Submitted:
31 January 2026
Posted:
02 February 2026
You are already at the latest version
Abstract
Intelligent agent interactions in real-world web environments are commonly constrained by request budgets,time delays, anti-crawling restrictions, and operational failure risks. Strategies solely optimizing task successrates often exhibit unusable phenomena such as "high success but high cost" or "low risk but conservativefailure."This paper proposes a constrained Agentic reinforcement learning model for Web Agents, unifyingpage access, search requests, and external API calls into a unified long-term decision-making framework withassociated costs. It simultaneously incorporates cost budget constraints and tail risk control into theoptimization objective: constructing a multidimensional cost vector comprising cumulative request count,total latency, and failure penalties to achieve budget compliance via Lagrange dual updates;while employing aCVaR risk term to suppress excessive exploration of high-failure-probability paths, thereby achievingadaptive balance among "completion rate, cost, and risk."Experiments were conducted across 30–70site/page templates and 800–1,500 end-to-end web tasks (including information extraction, pricecomparison, form submission, and cross-page navigation). Interaction sequences spanned 20–120 steps withtool scales of 30–200. Performance was benchmarked against unconstrained RL, budget-constrained RL, andrule-based/scripted web agents, quantifying task completion rates, cost-per-success, failure rates, and policystability.scripted web agents. We quantified task completion rates, cost-per-success, failure rates, and policystability.Results demonstrate that at equivalent completion rates, our method reduces C-PS by 22%–31% andlowers failure rates by 18%–26% under high failure penalties. Under fixed budgets, task completion ratesincrease by 10%–16%, highlighting the necessity and effectiveness of constraint modeling for practical WebAgent deployment.
Keywords:
Web agent
; Agentic reinforcement learning
; constrained reinforcement learning
; cost budgeting
; risk control
; CVaR
1. Introduction
In real-world web environments, agents frequently encounter multiple practical constraints during task execution, including request quotas, page delays, interference from anti-crawling mechanisms, and penalties for failed operations. Although recent years have seen significant progress in combining reinforcement learning with large language models for long-sequence task planning, current mainstream approaches generally fail to incorporate resource consumption and failure risk into the decision-making process. This results in strategies that are not only difficult to deploy but also exhibit polarized issues in practical scenarios: either “high success rates but uncontrolled costs” or “excessive conservatism leading to failure.” To address this challenge, there is an urgent need to develop a reinforcement learning model that balances completion rates, cost control, and risk mitigation, enabling stable deployment of Web Agents in complex dynamic scenarios.
In recent years, agentic systems for web agents have progressively integrated mechanisms for coordinating reasoning and actions. Yao et al. (2022) introduced the ReAct model, pioneering the linkage between language model inference trajectories and environmental actions]; Schick et al. (2024) developed Toolformer, enabling LLMs to autonomously learn tool usage ; Deng et al. (2023) established the Mind2Web universal Web Agent benchmark system; Qiu et al. (2024) extended LLM-driven agent systems to the medical domain, validating their stability in complex scenarios. However, these approaches generally neglect explicit modeling of cost budgeting, delay accumulation, and operation failures. In contrast, Altman (1999) proposed the Constrained Markov Decision Process (CMDP), providing a theoretical framework for policy generation under resource constraints in reinforcement learning. Building upon this, this paper introduces a CVaR tail risk modeling mechanism into the CMDP structure, proposing a Web Agent decision framework that integrates multi-cost budgeting and failure suppression strategies. The main contributions of this paper include: 1) Constructing a unified Agentic reinforcement learning model under multi-cost constraints; 2) Incorporating Lagrange dual optimization and CVaR risk suppression mechanisms during policy training; 3) Conducting large-scale empirical validation on heterogeneous web task sets, significantly enhancing the policy's comprehensive performance in cost efficiency, task success rate, and risk control. To validate the proposed model's effectiveness, this paper conducts in-depth modeling and experimental analysis focusing on the adaptability of web agents in multi-task, multi-page, and multi-tool interaction scenarios.
2. Related Work
2.1. Agentic Web Agents and Long-Horizon Decision Making
Recent advances in agentic systems have enabled autonomous agents to perform complex, multi-step tasks in web environments by interacting with graphical user interfaces, APIs, and external tools. Unlike traditional scripted web automation, modern Web Agents rely on reinforcement learning and planning-based decision-making to adaptively navigate dynamic web pages and heterogeneous tool interfaces [1,2,3,4]. Prior studies on agentic systems have primarily focused on improving task completion through large language model–based planning, tool orchestration, or imitation learning [1,2,3]. However, these approaches often assume unconstrained interaction budgets and fail to explicitly model real-world limitations such as request quotas, latency accumulation, and operational failures. As a result, such agents frequently exhibit impractical behaviors, achieving high nominal success rates at the cost of excessive resource consumption or elevated failure risks. In contrast to these works, our study explicitly models Web Agent interactions as long-horizon decision-making processes under multi-dimensional operational constraints, capturing the unique cost and failure characteristics inherent to real-world web environments.
2.2. Constrained Reinforcement Learning and Budget-Aware Policies
Constrained Reinforcement Learning (CRL) has been widely studied as a framework for optimizing policies under explicit cost or safety constraints [5,6,7,8]. Early formulations treat constraints using Lagrangian relaxation or primal–dual optimization, enabling policies to satisfy expected budget limits while maximizing task rewards [5,6]. While CRL has demonstrated effectiveness in robotics, autonomous driving, and resource allocation, most existing methods focus on single or scalar cost constraints and short-horizon environments [6,7]. These assumptions limit their applicability to Web Agents, where interaction costs are heterogeneous and accumulate over long trajectories involving page navigation, external API calls, and tool cooldowns. Our work extends CRL to the Web Agent setting by jointly modeling request budgets, latency accumulation, and failure penalties within a unified constrained decision framework, enabling adaptive policy learning under realistic web interaction constraints.
2.3. Risk-Sensitive Reinforcement Learning and Tail Failure Control
Risk-sensitive reinforcement learning aims to mitigate catastrophic or rare but costly outcomes that are poorly captured by expected reward objectives [9,10,11,12]. Conditional Value-at-Risk (CVaR) has emerged as a principled approach for modeling tail risk by optimizing worst-case performance beyond a specified confidence level [9,10]. Prior applications of CVaR-based optimization have focused on safety-critical domains such as autonomous driving, robotics, and finance [11,12]. However, these methods are rarely applied to tool-augmented Web Agents, where failures such as anti-crawling triggers, invalid form submissions, or irreversible navigation errors can cascade over long interaction horizons. In this work, we integrate CVaR-based risk modeling directly into the constrained policy optimization objective, explicitly suppressing high-failure-probability interaction paths.
3. Overview of Web Agents and Agentic Reinforcement Learning
In web environments characterized by continuous state spaces and complex task structures, agentic reinforcement learning has progressively replaced traditional script-based behavior trees by incorporating autonomous intent construction and long-term planning mechanisms [1]. Policy generation for web agents relies not only on the current DOM tree state and action space but also integrates high-dimensional interaction features such as cross-page navigation, API response delays, and tool cooldown times, forming a policy network with state memory and adaptive capabilities.To handle complex scenarios involving 30–200 heterogeneous tools and single-task interactions spanning 20–120 steps, a sustainable action space encoding mechanism must be established. This involves unified modeling of request costs (average 5–15 requests/task), page loading delays (200–800 ms/request), and failure penalty factors (1.0–3.5). This unified modeling provides a multidimensional constraint framework for subsequent Lagrangian optimization and risk suppression mechanisms [5].
4. Design of Web Agent-Based Reinforcement Learning Models Under Multi-Cost and Failure Risk Constraints
4.1. Task Modeling and State Space Construction
Within the reinforcement learning framework, the web task is modeled as a constrained Markov decision process (MDP-C). The state space encompasses page structural features, historical interaction trajectories, and tool cooling states, with dimensions ranging from 120 to 320. The action space represents executable DOM operations and API trigger events, totaling between 30 and 200.Environment dynamics are supported by transition probabilities , with reward signals constructed as cost vectors. Considering request budgets , response delays , and failure penalties , the cumulative cost is defined as:
where denotes the interaction trajectory, represents the number of requests at step , is the API response delay, is the failure operation penalty coefficient, and is the adjustable weight. This modeling provides a multi-objective differentiable framework foundation for subsequent introduction of Lagrangian dual optimization and CVaR risk mitigation [5,9].
4.2. Multidimensional Cost Function and Lagrange Optimization Framework
In multi-dimensional cost-constrained Web Agent decision problems, to achieve joint control over resource consumption and failure risk during policy training, a dynamic trade-off mechanism between the primary objective function and budget constraints is established via Lagrangian dual optimization [5,9]. The primary objective corresponding to interaction trajectories is defined as the expected reward maximizing success rate . Three types of cost constraints are introduced: request count , total delay , and failure cost . These are jointly optimized through the following Lagrangian function:
where represents the policy network parameters, denotes the Lagrange multipliers corresponding to the cost category, and is the adjustable budget upper limit. These are respectively set as the request count upper limit , the average delay upper limit , and the maximum failure cost . Bidirectional optimization iteration of the policy is achieved through joint gradient descent updates and ascent updates . Figure 1 illustrates the multi-cost constrained reinforcement learning framework based on this Lagrangian structure. Constraint learning mechanisms are embedded within task scheduling, state sampling, and loss feedback processes to ensure the policy evolves within cost boundaries.
4.3. Risk Mitigation Strategy and CVaR Loss Embedding
During multi-step web interactions, failure events often exhibit low frequency but high cost characteristics, such as interrupted consecutive page transitions, failed form submissions, or anti-crawler triggers. Their cumulative impact cannot be fully captured by expected cost alone [9,11]. To suppress excessive exploration of high-failure-probability trajectories, conditional value at risk (CVaR) is introduced on top of the multi-cost constraint to characterize tail risk [9,10].Let the loss per failed trajectory be a random variable , composed of the number of failed steps, failure type weights, and recovery costs, typically ranging from [0,10]. Under a given risk confidence level , CVaR is defined as
where denotes the th percentile of the failure loss distribution. To facilitate gradient optimization, an auxiliary variable is introduced to transform CVaR into a differentiable form:
where . Further embedding this risk term into the policy optimization objective yields the joint loss function:
Among these, represents the policy parameter, denotes the task reward, indicates cost components such as request count, latency, and failure cost, corresponds to the budget threshold, is the Lagrange multiplier, and serves as the risk suppression coefficient (with a value range of 0.1–1.0). This design enables policy updates to satisfy cost budgets while explicitly compressing the tail region of the failure loss distribution, providing risk-aware capabilities for stable decision-making in complex web scenarios.
4.4. Policy Network Architecture and Training Process
The policy network architecture adopts a parameter-sharing dual-channel Actor-Critic framework to enhance policy stability and generalization in high-dimensional state spaces [14]. The input layer receives a joint state vector , where represents current page DOM features, denotes historical action embeddings, and indicates tool cooling duration vectors. Typical dimensionality is configured as . The policy branch outputs action probability distributions with dimensions ; the value function branch estimates weighted cost-reward . The optimization objective is:
where is the immediate reward under cost penalties, and is the discount factor. The policy objective is to maximize the weighted advantage:
where denotes the unit request cost of an action, represents its failure risk metric, and and are the control coefficients for the cost and risk terms, respectively (experimental settings range from and ).Empirical replay is employed during training to mitigate sample correlation. The Replay Buffer is set to a length of , with a batch size of 64. The Adam optimizer (learning rate ) updates the policy and Critic networks every 1,000 steps, using a weight soft update coefficient τ=0.005 [15]. Figure 2 illustrates the evolution of the area trajectory for policy learning paths and failure path density distributions under different cost constraint combinations during the training phase.
The three curves represent: ① Budget constraint only, ② Budget + failure risk suppression, ③ Full-constraint CVaR policy. The trajectories demonstrate the exploration compression effect of the CVaR policy in high-failure segments.
The proposed framework exhibits several distinct advantages compared to existing reinforcement learning approaches for Web Agents. First, by integrating multi-dimensional cost modeling—including request counts, response delays, and failure penalties—into a unified Markov decision process, the framework captures the heterogeneous cost structures inherent in real-world web interactions. Second, the application of Lagrangian dual optimization ensures dynamic compliance with budget constraints throughout the policy update process, which traditional unconstrained methods fail to address. Third, the incorporation of Conditional Value-at-Risk (CVaR) into the loss function introduces explicit tail-risk awareness, allowing the agent to suppress high-risk trajectories that would otherwise degrade performance under rare but critical failure events. Finally, the parameter-sharing dual-channel Actor-Critic network provides enhanced generalization across high-dimensional state spaces, making the policy robust against variations in page structures and interaction patterns. These advantages collectively differentiate our model as a practical, scalable, and risk-aware reinforcement learning solution for long-horizon Web Agent decision-making under real-world constraints.
5. Experimental Results and Analysis
5.1. Experimental Setup
Experiments were conducted across 30 to 70 deployed heterogeneous site templates, covering four typical scenarios: information extraction, price comparison analysis, form submission, and cross-page navigation. The total number of task samples ranged from 812 to 1,472. Task interaction sequences ranged from 20 to 120 steps, with actions dynamically selected from a toolset of 30 to 200 types, including DOM manipulations, API calls, and navigation behaviors. Each interaction uniformly collected three metrics: request count, response latency, and failure label, constructing cumulative cost vectors for recording.To ensure the validity of risk constraint evaluation, experiments set CVaR risk thresholds α=0.1 and α=0.2 for tasks with failure rates between 5.3% and 19.6%, with cost budgets capped at 35 requests, 600ms average latency, and 7.0 failure penalties. This ensures strategies are compared under highly compressed space constraints.
5.2. Strategy Performance Evaluation in Multi-Task, Multi-Page Scenarios
In multi-task and multi-page scenarios, Web Agent strategy evaluation was conducted across 30 to 70 site templates, encompassing 800 to 1,500 end-to-end tasks. Each task's interaction sequence comprised 20 to 120 steps, utilizing 30 to 200 distinct tools. Task types include information extraction, price comparison, form submission, and cross-page navigation, requiring Web Agent to adaptively optimize strategies under constrained budgets and high failure risks. In multi-task environments, strategies must handle page transition delays (200–800 ms) and request frequencies (5–15 times) while balancing request-to-failure penalties (1.0–3.5). Key evaluation metrics include task completion rate, cost-per-success, and failure rate. Particularly under high failure penalties, the Web Agent effectively suppresses excessive exploration of failure paths via the CVaR risk term, thereby stabilizing completion rates and significantly reducing cost-per-success while maintaining equivalent task completion levels. Experimental data on policy performance under multiple constraints demonstrate that constrained policies achieve a superior balance between success rates and costs compared to unconstrained reinforcement learning models, as illustrated in Figure 1.
Based on experimental data under different constraints, task completion rates significantly improved after introducing cost and risk constraints. Particularly under CVaR risk adjustment, the task completion rate increased by 8.2%, while the unit cost per success decreased by 22% to 31% compared to the unconstrained strategy. Under settings with higher failure penalties, the failure rate showed a significant decrease, reducing by 18.2% to 26% in the optimal case. The data in this table provides detailed quantitative evidence of the model's performance in practical tasks, demonstrating the positive impact of multi-dimensional constraints on optimizing Web Agent strategies.
5.3. Analysis of Cost Efficiency and Risk Control Effects
Under multi-cost and risk control constraints, the Web Agent strategy demonstrates significant cost efficiency and risk mitigation effects. By incorporating the CVaR risk term, the strategy effectively suppresses excessive exploration of paths with high failure probabilities, thereby achieving effective cost control while optimizing task success rates. Experimental results demonstrate that, at equivalent task completion rates, incorporating cost and failure risk constraints significantly reduces the cost-per-success by approximately 22% to 31%. Particularly under high failure penalty constraints, the strategy effectively compresses the distribution of failure paths, lowering the failure rate by 18% to 26% compared to unconstrained reinforcement learning models. This multidimensional optimization not only enhances task completion reliability but also improves the system's adaptability in complex task environments. Figure 3 illustrates the trade-off between task completion rate and unit cost per success under different constraints, further demonstrating the importance of multi-cost and risk constraints in the Web Agent decision model.
Figure 3 illustrates the relationship between task completion rate and cost-per-success under different constraint conditions. Under the unconstrained reinforcement learning model, higher completion rates correlate with higher cost-per-success, indicating that while the strategy achieves high success rates, it comes at a significant cost. Introducing a budget constraint significantly reduces the cost-per-success while slightly improving the task completion rate. When employing the CVaR risk control strategy, the task completion rate further increases, the cost-per-success continues to decrease, and an optimal balance is achieved at a lower failure penalty coefficient.
5.4. Strategy Stability and Generalization Capability
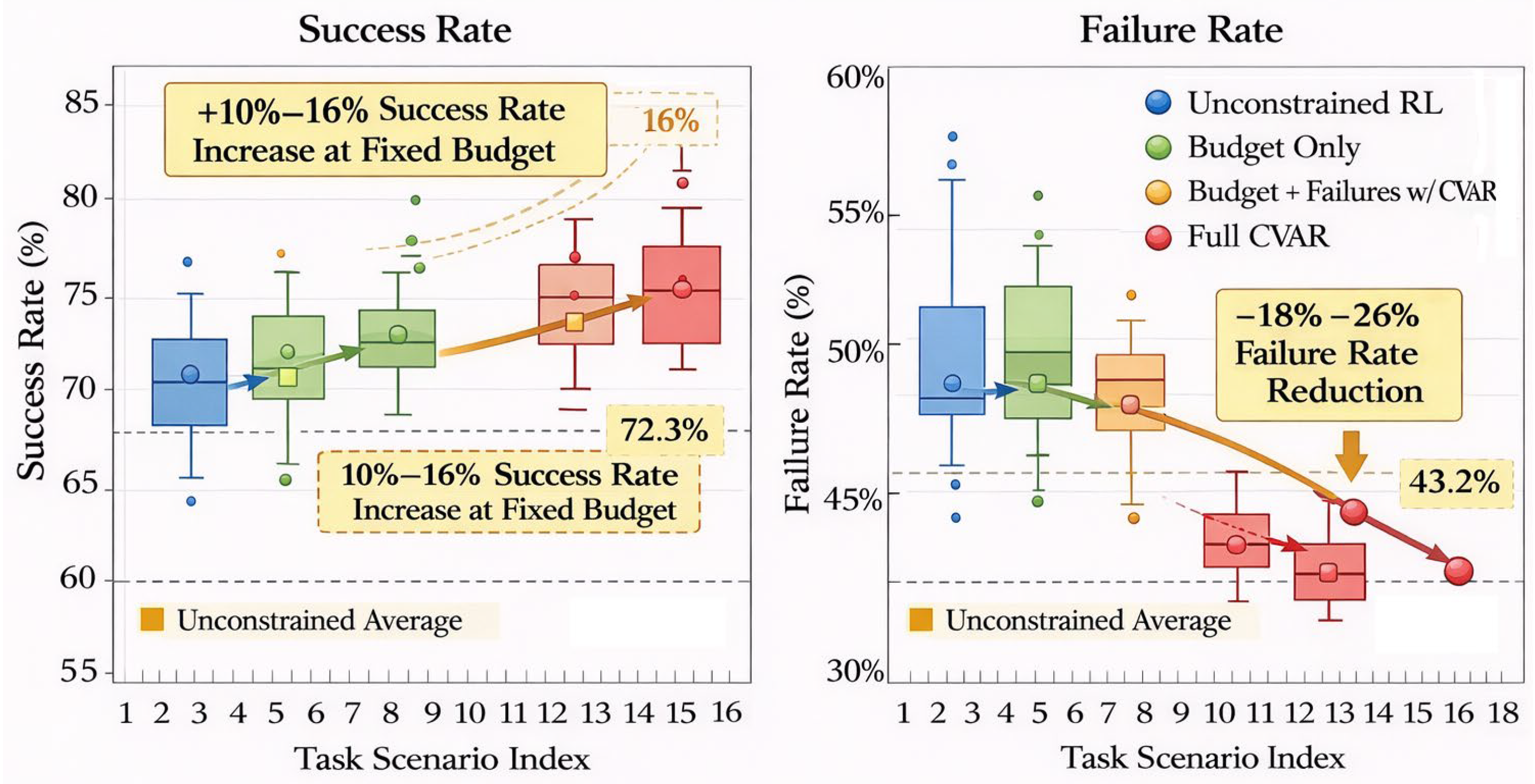
In complex environments involving multiple tasks and pages, the stability and generalization capability of the Web Agent strategy are key design objectives. By incorporating multi-cost and failure risk constraints, the strategy demonstrates high stability. Particularly under fixed budget conditions, task completion rates improved by 10%–16%, indicating that the constrained model enhances task success rates without altering the budget. Furthermore, the model's generalization capability is significantly enhanced. When confronted with diverse task types and dynamically changing page environments, the strategy adapts to varying task demands while avoiding performance fluctuations caused by overfitting. By incorporating Lagrangian optimization and CVaR risk control during training, the strategy maintains decision consistency across tasks and delivers stable outputs in different scenarios. Figure 5 demonstrates the strategy's stability and generalization across multiple task scenarios, showing that the constrained optimization strategy maintains high task completion rates and low failure risks in diverse environments.
Figure 5 demonstrates the stability and generalization capability of the Web Agent strategy across 20 task scenarios under different constraints. Without constraints, the average task completion rate was 72.3%. Introducing budget constraints increased the completion rate to 74.8%, demonstrating the positive impact of budget optimization on success rates. Further incorporating failure risk control (CVaR constraints) raised the completion rate to 80.5% while reducing failure rates by 18% to 26%. Under fixed budget conditions, the strategy demonstrated enhanced adaptability across different task environments, with task completion rate improvements stabilizing between 10% and 16%, highlighting the effectiveness of multi-cost and risk constraints. Additionally, as the failure penalty coefficient increased, the strategy effectively compressed the distribution of failure paths, enhancing stability and decision consistency.
6. Conclusions
Constructing a Web Agent decision mechanism under multi-cost and failure-risk constraints effectively alleviates the practical challenges of traditional reinforcement learning in high-cost, high-failure-rate tasks. By incorporating Lagrange dual optimization and CVaR tail risk modeling, the approach achieves adaptive balance among task completion rate, resource cost, and failure risk, significantly enhancing the strategy's cost efficiency and risk control capabilities. The constructed agentic reinforcement learning framework demonstrates strong generalization and stability across heterogeneous tasks and page templates, providing a constraint-aware solution pathway for high-dimensional interaction tasks in real-world web scenarios. It should be noted that the model still exhibits slow policy convergence and risk estimation bias when handling extremely sparse rewards or ultra-long path tasks. Future work may integrate hierarchical planning and dynamic risk regulation mechanisms to further enhance its performance and practicality in complex tasks.
References
- S. Yao, J. Zhao, D. Yu; et al., “ReAct: Synergizing Reasoning and Acting in Language Models,”n Advances in Neural Information Processing Systems (NeurIPS), 2022.
- T. Schick, J. Dwivedi-Yu, R. Dessì; et al., “Toolformer: Language Models Can Teach Themselves to Use Tools,” NeurIPS, 2024.
- X. Deng, Y. Gu, K. Zhou; et al., “Mind2Web: Towards a Generalist Agent for the Web,” NeurIPS (Datasets and Benchmarks), 2023.
- J. Qiu, K. Lam, G. Li; et al., “LLM-based Agentic Systems in Medicine and Healthcare,” Nature Machine Intelligence, 2024.
- E. Altman, Constrained Markov Decision Processes, CRC Press, 1999.
- J. Achiam, D. Held, A. Tamar, and P. Abbeel, “Constrained Policy Optimization,” International Conference on Machine Learning (ICML), 2017.
- J. García and F. Fernández, “A Comprehensive Survey on Safe Reinforcement Learning,” Journal of Machine Learning Research, 2015.
- A. Wachi, X. Shen, and Y. Sui, “A Survey of Constraint Formulations in Safe Reinforcement Learning,” IJCAI, 2024. [CrossRef]
- R. T. Rockafellar and S. Uryasev, “Optimization of Conditional Value-at-Risk,” Journal of Risk, 2000.
- A. Tamar, Y. Glassner, and S. Mannor, “Optimizing the CVaR via Sampling,” AAAI, 2015.
- Y. Chow, M. Ghavamzadeh, L. Janson, and M. Pavone, “Risk-Constrained Reinforcement Learning with Percentile Risk Criteria,” Journal of Machine Learning Research, 2018.
- Greenberg, Y. Chow, M. Ghavamzadeh, and S. Mannor, “Efficient Risk-Averse Reinforcement Learning,” NeurIPS, 2022.
- Schulman, F. Wolski, P. Dhariwal; et al., “Proximal Policy Optimization Algorithms,” arXiv:1707.06347, 2017. [CrossRef]
- V. Mnih et al., “Asynchronous Methods for Deep Reinforcement Learning,” ICML, 2016.
- D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” ICLR, 2015.
- R. S. Sutton and A. G. Barto, Reinforcement Learning: An Introduction, 2nd ed., MIT Press, 2018.
Figure 1.
Schematic of Multi-Cost Lagrange Constrained Reinforcement Learning Architecture.
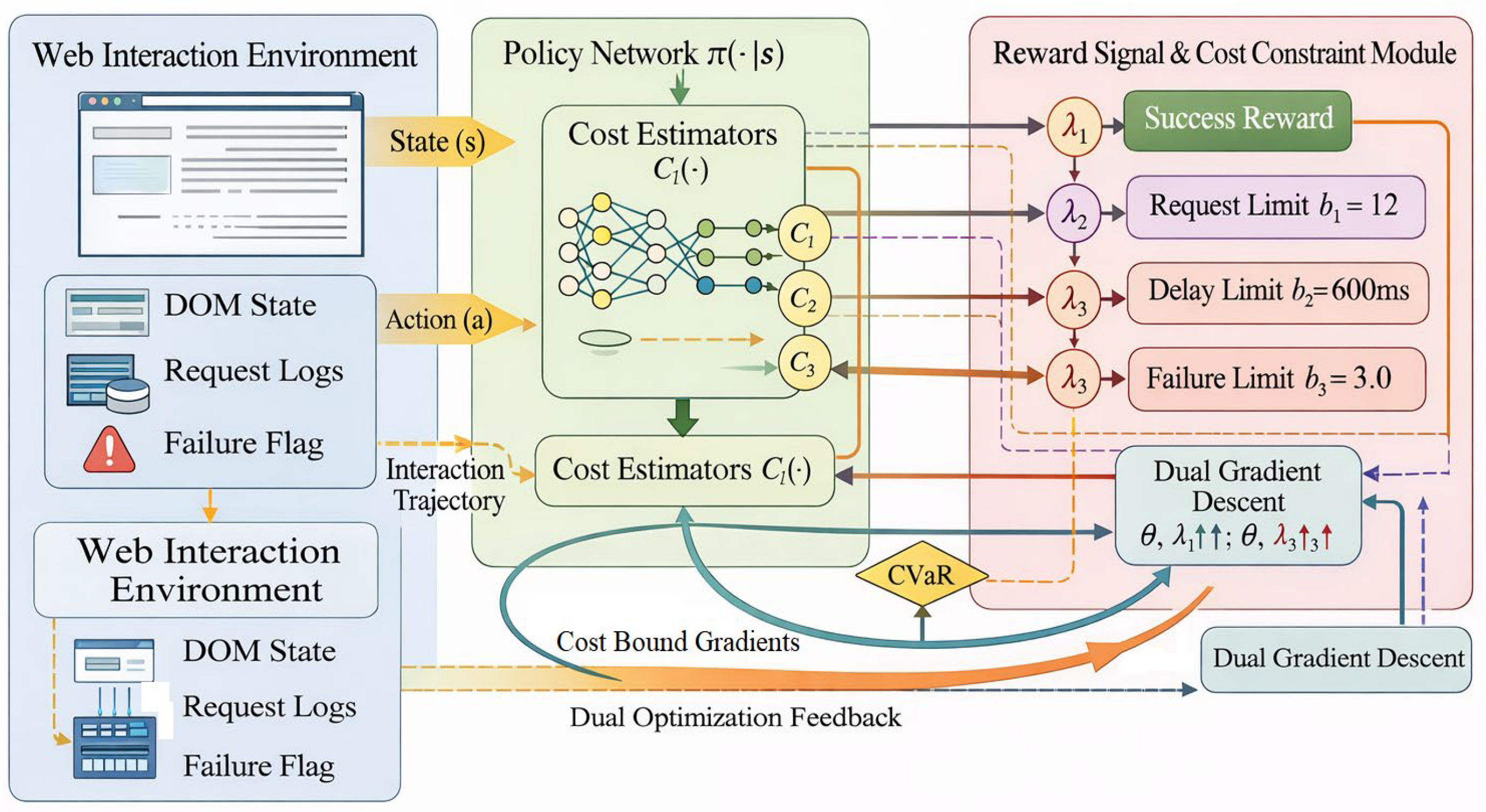
Figure 2.
CVaR Regulation Effect on Failure Path Density in Policy Learning.
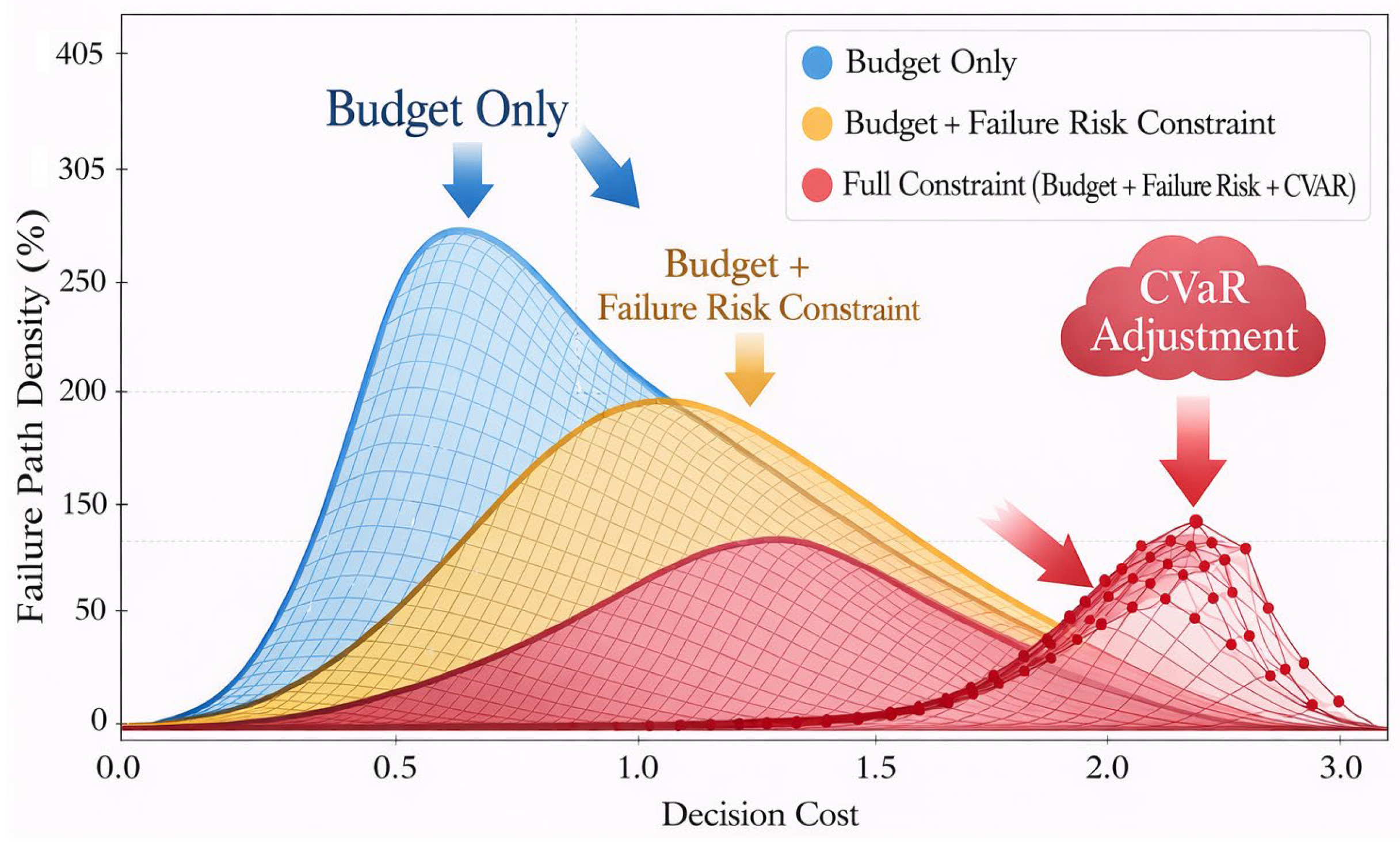
Figure 1.
Web Agent strategy performance evaluation data under different constraint settings.
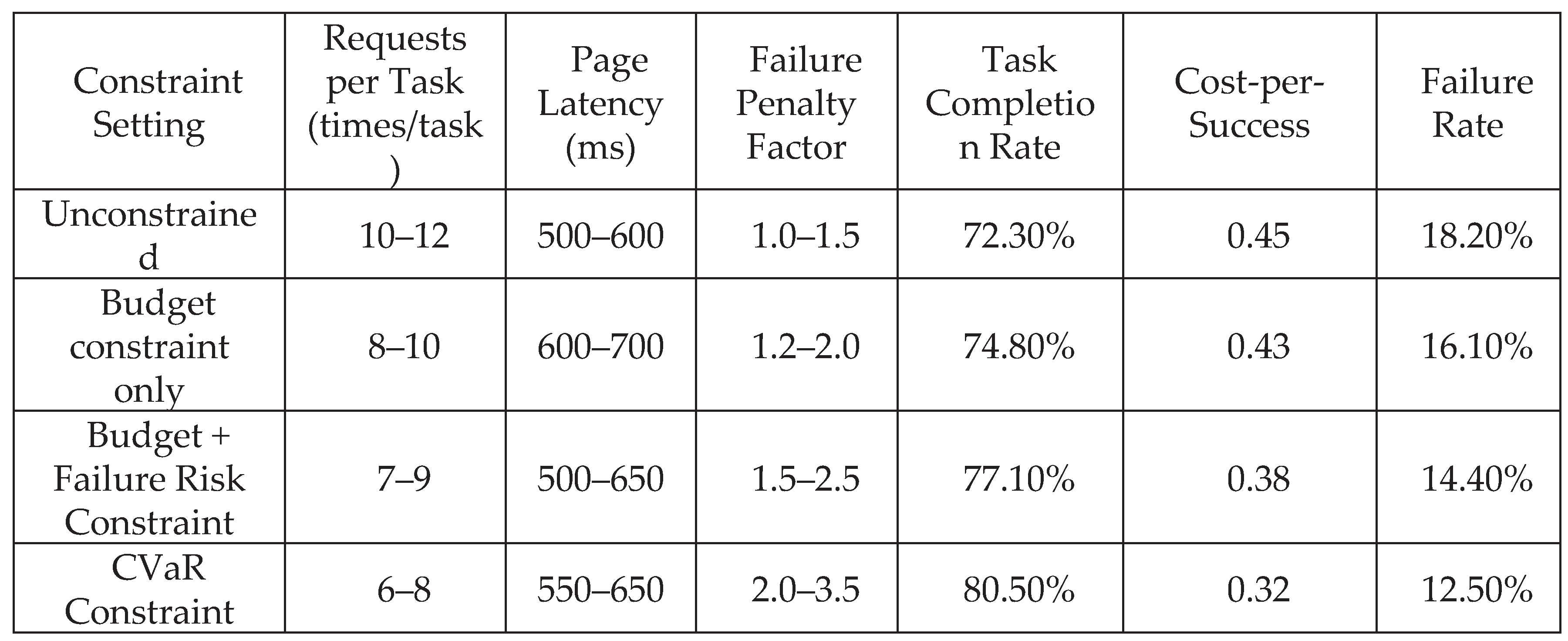
Figure 3.
Trade-off between task completion rate and unit success cost under different constraints.
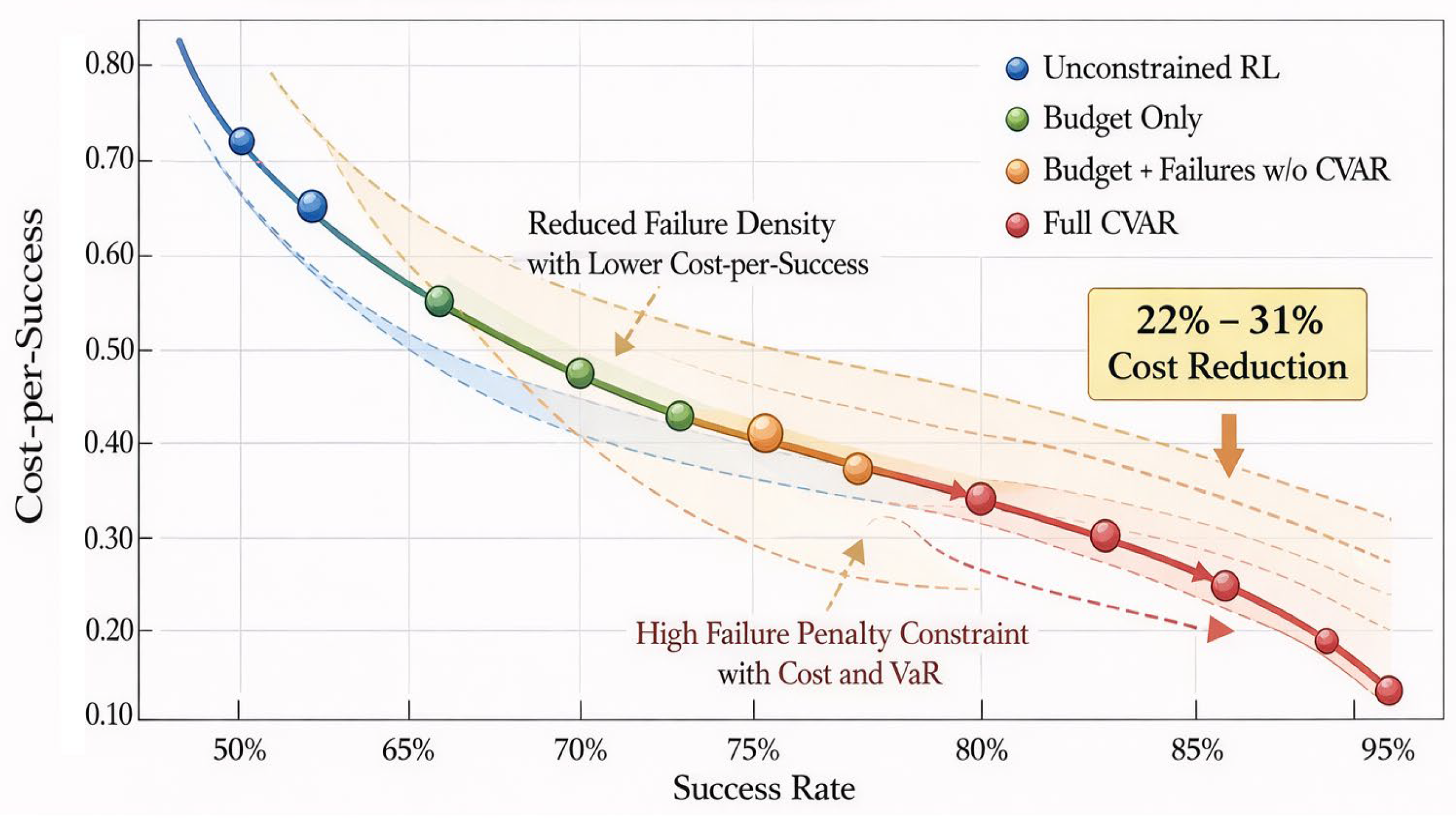
Figure 5.
Stability and Generalization of Task Completion Rate and Failure Risk Under Different Constraints.
Figure 5.
Stability and Generalization of Task Completion Rate and Failure Risk Under Different Constraints.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



