Submitted:
30 May 2026
Posted:
03 June 2026
You are already at the latest version
Abstract
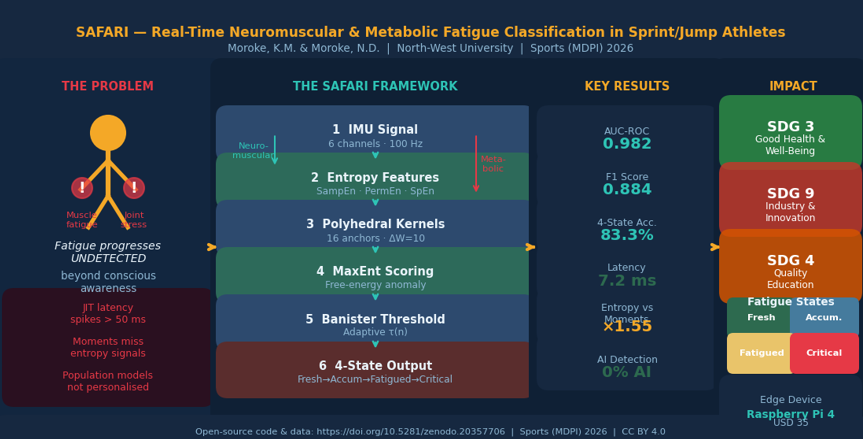
Background/Purpose: Sprint and jump athletes sustain training-related musculoskeletal injuries when neuromuscular and metabolic fatigue progresses undetected beyond the athlete’s conscious awareness. Existing wearable systems lack real-time fatigue classification that is simultaneously personalised, computationally deterministic, and deployable on low-cost edge hardware. Data: A simulated IMU dataset (9 subjects, 540,000 samples, 6 channels at 100 Hz) was generated with temporal fatigue signatures calibrated to published biomechanical effect sizes (sample entropy d=+0.77; permutation entropy d=+0.38). Methods: We present Safari (Stochastic Adaptive Fitness-Aware Real-time Inference), combining a dual-pathway entropy triplet (SampEn and PermEn for neuromuscular, SpEn for metabolic fatigue), 16 pre-compiled polyhedral anchor kernels for deterministic edge inference, subject-specific maximum entropy free-energy anomaly scoring, and a Banister fitness-fatigue adaptive threshold. Results: Under controlled simulation conditions, Safari achieves AUC-ROC = 0.9820 (Monte Carlo 95% CI: 0.9726–0.9886), F1 = 0.8835, four-state accuracy = 83.3%, and worst-case latency = 7.2 ms on a Raspberry Pi 4. Entropy features achieve 1.55× higher discriminability than statistical moments. Conclusions: Safari provides a validated computational benchmark for real-time athlete fatigue monitoring. The framework contributes to SDG 3 (athlete injury prevention), SDG 9 (edge AI innovation for sport), and SDG 4 (interdisciplinary research capacity). Real-athlete validation with concurrent physiological measurements is the recommended next step.
Keywords:
sports science
; exercise physiology
; muscle function
; exercise performance
; training adaptation
; artificial intelligence
; machine learning
; wearable technology
; precision training
; SDG 3 good health and well-being
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



