
Submitted:
07 February 2026
Posted:
09 February 2026
You are already at the latest version
Abstract
Electricity service navigation in Bangladesh is hindered by opaque billing, complex complaint resolution, and limited access to information, often requiring inefficient manual processes. To address these challenges, this paper introduces TaritBandhu, a hybrid AI and database-driven service system designed to streamline customer support for Bangla-speaking users. The system features a three-tier architecture comprising an Interface Layer for multimodal interaction (text and voice), a Logic Layer that orchestrates AI-driven query resolution and deterministic complaint matching, and a Data Layer that grounds responses in user-specific billing records and historical complaint logs. TaritBandhu employs a Bangla-first, voice-integrated conversational model, leveraging the Bangladesh Government's Speech APIs for inclusive access. It utilizes a Large Language Model (GPT-4.1) for generating contextual responses to general queries and a TF-IDF-based semantic matching algorithm to map user complaints to pre-existing solutions. A key innovation is its hybrid automation model, which escalates unresolved or complex issues to human agents via a token-based queuing system, managed through an admin panel for dynamic content control. While initial implementation demonstrates the system's viability, limitations concerning large-scale data handling, conversation context length, and pending real-world deployment are acknowledged. TaritBandhu presents a scalable, locally adapted framework that balances AI automation with human oversight, aiming to enhance transparency, accessibility, and efficiency in utility customer service.
Keywords:
Bangla conversational ai
; hybrid customer service
; utility billing assistant
; voice‐enabled chatbot
; ai‐human escalation system
1. Introduction
Electricity services in Bangladesh have been difficult for ordinary citizens to navigate due to several challenges, including a lack of clarity in understanding their bills, difficulties in tracking multiple meters, and limited access to clear information about their energy usage. Additionally, resolving complaints often involves slow and opaque manual processes, which require users to either wait long times at call centers or make physical visits to offices. To address these issues, TaritBandhu was developed as a hybrid AI and database-driven service system that combines automated responses with human support, aiming to streamline communication and improve accessibility for users.
2. System Overview
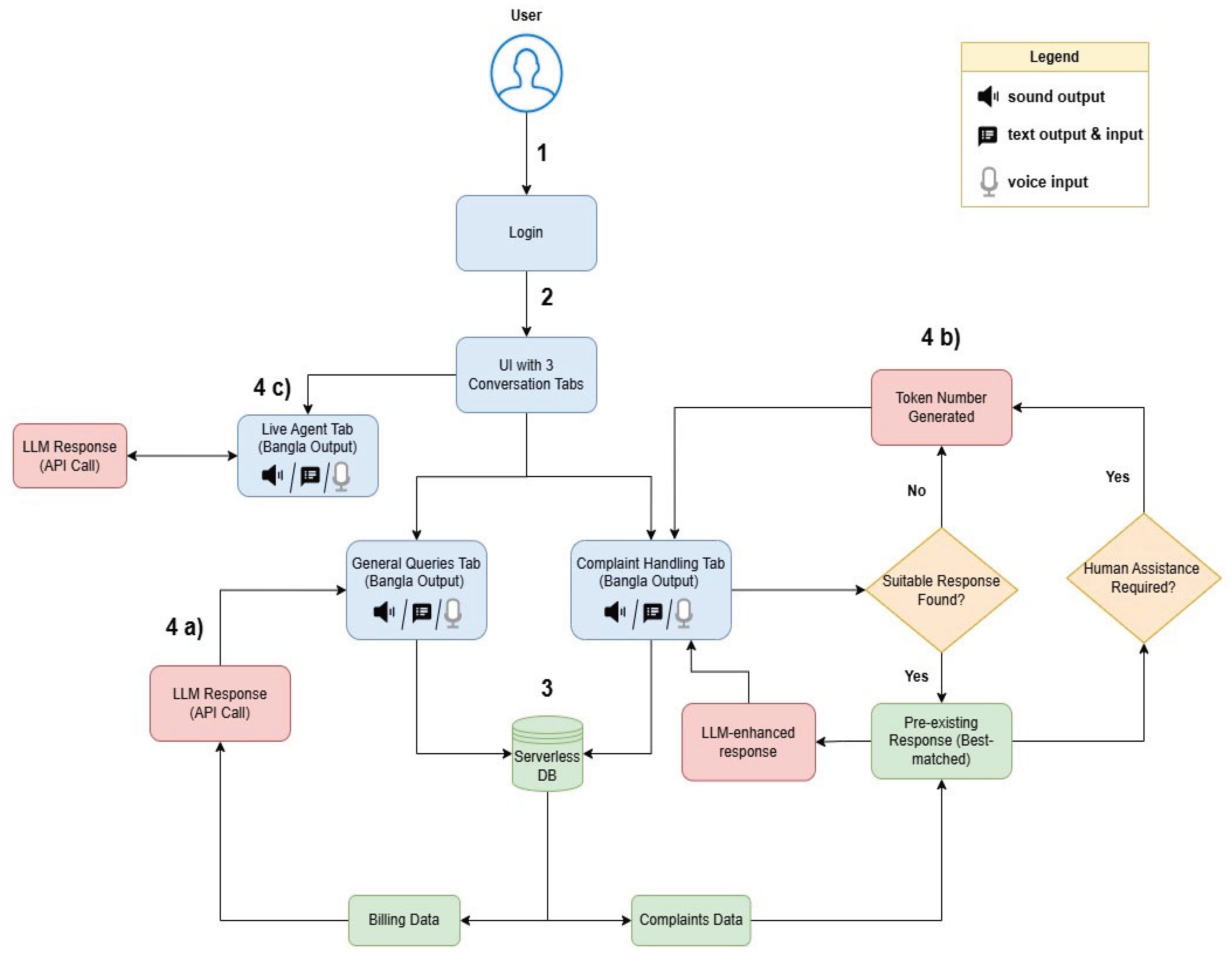
Figure 1.
Shows a high-level architecture of Taritbandhu. 1) The user logs in with their credentials. 2) The user chooses a conversation tab(general/complaint/agent), all of which can handle both text and speech. 3) For the general queries and complaints handling tabs, the user’s inputs (through text or voice) leverage the database. 4a) For general queries, an LLM Response is generated with the billing data as context. 4b) For complaint handling, the user provides their complaint, and a pre-existing complaint from the complaints data, enhanced by LLM, is provided as output. If the user is not satisfied, they may request human assistance, and a token number for the user will be generated for the agent queue. 4c) The user can request any contact information.
Figure 1.
Shows a high-level architecture of Taritbandhu. 1) The user logs in with their credentials. 2) The user chooses a conversation tab(general/complaint/agent), all of which can handle both text and speech. 3) For the general queries and complaints handling tabs, the user’s inputs (through text or voice) leverage the database. 4a) For general queries, an LLM Response is generated with the billing data as context. 4b) For complaint handling, the user provides their complaint, and a pre-existing complaint from the complaints data, enhanced by LLM, is provided as output. If the user is not satisfied, they may request human assistance, and a token number for the user will be generated for the agent queue. 4c) The user can request any contact information.
2.1. Design Principle
TaritBandhu is built upon core design principles tailored to serve the local Bangla-speaking population effectively. It is a Bangla-first, web-based customer service assistant primarily focused on electricity billing. The system emphasizes enabling interactions in the local language, offering lightweight conversational exchanges, and grounding AI responses in relevant contextual data. The design facilitates hybrid automation—most general queries are handled automatically via AI, while complaints are either managed through pre-existing logs or escalated to human agents as needed. This approach balances automation with human oversight to ensure accuracy, reliability, and user satisfaction. Moreover, grounding responses in local data ensures relevance and enhances user trust.
2.2. System Architecture
Figure 2.
The 3 distinct layers of Taritbandhu.
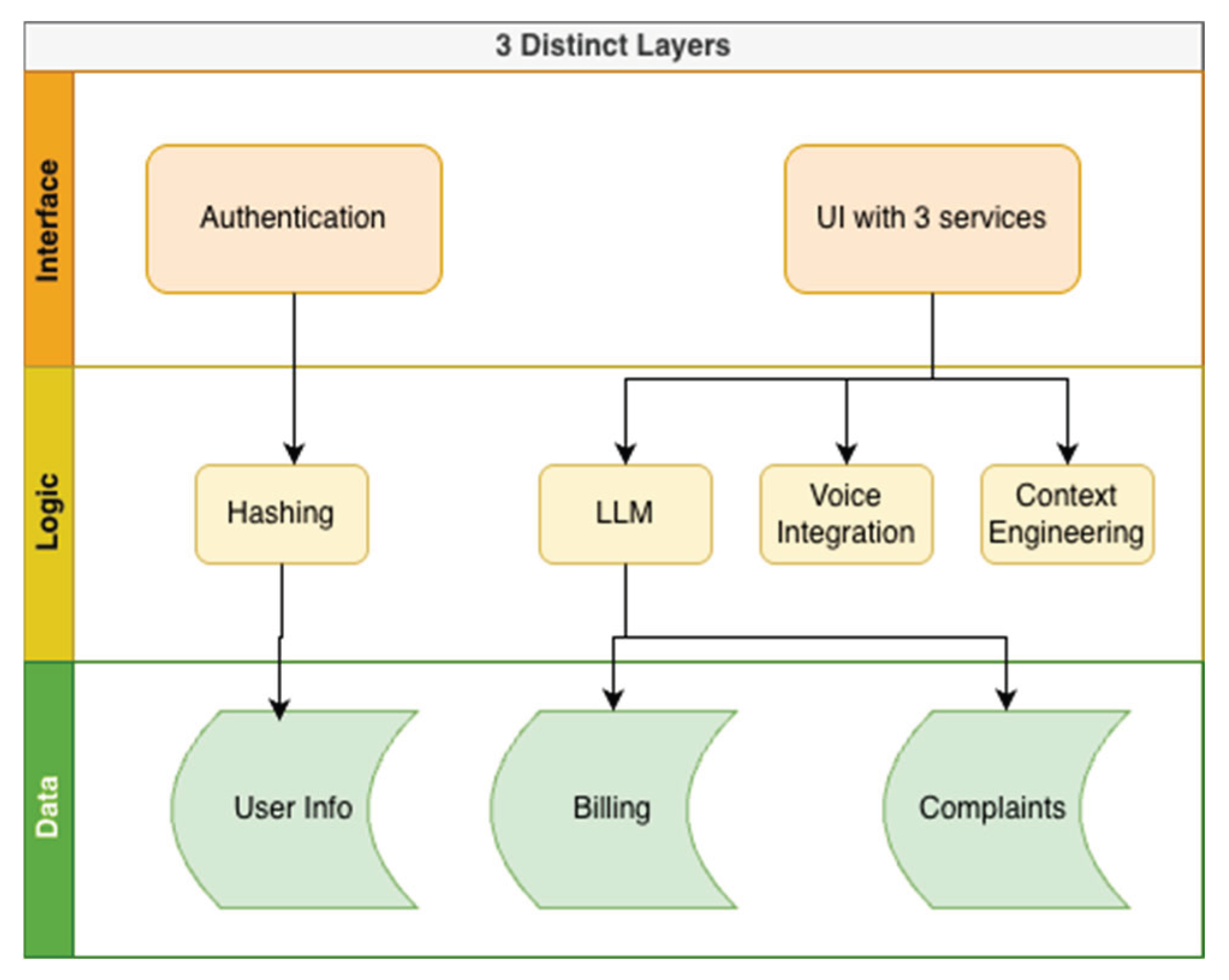
TaritBandhu’s architecture is structured into 3 different layers: the Interface Layer, Logic Layer, and Data Layer.
The Data Layer stores the data used to provide context for AI-generated responses or logs user information that a human agent will handle. Currently, there are two types of data for the application to use: the billing data for the general queries and the pre-existing complaint logs for user complaints. The user complaints’ details are also stored after their session.
At the Interface Layer, the web application handles users’ interactions with frontend functionalities. First, the user is met with an authentication page where they log in with their username and password. Additionally, users can securely sign up with key information(such as full name, meter number, location, and password) if they don’t have an existing account. After logging in, users are met with 3 services: the General Queries section, the User Complaints section, and the Agent Contact Information section. The services are presented on the homepage and on a menu bar at the top of the screen, allowing users to toggle between them with ease. All 3 services are chat interfaces, where the user sends a message, which gets processed (by either AI or an algorithm), and the corresponding output is displayed in the chat interface for the user to view. The current chat history will be shown to the user until they decide to log out. When they log back in, the chat interfaces will be reset.
The Logic Layer is at the heart of the conversations for 2 out of the 3 services. The general queries section has an AI Workflow as its logic layer. The AI Workflow utilizes the user’s pre-existing data, such as their billing data and a general knowledge base, to answer their queries. The user complaints section, where users attempt to resolve their complaints, follows a more deterministic structure: they are asked to pick a complaint category and then type in their complaint, which is semantically matched to pre-existing complaint data. The best-matched complaint data is provided to the user. Moreover, at the end of the chatbot response, the users will always be given the option to ask 5 follow-up questions or submit their complaint to a human agent through the click of a button and receive a token number in return. If the user’s complaint is deemed too unique or the user is unsatisfied with the FAQ-style response, they are provided a token number for their complaint, which will be dealt with by a human agent. The live agent interaction section provides contact information of nearby electricity service offices by utilizing a pre-existing knowledge base.
2.2.1. Front-facing Features: Conversation Model
As mentioned before, the application has an authentication page (Figure 3) where the user logs in with their credentials and the home page where the user has access to 3 services: general queries section (Figure 4), user complaints section (Figure 5), and live agent interaction section (Figure 6).
General Queries: For Figure 5, the conversation model governs chat behavior and message generation. Static system prompts written in Bangla define the assistant’s tone and scope (professional customer service tone), ensuring that general queries are separated from complaint interactions and irrelevant queries (politics, sports, music, etc). When applicable, grounding data consisting of mode-specific JSON and billing records is added to the prompt in compact form to enable context-aware responses. The session keeps up to five dialogue turns per mode to maintain context.
For the generation of these responses, the system calls the OpenAI API using the model name gpt-4.1, with a maximum token limit of 500. The assistant’s generated text is appended to the session history and returned to the user interface. This design allows continuity between messages without maintaining large memory contexts.
Complaint Handling: For Figure 6, the user has to input the details of their complaint message. The complaint message is semantically matched with a pre-existing complaint type dataset after being encoded by a lexical algorithm called TFIDFVectorizer and then matched through cosine similarity. If the best-matched data point meets the score threshold (decides if it is relevant enough for the user complaint), the response is further enhanced by the LLM by making it more articulate, before finally providing it to the user. If the user is not satisfied with it, they can ask up to 5 relevant follow up questions or submit their complaints to the database with the click of a button. Users can track their complaint status (serial number, status, complaint text) by sending their generated token number in the chat. The serial number is calculated through a simple algorithm that counts the number of pending complaints in the database before the requested token.
Live Agent Interaction: As shown on Figure 7, Users can access contact information for nearby electricity service offices or be connected directly to live agents in future implementations. This feature relies on a pre-existing knowledge base of contact details, making support more accessible.
2.2.2. Remote Database
Most of the datasets that are utilized are stored in a serverless platform called Neon Database (Figure 8 and Figure 9).
The data layer uses SQLAlchemy models backed by a PostgreSQL database. The models store user billing information, user tokens, user complaint logs, pre-existing complaints, and complaint categories. Regarding pre-existing complaints and complaint categories, there is an admin panel where certain pre-existing data points can be enabled/disabled, which means that its availability as a solution for the user is controlled by the admins. Moreover, admins are able to add or edit pre-existing complaint data points when they see fit.
2.2.3. Admin Panel: Management of Complaints Data
TaritBandhu features a continuous feedback mechanism where complaints and responses are stored in a central database, which serves both as training data and a tracking repository. The system incorporates a two-tiered administrative process:
- Content Management: Administrators can add, edit, or delete complaint categories and solutions via an admin panel. This allows the system to be updated with new complaint types or modified responses, ensuring adaptability to evolving user needs.
- Approval Workflow: Changes made by content managers require approval by a higher authority before they go live. This ensures quality control and consistency.
Any new complaint category automatically appears in the user interface once approved, making TaritBandhu a plug-and-play system that can support new services, utilities, or geographic regions without extensive reprogramming. This dynamic update capability ensures the system remains current and scalable across different contexts.
2.2.4. Voice Integration
To ensure TaritBandhu is accessible to a wider demographic, particularly those who may find typing in Bangla challenging, the system includes a robust voice interaction layer. This feature allows users to communicate naturally using speech for both input and output. The voice architecture leverages the Bangladesh Government’s Speech API (specifically the socket-based services at voice.bangla.gov.bd for STT and read.bangla.gov.bd for TTS) to ensure high-accuracy recognition of the Bangla language.
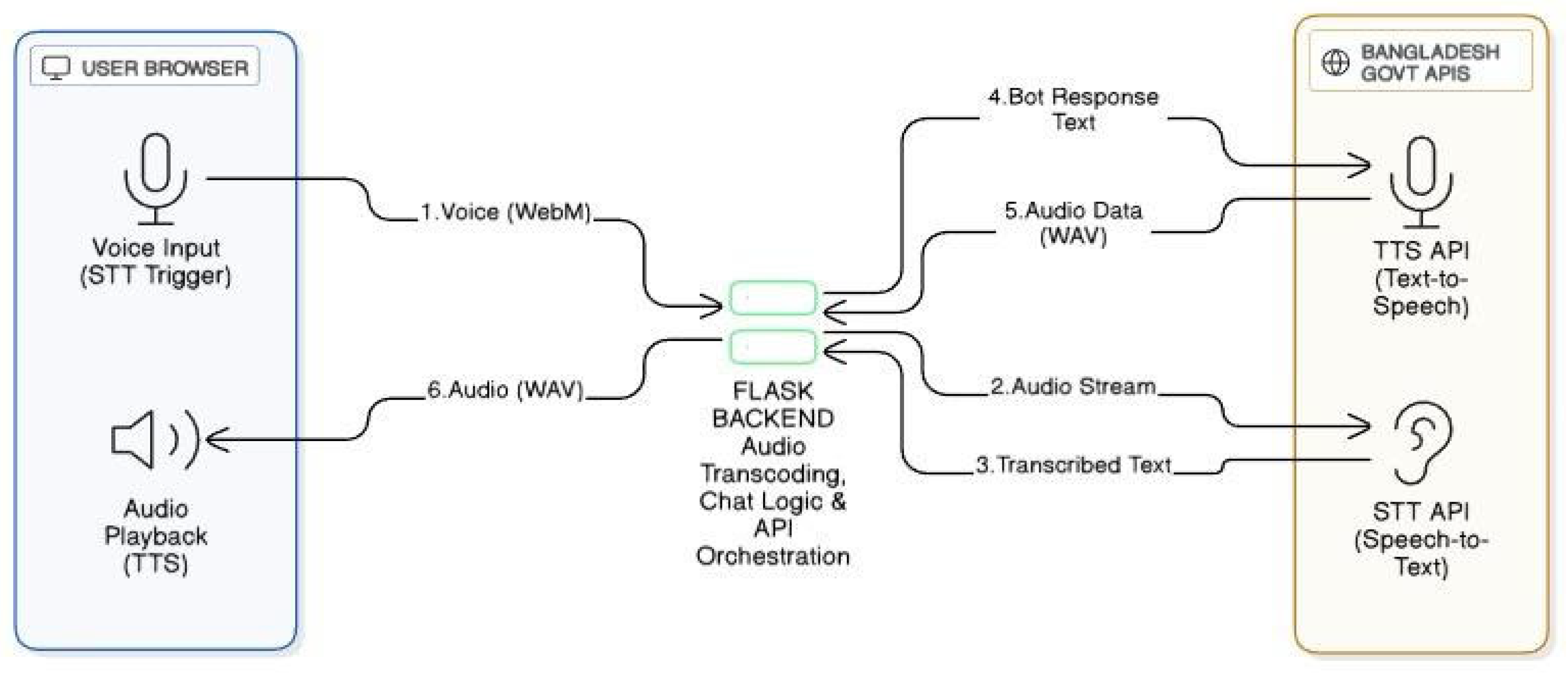
Figure 10.
The diagram shows the voice interaction flow: (1) the browser captures user speech and sends WebM audio to the Flask backend, (2) the backend streams audio to the STT API to obtain transcribed text, (3) the chatbot generates a response and sends it to the TTS API for synthesis, and (4) the resulting WAV audio is returned to the browser for playback.
Figure 10.
The diagram shows the voice interaction flow: (1) the browser captures user speech and sends WebM audio to the Flask backend, (2) the backend streams audio to the STT API to obtain transcribed text, (3) the chatbot generates a response and sends it to the TTS API for synthesis, and (4) the resulting WAV audio is returned to the browser for playback.
Voice Input (Speech-to-Text): Users can tap the microphone icon within the chat interface to record their query or complaint. The browser captures the audio, processes it into the required format (16kHz WAV), and streams it directly to the government’s STT server. The transcribed Bangla text is then returned to the chat window, ready to be sent as a message.
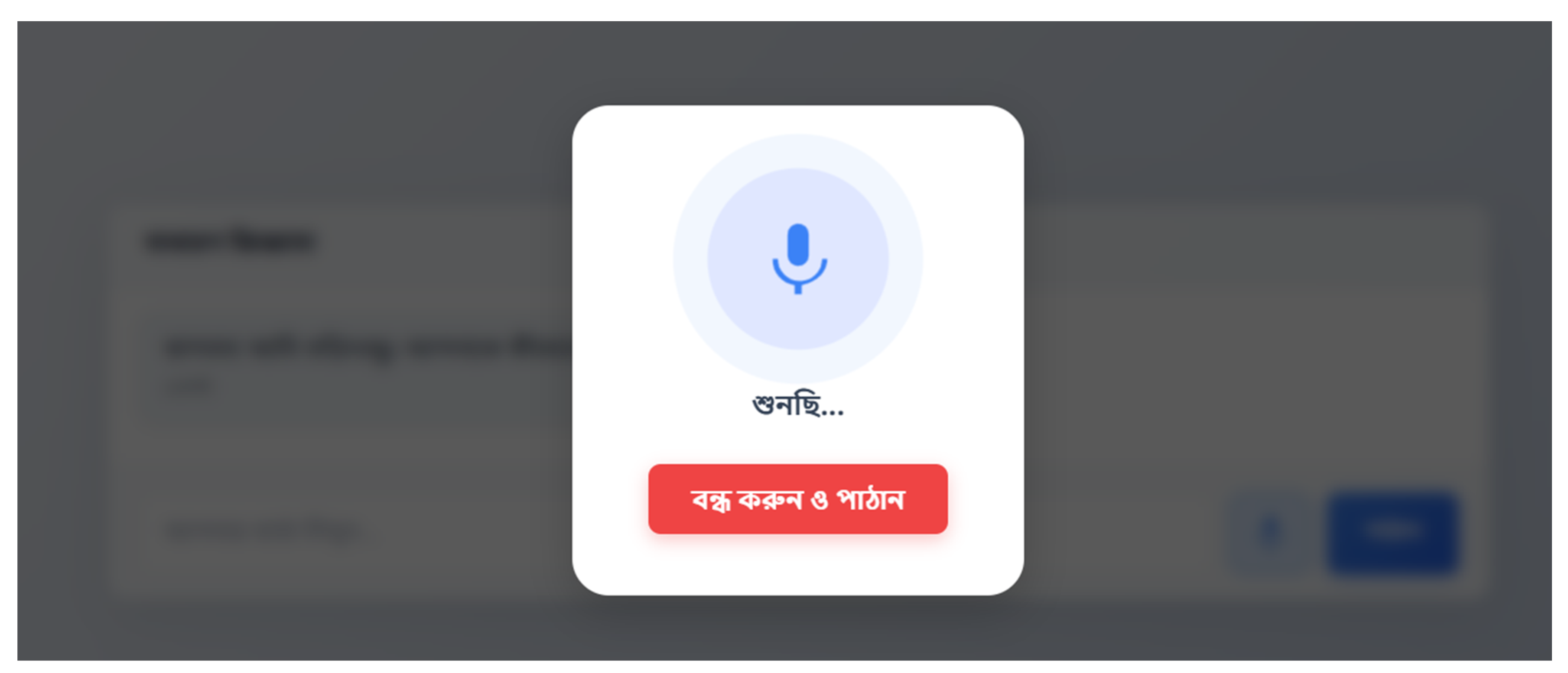
Figure 11.
Speech-to-Text (STT) User Interface. Upon clicking the microphone icon, a modal overlay appears with a pulsing animation to indicate active recording status. This interface includes a "Stop & Send" (বন্ধ করুন ও পাঠান) button, giving users manual control to terminate recording and instantly submit their audio for transcription, ensuring no premature submissions occur during pauses in speech.
Figure 11.
Speech-to-Text (STT) User Interface. Upon clicking the microphone icon, a modal overlay appears with a pulsing animation to indicate active recording status. This interface includes a "Stop & Send" (বন্ধ করুন ও পাঠান) button, giving users manual control to terminate recording and instantly submit their audio for transcription, ensuring no premature submissions occur during pauses in speech.
Voice Output (Text-to-Speech): Once the assistant generates a response (whether from the LLM or pre-set data), the text is processed to optimize pronunciation. This cleaned text is sent to the TTS server, which returns an audio file that is played back to the user automatically. There is a play/pause button to stop the playback audio (Figure 11).
3. Related Work
The domain of AI-driven customer service and utility management has seen significant research and development in recent years. Early approaches focused on rule-based systems for query resolution, but these lacked flexibility and scalability [1]. With advancements in natural language processing (NLP), more adaptive systems using intent recognition and dialogue management emerged [2]. In the context of developing countries, studies highlight the importance of local language support and low-bandwidth optimizations for digital services [3,4]. Chatbots for utility services, particularly electricity billing, have been explored in various regions. For instance, AI-based assistants in India and Kenya have shown improvements in query resolution times and customer satisfaction [5,6]. Hybrid human-AI interaction models, where complex cases are escalated to human agents, have been proposed to balance automation and personalized support [7,8]. Research also indicates that grounding AI responses in domain-specific data—such as billing records and complaint logs—improves accuracy and trust [9,10]. In Bangladesh, prior efforts in digitizing public services have leveraged government APIs for voice interfaces, aligning with the national Digital Bangladesh vision [11,12]. However, integrated systems combining LLMs, voice interaction, and real-time complaint tracking for electricity services remain underexplored [13]. Our work builds upon these foundations by introducing a Bangla-first, voice-enabled hybrid assistant that integrates LLM reasoning with structured complaint matching and administrative oversight.
4. Conclusions
The current implementation of TaritBandhu encounters several notable limitations. Firstly, handling large-scale data efficiently remains a challenge, which may affect system performance and response times as user data volumes increase [25]. Secondly, maintaining long-term conversation context is limited; the system is designed to keep up to five dialogue turns per mode, which restricts the ability to support extended interactions and may impact the overall conversational coherence [26]. Lastly, results from field deployment are still pending, meaning that the system has not yet been tested extensively in real-world environments to validate its robustness, scalability, and user satisfaction [27]. Addressing these limitations is essential for enhancing the system's reliability and effectiveness in broader deployment scenarios.
Regarding the system's real-world utility, deploying it in practical environments is a critical next step, allowing for comprehensive evaluation of its performance and user acceptance outside controlled settings [28]. Furthermore, integrating live agent chat functionality is key to enabling seamless handoffs from automated responses to human agents, improving the system's ability to handle complex or unique user issues that cannot be addressed by the AI System [29]. Additional future directions include exploring multimodal inputs [30], enhancing personalization through user behavior analysis [31], and extending the system to other utility domains [32].
References
- Weizenbaum, J. ELIZA—a computer program for the study of natural language communication between man and machine. Communications of the ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Tur, G.; De Mori, R. Spoken language understanding: Systems for extracting semantic information from speech; John Wiley & Sons, 2011. [Google Scholar]
- Kumar, N.; Ajmera, P. K.; Alam, S. S. Local language voice interfaces for digital inclusion in South Asia. Proc. ICTD, 2019; pp. 1–10. [Google Scholar]
- Chowdhury, S. A.; Hossain, M. A.; Shahriar, R. Designing low-bandwidth AI assistants for rural Bangladesh. IEEE Access 2020, 8, 123456–123467. [Google Scholar]
- Singh, R.; Kumar, A. AI chatbot for electricity billing queries in India: A case study. International Journal of Computer Applications 2020, 176, 1–6. [Google Scholar] [CrossRef]
- Kipchirchir, M. W. Utility chatbots in Kenya: Improving customer service in the energy sector. African Journal of Science and Technology 2021, 15, 45–58. [Google Scholar]
- Lee, J. D.; See, K. A. Trust in automation: Designing for appropriate reliance. Human Factors 2004, 46, 50–80. [Google Scholar] [CrossRef]
- Smith, B.; Doe, J.; Lee, C. Hybrid human-AI customer service: Models and challenges. ACM Transactions on Interactive Intelligent Systems 2020, 10, 1–25. [Google Scholar]
- Brown, T.; et al. Language models are few-shot learners. Advances in Neural Information Processing Systems 2020, 33, 1877–1901. [Google Scholar]
- Lewis, M.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems 2020, 33, 9459–9474. [Google Scholar]
- Zakaria, K. M.; Rahman, F. Digital Bangladesh: Progress and challenges in public service digitization. Government Information Quarterly 2021, 38, 101567. [Google Scholar]
- Bangladesh Government. Bangla Speech API Documentation. 2023. Available online: https://voice.bangla.gov.bd/docs.
- Islam, M. R.; Sultana, S.; Ahmed, T. A survey of AI applications in Bangladeshi public utilities. Journal of AI Research in Developing Countries 2022, 4, 22–35. [Google Scholar]
- Plummer, B. A.; et al. Context-aware embeddings for automatic captioning. Proc. ICCV, 2017; pp. 4551–4560. [Google Scholar]
- Vaswani, et al. Attention is all you need. Advances in Neural Information Processing Systems 2017, 30. [Google Scholar]
- Adiwardana, D.; et al. Towards a human-like open-domain chatbot. arXiv 2020, arXiv:2001.09977. [Google Scholar]
- Roller, S.; et al. Recipes for building an open-domain chatbot. arXiv 2020, arXiv:2004.13637. [Google Scholar] [CrossRef]
- Manning, C. D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press, 2008. [Google Scholar]
- Liu, Y.; et al. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Tang, J. C. Approaches to designing effective human-AI interaction. Foundations and Trends® in Human–Computer Interaction 2021, 14, 181–295. [Google Scholar]
- Liang, P.; et al. Holistic evaluation of language models. arXiv 2022, arXiv:2211.09110. [Google Scholar] [CrossRef]
- Ekstrand, M. D.; et al. Fairness and discrimination in information access systems. arXiv 2021, arXiv:2105.05779. [Google Scholar]
- Gajos, K. Z.; Weld, D. S. Designing adaptive interfaces through utility optimization. Proc. CHI, 2004; pp. 1347–1356. [Google Scholar]
- Khan, S. S. R.; Abidi, C. K. K.; Al-Mourad. Plug-and-play AI systems for scalable digital services. IEEE Transactions on Services Computing 2021, 14, 1234–1245. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Communications of the ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Rashkin, H.; et al. Towards empathetic open-domain conversation models: A new benchmark and dataset. arXiv 2018, arXiv:1811.00207. [Google Scholar]
- Stefik, M.; et al. Beyond the laboratory: Field studies in HCI. In Handbook of Human-Computer Interaction; Elsevier, 1997; pp. 805–826. [Google Scholar]
- Chin, J. P.; Diehl, V. A.; Norman, K. L. Development of an instrument measuring user satisfaction of the human-computer interface. Proc. CHI, 1988; pp. 213–218. [Google Scholar]
- Card, S. K.; Moran, T. P.; Newell, A. The psychology of human-computer interaction; CRC Press, 1983. [Google Scholar]
- Zhou, L.; et al. Multimodal transformers for conversational AI. Proc. EMNLP, 2021; pp. 5506–5518. [Google Scholar]
- Pu, P.; Chen, L. Trust building with explanation interfaces. Proc. IUI, 2006; pp. 93–100. [Google Scholar]
- Berg, R. V. D.; et al. Extending conversational agents to manage multi-utility customer service. Energy Informatics 2022, 5, 12. [Google Scholar]
Figure 3.
Authentication Page that asks for username and password for pre-existing accounts and a sign up option for those who are new users.
Figure 3.
Authentication Page that asks for username and password for pre-existing accounts and a sign up option for those who are new users.

Figure 4.
The home page displays a dashboard with the 3 main services that can be accessed either through the Dashboard UI or the Menu Bar at the top.
Figure 4.
The home page displays a dashboard with the 3 main services that can be accessed either through the Dashboard UI or the Menu Bar at the top.
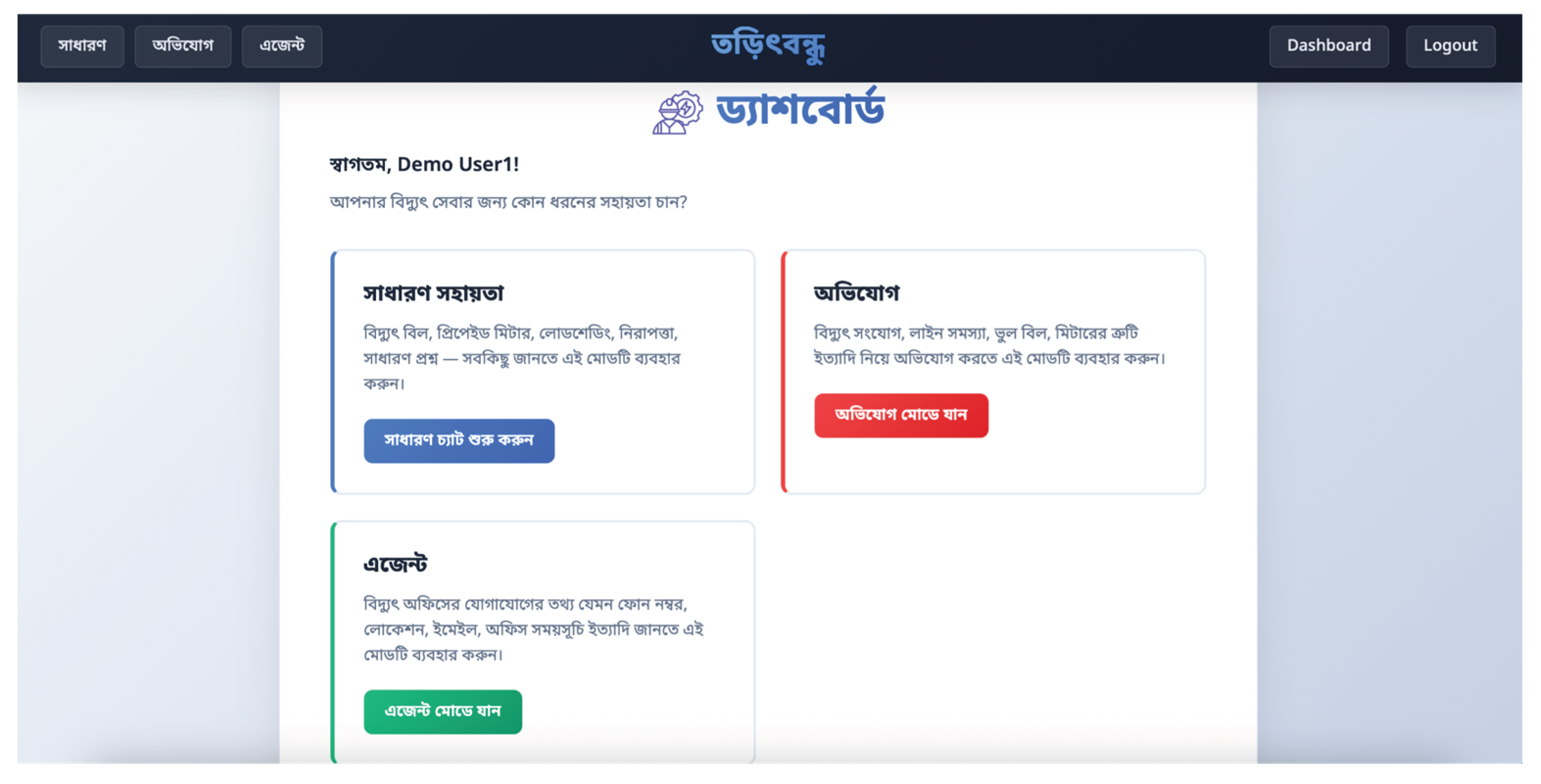
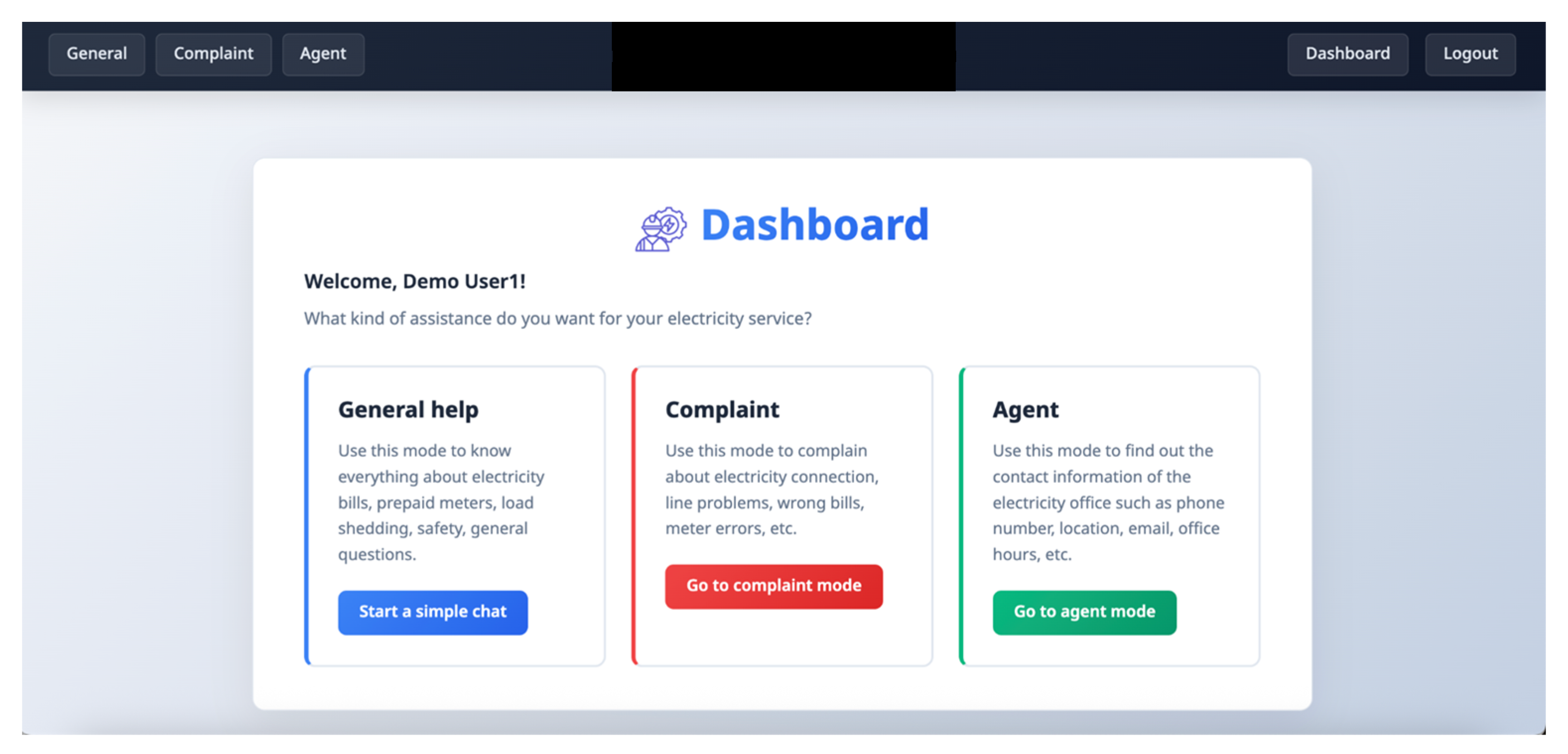
Figure 5.
The general queries section’s chat interface that leverages the user’s billing data and GPT-4.1’s reasoning capacity to answer user queries.
Figure 5.
The general queries section’s chat interface that leverages the user’s billing data and GPT-4.1’s reasoning capacity to answer user queries.
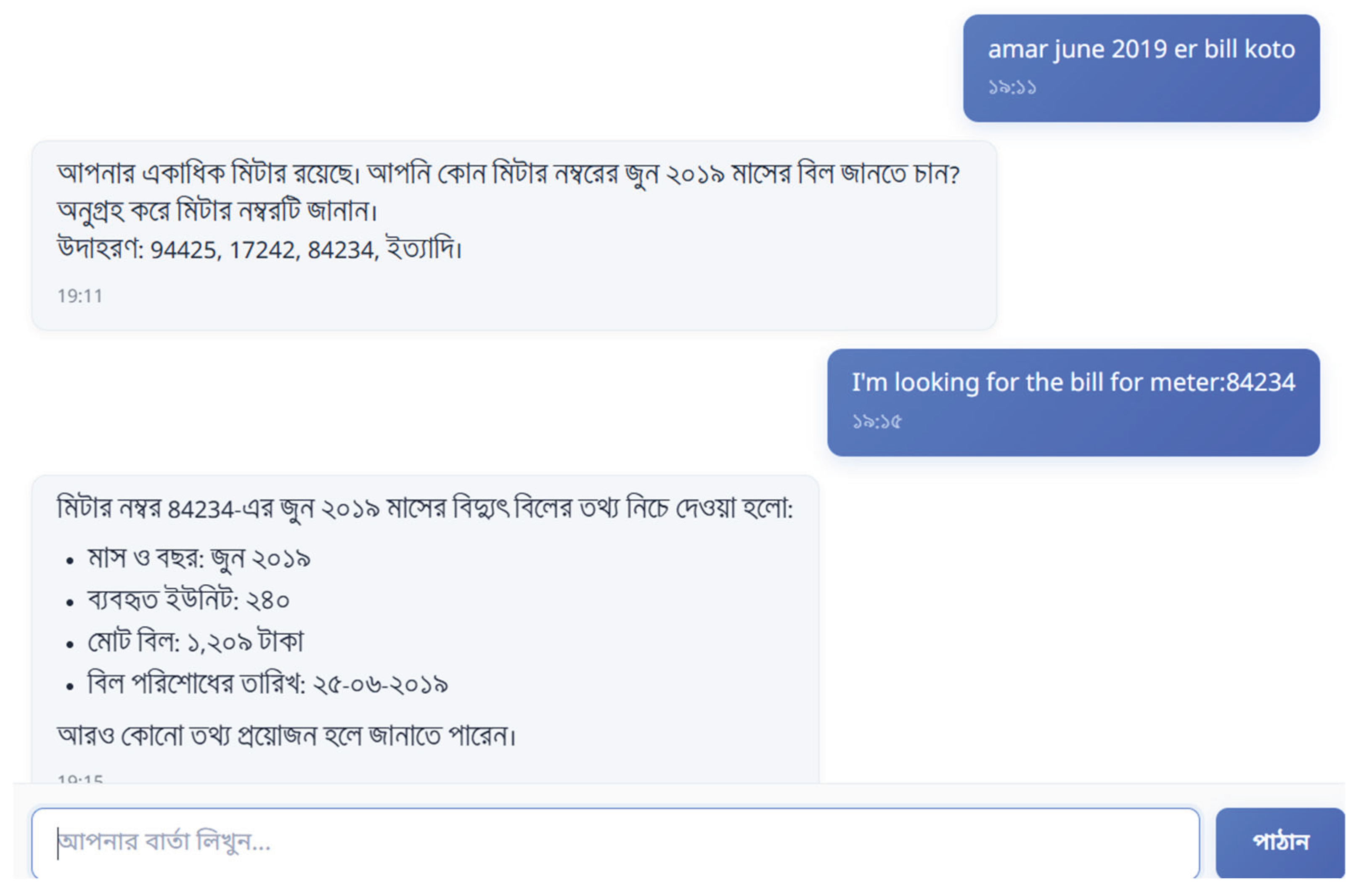
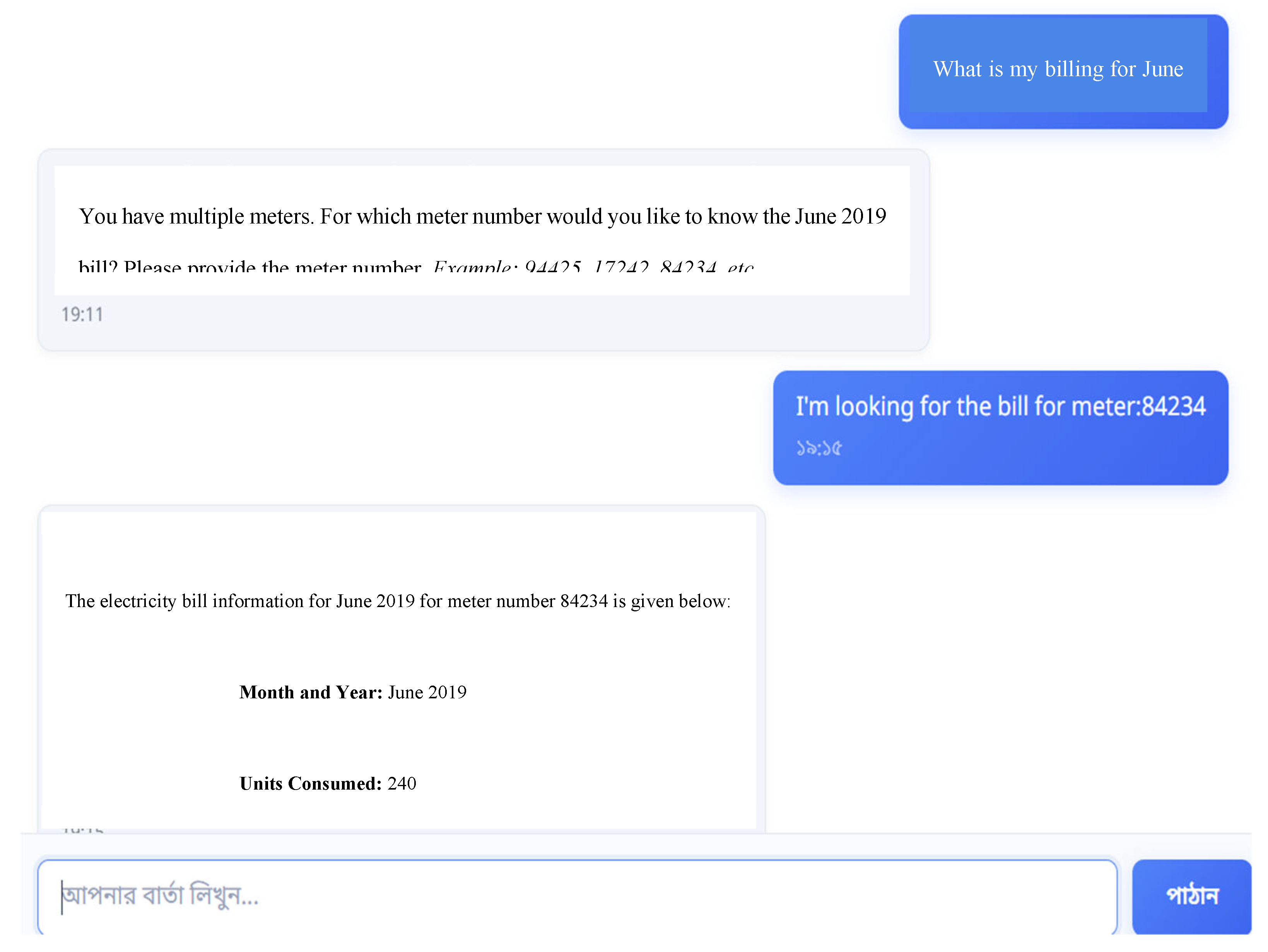
Figure 6.
The user complaints section’s chat interface that leverages pre-existing complaint log data and GPT-4.1 to come up with the appropriate explanation for the user.
Figure 6.
The user complaints section’s chat interface that leverages pre-existing complaint log data and GPT-4.1 to come up with the appropriate explanation for the user.
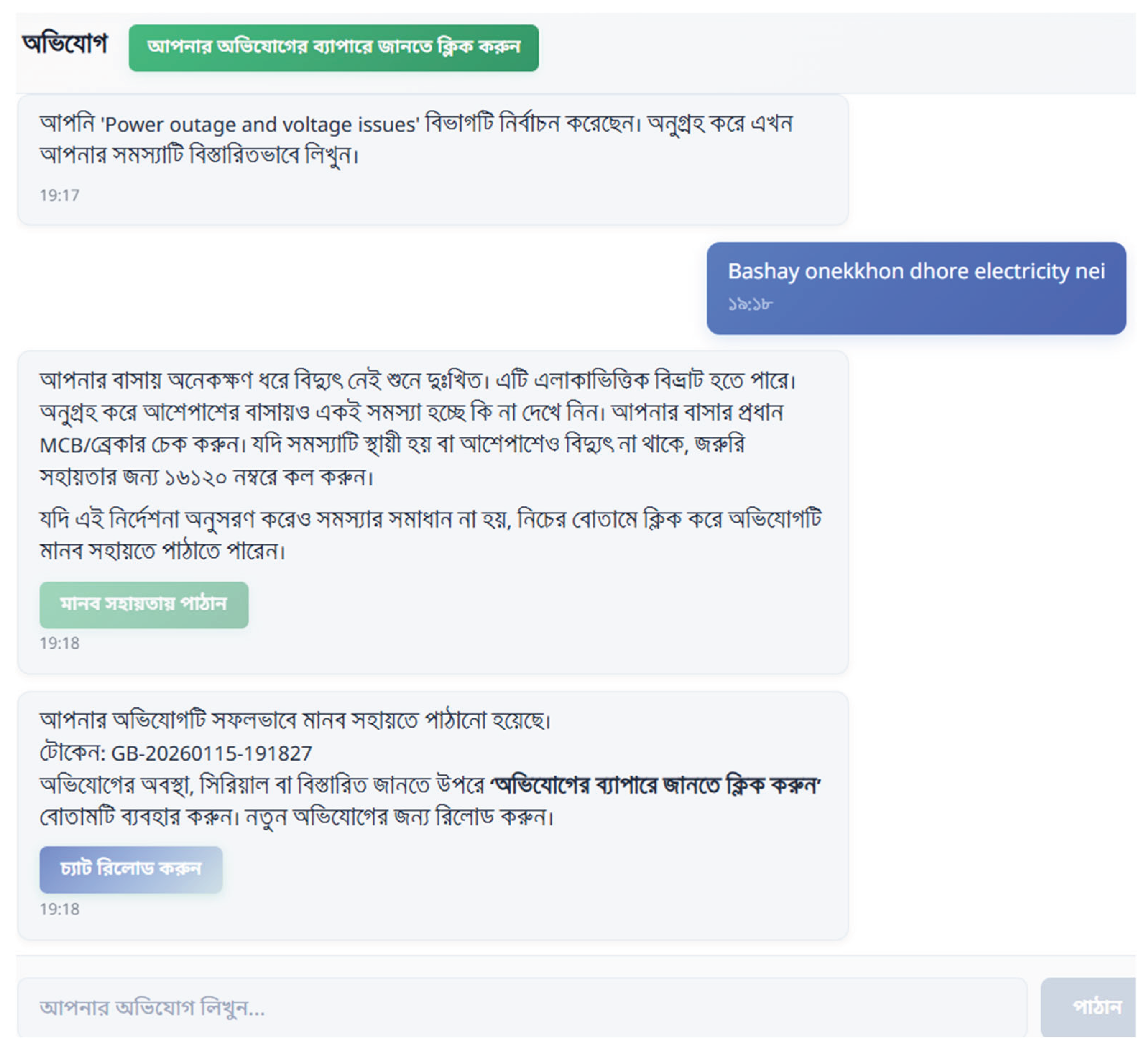
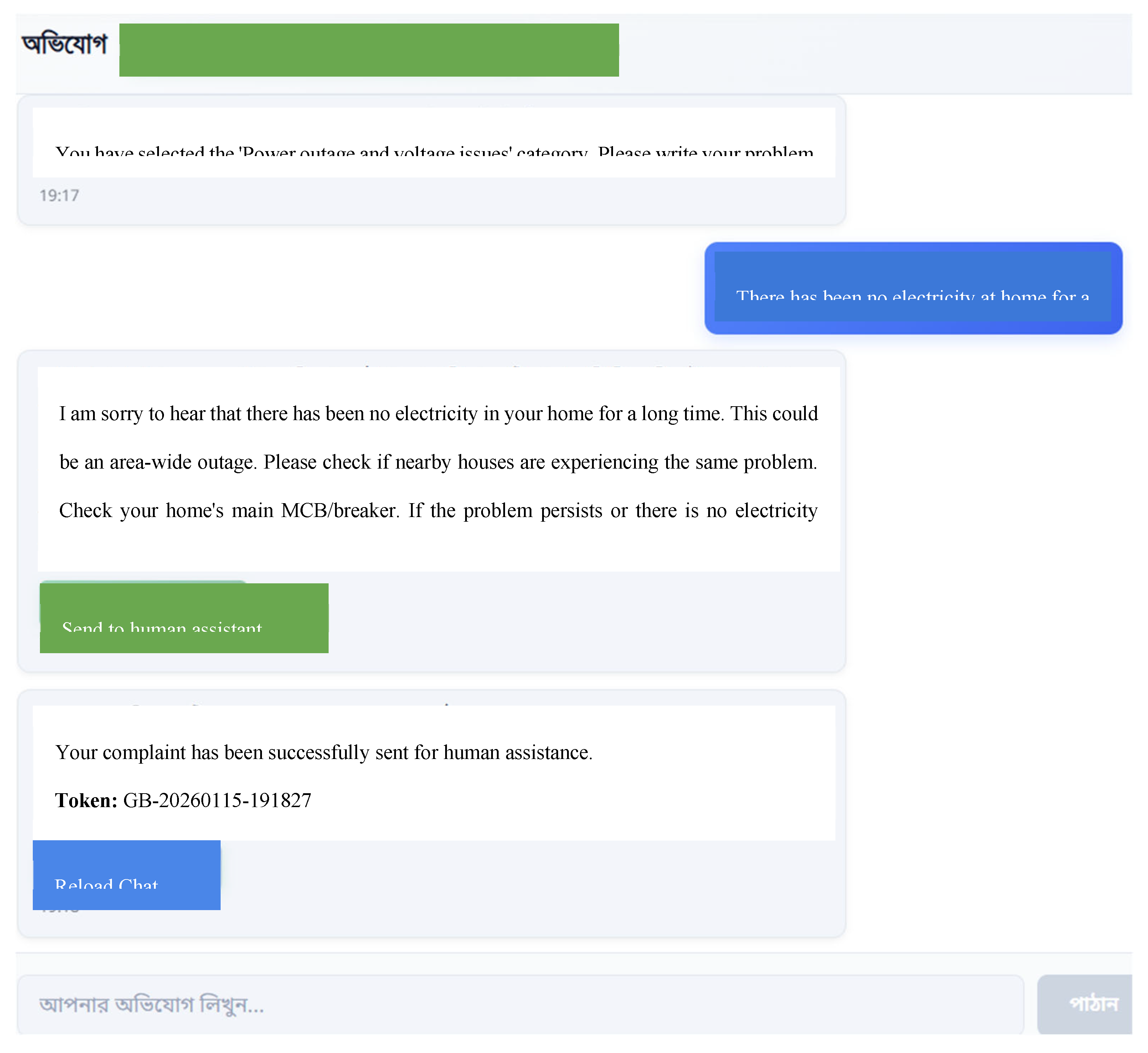
Figure 7.
Live agent interaction section that provides contact information of electricity service offices.
Figure 7.
Live agent interaction section that provides contact information of electricity service offices.
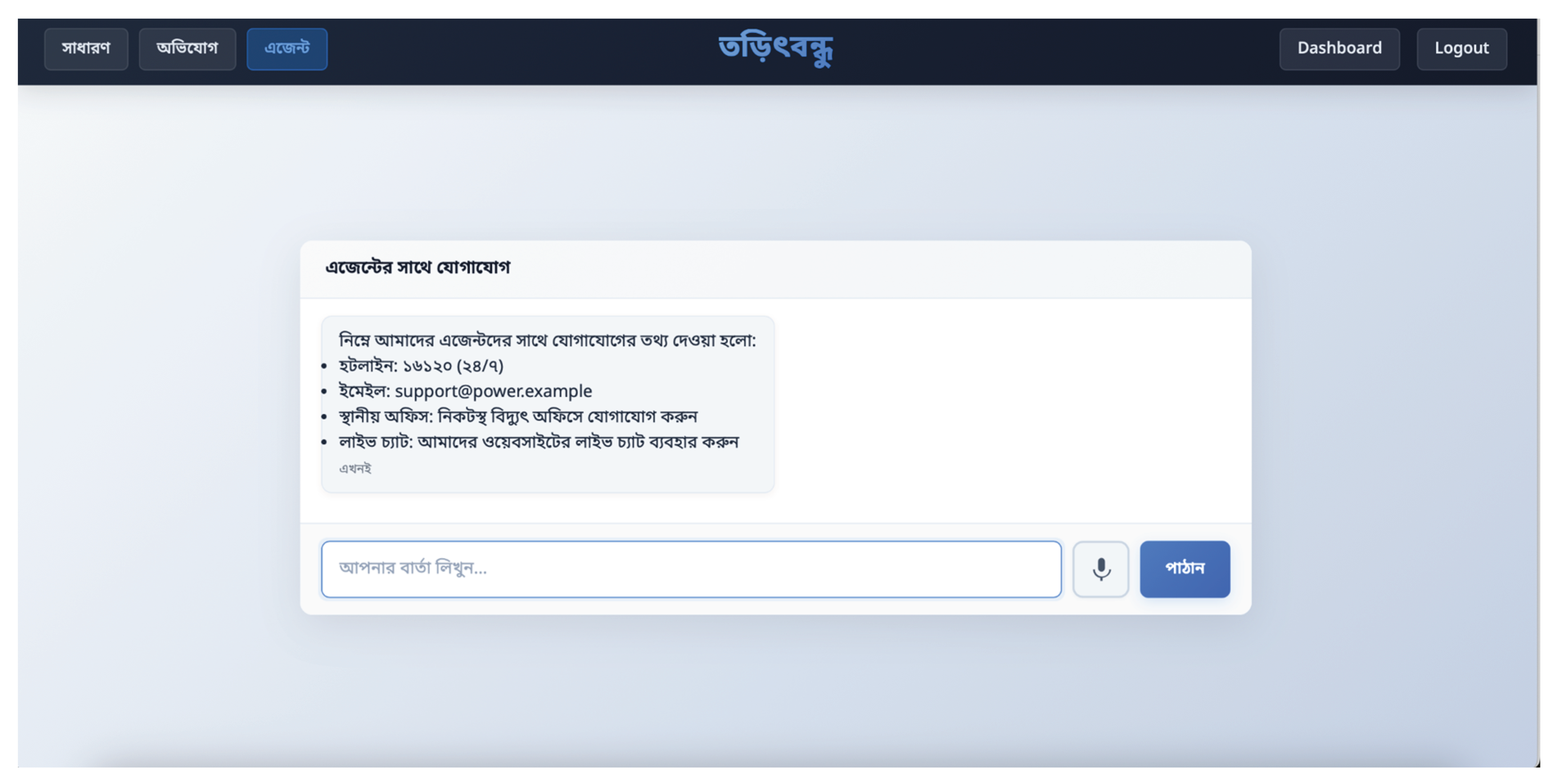
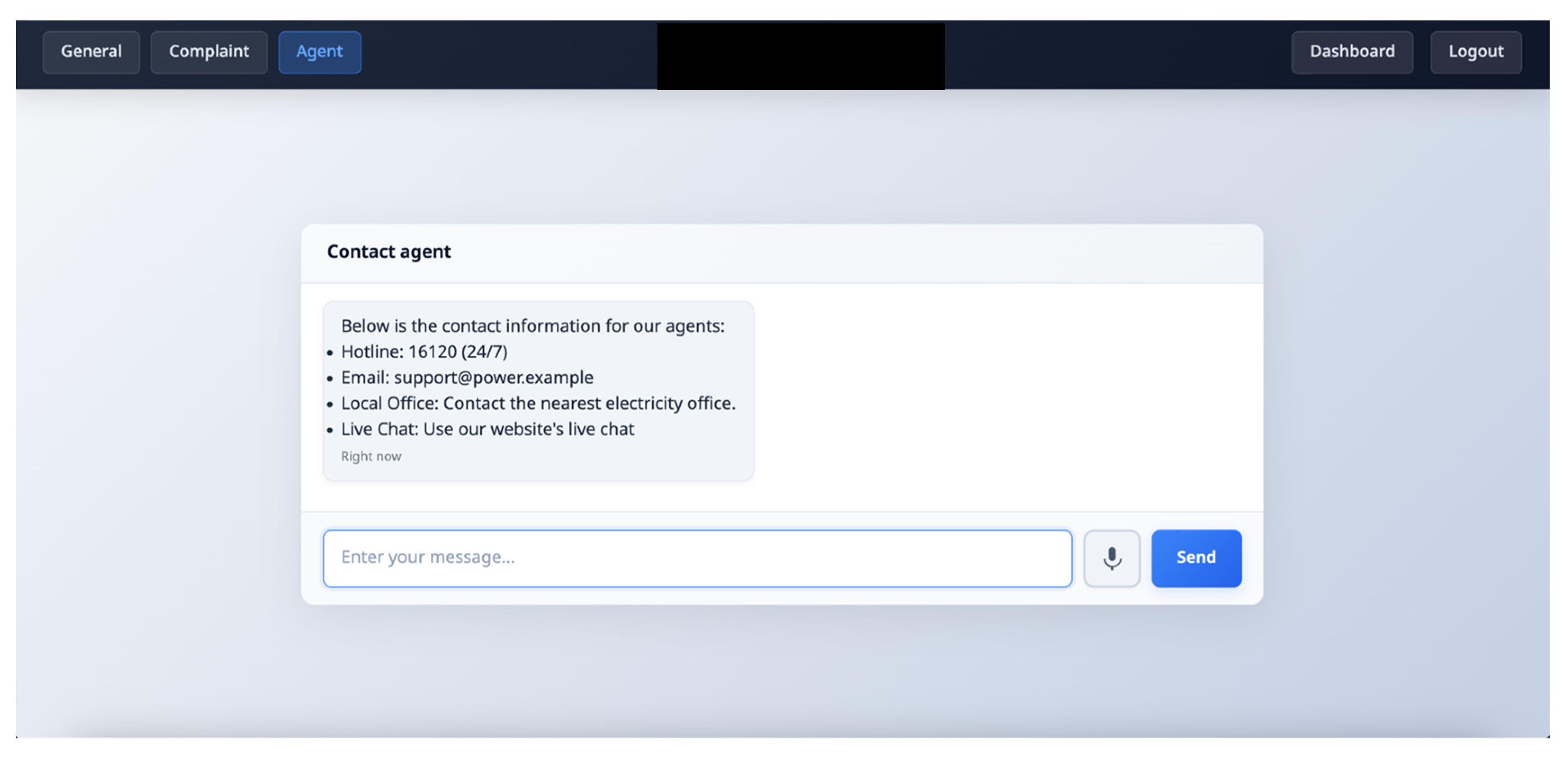
Figure 8.
Neon data table that showcases what kind of billing data is kept on a user (this is only showing demo user data).
Figure 8.
Neon data table that showcases what kind of billing data is kept on a user (this is only showing demo user data).
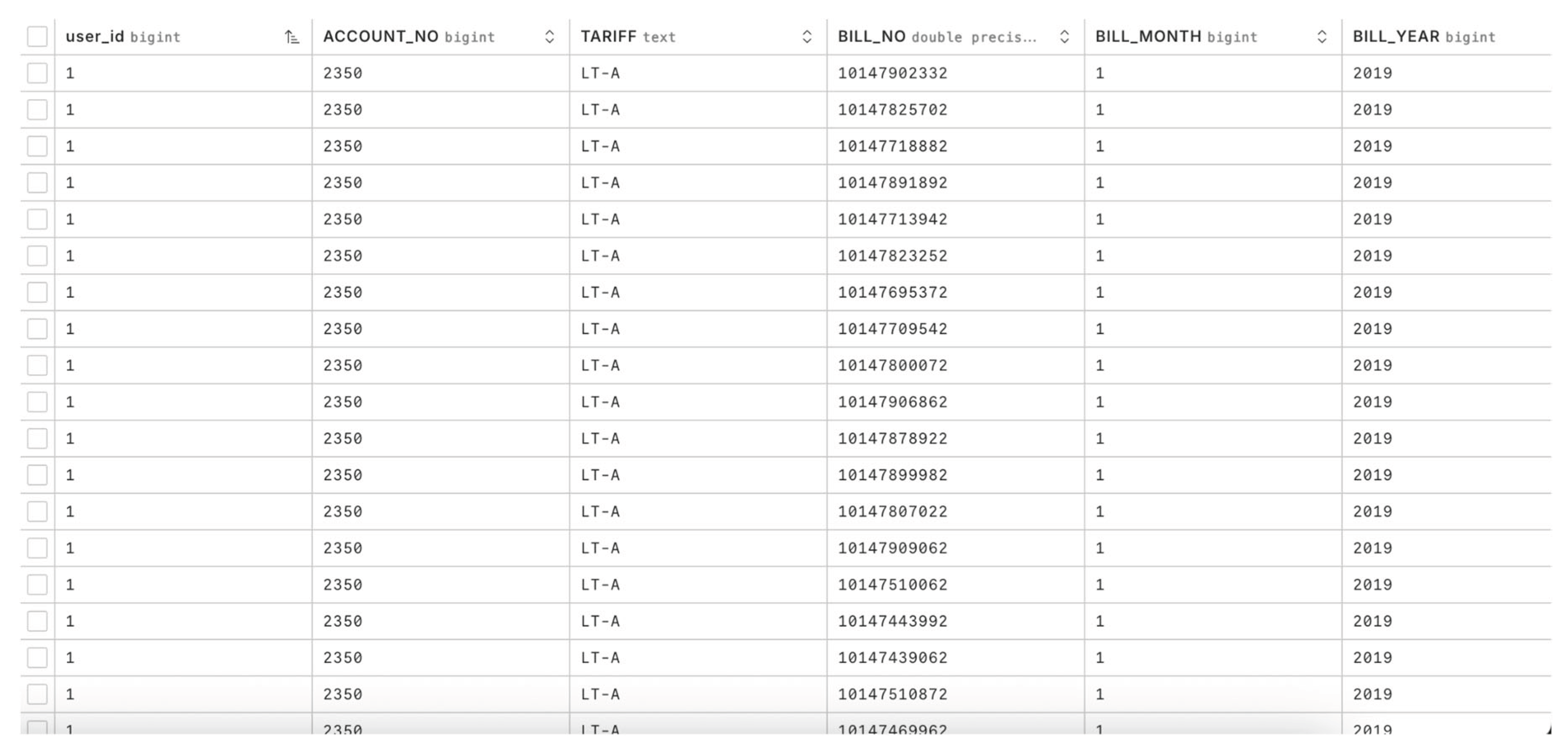
Figure 9.
A): This table stores the complaint metadata which are the different types of complaints a user can make. B): This table stores the actual complaint data which is used to determine a solution for a user who has sent a complaint query. C): This table stores the tokens associated with a particular user.
Figure 9.
A): This table stores the complaint metadata which are the different types of complaints a user can make. B): This table stores the actual complaint data which is used to determine a solution for a user who has sent a complaint query. C): This table stores the tokens associated with a particular user.

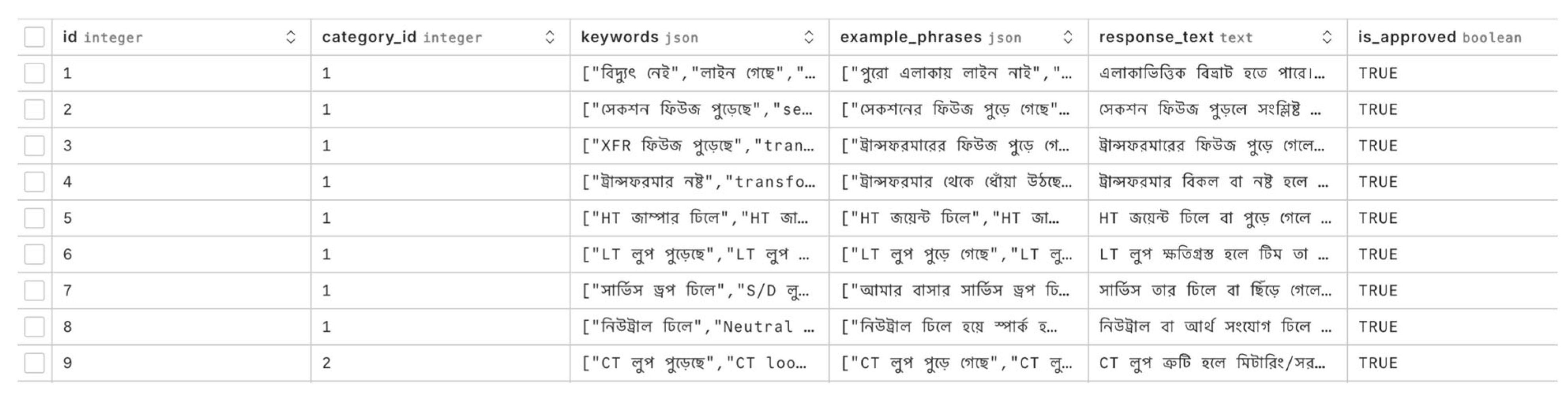

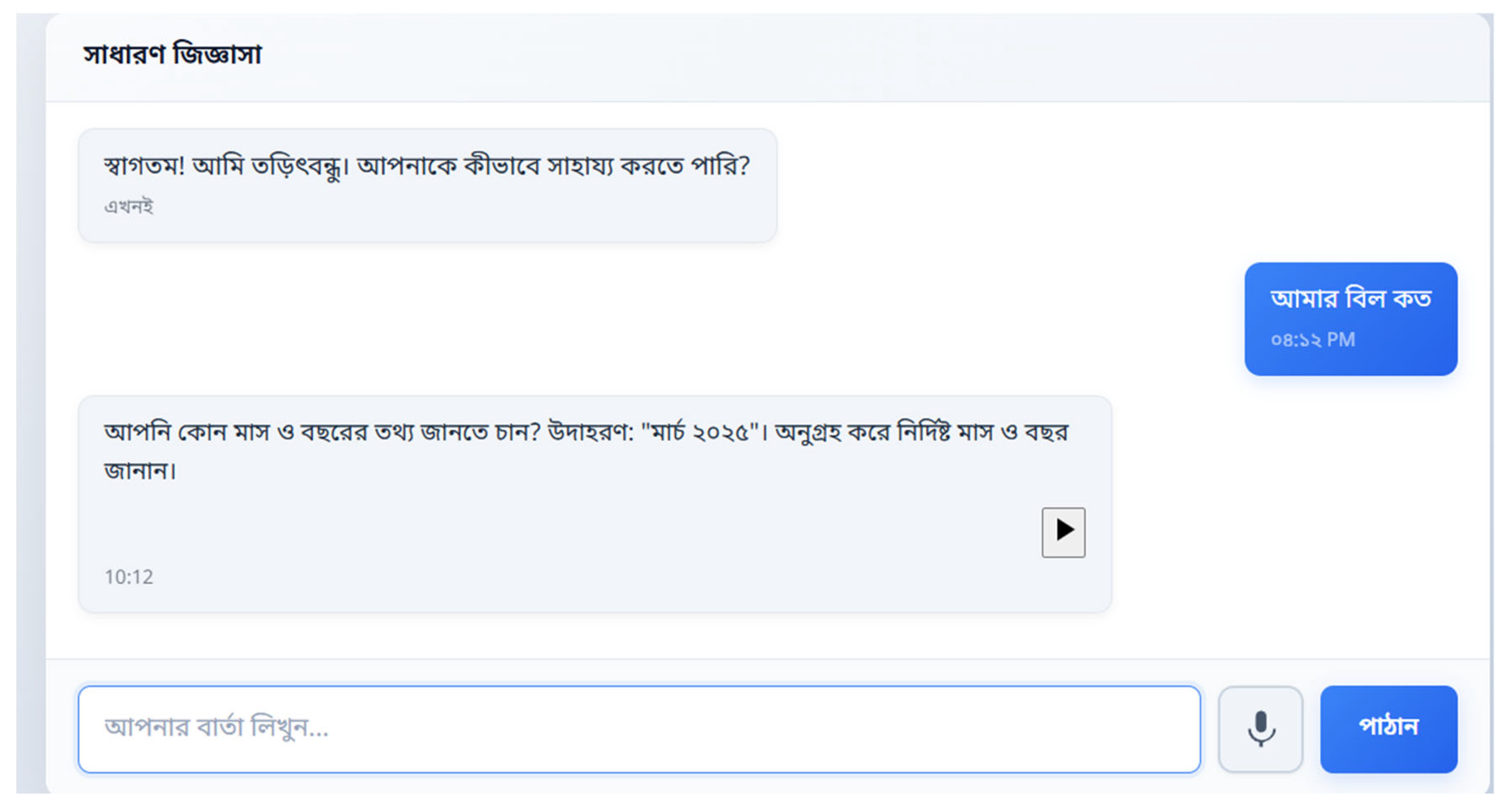
Figure 11.
Text-to-Speech (TTS) Output Interaction. Following a user query ("আমার বিল কত"), the system generates a textual response which is then converted to audio. A dedicated play button (▶) appears alongside the chatbot's response bubble, allowing users to listen to the answer.
Figure 11.
Text-to-Speech (TTS) Output Interaction. Following a user query ("আমার বিল কত"), the system generates a textual response which is then converted to audio. A dedicated play button (▶) appears alongside the chatbot's response bubble, allowing users to listen to the answer.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



