Submitted:
07 January 2026
Posted:
08 January 2026
Read the latest preprint version here
Abstract
Large Language Model (LLM)-based agents have fundamentally reshaped artificial intelligence by integrating external tools and planning capabilities. While memory mechanisms have emerged as the architectural cornerstone of these systems, current research remains fragmented, oscillating between operating system engineering and cognitive science. This theoretical divide prevents a unified view of technological synthesis and a coherent evolutionary perspective. To bridge this gap, this survey proposes a novel evolutionary framework for LLM agent memory mechanisms, formalizing the development process into three stages: Storage (trajectory preservation), Reflection (trajectory refinement), and Experience (trajectory abstraction). We first formally define these three stages before analyzing the three core drivers of this evolution: the necessity for long-range consistency, the challenges in dynamic environments, and the ultimate goal of continual learning. Furthermore, we specifically explore two transformative mechanisms in the frontier Experience stage: proactive exploration and cross-trajectory abstraction. By synthesizing these disparate views, this work offers robust design principles and a clear roadmap for the development of next-generation LLM agents.
Keywords:
LLM agents
; agent architectures
; memory mechanisms
; experience learning
1. Introduction
In recent years, the rapid advancement of Large Language Models (LLMs) has fundamentally reshaped the landscape of artificial intelligence [1,2,3]. To augment the capabilities of LLMs, researchers have developed LLM-based agents that integrate LLMs with external tools and modular components, thereby enabling planning, tool use, and environmental interaction [4,5,6]. However, the inherent statelessness of LLMs poses a critical challenge: it hinders agents from maintaining logical consistency across complex, multi-step tasks and precludes learning from prior interactions, often resulting in recurring reasoning errors [7,8]. Consequently, the development of effective memory mechanisms has emerged as an architectural cornerstone. By mitigating this deficiency, memory mechanisms underpin the robust operation of LLM-based agents and pave the way for self-evolution [9,10].
We identify two primary obstacles to advancing memory mechanisms for LLM agents: (i) Paradigmatic Fragmentation: Existing methodologies oscillate between two weakly integrated paradigms. One focuses on engineering, adopting design principles from operating systems for the management of memory data [11,12,13], while the other draws inspiration from cognitive science and psychology to simulate mechanisms for the formation, consolidation, and retrieval of human memory [14,15,16]. This lack of synergistic progress results in a fragmented body of research, preventing the formation of a coherent and continuous trajectory of evolution. (ii) The Absence of Technological Synthesis: Although numerous methods address isolated stages of memory processing, the field lacks a cohesive summary of the critical technologies that have historically propelled memory mechanism advancement [16,17,18]. Existing surveys have not sufficiently isolated these key technical drivers from general methodologies [19,20,21,22]. Consequently, the core technologies remain obscure, leaving future researchers without a clear roadmap of which innovations are robust enough to build upon.
While recent surveys have examined memory mechanisms for LLM agent systems, they lack a unified evolutionary perspective. This limitation obscures the internal drivers of memory development and impedes the in-depth exploration of architectures for next-generation agents. Specifically, Zhang et al. [23] focuses on the classification of engineering modules, but fails to systematically expound on the logic behind critical technological transformations throughout their development. Furthermore, while Hu et al. [24] addresses the dynamic processes of memory, its perspective remains confined to static functional categorizations, failing to reveal the underlying principles of dynamic evolution inherent to memory mechanisms.
To address these limitations, we propose a framework for memory mechanisms in LLM-based agents centered on dynamic evolution. We formalize this evolutionary process into three distinct stages: (i) Storage, which constructs diverse storage modes focused on the faithful recording of historical interaction trajectories; (ii) Reflection, which introduces a loop for dynamic evaluation to actively manage and refine these records; and (iii) Experience, which implements prospective guidance by abstracting high-level behavior patterns and strategies from clustered interactions (§ Section 2).
Building upon the proposed three stages of memory mechanisms, this survey follows a "Why-How-What" logic to address three interconnected research questions: RQ1: Why do memory mechanisms evolve? reveals how the requirements for long-range consistency, dynamic environment interaction, and continual learning serve as core catalysts driving mechanistic evolution (§ Section 3); RQ2: How do memory mechanisms evolve? delineates the evolutionary path from Storage to Reflection and then to Experience, analyzing the fundamental structural shifts involved (§ Section 4); and RQ3: What changes does Experience bring? provides an in-depth analysis of how frontier paradigms in the Experience stage, such as proactive exploration and cross-trajectory abstraction, address the bottlenecks in agent adaptability and autonomy (§ Section 5).
Finally, we outline future directions for LLM agent memory mechanisms. First, we emphasize that memory mechanisms should adopt more dynamic triggering modes based on task types (§ Section 6). Second, we highlight that the construction of working memory is a vital core of memory mechanisms. Next, we advocate for the development of more comprehensive datasets for memory mechanisms, especially for the Experience stage. Finally, we establish the coordination of distributed shared memory and the fusion of multimodal memory as critical breakthroughs for future research.
The overview of this survey and related datasets is documented in Appendix A and Appendix C, respectively.
2. Background
2.1. The LLM Agent Framework
We formalize an LLM-based agent as a decision-making entity parameterized by , interacting with a dynamic environment . The agent’s operation is governed by a policy , which maps the current context to a probability distribution over the action space .
At time step t, the agent receives an observation and retrieves relevant information from its memory module . The generated action is sampled as follows:
where denotes the static system instruction, and represents the context-specific memory. Crucially, we distinguish between the global memory repository and its retrieved instantiation at time t. In this survey, we define “LLM agent memory” as an externalized repository that bridges the frozen parametric knowledge in and the evolving environmental dynamics.
2.2. Taxonomy
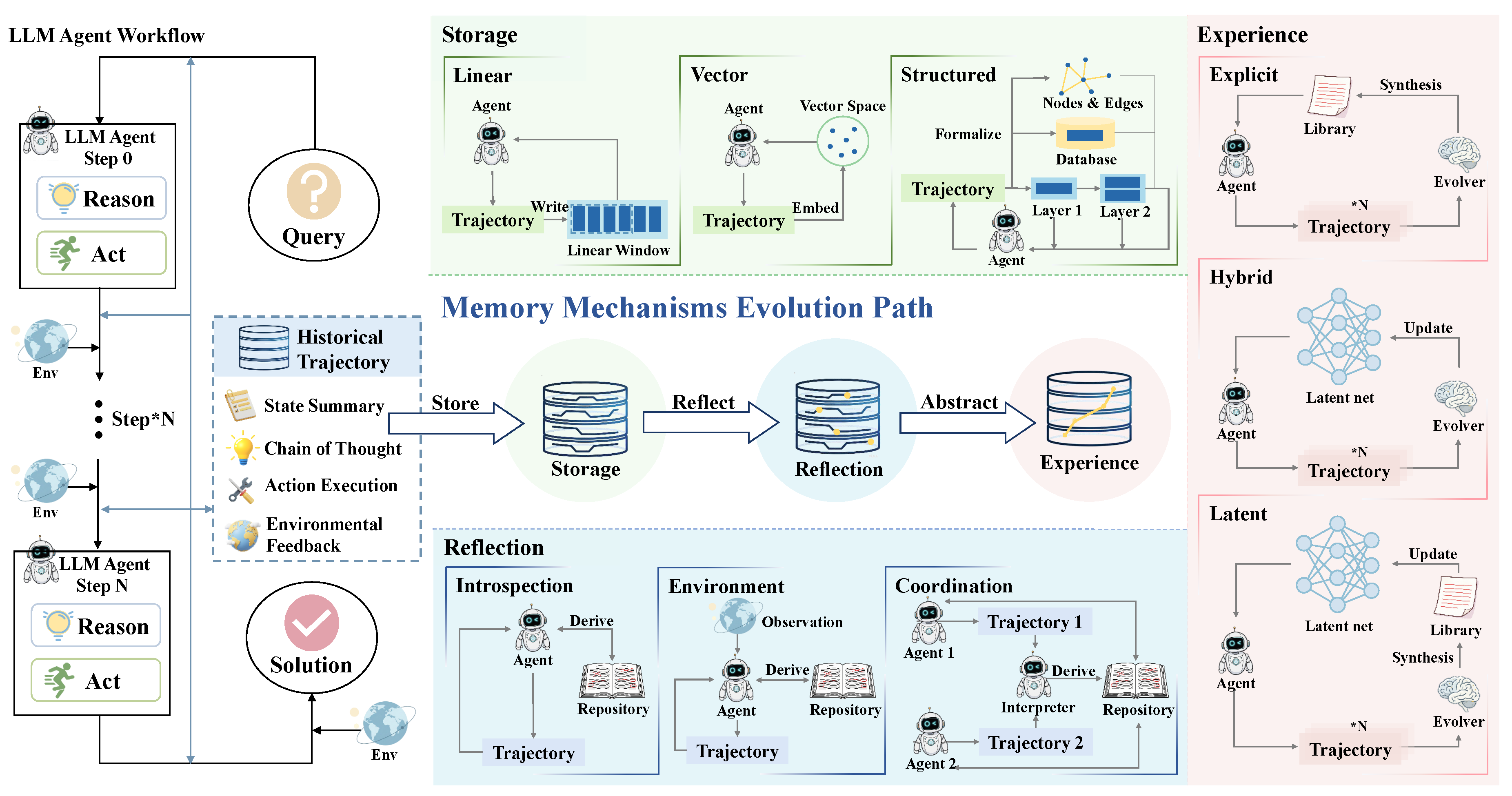
We classify the evolution of memory mechanisms into three tiers based on the level of information abstraction and cognitive processing.
Storage. Storage serves as the foundational layer. Unlike higher-level mechanisms, storage preserves trajectories with minimal transformation, maintaining a one-to-one correspondence between memory entries and execution traces. We define a trajectory as a chronological sequence of observation-action pairs within a task session:
The raw storage is formally defined as a cumulative set of historical trajectories:
where represents the space of all possible interaction trajectories.
Reflection. Reflection is modeled as a semantic transformation mapping , where denotes the space of evaluated or corrected reasoning paths. Similar to the storage phase, Reflection functions as a mechanism to populate the global repository , but with a focus on quality density rather than raw fidelity.
It operates by analyzing a completed trajectory to generate a refined memory unit , which encapsulates critiques or corrective insights:
where represents the evaluation criteria. The key distinction lies in the storage protocol: while standard Storage preserves raw interaction logs, Reflection acts as a semantic filter, injecting processed insights back into the repository (). Once stored, becomes an independent memory entry, decoupling the valuable logic from the specific noise of the original trajectory and serving as a refined reference for future retrieval.
Experience. Experience represents the highest cognitive layer, characterized by cross-trajectory abstraction. This stage aims to satisfy the Minimum Description Length (MDL) principle by compressing redundant trajectories into generalized schemas. Let be a subset of topologically similar trajectories. We define the Experience function as an inductive operator that extracts a set of universally applicable rules :

3. Evolutionary Drivers
To facilitate a comprehensive understanding regarding the evolution of memory mechanisms for LLM agents, we first address the fundamental question RQ1: Why do memory mechanisms evolve? In this section, we examine three core requirements for LLM agents to investigate how they drive the progression of memory mechanisms, thereby bridging the gap between models from pretraining and the real world.
3.1. Long-Term Consistency
Consistency across long horizons constitutes a prerequisite for the deployment of LLM agents within the real world and serves as the primary impetus for the early evolution of memory mechanisms. Although large language models exhibit robust local coherence within the context window, they frequently encounter issues such as redundant exploration, accumulation of errors, and discontinuities in reasoning during interactions involving multiple steps. We analyze the necessity of consistency over long durations through two dimensions: consistency of state and consistency of goals.
Coherence of State. The inherent statelessness of LLM agents results in a deficiency of internal mechanisms for explicit anchoring, which has catalyzed the emergence of modules for memory [11,25,26]. First, these modules maintain internal states for reasoning to ensure the coherence of thought [27,28]; second, they synchronize the cognition of the agent with the external world to prevent erroneous decisions arising from inaccurate internal perceptions [17,29]; finally, they internalize interactions into persistent traits of the persona to ensure uniformity in behavior [30,31,32].
Consistency of Goals. Due to the inherent nature of planning by the agent, LLM agents frequently optimize for actions with local consistency, which results in a departure from objectives at the global level [33,34]. Memory mechanisms mitigate this drift by providing persistent and explicit goals at a high level [12,35]. Furthermore, in systems with multiple agents, shared memory regarding goals can transform isolated behaviors into coordinated execution by the collective, thereby maintaining the unity of the final objective [36,37].
3.2. Dynamic Environments
The dynamic characteristics of the environment constitute a more enduring impetus for the evolution of memory mechanisms. In contrast to benchmarks of a static nature, the interplay between temporal validity and causality within the environment in settings from the real world renders fixed patterns for reasoning and static forms of storage rapidly fragile.
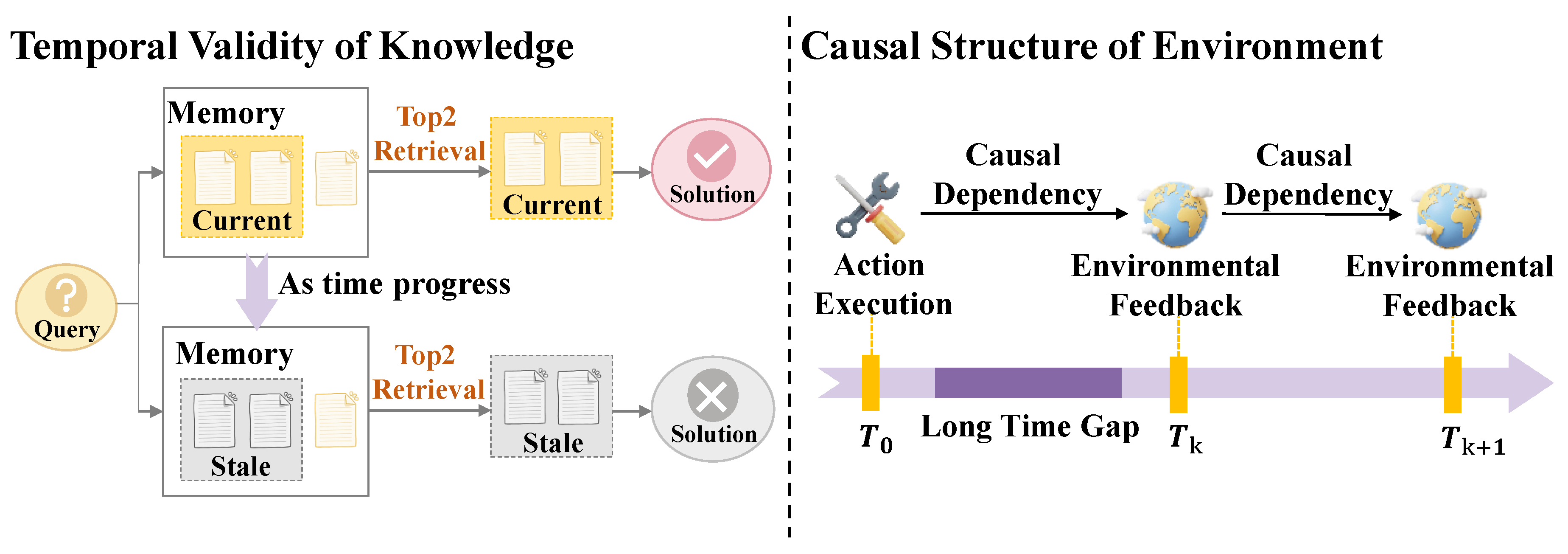
Figure 2.
The Drivers in Dynamic Environments.
The Temporal Validity of Knowledge. Knowledge within environments of a dynamic nature is typically conditional rather than eternally valid [38,39,40]. As the environment progresses, strategies for action that were once correct may experience a gradual loss of utility. Crucially, knowledge that is outdated often fails without overt indication [41,42,43]; although factually incorrect, such information may still exhibit significant relevance in its semantic representation. This necessity propels the evolution of memory mechanisms from the paradigm of static storage toward that of active management, integrating awareness of temporal factors, policies for decay, and methods for retrieval with enhanced flexibility [14,44,45,46,47].
The Causal Structure of the Environment. Causal relationships within the complex real world involve delayed outcomes and cascading effects [48,49,50]. This necessitates that memory mechanisms transcend the mere documentation of interactions to construct dependencies for causality of a complex nature across steps in time [29,51,52]. Consequently, planning with robustness is achieved through the realization of internal worlds characterized by consistency in causality [53,54,55].
3.3. Continual Learning
Continual learning represents the ultimate requirement for LLM agents. Deployment within an open world inevitably involves encountering patterns that reside outside of the distribution of training. Without the effective internalization of these memories into actionable knowledge for reuse, the LLM agent will remain confined to repetitive cycles of trial and error. Therefore, memory mechanisms must not only enable the reproduction of historical trajectories but also address the bottlenecks of scaling and the requirements for abstraction inherent in dense memory.
Constraints on The Storage of Memory. Interaction with the real world over extended durations results in the linear expansion of memory in storage [11,56]. Early memory mechanisms utilized techniques such as vectorization to scale storage capacity. However, recent research indicates that the unrestricted expansion of memory is detrimental to the performance of LLM agents, as errors propagate within the system for memory and contaminate the efficacy of learning [8,57]. This necessitates the exploration of more strategic policies for the addition and deletion of information within memory mechanisms [20,58].
The Requirement for Experience. The memory of most LLM agents is of an episodic nature and remains restricted to specific tasks [9,59]. This limitation necessitates the transformation of raw clusters of memory into experience to provide guidance for behavior across future scenarios. Consequently, research on memory mechanisms has begun to explore various methodologies for the abstraction of experience [60,61,62,63,64].

4. Evolutionary Path
Building upon these evolutionary drivers, we conduct an investigation in-depth into RQ2: How do memory mechanisms evolve? We categorize the trajectory of evolution into three primary stages: storage, reflection, and experience.
4.1. Storage
The stage of storage serves as the starting point for memory mechanisms, where the primary objective is to resolve the contradiction between the limited window of context within Large Language Models and the continuously expanding history of interaction. Memory mechanisms during this phase are dedicated to the faithful preservation of interaction trajectories to the greatest extent possible to maintain consistency in the actions of the agent.
Linear. Linear storage represents the most direct method of recording, in which interaction trajectories are treated as a stream of tokens ordered by time and managed typically through a strategy of first-in, first-out (FIFO). Research focuses on the extension of the window of context via modifications to the mechanism of attention or the encoding of position [65,66,67], as well as the achievement of information sparsification through the mechanical reduction of noise [68,69,70].
Vector. Vector storage encodes interaction trajectories into a high-dimensional space, which greatly expands the capacity for the storage of memory. Such methods shift the focus of research from the design of storage toward the optimization of retrieval, including retrieval based on semantic proximity [71,72,73] as well as weighted retrieval that incorporates temporal decay and scores for importance [14,30].
Structured. Structured storage employs explicit data architectures to transcend the limitations on capacity inherent in linear storage and the ambiguity associated with vector retrieval. For instance, these methods utilize the tabular formats of relational databases for the storage of memory [56,74,75], partition memory into distinct hierarchies to address the trade-off between storage capacity and speed of retrieval [11,76], and directly model the history of interaction as a topological network of entities and relations [77,78].
4.2. Reflection
Mechanisms for storage fail to address the quality of memory, as raw trajectories are inevitably contaminated by hallucinations, errors in logic, and ineffective attempts. This limitation necessitates a transition of memory mechanisms toward reflection. In this phase, memory is transformed from a passive recorder into an active critic, utilizing various signals of feedback to perform correction and denoising of past trajectories to enhance the quality of the repository of memory.
Introspection. Introspective reflection conceptualizes the LLM agent as an autonomous critic that leverages the internal knowledge of the model to refine memory without the requirement for external feedback. Research in this area focuses on the correction of errors within trajectories [55,79,80], the maintenance of the lifecycle of memory [13,81,82], and the compression and distillation of long trajectories [17,83,84,85].
Environment. Environmental reflection treats signals from the external environment as the primary anchors for the reflection of memory to mitigate the issue of hallucinations. This approach focuses on the utilization of outcomes from the real world to proactively optimize policies for behavior [86,87,88] and calibrate internal models of the world [86,89,90].
Coordination. Collaborative reflection extends this process to the collective, leveraging the division of roles and consensus to overcome bottlenecks in the cognition of individuals. This mechanism facilitates the reflection of memory through the construction of societies of heterogeneous agents [91,92,93,94].
4.3. Experience
Although reflection effectively mitigates noise and hallucinations, reflected memories are frequently fragmented and exhibit a high degree of dependence on context. This results in significant costs for retrieval and a heavy burden of inference for memory mechanisms when addressing new tasks. Moreover, recent research indicates that LLM agents often demonstrate a pronounced tendency to follow successful trajectories; corrected trajectories devoid of abstraction may still induce errors resulting from minor shifts in context. Consequently, memory in the stage of experience extracts universal heuristic wisdom by isolating similar trajectories from their specific contexts. This approach simultaneously compresses the originally vast repository of memory and enables a capacity for generalization to unknown environments through a form of intuition similar to that of humans.
Explicit. Explicit experience represents the integration of symbols, extracting human-readable and editable experiences with a high level of generalizability from clusters of interaction trajectories. This allows the LLM agent to achieve a highly interpretable process of self-evolution by either concretizing experiences into natural language policies [61,95,96,97] or directly abstracting them into executable entities [98,99,100].
Implicit. Implicit experience internalizes interaction histories into model parameters, aiming to resolve the inference overhead and context limitations inherent in explicit memory. Implicit experience can be realized by directly converting experiences into the model’s intrinsic capabilities through fine-tuning [63,101,102,103,104]. Furthermore, the research community is exploring the transformation of experience into latent variables within the model’s hidden layers, which are then dynamically invoked during the inference process [105,106].
Hybrid. Hybrid experience establishes a dynamic cycle of accumulation and internalization. Through a mechanism for experience transfer, explicit experience is treated as a high-capacity cache, which is subsequently compressed and internalized into the implicit weights of the model through periodic updates of parameters [10,107,108]. Summary & Ideas - Evolutionary Path

5. Transformative Experience
Following the exposition of the evolutionary trajectory for memory mechanisms, we address RQ3: What changes does Experience bring? In this section, we elucidate the distinct technical characteristics of experience as a novel stage in the development of memory mechanisms.
5.1. Active Exploration
Active exploration leverages memory mechanisms to transform LLM agents from passive recorders of information into collectors of experience driven by goals. In the stage of Experience, the core capability of memory mechanisms is no longer confined to the storage of history, but extends to the acquisition of valuable experience through the active exploration of the environment.
Exploration Mechanisms. The driving mechanisms for active exploration have transitioned from traditional strategies of random exploration toward more profound drivers of intrinsic motivation and feedback. Drivers based on signals of reward guide LLM agents to explore state spaces of greater value through the design and optimization of immediate reward functions [109,110,111]; drivers based on curricula facilitate exploration tasks of increasing difficulty through the dynamic generation and adjustment of sequences for tasks [112,113]; and drivers based on reuse enable exploration of high efficiency through the abstraction and reuse of trajectories from history [61,114].
Exploration Dimensions. The core of active exploration resides in the utilization of memory mechanisms to facilitate the expansion of the boundaries of capability for LLM agents. This process can be categorized into three critical dimensions: exploration of breadth aims to alleviate cognitive deficiencies of LLM agents in unfamiliar environments, transforming memory into experience that is structured through mechanisms of curiosity [101,115,116]; exploration of depth focuses on the extraction of skills of a high order within vertical tasks, driving the evolution of memory from the basic following of instructions to complex experiential strategies [62,117]; and exploration of strategy centers on the dynamic optimization of paths for decision making, leveraging the accumulation of experience to enhance the precision of decisions for LLM agents during planning over long horizons [118,119].
5.2. Cross-Trajectory Abstraction
Cross-trajectory abstraction compresses isolated trajectories into universal patterns, transforming scattered and episodic experiences into stable priors for policy. This enables LLM agents to transcend specific sequences of actions and engage in decision making at higher dimensions of abstraction, which provides prospective guidance for tasks that are unknown and facilitates an understanding of underlying regularities.
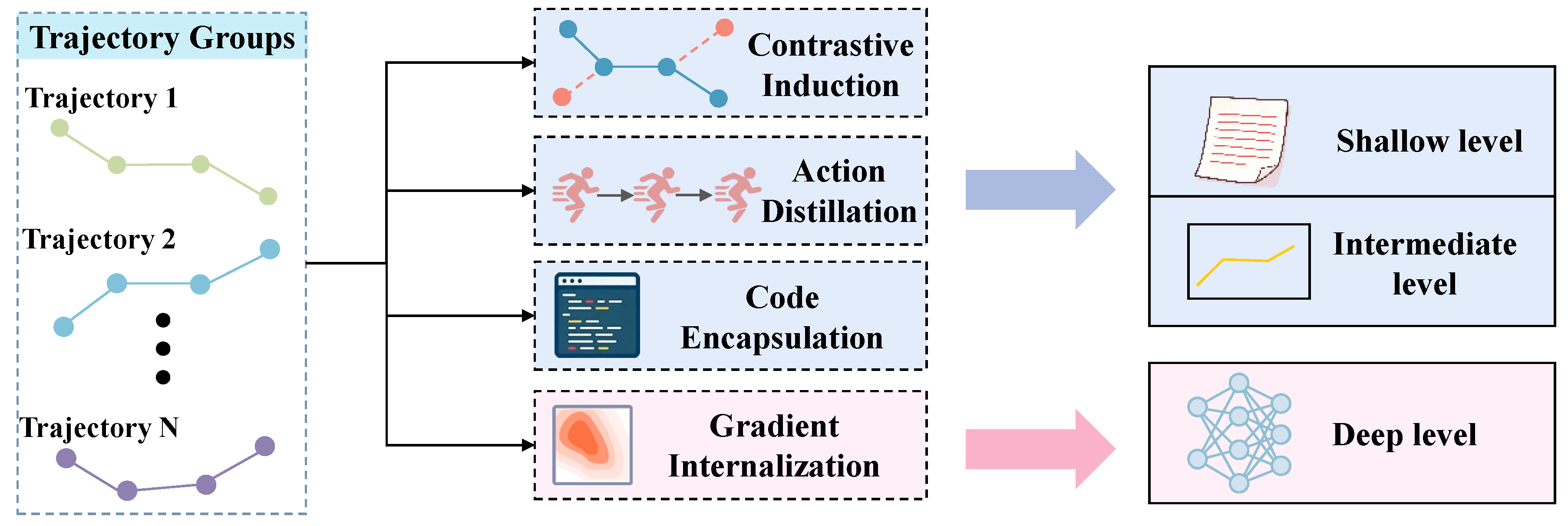
Figure 3.
Overview of Cross-Trajectory Abstraction.
Abstraction Mechanisms. The mechanism for abstraction serves as the core operator for the transformation of groups of raw interaction trajectories into experience that is universal. In contrast to mechanisms for reflection that focus on the correction of errors within single trajectories, abstraction during the stage of experience emphasizes the execution of inductive operations across trajectories. According to its operational logic, this process includes contrastive induction, which utilizes the opposition between successful and failed trajectories to delineate the boundaries of policy with precision [120,121]; the distillation of actions of fine granularity into patterns of thought of a high order through the chunking and aggregation of behavioral sequences across multiple levels of granularity [122,123]; the encapsulation of recurring patterns of behavior into program functions that are reusable by leveraging the compositionality of code [98,124,125]; and the internalization of groups of trajectories into the parameters of the model through techniques for fine-tuning [126,127].
Abstraction Granularity. The hierarchy of abstraction for memory mechanisms determines the boundaries for generalization and the degree of interpretability for experience. Based on the degree to which the results of abstraction deviate from original trajectories, these can be categorized into three progressive levels: abstraction at the shallow level retains a portion of semantic logic, utilizing “rules” described in natural language as experience [22,128,129,130]; abstraction at the intermediate level completely removes redundancies of natural language, extracting only modular skeletons for execution as experience [131,132,133]; and abstraction at the deep level compresses the distribution of trajectories into the weights of the model, enabling the complete transformation of experience into intuition for decision making [134,135,136].
Summary & Ideas - Transformative Experience
- Within the novel stage of memory mechanisms characterized by Experience, active exploration and abstraction across trajectories represent the two primary features of this phase.
- The feedback loop between exploration and abstraction serves as the central engine that drives the autonomous and continuous evolution of LLM agents during the phase of experience.

6. Future Directions
In this section, we discuss emerging prospects and promising directions for memory mechanisms for LLM agents.
Active Memory Perception. Currently, certain memory mechanisms still utilize modes of passive triggering, which necessitates that LLM agents perform the indiscriminate retrieval of a significant portion of the repository of memory [138,139]. More importantly, the persistent retrieval of irrelevant or obsolete memories can disrupt the coherence in reasoning of the LLM agent [16,140]. Recent work has begun to address this challenge through autonomous retrieval controllers [141]. Future research demands that memory mechanisms autonomously evaluate whether a task requires the introduction of additional memory and determine the specific type of memory to be integrated, ensuring that memory mechanisms function as resources that are invoked on demand.
Organization of Working Memory. As the complexity of tasks and the horizons encountered by LLM agents continue to expand, the construction of working memory within tasks has emerged as a primary bottleneck. LLM agents must reconstruct trajectories from the past into memory intervals that are dynamic and plastic to facilitate the effective allocation of attention [12,142]. Future research may focus on the isolation of interval memory, the retrospective integration of critical nodes for decision making, and the adaptive pruning of working memory [28,143,144].
Benchmark for Experience. Existing datasets primarily evaluate the capacity for retrieval and denoising of memory within the stages of storage and reflection, whereas the evaluation of the capacity for abstraction and generalization during the stage of experience remains significantly insufficient (Appendix C). The assessment of the lifecycle of experience is closely linked to the capacity for meta-learning in LLM agents, which is essential for the realization of systems for self evolution based on active generalization [129,145]. Consequently, the path of evolution we propose provides a valuable foundation for guiding the development of these benchmarks.
Distributed Shared Memory. Collaboration among multiple agents represents the essential pathway toward the realization of “Organizations.” This establishes distributed shared memory as central to current research [146]. At present, mechanisms for shared memory rely primarily on communication through explicit dialogue, which is not only constrained by bottlenecks in bandwidth but is also prone to the introduction of noise during the process of exchange [147,148,149]. To overcome current communication constraints, future efforts should prioritize the development of consensus memory systems. These systems aim to achieve efficient synchronization between individual perspectives and collective knowledge, thereby fostering a more agile process of socialized experience evolution [150,151].
Multimodal Memory. Multimodal memory represents a significant direction for the future development of memory mechanisms for LLM agents. This direction requires the integration of states of visual perception, processes of linguistic reasoning, and other perceptual modalities into memory units characterized by unified temporality and semantics [152,153,154]. For embodied intelligence in particular, the integrity of internal models of the world directly influences the planning and execution of tasks [155,156]. To achieve this objective, existing research explores novel memory mechanisms by investigating multimodal abstraction, temporal alignment across modalities, and the efficient consolidation of memory.
7. Conclusion
This survey provides a systematic review of memory mechanisms for LLM agents, establishing an evolutionary framework that encompasses three progressive stages: storage, reflection, and experience. Our analysis demonstrates that memory evolution is not merely the expansion of storage capacity but fundamentally involves the enhancement of information density and a transformation across cognitive abstraction dimensions. By introducing mechanisms such as active exploration and cross-trajectory abstraction, memory mechanisms within the experience stage enable agents to transcend situational constraints and acquire transferable behavioral experience. We hope this survey assists the community in designing more advanced memory mechanisms, guiding LLM agents toward the realization of true general artificial intelligence.
8. Limitations
This survey provides a comprehensive qualitative analysis of memory mechanisms for LLM agents; however, we acknowledge several limitations that warrant discussion.
Lack of Direct Quantitative Comparison. This survey adopts a qualitative analytical framework and lacks a comprehensive performance comparison of memory mechanisms. This is because the design objectives differ across the three stages of storage, reflection, and experience, and no unified benchmark currently exists for comprehensive evaluation across all stages. Moreover, variations in foundation models, environments, and prompts across original studies render direct numerical comparison potentially misleading.
Relation to Established Learning Paradigms. The experience stage, particularly implicit experience, intersects with fine-tuning, reinforcement learning, and meta-learning at a technical level. This taxonomy does not position experience as an entirely novel learning paradigm; rather, it emphasizes how these established techniques are deployed within memory-centric LLM agent architectures, serving as a critical intermediary between interaction trajectories and parameter updates.
Temporal Coverage and Recency Bias. Research on memory mechanisms for LLM agents has experienced rapid growth from 2024 to 2025, with the experience stage emerging as a coherent research direction only in the latter half of 2025. This temporal distribution is reflected in the coverage of this survey and brings two methodological implications: (i) early influential works may not have received attention commensurate with their historical contributions, and (ii) some recent preprints included in this survey have not yet undergone formal peer review. To balance academic rigor with timeliness, this survey prioritizes works that propose novel architectures or demonstrate reproducible results.
Appendix A. Overview
We first provide a formal definition for the operational framework of LLM agents and the evolutionary paradigms of memory mechanisms. Furthermore, we categorize the primary drivers for this evolution into three dimensions, emphasizing that these driving forces constitute the fundamental factors supporting transformations in memory mechanisms and the inherent capabilities of LLM agents. Based on the depth to which historical trajectories are utilized, this survey proposes an evolutionary framework consisting of three distinct stages:
- Storage: As the foundational layer of evolution, this stage focuses on the faithful preservation of trajectories from interactions over a long duration to address constraints regarding the memory capacity of LLM agents.
- Reflection: Through the introduction of loops for dynamic evaluation, the memory mechanism transitions from a recorder of information to an evaluator, thereby mitigating issues related to hallucinations and logical errors within the memory of LLM agents.
- Experience: Representing the highest level of cognition, this stage employs abstraction across multiple trajectories to extract behavioral patterns of a higher order. This process compresses redundant memory into heuristic strategies that are transferable and reusable.
Furthermore, we provide an in-depth discussion on two pivotal technological shifts required for memory mechanisms to advance toward the stage of experience: active exploration and abstraction across trajectories. These advancements enable LLM agents to transition from passive recipients of information to collectors of experience driven by specific goals, thereby enhancing the capacity for proactive generalization in tasks that are unknown. Finally, this survey discusses several valuable directions for the future of memory mechanisms.
Summary of Contribution. As a survey, our primary objective is the synthesis and analysis of existing research, while providing novel insights and perspectives for researchers who aim to understand and design memory mechanisms. We believe that our work offers significant novelty in the following aspects:
- Scope & Coverage: To address the absence of a perspective on evolution and the significant fragmentation in contemporary research on memory mechanisms, this survey provides a comprehensive overview that is forward-looking. This work encompasses research that has been overlooked, the most recent advancements, and theoretical perspectives of a broader nature.
- Organization & Structure: This survey constructs an evolutionary framework in three stages to organize the manuscript. On this basis, we systematically delineate the drivers and pathways for the development of memory mechanisms, as well as characteristics at the frontier. This perspective provides novel insights for research within this domain.
- Insights & Critical Analysis: This survey provides original interpretations and an in-depth analysis of the existing literature. For instance, we propose a taxonomy from an evolutionary perspective, using the degree of utilization for trajectories of past interaction as a benchmark. Furthermore, we summarize two pivotal characteristics of memory mechanisms in the stage of experience and identify several issues that remain underexplored or unresolved.
- Timeliness & Relevance: In the inaugural year of LLM agents, this work represents the first survey to systematically examine memory mechanisms from a perspective of evolution, capturing research at the frontier through 2025. It addresses the urgent necessity for adaptation and learning as agents encounter the real world for the first time. Through the synthesis of existing literature, we provide a new foundation for further exploration and innovation in this critical field.
Overall, this survey offers a novel perspective by providing comprehensive coverage and an innovative classification of memory evolution. We anticipate that these contributions will bridge the knowledge gap regarding LLM agent memory mechanisms and offer a foundational resource for future research.
Figure A1.
Taxonomy of LLM agent Memory Mechanisms

Appendix B. Detail within the Evolutionary Path
Due to space constraints in the main text, we provide detailed exposition of representative works within each stage of the memory mechanism evolution in this section. For each work, we describe its core contribution, technical mechanism, and position within the evolutionary trajectory.
Appendix B.1. Storage
The primary objective of the storage phase is the precise preservation of trajectories to the maximum extent possible, which enables LLM agents to maintain an accurate perception of both internal and external states [166]. Although the memory mechanisms of the storage phase provide the context necessary for continuity and reasoning, they remain inherently susceptible to contamination from the stochasticity and hallucinations of the underlying model. Prior research has addressed the requirements for the writing, management, and retrieval of memory within various environments by constructing memory architectures across three technical categories: linear, vector, and structured.
Linear. Linear storage represents the most primitive and intuitive form of memory mechanisms. It treats the records of interaction for LLM agents as a continuous stream of tokens arranged in chronological order, managing memory within the context window through strict adherence to a strategy of first-in, first-out (FIFO). The work in this phase can be categorized into two components: adjustment of the context window and sparsification of information.
- Context Window Adaptation: Context window adaptation techniques seek to extend the usable input length of LLMs by modifying attention mechanisms, positional encoding schemes, or input structures. Representative approaches include optimizing intrinsic attention computation [66], remapping positional encodings to enable longer sequences [67], and restructuring inputs to mitigate length constraints [65]. These methods expand raw storage capacity but do not alter the semantics of stored trajectories.
- Information Sparsification: Information sparsification treats memory compression as a mechanical denoising process independent of agent reflection. Methods typically rely on statistical or attention-based heuristics to remove low-utility tokens. For example, Zhang et al. [68] evicts tokens based on cumulative attention scores, while Tang et al. [157] and Xiao et al. [70] retrieve salient memory blocks via query–key similarity. Jiang et al. [69] further identifies redundant segments through perplexity estimation. While effective for efficiency, these methods operate without semantic abstraction.
Vector. Vector storage mitigates the constraints of capacity for memory storage by encoding interaction trajectories into spaces of high dimensionality. However, it also introduces a novel challenge: the efficient retrieval of memories relevant to the task from massive repositories. Consequently, the focus of research has transitioned toward the optimization of retrieval. We categorize these methodologies into two classes: semantic retrieval and weighted retrieval.
- Semantic Retrieval: Semantic retrieval constitutes the foundational approach to vector memory, where relevance is determined by geometric proximity in embedding space. Melz [71] retrieves historical reasoning chains via semantic alignment, while Liu et al. [72] integrates fine-grained retrieval-attention during decoding to sustain long-context reasoning. Das et al. [73] further internalizes episodic memory into a latent matrix, enabling one-shot read–write operations. Despite improved recall, these methods treat retrieved content as flat historical evidence.
- Weighted Retrieval: Weighted retrieval extends semantic similarity by assigning differentiated importance to memories using multi-dimensional scoring signals. Zhong et al. [14] models temporal decay via the Ebbinghaus Forgetting Curve, while Park et al. [30] retrieves memories based on a weighted combination of relevance, recency, and importance. Such mechanisms improve prioritization but remain retrieval-centric rather than abstraction-driven.
Structured. Structured storage preserves memory through predefined structures of relationships. This paradigm emphasizes the integrity and enforcement of knowledge within memory, which facilitates precise operations, complex reasoning based on logic, and efficient retrieval across multiple hops. Based on the method of organization, we categorize these systems into three classes: tabular databases, tiered architectures and semantic graphs.
- Tabular Database: Database-backed memory systems leverage mature relational databases to store agent knowledge in structured tabular form. Early work frames databases as symbolic memory [56], while subsequent approaches translate natural language queries into SQL via specialized controllers for secure and efficient access [74]. Multi-agent extensions further distribute database construction and maintenance across specialized roles [75].
- Tiered Architectures: Tiered memory architectures draw inspiration from computer storage hierarchies and human cognition to balance capacity and access latency. MemGPT [11] introduces a dual-layer design separating main and external context, enabling virtual context expansion. Cognitive-inspired systems such as SWIFT–SAGE [167] dynamically adjust retrieval intensity, while streaming-update architectures maintain long-term stability without exhaustive retrieval [76,168].
- Semantic Graphs: Graph memory represents interaction histories as networks of entities and relations, enabling structured reasoning beyond flat storage. Triplet-based extraction supports precise updates and retrieval [77], while neuro-symbolic approaches integrate logical constraints into graph representations [169]. Graph-based world models further support environment-centric reasoning [159], and coarse-to-fine traversal over text graphs enables efficient long-context retrieval [76,168].
Appendix B.2. Reflection
Although the storage stage explores diverse methods for the preservation of memory to ensure the consistency of LLM agents over the long term, these approaches do not fundamentally address the quality of memory. Raw trajectories of interaction inevitably conflate successful sequences with hallucinations, errors in logic, and attempts that are invalid [170,171,172]. Without the application of evaluation, the passive storage of all trajectories leads to an accumulation of errors and the repetition of failures. The reflection stage incorporates introspection, the environment, and coordination as signals for feedback to rectify and denoise historical trajectories, thereby producing memory of higher quality.
Introspection. Introspective reflection represents an internal cognitive process that utilizes the LLM agent’s own knowledge to evaluate, refine, and restructure memory without the need for external feedback. Current research achieves introspection through three distinct functional pathways: error rectification, dynamic maintenance, and knowledge compression.
- Error Rectification: targets hallucinations and multi-step reasoning errors by verifying and repairing stored trajectories through self-critique.Shinn et al. [59] introduces Reflexion, which prompts agents to reflect on failed trajectories and distill corrective feedback into textual memory. This mechanism enables systematic error correction and sustained performance improvement across episodes, establishing introspective reflection as a central mechanism rather than a peripheral heuristic.Building on this paradigm, Liu et al. [79] introduces a post-reasoning verification stage to retain only validated memories, while Zhang et al. [80] detects contradictory or erroneous segments through introspective consistency checks, thereby limiting error accumulation and propagation.
- Dynamic Maintenance: Dynamic maintenance focuses on lifecycle management of memory content. Li et al. [81] incrementally updates internal knowledge schemas via clustering, while Rasmussen et al. [139] and Chhikara et al. [82] maintain continuity by parsing and updating structured entity relations. At the system level, rule-based controllers inspired by operating systems strategically update and persist core memories [11,13,173].
- Knowledge Compression: Knowledge compression distills high-dimensional trajectories into compact and reusable representations. Huang et al. [83] generates structured reflections to extract coherent character profiles, while Han et al. [84] decomposes interaction sequences into modular procedural memories. Multi-granularity abstraction further aligns distilled memories with task demands [17,140], and context-folding techniques preserve working-context efficiency during reasoning [28,85,174].
Environment. While introspective reflection leverages knowledge within the model to refine memory, it inherently carries a risk of inconsistency with factual reality. To mitigate this risk, reflection from the environment utilizes outcomes in the real world to actively optimize behavior and calibrate the internal knowledge of the model. Current research primarily proceeds along two trajectories: environment modeling and decision optimization.
- Environment Modeling: Environmental modeling aligns internal memory with dynamic external conditions such as environments, tools, and user preferences. Sun et al. [86] enables agents to infer and validate world rules from demonstrations, while Xiao et al. [89] summarizes tool behavior from execution outcomes. Preference-aware updates integrate short-term variation with long-term trends [90], and EM-based formulations ensure memory consistency under distribution shifts [175].
- Decision Optimization: Decision optimization treats memory management as a learnable policy guided by environmental rewards or execution feedback. Yan et al. [88] learns discrete actions from outcome-based rewards, while Yan et al. [87] refines memory quality using value-annotated decision trajectories. For complex planning, interaction feedback is used to validate and prune goal hierarchies [160].
Coordination. Collaborative reflection leverages the specialization of roles and mechanisms for consensus within systems of multiple agents to extend the process of reflection from the level of the individual to that of the collective. Through deliberation across multiple agents, this paradigm alleviates cognitive bottlenecks and hallucinations that are common in architectures with a single model during the processing of trajectories of complex memory.
- Multi-dimensional Calibration: Multi-dimensional calibration realizes distributed memory management through heterogeneous agent societies. Wang and Chen [161] coordinates core, episodic, and semantic memory modules to process multimodal long contexts. Wang et al. [93] decomposes graph reasoning into perception, caching, and execution roles to reduce context loss. Narrative-level coherence is achieved by integrating episodic and semantic memories across agents [92].Furthermore, Ozer et al. [94] and Bo et al. [91] frameworks further enhance reasoning consistency and collaboration efficiency in agent societies by implementing collaborative reflection across diverse roles and personalized feedback mechanisms
Appendix B.3. Experience
Although reflection mechanisms mitigate hallucinations and noise through evaluation, their corrective efficacy remains at the level of trajectories and has not yet yielded knowledge at the level of strategy that is transferable. [59,176] In addition, reflection focused on trajectories may lead to a linear expansion of the memory bank, which imposes a burden for inference and may potentially result in a characteristic of following trajectories. [177,178,179] Consequently, memory mechanisms must transcend the limitations of reflecting on the past and move toward a stage of experience for the guidance of the future. At this stage, memory mechanisms abstract universal wisdom that is independent of context from clusters of trajectories; through this process, LLM agents truly liberate themselves from memory banks that are verbose and complex, achieving zero-shot transfer to scenarios that are unknown by means of skills or rules that are intuitive. Research on the stage of experience achieves prospective wisdom through the abstraction of experience in forms that are explicit, implicit, and hybrid.
Explicit. Explicit experience abstracts patterns of knowledge that are readable by humans, editable, and generalizable from clusters of trajectories, framing experiential memory as insights of wisdom that allow for direct retrieval and reuse, analogous to the consultation of a reference manual or a library of functions. This methodology not only alleviates the pressure of inference but also provides LLM agents with capabilities for interpretability and self-evolution. Research on explicit experience can generally be categorized into Heuristic Guidelines and Procedural Primitives.
- Heuristic Guidelines: Heuristic guidelines serve to crystallize implicit intuition into explicit natural language strategies. In this domain, researchers focus on distilling experience into textual rules: Ouyang et al. [108] abstracts key decision principles through contrastive analysis of successful and failed trajectories, while Suzgun et al. [180] proposes dynamically generated "prompt lists" for real-time heuristic guidance. Xu et al. [181] and Hassell et al. [96] investigate rule induction from supervisory signals, achieving textual experience transfer via "cross-domain knowledge diffusion" and "semantic task guidance," respectively. To transcend linear text limitations in modeling complex dependencies, recent work shifts toward structured schemas. Ho et al. [162] and Zhang et al. [95] abstract multi-turn reasoning traces into experience graphs, leveraging topological structures to capture logical dependencies and enable effective storage and reuse of collaboration patterns and high-level cognitive principles. Moreover, Cai et al. [61] organizes heuristic knowledge into modular and compositional units, enabling systematic reuse across tasks.
- Procedural Primitives: Procedural primitives represent the abstraction of complex reasoning chains into executable entities, designed to significantly reduce planning overhead. Wang et al. [98] proposes a skill induction mechanism that encapsulates high-frequency action sequences into functions, enabling agents to invoke complex skills as atomic actions. Zhang et al. [99] extends this executable paradigm to hardware optimization, enabling agents to accumulate kernel optimization skills that iteratively enhance accelerator performance. In this line of work, Huang et al. [164] enables the composition and cascading execution of such procedural primitives, allowing agents to construct complex behaviors through structured skill invocation.
Implicit. Implicit experience eschews the retrieval of discrete text and abstracts the history of interactions into implicit priors, thereby addressing the overhead of inference and the constraints of context. Experiential memory is transformed into latent variables within spaces of high dimensionality or into parameters of the neural network. Based on the form of implementation for the transformation, implicit experience is categorized into two trajectories: Latent Modulation and Parameter Internalization.
- Latent Modulation: Latent modulation operates on the cognitive stream within continuous high-dimensional latent space. By encoding experience into latent variables or activation states, this paradigm "weaves" historical insights into current reasoning in a parameter-free manner, circumventing expensive parameter updates. Zhang et al. [106] introduces the MemGen framework, employing a "Memory Weaver" to dynamically generate and inject latent token sequences conditioned on current reasoning state. Zhang et al. [105] achieves smooth transfer from historical experience to current decision-making without altering static parameters, using alternating Fast Retrieval and Slow Integration within latent space.
- Parameter Internalization: Parameter Internalization transforms explicit trajectories into intrinsic capabilities within model weights. Through gradient updates, this mechanism instills adaptive priors into LLM agents, enabling effective navigation of complex environments. For context distillation, Alakuijala et al. [63] proposes iterative distillation to internalize corrective hints into model weights. Liu et al. [182] converts business rules into model priors, alleviating retrieval overload in RAG systems, while Zhai et al. [101] introduces "Experience Stripping," eliminating retrieval segments during training to force internalization of explicit experience into autonomous reasoning capabilities independent of external auxiliaries. For Reinforcement Learning, Zhang et al. [102] proposes a pioneering early experience paradigm, leveraging implicit world models and sub-reflective prediction to internalize trial-and-error experience into policy priors without extrinsic rewards. Lyu et al. [183] achieves strategic transformation from Reflection to Experience by applying RL to student-generated reflections. Feng et al. [184] proposes group-based policy optimization for fine-grained experience internalization across multi-turn interactions. Jiang et al. [165] establishes standardized alignment between RL and tool invocation, enhancing agents’ capacity to transmute tool-use experience into intrinsic strategies.
Hybrid. Hybrid experience aims to transcend the dichotomy between explicit and implicit paradigms by establishing a dynamic "Accumulate-Internalize" cycle. This paradigm directly addresses the challenges of "Storage Explosion" and "Retrieval Latency" encountered by explicit experience repositories during long-term interactions, while simultaneously mitigating the tension caused by parameter updates lagging behind environmental dynamics.
- Experience Transfer: Experience Transfer facilitates capability internalization by progressively decoupling agents from external retrieval reliance. [10] employs offline distillation to abstract complex trajectories into structured experience for inference guidance, then uses these experiences to generate high-quality trajectories for policy optimization. By transferring knowledge from explicit experience pools into model parameters via gradient updates, this approach eliminates dependence on external retrieval systems. [107,108] maintains an explicit experience replay buffer preserving high-value exploration trajectories. Through a hybrid On-Policy and Off-Policy update strategy, this framework leverages explicit memory for immediate exploration while encoding successful experiences into network parameters via offline updates, ensuring agents sustain optimal performance through internalized "intuition" without external support.
Appendix C. Datasets
Recently, the research community has developed various datasets to evaluate the consistency over the long term and the capacity for self evolution of LLM agents within dynamic environments. However, existing benchmarks still primarily assess the storage and retrieval of static data, which results in a lack of evaluation for other critical capabilities of memory within scenarios of dynamic interaction. Following our proposed path of evolution (§Section 4), we categorize these benchmarks into stages of storage, reflection, and experience according to their primary areas of focus. Detailed information for these benchmarks is provided in Table A1.
Storage Stage. The storage stage serves as the cornerstone for mechanisms of memory, primarily evaluating the capacity of LLM agents for the accurate storage and retrieval of information over long distances across various scenarios, tasks, and modalities.
- Extreme Context: Extreme context types focus on probing the physical limits of memory in LLM agents, specifically the capacity for extracting and processing minute facts within massive volumes of distracting information. For instance, these benchmarks define the actual effective window of the model through the retrieval of multiple needles [185], assess the capabilities of agents by embedding reasoning tasks within backgrounds of a million words [186] and assessing the reliability of memory within a long context [187], or extend these challenges to the domain of vision [188]. The core of this area is the evaluation of the authentic capacity for memory in the model.
- Interactive Consistency: Research regarding the category of Interactive Consistency is based on interaction across sessions, which requires LLM agents to maintain memory with consistency throughout such interactions. Examples include the provision of frameworks for coherent dialogue at the scale of ten million words [189], the direct evaluation of the update of knowledge and the capacity for rejection during continuous interaction [190], and the detection of how consistency and accuracy for personas are maintained over histories of long duration [14,191]. The core of this stage is the assessment of the capacity for memory with consistency over long distances.
- Relational Fact: Benchmarks of the relational fact category primarily evaluate the capacity of LLM agents for semantic association and reasoning across multiple hops. This involves testing the ability of the model for the integration of facts across documents and reasoning in multiple steps within the context of personal trivia [192,193]. Furthermore, certain frameworks focus on emotional support and interactive scenarios to evaluate the model’s capacity for memory recall across proactive and passive paradigms [194].
Reflection Stage. The core of the Reflection stage is the evaluation of how agents transform raw trajectories into memory of high quality, with an emphasis on the denoising and fidelity of memory, the deep alignment with characteristics of users, and the support for perception within complex environments.
- Error Correction: Error correction primarily evaluates whether errors or hallucinations emerge during the lifecycle of the memory system. For instance, it involves testing operations for the search, editing, and matching of memory [195], examining the presence of hallucinations during the stages of extraction or update [196].
- Personalization: Personalization focuses on the capacity for the extraction of deep personalization from the history of the agent, which includes the mining of latent information through reflection to identify implicit preferences [197,198], traits of users [199,200], key information [201,202], and shared components [203,204].
- Dynamic Reasoning: Dynamic reasoning emphasizes the critical role of memory in reasoning across multiple steps and the perception of environments with high complexity. This involves the selective forgetting of memory [205], backtracking on decisions [206], scenarios in the real world [207,208], and the mechanisms for summarization and transition [190].
Experience Stage. The Experience Stage represents the pinnacle of the evolutionary path of memory mechanisms; at this phase, the focus shifts toward how LLM agents abstract general experience from fragmented trajectories within dynamic environments to facilitate continuous evolution through practical application. While benchmarks for this stage are relatively scarce, they possess a strong empirical character: Wu et al. [209] and Ai et al. [210] simulate environments for authentic deployment to evaluate the capacity of LLM agents for the extraction and internalization of experience within cycles of input and feedback; conversely, Wei et al. [129] and Zheng et al. [211] emphasize the capacity for the transfer of experience, measuring levels of abstraction and generalization by assessing the transfer of acquired experience to a diverse range of other tasks.

Table A1.
Representative datasets for LLM agent memory mechanism research.
| Stage | Dataset | Reference | Size | Description |
|---|---|---|---|---|
| Storage Stage Benchmark | LongBench | Bai et al. [212] | 4.7k | Evaluate faithful memory preservation and retrieval by performing information extraction and reasoning across multiple tasks with sequences up to 32k tokens. |
| LongBenchv2 | Bai et al. [213] | 503 | Answer complex multiple-choice questions through the processing of extremely long sequences with lengths between 8k and 2M words for the purpose of evaluating the capacity of memory and the precision of reasoning. | |
| RULER | Hsieh et al. [185] | Scalable | Evaluate the effectiveness of retrieval and synthesis within long contexts through tasks such as multi-needle extraction or multi-hop reasoning to identify true memory capacity. | |
| MMNeedle | Wang et al. [188] | 280k | Identify a target sub image within a massive collection of images through the analysis of textual descriptions and visual contents for the purpose of measuring the limits of multimodal retrieval. | |
| HotpotQA | Yang et al. [193] | 113k | Answer questions by performing reasoning across multiple hops over information scattered in diverse documents based on Wikipedia to provide accurate results and supporting facts. | |
| MemoryBank | Zhong et al. [14] | 194 | Answer questions by recalling pertinent information and summarizing user traits across a history of interactions spanning ten days to evaluate the precision of retrieval and the maintenance of user portraits for long-term dialogues. | |
| BABILong | Kuratov et al. [186] | Scalable | Answer questions by performing reasoning on facts scattered across extremely long documents of natural language to test the limits of memory and retrieval for contexts with length up to one million tokens. | |
| DialSim | Kim et al. [214] | 1.3k | Evaluate the precision of retrieval for memory by answering spontaneous questions across sessions of dialogue involving multiple parties with long durations. | |
| LongMemEval | Maharana et al. [190] | 500 | Answer questions through the extraction of information from histories of interactive chat with multiple sessions for the purpose of evaluating the performance of retrieval and reasoning across dependencies of long range. | |
| BEAM | Tavakoli et al. [189] | 100 | Evaluate the capacity of memory and the precision of retrieval by answering questions based on coherent and topically diverse conversations with length up to ten million tokens. | |
| MPR | Zhang et al. [192] | 108k | Answer complex questions by conducting reasoning across multiple hops of factual information specific to a user within a framework of explicit or implicit memory for the purpose of evaluating the precision of retrieval. | |
| LOCCO | Jia et al. [191] | 1.6k | Evaluate the persistence of memory and the retrieval of historical facts by analyzing chronological conversations across extended periods of time for the purpose of measuring information decay. | |
| MADial-Bench | He et al. [194] | 160 | Evaluate the effectiveness of retrieval and recognition for historical events across multiple turns of interaction by simulating paradigms of passive and proactive recall for the purpose of providing emotional support. | |
| HELMET | Yen et al. [187] | Scalable | Evaluate the effectiveness of models for long-context by performing information extraction and reasoning across seven diverse categories for sequences with lengths up to 128k tokens to provide a thorough assessment of memory capacity. | |
| Reflection Stage Benchmark | Minerva | Xia et al. [195] | Scalable | Analyze the proficiency of LLMs in utilizing and manipulating context memory through a programmable framework of atomic and composite tasks for the purpose of pinpointing specific functional deficiencies and providing actionable insights. |
| HaluMem | Chen et al. [196] | 3.5k | Evaluate the fidelity of memory by quantifying the occurrence of fabrication and omission during the stages of storage and retrieval across dialogues of multiple turns. | |
| MABench | Hu et al. [205] | 2.1k | Evaluate the competencies of accurate retrieval and learning at test time across sequences of incremental interactions with multiple turns. | |
| PRM | Yuan et al. [201] | 700 | Evaluate the capability of personalized assistants to maintain a dynamic memory bank by preserving evolving user knowledge and experiences across long term dialogues for the purpose of generating tailored responses. | |
| PersonMemv2 | Jiang et al. [197] | 1k | Generate personalized responses through the extraction of implicit personas from interactions with long context and thousands of preferences of users to evaluate the adaptation of agents. | |
| LoCoMo | Maharana et al. [190] | 50 | Evaluate the reliability of memory by executing question answering and event summarization across sequences of conversation with lengths of up to nine thousand tokens spanning thirty-five sessions. | |
| WebChoreArena | Miyai et al. [208] | 451 | Analyze the performance of memory for information retrieval and complex aggregation by performing multiple steps of navigation and reasoning across hundreds of web pages. | |
| MT-Mind2Web | Deng et al. [207] | 720 | Evaluate the performance of conversational web navigation via multiturn instruction following across sequential interactions with both users and environment for the purpose of managing context dependency and limited memory space. | |
| StoryBench | Wan and Ma [206] | 80 | Evaluate the capacity for reflection and sequential reasoning by navigating hierarchical decision trees within interactive fiction games to trace back and revise earlier choices independently across multiple turns. | |
| PerLTQA | Du et al. [199] | 8.6k | Answer personalized questions by retrieving and synthesizing semantic and episodic information from a memory bank of thirty characters to evaluate the accuracy of retrieval for memory. | |
| ImplexConv | Li et al. [202] | 2.5k | Evaluate implicit reasoning in personalized dialogues by retrieving and synthesizing subtle or semantically distant information from history encompassing 100 sessions to test the efficiency of hierarchical memory structures. | |
| Share | Kim et al. [204] | 3.2k | Improve the quality of interactions across long durations by extracting persona data and memories of shared history from scripts of movies to sustain a consistent relationship between two individuals. | |
| Mem-PAL | Huang et al. [198] | 100 | Evaluate the capability of personalization for assistants oriented toward service by identifying subjective traits and preferences of users from histories of dialogue and behavioral logs across multiple sessions for the purpose of generating tailored responses. | |
| PrefEval | Zhao et al. [200] | 3k | Quantify the robustness of proactive preference following by evaluating the ability of models to infer and satisfy explicit or implicit user traits amidst long context distractions for sequences with length up to 100k tokens. | |
| LIDB | Tsaknakis et al. [203] | 210 | Discover the latent preferences of users and generate personalized responses through interactions across multiple turns within a framework of three agents for the purpose of evaluating the efficiency of elicitation and adaptation. | |
| Experience Stage Benchmark | StreamBench | Wu et al. [209] | 9.7k | Evaluate the capacity for continuous improvement and online learning via iterative feedback processing across diverse task streams to measure the adaptation of agents after deployment. |
| MemoryBench | Ai et al. [210] | 20k | Evaluate the capacity for continual learning of Large Language Model systems by simulating the accumulation of feedback from users across multiple domains to measure the effectiveness of procedural memory. | |
| Evo-Memory | Wei et al. [129] | 3.7k | Evaluate the capacity for learning at test time and the evolution of memory by processing continuous streams of tasks for the purpose of reuse of experience across diverse scenarios. | |
| LABench | Zheng et al. [211] | 1.4k | Evaluate the lifelong learning ability and transfer of knowledge across sequences of interdependent tasks in dynamic environments for the purpose of measuring the acquisition and retention of skills. |
References
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. CoRR 2023, abs/2302.13971, [2302.13971]. [CrossRef]
- Hurst, A.; Lerer, A.; Goucher, A.P.; Perelman, A.; Ramesh, A.; Clark, A.; Ostrow, A.; Welihinda, A.; Hayes, A.; Radford, A.; et al. GPT-4o System Card. CoRR 2024, abs/2410.21276, [2410.21276]. [CrossRef]
- Yang, A.; Li, A.; Yang, B.; Zhang, B.; Hui, B.; Zheng, B.; Yu, B.; Gao, C.; Huang, C.; Lv, C.; et al. Qwen3 Technical Report. CoRR 2025, abs/2505.09388, [2505.09388]. p. 2505.09388. [CrossRef]
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models. ArXiv 2022. abs/2210.03629. [Google Scholar]
- Qin, Y.; Liang, S.; Ye, Y.; Zhu, K.; Yan, L.; Lu, Y.; Lin, Y.; Cong, X.; Tang, X.; Qian, B.; et al. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. In Proceedings of the The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024; OpenReview.net. 2024. [Google Scholar]
- Luo, Z.; Shen, Z.; Yang, W.; Zhao, Z.; Jwalapuram, P.; Saha, A.; Sahoo, D.; Savarese, S.; Xiong, C.; Li, J. MCP-Universe: Benchmarking Large Language Models with Real-World Model Context Protocol Servers. CoRR 2025, abs/2508.14704, [2508.14704]. [CrossRef]
- Huang, J.; Chen, X.; Mishra, S.; Zheng, H.S.; Yu, A.W.; Song, X.; Zhou, D. Large Language Models Cannot Self-Correct Reasoning Yet. ArXiv 2023. [Google Scholar]
- Xiong, Z.; Lin, Y.; Xie, W.; He, P.; Tang, J.; Lakkaraju, H.; Xiang, Z. How Memory Management Impacts LLM Agents: An Empirical Study of Experience-Following Behavior. ArXiv 2025. [Google Scholar]
- Wang, L.; Ma, C.; Feng, X.; Zhang, Z.; ran Yang, H.; Zhang, J.; Chen, Z.Y.; Tang, J.; Chen, X.; Lin, Y.; et al. A survey on large language model based autonomous agents. Frontiers of Computer Science 2023, 18. [Google Scholar] [CrossRef]
- Wu, R.; Wang, X.; Mei, J.; Cai, P.; Fu, D.; Yang, C.; Wen, L.; Yang, X.; Shen, Y.; Wang, Y.; et al. EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle. ArXiv 2025. [Google Scholar]
- Packer, C.; Fang, V.; Patil, S.G.; Lin, K.; Wooders, S.; Gonzalez, J. MemGPT: Towards LLMs as Operating Systems. ArXiv 2023. abs/2310.08560. [Google Scholar]
- Hu, M.; Chen, T.; Chen, Q.; Mu, Y.; Shao, W.; Luo, P. HiAgent: Hierarchical Working Memory Management for Solving Long-Horizon Agent Tasks with Large Language Model. ArXiv 2024. [Google Scholar]
- Kang, J.; Ji, M.; Zhao, Z.; Bai, T. Memory OS of AI Agent. ArXiv 2025. [Google Scholar]
- Zhong, W.; Guo, L.; Gao, Q.F.; Ye, H.; Wang, Y. MemoryBank: Enhancing Large Language Models with Long-Term Memory. ArXiv 2023. [Google Scholar] [CrossRef]
- Hou, Y.; Tamoto, H.; Miyashita, H. My agent understands me better": Integrating Dynamic Human-like Memory Recall and Consolidation in LLM-Based Agents. Extended Abstracts of the CHI Conference on Human Factors in Computing Systems; 2024. [Google Scholar]
- Xu, W.; Liang, Z.; Mei, K.; Gao, H.; Tan, J.; Zhang, Y. A-MEM: Agentic Memory for LLM Agents. ArXiv 2025. [Google Scholar]
- Yang, W.; Xiao, J.; Zhang, H.; Zhang, Q.; Wang, Y.; Xu, B. Coarse-to-Fine Grounded Memory for LLM Agent Planning. ArXiv 2025. [Google Scholar]
- Zhang, Z.; Dai, Q.; Chen, X.; Li, R.; Li, Z.; Dong, Z. MemEngine: A Unified and Modular Library for Developing Advanced Memory of LLM-based Agents. In Companion Proceedings of the ACM on Web Conference; 2025. [Google Scholar]
- Wu, Y.; Liang, S.; Zhang, C.; Wang, Y.; Zhang, Y.; Guo, H.; Tang, R.; Liu, Y. From Human Memory to AI Memory: A Survey on Memory Mechanisms in the Era of LLMs. ArXiv 2025. [Google Scholar]
- Du, Y.; Huang, W.; Zheng, D.; Wang, Z.; Montella, S.; Lapata, M.; Wong, K.F.; Pan, J.Z. Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions. ArXiv 2025. abs/2505.00675. [Google Scholar]
- Wu, S.; Shu, K. Memory in LLM-based Multi-agent Systems: Mechanisms, Challenges, and Collective Intelligence. 2025. [Google Scholar] [CrossRef]
- Cao, Z.; Deng, J.; Yu, L.; Zhou, W.; Liu, Z.; Ding, B.; Zhao, H. Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution. 2025. [Google Scholar] [CrossRef]
- Zhang, Z.; Dai, Q.; Bo, X.; Ma, C.; Li, R.; Chen, X.; Zhu, J.; Dong, Z.; Wen, J.R. A Survey on the Memory Mechanism of Large Language Model-based Agents. ACM Transactions on Information Systems 2024, 43, 1–47. [Google Scholar] [CrossRef]
- Hu, Y.; Liu, S.; Yue, Y.; Zhang, G.; Liu, B.; Zhu, F.; Lin, J.; Guo, H.; Dou, S.; Xi, Z.; et al. Memory in the Age of AI Agents. 2025. [Google Scholar] [CrossRef]
- Huang, Y.; Xu, J.; Jiang, Z.; Lai, J.; Li, Z.; Yao, Y.; Chen, T.; Yang, L.; Xin, Z.; Ma, X. Advancing Transformer Architecture in Long-Context Large Language Models: A Comprehensive Survey. ArXiv 2023. [Google Scholar]
- Sumers, T.R.; Yao, S.; Narasimhan, K.; Griffiths, T.L. Cognitive Architectures for Language Agents. Trans. Mach. Learn. Res. 2023, 2024. [Google Scholar]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.L.; Cao, Y.; Narasimhan, K. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. ArXiv 2023. [Google Scholar]
- Sun, W.; Lu, M.; Ling, Z.; Liu, K.; Yao, X.; Yang, Y.; Chen, J. Scaling Long-Horizon LLM Agent via Context-Folding. ArXiv 2025, abs/2510.11967. [Google Scholar]
- Majumder, B.P.; Dalvi, B.; Jansen, P.A.; Tafjord, O.; Tandon, N.; Zhang, L.; Callison-Burch, C.; Clark, P. CLIN: A Continually Learning Language Agent for Rapid Task Adaptation and Generalization. ArXiv 2023. [Google Scholar]
- Park, J.S.; O’Brien, J.C.; Cai, C.J.; Morris, M.R.; Liang, P.; Bernstein, M.S. Generative Agents: Interactive Simulacra of Human Behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology; 2023. [Google Scholar]
- Westhäußer, R.; Minker, W.; Zepf, S. Enabling Personalized Long-term Interactions in LLM-based Agents through Persistent Memory and User Profiles. ArXiv 2025. abs/2510.07925. [Google Scholar]
- Liang, J.; Li, H.; Li, C.; Zhou, J.; Jiang, S.; Wang, Z.; Ji, C.; Zhu, Z.; Liu, R.; Ren, T.; et al. AI Meets Brain: Memory Systems from Cognitive Neuroscience to Autonomous Agents. 2025. [Google Scholar] [CrossRef]
- Huang, X.; Liu, W.; Chen, X.; Wang, X.; Wang, H.; Lian, D.; Wang, Y.; Tang, R.; Chen, E. Understanding the planning of LLM agents: A survey. ArXiv 2024. [Google Scholar]
- Everitt, T.; Garbacea, C.; Bellot, A.; Richens, J.; Papadatos, H.; Campos, S.; Shah, R. Evaluating the Goal-Directedness of Large Language Models. ArXiv 2025. [Google Scholar]
- Li, Z.; Chang, Y.; Yu, G.; Le, X. HiPlan: Hierarchical Planning for LLM-Based Agents with Adaptive Global-Local Guidance. ArXiv 2025. [Google Scholar]
- Gao, D.; Li, Z.; Kuang, W.; Pan, X.; Chen, D.; Ma, Z.; Qian, B.; Yao, L.; Zhu, L.; Cheng, C.; et al. AgentScope: A Flexible yet Robust Multi-Agent Platform. ArXiv 2024. [Google Scholar]
- Liu, J.; Kong, Z.; Yang, C.; Yang, F.; Li, T.; Dong, P.; Nanjekye, J.; Tang, H.; Yuan, G.; Niu, W.; et al. RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory. ArXiv 2025. abs/2508.04903. [Google Scholar]
- Lazaridou, A.; Kuncoro, A.; Gribovskaya, E.; Agrawal, D.; Liska, A.; Terzi, T.; Giménez, M.; de Masson d’Autume, C.; Kociský, T.; Ruder, S.; et al. Mind the Gap: Assessing Temporal Generalization in Neural Language Models. In Proceedings of the Neural Information Processing Systems, 2021. [Google Scholar]
- Jang, J.; Ye, S.; Lee, C.; Yang, S.; Shin, J.; Han, J.; Kim, G.; Seo, M. TemporalWiki: A Lifelong Benchmark for Training and Evaluating Ever-Evolving Language Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2022. [Google Scholar]
- Ko, D.; Kim, J.; Choi, H.; Kim, G. GrowOVER: How Can LLMs Adapt to Growing Real-World Knowledge? In Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2024. [Google Scholar]
- Luu, K.; Khashabi, D.; Gururangan, S.; Mandyam, K.; Smith, N.A. Time Waits for No One! Analysis and Challenges of Temporal Misalignment. arXiv 2022, arXiv:2111.07408. [Google Scholar] [CrossRef]
- Kalai, A.T.; Vempala, S.S. Calibrated Language Models Must Hallucinate. In Proceedings of the 56th Annual ACM Symposium on Theory of Computing; 2023. [Google Scholar]
- Kasai, J.; Sakaguchi, K.; Takahashi, Y.; Bras, R.L.; Asai, A.; Yu, X.; Radev, D.; Smith, N.A.; Choi, Y.; Inui, K. RealTime QA: What’s the Answer Right Now? arXiv 2024, arXiv:cs. [Google Scholar]
- Siyue, Z.; Xue, Y.; Zhang, Y.; Wu, X.; Luu, A.T.; Chen, Z. MRAG: A Modular Retrieval Framework for Time-Sensitive Question Answering. ArXiv 2024. [Google Scholar]
- Salama, R.; Cai, J.; Yuan, M.; Currey, A.; Sunkara, M.; Zhang, Y.; Benajiba, Y. MemInsight: Autonomous Memory Augmentation for LLM Agents. ArXiv 2025. [Google Scholar]
- Du, X.; Li, L.; Zhang, D.; Song, L. MemR3: Memory Retrieval via Reflective Reasoning for LLM Agents. 2025. [Google Scholar]
- Houichime, T.; Souhar, A.; Amrani, Y.E. Memory as Resonance: A Biomimetic Architecture for Infinite Context Memory on Ergodic Phonetic Manifolds. 2025. [Google Scholar]
- Joshi, A.; Ahmad, A.; Modi, A. COLD: Causal reasOning in cLosed Daily activities. abs/2411.19500; ArXiv. 2024. [Google Scholar]
- Cui, S.; Mouchel, L.; Faltings, B. Uncertainty in Causality: A New Frontier. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2025. [Google Scholar]
- Liu, X.; Xu, P.; Wu, J.; Yuan, J.; Yang, Y.; Zhou, Y.; Liu, F.; Guan, T.; Wang, H.; Yu, T.; et al. Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey. ArXiv 2025. [Google Scholar]
- Du, Y.; Wang, B.; Xiang, Y.; Wang, Z.; Huang, W.; Xue, B.; Liang, B.; Zeng, X.; Mi, F.; Bai, H.; et al. Memory-T1: Reinforcement Learning for Temporal Reasoning in Multi-session Agents. 2025. [Google Scholar]
- Raman, V.; VijaiAravindh, R.; Ragav, A. REMI: A Novel Causal Schema Memory Architecture for Personalized Lifestyle Recommendation Agents. ArXiv 2025. abs/2509.06269. [Google Scholar]
- Tang, H.; Key, D.; Ellis, K. WorldCoder, a Model-Based LLM Agent: Building World Models by Writing Code and Interacting with the Environment. ArXiv 2024. [Google Scholar]
- Kim, M.; won Hwang, S. CoEx - Co-evolving World-model and Exploration. ArXiv 2025. [Google Scholar]
- Bohnet, B.; Kamienny, P.; Sedghi, H.; Gorur, D.; Awasthi, P.; Parisi, A.T.; Swersky, K.; Liu, R.; Nova, A.; Fiedel, N. Enhancing LLM Planning Capabilities through Intrinsic Self-Critique. 2025. [Google Scholar] [CrossRef]
- Hu, C.; Fu, J.; Du, C.; Luo, S.; Zhao, J.J.; Zhao, H. ChatDB: Augmenting LLMs with Databases as Their Symbolic Memory. ArXiv 2023. abs/2306.03901. [Google Scholar]
- Srivastava, S.S.; He, H. MemoryGraft: Persistent Compromise of LLM Agents via Poisoned Experience Retrieval. arXiv 2025, arXiv:2512.16962. [Google Scholar] [CrossRef]
- Liu, S.; Yang, J.; Jiang, B.; Li, Y.; Guo, J.; Liu, X.; Dai, B. Context as a Tool: Context Management for Long-Horizon SWE-Agents. 2025. [Google Scholar] [CrossRef]
- Shinn, N.; Cassano, F.; Labash, B.; Gopinath, A.; Narasimhan, K.; Yao, S. Reflexion: language agents with verbal reinforcement learning. In Proceedings of the Neural Information Processing Systems, 2023. [Google Scholar]
- Tang, X.; Qin, T.; Peng, T.; Zhou, Z.; Shao, Y.; Du, T.; Wei, X.; Xia, P.; Wu, F.; Zhu, H.; et al. Agent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving. ArXiv 2025. abs/2507.06229. [Google Scholar]
- Cai, Z.; Guo, X.; Pei, Y.; Feng, J.; Chen, J.; Zhang, Y.Q.; Ma, W.Y.; Wang, M.; Zhou, H. FLEX: Continuous Agent Evolution via Forward Learning from Experience. 2025. [Google Scholar] [CrossRef]
- Xia, P.; Xia, P.; Zeng, K.; Liu, J.; Qin, C.; Wu, F.; Zhou, Y.; Xiong, C.; Yao, H. Agent0: Unleashing Self-Evolving Agents from Zero Data via Tool-Integrated Reasoning. 2025. [Google Scholar]
- Alakuijala, M.; Gao, Y.; Ananov, G.; Kaski, S.; Marttinen, P.; Ilin, A.; Valpola, H. Memento No More: Coaching AI Agents to Master Multiple Tasks via Hints Internalization. ArXiv 2025. [Google Scholar]
- Guo, J.; Yang, L.; Chen, P.; Xiao, Q.; Wang, Y.; Juan, X.; Qiu, J.; Shen, K.; Wang, M. GenEnv: Difficulty-Aligned Co-Evolution Between LLM Agents and Environment Simulators. 2025. [Google Scholar]
- Ratner, N.; Levine, Y.; Belinkov, Y.; Ram, O.; Magar, I.; Abend, O.; Karpas, E.; Shashua, A.; Leyton-Brown, K.; Shoham, Y. Parallel Context Windows for Large Language Models. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2022. [Google Scholar]
- Xiao, G.; Tian, Y.; Chen, B.; Han, S.; Lewis, M. Efficient Streaming Language Models with Attention Sinks. ArXiv 2023. [Google Scholar]
- Jin, H.; Han, X.; Yang, J.; Jiang, Z.; Liu, Z.; yuan Chang, C.; Chen, H.; Hu, X. LLM Maybe LongLM: Self-Extend LLM Context Window Without Tuning. ArXiv 2024. abs/2401.01325.
- Zhang, Z.A.; Sheng, Y.; Zhou, T.; Chen, T.; Zheng, L.; Cai, R.; Song, Z.; Tian, Y.; Ré, C.; Barrett, C.W.; et al. H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models. ArXiv 2023. [Google Scholar]
- Jiang, H.; Wu, Q.; Lin, C.Y.; Yang, Y.; Qiu, L. LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2023. [Google Scholar]
- Xiao, C.; Zhang, P.; Han, X.; Xiao, G.; Lin, Y.; Zhang, Z.; Liu, Z.; Han, S.; Sun, M. InfLLM: Training-Free Long-Context Extrapolation for LLMs with an Efficient Context Memory. Advances in Neural Information Processing Systems 2024. [Google Scholar]
- Melz, E. Enhancing LLM Intelligence with ARM-RAG: Auxiliary Rationale Memory for Retrieval Augmented Generation. ArXiv 2023. [Google Scholar]
- Liu, W.; Tang, Z.; Li, J.; Chen, K.; Zhang, M. MemLong: Memory-Augmented Retrieval for Long Text Modeling. ArXiv 2024. [Google Scholar]
- Das, P.; Chaudhury, S.; Nelson, E.; Melnyk, I.; Swaminathan, S.; Dai, S.; Lozano, A.C.; Kollias, G.; Chenthamarakshan, V.; Navrátil, J.; et al. Larimar: Large Language Models with Episodic Memory Control. ArXiv 2024. [Google Scholar]
- Xue, S.; Jiang, C.; Shi, W.; Cheng, F.; Chen, K.; Yang, H.; Zhang, Z.; He, J.; Zhang, H.; Wei, G.; et al. DB-GPT: Empowering Database Interactions with Private Large Language Models. ArXiv 2023. [Google Scholar]
- Lee, S.; Ko, H. Training a Team of Language Models as Options to Build an SQL-Based Memory. In Applied Sciences; 2025. [Google Scholar]
- Lu, J.; An, S.; Lin, M.; Pergola, G.; He, Y.; Yin, D.; Sun, X.; Wu, Y. MemoChat: Tuning LLMs to Use Memos for Consistent Long-Range Open-Domain Conversation. ArXiv 2023. abs/2308.08239. [Google Scholar]
- Modarressi, A.; Köksal, A.; Imani, A.; Fayyaz, M.; Schutze, H. MemLLM: Finetuning LLMs to Use An Explicit Read-Write Memory. ArXiv 2024. [Google Scholar]
- Li, S.; He, Y.; Guo, H.; Bu, X.; Bai, G.; Liu, J.; Liu, J.; Qu, X.; Li, Y.; Ouyang, W.; et al. GraphReader: Building Graph-based Agent to Enhance Long-Context Abilities of Large Language Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2024. [Google Scholar]
- Liu, L.; Yang, X.; Shen, Y.; Hu, B.; Zhang, Z.; Gu, J.; Zhang, G. Think-in-Memory: Recalling and Post-thinking Enable LLMs with Long-Term Memory. ArXiv 2023. abs/2311.08719. [Google Scholar]
- Zhang, P.; Chen, X.; Feng, Y.; Jiang, Y.; Meng, L. Constructing coherent spatial memory in LLM agents through graph rectification. ArXiv 2025. [Google Scholar]
- Li, R.; Zhang, Z.; Bo, X.; Tian, Z.; Chen, X.; Dai, Q.; Dong, Z.; Tang, R. CAM: A Constructivist View of Agentic Memory for LLM-Based Reading Comprehension. ArXiv 2025. abs/2510.05520. [Google Scholar]
- Chhikara, P.; Khant, D.; Aryan, S.; Singh, T.; Yadav, D. Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory. ArXiv 2025. [Google Scholar]
- Huang, Y.; Liu, Y.; Zhao, R.; Zhong, X.; Yue, X.; Jiang, L. MemOrb: A Plug-and-Play Verbal-Reinforcement Memory Layer for E-Commerce Customer Service. ArXiv 2025. [Google Scholar]
- Han, D.; Couturier, C.; Diaz, D.M.; Zhang, X.; Rühle, V.; Rajmohan, S. LEGOMem: Modular Procedural Memory for Multi-agent LLM Systems for Workflow Automation. ArXiv 2025. abs/2510.04851. [Google Scholar]
- Ye, R.; Zhang, Z.; Li, K.; Yin, H.; Tao, Z.; Zhao, Y.; Su, L.; Zhang, L.; Qiao, Z.; Wang, X.; et al. AgentFold: Long-Horizon Web Agents with Proactive Context Management. ArXiv 2025. [Google Scholar]
- Sun, Z.; Shi, H.; Côté, M.A.; Berseth, G.; Yuan, X.; Liu, B. Enhancing Agent Learning through World Dynamics Modeling. ArXiv 2024. [Google Scholar]
- Yan, X.; Ou, Z.; Yang, M.; Song, Y.; Zhang, H.; Li, Y.; Wang, J. Memory-Driven Self-Improvement for Decision Making with Large Language Models. ArXiv 2025. abs/2509.26340. [Google Scholar]
- Yan, S.; Yang, X.; Huang, Z.; Nie, E.; Ding, Z.; Li, Z.; Ma, X.; Schutze, H.; Tresp, V.; Ma, Y. Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning. ArXiv 2025, abs/2508.19828.
- Xiao, Y.; Li, Y.; Wang, H.; Tang, Y.; Wang, Z.Z. ToolMem: Enhancing Multimodal Agents with Learnable Tool Capability Memory. ArXiv 2025. abs/2510.06664. [Google Scholar]
- Sun, H.; Zhang, Z.; Zeng, S. Preference-Aware Memory Update for Long-Term LLM Agents. ArXiv 2025. abs/2510.09720. [Google Scholar]
- Bo, X.; Zhang, Z.; Dai, Q.; Feng, X.; Wang, L.; Li, R.; Chen, X.; Wen, J.R. Reflective Multi-Agent Collaboration based on Large Language Models. Advances in Neural Information Processing Systems 2024. [Google Scholar]
- Balestri, R.; Pescatore, G. Narrative Memory in Machines: Multi-Agent Arc Extraction in Serialized TV. ArXiv 2025. [Google Scholar]
- Wang, R.; Liang, S.; Chen, Q.; Huang, Y.; Li, M.; Ma, Y.; Zhang, D.; Qin, K.; Leung, M.F. GraphCogent: Mitigating LLMs’Working Memory Constraints via Multi-Agent Collaboration in Complex Graph Understanding. 2025. [Google Scholar]
- Ozer, O.; Wu, G.; Wang, Y.; Dosti, D.; Zhang, H.; Rue, V.D.L. MAR:Multi-Agent Reflexion Improves Reasoning Abilities in LLMs. 2025. [Google Scholar]
- Zhang, G.M.; Fu, M.; Wan, G.; Yu, M.; Wang, K.; Yan, S. G-Memory: Tracing Hierarchical Memory for Multi-Agent Systems. ArXiv 2025. [Google Scholar]
- Hassell, J.; Zhang, D.; Kim, H.J.; Mitchell, T.; Hruschka, E. Learning from Supervision with Semantic and Episodic Memory: A Reflective Approach to Agent Adaptation. ArXiv 2025, abs/2510.19897. [Google Scholar]
- Wan, C.; Dai, X.; Wang, Z.; Li, M.; Wang, Y.; Mao, Y.; Lan, Y.; Xiao, Z. LoongFlow: Directed Evolutionary Search via a Cognitive Plan-Execute-Summarize Paradigm. 2025. [Google Scholar]
- Wang, Z.Z.; Gandhi, A.; Neubig, G.; Fried, D. Inducing Programmatic Skills for Agentic Tasks. ArXiv 2025. [Google Scholar]
- Zhang, G.; Zhu, S.; Wei, A.; Song, Z.; Nie, A.; Jia, Z.; Vijaykumar, N.; Wang, Y.; Olukotun, K. AccelOpt: A Self-Improving LLM Agentic System for AI Accelerator Kernel Optimization. 2025. [Google Scholar]
- Shi, Y.; Cai, Y.; Cai, S.; Xu, Z.; Chen, L.; Qin, Y.; Zhou, Z.; Fei, X.; Qiu, C.; Tan, X.; et al. Youtu-Agent: Scaling Agent Productivity with Automated Generation and Hybrid Policy Optimization. 2025. [Google Scholar] [CrossRef]
- Zhai, Y.; Tao, S.; Chen, C.; Zou, A.; Chen, Z.; Fu, Q.; Mai, S.; Yu, L.; Deng, J.; Cao, Z.; et al. AgentEvolver: Towards Efficient Self-Evolving Agent System. 2025. [Google Scholar]
- Zhang, K.; Chen, X.; Liu, B.; Xue, T.; Liao, Z.; Liu, Z.; Wang, X.; Ning, Y.; Chen, Z.; Fu, X.; et al. Agent Learning via Early Experience. ArXiv 2025. abs/2510.08558. [Google Scholar]
- Tandon, A.; Dalal, K.; Li, X.; Koceja, D.; Rod, M.; Buchanan, S.; Wang, X.; Leskovec, J.; Koyejo, S.; Hashimoto, T.; et al. End-to-End Test-Time Training for Long Context. 2025. [Google Scholar]
- Yu, W.; Liang, Z.; Huang, C.; Panaganti, K.; Fang, T.; Mi, H.; Yu, D. Guided Self-Evolving LLMs with Minimal Human Supervision. 2025. [Google Scholar] [CrossRef]
- Zhang, G.M.; Meng, F.; Wan, G.; Li, Z.; Wang, K.; Yin, Z.; Bai, L.; Yan, S. LatentEvolve: Self-Evolving Test-Time Scaling in Latent Space. ArXiv 2025. [Google Scholar]
- Zhang, G.M.; Fu, M.; Yan, S. MemGen: Weaving Generative Latent Memory for Self-Evolving Agents. ArXiv 2025. [Google Scholar]
- Anonymous. Exploratory Memory-Augmented LLM Agent via Hybrid On- and Off-Policy Optimization. In Proceedings of the Submitted to The Fourteenth International Conference on Learning Representations, 2025. under review. [Google Scholar]
- Ouyang, S.; Yan, J.; Hsu, I.H.; Chen, Y.; Jiang, K.; Wang, Z.; Han, R.; Le, L.T.; Daruki, S.; Tang, X.; et al. ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory. ArXiv 2025. abs/2509.25140. [Google Scholar]
- Zheng, Q.; Henaff, M.; Zhang, A.; Grover, A.; Amos, B. Online Intrinsic Rewards for Decision Making Agents from Large Language Model Feedback. ArXiv 2024. [Google Scholar]
- Pan, Y.; Liu, Z.; Wang, H. Wonder Wins Ways: Curiosity-Driven Exploration through Multi-Agent Contextual Calibration. ArXiv 2025. [Google Scholar]
- Sun, H.; Chai, Y.; Wang, S.; Sun, Y.; Wu, H.; Wang, H. Curiosity-Driven Reinforcement Learning from Human Feedback. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2025. [Google Scholar]
- Wei, Z.; Yao, W.; Liu, Y.; Zhang, W.; Lu, Q.; Qiu, L.; Yu, C.; Xu, P.; Zhang, C.; Yin, B.; et al. WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning. ArXiv 2025. [Google Scholar]
- Ahn, M.; Brohan, A.; Brown, N.; Chebotar, Y.; Cortes, O.; David, B.; Finn, C.; Gopalakrishnan, K.; Hausman, K.; Herzog, A.; et al. Do As I Can, Not As I Say: Grounding Language in Robotic Affordances. In Proceedings of the Conference on Robot Learning, 2022. [Google Scholar]
- Wang, Z.; Wang, K.; Wang, Q.; Zhang, P.; Li, L.; Yang, Z.; Yu, K.; Nguyen, M.N.; Liu, L.; Gottlieb, E.; et al. RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning. ArXiv 2025. [Google Scholar]
- Qi, Z.; Liu, X.; Iong, I.L.; Lai, H.; Sun, X.; Zhao, W.; Yang, Y.; Yang, X.; Sun, J.; Yao, S.; et al. WebRL: Training LLM Web Agents via Self-Evolving Online Curriculum Reinforcement Learning. arXiv 2025, arXiv:cs. [Google Scholar]
- Cheng, J.; Kumar, A.; Lal, R.; Rajasekaran, R.; Ramezani, H.; Khan, O.Z.; Rokhlenko, O.; Chiu-Webster, S.; Hua, G.; Amiri, H. WebATLAS: An LLM Agent with Experience-Driven Memory and Action Simulation. 2025. [Google Scholar]
- Liu, J.; Xiong, K.; Xia, P.; Zhou, Y.; Ji, H.; Feng, L.; Han, S.; Ding, M.; Yao, H. Agent0-VL: Exploring Self-Evolving Agent for Tool-Integrated Vision-Language Reasoning. 2025. [Google Scholar]
- Shi, Z.; Fang, M.; Chen, L. Monte Carlo Planning with Large Language Model for Text-Based Game Agents. ArXiv 2025, abs/2504.16855.
- Bidochko, A.; Vyklyuk, Y. Thought Management System for long-horizon, goal-driven LLM agents. Journal of Computational Science 2026, 93, 102740. [Google Scholar] [CrossRef]
- Forouzandeh, S.; Peng, W.; Moradi, P.; Yu, X.; Jalili, M. Learning Hierarchical Procedural Memory for LLM Agents through Bayesian Selection and Contrastive Refinement. 2025. [Google Scholar] [CrossRef]
- He, K.; Zhang, M.; Yan, S.; Wu, P.; Chen, Z. IDEA: Enhancing the Rule Learning Ability of Large Language Model Agent through Induction, Deduction, and Abduction. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2024. [Google Scholar]
- Fang, R.; Liang, Y.; Wang, X.; Wu, J.; Qiao, S.; Xie, P.; Huang, F.; Chen, H.; Zhang, N. Memp: Exploring Agent Procedural Memory. ArXiv 2025. abs/2508.06433. [Google Scholar]
- Latimer, C.; Boschi, N.; Neeser, A.; Bartholomew, C.; Srivastava, G.; Wang, X.; Ramakrishnan, N. Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects. 2025. [Google Scholar] [CrossRef]
- Yang, Y.; Kang, S.; Lee, J.; Lee, D.; Yun, S.; Lee, K. Automated Skill Discovery for Language Agents through Exploration and Iterative Feedback. ArXiv 2025. abs/2506.04287. [Google Scholar]
- Zhang, G.; Ren, H.; Zhan, C.; Zhou, Z.; Wang, J.; Zhu, H.; Zhou, W.; Yan, S. MemEvolve: Meta-Evolution of Agent Memory Systems. 2025. [Google Scholar]
- Ding, B.; Chen, Y.; Lv, J.; Yuan, J.; Zhu, Q.; Tian, S.; Zhu, D.; Wang, F.; Deng, H.; Mi, F.; et al. Rethinking Expert Trajectory Utilization in LLM Post-training. 2025. [Google Scholar] [CrossRef]
- Chen, S.; Zhu, T.; Wang, Z.; Zhang, J.; Wang, K.; Gao, S.; Xiao, T.; Teh, Y.W.; He, J.; Li, M. Internalizing World Models via Self-Play Finetuning for Agentic RL. ArXiv 2025. abs/2510.15047. [Google Scholar]
- Chen, S.; Lin, S.; Gu, X.; Shi, Y.; Lian, H.; Yun, L.; Chen, D.; Sun, W.; Cao, L.; Wang, Q. SWE-Exp: Experience-Driven Software Issue Resolution. ArXiv 2025. [Google Scholar]
- Wei, T.; Sachdeva, N.; Coleman, B.; He, Z.; Bei, Y.; Ning, X.; Ai, M.; Li, Y.; He, J.; hsin Chi, E.H.; et al. Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory. 2025. [Google Scholar]
- Hayashi, H.; Pang, B.; Zhao, W.; Liu, Y.; Gokul, A.; Bansal, S.; Xiong, C.; Yavuz, S.; Zhou, Y. Self-Abstraction from Grounded Experience for Plan-Guided Policy Refinement. 2025. [Google Scholar]
- Wang, Z.Z.; Mao, J.; Fried, D.; Neubig, G. Agent Workflow Memory. ArXiv 2024. [Google Scholar]
- Liu, Y.; Si, C.; Narasimhan, K.R.; Yao, S. Contextual Experience Replay for Self-Improvement of Language Agents. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2025. [Google Scholar]
- Yu, S.; Li, G.; Shi, W.; Qi, P. PolySkill: Learning Generalizable Skills Through Polymorphic Abstraction. ArXiv 2025. [Google Scholar]
- Cheng, M.; Jie, O.; Yu, S.; Yan, R.; Luo, Y.; Liu, Z.; Wang, D.; Liu, Q.; Chen, E. Agent-R1: Training Powerful LLM Agents with End-to-End Reinforcement Learning. 2025. [Google Scholar]
- Luo, X.; Zhang, Y.; He, Z.; Wang, Z.; Zhao, S.; Li, D.; Qiu, L.K.; Yang, Y. Agent Lightning: Train ANY AI Agents with Reinforcement Learning. ArXiv 2025. abs/2508.03680. [Google Scholar]
- Wang, J.; Yan, Q.; Wang, Y.; Tian, Y.; Mishra, S.S.; Xu, Z.; Gandhi, M.; Xu, P.; Cheong, L.L. Reinforcement Learning for Self-Improving Agent with Skill Library. 2025. [Google Scholar] [CrossRef]
- Gharat, H.; Agrawal, H.; Patro, G.K. From Personalization to Prejudice: Bias and Discrimination in Memory-Enhanced AI Agents for Recruitment. 2025. [Google Scholar] [CrossRef]
- Wang, P.; Tian, M.; Li, J.; Liang, Y.; Wang, Y.; Chen, Q.; Wang, T.; Lu, Z.; Ma, J.; Jiang, Y.E.; et al. O-Mem: Omni Memory System for Personalized, Long Horizon, Self-Evolving Agents. 2025. [Google Scholar]
- Rasmussen, P.; Paliychuk, P.; Beauvais, T.; Ryan, J.; Chalef, D. Zep: A Temporal Knowledge Graph Architecture for Agent Memory. ArXiv 2025, abs/2501.13956.
- Tan, Z.; Yan, J.; Hsu, I.H.; Han, R.; Wang, Z.; Le, L.T.; Song, Y.; Chen, Y.; Palangi, H.; Lee, G.; et al. Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents. ArXiv 2025. abs/2503.08026. [Google Scholar]
- Du, X.; Li, L.; Zhang, D.; Song, L. MemR3: Memory Retrieval via Reflective Reasoning for LLM Agents. arXiv 2025, arXiv:cs. [Google Scholar]
- Luo, H.; Morgan, N.; Li, T.; Zhao, D.; Ngo, A.V.; Schroeder, P.; Yang, L.; Ben-Kish, A.; O’Brien, J.; Glass, J.R. Beyond Context Limits: Subconscious Threads for Long-Horizon Reasoning. ArXiv 2025. [Google Scholar]
- Zhang, Y.; Shu, J.; Ma, Y.; Lin, X.; Wu, S.; Sang, J. Memory as Action: Autonomous Context Curation for Long-Horizon Agentic Tasks. arXiv 2025, arXiv:2510.12635. [Google Scholar] [CrossRef]
- Nan, J.; Ma, W.; Wu, W.; Chen, Y. Nemori: Self-Organizing Agent Memory Inspired by Cognitive Science. ArXiv 2025. [Google Scholar]
- Behrouz, A.; Zhong, P.; Mirrokni, V.S. Titans: Learning to Memorize at Test Time. ArXiv 2024. [Google Scholar]
- Wu, S.; et al. Memory in LLM-based Multi-agent Systems: Mechanisms, Challenges, and Collective Intelligence. TechRxiv 2025. [Google Scholar]
- Tran, K.T.; Dao, D.; Nguyen, M.D.; Pham, Q.V.; O’Sullivan, B.; Nguyen, H.D. Multi-Agent Collaboration Mechanisms: A Survey of LLMs. ArXiv 2025. abs/2501.06322. [Google Scholar]
- Liao, C.C.; Liao, D.; Gadiraju, S.S. AgentMaster: A Multi-Agent Conversational Framework Using A2A and MCP Protocols for Multimodal Information Retrieval and Analysis. ArXiv 2025. [Google Scholar]
- Zou, J.; Yang, X.; Qiu, R.; Li, G.; Tieu, K.; Lu, P.; Shen, K.; Tong, H.; Choi, Y.; He, J.; et al. Latent Collaboration in Multi-Agent Systems. 2025. [Google Scholar] [CrossRef]
- Yuen, S.; Medina, F.G.; Su, T.; Du, Y.; Sobey, A.J. Intrinsic Memory Agents: Heterogeneous Multi-Agent LLM Systems through Structured Contextual Memory. ArXiv 2025. abs/2508.08997. [Google Scholar]
- Rezazadeh, A.; Li, Z.; Lou, A.; Zhao, Y.; Wei, W.; Bao, Y. Collaborative Memory: Multi-User Memory Sharing in LLM Agents with Dynamic Access Control. ArXiv 2025. [Google Scholar]
- Liu, J.; Sun, Y.; Cheng, W.; Lei, H.; Chen, Y.; Wen, L.; Yang, X.; Fu, D.; Cai, P.; Deng, N.; et al. MemVerse: Multimodal Memory for Lifelong Learning Agents. 2025. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, X.; Liu, Y.; Zhao, Y.; Wang, X.; Li, Z.; Tian, J.; Xu, X. M2PA: A Multi-Memory Planning Agent for Open Worlds Inspired by Cognitive Theory. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2025. [Google Scholar]
- He, X.; Zhang, Y.; Gao, S.; Li, W.; Hong, L.; Chen, M.; Jiang, K.; Fu, J.; Zhang, W. RSAgent: Learning to Reason and Act for Text-Guided Segmentation via Multi-Turn Tool Invocations. 2025. [Google Scholar]
- Feng, T.; Wang, X.; Jiang, Y.G.; Zhu, W. Embodied AI: From LLMs to World Models. ArXiv 2025, abs/2509. [Google Scholar]
- Long, X.; Zhao, Q.; Zhang, K.; Zhang, Z.; Wang, D.; Liu, Y.; Shu, Z.; Lu, Y.; Wang, S.; Wei, X.; et al. A Survey: Learning Embodied Intelligence from Physical Simulators and World Models. ArXiv 2025. abs/2507.00917. [Google Scholar]
- Tang, J.; Zhao, Y.; Zhu, K.; Xiao, G.; Kasikci, B.; Han, S. Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference. ArXiv 2024. [Google Scholar]
- Li, Z.; Song, S.; Xi, C.; Wang, H.; Tang, C.; Niu, S.; Chen, D.; Yang, J.; Li, C.; Yu, Q.; et al. MemOS: A Memory OS for AI System. ArXiv 2025. [Google Scholar]
- Anokhin, P.; Semenov, N.; Sorokin, A.Y.; Evseev, D.; Burtsev, M.; Burnaev, E. AriGraph: Learning Knowledge Graph World Models with Episodic Memory for LLM Agents. In Proceedings of the International Joint Conference on Artificial Intelligence, 2024. [Google Scholar]
- Yang, R.; Chen, J.; Zhang, Y.; Yuan, S.; Chen, A.; Richardson, K.; Xiao, Y.; Yang, D. SelfGoal: Your Language Agents Already Know How to Achieve High-level Goals. ArXiv 2024. [Google Scholar]
- Wang, Y.; Chen, X. MIRIX: Multi-Agent Memory System for LLM-Based Agents. ArXiv 2025. [Google Scholar]
- Ho, M.; Si, C.; Feng, Z.; Yu, F.; Yang, Y.; Liu, Z.; Hu, Z.; Qin, L. ArcMemo: Abstract Reasoning Composition with Lifelong LLM Memory. ArXiv 2025. abs/2509.04439. [Google Scholar]
- Fang, J.; Deng, X.; Xu, H.; Jiang, Z.; Tang, Y.; Xu, Z.; Deng, S.; Yao, Y.; Wang, M.; Qiao, S.; et al. LightMem: Lightweight and Efficient Memory-Augmented Generation. ArXiv 2025. [Google Scholar]
- Huang, X.; Chen, J.; Fei, Y.; Li, Z.; Schwaller, P.; Ceder, G. CASCADE: Cumulative Agentic Skill Creation through Autonomous Development and Evolution. 2025. [Google Scholar] [CrossRef]
- Jiang, D.; Lu, Y.; Li, Z.; Lyu, Z.; Nie, P.; Wang, H.; Su, A.; Chen, H.; Zou, K.; Du, C.; et al. VerlTool: Towards Holistic Agentic Reinforcement Learning with Tool Use. ArXiv 2025. abs/2509.01055. [Google Scholar]
- Xi, Z.; Chen, W.; Guo, X.; He, W.; Ding, Y.; Hong, B.; Zhang, M.; Wang, J.; Jin, S.; Zhou, E.; et al. The Rise and Potential of Large Language Model Based Agents: A Survey. ArXiv 2023. [Google Scholar] [CrossRef]
- Lin, B.Y.; Fu, Y.; Yang, K.; Ammanabrolu, P.; Brahman, F.; Huang, S.; Bhagavatula, C.; Choi, Y.; Ren, X. SwiftSage: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks. ArXiv 2023. [Google Scholar]
- Zhou, W.; Jiang, Y.E.; Cui, P.; Wang, T.; Xiao, Z.; Hou, Y.; Cotterell, R.; Sachan, M. RecurrentGPT: Interactive Generation of (Arbitrarily) Long Text. ArXiv 2023. [Google Scholar]
- Wang, S.; Wei, Z.; Choi, Y.; Ren, X. Symbolic Working Memory Enhances Language Models for Complex Rule Application. ArXiv 2024. [Google Scholar]
- Zhang, M.; Press, O.; Merrill, W.; Liu, A.; Smith, N.A. How Language Model Hallucinations Can Snowball. ArXiv 2023. [Google Scholar]
- Ghasemabadi, A.; Niu, D. Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits. 2025. [Google Scholar] [CrossRef]
- Zhang, K.; Yao, Q.; Liu, S.; Zhang, W.; Cen, M.; Zhou, Y.; Fang, W.; Zhao, Y.; Lai, B.; Song, M. Replay Failures as Successes: Sample-Efficient Reinforcement Learning for Instruction Following. 2025. [Google Scholar] [CrossRef]
- Zhou, Z.; Qu, A.; Wu, Z.; Kim, S.; Kim, S.; Prakash, A.; Rus, D.; Zhao, J.; Low, B.K.H.; Liang, P. MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents. ArXiv 2025. [Google Scholar]
- Li, X.; Jiao, W.; Jin, J.; Dong, G.; Jin, J.; Wang, Y.; Wang, H.; Zhu, Y.; Wen, J.R.; Lu, Y.; et al. DeepAgent: A General Reasoning Agent with Scalable Toolsets. ArXiv 2025. [Google Scholar]
- Yin, Z.; Sun, Q.; Guo, Q.; Zeng, Z.; Cheng, Q.; Qiu, X.; Huang, X. Explicit Memory Learning with Expectation Maximization. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2024. [Google Scholar]
- Renze, M.; Guven, E. Self-Reflection in Large Language Model Agents: Effects on Problem-Solving Performance. 2024 2nd International Conference on Foundation and Large Language Models (FLLM); 2024; pp. 516–525. [Google Scholar]
- Hong, C.; He, Q. Enhancing memory retrieval in generative agents through LLM-trained cross attention networks. Frontiers in Psychology 2025, 16. [Google Scholar] [CrossRef]
- Zhu, K.; Liu, Z.; Li, B.; Tian, M.; Yang, Y.; Zhang, J.; Han, P.; Xie, Q.; Cui, F.; Zhang, W.; et al. Where LLM Agents Fail and How They can Learn From Failures. ArXiv 2025. abs/2509.25370. [Google Scholar]
- Fu, D.; He, K.; Wang, Y.; Hong, W.; Gongque, Z.; Zeng, W.; Wang, W.; Wang, J.; Cai, X.; Xu, W. AgentRefine: Enhancing Agent Generalization through Refinement Tuning. ArXiv 2025. abs/2501.01702. [Google Scholar]
- Suzgun, M.; Yüksekgönül, M.; Bianchi, F.; Jurafsky, D.; Zou, J. Dynamic Cheatsheet: Test-Time Learning with Adaptive Memory. ArXiv 2025. abs/2504.07952. [Google Scholar]
- Xu, H.; Hu, J.; Zhang, K.; Yu, L.; Tang, Y.; Song, X.; Duan, Y.; Ai, L.; Shi, B. SEDM: Scalable Self-Evolving Distributed Memory for Agents. ArXiv 2025. [Google Scholar]
- Liu, J.; Wang, Z.; Huang, X.; Li, Y.; Fan, X.; Li, X.; Guo, C.; Sarikaya, R.; Ji, H. Analyzing and Internalizing Complex Policy Documents for LLM Agents. ArXiv 2025, abs/2510.11588. 2025.
- Lyu, Y.; Wang, C.; Huang, J.; Xu, T. From Correction to Mastery: Reinforced Distillation of Large Language Model Agents. ArXiv 2025. [Google Scholar]
- Feng, L.; Xue, Z.; Liu, T.; An, B. Group-in-Group Policy Optimization for LLM Agent Training. ArXiv 2025, abs/2505.10978.
- Hsieh, C.P.; Sun, S.; Kriman, S.; Acharya, S.; Rekesh, D.; Jia, F.; Ginsburg, B. RULER: What’s the Real Context Size of Your Long-Context Language Models? ArXiv 2024. [Google Scholar]
- Kuratov, Y.; Bulatov, A.; Anokhin, P.; Rodkin, I.; Sorokin, D.; Sorokin, A.Y.; Burtsev, M. BABILong: Testing the Limits of LLMs with Long Context Reasoning-in-a-Haystack. ArXiv 2024. [Google Scholar]
- Yen, H.; Gao, T.; Hou, M.; Ding, K.; Fleischer, D.; Izsak, P.; Wasserblat, M.; Chen, D. HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly. ArXiv 2024. [Google Scholar]
- Wang, H.; Shi, H.; Tan, S.; Qin, W.; Wang, W.; Zhang, T.; Nambi, A.U.; Ganu, T.; Wang, H. Multimodal Needle in a Haystack: Benchmarking Long-Context Capability of Multimodal Large Language Models. In Proceedings of the North American Chapter of the Association for Computational Linguistics, 2024. [Google Scholar]
- Tavakoli, M.; Salemi, A.; Ye, C.; Abdalla, M.; Zamani, H.; Mitchell, J.R. Beyond a Million Tokens: Benchmarking and Enhancing Long-Term Memory in LLMs. ArXiv 2025. [Google Scholar]
- Maharana, A.; Lee, D.H.; Tulyakov, S.; Bansal, M.; Barbieri, F.; Fang, Y. Evaluating Very Long-Term Conversational Memory of LLM Agents. ArXiv 2024. [Google Scholar]
- Jia, Z.; Liu, Q.; Li, H.; Chen, Y.; Liu, J. Evaluating the Long-Term Memory of Large Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2025; Vienna, Austria, Che, W., Nabende, J., Shutova, E., Pilehvar, M.T., Eds.; 2025; pp. 19759–19777. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, Y.; Tan, H.; Li, R.; Chen, X. Explicit v.s. Implicit Memory: Exploring Multi-hop Complex Reasoning Over Personalized Information. ArXiv 2025. [Google Scholar]
- Yang, Z.; Qi, P.; Zhang, S.; Bengio, Y.; Cohen, W.W.; Salakhutdinov, R.; Manning, C.D. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2018. [Google Scholar]
- He, J.; Zhu, L.; Wang, R.; Wang, X.; Haffari, G.; Zhang, J. MADial-Bench: Towards Real-world Evaluation of Memory-Augmented Dialogue Generation. In Proceedings of the North American Chapter of the Association for Computational Linguistics, 2024. [Google Scholar]
- Xia, M.; Ruehle, V.; Rajmohan, S.; Shokri, R. Minerva: A Programmable Memory Test Benchmark for Language Models. ArXiv 2025. abs/2502.03358. [Google Scholar]
- Chen, D.; Niu, S.; Li, K.; Liu, P.; Zheng, X.; Tang, B.; Li, X.; Xiong, F.; Li, Z. HaluMem: Evaluating Hallucinations in Memory Systems of Agents. ArXiv 2025. abs/2511.03506. [Google Scholar]
- Jiang, B.; Yuan, Y.; Shen, M.; Hao, Z.; Xu, Z.; Chen, Z.; Liu, Z.; Vijjini, A.R.; He, J.; Yu, H.; et al. PersonaMem-v2: Towards Personalized Intelligence via Learning Implicit User Personas and Agentic Memory. 2025. [Google Scholar]
- Huang, Z.; Dai, Q.; Wu, G.; Wu, X.; Chen, K.; Yu, C.; Li, X.; Ge, T.; Wang, W.; Jin, Q. Mem-PAL: Towards Memory-based Personalized Dialogue Assistants for Long-term User-Agent Interaction. 2025. [Google Scholar]
- Du, Y.; Wang, H.; Zhao, Z.; Liang, B.; Wang, B.; Zhong, W.; Wang, Z.; Wong, K.F. PerLTQA: A Personal Long-Term Memory Dataset for Memory Classification, Retrieval, and Synthesis in Question Answering. ArXiv 2024. [Google Scholar]
- Zhao, S.; Hong, M.; Liu, Y.; Hazarika, D.; Lin, K. Do LLMs Recognize Your Preferences? Evaluating Personalized Preference Following in LLMs. ArXiv 2025. abs/2502.09597. [Google Scholar]
- Yuan, R.; Sun, S.; Wang, Z.; Cao, Z.; Li, W. Personalized Large Language Model Assistant with Evolving Conditional Memory. In Proceedings of the International Conference on Computational Linguistics, 2023. [Google Scholar]
- Li, X.; Bantupalli, J.; Dharmani, R.; Zhang, Y.; Shang, J. Toward Multi-Session Personalized Conversation: A Large-Scale Dataset and Hierarchical Tree Framework for Implicit Reasoning. ArXiv 2025. [Google Scholar]
- Tsaknakis, I.C.; Song, B.; Gan, S.; Kang, D.; García, A.; Liu, G.; Fleming, C.; Hong, M. Do LLMs Recognize Your Latent Preferences? A Benchmark for Latent Information Discovery in Personalized Interaction. ArXiv 2025. [Google Scholar]
- Kim, E.; Park, C.; Chang, B. SHARE: Shared Memory-Aware Open-Domain Long-Term Dialogue Dataset Constructed from Movie Script. ArXiv 2024. [Google Scholar]
- Hu, Y.; Wang, Y.; McAuley, J. Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions. ArXiv 2025. [Google Scholar]
- Wan, L.; Ma, W. StoryBench: A Dynamic Benchmark for Evaluating Long-Term Memory with Multi Turns. ArXiv 2025. [Google Scholar]
- Deng, Y.; Zhang, X.; Zhang, W.; Yuan, Y.; Ng, S.K.; Chua, T.S. On the Multi-turn Instruction Following for Conversational Web Agents. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2024. [Google Scholar]
- Miyai, A.; Zhao, Z.; Egashira, K.; Sato, A.; Sunada, T.; Onohara, S.; Yamanishi, H.; Toyooka, M.; Nishina, K.; Maeda, R.; et al. WebChoreArena: Evaluating Web Browsing Agents on Realistic Tedious Web Tasks. ArXiv 2025. abs/2506.01952. [Google Scholar]
- Wu, C.K.; Tam, Z.R.; Lin, C.Y.; Chen, Y.N.; yi Lee, H. StreamBench: Towards Benchmarking Continuous Improvement of Language Agents. ArXiv 2024. abs/2406.08747.
- Ai, Q.; Tang, Y.; Wang, C.; Long, J.; Su, W.; Liu, Y. MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems. ArXiv 2025, abs/2510.17281. [Google Scholar]
- Zheng, J.; Cai, X.; Li, Q.; Zhang, D.; Li, Z.; Zhang, Y.; Song, L.; Ma, Q. LifelongAgentBench: Evaluating LLM Agents as Lifelong Learners. ArXiv 2025. [Google Scholar]
- Bai, Y.; Lv, X.; Zhang, J.; Lyu, H.; Tang, J.; Huang, Z.; Du, Z.; Liu, X.; Zeng, A.; Hou, L.; et al. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. ArXiv 2023. [Google Scholar]
- Bai, Y.; Tu, S.; Zhang, J.; Peng, H.; Wang, X.; Lv, X.; Cao, S.; Xu, J.; Hou, L.; Dong, Y.; et al. LongBench v2: Towards Deeper Understanding and Reasoning on Realistic Long-context Multitasks. ArXiv 2024. [Google Scholar]
- Kim, J.; Chay, W.; Hwang, H.; Kyung, D.; Chung, H.; Cho, E.; Jo, Y.; Choi, E. DialSim: A Real-Time Simulator for Evaluating Long-Term Dialogue Understanding of Conversational Agents. ArXiv 2024. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



