
Submitted:
21 January 2026
Posted:
23 January 2026
You are already at the latest version
Abstract
There has been an ongoing discussion regarding the significance of corpus-based methods in Stylistics. This study therefore investigates how corpus-based approach can enrich our understanding of themes and style of a literary writer, using one of Niyi Osundare’s collections, titled, The Eye of the Earth. While previous studies on Osundare have richly examined his poems individually through qualitative close reading, none of this scholarship has attempted a corpus-based quantitative method. Using Mahberg’s (2013) criteria, KWIC analysis show that content keywords (i.e. earth, like, sun, forest, and rain) in poems foreground the themes of nature and human ecosystem, which is further verified by the deliberate deployment of Yoruba lexical items like Olosunta and Iroko having the highest frequency of occurrence in the entire collection. These quantitative patterns corroborate submissions by earlier qualitative studies (Onyejizu & Obi, 2020; Amore & Amusan, 2016). The study also identified certain stylistic regularities in the poem that may not be easily recognized by close reading. This shows how a corpus-assisted discourse method amplifies detail that might be hidden to close reading especially the integration of relevant Yoruba words in strategic positions to invoke realities that are deeply rooted in Yoruba oral traditions. The smooth flow of Yoruba language as a means of complementing the thematic ideas already captured in English language depicts Osundare as not just a literary icon but a linguistic genius whose literary idiolect is a product of premeditation and perspiration to reflect cultural identity, cosmology, ecology.
Keywords:
corpus stylistics
; corpus linguistics
; quantitative & qualitative methods
; KWIC
1. Introduction
For the past few decades, scholars in the field of humanities (i.e. Linguistics and Literature) have been curious about improving the method and approach to investigating themes, language use, imagery, symbolism and the context within which a literary text is situated. Meanwhile, some have sought a methodological replacement for the practice of close reading (a detailed analysis of a single text focusing on its language, structure and literary devices by interpreting the meaning of what the text says and how it says it, Moretti, 2000). In literature, the old tradition has been that literary critics conduct a close reading of a literary text and provide a critical criticism of it. In Linguistics, both literary and non-literary could be examined by closely identifying linguistic patterns in relatively small amount of text. This is often referred to as ‘Discourse Analysis’, a scope of applied linguistics which covers a vast range of area (Flowerdew, 2012, p.1) providing detail explanation about the use of language within a specific context to unravel the socio-cultural, ideological and contextual meanings (Jacobson, 1987). Sometimes, researchers are driven by the need to identify observable patterns in a text to situate the style of the writer, (this is often regarded as ‘stylistics’). However, since close reading deals with a single text, many critics have criticized the method to be highly limited in scope, subjective, and time consuming. This study, therefore, attempts a distant reading of a collection of poems by Niyi Osundare using quantitative computational approach to analyze literary meaning.
Niyi Osundare has been a prolific writer who has constantly influenced the global poetic space in the academic both in Nigeria and the world at large. For the past few decades, there have been a lot of studies on his works and particularly his linguistic idiolect (i.e. Bamikunle 1995, Arnold 2001, Anyokwu 2014, Amore and Amusan 2016, Egya 2017, Dahunsi and Babatunde 2017, Anolue 2024, Alexander, 2024, etc). One limitation is that the existing studies have only focused on closed reading or qualitative method using very few selected poems among his collections and then make general statement about his style. Affirmatively, what is common among these studies is making generalization about the poet’s style via a close analysis of some of his selected poems. None of these studies have attempted a systematic approach using corpus computational method to unravel Osundare’s linguistic idiolect, hence the focus of this study.
This study, therefore, examines a corpus stylistic analystic analysis of Niyi Osundare’s poetic work (The Eye of the Earth) with respect to how a researcher can interact with the large body of his poetic works to critically examine and investigate his linguistic/ poetic idiolect.
2. Theoretical and Empirical Background
The field of discourse studies has been said to embrace many areas of inter-disciplinary domains, as Flowerdew (2012) describes it as an area with the least clearly defined scope. Some scholars have argued that every event that deals with textual analysis and interpretation is discourse analysis, regardless of methods. This has initiated conversations about the relationship between Discourse Analysis and Corpus analysis. Flowerdew (2012) however noted that doing Corpus analysis is not the same as doing discourse analysis (Flowerdew, 2012, p.2). Leech (2000, pp. 678–680, cited in McEnery et al., 2006) also noted that there is a ‘cultural divide’ between Discourse Analysis and Corpus analysis. According to him, the emphasis of Discourse Analysis is the integrity of the text, while ‘corpus analysis’ tends to use representative samples. Leech (2000) submits that while Discourse Analysis is primarily qualitative and focuses on the content of the text, corpus analysis is essentially quantitative and is interested in language per se. Biber et al. (1998) also noted that the software tools adopted for corpus analysis do not lend themselves to focusing on deep syntactic and semantic characteristics of language, and are therefore not suitable for discourse analyses. Flowerdew (2012, p.6), pointed out that, unlike Corpus analysis, Discourse analysis is not a method as such in itself.
Meanwhile, other scholars have acknowledged that Corpus Analysis and Discourse Analysis are same side of a coin. For instance, McEnery et al. (2006, p. 111) noted that Leech’s cultural divide ‘is now diminishing’, and Partington (2004) proposes that corpus and discourse methods are complementary. One could then argue that the emergence of “Corpus-Assisted Discourse Studies” was based on the need to harmonize both domains. To support this claim, Flowerdew (2012, p. 3) noted that Corpus-based Discourse Analysis represents a complex approach that captures both corpus method and content-based analytical approaches to texts such as (i) textual (language choices meaning and patterns, as echoed by Swales, 2004), (ii) Critical Discourse Analysis (CDA) and (iii) contextual approach (sociolinguistic approach) as captured by Hyland (2009. p. 20). According to Flowerdew (2012), Corpus linguists working in Critical Discourse Analysis (CDA) attempt to use CDA to complement their corpus ‘method’ by linking recurring patterns in text with sociolinguistic features from the original contextual environment and vice versa.
Since this study deals with Corpus stylistics, it is therefore pertinent to establish the point of convergence and departure between the domains of Corpus Linguistics and Corpus stylistics. Mahlberg (2014, pp 378-380) defines corpus stylistics is a branch of stylistics that combines method and principles of corpus linguistics and literary stylistics. McIntyre (2015) defines corpus stylistics as the application of theories, models and framework from stylistics and corpus analysis. He further considers corpus stylistics as a branch of corpus linguistics with a different object of study, that is, literature as opposed to non-literary language. Abdulqader et al (2020) sees corpus stylistics as the statistical study of style. Toolan (2008) describes corpus stylistics as an extension of corpus linguistics established through its capacity to analyze massive datasets, detects patterns of collocation, frequency, phraseology etc. Jaafar (2017) demonstrate that corpus Stylistics applies similar techniques to explore literary style and aesthetic features. From the foregoing, it could be inferred that Corpus stylistics is a sub-discipline of Corpus Linguistics which is also a branch of Computational Linguistics (McEnery and Hardie, 2012). Sinclair (2004) noted that corpus linguistics is a ‘methodology’, that is, a phraseological, and syntagmatic approach to language data. One thing that Corpus stylistics and Corpus Linguistics tend to share in common is their ‘methodology’. However, McIntyre (2015) have further mentioned that Corpus Stylistics is different from Corpus Linguistics because Corpus stylistics does not just borrow tools from Computational linguistics; it also makes itself unique by using qualitative means and techniques of stylistics to analyze texts with the help of computational methods. This demonstrates that corpus analysis also allows for a quantitative close reading. In summary, what distinguishes Corpus stylistics from other forms of stylistics (literary or linguistic stylistics) and regular discourse analysis involves two strategies:
- (i)
- It is quantitative; that is, it involves a large number of datasets; and
- (ii)
- it adopts a systematic, principled and replicable analytical approach.
The study demonstrates how these strategies work with Niyi Osundare’s corpus data and it will also demonstrate how quantitative close reading can be achieved with corpus stylistics.
By combining structural description with patterned recurrence, Labov and Waletzky (1967) submit that meaningful interpretation emerges most powerfully when close reading of individual texts is placed in dialogue with distant or comparative reading across many texts, thereby establishing an early prototype for the kind of hybrid methodological logic that Corpus-Assisted Discourse Studies continues to refine today. This demonstrates that contemporary CADS flourishes by refusing a methodological binary and instead creating a productive dialogue between reading closely and reading distantly.
3. Previous Studies on Niyi Osundare
Niyi Osundare is a Nigerian-born poet who is reputable for his unique poetic rendition which Jeyifo (1985 p. 315) describes as “ninety percent perspiration and ten percent inspiration”. He foregrounds his style through his distinct use of language which often involves cross-linguistic transference between Yoruba and English. Although he writes in English, each line is a carrier of a million strands of Yoruba culture inscribing a signature of an ‘alter/native’ tradition. According to Anyokwu (2014, p. 28), Osundare, himself, admitted that he thinks out his poems in Yoruba and, thereafter, writes them in English. One of the most intriguing questions that have plagued the mind of his audience is how he manages to represent his thoughts using a harmony of two dissimilar languages that carry two conflicting cultures, yet he often manages to model his poetry on the Yoruba Oral forms such as ‘oríki (eulogy), ofò (incantation), ijálá (hunter’s chant), esè-ifá (ifa verses), aló-àpamo (folklore), owe (proverb) and ewi (poetic chant)’ in a foreign tongue through the tactics of transposition and transference, neologism and lexical coinages, idiophones, semantically meaningless words, phrases and sentences, repetition and parallelism, incorporation of musical accompaniment (Anyokwu, 2014, pp. 25-26).
Currently, Osundare has produced about 23 collections of poems since 1983 up till now, with each poem treating issues regarding nature, socio-political events in Nigeria, global politics and the likes. For the past few decades, there have been a lot of studies on his works and particularly his linguistic idiolect. One limitation is that the existing studies have only focused on closed reading or qualitative method using very few selected poems among his collections and then make general statement about his style.
For instance, Bamikunle (1995), using some random selection of poems from six published cpllections of Niyi Osundare, namely, Songs of the Marketplace (1983), Village Voices (1984), A Nib in the Pond (1986), The Eye of the Earth (1986), Moonsongs (1988), and Waiting Laughters (1990), investigated the development of Niyi Osundare’s poetry by surveying his themes and technique. The study found that that Osundare’s poetic idiolect reflects a tension between socio-political and natural discourse. The study acknowledged that his early poetry captures the ideals of revolutionary African poetry, his later works are grounded in linguistic creativity often reflected in his use of metaphors, symbolism, parallelism and so on. This has shaped his poetry into a more elitist, philosophical puzzle.
Amore and Amusan (2016) examined the use of conceptual metaphors in selected poems of Osundare using a qualitative method. The sample size was 3 poems from two collections. They are: The Word is an Egg; The Incantations of the Word, and Earth. The study concluded that Conceptual metaphors in Osundare’s poetry have rhetoric function because it offers the advantage of being at once expressive, compact and vivid about the adoration and illumination of truths about the Yoruba mythology. It identified that Osundare’s linguistic idiolect is reflected in his cognitive and aesthetic function of poetic metaphor and this has helped him convey the truth and beauty of African tradition. Using this finding, the study generalizes his style from the viewpoint of his use of metaphors.
On the same vein, Dahunsi and Babatunde (2017) uses the functional approach to examine one of Niyi Osundare’s poems titled “My Lord, Tell Me Where to Keep Your Bribe”. This study used Halliday’s Mood Structure Analysis and Thematization Patterns to unravel meanings in this poem. The study concluded that Osundare uses language to make meanings in the poem through lexical and paradigmatic choices and proper arrangements of distinct grammatical structures to convey different types of meanings.
Affirmatively, what is common among these studies is making generalization about the poet’s style via a close analysis of some of his selected poems. None of these studies have attempted a systematic approach using corpus computational method to unravel Osundare’s linguistic idiolect, hence the focus of this study.
4. Aim and Research Objectives
The overall aim of this study is to attempt a quantitative close reading of Niyi Osundare’s The Eye of the Earth. The specific objectives of this study are to:
- Identify and interpret the keywords in Niyi Osundare’s The Eye of the Earth
- Examine the concordance/connotation of the keywords and interpret them in light of the themes.
- Identify the significance of the quantitative output to the thematic relevance of the study.
5. Methodology/Corpus Design
The procedure for collecting data for this study involved a complex method of digitization of data, text cleaning and data annotation. The researcher extracted and stored data by first digitizing texts via scanning printed material and applying Optional Character Recognition (OCR) to extract the texts to a machine-readable text format using Tesseract python library (installed at /opt/homebrew/bin/tesseract).
6. Data Cleaning and Storage Procedure
One main challenge with the extraction of texts from PDF to txt is that OCR is notoriously unreliable with minority languages around the world since most of the programming libraries are mainly proficient with Western languages. Since Osundare’s poems are written in cross-linguistic features of English and Yoruba through transposition and transference, therefore, with OCR, extraction of Yoruba lexical dynamics remains a mystery. As a result, the researcher manually proofread and normalized the text to correct orthographic, typographic, layout and formatting issues.
Since poetry, unlike other literary genres, is heavily influenced by graphology, it is expedient to preserve the line structure of the poem as well as the punctuations because they contribute to the meaning of the poem. During the cleaning process, the researcher paid attention to poetry-specific features such as line breaks, indentation and spacing. After cleaning, the researcher stored data in three different structured formats namely: ‘UTF-8 plain text’, ‘Json’ and ‘CSV’ for easy analysis. One version of the data was stored in a UTF-8 plain text format to preserve the original poetic structure to include line breaks, line arrangement and so on in the poem to capture the original graphology of the poet which makes it ideal for deep stylistic interpretation. However, it lacks the ability to store complex metadata. Another version of the data was stored in JSON to handle the complex metadata: ‘poem title’, ‘year of publication’ and ‘title of collection’. Since JSON allows for hierarchical organization of data, the inclusion of such metadata ensures easier computational processing in other to identify the title origin of a specific pattern in the corpus while the lines are still preserved. JSON file is helpful to execute analysis of concordance and phraseology using AntConc. Unlike CSV storage, JSON is less convenient for statistical or tabular analysis. The CSV storage version is used to store tabular information such as token, lemma, POS tag, line number, and handle quantitative linguistic analysis, frequency counts, keyword, collocation studies, but it cannot represent nested structures or maintain original layout of the poem which is why plain text storage and JSON storage are also included.
7. Data Annotation
Within the designated corpus directory, the researcher created a master metadata file featuring poem title, original collection, publication date, and other relevant information. The lines containing Yoruba words were manually annotated by “< >” while the coinages were annotated by ‘@’ before each coinage. This is because it is difficult to find libraries that can accurately distinguish and identify these forms:
“<Ogééré> <amokéyeri>”
“The doom of @polithiefcians in <agbada> attires”
This kind of text annotation helps to execute a perfect analysis of patterns to include examining the syntactic position of Yoruba words in each line of the corpus where they occur (e.g. subject, Object etc) as this gives more information about the poet’s thematic organization and structure of his poems. It also helps to investigate the company each Yoruba word keeps as well as the cross-lingual coinages. This annotation would help to determine this form using libraries like AntConc to reveal concordance and n-gram.
Here is a detail information about the collection, “The Eye of the Earth”.

Table 1.
.
| Title of Collection | Year of Publication | Number of Poems | Number of Lines | Number of Sentences | Total No of Words (All Occurrences) | Total No of Unique Lex. Items |
|---|---|---|---|---|---|---|
| The Eye of the Earth | 1986 | 18 | 967 | 156 | 4995 | 1817 |
8. Quantitative Analysis of Niyi Osundare’s the Eye of the Earth
Scholars have prescribed different approaches to analyzing literary corpus data in corpus stylistics. Mahberg (2013) also identified three main steps to achieving corpus stylistics namely: (a) determine the keywords in the text; (b) find the connection between the resulted keyword and key semantic domain analysis and (c) look for lengthy n-grams and identify their significance, value and connection to overall meaning (Jaafar, 2017, p.4). Toolan (2008) posits that keywords offer information about the theme of the text and guide readers’ expectation. According to him, ‘keyword’ signals foregrounding as their reoccurrence primes readers to anticipate certain themes, events and motifs. Scott (2013) states that the purpose of examining words whose frequency is unusually high is to find out which words characterize the text. Scott (2013) designed the WordSmith tool to facilitate the analysis of such digital corpora such as keywords, collocations and clusters. Hayman (2010, p. 1) presented three main types of keywords: (i) proper nouns (ii) high frequency style indicators and (iii) aboutness keywords.
Against this background, this study attempted a quantitative analysis of the poem by investigating three things namely:
- Keywords
- Concordance
- N-gram
9. Keywords in Niyi Osundare’s the Eye of the Earth
This section presents the Keyword analysis of the Corpus data of Niyi Osundare’s The Eye of the Earth by identifying the frequencies of top keywords in the corpus.
Table 2.
Output of the Keywords from the corpus.
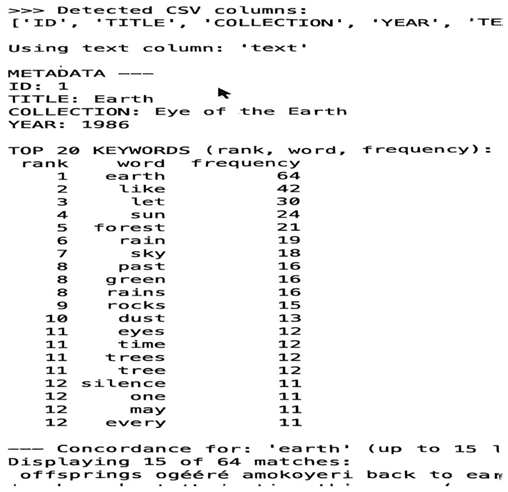 |
This computational representation demonstrates the keyword frequency output from Niyi Osundare’s The Eye of the Earth. The prominence of words such as earth (64 occurrences), like (42), and let (30) highlights recurring semantic and thematic preoccupations in the collection, revealing Osundare’s concerns about nature and human ecosystem. This shows how not just content words are significant to the discourse of the poem but also function words like ‘like’ and ‘let’. As stated by Stubb (2015), if corpus analysis only confirms what literary critics already suspect, it is still valuable because it provides systematic, objective evidence and makes patterns in the text that were previously implicit or intuitively explicit and measurable. The KWIC analysis of The Eye of the Earth offers quantitative support for several established qualitative interpretations of the collection. For instance, Onyejizu and Obi (2020), through close reading, argue that The Eye of the Earth foregrounds nature and other physical components of the earth. This submission finds empirical reinforcement in the prominence of ecological keywords revealed in this study through corpus analysis. Also, Amore and Amusan (2016) identify “Earth is Nature” as one of Osundare’s central metaphors, a submission that gains further validation from the frequency and distribution of nature-related lexical items in the corpus output. In that way, the keyword frequencies serve as a quantitative output that corroborates existing facts about the collection.
As noted by Jabbar (2014, p. 23), corpus-based analysis reveals features that might otherwise remain hidden in close reading. The Keyword findings in The Eye of the Earth demonstrates how Osundare employs comparative language via the word ‘like’. In this collection, like functions repeatedly as a marker of simile, enabling the poet to align natural phenomena with human experience in ways that amplify thematic resonance. Such quantitative endorsement reinforces earlier observations about Osundare’s preference for comparative structures and, in some instances (i.e. Amore and Amusan, 2016), for metaphorical transpositions. Therefore, the computational evidence has been able to complements established interpretive readings and also demonstrates how corpus procedures can unveil repeated stylistic features that traditional close reading may not readily quantify. Let functions as a rhetorical imperative, often initiating appeals or ethical assertions e.g., “let no tree challenge the palm.” Their frequency and semantic weight justify their inclusion as stylistically significant keywords. These two words (like and let) have stylistic relevance because they help the poet facilitate his constructive imagery of comparison (via ‘like’) and invocations (via ‘let’).
Meanwhile, Eve (2017) had suggested that corpus analysis should leave room for context-sensitive interpretation. Stubbs (2005) also stated that simply examining the keywords of a text is certainly not sufficient because keywords are not by definition evenly distributed across the text (Stubbs, 2005, p.12). Against this background, the researcher further investigated the contexts of the poems the keywords mostly featured, as they require a close reading. The poems are: They too are the Earth, Forest Echoes, and Let Earth’s Pain be Soothed.
Table 3.
The contexts of the poems the keywords mostly featured.
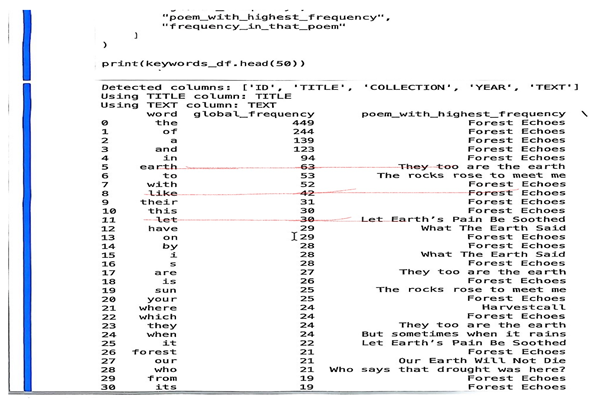 |
A close reading of the poems in the entire collection confirmed that virtually all the poems in the collection speak to the subject of nature and ecosystem as evident in the keywords analysis, hence complementing the results from the computational output. The keyword analysis reveals a strong lexical pattern dominated by high-frequency function words, many of which carry stylistic weight in the poetic corpus. It was discovered that the poet’s thematic experience was majorly represented in the three poems that contained the highest-ranking content keywords, demonstrating that these poems function as the core domains where Osundare consolidates the central ideas of the collection. Words like like and let, though grammatically common, emerge as vehicles for metaphor and invocative force, respectively. Their prominence across multiple poems reveals their role in shaping tone, imagery, and thematic resonance. This frequency data does not only show linguistic density of the poem but also demonstrates the poet’s artistic and linguistic idiolect.
10. Concordance in Niyi Osundare’s the Eye of the Earth
Concordance is another area of significance to Corpus method. It involves the listing of occurrences of words in context for syntactic and semantic purposes (Abdulgader, 2020). Concordance is also known as Key Word in Context (KWIC) because it reveals the immediate environment in which a word appears. Stubbs (1996) argues that investigating collocations can help determine the aboutness of a text to reveal the associations and connotations of keywords under examination (Stubbs 1996, p.172).
Meanwhile, the term, collocation, was coined by Firth (1957) as part of his theory of meaning to describe the company that words keep. Sinclair (1991) defines collocation as the occurrence of two or more words within a short space of each other in a text. Hoey (1991) defines is as the relationship a lexical item keeps with another item that appears with greater than random probability in its textual context. Like concordance, collocation shows what word occur together and compares distribution of close synonyms in context. But unlike it, collocation focuses on semantic relationship while concordance deals with contextual relationship.
To examine concordance and collocations in Niyi Osundare’s corpus, the study examined the linguistic context of the 3 keywords (Earth, like and let) by highlighting the companies of words they keep establishing collocation and connotations. Here is the output of the concordance extraction from the corpus:
Table 4.
Output of the concordance extraction from the corpus.
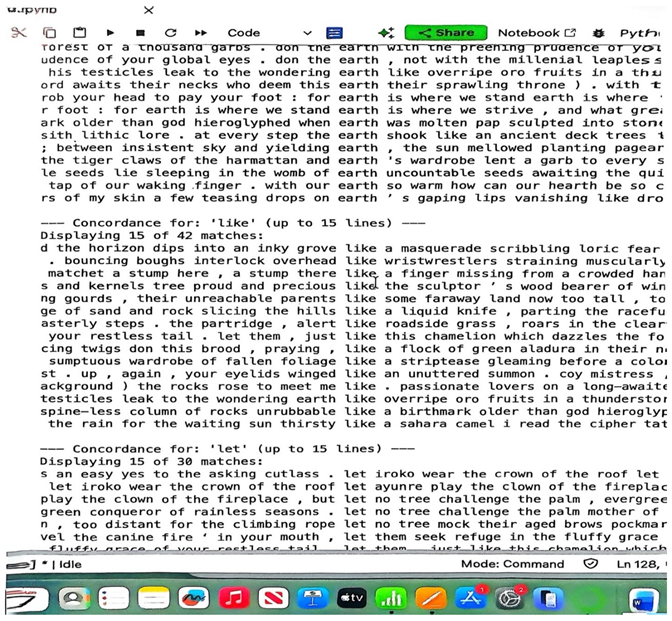 |
The concordance lines for words such as earth, like, and let reveal the immediate linguistic and semantic contexts in which these words occur. For instance, ‘like’ emerges as a tool of metaphorical expansion, while ‘let’ anchors the poet’s invocation of cultural and imagery ideas. This integration strengthens the bridge between quantitative analysis and literary insight. The word earth appears in various linguistic contexts capturing the ecological imagery (forest of a thousand garbs, yielding earth) to metaphorical and human-centered expressions (earth is where we stand, earth’s gaping lips). This highlights Osundare’s blend of nature and culture. Similarly, ‘like’ is a comparative marker which often functions as ‘similes’, a figurative device that enriches imagery and rhetorical texture. The use of ‘like’ in the context of this collection demonstrates the poet’s aesthetic strategies and narrative comparisons, whereby the Osundare presents ideas and concepts in via comparison with another. This finding aligns with Amore and Amusan’s (2016) discovery about Osundare’s use of Conceptual metaphors, a similar comparative device to simile. By systematically extracting these concordances, corpus methods provide quantitative measures of frequency and contextual variation, which complement close reading by surfacing patterns that might be overlooked in a purely qualitative approach. Scholars such as Stubbs (2005) and McIntyre & Walker (2019) have emphasized that such hybrid corpus techniques serve not as replacements for close reading but as augmentative tools, bridging quantitative rigor and qualitative interpretive depth, thereby producing a more holistic understanding of the text.
11. N-Gram in Niyi Osundare’s the Eye of the Earth
N-gram is the domain of clusters. Clusters, according to Mahlberg (2013), is another area of focus of corpus stylistics that examines the words in their immediate environments using automated tools like AntConc (designed by Anthony in 2011) to identify concordance and n-gram. He further states that the higher the n-gram, the lower its frequency. What distinguishes n-gram from others is that it deals with structural sequences. The following software tools are viable libraries that can help build wordlists, keyword analysis, colocation lists, n-gram/cluster list, and then analyze the concordance of the items of interest: Wmatrix3, AntConc, WordSmith, Sketch Engine, etc. Analyzing clusters in Niyi Osundare’s corpus data involves an evaluation of n-gram analysis of words, and phrases extracted from the poetic corpus of Niyi Osundare using AntConc and also test queries for the predominant syntactic structure.
Table 5.
Output of the n-gram extraction from the corpus.
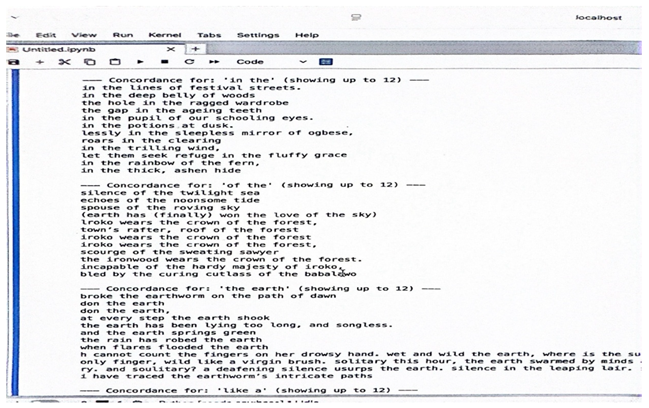 |
The 2-gram analysis of Eye of the Earth provides a clearer structure of Osundare’s lexical patterns and phraseological tendencies as captured in the poem. By examining pairs of words that co-occur, the analysis captures common syntactic relations and collocational sequences of the most frequent 2-grams, namely, “in the”, “of the” and “the earth” mostly functioning as a structural connector, depicting Osundare’s stylistic idiolect. They are evident in lines such as “silence of the twilight sea,” “echoes of the noonsome tide,” and “spouse of the roving sky,”. They project a harmony of metaphors (i.e. crown of the forest), cohesion and rhythmic continuity. The n-gram findings in this study helps to solidify earlier discovery about the parallel forms, metaphorical connotations and rhythms that form Osundare’s linguistic style. He has done it again as evident in this result by producing measurable co-occurrence data reinforcing the argument that corpus-assisted techniques can amplify textual structures and enrich close reading.
12. Yoruba Lexical Imprint in Osundare’s the Eye of the Earth
This study also attempted to examine Osundare’s linguistic magical representation of Yoruba lexical imprints in his works by attempting the following:
- extract all the Yoruba words in the corpus;
- identify their total number and their frequencies;
- identify their concordance to establish the company they keep.
This analysis is significant because it uncovers how Osundare’s linguistic idiolect is deeply rooted in Yoruba orature, even within he writes in colonial English language, confirming his multilingual artistic identity. This kind of blend is not often surprising because Osundare himself has confessed that he primarily thinks out his poems in Yoruba (Anyokwu, 2014, p. 28) but only uses English to represent them, therefore making English as a meta-representation of his Yoruba ideology. By investigating the patterned presence of Yoruba lexical items, the study unveils cultural, ecological, and ideological meanings that close reading alone might overlook.
Here is the tabular representation of Yoruba words in the data.
This study has successfully represented, with accuracy and precision, the amount of Yoruba lexical items that Osundare weaves into the language of The Eye of the Earth, a collection comprising eighteen poems, 967 lines, 156 sentences, and 4995 words in total. The occurrence of fifty-two (52) Yoruba words, representing thirty-four unique forms is strategic. While these words constitute a small proportion of the total lexical items, the distribution of Yoruba words indicates that they are strategically positioned in the text. Their presence in nearly 20% of sentences and across 39% of the poems suggests that Yoruba lexical items are selectively embedded to convey cultural, ecological, or thematic emphasis rather than appearing uniformly. For instance, the choice of the top keywords (i.e. Olosunta, Iroko/iroko, Oke, Abusoro, and others) seems to be deliberate. The word ‘Iroko” refers to a large hardwood tree commonly called “Iroko tree”. It is sometimes referred to as “African teak” due to its durable timber. Without any doubt, this word is a deliberate attempt to corroborate the theme of ‘nature’ that has been earlier mentioned as a significant subject matter in the collection. No wonder Jeyifo (1985 p. 315) describes his works as “ninety percent perspiration and ten percent inspiration. These items have successfully embellished his poetic rendition as they function indicators or carriers of cultural identity, cosmology, ecology, and collective memory within the foreign (English) tongue. Each Yoruba word was carefully deployed to invoke natural landscapes, deities, rituals, that are deeply rooted in the pristine Yoruba oral traditions. This enables him to craft an “alter/native” English form (a blend of English and Yoruba) in which the Yoruba linguistic forms are captured to reshape semantic and structural possibilities of English. The concordance analysis further reflects how the Yoruba lexical items appear in semantically charged and structurally prominent positions.
Table 6.
Tabular representation of Yoruba words in the data.
| Yoruba Words and Their Total Number of Occurrences in The Corpus | No | Out of the Total No | % |
| Total number of Yoruba words (all occurrences) | 52 | 4995 | 1.04% |
| Total number of unique Yoruba words | 34 | 1817 | 1.87% |
| Total number of lines containing Yoruba words | 7 | 967 | 0.72% |
| Total number of sentences containing Yoruba words | 31 | 156 | 19.87% |
| Total number of poems containing Yoruba words | 7 | 18 | 38.88% |
Table 6.
Representation of Yoruba words Frequencies.
 |
One major problem faced in this study was the lack of a comprehensive Yoruba NLP library that can automatically extract Yoruba words from the corpus. This necessitated the researcher to engage in manual annotation before computational extraction. Through this approach, the study discovered cultural features and labels that were difficult, or even impossible to retrieve through close reading alone, emphasizing the importance for a hybrid methodological approach to corpus analysis to ensure a better understanding of the poet’s linguistic idiolect and general style features captured in the field of poetry.
13. Conclusions
In summary, this study has demonstrated how quantitative keyword and concordance analyses can illuminate the stylistic force of not just content words but also function words as in ‘like’ and ‘let’ in contemporary ecological poetry, revealing their significant rhetorical functions to depict comparison and invocation. KWIC also buttresses Osundare’s thematic coloration regarding nature as captured in the frequency of words like “earth’, ‘sun’, ‘forest’, all depicting the natural ecosystem. To corroborate the theme of ‘nature’, Osundare, in his multilingual capacity, intentionally deployed strategic Yoruba words (Olosunta, Iroko/iroko, Oke, Abusoro,) which were identified as top keywords in the Yoruba sub-corpus in the study. The smooth flow of Yoruba language as a means of complementing the thematic ideas already captured in English language depicts Osundare as not just a literary icon but a linguistic genius whose literary idiolect is a product of premeditation and perspiration to reflect cultural identity, cosmology, ecology.
This study has also shown how a corpus stylistic method amplifies detail that might be obscure to close reading. The Keyword frequencies, concordances, collocations, and n-gram analyses have affirmed thematic and stylistic consistencies across a larger collection, demonstrating the strengths of distant reading without losing the interpretive depth of close reading.
For researchers who are interested in using corpus approach to stylistics and discourse analysis, future research may extend this approach to larger poetic corpora or compare stylistic patterns across different authors to further increase our understanding of how quantitative analysis of language can help in shaping literary meaning.
References
- Abdulqader, A. Khalil; Aba Sha’ar, Y. Mohammed; Murshed, H. Ahmed; Alyasery, H Abdulqawi. Corpus stylistics: Style and corpora applications. International Journal of Creative Research Thoughts 2020, 8(7). Available online: https://www.ijcrt.org.
- Alexander, J. Oluwafunmilayo. Domesticating the English language in Niyi Osundare’s The Word Is an Egg. Imbizo 2024, 14(2). [Google Scholar] [CrossRef] [PubMed]
- Amore, K. P., Amusan, K. V., & Okoye, C. J. 2016. Aspects of conceptual metaphor in selected poems of Niyi Osundare in (Ed) Ogunsiji Language and Style in Niyi Osundare’s Poetry, Ijagun.
- Anolue, Chukwunwike. Time and nature in the poetry of Niyi Osundare: Poetics of animism, Anthropocene, and Capitalocene.; Taylor & Francis Group: Oxford, UK, 2024. [Google Scholar]
- Anthony, Laurence. AntConc (Version 3.2.4m) Computer Software; Waseda University: Tokyo, Japan, 2011; Available online: http://www.antlab.sci.waseda.ac.jp/.
- Anyokwu, Christopher. Niyi Osundare and the poetics of change. Nigerian Journal of Oral Literatures 2014, 2, 15–32. [Google Scholar]
- Arnold, Stephen. Niyi Osundare: I am one of Africa's accidents. Matatu: Journal for African Culture and Society 2001, 23–24, 161–181. [Google Scholar]
- Bamikunle, Adebayo. The development of Niyi Osundare's poetry: A survey of themes and technique. Research in African Literatures 1995, 26(4), 121–137. [Google Scholar]
- Biber, Douglas; Conrad, Susan; Reppen, Randi. Corpus Linguistics: Investigating Language Structure and Use; Cambridge University Press: Cambridge, 1998. [Google Scholar]
- Dahunsi, N. Timothy; Babatunde, T. Sola. Mood structure analysis and thematisation patterns in Niyi Osundare’s My Lord, Tell Me Where to Keep Your Bribe. International Journal of English Linguistics 2017, 7(3), 129–137. [Google Scholar] [CrossRef]
- Egya, E. Sule. Niyi Osundare: A Literary Biography; Savage Publishers; Whiteline, 2017. [Google Scholar]
- Eve, Martin Paul. Close reading with computers: Textual scholarship, computational formalism, and David Mitchell’s Cloud Atlas; Stanford University Press, 2019. [Google Scholar]
- Firth, John Rupert. Papers in Linguistics; Oxford University Press: London, 1957a. [Google Scholar]
- Flowerdew, Lynne. Corpus-based discourse analysis. In Routledge handbook of discourse analysis; Gee, J. P., Handford, M., Eds.; Routledge, 2012; pp. 174–187. [Google Scholar] [CrossRef]
- Hayman, Nic. A corpus stylistic approach to Jack London’s The Call of the Wild; 2010; pp. 1–24. [Google Scholar]
- Hoey, Michael. Patterns of lexis in text; Oxford Univ. Press: Oxford, 1991. [Google Scholar]
- Hyland, Ken. Academic Discourse; Continuum: London, 2009. [Google Scholar]
- Jabbar, Nadia. A Corpus Stylistic Analysis of Selected Plays of the Theatre of Anger by John Osborne. MA thesis, University of Baghdad, Baghdad, Iraq, 2014. [Google Scholar]
- Jaafar, Eman Adil. Corpus stylistic analysis of Thomas Harris’ The Silence of the Lambs. KhazarJournal of Humanities and Social Sciences 2017, 20(1), 25–42. [Google Scholar]
- Jakobson, R. Linguistics and poetics. In Language in literature; Pomorska, K., Rudy, S., Eds.; Belknap Press, 1987; pp. 62–94. [Google Scholar]
- Jeyifo, Biodun. 'Niyi Osundare'. In Perspectives on Nigerian Literature 1700 to the Present, Volume Two; Guardian Books: Lagos; Print, 1985; pp. 314–321. [Google Scholar]
- Labov, William. and Waletzky, Judy.1967. “Narrative analysis: Oral versions of personal experience.” In Essays on the Verbal and Visual Arts, June Helm (ed.), 12–43. Seattle: University of Washington Press (PDF) Evaluation in emotion narratives. Helm, June (Ed.).
- Leech, Geoffrey. Grammar of spoken English: new outcomes of corpus-oriented research Learning. 2000, 50(4), 675–724. [Google Scholar] [CrossRef]
- Mahlberg, Michaela. Corpus Stylistics and Dickens’s Fiction; Routledge: London, 2013. [Google Scholar]
- McEnery, Tony; Xiao, Richard; Tono, Yasuhiko. Corpus-Based Language Studies; Routledge: London, 2006. [Google Scholar]
- McEnery, Tony; Hardie, Andrew. Corpus Linguistics: Methods, Theory and Practice; CU: Cambridge, 2012. [Google Scholar]
- McIntyre, Dan. Towards integrated corpus stylistics. Topics in Linguistics 2015, 16, 45–54. [Google Scholar] [CrossRef]
- McIntyre, Dan.; Walker, Brian. Corpus stylistics: Theory and practice; Edinburgh University Press, 2019. [Google Scholar]
- Moretti, Franco. Conjectures on World Literature. New Left Review 2000, I/1. [Google Scholar] [CrossRef]
- Onyejizu, C. Raphael; Obi, F. Uchenna. Ideological Commitment in Modern African Poetry: Redefining Cultural Aesthetics in Selected Poems of Niyi Osundare’s The Eye of the Earh and Village Voices. Journal of Language and Literature 2020, 14(10). [Google Scholar] [CrossRef]
- Scott, Mike. WordSmith Tools Manual 6.0. 2013. Available online: http://www.lexically.net/downloads/version6/wordsmith6.pdf.
- Sinclair, M. John. Corpus, Concordance, Collocation; Oxford University Press: Oxford, 1991. [Google Scholar]
- Sinclair, M. John. Trust the Text; Routledge: London, 2004. [Google Scholar]
- Stubbs, Michael. Text and Corpus Analysis; Blackwell: Oxford, 1996. [Google Scholar]
- Stubbs, Michael. Conrad in the computer: Examples of quantitative stylistic methods. Language and Literature 2005, 14(1), 5–24. [Google Scholar] [CrossRef]
- Swales, M. John. Research Genres. In Explorations and Applications; Cambridge University Press: Cambridge, 2004. [Google Scholar]
- Toolan, Michael. Narrative progression in the short story: First steps in a corpus stylistic approach. Narrative 2008, 16(2), 105–120. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



