Submitted:
18 May 2026
Posted:
19 May 2026
You are already at the latest version
Abstract
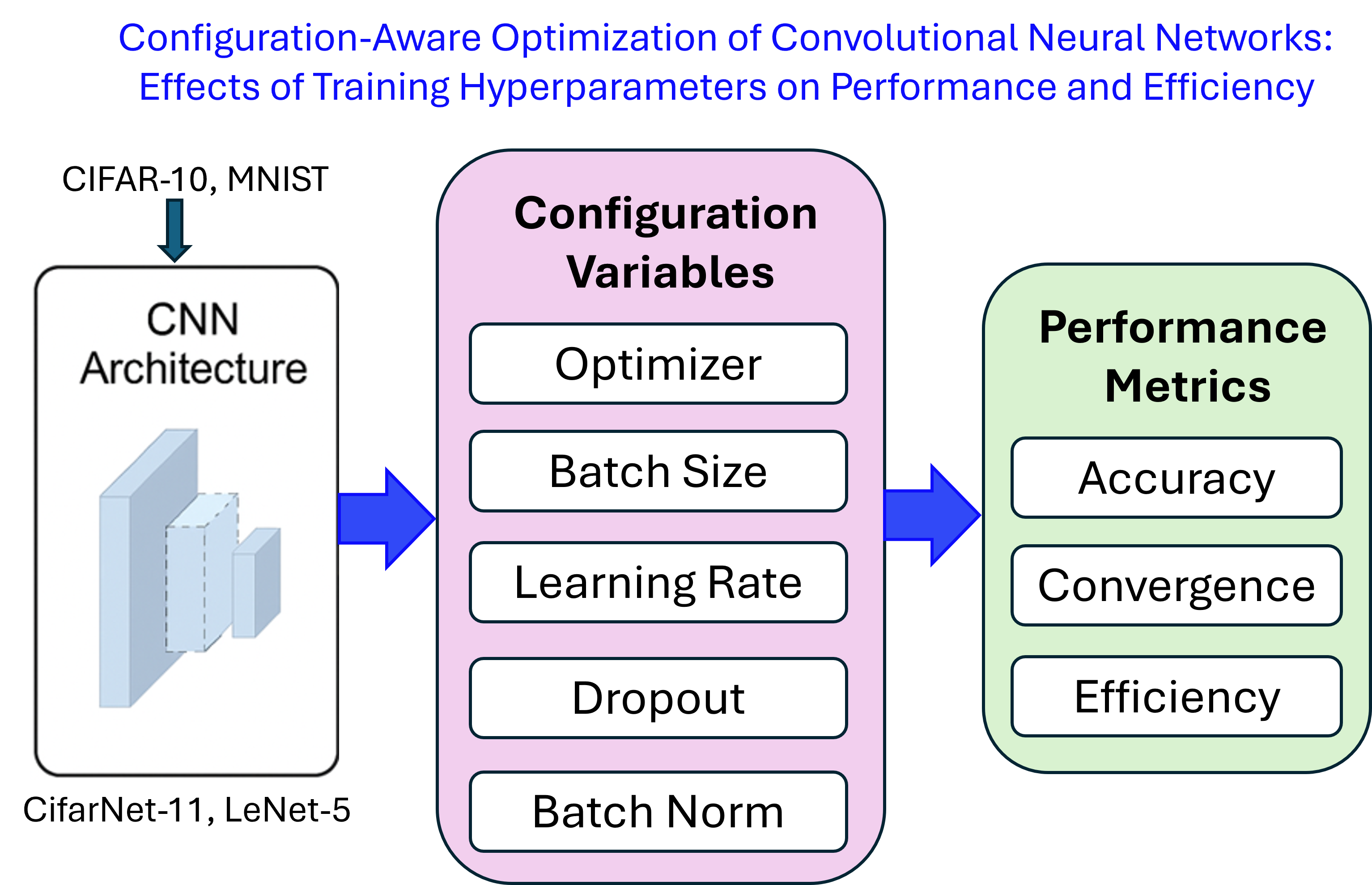
Convolutional Neural Networks (CNNs) constitute the foundation of modern computer vision systems, yet their empirical performance is frequently governed as much by training configuration choices as by architectural design. Despite this, critical hyperparameters—including optimizer selection, batch size, learning rate, training duration, dropout regularization, and batch normalization—are often selected heuristically or reported incompletely. Based on two benchmark datasets (CIFAR-10 and MNIST) and two classical CNNs (CifarNet-11 and LeNet-5), this paper presents a systematic, configuration-aware empirical study that quantifies how these variables influence predictive accuracy, convergence stability, generalization behavior, and computational efficiency of CNN models. Using a controlled experimental methodology in which individual configuration variables are isolated and evaluated under identical conditions, we demonstrate that configuration choices can induce performance variations comparable to those achieved through substantial architectural modifications. The results reveal explicit accuracy–efficiency trade-offs, identify regime-dependent optimal configurations, and highlight the central role of early stopping and normalization in stabilizing learning dynamics. These findings elevate configuration-aware optimization to a first-order design principle for reproducible research and reliable deployment of CNN-based artificial intelligence systems.
Keywords:
convolutional neural networks
; training configuration
; hyperparameter analysis
; deep learning optimization
; reproducible AI
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



