
Submitted:
10 February 2026
Posted:
12 February 2026
You are already at the latest version
Abstract
As large language models are increasingly used for contract drafting, case research and even judicial work, a central question is how to make their outputs trustworthy. This survey addresses that question through the lens of verified generation for legal AI, focusing on systems that are robust against hallucinations and traceable to authoritative legal sources. First, we propose a unified framework for verified generation in legal AI, linking reasoning, retrieval, and validation around factual reliability. Second, we cast reliability methods into two paradigms of epistemic negotiation, by failure and by conflict, enabling models to recognize and act on their competence limits. Third, we survey the legal-AI landscape and identify challenges for verifiable, governance-native systems. This survey outlines a roadmap for trustworthy legal AI and for reliable reasoning beyond the legal domain.
Keywords:
LLMs
; law applications
1. Introduction
Verified generation for Legal AI aims to ensure that outputs from Large Language Models (LLMs) satisfy standards of legal reasoning, factual accuracy and professional accountability in high-stakes contexts.As we enter the era of LLM, advances in model scale, data quality and neural architectures are transforming natural language understanding [136,181]. However, legal practice exposes specific requirements for verifiability, transparency, and responsibility, as emphasized in global regulatory frameworks such as the GDPR([148]), the EU AI Act ([149]), and related international guidelines [55]. These frameworks require outputs that are plausible, provably correct and traceable to authoritative sources, making law a testbed for methods for broader LLM use across domains.
In LegalAI, verifiability underpins well-defined scope, robust evidence grounding, and context-aware, accountable outputs.
Can generative systems deliver verifiable, up-to-date, and jurisdiction-aware answers with auditable reasoning steps?
Verified generation is a methodological shift, analogous to reinforcement learning with verifiable rewards on reasoning tasks [97]. Instead of maximizing preference alignment, it focuses on verifiable correctness via retrieval of legal sources and rule- or logic-based checks. In Legal AI, systems cross-check claims against statutes and case law before finalizing outputs, yielding legally sound text and generalizable methods for verifiable reasoning. General-purpose models such as GPT-4 [1] and Claude 3 [6] have demonstrated baseline reasoning abilities, while domain-specific systems, including ChatLaw [33] and SaulLM [31] extend these capabilities through targeted retrieval and formal-logic integration. New architectures pair large pretrained LLMs with verifiability modules that check output quality and citations, analogous to verifiable reward functions in recent Large Reasoning Models (LRMs) [150]. Yet there is no standard way to measure factual reliability in law, and automated legal evaluation remains challenging, so legal knowledge is hard to leverage for the broader LLM community. Most existing work targets at general QA, leaving domain-specific legal issues largely unaddressed, such as jurisdictional limits, doctrinal variation, and strict formatting and citation rules [56,138,141,176].
This survey reviews verified generation in Legal AI, covering formal reasoning, retrieval-based generation, verification architectures and evaluation, and outlines a roadmap for trustworthy systems for other safety-critical domains.
2. Constructions of LegalAI
2.1. Legal Reasoning
Faithfulness and Verifiability
Ensuring the faithfulness of generated rationales and adopting hypothesis-verification cycles have become paramount for developing interpretable and robust AI reasoning systems. [102] address the inherent unfaithfulness of vanilla Chain-of-Thought (CoT) by introducing a framework that translates natural language queries into executable symbolic reasoning chains. By delegating the final inference step to a deterministic solver, this approach enforces a causal alignment between the stated explanation and the model’s decision logic, thereby grounding linguistic reasoning in formal semantics. Complementing this, [166] formalize inductive reasoning as an iterative process of generating latent hypotheses from evidence and systematically validating them. This structured decomposition not only facilitates auditable inference but also enables verifiable reasoning within high-dimensional natural language representations, bridging the gap between neural flexibility and symbolic rigour. Recent advances in decompositional prompting extend these ideas by partitioning complex problems into modular, verifiable sub-goals. Khot et al. ([73]) propose decomposition strategies that embed symbolic functions or retrieval components into reasoning workflows, while Zhao et al. ([179]) develop verify-and-edit mechanisms that iteratively validate intermediate steps. Together, these techniques show how structured decomposition and verification can enhance both correctness and transparency in reasoning.
Recent advances in decompositional prompting extend these ideas by partitioning complex problems into modular, verifiable sub-goals. Khot et al. ([73]) propose decomposition strategies that embed symbolic functions or retrieval components into reasoning workflows, while Zhao et al. ([179]) develop verify-and-edit mechanisms that iteratively validate intermediate steps. Together, these techniques show how structured decomposition and verification can enhance both correctness and transparency in model reasoning.
Verifiability and Neuro-Symbolic Integration
Within formal reasoning domains, recent research has transitioned toward a generate-and-verify paradigm to mitigate the stochastic nature of language models. [158] and [120] demonstrate that integrating external verifiers and logical constraints can effectively enforce stepwise validity and curtail reasoning drift in long-form proofs. These frameworks often leverage autoformalization to map natural language into symbolic representations, utilizing Satisfiability Modulo Theories (SMT) solvers and automated theorem provers to check the internal consistency of generated steps. By transforming probabilistic outputs into machine-checkable logical artifacts, these neuro-symbolic systems provide a robust mechanism for certifying the correctness of complex deductive chains [10,185]. Shi et al. ([133]) demonstrate that process-level verification with targeted remediation, using verifiers to inspect and refine intermediate steps, improves logical consistency in judgment prediction. By contrast, Magesh et al. ([104]) report hallucination rates of 17–33% in leading legal RAG systems, driven largely by miscitations, and introduce an evaluation framework that separates correctness from groundedness across doctrine, jurisdiction, and factual recall. Persistent issues, including hallucination, data drift, and long-document degradation, underscore the need for domain-pretrained encoders, evidence-aligned retrieval systems, and human oversight to preserve jurisdictional accuracy, calibrated confidence, and auditable reasoning [47,104,182]. Accordingly, the emphasis shifts from linguistic plausibility towards legally grounded and verifiable correctness.
Conflict Calibration
In legal domain, models must communicate uncertainty to facilitate risk-aware decision-making. Beyond simple token probabilities, [93] demonstrate that verbalizing confidence directly improves transparency and human-AI collaboration. More recent techniques, such as semantic uncertainty, estimate confidence by measuring output invariance across semantically equivalent clusters, providing a more faithful characterization of model boundaries [76]. Theoretical analyzes further demonstrate that perfect calibration and zero hallucination cannot always be achieved simultaneously, motivating conservative behaviors in professional systems such as refusal thresholds, cautious defaults, and alert mechanisms [69]. Complementary methods that output confidence sets or coverage-controlled predictions allow models to operate safely in high-stakes settings by combining candidate sets with calibrated refusal, ensuring predictable error [30].
Within in-context learning, recent work improves few-shot calibration by increasing sample diversity and decomposing sources of uncertainty, producing more stable alignment between confidence levels and empirical accuracy [67,95]. To counter systematic overconfidence introduced by reinforcement learning from human feedback (RLHF), prompt- and format-level interventions explicitly elicit and recalibrate confidence estimates, improving the correlation between stated confidence and correctness without altering model weights [144]. These strategies help users better assess the reliability of model output in high-stakes decision contexts.
Effective uncertainty quantification aligns probabilistic surrogates with domain-specific risk structures, enforcing stringent thresholds for high-stakes inference while permitting broader tolerances for low-risk tasks. By disentangling epistemic uncertainty (knowledge gaps) from aleatoric or contextual ambiguity (input noise), systems can adaptively trigger retrieval mechanisms, elicit clarification, or defer to human expertise. Recent advances in conformal risk control [116] provide distribution-free error bounds and calibrated refusal policies, offering a principled framework for selective prediction and rigorous risk management in sensitive domains such as LegalAI.
Constrained Generation
Constrained generation enforces the structural and logical consistency required in professional domains. Hard constraints, such as those in NeuroLogic Decoding [99], and grammar-based decoding [46,134] ensure rule satisfaction and format validity for structured outputs, including legal contracts and filings. Soft constraints complement this by preserving fluency through distribution-aware alignment [106] and Pareto-optimized decoding [54], balancing factuality, coherence, and domain conformity. Task-oriented and adaptive approaches, such as GeLaTo [83] and CAAD decoding [109] integrate schema, knowledge, and contextual signals to enforce jurisdiction- and role-specific compliance. Invariant-based constraints further preserve numerical and logical consistency under paraphrase and other linguistic variation. Together, hard (logical and grammatical), soft (distributional), and adaptive (task-based) constraints form a coherent and auditable generation framework that supports reliability, interpretability, and regulatory compliance in professional LegalAI systems.
2.2. Foundation Model
Foundation models underpin LegalAI by distilling large-scale legal pretraining into transferable knowledge, enabling high-performance adaptation for specialized downstream reasoning tasks.
Supervised Finetuning Supervised fine-tuning (SFT) adapts pretrained language models to legal domains using labeled datasets that encode domain-specific structures and reasoning conventions. This aligns models with the legal field’s requirements for logical coherence, terminological precision, and interpretable justification, all of which are capabilities that general-purpose models typically lack [32,132]. Legal-LM [132] illustrates how integrating legal knowledge graphs and external resources via soft prompting and Direct Preference Optimization (DPO) embeds structured reasoning patterns into model parameters, providing both semantic guidance and preference correction. Combining domain-adaptive pretraining with task-oriented fine-tuning on statutes, case law, and contracts further improves factuality, calibration, and robustness [25].
High-quality labeled corpora are essential for SFT because legal texts exhibit distinctive linguistic and structural properties, including dense citations, long-form documents, and formalized argumentative style [25]. Benchmarks such as LexGLUE, MultiEURLEX, BillSum, LEDGAR, and COLIEE [19,22,75,121,147] provide multi-task supervision for classification, retrieval, summarization, and case-based reasoning. Methodologically, legal SFT often employs text-to-text frameworks [122] with structured decoding, ranking losses, and schema constraints to enhance auditability and citation precision [121]. Parameter-efficient approaches such as LoRA [146] enable scalable adaptation under resource constraints, while safety-aware fine-tuning (SaRFT) [180] promotes role alignment and guarded behavior in professional legal interactions.
Contemporary practice combines supervised fine-tuning with domain-adaptive pretraining, retrieval grounding, and rationale supervision [22,38,48,53]. Legal knowledge graphs and safety constraints further improve factual robustness, ethical behavior, and role alignment [32,45,132]. Domain-specific instruction tuning enhances controllability through structured prompts and synthetic task construction [127,156,157]. Parameter-efficient approaches such as LoRA, QLoRA, and adapter layers [39,58,118] support modular and privacy-preserving updates, while long-context architectures like Longformer and BigBird [11,173] enable efficient processing of statutes, contracts, and case reports. Hierarchical SFT and retrieval-augmented training further reduce hallucination and strengthen explainability by grounding intermediate rationales in evidence [40,82].
Evaluation relies on domain benchmarks such as LexGLUE and LegalBench [27,47]. COLIEE assesses retrieval and entailment tasks, while MultiEURLEX probes cross-jurisdictional generalization [21]. Responsible governance additionally requires dataset deduplication, anonymization, red-teaming, and citation verification to mitigate privacy and memorization risks [19,27].AIRA employs activation-informed singular value decomposition (SVD) initialization, dynamic rank allocation, and activation-aware training to efficiently adapt large models, achieving 53.66% accuracy on legal benchmarks while significantly reducing training time [90]. NoRA introduces a nested low-rank structure where an outer frozen LoRA layer preserves pre-trained knowledge, while an inner trainable LoRA layer captures task adaptations, demonstrating strong performance on legal tasks such as legal text analysis & generation [91].
Taken together, an effective LegalAI pipeline unifies domain-adaptive pretraining, high-quality multi-task SFT, structured instruction tuning, parameter-efficient adaptation, long-context modeling, and retrieval-guided rationale supervision. This integrated approach improves factual accuracy, citation precision, interpretability, and safety compliance across legal applications [11,24,38,48,82].
Reinforced Learning Reinforcement learning (RL) is moving LegalAI beyond surface-level text generation toward procedurally grounded reasoning by optimizing models with external signals of consistency, completeness, and legal compliance. These signals strengthen procedural alignment, adaptive reasoning, and logical structure, shifting LegalAI from retrieval-heavy pattern matching toward systems capable of structured deliberation. At scale, models such as SaulLM-54B and SaulLM-141B [32] combine continual domain pretraining with multi-level supervised fine-tuning to balance semantic grounding, legal robustness, and general reasoning capacity.
To mitigate over-specialization, [96] introduce General Capability Integration (GCI) and ALoRA, balancing domain-specific and general inference via dynamic attention routing. Research on alignment indicates that response diversity, rather than data volume, is critical for stable legal performance [137], while [45] demonstrate that short-instruction SFT under mixed supervision generalizes effectively to 128K-token sequences. While early efforts like LexGPT 0.1 [79] established legal instruction tuning and RLHF infrastructure, subsequent models like LexPam and LexNum integrate RL with curriculum learning to generate program-aligned, verifiable reasoning paths [175]. Most recently, Unilaw-R1 [15] combines structured-knowledge SFT with reinforcement learning to reach superior logical coherence and cross-domain generalization.
Efficiency and inference control form a complementary axis of progress. ASRR [178] modulates the trade-offs between accuracy and cost by adjusting the reasoning depth on demand, while Wu et al.[160] develop D3LM, an RL-based diagnostic model that integrates legal knowledge graphs to guide questioning and improve consultation accuracy. Similarly, Yao et al.[167] introduce LSIM, aligning fact–rule chains via RL to enhance interpretability and reduce hallucinations. Collectively, these developments mark a shift from static knowledge adherence to dynamic, procedurally compliant reasoning [15,160,167,175], establishing a multidimensional optimization paradigm that balances accuracy, efficiency, and regulatory compliance for interpretable and legally reliable AI systems.
2.3. Retrieval and Agentic Methods
Retrieval-augmented generation Advances in verifiable generation and retrieval-augmented generation (RAG) have substantially improved factual grounding by coupling neural generation with evidence retrieval from large corpora. This design mirrors the legal system’s “citation–argumentation” paradigm and enables auditing of evidence chains [80,182]. This field has progressed from sparse retrieval heuristics to differentiable retrievers and seq2seq marginalization over latent documents, supporting per-token evidence switching, hot-swappable indices, and improved factuality and diversity [94,119]. Modern verifiable-generation approaches further embed explicit checking stages, such as chain-of-checks and agentic debate, and introduce benchmarks that enforce evidence alignment and subsentence-level attribution [16,17].
RAG integrates LLMs with external knowledge bases, grounding model outputs in verifiable evidence and mitigating knowledge staleness and traceability challenges that affect purely parametric models [81]. In professional services, these systems retrieve statutes, regulations, or procedural documents to produce accurate, auditable, and compliant responses.
Within LegalAI, RAG enhances factual accuracy, reasoning quality, and regulatory alignment. In judicial document generation, Su et al. ([139]) introduce the JuDGE benchmark for Chinese case opinions, showing that RAG models surpass pure generators yet still struggle with logical coherence and structural fidelity. Xie et al. ([161]) develop DeliLaw, an advisory system that retrieves statutes and precedents to reduce hallucination and improve multilingual consultation. On the retrieval side, Zhang et al. ([174]) propose CFGL-LCR, enriching causal reasoning through graph-structured retrieval and counterfactual augmentation, while Ye et al. ([168]) present MileCut, which uses multi-view modeling and information compression to capture semantic hierarchy more effectively. Su et al. ([139]) also introduce Caseformer, an unsupervised dense pretraining framework for cross-case retrieval, and Askari et al. ([9]) design CLosER, a conversational RAG system with expertise-aware ranking for precise legal responses. In common-law contexts, Nigam et al. ([111]) propose NyayaRAG, combining factual narratives with semantically retrieved sources to emulate judicial reasoning. Collectively, legal RAG research now forms a cohesive pipeline that unifies retrieval-side knowledge modeling with generation-side reasoning alignment. This evolving framework moves LegalAI from information-augmented generation toward knowledge-aligned, verifiable reasoning [9,111,139,161,168,174].
However, precision in retrieval-augmented systems remains constrained by retrieval fidelity: missing or partially relevant passages propagate downstream errors, qualifiers disappear under aggressive compression, and performance deteriorates on tail facts or domain-specific corpora [57,143]. Fine-grained attribution metrics and benchmarks further reveal brittle subsentence attribution, noisy entailment on long documents, and limited robustness under distribution shift [85,87]. Achieving professional-grade verifiability therefore requires domain-calibrated retrieval, authority-aware entailment with explicit scope controls, and fully auditable pipelines that log micropropositions and supporting evidence end-to-end [165].
Tool-Augmented Generation Hybrid systems achieve a balance between accuracy and fluency by delegating fact selection to rule-based logic while utilizing language models for natural language synthesis [42]. To further enforce correctness, logic-constrained decoding integrates formal invariants and theorem provers directly into the generation process. This approach significantly mitigates hallucinations and bolsters trustworthiness without compromising computational efficiency [4].
LegalAI is thus evolving from single-model generation to multi-agent, tool-integrated systems that enhance transparency and interpretability in reasoning. Progress increasingly depends not on model size but on the integration of external knowledge, formal logic, and domain-specific tools. Wang et al. ([155]) exemplify this shift with LegalReasoner, a multi-stage framework that orchestrates contrastive learning, graph neural networks (GNNs), and generative adversarial networks (GANs) across legal knowledge injection, precedent retrieval, multi-hop reasoning, and judgment generation. This design yields notable gains in judgment-prediction accuracy. Xu et al. ([162]) further advance tool-embedded reasoning with the CLEAR framework, which employs a rule retriever and rule-insight generator to enforce statutory constraints during inference, significantly improving the interpretation of ambiguous provisions.
Continuing this trajectory, Petros et al. ([124]) propose PAKTON, a multi-agent tool-augmented system that integrates RAG with specialized agents coordinating fact extraction, clause interpretation, and compliance assessment for contract review. Bendová et al. ([12]) develop a hybrid extraction method combining regular expressions with LLMs to identify judicially recognized facts in Slovak criminal judgments. Their system produces structured factual annotations that strengthen downstream RAG pipelines, underscoring the central role of structured knowledge extraction in legal reasoning workflows.
Agentic-based Generation LegalAI research is shifting from isolated task models to adaptive multi-agent systems that mirror the deliberative structure of real-world legal reasoning. Chen et al. ([29]) introduce the Debate-Feedback framework, in which multiple LLM agents engage in iterative debate and critique to improve judgment prediction while reducing reliance on annotated data. Similarly, Yuan et al. ([170]) propose the MALR framework, showing that inter-agent collaboration deepens understanding of legal theories and accusatory structures, translating abstract jurisprudence into operational reasoning pathways.
Nguyen et al. ([108]) present a unified framework integrating rule-based, abductive, and case-based reasoning, providing a logical foundation for coordinated multi-agent systems. Yue et al. ([131]) introduce MASER, a multi-agent simulation environment that generates law-intensive interactive data to mitigate scarce supervision in dynamic legal dialogues. Chen G. et al. ([28]) develop AgentCourt, which models courtroom adversarial processes through evolutionary agent interactions, enabling lawyer agents to acquire professional expertise. Xu et al. ([163]) design LeGen, enabling controllable and consistent legal text generation via modular decomposition and concept-level verification. Klisura et al. ([74]) extend multi-agent collaboration to multilingual and dialectally diverse settings through a cooperative privacy-policy QA system that improves reasoning accuracy and inclusivity. Together, these works advance coordinated, tool-integrated LegalAI ecosystems in which specialized agents perform retrieval, argumentation, and validation, fostering self-calibrating and interpretable legal reasoning.
3. Evaluation of LegalAI
3.1. Merits of Legal Reasoning
LegalAI benchmarking is shifting from narrow task-specific evaluations towards theoretically grounded, multidimensional frameworks that integrate knowledge, logic, and semantics. Early benchmarks such as CaseHOLD quantified legal reasoning through citation prediction, demonstrating the benefits of domain-specific pretraining for legal language and logic [183]. LeCaRDv2 extended this paradigm to Chinese law, applying expert-defined relevance standards that reflect judicial reasoning [89]. Cross-lingual evaluations such as LeXFiles and LegalLAMA examined the transferability of legal knowledge across jurisdictions [25], while the Cambridge Law Corpus introduced ethical and privacy-aware methodologies for large-scale historical legal data research [117].
At the empirical level, LegalBench formalized 162 reasoning-oriented tasks, encompassing statutory interpretation, analogical reasoning, and inference, thereby enabling a systematic decomposition of legal cognition [49]. Within the Chinese context, CLAW and LAiW implemented clause-level and layered evaluation frameworks that assess retrieval fidelity, reasoning consistency, and interpretability [36,164]. Complementing these benchmarks, -Stance modeled judicial argumentation using polarity–intensity variables to capture fine-grained stance dynamics [52].
Evaluation has also expanded cross-jurisdictionally. Bilingual frameworks now measure alignment between translation fidelity and legal logic [77]. And enhanced Chinese models integrate statutes, precedents, and legal graphs to support end-to-end consulting [186]. Multi-agent architectures support modular evaluation by assigning retrieval, reasoning, and verification to distinct agents, forming a “checks-and-balances” configuration analogous to institutional governance structures [17,140].
Governance and transparency have become central to benchmark design. Model cards codify disclosure standards regarding model scope and limitations [105], while auditing frameworks emphasize traceability, reproducibility, and ethical accountability [13]. Regulatory frameworks, particularly in finance, further mandate interpretable, trustworthy, and auditable AI systems [100,187].
This evolution shifts assessment from task performance to reasoning coherence, verifying whether models reconstruct expert-justifiable logic [36,164]. Emerging certification standards now codify requirements for robustness, fairness, and post-deployment governance [130], reinforced by compliance emphasizing adversarial resilience and log integrity [129].
Research on adversarial safety integrates gradient-based attack modeling with defense mechanisms to mitigate vulnerabilities such as prompt injection, enabling safer LegalAI deployment in risk-sensitive settings [50]. Collectively, these advances articulate a trust architecture that grounds LegalAI in epistemic rigor, modular reasoning, and verifiable governance, supporting a shift from mere functionality to reliability, interpretability, and institutional trust [13,49,77,130,187].
The Chain-of-Verification (CoVe) method mitigates factual errors by iteratively drafting, interrogating, and revising outputs against retrieved evidence [41]. Similarly, "retrieve-rerank-verify" pipelines integrate external knowledge for multi-hop reasoning, while faithful Chain-of-Thought (CoT) validation audits intermediate steps to bolster factual fidelity and mechanistic transparency [102]. In legal applications, unifying detection metrics, evidence alignment, and controlled decoding into a single pipeline can preempt high-risk hallucinations while ensuring compliance and auditability, substantially improving the reliability and accountability of LegalAI systems [2].
LegalAI is shifting from raw text generation toward process-based evaluation centered on reliability, supported by knowledge alignment, open benchmarking, and explainable assessment. Early scrutiny focused on factual inaccuracies: Magesh et al. ([104]) found 17–33% hallucination rates in commercial LegalAI tools, even under RAG setups, challenging “hallucination-free” claims and motivating standardized evaluation infrastructures. LegalBench [47] offers 162 fine-grained tasks to evaluate legal reasoning across models and jurisdictions, while InternLM-Law [43] extends large-scale benchmarking to Chinese and multilingual settings. Luo et al. ([101]) integrate evaluation into the generation process with ATRIE, which measures variance in legal-concept entailment and signals a broader move toward task-embedded evaluation.
At the same time, definitions of reliability are expanding. Alsagheer et al. ([5]) identify trade-offs between model scale, logical consistency, and fairness, highlighting the need to evaluate ethical robustness alongside predictive accuracy. Eval-RAG [126] verifies generated outputs using external retrieval to enhance factual grounding, while DeCE [169] decomposes single-score metrics into precision and coverage dimensions to improve semantic resolution.
3.2. Knowledge Alignment
Evaluation paradigms increasingly internalize retrieval to determine the timing and scope of evidence acquisition. Self-RAG enables models to autonomously trigger retrieval, evaluate evidence quality, and critique outputs, significantly enhancing factual accuracy and citation reliability [7]. Complementing this, Active RAG leverages uncertainty signals to proactively retrieve information for multi-hop inference segments [66]. Finally, the Verify-and-Edit framework audits reasoning chains at the step level, iteratively validating and refining intermediate logic with external knowledge to balance interpretability and robustness [179].
In professional domains, retrieval-augmented training and knowledge organization are advancing together. RAFT (Retrieval-Augmented Fine-Tuning) annotates “gold” and “distractor” documents during fine-tuning, training interference-resistant evidence selection and improving domain adaptation in fields such as law and healthcare [177]. Adaptive RAG balances dialogue history and new retrievals to maintain multi-turn consistency and reduce context drift [154].
For highly structured legal settings, knowledge-graph–enhanced RAG unifies entity retrieval and relation-based inference along graph paths, capturing complex “provision–exception–condition” dependencies and improving both the completeness and auditability of evidence recall [152]. Collectively, advances in retrieval strategy learning, evidence quality control, verifiable reasoning, and structured knowledge integration make alignment in professional AI systems more discoverable, accurate, and explainable [152,177].
3.3. Hallucination Control
Achieving hallucination-free legal reasoning requires moving from post-generation verification to controlled generation. Hallucinations are categorized as intrinsic vs. extrinsic, guiding interventions at the data, model, and decoding levels [65]; and along factuality vs. faithfulness, structuring detection and mitigation strategies [59]. Detection methods now go beyond surface-level checks to task- and decision-level analysis, where internal consistency can be probed via natural language inference for contradiction-aware self-correction [107] Low-quality or fabricated citations are often associated with low token-level confidence, enabling uncertainty-based detectors [2]. Domain-specific evaluation has emerged for high-stakes areas. In law, even “hallucination-free” models may still commit citation errors, motivating workflow-oriented legal evaluations [103]; in medicine, clinical safety frameworks quantify factual, omission, and reasoning errors [8]. For embodied or sequential decision-making, hallucinations are classified as perceptual (environment misreadings) or planning (infeasible action sequences), with world models used to verify whether perceptions and planned actions are physically and procedurally feasible [20].
4. Challenge and Future
Safety and Privacy The rapid expansion of LegalAI has intensified concerns over safety, privacy, and governance, especially as larger models increase risks of hallucination, misgrounding, and sensitive data disclosure in regulated settings [3,104]. Legal practice requires confidentiality and auditability, yet current fine-tuning and reinforcement pipelines remain vulnerable to data leakage and overconfidence [63]. Governance-native frameworks tackle these issues by embedding compliance constraints directly into system architectures and integrating verifiable reasoning, calibrated refusal, and privacy-preserving methods such as federated and differential learning to keep models within verifiable, authoritative bounds [44,86,88]. Process-level safeguards and traceable inference pipelines further support professional accountability, while embedding jurisdictional limits, confidentiality, and privilege constraints into retrieval and generation reduces compliance risk [62,123]. The convergence of verifiable reasoning and privacy-aware computation thus defines the frontier of trustworthy Legal AI, making safety a foundational architectural principle rather than a post-hoc safeguard [88].
Personalization and Self-Evolution The next frontier for LegalAI is personalization—adapting reasoning and retrieval to specific practitioners and jurisdictions while ensuring compliance [29,108]. While adaptive multi-agent and reinforcement learning frameworks, such as the AdvEvol approach in AgentCourt, significantly improve expert-level reasoning, they also introduce challenges for liability and auditability [28]. To mitigate these risks, hybrid workflows use supervised checkpoints to ensure model updates remain reversible and verifiable [170]. Furthermore, self-evolving systems utilize incremental fine-tuning and rule-based memory anchoring to integrate new precedents without catastrophic forgetting [96]. Addressing potential biases and jurisdictional drift in autonomous updates requires transparent safeguards, including auditable logs and model certification, to maintain alignment with professional standards [14].
5. Conclusion
Legal foundation models can transform research, drafting, and compliance when anchored by verifiable reasoning and controlled retrieval. Reliable systems must integrate citation-anchored outputs with calibrated uncertainty to enable risk-aware abstention. However, significant challenges persist in cross-jurisdictional adaptation, analogical reasoning, and multilingual benchmark coverage. Advancing trustworthy LegalAI requires open, rights-cleared datasets and modular retrieval–reasoning–verification pipelines governed by rigorous oversight. Ultimately, deep collaboration between technologists and legal experts is essential to ensure that every inference remains auditable and aligned with verifiable ethical and legal standards.
6. Limitations
This survey offers a broad, text-focused synthesis and may give less attention to multimodal evidence and some lower-resource jurisdictions and languages. The review primarily reflects publicly available studies and benchmarks, which are evolving and may not capture practitioner considerations such as authority hierarchy, conflict resolution, and time- or jurisdiction-specific validity. Most findings are based on current snapshots rather than long-term observations, and operational topics such as liability allocation, privilege, and e-discovery costs are only briefly touched. Discussions of ethics, fairness, security, and agentic systems emphasize concepts and emerging practices, with limited large-scale field evidence to date. Considerations around data provenance, rights, and cross-border transfers are framed as areas for continued clarification. Some recommendations may be most readily implemented by well-resourced institutions, suggesting opportunities to adapt approaches for smaller organizations. Finally, choices about scope and citation inevitably reflect selectivity, indicating avenues for complementary work to extend coverage.
Appendix A. Related Work: Factuality Verified and Scope-Limited Generation
Figure A1.
Comparison between two paradigms of verified generation: Negotiation by Failure and Negotiation by Conflict. The former ensures logical consistency through constraint checking, while the latter calibrates answers via conflict detection and adjudication.
Figure A1.
Comparison between two paradigms of verified generation: Negotiation by Failure and Negotiation by Conflict. The former ensures logical consistency through constraint checking, while the latter calibrates answers via conflict detection and adjudication.
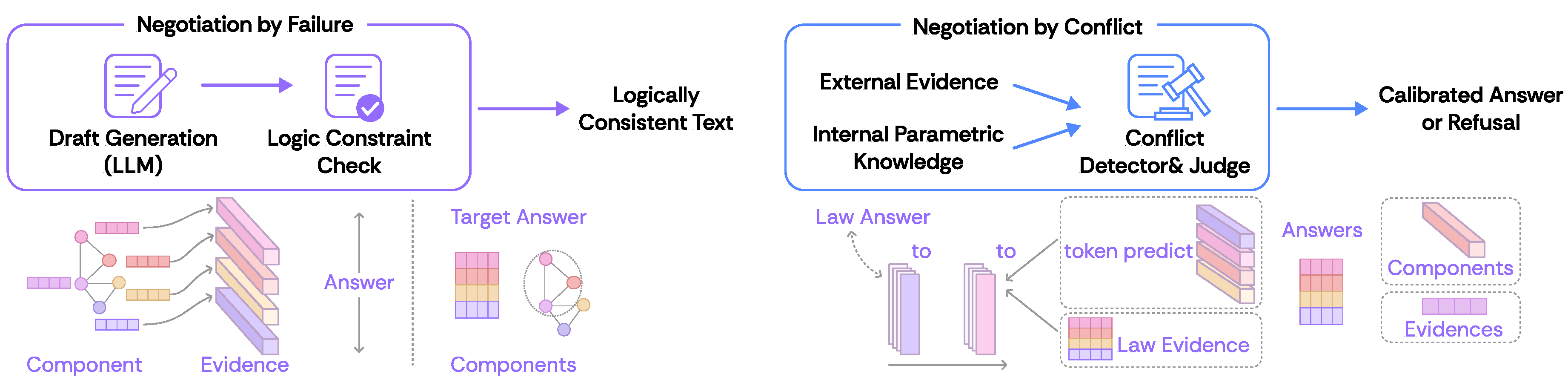
From the perspective of computational logic, verified generation is not merely a technological device for reducing errors but an epistemic discipline aimed at developing models that can recognize the limits of their own competence [70]. In this view, a verifiable system must implement an internal decision logic that differentiates between two fundamental forms of epistemic negotiation: negotiation by failure, in which the model identifies a contradiction and acknowledges that its inference is incorrect, and negotiation by conflict, in which the model detects insufficient support and withholds judgment [110]. The epistemological force of this negotiation lies in articulating a machine’s capacity for self-reflective reasoning, establishing a structured relationship between what the system is capable of inferring and what the available evidence permits, as illustrates in Figure A1.
Contemporary LLMs generate text through autoregressive next-token prediction over learned probability distributions [151]. This computational paradigm presents three fundamental challenges. First, models must develop capability boundary awareness: the ability to distinguish interpolation within their training distribution from extrapolation beyond it [51]. Because embedding spaces are continuous, models can produce fluent yet unfounded responses when queried outside their epistemic range. Second, standard maximum-likelihood training conflates statistical prevalence with factual correctness, motivating training-distribution alignment so that factual precision, rather than frequency, governs generation [64,98]. Third, the fixed computational depth of feedforward architectures limits a model’s capacity for iterative deliberation, making reflective reasoning dependent on auxiliary memory structures, external tools, and multi-pass generation strategies [115,128]. While traditional approaches impose correctness through post-hoc validation, verified generation advances toward meta-reasoning, wherein models explicitly evaluate the validity of their own inferences [18].
Techniques such as Chain-of-Verification (CoVe) implement this idea by having models propose provisional hypotheses, issue internal verification queries that operate as logical checks over their representations, and revise outputs when inconsistencies are detected [41]. Architecturally, this inserts a verification loop into the generative process: whereas conventional models compute , verified generation realizes , where the verification function acts as a learned consistency constraint [92].
The LLM-as-a-judge paradigm operationalizes this principle by introducing secondary evaluators that function as proof validators [153], conceptually paralleling logic-programming systems in which inference and verification act as dual computational processes. Verified generation therefore requires a shift from single-pass token prediction to architectures capable of global consistency reasoning, recasting generation not as a one-shot feedforward computation but as an iterative proof search over factually grounded hypotheses. At the implementation level, pipelines such as generate–verify–edit [125] instantiate these principles by embedding verification directly into model workflows, treating each generated statement as a propositional claim subject to falsification and revision. This design constitutes an applied form of computational epistemology that rather than training models to approximate omniscience, verified generation constrains reasoning within the boundaries of what can be formally demonstrated and empirically validated, thereby establishing a principled framework for epistemic accountability in language generation.
Appendix B. Formulation of Verified Generation
Complementing the Syllogistic definition, we formalize the probabilistic bounds required for Negotiation by Conflict and Uncertainty Calibration.
Standard autoregressive generation maximizes the likelihood for a prompt X. In a verified LegalAI framework, we introduce a verification function and an external knowledge base (e.g., statutes, case law). The generation objective is modified to maximize the joint probability of the token sequence and its logical validity:
Where:
- is the base LLM probability distribution.
- is the probability assigned by the verification module.
- is a hyperparameter weighing factual adherence against linguistic fluency.
To satisfy the requirement that models must "know when not to answer", generally define a Conformal Risk Control set for a legal query X. For a user-specified error rate (e.g., for high-stakes advice), we require:
The construction of relies on a calibration score (e.g., the refusal threshold). If the model’s confidence , where is the calibrated threshold derived from a hold-out set of legal experts, the system outputs the empty set ∅ (abstention) rather than a hallucination.
The loss function for optimizing the retriever R and generator G in this context minimizes the Kullback-Leibler divergence [78] between the generated rationale and the authoritative legal reasoning path :
where represents the logical invariants derived from formal theorem provers to ensure no contradiction exists in the generated chain.
Appendix C. Detailed Discussions on the Construction of LegalAI
A comprehensive list of the existing domain LLMs for law is provided in Table A1.
Figure A2.
Six Stages of the Trustworthy Legal AI
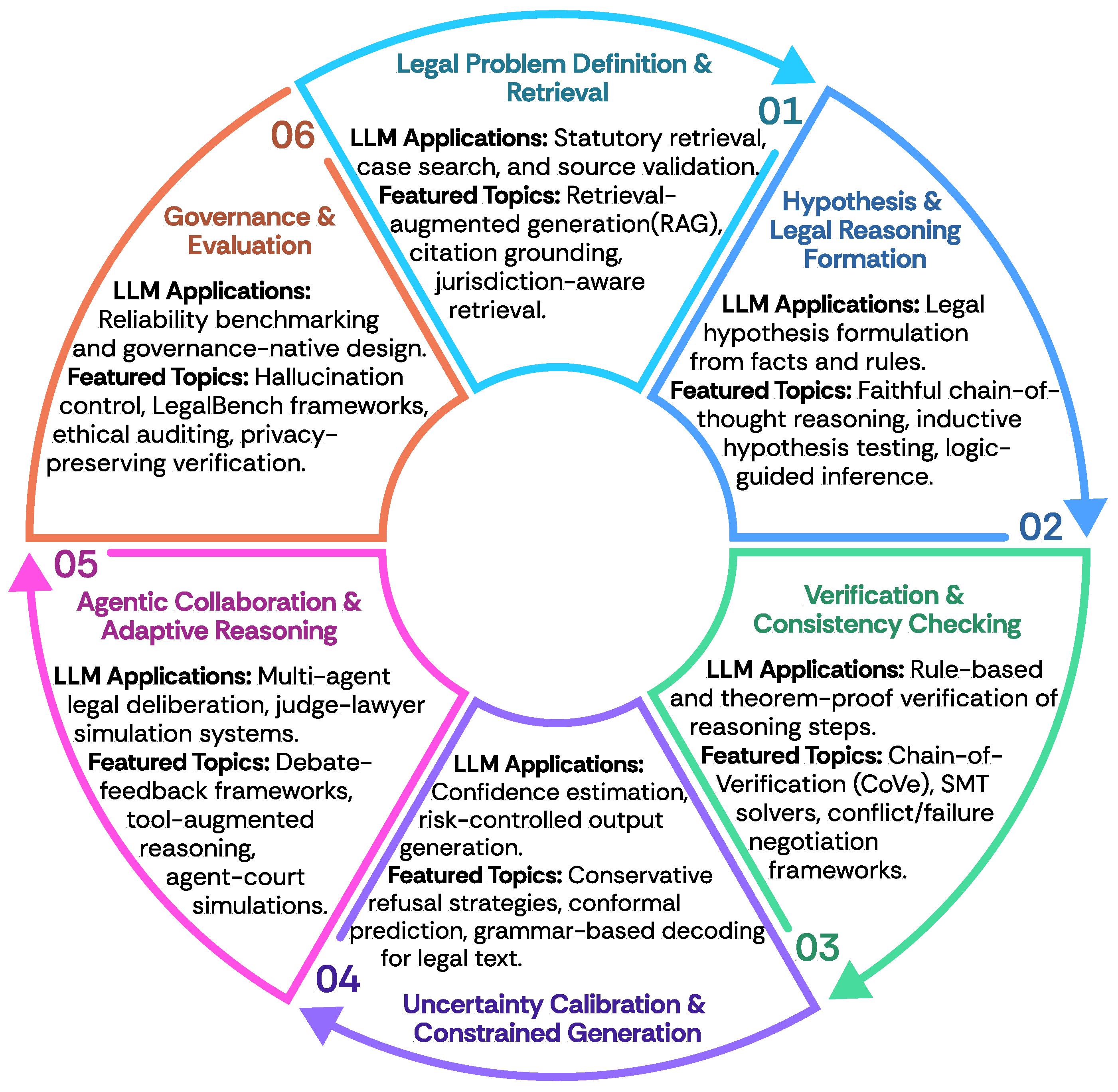

Table A1.
Statistics comparisons among Legal LLMs (R&D: Research and Development; PT: Pre-Train; SFT: Supervised Fine-Tune; RL: Reinforcement Learning).
Table A1.
Statistics comparisons among Legal LLMs (R&D: Research and Development; PT: Pre-Train; SFT: Supervised Fine-Tune; RL: Reinforcement Learning).
| Model / Framework | Country / Region | Parameters | Training Resources | PT | SFT | RL | Date |
|---|---|---|---|---|---|---|---|
| Legal-BERT [23] | Greece, United Kingdom | LEGAL-BERT-BASE(110M) | US contracts, EU legislation, ECHR cases | √ | - | - | 2020 |
| German BERT Base | Germany | bert-base-cased | Wiki, OpenLegalData, News | √ | √ | - | 2020 |
| CaseLaw-BERT | United States | bert-base-uncased(110M) | ILSI, ISS, ILDC Dataset | √ | √ | - | 2021 |
| CodeGen [112] | United States | CodeGen1/CodeGen2/CodeGen2.5(350M,1B,3B,7B,16B) | Jaxformer | √ | - | - | 2022 |
| ChatLaw [34] | China | InternLM(4x7B, MoE) | 93,000 court case decisions | √ | - | - | 2023 |
| DISC-LawLLM [172] | China | Qwen2.5-instruct 7B | DISC-Law-SFT | √ | √ | - | 2023 |
| HanFei | China | HanFei-1.0(7b) | Cases, regulations, indictments, legal news | √ | √ | - | 2023 |
| JurisLMs | China | LLaMA, GPT2 | Chinese legal corpus | √ | √ | - | 2023 |
| LaWGPT [186] | China | Chinese-alpaca-plus-7B | Awesome Chinese Legal Resources | √ | √ | - | 2023 |
| LexiLaw | China | ChatGLM-6B | BELLE 1.5M | - | √ | - | 2023 |
| WisdomInterrogatory | China | Baichuan-7B | 40G legal-related data | √ | √ | - | 2023 |
| Lawyer LLaMA [60] | China | quzhe/llama_chinese_13B, Chinese-LLaMA-13B | Alpaca-GPT4 (52k Chinese + 52k English) | √ | √ | - | 2023 |
| LAWGPT-zh | China | ChatGLM-6B | CrimeKgAssitant | - | √ | - | 2023 |
| BaoLuo LawAssistant | China | ChatGLM, sftglm-6b | Legal dataset | - | √ | - | 2023 |
| FedJudge [171] | China | baichuan-7b | C3VG, Lawyer LLaMA | - | √ | - | 2023 |
| Law-GLM | Germany, China | GLM-10B | 30GB of Chinese legal data | - | √ | - | 2023 |
| LexLM [26] | Denmark | RoBERTa large | LeXFiles corpus | √ | - | - | 2023 |
| legal-xlm-roberta-large [114] | Switzerland, Denmark, USA | XLM-R large | Multi Legal Pile | √ | - | - | 2023 |
| bert-large-portuguese-cased-legal | Brazil | BERTimbau large | assin, assin2, stsb_multi_mt pt, IRIS STS datasets | √ | √ | - | 2023 |
| SaulLM-7B [31] | United States, France, Portugal | Mistral-7B | Specialized data in the legal field | √ | - | - | 2024 |
| LawLLM [135] | United States | Gemma-7B | American legal data from the case.law platform | - | √ | - | 2024 |
| LegalΔ [35] | China | Qwen2.5-14B-Instruct | Lawbench, Lexeval, Disclaw | - | √ | √ | 2025 |
Appendix C.1. Formal Reasoning for Law: A Taxonomy
Definition. Let the legal reasoning space be , where R is the set of rules, F is the set of facts, C is the space of conclusions, is the temporal validity function, and is the jurisdiction function. A legal rule is represented as , and the validity constraint is defined as:
Syllogistic reasoning is formalized as:
Verifiability Theorem. An argument is valid if and only if:
where
denotes the rules applied, denotes the facts invoked, and ⊧ indicates logical entailment. The verification complexity is , where d is the reasoning depth.
Feasibility of SMT Solvers. Satisfiability Modulo Theories (SMT) solvers such as Z3 are well-suited for legal reasoning verification. Legal reasoning is essentially logical deduction under multiple constraints, which aligns precisely with the constraint satisfaction capabilities of SMT. Z3 supports combinations of theories such as first-order logic, temporal constraints, and set operations, naturally expressing the logical structure and spatiotemporal constraints of legal rules. By applying reductio ad absurdum, it efficiently determines validity and provides a strong technical foundation for constructing trustworthy legal reasoning evaluation frameworks.
SMT solvers let legal norms be encoded as machine-checkable logical formulas, where obligations, permissions, and prohibitions are expressed as constraints over entities, actions, and time. This supports automated consistency checking, revealing conflicts, hidden exceptions, or loopholes by searching for models that satisfy or violate certain rule combinations. Their support for quantifiers and rich data types (integers, reals, arrays, sets) matches the arithmetic and set-theoretic needs of domains like taxation, social benefits, and quantitative compliance. As a result, SMT-based encodings can accurately determine whether fact patterns fall within a rule’s scope and whether derived outcomes (such as sanctions or benefits) follow soundly from the premises.
SMT technology also supports counterfactual and what-if analysis. By systematically varying factual assumptions or modifying specific clauses, one can explore how outcomes change and thus assess the robustness, fairness, or potential bias of a legal framework. When a formula is unsatisfiable, modern SMT solvers like Z3 can produce unsat cores, i.e., minimal subsets of constraints that cause the contradiction. These cores can be mapped back to the underlying legal provisions, providing interpretable explanations of why a certain combination of rules and facts is inconsistent.
In the context of automated legal reasoning systems, SMT solvers can serve as a trusted back-end for both verification and execution. High-level legal-rule languages or graphical modeling tools can be compiled into SMT formulas, while the solver ensures that any derived conclusions are logically entailed by the formalized norms and facts. This separation of concerns allows domain experts to work at a conceptual level while relying on a mature, rigorously tested solver to guarantee correctness and completeness within the expressiveness of the chosen theories.
Finally, because SMT solvers are optimized for scalability and incrementality, they are suitable for large regulatory corpora and dynamically evolving case data. Incremental solving allows new facts or amended regulations to be added without recomputing everything from scratch. Altogether, these features make Z3 and related SMT technology a compelling backbone for building reliable, transparent, and auditable legal reasoning and evaluation frameworks.
Verification Algorithm.
Table A2.
Legal reasoning verification algorithm using SMT solver
| Algorithm: LegalReasoningVerification_SMT |
| Input: (rules), (facts), c (conclusion), t (time), j (jurisdiction) |
| Output: (validity, counterexample, violations) |
| 1: solver ← new Z3Solver() |
| 2: violations |
| 3: for each rule in do |
| 4: solver.add(ForAll) |
| 5: if or then |
| 6: violations.add |
| 7: if violations then |
| 8: return (False, None, violations) |
| 9: for each fact f in do |
| 10: solver.add(encode_fact) |
| 11: solver.add(Not) |
| 12: result ← solver.check() |
| 13: if result == UNSAT then |
| 14: return (True, None, ∅) |
| 15: else if result == SAT then |
| 16: return (False, solver.model(), {"insufficient reasoning"}) |
| 17: else |
| 18: return (Unknown, None, {"solver timeout"}) |
Appendix D. Products of LegalAI
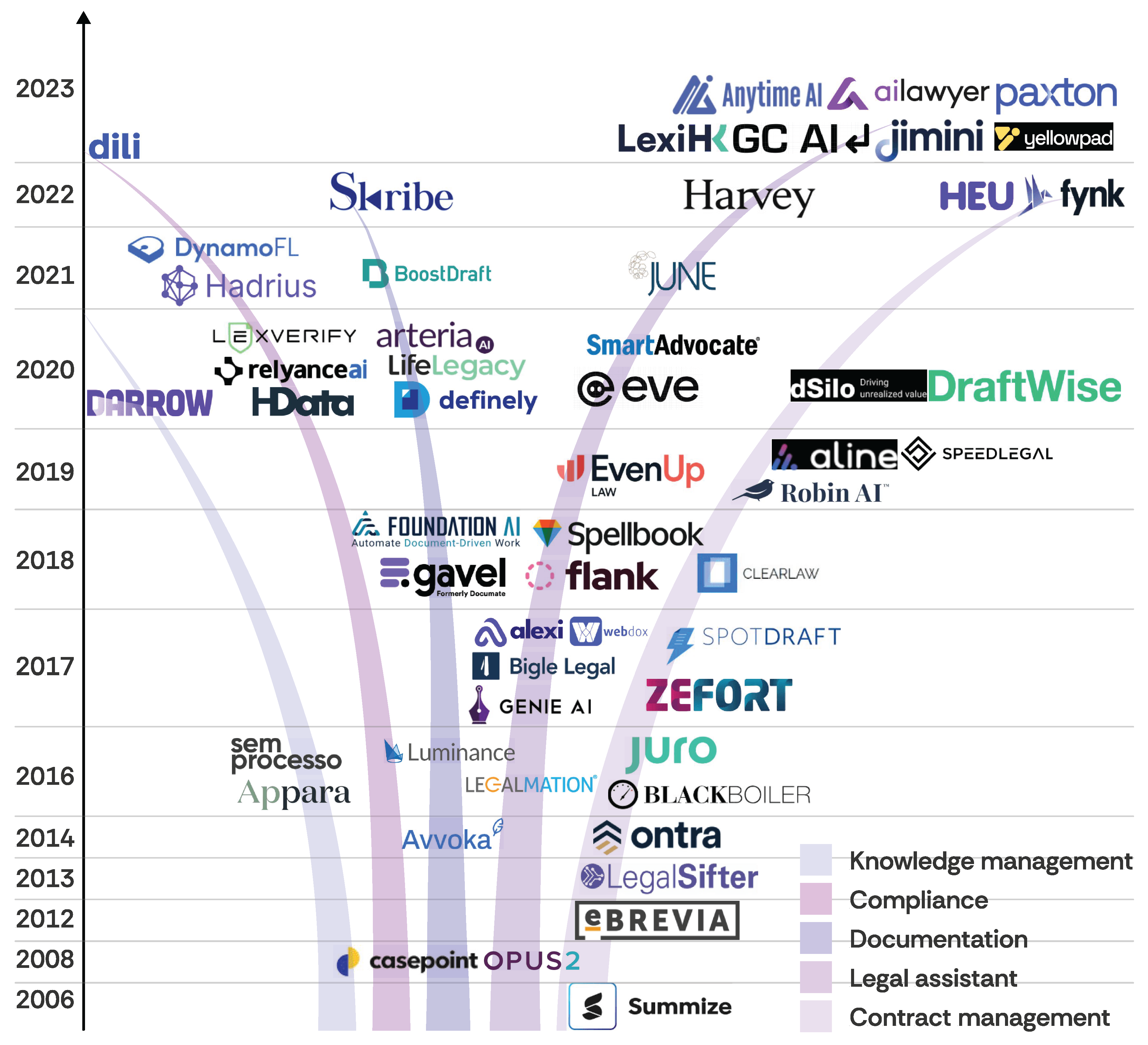
Legal AI has evolved from experimental prototypes to operational systems, reshaping both investigative and judicial processes. In forensics, deep-learning microservices such as YOLO and NudeNet automate the analysis of seized digital evidence, while models like CriminalNet-228 leverage surveillance data for real-time offender recognition with high accuracy. Judicial applications employ NLP and predictive analytics to promote fairness and consistency in sentencing, while symbolic and machine learning methods enhance semantic search and legislative annotation. The integration of explainable AI and hybrid reasoning frameworks underscores the growing emphasis on accountability and interpretability in legal decision-making. Meanwhile, LLMs such as ChatGPT, Harvey, and CoCounsel are redefining legal drafting and client communication, fostering collaborative workflows between humans and machines. Collectively, these developments signal a maturing and increasingly integrated Legal AI ecosystem that bridges investigation, adjudication, and legal practice.
Figure A3.
Evolution of generative AI-based legal products from 2006 to 2023, illustrating the emergence of different product categories such as knowledge management, documentation, legal assistance, and contract management.
Figure A3.
Evolution of generative AI-based legal products from 2006 to 2023, illustrating the emergence of different product categories such as knowledge management, documentation, legal assistance, and contract management.
Appendix E. Supplementary Materials
Appendix E.1. Ethical Concerns in Developing LegalAI
There has been an increasingly explicit call for governance-native frameworks in LLM-enhanced professional services, including LegalAI. A governance-native framework embeds governance constraints ex ante during model design and inference rather than relying on ex post correction. This shift reframes reliability, error resistance, and auditability as architectural commitments rather than downstream safeguards. Early rule-based tools were interpretable but brittle [182]. Deep learning vastly expanded capability but at the cost of opacity, motivating accountability-first designs that expose reasoning traces and intermediate steps. The push toward governance-native systems is driven by persistent failure modes such as hallucinations, misgrounding, and authority or temporal violations [104]. In response, faithfulness pipelines separate linguistic realization from underlying problem solving, enforcing consistency between reasoning and output. Theorem proving and certified interfaces constrain intermediate steps within verifiable logic, turning reasoning into a sequence of machine-checkable commitments [159]. Modular decomposition architectures isolate retrieval, citation verification, and hierarchical legal interpretation into dedicated, auditable components [72]. Complementary auditability tooling, including explainability instruments and fact-checking modules, further strengthens error resistance and supports traceable, accountable decision-making [37]. Yet statistical structure imposes hard limits on generative models. Even when trained on error-free corpora, cross-entropy–optimized generators retain irreducible uncertainty on closely confusable facts, producing “confident guesses” that reflect objective-function bias and inherent data ambiguity rather than engineering deficiencies [68]. Reinforcement-learning setups that score only right or wrong reward confidence and penalize uncertainty, therefore amplifying overconfidence and hallucination. In legal contexts, however, calibration—knowing when not to answer—is indispensable. Our framework therefore aims not at “a model that writes plausible legal language,” but at “a system that declines without evidence.” Concretely, it couples evidence-backed generation with calibrated confidence estimates and explicit abstention or deferral pathways for high-risk matters, favoring verifiable silence over eloquent error. The core hypothesis is that a governance-native architecture will raise sentence-level support accuracy, reduce out-of-scope reasoning and mis-citations, and improve task efficiency relative to standard approaches [133]. Metrics such as support accuracy, false support rate, verifier latency, and human audit time will measure the system’s impact [17]. By embedding verifiability into the generation process itself, this project develops a unified architecture where “backed by law” becomes a default, machine-checkable property. As datasets scaled, privacy shifted from afterthought to architecture. Federated learning enables cross organization training without pooling raw data, preserving legal compliance and data sovereignty [123]. Paired with process verified reasoning and auditability by design, it yields privacy preserving, transparent systems [44]. Safeguards now reason about context: Li et al. ([85,87]) embeds general policy of data protection into benchmarks and guardrail models, treating law as general safeguards for generative AI over roles, sensitivity, and jurisdiction. In legal AI, where leaking sealed records or enabling unlawful advice is unacceptable, these mechanisms enforce compliant generation, enabling calibrated refusals and end to end verification.
Appendix E.2. Differences with Existing Surveys
Several recent surveys have examined NLP and AI in legal contexts [71,184], but most treat technical methods and legal applications in isolation rather than integrating both perspectives. Our survey differs along four dimensions:
Holistic coverage of the LLM era. Earlier surveys predate the widespread adoption of large-scale pretrained models (e.g., GPT-3.5/4 [1,61], Claude 3 [6], LLaMA [145]) and instruction tuning paradigms. While Zhong’s works provide valuable taxonomies of legal NLP tasks, they primarily address pre-transformer methods or early BERT-style models [184]. Our survey centers on modern LLM architectures, including RAG, tool-use frameworks, and agentic workflows that have emerged since 2022.
Integration of technical and legal perspectives. Existing technical surveys [84] emphasize model architectures and benchmark performance but give limited attention to legal doctrine, professional responsibility, and regulatory compliance. Conversely, law-focused reviews [142] address ethical and policy dimensions but often lack technical depth. We explicitly bridge these gaps by co-developing technical and legal lenses, examining how architectural choices (e.g., citation-grounded generation, neuro-symbolic reasoning) align with legal requirements (e.g., explainability, precedent fidelity) and professional standards (e.g., Model Rules of Professional Conduct in the United States, Solicitors Regulation Authority standards in the United Kingdom).
Emphasis on deployment, governance, and real-world integration. Most surveys evaluate models on static benchmarks without addressing production deployment concerns. We systematically cover workflow integration patterns, human-in-the-loop review protocols, organizational controls (approval workflows, audit logs, version management), data governance (licensing, privacy, secure retrieval), and incident response, drawing on case studies from law firms, legal aid organizations, and courts.
Cross-jurisdictional and multilingual scope. Prior work predominantly focuses on U.S. or English-language legal systems. We instead address multilingual legal NLP, comparative law considerations, and adaptation strategies for civil-law, common-law, and mixed jurisdictions. This includes multilingual corpora such as MultiLegalPile [113]), translation-based transfer learning, and jurisdiction-specific fine-tuning.
References
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F. L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Agrawal, A., Suzgun, M., Mackey, L., Kalai, A. 2024103. Do Language Models Know When They’re Hallucinating References? Y. Graham M. Purver (), Findings of the Association for Computational Linguistics: EACL 2024 Findings of the association for computational linguistics: Eacl 2024 ( 912–928). St. Julian’s, MaltaAssociation for Computational Linguistics. Available online: https://aclanthology.org/2024.findings-eacl.62/ (accessed on).
- Agrawal, A.; Suzgun, M.; Mackey, L.; Kalai, A. 20242. Do language models know when they’re hallucinating references? Findings of the Association for Computational Linguistics: EACL 2024 Findings of the association for computational linguistics: Eacl 2024 ( 912–928).
- Alpay, F.; Alakkad, H. Truth-Aware Decoding: A Program-Logic Approach to Factual Language Generation. Truth-aware decoding: A program-logic approach to factual language generation. 2025. Available online: https://arxiv.org/abs/2510.07331.
- Alsagheer, D. R.; Kamal, A.; Kamal, M.; Wu, C. Y.; Shi, W. The Lawyer That Never Thinks: Consistency and Fairness as Keys to Reliable AI. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics 2025, Volume 1, 9943–9954. [Google Scholar]
- Anthropic. The Claude 3 Model Family: Opus, Sonnet, Haiku. The claude 3 model family: Opus, sonnet, haiku. 2024. Available online: https://assets.anthropic.com/m/61e7d27f8c8f5919/original/Claude-3-Model-Card.pdf.
- Asai, A.; Wu, Z.; Wang, Y.; Sil, A.; Hajishirzi, H. Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection. Self-rag: Learning to retrieve, generate, and critique through self-reflection. 2023. Available online: https://arxiv.org/abs/2310.11511.
- Asgari, E.; Montaña-Brown, N.; Dubois, M.; Khalil, S.; Balloch, J.; Yeung, J. A.; Pimenta, D. 2025may13. A Framework to Assess Clinical Safety and Hallucination Rates of LLMs for Medical Text Summarisation. NPJ Digital Medicine81274. [CrossRef] [PubMed] [PubMed Central]
- Askari, A.; Aliannejadi, M.; Abolghasemi, A.; Kanoulas, E.; Verberne, S. Closer: conversational legal longformer with expertise-aware passage response ranker for long contexts. In Proceedings of the 32nd ACM International Conference on information and knowledge management Proceedings of the 32nd acm international conference on information and knowledge management, 2023; pp. 25–35. [Google Scholar]
- Bayless, S.; Buliani, S.; Cassel, D.; Cook, B.; Clough, D.; Delmas, R.; Diallo, N.; Erata, F.; Feng, N.; Giannakopoulou, D.; Goel, A.; Gokhale, A.; Hendrix, J.; Hudak, M.; Jovanović, D.; Kent, A. M.; Kiesl-Reiter, B.; Kuna, J. J.; Labai, N.; Yao, J. A Neurosymbolic Approach to Natural Language Formalization and Verification. A neurosymbolic approach to natural language formalization and verification. 2025. Available online: https://arxiv.org/abs/2511.09008.
- Beltagy, I.; Peters, M. E.; Cohan, A. 2020. Longformer: The Long-Document Transformer. Longformer: The long-document transformer. Available online: https://arxiv.org/abs/2004.05150 (accessed on).
- Bendová, K.; Knap, T.; Černỳ, J.; Pour, V.; Savelka, J.; Kvapilíková, I.; Drápal, J. What Are the Facts? Automated Extraction of Court-Established Facts from Criminal-Court Opinions. arXiv 2025, arXiv:2511.05320. [Google Scholar]
- Birhane, A.; Steed, R.; Ojewale, V.; Vecchione, B.; Raji, I. D. 20241. AI auditing: The Broken Bus on the Road to AI Accountability. Ai auditing: The broken bus on the road to ai accountability. Available online: https://arxiv.org/abs/2401.14462 (accessed on).
- Birhane, A.; Steed, R.; Ojewale, V.; Vecchione, B.; Raji, I. D. AI auditing: The broken bus on the road to AI accountability. 2024 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) 2024 ieee conference on secure and trustworthy machine learning (satml), 20242; pp. 612–643. [Google Scholar]
- Cai, H.; Zhao, S.; Zhang, L.; Shen, X.; Xu, Q.; Shen, W.; Wen, Z.; Ban, T. Unilaw-R1: A Large Language Model for Legal Reasoning with Reinforcement Learning and Iterative Inference. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing Proceedings of the 2025 conference on empirical methods in natural language processing, 2025; pp. 18128–18142. [Google Scholar]
- Cao, C.; Li, M.; Dai, J.; Yang, J.; Zhao, Z.; Zhang, S.; Shi, W.; Liu, C.; Han, S.; Guo, Y. 2025. Towards Advanced Mathematical Reasoning for LLMs via First-Order Logic Theorem Proving. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: EMNLP 2025. Proceedings of the 2024 conference on empirical methods in natural language processing: Emnlp 2025.
- Cao, C.; Zhu, H.; Ji, J.; Sun, Q.; Zhu, Z.; Wu, Y.; Dai, J.; Yang, Y.; Han, S.; Guo, Y. SafeLawBench: Towards Safe Alignment of Large Language Models. In Findings of the Association for Computational Linguistics: ACL 2025 Findings of the association for computational linguistics: Acl 2025 ( 14015–14048); AustriaAssociation for Computational Linguistics: Vienna, 2025. [Google Scholar]
- Cao, S.; Wang, L. 202408. Verifiable Generation with Subsentence-Level Fine-Grained Citations. L.-W. Ku, A. Martins, V. Srikumar (), Findings of the Association for Computational Linguistics: ACL 2024 Findings of the association for computational linguistics: Acl 2024 ( 15584–15596). Bangkok, ThailandAssociation for Computational Linguistics. Available online: https://aclanthology.org/2024.findings-acl.920/. [CrossRef]
- Carlini, N.; Tramer, F.; Wallace, E.; Jagielski, M.; Herbert-Voss, A.; Lee, K.; Roberts, A.; Brown, T.; Song, D.; Erlingsson, U.; et al. Extracting training data from large language models. 30th USENIX security symposium (USENIX Security 21) 30th usenix security symposium (usenix security 21), 2021; pp. 2633–2650. [Google Scholar]
- Chakraborty, N.; Ornik, M.; Driggs-Campbell, K. 202503. Hallucination Detection in Foundation Models for Decision-Making: A Flexible Definition and Review of the State of the Art. ACM Computing Surveys5771–35. [CrossRef]
- Chalkidis, I., Fergadiotis, M., Androutsopoulos, I. 202111. MultiEURLEX - A multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer. M.-F. Moens, X. Huang, L. Specia, S. W.-t. Yih (), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing Proceedings of the 2021 conference on empirical methods in natural language processing ( 6974–6996). Online and Punta Cana, Dominican RepublicAssociation for Computational Linguistics. Available online: https://aclanthology.org/2021.emnlp-main.559/ (accessed on). [CrossRef]
- Chalkidis, I.; Fergadiotis, M.; Malakasiotis, P.; Aletras, N.; Androutsopoulos, I. LEGAL-BERT: The muppets straight out of law school. arXiv 2020, arXiv:2010.02559. [Google Scholar] [CrossRef]
- Chalkidis, I.; Fergadiotis, M.; Malakasiotis, P.; Aletras, N.; Androutsopoulos, I. 20202. LEGAL-BERT: The Muppets straight out of Law School. Legal-bert: The muppets straight out of law school. Available online: https://arxiv.org/abs/2010.02559.
- Chalkidis, I.; Fergadiotis, M.; Malakasiotis, P.; Aletras, N.; Androutsopoulos, I. Androutsopoulos, I. 2020311. LEGAL-BERT: The Muppets straight out of Law School. T. Cohn, Y. He, Y. Liu (), Findings of the Association for Computational Linguistics: EMNLP 2020 Findings of the association for computational linguistics: Emnlp 2020 ( 2898–2904). OnlineAssociation for Computational Linguistics. Available online: https://aclanthology.org/2020.findings-emnlp.261/ (accessed on). [CrossRef]
- Chalkidis, I.; Garneau, N.; Goanta, C.; Katz, D. M.; Søgaard, A. LeXFiles and LegalLAMA: Facilitating English multinational legal language model development. arXiv 2023, arXiv:2305.07507. [Google Scholar]
- Chalkidis, I.; Garneau, N.; Goanta, C.; Katz, D. M.; Søgaard, A. LeXFiles and LegalLAMA: Facilitating English Multinational Legal Language Model Development. Lexfiles and legallama: Facilitating english multinational legal language model development. 2023. Available online: https://arxiv.org/abs/2305.07507.
- Chalkidis, I.; Jana, A.; Hartung, D.; Bommarito, M.; Androutsopoulos, I.; Katz, D. M.; Aletras, N. LexGLUE: A Benchmark Dataset for Legal Language Understanding in English. Lexglue: A benchmark dataset for legal language understanding in english. 2022. Available online: https://arxiv.org/abs/2110.00976.
- Chen, G.; Fan, L.; Gong, Z.; Xie, N.; Li, Z.; Liu, Z.; Li, C.; Qu, Q.; Alinejad-Rokny, H.; Ni, S.; et al. Agentcourt: Simulating court with adversarial evolvable lawyer agents. Findings of the Association for Computational Linguistics: ACL 2025 Findings of the association for computational linguistics: Acl 2025, 2025, 5850–5865. [Google Scholar]
- Chen, X.; Mao, M.; Li, S.; Shangguan, H. Debate-feedback: A multi-agent framework for efficient legal judgment prediction. arXiv 2025, arXiv:2504.05358. [Google Scholar]
- Cherian, J. J.; Gibbs, I.; Candès, E. J. Large language model validity via enhanced conformal prediction methods. Large language model validity via enhanced conformal prediction methods. 2024. Available online: https://arxiv.org/abs/2406.09714.
- Colombo, P.; Pires, T. P.; Boudiaf, M.; Culver, D.; Melo, R.; Corro, C.; Martins, A. F. T.; Esposito, F.; Raposo, V. L.; Morgado, S.; Desa, M. 20241. SaulLM-7B: A pioneering Large Language Model for Law. Saullm-7b: A pioneering large language model for law. 1. Available online: https://arxiv.org/abs/2403.03883.
- Colombo, P.; Pires, T. P.; Boudiaf, M.; Culver, D.; Melo, R.; Corro, C.; Martins, A. F.; Esposito, F.; Raposo, V. L.; Morgado, S.; et al. Saullm-7b: A pioneering large language model for law. arXiv 2024, arXiv:2403.03883. [Google Scholar]
- Cui, J.; Ning, M.; Li, Z.; Chen, B.; Yan, Y.; Li, H.; Ling, B.; Tian, Y.; Yuan, L. Chatlaw: A multi-agent collaborative legal assistant with knowledge graph enhanced mixture-of-experts large language model. arXiv 2023, arXiv:2306.16092. [Google Scholar]
- Cui, J.; Ning, M.; Li, Z.; Chen, B.; Yan, Y.; Li, H.; Ling, B.; Tian, Y.; Yuan, L. Chatlaw: A Multi-Agent Collaborative Legal Assistant with Knowledge Graph Enhanced Mixture-of-Experts Large Language Model. Chatlaw: A multi-agent collaborative legal assistant with knowledge graph enhanced mixture-of-experts large language model. 2024. Available online: https://arxiv.org/abs/2306.16092.
- Dai, X.; Xu, B.; Liu, Z.; Yan, Y.; Xie, H.; Yi, X.; Wang, S.; Yu, G. LegalΔ: Enhancing Legal Reasoning in LLMs via Reinforcement Learning with Chain-of-Thought Guided Information Gain. Legalδ: Enhancing legal reasoning in llms via reinforcement learning with chain-of-thought guided information gain. 2025. Available online: https://arxiv.org/abs/2508.12281.
- Dai, Y.; Feng, D.; Huang, J.; Jia, H.; Xie, Q.; Zhang, Y.; Han, W.; Tian, W.; Wang, H. LAiW: A Chinese legal large language models benchmark. In Proceedings of the 31st International conference on computational linguistics Proceedings of the 31st international conference on computational linguistics, 2025; pp. 10738–10766. [Google Scholar]
- Dathathri, S.; Madotto, A.; Lan, J.; Hung, J.; Frank, E.; Molino, P.; Yosinski, J.; Liu, R. Plug and play language models: A simple approach to controlled text generation. Plug and play language models: A simple approach to controlled text generation. 2019. Available online: https://arxiv.org/abs/1912.02164.
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. 20231. QLORA: efficient finetuning of quantized LLMs. In Proceedings of the 37th International Conference on Neural Information Processing Systems. Proceedings of the 37th international conference on neural information processing systems, Red Hook, NY, USA; Curran Associates Inc.
- Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. 20232. QLoRA: Efficient Finetuning of Quantized LLMs. Qlora: Efficient finetuning of quantized llms. Available online: https://arxiv.org/abs/2305.14314.
- DeYoung, J., Jain, S., Rajani, N. F., Lehman, E., Xiong, C., Socher, R., Wallace, B. C. 202007. ERASER: A Benchmark to Evaluate Rationalized NLP Models. D. Jurafsky, J. Chai, N. Schluter, J. Tetreault (), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics Proceedings of the 58th annual meeting of the association for computational linguistics ( 4443–4458). OnlineAssociation for Computational Linguistics. Available online: https://aclanthology.org/2020.acl-main.408/ (accessed on). [CrossRef]
- Dhuliawala, S.; Komeili, M.; Xu, J.; Raileanu, R.; Li, X.; Celikyilmaz, A.; Weston, J. 202408. Chain-of-Verification Reduces Hallucination in Large Language Models. L.-W. Ku, A. Martins, V. Srikumar (), Findings of the Association for Computational Linguistics: ACL 2024 Findings of the association for computational linguistics: Acl 2024 ( 3563–3578). Bangkok, ThailandAssociation for Computational Linguistics. Available online: https://aclanthology.org/2024.findings-acl.212/. [CrossRef]
- Fang, H.; Balakrishnan, A.; Jhamtani, H.; Bufe, J.; Crawford, J.; Krishnamurthy, J.; Pauls, A.; Eisner, J.; Andreas, J.; Klein, D. 202307. The Whole Truth and Nothing But the Truth: Faithful and Controllable Dialogue Response Generation with Dataflow Transduction and Constrained Decoding. A. Rogers, J. Boyd-Graber, N. Okazaki (), Findings of the Association for Computational Linguistics: ACL 2023 Findings of the association for computational linguistics: Acl 2023 ( 5682–5700). Toronto, CanadaAssociation for Computational Linguistics. Available online: https://aclanthology.org/2023.findings-acl.351/ (accessed on). [CrossRef]
- Fei, Z.; Zhang, S.; Shen, X.; Zhu, D.; Wang, X.; Ge, J.; Ng, V. Internlm-law: An open-sourced chinese legal large language model. In Proceedings of the 31st International Conference on Computational Linguistics Proceedings of the 31st international conference on computational linguistics, 2025; pp. 9376–9392. [Google Scholar]
- Fernsel, L.; Kalff, Y.; Simbeck, K. Assessing the Auditability of AI-integrating Systems: A Framework and Learning Analytics Case Study. arXiv 2024, arXiv:2411.08906. [Google Scholar]
- Gao, T.; Wettig, A.; Yen, H.; Chen, D. How to train long-context language models (effectively). Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics 2025, Volume 1, 7376–7399. [Google Scholar]
- Geng, S.; Josifoski, M.; Peyrard, M.; West, R. Grammar-Constrained Decoding for Structured NLP Tasks without Finetuning. Grammar-constrained decoding for structured nlp tasks without finetuning. 2024. Available online: https://arxiv.org/abs/2305.13971.
- Guha, N.; Nyarko, J.; Ho, D.; Ré, C.; Chilton, A.; Chohlas-Wood, A.; Peters, A.; Waldon, B.; Rockmore, D.; Zambrano, D.; et al. Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models. Advances in neural information processing systems 2023, 3644123–44279. [Google Scholar] [CrossRef]
- Guha, N.; Nyarko, J.; Ho, D. E.; Ré, C.; Chilton, A.; Narayana, A.; Chohlas-Wood, A.; Peters, A.; Waldon, B.; Rockmore, D. N.; Zambrano, D.; Talisman, D.; Hoque, E.; Surani, F.; Fagan, F.; Sarfaty, G.; Dickinson, G. M.; Porat, H.; Hegland, J.; Li, Z. LEGALBENCH: a collaboratively built benchmark for measuring legal reasoning in large language models. In Proceedings of the 37th International Conference on Neural Information Processing Systems. Proceedings of the 37th international conference on neural information processing systems, Red Hook, NY, USA, 2023; Curran Associates Inc. [Google Scholar]
- Guha, N.; Nyarko, J.; Ho, D. E.; Ré, C.; Chilton, A.; Narayana, A.; Chohlas-Wood, A.; Peters, A.; Waldon, B.; Rockmore, D. N.; Zambrano, D.; Talisman, D.; Hoque, E.; Surani, F.; Fagan, F.; Sarfaty, G.; Dickinson, G. M.; Porat, H.; Hegland, J.; Li, Z. LegalBench: A Collaboratively Built Benchmark for Measuring Legal Reasoning in Large Language Models. Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models. 2023. Available online: https://arxiv.org/abs/2308.11462.
- Guo, C.; Sablayrolles, A.; Jégou, H.; Kiela, D. Gradient-based Adversarial Attacks against Text Transformers. Gradient-based adversarial attacks against text transformers. 2021. Available online: https://arxiv.org/abs/2104.13733.
- Guo, Q.; Dong, Y.; Tian, L.; Kang, Z.; Zhang, Y.; Wang, S. BANER: Boundary-aware LLMs for few-shot named entity recognition. In Proceedings of the 31st International Conference on Computational Linguistics Proceedings of the 31st international conference on computational linguistics, 2025; pp. 10375–10389. [Google Scholar]
- Gupta, A.; Rice, D.; O’Connor, B. -Stance: A Large-Scale Real World Dataset of Stances in Legal Argumentation. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics 2025, Volume 1, 31450–31467. [Google Scholar]
- Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., Smith, N. A. 202007. Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks. D. Jurafsky, J. Chai, N. Schluter, J. Tetreault (), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics Proceedings of the 58th annual meeting of the association for computational linguistics ( 8342–8360). OnlineAssociation for Computational Linguistics. Available online: https://aclanthology.org/2020.acl-main.740/ (accessed on). [CrossRef]
- 202511. Laniqo at WMT25 Terminology Translation Task: A Multi-Objective Reranking Strategy for Terminology-Aware Translation via Pareto-Optimal Decoding. B. Haddow, T. Kocmi, P. Koehn, C. Monz (), Proceedings of the Tenth Conference on Machine Translation Proceedings of the tenth conference on machine translation ( 1276–1283). Suzhou, ChinaAssociation for Computational Linguistics. Available online: https://aclanthology.org/2025.wmt-1.107/ (accessed on).
- Han, S.; Guo, Y.-K.; Huang, S. Hong Kong Generative Artificial Intelligence Technical and Application Guideline; Hong Kong SAR Government Press Release, 2025. [Google Scholar]
- Hepworth, I.; Olive, K.; Dasgupta, K.; Le, M.; Lodato, M.; Maruseac, M.; Meiklejohn, S.; Chaudhuri, S.; Minkus, T. Securing the AI Software Supply Chain Securing the ai software supply chain; Google, 2024. [Google Scholar]
- Hong Kong Productivity Council (HKPC). Hong Kong enterprise cyber security readiness index and AI security survey. Hong kong enterprise cyber security readiness index and ai security survey. Press Release. 2024n. Available online: https://www.hkpc.org/en/about-us/media-centre/press-releases/2024/hong-kong-enterprise-cyber-security-readiness-index.
- Hu, E. J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. Lora: Low-rank adaptation of large language models. 2021. Available online: https://arxiv.org/abs/2106.09685.
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H.; Chen, Q.; Peng, W.; Feng, X.; Qin, B.; Liu, T. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Transactions on Information Systems Available online. 2025, 4321–55. [Google Scholar] [CrossRef]
- Huang, Q.; Tao, M.; Zhang, C.; An, Z.; Jiang, C.; Chen, Z.; Wu, Z.; Feng, Y. Lawyer LLaMA Technical Report. Lawyer llama technical report. 2023. Available online: https://arxiv.org/abs/2305.15062.
- Hurst, A.; Lerer, A.; Goucher, A. P.; Perelman, A.; Ramesh, A.; Clark, A.; Ostrow, A.; Welihinda, A.; Hayes, A.; Radford, A.; et al. Gpt-4o system card. arXiv 2024, arXiv:2410.21276. [Google Scholar] [CrossRef]
- Ji, J.; Chen, X.; Pan, R.; Zhang, C.; Zhu, H.; Li, J.; Hong, D.; Chen, B.; Zhou, J.; Wang, K.; et al. Safe RLHF-V: Safe Reinforcement Learning from Multi-modal Human Feedback. arXiv 2025, arXiv:2503.17682. [Google Scholar]
- Ji, J.; Hong, D.; Zhang, B.; Chen, B.; Dai, J.; Zheng, B.; Qiu, T. A.; Zhou, J.; Wang, K.; Li, B.; Han, S.; Guo, Y.; Yang, Y. 202507. PKU-SafeRLHF: Towards Multi-Level Safety Alignment for LLMs with Human Preference. W. Che, J. Nabende, E. Shutova, M. T. Pilehvar (), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) Proceedings of the 63rd annual meeting of the association for computational linguistics (volume 1: Long papers) ( 31983–32016). Vienna, AustriaAssociation for Computational Linguistics. Available online: https://aclanthology.org/2025.acl-long.1544/ (accessed on). [CrossRef]
- Ji, J.; Qiu, T.; Chen, B.; Zhang, B.; Lou, H.; Wang, K.; Duan, Y.; He, Z.; Zhou, J.; Zhang, Z.; et al. Ai alignment: A comprehensive survey. arXiv 2023, arXiv:2310.19852. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y. J.; Madotto, A.; Fung, P. 202303. Survey of Hallucination in Natural Language Generation. ACM Computing Surveys55121–38. Available online: http://dx.doi.org/10.1145/3571730 (accessed on). [CrossRef]
- Jiang, Z.; Xu, F. F.; Gao, L.; Sun, Z.; Liu, Q.; Dwivedi-Yu, J.; Yang, Y.; Callan, J.; Neubig, G. Active Retrieval Augmented Generation. Active retrieval augmented generation. 2023. Available online: https://arxiv.org/abs/2305.06983.
- Ju, C.; Shi, W.; Liu, C.; Ji, J.; Zhang, J.; Zhang, R.; Xu, J.; Yang, Y.; Han, S.; Guo, Y. 2025. Benchmarking multi-national value alignment for large language models. Findings of the Association for Computational Linguistics: ACL 2025 Findings of the association for computational linguistics: Acl 2025 ( 20042–20058).
- Kalai, A. T.; Nachum, O.; Vempala, S. S.; Zhang, E. Why language models hallucinate. Why language models hallucinate. 2025. Available online: https://arxiv.org/abs/2509.04664.
- Kalai, A. T.; Vempala, S. S. Calibrated Language Models Must Hallucinate. In Proceedings of the 56th Annual ACM Symposium on Theory of Computing Proceedings of the 56th annual acm symposium on theory of computing ( 160–171), New York, NY, USA, 2024; Association for Computing Machinery. [Google Scholar] [CrossRef]
- Kaleeswaran, S.; Santhiar, A.; Kanade, A.; Gulwani, S. Semi-supervised verified feedback generation. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering Proceedings of the 2016 24th acm sigsoft international symposium on foundations of software engineering, 2016; pp. 739–750. [Google Scholar]
- Katz, D. M.; Hartung, D.; Gerlach, L.; Jana, A.; Bommarito, M. J., II. Natural language processing in the legal domain. arXiv 2023, arXiv:2302.12039. [Google Scholar] [CrossRef]
- Khot, T.; Trivedi, H.; Finlayson, M.; Fu, Y.; Richardson, K.; Clark, P.; Sabharwal, A. Decomposed prompting: A modular approach for solving complex tasks. Decomposed prompting: A modular approach for solving complex tasks. 2022. Available online: https://arxiv.org/abs/2210.02406.
- Khot, T.; Trivedi, H.; Finlayson, M.; Fu, Y.; Richardson, K.; Clark, P.; Sabharwal, A. Decomposed Prompting: A Modular Approach for Solving Complex Tasks. Decomposed prompting: A modular approach for solving complex tasks. 2023. Available online: https://arxiv.org/abs/2210.02406.
- Klisura, Đ.; Torres, A. R. B.; Gárate-Escamilla, A. K.; Biswal, R. R.; Yang, K.; Pataci, H.; Rios, A. A Multi-Agent Framework for Mitigating Dialect Biases in Privacy Policy Question-Answering Systems. arXiv 2025, arXiv:2506.02998. [Google Scholar]
- Kornilova, A.; Eidelman, V. BillSum: A corpus for automatic summarization of US legislation. In Proceedings of the 2nd Workshop on New Frontiers in Summarization Proceedings of the 2nd workshop on new frontiers in summarization, 2019; pp. 48–56. [Google Scholar]
- Kuhn, L.; Gal, Y.; Farquhar, S. Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. 2023. Available online: https://arxiv.org/abs/2302.09664.
- kui Sin, K.; Xuan, X.; Kit, C.; yan Chan, C. H.; kin Ip, H. H. Solving the Unsolvable: Translating Case Law in Hong Kong. Solving the unsolvable: Translating case law in hong kong. 2025. Available online: https://arxiv.org/abs/2501.09444.
- Kullback, S. Kullback-leibler divergence. Tech. Rep. 1951. [Google Scholar]
- Lee, J.-S. Lexgpt 0.1: pre-trained gpt-j models with pile of law. arXiv 2023, arXiv:2306.05431. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; K"uttler, H.; Lewis, M.; Yih, W.-t.; Rockt"aschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems Advances in neural information processing systems 2020, 33, 9459–9474. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.-t.; Rocktäschel, T.; Riedel, S.; Kiela, D. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems Advances in neural information processing systems 2020, 33, 9459–9474. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; tau Yih, W.; Rocktäschel, T.; Riedel, S.; Kiela, D. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Retrieval-augmented generation for knowledge-intensive nlp tasks. 2021. Available online: https://arxiv.org/abs/2005.11401.
- Li, C.; Wang, S.; Zhang, J.; Zong, C. 202406. Improving In-context Learning of Multilingual Generative Language Models with Cross-lingual Alignment. K. Duh, H. Gomez, S. Bethard (), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) Proceedings of the 2024 conference of the north american chapter of the association for computational linguistics: Human language technologies (volume 1: Long papers) ( 8058–8076). Mexico City, MexicoAssociation for Computational Linguistics. Available online: https://aclanthology.org/2024.naacl-long.445/ (accessed on). [CrossRef]
- Li, H.; Chen, Y.; Ai, Q.; Wu, Y.; Zhang, R.; Liu, Y. Lexeval: A comprehensive chinese legal benchmark for evaluating large language models. Advances in Neural Information Processing Systems 2024, 3725061–25094. [Google Scholar]
- Li, H.; Chen, Y.; Zeng, J.; Peng, H.; Jing, H.; Hu, W.; Yang, X.; Zeng, Z.; Han, S.; Song, Y. 20251. GSPR: Aligning LLM Safeguards as Generalizable Safety Policy Reasoners. Gspr: Aligning llm safeguards as generalizable safety policy reasoners. Available online: https://arxiv.org/abs/2509.24418.
- Li, H.; Chen, Y.; Zeng, J.; Peng, H.; Jing, H.; Hu, W.; Yang, X.; Zeng, Z.; Han, S.; Song, Y. GSPR: Aligning LLM Safeguards as Generalizable Safety Policy Reasoners. arXiv 2025, arXiv:2509.24418. [Google Scholar] [CrossRef]
- Li, H.; Hu, W.; Jing, H.; Chen, Y.; Hu, Q.; Han, S.; Chu, T.; Hu, P.; Song, Y. 20251. Privaci-bench: Evaluating privacy with contextual integrity and legal compliance. Privaci-bench: Evaluating privacy with contextual integrity and legal compliance. Available online: https://arxiv.org/abs/2502.17041.
- Li, H.; Hu, W.; Jing, H.; Chen, Y.; Hu, Q.; Han, S.; Chu, T.; Hu, P.; Song, Y. Privaci-bench: Evaluating privacy with contextual integrity and legal compliance. arXiv 2025, arXiv:2502.17041. [Google Scholar]
- Li, H.; Shao, Y.; Wu, Y.; Ai, Q.; Ma, Y.; Liu, Y. Lecardv2: A large-scale chinese legal case retrieval dataset. In Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval Proceedings of the 47th international acm sigir conference on research and development in information retrieval, 2024; pp. 2251–2260. [Google Scholar]
- Li, L.; Li, D.; Lin, C.; Li, W.; Xue, W.; Han, S.; Guo, Y. AIRA: Activation-Informed Low-Rank Adaptation for Large Models. In Proceedings of the IEEE/CVF International Conference on Computer Vision Proceedings of the ieee/cvf international conference on computer vision, 2025; pp. 1729–1739. [Google Scholar]
- Li, L.; Lin, C.; Li, D.; Huang, Y.-L.; Li, W.; Wu, T.; Zou, J.; Xue, W.; Han, S.; Guo, Y. Efficient Fine-Tuning of Large Models via Nested Low-Rank Adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Proceedings of the ieee/cvf international conference on computer vision, 2025; pp. 22252–22262. [Google Scholar]
- Li, X.; Cao, Y.; Pan, L.; Ma, Y.; Sun, A. 202408. Towards Verifiable Generation: A Benchmark for Knowledge-aware Language Model Attribution. L.-W. Ku, A. Martins, V. Srikumar (), Findings of the Association for Computational Linguistics: ACL 2024 Findings of the association for computational linguistics: Acl 2024 ( 493–516). Bangkok, ThailandAssociation for Computational Linguistics. Available online: https://aclanthology.org/2024.findings-acl.28/ (accessed on). 08. [CrossRef]
- Lin, S.; Hilton, J.; Evans, O. 20221. Teaching Models to Express Their Uncertainty in Words. Teaching models to express their uncertainty in words. Available online: https://arxiv.org/abs/2205.14334.
- Lin, S.; Hilton, J.; Evans, O. 20222. Teaching models to express their uncertainty in words. Teaching models to express their uncertainty in words. 2. Available online: https://arxiv.org/abs/2205.14334.
- Ling, C., Zhao, X., Zhang, X., Cheng, W., Liu, Y., Sun, Y., Oishi, M., Osaki, T., Matsuda, K., Ji, J., Bai, G., Zhao, L., Chen, H. 202406. Uncertainty Quantification for In-Context Learning of Large Language Models. K. Duh, H. Gomez, S. Bethard (), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) Proceedings of the 2024 conference of the north american chapter of the association for computational linguistics: Human language technologies (volume 1: Long papers) ( 3357–3370). Mexico City, MexicoAssociation for Computational Linguistics. Available online: https://aclanthology.org/2024.naacl-long.184/ (accessed on). [CrossRef]
- Liu, C.; Kang, Y.; Wang, S.; Qing, L.; Zhao, F.; Wu, C.; Sun, C.; Kuang, K.; Wu, F. More than catastrophic forgetting: Integrating general capabilities for domain-specific llms. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing Proceedings of the 2024 conference on empirical methods in natural language processing, 2024; pp. 7531–7548. [Google Scholar]
- Liu, X.; Liang, T.; He, Z.; Xu, J.; Wang, W.; He, P.; Tu, Z.; Mi, H.; Yu, D. Trust, But Verify: A Self-Verification Approach to Reinforcement Learning with Verifiable Rewards. arXiv 2025, arXiv:2505.13445. [Google Scholar] [CrossRef]
- Lu, H.; Fang, L.; Zhang, R.; Li, X.; Cai, J.; Cheng, H.; Tang, L.; Liu, Z.; Sun, Z.; Wang, T.; et al. Alignment and safety in large language models: Safety mechanisms, training paradigms, and emerging challenges. arXiv 2025, arXiv:2507.19672. [Google Scholar] [CrossRef]
- Lu, X.; West, P.; Zellers, R.; Le Bras, R.; Bhagavatula, C.; Choi, Y. 202106. NeuroLogic Decoding: (Un)supervised Neural Text Generation with Predicate Logic Constraints. K. Toutanova et al. (), Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies Proceedings of the 2021 conference of the north american chapter of the association for computational linguistics: Human language technologies ( 4288–4299). OnlineAssociation for Computational Linguistics. Available online: https://aclanthology.org/2021.naacl-main.339/ (accessed on). 202106. [CrossRef]
- Luo, J.; Kou, Z.; Yang, L.; Luo, X.; Huang, J.; Xiao, Z.; Peng, J.; Liu, C.; Ji, J.; Liu, X.; et al. FinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation. arXiv 2025, arXiv:2505.24714. [Google Scholar]
- Luo, K.; Huang, Q.; Jiang, C.; Feng, Y. Automating Legal Interpretation with LLMs: Retrieval, Generation, and Evaluation. arXiv 2025, arXiv:2501.01743. [Google Scholar] [CrossRef]
- Lyu, Q.; Havaldar, S.; Stein, A.; Zhang, L.; Rao, D.; Wong, E.; Apidianaki, M.; Callison-Burch, C. Faithful Chain-of-Thought Reasoning. Faithful chain-of-thought reasoning. 2023. Available online: https://arxiv.org/abs/2301.13379.
- Magesh, V.; Surani, F.; Dahl, M.; Suzgun, M.; Manning, C. D.; Ho, D. E. Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. Hallucination-free? assessing the reliability of leading ai legal research tools. 2024. Available online: https://arxiv.org/abs/2405.20362.
- Magesh, V.; Surani, F.; Dahl, M.; Suzgun, M.; Manning, C. D.; Ho, D. E. Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools. Journal of Empirical Legal Studies 2025, 222216–242. [Google Scholar] [CrossRef]
- Mitchell, M.; Wu, S.; Zaldivar, A.; Barnes, P.; Vasserman, L.; Hutchinson, B.; Spitzer, E.; Raji, I. D.; Gebru, T. 201901. Model Cards for Model Reporting. Proceedings of the Conference on Fairness, Accountability, and Transparency Proceedings of the conference on fairness, accountability, and transparency ( 220–229). ACM. Available online: http://dx.doi.org/10.1145/3287560.3287596 (accessed on). [CrossRef]
- Mudgal, S.; Lee, J.; Ganapathy, H.; Li, Y.; Wang, T.; Huang, Y.; Chen, Z.; Cheng, H.-T.; Collins, M.; Strohman, T.; Chen, J.; Beutel, A.; Beirami, A. Controlled Decoding from Language Models. Controlled decoding from language models. 2024. Available online: https://arxiv.org/abs/2310.17022.
- Mündler, N.; He, J.; Jenko, S.; Vechev, M. Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation. Self-contradictory hallucinations of large language models: Evaluation, detection and mitigation. 2024. Available online: https://arxiv.org/abs/2305.15852.
- Nguyen, H. T.; Fungwacharakorn, W.; Zin, M. M.; Goebel, R.; Toni, F.; Stathis, K.; Satoh, K. LLMs for legal reasoning: A unified framework and future perspectives. Computer Law & Security Review 2025, 58106165. [Google Scholar]
- Nguyen, M.; Gupta, S.; Le, H. CAAD: Context-Aware Adaptive Decoding for Truthful Text Generation. Caad: Context-aware adaptive decoding for truthful text generation. 2025. Available online: https://arxiv.org/abs/2508.02184.
- Ni, A.; Iyer, S.; Radev, D.; Stoyanov, V.; Yih, W.-t.; Wang, S.; Lin, X. V. Lever: Learning to verify language-to-code generation with execution. International Conference on Machine Learning International conference on machine learning, 2023; pp. 26106–26128. [Google Scholar]
- Nigam, S. K.; Patnaik, B. D.; Mishra, S.; Thomas, A. V.; Shallum, N.; Ghosh, K.; Bhattacharya, A. NyayaRAG: Realistic Legal Judgment Prediction with RAG under the Indian Common Law System. arXiv 2025, arXiv:2508.00709. [Google Scholar] [CrossRef]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. Codegen: An open large language model for code with multi-turn program synthesis. 2023. Available online: https://arxiv.org/abs/2203.13474.
- Niklaus, J.; Matoshi, V.; Stürmer, M.; Chalkidis, I.; Ho, D. E. Multilegalpile: A 689gb multilingual legal corpus. arXiv 2023, arXiv:2306.02069. [Google Scholar]
- Niklaus, J.; Matoshi, V.; Stürmer, M.; Chalkidis, I.; Ho, D. E. MultiLegalPile: A 689GB Multilingual Legal Corpus. Multilegalpile: A 689gb multilingual legal corpus. 2024. Available online: https://arxiv.org/abs/2306.02069.
- Nye, M.; Andreassen, A. J.; Gur-Ari, G.; Michalewski, H.; Austin, J.; Bieber, D.; Dohan, D.; Lewkowycz, A.; Bosma, M.; Luan, D.; et al. Show your work: Scratchpads for intermediate computation with language models. 2021. [Google Scholar] [CrossRef]
- Oehri, M.; Conti, G.; Pather, K.; Rossi, A.; Serra, L.; Parody, A.; Johannesen, R.; Petersen, A.; Krasniqi, A. Trusted Uncertainty in Large Language Models: A Unified Framework for Confidence Calibration and Risk-Controlled Refusal. Trusted uncertainty in large language models: A unified framework for confidence calibration and risk-controlled refusal. 2025. Available online: https://arxiv.org/abs/2509.01455.
- Östling, A.; Sargeant, H.; Xie, H.; Bull, L.; Terenin, A.; Jonsson, L.; Magnusson, M.; Steffek, F. The Cambridge law corpus: A dataset for legal AI research. Advances in Neural Information Processing Systems 2023, 3641355–41385. [Google Scholar] [CrossRef]
- Pfeiffer, J.; Kamath, A.; Rücklé, A.; Cho, K.; Gurevych, I. 202104. AdapterFusion: Non-Destructive Task Composition for Transfer Learning. P. Merlo, J. Tiedemann, R. Tsarfaty (), Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume Proceedings of the 16th conference of the european chapter of the association for computational linguistics: Main volume ( 487–503). OnlineAssociation for Computational Linguistics. Available online: https://aclanthology.org/2021.eacl-main.39/ (accessed on). 04. [CrossRef]
- Poesia, G.; Gandhi, K.; Zelikman, E.; Goodman, N. D. 20231. Certified deductive reasoning with language models. Certified deductive reasoning with language models. Available online: https://arxiv.org/abs/2306.04031.
- Poesia, G.; Gandhi, K.; Zelikman, E.; Goodman, N. D. 20232. Certified Reasoning with Language Models. ArXivabs/2306.04031. Available online: https://api.semanticscholar.org/CorpusID:259095869.
- Rabelo, J.; Kim, M.-Y.; Goebel, R.; Yoshioka, M.; Kano, Y.; Satoh, K. 2020. COLIEE 2020: Methods for Legal Document Retrieval and Entailment. New Frontiers in Artificial Intelligence: JSAI-IsAI 2020 Workshops, JURISIN, LENLS 2020 Workshops, Virtual Event, November 15–17, 2020, Revised Selected Papers New frontiers in artificial intelligence: Jsai-isai 2020 workshops, jurisin, lenls 2020 workshops, virtual event, november 15–17, 2020, revised selected papers ( 196–210). Berlin, HeidelbergSpringer-Verlag. Available online: https://doi.org/10.1007/978-3-030-79942-7_13 (accessed on). [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res.211. 2020. [Google Scholar]
- Raji, I. D.; Smart, A.; White, R. N.; Mitchell, M.; Gebru, T.; Hutchinson, B.; Smith-Loud, J.; Theron, D.; Barnes, P. 2020. Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic auditing. Proceedings of the 2020 conference on fairness, accountability, and transparency Proceedings of the 2020 conference on fairness, accountability, and transparency ( 33–44).
- Raptopoulos, P.; Filandrianos, G.; Lymperaiou, M.; Stamou, G. PAKTON: A Multi-Agent Framework for Question Answering in Long Legal Agreements. arXiv 2025, arXiv:2506.00608. [Google Scholar] [CrossRef]
- ritun16. Chain-of-Verification Implementation. Chain-of-verification implementation. GitHub repository. 2024. Available online: https://github.com/ritun16/chain-of-verification.
- Ryu, C.; Lee, S.; Pang, S.; Choi, C.; Choi, H.; Min, M.; Sohn, J.-Y. Retrieval-based evaluation for LLMs: a case study in Korean legal QA. In Proceedings of the Natural Legal Language Processing Workshop 2023 Proceedings of the natural legal language processing workshop 2023, 2023; pp. 132–137. [Google Scholar]
- Sanh, V.; Webson, A.; Raffel, C.; Bach, S. H.; Sutawika, L.; Alyafeai, Z.; Chaffin, A.; Stiegler, A.; Scao, T. L.; Raja, A.; Dey, M.; Bari, M. S.; Xu, C.; Thakker, U.; Sharma, S. S.; Szczechla, E.; Kim, T.; Chhablani, G.; Nayak, N.; Rush, A. M. Multitask Prompted Training Enables Zero-Shot Task Generalization. Multitask prompted training enables zero-shot task generalization. 2022. Available online: https://arxiv.org/abs/2110.08207.
- Schick, T.; Dwivedi-Yu, J.; Dessì, R.; Raileanu, R.; Lomeli, M.; Hambro, E.; Zettlemoyer, L.; Cancedda, N.; Scialom, T. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems 2023, 3668539–68551. [Google Scholar]
- Schöning, J.; Kruse, N. Compliance of AI Systems. arXiv 2025, arXiv:2503.05571. [Google Scholar] [CrossRef]
- Schweighofer, K.; Brune, B.; Gruber, L.; Schmid, S.; Aufreiter, A.; Gruber, A.; Doms, T.; Eder, S.; Mayer, F.; Stadlbauer, X.-P.; Schwald, C.; Zellinger, W.; Nessler, B.; Hochreiter, S. Safe and Certifiable AI Systems: Concepts, Challenges, and Lessons Learned. Safe and certifiable ai systems: Concepts, challenges, and lessons learned. 2025. Available online: https://arxiv.org/abs/2509.08852.
- ShengbinYue, S.; Huang, T.; Jia, Z.; Wang, S.; Liu, S.; Song, Y.; Huang, X.-J.; Wei, Z. Multi-agent simulator drives language models for legal intensive interaction. Findings of the Association for Computational Linguistics: NAACL 2025 Findings of the association for computational linguistics: Naacl 2025, 2025, 6537–6570. [Google Scholar]
- Shi, J.; Guo, Q.; Liao, Y.; Wang, Y.; Chen, S.; Liang, S. Legal-LM: Knowledge graph enhanced large language models for law consulting. International conference on intelligent computing International conference on intelligent computing, 2024; pp. 175–186. [Google Scholar]
- Shi, W.; Zhu, H.; Ji, J.; Li, M.; Zhang, J.; Zhang, R.; Zhu, J.; Xu, J.; Han, S.; Guo, Y. LegalReasoner: Step-wised Verification-Correction for Legal Judgment Reasoning. arXiv 2025, arXiv:2506.07443. [Google Scholar]
- Shin, R.; Lin, C.; Thomson, S.; Chen, C.; Roy, S.; Platanios, E. A.; Pauls, A.; Klein, D.; Eisner, J.; Van Durme, B.; Moens, M.-F.; Huang, X.; Specia, L.; Yih (), S. W.-t. 202111. Constrained Language Models Yield Few-Shot Semantic Parsers. M.-F. Moens, X. Huang, L. Specia, S. W.-t. Yih (), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing Proceedings of the 2021 conference on empirical methods in natural language processing ( 7699–7715). Online and Punta Cana, Dominican RepublicAssociation for Computational Linguistics. Available online: https://aclanthology.org/2021.emnlp-main.608/ (accessed on). [CrossRef]
- Shu, D.; Zhao, H.; Liu, X.; Demeter, D.; Du, M.; Zhang, Y. 202410. LawLLM: Law Large Language Model for the US Legal System. Proceedings of the 33rd ACM International Conference on Information and Knowledge Management Proceedings of the 33rd acm international conference on information and knowledge management ( 4882–4889). ACM. Available online: http://dx.doi.org/10.1145/3627673.3680020 (accessed on). [CrossRef]
- Smith, J.; Jones, A.; Williams, B. A Comprehensive Overview of the Development and Impact of Large Language Models. Journal of Artificial Intelligence Research 2023, 701–50. [Google Scholar]
- Song, F.; Yu, B.; Lang, H.; Yu, H.; Huang, F.; Wang, H.; Li, Y. Scaling data diversity for fine-tuning language models in human alignment. arXiv 2024, arXiv:2403.11124. [Google Scholar] [CrossRef]
- South, T. Private, Verifiable, and Auditable AI Systems. Private, verifiable, and auditable ai systems. 2025. Available online: https://arxiv.org/abs/2509.00085.
- Su, W.; Yue, B.; Ai, Q.; Hu, Y.; Li, J.; Wang, C.; Zhang, K.; Wu, Y.; Liu, Y. Judge: Benchmarking judgment document generation for chinese legal system. In Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval Proceedings of the 48th international acm sigir conference on research and development in information retrieval, 2025; pp. 3573–3583. [Google Scholar]
- Sun, J.; Dai, C.; Luo, Z.; Chang, Y.; Li, Y. LawLuo: A Multi-Agent Collaborative Framework for Multi-Round Chinese Legal Consultation. Lawluo: A multi-agent collaborative framework for multi-round chinese legal consultation. 2024. Available online: https://arxiv.org/abs/2407.16252.
- Sun, K.; Wu, J.; Guo, M.; Li, J.; Huang, J. Accurate Target Privacy Preserving Federated Learning Balancing Fairness and Utility. Accurate target privacy preserving federated learning balancing fairness and utility. 2025. Available online: https://arxiv.org/abs/2510.26841.
- Surden, H. Artificial intelligence and law: An overview. Ga. St. UL Rev. 2018, 351305. [Google Scholar]
- The Law Society of Hong Kong (LSHK). The impact of artificial intelligence on the legal profession: Position paper. The impact of artificial intelligence on the legal profession: Position paper. Position Paper. 2024j. Available online: https://www.hklawsoc.org.hk/-/media/HKLS/Home/News/2024/LSHK-Position-Paper_AI_EN.pdf.
- Tian, K.; Mitchell, E.; Zhou, A.; Sharma, A.; Rafailov, R.; Yao, H.; Finn, C.; Manning, C. D. Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. 2023. Available online: https://arxiv.org/abs/2305.14975.
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar] [CrossRef]
- Tran, H. T. H.; Chatterjee, N.; Pollak, S.; Doucet, A. Deberta beats behemoths: A comparative analysis of fine-tuning, prompting, and peft approaches on legallensner. Proceedings of the Natural Legal Language Processing Workshop 2024 Proceedings of the natural legal language processing workshop 2024, 2024, 371–380. [Google Scholar]
- Tuggener, D.; Von Däniken, P.; Peetz, T.; Cieliebak, M. LEDGAR: a large-scale multi-label corpus for text classification of legal provisions in contracts. In Proceedings of the twelfth language resources and evaluation conference Proceedings of the twelfth language resources and evaluation conference, 2020; pp. 1235–1241. [Google Scholar]
- Union, E. 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation). Regulation (eu) 2016/679 of the european parliament and of the council of 27 april 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing directive 95/46/ec (general data protection regulation). Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32016R0679 (accessed on). Official Journal of the European Union: L 119, 4 May 2016, pp. 1–88; Entered into force: 25 May 2018.
- Union, E. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council of 13 June 2024 laying down harmonised rules on artificial intelligence (Artificial Intelligence Act). Regulation (eu) 2024/1689 of the european parliament and of the council of 13 june 2024 laying down harmonised rules on artificial intelligence (artificial intelligence act). Available online: https://www.aiact-info.eu/full-text-and-pdf-download/ (accessed on). Content consistent with Official Journal of the European Union (L 2024/1689, 12 July 2024); Entered into force: 1 August 2024; PDF and full text provided by EU-authorised platform (aiact-info.eu).
- Valmeekam, K.; Stechly, K.; Kambhampati, S. LLMs Still Can’t Plan; Can LRMs? A Preliminary Evaluation of OpenAI’s o1 on PlanBench. Llms still can’t plan; can lrms? a preliminary evaluation of openai’s o1 on planbench. 2024. Available online: https://arxiv.org/abs/2409.13373.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, *!!! REPLACE !!!*; Polosukhin, I. Attention is all you need. In Advances in neural information processing systems30; 2017. [Google Scholar]
- Wang, S.; Fan, W.; Feng, Y.; Lin, S.; Ma, X.; Wang, S.; Yin, D. Knowledge Graph Retrieval-Augmented Generation for LLM-based Recommendation. Knowledge graph retrieval-augmented generation for llm-based recommendation. 2025. Available online: https://arxiv.org/abs/2501.02226.
- Wang, T.; Yu, P.; Tan, X. E.; O’Brien, S.; Pasunuru, R.; Dwivedi-Yu, J.; Golovneva, O.; Zettlemoyer, L.; Fazel-Zarandi, M.; Celikyilmaz, A. Shepherd: A critic for language model generation. arXiv 2023, arXiv:2308.04592. [Google Scholar] [CrossRef]
- Wang, X.; Sen, P.; Li, R.; Yilmaz, E. 202504. Adaptive Retrieval-Augmented Generation for Conversational Systems. L. Chiruzzo, A. Ritter, L. Wang (), Findings of the Association for Computational Linguistics: NAACL 2025 Findings of the association for computational linguistics: Naacl 2025 ( 491–503). Albuquerque, New MexicoAssociation for Computational Linguistics. Available online: https://aclanthology.org/2025.findings-naacl.30/ (accessed on). [CrossRef]
- Wang, X.; Zhang, X.; Hoo, V.; Shao, Z.; Zhang, X. LegalReasoner: A multi-stage framework for legal judgment prediction via large language models and knowledge integration. IEEE Access. 2024. [Google Scholar] [CrossRef]
- Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N. A.; Khashabi, D.; Hajishirzi, H. Self-Instruct: Aligning Language Models with Self-Generated Instructions. Self-instruct: Aligning language models with self-generated instructions. 2023. Available online: https://arxiv.org/abs/2212.10560.
- Wei, J.; Bosma, M.; Zhao, V. Y.; Guu, K.; Yu, A. W.; Lester, B.; Du, N.; Dai, A. M.; Le, Q. V. Finetuned Language Models Are Zero-Shot Learners. Finetuned language models are zero-shot learners. 2022. Available online: https://arxiv.org/abs/2109.01652.
- Welleck, S.; Liu, J.; Lu, X.; Hajishirzi, H.; Choi, Y. 20221. NaturalProver: Grounded Mathematical Proof Generation with Language Models. Naturalprover: Grounded mathematical proof generation with language models. Available online: https://arxiv.org/abs/2205.12910.
- Welleck, S.; Liu, J.; Lu, X.; Hajishirzi, H.; Choi, Y. Naturalprover: Grounded mathematical proof generation with language models. Advances in Neural Information Processing Systems Advances in neural information processing systems 2022, 35, 4913–4927. [Google Scholar]
- Wu, Y.; Wang, C.; Gumusel, E.; Liu, X. Knowledge-infused legal wisdom: Navigating llm consultation through the lens of diagnostics and positive-unlabeled reinforcement learning. arXiv 2024, arXiv:2406.03600. [Google Scholar]
- Xie, N.; Bai, Y.; Gao, H.; Xue, Z.; Fang, F.; Zhao, Q.; Li, Z.; Zhu, L.; Ni, S.; Yang, M. Delilaw: A chinese legal counselling system based on a large language model. In Proceedings of the 33rd ACM International Conference on Information and Knowledge Management Proceedings of the 33rd acm international conference on information and knowledge management, 2024; pp. 5299–5303. [Google Scholar]
- Xu, Q.; Liu, Q.; Fei, H.; Yu, H.; Guan, S.; Wei, X. CLEAR: A Framework Enabling Large Language Models to Discern Confusing Legal Paragraphs. Findings of the Association for Computational Linguistics: EMNLP 2025 Findings of the association for computational linguistics: Emnlp 2025, 8937–8953. [Google Scholar]
- Xu, Q.; Wei, X.; Yu, H.; Liu, Q.; Fei, H. Divide and Conquer: Legal Concept-guided Criminal Court View Generation. Findings of the Association for Computational Linguistics: EMNLP 2024 Findings of the association for computational linguistics: Emnlp 2024, 2024, 3395–3410. [Google Scholar]
- Xu, X.; Zhao, L.; Xu, H.; Chen, C. CLaw: Benchmarking Chinese Legal Knowledge in Large Language Models-A Fine-grained Corpus and Reasoning Analysis. arXiv 2025, arXiv:2509.21208. [Google Scholar]
- Yang, X.-W.; Shao, J.-J.; Guo, L.-Z.; Zhang, B.-W.; Zhou, Z.; Jia, L.-H.; Dai, W.-Z.; Li, Y. Neuro-symbolic artificial intelligence: Towards improving the reasoning abilities of large language models. Neuro-symbolic artificial intelligence: Towards improving the reasoning abilities of large language models. 2025. Available online: https://arxiv.org/abs/2508.13678.
- Yang, Z.; Dong, L.; Du, X.; Cheng, H.; Cambria, E.; Liu, X.; Gao, J.; Wei, F. Language Models as Inductive Reasoners. Language models as inductive reasoners. 2024. Available online: https://arxiv.org/abs/2212.10923.
- Yao, R.; Wu, Y.; Wang, C.; Xiong, J.; Wang, F.; Liu, X. Elevating legal LLM responses: harnessing trainable logical structures and semantic knowledge with legal reasoning. arXiv 2025, arXiv:2502.07912. [Google Scholar] [CrossRef]
- Ye, F.; Li, S. MileCut: A multi-view truncation framework for legal case retrieval. Proceedings of the ACM Web Conference 2024 Proceedings of the acm web conference 2024, 2024, 1341–1349. [Google Scholar]
- Yu, F.; Seedat, N.; Herrmannova, D.; Schilder, F.; Schwarz, J. R. Beyond Pointwise Scores: Decomposed Criteria-Based Evaluation of LLM Responses. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track Proceedings of the 2025 conference on empirical methods in natural language processing: Industry track ( 1931–1954), 2025. [Google Scholar]
- Yuan, W.; Cao, J.; Jiang, Z.; Kang, Y.; Lin, J.; Song, K.; Lin, T.; Yan, P.; Sun, C.; Liu, X. Can large language models grasp legal theories? enhance legal reasoning with insights from multi-agent collaboration. Findings of the association for computational linguistics: EMNLP 2024 Findings of the association for computational linguistics: Emnlp 2024, 2024, 7577–7597. [Google Scholar]
- Yue, L.; Liu, Q.; Du, Y.; Gao, W.; Liu, Y.; Yao, F. FedJudge: Federated Legal Large Language Model. Fedjudge: Federated legal large language model. 2024. Available online: https://arxiv.org/abs/2309.08173.
- Yue, S.; Chen, W.; Wang, S.; Li, B.; Shen, C.; Liu, S.; Zhou, Y.; Xiao, Y.; Yun, S.; Huang, X.; Wei, Z. DISC-LawLLM: Fine-tuning Large Language Models for Intelligent Legal Services. Disc-lawllm: Fine-tuning large language models for intelligent legal services. 2023. Available online: https://arxiv.org/abs/2309.11325.
- Zaheer, M.; Guruganesh, G.; Dubey, A.; Ainslie, J.; Alberti, C.; Ontanon, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; Ahmed, A. Big bird: transformers for longer sequences. In Proceedings of the 34th International Conference on Neural Information Processing Systems. Proceedings of the 34th international conference on neural information processing systems, Red Hook, NY, USA, 2020; Curran Associates Inc. [Google Scholar]
- Zhang, K.; Chen, C.; Wang, Y.; Tian, Q.; Bai, L. Cfgl-lcr: A counterfactual graph learning framework for legal case retrieval. In Proceedings of the 29th ACM SIGKDD Conference on knowledge discovery and data mining Proceedings of the 29th acm sigkdd conference on knowledge discovery and data mining, 2023; pp. 3332–3341. [Google Scholar]
- Zhang, K.; Xie, G.; Yu, W.; Xu, M.; Tang, X.; Li, Y.; Xu, J. Legal Mathematical Reasoning with LLMs: Procedural Alignment through Two-Stage Reinforcement Learning. arXiv 2025, arXiv:2504.02590. [Google Scholar]
- Zhang, R.; Sullivan, D.; Jackson, K.; Xie, P.; Chen, M. 202504. Defense against Prompt Injection Attacks via Mixture of Encodings. L. Chiruzzo, A. Ritter, L. Wang (), Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers) Proceedings of the 2025 conference of the nations of the americas chapter of the association for computational linguistics: Human language technologies (volume 2: Short papers) ( 244–252). Albuquerque, New MexicoAssociation for Computational Linguistics. Available online: https://aclanthology.org/2025.naacl-short.21/ (accessed on). [CrossRef]
- Zhang, T.; Patil, S. G.; Jain, N.; Shen, S.; Zaharia, M.; Stoica, I.; Gonzalez, J. E. RAFT: Adapting Language Model to Domain Specific RAG. Raft: Adapting language model to domain specific rag. 2024. Available online: https://arxiv.org/abs/2403.10131.
- Zhang, X.; Ruan, J.; Ma, X.; Zhu, Y.; Zhao, H.; Li, H.; Chen, J.; Zeng, K.; Cai, X. When to continue thinking: Adaptive thinking mode switching for efficient reasoning. arXiv 2025, arXiv:2505.15400. [Google Scholar] [CrossRef]
- Zhao, R.; Li, X.; Joty, S.; Qin, C.; Bing, L. Verify-and-Edit: A Knowledge-Enhanced Chain-of-Thought Framework. Verify-and-edit: A knowledge-enhanced chain-of-thought framework. 2023. Available online: https://arxiv.org/abs/2305.03268.
- ZHAO, W.; HU, Y.; DENG, Y.; GUO, J.; SUI, X.; HAN, X.; ZHANG, A.; ZHAO, Y.; QIN, B.; CHUA, T.-S.; et al. Beware of your Po! Measuring and mitigating AI safety risks in role-play fine-tuning of LLMs. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, Vienna, Austria Proceedings of the 63rd annual meeting of the association for computational linguistics, vienna, austria, 2025; pp. 5131–5157. [Google Scholar]
- Zhao, W. X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.1822312. [Google Scholar] [PubMed]
- Zheng, L.; Guha, N.; Anderson, B. R.; Henderson, P.; Ho, D. E. 20211. When does pretraining help? assessing self-supervised learning for law and the casehold dataset of 53,000+ legal holdings. Proceedings of the eighteenth international conference on artificial intelligence and law Proceedings of the eighteenth international conference on artificial intelligence and law ( 159–168).
- Zheng, L.; Guha, N.; Anderson, B. R.; Henderson, P.; Ho, D. E. 20212. When does pretraining help? assessing self-supervised learning for law and the casehold dataset of 53,000+ legal holdings. Proceedings of the eighteenth international conference on artificial intelligence and law Proceedings of the eighteenth international conference on artificial intelligence and law ( 159–168).
- Zhong, H.; Xiao, C.; Tu, C.; Zhang, T.; Liu, Z.; Sun, M. How does NLP benefit legal system: A summary of legal artificial intelligence. arXiv 2020, arXiv:2004.12158. [Google Scholar] [CrossRef]
- Zhou, J. P.; Staats, C.; Li, W.; Szegedy, C.; Weinberger, K. Q.; Wu, Y. Don’t Trust: Verify – Grounding LLM Quantitative Reasoning with Autoformalization. Don’t trust: Verify – grounding llm quantitative reasoning with autoformalization. Available online: https://arxiv.org/abs/2403.18120.
- Zhou, Z.; Shi, J.-X.; Song, P.-X.; Yang, X.-W.; Jin, Y.-X.; Guo, L.-Z.; Li, Y.-F. LawGPT: A Chinese Legal Knowledge-Enhanced Large Language Model. Lawgpt: A chinese legal knowledge-enhanced large language model. 2024. Available online: https://arxiv.org/abs/2406.04614.
- Zöller, M.-A.; Iurshina, A.; Röder, I. 2025. Trustworthy Generative AI for Financial Services (Practitioner Track). Symposium on Scaling AI Assessments (SAIA 2024) Symposium on scaling ai assessments (saia 2024) ( 2–1).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



