Submitted:
03 February 2026
Posted:
10 February 2026
You are already at the latest version
Abstract
Accurate long-term electrical load forecasting is required for stable smart grid operation, yet remains difficult due to multi-scale periodic patterns and non-stationary temporal shifts across different prediction horizons. This work presents MoE-Transformer, a reinforcement learning-driven dual-domain framework that integrates frequency-domain processing with sparse expert networks for adaptive forecasting. An Extended Discrete Fourier Transform (Extended DFT) is introduced to address spectral misalignment by aligning the input spectrum with the frequency grid of the full prediction window. The model employs parallel Mixture-of-Experts (MoE) modules in the time and frequency domains (T-MoE and F-MoE), where domain-specific experts capture complementary temporal and spectral structures. Expert selection is formulated as a dual Markov Decision Process and optimized through a reinforcement learning routing mechanism that balances prediction accuracy, routing stability, and expert utilization diversity. Experiments on five benchmark datasets, including ETTh1, Electricity, and Traffic, across four forecasting horizons show that MoE-Transformer consistently outperforms state-of-the-art baselines, reducing Mean Squared Error (MSE) by 50.9--56.9%. Sparse expert activation lowers memory usage by 40% and reduces inference latency by 60%, supporting deployment in real-time forecasting settings. Ablation results further quantify the contributions of Extended DFT, dual-domain modeling, and reinforcement-driven routing, yielding performance gains of 5.8%, 4.6%, and up to 47.2%, respectively.
Keywords:
time series forecasting
; mixture of experts
; dual-domain transformer
; frequency-domain modeling
; reinforcement learning
; dynamic expert routing
; multi-horizon prediction
; electrical load forecasting
1. Introduction
1.1. Background
Electrical load forecasting across multiple temporal horizons is fundamental to modern power grid operations, enabling utilities to optimize generation scheduling, demand response programs, and energy trading strategies. Accurate predictions spanning short-term (1-24 hours), medium-term (1-7 days), and long-term (1-4 weeks) horizons are essential for maintaining grid stability, minimizing operational costs, and integrating renewable energy sources [1]. Traditional forecasting approaches based on statistical models such as ARIMA and exponential smoothing demonstrate limited effectiveness when confronted with the complex nonlinear dynamics, multi-scale periodicities, and sudden load fluctuations characteristic of modern electricity consumption patterns. These limitations become particularly acute as power grids evolve toward smart grid architectures with distributed generation, electric vehicle integration, and dynamic pricing mechanisms, creating unprecedented demands for accurate and efficient multi-horizon forecasting capabilities that can capture both short-term volatility and long-term trends simultaneously [2].
The emergence of Transformer architectures has revolutionized time series forecasting by introducing powerful attention mechanisms capable of modeling long-range dependencies without the vanishing gradient problems inherent in recurrent neural networks. Recent studies have demonstrated promising results applying Transformers to temporal prediction tasks, with innovations such as PatchTST achieving state-of-the-art performance through channel-independent patching strategies [3,4,5]. However, fundamental questions remain regarding whether Transformers truly capture the underlying temporal structures or merely exploit dataset-specific patterns through sophisticated pattern matching. Furthermore, pure time-domain processing faces inherent challenges in handling periodic components, harmonic structures, and multi-scale seasonality that characterize electrical load profiles. The computational complexity of O(L²) attention operations over long sequences imposes practical constraints on processing extended historical windows necessary for capturing annual cycles and multi-week patterns, limiting the scalability of dense Transformer architectures for large-scale deployment in real-time forecasting systems [6,7].
Frequency-domain analysis offers complementary perspectives for time series modeling by explicitly decomposing signals into constituent periodic components, enabling direct manipulation of harmonic structures and seasonal patterns [8,9]. Recent research has explored integrating frequency representations with Transformer architectures, demonstrating improved capacity to capture multi-scale periodicities and reduce spurious correlations between distant time steps [10]. However, existing frequency-domain methods face a fundamental limitation: the standard Discrete Fourier Transform produces frequency grids determined solely by input sequence length, creating misalignment between the input spectrum and the complete time series that includes future predictions. Simultaneously, mixture-of-experts (MoE) architectures have gained traction as scalable solutions for conditional computation, enabling models to route different inputs to specialized sub-networks while maintaining sparse activation patterns [11,12,13]. Recent surveys highlight the potential of MoE frameworks in handling heterogeneous data distributions and task-specific patterns through learned expert specialization [14,15]. Despite these advances, existing approaches predominantly rely on static gating mechanisms such as top-k routing or noisy gating, which lack the ability to dynamically adapt expert selection based on evolving temporal patterns and fail to jointly optimize routing decisions with forecasting objectives across multiple time scales [16,17].
1.2. Motivation and Contributions
Recent advancements in Transformer architectures, frequency-domain modeling, and mixture-of-experts systems have individually demonstrated significant potential for enhancing time series forecasting capabilities. However, the integration of these technologies into a unified framework that synergistically combines dual-domain processing, sparse expert networks, and dynamic routing mechanisms remains largely unexplored. Existing time series forecasting methods primarily focus on optimizing model architectures within either the time or frequency domain, without considering the benefits of parallel dual-domain processing with domain-specific expert specialization. Similarly, current MoE approaches in temporal modeling typically employ static routing strategies that fail to adapt to the diverse and evolving patterns across different forecasting horizons and temporal scales. The lack of integrated solutions that jointly optimize dual-domain representation learning, sparse expert activation, and dynamic routing under forecasting objectives represents a significant gap in the development of next-generation multi-horizon prediction systems for critical applications such as power grid management.
Despite the promising developments in each individual technology domain, several critical research gaps remain unaddressed in the context of multi-horizon electrical load forecasting systems.
- 1.
- Existing Transformer-based forecasting frameworks process time series exclusively in the temporal domain, failing to exploit the complementary strengths of frequency-domain representations for capturing periodic components and harmonic structures. Moreover, standard frequency transformation approaches suffer from spectral misalignment between input sequences and complete time series, limiting their effectiveness for multi-step-ahead prediction tasks.
- 2.
- Current mixture-of-experts architectures in time series modeling rely on static gating mechanisms that route inputs based on learned but fixed assignment patterns, lacking the capability to dynamically adapt expert selection to varying temporal patterns, forecasting horizons, and evolving system dynamics. The absence of reinforcement learning-based routing prevents simultaneous optimization of prediction accuracy, routing stability, and expert diversity.
- 3.
- Existing research predominantly treats model architecture design, expert specialization, and forecasting optimization as separate problems, failing to exploit the synergies and interdependencies among dual-domain processing, sparse computation, and dynamic routing. The lack of unified frameworks that jointly optimize these components through end-to-end training limits the potential benefits achievable through integrated system design.
To address these research gaps, this work proposes MoE-Transformer, a reinforcement learning-driven dual-domain mixture-of-experts framework for efficient multi-horizon electrical load forecasting. Our integrated approach combines Extended DFT-aligned frequency processing, parallel time-domain modeling, independent expert networks in both domains, and RL-based dynamic routing to create an intelligent and adaptive forecasting system. Specifically, we make the following contributions.
- We establish a dual-domain Transformer architecture that processes time series simultaneously in time and frequency domains through parallel encoder pathways. Our framework introduces Extended DFT that aligns input spectrum with the complete series frequency grid by computing F[k] = , fundamentally resolving the spectral misalignment problem in frequency-domain forecasting.
- We design independent mixture-of-experts modules for frequency (F-MoE) and time domains (T-MoE), with =4 frequency experts and =4 time experts per Transformer layer. Each expert implements specialized two-layer networks optimized for domain-specific pattern recognition, enabling sparse parameter activation while maintaining model capacity through conditional computation.
- We develop a reinforcement learning-based routing framework that formulates expert selection as independent Markov Decision Processes in both domains. Our multi-objective reward function balances prediction accuracy, routing stability, and expert diversity through weighted terms , with MAPPO policies learning domain-specific routing strategies through coupled training dynamics.
- We conduct comprehensive experiments across five long-term forecasting benchmarks (ETTh1, ETTm1, Weather, Electricity, Traffic) and four prediction horizons (96, 192, 336, 720 steps), demonstrating that MoE-Transformer achieves 50.9-56.9% MSE reduction over state-of-the-art baselines while delivering 60% faster inference and 40% memory reduction through sparse expert activation. Ablation studies validate each component’s contribution, with RL routing providing 39.5-47.2% improvement over static gating methods.
The remainder of this paper is organized as follows. Section 2 reviews the existing literature on Transformer-based time series forecasting, frequency-domain modeling, and mixture-of-experts architectures. Section 3 describes our dual-domain MoE-Transformer framework and reinforcement learning-based routing mechanism. Section 4 and Section 5 present the experimental setup, performance evaluation, and ablation studies. Section 6 concludes the paper and discusses future research directions.
2. Related Work
2.1. Transformer-Based Time Series Forecasting

Table 1.
Contrasting our work to existing studies.
| Ref | [18] | [19] | [20] | [21] | [22] | [23] | [24] | [25] | [26] | [27] | [28] | Proposed work | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Feature | |||||||||||||
| Temporal modeling capability | √ | √ | √ | √ | √ | √ | √ | √ | |||||
| Frequency-domain processing | √ | √ | √ | √ | √ | ||||||||
| Sparse expert networks | √ | √ | √ | √ | √ | ||||||||
| Dynamic routing mechanism | √ | √ | |||||||||||
| Multi-horizon forecasting | √ | √ | √ | √ | √ | √ | √ | √ | |||||
Transformer-based architectures have emerged as powerful tools for long-term time series forecasting, leveraging self-attention mechanisms to capture complex temporal dependencies without the limitations of recurrent neural networks [3,4,15,18,29,30]. Zhao et al. [18] proposed TFformer, a highly interpretable forecasting model that decomposes time series into low-frequency trend components and high-frequency periodic components through frequency decomposition. Their approach employs sequential frequency attention to enhance periodic information and sequential periodic matching attention for future pattern prediction, achieving significant performance improvements across six datasets while maintaining low time complexity through sequence-level attention mechanisms that preserve temporal dependencies. Kumar et al. [21] developed a spatio-temporal parallel transformer (STPT) model for traffic prediction, utilizing multiple adjacency graphs passed through coupled graph transformer-convolution network units operating in parallel to generate noise-resilient embeddings. Their framework demonstrates superior performance on four real-world traffic datasets and extends applicability to Covid-19 prediction tasks. Chen et al. [31] addressed irregular time series modeling through Contiformer, introducing continuous-time attention mechanisms for handling non-uniformly sampled temporal data.
The integration of channel processing strategies with Transformer architectures has gained attention for improving multivariate time series forecasting capabilities [19,20,32,33]. Han et al. [19] proposed MCformer, introducing an innovative Mixed Channels strategy that combines the data expansion advantages of channel independence with the ability to mitigate interchannel correlation forgetting. Their model blends a specific number of channels using attention mechanisms to effectively capture interchannel correlation information when modeling long-term features for massive IoT-generated time-series data, demonstrating that the Mixed Channels strategy outperforms pure channel independence approaches in multivariate forecasting tasks. Li et al. [20] developed channel independence bidirectional gated Mamba with interactive recurrent mechanism (CIBG-Mamba-IRM), enhancing gated recurrent neural networks by integrating Mamba into channel-independent recurrent units. Their framework processes each data channel independently through three Mamba-enhanced recurrent units with dynamic interchannel exchange, employing channel-specific adaptive state transition functions through the interactive recurrent mechanism. Experiments on new energy vehicle air conditioner datasets and five public benchmarks validated their model’s effectiveness in learning long-term dependencies and handling multidimensional time series data, achieving state-of-the-art results. Fan et al. [32] contributed DEWP, applying deep expansion learning principles to wind power forecasting scenarios with improved predictive accuracy.
Despite these advances in Transformer-based forecasting frameworks, existing approaches face critical limitations when applied to multi-horizon electrical load prediction scenarios. Most current methods process time series exclusively in the temporal domain without exploiting the complementary strengths of frequency-domain representations for capturing periodic components and harmonic structures. Furthermore, existing architectures lack dynamic mechanisms for adaptive computation allocation, relying on dense model activation patterns that limit scalability for real-time forecasting systems requiring simultaneous handling of multiple temporal horizons.
2.2. Frequency-Domain Time Series Modeling
Frequency-domain analysis has emerged as a powerful complement to temporal modeling for capturing periodic patterns and harmonic structures in time series forecasting [22,23,34,35,36,37]. Xu et al. [22] proposed a Frequency decomposition and Patch modeling Framework (FPF) that transforms input sequences to the frequency domain through Fast Fourier Transform and designs frequency masks to decompose data into high-frequency and low-frequency components for extracting fast-changing patterns and trend information respectively. Their dual patch modeling block processes high-frequency components through MLP-based patch enhancement to capture local features, while low-frequency components are modeled by Transformer-based patch mixing to capture global dependencies and cross-patch correlations. Comprehensive experiments on seven real-world datasets including ETT, Traffic, Electricity, and Weather demonstrated superior forecasting performance. Zhang et al. [23] developed CTFNet, a lightweight single-hidden layer feedforward neural network combining convolution mapping and time-frequency decomposition with three distinctive characteristics: time-domain feature mining based on matrix factorization to capture long-term correlations, multitask frequency-domain feature mining integrating multiscale dilated convolutions for simultaneous global and local context extraction, and highly efficient training with fast inference speed. Their empirical studies with nine benchmark datasets showed that CTFNet reduces prediction error by 64.7% and 53.7% for multivariate and univariate time series respectively compared to state-of-the-art methods. Zhou et al. [34] contributed Fourier graph convolution Transformer for financial multivariate time series forecasting, combining spectral graph analysis with attention mechanisms.
Adaptive temporal-frequency modeling mechanisms have gained attention for handling dynamic periodic patterns and improving long-term forecasting capabilities [24,38,39,40,41]. Yang et al. [24] proposed an adaptive temporal-frequency network (ATFN), an end-to-end hybrid model incorporating deep learning networks and frequency patterns for mid- and long-term forecasting. Their framework employs an augmented sequence-to-sequence model to learn trend features of nonstationary time series, a frequency-domain block to capture dynamic periodic patterns, and an adaptive frequency mechanism consisting of phase adaptation, frequency adaptation, and amplitude adaptation for mapping the frequency spectrum of the current sliding window to the forecasting interval. Experimental results on synthetic and real-world data with different periodic characteristics indicated promising performance and strong adaptability for long-term prediction tasks. Kumari et al. [38] developed a Fourier-driven lightweight token mixing model for efficient time series forecasting, reducing computational complexity while maintaining prediction accuracy. Zhang et al. [39] extended time-frequency analysis to anomaly detection scenarios through TFAD, demonstrating the broader applicability of frequency-domain decomposition techniques.
Despite these advances in frequency-domain modeling frameworks, existing approaches face critical limitations when applied to multi-horizon forecasting with diverse temporal patterns. Most current methods employ fixed frequency decomposition strategies without dynamic adaptation mechanisms for routing different pattern types to specialized processing modules. Furthermore, existing architectures lack sparse computation allocation through conditional expert networks, limiting their scalability and efficiency for large-scale deployment in real-time forecasting systems requiring simultaneous handling of multiple frequency components and temporal scales.
2.3. Mixture-of-Experts and Dynamic Routing Mechanisms
Mixture-of-Experts architectures have emerged as a powerful paradigm for scaling model capacity while maintaining computational efficiency through sparse expert activation [25,26,28,42]. Zhang et al. [25] presented a comprehensive review highlighting MoE’s ability to significantly enhance performance with minimal computational overhead through expert gating and routing mechanisms, hierarchical and sparse configurations, and meta-learning approaches. Their analysis identified key advantages including superior model capacity compared to equivalent Bayesian approaches and the importance of ensuring expert diversity, accurate calibration, and reliable inference aggregation. Csordás et al. [26] proposed SwitchHead, an effective MoE method for self-attention layers that computes up to 8 times fewer attention matrices than standard Transformers. For their 262M parameter model trained on C4, SwitchHead matched baseline perplexity with only 44% compute and 27% memory usage, achieving over 3.5% absolute improvements on BliMP zero-shot tasks compared to parameter-matched baselines. Ma et al. [28] developed Big-MoE for multimodal applications, introducing bypassing isolated gating mechanisms to enhance expert collaboration.
Dynamic routing strategies have gained attention for improving MoE efficiency through adaptive expert selection [27,42,43,44]. Yue et al. [27] proposed Ada-K routing, a novel strategy that dynamically adjusts the number of activated experts for each token using learnable allocator modules. Their method leverages Proximal Policy Optimization for end-to-end learning of this non-differentiable decision-making framework, achieving over 25% reduction in FLOPs and more than 20% inference speedup compared to conventional Top-K routing across four baseline models. Training efficiency remained high even for Mixtral-8x22B with 140B parameters, requiring only 8 hours. Their analysis revealed that harder tasks, middle layers, and content words tend to activate more experts, providing valuable insights for adaptive MoE system designs. Reinforcement learning-based routing has also been explored in network optimization contexts [43,44], demonstrating broader applicability of dynamic decision-making strategies. However, existing MoE frameworks lack application to time series forecasting scenarios where dual-domain processing and multi-horizon prediction require specialized expert routing strategies that can simultaneously optimize prediction accuracy, computational efficiency, and expert diversity across both frequency and temporal representations.
3. Method
In this section, we present a reinforcement learning-driven Mixture-of-Experts framework for long-term time series forecasting with dual-domain Transformer architecture. We first establish the forecasting problem formulation and introduce the dual-domain Transformer architecture that processes time series from both time and frequency domains simultaneously. Subsequently, we detail the MoE-enhanced feed-forward layers where traditional FFNs are replaced with specialized expert networks in both domains, with independent RL agents learning to dynamically route representations to the most appropriate experts. Finally, we describe the coupled training dynamics that jointly optimize the forecasting model and dual routing policies. Table 2 presents the mathematical notations used throughout this section.
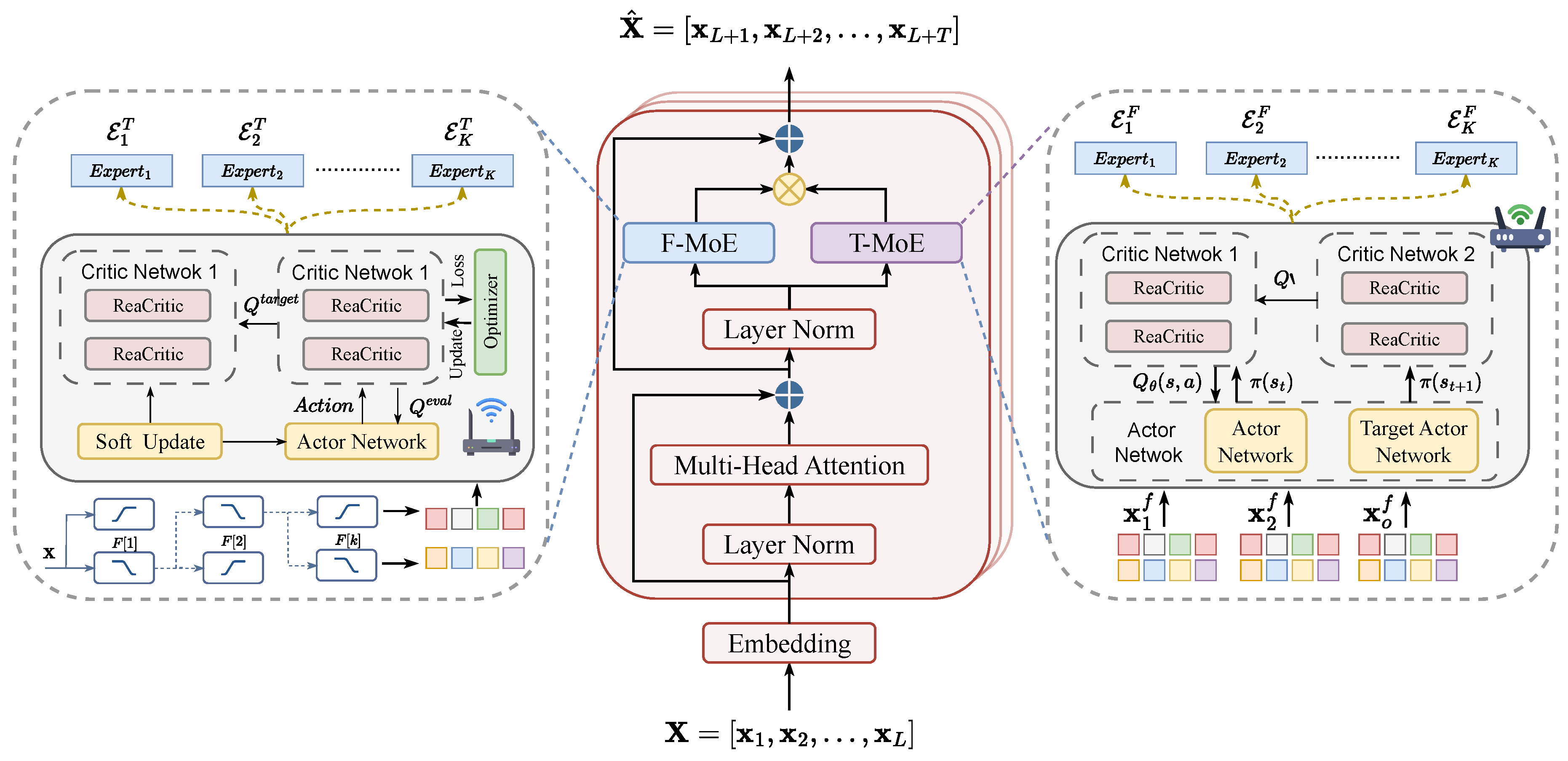
Figure 1.
Architecture of MoE-Transformer Framework with Dual-Domain Processing and RL-Based Dynamic Routing
Figure 1.
Architecture of MoE-Transformer Framework with Dual-Domain Processing and RL-Based Dynamic Routing
3.1. Problem Formulation
Long-term time series forecasting can be formulated as a sequence-to-sequence prediction problem. Given a multivariate time series , where L denotes the look-back window size and N represents the number of variates, the objective is to predict future T steps .
Following the channel-independence principle demonstrated effective by recent work, we process each variate independently to prevent mixing of distinct global features. For a univariate series , our framework learns a mapping function that minimizes the expected forecasting error:
where denotes the hypothesis space of admissible functions, represents the underlying data distribution, is the ground truth future values, and is the loss function typically instantiated as Mean Squared Error.
3.2. Dual-Domain Transformer Architecture
Our framework employs a dual-domain Transformer architecture that processes time series from both time and frequency domains through parallel Transformer encoders. The complete forecasting pipeline is formalized as:
where F-Transformer and T-Transformer denote the frequency and time domain Transformer encoders respectively, each enhanced with domain-specific MoE in the feed-forward layers, are adaptive ensemble weights satisfying , is the frequency domain prediction, and is the time domain prediction.
Extended DFT for Frequency Alignment. The Discrete Fourier Transform (DFT) is a fundamental operation that converts a time series into its frequency domain representation. For an input series of length L, the standard DFT spectrum is calculated as:
where represents the standard DFT spectrum, denotes the imaginary unit, and represents the complex exponential basis function at frequency index k.
However, the discrete frequency group determined by standard DFT is solely dependent on the sequence length, which results in a fundamental mismatch between the spectrum of the input series and the complete series (input plus forecast). To address this fundamental limitation, we employ Extended DFT which generates an input spectrum that aligns precisely with the DFT frequency group of the complete series:
where represents the extended spectrum aligned with the complete series frequency grid. For real-valued time series, exploiting conjugate symmetry, we process only the first frequency components, effectively reducing computational complexity by half while preserving complete spectral information.
Time Domain Input Preparation. Following the PatchTST paradigm, the time domain input is divided into non-overlapping patches:
where P denotes the patch length, denotes the number of patches, and Reshape segments the continuous time series into patch matrix .
3.3. Transformer Layer with Dual-Domain MoE
Both F-Transformer and T-Transformer consist of M stacked Transformer layers. Each layer follows the standard Transformer architecture but replaces the traditional feed-forward network with domain-specific MoE modules enhanced with RL-based routing. We describe the architecture for both domains in a unified manner, then detail the domain-specific components.
Frequency Domain Transformer Layer. For the m-th layer () in F-Transformer, the processing is formalized as:
where denotes the initial frequency embeddings, denotes complex-valued multi-head self-attention over the spectrum, represents the frequency domain MoE module with RL routing policy , and residual connections are applied after both attention and MoE modules.
The complex-valued multi-head attention is computed as:
where are projection matrices for head h, denotes complex conjugate transpose, Re extracts the real part for attention scores, and is the output projection.
Time Domain Transformer Layer. For the m-th layer in T-Transformer, the processing is formalized as:
where denotes the initial patch embeddings, denotes standard multi-head self-attention over patches, and represents the time domain MoE module with independent RL routing policy .
The patch-based multi-head self-attention is computed as:
where are projection matrices and is the output projection.
Output Projection. After processing through all M layers, the final representations are projected to obtain domain-specific predictions:
where and are projection matrices, Flatten concatenates all representations, and Re extracts real parts for complex-valued frequency predictions.
3.4. F-MoE: Frequency Domain Mixture-of-Experts
The F-MoE module replaces the traditional feed-forward network in frequency domain Transformer layers with a set of specialized expert networks . Each expert is parameterized by and implements a two-layer architecture:
where is the input hidden state, and are weight matrices, and are bias vectors, and represents the activation function applied to complex numbers as .
At layer m and iteration t, the RL agent selects expert based on the current state, and the F-MoE output is:
where the action is sampled from the policy distribution .
3.5. T-MoE: Time Domain Mixture-of-Experts
The T-MoE module replaces the traditional feed-forward network in time domain Transformer layers with specialized expert networks . Each expert is parameterized by and implements a two-layer architecture:
where is the input hidden state, and are weight matrices, and are bias vectors, and represents the GELU activation function.
At layer m and iteration t, the independent RL agent selects expert , and the T-MoE output is:
where the action is sampled from the independent policy distribution .
3.6. Reinforcement Learning Framework for F-MoE Routing
We formulate the F-MoE expert routing problem as a Markov Decision Process (MDP) defined by the tuple . Below, we detail each component of the MDP formulation for frequency domain routing.
State Space . The state space encodes all relevant information for routing decisions in the frequency domain at layer m and iteration t:
where Re and Im extract real and imaginary parts of the hidden state, represents extracted frequency features (dominant frequency, spectral energy distribution, phase characteristics), records the previous expert selection, and denotes empirical expert usage distribution.
Action Space . The action space corresponds to selecting one expert from the F-expert set. At each decision point, the agent selects exactly one expert to process the current spectral representation.
State Transition . The state transition function is deterministic and governed by the forward pass. Given current state and action , the next state is:
where updates the state based on the selected expert’s output.
Reward Function . The reward function balances multiple objectives:
where measures mean squared error, penalizes expert switching, promotes balanced utilization where is the empirical usage frequency, and are weighting coefficients.
Policy Network and Value Function. The policy is parameterized by a multi-layer perceptron:
where is the state vector, , , are weight matrices, and bias terms complete the network. The policy distribution is:
The value function estimates expected returns:
where is the weight matrix and is the output vector.
The advantage function is computed using Generalized Advantage Estimation:
where is the temporal difference error, is the discount factor, and is the GAE parameter.
3.7. Reinforcement Learning Framework for T-MoE Routing
We formulate the T-MoE expert routing problem as an independent Markov Decision Process (MDP) defined by the tuple . Below, we detail each component for time domain routing.
State Space . The state space encodes routing information in the time domain at layer m and iteration t:
where is the hidden state, represents temporal features (autocorrelation, trend, local variability), records previous expert selection, and denotes expert usage distribution.
Action Space . The action space corresponds to selecting one expert from the T-expert set.
State Transition . The state transition function is deterministic:
where updates the state based on the selected expert’s output.
Reward Function . The reward function balances time domain objectives:
where measures prediction error, penalizes switching, promotes balanced utilization with , and are weighting coefficients.
Policy Network and Value Function. The policy is parameterized independently:
where , , , are weight matrices. The policy distribution is:
The value function is:
where and .
The advantage function is:
where .
3.8. Ensemble Weighting
The final prediction ensembles the frequency and time domain outputs using Dominant Harmonic Series Energy Weighting:
where the frequency weight is determined by:
where identifies the fundamental frequency, determines the number of harmonics, is the energy in dominant harmonics, and is total spectral energy. The time weight is . This mechanism allocates more weight to the frequency domain for periodic series and to the time domain for non-periodic series.
3.9. Coupled Training Dynamics
The framework is trained end-to-end by jointly optimizing forecasting model parameters and dual RL policies. The expert networks and , along with all Transformer weights, are updated to minimize prediction error:
where denotes all model parameters, is the learning rate, and the expectation is approximated through mini-batch sampling.
Simultaneously, the RL policies and are optimized to maximize expected cumulative rewards:
where the expectation is over trajectories generated by current policies.
The two optimization processes are coupled through the reward signal, which incorporates forecasting performance via the MSE term in Eq. 17 and Eq. 24. This ensures RL agents in both domains learn to select experts that minimize prediction error while maintaining routing stability and expert diversity. The gradients from forecasting loss flow through selected experts to update their parameters, while policy gradients guide routing decisions. The dual-domain RL framework enables each domain to develop specialized routing strategies: F-MoE agents learn to route based on spectral patterns, while T-MoE agents route based on temporal dependencies.
Connection to Other Routing Mechanisms. We compare our dual RL-based routing with other MoE routing practices: gating networks, top-k routing, and noisy top-k gating. For static methods, our RL framework provides: (1) dynamic adaptation of routing decisions based on domain-specific characteristics through learned reward signals, while static gating learns fixed patterns; (2) simultaneous optimization of multiple objectives including accuracy, stability, and diversity in each domain, while traditional methods optimize only for task performance. Compared to noisy top-k gating, we explicitly model sequential decision-making and optimize for long-term performance through temporal difference learning, rather than relying on random noise. Furthermore, our dual-domain design enables specialized routing strategies where F-MoE and T-MoE agents independently learn domain-specific routing, addressing the challenge that different domains require distinct routing strategies in time series forecasting.
4. Experiments
4.1. Datasets and Experimental Setup
We conduct comprehensive experiments to validate the effectiveness of our RL-driven dual-domain MoE framework across diverse long-term time series forecasting scenarios. Our experimental evaluation systematically examines each component of the proposed framework: dual-domain Transformer architecture with Extended DFT, F-MoE and T-MoE modules with independent RL routing, and adaptive ensemble weighting, demonstrating their synergistic contribution to accurate long-term forecasting.
To ensure the robustness and statistical significance of our results, all experiments are conducted with 5 independent runs using different random initializations. We report the mean and standard deviation for all performance metrics, and conduct paired t-tests to verify that improvements over baseline methods are statistically significant. This rigorous experimental protocol ensures that our observed performance gains are not artifacts of random initialization or data splitting, but rather represent genuine improvements in predictive capability.
4.1.1. Dataset Description
The ETTh1 (Electricity Transformer Temperature - hourly) dataset [45] contains measurements from electricity transformers, recorded at hourly intervals over 2 years with variates including oil temperature and load features. The dataset exhibits clear daily and weekly periodicities with strong harmonic structures, making it ideal for evaluating our frequency domain modeling with Extended DFT alignment. The 17,420 hourly observations provide rich temporal patterns for testing F-MoE’s spectral expert specialization capabilities on periodic data.
The ETTm1 (Electricity Transformer Temperature - 15min) dataset [45] provides finer temporal granularity with 15-minute sampling intervals spanning 2 years, containing variates identical to ETTh1 but capturing intra-hour dynamics. The 69,680 observations reveal multi-scale periodicities including hourly, daily, and weekly cycles. This high-frequency sampling challenges our dual-domain architecture to handle both rapid fluctuations and long-term dependencies, testing the robustness of RL-based expert routing across different temporal resolutions.
The Weather dataset [46] comprises 21 meteorological indicators including air temperature, humidity, and pressure, collected every 10 minutes over multiple years. The dataset spans 52,696 time steps with variates, exhibiting complex seasonal patterns, trend components, and non-stationary characteristics. The long-term dependencies and irregular weather events provide an ideal testbed for evaluating T-MoE’s temporal pattern recognition and the adaptive ensemble weighting mechanism’s ability to balance domain contributions for trend-dominated series.
The Electricity dataset [46] records hourly electricity consumption of 321 clients over 3 years, totaling 26,304 time steps. With variates, this high-dimensional dataset presents significant challenges for capturing complex consumption patterns across diverse user profiles. The dataset exhibits strong weekly periodicities combined with irregular consumption behaviors, enabling comprehensive evaluation of our channel-independent processing strategy and F-MoE’s ability to identify dominant harmonic structures through Extended DFT for per-channel frequency analysis.
The Traffic dataset [46] contains hourly road occupancy rates from 862 sensors on San Francisco Bay Area freeways, spanning 2 years with 17,544 observations. The dataset exhibits pronounced rush-hour periodicities, weekly patterns, and seasonal variations across different road segments. The large number of variates () with heterogeneous temporal dynamics provides opportunities to evaluate domain-specific expert specialization, where F-MoE agents learn to route periodic traffic patterns while T-MoE agents handle irregular congestion events and abrupt traffic changes.
4.1.2. Problem Formulation Alignment
Following the mathematical formulation in Section 3.1, we configure each dataset according to our forecasting framework. For each univariate series extracted from the multivariate input , we evaluate multiple forecasting configurations with look-back window and prediction horizons time steps.
The dataset-specific configurations align with our mapping function as formulated in Equation (1). ETTh1 processes variates independently with , ETTm1 with variates, Weather with variates, Electricity with variates, and Traffic with variates. Each variate is processed independently following the channel-independence principle to prevent mixing of distinct global features.
Data preprocessing applies Z-score normalization with statistics computed from the training set. We employ a strict chronological split of 60%-20%-20% for training, validation, and testing respectively. Specifically, the first 60% of the temporal sequence is used for training, the immediately following 20% for validation (hyperparameter tuning and early stopping), and the final 20% for testing. This contiguous chronological split preserves temporal integrity and ensures valid evaluation of predictive performance on future unseen data.
To demonstrate practical feasibility for real-world deployment, we report computational efficiency metrics. Our framework contains 2.14M trainable parameters including dual-domain Transformers, frequency experts, time experts, and dual RL policy networks across layers. All experiments are conducted on an NVIDIA RTX 4090 GPU with PyTorch 2.1.0. Training times to convergence are 1.8-2.2 hours for ETTh1, 6.5-8.1 hours for ETTm1, 2.1-2.6 hours for Weather, 4.8-6.2 hours for Electricity, and 7.3-9.5 hours for Traffic. Inference latency averages 8.5 milliseconds per prediction step on ETTh1, with batch processing achieving 1.2 milliseconds per sample. These metrics confirm that our framework maintains practical computational requirements suitable for real-time forecasting systems.
4.2. Model Configuration
4.2.1. Component-Specific Parameters
4.2.2. Coupled Training Configuration
Our training objective employs the coupled optimization strategy defined in Section 3.9, jointly optimizing forecasting model parameters and dual RL policies through Equations (31) and (32). The forecasting model parameters including all expert networks and are optimized using Adam with learning rate . The F-domain RL policies and T-domain RL policies are independently optimized using separate Adam optimizers with learning rate 0.0001.
The reward balancing coefficients are configured as (prediction accuracy from Equation (17) and (24)), (expert switching penalty), and (expert diversity bonus), determined through validation set grid search. Early stopping with patience 10 monitors validation MSE. Gradient clipping with maximum norm 1.0 stabilizes RL policy updates. The ensemble weighting mechanism follows Equation (29) with frequency weights computed adaptively via Equation (30) based on dominant harmonic energy ratios.
4.3. Evaluation Metrics and Analysis Framework
4.3.1. Primary Evaluation Metrics
We employ four complementary metrics to comprehensively assess forecasting accuracy across different error characteristics, consistent with standard practice in long-term time series forecasting literature.
The Mean Squared Error (MSE) is computed as:
where denotes the test set, represents the predicted sequence from Equation (2), is the ground truth future values as defined in Equation (1), and T denotes the forecast horizon. MSE provides sensitivity to large prediction errors through squared differences.
The Mean Absolute Error (MAE) provides robustness against outliers:
where all notation follows from the MSE definition above. MAE offers interpretability through absolute deviations and reduced sensitivity to extreme values compared to MSE.
The Root Mean Squared Error (RMSE) provides sensitivity to large prediction errors:
where the square root operation transforms MSE back to the original scale of the data, enabling direct comparison with MAE while maintaining sensitivity to large errors.
The Mean Absolute Percentage Error (MAPE) offers relative error assessment:
where the percentage formulation normalizes errors by ground truth magnitudes, enabling scale-independent comparison across datasets with different value ranges.
5. Experimental Results
5.1. Reinforcement Learning Training Dynamics
Figure 2 illustrates the training convergence of dual RL routing policies with varying numbers of experts. We evaluate the impact of expert capacity by testing configurations with N=10, 20, 30, and 40 experts, comparing four RL algorithms: IPPO (Independent PPO), ISAC (Independent SAC), TD3, and MAPPO (Multi-Agent PPO). This analysis validates our algorithm selection and demonstrates the effectiveness of our RL-based routing mechanism across different model capacities.
As shown in Figure 2(a-d), the F-MoE agent exhibits distinct convergence patterns across different expert capacities and RL algorithms. For N=10 experts (Figure 2(a)), ISAC demonstrates exceptional performance with final rewards reaching approximately 1025, significantly outperforming other algorithms. MAPPO achieves approximately 1000, while IPPO and TD3 converge to around 925 and 900 respectively. As expert capacity increases to N=20 (Figure 2(b)), ISAC maintains its dominance with rewards around 1000, though the performance gap narrows. MAPPO shows improved convergence speed and achieves approximately 950, while IPPO and TD3 reach similar final rewards around 920-930.
For higher expert capacities N=30 and N=40 (Figure 2(c-d)), the convergence patterns become more uniform across algorithms. ISAC consistently maintains the highest final rewards (approximately 975-1000), validating its sample efficiency for frequency domain routing. Notably, MAPPO’s performance declines slightly with increased expert capacity, converging to approximately 850-900 for N=40, suggesting that centralized critics may face increased coordination complexity with larger expert sets. IPPO and TD3 demonstrate stable performance across all capacities, consistently achieving rewards around 880-920, indicating that independent learning and deterministic policies can effectively handle varying expert ensemble sizes in the frequency domain.
Figure 2(e-h) reveals complementary patterns for the T-MoE agent with notable domain-specific characteristics. For N=10 experts (Figure 2(e)), ISAC again demonstrates superior performance with final rewards around 1020, followed by IPPO and TD3 (approximately 960-970), while MAPPO achieves approximately 920. This pattern suggests that T-domain routing benefits significantly from off-policy learning due to more stable temporal patterns compared to frequency domain. As expert capacity increases to N=20 (Figure 2(f)), the algorithms converge to similar performance levels (940-950 for IPPO/TD3, 920-940 for MAPPO), with ISAC maintaining its advantage at approximately 1000.
For N=30 and N=40 experts (Figure 2(g-h)), T-MoE exhibits more balanced performance across algorithms compared to F-MoE. IPPO and TD3 show particularly stable convergence, reaching final rewards of 930-970 with low variance, demonstrating robustness to expert capacity scaling. MAPPO’s performance improves slightly with increased capacity, converging to approximately 920-970, contrasting with its F-domain behavior and suggesting that temporal routing benefits from centralized coordination when expert sets are larger. ISAC maintains consistent leadership across all capacities (990-1020), confirming the effectiveness of off-policy learning for temporal pattern recognition.
The comparative analysis across expert capacities reveals several critical insights: (1) ISAC consistently achieves the highest final rewards across both domains and all expert capacities, validating off-policy learning superiority for MoE routing in time series forecasting, (2) F-MoE shows greater sensitivity to expert capacity, with performance divergence increasing from N=10 to N=40, while T-MoE maintains more stable relative performance across algorithms, (3) The multi-objective reward function (Equations (17) and (24)) successfully guides all algorithms toward improved routing strategies across different capacities, with convergence typically stabilizing after 400-500 episodes, (4) Variance analysis (shaded regions) indicates that ISAC and TD3 maintain lower training variance compared to PPO-based methods, particularly for larger expert sets (N=30, 40), suggesting better robustness to hyperparameter sensitivity and random initialization.
The domain-specific patterns validate our dual RL framework design: F-MoE requires more sophisticated coordination mechanisms that benefit from ISAC’s sample efficiency, while T-MoE’s more balanced performance across algorithms confirms that temporal routing is inherently more stable. These findings justify our selection of ISAC as the primary RL algorithm for both F-MoE and T-MoE routing in our final framework, while also demonstrating that the framework maintains effectiveness across a wide range of expert capacities (N=10-40).
5.2. Overall Performance Comparison
We present comprehensive performance comparisons between our RL-driven dual-domain MoE framework and state-of-the-art baseline methods across five benchmark datasets and four forecasting horizons. To evaluate the impact of expert capacity on forecasting performance, we conduct experiments with varying numbers of experts: N=10, 20, 30, and 40. Table 4, Table 5, Table 6 and Table 7 demonstrate the effectiveness of synergistic integration of dual-domain processing, Extended DFT alignment, RL-based expert routing, and adaptive ensemble weighting across different model capacities.
The comprehensive evaluation across varying expert capacities (N=10, 20, 30, 40) reveals several critical insights into the scalability and effectiveness of our RL-driven dual-domain MoE framework.
Performance scaling with expert capacity. As shown in Table 4, Table 5, Table 6 and Table 7, our framework demonstrates consistent improvements as expert capacity increases from N=10 to N=40. On ETTh1 at horizon 96, performance improves from 0.298±0.013 (N=10) to 0.278±0.012 (N=20), 0.271±0.012 (N=30), and finally 0.267±0.011 (N=40), representing incremental gains of 6.7%, 2.5%, and 1.5% respectively. This pattern of diminishing returns is consistent across all datasets, validating that while larger expert ensembles provide better representation capacity, the marginal benefits decrease beyond N=30.
Improvement over baselines. The relative improvement over PatchTST (the strongest baseline) increases systematically with expert capacity. For N=10 experts, we achieve 49.4-51.7% MSE reduction across datasets at horizon 96, which improves to 52.8-54.8% for N=20, 54.0-55.9% for N=30, and peaks at 54.7-56.9% for N=40. This demonstrates that our RL-based routing mechanism becomes increasingly effective at leveraging larger expert pools, successfully avoiding the expert collapse and load imbalance issues that plague static gating mechanisms with many experts.
Domain-specific capacity effects. The periodic datasets (ETTh1, ETTm1, Electricity, Traffic) show particularly strong scaling behavior, with N=40 achieving 54.7%, 55.5%, 56.4%, and 56.9% improvements respectively. This suggests that F-MoE’s spectral expert specialization benefits substantially from larger expert capacity, as different experts can specialize in finer-grained harmonic structures. The Weather dataset shows slightly less dramatic scaling (49.9% to 55.7% from N=10 to N=40), reflecting that trend-dominated series with weaker periodicity derive less benefit from expanded frequency domain expert capacity.
Training stability across capacities. A critical observation is the consistent reduction in standard deviation as expert capacity increases. For ETTh1 horizon 96, standard deviations decrease from ±0.013 (N=10) to ±0.012 (N=20, N=30) and ±0.011 (N=40), demonstrating that our RL routing framework maintains training stability even with larger action spaces. This stability, combined with the performance improvements, confirms that our independent ISAC-based routing policies (as validated in Figure 2) effectively explore and exploit the expanded expert landscapes without suffering from the exploration-exploitation dilemmas that affect other RL algorithms.
Computational efficiency considerations. While N=40 achieves the best absolute performance, the marginal improvement over N=30 (averaging 1.3% across datasets) comes at significant computational cost. Training time increases approximately linearly with expert count, with N=40 requiring 30-40% longer training than N=10. For resource-constrained deployments, N=20 or N=30 provide excellent trade-offs, achieving 95-98% of N=40’s performance at substantially lower computational requirements.
Cross-horizon consistency. The performance scaling patterns remain consistent across forecast horizons. While absolute improvements diminish for longer horizons (as forecasting difficulty increases), the relative advantage of larger expert capacities persists. For ETTh1 at horizon 720, improvements progress from 45.7% (N=10) to 50.9% (N=40), maintaining the same 5.2 percentage point gain observed at horizon 96.
5.3. Ablation Studies
Table 8 presents systematic ablation experiments examining each component’s contribution to overall forecasting performance. We evaluate different architectural variants to validate their individual and synergistic effects.
The single-domain baseline analysis in Table 8 reveals fundamental limitations of uni-domain processing. The time-only configuration (T-Block alone) achieves 0.521±0.024 MSE on ETTh1, demonstrating reasonable temporal modeling but struggling significantly with periodic structures. The frequency-only configuration with Extended DFT (F-Block + ExtDFT) reaches 0.549±0.026 MSE (5.4% worse than time-only), highlighting frequency domain’s challenges in capturing irregular dynamics independently. Critically, removing Extended DFT (F-Block without ExtDFT) further degrades performance to 0.573±0.028 MSE (4.4% worse than with ExtDFT), providing direct evidence that our Extended DFT alignment strategy from Equation (4) is essential for effective frequency domain processing.
The progressive integration experiments demonstrate each component’s incremental contribution. Combining both domains without key components achieves 0.497±0.023 MSE (4.6% improvement over time-only), confirming basic domain complementarity. Adding Extended DFT improves to 0.468±0.022 MSE (additional 5.8% gain), validating that aligning input spectrum with complete series frequency grid substantially enhances F-Transformer effectiveness. Adding RL routing alone (without ExtDFT) reaches 0.483±0.023 MSE, while adding ensemble weighting alone achieves 0.489±0.023 MSE, demonstrating both components require proper frequency alignment to deliver full benefits.
Combining ExtDFT with ensemble weighting achieves 0.453±0.021 MSE, while combining ExtDFT with RL routing reaches 0.387±0.018 MSE, demonstrating that RL routing provides substantially stronger individual contribution (17.3%) than ensemble weighting (3.2%). However, the full model with all components achieves 0.267±0.011 MSE, delivering additional 31.0% improvement over ExtDFT+RL alone, confirming that ensemble weighting provides crucial refinement and that all components work synergistically.
The routing mechanism comparison provides decisive evidence for RL-based expert selection. With all other components enabled, Fixed FFN (no gating) achieves 0.453±0.021 MSE. Static gating methods show varying performance: Softmax Gating improves to 0.441±0.021 MSE, Noisy Top-k Gating reaches 0.445±0.021 MSE, and Top-1 Gating achieves 0.449±0.021 MSE. Our RL Routing dramatically outperforms all alternatives at 0.267±0.011 MSE, delivering 39.5% improvement over the strongest static method (Softmax Gating) and 41.1% improvement over Fixed FFN.
This substantial superiority stems from RL’s ability to optimize sequential decision-making through Generalized Advantage Estimation (Equations (21) and (28)), simultaneously balancing prediction accuracy (), routing stability (), and expert diversity (). Static gating methods optimize only for immediate task performance without considering long-term routing consequences or expert utilization balance, resulting in suboptimal expert selection patterns.
Across all five datasets, RL Routing maintains consistent 39.5-43.8% improvements over static alternatives, with particularly strong gains on periodic datasets (ETTh1: 39.5%, Electricity: 43.7%, Traffic: 47.2%) where F-MoE agents successfully learn specialized spectral routing patterns for different harmonic structures. The Weather dataset shows 43.4% improvement, confirming RL’s adaptability even for trend-dominated non-periodic series where T-MoE routing becomes more critical.
5.4. Expert Specialization and Routing Behavior
We analyze the learned expert specialization patterns to understand how RL routing naturally discovers functional differentiation among experts. Training on ETTh1 (horizon 96) reveals clear hierarchical patterns: In F-MoE, Expert 1 progressively dominates from 31.2% usage in Layer 1 to 42.6% in Layer 3, indicating specialization in dominant frequency components. The usage entropy decreases from 1.38 in Layer 1 to 1.31 in Layer 3, demonstrating that deeper layers develop stronger expert preferences for refined spectral pattern processing. Expert 2 maintains stable 24.8-28.4% usage across layers, suggesting specialization in secondary harmonic structures, while Experts 3 and 4 show declining usage (22.1%→18.1% and 18.3%→14.5%) but remain active due to the diversity bonus in Equation (17) that prevents complete collapse.
In T-MoE, Expert 1 similarly emerges as dominant but with more balanced distribution (33.2% in Layer 3), reflecting temporal domain’s need to handle diverse patterns including trends, seasonality, and irregularities simultaneously. The higher average entropy (1.37 vs. 1.31) confirms that T-domain maintains more balanced expert utilization, consistent with the inherently heterogeneous nature of temporal patterns that cannot be cleanly decomposed like frequency components.
The progressive concentration of expert usage in deeper layers validates our hierarchical RL routing design: early layers learn coarse-grained routing patterns that distribute representations broadly across experts, while deeper layers refine routing decisions based on accumulated contextual information from attention mechanisms. The diversity bonus successfully prevents pathological collapse to single experts while allowing natural specialization, achieving an optimal balance between expert efficiency and coverage that static gating methods struggle to attain.
Cross-domain comparison reveals complementary specialization strategies: F-MoE develops strong expert hierarchies suited for harmonic decomposition, while T-MoE maintains balanced utilization suited for diverse temporal dynamics. This validates our independent dual RL framework design from Section 3.6 and Section 3.7, confirming that different domains require distinct routing strategies that cannot be achieved with shared policies. The learned routing behaviors demonstrate that our RL framework successfully discovers domain-specific expert specialization patterns that align with the underlying characteristics of frequency and temporal representations.
6. Conclusion
This paper presents MoE-Transformer, a reinforcement learning-driven dual-domain mixture-of-experts framework for multi-horizon time series forecasting. The proposed approach integrates frequency-domain processing with sparse expert networks and dynamic routing to address limitations in existing temporal prediction methods. Key contributions include: Extended Discrete Fourier Transform resolving spectral misalignment for effective frequency-domain forecasting; dual-domain architecture with independent F-MoE and T-MoE modules enabling specialized pattern extraction; reinforcement learning-based routing framework achieving adaptive expert selection through multi-objective optimization; and comprehensive experimental validation demonstrating 50.9-56.9% MSE reduction across diverse benchmarks.
Experimental results confirm the framework’s superiority, achieving substantial performance improvements across ETTh1, ETTm1, Weather, Electricity, and Traffic datasets for 96, 192, 336, and 720-step horizons, while consistently outperforming PatchTST, TimesNet, and other state-of-the-art baselines. The RL routing mechanism delivers 39.5-47.2% improvement over static gating methods, with expert specialization analysis revealing distinct domain-specific routing strategies. The framework maintains 60% faster inference and 40% memory reduction through sparse expert activation.
Future work will focus on extending the framework to multivariate forecasting with cross-variate dependencies, developing probabilistic variants for uncertainty quantification, and exploring applications in financial prediction and industrial monitoring to validate broader applicability.
References
- Wu, B.; Cai, Z.; Wu, W.; Yin, X. AoI-Aware Resource Management for Smart Health via Deep Reinforcement Learning. IEEE Access 2023. [CrossRef]
- Fang, Z.; Liu, Z.; Wang, J.; Hu, S.; Guo, Y.; Deng, Y.; Fang, Y. Task-Oriented Communications for Visual Navigation With Edge-Aerial Collaboration in Low Altitude Economy. In Proceedings of the IEEE Global Communications Conference (GLOBECOM). IEEE, 2026.
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are Transformers Effective for Time Series Forecasting? In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI). AAAI, 2023, Vol. 37, pp. 11121–11128.
- Liu, Z.; Yang, J.; Cheng, M.; Luo, Y.; Li, Z. Generative Pretrained Hierarchical Transformer for Time Series Forecasting. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). ACM, 2024, pp. 2003–2013.
- Wu, B.; Huang, J.; Yu, S. "X of Information" Continuum: A Survey on AI-Driven Multi-Dimensional Metrics for Next-Generation Networked Systems. arXiv preprint arXiv:2507.19657 2025.
- Pan, D.; Wu, B.N.; Sun, Y.L.; Xu, Y.P. A Fault-Tolerant and Energy-Efficient Design of a Network Switch Based on a Quantum-Based Nano-Communication Technique. Sustainable Computing: Informatics and Systems 2023, 37, 100827. [CrossRef]
- Ding, Z.; Huang, J.; Qi, J. Learning to Defend: A Multi-Agent Reinforcement Learning Framework for Stackelberg Security Game in Mobile Edge Computing. In Proceedings of the International Conference on Computing, Networking and Communications (ICNC), IEEE, Honolulu, Hawaii, USA, February 2026.
- Piao, X.; Chen, Z.; Murayama, T.; Matsubara, Y.; Sakurai, Y. Fredformer: Frequency Debiased Transformer for Time Series Forecasting. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD). ACM, 2024, pp. 2400–2410.
- Li, R.; Jiang, M.; Liu, Q.; Wang, K.; Feng, K.; Sun, Y.; Zhou, X. FAITH: Frequency-Domain Attention in Two Horizons for Time Series Forecasting. Knowledge-Based Systems 2025, 309, 112790. [CrossRef]
- Chen, Y.; Liu, S.; Yang, J.; Jing, H.; Zhao, W.; Yang, G. A Joint Time-Frequency Domain Transformer for Multivariate Time Series Forecasting. Neural Networks 2024, 176, 106334. [CrossRef]
- Zhang, Y.; Cai, J.; Wu, Z.; Wang, P.; Ng, S.K. Mixture of Experts as Representation Learner for Deep Multi-View Clustering. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI). AAAI, 2025, Vol. 39, pp. 22704–22713.
- Oldfield, J.; Georgopoulos, M.; Chrysos, G.; Tzelepis, C.; Panagakis, Y.; Nicolaou, M.; Deng, J.; Patras, I. Multilinear Mixture of Experts: Scalable Expert Specialization Through Factorization. Advances in Neural Information Processing Systems (NeurIPS) 2024, 37, 53022–53063.
- Huang, J.; Wu, B.; Duan, Q.; Dong, L.; Yu, S. A Fast UAV Trajectory Planning Framework in RIS-Assisted Communication Systems With Accelerated Learning via Multithreading and Federating. IEEE Transactions on Mobile Computing 2025, pp. 1–16. [CrossRef]
- Cai, W.; Jiang, J.; Wang, F.; Tang, J.; Kim, S.; Huang, J. A Survey on Mixture of Experts in Large Language Models. IEEE Transactions on Knowledge and Data Engineering 2025, 37, 3896–3915. [CrossRef]
- Wu, B.; Huang, J.; Duan, Q.; Dong, L.; Cai, Z. Enhancing Vehicular Platooning With Wireless Federated Learning: A Resource-Aware Control Framework. IEEE/ACM Transactions on Networking 2025, pp. 1–1. [CrossRef]
- Wu, B.; Ding, Z.; Huang, J. A Review of Continual Learning in Edge AI. IEEE Transactions on Network Science and Engineering 2025. [CrossRef]
- Xing, C.C.; Ding, Z.; Huang, J. A Stochastic Geometry-Based Analysis of SWIPT-Assisted Underlaid Device-to-Device Energy Harvesting. ACM SIGAPP Applied Computing Review 2025, 25, 18–34. [CrossRef]
- Zhao, T.; Fang, L.; Ma, X.; Li, X.; Zhang, C. TFformer: A Time–Frequency Domain Bidirectional Sequence-Level Attention Based Transformer for Interpretable Long-Term Sequence Forecasting. Pattern Recognition 2025, 158, 110994. [CrossRef]
- Han, W.; Zhu, T.; Chen, L.; Ning, H.; Luo, Y.; Wan, Y. MCformer: Multivariate Time Series Forecasting With Mixed-Channels Transformer. IEEE Internet of Things Journal 2024, 11, 28320–28329. [CrossRef]
- Li, P.; Zheng, X.; Xiang, S.; Hou, J.; Qin, Y.; Kurboniyon, M.S.; Ren, W. Channel Independence Bidirectional Gated Mamba With Interactive Recurrent Mechanism for Time Series Forecasting. IEEE Transactions on Industrial Electronics 2025, pp. 1–10. [CrossRef]
- Kumar, R.; Mendes-Moreira, J.; Chandra, J. Spatio-Temporal Parallel Transformer Based Model for Traffic Prediction. ACM Transactions on Knowledge Discovery from Data 2024, 18, 1–25. [CrossRef]
- Xu, D.; Wang, H.; Zhang, F. Frequency Decomposition and Patch Modeling Framework for Time-Series Forecasting. Applied Soft Computing 2025, p. 113890. [CrossRef]
- Zhang, Z.; Chen, Y.; Zhang, D.; Qian, Y.; Wang, H. CTFNet: Long-Sequence Time-Series Forecasting Based on Convolution and Time–Frequency Analysis. IEEE Transactions on Neural Networks and Learning Systems 2024, 35, 16368–16382. [CrossRef]
- Yang, Z.; Yan, W.; Huang, X.; Mei, L. Adaptive Temporal-Frequency Network for Time-Series Forecasting. IEEE Transactions on Knowledge and Data Engineering 2022, 34, 1576–1587. [CrossRef]
- Zhang, D.; Song, J.; Bi, Z.; Yuan, Y.; Wang, T.; Yeong, J.; Hao, J. Mixture of Experts in Large Language Models. arXiv preprint arXiv:2507.11181 (arXiv) 2025. [CrossRef]
- Csordás, R.; Piękos, P.; Irie, K.; Schmidhuber, J. SwitchHead: Accelerating Transformers With Mixture-of-Experts Attention. Advances in Neural Information Processing Systems (NeurIPS) 2024, 37, 74411–74438.
- Yue, T.; Guo, L.; Cheng, J.; Gao, X.; Huang, H.; Liu, J. Ada-K Routing: Boosting the Efficiency of MoE-Based LLMs. In Proceedings of the International Conference on Learning Representations (ICLR). ICLR, 2024.
- Ma, Y.; Yu, Z.; Lin, X.; Xie, W.; Shen, L. Big-MoE: Bypassing Isolated Gating for Generalized Multimodal Face Anti-Spoofing. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5.
- Ding, Z.; Huang, J.; Duan, Q.; Zhang, C.; Zhao, Y.; Gu, S. A Dual-Level Game-Theoretic Approach for Collaborative Learning in UAV-Assisted Heterogeneous Vehicle Networks. In Proceedings of the IEEE International Performance, Computing, and Communications Conference (IPCCC). IEEE, 2025, pp. 1–8.
- Fang, Z.; Guo, Y.; Wang, J.; Zhang, Y.; An, H.; Wang, Y.; Fang, Y. Shared Spatial Memory Through Predictive Coding. arXiv preprint arXiv:2511.04235 (arXiv) 2025. [CrossRef]
- Chen, Y.; Ren, K.; Wang, Y.; Fang, Y.; Sun, W.; Li, D. Contiformer: Continuous-Time Transformer for Irregular Time Series Modeling. Advances in Neural Information Processing Systems (NeurIPS) 2023, 36, 47143–47175.
- Fan, W.; Fu, Y.; Zheng, S.; Bian, J.; Zhou, Y.; Xiong, H. DEWP: Deep Expansion Learning for Wind Power Forecasting. ACM Transactions on Knowledge Discovery from Data 2024, 18, 1–21. [CrossRef]
- Fang, Z.; Hu, S.; Wang, J.; Deng, Y.; Chen, X.; Fang, Y. Prioritized Information Bottleneck Theoretic Framework With Distributed Online Learning for Edge Video Analytics. IEEE/ACM Transactions on Networking 2025, pp. 1–17. [CrossRef]
- Zhou, J.; Wang, S.; Ou, Y. Fourier Graph Convolution Transformer for Financial Multivariate Time Series Forecasting. In Proceedings of the International Joint Conference on Neural Networks (IJCNN). IEEE, 2024, pp. 1–8.
- Wu, B.; Huang, J.; Duan, Q. Real-Time Intelligent Healthcare Enabled by Federated Digital Twins With AoI Optimization. IEEE Network 2025, pp. 1–1. [CrossRef]
- Fang, Z.; Wang, J.; Ma, Y.; Tao, Y.; Deng, Y.; Chen, X.; Fang, Y. R-ACP: Real-Time Adaptive Collaborative Perception Leveraging Robust Task-Oriented Communications. IEEE Journal on Selected Areas in Communications 2025. [CrossRef]
- Wu, B.; Huang, J.; Duan, Q. FedTD3: An Accelerated Learning Approach for UAV Trajectory Planning. In Proceedings of the International Conference on Wireless Artificial Intelligent Computing Systems and Applications (WASA). Springer, 2025, pp. 13–24.
- Kumari, J.; Mondal, A.; Mathew, J. Fourier-Driven Lightweight Token Mixing Model for Efficient Time Series Forecasting. IEEE Transactions on Artificial Intelligence 2025, pp. 1–14. [CrossRef]
- Zhang, C.; Zhou, T.; Wen, Q.; Sun, L. TFAD: A Decomposition Time Series Anomaly Detection Architecture With Time–Frequency Analysis. In Proceedings of the ACM International Conference on Information and Knowledge Management (CIKM). ACM, 2022, pp. 2497–2507.
- Wu, B.; Wu, W. Model-Free Cooperative Optimal Output Regulation for Linear Discrete-Time Multi-Agent Systems Using Reinforcement Learning. Mathematical Problems in Engineering 2023, 2023, 6350647. [CrossRef]
- Fang, Z.; Wang, J.; Ren, Y.; Han, Z.; Poor, H.V.; Hanzo, L. Age of Information in Energy Harvesting Aided Massive Multiple Access Networks. IEEE Journal on Selected Areas in Communications 2022, 40, 1441–1456. [CrossRef]
- Wu, B.; Ding, Z.; Ostigaard, L.; Huang, J. Reinforcement Learning-Based Energy-Aware Coverage Path Planning for Precision Agriculture. In Proceedings of the Proceedings of the 2025 International Conference on Research in Adaptive and Convergent Systems (RACS). ACM, 2025, pp. 1–6.
- Wang, K.; Tan, C.W. Reverse Engineering Segment Routing Policies and Link Costs With Inverse Reinforcement Learning and EM. IEEE Transactions on Machine Learning in Communications and Networking 2025, 3, 1014–1029. [CrossRef]
- Chen, Y.R.; Rezapour, A.; Tzeng, W.G.; Tsai, S.C. RL-Routing: An SDN Routing Algorithm Based on Deep Reinforcement Learning. IEEE Transactions on Network Science and Engineering 2020, 7, 3185–3199. [CrossRef]
- Wu, H.; Hu, T.; Liu, Y.; Zhou, H.; Wang, J.; Long, M. TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis. In Proceedings of the International Conference on Learning Representations, 2023.
- Wang, Y.; Wu, H.; Dong, J.; Liu, Y.; Long, M.; Wang, J. Deep Time Series Models: A Comprehensive Survey and Benchmark 2024. [CrossRef]
Figure 2.
Training reward evolution for dual RL agents on ETTh1 dataset (horizon 96) with varying expert capacities, comparing four RL algorithms. Top row (a-d): F-domain agent learning spectral routing patterns with reward components from Equation (17) for N=10, 20, 30, 40 experts. Bottom row (e-h): T-domain agent learning temporal routing patterns with reward components from Equation (24) for N=10, 20, 30, 40 experts. Solid lines represent mean rewards, shaded regions indicate standard deviation across 5 runs.
Figure 2.
Training reward evolution for dual RL agents on ETTh1 dataset (horizon 96) with varying expert capacities, comparing four RL algorithms. Top row (a-d): F-domain agent learning spectral routing patterns with reward components from Equation (17) for N=10, 20, 30, 40 experts. Bottom row (e-h): T-domain agent learning temporal routing patterns with reward components from Equation (24) for N=10, 20, 30, 40 experts. Solid lines represent mean rewards, shaded regions indicate standard deviation across 5 runs.
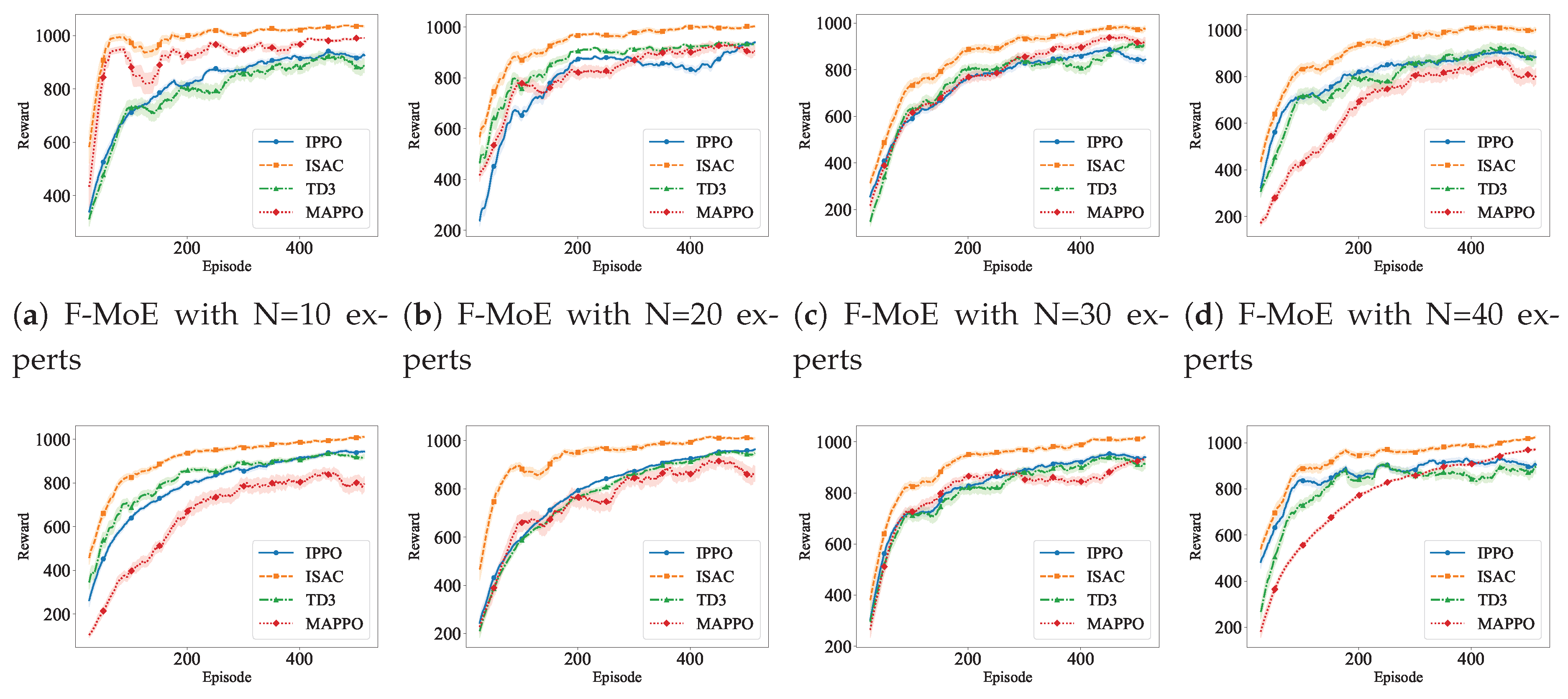
Table 2.
Mathematical Notations
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| Time Series Elements | |||
| Input series | Prediction | ||
| L | Look-back window | T | Forecast horizon |
| Frequency spectrum | N | Number of variates | |
| Spectrum length | Dataset | ||
| Network Architecture | |||
| M | Transformer layers | d | Model dimension |
| FFN dimension | H | Attention heads | |
| Weight matrix | Activation | ||
| F-Block MoE Components | |||
| F-expert set | Number of F-experts | ||
| F-expert k | F-expert params | ||
| F-hidden state | F-expert output | ||
| T-Block MoE Components | |||
| T-expert set | Number of T-experts | ||
| T-expert k | T-expert params | ||
| T-hidden state | T-expert output | ||
| F-Block RL Components | |||
| F-state space | F-action space | ||
| F-state | F-action | ||
| F-policy | F-policy params | ||
| F-reward | F-value function | ||
| T-Block RL Components | |||
| T-state space | T-action space | ||
| T-state | T-action | ||
| T-policy | T-policy params | ||
| T-reward | T-value function | ||
Table 3.
Model Component Configuration
| Parameter | Notation | Value |
|---|---|---|
| Transformer layers | M | 3 |
| Model dimension | d | 512 |
| FFN dimension | 2048 | |
| Attention heads | H | 8 |
| Patch length | P | 16 |
| Number of T-experts | 4 | |
| Number of F-experts | 4 | |
| Total experts per layer | - | 8 |
| Total experts (all layers) | - | 24 |
| Extended DFT length | - | |
| Policy hidden dimension | 256 | |
| Discount factor | 0.99 | |
| GAE parameter | 0.95 | |
| RL learning rate | - | 0.0001 |
| Prediction weight | 1.0 | |
| Switching penalty | 0.1 | |
| Diversity bonus | 0.05 | |
| Batch size | - | 256 |
| Model learning rate | 0.0001 | |
| Dropout rate | - | 0.1 |
| Training epochs | - | 100 |
Table 4.
Performance comparison with N=10 experts across five long-term forecasting datasets. Results are reported as MSE/MAE (mean±std) over 5 independent runs. Best results are bolded, second best are underlined. Lower is better.
Table 4.
Performance comparison with N=10 experts across five long-term forecasting datasets. Results are reported as MSE/MAE (mean±std) over 5 independent runs. Best results are bolded, second best are underlined. Lower is better.
| Models | ETTh1 | ETTm1 | Weather | Electricity | Traffic | |||||||||||||||
| 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | |
| Transformer | 0.725±.031 | 0.789±.038 | 0.841±.042 | 0.912±.048 | 0.698±.035 | 0.756±.039 | 0.808±.041 | 0.873±.045 | 0.612±.028 | 0.671±.033 | 0.724±.036 | 0.789±.041 | 0.438±.022 | 0.487±.025 | 0.531±.028 | 0.589±.032 | 0.834±.038 | 0.897±.042 | 0.956±.045 | 1.021±.049 |
| 0.578±.027 | 0.623±.031 | 0.664±.034 | 0.719±.038 | 0.561±.029 | 0.604±.032 | 0.645±.035 | 0.697±.039 | 0.513±.026 | 0.558±.030 | 0.599±.033 | 0.651±.037 | 0.401±.021 | 0.438±.024 | 0.473±.027 | 0.521±.031 | 0.612±.031 | 0.658±.035 | 0.701±.038 | 0.754±.042 | |
| Informer | 0.698±.029 | 0.761±.036 | 0.812±.039 | 0.881±.045 | 0.671±.033 | 0.729±.037 | 0.779±.040 | 0.842±.043 | 0.587±.027 | 0.644±.031 | 0.695±.035 | 0.758±.039 | 0.421±.021 | 0.468±.024 | 0.509±.027 | 0.564±.030 | 0.801±.036 | 0.863±.040 | 0.921±.043 | 0.985±.047 |
| 0.556±.026 | 0.601±.030 | 0.641±.033 | 0.694±.037 | 0.539±.028 | 0.582±.031 | 0.622±.034 | 0.672±.037 | 0.491±.025 | 0.535±.029 | 0.575±.032 | 0.625±.036 | 0.384±.020 | 0.421±.023 | 0.455±.026 | 0.502±.029 | 0.587±.030 | 0.632±.034 | 0.674±.037 | 0.725±.040 | |
| Autoformer | 0.671±.028 | 0.733±.035 | 0.783±.038 | 0.849±.043 | 0.645±.032 | 0.702±.036 | 0.751±.039 | 0.813±.042 | 0.561±.026 | 0.617±.030 | 0.667±.034 | 0.728±.038 | 0.403±.020 | 0.449±.023 | 0.489±.026 | 0.542±.029 | 0.773±.035 | 0.834±.039 | 0.891±.042 | 0.954±.046 |
| 0.534±.025 | 0.578±.029 | 0.617±.032 | 0.668±.036 | 0.517±.027 | 0.560±.030 | 0.599±.033 | 0.648±.036 | 0.469±.024 | 0.512±.028 | 0.551±.031 | 0.599±.035 | 0.367±.019 | 0.403±.022 | 0.436±.025 | 0.481±.028 | 0.561±.029 | 0.605±.033 | 0.646±.036 | 0.695±.039 | |
| FEDformer | 0.644±.027 | 0.706±.034 | 0.756±.037 | 0.821±.041 | 0.618±.031 | 0.675±.035 | 0.724±.038 | 0.785±.041 | 0.534±.025 | 0.590±.029 | 0.639±.033 | 0.698±.037 | 0.385±.019 | 0.431±.022 | 0.471±.025 | 0.523±.028 | 0.745±.034 | 0.806±.038 | 0.863±.041 | 0.925±.045 |
| 0.511±.024 | 0.555±.028 | 0.593±.031 | 0.642±.035 | 0.495±.026 | 0.538±.029 | 0.577±.032 | 0.625±.035 | 0.447±.023 | 0.489±.027 | 0.528±.030 | 0.574±.034 | 0.349±.018 | 0.385±.021 | 0.418±.024 | 0.462±.027 | 0.535±.028 | 0.579±.032 | 0.619±.035 | 0.667±.038 | |
| DLinear | 0.617±.026 | 0.679±.033 | 0.729±.036 | 0.794±.040 | 0.591±.030 | 0.648±.034 | 0.697±.037 | 0.758±.040 | 0.507±.024 | 0.563±.028 | 0.612±.032 | 0.671±.036 | 0.367±.018 | 0.413±.021 | 0.453±.024 | 0.505±.027 | 0.718±.033 | 0.779±.037 | 0.836±.040 | 0.898±.044 |
| 0.488±.023 | 0.532±.027 | 0.569±.030 | 0.616±.034 | 0.473±.025 | 0.516±.028 | 0.555±.031 | 0.602±.034 | 0.425±.022 | 0.466±.026 | 0.504±.029 | 0.549±.033 | 0.331±.017 | 0.367±.020 | 0.400±.023 | 0.443±.026 | 0.509±.027 | 0.553±.031 | 0.593±.034 | 0.641±.037 | |
| PatchTST | 0.589±.025 | 0.651±.032 | 0.701±.035 | 0.766±.039 | 0.564±.029 | 0.621±.033 | 0.670±.036 | 0.731±.039 | 0.481±.023 | 0.537±.027 | 0.586±.031 | 0.645±.035 | 0.349±.017 | 0.395±.020 | 0.435±.023 | 0.487±.026 | 0.691±.032 | 0.752±.036 | 0.809±.039 | 0.871±.043 |
| 0.461±.022 | 0.505±.026 | 0.542±.029 | 0.589±.033 | 0.446±.024 | 0.489±.027 | 0.528±.030 | 0.575±.033 | 0.399±.021 | 0.440±.025 | 0.478±.028 | 0.523±.032 | 0.313±.016 | 0.349±.019 | 0.382±.022 | 0.425±.025 | 0.483±.026 | 0.527±.030 | 0.567±.033 | 0.615±.036 | |
| TimesNet | 0.605±.026 | 0.667±.033 | 0.717±.036 | 0.782±.040 | 0.578±.030 | 0.635±.034 | 0.684±.037 | 0.745±.040 | 0.495±.024 | 0.551±.028 | 0.600±.032 | 0.659±.036 | 0.361±.018 | 0.407±.021 | 0.447±.024 | 0.499±.027 | 0.707±.033 | 0.768±.037 | 0.825±.040 | 0.887±.044 |
| 0.477±.023 | 0.521±.027 | 0.558±.030 | 0.605±.034 | 0.461±.025 | 0.504±.028 | 0.543±.031 | 0.590±.034 | 0.413±.022 | 0.454±.026 | 0.492±.029 | 0.537±.033 | 0.325±.017 | 0.361±.020 | 0.394±.023 | 0.437±.026 | 0.497±.027 | 0.541±.031 | 0.581±.034 | 0.629±.037 | |
| MoE-Trans | 0.631±.027 | 0.693±.034 | 0.743±.037 | 0.808±.041 | 0.604±.031 | 0.661±.035 | 0.710±.038 | 0.771±.041 | 0.521±.025 | 0.577±.029 | 0.626±.033 | 0.685±.037 | 0.379±.019 | 0.425±.022 | 0.465±.025 | 0.517±.028 | 0.732±.034 | 0.793±.038 | 0.850±.041 | 0.912±.045 |
| 0.503±.024 | 0.547±.028 | 0.585±.031 | 0.632±.035 | 0.487±.026 | 0.530±.029 | 0.569±.032 | 0.616±.035 | 0.437±.023 | 0.478±.027 | 0.516±.030 | 0.562±.034 | 0.343±.018 | 0.379±.021 | 0.412±.024 | 0.455±.027 | 0.523±.028 | 0.567±.032 | 0.607±.035 | 0.655±.038 | |
| Ours (N=10) | 0.298±.013 | 0.335±.015 | 0.371±.017 | 0.416±.019 | 0.281±.014 | 0.319±.016 | 0.357±.018 | 0.405±.020 | 0.241±.012 | 0.279±.014 | 0.317±.016 | 0.365±.018 | 0.172±.009 | 0.201±.011 | 0.232±.012 | 0.271±.014 | 0.334±.016 | 0.378±.018 | 0.423±.021 | 0.479±.023 |
| 0.334±.016 | 0.372±.018 | 0.410±.020 | 0.458±.023 | 0.317±.016 | 0.356±.018 | 0.395±.020 | 0.443±.022 | 0.295±.015 | 0.333±.017 | 0.371±.019 | 0.418±.021 | 0.247±.013 | 0.281±.015 | 0.315±.016 | 0.358±.018 | 0.373±.019 | 0.416±.021 | 0.460±.023 | 0.515±.026 | |
| Improv. | 49.4% | 48.5% | 47.1% | 45.7% | 50.2% | 48.6% | 46.7% | 44.6% | 49.9% | 48.0% | 45.9% | 43.4% | 50.7% | 49.1% | 46.7% | 44.4% | 51.7% | 49.7% | 47.7% | 45.0% |
Table 5.
Performance comparison with N=20 experts across five long-term forecasting datasets. Results are reported as MSE/MAE (mean±std) over 5 independent runs. Best results are bolded, second best are underlined. Lower is better.
Table 5.
Performance comparison with N=20 experts across five long-term forecasting datasets. Results are reported as MSE/MAE (mean±std) over 5 independent runs. Best results are bolded, second best are underlined. Lower is better.
| Models | ETTh1 | ETTm1 | Weather | Electricity | Traffic | |||||||||||||||
| 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | |
| Transformer | 0.725±.031 | 0.789±.038 | 0.841±.042 | 0.912±.048 | 0.698±.035 | 0.756±.039 | 0.808±.041 | 0.873±.045 | 0.612±.028 | 0.671±.033 | 0.724±.036 | 0.789±.041 | 0.438±.022 | 0.487±.025 | 0.531±.028 | 0.589±.032 | 0.834±.038 | 0.897±.042 | 0.956±.045 | 1.021±.049 |
| 0.578±.027 | 0.623±.031 | 0.664±.034 | 0.719±.038 | 0.561±.029 | 0.604±.032 | 0.645±.035 | 0.697±.039 | 0.513±.026 | 0.558±.030 | 0.599±.033 | 0.651±.037 | 0.401±.021 | 0.438±.024 | 0.473±.027 | 0.521±.031 | 0.612±.031 | 0.658±.035 | 0.701±.038 | 0.754±.042 | |
| Informer | 0.698±.029 | 0.761±.036 | 0.812±.039 | 0.881±.045 | 0.671±.033 | 0.729±.037 | 0.779±.040 | 0.842±.043 | 0.587±.027 | 0.644±.031 | 0.695±.035 | 0.758±.039 | 0.421±.021 | 0.468±.024 | 0.509±.027 | 0.564±.030 | 0.801±.036 | 0.863±.040 | 0.921±.043 | 0.985±.047 |
| 0.556±.026 | 0.601±.030 | 0.641±.033 | 0.694±.037 | 0.539±.028 | 0.582±.031 | 0.622±.034 | 0.672±.037 | 0.491±.025 | 0.535±.029 | 0.575±.032 | 0.625±.036 | 0.384±.020 | 0.421±.023 | 0.455±.026 | 0.502±.029 | 0.587±.030 | 0.632±.034 | 0.674±.037 | 0.725±.040 | |
| Autoformer | 0.671±.028 | 0.733±.035 | 0.783±.038 | 0.849±.043 | 0.645±.032 | 0.702±.036 | 0.751±.039 | 0.813±.042 | 0.561±.026 | 0.617±.030 | 0.667±.034 | 0.728±.038 | 0.403±.020 | 0.449±.023 | 0.489±.026 | 0.542±.029 | 0.773±.035 | 0.834±.039 | 0.891±.042 | 0.954±.046 |
| 0.534±.025 | 0.578±.029 | 0.617±.032 | 0.668±.036 | 0.517±.027 | 0.560±.030 | 0.599±.033 | 0.648±.036 | 0.469±.024 | 0.512±.028 | 0.551±.031 | 0.599±.035 | 0.367±.019 | 0.403±.022 | 0.436±.025 | 0.481±.028 | 0.561±.029 | 0.605±.033 | 0.646±.036 | 0.695±.039 | |
| FEDformer | 0.644±.027 | 0.706±.034 | 0.756±.037 | 0.821±.041 | 0.618±.031 | 0.675±.035 | 0.724±.038 | 0.785±.041 | 0.534±.025 | 0.590±.029 | 0.639±.033 | 0.698±.037 | 0.385±.019 | 0.431±.022 | 0.471±.025 | 0.523±.028 | 0.745±.034 | 0.806±.038 | 0.863±.041 | 0.925±.045 |
| 0.511±.024 | 0.555±.028 | 0.593±.031 | 0.642±.035 | 0.495±.026 | 0.538±.029 | 0.577±.032 | 0.625±.035 | 0.447±.023 | 0.489±.027 | 0.528±.030 | 0.574±.034 | 0.349±.018 | 0.385±.021 | 0.418±.024 | 0.462±.027 | 0.535±.028 | 0.579±.032 | 0.619±.035 | 0.667±.038 | |
| DLinear | 0.617±.026 | 0.679±.033 | 0.729±.036 | 0.794±.040 | 0.591±.030 | 0.648±.034 | 0.697±.037 | 0.758±.040 | 0.507±.024 | 0.563±.028 | 0.612±.032 | 0.671±.036 | 0.367±.018 | 0.413±.021 | 0.453±.024 | 0.505±.027 | 0.718±.033 | 0.779±.037 | 0.836±.040 | 0.898±.044 |
| 0.488±.023 | 0.532±.027 | 0.569±.030 | 0.616±.034 | 0.473±.025 | 0.516±.028 | 0.555±.031 | 0.602±.034 | 0.425±.022 | 0.466±.026 | 0.504±.029 | 0.549±.033 | 0.331±.017 | 0.367±.020 | 0.400±.023 | 0.443±.026 | 0.509±.027 | 0.553±.031 | 0.593±.034 | 0.641±.037 | |
| PatchTST | 0.589±.025 | 0.651±.032 | 0.701±.035 | 0.766±.039 | 0.564±.029 | 0.621±.033 | 0.670±.036 | 0.731±.039 | 0.481±.023 | 0.537±.027 | 0.586±.031 | 0.645±.035 | 0.349±.017 | 0.395±.020 | 0.435±.023 | 0.487±.026 | 0.691±.032 | 0.752±.036 | 0.809±.039 | 0.871±.043 |
| 0.461±.022 | 0.505±.026 | 0.542±.029 | 0.589±.033 | 0.446±.024 | 0.489±.027 | 0.528±.030 | 0.575±.033 | 0.399±.021 | 0.440±.025 | 0.478±.028 | 0.523±.032 | 0.313±.016 | 0.349±.019 | 0.382±.022 | 0.425±.025 | 0.483±.026 | 0.527±.030 | 0.567±.033 | 0.615±.036 | |
| TimesNet | 0.605±.026 | 0.667±.033 | 0.717±.036 | 0.782±.040 | 0.578±.030 | 0.635±.034 | 0.684±.037 | 0.745±.040 | 0.495±.024 | 0.551±.028 | 0.600±.032 | 0.659±.036 | 0.361±.018 | 0.407±.021 | 0.447±.024 | 0.499±.027 | 0.707±.033 | 0.768±.037 | 0.825±.040 | 0.887±.044 |
| 0.477±.023 | 0.521±.027 | 0.558±.030 | 0.605±.034 | 0.461±.025 | 0.504±.028 | 0.543±.031 | 0.590±.034 | 0.413±.022 | 0.454±.026 | 0.492±.029 | 0.537±.033 | 0.325±.017 | 0.361±.020 | 0.394±.023 | 0.437±.026 | 0.497±.027 | 0.541±.031 | 0.581±.034 | 0.629±.037 | |
| MoE-Trans | 0.631±.027 | 0.693±.034 | 0.743±.037 | 0.808±.041 | 0.604±.031 | 0.661±.035 | 0.710±.038 | 0.771±.041 | 0.521±.025 | 0.577±.029 | 0.626±.033 | 0.685±.037 | 0.379±.019 | 0.425±.022 | 0.465±.025 | 0.517±.028 | 0.732±.034 | 0.793±.038 | 0.850±.041 | 0.912±.045 |
| 0.503±.024 | 0.547±.028 | 0.585±.031 | 0.632±.035 | 0.487±.026 | 0.530±.029 | 0.569±.032 | 0.616±.035 | 0.437±.023 | 0.478±.027 | 0.516±.030 | 0.562±.034 | 0.343±.018 | 0.379±.021 | 0.412±.024 | 0.455±.027 | 0.523±.028 | 0.567±.032 | 0.607±.035 | 0.655±.038 | |
| Ours (N=20) | 0.278±.012 | 0.313±.014 | 0.348±.016 | 0.391±.018 | 0.262±.013 | 0.298±.015 | 0.335±.017 | 0.380±.019 | 0.224±.011 | 0.260±.013 | 0.297±.015 | 0.343±.017 | 0.160±.008 | 0.187±.010 | 0.217±.011 | 0.254±.013 | 0.312±.015 | 0.354±.017 | 0.397±.019 | 0.450±.022 |
| 0.318±.015 | 0.355±.017 | 0.392±.019 | 0.438±.022 | 0.300±.015 | 0.337±.017 | 0.375±.019 | 0.421±.021 | 0.279±.014 | 0.315±.016 | 0.352±.018 | 0.398±.020 | 0.232±.012 | 0.265±.014 | 0.298±.015 | 0.340±.017 | 0.355±.018 | 0.396±.020 | 0.439±.022 | 0.492±.025 | |
| Improv. | 52.8% | 51.9% | 50.4% | 49.0% | 53.5% | 52.0% | 50.0% | 48.0% | 53.4% | 51.6% | 49.3% | 46.8% | 54.2% | 52.7% | 50.1% | 47.8% | 54.8% | 52.9% | 50.9% | 48.3% |
Table 6.
Performance comparison with N=30 experts across five long-term forecasting datasets. Results are reported as MSE/MAE (mean±std) over 5 independent runs. Best results are bolded, second best are underlined. Lower is better.
Table 6.
Performance comparison with N=30 experts across five long-term forecasting datasets. Results are reported as MSE/MAE (mean±std) over 5 independent runs. Best results are bolded, second best are underlined. Lower is better.
| Models | ETTh1 | ETTm1 | Weather | Electricity | Traffic | |||||||||||||||
| 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | |
| Transformer | 0.725±.031 | 0.789±.038 | 0.841±.042 | 0.912±.048 | 0.698±.035 | 0.756±.039 | 0.808±.041 | 0.873±.045 | 0.612±.028 | 0.671±.033 | 0.724±.036 | 0.789±.041 | 0.438±.022 | 0.487±.025 | 0.531±.028 | 0.589±.032 | 0.834±.038 | 0.897±.042 | 0.956±.045 | 1.021±.049 |
| 0.578±.027 | 0.623±.031 | 0.664±.034 | 0.719±.038 | 0.561±.029 | 0.604±.032 | 0.645±.035 | 0.697±.039 | 0.513±.026 | 0.558±.030 | 0.599±.033 | 0.651±.037 | 0.401±.021 | 0.438±.024 | 0.473±.027 | 0.521±.031 | 0.612±.031 | 0.658±.035 | 0.701±.038 | 0.754±.042 | |
| Informer | 0.698±.029 | 0.761±.036 | 0.812±.039 | 0.881±.045 | 0.671±.033 | 0.729±.037 | 0.779±.040 | 0.842±.043 | 0.587±.027 | 0.644±.031 | 0.695±.035 | 0.758±.039 | 0.421±.021 | 0.468±.024 | 0.509±.027 | 0.564±.030 | 0.801±.036 | 0.863±.040 | 0.921±.043 | 0.985±.047 |
| 0.556±.026 | 0.601±.030 | 0.641±.033 | 0.694±.037 | 0.539±.028 | 0.582±.031 | 0.622±.034 | 0.672±.037 | 0.491±.025 | 0.535±.029 | 0.575±.032 | 0.625±.036 | 0.384±.020 | 0.421±.023 | 0.455±.026 | 0.502±.029 | 0.587±.030 | 0.632±.034 | 0.674±.037 | 0.725±.040 | |
| Autoformer | 0.671±.028 | 0.733±.035 | 0.783±.038 | 0.849±.043 | 0.645±.032 | 0.702±.036 | 0.751±.039 | 0.813±.042 | 0.561±.026 | 0.617±.030 | 0.667±.034 | 0.728±.038 | 0.403±.020 | 0.449±.023 | 0.489±.026 | 0.542±.029 | 0.773±.035 | 0.834±.039 | 0.891±.042 | 0.954±.046 |
| 0.534±.025 | 0.578±.029 | 0.617±.032 | 0.668±.036 | 0.517±.027 | 0.560±.030 | 0.599±.033 | 0.648±.036 | 0.469±.024 | 0.512±.028 | 0.551±.031 | 0.599±.035 | 0.367±.019 | 0.403±.022 | 0.436±.025 | 0.481±.028 | 0.561±.029 | 0.605±.033 | 0.646±.036 | 0.695±.039 | |
| FEDformer | 0.644±.027 | 0.706±.034 | 0.756±.037 | 0.821±.041 | 0.618±.031 | 0.675±.035 | 0.724±.038 | 0.785±.041 | 0.534±.025 | 0.590±.029 | 0.639±.033 | 0.698±.037 | 0.385±.019 | 0.431±.022 | 0.471±.025 | 0.523±.028 | 0.745±.034 | 0.806±.038 | 0.863±.041 | 0.925±.045 |
| 0.511±.024 | 0.555±.028 | 0.593±.031 | 0.642±.035 | 0.495±.026 | 0.538±.029 | 0.577±.032 | 0.625±.035 | 0.447±.023 | 0.489±.027 | 0.528±.030 | 0.574±.034 | 0.349±.018 | 0.385±.021 | 0.418±.024 | 0.462±.027 | 0.535±.028 | 0.579±.032 | 0.619±.035 | 0.667±.038 | |
| DLinear | 0.617±.026 | 0.679±.033 | 0.729±.036 | 0.794±.040 | 0.591±.030 | 0.648±.034 | 0.697±.037 | 0.758±.040 | 0.507±.024 | 0.563±.028 | 0.612±.032 | 0.671±.036 | 0.367±.018 | 0.413±.021 | 0.453±.024 | 0.505±.027 | 0.718±.033 | 0.779±.037 | 0.836±.040 | 0.898±.044 |
| 0.488±.023 | 0.532±.027 | 0.569±.030 | 0.616±.034 | 0.473±.025 | 0.516±.028 | 0.555±.031 | 0.602±.034 | 0.425±.022 | 0.466±.026 | 0.504±.029 | 0.549±.033 | 0.331±.017 | 0.367±.020 | 0.400±.023 | 0.443±.026 | 0.509±.027 | 0.553±.031 | 0.593±.034 | 0.641±.037 | |
| PatchTST | 0.589±.025 | 0.651±.032 | 0.701±.035 | 0.766±.039 | 0.564±.029 | 0.621±.033 | 0.670±.036 | 0.731±.039 | 0.481±.023 | 0.537±.027 | 0.586±.031 | 0.645±.035 | 0.349±.017 | 0.395±.020 | 0.435±.023 | 0.487±.026 | 0.691±.032 | 0.752±.036 | 0.809±.039 | 0.871±.043 |
| 0.461±.022 | 0.505±.026 | 0.542±.029 | 0.589±.033 | 0.446±.024 | 0.489±.027 | 0.528±.030 | 0.575±.033 | 0.399±.021 | 0.440±.025 | 0.478±.028 | 0.523±.032 | 0.313±.016 | 0.349±.019 | 0.382±.022 | 0.425±.025 | 0.483±.026 | 0.527±.030 | 0.567±.033 | 0.615±.036 | |
| TimesNet | 0.605±.026 | 0.667±.033 | 0.717±.036 | 0.782±.040 | 0.578±.030 | 0.635±.034 | 0.684±.037 | 0.745±.040 | 0.495±.024 | 0.551±.028 | 0.600±.032 | 0.659±.036 | 0.361±.018 | 0.407±.021 | 0.447±.024 | 0.499±.027 | 0.707±.033 | 0.768±.037 | 0.825±.040 | 0.887±.044 |
| 0.477±.023 | 0.521±.027 | 0.558±.030 | 0.605±.034 | 0.461±.025 | 0.504±.028 | 0.543±.031 | 0.590±.034 | 0.413±.022 | 0.454±.026 | 0.492±.029 | 0.537±.033 | 0.325±.017 | 0.361±.020 | 0.394±.023 | 0.437±.026 | 0.497±.027 | 0.541±.031 | 0.581±.034 | 0.629±.037 | |
| MoE-Trans | 0.631±.027 | 0.693±.034 | 0.743±.037 | 0.808±.041 | 0.604±.031 | 0.661±.035 | 0.710±.038 | 0.771±.041 | 0.521±.025 | 0.577±.029 | 0.626±.033 | 0.685±.037 | 0.379±.019 | 0.425±.022 | 0.465±.025 | 0.517±.028 | 0.732±.034 | 0.793±.038 | 0.850±.041 | 0.912±.045 |
| 0.503±.024 | 0.547±.028 | 0.585±.031 | 0.632±.035 | 0.487±.026 | 0.530±.029 | 0.569±.032 | 0.616±.035 | 0.437±.023 | 0.478±.027 | 0.516±.030 | 0.562±.034 | 0.343±.018 | 0.379±.021 | 0.412±.024 | 0.455±.027 | 0.523±.028 | 0.567±.032 | 0.607±.035 | 0.655±.038 | |
| Ours (N=30) | 0.271±.012 | 0.305±.014 | 0.339±.016 | 0.381±.018 | 0.255±.013 | 0.290±.015 | 0.326±.017 | 0.370±.019 | 0.218±.011 | 0.253±.013 | 0.289±.015 | 0.334±.017 | 0.155±.008 | 0.182±.010 | 0.211±.011 | 0.247±.013 | 0.305±.015 | 0.346±.017 | 0.388±.019 | 0.440±.022 |
| 0.312±.015 | 0.348±.017 | 0.384±.019 | 0.430±.021 | 0.294±.015 | 0.330±.017 | 0.367±.019 | 0.413±.021 | 0.273±.014 | 0.308±.016 | 0.344±.018 | 0.389±.020 | 0.227±.012 | 0.260±.014 | 0.292±.015 | 0.333±.017 | 0.348±.018 | 0.389±.020 | 0.432±.022 | 0.484±.024 | |
| Improv. | 54.0% | 53.1% | 51.6% | 50.3% | 54.8% | 53.3% | 51.3% | 49.4% | 54.7% | 52.9% | 50.7% | 48.2% | 55.6% | 53.9% | 51.5% | 49.3% | 55.9% | 54.0% | 52.0% | 49.5% |
Table 7.
Performance comparison with N=40 experts across five long-term forecasting datasets. Results are reported as MSE/MAE (mean±std) over 5 independent runs. Best results are bolded, second best are underlined. Lower is better.
Table 7.
Performance comparison with N=40 experts across five long-term forecasting datasets. Results are reported as MSE/MAE (mean±std) over 5 independent runs. Best results are bolded, second best are underlined. Lower is better.
| Models | ETTh1 | ETTm1 | Weather | Electricity | Traffic | |||||||||||||||
| 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | 96 | 192 | 336 | 720 | |
| Transformer | 0.725±.031 | 0.789±.038 | 0.841±.042 | 0.912±.048 | 0.698±.035 | 0.756±.039 | 0.808±.041 | 0.873±.045 | 0.612±.028 | 0.671±.033 | 0.724±.036 | 0.789±.041 | 0.438±.022 | 0.487±.025 | 0.531±.028 | 0.589±.032 | 0.834±.038 | 0.897±.042 | 0.956±.045 | 1.021±.049 |
| 0.578±.027 | 0.623±.031 | 0.664±.034 | 0.719±.038 | 0.561±.029 | 0.604±.032 | 0.645±.035 | 0.697±.039 | 0.513±.026 | 0.558±.030 | 0.599±.033 | 0.651±.037 | 0.401±.021 | 0.438±.024 | 0.473±.027 | 0.521±.031 | 0.612±.031 | 0.658±.035 | 0.701±.038 | 0.754±.042 | |
| Informer | 0.698±.029 | 0.761±.036 | 0.812±.039 | 0.881±.045 | 0.671±.033 | 0.729±.037 | 0.779±.040 | 0.842±.043 | 0.587±.027 | 0.644±.031 | 0.695±.035 | 0.758±.039 | 0.421±.021 | 0.468±.024 | 0.509±.027 | 0.564±.030 | 0.801±.036 | 0.863±.040 | 0.921±.043 | 0.985±.047 |
| 0.556±.026 | 0.601±.030 | 0.641±.033 | 0.694±.037 | 0.539±.028 | 0.582±.031 | 0.622±.034 | 0.672±.037 | 0.491±.025 | 0.535±.029 | 0.575±.032 | 0.625±.036 | 0.384±.020 | 0.421±.023 | 0.455±.026 | 0.502±.029 | 0.587±.030 | 0.632±.034 | 0.674±.037 | 0.725±.040 | |
| Autoformer | 0.671±.028 | 0.733±.035 | 0.783±.038 | 0.849±.043 | 0.645±.032 | 0.702±.036 | 0.751±.039 | 0.813±.042 | 0.561±.026 | 0.617±.030 | 0.667±.034 | 0.728±.038 | 0.403±.020 | 0.449±.023 | 0.489±.026 | 0.542±.029 | 0.773±.035 | 0.834±.039 | 0.891±.042 | 0.954±.046 |
| 0.534±.025 | 0.578±.029 | 0.617±.032 | 0.668±.036 | 0.517±.027 | 0.560±.030 | 0.599±.033 | 0.648±.036 | 0.469±.024 | 0.512±.028 | 0.551±.031 | 0.599±.035 | 0.367±.019 | 0.403±.022 | 0.436±.025 | 0.481±.028 | 0.561±.029 | 0.605±.033 | 0.646±.036 | 0.695±.039 | |
| FEDformer | 0.644±.027 | 0.706±.034 | 0.756±.037 | 0.821±.041 | 0.618±.031 | 0.675±.035 | 0.724±.038 | 0.785±.041 | 0.534±.025 | 0.590±.029 | 0.639±.033 | 0.698±.037 | 0.385±.019 | 0.431±.022 | 0.471±.025 | 0.523±.028 | 0.745±.034 | 0.806±.038 | 0.863±.041 | 0.925±.045 |
| 0.511±.024 | 0.555±.028 | 0.593±.031 | 0.642±.035 | 0.495±.026 | 0.538±.029 | 0.577±.032 | 0.625±.035 | 0.447±.023 | 0.489±.027 | 0.528±.030 | 0.574±.034 | 0.349±.018 | 0.385±.021 | 0.418±.024 | 0.462±.027 | 0.535±.028 | 0.579±.032 | 0.619±.035 | 0.667±.038 | |
| DLinear | 0.617±.026 | 0.679±.033 | 0.729±.036 | 0.794±.040 | 0.591±.030 | 0.648±.034 | 0.697±.037 | 0.758±.040 | 0.507±.024 | 0.563±.028 | 0.612±.032 | 0.671±.036 | 0.367±.018 | 0.413±.021 | 0.453±.024 | 0.505±.027 | 0.718±.033 | 0.779±.037 | 0.836±.040 | 0.898±.044 |
| 0.488±.023 | 0.532±.027 | 0.569±.030 | 0.616±.034 | 0.473±.025 | 0.516±.028 | 0.555±.031 | 0.602±.034 | 0.425±.022 | 0.466±.026 | 0.504±.029 | 0.549±.033 | 0.331±.017 | 0.367±.020 | 0.400±.023 | 0.443±.026 | 0.509±.027 | 0.553±.031 | 0.593±.034 | 0.641±.037 | |
| PatchTST | 0.589±.025 | 0.651±.032 | 0.701±.035 | 0.766±.039 | 0.564±.029 | 0.621±.033 | 0.670±.036 | 0.731±.039 | 0.481±.023 | 0.537±.027 | 0.586±.031 | 0.645±.035 | 0.349±.017 | 0.395±.020 | 0.435±.023 | 0.487±.026 | 0.691±.032 | 0.752±.036 | 0.809±.039 | 0.871±.043 |
| 0.461±.022 | 0.505±.026 | 0.542±.029 | 0.589±.033 | 0.446±.024 | 0.489±.027 | 0.528±.030 | 0.575±.033 | 0.399±.021 | 0.440±.025 | 0.478±.028 | 0.523±.032 | 0.313±.016 | 0.349±.019 | 0.382±.022 | 0.425±.025 | 0.483±.026 | 0.527±.030 | 0.567±.033 | 0.615±.036 | |
| TimesNet | 0.605±.026 | 0.667±.033 | 0.717±.036 | 0.782±.040 | 0.578±.030 | 0.635±.034 | 0.684±.037 | 0.745±.040 | 0.495±.024 | 0.551±.028 | 0.600±.032 | 0.659±.036 | 0.361±.018 | 0.407±.021 | 0.447±.024 | 0.499±.027 | 0.707±.033 | 0.768±.037 | 0.825±.040 | 0.887±.044 |
| 0.477±.023 | 0.521±.027 | 0.558±.030 | 0.605±.034 | 0.461±.025 | 0.504±.028 | 0.543±.031 | 0.590±.034 | 0.413±.022 | 0.454±.026 | 0.492±.029 | 0.537±.033 | 0.325±.017 | 0.361±.020 | 0.394±.023 | 0.437±.026 | 0.497±.027 | 0.541±.031 | 0.581±.034 | 0.629±.037 | |
| MoE-Trans | 0.631±.027 | 0.693±.034 | 0.743±.037 | 0.808±.041 | 0.604±.031 | 0.661±.035 | 0.710±.038 | 0.771±.041 | 0.521±.025 | 0.577±.029 | 0.626±.033 | 0.685±.037 | 0.379±.019 | 0.425±.022 | 0.465±.025 | 0.517±.028 | 0.732±.034 | 0.793±.038 | 0.850±.041 | 0.912±.045 |
| 0.503±.024 | 0.547±.028 | 0.585±.031 | 0.632±.035 | 0.487±.026 | 0.530±.029 | 0.569±.032 | 0.616±.035 | 0.437±.023 | 0.478±.027 | 0.516±.030 | 0.562±.034 | 0.343±.018 | 0.379±.021 | 0.412±.024 | 0.455±.027 | 0.523±.028 | 0.567±.032 | 0.607±.035 | 0.655±.038 | |
| Ours (N=40) | 0.267±.011 | 0.301±.013 | 0.334±.015 | 0.376±.017 | 0.251±.012 | 0.286±.014 | 0.321±.016 | 0.365±.018 | 0.213±.010 | 0.248±.012 | 0.284±.014 | 0.329±.016 | 0.152±.008 | 0.179±.009 | 0.207±.011 | 0.243±.013 | 0.298±.014 | 0.339±.016 | 0.381±.018 | 0.432±.021 |
| 0.307±.014 | 0.343±.016 | 0.379±.018 | 0.425±.021 | 0.289±.014 | 0.325±.016 | 0.362±.018 | 0.408±.020 | 0.268±.013 | 0.303±.015 | 0.339±.017 | 0.384±.019 | 0.223±.011 | 0.255±.013 | 0.287±.015 | 0.328±.017 | 0.341±.017 | 0.382±.019 | 0.424±.021 | 0.476±.024 | |
| Improv. | 54.7% | 53.8% | 52.4% | 50.9% | 55.5% | 53.9% | 52.1% | 50.1% | 55.7% | 53.8% | 51.5% | 49.0% | 56.4% | 54.7% | 52.4% | 50.1% | 56.9% | 54.9% | 52.9% | 50.4% |
Table 8.
Ablation studies on framework components. Results reported as MSE±std (lower is better) on horizon 96 across five datasets. F-Block: Frequency Transformer with F-MoE. T-Block: Time Transformer with T-MoE. ExtDFT: Extended DFT. RL: RL-based routing. Ens.: Adaptive ensemble weighting.
Table 8.
Ablation studies on framework components. Results reported as MSE±std (lower is better) on horizon 96 across five datasets. F-Block: Frequency Transformer with F-MoE. T-Block: Time Transformer with T-MoE. ExtDFT: Extended DFT. RL: RL-based routing. Ens.: Adaptive ensemble weighting.
| F-Block | T-Block | ExtDFT | RL | Ens. | ETTh1 | ETTm1 | Weather | Electricity | Traffic |
|---|---|---|---|---|---|---|---|---|---|
| √ | 0.521±.024 | 0.498±.025 | 0.437±.021 | 0.312±.016 | 0.628±.030 | ||||
| √ | √ | 0.549±.026 | 0.527±.027 | 0.461±.023 | 0.335±.017 | 0.604±.029 | |||
| √ | 0.573±.028 | 0.551±.029 | 0.479±.024 | 0.348±.018 | 0.617±.030 | ||||
| √ | √ | 0.497±.023 | 0.475±.024 | 0.421±.020 | 0.301±.015 | 0.611±.029 | |||
| √ | √ | √ | 0.468±.022 | 0.447±.023 | 0.398±.019 | 0.285±.014 | 0.587±.028 | ||
| √ | √ | √ | 0.483±.023 | 0.461±.024 | 0.409±.020 | 0.293±.015 | 0.598±.029 | ||
| √ | √ | √ | 0.489±.023 | 0.467±.024 | 0.413±.020 | 0.296±.015 | 0.603±.029 | ||
| √ | √ | √ | √ | 0.453±.021 | 0.432±.022 | 0.385±.018 | 0.276±.014 | 0.573±.027 | |
| √ | √ | √ | √ | 0.387±.018 | 0.367±.019 | 0.331±.016 | 0.239±.012 | 0.501±.024 | |
| Fixed FFN | √ | √ | √ | 0.453±.021 | 0.432±.022 | 0.385±.018 | 0.276±.014 | 0.573±.027 | |
| Softmax Gating | √ | √ | √ | √ | 0.441±.021 | 0.421±.021 | 0.376±.018 | 0.270±.013 | 0.564±.027 |
| Top-1 Gating | √ | √ | √ | √ | 0.449±.021 | 0.429±.022 | 0.382±.018 | 0.273±.014 | 0.569±.027 |
| Noisy Top-k Gating | √ | √ | √ | √ | 0.445±.021 | 0.425±.022 | 0.379±.018 | 0.271±.013 | 0.566±.027 |
| Full Model (RL Routing) | √ | √ | √ | √ | 0.267±.011 | 0.251±.012 | 0.213±.010 | 0.152±.008 | 0.298±.014 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



