
Submitted:
14 January 2026
Posted:
15 January 2026
You are already at the latest version
Abstract
Standard autoregressive language models typically generate text in an open-loop fashion, ignoring the accumulation of errors over time. Consequently, despite their local fluency, these systems frequently suffer from long-horizon pathologies such as repetitive loops, diminished lexical diversity, and distributional collapse when relying on truncation-based sampling. To address this, we present Narrative-Dynamical Systems (NDS), a closed-loop decoding architecture that couples a frozen generator with a frozen encoder through a modular pre-sampling logit processor. NDS actively monitors online statistics across three channels—representation drift, token-level redundancy, and distributional concentration—and intervenes only when these signals jointly indicate a transition into a degenerate regime (low-drift/high-redundancy). The control action is injected directly into the logit space as a combination of (i) an orthogonally projected ascent step derived from a quadratic KL trust-region surrogate, and (ii) a sparse dynamic barrier designed to suppress empirically identified attractor token sets. We provide explicit derivations for the KL approximation and projection steps, alongside a closed-form bound demonstrating the exponential attenuation of probability mass assigned to the attractor set.
Keywords:
autoregressive decoding
; closed-loop text generation
; logit space control
; decoding-time intervention
; long-horizon degeneration
; representation drift
; entropy regularization
; dynamic barriers
; KL trust region
; language model inference
1. Introduction
The ability of neural language models to sustain coherent open-ended generation is not solely a function of model scale or training data; it remains critically sensitive to the decoding algorithm employed at inference time. While models are capable of high-quality outputs, standard truncation heuristics and mode-seeking objectives can produce text that is locally grammatical yet globally degenerate, exhibiting high redundancy and diminished diversity over long horizons [1,2]. This phenomenon highlights a fundamental probability–quality tension, explaining why favoring high-probability continuations often results in dull or repetitive sequences in unconstrained settings [3].
To mitigate these issues, recent inference-time strategies have proposed alternative sampling rules that regulate local information content [4] or employ diversity-oriented decoding objectives, such as diversity-augmented beam search [5]. A complementary line of work introduces auxiliary predictors or experts to steer generation without updating the base generator parameters [6,7,8]. Furthermore, representation-aware decoding approaches based on contrastive objectives provide evidence that degeneration can be mediated by interventions that explicitly couple token selection to representation geometry [9].
In this work, we adopt a systems engineering perspective: we treat long-horizon decoding as a feedback process where the model constantly conditions on its own prior outputs. Within this framework, the induced closed-loop dynamics can drift into unstable regimes characterized by low representation drift, high token redundancy, and collapsing entropy. NDS targets this mechanism by specifying an explicit architecture and a logit-level control law that (i) ensures the model remains within a local trust region around the base distribution and (ii) actively suppresses empirically detected attractor sets. By treating the generator as a fixed inference component that exposes logits prior to sampling, we implement this control action as a modular, plug-and-play logit processor.
2. Related Work
Degeneration under open-ended decoding was characterized by Holtzman et al. [1], who show that truncation-based sampling changes the shape of the sampled distribution yet does not eliminate repetitive failure modes. Unlikelihood training penalizes repeated tokens at training time and provides a widely used point of comparison when parameter updates are permitted [2]. Meister et al. analyze the probability–quality paradox [3] and propose locally typical sampling as an inference-time correction [4]. Diversity-promoting decoding has been studied in the context of structured search procedures such as Diverse Beam Search [5]. Controlled generation methods such as PPLM and FUDGE modify token probabilities using auxiliary predictors while keeping the base generator frozen [6,7]; decoding-time expert mixtures provide another parameter-free control mechanism [8]. Contrastive frameworks connect degeneration to representation anisotropy and propose decoding rules that trade off plausibility and diversity in representation space [9]. Distributional evaluation metrics such as MAUVE quantify the gap between generated and reference text distributions under decoding interventions [10]; benchmarking toolkits such as Texygen support standardized evaluation of diverse generators and metrics [11].
3. System Architecture
NDS is defined as the composition of a frozen autoregressive generator, a frozen encoder, online statistics maintained over a sliding window, and a pre-sampling logit processor that injects control.
3.1. Components and Interfaces
Let be a generator (decoder-only LM) that maps a prefix to logits :
Let be an encoder that maps the same prefix to a compact state:
The control module computes from , token and distribution statistics on a sliding window, and a one-step candidate set computed from . The controlled distribution is
The generator parameters and encoder parameters remain fixed throughout inference; all interventions are applied to logits prior to sampling.
Figure 1.
NDS architecture. Control is injected as a logit processor prior to sampling; the encoder and generator remain frozen.
Figure 1.
NDS architecture. Control is injected as a logit processor prior to sampling; the encoder and generator remain frozen.
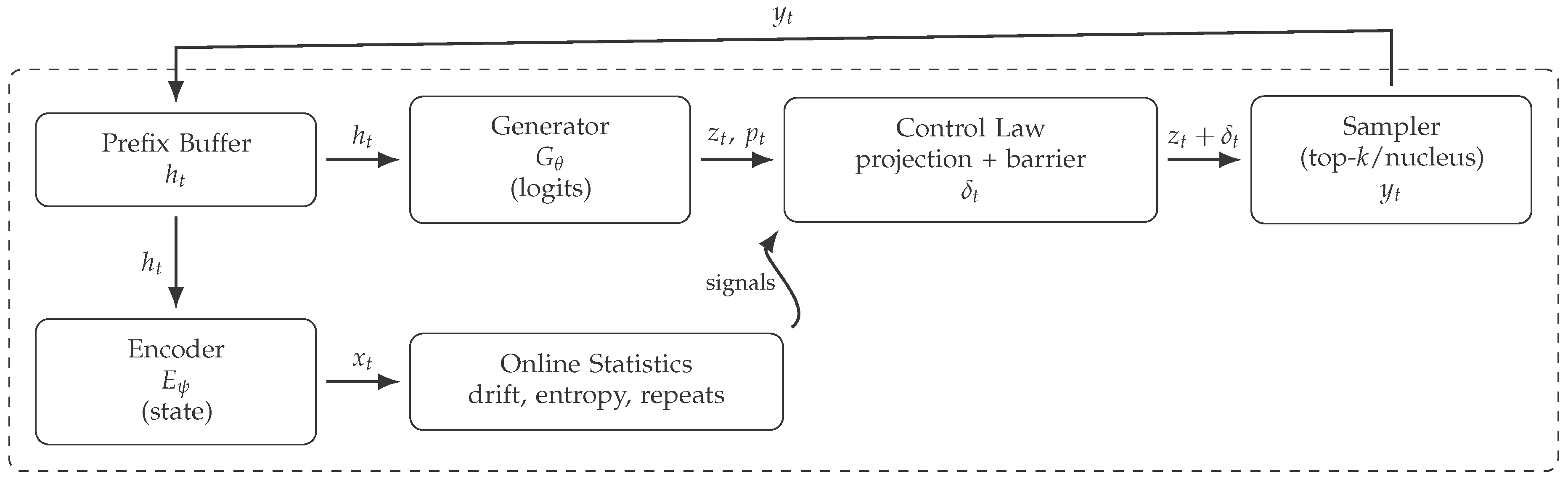
4. Coupled Diagnostics for Long-Horizon Degeneration
NDS does not rely on a single proxy. Instead, it triggers control when evidence is consistent across (i) representation drift, (ii) token redundancy, and (iii) distributional concentration.
4.1. Representation Drift
Define the state and drift:
Let be a windowed drift average:
Low indicates that the representation evolves slowly under the current decoding regime.
4.2. Token Redundancy
Let be the multiset of n-grams in the last W tokens of . Define the repeated n-gram participation rate:
This quantity is invariant to embedding choices and detects local redundancy in the generated token stream.
4.3. Distributional Concentration
4.4. Trigger Predicate
Definition
(Trigger predicate). For thresholds ,
Triggering is intentionally conservative: the controller activates only when all three channels indicate entry into a low-drift, high-redundancy, low-entropy regime.
5. Attractor Sets and Dynamic Barriers
NDS constructs an attractor set online from windowed statistics and imposes a sparse barrier in logit space.
5.1. Frequency and Repetition Criteria
Let be the empirical frequency of token w in the last W steps:
Fix thresholds . Define the attractor set:
5.2. Barrier Definition
Let be a smooth step function (e.g., logistic). Define the recent attractor density
The barrier is a sparse logit penalty:
Proposition
(Barrier suppresses attractor-set probability mass). Let and let . Define where for and 0 otherwise, with . Then
Proof.
Since , we have
The inequality follows by bounding the denominator below by . □
6. Control Law: Orthogonal Projection under a KL Trust Region
When , NDS computes a projected step designed to increase a one-step diversification surrogate while remaining near the base distribution.
6.1. One-Step Surrogate and Score-Function Direction
Define the window centroid in state space:
Construct a candidate set from (top-k or nucleus). Define one-step scores
Using , define a finite-sum score-function direction:
where are normalized base probabilities restricted to and is a baseline (e.g., the weighted mean of over ).
6.2. Second-Order KL Approximation
Let and . For sufficiently small , a second-order approximation holds.
Lemma
(Second-order KL approximation in logit space). Let and . Then
Proof.
A Taylor expansion of around yields a zero first-order term and a Hessian equal to the Fisher information of the categorical family parameterized by logits, namely . □
6.3. Orthogonal Projection and Minimum-Norm Characterization
Let be a constraint direction. Define the orthogonal projection:
Lemma
(Minimum-norm projection). For , is the unique solution of
Proof.
Let . Stationarity gives . Enforcing yields , and thus . □
6.4. Trust-Region Scaling
A practical scaled step is obtained by using the quadratic KL surrogate:
6.5. Composite Control
The final control is
7. Algorithm
Algorithm 1
NDS closed-loop decoding (single step) |
Require:
prefix , logits , window size W
|
8. Implementation Considerations
NDS requires two operational interfaces: (i) an encoder that maps the evolving prefix to a fixed-dimensional representation, and (ii) a generator runtime that exposes logits prior to sampling so that a logit processor can inject . The fragments below illustrate a deterministic windowed-state implementation and sparse logit-bias injection using the llama.cpp library [13]; they are representative of a standard inference stack where pre-sampling hooks are available.
8.1. Windowed Statistics and Attractor-Set Construction
A ring buffer maintains the last W tokens and W embeddings, along with a hash map for token frequencies. Repeated n-gram participation is computed on the token ring buffer; in a production setting the repeated n-gram detector is implemented with rolling hashes to avoid quadratic scans in W.
Listing 1. C++: windowed statistics and frequency-based attractor set.


8.2. Sparse Logit Injection
Projection is computed on candidate-supported vectors; the barrier is applied only to the sparse attractor set . Both enter as additive bias terms prior to the sampling decision.
Listing 2. C++: sparse barrier insertion in a sampler chain.

9. Evaluation Methodology
This section states an experimental design aligned with prior decoding studies.
9.1. Baselines
Baselines are implemented as alternative pre-sampling interventions operating on the same generator logits. We include: (i) nucleus sampling [1], (ii) locally typical sampling [4], (iii) diversity-oriented search procedures [5], (iv) auxiliary-predictor steering [6,7], and (v) decoding-time expert mixtures [8]. Where applicable, representation-aware decoding rules are included for comparison [9]. All methods share identical tokenization, stopping criteria, and prompt suite.
9.2. Prompt Suite
A fixed prompt suite is used with stratified lengths and styles to probe long-horizon behavior. For each prompt, generation is run for a fixed token budget and evaluated under identical termination rules. The prompt suite is held constant across methods to isolate the effect of decoding-time interventions.
9.3. Metrics
We report complementary metrics capturing redundancy, diversity, and distributional shift: (i) Distinct-n (ratio of unique n-grams to total n-grams) [11]; (ii) repetition rate via repeated n-gram participation aggregated over the generation; (iii) Self-BLEU as a corpus-level indicator of mode concentration [11]; and (iv) MAUVE as a distributional metric comparing generated and reference text [10]. Metrics are interpreted jointly due to known trade-offs between diversity and local coherence under decoding interventions.
10. Conclusion
NDS formalizes long-horizon decoding as a feedback process and proposes a closed-loop architecture in which a fixed generator is coupled to a fixed encoder through a pre-sampling logit processor. Control is activated only under conservative, multi-signal triggering and is implemented as the sum of an orthogonally projected trust-region step and a sparse dynamic barrier that exponentially suppresses probability mass on empirically identified attractor sets. The analysis provides closed-form derivations for the KL surrogate and the projection operator, together with an explicit attenuation bound for attractor-set mass, yielding a principled decoding-time intervention that does not require updating generator parameters.
References
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The curious case of neural text degeneration. arXiv 2020, arXiv:1904.09751. [Google Scholar] [CrossRef]
- Welleck, S.; Kulikov, I.; Roller, S.; Dinan, E.; Cho, K.; Weston, J. Neural text generation with unlikelihood training. arXiv 2019, arXiv:1908.04319. [Google Scholar] [CrossRef]
- Meister, C.; Wiher, G.; Pimentel, T.; Cotterell, R. On the probability–quality paradox in language generation. arXiv 2022, arXiv:2203.17217. [Google Scholar]
- Meister, C.; Pimentel, T.; Wiher, G.; Cotterell, R. Locally typical sampling. arXiv 2022, arXiv:2202.00666. [Google Scholar] [CrossRef]
- Vijayakumar, A. K.; Cogswell, M.; Selvaraju, R. R.; Sun, Q.; Lee, S.; Crandall, D.; Batra, D. Diverse beam search: Decoding diverse solutions from neural sequence models. arXiv 2018, arXiv:1610.02424. [Google Scholar] [CrossRef]
- Dathathri, S.; Madotto, A.; Lan, J.; Hung, J.; Frank, E.; Molino, P.; Yosinski, J.; Liu, R. Plug and play language models: A simple approach to controlled text generation. arXiv 2020, arXiv:1912.02164. [Google Scholar] [CrossRef]
- K. Yang and D. Klein. FUDGE: Controlled text generation with future discriminators. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3511–3535, 2021.
- Liu, A.; Sap, M.; Lu, X.; Swayamdipta, S.; Bhagavatula, C.; Smith, N. A.; Choi, Y. DExperts: Decoding-time controlled text generation with experts and anti-experts. arXiv 2021, arXiv:2105.03023. [Google Scholar] [CrossRef]
- Su, Y.; Lan, T.; Wang, Y.; Yogatama, D.; Kong, L.; Collier, N. A contrastive framework for neural text generation. arXiv 2022, arXiv:2202.06417. [Google Scholar] [CrossRef]
- Pillutla, K.; Swayamdipta, S.; Zellers, R.; Thickstun, J.; Welleck, S.; Choi, Y.; Harchaoui, Z. MAUVE: Measuring the gap between neural text and human text using divergence frontiers. arXiv 2021, arXiv:2102.01454. [Google Scholar] [CrossRef]
- Zhu, Y.; Lu, S.; Zheng, L.; Guo, J.; Zhang, W.; Wang, J.; Yu, Y. Texygen: A benchmarking platform for text generation models. arXiv 2018, arXiv:1802.01886. [Google Scholar] [CrossRef]
- Keskar, N. S.; McCann, B.; Varshney, L. R.; Xiong, C.; Socher, R. CTRL: A conditional transformer language model for controllable generation. arXiv 2019, arXiv:1909.05858. [Google Scholar] [CrossRef]
- Gerganov, G. llama.cpp: Port of Facebook’s LLaMA model in C/C++. GitHub repository. 2023. Available online: https://github.com/ggerganov/llama.cpp.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



