Submitted:
03 February 2026
Posted:
04 February 2026
Read the latest preprint version here
Abstract
Text-attributed graph node classification is still a challenge since it needs to reason about the topology structure simultaneously with the free-text semantics. Although graph neural network can perform well on structural propagation,they tend to be blind for the details in the text associated with nodes. On the other hand, LLMs have excellent NLU skills and are weak on structured,multi-hop reasoning over network agents.To address the above gap, in this work we propose FinSCRA, a novel LLM-powered multi-chain reasoning framework to inject domain-aware reasoning capability into a financial LLM with parameters efficient fine-tuning. Specifically, our framework designs a hierarchy of structured reasoning chains (single-hint,parallel, cascaded, and hybrid methods to extract and fuse the semantic signals like sentiment, correlation, and risk signals in the nodes’ text.A fusion layer based on fuzzy logic fuses the results of different reasoning lines for better robustness and explainability.While FinSCRA is generic and can be applied to other types of text-attributed graphs, here we assess its performance on credit risk analysis in supply chain networks,on the task of entity relation extraction, in which entities are related through their financial relation and described with rich text reports; we show experimentally on realworld datasets that our model FinSCRA greatly outperforms graphbased as well as LLM-based baselines,as an accurate and explainable technique to perform node classification over complex networked systems.We release our code and models for further research on LLM-grap.
Keywords:
FinLLM
; explainable AI
; supply chain risk
; credit risk
I. Introduction
The combination of both structural and semantic reasoning in the context of complex networked systems poses an important algorithmic problem, especially where nodes represent rich unstructured text [1]. While traditional graph-based algorithms have been successful in modelling the topological propagation, cannot capture or understand the subtle semantic information within text attached on nodes.On the other hand, recent works like ESIB emphasize filtering textual redundancy to capture essential reasoning features [2]. Furhthermore, LLMs demonstrate strong natural language understanding while failing at structured, multi-hop reasoning which involves not only the network topology but also the specific domain knowledge [3].
In this paper, we propose FinSCRA, a novel reasoning framework that algorithmically unifies graph-aware structural induction with finetuned linguistic reasoning via a FinLLM. Our core contribution is a structured multiple-chain reasoning mechanism that decomposes complex node classification into a series of interpretable, intermediate inference steps. FinSCRA instead performs promptbased hierarchical chain-of-thought (CoT) reasoning on the given text rather than using them as pure features—single-hint, parallel, cascading, and hybrid approaches – to explicitly mine and combine risk indicative signals (e.g., sentiment, network correlation)and tags. These chains are designed for simulating systematic thinking both on the text space and also on the topology space.
To ground our FinLLM on domain-aware reasoning, we utilize Low-Rank Adaption(LoRA) to inject knowledge efficiently [4]. Lastly, we design a multi-chain decision fusion module to fuse the results of different reasoning chains through fuzzy aggregation and centroid defuzzification, improving robustness and/or interpretability [5].
Our work makes three key algorithmic contributions:
- (1)
- We formulate node classification in text-attributed graphs as a multi-chain reasoning problem and propose a modular prompting architecture to support scalable and interpretable inference.
- (2)
- We finetune a FinLLM in an efficient manner so that it can perform the kind of reasoning chain we expect from domain-informed knowledge with sufficient expressiveness while remaining computationally tractable.
- (3)
- A fusion method to aggregate the outcomes of multi-view reasoning for better accuracy and explainability in decision making process.
Although our proposal can be applied to arbitrary text-attributed graphs, we showcase it on a concrete application scenario for credit risk assessment of supply chains — an area where there are abundant text descriptions as well as intricate dependencies between different parties [7]. We conduct experiments with two public SC datasets, showing that FinSCRA achieves superior performance over pure graphbased models or vanilla LLMs, concluding that it is indeed an effective and interpretable reasoning tool over relational information.
II. Related Work
Graph Neural Networks and Reasoning. Graph based approaches has seen tremendous progresses towards the modelling of relational data, where Graph Neural Network (GNNs) enable to perform effi- cient nodes and graph level representation via message passing [7,8]. However, most GNNs work with homogenous or numeric node features, and do not reason over unstructured text. Beyond the above-mentioned graph-based approaches, deep learning models have been extensively used in a variety of financial risk applications.e.g., Ke et al.(2025), who built a crypto reversal early-warning system based on regulation signal and external sentiments; their multiple sources information fusion method brought us useful methodological inspirations on designing our hierarchical reasoning structure to capture different text clues [9].
LLM-based Structured Reasoning. CoT prompt and its variations show the potential to decompose a complex question into several reasoning steps [10]. On graphs, however, most LLMs are still restricted in single-node/single-hop QA tasks and approaches like Graph-CoT try to generalize CoT on the graph yet they mostly view the topology as static background knowledge instead of dynamic interaction between text-based reasoning [10]. In this vein, we propose to build the reasoning chain topologyaware in such a way that it can connect text evidences between nodes explicitly.
Multi-Modal Learning over Text-Attributed Graphs. Recently, the study of TAGs aims at jointly modeling structure and semantic information. Methods include using pretrained language models to encode texts then propagating in graphs, or leveraging GNNs to polish the text-enhanced embedding [11,12]. Although effective, such methods generally fuse modalities on representation-level instead of reasoninglevel which misses the chance to reason in a step-wise, interpretable inference similar to what humans do.
Lightweight Fine-Tuning. Efficient parameter efficient tuning approaches like LoRA allow for fast domain adaption of large language models at low cost [6]. For graphs, however, they are still not well-explored, in particular for the task of reasoning-heavy applications [14]. FinSCRA uses LoRA to inject domain-specific reasoning capability into a FinLLM, teaching it to gain this structure-based inference ability without losing its general language knowledge.
Conventional credit risk models concentrate on firm-level financial well-being [15,16]. The network view sees that the risk of a firm as system-wide contagious. Graph-theoretic, epidemic and cascading failure algorithms [17] have all been used to model the contagion of risk through financial networks.While these models can be used for flow simulation, their empirical scopes are often constrained to quantitative network data, where no incorporation of qualitative text-based early warning signal is allowed.
Reasoning View Aggregation. Ensemble and fusion methods have been extensively studied by the ML community, however they haven’t been applied for multiple chain LLM reasoning yet [18]. In FinSCRA we propose a fuzzy aggregation technique that aggregates output of different reasoning views, providing a principled approach for resolving disagreements and reinforcing agreement thus improving the robustness of decisions as well as their transparency.
III. Model
Figure 1 shows FinSCRA framework proposed to evaluate the credit risk of multiplex supply chain entities by the reasonings over concurring financial texts, including 3 constituent parts: (1) supply chain risk knowledge injection, (2) hierarchical reasoning chain construction, (3) multi-chain decision fusion.
A. Task Definition
For given multi-plexed SCN G with entities (nodes) V, and corpora of financial texts Tv for each entity v∈V (e.g., news articles, earnings reports, regulatory filings), the task is to assign a credit risk category(e.g., High Risk, Medium Risk, Low Risk) to each entity [19,20]. The model should also identify and output a set of risk hints that explain the reasoning behind the classification, drawing on the contents of Tv.
B. Supply Chain Risk Knowledge Injection
To imbue the generic LM with domain knowledge, we lightly-tune on a curated dataset of SC risk instances [21]. To do lightweighttuning, we utilize Low-Rank Adaptation (LoRA)—that modifies only a low-rank matrix in our setting—to update a small number of parameters and therefore can perform this task on limited hardware [22,23,24].We fix LoRA rank r = 16 and scaling factor α= 32, insert adapters to QKV projection and output projection of every self-attention layer of the ChatGLM3-6B model and train it for 10 epochs with batch size 8, using the AdamW optimizer (learning rate 2*) [25].
Instruction-Tuning Corpus: We construct a dataset Z={()} of 12, 000 examples, where is a textual context describing a supply chain entity and its situation, and is the target risk classification along with explanatory hints [26,27,28,29,30]. The dataset is balanced across the three risk categories (High, Medium, Low). Each example is formatted using a structured prompt that incorporates key supply chain risk concepts (e.g., supplier concentration, geopolitical exposure). [31]
FinLLM Choice: Our choice of base model is ChatGLM3-6B because it has good performance on Chinese (which applies to our dataset).open-source aspect, and compactness to balance efficiency against deployability and privacy of user’s data [32]. We employ the base variant without further dialogue finetuning.
C. Hierarchical Reasoning Chain Construction
Naively asking the LLMs to predict risk might lead to superficial answers [33]. FinSCRA decomposes the prediction task as a sequence of easier sub-tasks via wellstructured reasoning chain [34,35,36]. We find there are three important risk hints which need to be mined out from texts. Risk Keywords (): A set of key terms or phrases from the text indicative of specific supply chain risks (e.g., “production halt, ” “payment delay, ” “trade sanction”).
As shown in Figure 1, we design the following four kinds of reasoning chains for utilizing such hints: Single-Hint Chain (C1-C3): Only use a single hint(e.g., (C4): extracts each of the three hints separately, then concatenate them as a whole for final judgement. Cascading MultiHints Chain (C5): extract the hints in order, where the output of a previous (e.g., sentiment) is used to provide context for extracting the following (e.g., correlation).Multi-Hints Hybrid Chain (C6-C7): A hybrid chain (i.e., the combination of multiple strategies, e.g., we use both sentiment and correlation together for guiding keyword extraction).
Prompt Design and Neighbor Selection: Each chain applies a series of templated prompts [37,38,39]. For example, the prompt for extracting is: “Given the following financial news about [Entity]: {Text Snippet}. Assess the overall sentiment from a credit risk perspective. Choose one: Positive, Neutral, Negative.”
To compute , we first identify neighboring entities in the graph that are co-mentioned in the text [40,41,42]. We select up to 5 direct neighbors with the highest textual co-occurrence frequency. The prompt then incorporates this neighbor list: “The news mentions the following related companies: {Neighbor List} [43,44,45]. Which of them are described as having financial difficulties that might affect [Entity]?”
Textual Context Formation: For each entity v, we construct the input text {CONTENT}by concatenating the titles and leading paragraphs of up to 5 most recent financial news articles from , ensuring the total length does not exceed 512 tokens.
D. Multi-Chain Decision Fusion
Since different reasoning paths can produce different risks because of the semantics hints, we propose a fuzzy rule based ensemble strategy to fuse results from multiple paths, therefore helping to make decision-making stronger and transparent.
First, the output of each reasoning chain is transformed into a fuzzy membership vector ∈, where K denotes the number of risk categories (e.g., High, Medium, Low) [46,47,48]. A learnable mapping function converts the raw chain output—comprising the answer and explanation —into fuzzy membership degrees [49,50,51]:
Here, is implemented as a lightweight feedforward network trained on human-annotated fuzzy membership labels, ensuring alignment with domain-specific risk semantics [52].
Subsequently, the fuzzy outputs from all N chains are aggregated via a weighted average scheme:
where represents a confidence weight assigned to chain . These weights can be optimized using validation data or set uniformly if no prior preference exists [53].
Finally, centroid defuzzification is applied to the aggregated fuzzy set to obtain a crisp risk category:
IV. Experiments
A. Experiment Settings
SCRD (Supply Chain Risk Dataset): The dataset consists of 5, 000+ Chinese listed companies with annotated SC relations as well as credit risk labels (High, Medium, Low) from the financial reports and news of period 2018–2023. In order to avoid temporal leakage and mimic real-world forecasting, we follow a hard chronological split [56,57]: Train set (2018-2021): ca. 3, 000 entities (60%) based on documents with date no later than December 31, 2021. Validation Set (2022): ~1, 000 entities (20%), with texts strictly from the year 2022Test Set (2023): ~1, 000 entities (20%), with texts strictly from the year 2023. We further remove duplicate news articles that appear across different years and verify that no test entity has textual data overlapping with the training period.
FinNews-Risk: This is a public dataset containing financial news articles annotated for company specific risk events which we use only to pre-train the hint extraction modules [58]. In order not to contaminate the main SCRD evaluation, we split it randomly to 80% train / 10% val / 10% test without overlapping entities with SCRD test.
Evaluation Metrics: We formulate the risk prediction task as a multi-class classification problem and measure node-level performances by Accuracy, Macro-Averaged Precision, Recall and F1-Score.
Implementation Details: Experiments are carried out in 4×NVIDIA A6000 GPUs with the help of the HuggingFace Transformers and PEFT libraries [59,60]. We set the max input sequence length as 512 tokens, and for each entity we concatenate at most 5 latest news articles (if any are present). Average inference time per entity is 2.3 sec. We shall release code and config files with the paper.
B. Multi-Chain Decision Fusion
We compare FinSCRA against several baselines:
Graph-based: GFHF, SMRW, OMNI-Prop (classic label propagation on the network topology only).
LLM-based: Vanilla ChatGLM3-6B, Qwen2-7B-Instruct (zero-shot and few-shot) [22].
Finance-specific LLM: DISC-FinLLM (fine-tuned on general finance corpus).
BERT+GCN: We encode each node’s text using a pre-trained BERT model, take the [CLS] vector as the node feature, and apply a 2-layer Graph Convolutional Network (GCN) for classification.
GraphSAGE+RoBERTa: We use RoBERTa to generate text embeddings, which are then aggregated via GraphSAGE with mean pooling over neighbor embeddings.
FinSCRA is much better than all baselines showing that combining text reasoning and network-aware risk calculation work nicely. The LM methods do not work well without reasoning structures tuned for tasks, and the graph-only methods fail to capture informative textual signals.

Table 1.
Performance Comparison on SCRD.
| Model | Accuracy | Macro-F1 | Precision | Recall |
|---|---|---|---|---|
| GFHF | 0.543 | 0.49 | 0.502 | 0.4689 |
| SMRW | 0.738 | 0.749 | 0.738 | 0.7615 |
| OMNI-P | 0.727 | 0.735 | 0.727 | 0.7419 |
| ChatGL | 0.326 | 0.271 | 0.174 | 0.3281 |
| Qwen2 | 0.523 | 0.474 | 0.21 | 0.5615 |
| BERT+ | 0.782±0.01 | 0.776±0.01 | 0.781±0.01 | 0.773±0.010 |
| Graph+ | 0.791±0.01 | 0.785±0.01 | 0.789±0.01 | 0.782±0.009 |
| FinSCR | 0.850±0.01 | 0.841±0.01 | 0.845±0.01 | 0.838±0.008 |
Significance & Per Class Metrics: We execute every experiment for 5 different random seed, and present average and standard deviation. In order to check the significance, we conduct a paired t-test of FinSCRA vs the best baseline (GraphSAGE+RoBERTa) over the Macro-F1 scores across seeds;is the improvement is statistically signifi- cant (p < 0.01).Per-class results including Precision, Recall and F1 are presented in Table 2 belw which shows that FinSCRA significantly surpasses the baselines on every class, especially for the more difficult “High Risk” category.
C. Ablation Study
We verify the contribution of main elements: Impact of Reasoning Chains: The use of only one-hint chains leads to worse performances (F1 ~0.67). The multi-hint chains lead to better results, and our fusion of all 7 chains performs the best (F1 0.8405) which confirms that different perspective of reasoning is valuable; Fine-tuning Effect: using prompt-tuning v2, or the base model w/o fine-tune instead of Finetuning LoRA leads to big loss on performances(F1 drop more than 25%);) that proves to be effective in injecting the knowledge of the domain. Effect of Hints: Without the hint extraction step (direct classification) our method loses explainability as well as accuracy, indicating that the intermediate reasoning steps help provide a hand for guiding the model.
D. Case Study
We give an example explaining the cascade risk contagion from a largest consumer of batteries for cars (Company A) to its biggest battery lithium supplier (Company B) in 2023. When inputting recent news (i.e., production delay due to the shortage of supply chain of Company A) to FinSCRA, it reveals through its explanation graphs that (1) there is an upcoming product (P1) by Company A and it is crucial to all the markets of Company A (i.e., for Company A’s products, they are unable to sell without P1 from Company A’s suppliers); (2) there is a limited time budget for acquiring P1; (3) the raw resources (i.e., P2) of P1 is produced by Company B, which mainly rely on import (i.e., P2 produced by its domestic factory and imported from Company C); (4) Company C just now faced economic pressure from another industry (i.e., it need to invest in P3); (5) and there are just five days left for producing P2 from Company C. : Negative.
: Strong (explicit mention of Supplier B as the cause).
: {production delay, bottleneck, supply shortage}.
Although the cascading chain reasoning went through the negative sentiment to reason by the correlation, then identified the specific risk keywords, finSCRA made its risk score of Company B High several days ahead of Company B itself revealing financial distress, indicating finSCRA’s capacity of providing earlier warning.
V. Conclusions and Suggestions
In this paper, we presented FinSCRA, an algorithmically structured reasoning framework that integrates finetuned FinLLMs with multi-chain prompting to perform interpretable node classification in text-attributed graphs. The core of our approach lies in its hierarchical reasoning design, which breaks down the inference process in textand topology-wise sub-processes, and a parameter-efficient adaption method to bridge the gap between LLMs and the knowledge-driven logical reasoning rules.
Although FinSCRA can be applied for any domain with graphs associated and textual information, we test our model on a case study dealing with supply chain networks, where entities are related by financial relationship, and described with rich texts reports. Experiments on the real world supply-chain risk dataset show that our approach is superior to existing baseline, checking whether it can use the structure as well as language for reasoning in a correct and explainable way.
References
- Maheshwari, H.; Bandyopadhyay, S.; Garimella, A.; Natarajan, A. Presentations are not always linear! GNN meets LLM for document-to-presentation transformation with attribution. arXiv 2024, arXiv:2405.13095. [Google Scholar] [CrossRef]
- Li, W.; Zhou, H.; Yu, J.; Song, Z.; Yang, W. Coupled mamba: Enhanced multimodal fusion with coupled state space model. Advances in Neural Information Processing Systems 2024, 37, 59808–59832. [Google Scholar]
- Das, D.; Gupta, I.; Srivastava, J.; Kang, D. Which modality should I use-text, motif, or image?: Understanding graphs with large language models. Findings of the Association for Computational Linguistics: NAACL 2024, 2024, June; pp. 503–519. [Google Scholar]
- Ouyang, K.; Ke, Z.; Fu, S.; Liu, L.; Zhao, P.; Hu, D. Learn from global correlations: Enhancing evolutionary algorithm via spectral gnn. arXiv 2024, arXiv:2412.17629. [Google Scholar] [CrossRef]
- Refael, Y.; Arbel, I.; Lindenbaum, O.; Tirer, T. LORENZA: Enhancing generalization in low-rank gradient LLM training via efficient zeroth-order adaptive SAM. arXiv 2025, arXiv:2502.19571. [Google Scholar] [CrossRef]
- Wan, W.; Zhou, F.; Liu, L.; Fang, L.; Chen, X. Ownership structure and R&D: The role of regional governance environment. International Review of Economics & Finance 2021, 72, 45–58. [Google Scholar] [CrossRef]
- Ogbuonyalu, U. O.; Abiodun, K.; Dzamefe, S.; Vera, E. N.; Oyinlola, A.; Igba, E. Beyond the credit score: The untapped power of LLMS in banking risk models. Finance & Accounting Research Journal 2025. [Google Scholar]
- Wei, D.; Wang, Z.; Kang, H.; Sha, X.; Xie, Y.; Dai, A.; Ouyang, K. A comprehensive analysis of digital inclusive finance’s influence on high quality enterprise development through fixed effects and deep learning frameworks. Scientific Reports 2025, 15(1), 30095. [Google Scholar] [CrossRef]
- Ke, Z.; Cao, Y.; Chen, Z.; Yin, Y.; He, S.; Cheng, Y. Early warning of cryptocurrency reversal risks via multi-source data. Finance Research Letters 2025, 107890. [Google Scholar]
- Nguyen, M. V.; Luo, L.; Shiri, F.; Phung, D.; Li, Y. F.; Vu, T.; Haffari, G. Direct evaluation of chain-of-thought in multi-hop reasoning with knowledge graphs. Findings of the Association for Computational Linguistics: ACL 2024, 2024, August; pp. 2862–2883. [Google Scholar]
- Roy, A.; Yan, N.; Mortazavi, M. Llm-driven knowledge distillation for dynamic text-attributed graphs. arXiv 2025, arXiv:2502.10914. [Google Scholar] [CrossRef]
- Wang, Qin; Huang, Bolin; Liu, Qianying. Deep Learning-Based Design Framework for Circular Economy Supply Chain Networks: A Sustainability Perspective. In Proceedings of the 2025 2nd International Conference on Digital Economy and Computer Science (DECS ‘25); Association for Computing Machinery: New York, NY, USA, 2026; pp. 836–840. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, L.; Fang, L. An Enhanced Credit Risk Evaluation by Incorporating Related Party Transaction in Blockchain Firms of China. Mathematics 2024, 12(17), 2673. [Google Scholar] [CrossRef]
- Ilyushin, P.; Gaisin, B.; Shahmaev, I.; Suslov, K. An Algorithm for Identifying the Possibilities of Cascading Failure Processes and Their Development Trajectories in Electric Power Systems. Algorithms 2025, 18(4), 183. [Google Scholar] [CrossRef]
- Tapia-Rosero, A.; Bronselaer, A.; De Mol, R.; De Tré, G. Fusion of preferences from different perspectives in a decision-making context. Information fusion 2016, 29, 120–131. [Google Scholar] [CrossRef]
- Zheng, H.; Lin, Y.; He, Q.; Zou, Y.; Wang, H. Blockchain Payment Fraud Detection with a Hybrid CNN-GNN-LSTM Model. 30 January 2026. Available online: Https://Www.researchgate.net/Publication/400235797_Blockchain_Payment_Fraud_Detection_with_a_Hybrid_CNN-GNN-LSTM_Model. [CrossRef]
- Ke, Zong; Shen, Jiaqing; Zhao, Xuanyi; Fu, Xinghao; Wang, Yang; Li, Zichao; Liu, Lingjie; Mu, Huailing. A stable technical feature with GRU-CNN-GA fusion. Applied Soft Computing 2025, 114302. [Google Scholar] [CrossRef]
- McCoy, R. T.; Pavlick, E.; Linzen, T. Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference. arXiv 2019, arXiv:1902.01007. [Google Scholar] [CrossRef]
- He, Yangfan; Li, Sida; Wang, Jianhui; Li, Kun; Song, Xinyuan; Yuan, Xinhang; Li, Keqin; et al. Enhancing low-cost video editing with lightweight adaptors and temporal-aware inversion. arXiv 2025, arXiv:2501.04606. [Google Scholar] [CrossRef]
- Sui, Mingxiu; Su, Yiyun; Shen, Jiaqing; et al. Intelligent Anti-Money Laundering on Cryptocurrency: A CNN-GNN Fusion Approach. Authorea 2026. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, G.; Wang, H.; Li, J.; Zhang, C. Multi-scale video super-resolution transformer with polynomial approximation. IEEE Transactions on Circuits and Systems for Video Technology 2023, 33(9), 4496–4506. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, R.; Wang, T. Self-Destructive Language Model. arXiv 2025, arXiv:2505.12186. [Google Scholar] [CrossRef]
- He, Yangfan; Wang, Jianhui; Li, Kun; Wang, Yijin; Sun, Li; Yin, Jun; Zhang, Miao; Wang, Xueqian. Enhancing intent understanding for ambiguous prompts through human-machine co-adaptation. arXiv 2025. [Google Scholar] [CrossRef]
- Yu, Z.; Idris, M. Y. I.; Wang, P. Visualizing our changing Earth: A creative AI framework for democratizing environmental storytelling through satellite imagery. The Thirty-ninth Annual Conference on Neural Information Processing Systems Creative AI Track: Humanity; 2025. [Google Scholar]
- Zhang, F.; Chen, G.; Wang, H.; Zhang, C. CF-DAN: Facial-expression recognition based on cross-fusion dual-attention network. Computational Visual Media 2024, 10(3), 593–608. [Google Scholar] [CrossRef]
- Kang, Zhaolu; Gong, Junhao; Yan, Jiaxu; Xia, Wanke; Wang, Yian; Wang, Ziwen; Ding, Huaxuan; et al. HSSBench: Benchmarking Humanities and Social Sciences Ability for Multimodal Large Language Models. arXiv 2025, arXiv:2506.03922. [Google Scholar] [CrossRef]
- Ouyang, K.; Fu, S.; Chen, Y.; Chen, H. Dynamic Graph Neural Evolution: An Evolutionary Framework Integrating Graph Neural Networks with Adaptive Filtering. 2025 IEEE Congress on Evolutionary Computation (CEC), 2025, June; IEEE; pp. 1–8. [Google Scholar]
- Liu, S.; Xu, S.; Qiu, W.; Zhang, H.; Zhu, M. Explainable reinforcement learning from human feedback to improve alignment. arXiv 2025, arXiv:2512.13837. [Google Scholar] [CrossRef]
- Li, Y.; Yang, J.; Yun, T.; Feng, P.; Huang, J.; Tang, R. Taco: Enhancing multimodal in-context learning via task mapping-guided sequence configuration. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, November; pp. 736–763. [Google Scholar]
- Guo, H.; Wu, Q.; Wang, Y. AUHF-DETR: A Lightweight Transformer with Spatial Attention and Wavelet Convolution for Embedded UAV Small Object Detection. Remote Sensing 2025, 17(11), 1920. [Google Scholar] [CrossRef]
- Shi, Ge; Liu, Jiahang; Yang, Chang; An, Quan; Tian, Zhuang; Chen, Chuang; Zhang, Jingran; Li, Xinyu; Zhang, Yunpeng; Xu, Jinghai. Study on the spatiotemporal evolution of urban spatial structure in Nanjing’s main urban area: A coupling study of POI and nighttime light data. Frontiers of Architectural Research 2025, 14(6), 1780–1793. [Google Scholar] [CrossRef]
- Zeng, Yiming; Yu, Wanhao; Li, Zexin; Ren, Tao; Ma, Yu; Cao, Jinghan; Chen, Xiyan; Yu, Tingting. Bridging the Editing Gap in LLMs: FineEdit for Precise and Targeted Text Modifications. arXiv 2025. [Google Scholar] [CrossRef]
- He, L.; Tang, P.; Zhang, Y.; Zhou, P.; Su, S. Mitigating privacy risks in Retrieval-Augmented Generation via locally private entity perturbation. Information Processing & Management 2025, 62(4), 104150. [Google Scholar] [CrossRef]
- Zhao, Y.; Dai, C.; Zhuo, W.; Xiu, Y.; Niyato, D. CLAUSE: Agentic Neuro-Symbolic Knowledge Graph Reasoning via Dynamic Learnable Context Engineering. arXiv 2025, arXiv:2509.21035. [Google Scholar] [CrossRef]
- Hou, Y.; Xu, T.; Hu, H.; Wang, P.; Xue, H.; Bai, Y. MdpCaps-CSL for SAR image target recognition with limited labeled training data. IEEE Access 2020, 8, 176217–176231. [Google Scholar] [CrossRef]
- Yuan, Keyu; Lin, Yuqing; Wu, Wenjun; et al. Detection of Blockchain Online Payment Fraud Via CNN-LSTM. Authorea 2026. [Google Scholar] [CrossRef]
- Shen, J. L.; Wu, X. Y. Periodic-soliton and periodic-type solutions of the (3+ 1)-dimensional Boiti–Leon–Manna–Pempinelli equation by using BNNM. Nonlinear Dynamics 2021, 106(1), 831–840. [Google Scholar] [CrossRef]
- Min, M.; Duan, J.; Liu, M.; Wang, N.; Zhao, P.; Zhang, H.; Han, Z. Task Offloading with Differential Privacy in Multi-Access Edge Computing: An A3C-Based Approach. IEEE Transactions on Cognitive Communications and Networking 2026. [Google Scholar] [CrossRef]
- Li, Yanshu; Cao, Yi; He, Hongyang; Cheng, Qisen; Fu, Xiang; Xiao, Xi; Wang, Tianyang; Tang, Ruixiang. M²IV: Towards efficient and fine-grained multimodal in-context learning via representation engineering. Second Conference on Language Modeling; 2025. [Google Scholar]
- Luo, J.; Wu, Q.; Wang, Y.; Zhou, Z.; Zhuo, Z.; Guo, H. MSHF-YOLO: Cotton growth detection algorithm integrated multi-semantic and high-frequency features. Digital Signal Processing 2025, 167, 105423. [Google Scholar] [CrossRef]
- He, L.; Li, C.; Tang, P.; Su, S. Going Deeper into Locally Differentially Private Graph Neural Networks. Forty-second International Conference on Machine Learning; 2025. [Google Scholar]
- Ma, Ke; Fang, Yizhou; Weibel, Jean-Baptiste; Tan, Shuai; Wang, Xinggang; Xiao, Yang; Fang, Yi; Xia, Tian. Phys-Liquid: A Physics-Informed Dataset for Estimating 3D Geometry and Volume of Transparent Deformable Liquids. arXiv 2025, arXiv:2511.11077. [Google Scholar] [CrossRef]
- Zhao, Y.; Dai, C.; Xiu, Y.; Kou, M.; Zheng, Y.; Niyato, D. ShardMemo: Masked MoE Routing for Sharded Agentic LLM Memory. arXiv 2026. Available online: https://arxiv.org/abs/2601.21545. [CrossRef]
- Hou, Y.; Wang, Y.; Xia, X.; Tian, Y.; Li, Z.; Quek, T. Q. Toward Secure SAR Image Generation via Federated Angle-Aware Generative Diffusion Framework. IEEE Internet of Things Journal 2025, 13(2), 2713–2730. [Google Scholar] [CrossRef]
- Li, Long; Hao, Jiaran; Liu, Jason Klein; Zhou, Zhijian; Miao, Yanting; Pang, Wei; Tan, Xiaoyu; et al. The choice of divergence: A neglected key to mitigating diversity collapse in reinforcement learning with verifiable reward. arXiv 2025, arXiv:2509.07430. [Google Scholar] [CrossRef]
- Wang, Y.; Li, C.; Chen, G.; Liang, J.; Wang, T. Reasoning or Retrieval? A Study of Answer Attribution on Large Reasoning Models. arXiv 2025, arXiv:2509.24156. [Google Scholar] [CrossRef]
- Peng, W.; Zhang, K. HarmoniDPO: Video-guided Audio Generation via Preference-Optimized Diffusion: W. Peng, K. Zhang. International Journal of Computer Vision 2026, 134(2), 77. [Google Scholar] [CrossRef]
- Wei, Dedai; Wang, Zimo; Qiu, Minyu; Yu, Juntao; Yu, Jiaquan; Jin, Yurun; Sha, Xinye; Ouyang, Kaichen. Multiple objectives escaping bird search optimization and its application in stock market prediction based on transformer model. Scientific Reports 2025, 15(1), 5730. [Google Scholar] [CrossRef] [PubMed]
- Ke, Z.; Yin, Y. Tail risk alert based on conditional autoregressive var by regression quantiles and machine learning algorithms. 2024 5th International Conference on Artificial Intelligence and Computer Engineering (ICAICE), 2024, November; IEEE; pp. 527–532. [Google Scholar]
- Yu, Z.; Idris, M. Y. I.; Wang, P.; Qureshi, R. CoTextor: Training-free modular multilingual text editing via layered disentanglement and depth-aware fusion. The Thirty-ninth Annual Conference on Neural Information Processing Systems Creative AI Track: Humanity; 2025. [Google Scholar]
- Peng, W.; Zhang, K.; Yang, Y.; Zhang, H.; Qiao, Y. Data adaptive traceback for vision-language foundation models in image classification. In Proceedings of the AAAI Conference on Artificial Intelligence, 2024, March; Vol. 38, pp. 4506–4514. [Google Scholar]
- He, L.; Tang, P.; Sun, L.; Su, S. The Devil Within, The Cure Without: Securing Locally Private Graph Learning under Poisoning. In Proceedings of the ACM on Web Conference 2026; 2026. [Google Scholar]
- Shi, G.; Sun, L.; An, Q.; Tang, L.; Shi, J.; Chen, C.; Feng, L.; Ma, H. Quantifying Urban Park Cooling Effects and Tri-Factor Synergistic Mechanisms: A Case Study of Nanjing’s Central Districts. Systems 2026, 14(2), 130. [Google Scholar] [CrossRef]
- Peng, W.; Zhang, K.; Zhang, S. Q. T3M: Text Guided 3D Human Motion Synthesis from Speech. arXiv 2024, arXiv:2408.12885. [Google Scholar] [CrossRef]
- Li, X.; Ma, Y.; Ye, K.; Cao, J.; Zhou, M.; Zhou, Y. Hy-facial: Hybrid feature extraction by dimensionality reduction methods for enhanced facial expression classification. arXiv 2025, arXiv:2509.26614. [Google Scholar] [CrossRef]
- Zeng, Shuang; Qi, Dekang; Chang, Xinyuan; Xiong, Feng; Xie, Shichao; Wu, Xiaolong; Liang, Shiyi; Xu, Mu; Wei, Xing. Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation. arXiv 2025, arXiv:2509.22548. [Google Scholar] [CrossRef]
- Zhou, Y. A Unified Reinforcement Learning Framework for Dynamic User Profiling and Predictive Recommendation. 2025 3rd International Conference on Artificial Intelligence and Automation Control (AIAC), 2025, October; IEEE; pp. 432–436. [Google Scholar]
Figure 1.
Overview of the FinSCRA Framework for Supply Chain Credit Risk Assessment.
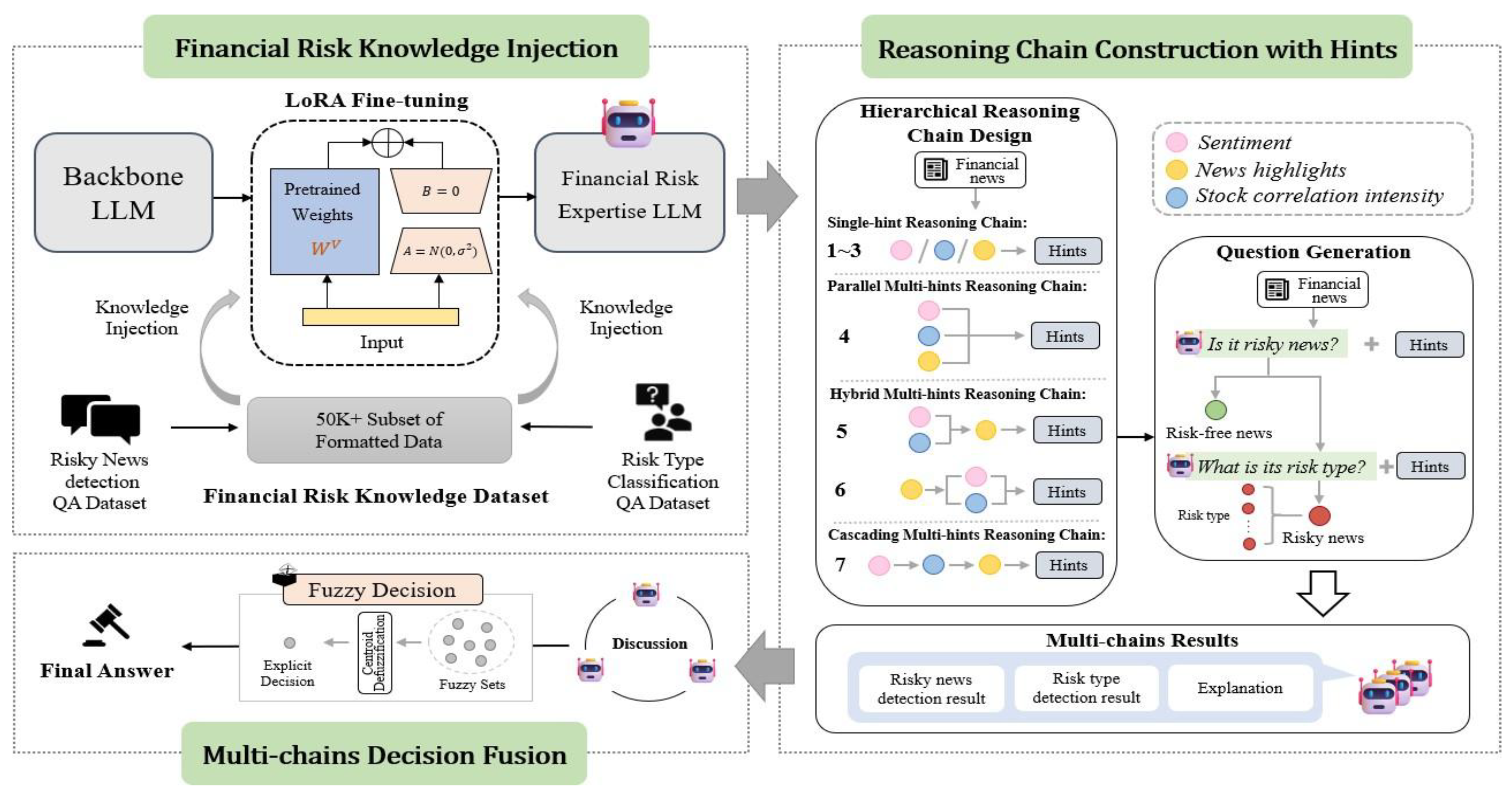
Table 2.
Per-Class Performance on SCRD Test Set.
| Model | Class | Precision | Recall | F1 |
|---|---|---|---|---|
| BERT+GCN | High | 0.75 | 0.72 | 0.76 |
| Medium | 0.79 | 0.81 | 0.8 | |
| Low | 0.8 | 0.79 | 0.8 | |
| GraphSAGE+RoBERTa | High | 0.76 | 0.74 | 0.75 |
| Medium | 0.8 | 0.83 | 0.82 | |
| Low | 0.81 | 0.8 | 0.81 | |
| FinSCRA (Ours) | High | 0.86 | 0.84 | 0.85 |
| Medium | 0.85 | 0.86 | 0.86 | |
| Low | 0.83 | 0.84 | 0.84 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



