
Submitted:
27 April 2017
Posted:
27 April 2017
You are already at the latest version
Abstract
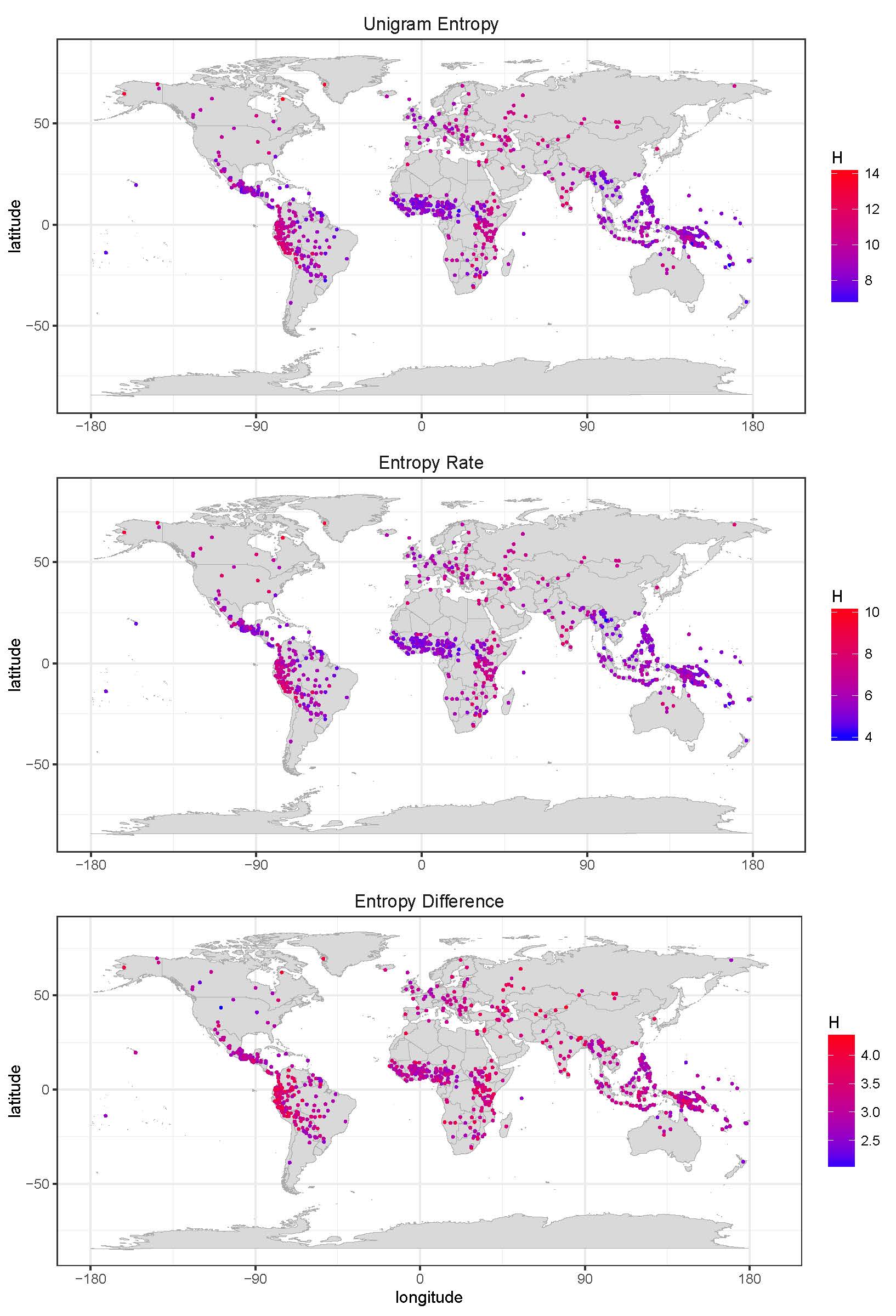
The choice associated with words is a fundamental property of natural languages. It lies at the heart of quantitative linguistics, computational linguistics, and language sciences more generally. Information-theory gives us tools at hand to measure precisely the average amount of choice associated with words—the word entropy. Here we use three parallel corpora—encompassing ca. 450 million words in 1916 texts and 1259 languages—to tackle some of the major conceptual and practical problems of word entropy estimation: dependence on text size, register, style and estimation method, as well as non-independence of words in co-text. We present three main results: 1) a text size of 50K tokens is sufficient for word entropies to stabilize throughout the text, 2) across languages of the world, word entropies display a unimodal distribution that is skewed to the right. This suggests that there is a trade-off between the learnability and expressivity of words across languages of the world. 3) There is a strong linear relationship between unigram entropies and entropy rates, suggesting that they are inherently linked. We discuss the implications of these results for studying the diversity and evolution of languages from an information-theoretic point of view.
Keywords:
natural language
; unigram entropy
; entropy rate
; learnability
; expressivity
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



