Submitted:
13 January 2026
Posted:
14 January 2026
You are already at the latest version
Abstract
Autonomous driving technology represents a critical component in the advancement of new energy vehicles and serves as an essential enabler for the achievement of sustainable development goals at the societal level. However, autonomous driving in nighttime scenarios suffers from unstable perception under low-light conditions and limited effectiveness, which significantly constrains the practical performance of existing perception systems. This is attributed to the fact that visual degradation and modal reliability imbalance prevalent in nighttime scenarios give rise to erratic feature fusion dynamics within 3D detection paradigms, which is the key technology in autonomous driving, consequently undermining the detection precision.
In this paper, a BEV-based multi-modal 3D object detection approach is presented for nighttime autonomous driving that incorporates adaptive modeling components tailored for nighttime scenarios while preserving the original BEV representation and detection pipeline. Without modifying the core inference structure, the method improves robustness to low-light conditions and enhances the stability of cross-modal feature integration, thereby maintaining reliable perception performance under challenging illumination conditions. Extensive experiments are conducted on the nuScenes nighttime subset to evaluate the effectiveness of the proposed approach. The experimental results demonstrate that the proposed method consistently outperforms the BEVFusion baseline while introducing negligible additional model parameters and inference overhead. In particular, an overall NDS improvement of 1.13\% is achieved under nighttime conditions, validating the effectiveness and practical applicability of the proposed approach for low-light and complex autonomous driving environments.
Keywords:
dual-modal gated fusion
; learnable gama enhancer
; nighttime autonomous driving scenarios
; 3D object detection
; intelligent transportation systems
1. Introduction
With the rapid advancement of science and technology, sustainable development has become a pivotal objective of contemporary economic and social progress. As a crucial driving force behind the evolution of new energy vehicles, autonomous driving technology stands as one of the indispensable enablers for achieving sustainable development goals, attracting extensive attention from researchers in both the artificial intelligence and automotive engineering communities. With the rapid development of autonomous driving technologies, the detection of multi-modal 3D objects has become a key component of environmental perception systems [1,2,3]. By merging information from cameras and LiDAR sensors, existing methods have achieved significant progress in complex traffic scenarios [4,5,6,7,8,9,10]. Among them, Bird’s-Eye View (BEV)–based fusion frameworks have attracted considerable attention due to their unified spatial representation and strong scalability. However, in nighttime or low-light environments, the quality of sensor data degrades significantly, and visual features suffer severe deterioration, which leads to a noticeable decline in the overall performance of multi-modal perception systems.
Most existing multi-modal BEV-based detection methods are primarily designed for daytime or well-illuminated scenarios, and thus face multiple challenges when deployed in nighttime environments. On the one hand, nighttime images suffer from insufficient illumination, increased noise, and reduced contrast, which significantly weakens the discriminative capability of visual features and consequently degrades the effectiveness of cross-modal fusion. On the other hand, some approaches rely on Transformer-based cross-modal attention mechanisms to achieve deep feature interaction; however, their high computational complexity and memory consumption limit practical deployment on resource-constrained platforms. In addition, nighttime datasets typically contain a higher proportion of small objects and sparse-category samples. The use of a unified loss function often fails to effectively model the varying importance of different samples, leading to unstable training behavior or constrained performance.
Motivated by the prevalent challenges in nighttime multi-modal 3D object detection, including perception degradation, imbalanced cross-modal reliability, and uneven training supervision, this work explores a lightweight BEV-based detection framework tailored for nighttime autonomous driving scenarios. Unlike conventional approaches that primarily focus on enhancing the feature fusion stage, we adopt a task-driven perspective that jointly considers nighttime visual characteristics, cross-modal information interaction, and supervision modeling within a unified detection framework.
The main contributions of this paper are summarized as follows:
- A lightweight multi-modal 3D object detection framework tailored for nighttime autonomous driving scenarios is proposed. Based on the BEVFusion baseline, the framework adopts a task-driven joint modeling strategy, which effectively enhances perception performance under complex nighttime illumination conditions without introducing a significant increase in computational overhead.
- A Dual-modal Gated Fusion(DMGF) mechanism is designed. By adaptively adjusting the feature weights of camera and LiDAR modalities, this mechanism enables stable cross-modal information interaction and effectively mitigates the adverse impact of single-modality degradation on detection performance in nighttime environments.
- In response to the high proportion of small objects, abundant weakly supervised samples, and unstable training in nighttime scenarios, an adaptive supervision strategy based on learnable weight modulation is proposed. By integrating a learnable gamma enhancer module with a night-aware and small-object adaptive weighting mechanism, the supervision strength for different.
The rest of this paper is organized as follows. Section 2 introduces the background and challenges of this study. Section 3 describes the framework of the proposed detection model, which is the core of this study. The evaluation criterion simulation results are presented in Section 4 and, finally, Section 5 gives the conclusions.
2. Background
2.1. Multi-modal BEV 3D Object Detection
In recent years, multi-modal 3D object detection has gradually evolved from early point-cloud-dominated approaches toward unified perception frameworks based on BEV representations[11,12,13,14,15,16,17]. Representative works such as BEVFusion[18] project multi-view image features and LiDAR features into a shared BEV space, and achieve cross-modal fusion through feature concatenation and convolution, striking a favorable balance between detection accuracy and computational efficiency.
Building upon this line of work, some studies further introduce attention-based cross-modal interaction mechanisms to enhance the information flow between modalities. For example, methods such as TransFusion[19] and dual cross-attention employ Transformer architectures[20] or bidirectional attention mechanisms to model global dependencies between image and point-cloud features, achieving strong detection performance in complex scenarios[21,22]. However, such approaches are typically accompanied by high computational complexity and substantial memory consumption. When applied to high-resolution BEV features or multi-view inputs, they impose significant hardware requirements, which limit their applicability in practical engineering scenarios.
In contrast, some studies attempt to achieve cross-modal information interaction through lightweight designs, such as using convolutional or gating mechanisms to perform adaptive weighted fusion of multi-modal features. Although these methods are generally less expressive than global attention–based models, they offer clear advantages in terms of computational efficiency and practical deployability in real-world systems.
2.2. Nighttime and Low-Light Visual Perception Enhancement
Given the degradation of image modality information under nighttime or low-light conditions, a substantial body of research has investigated image enhancement–based solutions[23,24,25]. Traditional methods, such as Contrast Limited Adaptive Histogram Equalization (CLAHE) and enhancement algorithms based on Retinex theory, are training-free and computationally efficient. However, under complex lighting conditions, they are prone to introducing noise or causing over-enhancement effects[26].
In recent years, deep learning–based methods have achieved significant progress in the field of low-light image enhancement. Representative approaches such as RetinexNet[27], Zero-DCE[28], and SCI (Self-Calibrated Illumination) [29]model illumination mapping through convolutional neural networks, demonstrating strong performance in both subjective visual quality and quantitative metrics. However, these methods are typically optimized for image reconstruction or perceptual quality, require separate pre-training, and are not jointly optimized with downstream 3D object detection tasks. As a result, the enhanced images are not necessarily optimal for detection performance.
In the context of multi-modal 3D object detection, how to enable the low-light enhancement process to directly serve the detection task—without introducing additional training burdens or significant computational overhead—remains an open problem that warrants further investigation[30].
3. Method
3.1. Overall Framework
The proposed method is built upon the multi-modal BEV detection paradigm of BEVFusion. While preserving the original BEV representation and detection pipeline, targeted extensions are introduced to enhance key components for nighttime scenarios. Although BEVFusion provides a unified multi-modal BEV perception framework, its original design is primarily oriented toward well-illuminated conditions and lacks explicit modeling of visual feature degradation, imbalanced modality reliability, and inadequate supervision adaptation under nighttime environments.
Based on these considerations, the overall framework is designed from three interconnected stages, including input modeling, cross-modal feature fusion, and supervision modeling. These stages are organized in a progressive and interdependent manner, forming a closed-loop design that evolves from perception enhancement to feature representation and further to supervision optimization. As a result, an end-to-end multi-modal 3D object detection framework tailored for nighttime scenarios is established, with practical deployment in real-world nighttime urban environments in mind. The overall architecture of the proposed method is illustrated in Figure 1.
3.2. Learnable Gamma Enhancer Module
Under nighttime conditions, the image modality commonly suffers from insufficient illumination, increased noise, and reduced contrast, which significantly degrades the discriminative capability of visual features and consequently affects multi-modal fusion and 3D object detection performance. Most existing low-light enhancement methods are optimized for image reconstruction or subjective visual quality, typically require separate pre-training, and do not necessarily yield results that are optimal for downstream detection tasks. In light of this issue, this paper introduces a Learnable Gamma Enhancer and embeds it into the image branch of BEVFusion in an end-to-end manner, allowing the brightness modeling process to be directly optimized by the 3D object detection loss. By adaptively modeling the global illumination characteristics of nighttime images, the proposed module effectively alleviates visual feature degradation caused by low-light conditions with almost no additional computational overhead, thereby providing more stable visual representations for subsequent cross-modal fusion. The overall structure is illustrated in Figure 2.
3.2.1. Learnable Gamma Parameter Estimation
This module is designed to adaptively predict a physically plausible and stable Gamma parameter based on the global illumination characteristics of the input image.
Given an input image , the module first employs a lightweight network composed of convolutional layers and global average pooling to model the global illumination characteristics of the image and predict a corresponding raw Gamma value. This process can be formulated as follows:
Here, denotes a lightweight convolutional prediction network with a very small number of parameters. To ensure the stability and physical plausibility of the Gamma value, a Sigmoid function is applied to normalize the predicted output, which is then linearly mapped to a predefined Gamma range , yielding the final adaptive Gamma parameter:
To avoid overly aggressive enhancement during the early stages of training, the prediction network is initialized to produce a moderate Gamma value that is close to an identity transformation.
3.2.2. Gamma-based Low-light Intensity Enhancement
This module applies controlled nonlinear brightness enhancement to low-light images using the predicted adaptive Gamma parameter.
After obtaining the adaptive Gamma parameter, standard Gamma correction is applied to the input image for brightness enhancement, which can be expressed as follows:
Where is a small constant introduced to prevent numerical instability during the application of the power-law transformation.
When , this operation effectively enhances low-intensity regions, thereby alleviating the degradation of image modality information at nighttime scenarios.
3.2.3. End-to-end Training with Multi-view Support
The proposed Learnable Gamma Enhancer is directly embedded at the front end of the image branch and jointly trained with the BEVFusion backbone network. Since the Gamma parameter is connected to the detection loss through Eqs. (1)–(4) in an end-to-end differentiable manner, the enhancement strategy can be learned via backpropagation driven by the downstream 3D object detection loss. As a result, the brightness transformation is automatically adjusted toward a form that is most beneficial for the detection task.
In addition, the proposed module naturally supports multi-view input settings. Under a multi-camera configuration, an independent Gamma parameter is estimated for each view, and a consistent enhancement operation is applied accordingly, enabling seamless integration with the multi-view BEV perception framework of BEVFusion.
3.3. Dual-Modal Gated Fusion
In the BEVFusion framework, the fusion strategy between image and LiDAR features plays a decisive role in the performance of multi-modal 3D object detection. Simple feature concatenation lacks explicit modeling of cross-modal interactions, while Transformer-based cross-modal attention mechanisms, although capable of capturing global dependencies, incur computational complexity and memory consumption that grow significantly with BEV resolution, thereby limiting practical deployment in resource-constrained environments. To achieve a more favorable balance between fusion effectiveness and computational efficiency, this paper proposes the DMGF module.
The proposed module employs a convolution-based gating mechanism to approximate bidirectional cross-modal attention, enabling effective information interaction between image and LiDAR BEV features while substantially reducing computational overhead. As a result, it enhances the stability and robustness of multi-modal perception in nighttime scenarios. The overall structure of the DMGF module is illustrated in Figure 3.
3.3.1. Feature Projection and Alignment
This module aims to construct a unified and comparable feature representation space for multi-modal feature fusion, thereby providing a consistent embedding basis for subsequent cross-modal interactions.
Given the BEV features from the image branch and the LiDAR branch, denoted as and , respectively, convolutional projections are first applied to map the two modal features into a unified embedding space with aligned channel dimensions. This process can be expressed as follows:
where and denote lightweight convolutional projection functions, producing output features with identical dimensions.
3.3.2. Cross-modal Gated Weight Estimation
This module provides adaptive weighting constraints for cross-modal information fusion by modeling the relative reliability between different modal features.
To capture the cross-modal dependencies between image and LiDAR features, convolutional operations are applied to the concatenated features as an efficient approximation of conventional cross-modal attention mechanisms. Specifically, the two modal features are first concatenated along the channel dimension as follows:
Subsequently, convolutional layers followed by a Sigmoid activation function are used to predict the corresponding cross-modal weighting maps:
where and denote convolutional weight prediction functions, whose outputs are constrained to the range and are used to control the strength of cross-modal information enhancement.
3.3.3. Bidirectional Gated Feature Enhancement
This module enhances the complementarity between multi-modal features through a controlled cross-modal interaction mechanism, thereby improving overall perception robustness in complex scenarios.
Based on the predicted cross-modal weights, a bidirectional cross-modal enhancement mechanism is designed to enable mutual reinforcement between image and LiDAR features. Specifically, the enhanced feature representations are formulated as follows:
where ⊙ denotes element-wise multiplication. With this design, the two modalities can complement each other under spatial alignment, thereby enhancing perception robustness in nighttime scenarios.
3.3.4. Fusion Output
Finally, the bidirectionally enhanced features are concatenated along the channel dimension and passed through a convolutional layer to generate the fused output feature representation:
3.4. Night-aware and Small Object Adaptive Loss
In nighttime autonomous driving scenarios, small-scale objects often co-occur with low-light conditions, and their combined effects significantly increase the difficulty of 3D object detection. Conventional detection loss functions typically treat different illumination conditions and object scales uniformly, which can cause nighttime small-object samples to be dominated by large objects or high-confidence samples during training, thereby limiting the model’s ability to learn from difficult cases. Based on this consideration, this paper proposes a Night-aware and Small-object Adaptive Loss, which dynamically reweights the detection loss by jointly modeling scene illumination information and object scale characteristics. Without introducing additional network parameters, the proposed design effectively strengthens the supervision for nighttime small-object samples, improving training stability and detection robustness in complex low-light environments. The module structure is illustrated in Figure 4.
3.4.1. Night-aware Difficulty Weight Modeling
This module aims to adaptively model sample difficulty weights based on the degree of low illumination in nighttime images, thereby strengthening the model’s focus on learning from nighttime and low-light samples.
To enhance the model’s learning capability for nighttime low-light samples, a continuous night-aware weighting function is first constructed based on the global brightness information of the input image. Given a normalized brightness value ( B ), the night-aware weighting coefficient is defined as follows:
where denotes the maximum night-time weighting factor, and represents the brightness threshold. When the image brightness exceeds the threshold, the night-aware weight degenerates to 1; as the brightness decreases, the weight increases continuously, thereby amplifying the influence of low-light samples on model updates.
3.4.2. Small-object Difficulty Weight Modeling
This module aims to adaptively model the detection difficulty weights of small-object samples based on their scale in the BEV space, thereby enhancing the model’s focus on learning small-scale targets.
To address the high proportion of small objects and the increased difficulty in regression and classification under nighttime conditions, a scale-adaptive weighting strategy based on the object footprint in the BEV plane is further introduced. Given the occupied area of an object in the BEV space, defined as , the small-object weighting factor is defined as follows:
where denotes the maximum weighting factor for small objects, and is the scale control threshold. This design assigns higher supervision weights to smaller objects, while the weighting factor for large objects gradually degenerates to 1, thereby avoiding excessive emphasis on large-scale targets.
3.4.3. Adaptive Loss Reweighting
This module adaptively reweights the detection loss by integrating the night-aware and small-object difficulty weights, thereby strengthening supervision for key challenging samples while maintaining training stability.
After obtaining the night-aware weight and the small-object weight, they are combined in an additive manner, and a clipping operation is applied to constrain the overall weight range to ensure stable training. The final adaptive weighting factor is defined as follows:
where denotes the upper bound of the weighting factor. This adaptive weight is directly applied to the classification loss, yielding the final night-aware and small-object adaptive weighted loss as follows:
With this design, nighttime small-object samples receive stronger supervision signals during training, while the training weights for daytime or large-object samples remain largely unchanged.
3.5. Discussion
From the perspectives of computational complexity and practical engineering implementation, all modules proposed in this work achieve a favorable balance between performance improvement and efficiency. The brightness-aware adaptive enhancement module introduces only a very small number of learnable parameters and performs global brightness adjustment of nighttime images by predicting a single global Gamma value. This design avoids the additional complexity brought by pixel-wise enhancement while effectively reducing the risk of overfitting to local illumination noise. As a result, the lightweight enhancement mechanism can be stably integrated into the detection framework without causing a noticeable impact on overall training and inference efficiency. Furthermore, at the stage of cross-modal feature fusion, the adopted controlled bidirectional interaction mechanism reduces the computational complexity from the quadratic growth characteristic of Transformer-based methods to linear complexity. While preserving bidirectional cross-modal information exchange, it significantly lowers memory consumption, which also explains why the proposed method maintains stable performance under high-resolution BEV representations. In addition, at the supervision level, the Night-aware and Small-object Adaptive Loss adaptively models nighttime and small-object samples through continuous difficulty-aware weighting without introducing additional network parameters. This design enhances learning effectiveness for challenging samples while ensuring training stability and good generalization capability.
4. Experiments
To comprehensively evaluate the detection performance, generalization ability, and robustness of the proposed method under nighttime conditions, a series of systematic experiments is designed and conducted. These experiments include not only comparative analyses of overall performance against existing methods, but also further investigations into model behavior with respect to category distribution characteristics and under different testing conditions.
4.1. Experimental Setup
4.1.1. Dataset and Evaluation Metrics
All experiments in this study are conducted on the nuScenes dataset. To specifically investigate multi-modal perception under nighttime conditions, a nuScenes-Night subset is constructed by filtering the original nuScenes dataset to include only multi-modal data collected in nighttime or low-light environments. During training, all models are trained exclusively on the nuScenes-Night subset. During testing, evaluations are consistently performed on the nuScenes-Night validation set. Model performance is assessed using the official nuScenes evaluation metrics, primarily including mAP and NDS. The classification of the dataset is shown in Figure 5.
As shown in Figure 5, the training and validation sets exhibit consistent overall trends in category distribution, both displaying pronounced long-tailed characteristics. Among all categories, cars and pedestrians dominate in terms of sample quantity, significantly exceeding other classes, which reflects the high occurrence frequency of vehicles and pedestrians in real-world driving scenarios.
In contrast, categories such as Construction Vehicle, Trailer, and Barrier contain substantially fewer samples and can be regarded as typical low-frequency classes. These categories are more susceptible to the effects of class imbalance during training. Under such data distribution characteristics, overall detection performance is inherently constrained. Nevertheless, even in the presence of severe class imbalance and long-tailed distributions, the proposed method achieves stable performance improvements, demonstrating its effectiveness and robustness in complex data distribution scenarios.
On the nuScenes dataset, model performance is evaluated using the official nuScenes evaluation protocol. Overall detection performance is primarily measured by the nuScenes Detection Score (NDS). In addition, mean Average Precision (mAP) and mean Translation Error (mATE) are reported to characterize detection accuracy and 3D spatial localization precision, respectively.
In this work, model performance on the nuScenes dataset is evaluated using the official nuScenes evaluation protocol. The primary metric used for overall detection performance is the nuScenes Detection Score (NDS), which is a comprehensive measure that reflects both detection coverage and quality by combining multiple evaluation aspects into a unified score. Specifically, NDS integrates average precision with multiple true positive error terms to provide a balanced assessment of detection completeness and localization accuracy under various conditions[32].
In addition to NDS, the mean Average Precision (mAP) is reported to quantify the detection coverage capability. In the context of nuScenes, mAP measures the ability of the model to detect and correctly localize objects within predefined center-distance thresholds, averaging precision scores across different object categories. A higher mAP indicates better overall recall and precision in object detection[32].
To further characterize localization performance, the mean Average Translation Error (mATE) is used to evaluate the average deviation between predicted and ground-truth 3D object centers. Lower mATE values correspond to more precise 3D spatial localization, which is essential for accurate perception in autonomous driving systems[32].
4.1.2. Implementation Details
The proposed method is implemented based on the BEVFusion framework. Model training is performed using the AdamW optimizer with an initial learning rate of 0.0002, together with a learning rate scheduling strategy consisting of linear warm-up (500 iterations) followed by cosine annealing. During training, the batch size is set to 6, and all models are trained for 20 epochs. Unless otherwise specified, all comparison methods and ablation experiments adopt identical training configurations to ensure fairness and comparability of the experimental results. All experiments are conducted on an NVIDIA A6000 GPU with 48 GB of memory. The software environment includes Linux, Python 3.10.19, PyTorch 2.0.1, CUDA 11.8, and cuDNN 8.7. The models are implemented using the MMDetection3D framework.
4.1.3. Comparison Methods and Ablation Settings
To systematically evaluate the impact of each component on nighttime multi-modal 3D object detection, BEVFusion is adopted as the baseline multi-modal detection framework. Based on this baseline, a learnable gamma enhancer module, a DMGF module, and a night-aware and small object adaptive loss function are progressively incorporated to construct different model variants for ablation studies. By comparing the detection results of these variants under identical experimental conditions, the individual contributions and collaborative effects of each module on the overall performance are analyzed. To ensure the reliability and comparability of the experimental conclusions, all ablation experiments are conducted using consistent dataset splits, training strategies, and evaluation metrics.
For the overall performance comparison, CenterPoint is selected as a representative single-modality LiDAR-based 3D object detection method to analyze the performance differences between multi-modal fusion approaches and single-modality solutions in complex nighttime scenarios. In addition, FCOS3D, a representative monocular 3D detection method, is included as an additional baseline to provide a broader comparative perspective, enabling a more comprehensive evaluation of the effectiveness and robustness of the proposed method under nighttime conditions.
4.1.4. Generalization and Robustness Evaluation Setup
To evaluate the generalization ability and robustness of the proposed method under nighttime conditions, a series of experiments is designed and conducted without retraining the model, using the weights obtained after training. All experiments are performed on the full nuScenes validation set to ensure completeness and consistency of the evaluation.
For both generalization and robustness assessments, inference and performance evaluation are carried out on the full nuScenes validation set using the trained model weights, without any additional fine-tuning. By keeping the model architecture, learned parameters, and inference settings unchanged, and only altering the input conditions at the testing stage, the model’s performance under different test scenarios can be systematically analyzed.
Specifically, for the generalization evaluation, the model is directly tested on the original full nuScenes validation set to assess its overall generalization performance under the complete data distribution. For the robustness evaluation, additional nighttime noise perturbations are introduced into the validation inputs to simulate sensor noise and imaging instability commonly encountered in nighttime scenarios. The detection results under noisy conditions are then compared with those obtained under noise-free settings, enabling a quantitative assessment of the model’s stability and robustness under degraded input conditions. All experiments are evaluated using the same set of metrics to ensure comparability across different testing conditions. The corresponding experimental results and analyses are presented in subsequent sections.
4.2. Overall Performance Comparison
Given the differences in perception reliability across modalities in nighttime scenarios, multi-modal fusion strategies have a significant impact on detection performance. Therefore, under a unified experimental setup, this paper conducts comparative experiments to analyze the proposed method alongside various representative detection methods. In addition to the multi-modal baseline model, CenterPoint and FCOS3D[31] are also introduced as comparison objects. FCOS3D is a single-modality image-based detection method, while CenterPoint is a single-modality LiDAR-based detection method. This paper compares the performance of FCOS3D and CenterPoint as reference methods. The experimental results are summarized in Table 1.

Table 1.
Comparison of different methods on nuScenes-Night dataset
| Method | Modality | mAP | NDS | mATE |
|---|---|---|---|---|
| Bevfusion(baseline) | C+L | 0.2727 | 0.3292 | 0.5572 |
| CenterPoint | L | 0.2579 | 0.3603 | 0.4569 |
| FCOS3D | C | 0.0494 | 0.1344 | 0.9492 |
| +DMGF | C+L | 0.2700 | 0.3336 | 0.5379 |
| Ours | C+L | 0.2753 | 0.3405 | 0.5272 |
The proposed method, Ours, achieves the best performance in balancing detection accuracy and localization precision, with mAP and NDS values of 0.2753 and 0.3405, respectively, and a reduced mATE of 0.5272.
In contrast, the CenterPoint method, relying solely on LiDAR, shows lower localization error (mATE = 0.4569) but significantly lower mAP, indicating that relying on a single modality in nighttime scenarios limits detection performance.
FCOS3D performs poorly with low mAP (0.0494), NDS (0.1344), and high mATE (0.9492), indicating its weakness in both object detection and localization, particularly in complex or low-light environments.
Multi-modal methods, combining camera and LiDAR data, offer more stable performance. Introducing the DMGF module to the BevFusion baseline model improves NDS from 0.3292 to 0.3336 and reduces mATE from 0.5572 to 0.5379, highlighting the value of cross-modal feature fusion.
Finally, Ours outperforms the baseline with +0.0026 in mAP, +0.0113 in NDS, and -0.0300 in mATE, demonstrating the effectiveness of the proposed multi-modal co-modeling approach.
Despite challenges like low illumination, small objects, and class imbalance in nighttime scenarios, the proposed method consistently improves performance across evaluation metrics, proving its robustness in complex detection tasks.
4.3. Ablation Study
4.3.1. Module-wise and Ablation Study Analysis
Although the proposed method improves nighttime perception performance through coordinated modeling of multiple modules, it is still necessary to disentangle and analyze the individual contributions of each component to the overall performance gains. Therefore, this section conducts ablation experiments to further investigate the effects of the input enhancement module, the cross-modal fusion module, and the loss modeling strategy. The experimental results are summarized in Table 2.
Table 2.
Ablation study of different modules on the night-time detection task.
| DMGF | Gamma | Final Loss | mAP | NDS |
|---|---|---|---|---|
| × | × | × | 0.2727 | 0.3292 |
| × | × | 0.2700 | 0.3336 | |
| × | × | 0.2537 | 0.3204 | |
| × | × | 0.2591 | 0.3381 | |
| 0.2753 | 0.3405 |
Table 2 reports the ablation results of the proposed key modules on the nuScenes nighttime subset. Based on these metrics, introducing the DMGF module alone yields a stable improvement in NDS, validating its effectiveness in facilitating multi-modal feature interaction under nighttime conditions.
When the learnable Gamma enhancement module is applied in isolation, a slight degradation in overall performance is observed. This indicates that relying solely on low-light enhancement without sufficient task-level constraints may lead to brightness adjustments that are not well aligned with the detection objective.
In contrast, the night-aware and small-object adaptive loss achieves a notable improvement in NDS even without image enhancement, highlighting its capability to effectively model weakly supervised samples in nighttime scenarios. When all three modules are jointly employed, the model attains the best performance on both mAP and NDS. This demonstrates that the proposed low-light enhancement, cross-modal fusion, and adaptive loss components exhibit strong synergy and complementarity, leading to a significant improvement in overall nighttime multi-modal 3D object detection performance.
4.3.2. Training Stability Analysis
To further analyze the impact of different modules on training behavior and optimization dynamics, a comparative analysis of training stability is conducted based on the ablation experiments. Specifically, the baseline model BEVFusion, the model equipped with the +DMGF module, and the full model Ours are selected for comparison. Their gradient evolution and performance convergence behaviors during training are analyzed, as illustrated in Figure 6.
Figure 6.(a) illustrates the evolution of gradient norms during training for different methods. It can be observed that the baseline model exhibits noticeable gradient fluctuations in the early training stage. After introducing the DMGF module, the gradient variations become smoother, indicating that conflicts between cross-modal features are alleviated to some extent. In comparison, the full model maintains stable gradient behavior while exhibiting a higher overall gradient magnitude, suggesting that the introduced enhancement and supervision mechanisms provide richer and more stable training signals.
Figure 6.(b)–(d) present the evolution of mAP, matched IoU, and NDS throughout the training process. The full model demonstrates more stable performance improvements in the middle and later stages of training and consistently outperforms the compared methods across multiple evaluation metrics. This indicates that the proposed approach not only achieves superior final performance, but also exhibits improved convergence quality and training stability.
It should be noted that, in the training dynamics analysis, training curves for the learnable Gamma enhancer module and the night-aware loss function are not plotted separately. This is because the Gamma enhancement primarily affects feature distribution modeling at the input level and does not directly introduce new optimization dynamics, while the influence of the night-aware and small-object adaptive loss on training behavior is already reflected in the overall gradient evolution and performance convergence of the full model. Therefore, the effectiveness of these modules is validated through a combination of ablation results and overall training dynamics analysis, avoiding redundant visualization of intermediate processes.
4.4. Performance Analysis on Representative Nighttime Categories
Although overall metrics can reflect the general detection capability of a model, they are insufficient to reveal the specific perception challenges faced by different object categories under nighttime conditions. Therefore, this section conducts a category-wise detection accuracy analysis to examine the performance variations of the proposed method across representative nighttime categories. The experimental results are summarized in Table 3.
Table 3.
Per-class detection accuracy comparison on representative night-time categories.
| Method | Car | Pedestrian | Motorcycle | Bicycle | Barrier | Truck |
|---|---|---|---|---|---|---|
| Baseline | 0.8222 | 0.4345 | 0.6435 | 0.2519 | 0.0552 | 0.5193 |
| +DMGF | 0.8244 | 0.4453 | 0.6454 | 0.1276 | 0.0421 | 0.6154 |
| Ours | 0.8419 | 0.4205 | 0.7665 | 0.2067 | 0.0604 | 0.4574 |
It can be observed that the proposed lightweight cross-modal fusion module achieves consistent performance improvements on categories such as Car, Motorcycle, and Truck, indicating its effectiveness in enhancing complementary information between image and LiDAR features.
For extremely small-object categories such as Bicycle and Barrier, performance fluctuations are observed for some methods when cross-modal fusion is introduced alone, due to the limited number of nighttime samples and increased noise levels. When combined with the night-aware adaptive enhancement and loss reweighting strategies, the complete model delivers more consistent performance across most key nighttime categories. These results further validate the effectiveness and robustness of the proposed approach for nighttime multi-modal 3D object detection.
4.5. Efficiency Comparison
Given the stringent requirements on real-time performance and computational resources in nighttime autonomous driving perception systems, computational efficiency is as critical as detection accuracy. Therefore, this section presents a comparative analysis of the proposed method and the baseline model in terms of parameter scale and inference efficiency. The experimental results are summarized in Table 4.
Table 4.
Efficiency comparison of different fusion strategies.
| Method | Params (M) | Fusion Params (M) | FPS (batch=1) | GFLOPs |
|---|---|---|---|---|
| BEVFusion | 40.80 | 0.77 | 2.69 | 89.61 |
| +DMGF | 41.02 | 1.00 | 2.69 | 96.81 |
| +Dual Cross-Attention | 46.87 | 6.84 | N/A | 64.84 |
| Ours | 41.02 | 1.00 | 2.68 | 96.81 |
In terms of model size, the original BEVFusion model contains a total of 40.80M parameters, of which approximately 0.77M are attributed to the fusion module. After introducing the DMGF module, the total number of parameters increases only marginally to 41.02M. The additional parameters mainly originate from the fusion layers, resulting in an overall increase of less than 1%, which indicates that the proposed fusion design imposes almost no additional burden on model complexity.
In contrast, the Dual Cross-Attention fusion scheme based on global attention mechanisms significantly increases model complexity. Its total parameter count reaches 46.87M, with the fusion module alone accounting for 6.84M parameters. This demonstrates that although Transformer-based cross-modal attention enhances feature interaction, it introduces substantial parameter and computational overhead, making it less suitable for deployment in resource-constrained scenarios.
With respect to inference efficiency, the BEVFusion baseline achieves an inference speed of 2.69 FPS. After incorporating DMGF and the complete proposed method, the inference speed remains approximately 2.69 FPS, with no noticeable degradation. This indicates that the proposed lightweight cross-modal fusion and low-light enhancement strategies can improve detection performance without sacrificing inference efficiency. Due to the large memory consumption of the Dual Cross-Attention module under the current hardware configuration, stable inference could not be achieved; therefore, its FPS results are not reported.
While improving detection performance, inference efficiency remains a critical factor for practical autonomous driving applications. To further analyze the trade-off between performance and efficiency, a comparative evaluation of detection performance versus inference speed under identical inference settings is conducted for different methods, as illustrated in Figure 7.
As illustrated in Figure 7.(a) and Figure 7.(b), the compared methods exhibit a clear accuracy–efficiency trade-off in the FPS–NDS and FPS–mAP spaces. Compared with the BEVFusion baseline, +DMGF achieves noticeable performance gains while maintaining almost identical inference speed. The proposed full model attains the highest NDS and mAP with only a marginal reduction in inference speed (from 2.69 FPS to 2.68 FPS), demonstrating superior overall detection performance. These results indicate that the proposed approach achieves substantial accuracy improvements at a negligible efficiency cost, yielding a more favorable Pareto-optimal solution for multi-modal nighttime detection tasks.
4.6. Generalization and Robustness Experiments
To evaluate the generalization capability of the proposed method under different scene distributions and perception degradation conditions, this section designs generalization experiments by validating the trained model weights on the full nuScenes validation set. For robustness evaluation, simulated nighttime noise perturbations are introduced into the full nuScenes validation set to mimic additional input degradations caused by sensor noise and imaging instability commonly encountered in nighttime scenarios. This setup aims to assess the stability of the proposed method under more challenging nighttime conditions. The experimental results are summarized in Table 5 and Figure 8.
Figure 8 visualizes the variations in NDS and mAP of different methods under noise-free conditions and with simulated nighttime noise perturbations. It can be observed that after introducing nighttime noise, the detection performance of all methods degrades to some extent; however, clear differences are evident in their performance trends. In particular, the proposed method maintains relatively smooth performance variations before and after noise perturbation, exhibiting more stable detection behavior.
Table 5.
Generalization and robustness performance of different methods evaluated on the full nuScenes validation set after training on the nuScenes-Night dataset.
Table 5.
Generalization and robustness performance of different methods evaluated on the full nuScenes validation set after training on the nuScenes-Night dataset.
| Method | Noise | NDS | NDS ↓ | mAP | mAP ↓ |
|---|---|---|---|---|---|
| BEVFusion | × | 0.2818 | – | 0.1874 | – |
| 0.2583 | -0.0235 | 0.1506 | -0.0368 | ||
| +DMGF | × | 0.2890 | – | 0.1810 | – |
| 0.2635 | -0.0255 | 0.1624 | -0.0186 | ||
| Ours | × | 0.3268 | – | 0.2164 | – |
| 0.3145 | -0.0123 | 0.2106 | -0.0061 |
Furthermore, Table 5 provides a quantitative analysis of performance degradation for different methods under noisy conditions. By comparing the changes in NDS and mAP, it is evident that, relative to the baseline and the model equipped only with DMGF, the proposed method experiences a smaller degree of performance degradation under nighttime noise perturbations. This demonstrates its superior stability and robustness when faced with input degradations.
Despite these challenges, the model is able to stably detect major traffic participants, such as vehicles, pedestrians, and two-wheeled objects, across most views, while maintaining reasonable spatial layouts and object orientations in the BEV representation. The missed detections do not introduce noticeable disruptions to the overall spatial modeling, indicating that the proposed method exhibits good detection stability and robust multi-modal fusion capability in complex nighttime environments.
4.7. Visualization Result Analysis
To further provide an intuitive analysis of the detection behavior and spatial modeling capability of the proposed method under complex night-time scenarios, this section presents qualitative visualizations and analyses of multi-modal 3D object detection results in representative nighttime scenes. The results are illustrated in Figure 9.
Figure 9 shows multi-view camera images and the corresponding BEV-based 3D detection results under nighttime conditions. In the visualizations, solid 3D bounding boxes indicate successfully detected objects, while dashed bounding boxes denote missed targets under extremely challenging nighttime conditions.
From the camera-view images, it can be observed that nighttime scenes are generally affected by insufficient illumination, local strong light interference, and the small scale of distant objects. Under such conditions, certain targets, especially small or occluded objects at long distances, may still be missed, which is to some extent unavoidable in nighttime autonomous driving perception tasks.
Despite these challenges, the proposed model is able to stably detect major traffic participants, such as vehicles, pedestrians, and two-wheeled objects, across most viewpoints, while maintaining reasonable spatial layouts and object orientations in the BEV representation. Moreover, the missed detections do not cause noticeable disruption to the overall spatial modeling, indicating that the proposed method exhibits satisfactory detection stability and robustness in multi-modal fusion under complex nighttime environments.
5. Conclusion
This paper addresses the challenges of perception degradation and limited cross-modal fusion efficiency in nighttime autonomous driving scenarios by proposing a lightweight night-adaptive multi-modal 3D object detection method based on BEVFusion. Without altering the original BEV representation or detection pipeline, the proposed approach jointly considers low-light image modeling, cross-modal feature fusion, and supervision modeling, thereby constructing an end-to-end trainable and computationally efficient nighttime perception framework. Experiments conducted on the nuScenes nighttime subset demonstrate that the proposed method achieves stable improvements in overall detection performance with negligible increases in model parameters and computational cost, validating the effectiveness and complementarity of the proposed components for nighttime multi-modal 3D object detection. Beyond technical performance gains, the proposed approach enhances the reliability of autonomous driving perception under nighttime and low-visibility conditions, which is a critical prerequisite for safe vehicle operation in real-world urban environments. From a broader perspective, improved robustness in nighttime perception supports safer and more resilient urban mobility systems, contributing to the long-term sustainability of intelligent transportation in complex cities. These results indicate that coordinated design across perception modeling, feature fusion, and supervision optimization provides an effective and practical solution for nighttime multi-modal 3D object detection and offers a flexible foundation for future research toward more challenging low-visibility scenarios.
Acknowledgments
This work was supported by Changzhou Science and Technology project: [grant No. CQ20240062].
References
- Wang, L.; Zhang, X.; Song, Z.; et al. Multi-modal 3D object detection in autonomous driving: A survey and taxonomy. IEEE Transactions on Intelligent Vehicles 2023, 8(7), 3781–3798. [Google Scholar] [CrossRef]
- Shi, P.; Yang, L.; Dong, X.; et al. Research progress on multi-modal fusion object detection algorithms for autonomous driving: A review. Computer Modeling in Engineering & Sciences 2025, 83(3). [Google Scholar]
- Alaba, S.Y.; Gurbuz, A.C.; Ball, J.E. Emerging trends in autonomous vehicle perception: Multimodal fusion for 3D object detection. World Electric Vehicle Journal 2024, 15(1), 20. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; et al. Multi-view 3D object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Chen, X.; Zhang, T.; Wang, Y.; et al. FUTR3D: A unified sensor fusion framework for 3D detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 172–181. [Google Scholar]
- Xu, S.; Zhou, D.; Fang, J.; et al. FusionPainting: Multimodal fusion with adaptive attention for 3D object detection. In Proceedings of the IEEE Intelligent Transportation Systems Conference, Indianapolis, IN, USA, 19–22 September 2021; pp. 3047–3054. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; et al. DeepFusion: LiDAR-camera deep fusion for multi-modal 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 17182–17191. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Multimodal virtual point 3D detection. Advances in Neural Information Processing Systems 2021, 34, 16494–16507. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; et al. PointPainting: Sequential fusion for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4604–4612. [Google Scholar]
- Huang, J.; Huang, G. BEVDet4D: Exploit temporal cues in multi-camera 3D object detection. arXiv 2022, arXiv:2203.17054. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; et al. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; et al. PointNet++: Deep hierarchical feature learning on point sets in a metric space. Advances in Neural Information Processing Systems 2017, 30. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; et al. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-end learning for point cloud-based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; et al. PointPillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Huang, J.; Huang, G.; Zhu, Z.; et al. BEVDet: High-performance multi-camera 3D object detection in bird’s-eye view. arXiv 2021, arXiv:2112.11790. [Google Scholar]
- Yin, T.; Zhou, X.; Krähenbühl, P. Center-based 3D object detection and tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11784–11793. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; et al. BEVFusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. arXiv 2022, arXiv:2205.13542. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; et al. TransFusion: Robust LiDAR-camera fusion for 3D object detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1090–1099. [Google Scholar]
- Yang, Z.; Chen, J.; Miao, Z.; et al. DeepInteraction: 3D object detection via modality interaction. Advances in Neural Information Processing Systems 2022, 35, 1992–2005. [Google Scholar]
- Liu, S.; Xu, C.; Wang, Q.; et al. AG-Fusion: Adaptive gated multimodal fusion for 3D object detection in complex scenes. arXiv 2025, arXiv:2510.23151. [Google Scholar] [CrossRef]
- Li, Y.; Yu, A.W.; Meng, T.; et al. DeepFusion: LiDAR-camera deep fusion for multi-modal 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17182–17191. [Google Scholar]
- Liu, F.; Fan, L. A review of advancements in low-light image enhancement using deep learning. arXiv 2025, arXiv:2505.05759. [Google Scholar] [CrossRef]
- Tian, Z.; Qu, P.; Li, J.; et al. A survey of deep learning-based low-light image enhancement. Sensors 2023, 23, 7763. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Ma, J.; García-Fernández, Á.F.; et al. A survey on image enhancement for low-light images. Heliyon 2023, 9, e15028. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Gong, X.; Liu, D.; et al. EnlightenGAN: Deep light enhancement without paired supervision. IEEE Transactions on Image Processing 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.; Wang, W.; Yang, W.; et al. Deep Retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar] [CrossRef]
- Guo, C.; Li, C.; Guo, J.; et al. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Ma, L.; Ma, T.; Liu, R.; et al. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5637–5646. [Google Scholar]
- Debnath, B.; Ray, S.; Ghosh, S. Low-light image enhancement using gamma learning and attention-enabled encoder–decoder networks. arXiv 2025, arXiv:2510.22547. [Google Scholar]
- Wang, T.; Zhu, X.; Pang, J.; et al. FCOS3D: Fully convolutional one-stage monocular 3D object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 913–922. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; et al. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
Figure 1.
Overall architecture of the proposed nighttime perception-oriented multi-modal 3D detection framework. The learnable gamma enhancer module is embedded into the image branch and jointly optimized with the dual-modal gated fusion module and the adaptive loss function.
Figure 1.
Overall architecture of the proposed nighttime perception-oriented multi-modal 3D detection framework. The learnable gamma enhancer module is embedded into the image branch and jointly optimized with the dual-modal gated fusion module and the adaptive loss function.
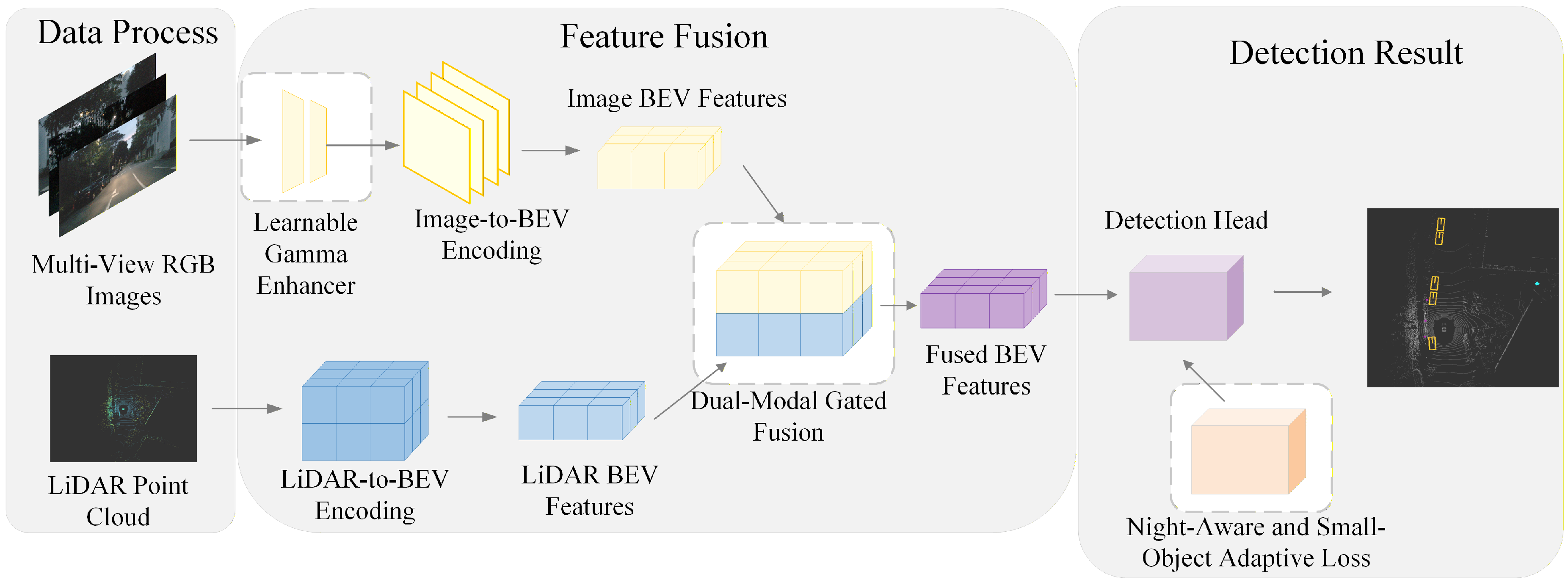
Figure 2.
Workflow of the learnable gamma enhancer. A lightweight CNN predicts an adaptive gamma parameter, enabling end-to-end low-light enhancement driven by the detection loss.
Figure 2.
Workflow of the learnable gamma enhancer. A lightweight CNN predicts an adaptive gamma parameter, enabling end-to-end low-light enhancement driven by the detection loss.
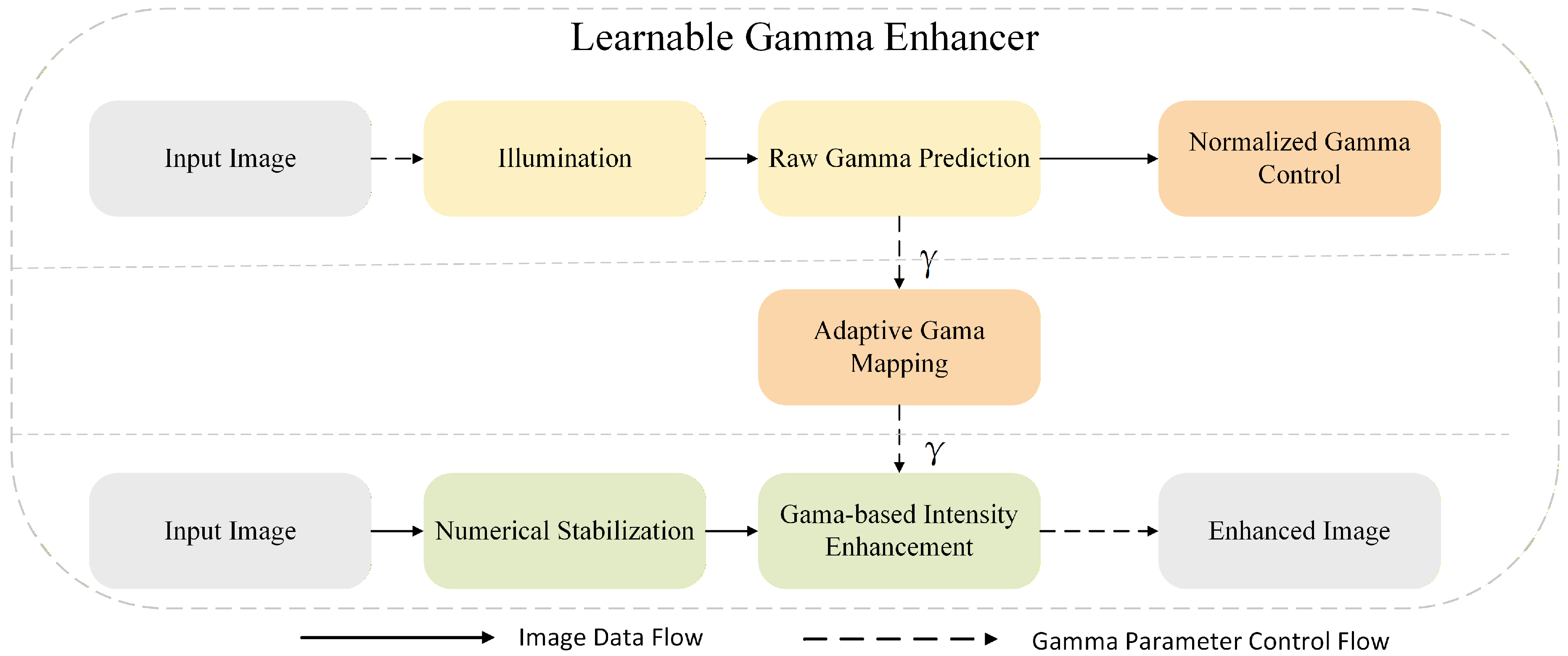
Figure 3.
Structure of the proposed dual-modal gated fusion module. Convolution-based gating is employed to approximate bidirectional cross-modal attention while significantly reducing computational cost.
Figure 3.
Structure of the proposed dual-modal gated fusion module. Convolution-based gating is employed to approximate bidirectional cross-modal attention while significantly reducing computational cost.
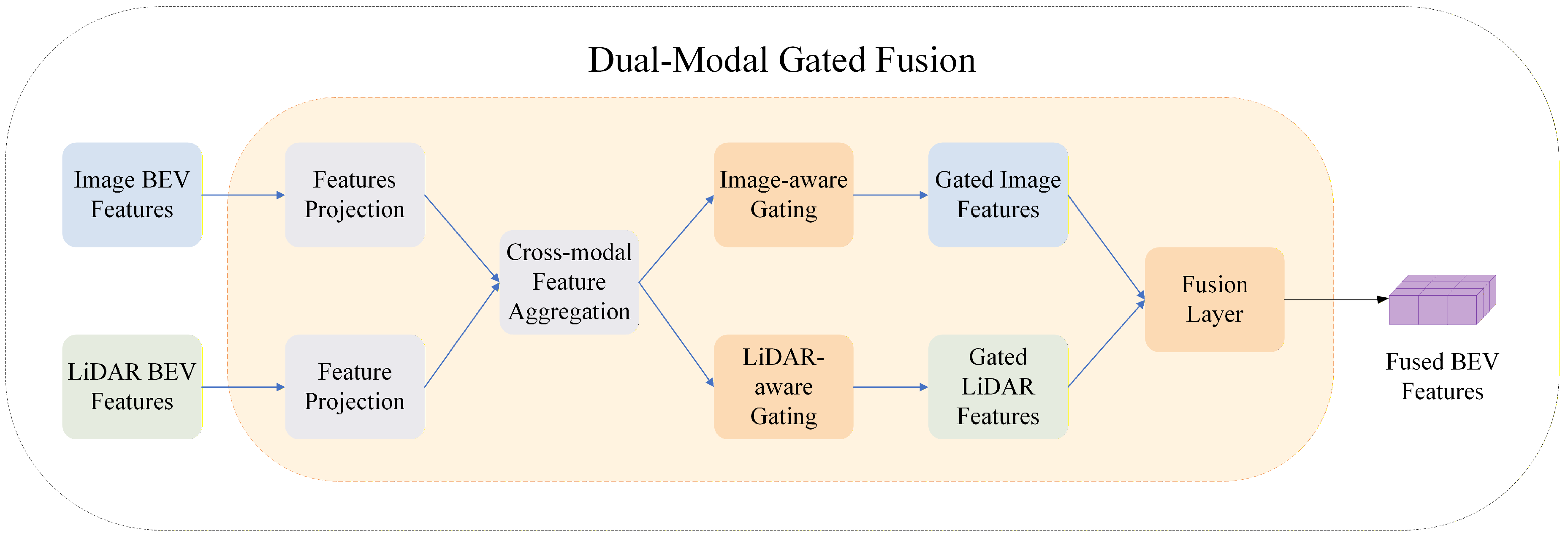
Figure 4.
Illustration of the proposed Night-aware and Small-object Adaptive Loss, where the loss weights are dynamically adjusted according to image brightness and object footprints in the BEV space.
Figure 4.
Illustration of the proposed Night-aware and Small-object Adaptive Loss, where the loss weights are dynamically adjusted according to image brightness and object footprints in the BEV space.
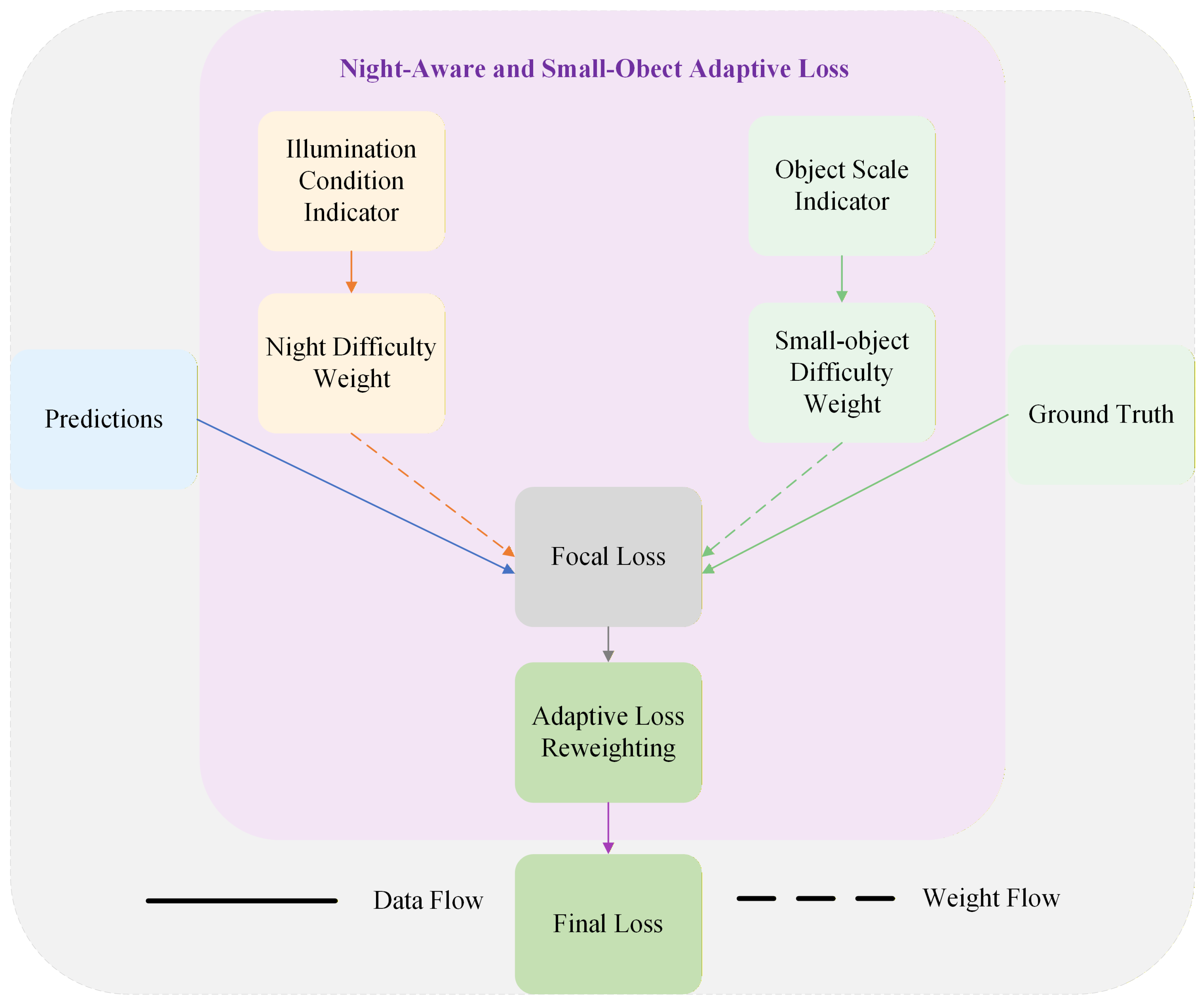
Figure 5.
Category distribution of the training and validation sets: (a) Distribution of object instances in the training set. (b) Distribution of object instances in the validation set.
Figure 5.
Category distribution of the training and validation sets: (a) Distribution of object instances in the training set. (b) Distribution of object instances in the validation set.
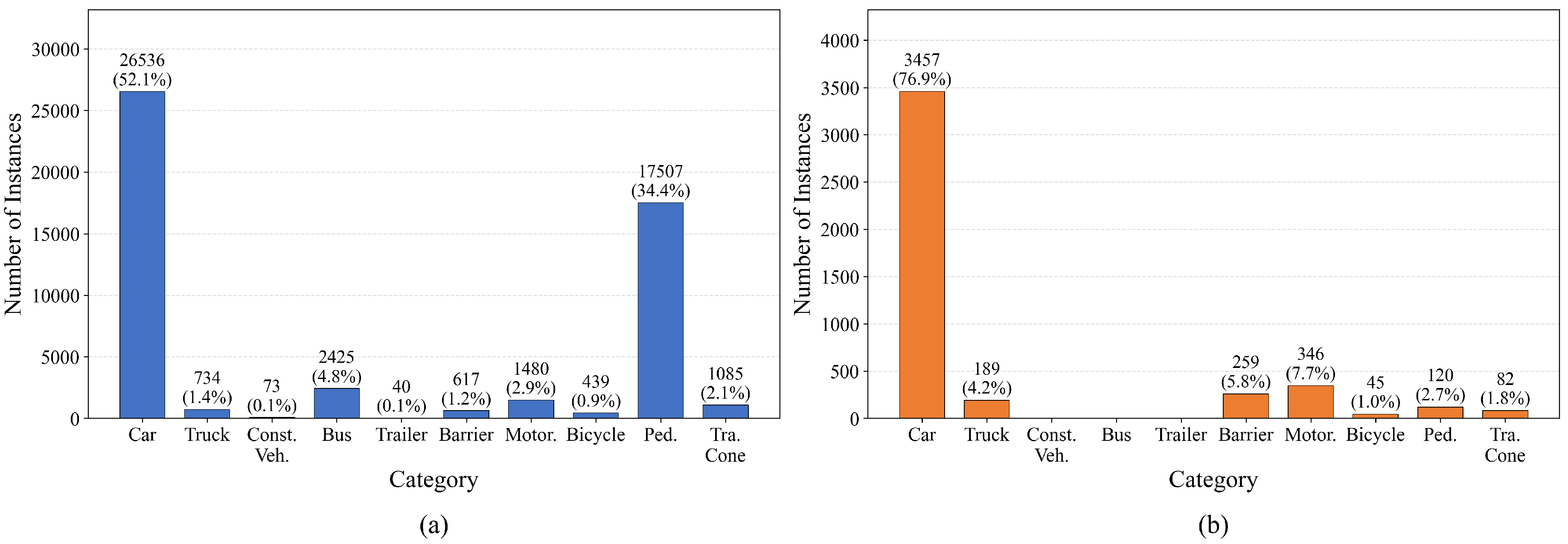
Figure 6.
Training dynamics and convergence behavior of different methods on the nuScenes dataset: (a) Evolution of gradient norms during training. (b) Convergence behavior of mAP. (c) Convergence behavior of matched IoU. (d) Convergence behavior of NDS.
Figure 6.
Training dynamics and convergence behavior of different methods on the nuScenes dataset: (a) Evolution of gradient norms during training. (b) Convergence behavior of mAP. (c) Convergence behavior of matched IoU. (d) Convergence behavior of NDS.
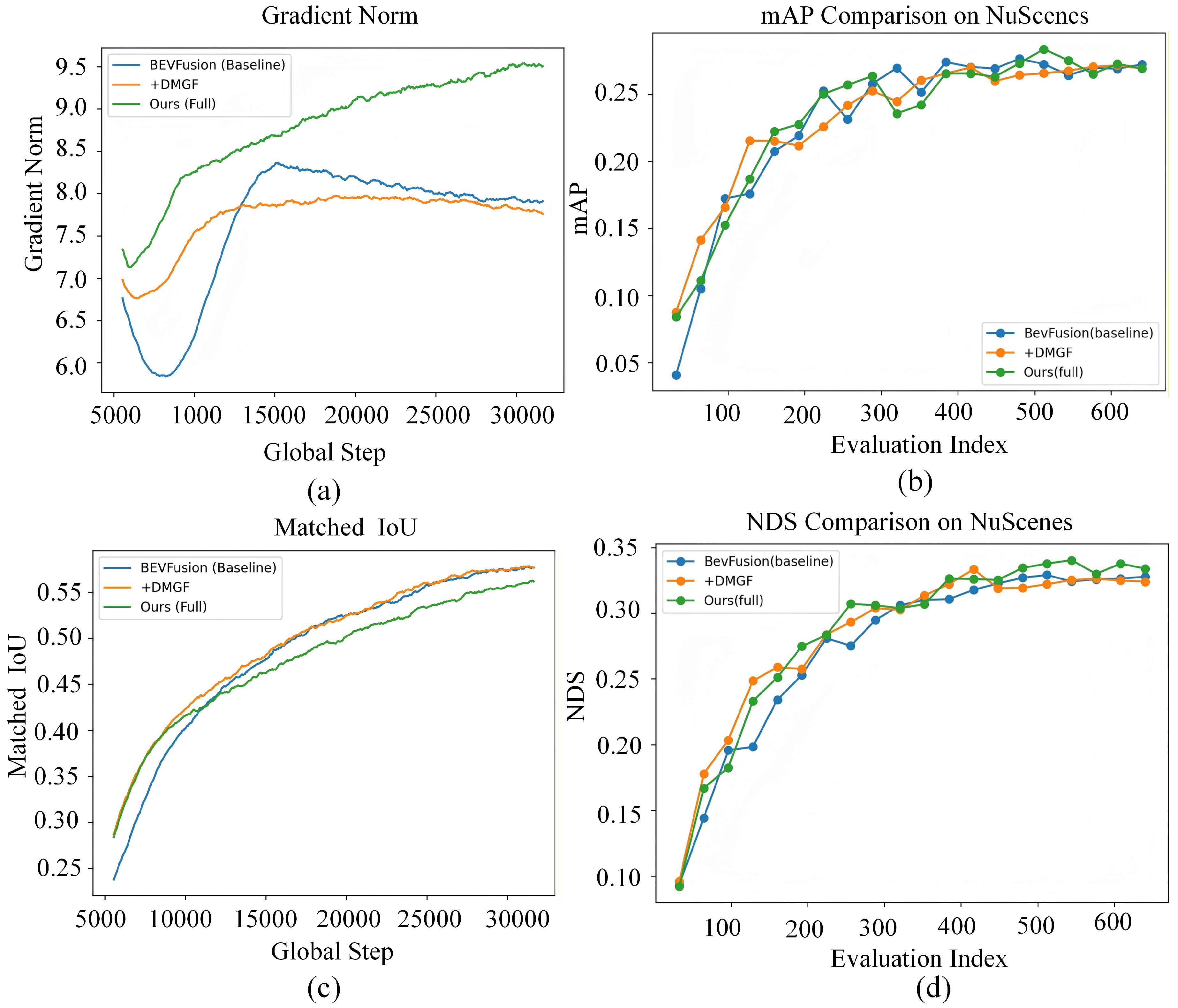
Figure 7.
Visualization of detection performance and inference speed for different methods under nighttime conditions: (a) NDS versus FPS. (b) mAP versus FPS .
Figure 7.
Visualization of detection performance and inference speed for different methods under nighttime conditions: (a) NDS versus FPS. (b) mAP versus FPS .
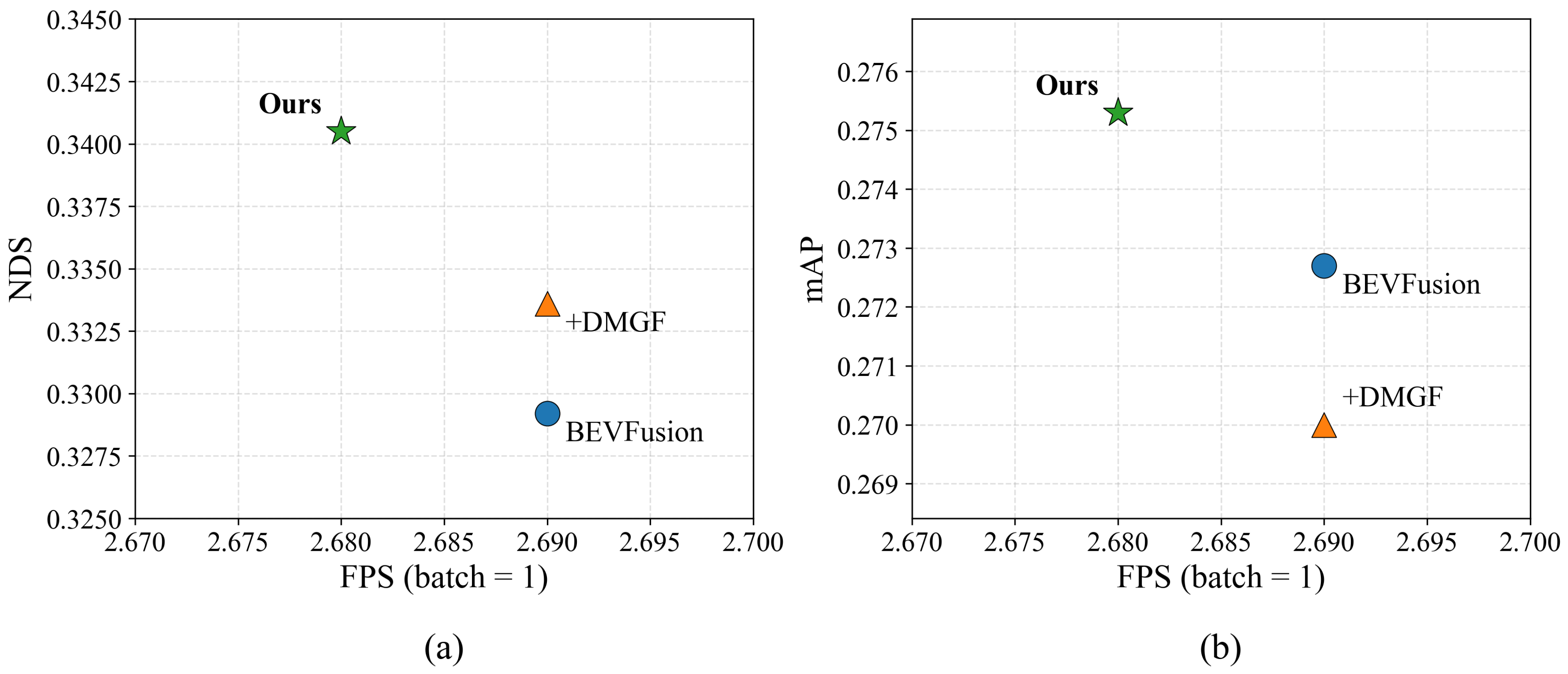
Figure 8.
Performance comparison of different methods under noisy and noise-free conditions: (a) Comparison of NDS under noise perturbation. (b) Comparison of NDS under noise-free conditions. (c) Comparison of mAP under noise perturbation. (d) Comparison of mAP under noise-free conditions.
Figure 8.
Performance comparison of different methods under noisy and noise-free conditions: (a) Comparison of NDS under noise perturbation. (b) Comparison of NDS under noise-free conditions. (c) Comparison of mAP under noise perturbation. (d) Comparison of mAP under noise-free conditions.
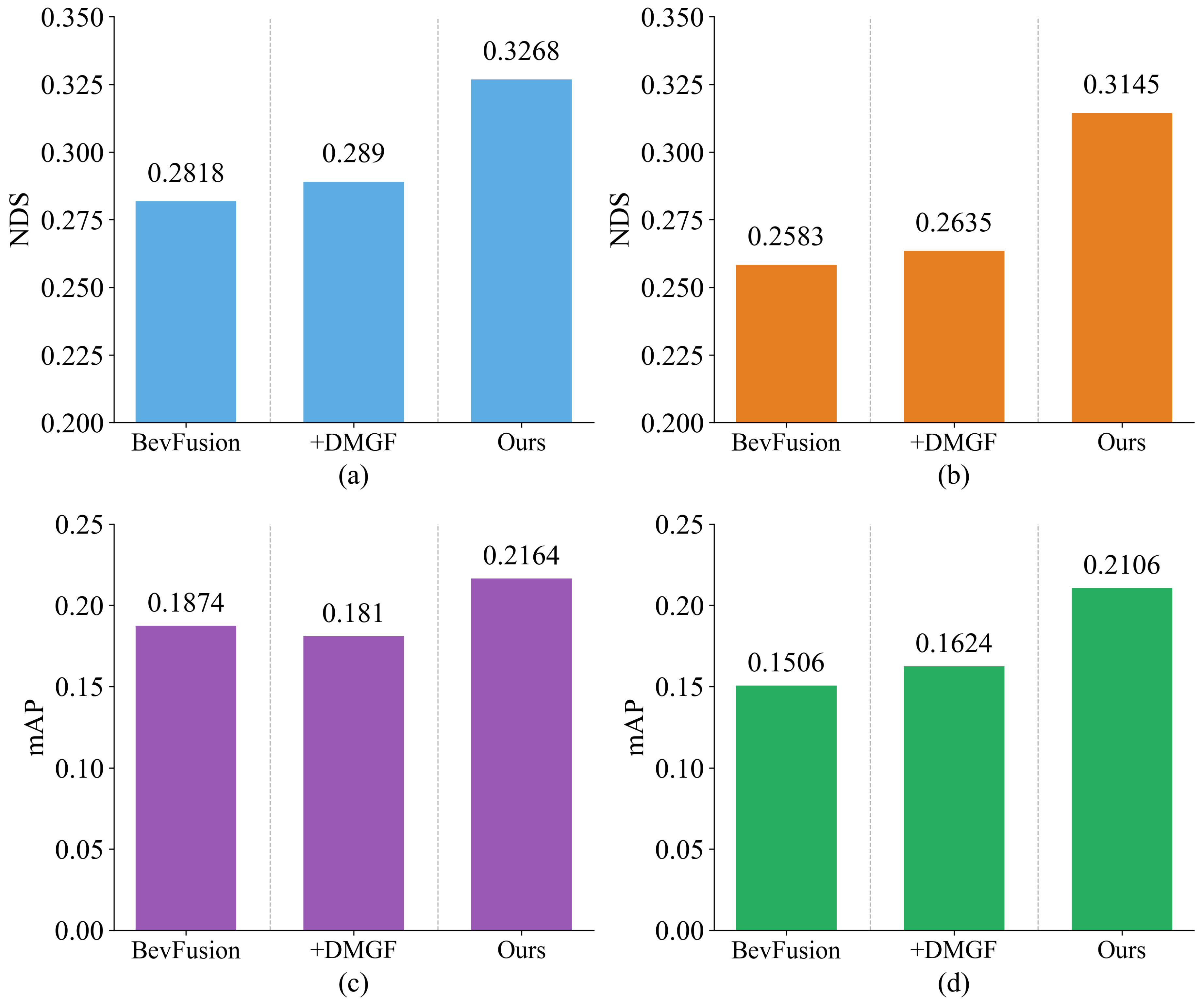
Figure 9.
Qualitative visualization of multi-modal 3D object detection results in representative nighttime scenarios.
Figure 9.
Qualitative visualization of multi-modal 3D object detection results in representative nighttime scenarios.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



