
Submitted:
06 February 2026
Posted:
09 February 2026
You are already at the latest version
Abstract
A video mini-lecture on the new mathematical theory of transformatics, as applied to basic sequence analysis was delivered on 3rd FEB, 2026 by inventor of the theory and also principal investigator on the Transforming Executable Alphabet (TEA) computer programming language project --- currently one of the best examples of how transformatics can be applied in practice. The lecture was the first to be delivered explicitly for the purpose of introducing transformatics to new audiences, and it happens to have come at a time when the most critically important work on formalizing Transformatics --- the ``Transformatics 101" mini-thesis, a review and distillation of all earlier work underlying transformatics, is undergoing further revision, and is also being integrated into an upcoming book on applying transformatics in genetics (slated for 2026). However, not everyone coming to transformatics has fair footing in the associated background theory and ideas, and thus this necessary paper, that is actually in the form of an interview, in which I respond to 8 important problems raised by members in the audience concerning that introductory lecture, especially touching on; the notation used in transformatics, the important matter of different kinds of symbol sets, the Anagram Distance Measure (ADM) introduced in the lecture, and what lies ahead beyond just the ADM for interested students and researchers. The material has been presented almost verbatim --- with some questions being presented in the native languages (Ganda/Luganda and Cwezi/Runyakitara) as they first came to us --- all based on the points solicited from community members since the lecture first went online, and the answers are then augmented with sufficient references to existing transformatics literature to help galvanize the discussion and make this paper serve as an authoritative future reference too.
Keywords:
review
; interview
; mathematics
; foundations
; transformatics
; sequence analysis
; notation
; symbol sets
; anagram distance measure
1. About and Accessing The Transformatics Introductory Lecture of 3rd FEB, 2026
Titled “TRANSFORMATICS for beginners!”, the lecture can be accessed online via either YouTube or via Telegram on the following links:
- 1.
- YOUTUBE (Nuchwezi Research Community): https://youtu.be/YvBmLM6FgUg
- 2.
- TELEGRAM (Blackboard Computing Adventures): https://t.me/bclectures/1260
In this mini (meaning very brief) video lecture, Fut. Prof. Joseph Willrich (currently Nuchwezi Research) introduces one of the most vital and generally useful results from research in developing the new Mathematics of TRANSFORMATICS thus far;
ADM, the Anagram Distance Measure, is introduced, and we see how it might help anyone quantifiably evaluate if any two sequences (ordered sets possibly with redundant elements) are similar (equivalent) or dissimilar, and by how much (ADM results in a real positive number):
This theory is being used to develop new methods of sequence analysis, with applications (thus far) in GENETICS (applied biology), Hemomath, Statistics, Machine Learning, Cryptography, Esoteric Science and more...
Checkout and follow progress on this front via:
- 1.
- JWL Scholar Portfolio: https://bit.ly/jwlgsch
- 2.
- The TEA Project: https://tea.nuchwezi.com
- 3.
-
and upcoming book on TRANSFORMATICS for GENETICS:
—Original Lecture Description and Notes
Figure 1.
A blackboard snapshot from the author’s Blackboard Adventures series on Telegram, as posted on 3rd FEB, 2026
Figure 1.
A blackboard snapshot from the author’s Blackboard Adventures series on Telegram, as posted on 3rd FEB, 2026

2. The Interview (8 Questions)
In the rest of this paper, we present each review or reviewer’s question under its own section and title, with the question in its original/verbatim form—sometimes not in English, coming first, and then the same question well presented in clear English, and then after which we present the relevant answer provided in response to a particular reviewer’s matter, with references being included inline, as phrased by Joseph so as to address the matters raised—almost in plain English so as to keep the discussion open and accessible to the widest audience including non-mathematicians.
2.1. Question 1: Angled Brackets for Sequences and Whether There’s Any Relationship with Lu-Numbers
Mwaka guhoire ogwo.. ’25, haliho filimu za akademics ezaturukire.. most likely kuruga ha NML channel ya Professor waitu Mukama Joseph Weira. Bakabaza ha Lu-Numbers ezo na Lu-Number System yagisoboora. Milingo y’okwegesa ebimanyirwe ha byoma binu ebya Linux kukenga ebisisani, gamba nk’ebirumu ente obba abantu, nibyeyambisa okubara kwina enamba ibiri zonka, “Signal” na “Anti-signal”. Is it that brackets.. oburorwaho bunu obwa Lu-Numbers obuyatwanjulire, nibwo bumu obuli mu TRANSFORMATICS?
—Originally asked in CWEZI/Runyakitaara, Cwezi Empire IC (WhatsApp)
I did see an interesting video on YouTube, concerning the July 2025 paper on Lu-Numbers and the Lu-Number System. I think it was published via Preprints, by Future Prof. Joseph, that was telling us things about using these bracket symbols, “Signal” and “Anti-signal”, to automate machine learning tasks such as the counting of cows, goats or people in a kraal using.. Photos and Computer Vision on Linux? Is this related with this TRANSFORMATICS stuff?
Sure, in transformatics, the convention since around the arrival of the TRANSFORMATICS 101 mini-thesis of October 2025 [1] has been to express sequences using < and > as delimiters and not for example { and } (as do sets) nor [ and ] (as do lists in computer programming or ranges in calculus).
But no, the use of < and > in transformatics has nothing to do with the theory of Lu-Numbers [2] that define < as signal and > as anti-signal (something like 1 and 0 for arbitrary information expressed in binary form) even though both theories have been discovered and developed by the same person; I, aka, Fut. Prof. Joseph Willrich of Nuchwezi1.
However, it still does make sense, especially when parsing complex sequences or rather higher-order sequences [1] such as a sequence of English words expressing an essay as a collection of paragraphs: the main sequence would start with < and after that, the next occurrences of < would help indicate further levels of nesting or individuation; paragraphs, sentences and then individual words—inside which a word sequence then merely has commas between terms (such as its letters) and closes with a single > symbol. Then the essay as a sequence of words, sentences, and paragraphs can be analyzed at the most abstract level using just signal “<” and anti-signal “>” so that without even bothering to look at or count the letters, and without even concerns about the language the essay is written in, one can analyze the sequence for how many paragraphs, sentences or words it contains merely by processing those two Lu-Number symbols. Also, whether or not some paragraphs are merely sentences or whether some sentences contain just one word can be determined even with all letters and punctuation having been eliminated from the essay, as long as these structure-defining symbols have been well preserved or applied2.
EXAMPLE Sequence Analysis using Transformatics and LNS-projections:
“Hello world! Please consider this a message to you, from the future.”
〈Hello world! Please consider this a message to you, from the future.〉
〈〈Hello world!〉〈Please consider this a message to you, from the future.〉〉
〈〈〈Hello〉〈world!〉〉〈〈Please〉〈consider〉〈this〉〈a〉〈message〉〈to〉〈you,〉〈from〉〈the〉〈future.〉〉〉
〈〈〈〉〈〉〉〈〈〉〈〉〈〉〈〉〈〉〈〉〈〉〈〉〈〉〈〉〉〉
So, we could apply LNS analysis in special kinds of sequence analysis—analyzing sequence notation expressions (such as in parsers) to be precise, but no, transformatics doesn’t necessarily use them because of their LNS meaning or relevance.
2.2. Question 2: How Inverted PI Became a Length Quantifier
My background is in the engineering sciences mostly, and symbols in mathematical formulas and especially in physics do mean a lot for me; such as when the extended “S” is used to mean integration in Newtonian Mechanics or when we use Sigma symbol to mean summation in Riemann Sums. So what is the logic or history behind this use of the Inverted PI, because it seems as though I don’t follow quite well, and yet it’s possibly nothing to do with the constant 3.14?
—Asked by a female student in Mechanics, UGANDA IC (Telegram)
First of all, the idea of cardinality [1] used in transformatics relates to that of the length of an expression, which for most cases in transformatics definitely means the length of a sequence or rather how many elements or members a sequence contains.
This idea is one of the first fundamental concepts that was developed by the inventor of this theory, since it goes back to the first mathematics papers that I wrote as early as 2020 [4], when formalizing and laying down my ideas on the General Cardinality of Numbers as well as placing finite bounds on the size of expressions that might result from the addition, subtraction but also division and multiplication of two or more numbers.
So, GTNC first presented the notion of a sequence’s cardinality as used in transformatics, however, later, after these ideas had been extended to quantifying and analyzing expressions that aren’t numbers [2,5]; such as sequences of English words, Strings in computer programs, etc., it was decided to abandon the original C or , etc. symbols and instead use a more unique symbol, and thus the inverted Pi, , symbol got chosen—perhaps first formally defined in the Anagram Distance paper [6]3—especially because of its distinctiveness and how relevant this measure was in formalizing many of the other ideas already being developed in transformatics.
No, it has nothing to do with the use of PI symbol, , in geometry, and no, it isn’t related to the mathematical constant used to express the ratio of a circle’s circumference to its diameter [7].
Perhaps, its relevance might also be related to the fact that at the time it was first formalized in transformatics [5,6], indeed, the inventor of that theory was without doubt the Pi (Principal Investigator) at Nuchwezi Research, and yes, he still is, and this decision on what notation to use for the critical parts of the theory heavily still are his to make as the sole benevolent dictator of all our transformatics theory.
2.3. Question 3: Stars vs Rats and Whether Transformatics Can Help Us Identify Palindromes
Omanyi, Polofesa Lutalo olusi asesa busesa.. bwagamba nti “Stars”, emunyenye, ziyinza okuva mu “Ratss”, emese, magezi ga kiika kyi gano gayogelako? Zino ngeli za kufula..? Gamba nga TRANSFORMATICS zetwawulila mu LUMTAUTO, oba waliwo engeli z’okubala endala zetutanategela? Nadala ebintu ebyenjaulo nae nga olusi bifuka-fuka, ate nebitandika nokufanagana!
—Originally asked in GANDA, Bugabo-Bukaya IC (WhatsApp)
So, with regards to this bit about the choice of sequence expressions depicted in this lecture.. (laughs) What exactly is being meant with the joke about “RATSS” being or becoming “STARS” or perhaps something along those lines...? And does this have anything to do with the magical transformations that he also once taught about in his book on TRANSFORMATICS for magicians, the book GRIMOIRE LUMTAUTO?
First, note that many people new to such mathematics as transformatics shall without doubt get lost and only see stars if we had written most or all of the mathematics using say traditionally palatable Greek letters or perhaps some of the recently well introduced alternative modern African hieroglyphics alphabets such as OZIN [7,8] or perhaps CRYPT OF MEDINA that were first formalized in the book GRIMOIRE LUMTAUTO [7], around late 2025.
And yes, even though books like LUMTAUTO that without doubt help bring the Mathematics of Transformatics to the Arts and Humanities likewise contained many mentions of peculiar magical things such as transforming words using literal mirror operations4 so as to invert or reverse spells laterally, or perhaps to work against any such reversible magics—perhaps, and somewhat reminiscent of computer science concepts such as palindromes or palindromic expressions—of which, yes, the choice of “STAR” as a word that also reads as “RATS” when inverted might be a bad choice than if we had for example used the words “EWE”, E-W-E, or “EYE”, E-Y-E, which reads the same from the right as from the left—words that would remain resistant against any kinds of mirror transforms, but no! This wasn’t about palindromes even though it somehow might be related.
The idea being communicated here is that we might discover interesting things about certain expressions when we look and re-look at them under the transformatics sequence analysis microscopes.
We for example can find that two or more words share the same root—something that in transformatics we might relate to the Linear Algebra concept of a basis5. So that, and as we see demonstrated in this lecture, the two different sequence expressions, “S-T-A-R-S”, and “R-A-T-S-S” that one might quickly read as “Star S” and “Rat SS”, despite being funny—perhaps as great jokes about schools that only wish to focus on arts and making their students “artiste stars”—are in fact a great example of how we can reduce expressions to only their unique set of elements; what we are referring to as “Symbol Sets” in transformatics, and yes, we find that these two expressions both map to the same exact four letter set “A-R-S-T” even though both are themselves 5 letter expressions and that they are spelled differently but also mean different things.
Transformatics is great at exploring many such problems involving treating of things as sequences and not as just words or numbers as might be treated of in for example linguistics or in ordinary mathematics respectively. So, hopefully this clears up the confusion and ratty jokes.
2.4. Question 4: Two Types of Symbol Sets or One?
Zinu endimi za Symbol Seti, zikuzooka nizibuza-buza.. Obundi tuhura “naturali”, obundi “specifica” obundi “unspecifica”. Hati mutusoboole, ebika bya symbol set zinu, bingaha? Kandi bimanyisa ki?
—Originally asked in CWEZI, UIC (Telegram)
These symbol set concepts sometimes become confusing, because we sometimes hear of “natural symbol sets”, then also “specific” and sometimes “unspecific” symbol sets. So, how many kinds of symbol set families exist, and are they two, one or more?
Interesting and quite important that readers and especially students of transformatics learn to distinguish between these different concepts of symbol sets6.
First, concerning what is meant by “symbol set”, note that for any expression or rather sequence expression—whether a number or any arbitrary collection of symbols such as letters that form a message in English or perhaps the sequence of symbols that define a TEA computer program, when we reduce any such expression to only its unique, distinct elements, then we have what in transformatics is known as a symbol set [1,4].
The term “set” in symbol set is important, because unlike the sequences that most of transformatics is about, a set can not contain the same element more than once, but also, and important with regards to transformatics which especially focuses on the study and analysis of ordered sets; once we need to care about how the elements in the set are ordered.. such as which symbol should appear before the others, then we start to consider structures more advanced than sets, and thus sequences.
For the case of symbol sets, order especially comes in-handy when we wish to preserve some information about where the elements in a symbol set originated from or how they were first encountered. So, in this lecture we are shown two sequences, and we see that if we reduce the first one to only its unique elements while preserving the order of first occurrence in either sequence, then we end up with “Star S” becoming just “Star”, while “Rat SS” definitely becomes merely “Rats”. In either case, we eliminate repeated terms, but otherwise preserve the order in which the symbols occurred in either original expression.
These kinds of symbol sets are technically called “Implicit Symbol Sets” [9]7—when the only thing that matters is that we know what the unique symbols in a sequence are, but otherwise called “Unspecific Symbol Sets” [9]8 when they only focus on the ordering of elements by their order of first occurrence in the original sequence and by no other criteria other than avoiding repetitions otherwise. We usually write such symbol sets as shown in the first two cases, using just the Greek letter “Psi”, , followed by the symbol of the sequence being analyzed within two round brackets—such as —when we want to talk about the implicit symbol sets, and otherwise also decorate the “Psi” with a hat accent— —when dealing with the unspecific symbol sets.
Concerning these two types, it is worth noting that many times in transformatics, we might just write the notation for the implicit symbol set when we actually imply or mean the unspecific symbol set. This especially because either kinds of symbol sets only focus on the sequence being analyzed, and also that, the unspecific symbol set is just another version of an implicit symbol set that a given sequence might have.
The other important type is that of the “Natural Symbol Set”. In this type of symbol set, which we write in a similar way but with the Psi symbol bearing a subscript such as shown in the bottom left expressions on the blackboard—for example as , we process the symbol set relative to some base, , or some reference alphabet—such as in this case. For example, in this lecture we process the two sequences relative to the Latin Alphabet, and that’s why we see “Psi-az”, and so that, as with all natural symbol sets, the resulting sequences are such that the terms are ordered in a way so that the terms in the resultant sequence preserve their natural order of first occurrence in the corresponding base’s ordered symbol set.
Thus, even though both example expressions had different orderings of the four letters “R-A-T-S”, and yet, when transformed into their natural symbol sets under base AZ (or perhaps more Mathematically correct, under base-36—since it contains all 10 digits in their natural ascending order, suffixed by all the 26 letters of the Latin Alphabet in their natural order too), so that then, we correctly see that either sequence then reduced to the same natural symbol set having the ordered terms “A-R-S-T” and nothing else when processed under the same base— and .
Also, note that since the o-SSI paper [9], we also sometimes refer to the natural symbol set as the “Base Symbol Set”.
And then, perhaps also less commonly found in our transformatics literature thus far, are what we call “Specific Symbol Sets”. These were also first formalized9 in that Orthogonal symbol set identity paper of April 2025 [9], and these, though somewhat related to the base symbol set or the natural symbol set in the sense that they are computed with some specific base in mind, and that we differentiate them from natural symbol sets by adding a “hat” accent to the “Psi-base” symbol when expressing the symbol set— , are different from all the other kinds we have discussed, because, apart from ordering the terms in the resultant sequence based on the natural order of first occurrence in the referenced base’s alphabet, also enforce a filter on the sequence expression being processed or being analyzed so that only symbols in the base being referenced are allowed to appear in the specific symbol set for the expression relative to that base.
What this means for example, is that, if we had an expression such as “Star S1 01” to for example mean the best student in a school’s Senior 1 class, stream “01”, when reduced to its unspecific or implicit symbol set— or —would result in the sequence “S-T-A-R-1-0” for example, while its natural symbol set under base-36—— would be “0-1-A-R-S-T” and yet, if we compute its Specific Symbol Set under base-2 which only recognizes only two symbols “1” and “0”, the resulting symbol set for that expression under base-2— —would then just be “0-1”.
Important to note, in case we had to compute the natural symbol set () of that expression under a restrictive base such as base-2, and yet the sequence being analyzed had some symbols not belonging to that base, then a plausible solution would be to still process the symbols in the referenced base by their natural order in the base, and then sort the remaining symbols by their order of first occurrence within the expression10. This corner case had never been well formalized, but is indeed derivable from what we know by now, and if we can’t call it the natural symbol set, perhaps we might call it the “extended natural symbol set” or perhaps the “natural unspecific” or perhaps (laughs) the “preternatural” symbol set, so as emphasize the fact that it is not exactly like the natural kind.
As for cases where we have to compute a specific symbol set, , yet the sequence being processed contains no elements in the specified base, then the result would merely be the empty sequence or empty set, ∅.
Oh, and almost last but not least, especially because we mentioned the o-SSI paper that also helped clear much of the earlier confusion about symbol sets in transformatics, note that a special kind of symbol sets we might refer to as “orthogonal symbol sets”11 are merely a kind of [implicit] symbol set that exactly reduces a sequence or expression to some anagram of a particular base’s symbol set. Thus, orthogonal symbol sets might be in any order—just like any implicit symbol sets, but they must consist of all the elements that make up the alphabet of some base—in this regard then, we might also liken them to specific symbol sets!
For example, the strange and interesting expression that I discovered while studying calculator interfaces, and which number expression we called the “Hi-Fi o-SSI”12 [8], consists of the 10 digits from the base-10 symbol set, but their order is as “8-6-4-9-1-3-7-5-2-0” which one might memorize using the mnemonic “Hi-Fi-DIM-GET” if you know of or care about those esoteric masonic memory tricks from ancient days...
The very interesting thing about orthogonal symbol sets, just as with the o-SSIs—orthogonal symbol set identities—upon which we are basing them, is that, if you shuffle their elements in any order, even the resulting sequence still remains an orthogonal symbol set relative to the same base! It is just an anagram. However, of all possible orthogonal symbol sets of a base such as 10, 36, the Latin Alphabet or for biologists, the DNA alphabet13, there shall only always exist only one single correct natural symbol set that’s also orthogonal14.
So, to wrap up, we have encountered
- Natural or “base” symbol sets
- Implicit symbol sets
- Unspecific symbol sets
- Specific symbol sets
- Unnatural or “Preternatural” symbol sets
- and Orthogonal symbol sets
With those last two kinds only having been mentioned or introduced as a consequence of reflection during this interview. So, that’s a total of 6 different kinds of symbol sets, and hopefully all the confusion about symbol sets is reduced to nothing by now, however, and as you might realized through practice and further study, in practice, you most likely shall need to know or use just about three kinds of symbol sets—especially the implicit, natural and specific symbol set types. In reality, but also in the literature, there shall be, and might be other kinds too, and we might even define or develop more types in the future, however, those are most likely the important ones as of now or based on what we currently know.
2.5. Question 5: Concerning the Arrow Symbolism Very Common in Almost All of Transformatics Literature and Formulations
Is the use of arrows in transformatics similar to use of arrows in Calculus? Does it have anything to do with limits or not? And what of their relation to the arrow of implication?
—Asked by a male student of Advanced Calculus, r/1Internet (Reddit)
That’s such a wonderful, in fact beautiful question! And great that it was asked by a student of mathematics.
So, for starters, note that transformatics especially employs arrows in two major contexts: first, when introducing the signature of a sequence transformer15, and secondly, when applying a transformer such as in expressing a sequence transformation16.
Sequence Transformers are the core of this proposed new branch of mathematics, and as you shall come to appreciate in a chapter dedicated to discussing and explaining how transformatics as a field of mathematics relates to other existing and earlier fields such as Statistics, Set Theory, Logic, Linear Algebra, Calculus and others.. a work which I would rather not divulge prematurely until when your get to read or see it in my upcoming book on Applying TRANSFORMATICS in GENETICS17, you’ll indeed appreciate that sequence transformers are in fact a furthering of several earlier mathematical ideas and notations such as mappings that are very common in fields like linear algebra and calculus for example.
However, in transformatics, the arrow used in the signature of a transformer is meant to especially do away with the problems earlier notations such as the use of the equal sign, “=”, in formalisms such as Bird-Meerten’s transformation logic notation would create. That particular case of problems for example, are among older mathematical formalisms that I discussed and critiqued as part of my review [10] of Oxford professor Gibbons’ 1991 thesis on Tree Algebras. In particular, given that sometimes a transformation results in a change that cannot be reversed or which can’t directly return from the result to the original sequence, we then would want to avoid problematic notations such as the use of an equal sign to depict for example a general or arbitrary chemical reaction or chemical transformation in Chemistry. But also notations such as in scenarios where a colon, “:”, is used in mappings for cases such as in some algebras18, but also where others might use an equation to imply an otherwise one-way transform such as in the case of Bird-Meerten formalisms, we would rather write our mathematics differently even though we might sometimes be meaning or appealing to similar concepts.
Arrows in transformatics indicate the direction of a transformation, which means, there would be no problem with using an arrow that points both to the left and right, ↔, in transformatics—such as we might find in the definition of the interesting LUMTAUTO transformer19 formally introduced in the occult mathematics book “Novus Modernus Grimoire LUMTAUTO” that I wrote [7] under the alter “Most Ancient Priest Psymaz MAGINA” in late 2025. That transformer would help demonstrate the rare cases in transformatics where we might have allowed the transformer arrow to be replaced by an equal sign—this because, the sequences that are transformed via the LUMTAUTO transformer can later be sent back into it without modification, and then produce the original sequence that produced the input! For example, the word “language” becoming “lumtauto”, and then applying the same exact transformer to “lumtauto” to produce “language” once again. In such cases, we can also think of the transformer arrow as an arrow of [double] implication, ⇔.
However, that’s about it. Transformatics arrows aren’t a notation that is like how arrows in calculus with formalisms such as indicating the tendency of some variable approaching some constant as we see used commonly when expressing limits20. In our case, it is not a tendency, it is an actuality; the arrow actually means that the value on the left eventually, and in fact, must, become the value on the right and vice versa if it either is “double implying” or if it was right-to-left pointing.
Typically though, for transformers, we write the transformer function name and function signature at the top of the arrow, which typically points from left to right, and then place the source sequence to the left of that, and the resultant sequence to the right of that. And also, many times, shall extend such an expression with one or more logical expressions—especially using basic mathematical logic and set theory notations, that help rigorously specify the conditions or constraints on both the source and resultant sequence given their signatures, types, the nature of the transform, etc. These other specification expressions might typically be placed immediately after, or conventionally below the opening transformer signature expression21, after a single semi-colon, “;”:
Transformer 1
(A Generic Arbitrary Transformer, ).
In sequence transformation expressions though, we might either place the transformer name above the arrow or entirely omit it such as we see shown in the examples in this blackboard lecture.
2.6. Question 6: Concerning the Limits on the Anagram Distance Measure
ADM is a real positive number, but does it really mean it can grow indefinitely towards infinity even for finite sequences or might there be a finite upper limit for ADM that’s perhaps a function of the cardinalities of the two sequences involved?
We see you’ve managed to define absolute limits (even finite ones) on the bounds of all the four basic arithmetical operations with your GTNC theory, might you have similar theories on the limits applicable to the Anagram Distance Measure?
—Asked by same student of Advanced Calculus, r/1Internet (Reddit)
Wow! Thanks! You’re my favorite students! Thanks for bringing this up22.
So, yes, the Anagram Distance Measure, ADM, is indeed a real positive number, which would mean that it can range from 0 to positive infinity, but you’re also right to be concerned as to whether it has not finite upper limit other than just infinity.
First of all, realize that ADM is a measure that is only well defined for two sequences that at minimum have exactly the same length and which contain the same distribution of elements even though their relative ordering in either sequence might be different. So, we shall for now only be concerned with such legitimate scenarios only; essentially, analyzing anagrams or what are also known as permutations in high-school mathematics sometimes.
That ADM cannot fall below zero is guaranteed by the fact that in cases where any two sequences of the same length differ by a difference in at least two positions – and I stress two here, because, if you started with a sequence such as “T-W-O” which spells out the word “two”, and tried to shift any of its letters to a new position, then at minimum, you must end up shifting two elements; there is no way to move the letter “T” to a new position without also shifting one other letter; similarly for the other letters “W” and “O” in that word. Thus, our most basic anagram transform might be a mere swap of two neighboring letters such as when we swap “W” and “O” so as to end up with the resultant sequence “T-O-W”, which spells the word “tow”—which means “to pull something.”
So, in this case you see that since the first letter wasn’t shifted, its corresponding value in the ADM formula shall result in , and in case we hadn’t shifted any of the other letters from their original positions too, then the entire numerator part of the ADM ratio would result in 0, and so that, irrespective of the size of the sequence, the ADM would be 0 in cases where a transform results in no change of the position or location of any of the original sequence elements. So zero is our lower limit for this reason.
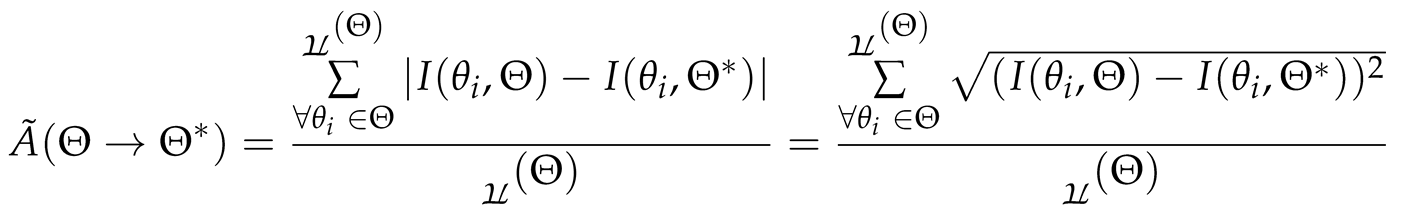
However, such as in the case of “two” and “tow”, we find that we have some noticeable differences in the letter positions when we compute the location updates. In this case for example, we see that, processing the letters left-to-right, we have updates such as , and , which would result in 0, and , and which, if we just summed them up without computing their absolutes, would have resulted in which would seem like telling us that the sequence “T-W-O” and “T-O-W” are the same! That would be absurd. So no, in ADM [6], we compute the sum of the absolute differences, so that then, in our example case, we should instead have as our numerator. Thus the numerator is guaranteed to always be a positive integer or positive whole number or pure number in my language of the GTNC theory23.
The denominator on the other hand is just the cardinality of the input sequence——and this wouldn’t matter even if it were the cardinality of the resultant sequence ,(), because ADM deals with anagrams as we have seen, and these essentially always have the same length to begin with. Moreover, the ADM can’t be applied to a case where one of the sequences is of zero length because that wouldn’t make sense still24, and so, we know that the denominator in the ADM shall always also be a positive pure number since there is no sequence that can have negative number of items.. essentially, there is no negative counting number possible25.
Thus, taken together, the ADM is a ratio of a positive whole number to a positive whole number26, and such that the denominator is guaranteed to always be greater than or equal to 1. This then means the ADM might take on values from 0 to positive infinity since we know that there are legitimate cases where a fraction results in a numerator greater than the denominator.
However, that’s just the preliminary analysis... Anything further than that is exactly where we might want to put everything else aside and scrutinize this matter deeply.. the stuff of real analysis which perhaps as a student of advanced calculus you are very interested in. It surely does explain your major concern with regards to whether we might not be able to specify a finite upper limit to the ADM just like we managed to do with results of either Addition, Subtraction, Multiplication and Division when we developed the General Theory of Number Cardinality in 2020.
But, this is an interview, it is 4th February and this lecture was just yesterday! And I’ve hardly finished my breakfast! It’s also my son’s birthday and we must be gone to buy him a cake that we shall perhaps divide amongst a non-zero positive number of attendants. So, basically not enough time right now to complete this interesting further analysis, but now I see your point and see a route towards a potential solution. So, just know that I’ll do it and present the results in a paper or a book some day not so far in the future.
(laughs) You’re such a great fellow to go to picnics with.. perhaps you must come along to this birthday I’m talking of and we solve this problem over some cake and Tea!
2.7. Question 7: Concerning Cases Where ADM Is Applied to Sequences of Unequal Lengths
Singa wesanga olina abaana nga kumi na mwenda mukibiina, ela nga oyagala batule mubibuzo munyiriri nga biri obba satu zoka okulema okwekoopa, nae nga tezenkana-nkana, osobola okutegela oba batabudwa-tabudwa bulungi ngaweyambisa eno Anagram Distance, singa entula yabwe ekyuka-kyuka buli luvanyuma lwekibuzo ekimu? Obba needa?
—Originally asked in GANDA, UIC (WhatsApp)
What happens if you have to compute the ADM for two sequences that aren’t the same length? Such as if we have to form two or three columns of 19 students in an exam room such that their relative seating order changes after every exam, and so they don’t have a chance to copy each other like when two friends always sit next to each other in two or more exams. Is it feasible? Because looks like the ADM formula wouldn’t be able to handle such cases...
(laughs) Alright, this one is also funny. But yes, we could use the ADM to analyze the ordering of student seat allocation in an examination room between sessions so as to prevent having the same relative ordering across two or more exams sessions. However, some careful modeling would be necessary to make this particular kind of problem scenario readily tractable.
For starters, note that, if we model our classroom as a cartesian grid or matrix of say , meaning it would sit utmost 12 students instead of the 19 that the question is about. This simplification shall make sense, because, as with many kinds of problem solving using mathematics, we many times can solve a hard problem by first solving a simpler version of it. And so, assuming we have this room in which we form 3 columns of seats, and that we wish to ensure we can detect if any two students are sitting close to each other across more than one exam, it is important to note that there are multiple ways this kind of analysis might be done—with some analysis methods likely to be more complicated or difficult to model than others.
For example, a complex analysis situation would be, if we wish to ensure that no two students seat next to each across any two exams, and yet, our meaning of “closeness” or “proximity” takes into considering one’s immediate neighbors in the same column, but also on the same row, and also immediate neighbors by diagonal orientation—essentially, meaning, everyone in a circle around one’s seat, where the radius is like just one seat. This situation or model might be solvable using Anagram Distance Measure, however, it would perhaps mean we apply it in the most unconventional ways, and this lecture was meant for beginners not for professors or PhD mathematics students! So, this analysis scenario should be avoided to keep the discussion and methods simple for most of those in the audience...
Figure 2.
EXAM Seating Analysis: SCENARIO 1 - analyzing in a circle: by rows and columns and diagonals. The positions shaded red indicate the problematic seats given where those students (coded using letters A to K) sat in an earlier exam. The seats in white in the second exam are the ones which share no earlier neighbors, meaning they are malpractice-safe.
Figure 2.
EXAM Seating Analysis: SCENARIO 1 - analyzing in a circle: by rows and columns and diagonals. The positions shaded red indicate the problematic seats given where those students (coded using letters A to K) sat in an earlier exam. The seats in white in the second exam are the ones which share no earlier neighbors, meaning they are malpractice-safe.
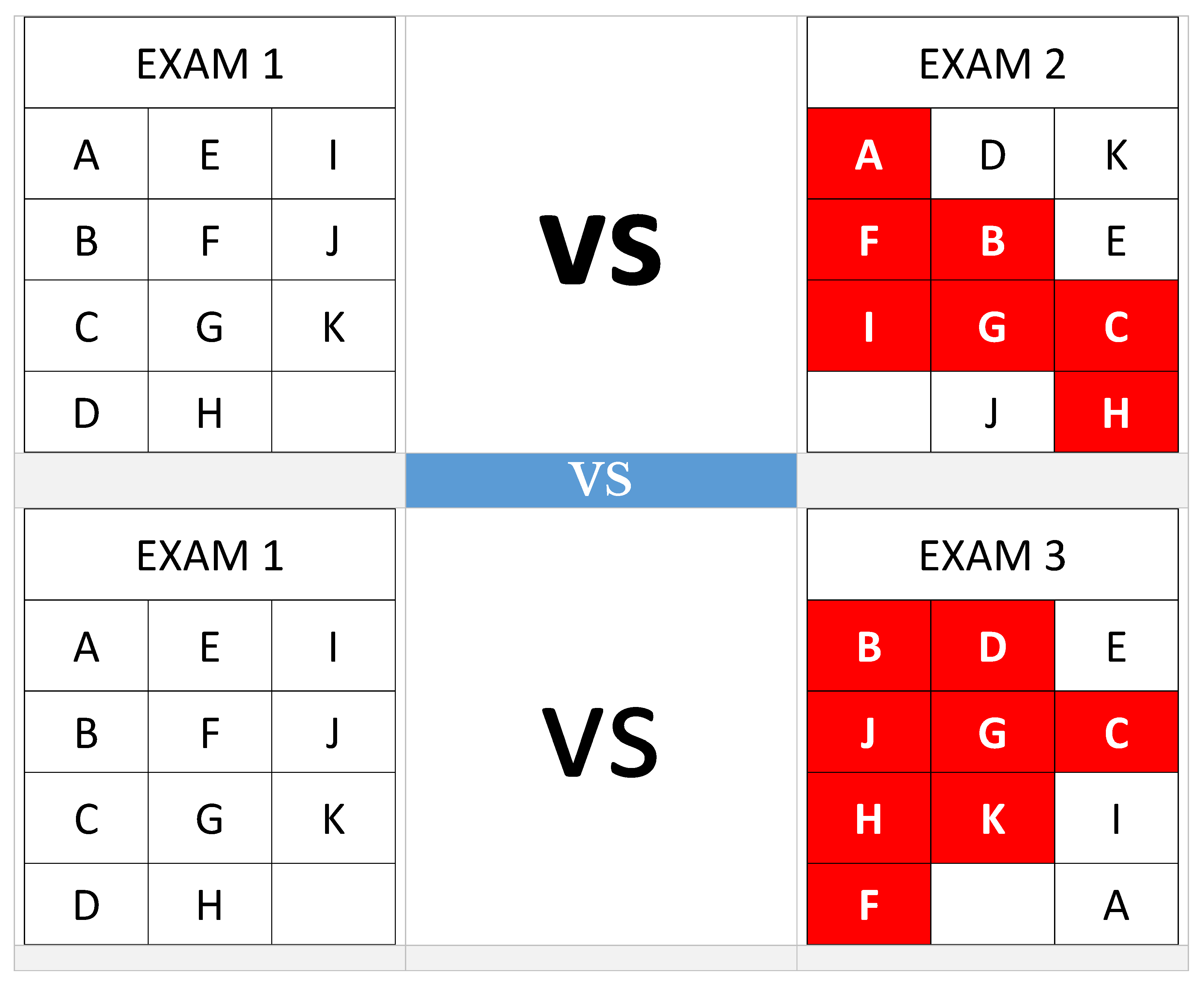
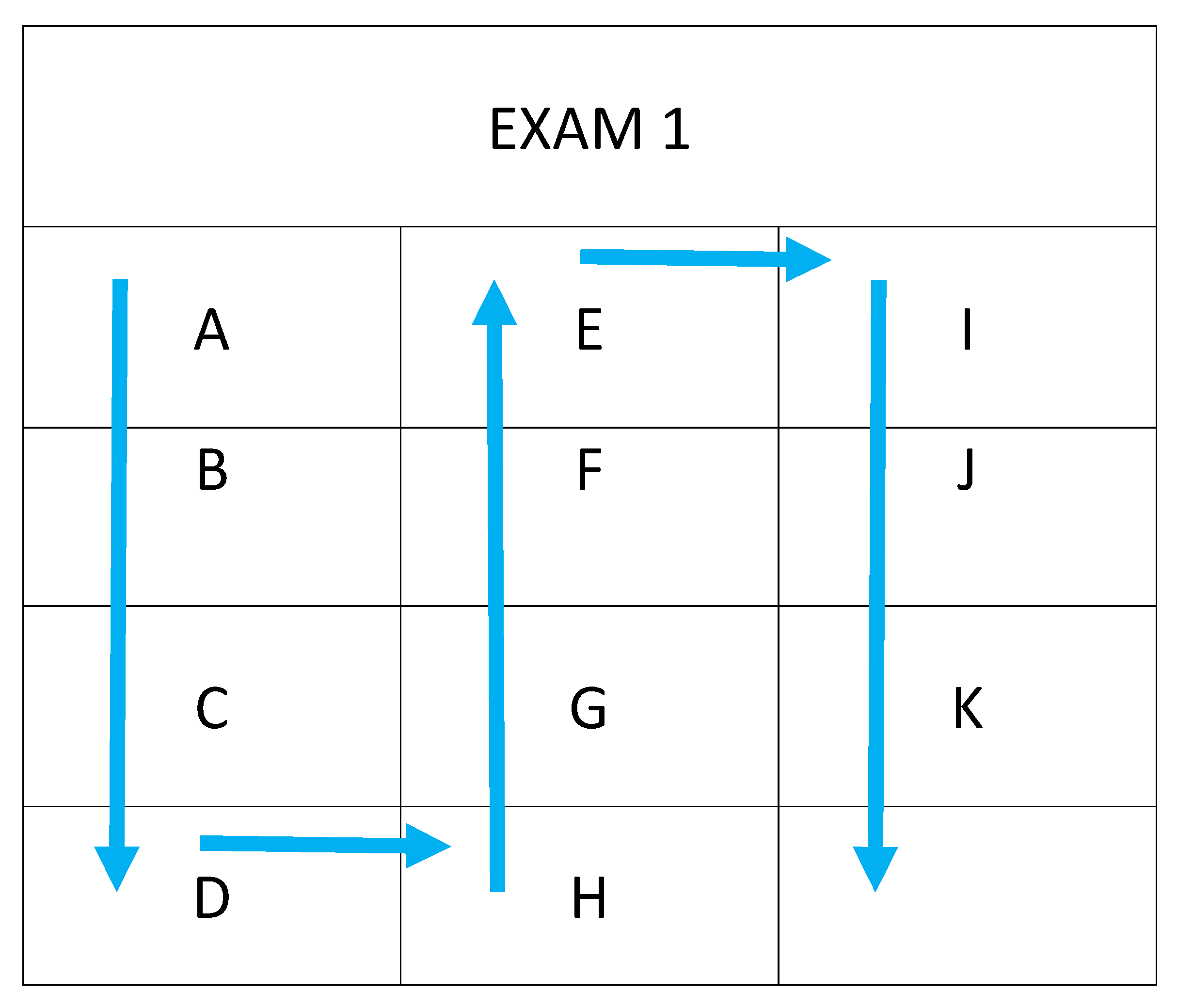
And so, if we are to approach this in a somewhat simpler manner, note that if we ignore the fact that we form two or three columns.. which is like dealing with a higher-order sequence such as a matrix, and instead focus on reducing the ordering to just a long flat sequence that merely wraps around—problems and theory that you’ll find we have covered when dealing with TRANSFORMATICS in GENETICS [8]; for example, like when dealing with sequences of n-grams—then, we can merely treat of all the members in the exam room as elements in one flat-sequence of say seats, or as might do when simplifying our earlier model, as a sequence—perhaps a vector or in computer science terms, a “list”.
With this approach then, using a flat-sequence, it doesn’t even matter how many rows or columns we form in the exam room, all that matters is that we can enumerate the seats one by one in some consistent order from the first to the last, to specify a sequence. We might for example count down the first, left-most column, then up the next column, and then down the next, etc. up to the final column.
Figure 3.
EXAM Basic Seating with Sequential Enumeration.
The more important factor here being that we need to follow the same direction of counting or enumerating the occupied positions such that in all seating arrangements for example, all the first N seats are occupied even though the order of the students was modified since the last exam.
Figure 4.
EXAM Seating Analysis 2.1 - sequential analysis only: EXAM 1 vs EXAM 2.
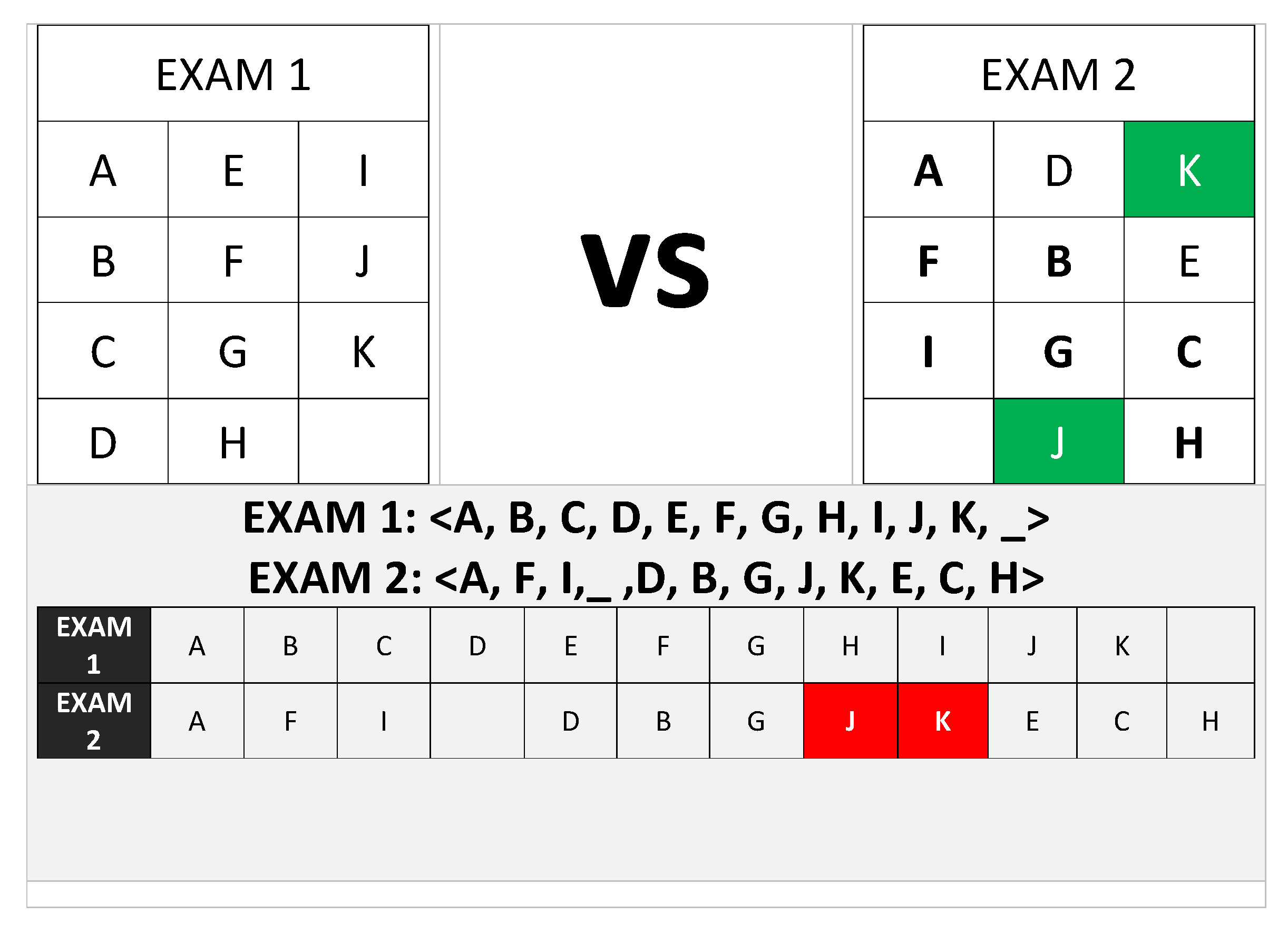
If we do that, then we can merely compute the ADM between any two given seating arrangements as long the students attending the exam are the same and that no two or more students occupy the same seat at the same time.
This can help us determine when we have kept students seated in similar positions for too long, and which might create both stagnation and other intellectual problems in a class community.
Concerning how we would leverage the ADM results, it would be worth noting that the larger the ADM between any pair of seating arrangements being compared, the better. That means, if Exam 1 Vs Exam 2 gives us an ADM value of 0.66, and yet Exam 1 Vs Exam 3 gives us an ADM value of 1.414, then it means the difference between the seating in Exam 1 when compared to that in Exam 3 was more randomized, and thus better.
Figure 5.
EXAM Seating Analysis 2.2 - sequential analysis only: EXAM 1 vs EXAM 3.
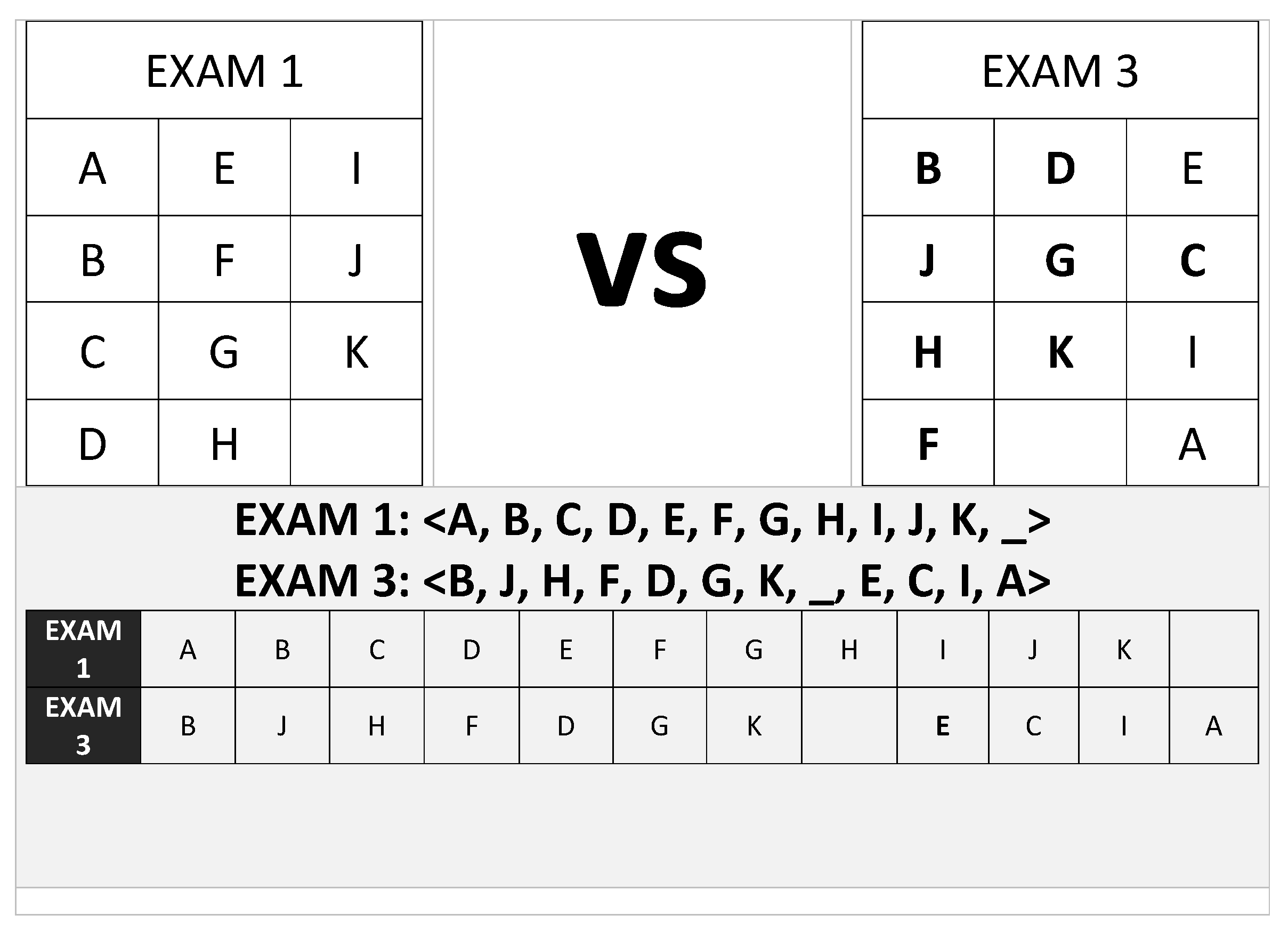
However, in case either there exist seats that are left blank between students when in another session they had been occupied even though the same number of students still are in the exam room, this would need to treated with care when computing the ADM using the standard formula, because then, we would want to assign some labels to those vacant seats—(laughs) perhaps for ghost students—however, the other workaround in such a case might be to merely skip vacant positions as though the neighboring occupied seats were still right next to each other.
The other tricky case would be when some students had to leave between different exams, or that some new or extra students were introduced that weren’t in the other exam sessions we are analyzing against. In such a case then, the ADM as it currently is defined would fail and to use it, one must modify or develop a different version or perhaps they must do what many mathematicians and scientists do when applying their theories to actual problems in nature or reality; either the theory shall need to be somewhat modified—such as being extended or improved—to fit or model the problem better, or that the problem shall need to be modified—such as simplifying it—or that it gets to be modeled differently, so as to suit the existing theory.
In all such cases however, the creative and thoughtful mathematician shall still find a way to be able to use the Anagram Distance idea, but with alternative formulations that might not necessarily look exactly like what we have currently on the blackboard or in the transformatics literature.
What’s most important is the idea. How it is applied can many times be adapted to particular, special or tricky cases. For example, when two sequences of unequal lengths must be compared using the ADM that instead expects sequences of the same length, one workaround—and this shall also be useful when dealing with very large sequences such as genetic or DNA sequences—is to reduce each sequence to just its modal sequence statistic, and instead apply the ADM to those summarized sequence projections. Otherwise, mathematics is mathematics, and once a formula works as proven for a particular model or problem specification, then it shall always continue to be true irrespective of where or who is applying that theory as long as the problem is modified to fit or already fits the theory and corresponding models.
2.8. QUESTION 8: Concerning Other Sequence Analysis Measures in TRANSFORMATICS.
Baitu Iwe Mukama.. Manya Owobusoboozi Rufooka Abaara, tukwenda otwegese emilingo yoona eyokwiha amaraaka n’ebitekerezo omumabale gaikalire omurukurato. Kikuzoka tukengere ADM enu kurungi, baitu hakutekwa kuba haliyo n’amagezi gandi agataina rangi... za TRANSFORMATICS. Mutuyambe, mutwegese philosophy zinu empyaka.
—Originally asked in CWEZI, UIC (Telegram)
That we have liked these mathematical elucidations so much, and have picked up lots of insights concerning what this Anagram Distance Measure and Transformatics is all about. However, what are the other ways in Transformatics by which we might quantify the differences or similarities between sequences or for analyzing items in some sequence? Please educate us more concerning these.
Yes, and thanks for being attentive and picking something or more from all this discussion.
Sure. Transformatics is bigger than just Anagram Distance theory [6]. In fact, if you look at the “Transformatics 101” thesis [1], which lists 10 foundational results for this field, as well as 10 foundational proposed applications of its core theory, you’ll find that ADM is just one of the 10 proposed domains for applying this new mathematics. In the thesis, it is just Proposal #2.
Concerning other methods and theories relating to how to quantity the similarities or differences between sequences, note that the transformatics thesis also lists, introduces but also discusses other ideas such as the TCR—Transformer Compression Ratio27
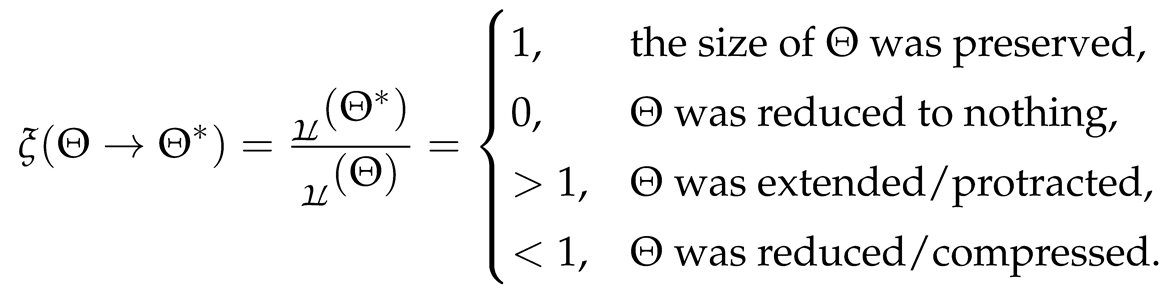
It treats of cases where you care less about the composition and relative ordering of members in any two sequences involved in a transformation and instead only are concerned with whether the cardinalities of the sequences change or not, and by how much in case they do change. It results in a real positive number that can tell us whether a transformation resulted in a protraction (such as when, by adding yeast to baking dough, results in a bread, chapati or mandazi mass occupying a larger volume than without). And if a transform resulted in a compression—such as when the ultra-freezing of a gas results in a liquid that occupies less volume than the original gaseous form of the matter28.
Then in Proposal #4 we find the PCR: the Piecemeal Compression Ratio [1], which also helps in quantifying changes in size across a transformation, however, which, unlike the TCR, looks deeper into the composition of the two sequences involved, and that it focuses on the relative composition of the common subset of elements in either sequence before and after a transformation.
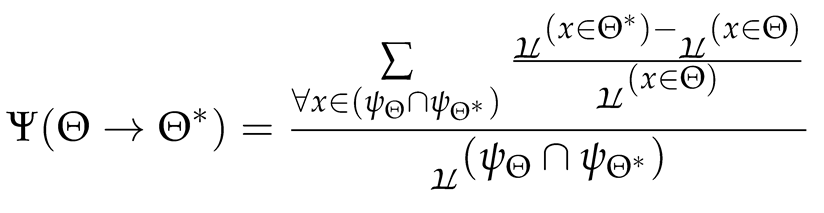
It likewise results in a real number, however, unlike ADM and TCR, the PCR can be negative, in addition to the possibility of being a pure fractional number.
And then, especially when we wish to analyze two sequences of possibly different lengths but which still share a similar symbol set, we also have other measures such as the very useful Modal Sequence Statistic29, MSS, that can also be very useful in building solutions that compare a sequence to a collection of other sequences30 or in problems such as we find in artificial intelligence and machine learning such as classification, clustering and logic leveraging learned decision surfaces.
Then, notice that there might be scenarios such as when one wishes to compare more than two sequences at once, or when one wishes to only analyze a single sequence and nothing else. Some of the other things transformatics has made possible include the ability to compute transforms on any sequence in almost arbitrary ways and for arbitrary ends or purposes, via use of what we call higher-order [sequence] transformers31 such as TEA programs [11,12]. And then, for very special cases, one might wish to compute a single number that somewhat describes or summarizes any kind of sequence32 in the most abstract, philosophical way. In that case, transformatics has proposed a new measure, somewhat in the spirit of Claude Shannon’s 20th century information theoretic measure for information in any arbitrary message; ours is more equipped for doing this for arbitrary messages in the form of sequences, and we call it the sequence entropy measure [1]33.
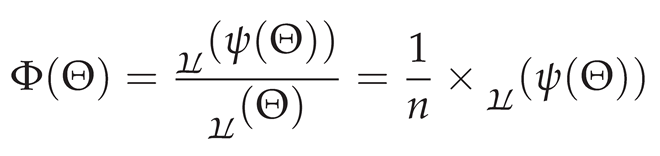
Overall, transformatics, despite being a very young field of Mathematics34 and that most of the work and theory it presents has been developed, applied and reported by a single researcher, myself—Future Professor Joseph Willrich Lutalo35 at Nuchwezi Research36 (yes, that’s me, myself and I), and yet, as time goes on, and as more people become familiar with these ideas, the theory and applications—such as the related new computer programming language TEA: the Transforming Executable Alphabet37, that is based on it—and then the wider body of knowledge, theories and applications leveraging and extending transformatics shall grow and perhaps transform into a compelling mathematical machine or mechanics38 that people can readily leverage to simplify and solve difficult problems not just in this century of ever growing computational complexity, but also for many centuries and millennia to follow hereafter; both in theory and practice; as a beautiful extension of mankind’s universal mathematics language.
3. Conclusions
In this undertaking, a formal interview, we have engaged the founder, inventor of the new theory and sub-field of mathematics known as transformatics, Joseph Willrich Lutalo of Nuchwezi Research and also alumnus of Makerere University, concerning the important introductory lecture he delivered to especially the local and global audience as a video lecture on 3rd February of 2026. The interview, based on questions gleaned from real and hypothetical interactions with members of various Internet Communities that Joseph supports, consists of 8 questions relating to various aspects of transformatics as presented in a single blackboard snapshot that was the basis of all his teaching during that lecture introducing transformatics to beginners, and especially focusing on sequence analysis using the Anagram Distance Measure applied to just two simple sequences of Latin Alphabet letters. The material covered in this interview though, extends significantly beyond just what was introduced in that lecture and the associated blackboard snapshot, covering matters on the notation and terminologies used in transformatics; the various kinds of symbol sets used in sequence analysis; whether or not ADM has finite limits or not and finally, a discussion of some of the other, non-ADM methods that transformatics presents as means of studying and analyzing sequences. Much of what has been discussed is reflected in, and based on the work that Joseph presented in the Transformatics 101 thesis of 2025, however, there is also indication that much of the new theory since then, has also been mentioned in this interview, but that it shall only be well appreciated and presented formally in upcoming papers and a book or more lectures nonetheless! Mathematics keeps growing, and very often stays ahead of its applications across all fields! Thus, given that transformatics is still young, it’s very likely that unless one jumps in and starts to familiarize themselves with what new ground is being broken, many might stay in the dark, and that many otherwise useful applications of this beautiful theory shall remain inaccessible to most until several years later!
ACCESS the INTERVIEW:
Intro & Greetings (13Min):
Part 1 (Q1-Q5) (1Hr):
Part 2 (Q6-Q8) (30Min):
References
- Lutalo, J.W. TRANSFORMATICS 101 - explained. Thesis 2025, p. 20. https://www.academia.edu/144344109/. 20.
- Lutalo, J.W. Philosophical and Mathematical Foundations of A Number Generating System: The Lu-Number System. PrePrints. 2025. Available online: https://www.preprints.org/frontend/manuscript/65675cdcfc92eaced19494771ba02fbd/download_pub.
- Lutalo, J.W. TEA TAZ - Transforming Executable Alphabet A: To Z: COMMAND SPACE SPECIFICATION. Academia.edu. 2024. Available online: https://www.academia.edu/122871672/.
- Lutalo, J.W. A general theory of number cardinality. Academia.edu. 2024. Available online: https://www.academia.edu/43197243/A_General_Theory_of_Number_Cardinality.
- Lutalo, J.W. : The 3 Information Sequence Transformer Families (Anagrammatizers, Protractors, Compressors) and 4 New and Relevant Statistical Measures Applicable to Them: Anagram Distance, Modal Sequence Statistic, Transformation Compression Ratio and Piecemeal Compression Ratio. Academia. 2025. Available online: https://www.academia.edu/download/123730923/TRANSFORMATICS_Theory_Of_Sequence_Transformers_10JUL2025_JWL_NuchweziResearch_v3.pdf.
- Lutalo, J.W. Introducing The Anagram Distance Statistic, Ã, A Quantifier of Lexical Proximity For Base-10 o-SSI And Any Arbitrary Length Ordered Sequences, Its Relevance And Proposed Applications in Computer Science, Engineering And Mathematical Statistics. Academia.edu. 2025. Available online: https://www.academia.edu/download/123454710/arxiv_version_ADT_Anagram_Distance_Theory_paper_25JUNE2025_JWL.pdf.
- Lutalo, J.W. NOVUS MODERNUS GRIMOIRE LUMTAUTO MAGIA - A Modern Grimoire of 5 Eternal Magickal Languages. I*POW. 2025. Available online: https://www.academia.edu/resource/work/145086513.
- Lutalo, J.W. Applying TRANSFORMATICS in GENETICS. I*POW 2025, 1–206. Available online: https://www.academia.edu/143516392/.
- Lutalo, J.W. Concerning A Special Summation That Preserves The Base-10 Orthogonal Symbol Set Identity In Both Addends And The Sum. Academia. 2025. Available online: https://www.academia.edu/download/122499576/The_Symbol_Set_Identity_paper_Joseph_Willrich_Lutalo_25APR2025.pdf.
- Lutalo, J.W. A Comparative Review and Critique of Tree Algebras: Revisiting Gibbons (1991) Thesis in Light of Contemporary Modern Transformatics. In Academia; 2025; Available online: https://www.academia.edu/144711639/.
- Lutalo, J.W. TEA TAZ - Transforming Executable Alphabet A: To Z: COMMAND SPACE SPECIFICATION. Academia.edu. 2024. Available online: https://www.academia.edu/122871672/TEA_TAZ_Transforming_Executable_Alphabet_A_to_Z_COMMAND_SPACE_SPECIFICATION (accessed on 14 May 2025).
- Lutalo, J.W. TEA GitHub Project | The Reference Implementation of TEA (Transforming Executable Alphabet) computer programming language. https://github.com/mcnemesis/cli_tttt/, 2024. Single Source of Truth concerning the reference standards of TEA on the web and native operating systems.
| 1 | |
| 2 | This kind of processing is also similar to families of text transforms one might accomplish with TEA commands such as R: and R!:—refer to latest TAZ [3] for examples and discussion. |
| 3 | Refer to Definition 1 in [6]. |
| 4 | Refer to Chapter 3 of [7]. |
| 5 | Again, more on these kinds of analyses are covered in [7]—see for example Appendix A
|
| 6 | Refer to Result 2 in [1]. |
| 7 | Refer to Definition 6 in [9]. |
| 8 | Refer to Definition 4 in [9]. |
| 9 | Refer to Definition 3 in [9]. |
| 10 | Somewhat like combining the ideas of a natural symbol set,, with an unspecific symbol set,
|
| 11 | Never defined before, but otherwise related to and deriving from the concept of the orthogonal symbol set identity and natural symbol set identity first introduce in Definition 9 and Definition 8 in [9] respectively. |
| 12 | Refer to Section 5.2 of [9], but also note that; apart from this special number being a base-10 o-SSI, it also has other interesting and peculiar properties too; such as being the number (perhaps the only one?) whose factors include all digits from the base-10 symbol set, , except 0 and 7! And though the method hasn’t been properly rigorously developed nor extensively applied, but it is a magical number too; creates chaos from order; such as when used as a seed sequence to generate sequence anagrams or to shuffle lists—see related treatments concerning special RNGs in [8], specifically Chapter 8 that covers the FLSA and SLSA algorithms. |
| 13 | Refer to defined in [8]. |
| 14 | A consequence of Theorem 4 in [9]. |
| 15 | Refer to Result 7 in [1]. |
| 16 | Refer to Result 6 in [1] |
| 17 | Of course, the earlier edition, released under our own I*POW online publisher is still openly accessible via [8], however, this newer, more robust, and richer edition shall be published commercially and physically by Taylor & Francis, a more traditional publisher, most likely starting in 2026. |
| 18 | So that, instead of notations such as we perhaps write —or to expand upon succinct, but similar notations such as —especially so as to help increase or improve the rigor in formalizing such mappings or the transforms they imply, etc. |
| 19 | Refer to Chapter 2, and specifically Transformer 2 in [7]. |
| 20 | Such as in
|
| 21 | Especially when they are numerous or that didiving them across several lines via logical chaining operations such as ∧ and ∨ shall help keep the entire signature clean yet rigorous enough. |
| 22 | For those interested in seeing my earlier work on specifying the limits on the cardinality of the result of any arithmetic operations () when applied to two or more number sequence expressions, checkout the GTNC paper [4]—especially checkout Equation 49 and Equation 50 for the final results. |
| 23 | The GTNC paper [4] first introduced and formally defined the terms “pure fractional number”, “fractional number” and “pure number” among other interesting and useful new mathematical terminologies relevant in not just transformatics, but also fields like number theory and all of mathematics! |
| 24 | Plus, we don’t want to attempt the impossible by trying to divide by 0 anyways! |
| 25 | NOTE: —also refer to Result 4 in [1]. |
| 26 | This is well presented in [EQADMSUMMARY]Equation 3 here, and which somewhat is a better formulation of the relation between the two terms in the ratio specifying the ADM than an earlier equation such as Equation 6 in [6]—essentially, that the denominator is not part of the summation happening in the numerator and thus could be either pulled out in the original formulation—such as in [ADMFORMULA]Equation 1, or might otherwise be treated as a constant. |
| 27 | Also that we might sometimes just refer to as “Transformation Compression Ratio”, and which is covered in Proposal 3 in [1]. |
| 28 | A consequence of liquid being a generally denser form than gases based on natural laws. However compression and liquefaction under freezing has some exceptions; famous outliers might be such as the case water vapour; which, when frozen, might skip the liquid step altogether and directly go to solid (as frost), and also that, though generally freezing might compress matter, and yet, for substances like water, its solid form as ice somewhat occupies more space than the liquid! |
| 29 | See Proposal 5 in [1]. |
| 30 | Refer to Scenario D in Section 6.6 of [8]. |
| 31 | Refer to Proposal 9 in [1]. |
| 32 | Such as with Gdel numbers—see Chapter 6, Section 6.7 of [8]. |
| 33 | Refer to Proposal 10 in [1]. |
| 34 | The first attempt at defining the field and foundation theories [5] only occurred in mid 2025! |
| 35 | Follow via Google Scholar: https://scholar.google.com/citations?user=68FYSDcAAAAJ&hl=en
|
| 36 | Visit https://nuchwezi.com
|
| 37 | Refer to TEA Project Homepage: https://tea.nuchwezi.com
|
| 38 | Hopefully not a beast! |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



