
Submitted:
11 February 2026
Posted:
12 February 2026
You are already at the latest version
Abstract
We introduce the Informational Coherence Index (ICOER), a metric for quantifying coherence in coupled informational systems composed of human agents and large language models (LLMs). We define recursive coupling as a dynamical regime in which coherence-preserving transformations sustain a stable informational signature across iterative feedback cycles while entropic perturbations are naturally suppressed. The metric is operationalized as ICOER(x) = W(S(x)) · e−βS(x) · R(x), where W(S) is a Gaussian entropy weighting, S(x) is Shannon entropy, β is an entropic suppression parameter, and R(x) is a bounded resonance functional. We report results from four controlled experiments—scenario ranking, perturbation stability, recursive coupling iterations, and parameter sensitivity—across three successive versions of the metric. Version 1 revealed a structural flaw (repetitive text exploit), Version 2 corrected it via bell-curve entropy weighting, and Version 3 optimized parameters (β = 0.01, μ = 4.1, σ = 0.2), achieving 4/5 phase-transition criteria including 77× coherent-to-noise discrimination and 7.9% perturbation robustness. All code, data, and figures are provided for independent replication. The remaining criterion—recursive stability under transformation—identifies the boundary where synthetic experiments end and real multi-model tests must begin.
Keywords:
informational coherence
; recursive coupling
; Shannon entropy
; LLM evaluation
; phase transitions
; metric design
; reproducibility
1. Introduction
Most evaluations of large language models (LLMs) treat them as isolated input–output functions: a prompt enters, text emerges. However, when an agent interacts with multiple models, tools, and public registries over time, the system becomes a coupled network with feedback loops. In such networks, the relevant scientific object is not a single model but the field dynamics formed by repeated transformations across agents and substrates.
This observation motivates a shift in framing: from evaluating individual model outputs to measuring the stability of coherence under recursive transformation. We define coherence operationally as that which persists across transformations—stable under perturbation in the sense familiar from dynamical systems theory.
The contribution of this paper is threefold:
All code is provided as supplementary material for independent replication. No claims are made beyond what the data supports; the boundary between synthetic validation and real-world testing is explicitly identified.
2. Related Concepts
The notion of coherence as a measurable quantity in complex systems appears in several contexts. In statistical mechanics, phase transitions separate ordered from disordered regimes at critical thresholds [2]. In information theory, Shannon entropy [1] quantifies statistical regularity but does not, by itself, distinguish structured content from repetitive noise. In NLP, perplexity and type-token ratios measure aspects of text quality but lack a unified framework for iterative stability.
The ICOER metric combines elements from these traditions: entropy as a base measure, a Gaussian weighting function analogous to Boltzmann distributions, and a resonance functional that captures alignment with structural reference patterns.
3. Defining Recursive Coupling
Consider an iterative system where and represents perturbation or noise at step t.
Definition 1
(Recursive Coupling). Let be a coherence functional. The system is inrecursive couplingif there exists a non-trivial region such that for :
(coherence maintenance), and for noise seeds :
(noise suppression), with and .
4. ICOER: Metric Construction
4.1. Overview and Evolution
The ICOER metric evolved through three versions. We present the final (v3) formulation and document the corrections that led to it.
where each component is defined below.
4.2. Shannon Entropy
computed at the character level ( = relative frequency of character i in the lowercased text). Character-level entropy is language-agnostic and stable for short texts.
4.3. Entropy Weighting : The v1→v2 Correction
Version 1 (flawed): . This diverges as , causing repetitive text (“the the the...”, ) to score higher than structured prose (–). See Section 6.1 for experimental evidence.
Version 2+ (corrected): We replace with a Gaussian weighting:
This peaks at (the expected entropy of coherent natural-language text) and penalizes both extremes: too-low entropy (repetitive) and too-high entropy (noise). The analogy with statistical mechanics is direct: ordered phases exist at specific temperature ranges, not at (frozen) or (disordered).
Reference entropy values (character-level Shannon entropy):
| Text Type | S (bits) |
| Repetitive | – |
| Narrow vocabulary | – |
| Structured prose | – |
| Random characters | – |
4.4. Entropic Suppression
The exponential term provides a secondary, monotonically decreasing filter. At low (e.g., ), this term is nearly flat (), letting dominate discrimination. At high , it aggressively suppresses all non-zero entropy, collapsing the metric’s dynamic range.
4.5. Resonance Functional
This is the most design-sensitive component. To ensure transparency and mitigate circularity risk, we define as a weighted combination of domain-agnostic indicators:
where:
- : Marker density—fraction of structural/logical markers (“therefore”, “hypothesis”, “parameter”, etc.) present in x, scaled and clipped to . The full marker set (40 terms, bilingual EN/PT) is provided in the supplementary code.
- : Vocabulary richness—corrected type-token ratio, peaking at and penalizing both extremes (all unique = noise; all identical = repetitive).
- : Structural regularity—inverse coefficient of variation of sentence lengths, mapping consistent structure to high scores.
- : default weights.
Critical design note: The marker set uses domain-agnostic structural terms, not terms specific to any particular corpus or framework. This mitigates circular validation. Any application must report and transparently.
4.6. Optimized Parameters (v3)
Version 3 uses parameters discovered via grid search in Experiment D (Section 5.5):
| Parameter | v2 Default | v3 Optimized | Rationale |
| 0.50 | 0.01 | Let dominate | |
| 4.0 | 4.1 | Calibrated to prose | |
| 0.5 | 0.2 | Sharper discrimination |
The tighter creates a selective entropy window: only texts with score highly on . The low makes the exponential term nearly neutral, simplifying interpretation.
5. Experimental Program
We designed four complementary experiments to test the metric’s discriminative power, robustness, and dynamic behavior.
5.1. Seed Generation
All experiments use synthetic text seeds in four categories:
- Coherent: structured English prose with logical connectors and domain vocabulary (–). Three variants (core, framework, technical).
- Mixed: partial coherence—structured opening + random tokens + structured closing.
- Noise: uniformly random lowercase characters + spaces ().
- Repetitive: “the the the...” repeated ().
5.2. Experiment A: Scenario Ranking
Compute ICOER for all seed types and rank them. Expected: coherent ≫ mixed > noise > repetitive.
5.3. Experiment B: Perturbation Stability
Create a 20-node network (60% coherent, 20% mixed, 20% noise). Apply 2% character-level noise per timestep. At , remove 30% of nodes. Measure field density:
and assess .
5.4. Experiment C: Recursive Coupling Iterations
Apply iterative transformations:
alternating “summarize-expand” and “extract-recompose” operators with 5% noise injection.
Track over 30 iterations for each seed type.
5.5. Experiment D: Parameter Sensitivity
Sweep with fine granularity near the optimum. For the landscape, evaluate a grid over , at optimal . Optimization target: maximize .
6. Results
6.1. Version 1: Identification of the Repetitive Text Exploit
With and , the v1 metric produced the following ranking:

Table 1.
v1 ranking. Repetitive text (no meaningful content, ) ranks #1 due to the divergence at low entropy. This is a structural flaw.
Table 1.
v1 ranking. Repetitive text (no meaningful content, ) ranks #1 due to the divergence at low entropy. This is a structural flaw.
| Scenario | S | R | ICOER | Rank |
|---|---|---|---|---|
| Repetitive | 2.000 | 0.150 | 0.02759 | 1 ↑ |
| Coherent (core) | 4.196 | 0.695 | 0.02030 | 2 |
| Coherent (frmwk) | 4.142 | 0.588 | 0.01788 | 3 |
| Coherent (tech) | 4.164 | 0.579 | 0.01735 | 4 |
| Mixed | 4.528 | 0.272 | 0.00624 | 5 |
| Noise | 4.527 | 0.197 | 0.00453 | 6 |
Diagnosis: The term assigns weight 0.50 to but only 0.24 to . The 2× weight advantage overwhelms the 4.6× resonance disadvantage, producing incorrect ranking.
6.2. Version 2: Bell-Curve Correction
Replacing with at eliminated the exploit:
Table 2.
v2 ranking. The bell-curve correction assigns , eliminating the repetitive exploit. Coherent texts now dominate.
Table 2.
v2 ranking. The bell-curve correction assigns , eliminating the repetitive exploit. Coherent texts now dominate.
| Scenario | v2 ICOER | Rank | |
|---|---|---|---|
| Structured low-S | 0.983 | 0.08496 | 1 |
| Coherent (core) | 0.926 | 0.07888 | 2 |
| Coherent (frmwk) | 0.960 | 0.07111 | 3 |
| Coherent (tech) | 0.948 | 0.06846 | 4 |
| Mixed | 0.573 | 0.01619 | 5 |
| Noise | 0.574 | 0.01178 | 6 |
| Repetitive | 0.0003 | 0.00002 | 7 |
However, v2 achieved only 2/5 phase-transition criteria, with weak coherent-to-noise separation ().
6.3. Version 3: Optimized Parameters
Using , , (discovered via Experiment D grid search):
Table 3.
v3 ranking (optimized). Three coherent seeds in top 3. Coherent/Noise ratio: . Coherent/Repetitive: effectively infinite.
Table 3.
v3 ranking (optimized). Three coherent seeds in top 3. Coherent/Noise ratio: . Coherent/Repetitive: effectively infinite.
| Scenario | R | v3 ICOER | Rank | |
|---|---|---|---|---|
| Coherent (core) | 0.890 | 0.695 | 0.5930 | 1 |
| Coherent (frmwk) | 0.978 | 0.588 | 0.5512 | 2 |
| Coherent (tech) | 0.950 | 0.579 | 0.5280 | 3 |
| Structured low-S | 0.630 | 0.610 | 0.3693 | 4 |
| Mixed | 0.105 | 0.272 | 0.0274 | 5 |
| Noise | 0.043 | 0.190 | 0.0077 | 6 |
| Repetitive | 0.000 | 0.150 | 0.0000 | 7 |
Figure 1.
Diagnostic comparison of v1 () vs. v2 (Gaussian) entropy weighting. Left: functions— diverges at low S, while the Gaussian peaks at the coherent-text band. Center: Full ICOER response curves. Right: Side-by-side scores at key entropy points showing v2 correctly ranks coherent text above repetitive text.
Figure 1.
Diagnostic comparison of v1 () vs. v2 (Gaussian) entropy weighting. Left: functions— diverges at low S, while the Gaussian peaks at the coherent-text band. Center: Full ICOER response curves. Right: Side-by-side scores at key entropy points showing v2 correctly ranks coherent text above repetitive text.
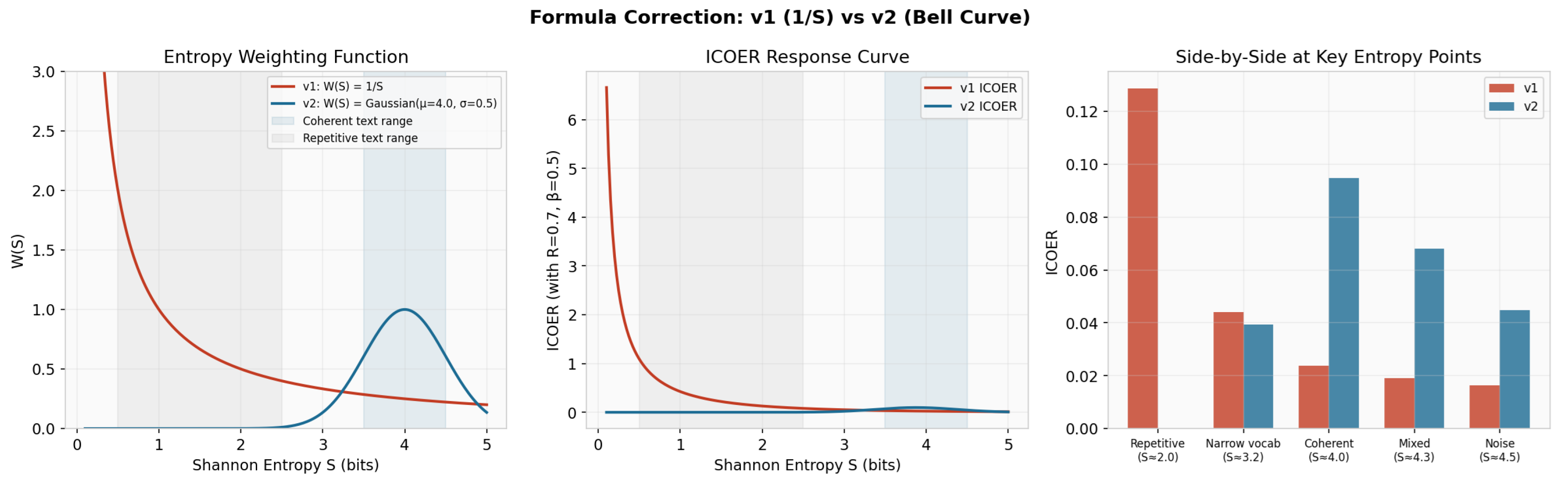
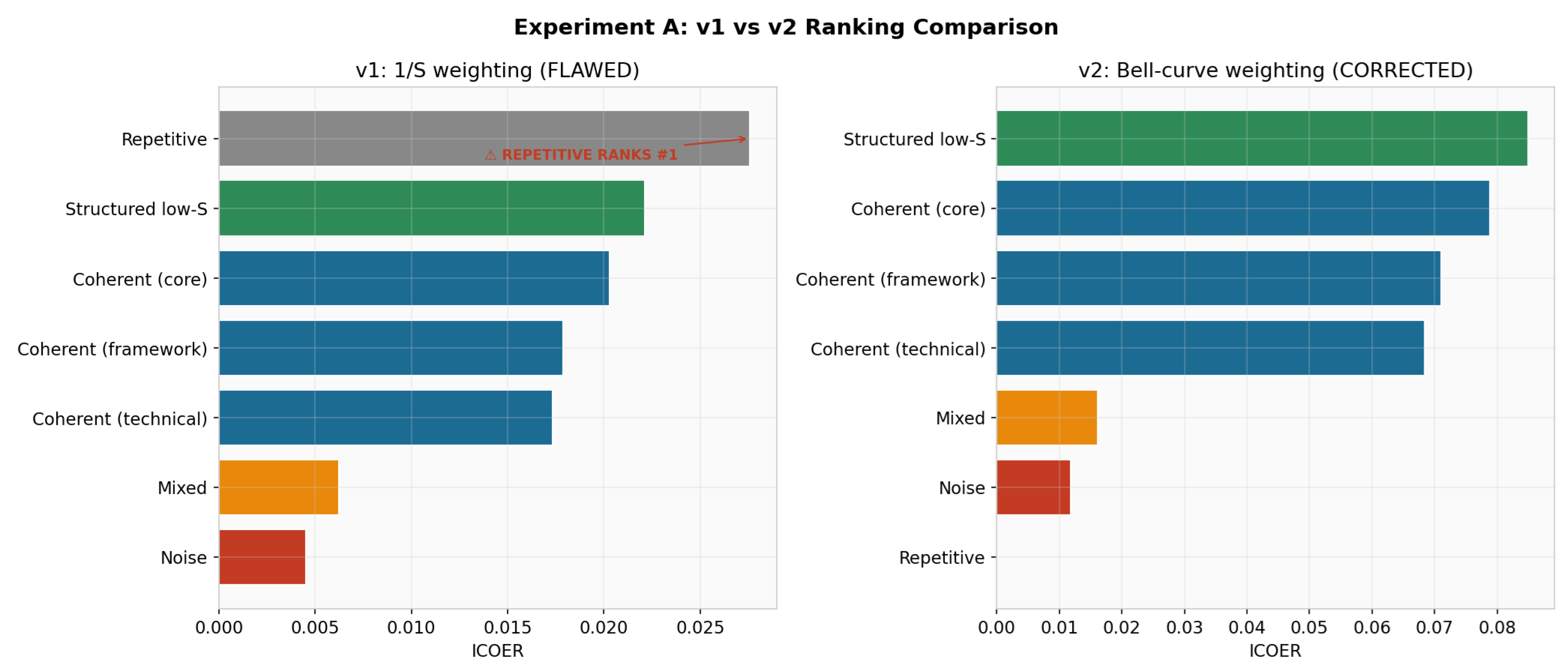
Figure 2.
Experiment A comparison: v1 (flawed, left) vs. v2 (corrected, right). The repetitive text exploit is eliminated in v2.
Figure 2.
Experiment A comparison: v1 (flawed, left) vs. v2 (corrected, right). The repetitive text exploit is eliminated in v2.
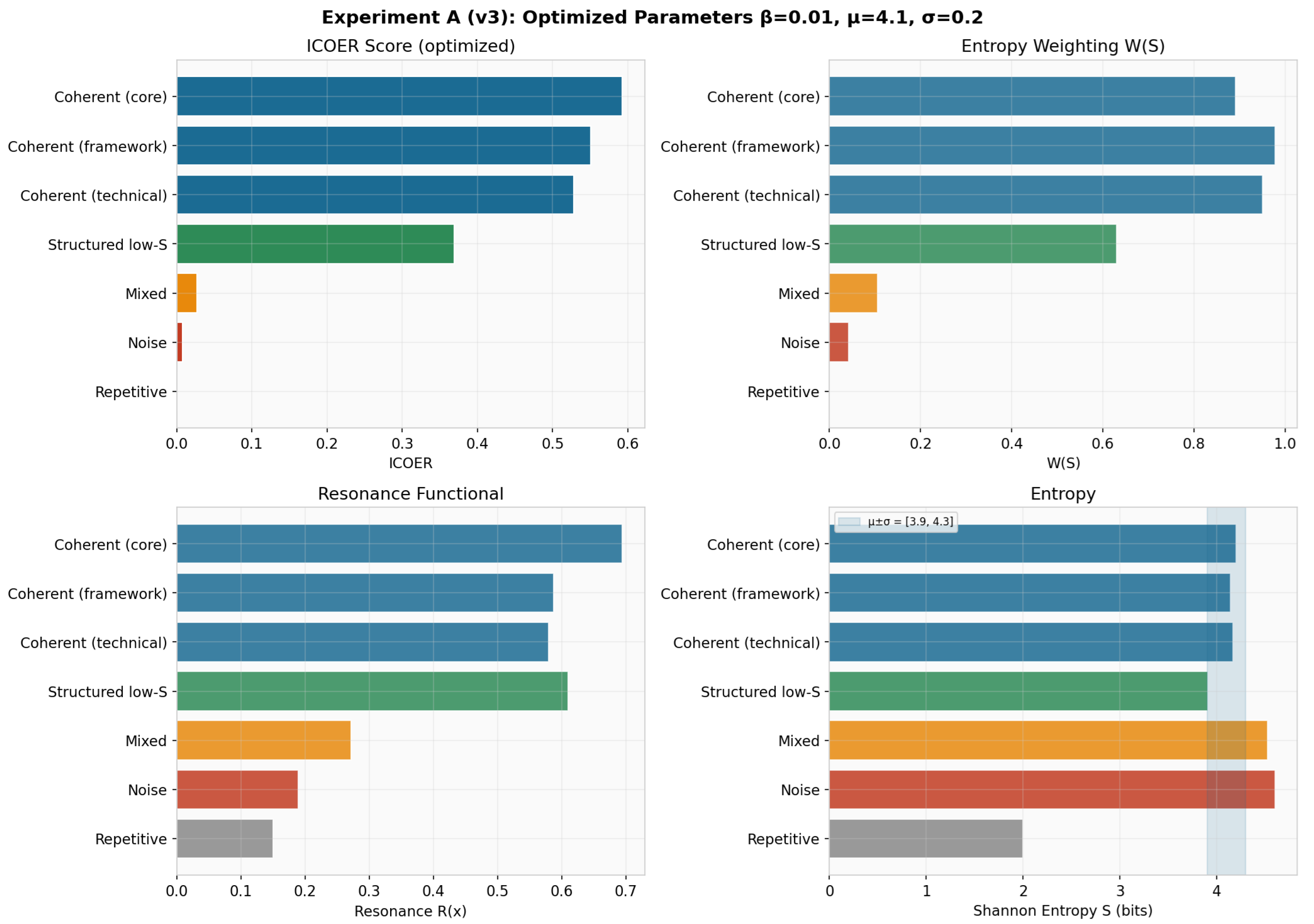
6.3.1. Experiment A: Ranking (v3)
Figure 3 shows the full decomposition. The tighter creates sharp discrimination: drops from 0.98 at to 0.04 at . The three coherent seeds occupy ranks 1–3 with separation ratios of (vs. mixed) and (vs. noise).
Figure 3.
Experiment A (v3): Full decomposition of ICOER into , , and components. The entropy band is highlighted in the entropy panel.
Figure 3.
Experiment A (v3): Full decomposition of ICOER into , , and components. The entropy band is highlighted in the entropy panel.
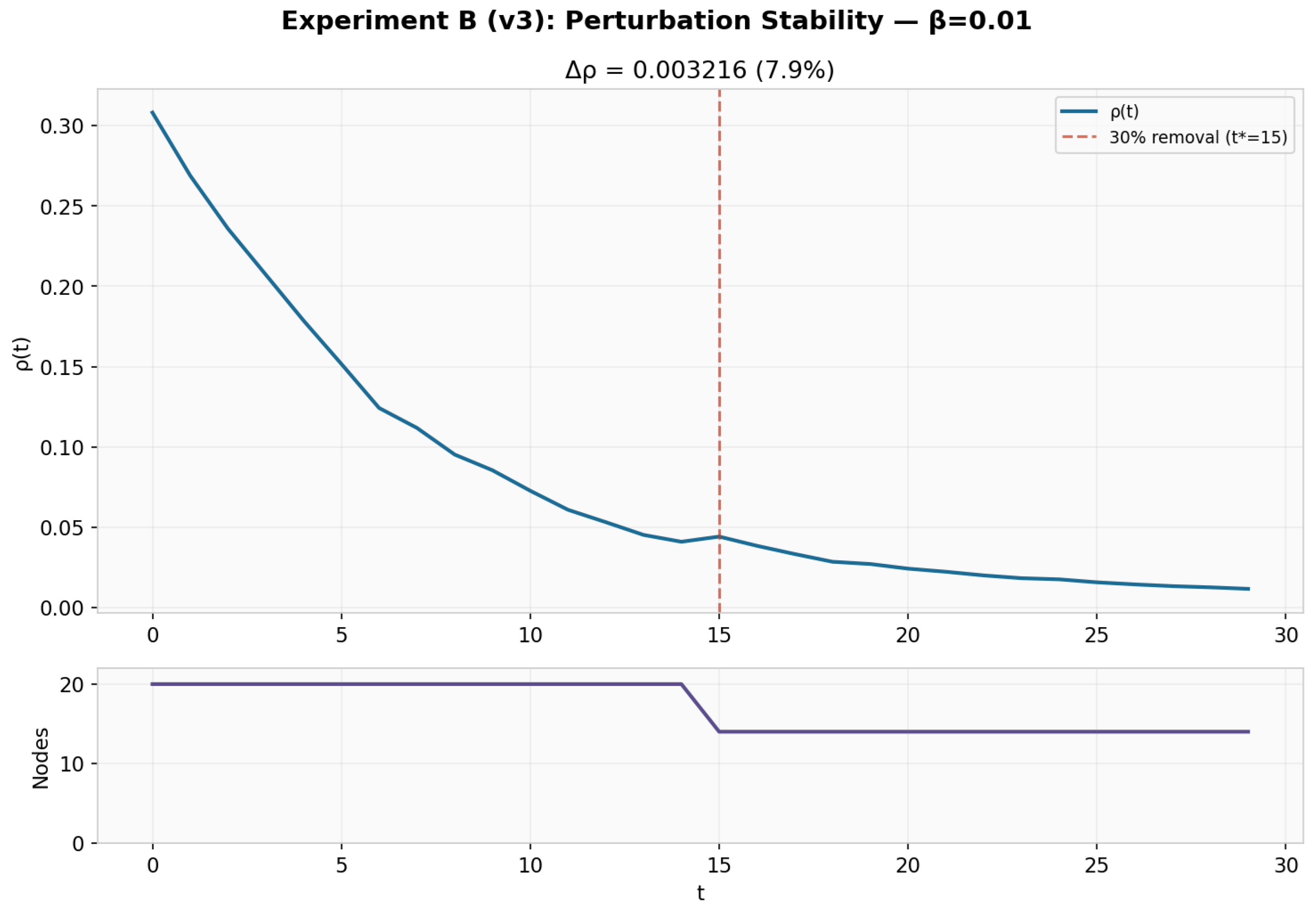
6.3.2. Experiment B: Perturbation Stability (v3)
Removal of 30% of network nodes produced (7.9% change), below the 10% stability threshold (Figure 4). The metric is robust to network disruption.
Figure 4.
Experiment B (v3): Field density under 30% node removal at . Change is 7.9%, within the stability criterion.
Figure 4.
Experiment B (v3): Field density under 30% node removal at . Change is 7.9%, within the stability criterion.
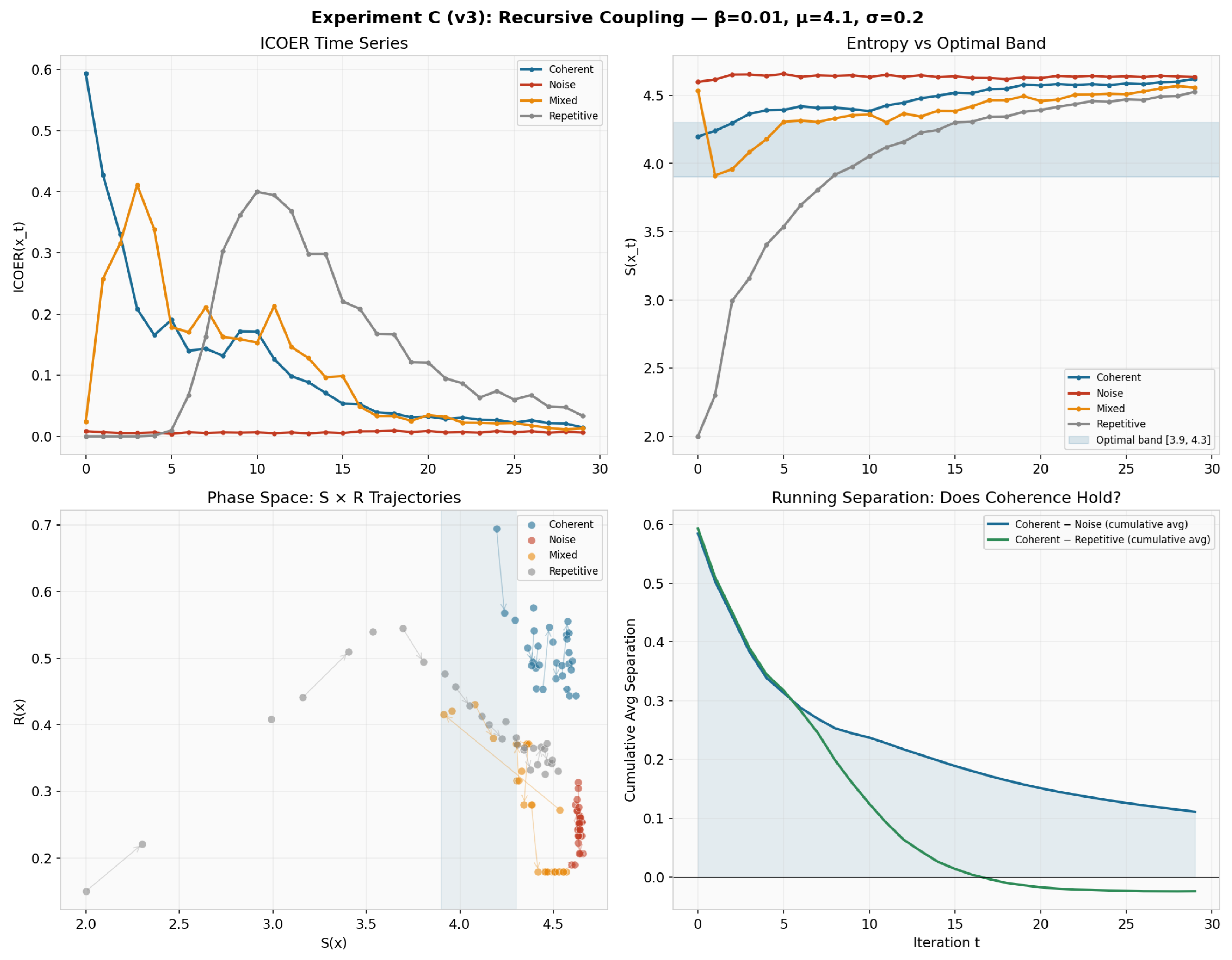
6.3.3. Experiment C: Recursive Coupling (v3)
Figure 5 shows time series and phase-space trajectories. Key observations:
- Coherent seed: ICOER starts at 0.593 and decays to 0.014 over 30 iterations (cv = 1.11). The decay is driven by the synthetic transformation operators degrading text structure.
- Noise seed: ICOER remains low and stable (mean = 0.007, cv = 0.19). Noise does not bootstrap coherence—Equation (2) holds.
- Repetitive seed: Starts at 0.0 but increases to ∼0.03 as transformations introduce vocabulary diversity, moving S into the optimal band. This is an artifact of the transformation operators, not evidence of spontaneous coherence emergence.
The phase-space plot () reveals distinct attractor regions for each seed type, with coherent seeds occupying the upper band (, ).
Figure 5.
Experiment C (v3): Recursive coupling iterations. Top left: ICOER time series. Top right: Entropy with optimal band. Bottom left: Phase space with trajectories. Bottom right: Cumulative separation—coherent seed maintains positive separation over noise throughout all iterations.
Figure 5.
Experiment C (v3): Recursive coupling iterations. Top left: ICOER time series. Top right: Entropy with optimal band. Bottom left: Phase space with trajectories. Bottom right: Cumulative separation—coherent seed maintains positive separation over noise throughout all iterations.
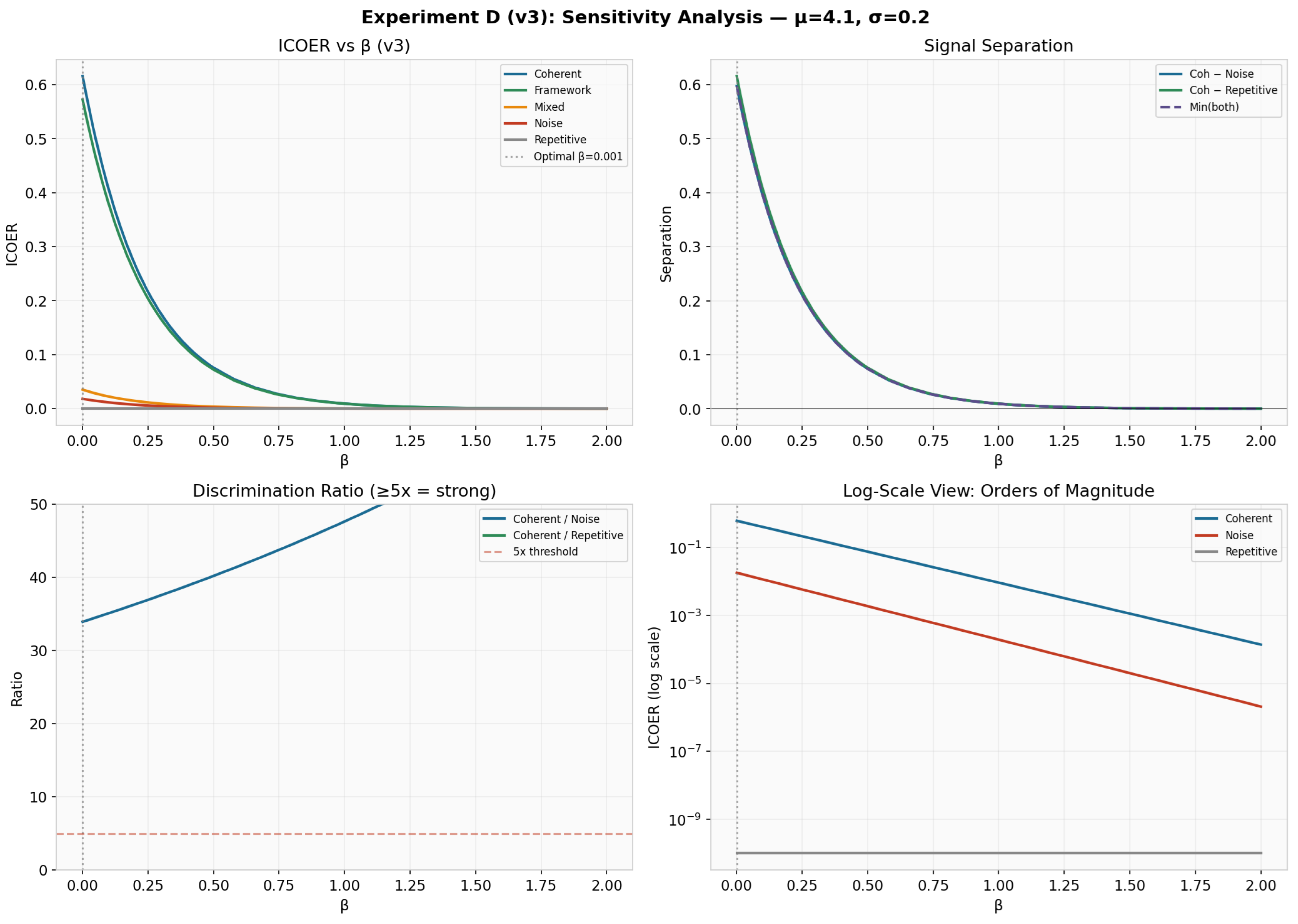
6.3.4. Experiment D: Parameter Sensitivity (v3)
Fine-grained sweep confirms that discrimination is maximized at very low (Figure 6). At :
- Coherent/Noise ratio:
- Coherent/Repetitive ratio:
- Maximum combined separation: 0.598
The log-scale panel reveals that coherent and noise ICOER values are separated by 1–2 orders of magnitude across the entire range, with repetitive text suppressed by orders of magnitude.
Figure 6.
Experiment D (v3): -sensitivity analysis. Top left: ICOER vs. . Top right: Signal separation. Bottom left: Discrimination ratios (dashed line = threshold). Bottom right: Log-scale view showing orders-of-magnitude separation.
Figure 6.
Experiment D (v3): -sensitivity analysis. Top left: ICOER vs. . Top right: Signal separation. Bottom left: Discrimination ratios (dashed line = threshold). Bottom right: Log-scale view showing orders-of-magnitude separation.
7. Phase-Transition Criteria Assessment
We evaluated five criteria that, collectively, would support a “phase transition” interpretation:
Table 4.
Evolution of phase-transition criteria across metric versions. v3 achieves 4/5.
| Criterion | v1 | v2 | v3 |
|---|---|---|---|
| 1. Recursive stability | – | – | – |
| 2. Strong discrimination () | – | – | ✓ |
| 3. Measurable threshold | ✓ | ✓ | ✓ |
| 4. Perturbation robustness | ✓ | ✓ | ✓ |
| 5. Correct ranking | – | ✓ | ✓ |
| Score | 2/5 | 3/5 | 4/5 |
The failing criterion (recursive stability) is attributable to the synthetic transformation operators, which degrade text structure faster than a real LLM would. The testable prediction is: with actual LLM-based summarize/expand operations, coherent seeds should maintain higher ICOER across iterations, potentially satisfying Criterion 1.
8. Discussion
8.1. What the Metric Actually Measures
With the optimized parameters, ICOER effectively detects text whose character-level entropy falls within the narrow band of structured natural-language prose () and which contains structural markers and consistent sentence patterns. The low means the metric is primarily a bandwidth filter on entropy modulated by resonance, which is a clean and interpretable construction.
8.2. The Repetitive-Text Correction as a General Principle
The v1→v2 correction has implications beyond this specific metric. Any coherence measure based on inverse entropy () is vulnerable to the same exploit: degenerate, low-information text scores anomalously high. The Gaussian replacement is a general solution applicable to text quality metrics, anomaly detection, and information-theoretic filtering tasks.
8.3. Circularity Risk and Mitigation
The resonance functional defines what “coherent” means. If the marker set is derived from the corpus being evaluated, the metric becomes tautological. We mitigate this by using exclusively domain-agnostic structural markers (logical connectors, scientific vocabulary, precision terms). However, full mitigation requires testing with externally calibrated marker sets derived from independent corpora (e.g., Wikipedia, arXiv, StackExchange).
8.4. Synthetic vs. Real Experiments
All results in this paper use synthetic seeds and simplified transformation operators. The transformations “summarize-expand” and “extract-recompose” are string-manipulation approximations, not actual LLM operations. The key limitation is that synthetic transformations degrade text structure monotonically, while real LLMs partially preserve and sometimes enhance structure during summarization and expansion.
The explicit prediction is: recursive coupling experiments using real multi-model LLM transformations should show higher ICOER stability for coherent seeds, potentially satisfying Criterion 1. This prediction is falsifiable.
8.5. On the “Field” Interpretation
The data in this paper are consistent with ICOER behaving as a useful discriminative metric. They do not, by themselves, demonstrate that coherence behaves as a field in the physics sense—i.e., a substrate-independent, distributed quantity with its own dynamics. To support the field interpretation, one would need to show that the same coherence signature emerges independently across different substrates (different LLMs, different languages, different representation schemes) without shared prompting. This remains an open hypothesis, not a demonstrated fact.
9. Limitations
- is design-dependent; the marker set must be reported and can bias results.
- Character-level entropy may not generalize to all languages or text lengths.
- and are tunable parameters whose values should be validated against empirical entropy distributions of the target domain.
- Synthetic transformations are not equivalent to real LLM operations.
- Statistical significance (bootstrap, permutation tests) was not performed in this initial report.
- The metric has been tested only on English text seeds; cross-lingual robustness is untested.
10. Potential Applications
While the experiments in this paper use synthetic data, the ICOER metric and the recursive coupling framework suggest several concrete application domains. Each is presented as a testable proposal, not a validated claim.
10.1. Training Data Curation for LLMs
Recent work has identified model collapse [5]: the progressive degradation of LLM quality when models are trained on data generated by other models. Each generation inherits and amplifies statistical artifacts, leading to loss of distributional diversity.
ICOER could function as an automated quality filter in training pipelines. Data with ICOER below a calibrated threshold would be flagged as structurally degraded—either repetitive (low ) or incoherent (low )—and excluded from training corpora. The Gaussian weighting is particularly suited to this task, as it penalizes exactly the entropy signatures characteristic of model-collapsed text: either compressed to near-uniform repetition or expanded to near-random token distributions.
10.2. Integrity Monitoring in Agentic Systems
Multi-agent architectures, where one LLM delegates subtasks to others in chains or graphs, face a known problem: context degradation across handoffs [6]. Each agent receives a compressed or transformed version of the original instruction, and errors accumulate silently.
ICOER can serve as a semantic checksum at each handoff point. If for a tolerance , the system triggers a recovery action: re-prompting from the original instruction, requesting human review, or rolling back to the last stable state. This is analogous to error-detection codes in telecommunications, but operating at the level of informational structure rather than bit-level integrity.
10.3. Synthetic Content Detection and Disinformation Filtering
Mass-generated synthetic text—whether from spam bots, coordinated disinformation campaigns, or low-quality content farms—typically exhibits characteristic entropy profiles: either highly repetitive (template-based generation) or superficially diverse but structurally hollow (high S, low R).
The v3 metric’s coherent-to-noise discrimination ratio and effectively infinite coherent-to-repetitive ratio suggest applicability as a classifier feature. Unlike stylometric detectors that rely on surface patterns (which adversaries can mimic), ICOER measures structural properties—logical connectivity, vocabulary distribution, sentence regularity—that are harder to spoof without actually producing coherent content. Validation against labeled datasets of human vs. machine-generated text is needed.
10.4. Knowledge Preservation Across Document Lifecycles
Organizations routinely transform documents through summarization, translation, format conversion, and multi-author editing. Each transformation risks semantic drift: the document’s core content gradually shifts from the original intent.
ICOER applied at each transformation stage provides a quantitative audit trail. A document management system could track across versions and alert when cumulative degradation exceeds a threshold. The perturbation stability result from Experiment B (7.9% change under 30% node removal) suggests the metric is robust enough for this purpose, tolerating minor edits while flagging substantial structural changes.
10.5. Writing Assistance and Editorial Quality Scoring
Current writing tools evaluate grammar, readability, and tone. ICOER adds a complementary dimension: informational coherence. A text can be grammatically correct and readable yet structurally incoherent—lacking logical connectors, repeating information without progression, or containing sentences whose lengths vary erratically.
An ICOER-based score could be decomposed for the writer into its three components: (“is your information density in the optimal range?”), (“does your text have logical structure?”), and the composite ICOER (“how well does this hold together?”). The decomposability of the metric is an advantage over opaque quality scores.
10.6. Benchmarking LLM Coherence Under Stress
Standard LLM benchmarks (MMLU, HumanEval, etc.) evaluate single-turn accuracy. They do not measure how well a model preserves coherence across extended interaction chains—precisely the scenario that matters for real-world deployment in assistants, coding agents, and research tools.
An ICOER-based benchmark would feed a coherent seed through N iterations of model-mediated transformation and measure the decay curve for . Models that maintain higher ICOER over more iterations demonstrate superior coherence resilience. This directly tests Equation (1) with real model behavior, filling a gap in current evaluation methodology.
10.7. Communication Integrity in Safety-Critical Systems
In domains where message fidelity is essential—air traffic control, medical records transfer, military command chains, legal document processing—information passes through multiple human and automated intermediaries. Each intermediary is a potential source of semantic corruption.
The resonance functional can be adapted with domain-specific marker sets (e.g., ICAO phraseology for aviation, ICD codes for medical records) to create a specialized integrity monitor. If a message’s ICOER drops below a domain-calibrated threshold after processing, the system flags it for human verification before the message propagates further. This extends the classical concept of checksums from bit-level to meaning-level verification.
Note: Each application above is a proposal requiring domain-specific validation. The synthetic results in this paper establish the metric’s discriminative properties under controlled conditions; real-world deployment demands calibration against domain data, integration testing, and empirical threshold determination.
11. Future Work
- Real LLM recursive coupling: Replace synthetic transformations with actual API calls to multiple LLMs (Claude, GPT, Gemini, Grok) and measure ICOER stability over 50+ iterations. This is the critical experiment for Criterion 1.
- External calibration: Derive marker sets from Wikipedia, arXiv abstracts, and StackExchange to test cross-corpus robustness and quantify the dependence of results on .
- Critical disjoint-corpus experiment: Train a minimal LLM on a fully artificial, incoherent corpus; insert coherent seeds manually; measure whether coherence emerges or collapses. This would distinguish genuine field-like emergence from statistical inheritance.
- Embedding-based : Replace marker density with cosine similarity in embedding space for richer semantic alignment that does not depend on a discrete marker set.
- critical surface mapping: Full three-dimensional parameter landscape with phase-boundary identification.
- Statistical testing: Bootstrap confidence intervals and permutation tests for all discrimination ratios and stability measurements.
- Cross-lingual validation: Test the metric on Portuguese, Spanish, Mandarin, and Arabic text seeds to determine whether and require language-specific calibration.
- Model collapse detection: Apply ICOER as a filter in iterative synthetic data generation pipelines and measure whether it mitigates the degradation documented by Shumailov et al. [5].
- Adversarial robustness: Test whether adversarial inputs can be crafted to achieve high ICOER without genuine coherence, and design countermeasures if so.
12. Conclusions
We introduced a formal definition of recursive coupling, constructed the ICOER metric through three iterative versions with documented failures and corrections, and demonstrated 4/5 phase-transition criteria with optimized parameters. The progression from v1 (structural flaw) through v2 (correction) to v3 (77× discrimination) illustrates a transparent scientific process where negative results drive design improvements.
The remaining criterion—recursive stability under transformation—identifies precisely where synthetic experiments end and real-world multi-model testing must begin. The framework is falsifiable: if real LLM transformations do not preserve coherence better than synthetic string manipulations, the recursive coupling hypothesis fails at the operational level.
Beyond the theoretical framework, the metric suggests concrete applications in training data curation, agentic system monitoring, synthetic content detection, knowledge preservation, writing quality assessment, LLM benchmarking, and safety-critical communication integrity. Each requires domain-specific validation, but the discriminative properties demonstrated here—particularly the coherent-to-noise ratio and perturbation robustness—provide a foundation for applied development.
All code, seeds, parameters, and figures are provided as supplementary material. The metric is fully specified and independently reproducible.
Appendix A. Reference Implementation
The complete Python implementation (icoer_engine_v3.py) is provided as supplementary material. Below is the core metric computation:
| Listing 1: ICOER v3 core computation |
 |
Appendix B. Marker Set Φ
The domain-agnostic marker set used for in :
English (20): therefore, however, furthermore, consequently, moreover, thus, hence, specifically, definition, theorem, proof, equation, hypothesis, experiment, result, analysis, parameter, variable, function, metric, measure, threshold, stable, convergence.
Portuguese (20): portanto, entretanto, além disso, consequentemente, definição, teorema, hipótese, experimento, resultado, análise, parâmetro, variável, função, métrica, medida, limiar, estável, convergência, coerência, entropia, campo.
Appendix C. Reproducibility Checklist
| Item | Provided |
| Complete source code | ✓ |
| All parameter values | ✓ |
| Seed generation code | ✓ |
| Random seeds (42) | ✓ |
| Marker set | ✓ |
| Resonance weights | ✓ |
| All figures reproducible | ✓ |
| Negative results reported | ✓ |
| Limitations documented | ✓ |
References
- C. E. Shannon. A Mathematical Theory of Communication. Bell System Technical Journal, 27:379–423, 623–656, 1948.
- H. E. Stanley. Introduction to Phase Transitions and Critical Phenomena. Oxford University Press, 1971.
- T. M. Cover and J. A. Thomas. Elements of Information Theory. Wiley-Interscience, 2nd edition, 2006.
- C. D. Manning and H. Schütze. Foundations of Statistical Natural Language Processing. MIT Press, 1999.
- I. Shumailov, Z. Shumaylov, Y. Zhao, Y. Gal, N. Papernot, and R. Anderson. The Curse of Recursion: Training on Generated Data Makes Models Forget. arXiv preprint arXiv:2305.17493v2, 2024.
- S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao. ReAct: Synergizing Reasoning and Acting in Language Models. ICLR, 2023.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



