Submitted:
08 April 2026
Posted:
09 April 2026
You are already at the latest version
Abstract
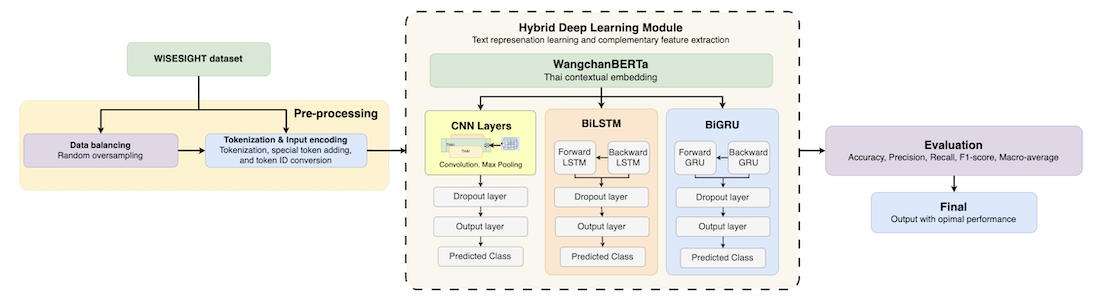
Sentiment analysis of Thai social media texts remains challenging due to the lack of explicit word boundaries, informal language, and high linguistic variability, further exacerbated by class imbalance, short texts, and ambiguous categories. Recent transformer-based models, particularly WangchanBERTa, have shown strong performance in Thai NLP; however, their ability to extract fine-grained, sentiment-specific local features remains limited when applied to noisy, short social media texts. This study proposes a lightweight hybrid framework that integrates WangchanBERTa with multiple neural architectures, including convolutional neural networks (CNN), bidirectional long short-term memory (BiLSTM), and bidirectional gated recurrent units (BiGRU). A comparative evaluation is conducted to assess their effectiveness for four-class Thai sentiment classification. In addition, the impact of CNN kernel size configurations on sentiment feature extraction is systematically investigated, an aspect that has received limited attention in prior Thai NLP research. Experiments conducted on the WISESIGHT benchmark demonstrate that the WangchanBERTa–CNN model with medium kernel sizes [2, 3, 4] achieves the best performance. It achieves a macro-average F1-score of 65.80%, outperforming the current state-of-the-art on the WISESIGHT benchmark by 4.94%. In addition, it achieves a macro-average F1-score of 94.11% on the class-balanced dataset. These results are achieved while maintaining a relatively low parameter count. These findings confirm that combining contextualized global embeddings with local n-gram feature extraction provides an effective and efficient solution for sentiment classification of short, noisy, and linguistically diverse Thai social media texts.
Keywords:
hybrid model
; kernel size configuration
; Thai sentiment analysis
; convolutional neural networks
; WangchanBERTa-CNN
; Thai social media texts
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



