [Google Scholar] [CrossRef]
- Gugelmann, D.; Sommer, D.; Lenders, V.; Happe, M.; Vanbever, L. Screen watermarking for data theft investigation and attribution. In Proceedings of the 10th International Conference on Cyber Conflict; IEEE: Tallinn, Estonia, 2018; pp. 391–408. [Google Scholar] [CrossRef]
- Dong, L.; Chen, J.; Peng, C.; Li, Y.; Sun, W. Watermark-preserving keypoint enhancement for screen-shooting resilient watermarking. In Proceedings of the IEEE International Conference on Multimedia and Expo. IEEE: Taipei, Taiwan; 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Bai, R.; Li, L.; Zhang, S.; Lu, J.; Chang, C.C. SSDeN: Framework for screen-shooting resilient watermarking via deep networks in the frequency domain. Appl. Sci.-Basel. 2022, 12, 9780. [Google Scholar] [CrossRef]
- Lu, J.; Ni, J.; Su, W.; Xie, H. Wavelet-based CNN for robust and high-capacity image watermarking. In Proceedings of the IEEE International Conference on Multimedia and Expo. IEEE: Taipei, Taiwan; 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Boujerfaoui, S.; Douzi, H.; Harba, R.; Gourrame, K. Robust Fourier watermarking for print-cam process using convolutional neural networks. In Proceedings of the 7th International Conference on Signal and Image Processing. IEEE: Suzhou, China; 2022; pp. 347–351. [Google Scholar] [CrossRef]
- Jia, J.; Gao, Z.; Chen, K.; Hu, M.; Min, X.; Zhai, G.; Yang, X. RIHOOP: Robust invisible hyperlinks in offline and online photographs. IEEE T. Cybern. 2020, 52, 7094–7106. [Google Scholar] [CrossRef]
- Fang, H.; Jia, Z.; Ma, Z.; Chang, E.C.; Zhang, W. PIMoG: An effective screen-shooting noise-layer simulation for deep-learning-based watermarking network. In Proceedings of the 30th ACM International Conference on Multimedia. ACM: New York, NY, USA; 2022; pp. 2267–2275. [Google Scholar] [CrossRef]
- Yoo, I.; Chang, H.; Luo, X.; Stava, O.; Liu, C.; Milanfar, P.; Yang, F. Deep 3D-to-2D watermarking: Embedding messages in 3D meshes and extracting them from 2D renderings. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE: New Orleans, LA, USA; 2022; pp. 10031–10040. [Google Scholar] [CrossRef]
- Tancik, M.; Mildenhall, B.; Ng, R. Stegastamp: Invisible hyperlinks in physical photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE: Seattle, WA, USA; 2020; pp. 2117–2126. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Coference on Medical Image Computing and Computer-Assisted Intervention. Springer: Munich, Germany; 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Huiskes, M.J.; Lew, M.S. The mir flickr retrieval evaluation. In Proceedings of the 1st ACM International Conference on Multimedia Information Retrieval. ACM: New York, NY, USA; 2008; pp. 39–43. [Google Scholar] [CrossRef]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE: Boston, MA, USA; 2015; pp. 1912–1920. [Google Scholar] [CrossRef]
- Chen, Y.P.; Fan, T.Y.; Chao, H.C. Wmnet: A lossless watermarking technique using deep learning for medical image authentication. Electronics 2021, 10, 932. [Google Scholar] [CrossRef]
- Xu, D.; Zhu, C.; Ren, N. A zero-watermark algorithm for copyright protection of remote sensing image based on blockchain. In Proceedings of the International Conference on Blockchain Technology and Information Security. IEEE: Huaihua City, China; 2022; pp. 111–116. [Google Scholar] [CrossRef]
- Luo, X.; Zhan, R.; Chang, H.; Yang, F.; Milanfar, P. Distortion agnostic deep watermarking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE: Seattle, WA, USA; 2020; pp. 13548–13557. [Google Scholar] [CrossRef]
- Zhang, C.; Karjauv, A.; Benz, P.; Kweon, I.S. Towards robust deep hiding under non-differentiable distortions for practical blind watermarking. In Proceedings of the 29th ACM International Conference on Multimedia; ACM: New York, NY, USA, 2021; pp. 5158–5166. [Google Scholar] [CrossRef]
- Zheng, X.; Dong, Q.; Fu, A. WMDefense: Using watermark to defense byzantine attacks in federated learning. In Proceedings of the IEEE Conference on Computer Communications Workshops. IEEE: New York, NY, USA; 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems 2020, 33, 6840–6851. [Google Scholar]
- Song, J.; Meng, C.; Ermon, S. Denoising diffusion implicit models. arXiv preprint 2020, arXiv:2010.02502. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat GANs on image synthesis. Advances in Neural Information Processing Systems 2021, 34, 8780–8794. [Google Scholar]
Figure 1.
Classification of image forensic techniques.
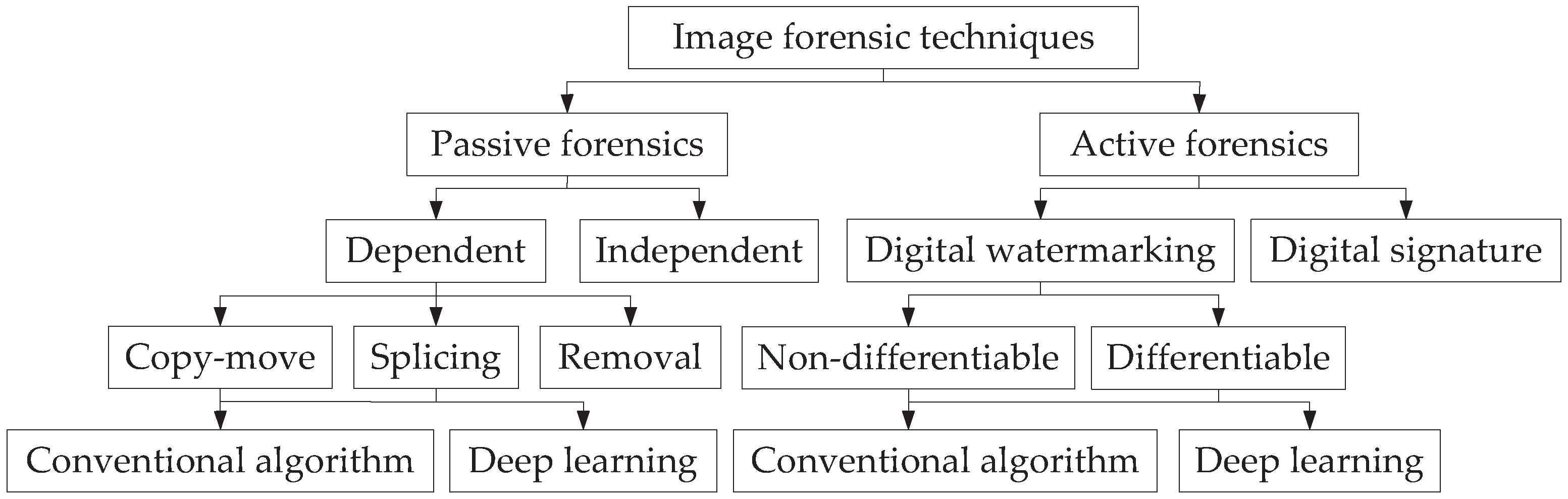
Figure 2.
A basic framework of image forgery detection based on deep learning.
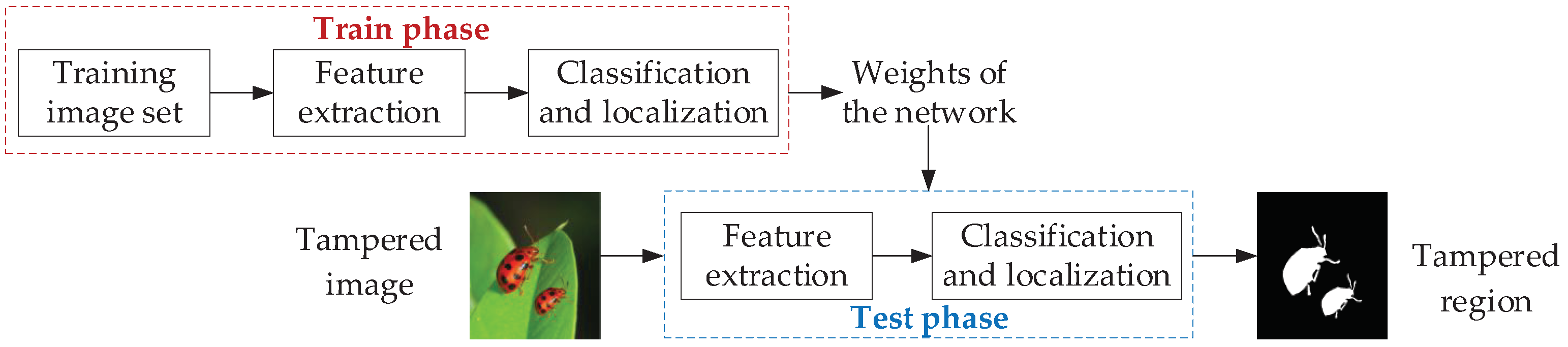
Figure 3.
A basic framework of end-to-end robust watermarking based on deep learning.
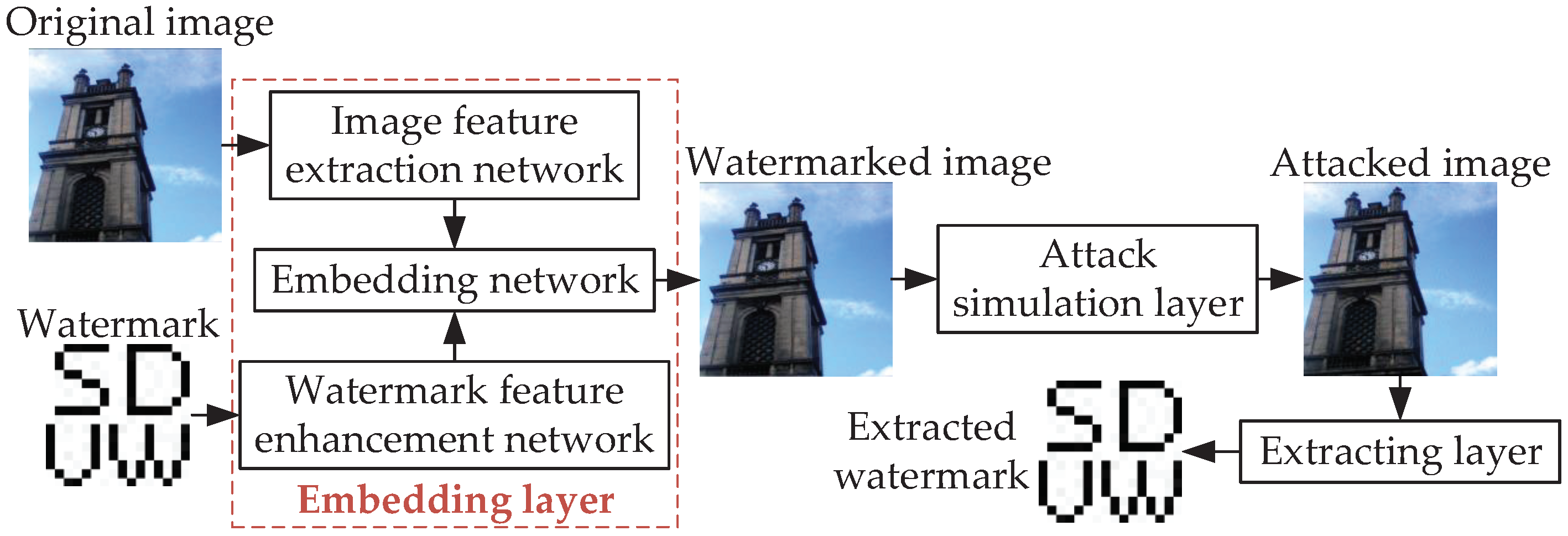
Figure 4.
A flowchart of JPEG compression.
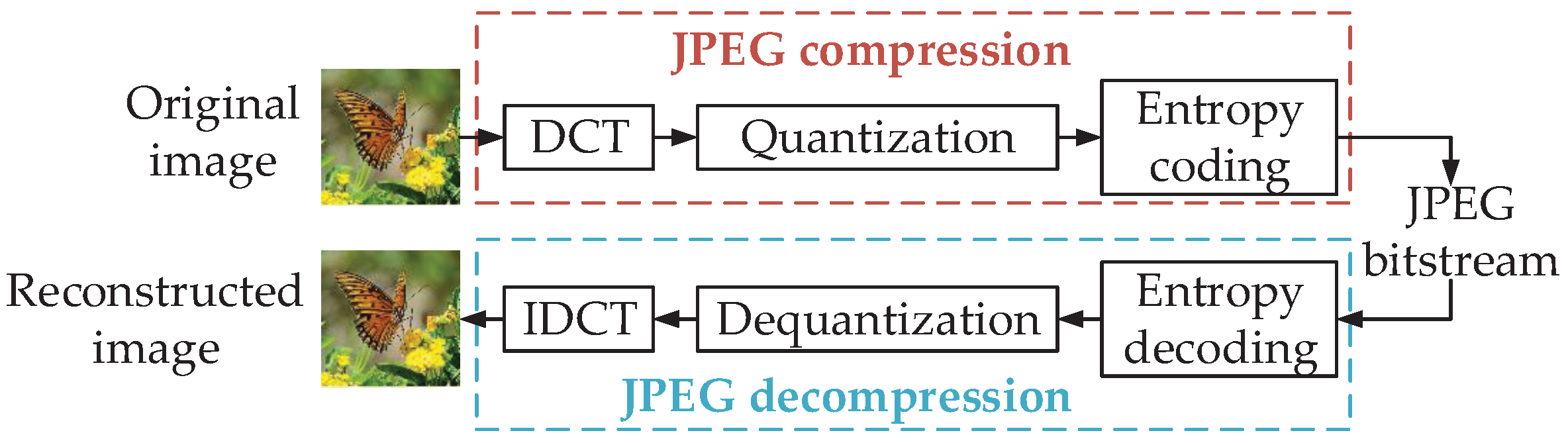
Figure 5.
An overview of image forgery detection based on deep learning.
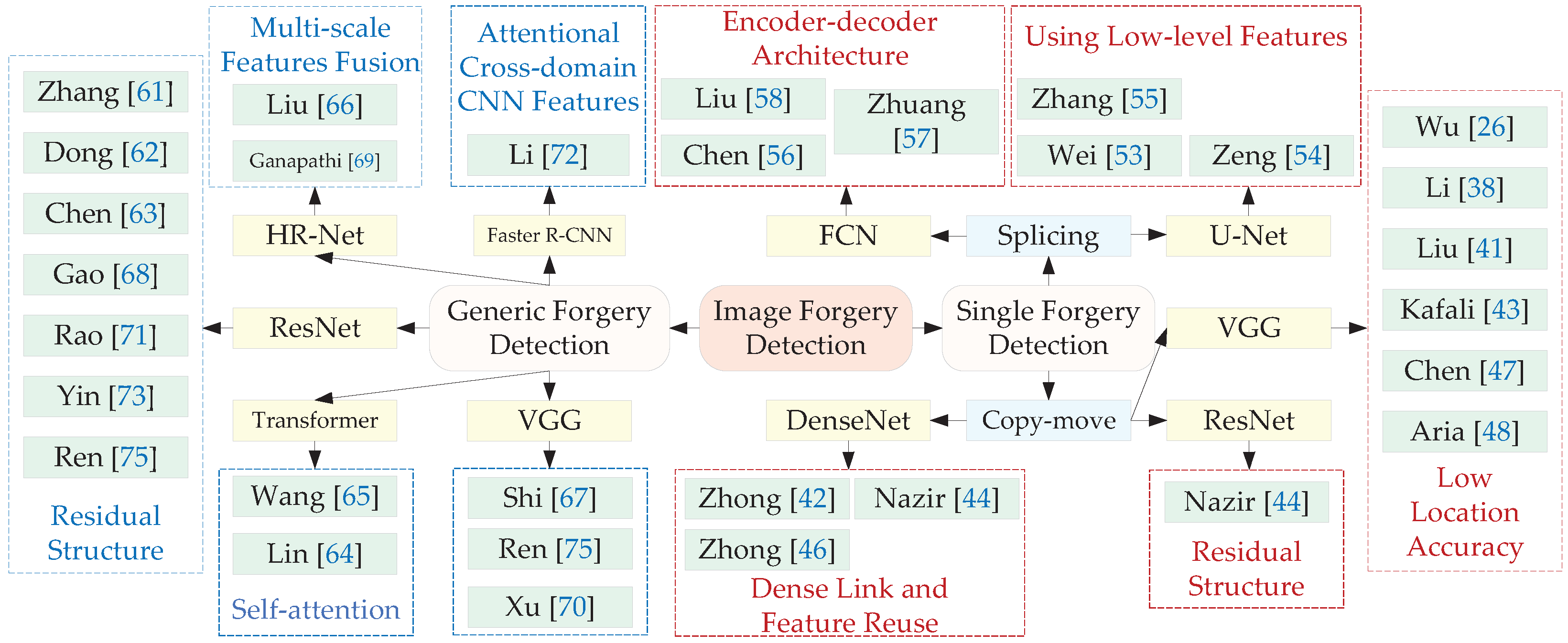
Figure 6.
A serial network for CMFD: (a) the architecture of the proposed scheme and (b) the architecture of copy-move similarity detection network. Adapted from [47].
Figure 6.
A serial network for CMFD: (a) the architecture of the proposed scheme and (b) the architecture of copy-move similarity detection network. Adapted from [47].
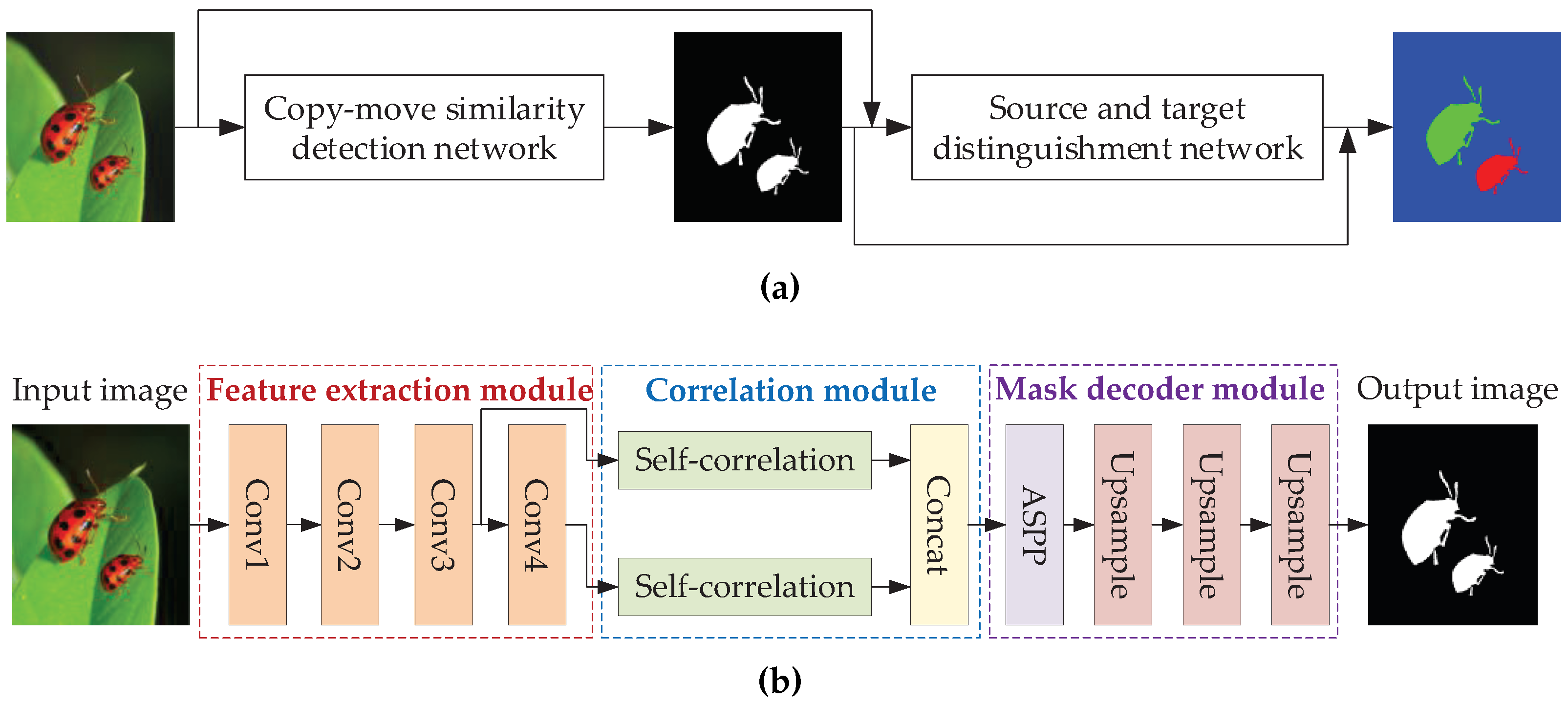
Figure 7.
An overview of robustness enhancement methods for differential attacks.
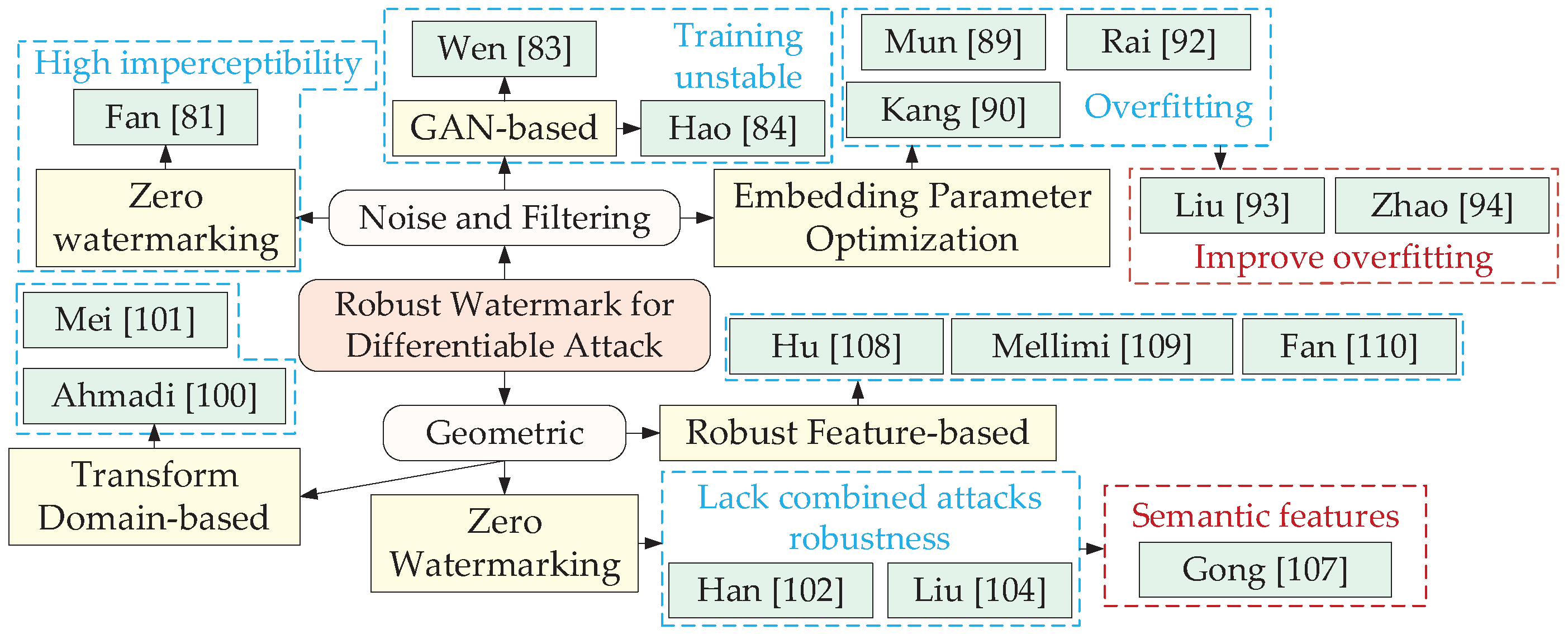
Figure 8.
An overview of robustness enhancement methods for non-differential attacks.
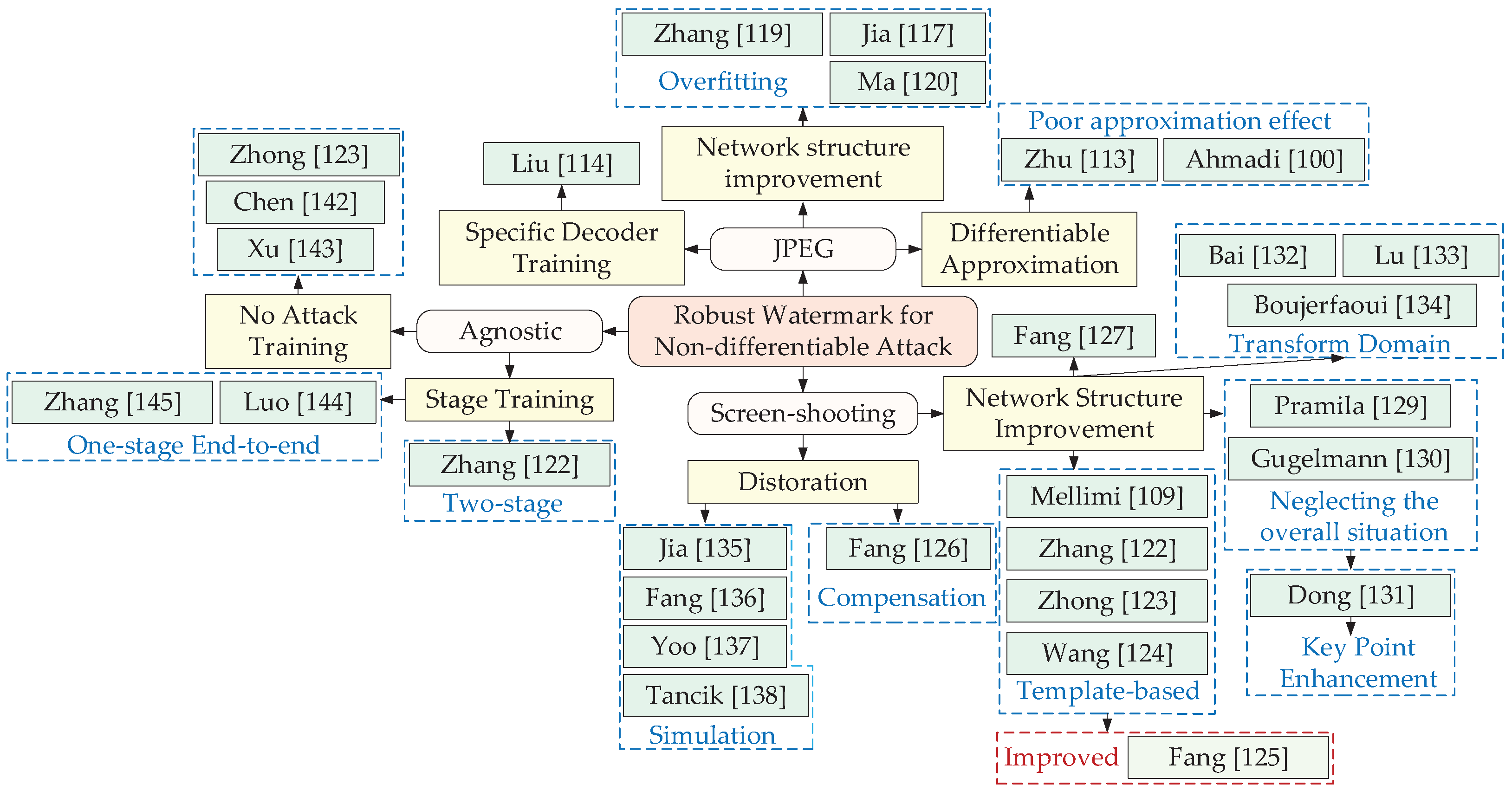

Table 1.
Datasets for image forgery detection.
| Dataset | Year | Type of Forgery | Number of Forged Images/ Authentic Images | Image Format | Image Resolution |
|---|---|---|---|---|---|
| Columbia color [19] | 2006 | Splicing | 183/180 | BMP, TIF | 757 × 568 – 1152 × 768 |
| MICC-F220 [20] | 2011 | Copy-move | 110/1100 | JPG | 480 × 722 – 1070 × 800 |
| MICC-F600 [20] | 2011 | Copy-move | 160/440 | JPG, PNG | 722 × 480 – 800 × 600 |
| MICC-F2000 [20] | 2011 | Copy-move | 700/1300 | JPG | 2048 × 1536 |
| CASIA V1 [21] | 2013 | Copy-move, Splicing | 921/800 | JPG | 284 × 256 |
| CASIA V2 [21] | 2013 | Copy-move, Splicing | 5123/7200 | JPG, BMP, TIF | 320 × 240 – 800 × 600 |
| Carvalho [22] | 2013 | Splicing | 100/100 | PNG | 2048 × 1536 |
| CoMoFoD [23] | 2013 | Copy-move | 4800/4800 | PNG, JPG | 512 × 512 – 3000 × 2500 |
| COVERAGE [24] | 2016 | Copy-move | 100/100 | TIF | 2048 × 1536 |
| Korus [25] | 2017 | Copy-move, Splicing | 220/220 | TIF | 1920 × 1080 |
| USCISI [26] | 2018 | Copy-move | 100000/- | PNG | 320 × 240 – 640 × 575 |
| MFC 18 [27] | 2019 | Multiple manipulation | 3265/14156 | RAW, PNG, BMP, JPG, TIF | 128 × 104 – 7952 × 5304 |
| DEFACTO [28] | 2019 | Multiple manipulation | 229000/- | TIF | 240 × 320 – 640 × 6405 |
| IMD 2020 [29] | 2020 | Multiple manipulation | 37010/37010 | PNG, JPG | 193 × 260 – 4437 × 2958 |
Table 2.
The comparision of deep learning-based passive forgery detection methods .
| Ref. | Year | Type of Detection | Backbone | Robustness Performance | Dataset |
|---|---|---|---|---|---|
| Li et al. [38] | 2022 | Copy-move forgery | VGG 16, Atrous convolution | Brightness change, Image blurring, JPEG compression, Color reduction, Contrast adjustments, Noise adding | USCISI, CoMoFoD, CASIA V2 |
| Liu et al. [41] | 2022 | Copy-move forgery | VGG 16, SuperGlue | Rotation, Scaling, Noise adding, JPEG compression | Self-datasets |
| Zhong et al. [42] | 2020 | Copy-move forgery | DenseNet | Rotation, Scaling, Noise adding, JPEG compression | FAU, CoMoFoD, CASIA V2 |
| Kafali et al. [43] | 2021 | Copy-move forgery | VGG 16, Volterra convolution | Brightness change, Image blurring, JPEG compression, Color reduction, Contrast adjustments, Noise adding | USCISI, CoMoFoD, CASIA |
| Nazir et al. [44] | 2022 | Copy-move forgery | DenseNet, RCNN | Brightness change, Image blurring, JPEG compression, Color reduction, Contrast adjustments, Noise adding | CoMoFoD, MICC-F2000, CASIA V2 |
| Zhong et al. [46] | 2022 | Copy-move forgery | DenseNet | Brightness change, Image blurring, JPEG compression, Color reduction, Contrast adjustments, Noise adding | IMD, CoMoFoD, CMHD [76] |
| Wu et al. [26] | 2018 | Copy-move forgery | VGG 16 | Brightness change, Image blurring, JPEG compression, Color reduction, Contrast adjustments, Noise adding | USCISI, CoMoFoD, CASIA V2 |
| Chen et al. [47] | 2021 | Copy-move forgery | VGG 16, Attention module | Brightness change, Image blurring, JPEG compression, Color reduction, Contrast adjustments, Noise adding | USCISI, CoMoFoD, CASIA V2, COVERAGE |
| Aria et al. [48] | 2022 | Copy-move forgery | VGG 16 | Brightness change, Image blurring, JPEG compression, Color reduction, Contrast adjustments, Noise adding | USCISI, CoMoFoD, CASIA V2 |
| Barni et al. [49] | 2021 | Copy-move forgery | ResNet 50 | JPEG compression, Noise, Scaling | SYN-Ts, USCISI, CASIA, Grip [77] |
| Wei et al. [53] | 2021 | Splicing forgery | U-Net, Ringed residual structure | JPEG compression, Gaussian noise, Combined attack, Scaling, Rotation | CASIA, Columbia |
| Zeng et al. [54] | 2022 | Splicing forgery | U-Net, ASPP | JPEG compression, Gaussian blurring | CASIA |
| Zhang et al. [55] | 2021 | Splicing forgery | U-Net, SEAM | JPEG compression, Scaling, Gaussian filtering, Image sharpening | Columbia, CASIA, Carvalho |
| Chen et al. [56] | 2020 | Splicing forgery | FCN | JPEG compression, Gaussian blur, Gaussian noise | DVMM [78], CASIA, NC17, MFC18 |
| Zhuang et al. [57] | 2021 | Splicing forgery | FCN | JPEG compression, Scaling | PS-scripted dataset, NIST16 [27] |
| Liu et al. [58] | 2022 | Splicing forgery | FCN, SRM | Gaussian noise, JPEG compression, Gaussian blurring | CASIA, Columbia |
| Ren et al. [59] | 2022 | Splicing forgery | ResNet 50 | JPEG compression, Gaussian noise, Scaling | CASIA, IMD2020, DEFACTO, SMI20K |
| Sun et al. [60] | 2022 | Splicing forgery | Transformer | JPEG compression, Media blur, Scaling | CASIA, NC2016 [79] |
| Zhang et al. [61] | 2022 | Multiple types of tampering detection | ResNet 34, Non-local module | JPEG compression, Gaussian blur | CASIA, COVERAGE, Columbia, NIST16 |
| Dong et al. [62] | 2023 | Multiple types of tampering detection | ResNet 50 | JPEG compression, Gaussian blur | CASIA V2,COVERAGE, Columbia, NIST16 |
| Chen et al. [63] | 2023 | Multiple types of tampering detection | ResNet 101 | JPEG compression, Gaussian blur, Median blur | Self-datasets, NIST16, Columbia, CASIA |
| Lin et al. [64] | 2023 | Multiple types of tampering detection | ResNet 50, Swin transformer | JPEG compression, Gaussian blur, Gaussian noise | CASIA, NIST16, Columbia, COVERAGE, CoMoFoD |
| Wang et al. [65] | 2022 | Multiple types of tampering detection | Multimodal transformer | JPEG compression, Gaussian blur, Gaussian noise, Scaling | CASIA, Columbia, Carvalho, NIST16, IMD2020 |
| Liu et al. [66] | 2022 | Multiple types of tampering detection | HR-Net | JPEG compression, Scaling, Gaussian blur, Gaussian noise | Columbia, COVERAGE, CASIA, NIST16, IMD2020 |
| Shi et al. [67] | 2022 | Multiple types of tampering detection | VGG 19, Rotated residual | JPEG compression, Gaussian blur, Gaussian noise | NIST16, COVERAGE, CASIA, In-The-Wild |
| Gao et al. [68] | 2022 | Multiple types of tampering detection | ResNet 101 | JPEG compression, Scaling | CASIA, Carvalho, COVERAGE, NIST16, IMD2020 |
| Ganapathi et al. [69] | 2022 | Multiple types of tampering detection | HR-Net | Flipped horizontally and vertically, Saturation, Brightness | CASIA V2, NIST16, Carvalho, Columbia |
| Xu et al. [70] | 2022 | Multiple types of tampering detection | VGG 16 | JPEG compression, Scaling, Gaussian blur, Gaussian noise | NIST16, COVERAGE, CASIA, IMD2020 |
| Rao et al. [71] | 2022 | Multiple types of tampering detection | Residual unit, CRF-based attention, ASPP | JPEG compression, Scaling | COVERAGE, CASIA, Carvalho, IFC |
| Li et al. [72] | 2022 | Multiple types of tampering detection | ResNet101, Faster R-CNN | Median filtering, Gaussian noise, Gaussian blur, Resampling | CASIA, Columbia, COVERAGE, NIST16 |
| Yin et al. [73] | 2022 | Multiple types of tampering detection | Convolution and Residual block | JPEG compression, Gaussian blur, Gaussian noise, Scaling | NIST16, CASIA, COVERAGE, Columbia |
| Zhou et al. [74] | 2022 | Multiple types of tampering detection | VGG-style block | JPEG compression, Gaussian noise, Gaussian blur, Scaling | DEFACTO, Columbia, CASIA, COVERAGE, NIST16 |
| Ren et al. [75] | 2022 | Multiple types of tampering detection | ResNet 50 | JPEG compression, Gaussian noise, Scaling | NIST16, CASIA, MSM30K |
Table 3.
The comparision of deep learning-based image watermarking against noise and filtering .
| Ref. | Watermark Size (Container Size) |
Category | Method (Effect) | Robustness (Attack, Parameter) | Dataset | |
|---|---|---|---|---|---|---|
| BER (%) | NC | |||||
| Hao et al. [84] | 30 (64 × 64) |
GAN-based | GAN (Improving visual quaility) | 0.5 (Gaussian blur, 3 × 3, = 2.0) | – | COCO [95] |
| Mun et al. [89] | 24 (512 × 512) |
Embedding parameter optimization | CNN (Feature extraction) | – | 0.9625 (Gaussian blur, 3 × 3, = 1) | MPEG-7 CE Shape-1 [96] |
| Kang et al. [90] | 1024 (1024 × 1024) |
Embedding parameter optimization | PSO (Selecting best DCT coefficient) | 0 (Gaussian filtering, 3 × 3, = 0.5) | 0.990 (Gaussian filtering, 3 × 3, = 0.5) | USC-SIPI [97] |
| Rai et al. [92] | 32 (96 × 96) |
Embedding parameter optimization | SSO (Gaining ideal embedding parameter) | – | 0.8259 (Gaussian noise, = 0.01) | Self-datasets |
| Zhao et al. [94] | 32 × 32 (512 × 512) |
Embedding parameter optimization | Spatial and channel attention mechanism (Improving robustness) | 0.09 (Gaussian noise, = 0.05) | 0.9988 (Gaussian noise, = 0.05) | BOSS Base [98], CIFAR 10 [99] |
Table 4.
The comparision of deep learning-based image watermarking against geometric attacks.
| Ref. | Watermark Size (Container Size) |
Category | Method (Effect) | Robustness (Attack, Parameter) | Dataset | |
|---|---|---|---|---|---|---|
| BER (%) | NC | |||||
| Ahmadi et al. [100] | 1024 (512 × 512) |
Transform domain-based | Circular convolution (Diffusing watermark information), Residual connection (Fusing low-level character) | 5.9 (Scaling, = 0.5) |
– | CIAFAR 10 [99], Pascal VOC [111] |
| Mei et al. [101] | 1024 (512 × 512) |
Transform domain-based | DCT, Attention, Joint source-channel coding (Improving robustness) | 0.96 (Cropping, = 0.75), 0.34 (Cropping, = 0.5) |
– | COCO [95] |
| Han et al. [102] | – | Zero- watermark |
VGG19, DFT (Feature extraction) | – | 0.87509 | |
| ( = 50) | Self-datasets | |||||
| Liu et al. [104] | – | Zero- watermark |
VGG19 (Feature extraction) | – | 0.95 ( = 40), 0.96 (Scaling, = 0.5) |
Waterloo Exploration Database [112] |
| Gong et al. [107] | – | Zero- watermark |
Residual-DenseNet (Feature extraction) | – | 0.89 (Rotation, = 45) |
Self-datasets |
| Hu and Xiang [108] | 128 (512 × 512) |
Robust feature-based | CNN (Feature extraction), GAN (Visual improvement) | 0.6 (Scaling, = 2) |
– | USC-SIPI [97] |
| Mellimi et al. [109] | 1024 (512 × 512) |
Robust feature-based | DNN (Optimal embbeding subband selection) | 1.78 (Scaling, = 0.65), 0.2 (Scaling, = 0.75) |
0.9353 (Scaling, = 0.65), 0.9930 (Scaling, = 0.75) |
USC-SIPI [97] |
Table 5.
The comparision of deep learning-based image watermarking against JPEG attack.
| Ref. | Watermark Size (Container Size) |
Method | Structure | Robustness (BER (%, )) |
Dataset |
|---|---|---|---|---|---|
| Ahmadi et al. [100] | 1024 (512 × 512) |
Differentiable approximation | CNN, Residual connection, Circular convolution | 1.2 (50), 0 (70), 0 (90) |
CIFAR 10 [99], Pascal VOC [111] |
| Liu et al. [114] | 30 (128 × 128) |
Specific decoder training | CNN, GAN | 23.8 (50) | COCO [95], CIFAR 10 [99] |
| Chen et al. [115] | 1024 (256 × 256) |
Network structure improvement | CNN, JSNet | 0.097 (90), 32.421(80) | ImageNet [116], Boss Base [98] |
| Jia et al. [117] | 64 (128 × 128) |
Network structure improvement | CNN, Residual connection | 4.14 (50) | COCO [95] |
| Zhang et al. [119] | 30 (128 × 128) |
One-stage end-to-end | Backward ASL | 12.64 | – |
| Ma et al. [120] | 30 (128 × 128) |
Network structure improvement | DEM, Non-invertible attention module | 0.76 (50) | COCO [95] |
Table 6.
The comparision of deep learning-based image watermarking against screen-shooting attack with BER metrics.
Table 6.
The comparision of deep learning-based image watermarking against screen-shooting attack with BER metrics.
| Ref. | Watermark Size (Container Size) |
Category | Robustness (BER (%)) | Dataset | |
|---|---|---|---|---|---|
| Distance (cm) | Angle (°) | ||||
| Fang et al. [125] | 128 (512 × 512) |
Templated- based | 1.95 (20), 2.73 (40), 11.72 (60) | 4.3 (Up40), 1.17 (Up20), 7.03 (Down20), 7.03 (Down40), 5.47 (Left40), 3.91 (Left20), 2.73 (Right20), 3.52 (Right40) | ImageNet [116], USC-SIPI [97] |
| Fang et al. [126] | 48 (256 × 256) |
Decoding based on attention mechanism | 5.1 (15), 9.9 (35) | 9.4 (Up45) 8.1 (Up30), 8.9 (Down30), 9.45 (Down45), 9.7 (Left45), 8.9 (Left30) , 9.8 (Right30), 9.3 (Right45) | Self-datasets |
| Fang et al. [127] | 32 (512 × 512) |
Distortion compensation | 2.54 (30), 3.71 (50), 5.27 (70) | 6.25 (Up30), 3.13 (Up15), 12.73 (Down15), 14.12 (Down30), 7.05 (Left15), 14.46 (Left40), 5.27 (Right15), 11.52 (Right30) | COCO [95] |
| Dong et al. [131] | 64 (64 × 64) |
Key point enhancement | 0.43 (45), 0.35 (65) , 0.67 (75) | 2.0 (Left60), 0.66 (Left30), 0.67 (Right30), 2.68 (Right60) | Self-datasets |
| Jia et al. [135] | 100 (400 × 400) |
Distortion simulation | – | 1.0 (Left65), 0.7 (Left30), 0.7 (Right30), 5.3 (Right65) | Pascal VOC [111], USC-SIPI [97] |
| Fang et al. [136] | 30 (128 × 128) |
Tamper detection | 2.08 (40), 1.25 (60), 0.62 (20) | 2.92/1.25 (Left/Up40), 1.25/0.93 (Left/Up20), 1.05/1.04 (Right/Down20), 0.62/0.83 (Right/Down40) | USC-SIPI [97] |
Table 7.
The comparision of deep learning-based image watermarking against screen-shooting attack with other experiment condition.
Table 7.
The comparision of deep learning-based image watermarking against screen-shooting attack with other experiment condition.
| Ref. | Watermark Size (Container Size) |
Category | Robustness (BER (%)) | Dataset |
|---|---|---|---|---|
| Lu et al. [133] | 400 (400 × 400) |
Transform domain | 11.18 | MIR Flickr [140] |
| Yoo et al. [137] | – | Distortion simulation | 9.72 ( = 30) | ModelNet 40-class [141] |
| Tancik et al. [138] | 100 (400 × 400) |
Distortion simulation | 0.2 | ImageNet [116] |
Table 8.
The comparision of deep learning-based image watermarking against agnostic attack.
| Ref. | Watermark Size (Container Size) |
Category | Structure | Robustness (Attack, Parameter) | Dataset |
|---|---|---|---|---|---|
| Zhang et al. [119] | 30 (128 × 128) |
One-stage end-to-end | Backward ASL | BER: 12.64 (JPEG, = 50) | – |
| Zhang et al. [122] | 64 (224 × 224) |
Two-stage separable training | CNN, GAN, Attack classification discriminator, Residual network | BER: 18.54 (JPEG, = 50), 8.47 (Cropping, = 0.7), 11.79 (Rotation, 15), 1.27 (Salt and pepper noise, = 0.01), 1.9 (Gauss filtering, 3 × 3, = 2) | Pascal VOC [111] |
| Zhong et al. [123] | 32 × 32 (128 × 128) |
One-stage end-to-end training | Multi-scale convolution blocks, Invariance layer | BER: 8.16 (JPEG, = 10), 6.61 (Cropping, 0.8), 0.97 (Salt and pepper, = 0.05) | ImageNet [116], CIFAR 10 [99] |
| Chen et al. [142] | 64 × 64 (512 × 512) |
No attack training | WMNet, CNN | Classification accuracy: 0.978 | - |
| Luo et al. [144] | 30 (128 × 128) |
No attack training | Channel coding, CNN, GAN | BER: 10.5 (Gaussian noise, = 0.1), 22.9 (Salt and pepper noise, = 0.15) | COCO [95] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



