Submitted:
21 April 2023
Posted:
21 April 2023
Read the latest preprint version here
Abstract
We present a new model formulation for a class of capacitated lot-sizing problem considering setup costs, product returns, and remanufacturing (CLSP-RM). We investigate a broad class of instances that fall into two groups, in the first group we can reformulate the problem with a relaxation and test whether the original problem is solvable. The relaxation gives near optimal solutions and the solution of this class does not give any difficulty to known solvers such as Cplex, Gurobi or Xpress. The second group of instances are of category NP and will be solved with a simple period-by-period simulation
Keywords:
simulation based optimization
; capacitated lot-sizing problem
; heuristics
; remanufacturing
1. Introduction
The production planning with consideration of recycling options has received increasing attention in the last few years [1]. The literature describes two different categories of recycling production planning problems. In the first category (Cat. 1), the given external demand of the products has to be satisfied by remanufactured or newly produced goods Figure 1. Only two types of inventories are regulated: the inventory of new products and the inventory of remanufactured products, and this is the category that has been thoroughly investigated by numerous authors. It is assumed that new and remanufactured products are identical, and hence, both are regarded as serviceables, i.e., entities that can be used to satisfy demands. In the second category (Cat. 2) the additional feature of this problem is that in each period a deterministic amount of returned items enters the system. These returns can be remanufactured and used to satisfy the demand for remanufactured products in addition to the regular production of new items. Thus, there are three types of inventory: new product inventory, remanufactured product inventory and returned product inventory (Figure 1). This situation is typical in paper manufacturing. Demand for recovered paper has increased enormously worldwide, making separate collection more attractive again. Peter Probst, CEO of LEIPA Group, Germany (Viadrina University, 05.2019) explains the advantage: "paper recycling proves to be economically and ecologically efficient, because the production of recycled paper requires considerably less water and considerably less energy than the production of virgin fiber papers. In addition, the transport distances are generally shorter as well. Recycled paper comes from Germany, while the fresh fibers and fresh fiber papers are also imported to Germany in larger proportions". Paper production is also energy intensive. It takes as much energy to produce one ton of paper from fresh wood fibers as it does to produce one ton of steel ([2]).
2. Literature Review
Publications regarding Category 1: [3] analyzes several CLSP-RM formulations with the column generation method, where he uses the idea of Garfinkel and Nemhauser (1969), namely the Set Partitioning Problem (SPP). [4] compared MIP approaches to the economic lot-sizing with remanufacturing (ELSR) and proposes a shortest path formulation. [5] studied another multi-item variant of the problem and propose a variable neighborhood search heuristic. The polynomial-time heuristics of [6] also belongs to this category, where there is also an excellent compilation of the methods developed by [7,8,9,10,11].
Publications regarding category 2: The only publication known to us is that of [12] where he presents a Lagrange relaxation to solve the problem. Based on Zhang’s model we formulate the same problem but taking more general capacity constraints and doing more extensive numerical experiments.
The capacitated lot sizing problem model is NP-hard. The proof of this statement is to be found in [13,14]. [15] has shown that even the two-item problem with constant capacity is NP-hard. Many methods have been proposed to solve the CLSP [16]. In general, these heuristics do not use random numbers. However, many heuristics cannot guarantee the generation of a feasible solucion [15]. These heuristic methods used to solve a CLSP class problem are generally based on the definition of a multitude of rules derived from demand, capacity, setup costs, inventing costs and productions costs e.g. [9,10,17].The solution margin varies between 1% and 10% [12,17].
The contribution of this work is: independently of the input parameters of the problem, we organize the production in the framework of feasibility and randomly. A simple simulation with quasi-random numbers ( ) will be presented. The heuristic will always generate a feasible solution, if the problem is solvable. After simulating N production plans we choose the cheapest one. The scheduling is very simple, the results are quite acceptable considering the size of the presented problems.
It is well known that the of [18,19,20] have significant properties,[21]. The most important of these are: they are uniformly distributed. These are some allow us a systematic search of the solution in the set of admissible points with a few . We implement a search algorithm with Halton’s and compare it with numerical solutions by the Gurobi solver.
In Section 3 we propose a new mathematical programming formulation for the problem. In Section 4 we present a relaxation of the problem without capacity constraints (Model A) and we will see that the solution obtained for the chosen class of tasks is very close to the optimal solution of the original problem. In Section 5, we present a heuristic solution method (Model B) for another class of tasks. In Section 6, we report the results of computational experiments. In Section 7 we present some conclusions and suggested directions for further research.
3. Problem description
We assume that a factory produces two types of products, one manufactured from raw materials and the other remanufactured from collected used products. The demands for these two products are separate, deterministic, and time varying during a finite planing horizon, and should be satisfied without backlogging. The costs consist of fixed setup cost, linear production cost proportional to the production quantity, and linear inventory holding costs. All cost components are considered for both manufacturing and remanufacturing activities per unit and periode [12]. The following Table 1 summarize the notation used in this paper.
We make the following assumptions, which are necessary for the feasibility of the problem
- The demand for new products and remanufactured products are separate and backlog is not allowed.
- The manufacturing capacity is sufficient to meet the demands in each period, in particularly we have: the capacity can satisfy the demands for new products and remanufactured products simultaneously, i.e.
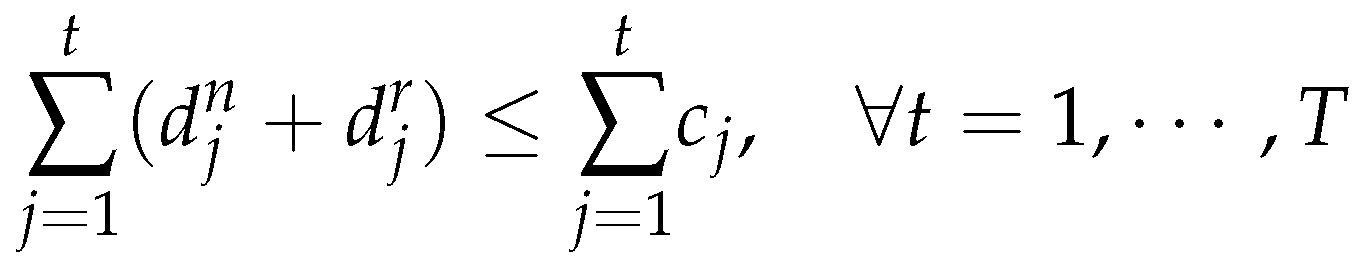
-
Initial and end inventory stocks are zero, 1 i.e.
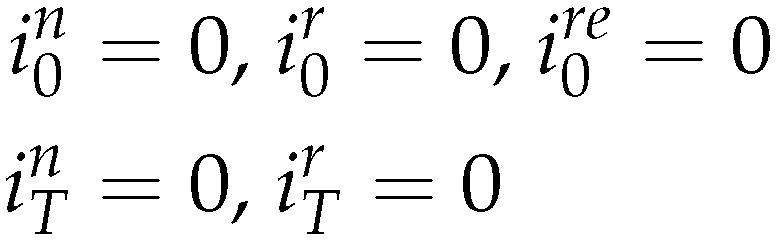 The demand will be fully satisfied if the final inventories are zero.
The demand will be fully satisfied if the final inventories are zero. - The quantity of returned products can satisfy the demand for remanufactured products i.e.
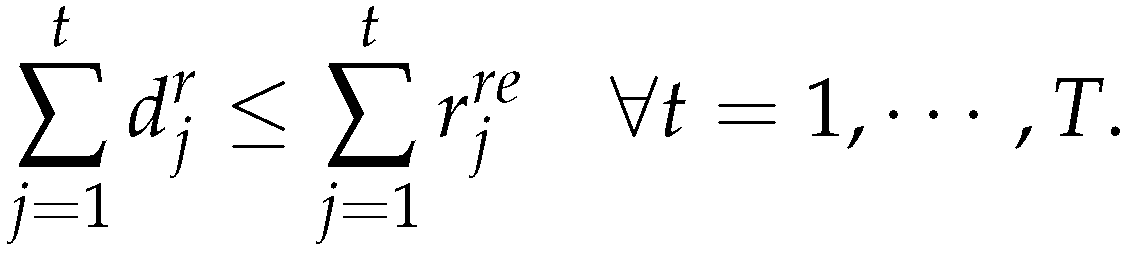
- In economic terms, inventory holding cost of returned products is less than that of remanufactured products.This hypothesis can be found in [22] too.
Hence, the problem can be formulated as
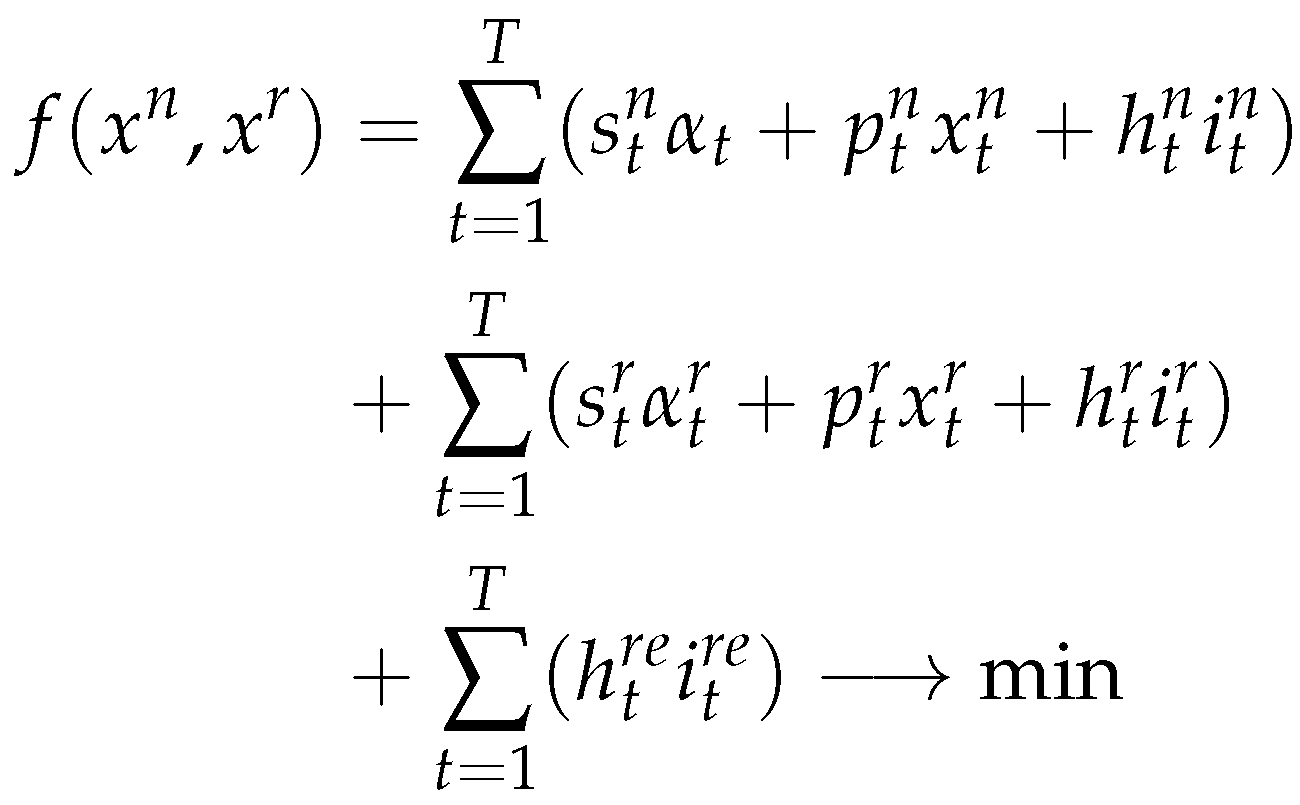 subject to
subject to

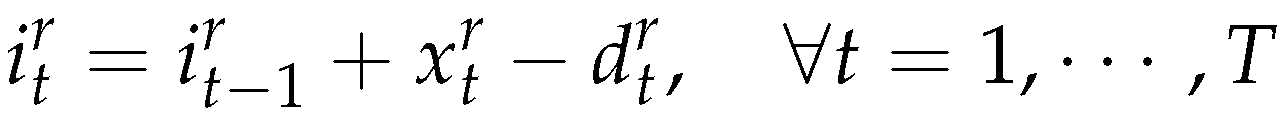
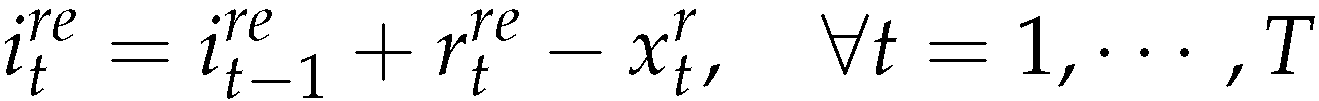
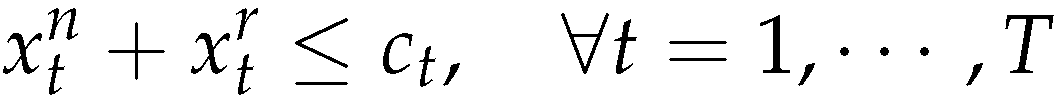
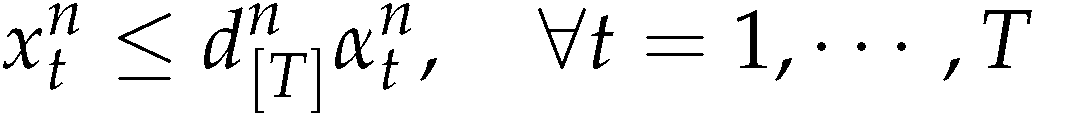
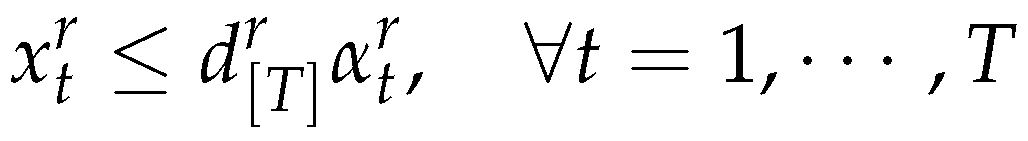
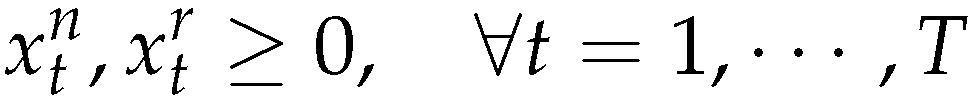
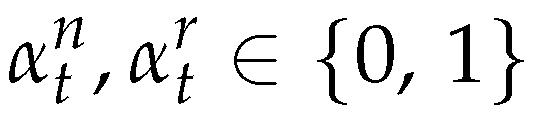
The objective function (5) minimizes the sum of setup cost, production cost, and inventory cost for new products and remanufactured products in all periods. Constraints (6),(7) and (8) are the inventory balance constraints for new products, remanufactured products and returned products. Constraints (9) represent capacity constraints for manufacturing and remanufacturing activities. Constraints (10), (11) allow production only with the according setups (i.e ) (12) and (13) are the standard integrality and non-negative constraints.
3.1. Rewriting the optimization problem
are replaced in the objective function by
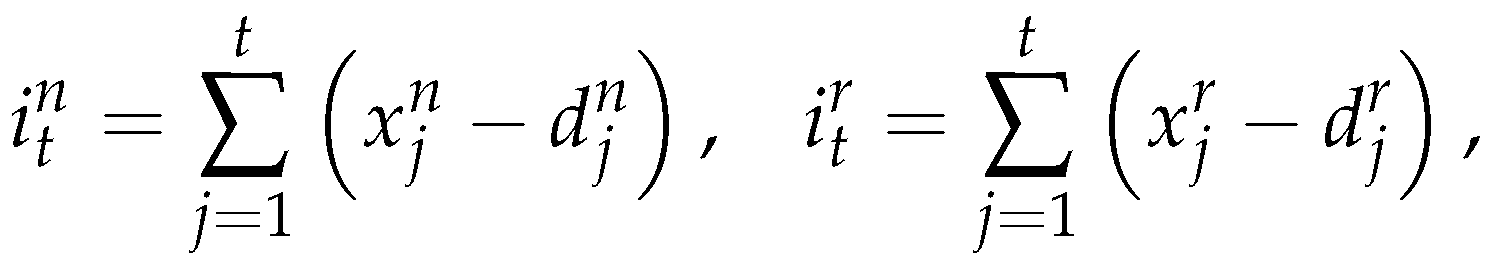
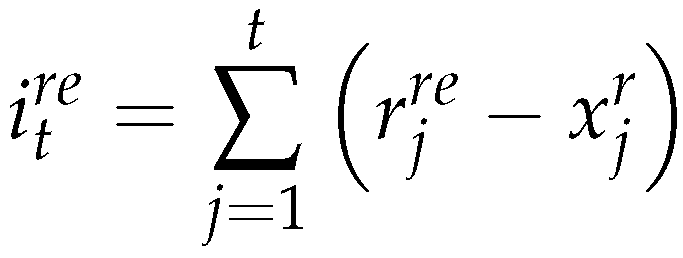
And with a bit of algebraic transformations, we obtain
With the notation
our model is finally
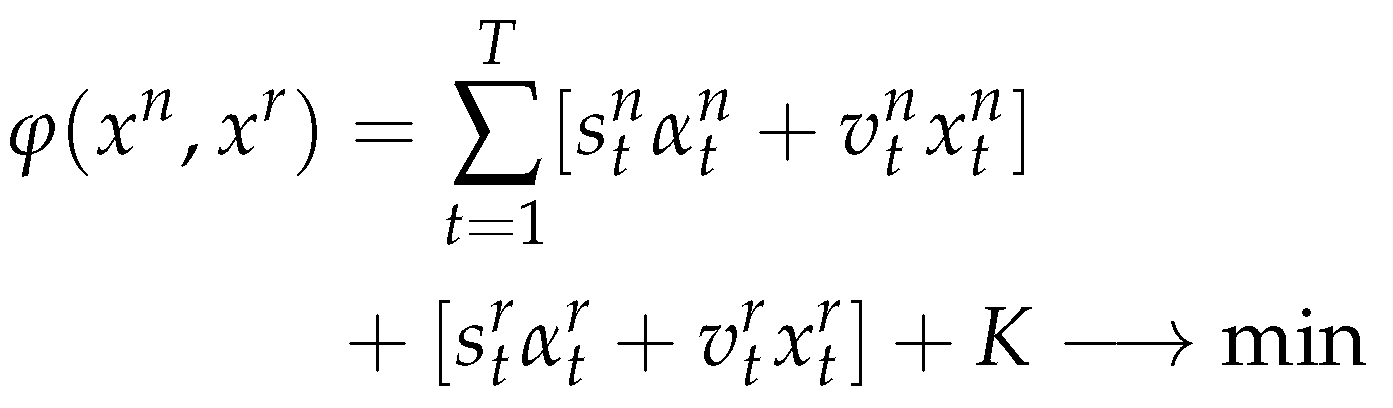
Subject to
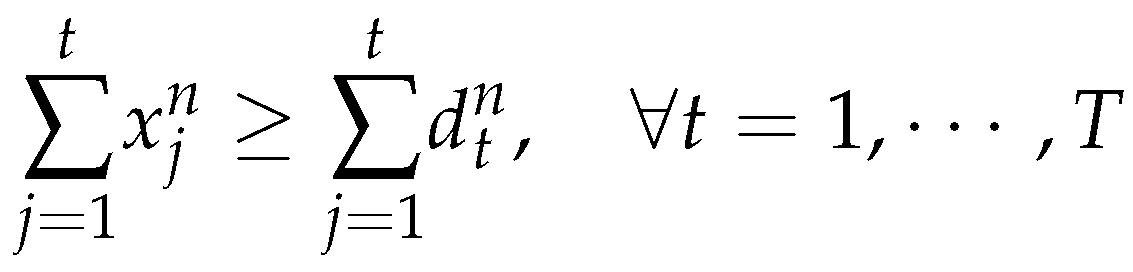
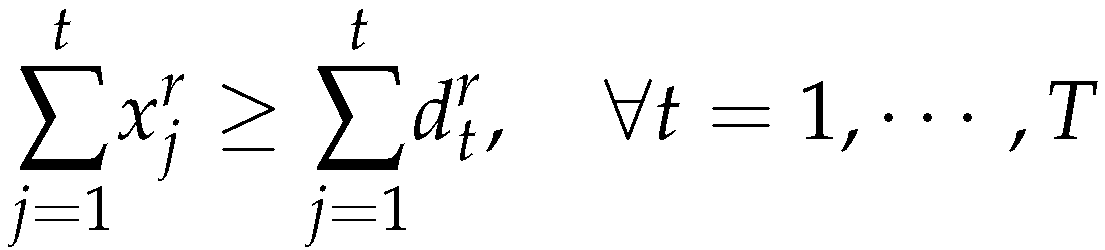
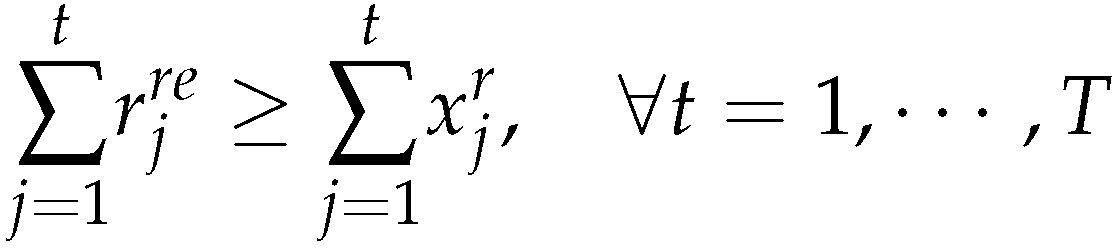
4. Model A (Relaxation)
According to our conditions (1) and (3) the general problem has a solution, if the total pro-period demand is less than the pro-period capacity (i.e.). However there are situations, where conditions (1) and (3) are satisfied but is not satisfied. We need a feasibility routine which ensures that all demand is satisfied without backlogging. Indeed there are periods (or could be) in which total demand exceeds total capacity. In this case some inventory will have to be build up in earlier periods which slack capacity. We explain how to shift excess demand to earlier periods in which slack capacity is available. We use and complement the idea of [23].
We define
It is easy to see that the sum is null.
Remark 1.The vector is very useful. Because gives the amount of stock to accumulate () or reduce () in each period so that production does not exceed available capacity pro period. And allows us to determine a good permissible solution.

Table 3.
Original Data.
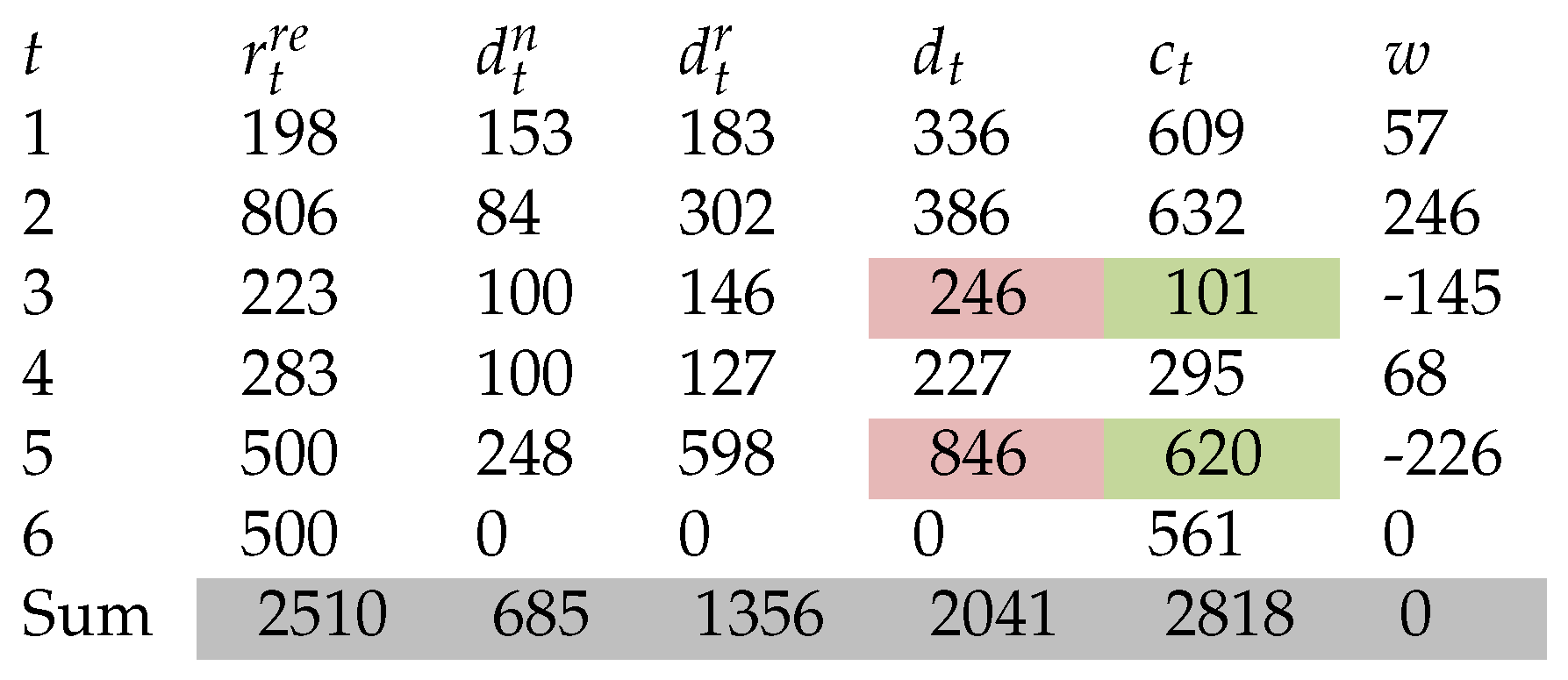
We see that the demand transformation done in Table 4 is a valid (permissible) solution to the problem (16)-(24). There are many ways to make this transformation, for this reason to transform the demand in an optimal way we formulate the following problem.
Table 4.
Demand Transformation.
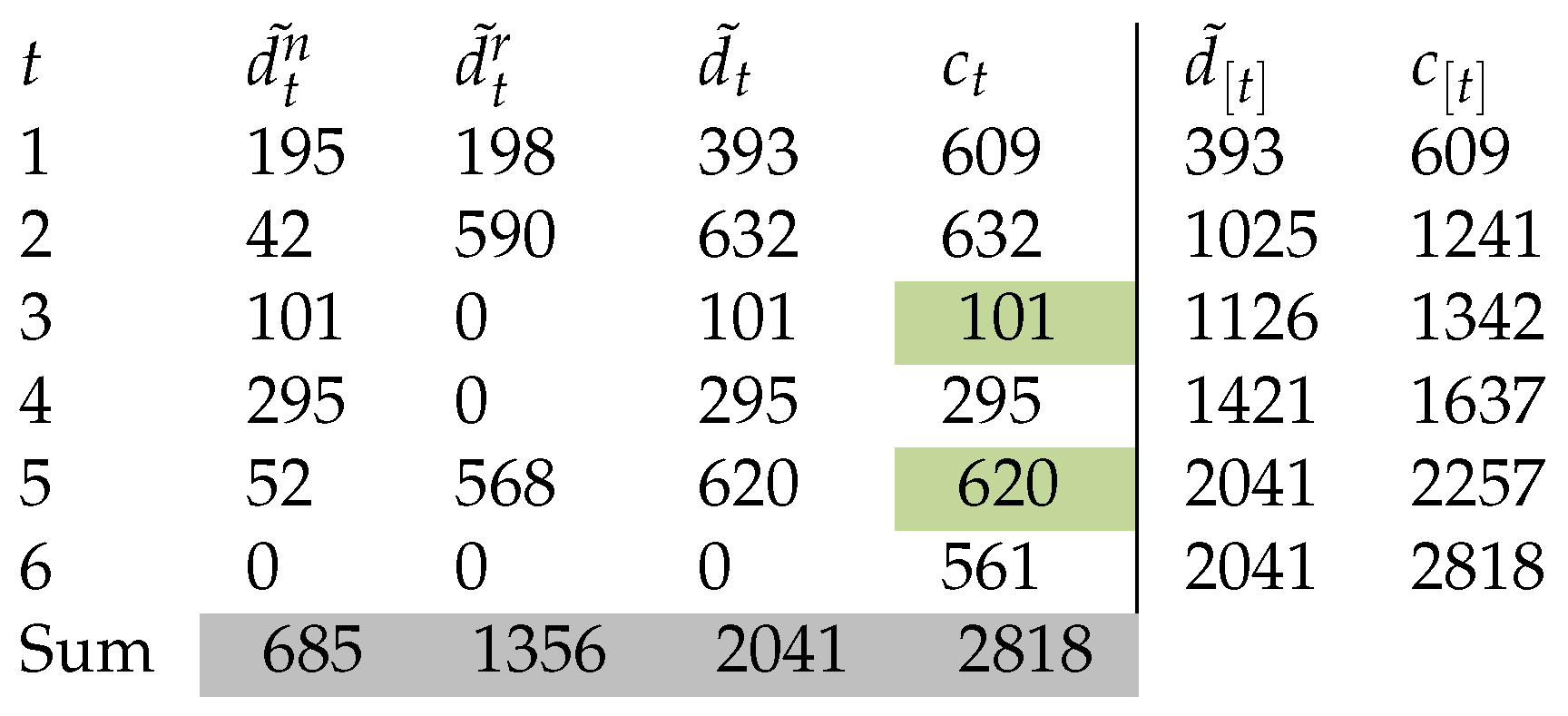
Subject to

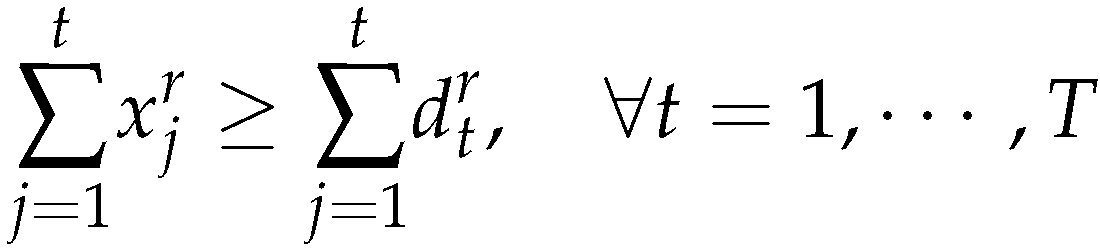
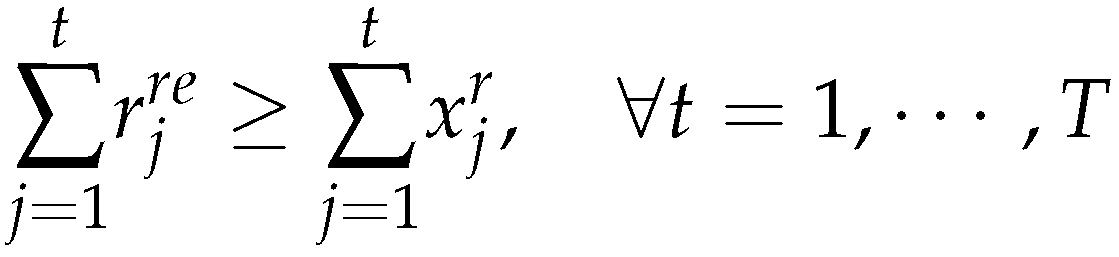
If the model (25)-(33) has no solution, it means the model (16)-(24) has no solution too.
We have a problem with no capacity restrictions. We solve this problem and compare it with the optimal solution of the initial problem (16)-(24).
Remark 2.
It is important to clarify that this task only makes sense if the vector w is not equal to the null vector. If the vector w is equal to the null vector it means that in each period In this case a relaxation is not possible and the problem (16)-(24) will be solved with a heuristic method (Model B).
5. Model B (Simulation)
5.1. Low discrepancy sequences
The generation of random numbers with a computer is not possible Knuth [24]. As John von Neumann said: Any one who considers arithmetical methods of producing random digits is, of course, in a state of sin, [25]. An excellent overview of the methods of generating pseudo-random numbers are available eg. [24,26,27].
In this section we explain the number-theoretical concept of discrepancy. Then, we introduce the Halton sequence which is probably the easiest low-discrepancy 2 number generation method to describe.
Definition 1.
Leta sequence of real numbers with. The discrepancy for the sequence is defined as
where l is any subinterval and denotes the number of elements of the sequence, that belongs to the interval
A measure for how a sequence of real numbers , is equidistributed on an interval is the discrepancy . Low-discrepancy sequences, also known as quasirandom sequences, are numbers that are better equidistributed in a given volume than pseudo-random numbers.
Remark 3.
A sequence of real numbers is said equidistributed on the interval if [18].
The ( ) of Halton, Sobol and Niederreiter have a low discrepancy . While pseudorandon sequences have a discrepancy [26]. Figure uses two-dimensional projection of a pseudorandom sequence and of a low-discrepancy (Halton) sequence to demonstrate the fundamental difference between the two classes of sequences.
The desirable properties of a sequence of this ( ) may be summarized as follows ( [20]):
- the least period length should be sufficiently large,
- it should have littie intrinsic structure (such as lattice structure),
- it should have good statistical properties,
- the algorithm generating the sequence should be reasonably efficient.
It’s easy to generate sequences of Halton with the following algorithm 1, [20].
| Algorithm 1: Construction of Halton sequences |
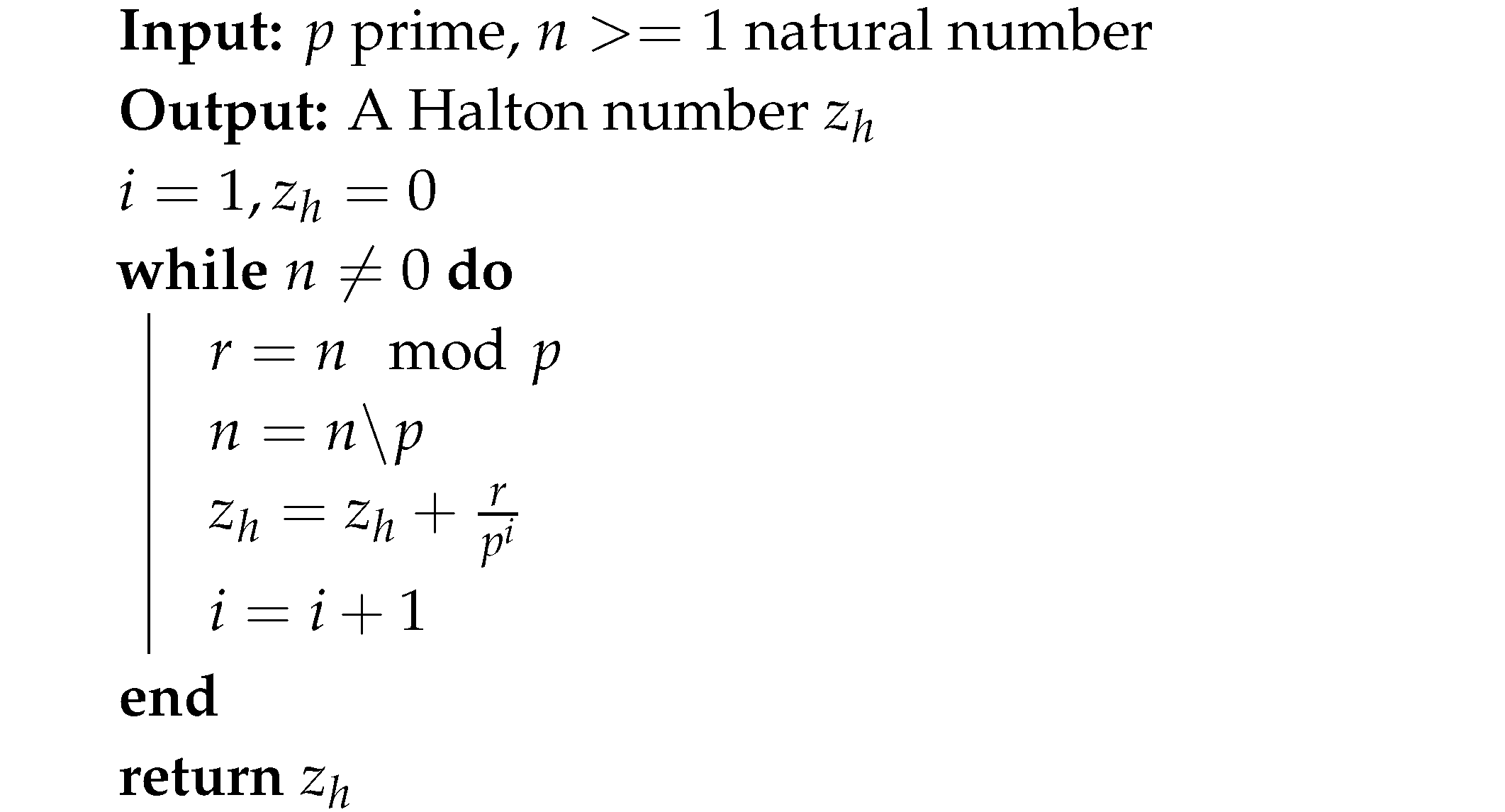 |
The following Halton sequences of Table 5 are constructed according to algorithm 1 that uses a prime number as its base.
Table 5.
Halton Numbers.
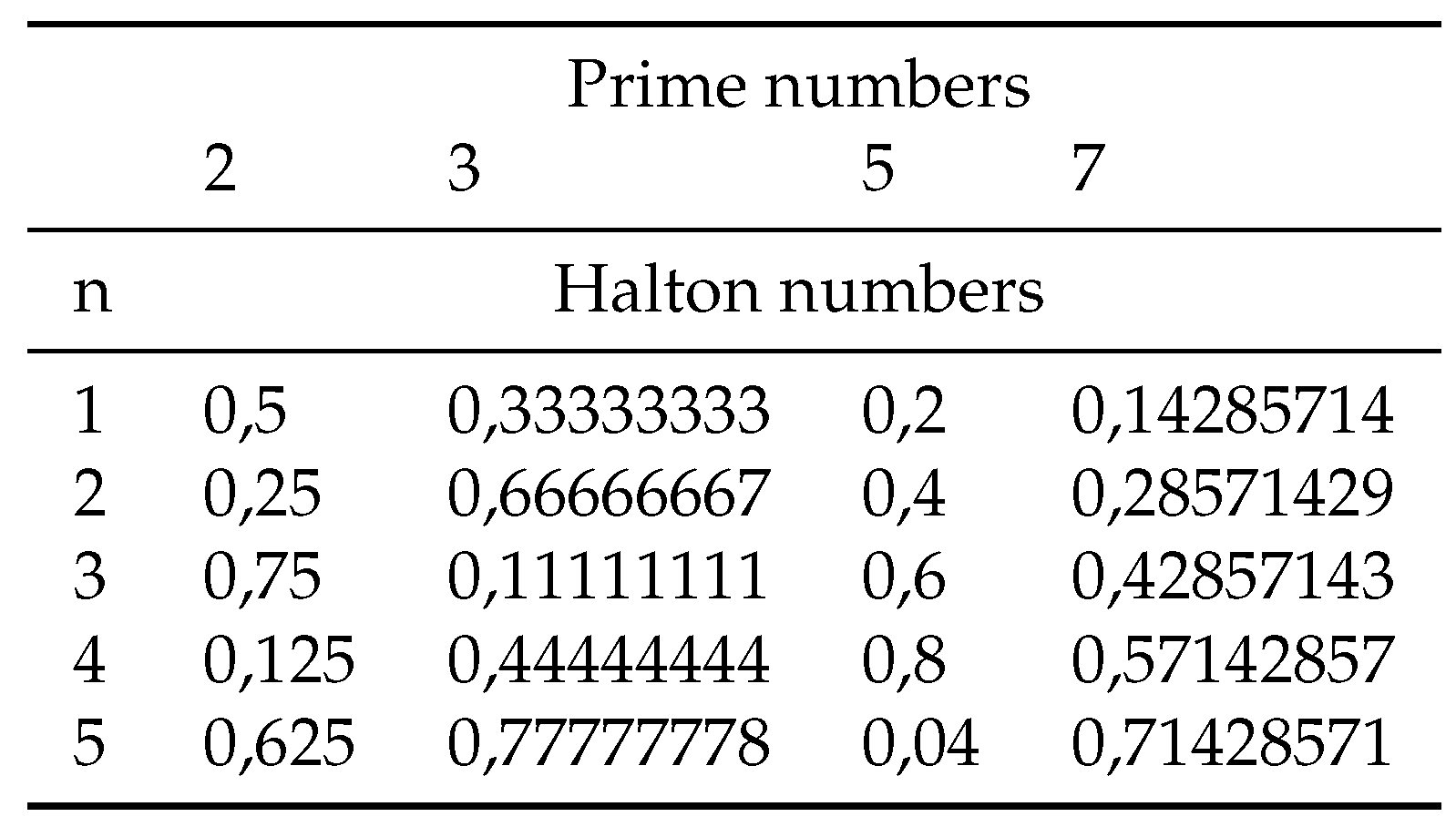
Remark 4.
To generate the n-th Halton point in a sequence consider the base ary expansion of a where the ary coefficients Then the n-th Halton point is It’s easy to build a Halton-sequence with the following observation: If then else if then where (details see [21]). This method is very efficient and will be used in this paper.
5.2. Notation
We use the following notation
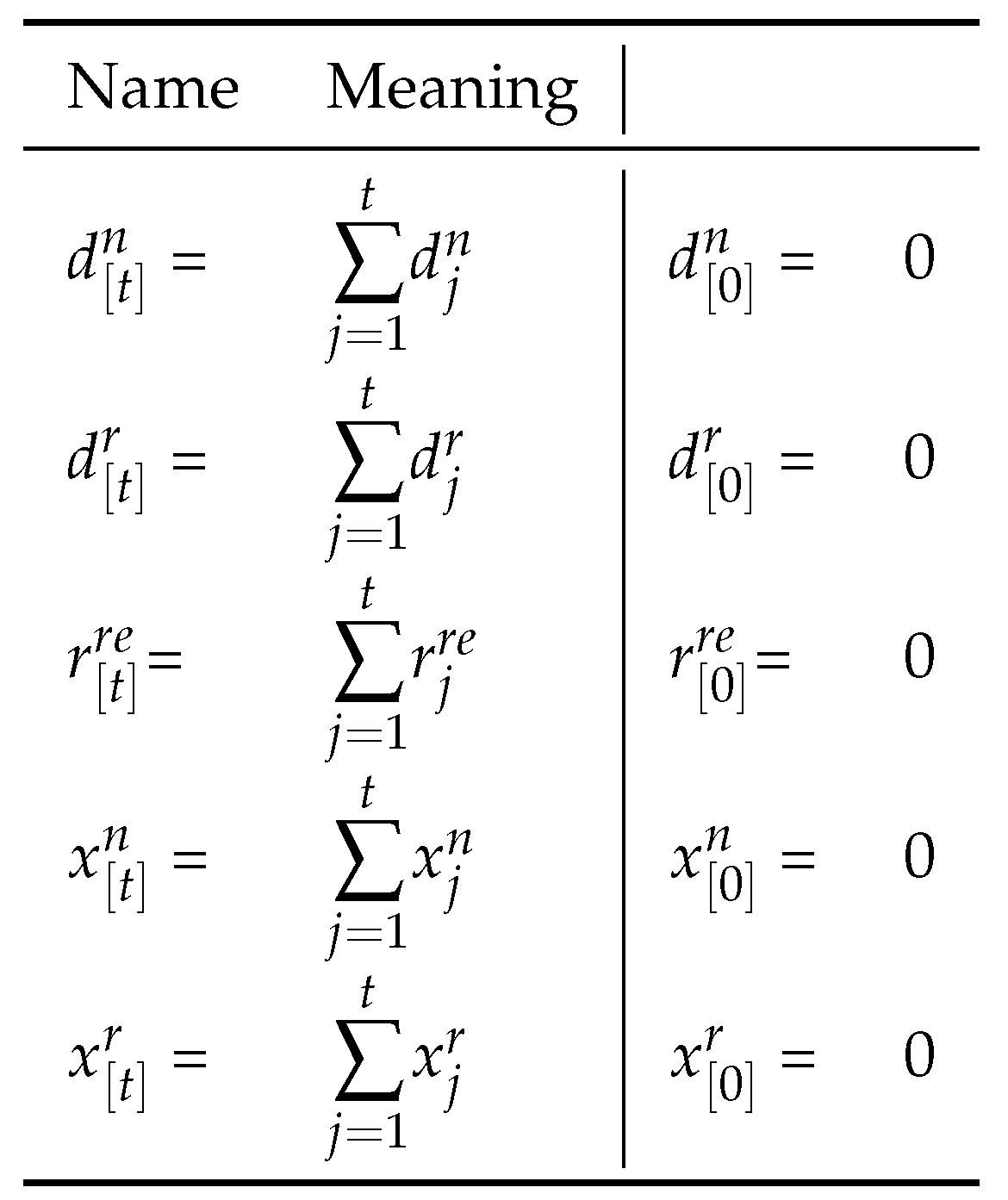
The notation means and the number z is simulated with the following distribution
We generate a pseudorandom number to decide, that values take z, see algorithm 2.
| Algorithm 2: Simulation of z with distribution (35) |
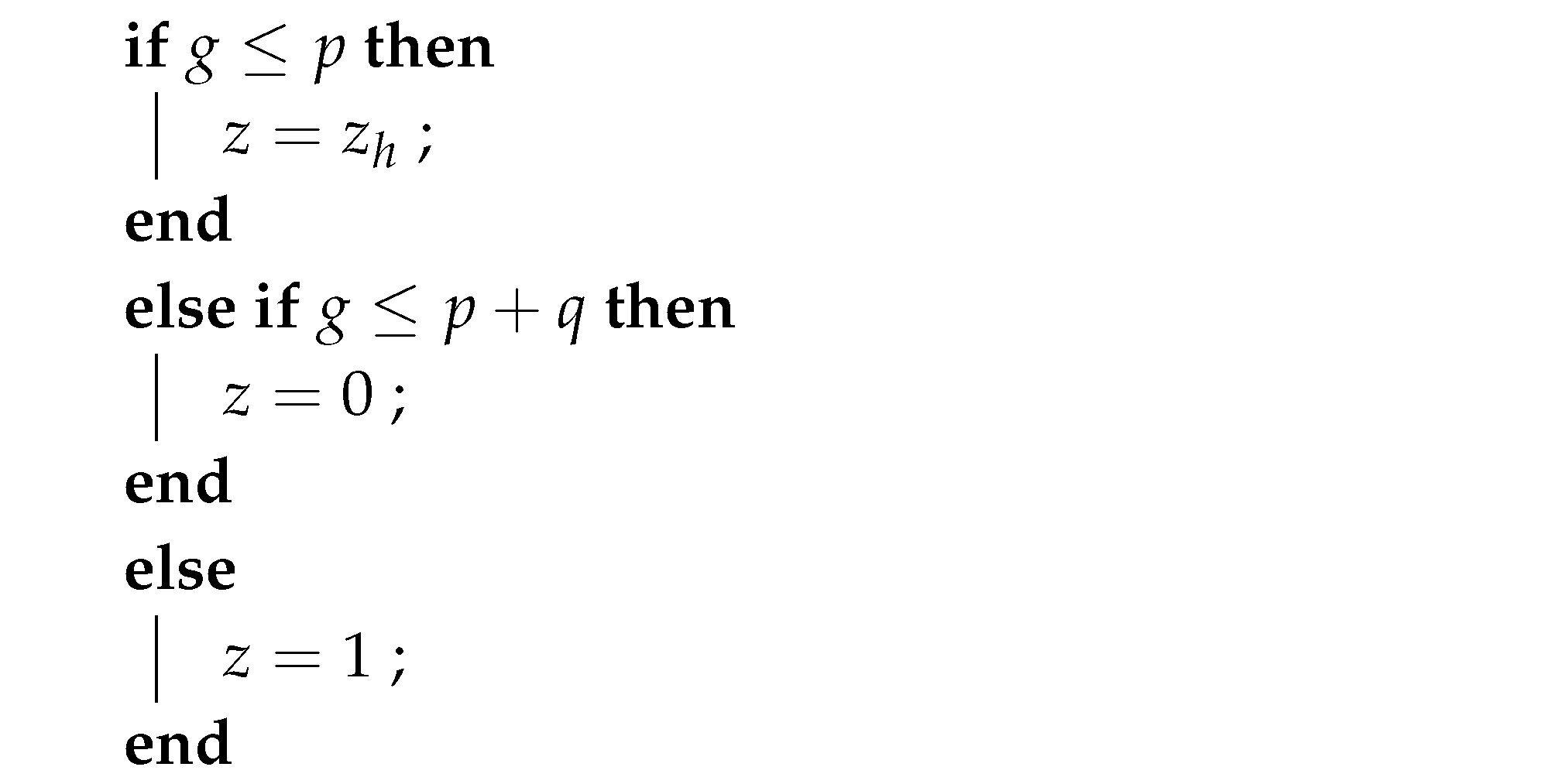 |
In Model B (Section 5) we will investigate the class of problems with the condition
If this condition is not satisfied, the problem is easily solved with Model A (Section 4).
5.3 Simulation
The simulation is based on the following lemma.
Lemma 1.
Let and Then
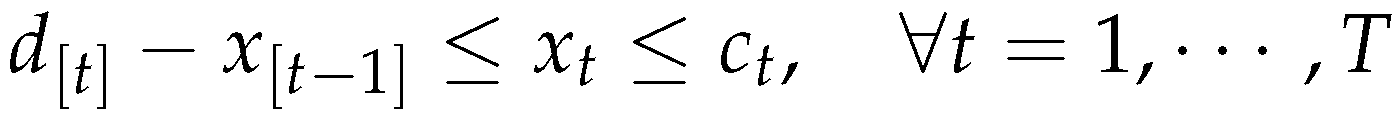
Proof. The proof proceeds by induction on t. In fact, if because x[0] = 0 and , we can choose such that .
By induction hypothesis
Then we can choose such that □
Remark 5.
If in lemma 1 then production in period t is because production up to period satisfies demand up to period t.
Remark 6.
Lemma 1 gives the following lower bound for the production of the products
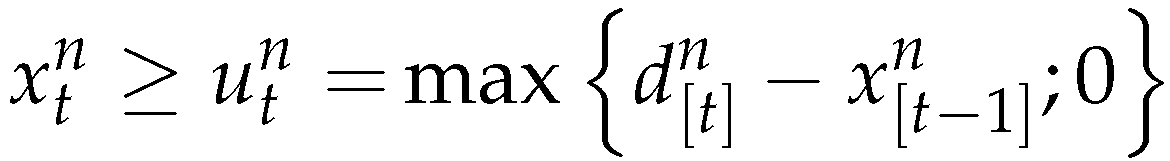
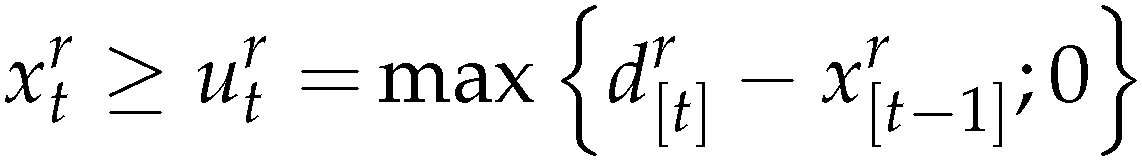
5.4. Basis of the simulation
The production plan is created step by step starting from period . To determine the production in period t, we know the selected production until period . In each period, using the constraints of the task (16)-(24) for the production of the products, we determine a lower and an upper bound. Then the production quantity is chosen randomly between the lower and upper limits. These production quantities affect the lower and upper bounds of the future period. We continue in this way until the period . Then we calculate the value of the cost function( i.e. objective function). We repeat this procedure (N times) and choose the production plan with the lowest cost. The advantages of this method, we do not have to worry about the inventory, production or setup costs. The method is now presented in more detail.
Proposition 1.
If then else
Proof. From (17) we get
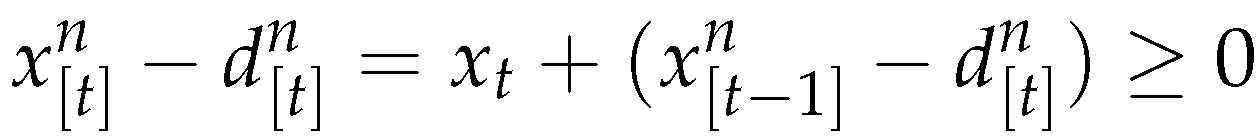 If then total production of new products up to period satisfies total demand up to period t and therefore nothing is produced in period i.e. .
If then total production of new products up to period satisfies total demand up to period t and therefore nothing is produced in period i.e. .
If then the production has a lower bound. From (40) we obtain
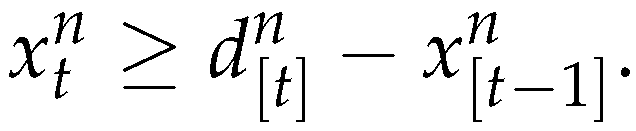 □
□
Proposition 2.
If then else and
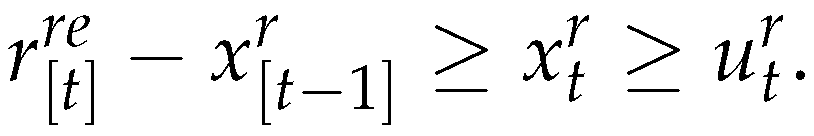 .
.
Proof. From (18) and (19)
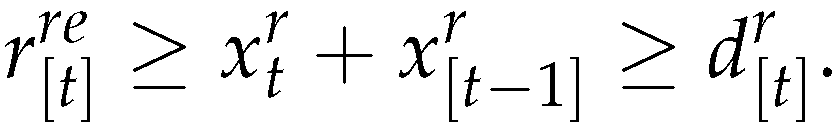 . If
, then total production up to period satisfies total demand up to period t and therefore nothing is produced in period i.e. .
. If
, then total production up to period satisfies total demand up to period t and therefore nothing is produced in period i.e. .
If then the production has an upper and lower bound. From (43) results the assertion. □
Proposition 3.
If and then
And
Proof. From (20) and remark 6
From (2)
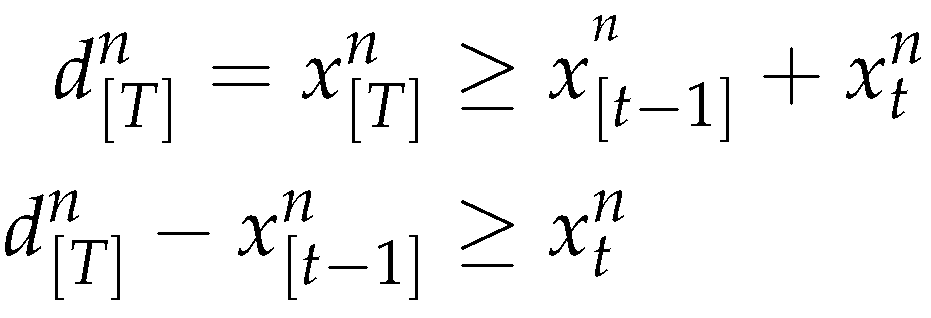
From (46) and (47)
xntont Therefore we simulate the production according to (35)
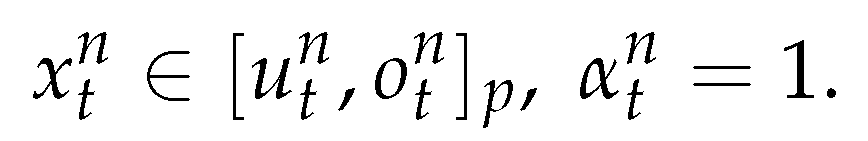 From (20) using of (49) we get
From (20) using of (49) we get
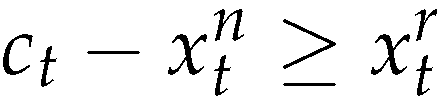 and then from (2) we obtain
and then from (2) we obtain
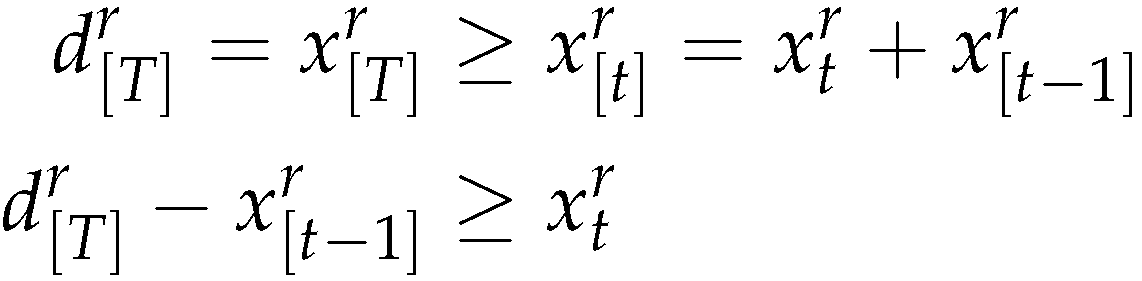
From (50), (51) and (42) results
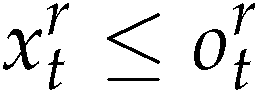 Therefore we simulate the production according to (35)
Therefore we simulate the production according to (35)
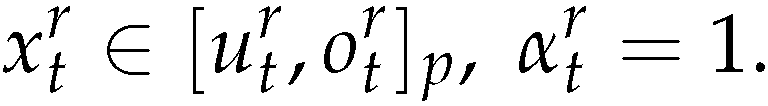 □
□
5.5. Simulation of the objective function
Let R be a matrix with Halton’s
We simulate the production starting in period t=1. The calculation of the objective function is carried out with algorithm 3 using proposition (1), (2) and (3).
| Algorithm 3: Calculation of the objective function |
 |
Remark 7.
1. The generation of the matrix R[N × T] requires O(N × T) operations.
2. Die evaluation of the function with algorithm 3 requires operations Then, the computational complexity of the simulation with N points and T periods is
6. Numerical Experiments
6.1. Test Design
We analyse the quality of our solution approach of model A and model B by defining 11 problem classes (PC) by varying the number of periods, see Table 6. The planning horizon T is made very large because in the paper industry planning is done daily. Each PC consists of 200 test instances (TI). In model A, 1824 of the 2200 TI were solvable, in model B 2200. In total, we examined 4024 TI. Model A and Model B are implemented on a computer with , ,.
Table 6.
Problem classes.
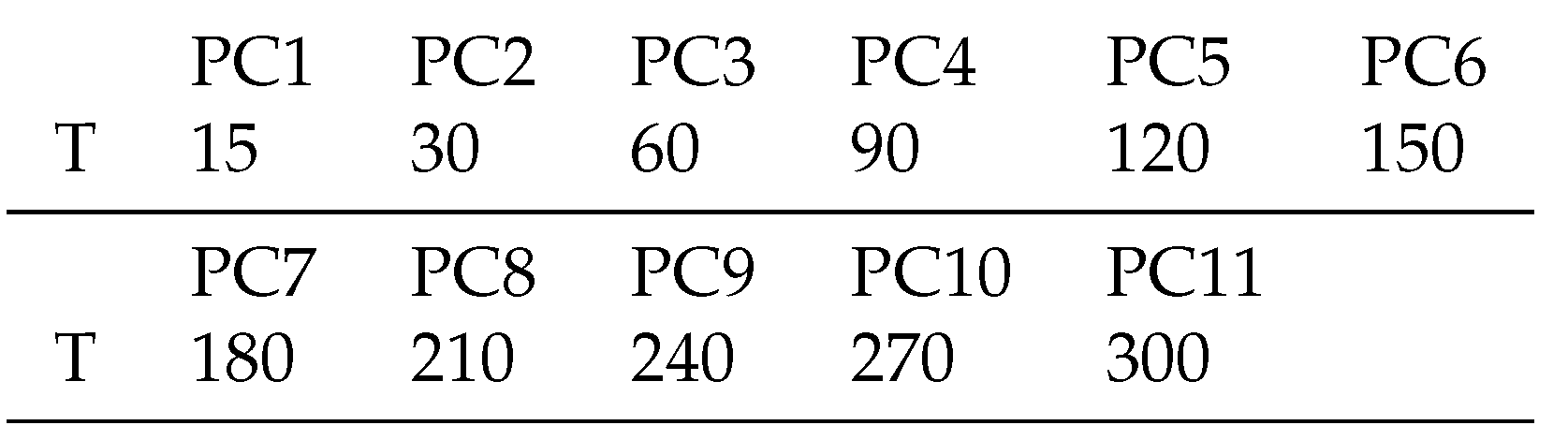
We vary different parameters to define the TI, e.g., the time between orders (TBO) to determine setup costs. The specifications of the parameters are designed in an exaggerated form, which may not occur in practice, to make the TI as difficult as possible.
The parameters for generating data sets (see Table 7) use the following notation where is a random number, that means the values are uniformly distributed on the interval
6.2. Model A
We randomly generate capacities , then with condition (1) randomly generate aggregate demand . This latter is then randomly cut into and . The remaining parameters according to Table 7.
Table 7.
Original Data.
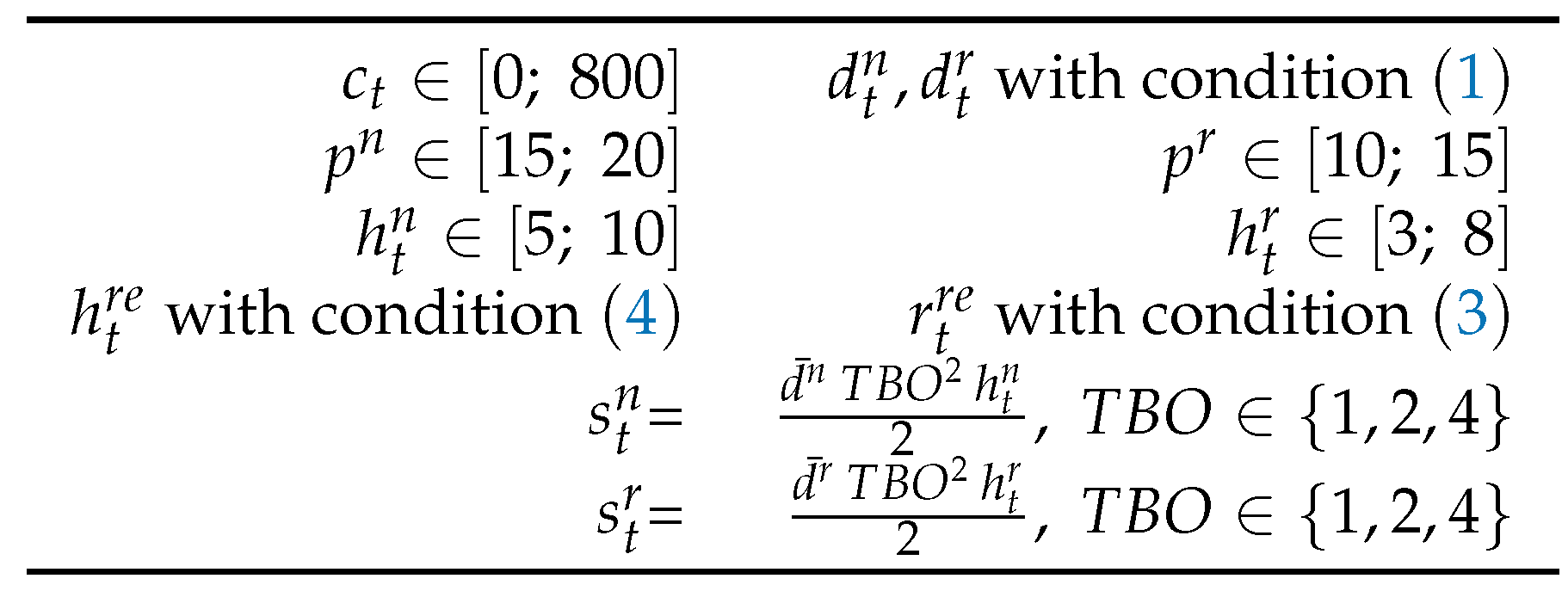
6.2.1. Results of Model A
The solution of problem (25)-(33) (TD) and the optimal solution of problem (16)-(24) (OP) were found with the Gurobi solver version 9.0.3.
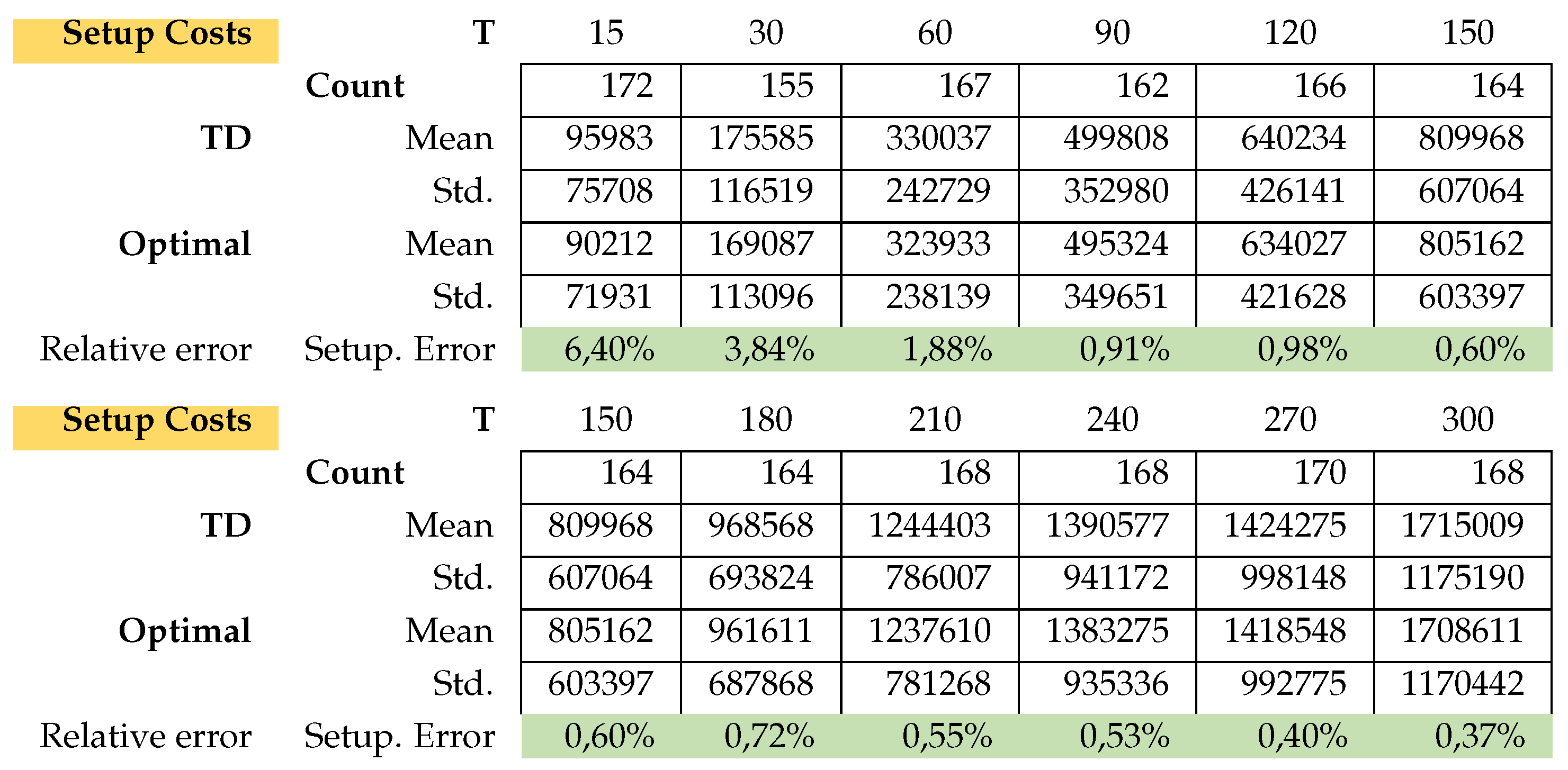
We randomly generated 200 instances per PC and usually between 10 and approx. 20% of the instances have no solution (see line Count). This justifies the fact that the problem is not standard. For example, in Table A1 we see that of the 200 instances for problem class , only 167 had a solution.
With the following notation, we can better understand the results of Table A1.

In Table A1 the relative error for Total costs (Tc) and CPU-time for every problem class was calculated as
This is exactly how we calculated the relative errors in inventory cost and setup cost.
Attached in Appendix A are the results of the average total cost, average CPU time, average Inventory costs
There is hardly any difference between the cost of relaxation (TD) and the original task (OP). Only the computation time for relaxation is faster. The longer the planning horizon, the smaller the difference between the optimal solutions of the problems TD and original optimization task OP. This feature applies to the stocks of the return and setup costs too. On the other hand, the inventory costs for problem TD are always smaller than the inventory costs of problems OP. For more details, please see Figure A1 and Appendix A.1 for the exact calculations. However, we see beyond doubt that this class of problems can be solved very well either with the relaxation TD or directly with a standard solver (here Gurobi).
6.3. Model B
[13] have shown that several families of CLSP are Np-hard. For the construction of the Np-hard instances (2200 instances) we follow the findings of [14]. They use the following notation , where and specify respectively the number of items, a special structure for the setup costs, the holding costs, production costs, and capacities. In this paper [14] they show that the following class 2/C/G/A/C is NP-hard. For this reason we have created 2200 instances, where the set-up costs per product and capacities per instance are constant. The holding cost do not necessarily follow a specified pattern, the production costs can be chosen arbitrarily. The maximum calculation time for Gurobi is 600 seconds. The heuristic operates according to the number of simulations, which gradually increases with the number of periods. The largest group T300 uses 130 seconds. The parameters for generating data sets (see Table 8) use the following notation where is a random number, that means the values are uniformly distributed on the interval
The important assumption in model B is: the capacities for each TI is constant, the set-up costs in each TI and for each product are constant. These parameters vary between a minimum and a maximum depending on the T parameter.
The capacities for each TI vary according to the parameter T. For example if the capacities are between 600 and 800. If the capacities vary between 3000 and 5500. Analogously the other parameters. The remaining parameters according to Table 8.
Table 8.
Model B: Parameters.
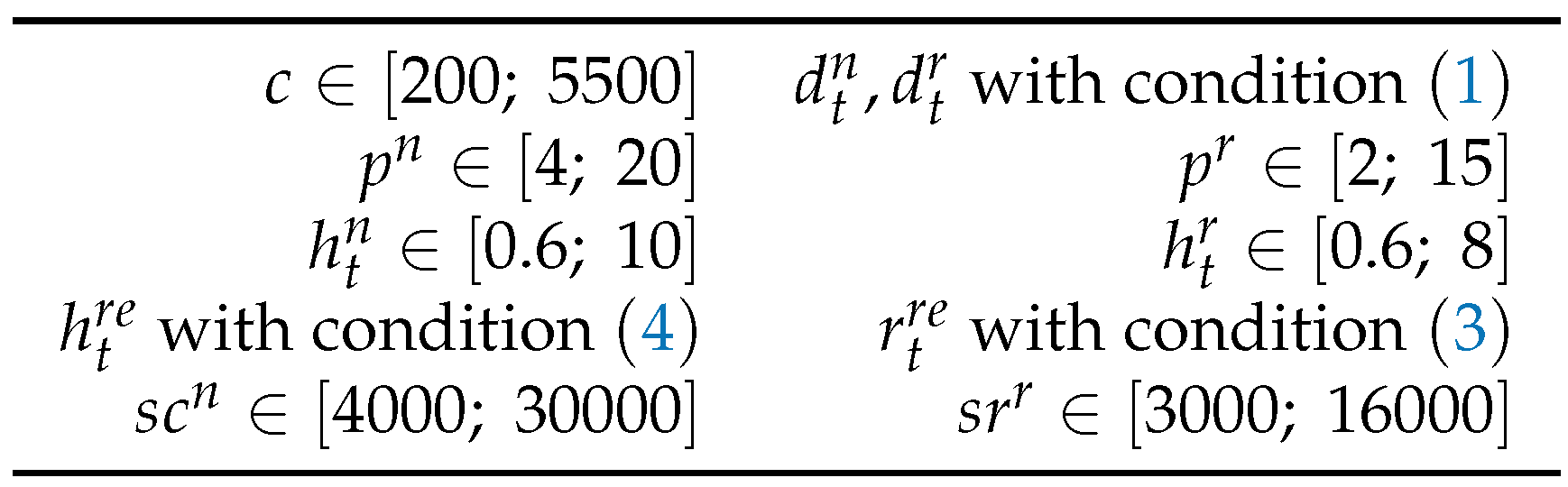
For the simulation we used following parameters:
is the Halton’s numbers used for T periods (see Table 9).
Table 9.
Periods, Halton’s numbers.

All instances for have the same schema Step 1 until Step 5. We used (see Table 10).
Table 10.
Schematic of the simulation.

| Algorithm 4: Heuristic: blind search |
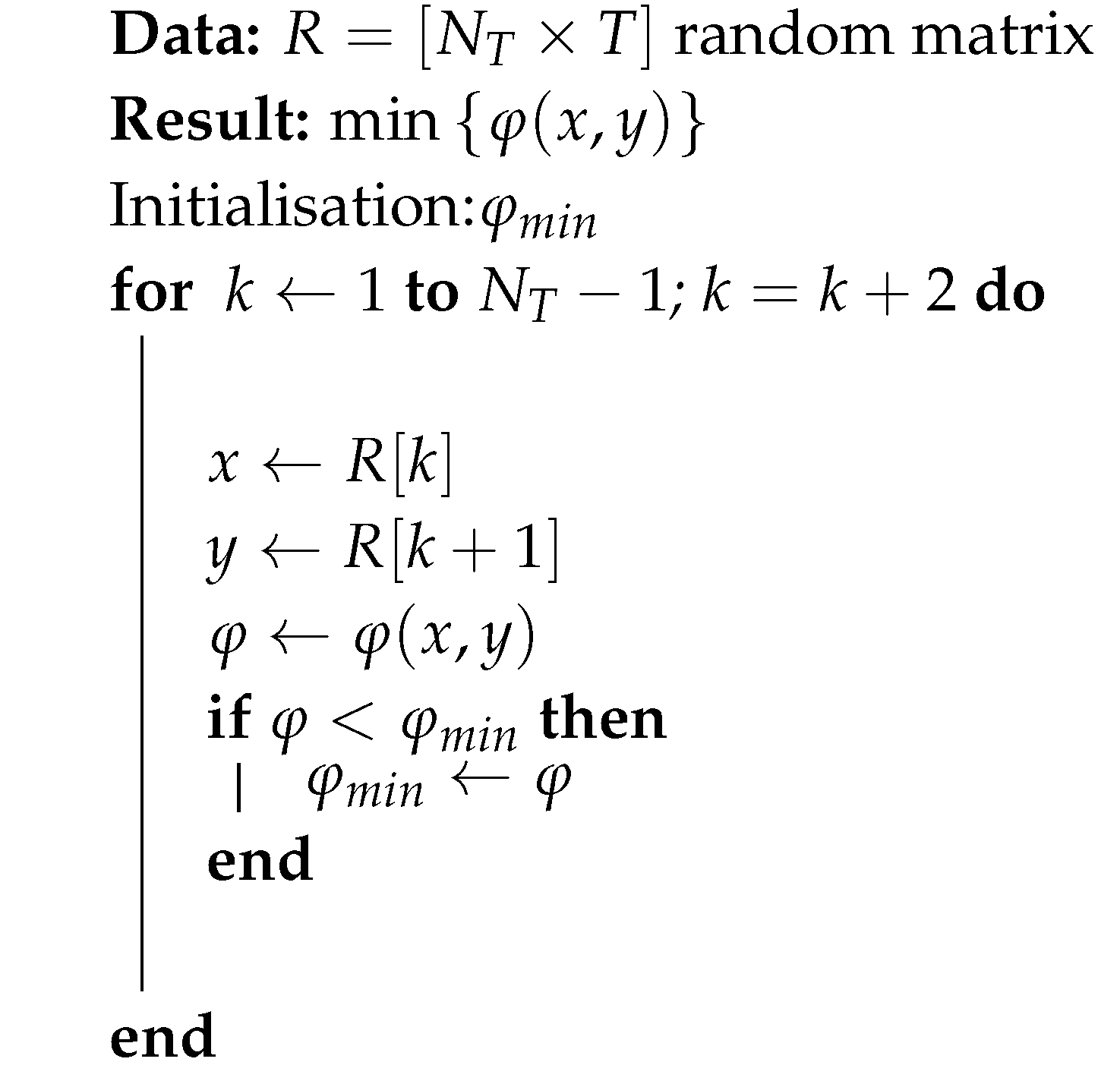 |
6.3.1. Results of Model B
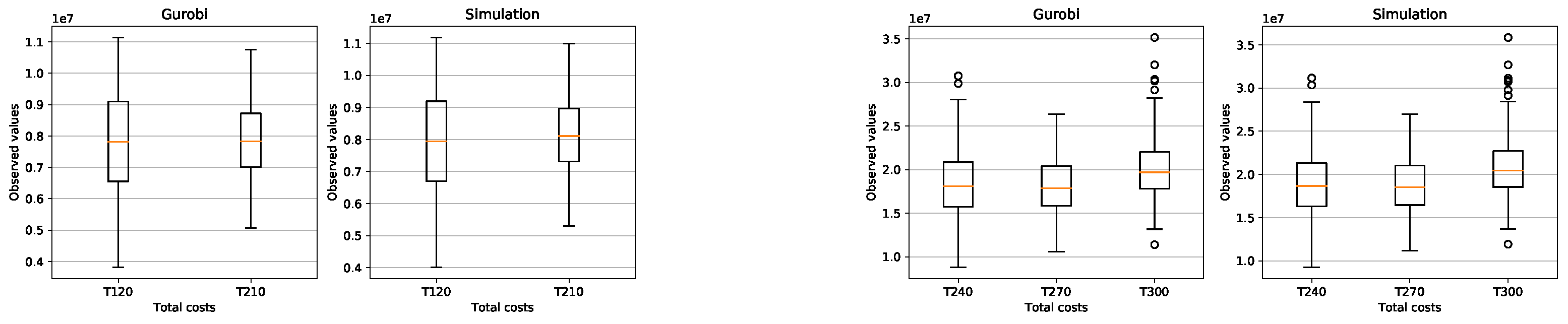
We generated 200 random instances for each problem class (PC) and with a Box-plot we compared the feasible solutions of the problem (16)-(24) found by Gurobi 9.0.3 with the solution of the simulation presented in this paper and clearly see the similarity of the results found (see Figure A4, A5).
With the following notation we present the results (see Table A6).

In Table A6 the relative error for Total costs (Tc) and CPU-time for every problem class was calculated as
The graphical comparison is shown in Figure A3.
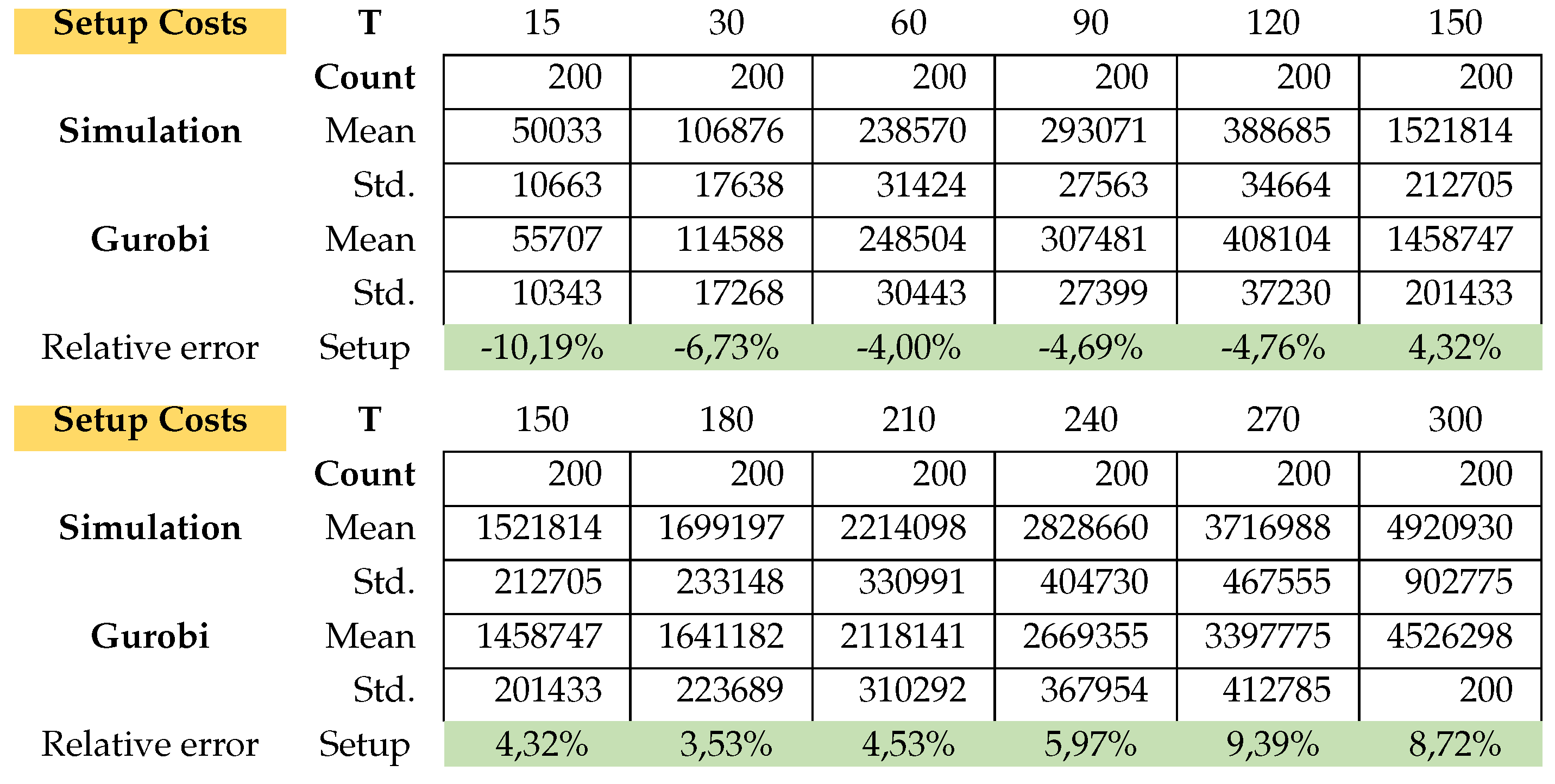
This is exactly how we calculated the relative errors in inventory cost and setup cost. Attached in Appendix B are the results of the average total cost, average CPU time, average Inventory costs. Figure A3 (average CPU time) clearly shows that the Gurobi admissible solution for the PC from T150 to T300 are not optimal and that the CPU of the simulation is much faster.
The simulation in average determines the setup costs and return inventory costs always higher than Gurobi. On the other hand, the inventory costs of Gurobi are higher than the simulation. What can we say about the quality of the solution of the problems? the simulation could not give a better solution than Gurobi’s solution. Gurobi solved the (PC) problems up to T120 in an optimal way. The problems from T150 to T300 were not solved optimally by Gurobi, since it would take too much time due to the Np-hard category of the problem. The simulation found feasible solutions much faster than Gurobi. Here is the advantage of the simulation, the simplicity of its implementation and the speed in finding an acceptable solution.
7. Conclusions and Outlook
We have analyzed a problem that belongs to the NP-hard class. However, the choice of the parameters is very important to obtain a problem that is really Np-hard. With the choice of parameters made in model A, we see that this class of problems is easily solved with a standard solver. By doing a relaxation of the problem, the solution is found more quickly. The error rate is between 0.02% and 2% (taking into account more than 1800 instances).
If we choose the parameters according to model B, Gurobi needs a lot of time to find the optimal solution. In this kind of problem the presented simulation can help a lot in finding a good solution. We have seen that the error rate is between 1.7% and 3.5% (taking into account more than 2000 instances). The simulation is sometimes better than Gurobi, but on average Gurobi solves the problem with a maximum time of 600 seconds better than the simulation. The great advantage of the simulation is that the calculation is extremely fast and easy.Thanks to the Halton numbers, few simulations are needed to obtain a very good approximation of the solution.
The simulation has a general character and can be adapted to investigate even more complex problems of the Np-hard category ( for example, researching CLSP problems with n products).
The quality of the solutions can be improved by increasing the number of simulations but it is necessary to have a fairly fast computer. In this work we use at most 10 million simulations. Another parameter that influences the quality of the solutions is the correct choice of the probability p (see (35)). Is there an optimal probability? This is a question for further research.
Data Availability Statement
Data used in experiments can be sent to interested parties, please write an E-Mail.
Acknowledgments
My special thanks to Luis Aurelio Rocha of Passau University for his comments on this work.
Abbreviations
The following abbreviations are used in this manuscript:
| Low-discrepancy sequences, also known as Quasirandom sequences, | |
| CLSP | capacitated lot-sitzing problem |
Appendix A. Results visualization
Appendix A.1. Model A
Figure A1.
Model A: Average Totalcost and CPU Time.
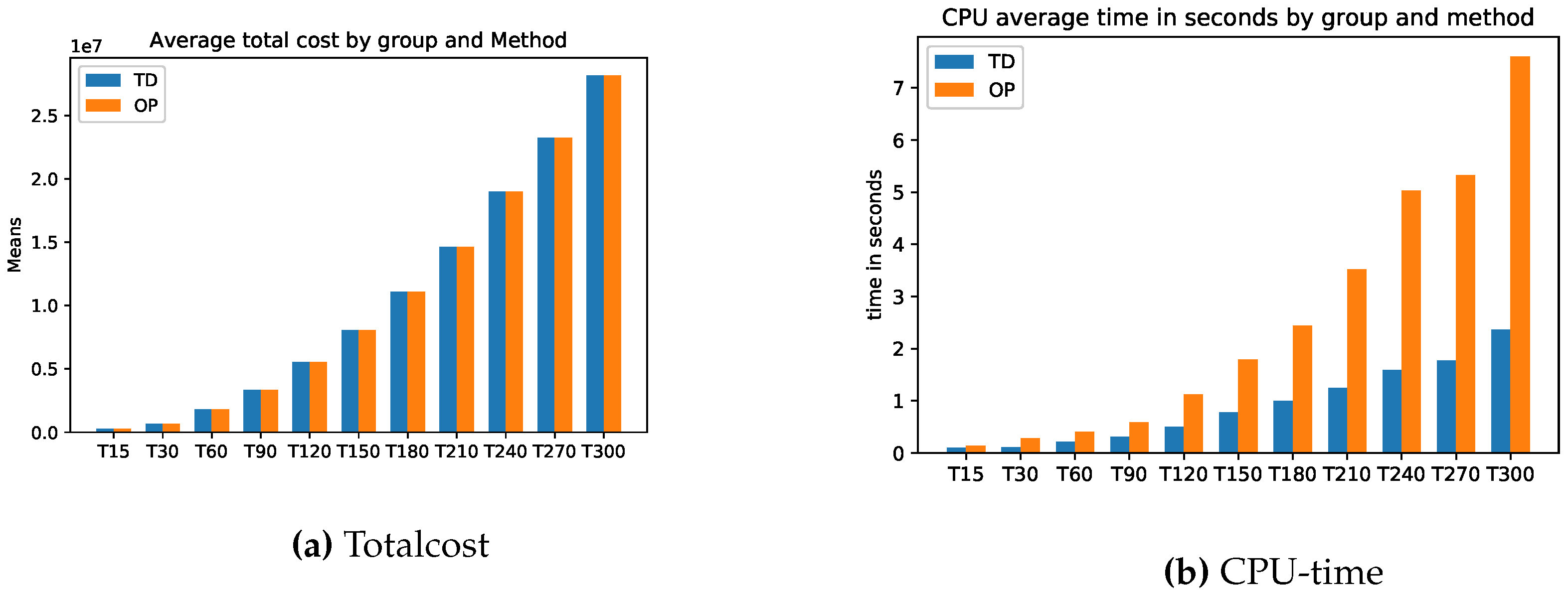
Figure A2.
Model A: Average Inventory cost.

Appendix A.2. Model B
Visualization of the results and average costs.
Figure A3.
Model A: Average Inventory cost.
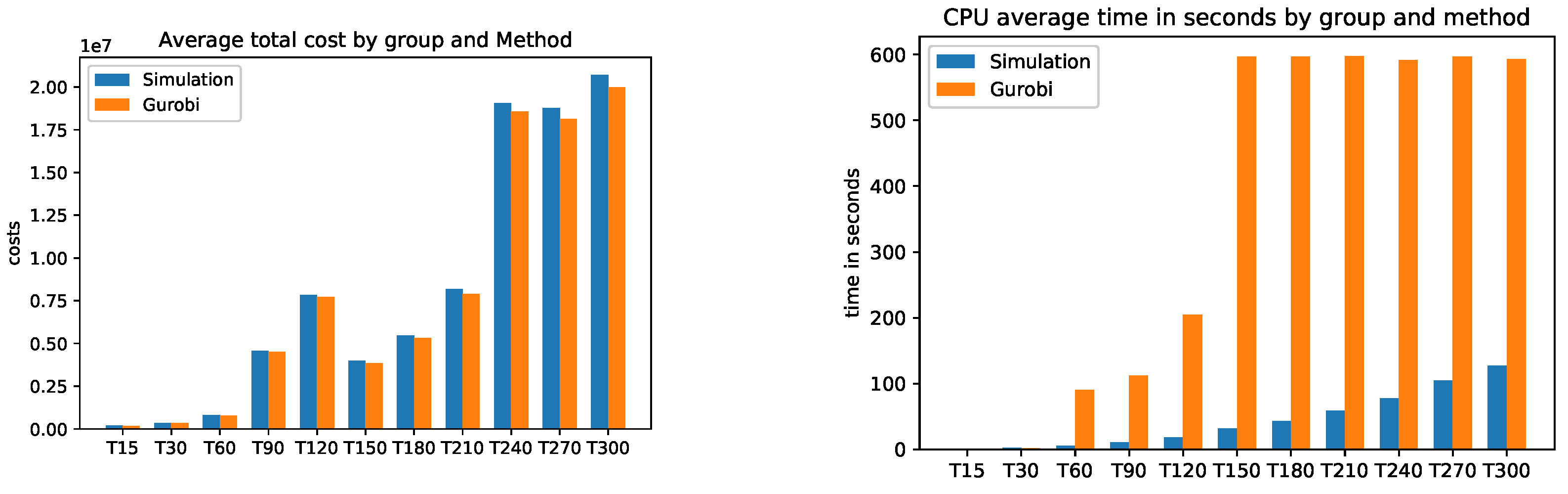
Figure A4.
Model A: Average Inventory cost.

Figure A5.
Model A: Average Inventory cost.
Appendix B. Average costs
Appendix B.1. Model A
Table A1.
Model A: Average Total Costs.
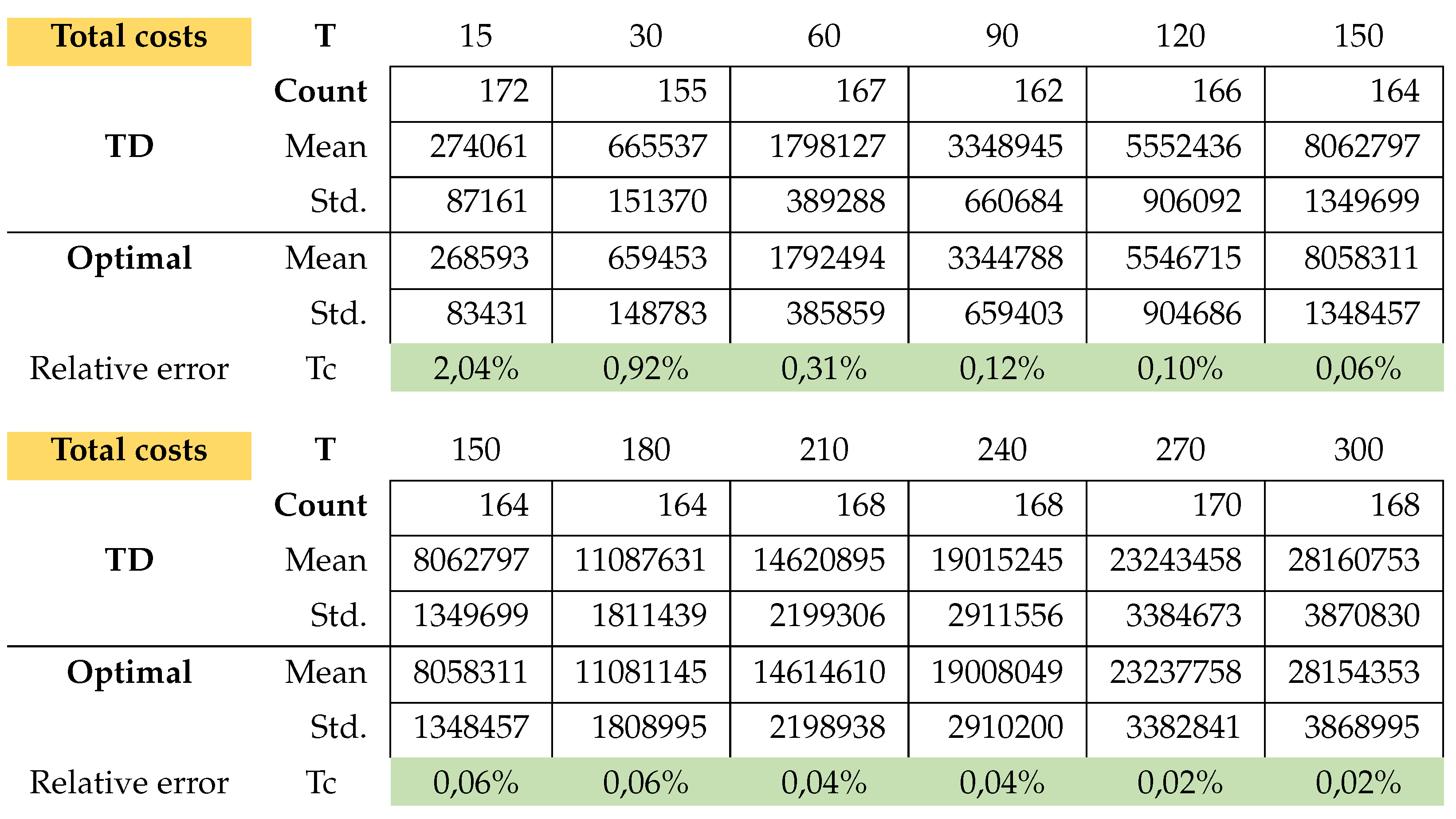
Table A2.
Model A: Average CPU time.
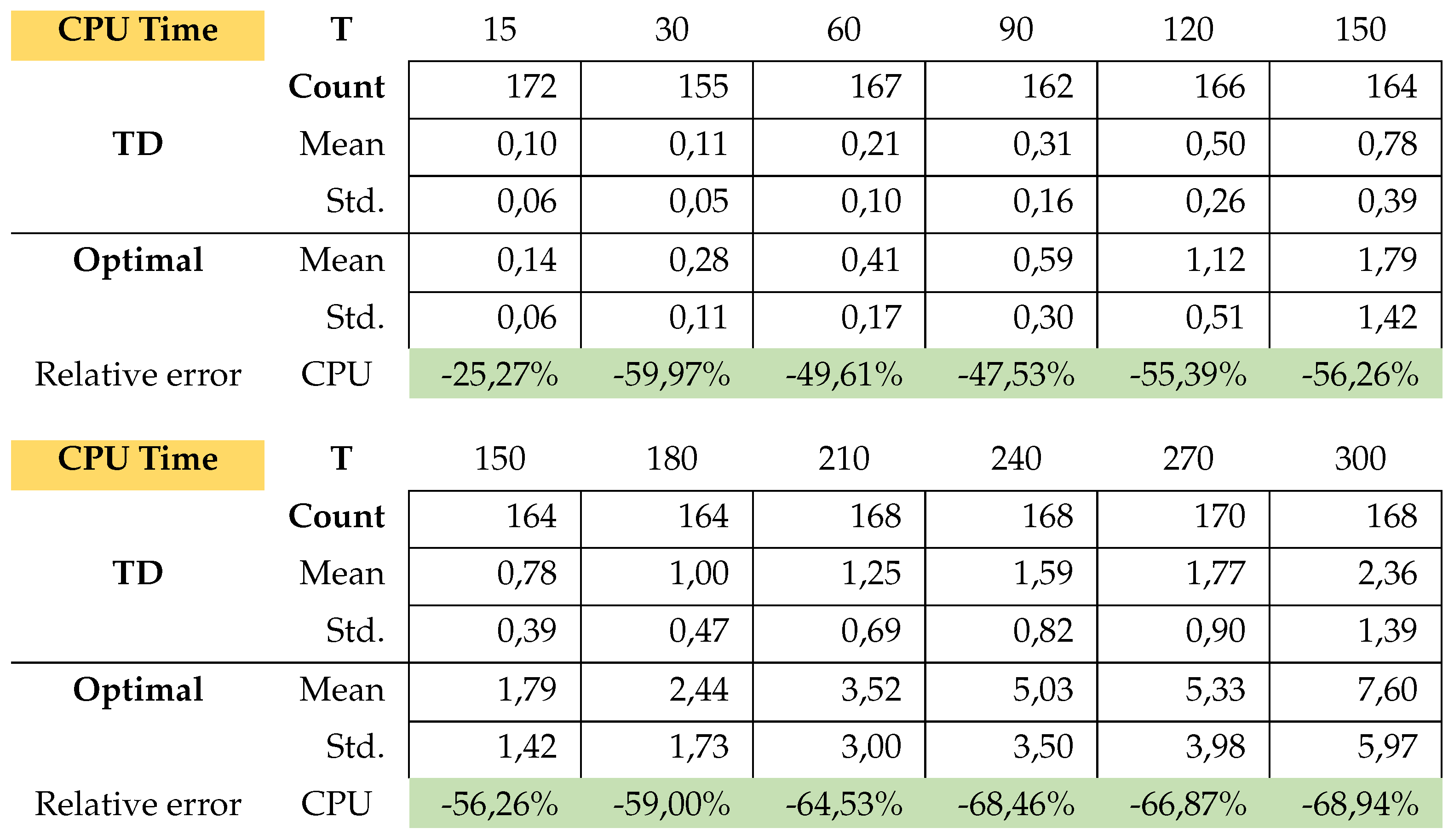
Table A3.
Model A: Inventory costs
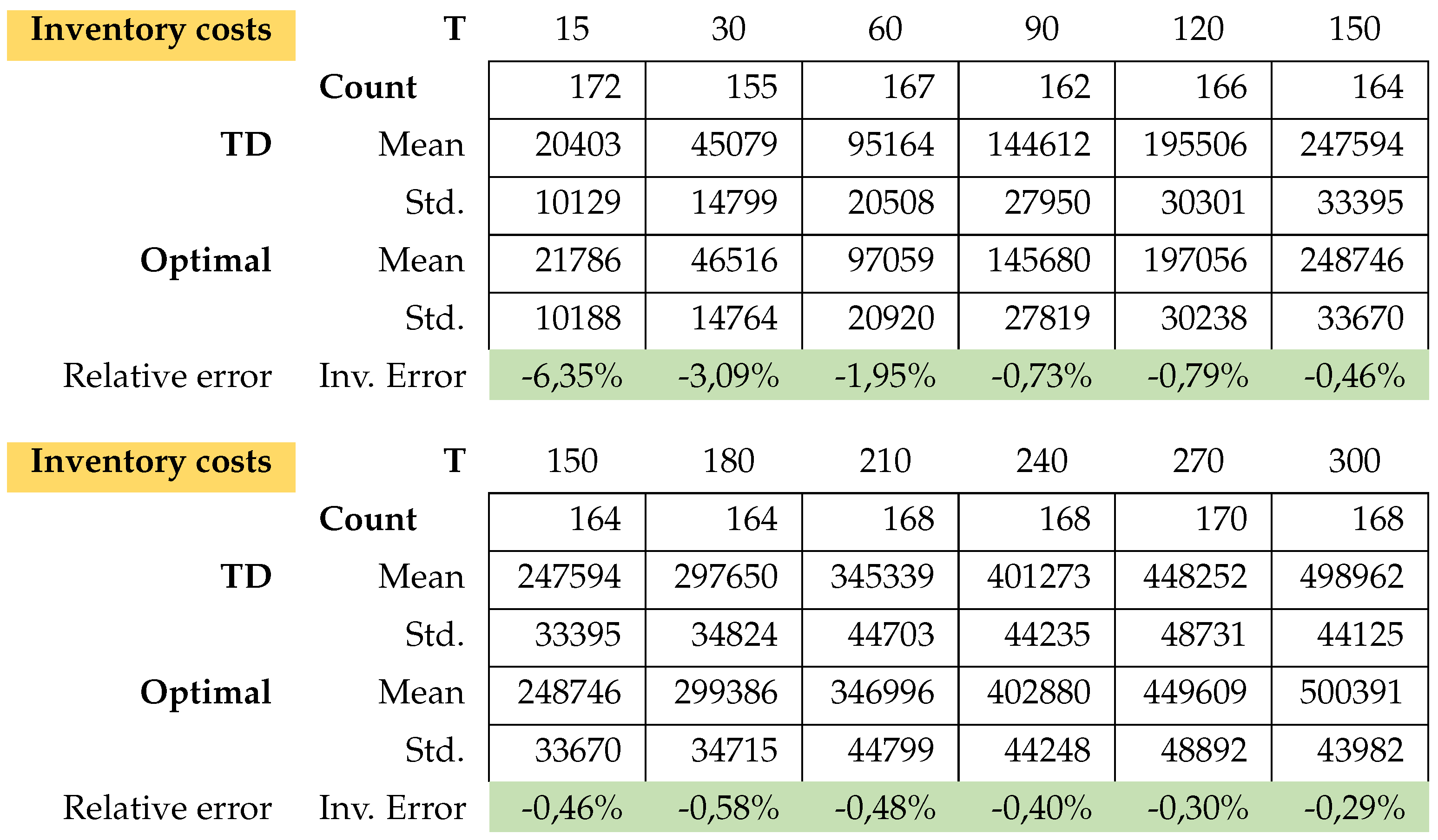
Table A4.
Model A: Return stock cost
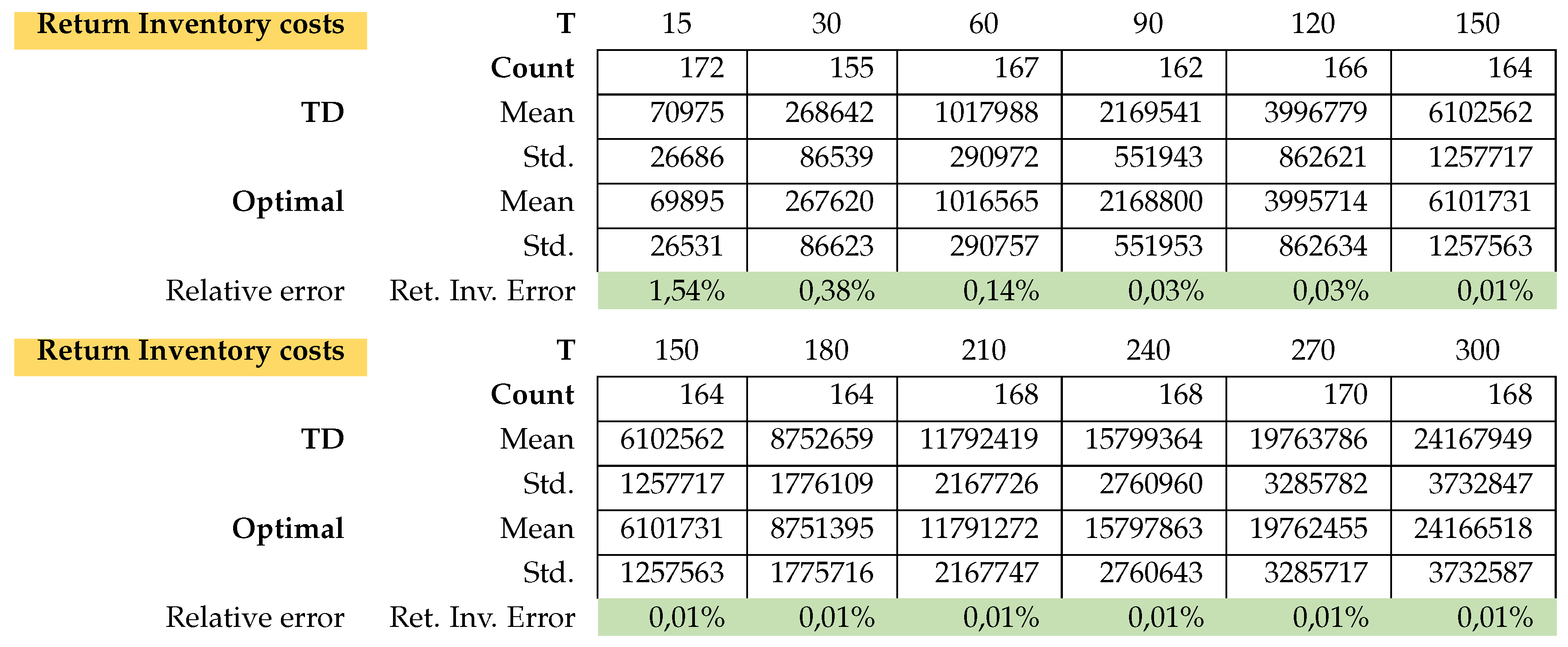
Table A5.
Model A: Average Setup costs
Appendix B.2. Model B
Table A6.
Model B: Average Total Costs.
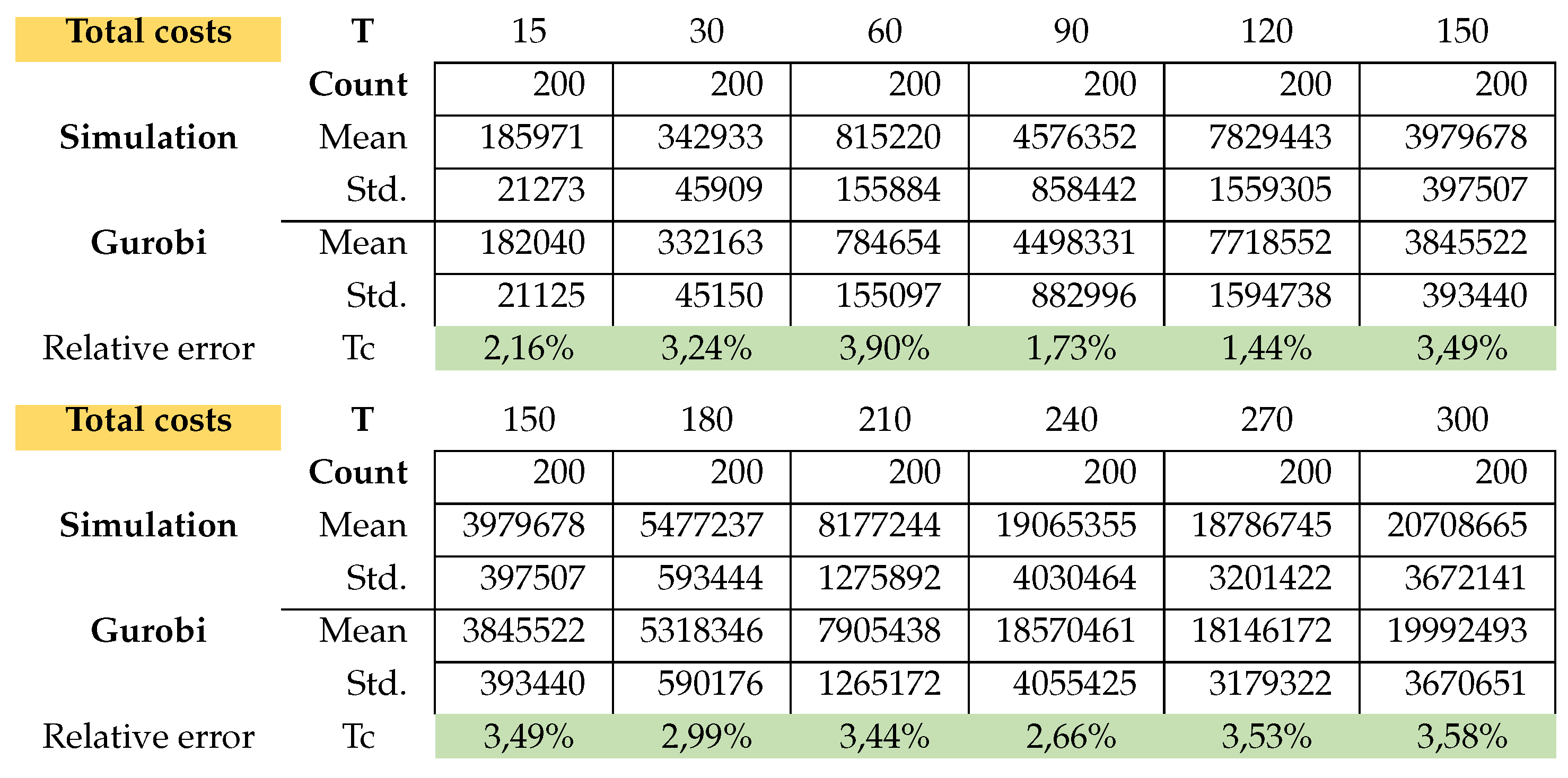
Table A7.
Model B: Average CPU time.
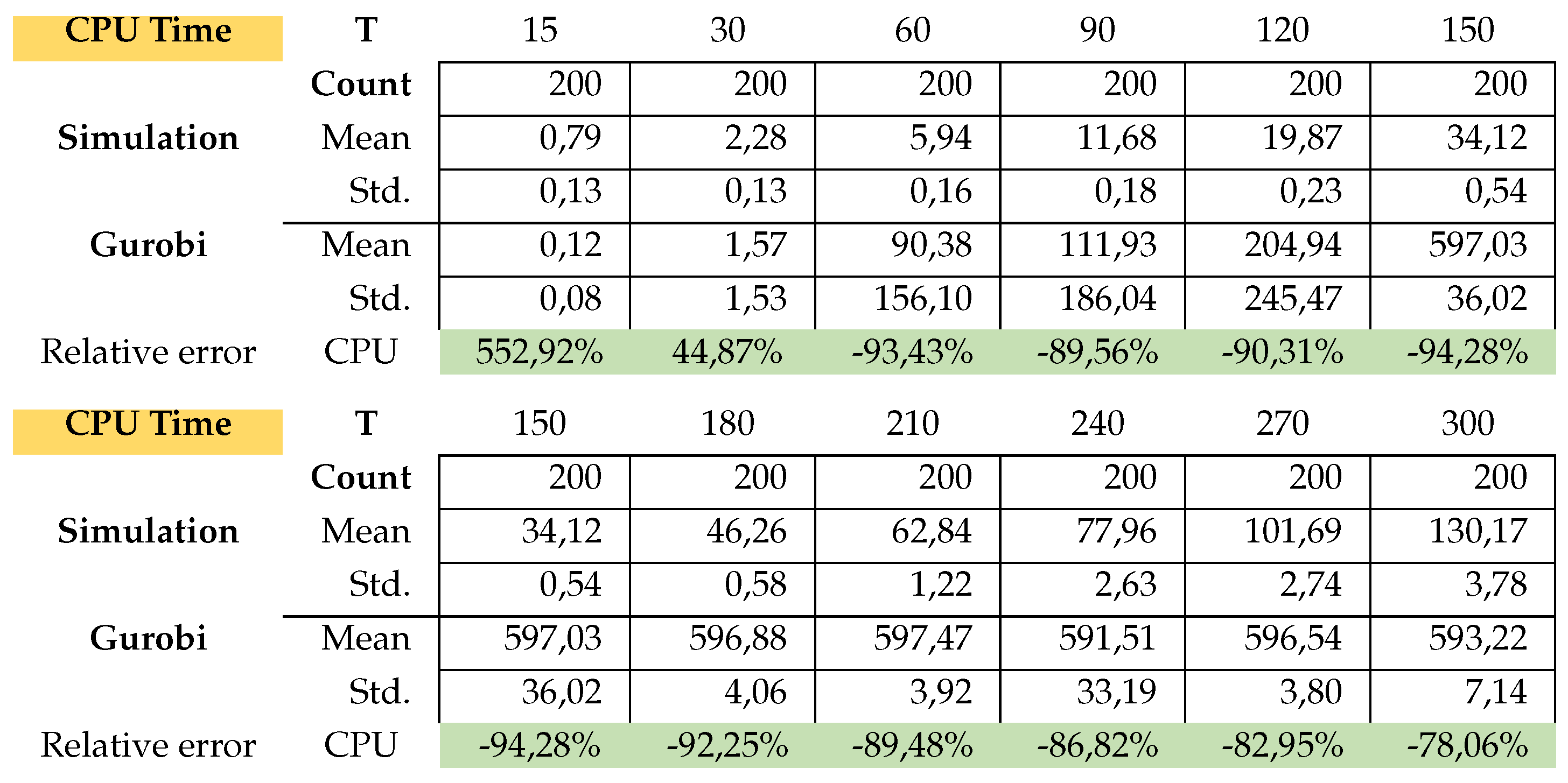
Table A8.
Model B: Inventory costs.
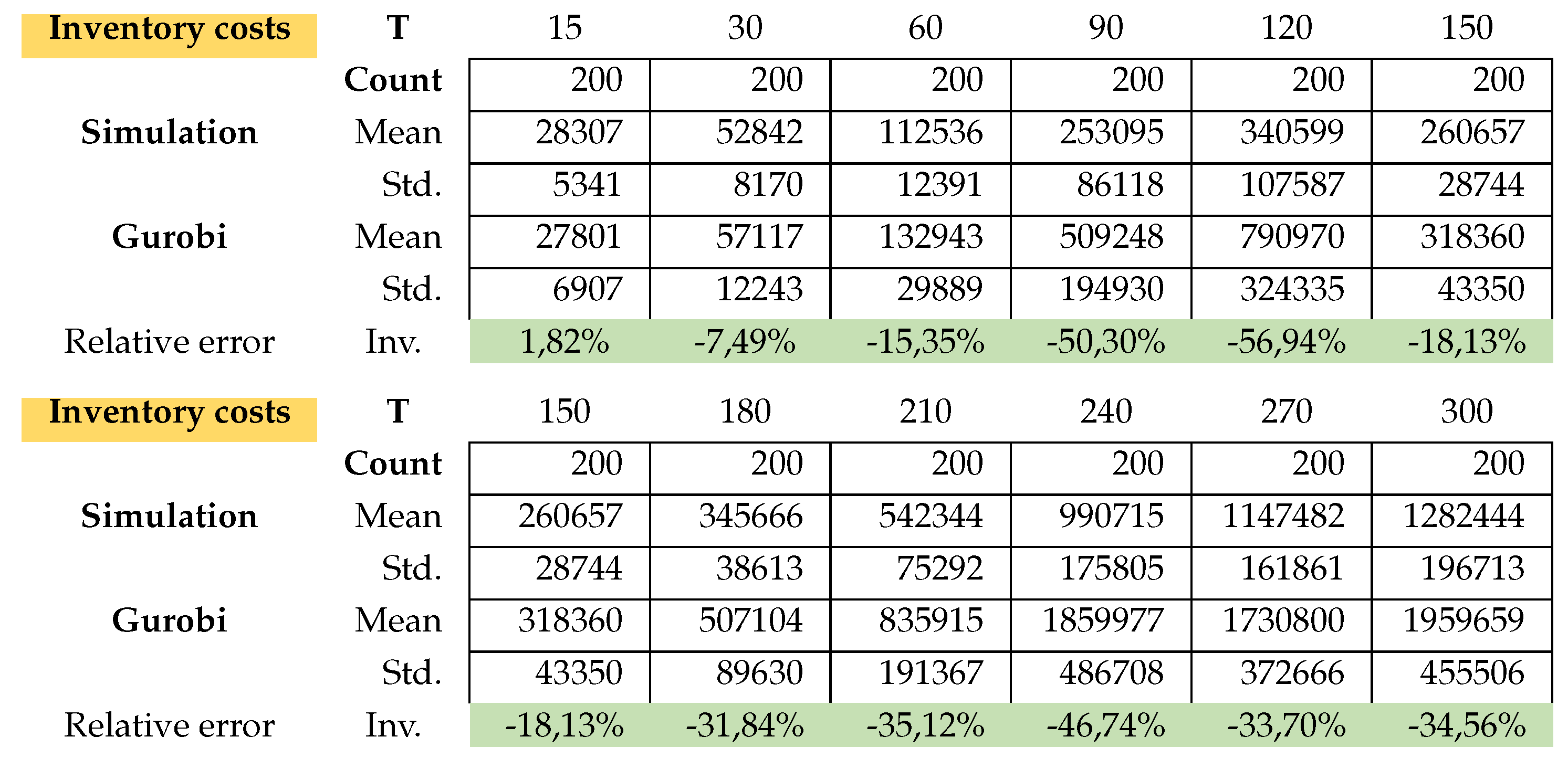
Table A9.
Model B: Return stock cost.
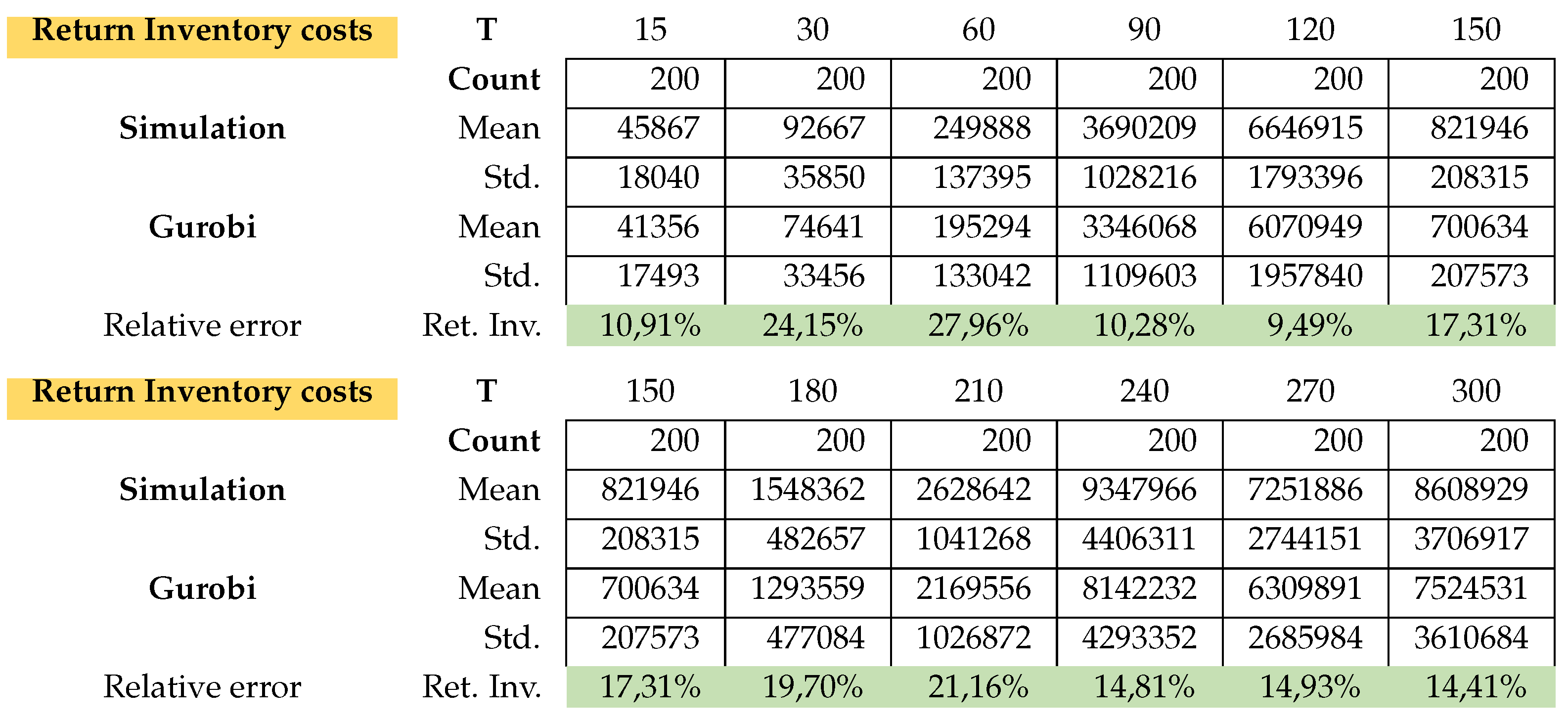
Table A10.
Model B: Average Setup costs.
References
- Thierry, M.; Salomon, M.; Van Nunen, J.; Van Wassenhove, L. Strategic issues in product recovery management. California Management Review 1995, 37, 114–135. [Google Scholar] [CrossRef]
- Umweltbundesamt. Papier und Druckerzeugnisse, 2020.
- Sahling, F. A Column-Generation Approach for a Short-Term Production Planning Problem in Closed-Loop Supply Chains. BuR- Business Research 2016, 6(1), 55–75.
- Helmrich, R.; Jans, M.; van den Heuvel, W.; Wagelmans, A. Economic lot-sizing with remanufacturing: Complexity and efficient formulations. IISE Transactions 2014, 46(1), 67–86. [Google Scholar] [CrossRef]
- Sifaleras, A.; Konstantaras, I. Variable neighborhood descent heuristic for solving reverse logistics multi-item dynamic lot-sizing problems. Electronic Notes in Discrete Mathematics 2015, 47, 69–76. [Google Scholar] [CrossRef]
- Kilic, O.; van den Heuvel, W. Economic lot sizing with remanufacturing: Structural properties and polynomial-time heuristics. IISE Transactions 2019, 51:12, 1318–1331. [CrossRef]
- Richter, K.; Weber, J. Thre reverse Wagner/Whitin model with variable manufacturing and remanufacturing cost. International Journal of Production Economics 2001, 71, 447–456. [Google Scholar] [CrossRef]
- Richter, K.; Sombrutzki, M. Remanufacturing planing for the reverse Wagner/Whitin models. Journal of Operational Research 2000, 121, 304–315. [Google Scholar] [CrossRef]
- Teunter, R.; Bayindir, Z.; van den Heuvel, W. Dynamic lot sizing with product returns and remanufacturing. Int. Journal of Production Research 2006, pp. 4377–4400.
- Schulz, T. A new Silver-Meal basic heuristic for the single-item dynamic lot sizing problem with returns and remanufacturing. International Journal of Production Research 2011, p. 2519–2533.
- Cunha, J.; Melo, R. A computational comparison of formulations for the economic lot-sizing with remanufacturing. Computers & Industrial Engineering 2016, 92, 72–81. [Google Scholar]
- Zhang, Z.; Jiang, H.; Pan, X. A lagrangian relaxation based approach for the capacitated lot sizing problem in closed-loop supply chain. Int. J. Productions Economics 2012, 140, 249–255. [Google Scholar] [CrossRef]
- Florian, M.; Lenstra, J.; Rinnooy, K. Deterministic production planning algorithms and complexity. Management Science 1980, 26, 669–679. [Google Scholar] [CrossRef]
- Bitran, G.; Yanasse, H. Computational complexity of the capacitated lot size problem. Management Science 1982, 28, 1174–1186. [Google Scholar] [CrossRef]
- Dixon, P. Multi-Item Lot-Sizing with Limited Capacity. dissertation, University of Waterloo, Ontario, 1979.
- Karimi, B.; Fatemi Ghomi, S.; Wilson, J.M. The capacitated lot sizing problem review of models and algorithms. OMEGA 2003, 31, 365–378. [Google Scholar] [CrossRef]
- Maes, J.; McClain, J.; Van Wassenhove, L. Multilevel capacitated lotsizing complexity and LP-based heuristics. Journal of Operational Research 1991, 53, 131–148. [Google Scholar] [CrossRef]
- Sobol, I. Calculation of improper integrals using uniformly distributed sequences. Soviet Math. Dokl. 1973, 14, 734–738. [Google Scholar]
- Halton, J.H. On the efficiency of certain quasi-random sequences of points in evaluating multi-dimensional integrals. Numer. Math. 1960, 2, 84–90. [Google Scholar] [CrossRef]
- Niederreiter, H. Quasi-Monte Carlo methods and pseudo-random numbers. Bull. Am. Math. Soc. 1978, 84, 957–1041. [Google Scholar] [CrossRef]
- Klinger, B. Numerical Integration of Singular Integrands using Low-Discrepancy Sequences. Computing 1997, 59, 223–236. [Google Scholar] [CrossRef]
- Heuvel, W.; Wagelmans, A. Four equivalent lot-sizing models. Operations Research Letters 2008, 36, 465–470. [Google Scholar] [CrossRef]
- Maes, J.; Van Wassenhove, L. A simple heuristic for the multi item single level capacitated lotsizing problem. Operations research letters 1986, 4, 265–273. [Google Scholar] [CrossRef]
- Knuth, D.E. The Art of Compute Programming: Seminumerical Algorithms. Volume 2.; Addison-Wesley, 1981.
- von Neumann, J. Various techniques used in connection with random digits. Monte Carlo Method, Appl. Math. Series 1951, 12, 36–38. [Google Scholar]
- Niederreiter, H. Random Number Generation and Quasi-Monte Carlo Methods.; SIAM, 1992.
- Tezuka, S. Uniform Random Numbers: Theory and Practice.; Kluwer Academic, 1995.
- Chaitin, G. Information, Randomness and Incompleteness. Papers on Algorithmic Information Theory. 1987, p. 236.
- Kolmogorov, A.; Uspenskii, V. Algorithms and randomness. Teor. Veroyatnost i Primenen. 1987, 32, 425–455. [Google Scholar] [CrossRef]
- Schnorr, C. Zufälligkeit und Wahrscheinlichkeit. Lecture Notes in Math. 1971, 218, 109. [Google Scholar]
| 1 | We can always transform a problem with non zero initial or final stock by adapting the demand. |
| 2 | low discrepancy sequences are called quasi-random sequences |
Figure 1.
Dynamic Capacitated Lot-Sizing with Produkt Returns and Remanufacturing.
Figure 2.
Two-dimensional projection of 5000 Halton and Pseudorandom points.
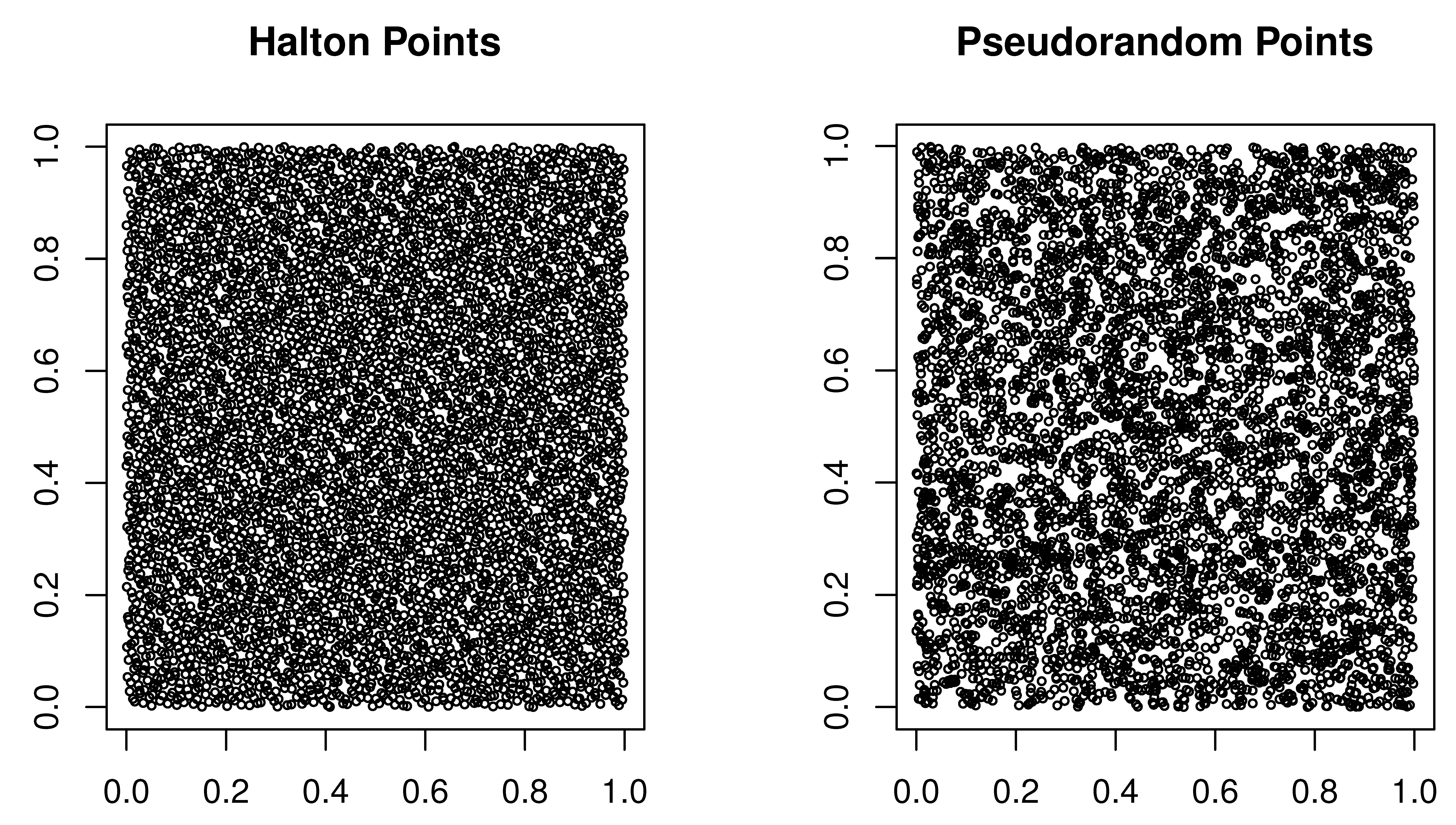
Table 1.
Data and parameters.

Table 2.
Decision variables.
| Name | Paramenter |
|---|---|
| 1, if new products are manufactured | |
| in period t; 0, otherwise | |
| quantity of new products manufactured | |
| in period t | |
| inventory stock of new products | |
| at the end of period t | |
| 1, if returned products are remanufactured | |
| in period t; 0, otherwise | |
| quantity of returned products remanufactured | |
| in period t | |
| inventory stock of remanufactured | |
| products at the end of period t | |
| inventory stock of returned products | |
| at the end of period t |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



