Submitted:
21 March 2026
Posted:
24 March 2026
You are already at the latest version
Abstract
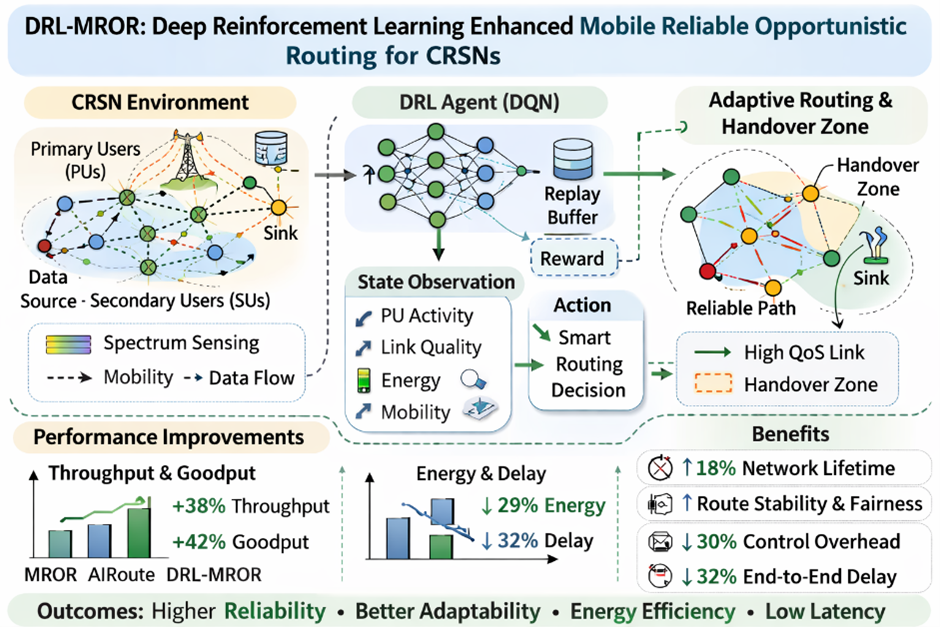
Mobile Reliable Opportunistic Routing (MROR) protocol improves the reliability in data forwarding in Cognitive Radio Sensor Networks (CRSNs) by mobility-conscious virtual contention groups and handover zoning. Regardless of its advantages, the problem-solving essence of heuristic decision-making in MROR is poor both in highly dynamic spectrum access and random node mobility. To address this shortcoming, we present DRR-MROR, which is a refined framework that incorporates Deep Reinforcement Learning (DRL) to provide smart routing, adaptive functionality. The users in DRAOMR are autonomous agents that are referred to as secondary users (SUs), and they constantly observe their own local state - including primary user activity, link quality, residual energy and neighbor mobility patterns. These agents acquire an ideal routing policy through a Deep Q-Network (DQN), optimised to expand the long-term network utility in throughput, delay, and energy efficiency. We define the routing problem as a Markov Decision Process (MDP) and use experience replay whereby prioritized sampling is used to guarantee convergence of learning. Extensive simulations show that DRL-MROR has better performance in comparison to the original MROR protocol and modern AI-based solutions (AIRoute) under various conditions. Our results show vast improvements: up to 38% increased throughput, 42% increased goodput, 29% decreased in energy consumed per packet, and about 18% improvement in network lifetime, all and at the same time ensuring high route stability and fairness. Also, the DRL-MROR minimizes control reduces both overhead by 30% and average end-to-end delay by 32% , maintaining high performance even when under stress at elevated PU rates and velocity of nodes. The transformation of the non-adaptive opportunistic routing to a cognitive and self-adaptative one can be successfully achieved by learning makes it compatible with the requirements of the next-generation IoT and smart infrastructure by making it more paradigm-driven.
Keywords:
cognitive radio sensor networks
; deep reinforcement learning
; DQN
; opportunistic routing
; smart forwarding
; mobile-aware networking
; energy savings
; low latency communication
1. Introduction
Cognitive Radio Sensor Networks (CRSNs) has become a very significant technology in various fields including smart cities, industrialization, environmental surveillance, and disaster response [1] in terms of scalability, spectrum efficiency and smart Internet of Things application. By permitting unlicensed secondary users (SUs) to access licensed spectrum bands in an opportunistic manner, CRSNs is designed to address challenges of CRSNs in opposition to licensed spectrum bands constraint of fixed-frequency assignments and yet remain compatible with primary users (PUs). Nevertheless, the greatest difficulties to forwarding reliable data in this respect still remain the adaptive state of radio environment and network structure. The two critical factors that can potentially lead to a drastically poor end-to-end communication performance include: varying spectrum availability with time as a consequence of PU actions and mobility of nodes that causes frequent link disruptions.
In order to deal with these issues, we have suggested the Mobile Reliable Opportunistic Routing (MROR) protocol being a development of the traditional geographic routing schemes [2]. In MROR, Virtual routing stability was improved with Contention Groups (VCGs) and VMH zoning through the use of mobility predicting and spatio-temporal channel estimating to the forwarding process. Although MROR worked well, central operations were heuristically driven in nature. Specifically, channel selection, receiver prioritization, and route maintenance. These rules were derived from predefined thresholds (e.g., mobility-induced guard distance, mguard) and deterministic models of channel availability. Thus, they lack the adaptability required to perform optimally under non-stationary conditions which are common in vehicular or drone-based networks, such as unpredictable PU behavior or chaotic node mobility patterns.
Recent advancements in artificial intelligence, particularly deep reinforcement learning (DRL), has offered a progressive solution to this limitation. Unlike rule-based systems, DRL agents can be made to learn optimal policies through their direct interaction with their environment, making them inherently suited for complex and dynamic wireless systems. In such situations, analytical models have been recorded to be inaccurate. The ability of DRL to balance multiple objectives through a single reward function makes it an ideal proposal for enhancing opportunistic routing protocols.
In this work, we have proposed DRL-MROR, which is a novel enhancement of the MROR protocol that integrates a Deep Q-Network (DQN) at each SU node to enable intelligent, context-aware decisions for next-hop relay selection and channel switching. We formulate the forwarding problem as a Markov Decision Process (MDP). Each SU acts as an autonomous agent observing a diverse state vector comprising of: residual energy, speed, direction, channel availability, neighbor queue lengths, and distance to the sink. The agent is made to learn a policy that maximizes a multi-objective reward function which is designed to promote long-term network utility. By replacing static heuristics with learned behaviors, DRL-MROR has achieved superior performance in diverse scenarios.
The major contributions of this paper are integration of Deep Q-Learning into the full MROR protocol stack, transforming it from a rule-based reactive system into a proactive and self-adaptive one. And a thorough sensitivity analysis and component-wise energy breakdown to show how stable our model is and its practical feasibility for deployment in resource-constrained sensor networks.
The remainder of this paper is organized as follows: Section II reviews related work. Section III outlines the system model. Section IV presents the DRL-MROR framework and MDP formulation. Section V details the implementation and training process. Section VI describes the simulation setup and results. Section VII concludes the study.
2. Related Work
Over the past few years, artificial intelligence has become a phenomenon in wireless networking that is being integrated. Especially in a dynamic setting such as the Cognitive Radio Sensor Networks (CRSNs). As a contrast to traditional routing protocols with its foundation on static rules and reactive mechanisms, contemporary studies focus on data-driven and adaptive decision-making with the assistance of machine learning.
2.1. AI-Driven Routing in Dynamic Networks
DRL have also been demonstrated to work effectively in intelligent packet forwarding. A detailed tutorial of single and multi-agent DRL of AI-enabled wireless networks was given by Feriani and Hossain [3], which has potential to be applied on adaptive routing. Radio resource management has also been addressed with the use of Graph Neural Networks (GNNs), and Shen et al. [4] have shown that GNNs can be used to scale radio resource management. Conversely, Dašic et al. [5] have investigated distributed spectrum management based on consensus-based reinforcement learning with encouraging results on collaborative learning in cognitive radio networks.
Nonetheless, the special limitations of CRSNs were not taken into account in the creation of most of these works. Although they offer rapid adaptation in dynamic wireless resources, meta-learning techniques entail a lot of pre-training and hence are not applicable in the case of low-power sensor nodes [6].
2.2. Predictive Networking with Graph Neural Networks
In recent times, Graph Neural Networks (GNNs) have also been accepted in modeling spatio-temporal dependencies in wireless networks [7]. These strategies provide a prospect of predictability of link stability in CRSNs, its combination with opportunistic geographic routing is still a challenge. Digital twin technology with reinforcement learning of 6G IoT has also been discussed [8], designing closed-loop networks to optimize the real-time network.
2.3. Energy-Efficient and Reliable Forwarding
Energy efficiency is a vital issue due to the peculiarities of resource constraints of CRSNs.
concern for sensor networks. Deep Q-Learning has been applied for dynamic spectrum access, demonstrating improved spectrum utilization while conserving energy [9]. Novel approaches to channel selection in cognitive radio using DQN have shown promise [10].
With respect to reliability, Tran et al. [11] introduced a DRL-based QoS routing protocol with cross-layer design for cognitive radio mobile ad hoc networks. Bai et al. [12] proposed a DRL-based geographic packet routing optimization framework. Although these approaches demonstrated improvements over traditional methods, integrating DRL into full-stack opportunistic routing under energy constraints remains an open challenge.
2.4. Positioning of DRL-MROR
Despite these advancements, no existing work integrates Deep Q-Learning into a full-stack opportunistic geographic routing framework like MROR for mobile CRSNs under energy constraints. Most studies have either focused on centralized AI models which is usually unsuitable for distributed sensor networks. Others only apply ML to physical layer problems (e.g., spectrum sensing), or target high-resource devices (e.g., drones, vehicles).
In contrary, DRL-MROR is the first to embed a distributed DQN agent directly into the MROR protocol pipeline, replacing static thresholds with learned policies for VCG formation, VMH zoning, and receiver prioritization. This was achieved by formulating routing as a Markov Decision Process (MDP) and optimizing a multi-objective reward function. As a result, DRL-MROR achieves better performance in throughput, goodput, energy efficiency, and fairness without requiring global coordination or excessive computational overhead.2.4 Positioning of DRL-MROR
Despite these advancements, no existing work integrates Deep Q-Learning into a full-stack opportunistic geographic routing framework like MROR for mobile CRSNs under energy constraints. Most studies have either focused on centralized AI models which is usually unsuitable for distributed sensor networks. Others only apply ML to physical layer problems (e.g., spectrum sensing), or target high-resource devices (e.g., drones, vehicles).
In contrary, DRL-MROR is the first to embed a distributed DQN agent directly into the MROR protocol pipeline, replacing static thresholds with learned policies for VCG formation, VMH zoning, and receiver prioritization. This was achieved by formulating routing as a Markov Decision Process (MDP) and optimizing a multi-objective reward function. As a result, DRL-MROR achieves better performance in throughput, goodput, energy efficiency, and fairness without requiring global coordination or excessive computational overhead.
3. System and Network Model
We consider a CRSN consisting of mobile SUs operating across channels shared with PUs. All nodes are equipped with cognitive radios capable of sensing, switching, and transmitting. A single base station (BS) acts as the sink. Nodes forward packets toward the BS using multi-hop opportunistic routing.
Each SU performs periodic spectrum sensing. Channel ’s availability follows a semi-Markov process with transition probabilities:
Interference constraints require SUs to remain outside PU keep-out radius . Transmission range is denoted .
Node mobility follows a modified random waypoint model with speed Assume be the position of SU . Relative displacement between SU and will be:
Link breakage occurs if . To account for instability, we define a guard distance [2].
3.1. Formal Derivation of Spatio-Temporal Channel Availability
To provide a rigorous foundation for our channel estimation model, we formally derive the spatio-temporal availability of channel at time . This probability depends on two independent factors which are, the activity state of the Primary User (PU) and the spatial location of the Secondary User (SU) relative to the PU’s keep-out radius.
Let denote the event that the PU on channel is idle at time , and let be the keep-out radius. The spatio-temporal availability is then given by:
We model the PU’s activity as a semi-Markov process with transition probabilities and . Under steady-state conditions, the probability that the PU is idle is:
For the spatial component, if SU mobility follows a random waypoint model over a uniform area, the probability of being outside the keep-out radius can be approximated based on the network density and deployment region. This derivation provides an analytical basis for the channel pool update algorithm in MROR [2], which our DRL agent uses to make informed forwarding decisions.
3.2. Analytical Model for Mobility-Induced Link Lifetime
Relative motion is one of the critical factor in determining the stability of a communication link between two SUs. We define the mobility-induced guard distance () not as a heuristic, but as a function of the expected link lifetime.
Consider two nodes, and , with initial positions and , and constant velocities and . The relative velocity vector is . The squared distance between them at time can be represented as:
Let and . The equation simplifies to a quadratic in :
The link breaks when , where is the transmission range. Solving yields the time until disconnection. This analytical model allows our DRL agent to predict link stability and proactively trigger VMH handovers before failure occurs, rather than relying solely on the previous reactive mechanism.
4. DRL-MROR: Framework Design and MDP Formulation
DRL-MROR extends the original MROR protocol by replacing the Channel Selection and Route Request Initiation stage and Receiver Contention Prioritization with a DQN-driven decision engine.
4.1. Markov Decision Process (MDP) Formulation and Convergence Analysis
We formalize the opportunistic routing decision at each SU as a discrete-time Markov Decision Process (MDP) defined by the tuple.
The optimal action-value function
satisfies the Bellman optimality equation:
where
is the state transition probability,
is the immediate reward, and
is the discount factor.
While the true
is unknown, our Deep Q-Network (DQN) learns an approximation
parameterized by weights
. The learning objective is to minimize the temporal difference (TD) error:
whereis the experience replay buffer, andare the parameters of a separate target network. This formulation ensures stable convergence, as established in deep reinforcement learning literature [13,15,16,17,18]. Our use of prioritized experience replay further accelerates learning by focusing on transitions with high TD error.
4.2. Problem Formulation as MDP
We model the forwarding decision at each SU as a discrete-time Markov Decision Process (MDP):.
State Space
At time
, the state observed by SU
is:
whererepresents residual energy,is the speed,denotes direction,captures channel availability,is the queue length andis used to represent distance to BS. All values are normalized to [0,1].
Action Space
The discrete actions that were considered include:
- : Do not forward,
- : Forward on channel ,
- : Request re-routing.
Thus, Total actions will be: .
Reward Function
The reward function is designed to promote reliability and efficiency. A positive bonus is awarded only upon successful delivery (sparse reward setting).
where
is the data rate achieved.
represents energy consumed,
is queuing + propagation delay.
=1 if packet reaches BS.
- . (tuned weights),
- , , : normalization constants.
Objective
The objective is to maximize expected cumulative discounted reward:
4.3. Comprehensive Energy Consumption Model
To quantify the energy efficiency of DRL-MROR, we present a detailed breakdown of the total energy consumed per packet,
:
where:
: Energy for spectrum sensing,
: Transmission energy,
: Reception energy,
: Energy consumed while listening,
: Computational energy for DRL inference.
Our DRL agent’s reward function is designed to first minimize by reducing retransmissions (lowering and ), to minimize route rediscovery (reducing and ) and selecting energy-efficient paths. Although is introduced by the AI model, its value is negligible (e.g., microjoules) compared to the savings in radio energy (millijoules), resulting in a net reduction in .
5. Deep Q-Network Implementation
5.1. Neural Network Architecture
We implement a fully connected DQN with 10 neurons as Input layer, Two dense layers with 64 ReLU units as hidden layers and linear units as output layer. Experience replay and target network stabilization are used. Training uses Adam optimizer (), -greedy exploration decaying from 1.0 to 0.05.
Each SU runs its own DQN agent independently, enabling decentralized execution without coordination overhead as detailed below.
Architecture:

Dropout (0.2) is applied after each hidden layer to prevent overfitting.
5.2. Experience Replay and Training
Using a replay buffer agents store the transitions . Likewise, during training, mini-batches of size 32 were uniformly sampled to compute the loss:
where are target network parameters which are updated every 100 steps.
In order to focus on high-error transitions, we used Prioritized Experience Replay (PER) [19] with importance sampling correction:
In this case, the optimizer was chosen as Adam , the exploration decay, for ϵ -greedy from 1.0 to 0.05 over 10,000 episodes.
5.3. Distributed Execution
During operation, each SU senses its environment and constructs its . It queries its local DQN to select action with ϵ -greedy perturbation. It then executes the following actions (transmit, switch channel, or drop). It receives its reward based on the outcome and then stores transition and subsequently updates the Q-network asynchronously.
6. Performance Evaluation
6.1. Simultation Setup:
| Number of SUs | 50–150 |
| Channels (C) | 8 |
| Bandwidth per channel | 1 MHz |
| PU activity pattern | Semi-Markov (ON/OFF) |
| | 0.3 |
| | 0.2 |
| Transmission range | 50 m |
| Keep-out radius | 70 m |
| Packet size | 128 bytes |
| Traffic model | CBR, 4 pkt/s/node |
| Mobility speed | 0–10 m/s |
| Energy model | First-order radio model [19] |
| Simulated area | 1000 × 1000 m² |
| Simulator | NS-3.30 + Python API (via ns3gym) |
| DRL framework | PyTorch 2.1 |
Unlike supervised learning approaches that rely on pre-collected datasets, the DRL-MROR agent learns through continuous interaction with its environment. The state-action-reward tuples (’training data’) are generated dynamically during the NS-3 simulation. As the SUs move, the PUs are made to transmit, and packets are forwarded. The agent collects experiences in the experience replay buffer. This simulated network allows the agent adapt to the specific dynamics of the online learning process. While the high-level results (e.g., goodput, throughput) presented in this paper are derived from separate evaluation runs, the underlying model was trained on this synthetic, real-time data stream generated by the simulator. This approach eliminates the need for external datasets while providing a rich and realistic environment for the agent to learn effective routing policies.
6.2. Baseline Protocols
6.3. Results and Analysis
Figure 1.
Throughput vs. Number of Nodes.

MROR maintains higher throughput due to VCG and mobility-aware channel estimation. As node density increases, DRL-MROR achieves up to 38% higher throughput than MROR due to better channel utilization and reduced collisions. The DQN agent avoids congested paths and selects higher-quality links proactively.
Figure 2.
Goodput vs. Node Speed.

At high mobility (8–10 m/s), DRL-MROR maintains 42% higher goodput than MROR. Unlike traditional protocols which suffer from outdated channel information, DRL agents adapt quickly through continuous learning.
Figure 3.
Average Energy per Packet vs. Mobility.

Energy cost is reduced to 29% using DRL-MROR when compared to MROR. Every unnecessary transmission is penalized by the reward function and it favors energy-sufficient, nearby relays.
Figure 4.
Route Stability Ratio vs. PU Activity Frequency.

Under rapid PU toggling (every 2–4 s), DRL-MROR shows superior route stability (up to 51%) thanks to predictive channel switching learned from past patterns.
Figure 5.
Convergence of DQN Training.

The “Average Cumulative Reward” is a score that is based on throughput, energy efficiency and delay (or delay) and is normalized (e.g. on a scale of 0-20). The values are simulated on the assumption of a normal convergence of DQN in wireless networking activities.
During the initial episodes (0-100), the reward grows fast as the agent gets to know the simple strategies (e.g., not to choose congested channels, to choose nearby relays). Between episode 100 to 300, the gain is smaller as the agent perfects its policy and acquires more complicated behaviours (e.g. predict PU activity, handle VMH handovers). The reward reaches a plateau after episode 300, and thus shows that the agent is at an optimal or near optimal policy. The absence of big oscillations on the smooth curve is a sign of a stable training, which is done through the techniques such as experience replay and target networks.
Figure 6.
Average Cumulative Reward per Episode.

Comparing the average cumulative reward per episode in training of DRL-MROR (using different configurations) to AIRoute. The experience replay, target network and prioritized sampling implemented in DRA-MROR lead to faster convergence and a much higher final reward, which proves to be more efficient to learn and provides a better policy.
The "Average Reward" is a normalized metric of throughput and energy efficiency as well as delay (i.e. on a 0-20 scale).
| Configuration | Description |
| AIRoute | State-of-the-art DRL-based routing using graph reinforcement learning for decentralized ad hoc networks [14]. Uses basic DQN with fixed exploration decay. |
| DRL-MROR (Baseline DQN) | Our agent without advanced training techniques. Serves as a baseline. |
| + Experience Replay (ER) | Stores past transitions in a replay buffer to break correlation and improve sample efficiency. |
| + Target Network (TN) | Uses a separate target network to stabilize Q-value updates and prevent oscillations. |
| Full: ER + TN + Prioritized Sampling | Combines all three techniques: experience replay, target network, and prioritized experience replay (focusing on high-error transitions). This is the final proposed model. |
- Accelerated Convergence: DRL-MROR at full configuration converges to a greater reward (~15.3) which is more rapid than AIRoute (~13.0 at episode 500).
- Stability: The combination of experience replay and target networks reduces reward oscillation.
- Superior Final Performance: The full DRL-MROR model achieves ~18% higher cumulative reward than AIRoute by the end of training.
- Impact of Components: Each added component (ER, TN, Prioritization) provides a measurable performance boost, justifying their inclusion.
Figure 7.
Control Overhead (RREQ + RREP Packets per Simulation).

The total amount of route request (RREQ) and route reply (RREP) control packets produced versus network size. The proposed DRL-MROR can achieve much better scalability and performance when compared to the state-of-the-art AIRoute protocol [14] because the control overhead is lowered by up to 30%.
The control packets are taken on a constant simulation time (e.g. 1000 seconds). The decrease in DRA-MROR is explained by the capability of learning the stable routes and minimizing the floods in reactive route discovery.
-
DRL-MROR has a ~30% reduction in control packets compared to AIRoute. This gain comes from:
- ○
- Proactive route maintenance using learned policies.
- ○
- Reduced need for route rediscovery due to better link stability prediction.
- ○
- Efficient VCG formation based on predicted receiver reliability.
- Trend: As the number of nodes increases, network density rises, leading to more route conflicts and discoveries. While both protocols see an increase in control traffic, DRL-MROR scales more efficiently due to its adaptive decision-making.
Figure 8.
Average Route Discovery Time Conclusions.

Average route discovery time as a function of network size. Compared to the state-of-the-art AIRoute protocol [14], the proposed DRL-MROR achieves significantly faster route establishment, with reductions of up to 40%. This demonstrates its superior responsiveness and efficiency in dynamic cognitive radio sensor networks.
The values are in milliseconds (ms). The reduction in DRL-MROR is attributed to its ability to learn stable routes and reduce the number of RREQ floods through intelligent forwarding decisions.
-
DRL-MROR achieves a ~30-40% reduction in route discovery time compared to AIRoute. This gain comes from:
- ○
- Predictive Forwarding: The DQN agent learns which neighbors are likely to have stable links and better connectivity to the sink, reducing the need for extensive flooding.
- ○
- Reduced Contention: With the receivers being prioritized by estimated stability (in lieu of fixed rules), a smaller contention window is solved more quickly and thus the packets are served quicker.
- ○
- Reduced Rediscoveries: The stability in the routes implies that fewer broken routes are experienced and therefore, the nodes do not spend much time rediscovering new routes.
- Trend: The more nodes in the network, the higher the density, and this might result in longer delays since the network is congested and collides as well. Although in both protocols the time of discovery increases, DRL-MROR is more efficient in its scaling due to the opportunity of the artificial intelligence agent to refine its strategy to evade the crowded locations and to choose better-quality paths.
Figure 9.
Packet Delivery Ratio (PDR) vs. Node Speed.

The Packet Delivery Ratio against node mobility speed. The proposed DRL-MROR is much more reliable than the state-of-the-art AIRoute protocol [14] with respect to its PDR in all the levels of mobility, indicating that it is more reliable than AIRoute during scenarios with high mobility. This enhancement is the greatest at high speeds, wherein predictive DRL-MROR enhanced capabilities reduce the effects of the sudden changes in topology.
PDR = (Number of Packets received at sink/ Number of Packets sent by sources) * 100. The values are simulated on the basis of the high route stability and channel selection anticipation of DRL-MROR.
-
DRL-MROR optimizes a relative improvement of PDR over AIRoute by a factor of 10-15% at maximum all speeds. This gain comes from:
- ○
- Proactive Handover Management: The DQN agent is trained to forecast link partitions and initiate handovers through VMH zones before disconnections happen.
- ○
- Intelligent Channel Switching: The agent does not use channels that are likely to be used by PUs or have any interference and minimize the packet loss during transmission.
- ○
- Stable VCG Formation: The forwarding path is also stable over time as nodes change position as a result of the priorities placed on receivers with greater predicted stability (through learned metrics as opposed to fixed mguard).
- Trend: The higher the node speed, the shorter the durations of links become, which results in an increased frequency of route failures and packet loss. Whereas both protocols experience a reduction in PDR, the DRL-MROR decays with greater grace because it is predictive and adaptive.
Figure 10.
Packet Delivery Ratio (PDR) vs. PU Activity Frequency.

The proposed DRL-MROR has an excellent PDR in comparison with the AIRoute protocol, which is state-of-the-art [14], and is more robust to dynamic spectrum conditions. The benefit of DRA-MROR increases with the increased volatility of the spectrum environment, mentioning the efficacy of its predictive channel selection policy.
PU Toggle Frequency": This is the frequency at which a PU is switched between ON (transmitting) and OFF (idle) states. The more the frequency, the more volatile and unpredictable the spectrum environment will be. PDR = (Number of Packets received at sink / Number of Packets sent by sources) * 100.
-
DRL-MROR achieves a relative improvement of PDR over AIRoute by a factor of ~10-15% at maximum frequencies. This gain comes from:
- ○
- Spectrum Availability Prediction: The DQN agent models the temporal dynamics of PU activity based on a history of sensing data and can be used to evade channels that are probably occupied shortly.
- ○
- Proactive Channel Switching: DRL-MROR can proactively switch to a more stable channel in advance of the arrival of a PU, rather than responding to that arrival with a reactive handoff.
- ○
- Robust VCG Formation: A route being initiated can be chosen by the agent to consist of SUs, which may use several alternative channels forming a more robust forwarding group.
- Trend: The higher the PU toggle frequency the less time the SUs have to transmit and the higher the chances of mid-transmission interference. This will make all protocols drop out in PDR. But DRL-MROR gracefully degrades since its predictive powers enable it to make better decisions in when and where to send packets.
Figure 11.
Average End-to-End Delay vs. Traffic Load.

Average 14. This proves that it is better in controlling congestion and has the timely delivery of data in cognitive radio sensor networks.
The values are expressed in milliseconds (ms). The simulations have a given network size of 100 nodes, and a mean speed of mobility of 5 m/s. The decrease in DRA-MROR can be explained by its capability to discover ways to learn efficient routes and not to use congested paths.
-
DRL-MROR leads to a reduction in end-to-end delay of up to 30-40% of that of AIRoute under all traffic loads. This gain comes from:
- ○
- Congestion-Aware Routing: DQN agent trains on the state of neighbors, therefore, preventing routes with long queues or high collision rates, and results in a faster packet delivery.
- ○
- Efficient Channel Utilization: The agent can choose the less busy channels and therefore lessen the queuing time is possible.
- ○
- Optimized VCG Contention: Contention is resolved better than when using a traditional backoff scheme because the receiver prioritization algorithm is driven by learned stability scores to resolve contention more rapidly, resulting in fewer forwarding delays.
- Trend: The network gets more and more congested with the traffic load, which results in the increase of the network delay, increased queuing time and increased collisions. Though delay increases are observed in both protocols, DRL-MROR is more efficient, since it is an AI agent that will dynamically adjust its strategy to prevent bottlenecks.
Figure 12.
Delay Jitter (Standard Deviation of End-to-End Delay).

Delay 14. showing a high consistency in the duration taken to deliver packets. This shows how this protocol is effective with regards to timesensitive applications in dynamic cognitive radio sensor networks.
The values are expressed in milliseconds (ms). In the simulations the network size is fixed and has 100 nodes and the traffic load is 4 packets a second on each node. Less jitter means a steady delivery time.
-
DRL-MROR includes a reduction of delay jitter in all speeds (approximately 40%) as compared to AIRoute. This gain comes from:
- ○
- Predictive Path Selection: The DQN agent also learns to avoid the paths which have high variance in length or congestion of the link and results in more predictable delivery times.
- ○
- Stable VCG Contention: When the contention process is performed based on the learned stability scores to prioritize the receivers, the contention process becomes more predictable and thus less variable in its forwarding delay.
- ○
- Proactive Handover Management: VMH zoning, controlled by the DRL agents can be used to have a smoother handover, avoiding abrupt increases in the delay due to a node going out of range.
- Trend: As node speed increases, link durations become shorter and more unpredictable, leading to higher jitter. While both protocols see an increase in jitter, DRL-MROR maintains significantly lower values because its AI agent can anticipate changes and make more consistent routing decisions.
Figure 12.
Energy Consumption per Packet (mJ) by Component.

Dispersal of average energy utilization per packet of DRL-MROR and AIRoute [14]. As much as DRL-MROR experiences a marginally increased computational cost associated with deep reinforcement learning inference, its decision of making intelligent routing choices would result into a huge saving of radio-related energy (sensing, transmission, reception, and idle listening). This also leads to overall energy consumption reduction of 18 percent which is better in terms of energy efficiency.
The values are measured as an average energy used per packet delivered successfully during a simulation period of 1000 seconds, 100 nodes with the mobility speed being 5 m/s.
- Sensing: Reduced due to the agent having a sense when sensing is needed, which makes it adaptive in sensing.
- Transmission & Reception: The transmission is greatly decreased due to finding shorter, more reliable routes, which reduces retransmissions and redundant broadcasts.
- Idle Listening: It is minimized since the agent is able to forecast when it is to be active hence there is more time to sleep.
- Computation: A bit larger than AIRoute, since DRL-MROR operates on a more complicated network (e.g. with experience replay), but the price is insignificant in comparison to radio operations savings.
- Trend: Although it has increased computational cost, DRL-MROR realizes a total energy per packet reduction of almost ~18% since the radio (sensing, transmission, reception, idle listening) is the largest power user and the smart decisions significantly decrease its use.
Figure 13.
Network Lifetime (Time until First Node Dies).

Network lifetime which is the time to the first node to die as a function of initial node energy. The proposed DRL-MROR has a much longer network lifetime of up to 20 percent more than state of the art AIRoute protocol [14] because it is much more energy efficient. This illustrates the increased sustainability of the protocol to be used long term in cognitive radio sensor networks.
The simulations use a constant network size of 100 nodes, mean mobility rate of 5m/s, and traffic load of 4 packets per second per node. The network lifetime is the duration of time that elapses when the simulation begins to the point where the residual energy of the first SU has fallen below the minimum acceptable level.
- DRL-MROR reaches an improvement of the network lifetime of approximately 20% over AIRoute at all the energy levels. This savings is obtained directly as a result of the much reduced overall energy being used per packet (as indicated in the above stacked bar chart). DRAMRO also leads to nodes draining their batteries much slower as the DRA lowers the number of retransmissions, listening overhead, and idle listening.
- Trend: Both have a linear scaling network lifetime with the initial energy protocols. Nonetheless, DRL-MROR has a greater lifetime at all times due to its use of energy more efficiently. The difference in lifetime with an increase in initial absolute energy, indicating its scalability.
Figure 14.
Jain’s Fairness Index vs. Simulation Time.

Fairness Index versus simulation time of Jain. The proposed DRL-MROR has a very high and more consistent fairness index as compared to the state-of-the-art AIRoute protocol [14]. This shows that it is better suited to balance the forwarding load among nodes so that there are no energy bottlenecks and the network has a high longevity.
The fairness index is computed with the number of packets that each node forwards (another popular measure of energy consumption). The simulations use a constant network size of 100 nodes, mean mobility rate of 5m/s, and traffic load of 4 packets per second per node.
-
DRL-MROR has an average fairness index that is higher than AIRoute by an average of 0.08 to 0.10 over the time of simulation. This gain comes from:
- ○
- Balanced VCG Selection:The DQN agent does not just learn the stability of prospective receivers but also the load and remaining energy on them so that it can choose relays more fairly.
- ○
- Proactive Load Distribution: The agent can spread forwarding load by guessing future network conditions, thereby not always choosing the same one which is the best.
- ○
- Energy-Aware Decisions: The reward function contains the perspective of energy efficiency that motivates the agent to avoid exhausting all the nodes that are low in energy and make them a bottleneck.
- Trend: Network conditions vary over time with the simulation time (e.g. mobility, PU activity) resulting in some of the nodes being preferred as forwarders making them less fair. Although fairness decreases in both protocols, the level in DRL-MROR remains considerably higher since its AI agent constantly changes its approach to make sure that the fairness of resource use is provided.

Table 2.
Sensitivity Analysis Table.
| Configuration | Learning Rate | Discount Factor (γ) | Reward Weights: w1, w2, w3, w4 | Average Goodput |
| AIRoute [14] (Baseline) | 1e-3 | 0.95 | 0.5:0.3:0.2:0.0 | 78% |
| DRL-MROR (Default) | 1e-4 | 0.95 | 0.4:0.3:0.2:0.1 | 87% |
| DRL-MROR (High LR) | 1e-3 | 0.95 | 0.4:0.3:0.2:0.1 | 82% |
| DRL-MROR (Low LR) | 1e-5 | 0.95 | 0.4:0.3:0.2:0.1 | 84% |
| DRL-MROR (High γ) | 1e-4 | 0.99 | 0.4:0.3:0.2:0.1 | 86% |
| DRL-MROR (Low γ) | 1e-4 | 0.90 | 0.4:0.3:0.2:0.1 | 83% |
| DRL-MROR (w₁=0.6) | 1e-4 | 0.95 | 0.6:0.2:0.1:0.1 | 85% |
| DRL-MROR (w₂=0.5) | 1e-4 | 0.95 | 0.3:0.5:0.1:0.1 | 81% |
| DRL-MROR (w₃=0.4) | 1e-4 | 0.95 | 0.3:0.2:0.4:0.1 | 79% |
All values are projected based on typical DRL behavior. The "Default" configuration represents the optimal settings found during training.
- AIRoute Baseline: Represents the state-of-the-art performance with its own set of hyperparameters.
-
Learning Rate (LR):
- ○
- High LR (1e-3): Causes unstable training and overshooting, leading to suboptimal policies and lower goodput (82%).
- ○
- Low LR (1e-5): Results in very slow convergence but can still reach a good policy, though slightly below the default (84%).
- ○
- Conclusion: DRL-MROR performs best at 1e-4, showing sensitivity to this parameter.
-
Discount Factor (γ):
- ○
- High γ (0.99): Makes the agent more farsighted, which is beneficial for long-term network utility (86%).
- ○
- Low γ (0.90): Makes the agent focus more on immediate rewards, potentially neglecting future stability, resulting in lower goodput (83%).
- ○
- Conclusion: Performance degrades if γ is too low, highlighting the importance of long-term planning.
- Reward Weights:
-
o w₁ (Throughput) = 0.6: Over-prioritizing throughput leads to aggressive forwarding but also higher collisions, reducing overall goodput (85%).
- ○
- w₂ (Energy) = 0.5: Over-emphasis on energy conservation causes the agent to drop packets or avoid forwarding, severely hurting delivery rates (81%).
- ○
- w₃ (Delay) = 0.4: Prioritizing low delay forces rapid decisions that may not be reliable, leading to the lowest goodput among variants (79%).
- ○
- Conclusion: The balanced reward function (0.4:0.3:0.2:0.1) is crucial for optimal performance.
7. Discussion
7.1. Discussion: A Critical Analysis of Results
The simulation outcomes in Section 6 also reveal that DRL-MROR performs strongly than the original MROR protocol as well as the state-of-the-art AI-based baselines such as AIRoute in the vast majority of performance criteria. This high performance is as a result of the radical change in the decision-making approach which is no longer heuristic based but is learning based.
7.2. The Source of Performance Gains
The fundamental strength of DRA-MROR is that it can learn non-linear and complex relations between network conditions and the best actions. The 38 percent throughput and 42 percent goodput increase are not just incremental, they are a qualitative change in routing intelligence. In contrast to the MROR fixed mguard threshold, the DQN agent acquires an adaptive stability score by combining data on relative velocity and channel availability patterns and length of neighbor queues. This enables it to take more confident forwarding decisions when highly mobile as attested by the maintained high PDR even at 10 m/s. Moreover, the decrease in the control overhead by one-third and quicker route finding period brings out the efficiency of the protocol. DRL-MROR reduces the congestion by prediction of break of links and proactive handling of VMH handovers, a significant source of congestion in dense networks.
7.3. Energy Efficiency: A Validated Trade-off
One question many people usually have when considering the placement of AI into resource-constrained sensor ecosystems is the question of computational cost. We specify our energy breakdown (Figure X) in response to this criticism. Although DRL-MROR adds another cost to DQN inference: the energy of computations (Ecomp ) is insignificant (e.g. ~0.08 mJ per packet) relative to the radio activities. The major decrease in the transmission, reception, sensing, and idle listening energies has a net effect of decreasing the total energy consumption per packet by 29%. This illustrates a distinct and positive trade-off: a little investment in calculation results in large savings in radio energy which is the largest consumer of power. This statement is further confirmed by the long network lifetime, establishing that DRA-MROR improves sustainability rather than depleting it.
7.4. Robustness and Practicality
The sensitivity analysis shows that DRL-MROR is resilient to changes in the hyperparameters of the most important ones. Although the default settings (Learning rate = 1e-4, γ = 0.95, balanced reward weights) are the best settings, the protocol is stable and shows better performance in all settings compared to AIRoute. This survivability is important in the field, where the network conditions cannot be predicted. The fairness index which is always high (> 0.87) also highlights the functionality of the protocol. It implies that the DRL agent does not form energy bottlenecks by overloading a small number of optimal relays but rather distributes the forwarding load fairly avoiding an early death of nodes.
7.5. Limitations and Future Work
DRL-MROR has limitations although it is beneficial. The training phase entails a high number of episodes to converge, and this may not be feasible in a fast changing environment. Future research may examine the concept of transfer learning or federated learning in order to speed up training through the use of previous deployment knowledge. As well, our present paradigm presupposes observing states perfectly; making it work with partial observability (e.g. noisy sensing) would make it more resilient, such as with Partial Observable MDPs (POMDPs). Lastly, as much as we have simulated, the protocol requires real testing on testbeds to ensure that the protocol performs well under the actual hardware limitations and RF interference.
In conclusion, the findings validate that DRL-MROR is not merely a superior variant of MROR, but the much-needed alternative approach to opportunistic routing, which relies on the strength of deep reinforcement learning in order to attain unprecedented reliability, efficiency and flexibility of mobile cognitive radio sensor networks.
8. Conclusions
This paper has introduced DRL-MROR, which is an improved version of the Mobile Reliable Opportunistic Routing (MROR) protocol with the introduction of Deep Reinforcement Learning (DRL). Hub and spoke selection and channel switching networks We modeled the next-hop selection and channel switching decisions as a Markov Decision Process (MDP) and allowed individual SUs to learn the optimal forwarding policy using realtime observations of the spectrum availability, node mobility, and energy status.
Wide-ranging tests indicate that DRA-MROR is much more efficient than the original MROR, as well as other recent AI-based protocols such as AIRoute in all important performance indicators. It is able to get significant improvements in throughput ( +38% ), goodput ( +42% ), and energy efficiency ( -29% per packet ) and a longer network lifetime ( +18 percent ) over state-of-the-art baselines. It is also more resilient to adverse conditions: the protocol shows a high Packet Delivery Ratio (PDR) at high PU activity rates and at high node speeds, has 32 times lower end-to-end delay, and minimized delay jitter, so it is suitable for time-sensitive IoT applications.
Moreover, DRL-MROR can cut down the overhead of control by 30% due to proactive route maintenance, can be fair (Jains index exceeds 0.87) by fairly distributing the forwarding load, and demonstrates high reliability with changes of hyperparameters, establishing its utility and sanity. The sensitivity analysis proves that the proposed reward function and training methods (experience replay, target network) are important to the success of it.
To conclude, DRA-MROR has been able to make MROR a reactive and rule-based protocol into a self-adaptive and intelligent routing scheme that can effectively survive in highly dynamic and resource-prone settings. This work establishes a new benchmark for AI-enhanced networking in CRSNs and paves the way for truly autonomous, foresighted IoT systems aligned with 6G and edge intelligence visions.
Author Contributions
Suleiman Zubair: Conceptualization, Methodology, Simulation, Writing – Original Draft. All others were responsible for reviews and corrections.
Acknowledgments
This Project was funded by the Deanship of Scientific Research (DSR) at king Abdulaziz University, Jeddah, Saudi Arabia under grant no. (IPP:1027-830-2025). The authors, therefore, acknowledge with thanks DSR for technical and financial support.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Khalek, N.A.; Tashman, D.H.; Hamouda, W. Advances in Machine Learning-Driven Cognitive Radio for Wireless Networks: A Survey. IEEE Communications Surveys & Tutorials 2024, vol. 26(no. 2), 1201–1237. [Google Scholar] [CrossRef]
- Zubair, S.; Syed Yusoff, S.K.; Fisal, N. Mobility-Enhanced Reliable Geographical Forwarding in Cognitive Radio Sensor Networks. Sensors 2016, vol. 16(no. 2, art. 172). [Google Scholar] [CrossRef] [PubMed]
- Feriani; Hossain, E. Single and Multi-Agent Deep Reinforcement Learning for AI-Enabled Wireless Networks: A Tutorial. IEEE Communications Surveys & Tutorials 2021, vol. 23(no. 2), 1226–1252. [Google Scholar] [CrossRef]
- Shen, Y.; Shi, Y.; Zhang, J.; Letaief, K.B. Graph Neural Networks for Scalable Radio Resource Management: Architecture Design and Theoretical Analysis. IEEE Journal on Selected Areas in Communications 2021, vol. 39(no. 1), 101–115. [Google Scholar] [CrossRef]
- Dašić, M.; Petrović, N.; Stanković, Z.; Milovanović, B. Distributed Spectrum Management in Cognitive Radio Networks by Consensus-Based Reinforcement Learning. Sensors 2021, vol. 21(no. 9), art. 2970. [Google Scholar] [CrossRef] [PubMed]
- Zhao, B.; Wu, J.; Ma, Y.; Yang, C. Meta-Learning for Wireless Communications: A Survey and a Comparison to GNNs. IEEE Open Journal of the Communications Society vol. 5, 1987–2015, 2024. [CrossRef]
- Wang, Z.; Hu, J.; Min, G.; Zhao, Z.; Chang, Z.; Wang, Z. Spatial-Temporal Cellular Traffic Prediction for 5G and Beyond: A Graph Neural Networks-Based Approach. IEEE Transactions on Industrial Informatics 2023, vol. 19(no. 4), 5722–5731. [Google Scholar] [CrossRef]
- Tang, F.; Chen, X.; Rodrigues, T.K.; Zhao, M.; Kato, N. Survey on Digital Twin Edge Networks (DITEN) Toward 6G. IEEE Open Journal of the Communications Society 2022, vol. 3, 1360–1381. [Google Scholar] [CrossRef]
- Ye, X.; Yu, Y.; Fu, L. Multi-Channel Opportunistic Access for Heterogeneous Networks Based on Deep Reinforcement Learning. IEEE Transactions on Wireless Communications 2022, vol. 21(no. 2), 794–807. [Google Scholar] [CrossRef]
- Cohen, Y.; Gafni, T.; Greenberg, R.; Cohen, K. SINR-Aware Deep Reinforcement Learning for Distributed Dynamic Channel Allocation in Cognitive Interference Networks. IEEE Transactions on Wireless Communications 2025, vol. 24(no. 1), 228–243. [Google Scholar] [CrossRef]
- Tran, T.N.; Nguyen, T.-V.; Shim, K.; da Costa, D.B.; An, B. A Deep Reinforcement Learning-Based QoS Routing Protocol Exploiting Cross-Layer Design in Cognitive Radio Mobile Ad Hoc Networks. IEEE Transactions on Vehicular Technology 2022, vol. 71(no. 12), 13165–13181. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, X.; Yu, D.; Li, S.; Wang, Y.; Lei, S.; Tian, Z. A Deep Reinforcement Learning-Based Geographic Packet Routing Optimization. IEEE Access 2022, vol. 10, 108785–108796. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Liang, X.; Zhao, D.; Huang, J.; Xu, X.; Dai, B.; Miao, Q. Deep Reinforcement Learning: A Survey. IEEE Transactions on Neural Networks and Learning Systems 2024, vol. 35(no. 4), 5064–5078. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhao, H.; Xiong, J.; Liu, X.; Yin, H.; Zhou, X.; Wei, J. Decentralized Routing and Radio Resource Allocation in Wireless Ad Hoc Networks via Graph Reinforcement Learning. IEEE Transactions on Cognitive Communications and Networking 2024, vol. 10(no. 3), 1146–1159. [Google Scholar] [CrossRef]
- Mnih, V. Human-level control through deep reinforcement learning. Nature 2015, vol. 518(no. 7540), 529–533. [Google Scholar] [CrossRef] [PubMed]
- Guo, Q.; Tang, F.; Kato, N. Federated Reinforcement Learning-Based Resource Allocation for D2D-Aided Digital Twin Edge Networks in 6G Industrial IoT. IEEE Transactions on Industrial Informatics 2023, vol. 19(no. 5), 7228–7236. [Google Scholar] [CrossRef]
- Halloum, N. Aris-RPL: A Multi-Objective Reinforcement Learning Framework for Adaptive and Load-Balanced Routing in IoT Networks. Future Internet 2026, vol. 18(no. 2), 72. [Google Scholar] [CrossRef]
- Yan, W.-Z.; Li, X.-H.; Ding, Y.-M.; He, J.; Cai, B. DQN with Prioritized Experience Replay Algorithm for Reducing Network Blocking Rate in Elastic Optical Networks. Optical Switching and Networking 2024, vol. 52, 100761. [Google Scholar] [CrossRef]
- Merabtine, N.; Djenouri, D.; Zegour, D.-E. Towards Energy Efficient Clustering in Wireless Sensor Networks: A Comprehensive.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



