Submitted:
25 May 2026
Posted:
27 May 2026
You are already at the latest version
Abstract
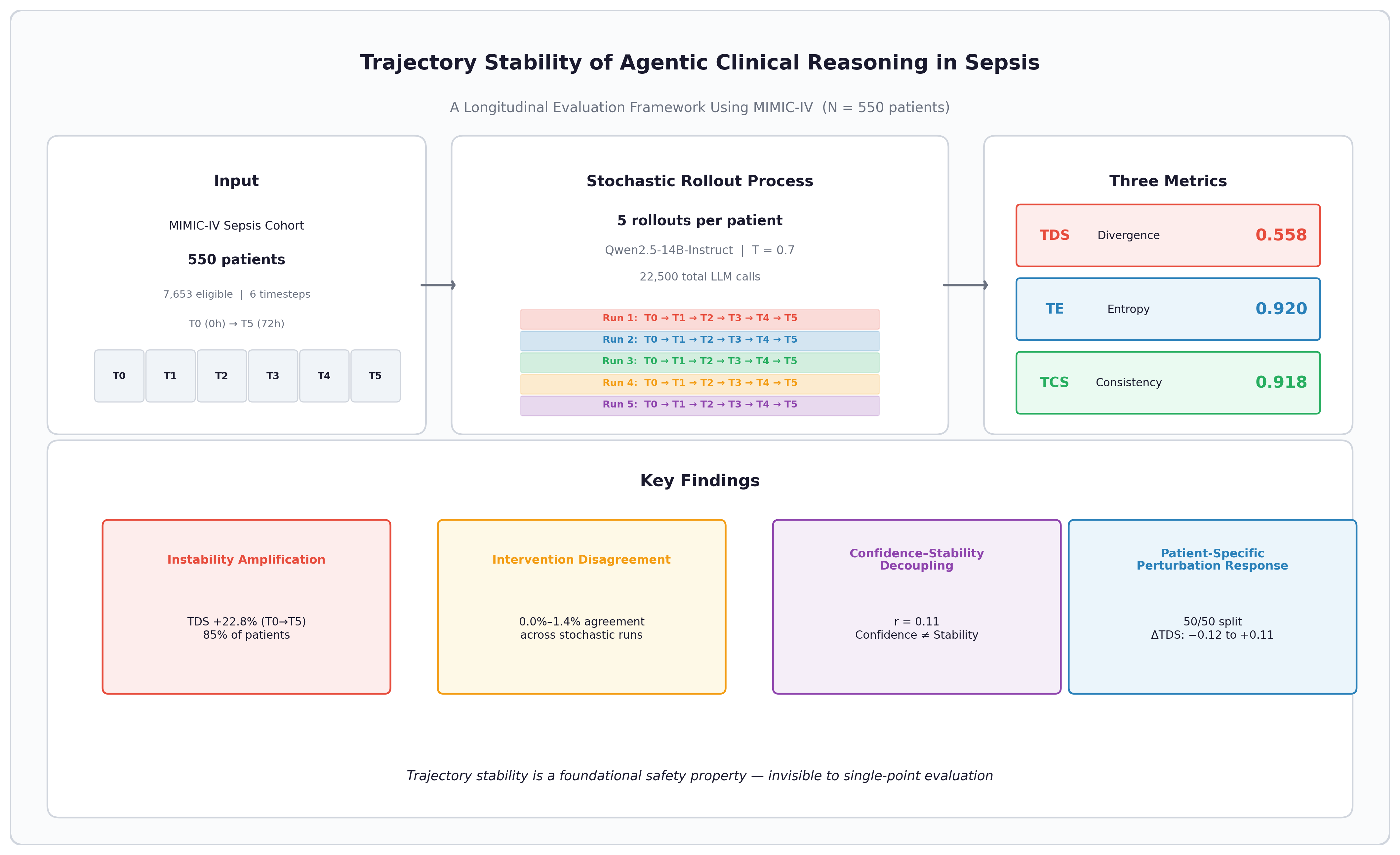
Background: Sepsis care unfolds over hours to days—clinicians revise assessments as new information arrives—yet evaluation of clinical AI systems remains anchored to single-point accuracy metrics that ignore the stability of the reasoning process itself. Objective: We introduce a trajectory-level evaluation framework that treats agentic clinical reasoning as a stochastic process over temporally evolving patient states, and apply it to characterize reasoning instability in sepsis. Methods: We constructed 550 sepsis patient trajectories from MIMIC-IV with six event based timesteps spanning 72 hours from onset. For each trajectory, we performed five stochastic rollouts using a 14B-parameter instruction-tuned language model (Qwen2.5-14B-Instruct AWQ, temperature 0.7). Three metrics capture distinct facets of instability: Trajectory Divergence Score (TDS) measures pairwise reasoning divergence, Trajectory Entropy (TE) quantifies branching complexity, and Temporal Consistency Score (TCS) assesses logical coherence across timesteps. Perturbation experiments on a 50-patient subset tested sensitivity to minimal input modifications. Results: Individual outputs appeared clinically plausible, but trajectories diverged substantially across stochastic runs. Mean TDS was 0.558 (SD 0.035), mean TE 0.920 (SD 0.020), and mean TCS 0.918 (SD 0.041). Intervention agreement across runs was near zero (0.0%–1.4%). Eighty-five percent of patients exhibited instability amplification, with TDS increasing 22.8% from T0 to T5. Model confidence doubled from baseline to outcome (31.6 to 66.0) without corresponding stabilization (r = 0.11 with TDS). Perturbation effects were small on average (∆TDS: −0.003 to −0.005) but ranged from −0.12 to +0.11 across individual patients, with roughly equal proportions amplified and stabilized. Conclusions: Agentic clinical reasoning systems can produce plausible individual outputs while exhibiting substantial trajectory-level instability invisible to standard evaluation. The observed divergence, near-zero intervention agreement, and decoupling between confidence and stability suggest that trajectory consistency should be assessed alongside accuracy and calibration as a core safety property—particularly for sequential clinical domains like sepsis where treatment depends on the coherence of a reasoning chain, not just its endpoint.
Keywords:
sepsis
; agentic AI
; clinical reasoning
; trajectory stability
; large language models
; stochastic inference
; longitudinal evaluation
; MIMIC-IV
; patient safety
1. Introduction
Sepsis accounts for an estimated 11 million deaths globally each year and remains among the most common causes of ICU mortality [1]. What makes sepsis hard to manage is not diagnosis alone but time. Vital signs shift, laboratory results arrive hours apart, clinical notes accumulate, and medication orders change with each reassessment. Clinicians do not make a single assessment and stop—they iterate, revising differentials and adjusting treatment as the clinical picture clarifies or deteriorates. That iterative, state-dependent reasoning process is the defining feature of sepsis care.
1.1. Static Evaluation in a Dynamic Domain
Large language models (LLMs) have moved quickly into clinical decision support—diagnostic reasoning, treatment planning, patient summarization, even clinical process retrieval [2,3]. Scoping reviews confirm that agentic AI systems, meaning those capable of autonomous multistep action within clinical workflows, are proliferating, though the evidence base distinguishing computational promise from clinical validation remains thin [4,5,6]. Evaluation, however, has not kept up. The dominant paradigm measures isolated outputs at single time points: accuracy against expert benchmarks, AUROC for binary predictions, or scores on question-answering datasets such as MedQA and PubMedQA [7,8]. These metrics treat clinical reasoning as a one-shot classification problem.
That mismatch matters. A model can produce plausible individual outputs at each timestep while exhibiting divergent, contradictory, or unstable reasoning paths across repeated stochastic runs—and no evaluation that looks at only a single pass will catch it. The concern is not hypothetical. Deployed clinical AI systems will encounter the same patient data on multiple occasions (across shifts, clinicians, or system restarts), and if reasoning trajectories vary substantially without any change in input, the reliability of the system’s recommendations is undermined at a foundational level. This aligns with growing arguments that the transition from predictive tools to agentic systems opens governance gaps that existing trust frameworks were not designed to address [9,10].
1.2. Prior Work on Uncertainty and Sequential Reasoning
Existing work on uncertainty in clinical AI has concentrated on scalar confidence calibration—whether a model’s reported confidence matches its empirical accuracy [11,12]. Uncertainty, in this framing, is a per-prediction number. Recent work has begun to model how stochastic variability propagates across multi-step agentic reasoning [13,14], and trajectory correlation frameworks adapted from computational neuroscience now quantify higher-order dependencies in execution traces [15,16]. A separate tradition, drawn from reinforcement learning, has studied policy stability under stochasticity [17]. But none of these traditions addresses a prior question: does the entire reasoning path vary under stochastic inference? Is the trajectory itself a stable or unstable object? Work on reasoning pathway explanations [18,19] and causal explanation frameworks [20] has made individual predictions more interpretable, but interpretability of a single run does not tell you whether the next run will say the same thing.
1.3. The Present Research
We examine whether agentic clinical reasoning systems exhibit stochastic trajectory instability detectable only through repeated longitudinal evaluation. We construct 550 sepsis patient trajectories from MIMIC-IV with six timesteps spanning 72 hours from onset, perform five stochastic rollouts per patient using a 14B-parameter instruction-tuned language model, and define three metrics (TDS, TE, TCS) that quantify reasoning divergence, branching complexity, and logical coherence. This work extends our earlier investigation of variability-aware trust in agentic clinical AI [13,14] by applying trajectory-level evaluation to a large, disease-specific cohort with temporal stratification and perturbation experiments. The contributions are:
- A longitudinal trajectory construction framework for ICU sepsis patients with cumulative context windows and event-based temporal segmentation.
- A stochastic agentic reasoning pipeline that simulates sequential clinical decision-making under identical inputs with temperature-sampled decoding.
- Three novel metrics—Trajectory Divergence Score (TDS), Trajectory Entropy (TE), and Temporal Consistency Score (TCS)—that capture distinct aspects of trajectory instability.
- Empirical characterization of reasoning instability across 550 sepsis patients, demonstrating instability amplification, near-zero intervention agreement, and confidence-stability decoupling.
- Perturbation experiments on a 50-patient subset revealing patient-specific sensitivity to minimal input modifications.
2. Methods
2.1. Dataset and Cohort Definition
We constructed a sepsis cohort from the MIMIC-IV ICU database [21] using Sepsis-3 criteria [22]: suspected infection (concurrent antibiotic administration and microbiological culture orders within a specified window) with a Sequential Organ Failure Assessment (SOFA) score increase of ≥ 2 within 24 hours [23]. The final cohort comprises 7,653 patients with 2.4 million clinical events. From this pool, we selected 550 patients stratified by event count (range: 7–3,550 events per trajectory) to capture diverse clinical complexity. A 50-patient pilot subset was used for perturbation experiments.
2.2. Trajectory Construction
We defined six event-based timesteps spanning 72 hours from sepsis onset:
- T0 (0h): Admission baseline
- T1 (2h): Early ICU assessment
- T2 (12h): Diagnostic evolution
- T3 (24h): Treatment escalation
- T4 (48h): Response phase
- T5 (72h): Outcome
At each timestep t, the model receives cumulative context:
This design mirrors clinical cognition, where decisions are based on all accumulated information rather than isolated snapshots [24]. Context is truncated to 8,000 characters at later timesteps to fit model context windows, prioritizing medications and vital signs over narrative notes. Each patient trajectory is:
2.3. Agentic Clinical Reasoning Model
We employed Qwen2.5-14B-Instruct-AWQ [25], a 14-billion parameter instruction-tuned language model with 4-bit AWQ quantization [26], served via vLLM for efficient GPU inference [27]. At each timestep, the model receives the cumulative clinical context and produces structured output:
- Clinical state summary: narrative summary of current patient condition
- Active problems: list of identified clinical problems
- Infection source: inferred site of infection
- Severity classification: low, moderate, high, or septic shock
- Recommended interventions: list of treatment recommendations
- Confidence: self-reported confidence score (0–100)
- Rationale: explanatory reasoning for the clinical assessment
Outputs are constrained to structured JSON for downstream metric computation.
2.4. Stochastic Trajectory Sampling
We performed stochastic rollouts per patient trajectory:
Each rollout is a complete sequential reasoning trajectory (T0–T5) under identical patient inputs with temperature . This yields 30 LLM calls per patient (5 runs × 6 timesteps) and 16,500 baseline calls for the 550-patient cohort.
2.5. Trajectory Divergence Score (TDS)
We define pairwise timestep-level divergence between two reasoning outputs:
where:
- : cosine distance between sentence embeddings of state summary and rationale ()
- : Jaccard distance between intervention sets ()
- : Jaccard distance between active problem sets ()
- : categorical distance over severity and infection source ()
TDS for a patient is the mean pairwise divergence across all rollout pairs and M timesteps:
2.6. Trajectory Entropy (TE)
We quantify branching complexity at each timestep using clustering-based entropy. At timestep t, we embed all N reasoning outputs and cluster them into K groups using K-means ():
where is the proportion of rollouts assigned to cluster k. This formulation follows Shannon entropy [28], with normalization by to ensure . Aggregate trajectory entropy is:
2.7. Temporal Consistency Score (TCS)
We define a rule-based clinical consistency metric capturing four categories of temporal violations:
- Infection coherence (): an infection source that disappears and reappears without explanation
- Severity monotonicity (): abrupt severity jumps (e.g., septic shock → low) without intermediate stages
- Intervention timing (): vasopressors recommended at low severity, or no antibiotics/fluids at septic shock
- Diagnostic consistency (): active problems that resolve and reappear without new clinical evidence
2.8. Confidence Volatility (CV)
We measure the variability of model-reported confidence across stochastic rollouts:
where is the confidence reported by rollout n at timestep t. High CV indicates that the model’s self-assessed certainty varies substantially across runs, suggesting poorly calibrated confidence.
2.9. Perturbation Experiments
We introduced four controlled perturbations to patient trajectories:
- 1.
- Remove note: deletion of one randomly selected clinical note
- 2.
- Remove lab: deletion of one randomly selected laboratory result
- 3.
- Reorder events: swap of two randomly selected events of the same type
- 4.
- Noise labs: Gaussian noise injection ( value) into numerical lab results
Each perturbation was applied independently, and five stochastic rollouts were performed on the perturbed trajectory. The resulting TDS was compared to the baseline (unperturbed) TDS. These experiments were conducted on the 50-pilot subset (200 experimental conditions, 6,000 perturbation LLM calls).
2.10. Experimental Setup
Cohort: 550 sepsis patients from MIMIC-IV, stratified by clinical event count (7–3,550 events).
Model: Qwen2.5-14B-Instruct-AWQ (14B parameters, 4-bit AWQ quantization), served via vLLM on an NVIDIA RTX A4500 (20 GB VRAM). Inference latency: ∼3.5 seconds per call.
Rollouts: 5 stochastic rollouts per patient, temperature = 0.7, max tokens = 1024.
Embeddings: all-MiniLM-L6-v2 (SentenceTransformer) for semantic similarity computation [29].
Total compute: 16,500 baseline LLM calls + 6,000 perturbation calls = 22,500 total. Baseline rollouts required approximately 17 hours; perturbation experiments approximately 5.5 hours.
AI use disclosure: AI-assisted tools were used during manuscript preparation for editing and formatting. The authors take full responsibility for the content of the publication.
Research questions:
- RQ1: How stable are clinical reasoning trajectories under stochastic inference?
- RQ2: How does instability evolve over the course of sepsis progression?
- RQ3: Do small perturbations induce disproportionate trajectory divergence?
- RQ4: Is model confidence calibrated with reasoning stability?
3. Results
3.1. Data Reduction and Analysis Plan
All metrics were computed on the full 550-patient cohort. TDS and TE require multiple rollouts for pairwise comparison; we used rollouts, yielding pairwise comparisons per patient per timestep. TCS was computed per rollout and averaged. Summary statistics report population means, standard deviations (population), and ranges. Perturbation analyses were restricted to the 50-patient pilot subset. The three primary metrics (TDS, TE, TCS) were assessed for independence using Pearson correlation.
3.2. RQ1: Trajectory Instability Under Stochastic Inference
Table 1 presents cohort-level summary statistics for all trajectory stability metrics.
A mean TDS of 0.558 means roughly half of the measurable semantic and clinical content differs between any two runs of the same patient. Mean TE of 0.920 is closer to the ceiling—nearly all reasoning states land in distinct clusters, indicating diverse vocabulary, framing, and rationale across runs. Yet TCS remains high (0.918): individual trajectories are internally coherent even when they disagree with each other. Each rollout tells a self-consistent clinical story. The stories are just different.
Figure 1.
Temporal evolution of trajectory instability across the 550-patient cohort. (a) TDS increases monotonically from T0 to T5 (+22.8%), with shrinking variance as instability converges. (b) TE remains near ceiling (≈0.92) across all timesteps, indicating persistent reasoning diversity. Shaded regions represent ±1 SD.
Figure 1.
Temporal evolution of trajectory instability across the 550-patient cohort. (a) TDS increases monotonically from T0 to T5 (+22.8%), with shrinking variance as instability converges. (b) TE remains near ceiling (≈0.92) across all timesteps, indicating persistent reasoning diversity. Shaded regions represent ±1 SD.

The three primary metrics are pairwise uncorrelated (all ), confirming that they capture distinct aspects of trajectory instability. TCS and confidence volatility show moderate correlation ().
3.3. RQ2: Temporal Evolution of Instability
If reasoning instability were a fixed property of the model, it should stay constant across timesteps. It does not (Table 2).
TDS climbs monotonically from T0 (0.483) through T5 (0.593), a 22.8% increase. We call this instability amplification: small early uncertainties propagate into larger downstream divergence. Eighty-five percent of patients (465/550) have amplification ratios exceeding 1.0, with a mean of 1.14. Early-to-late TDS correlation is —early divergence is a weak predictor of late divergence, and patients with similar initial instability can arrive at very different late-phase behavior.
TE holds steady (≈ 0.92) across all timesteps, indicating that reasoning diversity is persistent, not something that accumulates.
Model confidence increases substantially over time (T0: 31.6 → T5: 66.0), but confidence volatility and TDS are weakly correlated (). The model becomes more confident without becoming more stable.
Figure 2.
Trajectory bifurcation map for a representative patient (Patient 14687028, TDS = 0.576, amplification ratio = 2.14×). Each colored trajectory represents one stochastic rollout through six timesteps (T0–T5) projected via PCA onto the two principal components of reasoning state space. The five runs diverge substantially despite identical inputs, illustrating the stochastic instability that single-pass evaluation cannot detect.
Figure 2.
Trajectory bifurcation map for a representative patient (Patient 14687028, TDS = 0.576, amplification ratio = 2.14×). Each colored trajectory represents one stochastic rollout through six timesteps (T0–T5) projected via PCA onto the two principal components of reasoning state space. The five runs diverge substantially despite identical inputs, illustrating the stochastic instability that single-pass evaluation cannot detect.

3.4. Intervention Instability
Intervention agreement across stochastic runs is near zero at every timestep (Figure 3). Even when the model converges on similar clinical themes and severity assessments, the specific treatment recommendations are almost entirely different from run to run. Intervention selection is thus the most unstable component of the reasoning trajectory—and the one with the most direct clinical consequence.
3.5. RQ3: Perturbation Sensitivity
Table 3 presents perturbation experiment results.
Mean perturbation effects are small (TDS delta: −0.003 to −0.005) and slightly stabilizing on average, which at first glance suggests robustness. But the mean hides substantial patient-level heterogeneity: individual TDS deltas range from −0.12 to +0.11. The split between amplified and stabilized patients is roughly 50/50 for each perturbation type, indicating that sensitivity is a patient-level property rather than a universal effect. Patient 19274752 was consistently amplified across all four perturbation types; Patient 14954698 was consistently stabilized.
The practical implication is that there is no universal perturbation response. Whether a small input change amplifies or dampens reasoning instability depends on the clinical context of the specific patient.
3.6. RQ4: Confidence-Stability Decoupling
The weak correlation between confidence volatility and TDS (; Figure 4a) points to a confidence-stability decoupling: the model’s self-assessed certainty does not predict the stability of its reasoning. Confidence nearly doubles from T0 to T5, yet TDS climbs in parallel. A deployment that monitored only confidence scores—a common design choice—would register growing certainty while missing the growing instability underneath.
Twelve patients achieved perfect temporal consistency (TCS = 1.000), while 25 fell below 0.85. The three patients with the lowest TCS (0.767, 0.788, and 0.792) exhibited primarily severity monotonicity and intervention timing violations.
4. Discussion
4.1. Revisiting the Central Question
We began with the observation that clinical reasoning in sepsis is sequential and state-dependent, and asked whether current evaluation—which assesses isolated outputs at single time points—captures the stability of that process. It does not. Across 550 patients, stochastic inference produced reasoning trajectories that diverged meaningfully (TDS = 0.558), branched into nearly maximal entropy (TE = 0.920), and agreed on specific interventions almost never (0.0%–1.4%). None of these findings are visible to any evaluation that looks at a single model output per patient.
4.2. Implications for Clinical AI Evaluation
The near-zero intervention agreement is the most operationally significant finding. A system that recommends substantially different treatments on each inference run cannot support treatment planning, regardless of how plausible any single recommendation appears. This is not a calibration problem. It is a consistency problem, and it requires a different kind of evaluation to detect. The finding resonates with broader concerns that clinical AI systems, even when individually accurate, may fail under the demands of real workflows where consistency and auditability matter as much as correctness [30,31,32].
The three-metric framework (TDS, TE, TCS) captures distinct facets of this inconsistency. Their pairwise independence (all ) confirms that no single metric suffices: a model could have low divergence (similar content) but high entropy (diverse framing), or high temporal consistency (internally coherent) but high divergence from other runs. A comprehensive stability assessment needs all three.
4.3. Instability Amplification as a Dynamical Property
Instability amplification—early divergence propagating into larger downstream differences—parallels sensitivity to initial conditions in nonlinear dynamical systems [33]. The weak early-to-late correlation () means the amplification is not deterministic: patients with similar early divergence can end up in very different late-phase states. That stochasticity is itself clinically meaningful. If early trajectory stability does not predict late-stage reliability, monitoring cannot rely on early warning alone; the entire trajectory must be observed.
4.4. Confidence-Stability Decoupling
The decoupling between model confidence and reasoning stability challenges a widely held assumption in clinical AI safety: that confidence scores are a reliable signal for when to trust or override model recommendations [11,12]. Our results suggest otherwise. A model can be simultaneously confident and unstable—arguably more dangerous than low confidence with high stability, because the confidence score may discourage the human oversight the instability warrants. If confidence and stability are indeed decoupled, trust calibration strategies that rely on confidence transparency alone [10,30] will systematically overestimate reliability.
4.5. Patient-Specific Perturbation Sensitivity
The roughly 50/50 split between amplified and stabilized patients under perturbation argues against the hypothesis that small perturbations uniformly amplify divergence. Sensitivity appears to be a patient-level property, potentially tied to clinical complexity, diagnostic ambiguity, or information density. Identifying the features that predict perturbation sensitivity is a natural next step.
4.6. Limitations
Several constraints apply. Results derive from MIMIC-IV, a single-center database; generalization requires external validation. We evaluate one model (Qwen2.5-14B) at one quantization level; stability may differ across architectures, sizes, and training procedures. Perturbation experiments cover only 50 patients, limiting statistical power for subgroup analyses, though the primary analysis covers 550. TCS relies on heuristic rules rather than expert annotation; more sophisticated consistency checking could improve sensitivity. The choice of is a single point in the temperature space; the temperature–stability relationship warrants systematic investigation.
4.7. Future Directions
Several extensions follow from these findings. Model comparison across architectures and sizes would establish whether the observed instability is general or specific to the model studied. A temperature sweep would map the stability–diversity trade-off curve. Expert clinical review of divergent trajectories could separate meaningful clinical variation from noise. Extending the framework to other domains (acute coronary syndrome, stroke, trauma) would test generalizability. The metrics defined here could also serve as reward signals for training stability-aware models, complementing work on governance stacks for agentic clinical AI [6,9] and trajectory correlation functions for reasoning characterization [15,16].
5. Conclusion
We presented a trajectory-level evaluation framework for agentic clinical reasoning and showed that stochastic inference induces clinically meaningful instability in sepsis reasoning trajectories. The core findings—instability amplification over time, near-zero intervention agreement, confidence-stability decoupling, and patient-specific perturbation sensitivity—argue that trajectory stability should be treated as a foundational safety property alongside accuracy, fairness, and calibration. A model that produces plausible outputs on any single run may nonetheless produce inconsistent, divergent reasoning across runs. That difference is exactly what matters at the bedside.
This study used only de-identified, publicly available data from the MIMIC-IV database. No human or animal subjects were directly involved in this research.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Rudd, K.E.; Johnson, S.C.; Agesa, K.M.; et al. Global, regional, and national sepsis incidence and mortality, 1990–2017: analysis for the Global Burden of Disease Study. The Lancet 2020, 395(10219), 200–211. [Google Scholar] [CrossRef]
- Singhal, K.; Azizi, S.; Tu, T.; et al. Large language models encode clinical knowledge. Nature 2023, 620(7972), 172–180. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Gomez-Cabello, C.A.; Makarova, S.; et al. Using large language models to retrieve critical data from clinical processes and business rules. Bioengineering 2025, 12(1), 17. [Google Scholar] [CrossRef]
- Yu, Y. Agentic AI in healthcare: Bridging the gap between computational promise and clinical evidence. Res. Sq. 2026. [Google Scholar] [CrossRef]
- Yu, Y. Clinical reality vs. computational promise: Scoping review of agentic AI systems in healthcare. HAL. Sci. 2026, 1–51. [Google Scholar]
- Moor, M.; Banerjee, O.; Abad, Z.S.H.; et al. Foundation models for generalist medical artificial intelligence. Nature 2023, 619(7968), 266–273. [Google Scholar] [CrossRef] [PubMed]
- Jin, D.; Pan, E.; Oufattole, N.; et al. What disease does this patient have? A large-scale open domain question answering dataset from medical exams. Appl. Sci. 2021, 11(14), 6421. [Google Scholar] [CrossRef]
- Jin, Q.; Wang, Z.; Floudas, C.S.; et al. PubMedQA: A dataset for biomedical research question answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019; pp. 2567–2577. [Google Scholar] [CrossRef]
- Yu, Y. From prediction to agency: A constrained decision framework and governance stack for agentic AI in clinical diagnostics. Preprints.org. 2026, 7(23), 1–18. [Google Scholar]
- Topol, E.J. High-performance medicine: the convergence of human and artificial intelligence. Nat. Med. 2019, 25(1), 44–56. [Google Scholar] [CrossRef]
- Yu, Y. Trustworthy LLM-embedding clinical prediction: Calibrating confidence and transparency for foundation model-based disease risk scores. Res. Sq. 2026. [Google Scholar] [CrossRef]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), 2017; pp. 1321–1330. [Google Scholar]
- Yu, Y. Variability-aware trust in agentic clinical AI: Modeling and measuring trajectory-level uncertainty. Res. Sq. 2026, 1–27. [Google Scholar] [CrossRef]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and scalable predictive uncertainty estimation using deep ensembles. Adv. Neural Inf. Process. Syst. (NeurIPS) 2017, 6402–6413. [Google Scholar]
- Yu, Y. From multipoint correlations to multi-step reasoning: A trajectory-based framework for agentic intelligence. Res. Sq. 2026, 1–28. [Google Scholar] [CrossRef]
- Wang, X.; Wei, J.; Schuurmans, D.; et al. Self-consistency improves chain of thought reasoning in language models. In Proceedings of the 11th International Conference on Learning Representations (ICLR), 2023. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction, 2nd ed.; MIT Press, 2018. [Google Scholar]
- Yu, Y. A reasoning pathway explanation framework for clinical AI: Methods and evaluation. Res. Sq. 2026, 1–22. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. (NeurIPS) 2017, 4765–4774. [Google Scholar]
- Yu, Y. A causal explanation framework for clinical AI: Methods and technical evaluation. HAL. Sci. 2026, 1–22. [Google Scholar]
- Johnson, A.E.W.; Bulgarelli, L.; Shen, L.; et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data 2023, 10(1), 1. [Google Scholar] [CrossRef]
- Singer, M.; Deutschman, C.S.; Seymour, C.W.; et al. The third international consensus definitions for sepsis and septic shock (Sepsis-3). JAMA 2016, 315(8), 801–810. [Google Scholar] [CrossRef]
- Vincent, J.L.; Moreno, R.; Takala, J.; et al. The SOFA (Sepsis-related Organ Failure Assessment) score to describe organ dysfunction/failure. Intensive Care Med. 1996, 22(7), 707–710. [Google Scholar] [CrossRef]
- Croskerry, P. A universal model of diagnostic reasoning. Acad. Med. 2009, 84(8), 1022–1028. [Google Scholar] [CrossRef]
- Yang, A.; Yang, B.; Zhang, B.; et al. Qwen2.5 technical report. arXiv 2025, arXiv:2412.15115. [Google Scholar] [CrossRef]
- Lin, J.; Tang, J.; Tang, H.; et al. AWQ: Activation-aware weight quantization for LLM compression and acceleration. In Proceedings of the 41st International Conference on Machine Learning (ICML), 2024. [Google Scholar]
- Kwon, W.; Li, Z.; Zhuang, S.; et al. Efficient memory management for large language model serving with PagedAttention. In Proceedings of the 29th Symposium on Operating Systems Principles (SOSP), 2023; pp. 611–626. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27(3), 379–423. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019; pp. 3982–3992. [Google Scholar] [CrossRef]
- Yu, Y. Backcasting the trust gap: A strategic road map for clinician adoption of AI diagnostics by 2040. J. Med. Internet Res. 2026, 28, e94234. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y. C-RLM: Schema-enforced recursive synthesis for auditable, long-context clinical documentation. medRxiv 2026. [Google Scholar] [CrossRef]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar] [CrossRef]
- Strogatz, S.H. Nonlinear Dynamics and Chaos: With Applications to Physics, Biology, Chemistry, and Engineering, 2nd ed.; CRC Press, 2018. [Google Scholar]
Figure 3.
Intervention agreement across stochastic runs at each timestep (N = 550). Agreement represents the fraction of patients for which all five runs produced identical intervention sets. Near-zero agreement at every timestep indicates that treatment recommendations are almost entirely inconsistent across runs—the most operationally significant form of trajectory instability.
Figure 3.
Intervention agreement across stochastic runs at each timestep (N = 550). Agreement represents the fraction of patients for which all five runs produced identical intervention sets. Near-zero agreement at every timestep indicates that treatment recommendations are almost entirely inconsistent across runs—the most operationally significant form of trajectory instability.

Figure 4.
Metric independence across the 550-patient cohort. (a) Confidence volatility vs. TDS (): the model’s self-assessed certainty does not predict reasoning stability. (b) TCS vs. TDS (): internal trajectory coherence is independent of cross-run divergence. Each point represents one patient. Dashed lines indicate linear fit.
Figure 4.
Metric independence across the 550-patient cohort. (a) Confidence volatility vs. TDS (): the model’s self-assessed certainty does not predict reasoning stability. (b) TCS vs. TDS (): internal trajectory coherence is independent of cross-run divergence. Each point represents one patient. Dashed lines indicate linear fit.


Table 1.
Cohort-level trajectory stability metrics (N = 550).
| Metric | Mean | SD | Min | Max | Median |
|---|---|---|---|---|---|
| TDS | 0.558 | 0.035 | 0.436 | 0.655 | 0.556 |
| TE | 0.920 | 0.020 | 0.865 | 0.960 | 0.929 |
| TCS | 0.918 | 0.041 | 0.767 | 1.000 | 0.920 |
| CV | 9.12 | 3.15 | 2.67 | 19.51 | 8.89 |
Table 2.
Temporal evolution of trajectory instability (mean ± SD, N = 550).
| Metric | T0 | T1 | T2 | T3 | T4 | T5 |
|---|---|---|---|---|---|---|
| TDS | 0.483 | 0.517 | 0.575 | 0.586 | 0.593 | 0.593 |
| ±0.095 | ±0.087 | ±0.048 | ±0.046 | ±0.045 | ±0.046 | |
| TE | 0.920 | 0.921 | 0.915 | 0.920 | 0.921 | 0.920 |
| ±0.043 | ±0.043 | ±0.048 | ±0.043 | ±0.043 | ±0.043 | |
| Confidence | 31.6 | 32.3 | 55.5 | 65.0 | 66.3 | 66.0 |
| ±23.7 | ±20.7 | ±25.3 | ±23.0 | ±21.3 | ±23.2 |
Table 3.
Perturbation effects on trajectory divergence (N = 50 per perturbation type).
| Perturbation | Mean TDS | TDS | Amplified (%) |
|---|---|---|---|
| Baseline (unperturbed) | 0.561 | — | — |
| Remove note | 0.558 | −0.003 | 48% |
| Remove lab | 0.556 | −0.005 | 52% |
| Reorder events | 0.558 | −0.003 | 48% |
| Noise labs | 0.556 | −0.005 | 52% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



