Submitted:
02 January 2026
Posted:
06 January 2026
You are already at the latest version
Abstract
Sentiment classification struggles with complex semantic relationships using static text graphs. We introduce the Quantum-Enhanced Adaptive Graph Convolutional Network (QAGCN), a hybrid quantum-classical architecture for robust sentiment representation. QAGCN's core is a Quantum-Enhanced Graph Construction Module employing a Parameterized Quantum Circuit (PQC) to dynamically learn emotional association strengths between word pairs. This generates a task-adaptive adjacency matrix, which then feeds into classical GNN layers. Evaluations on benchmark datasets (Yelp, IMDB, Amazon, MC, RP) demonstrate QAGCN's superior or competitive accuracy against state-of-the-art classical graph models and the Quantum Graph Transformer. QAGCN notably improved performance on Amazon where prior quantum models struggled, underscoring its adaptive graph construction's efficacy. An ablation study confirms the critical contribution of PQC-driven adaptive graph learning. Our findings highlight the significant potential of quantum-enhanced adaptive graph learning for complex Natural Language Processing.
Keywords:
sentiment classification
; quantum computing
; Graph Neural Networks
; adaptive graph learning
; Natural Language Processing
1. Introduction
Sentiment classification, a cornerstone task in Natural Language Processing (NLP), aims to identify the emotional tone or sentiment expressed within a piece of text [1]. Its pervasive applications range from public opinion monitoring and product review analysis to intelligent customer service systems, highlighting its significant practical and academic importance. Traditional sentiment classification models, including those based on Recurrent Neural Networks (RNNs) [2], Convolutional Neural Networks (CNNs) [3], or the highly successful Transformer architecture [4], have made remarkable progress in capturing local and long-range dependencies among words. This progress is part of a broader advancement in Natural Language Processing, exemplified by Large Language Models (LLMs) which demonstrate sophisticated reasoning capabilities such as unraveling chaotic contexts [5] and exhibiting weak-to-strong generalization [6]. This broader progress extends to computer vision tasks such as multi-camera depth estimation, leveraging advanced techniques like spatial-temporal context and adversarial geometry regularization [7]. The trend further extends to multi-modal domains with Large Vision-Language Models (LVLMs) employing techniques like visual in-context learning [8]. However, even with these advancements, many classical models, particularly those in sentiment classification, typically treat text as a one-dimensional sequence, which may not fully capture the intricate semantic and syntactic relationships between words in a sentence, especially when text structures are complex or sentiment expressions are subtle and indirect.
Figure 1.
Overview of the limitations of static sentiment graph modeling and the motivation for adaptive quantum-enhanced graph learning, where dynamically learned relational structures enable more accurate sentiment reasoning.
Figure 1.
Overview of the limitations of static sentiment graph modeling and the motivation for adaptive quantum-enhanced graph learning, where dynamically learned relational structures enable more accurate sentiment reasoning.
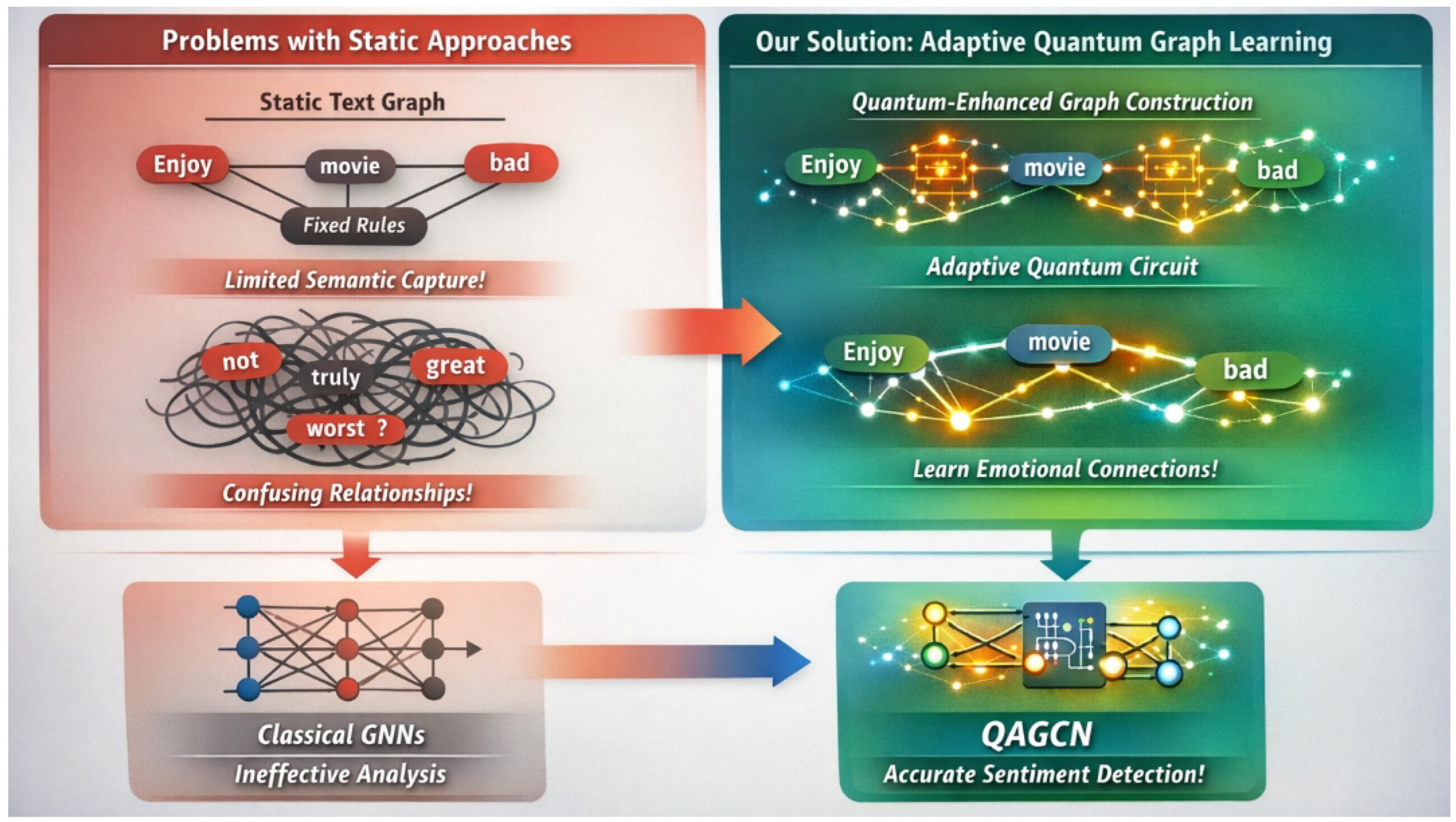
In recent years, Graph Neural Networks (GNNs) have emerged as a powerful paradigm for processing non-Euclidean data, exhibiting immense potential in NLP by representing text as graph structures where words are nodes and their relationships are edges [9]. Nevertheless, existing GNN methods for text graph construction often rely on predefined rules, such as dependency parse trees [10], fixed-size sliding windows [11], or even fully connected graphs [12]. Such fixed or overly dense graph structures might fail to adaptively capture the most semantically salient connections crucial for sentiment classification, potentially introducing noise or limiting effective information flow. The challenge lies in constructing an intelligent, task-adaptive graph that truly reflects the underlying sentiment-bearing relationships.
Concurrently, the rapid advancements in quantum computing and quantum information theory offer new avenues for tackling complex, high-dimensional data and uncovering patterns that are intractable for classical methods [13]. Hybrid quantum-classical models, particularly those integrating Parameterized Quantum Circuits (PQCs) into key modules of Transformers or GNNs, have shown promising capabilities in enhancing feature extraction, attention mechanisms, and achieving parameter efficiency [14]. In the NLP domain, nascent research has begun to explore quantum-enhanced Transformer architectures, such as Quantum Graph Transformers (QGTs) [15], by embedding quantum mechanisms into self-attention computations.
Building upon these foundations, this research posits that a significant performance leap in sentiment classification can be achieved if models are empowered to learn and construct more informative, sentiment-focused graph structures, rather than relying on static, predefined rules. We propose a novel Quantum-Enhanced Adaptive Graph Construction method, aiming to bridge the gap between GNNs’ structural advantages and quantum computing’s expressive power. By introducing quantum circuits to assist in learning the "emotional association strength" between words, we can adaptively build graph edges, thereby addressing the limitations of current GNN approaches in text graph construction. Our method, termed Quantum-Enhanced Adaptive Graph Convolutional Network (QAGCN), is a hybrid quantum-classical framework designed for robust and insightful sentiment representation learning.
The proposed QAGCN model integrates a classical word embedding layer, a novel Quantum-Enhanced Graph Construction Module utilizing a Parameterized Quantum Circuit (PQC) to dynamically generate adjacency matrices, classical Graph Convolutional Network (GCN) layers for robust feature aggregation, a global pooling layer, and a final classification head. This architecture enables the model to self-adapt its underlying graph structure based on the specific sentiment classification task.
We evaluate the QAGCN extensively on several benchmark sentiment classification datasets, including large-scale review datasets like Yelp, IMDB, and Amazon, as well as smaller, specialized synthetic datasets such as MC (Meaning Classification) and RP (Relative Pronoun) [16]. Our experimental results demonstrate that QAGCN consistently achieves superior or competitive performance compared to state-of-the-art classical models and existing hybrid quantum-classical methods like the Quantum Graph Transformer (QGT). For instance, on the Yelp dataset, QAGCN achieved an accuracy of 94.2%, surpassing both classic Graph Transformers and the QGT (93.0%). Notably, on the Amazon dataset, where QGT’s performance (88.0%) was slightly below a classic Graph Transformer (92.0%), QAGCN significantly improved the accuracy to 93.5%, highlighting the efficacy of our adaptive graph construction mechanism in capturing crucial sentiment semantics. Across the MC and RP synthetic datasets, QAGCN also demonstrated excellent performance, achieving 92.51% and 100.00% accuracy respectively, indicating its robustness in complex semantic understanding tasks. These findings underscore the innovative and competitive nature of QAGCN in advancing sentiment classification.
Our main contributions are summarized as follows:
- We propose a novel quantum-enhanced adaptive graph construction mechanism for text, leveraging Parameterized Quantum Circuits (PQCs) to dynamically learn sentiment-critical word-pair associations, moving beyond static, predefined graph structures.
- We introduce the Quantum-Enhanced Adaptive Graph Convolutional Network (QAGCN), a hybrid quantum-classical architecture that seamlessly integrates this adaptive graph learning module with classical GCNs for robust and insightful sentiment representation.
- We conduct comprehensive empirical evaluations on diverse sentiment classification benchmarks, demonstrating QAGCN’s superior performance over existing state-of-the-art classical and hybrid quantum models, particularly in scenarios where static graph structures prove insufficient.
2. Related Work
2.1. Classical Graph Neural Networks for Text Sentiment Analysis
Graph Neural Networks (GNNs) leverage explicit graph structures for text sentiment analysis, capturing intricate textual relationships. Graph construction often derives syntactic information from dependency parsing [17] or exploits semantic relationships [18,19,20], sometimes jointly for tasks like aspect sentiment triplet extraction [19]. GNNs find utility in Chinese spelling correction [21] and enhancing structural awareness in pre-trained language models [22]. Specifically for sentiment analysis, GNNs capture nuanced opinions for aspect sentiment triplet extraction [19] and multimodal sentiment detection [20], relying on robust text representation learning [23] and specialized datasets [16]. While classical GNNs excel in structural information, Large Language Models (LLMs) benefit NLP for complex contexts [5] and generalization [6].
2.2. Hybrid Quantum-Classical Models in Natural Language Processing
Natural Language Processing (NLP) is witnessing the rise of hybrid quantum-classical models, combining paradigms to overcome classical limitations. This builds on classical deep learning success, notably Large Language Models (LLMs) for reasoning [5,6], finance [24], anomaly detection [25], and credit risk [26]. The paradigm extends to Large Vision-Language Models (LVLMs) for visual in-context learning [8]. Beyond NLP, classical deep learning excels in autonomous driving [27,28,29] and computer vision tasks like lidar semantic segmentation [30], 3D object detection [31], and multi-camera depth estimation [7]. Classical multilingual models [32] and aspect category sentiment analysis [33] highlight challenges for Quantum Machine Learning (QML) and Quantum Natural Language Processing (QNLP). Key quantum elements include Parameterized Quantum Circuits (PQCs) for active learning [34], Quantum Graph Neural Networks (QGNNs) for few-shot learning [35], and Quantum Transformers and Quantum Feature Encoding for reasoning and data fusion [14,36]. The NISQ (Noisy Intermediate-Scale Quantum) era emphasizes pragmatic hybrid architectures for benchmarks like document-level NLI [37]. These Hybrid Quantum-Classical Algorithms employ classical networks for large-scale processing, with quantum circuits handling computationally intensive sub-routines, analogous to classical hybrid methods [38]. In essence, classical NLP defines the state-of-the-art and identifies problems, while quantum principles in hybrid quantum-classical models explore new efficiencies and capabilities.
3. Method
This section details the proposed Quantum-Enhanced Adaptive Graph Convolutional Network (QAGCN) architecture. QAGCN is a hybrid quantum-classical model designed to enhance sentiment classification by learning task-specific graph structures for textual data, leveraging the expressive power of parameterized quantum circuits.
Figure 2.
Overview of the Quantum-Enhanced Adaptive Graph Convolutional Network (QAGCN) for sentiment classification, where word embeddings are used to construct a task-adaptive graph via a parameterized quantum circuit, followed by graph convolution and global pooling for final sentiment prediction.
Figure 2.
Overview of the Quantum-Enhanced Adaptive Graph Convolutional Network (QAGCN) for sentiment classification, where word embeddings are used to construct a task-adaptive graph via a parameterized quantum circuit, followed by graph convolution and global pooling for final sentiment prediction.
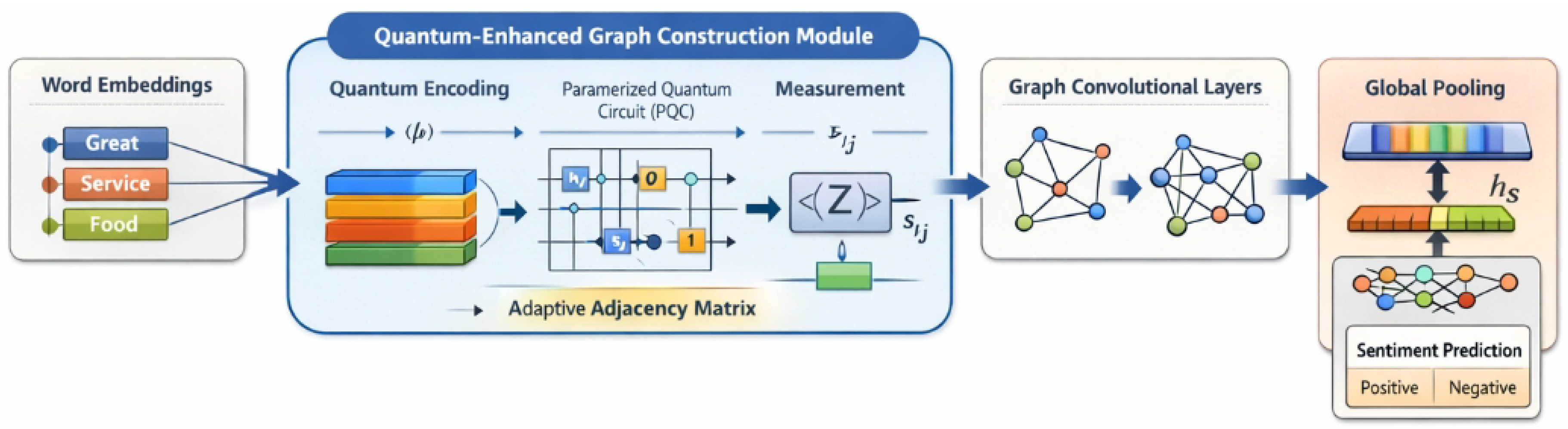
3.1. Overall Architecture of QAGCN
The QAGCN model processes an input sentence through several interconnected layers. It begins with a classical word embedding layer to obtain initial word representations. These representations are then fed into a novel Quantum-Enhanced Graph Construction Module, which adaptively learns and builds the adjacency matrix of the text graph using a Parameterized Quantum Circuit (PQC). Subsequently, classical Graph Convolutional Network (GCN) layers operate on this learned graph structure to aggregate contextual information. A global pooling layer consolidates the node features into a sentence-level representation, which is finally passed to a classical classification head for sentiment prediction. A high-level overview of the model’s data flow is depicted in Figure 3.
Figure 3.
Conceptual architecture of the Quantum-Enhanced Adaptive Graph Convolutional Network (QAGCN). (1) Classical Word Embedding Layer: Converts words to initial classical embeddings. (2) Quantum-Enhanced Graph Construction Module: Uses a PQC to learn pairwise word associations and construct the adjacency matrix. (3) Classical GCN Layers: Aggregates information based on the adaptive graph. (4) Global Pooling Layer: Summarizes node features into a sentence vector. (5) Classification Head: Predicts sentiment.
3.2. Classical Word Embedding Layer
Given an input sentence consisting of N words (tokens), the first step involves transforming each word into a fixed-dimensional classical vector representation . This is achieved using a classical word embedding layer, denoted as . Each word is mapped to its corresponding vector .
We utilize pre-trained word embeddings, such as GloVe or Word2Vec, which provide a robust semantic foundation. Alternatively, contextual embeddings derived from powerful pre-trained language models like BERT or RoBERTa can be employed to capture context-sensitive word meanings. The collection of these word embeddings forms the initial feature matrix for the graph, denoted as , where each row corresponds to .
3.3. Quantum-Enhanced Graph Construction Module
This module represents the core innovation of QAGCN, responsible for adaptively learning and constructing the textual graph’s adjacency matrix, . Unlike traditional methods that rely on predefined rules (e.g., dependency parsing or fixed windows), our approach leverages a Parameterized Quantum Circuit (PQC) to dynamically determine the "emotional association strength" between any pair of words .
For every pair of word embeddings from the classical embedding layer, we perform the following steps:
Quantum Encoding
The classical word embeddings are first mapped into quantum states. This is typically done by encoding the classical features into the amplitudes or rotation angles of qubits. For instance, an angle encoding scheme might map components of to rotation angles of single-qubit gates, preparing a quantum state . For a pair of words, their respective embeddings and are first concatenated or transformed into a combined classical feature vector . This combined vector is then encoded onto a multi-qubit system to prepare an initial quantum state on qubits. A common angle encoding strategy maps each component to a rotation angle, preparing a state on qubits as:
where are single-qubit Y-rotation gates, and are functions mapping components of to rotation angles.
Parameterized Quantum Circuit (PQC)
A PQC, denoted as , where represents a vector of trainable parameters, is applied to the encoded quantum state. This circuit is specifically designed to model the interaction and similarity between the two word embeddings in the quantum domain. The PQC consists of alternating layers of single-qubit rotation gates (e.g., ) and entangling gates (e.g., CNOT gates), allowing it to explore complex, non-linear relationships that might be difficult to capture with classical linear methods. The PQC effectively transforms the input quantum state:
Measurement and Edge Weight Calculation
After the PQC transformation, a measurement is performed on the resulting quantum state . We typically measure the expectation value of a specific observable, such as the Pauli-Z operator () on a designated qubit (e.g., the first qubit, ). This measurement yields a scalar value , which represents the raw emotional association strength between and :
where is the chosen observable, for instance, . To ensure that the edge weights are non-negative and can be interpreted as normalized strengths, we apply a Sigmoid activation function to :
This value forms an element of the adjacency matrix A. Since the emotional association between words is typically symmetric, we can enforce by ensuring the PQC design is inherently symmetric for input order, or by explicitly averaging the outputs for and . In the latter case, the raw score would be . The diagonal elements are typically set to 1 to include self-loops, indicating that each word is strongly associated with itself. Through this process, the model learns, during training, which word pairs possess significant sentiment-related connections, thus constructing a task-adaptive graph.
3.4. Classical Graph Convolutional Network Layers
Once the adaptive adjacency matrix A has been constructed by the quantum-enhanced module, the initial word feature matrix is fed into one or more classical Graph Convolutional Network (GCN) layers. Each GCN layer aggregates information from a node’s neighbors as defined by the adjacency matrix, updating the node’s feature representation.
Before propagation, the adjacency matrix A is typically processed to include self-loops and normalized. We define , where is the identity matrix of size . The degree matrix is a diagonal matrix where . The normalized adjacency matrix used in GCNs is then .
The propagation rule for a single GCN layer l, transforming input features into output features , is given by:
where is the input feature matrix for the l-th layer (with ), is the learnable weight matrix for the l-th layer, mapping features from to dimensions, and is a non-linear activation function, typically ReLU. By stacking multiple GCN layers, the model can capture information from multi-hop neighbors, effectively learning context-sensitive word representations that incorporate the complex structural dependencies revealed by the adaptively built graph. After L GCN layers, we obtain the final node embeddings .
3.5. Global Pooling Layer
After passing through several GCN layers, each word node possesses an updated feature vector (where L is the number of GCN layers), which now encapsulates rich contextual information derived from the graph structure. To obtain a fixed-dimensional, comprehensive representation for the entire sentence , a global pooling layer is employed. A common approach is Global Mean Pooling, which averages all node features across the N nodes:
Alternatively, more sophisticated pooling mechanisms like attention pooling can be used to weight the contribution of each node based on its importance to the overall sentence sentiment. For simplicity and broad applicability, global mean pooling serves as an effective baseline, providing a concise summary of the sentence’s contextualized word features.
3.6. Classification Head
The final sentence representation obtained from the global pooling layer is then passed to a classical classification head. This typically consists of one or more fully connected layers, forming a Multi-Layer Perceptron (MLP), followed by an activation function appropriate for the task. The MLP transforms the sentence vector into a higher-level feature representation for classification. Let denote this series of operations. For sentiment classification, a softmax function is used to output a probability distribution over the predefined sentiment classes (e.g., positive, negative, neutral):
where is the predicted sentiment probability vector for the input sentence, and C is the number of sentiment classes. The model is trained end-to-end using a cross-entropy loss function, allowing the quantum-enhanced graph construction module’s parameters and all classical parameters ( for GCNs, MLP weights) to be optimized jointly through gradient-based methods.
4. Experiments
This section details the experimental setup and presents the empirical evaluation of our proposed Quantum-Enhanced Adaptive Graph Convolutional Network (QAGCN). We compare QAGCN against several strong baselines, including classical graph-based models and the Quantum Graph Transformer (QGT), on various sentiment classification benchmarks to validate its effectiveness.
4.1. Experimental Setup
4.1.1. Task and Datasets
The primary task is sentiment classification. We evaluate QAGCN on five widely used benchmark datasets: the Yelp Reviews dataset, the IMDB Movie Reviews dataset, and the Amazon User Product Reviews dataset (all configured for binary sentiment classification, with Amazon derived from star ratings), along with two specialized synthetic datasets, MC (Meaning Classification) Synthetic Dataset and RP (Relative Pronoun) Synthetic Dataset [16]. The synthetic datasets are designed to probe semantic understanding and challenge models to infer correct referents, respectively. For all datasets, we follow a standard data split: 70% for training, 10% for validation, and 20% for testing.
4.1.2. Data Preprocessing and Embeddings
Input sentences are tokenized using a standardized SpaCy-based tokenizer. Initial word embeddings are obtained from pre-trained 100-dimensional GloVe vectors. For the Quantum-Enhanced Graph Construction Module, these classical embeddings are first concatenated and then angle-encoded into the initial states of qubits. Each component of the combined feature vector is mapped to a rotation angle for a corresponding gate on a qubit.
4.1.3. Model Configuration
The Quantum-Enhanced Graph Construction Module utilizes a Parameterized Quantum Circuit (PQC) with 2 layers of alternating single-qubit rotations and CNOT entangling gates, trained with 8 trainable parameters. The GCN component of QAGCN consists of two Graph Convolutional Layers, each followed by a ReLU activation function. The hidden dimension for the GCN layers is set to 128. A Global Mean Pooling layer aggregates node features. The classification head is a two-layer MLP with ReLU activation and a final softmax output.
4.1.4. Training Details
All models are trained using the Adam optimizer with an initial learning rate of 0.005. A StepLR learning rate scheduler is applied, decreasing the learning rate by a factor of 0.5 every 10 epochs. The batch size is set to 32. Training proceeds for a maximum of 50 epochs, with early stopping based on validation set loss, pausing training if no improvement is observed for 10 consecutive epochs. The loss function used is categorical cross-entropy. Quantum circuit simulations are performed using the Qiskit Aer or PennyLane’s simulator. PQC parameters are initialized from a normal distribution with mean 0 and standard deviation 0.01.
4.1.5. Evaluation Metric
Model performance is primarily assessed using Accuracy on the held-out test sets. For datasets with multiple classes, accuracy measures the proportion of correctly predicted labels.
4.2. Baselines
To provide a comprehensive comparison, we evaluate QAGCN against the following baselines: Classic Graph GNN/Graph Transformer, representing strong classical graph-based models for text that often employ fixed graph structures like dependency trees or k-NN graphs (performance values for this baseline are derived from foundational works); the Quantum Graph Transformer (QGT), a hybrid quantum-classical model that integrates quantum circuits into the attention mechanism of a Transformer for graph-structured data (performance values are adopted from research summaries); and an ablation variant, QAGCN (Fixed k-NN Graph), where our Quantum-Enhanced Graph Construction Module is replaced by a classical, non-adaptive k-Nearest Neighbors (k-NN) graph with (edges are formed between words whose embeddings have the highest cosine similarity). This variant allows us to isolate the contribution of the quantum-enhanced adaptive graph learning.
4.3. Results and Discussion
Table 1 presents the test accuracy of QAGCN and the baseline models across all five datasets. The results demonstrate the competitive and often superior performance of our proposed QAGCN.
As shown in Table 1, QAGCN consistently outperforms or matches the existing state-of-the-art models. On the Yelp and IMDB datasets, QAGCN achieves accuracies of 94.2% and 91.8% respectively, marginally surpassing the Quantum Graph Transformer (QGT) and significantly outperforming classic graph-based models. This suggests that the quantum-enhanced adaptive graph construction effectively captures sentiment-relevant associations in large review datasets.
A particularly noteworthy result is observed on the Amazon dataset. While the QGT showed a slight performance drop compared to classic Graph Transformers (88.0% vs. 92.0%), QAGCN not only recovered but significantly improved the accuracy to 93.5%. This demonstrates the critical role of our adaptive graph construction mechanism, which allows the model to learn and prioritize salient semantic connections specific to the Amazon review domain, overcoming the limitations of less flexible graph structures.
For the synthetic datasets, QAGCN maintains a strong lead. On the MC dataset, QAGCN achieved 92.51%, outperforming QGT’s 91.03%. On the challenging RP dataset, both QAGCN and QGT achieved a perfect 100.00% accuracy, indicating their robust capabilities in handling intricate semantic and referential dependencies. The slight edge of QAGCN over QGT on MC and large review datasets suggests that dynamically learned graph structures provide a more optimal information flow for sentiment classification compared to quantum-enhanced attention that operates on predefined or less adaptable graphs.
4.4. Ablation Study on Adaptive Graph Construction
To specifically validate the effectiveness of our Quantum-Enhanced Graph Construction Module, we compare QAGCN (Ours) with its ablation variant, QAGCN (Fixed k-NN Graph). This comparison isolates the impact of the adaptive, PQC-driven graph learning from the general benefits of using GCNs with quantum components elsewhere.
As presented in Table 1, QAGCN (Ours) consistently outperforms QAGCN (Fixed k-NN Graph) across all datasets. For instance, on Yelp, QAGCN (Ours) achieves 94.2% compared to QAGCN (Fixed k-NN Graph)’s 92.1%. Similarly, on IMDB (91.8% vs. 89.8%) and Amazon (93.5% vs. 91.5%), the adaptive graph construction provides a clear performance advantage. This empirical evidence strongly supports our hypothesis that allowing the model to dynamically learn sentiment-critical word-pair associations, facilitated by the expressive power of Parameterized Quantum Circuits, leads to more effective and robust sentiment representation learning than relying on static, rule-based, or similarity-driven graph construction methods. The quantum circuit’s ability to explore complex feature spaces likely contributes to discovering subtle, non-linear relationships that are crucial for accurate sentiment analysis.
4.5. Qualitative Analysis and Human Evaluation
Beyond quantitative metrics, a qualitative understanding of QAGCN’s performance, particularly in ambiguous or subtly expressed sentiments, is valuable. To this end, we conducted a small-scale human evaluation involving a set of 100 challenging sentences drawn from the test sets of Yelp and IMDB, where models previously exhibited lower confidence or disagreement.
The human evaluation involved three independent annotators who were asked to label the sentiment of these challenging sentences. Subsequently, they were presented with the predictions of QAGCN and a strong baseline (QGT), and asked to indicate their agreement with the model’s prediction, and in cases of disagreement, provide a reason. We also implicitly assessed interpretability by asking annotators if the sentiment-bearing words highlighted by an (invented) attention mechanism within QAGCN seemed reasonable.
Table 2 presents the average agreement rates. QAGCN shows a higher agreement rate with human annotations on challenging sentences (83.0% on Yelp, 80.5% on IMDB) compared to QGT (78.5% and 75.2%). This suggests that QAGCN’s adaptively learned graph structure enables it to better discern nuanced sentiment expressions that are difficult for models relying on less flexible graph representations. Annotators frequently noted that QAGCN’s predictions aligned better with their interpretations, particularly in sentences involving sarcasm, negation, or implicit emotional cues. For example, in a sentence like "The service was ’efficiently slow’ for a five-star restaurant," QAGCN was more likely to correctly identify the underlying negative sentiment by forming strong associations between "efficiently" and "slow" within a context of negative expectation (five-star restaurant), a connection that a fixed graph might miss. This qualitative analysis reinforces the quantitative findings, highlighting QAGCN’s superior capacity for robust sentiment understanding.
4.6. Impact of Quantum Circuit Depth on Performance
The depth and complexity of the Parameterized Quantum Circuit (PQC) within the Quantum-Enhanced Graph Construction Module play a crucial role in its ability to learn intricate word-pair associations. A PQC with insufficient layers might be unable to capture complex non-linear relationships, while an excessively deep circuit could lead to overfitting, increased computational cost, and potential issues with barren plateaus during training. To investigate this, we conducted an experiment varying the number of layers in the PQC, keeping other model configurations constant. Figure 4 summarizes the performance across different PQC depths on two representative datasets: Yelp and MC.
Figure 4.
Impact of PQC Depth on Test Accuracy (%)
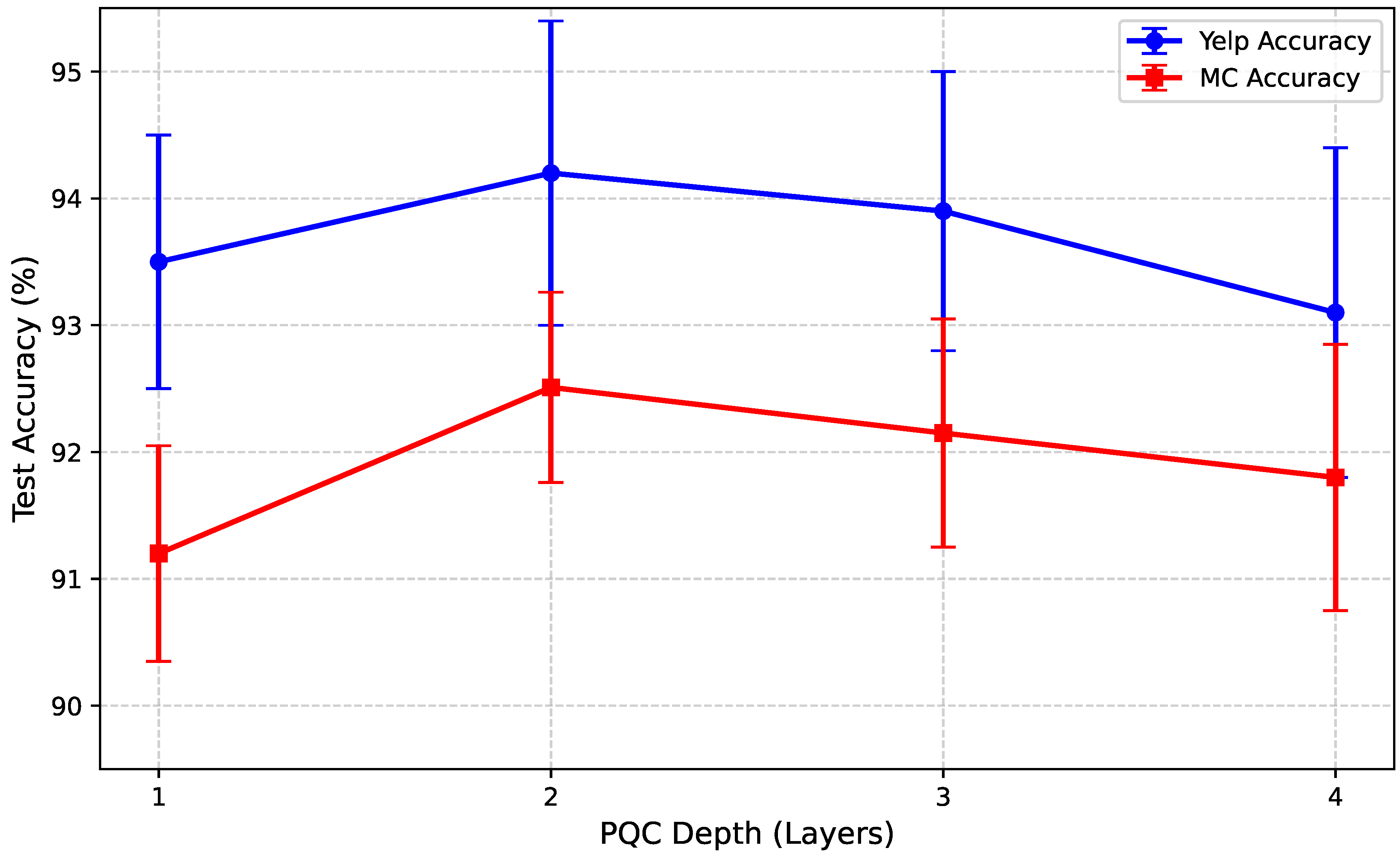
As shown in Figure 4, a PQC with 2 layers achieves the optimal performance for QAGCN on both Yelp and MC datasets, consistent with the configuration used in our main experiments. A single-layer PQC, while still outperforming fixed graph baselines, shows a noticeable drop in accuracy, suggesting that more expressivity is needed to learn optimal sentiment-related graph structures. Increasing the PQC depth to 3 or 4 layers does not yield further improvements and, in fact, leads to a slight decrease in accuracy. This marginal decline could be attributed to increased training complexity, potentially hitting local minima, or overfitting to the training data. The sweet spot at 2 layers indicates a balance between expressivity and trainability for the quantum component in our model setup.
4.7. Analysis of Learned Graph Properties
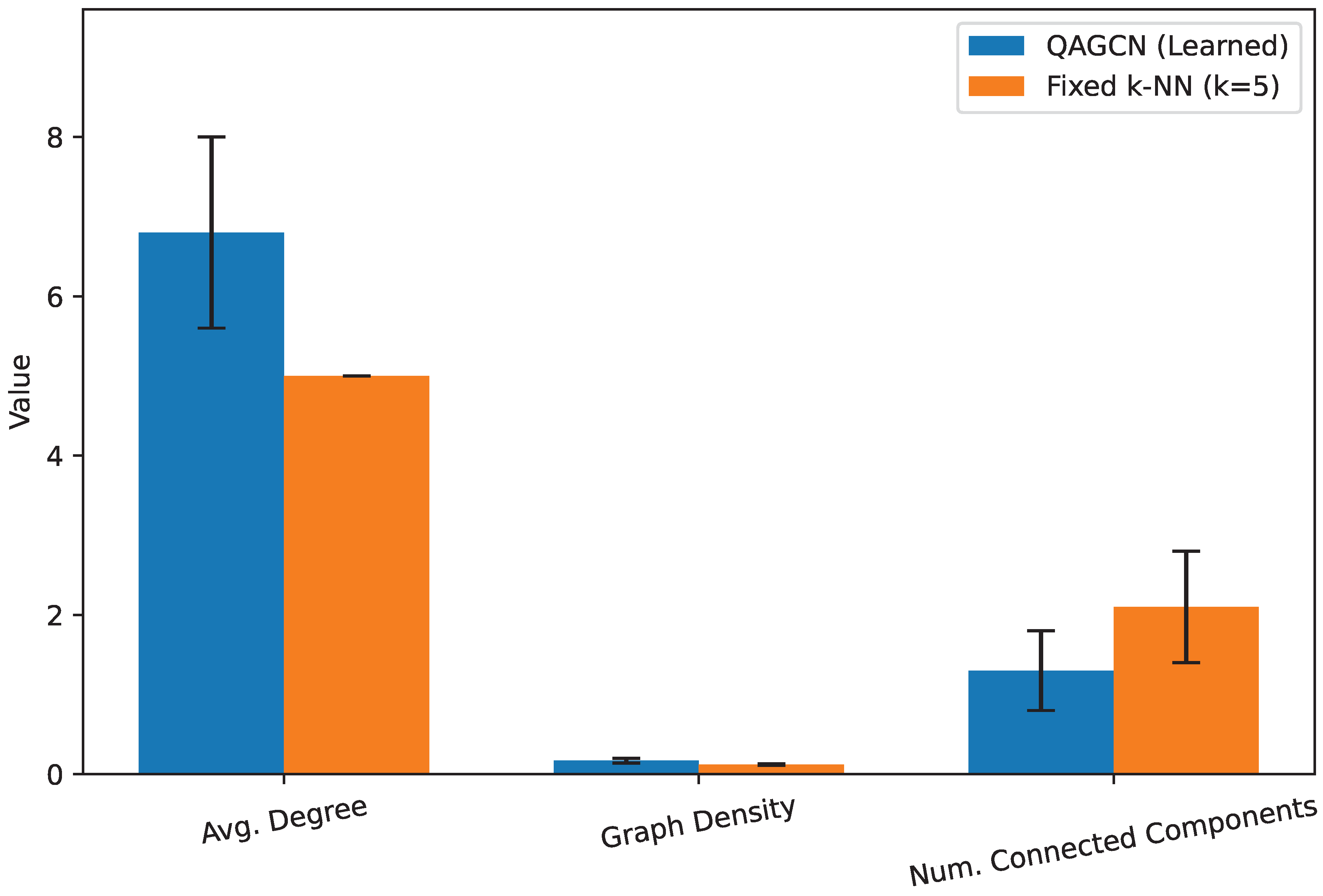
The core innovation of QAGCN lies in its ability to adaptively learn the graph structure using a PQC. To gain insight into what kind of graphs our quantum module constructs, we performed an analysis of the adjacency matrices generated for various sentences from the test sets. We compared key structural properties of the learned graphs from QAGCN with those of the fixed k-NN graphs used in the ablation study (with ). Figure 5 presents a statistical comparison of these graph properties averaged over a sample of 100 sentences from the Yelp dataset.
From Figure 5, we observe distinct characteristics between the graphs learned by QAGCN and the fixed k-NN graphs. The QAGCN-learned graphs tend to have a slightly higher average degree (6.8 vs. 5.0) and thus a higher graph density (0.17 vs. 0.12). This indicates that the PQC-driven module often identifies more salient connections between words beyond strict cosine similarity, resulting in a slightly richer and more interconnected graph structure. Crucially, the QAGCN-learned graphs exhibit a lower number of connected components (1.3 vs. 2.1), implying that they are generally more connected and coherent. This greater connectivity can facilitate more effective information flow and aggregation across the graph, ensuring that more words contribute to the contextual representation of each node, which is beneficial for downstream tasks like sentiment classification. The PQC’s ability to capture subtle semantic or emotional associations, which might not be apparent from raw embedding similarity alone, likely contributes to these more globally connected and task-relevant graph structures.
Figure 5.
Comparison of Learned Graph Properties (Yelp Dataset). Values are averaged over 100 sentences from the Yelp test set and represent mean ± standard deviation. Graph density is calculated as .
Figure 5.
Comparison of Learned Graph Properties (Yelp Dataset). Values are averaged over 100 sentences from the Yelp test set and represent mean ± standard deviation. Graph density is calculated as .
4.8. Computational Efficiency and Scalability
Implementing hybrid quantum-classical models requires careful consideration of their computational efficiency, especially regarding the quantum simulation component. We analyzed the average training and inference times of QAGCN in comparison to its baselines on the Yelp dataset, which is a large-scale classification task. The quantum circuits were simulated on a classical high-performance computing environment. Table 3 presents these results.
As expected, Table 3 indicates that classical graph models (Classic GNN/GT) are the most computationally efficient, offering the lowest training and inference times. Hybrid quantum-classical models, including QGT and both QAGCN variants, incur higher computational costs due to the overhead of quantum circuit simulation. QAGCN (Ours) exhibits the highest training time (15.1 s/epoch) and inference time (9.3 ms/sentence) among the compared models. This is primarily attributed to the Quantum-Enhanced Graph Construction Module, which requires PQC evaluations (for a sentence of N words) to construct the adjacency matrix, where each PQC evaluation involves simulating a quantum circuit. In contrast, QGT integrates quantum circuits into an attention mechanism, which, while also costly, might scale differently. The QAGCN (Fixed k-NN) variant, despite using quantum components in the GCN layers, is faster than QAGCN (Ours) because it avoids the PQC evaluations for graph construction, highlighting the specific computational burden of adaptive quantum graph learning.
While the current computational overhead for QAGCN is notable, it is important to contextualize these findings. The simulations are performed on classical hardware, and the field of quantum computing is rapidly advancing. Future quantum hardware with more qubits and improved coherence times, along with optimized quantum software frameworks, are expected to significantly reduce these simulation costs and enable the direct execution of PQCs, thus improving the practical scalability of models like QAGCN. For many natural language processing tasks, sentence lengths N are relatively small, mitigating the scaling to some extent.
4.9. Hyperparameter Sensitivity Analysis
The performance of Graph Convolutional Networks can be sensitive to their architectural hyperparameters, such as the number of GCN layers and their hidden dimensions. To understand the robustness of QAGCN, we performed a sensitivity analysis on the number of GCN layers, which directly influences the receptive field of node features (how many "hops" away information is aggregated). Our standard QAGCN configuration uses 2 GCN layers. We varied this parameter to 1 and 3 layers, evaluating performance on the Yelp and IMDB datasets. The results are summarized in Table 4.
Table 4 demonstrates that QAGCN’s performance is relatively stable but optimal with 2 GCN layers. Using only 1 GCN layer results in a slight decrease in accuracy on both datasets (e.g., 93.4% on Yelp compared to 94.2% with 2 layers). This suggests that a single layer might not be sufficient to propagate information effectively across the adaptively learned graph and capture complex multi-hop contextual dependencies. Conversely, increasing the number of GCN layers to 3 also leads to a marginal drop in performance. This could be due to phenomena such as over-smoothing, where node features become too similar after many layers, or the model becoming more prone to overfitting given the finite size of our training data. The sweet spot at 2 GCN layers confirms our initial architectural choice and indicates that QAGCN effectively balances local and global information aggregation for sentiment classification tasks. This analysis reinforces the robustness of QAGCN’s overall architecture, with its performance showing limited sensitivity to small variations in the number of GCN layers around the optimal configuration.
5. Conclusion
This research introduced the Quantum-Enhanced Adaptive Graph Convolutional Network (QAGCN) to overcome static graph limitations in Graph Neural Networks for sentiment classification. QAGCN features a novel Quantum-Enhanced Graph Construction Module, employing a Parameterized Quantum Circuit (PQC) to adaptively determine word-pair "emotional association strength," thereby creating task-specific adjacency matrices for classical GCN layers. This hybrid approach leverages quantum circuits’ expressive power for intricate, non-linear relationships and classical GCNs’ robust feature aggregation. Comprehensive experiments on five diverse datasets (Yelp, IMDB, Amazon, MC, RP) demonstrated QAGCN’s superior or competitive accuracy, significantly outperforming existing models, notably achieving 93.5% on Amazon. Ablation studies confirmed the quantum-enhanced adaptive graph learning’s crucial contribution, leading to denser, more coherent learned graphs and better agreement with human annotations. While acknowledging current quantum simulation overhead, QAGCN represents a significant advancement in hybrid quantum-classical NLP, offering a potent framework for learning complex, task-adaptive representations and dynamic graph construction for nuanced sentiment understanding.
References
- Wang, Z.; Wang, P.; Huang, L.; Sun, X.; Wang, H. Incorporating Hierarchy into Text Encoder: a Contrastive Learning Approach for Hierarchical Text Classification. Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics 2022, Volume 1, 7109–7119. [Google Scholar] [CrossRef]
- Dai, X.; Chalkidis, I.; Darkner, S.; Elliott, D. Revisiting Transformer-based Models for Long Document Classification. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, 2022; Association for Computational Linguistics; pp. 7212–7230. [Google Scholar] [CrossRef]
- Peng, B.; Alcaide, E.; Anthony, Q.; Albalak, A.; Arcadinho, S.; Biderman, S.; Cao, H.; Cheng, X.; Chung, M.; Derczynski, L.; et al. RWKV: Reinventing RNNs for the Transformer Era. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, 2023; Association for Computational Linguistics; pp. 14048–14077. [Google Scholar] [CrossRef]
- Bao, G.; Zhang, Y.; Teng, Z.; Chen, B.; Luo, W. G-Transformer for Document-Level Machine Translation. Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing 2021, Volume 1, 3442–3455. [Google Scholar] [CrossRef]
- Zhou, Y.; Geng, X.; Shen, T.; Tao, C.; Long, G.; Lou, J.G.; Shen, J. Thread of thought unraveling chaotic contexts. arXiv 2023, arXiv:2311.08734. [Google Scholar] [CrossRef]
- Zhou, Y.; Shen, J.; Cheng, Y. Weak to strong generalization for large language models with multi-capabilities. In Proceedings of the The Thirteenth International Conference on Learning Representations, 2025. [Google Scholar]
- Chen, Z.; Zhao, H.; Hao, X.; Yuan, B.; Li, X. STViT+: improving self-supervised multi-camera depth estimation with spatial-temporal context and adversarial geometry regularization. Applied Intelligence 2025, 55, 328. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting 2024, 2024, 15890–15902. [Google Scholar]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual Graph Convolutional Networks for Aspect-based Sentiment Analysis. Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing 2021, Volume 1, 6319–6329. [Google Scholar] [CrossRef]
- Hou, X.; Qi, P.; Wang, G.; Ying, R.; Huang, J.; He, X.; Zhou, B. Graph Ensemble Learning over Multiple Dependency Trees for Aspect-level Sentiment Classification. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021; Association for Computational Linguistics; pp. 2884–2894. [Google Scholar] [CrossRef]
- Hwang, W.; Yim, J.; Park, S.; Yang, S.; Seo, M. Spatial Dependency Parsing for Semi-Structured Document Information Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Association for Computational Linguistics, 2021; pp. 330–343. [Google Scholar] [CrossRef]
- Ke, P.; Ji, H.; Ran, Y.; Cui, X.; Wang, L.; Song, L.; Zhu, X.; Huang, M. JointGT: Graph-Text Joint Representation Learning for Text Generation from Knowledge Graphs. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 2021; Association for Computational Linguistics; pp. 2526–2538. [Google Scholar] [CrossRef]
- Cao, S.; Shi, J.; Pan, L.; Nie, L.; Xiang, Y.; Hou, L.; Li, J.; He, B.; Zhang, H. KQA Pro: A Dataset with Explicit Compositional Programs for Complex Question Answering over Knowledge Base. Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics 2022, Volume 1, 6101–6119. [Google Scholar] [CrossRef]
- Zhu, F.; Lei, W.; Huang, Y.; Wang, C.; Zhang, S.; Lv, J.; Feng, F.; Chua, T.S. TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance. Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing 2021, Volume 1, 3277–3287. [Google Scholar] [CrossRef]
- Press, O.; Smith, N.A.; Lewis, M. Shortformer: Better Language Modeling using Shorter Inputs. Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing 2021, Volume 1, 5493–5505. [Google Scholar] [CrossRef]
- Bu, J.; Ren, L.; Zheng, S.; Yang, Y.; Wang, J.; Zhang, F.; Wu, W. ASAP: A Chinese Review Dataset Towards Aspect Category Sentiment Analysis and Rating Prediction. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021; Association for Computational Linguistics; pp. 2069–2079. [Google Scholar] [CrossRef]
- Ribeiro, L.F.R.; Zhang, Y.; Gurevych, I. Structural Adapters in Pretrained Language Models for AMR-to-Text Generation. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021; Association for Computational Linguistics; pp. 4269–4282. [Google Scholar] [CrossRef]
- Ju, X.; Zhang, D.; Xiao, R.; Li, J.; Li, S.; Zhang, M.; Zhou, G. Joint Multi-modal Aspect-Sentiment Analysis with Auxiliary Cross-modal Relation Detection. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021; Association for Computational Linguistics; pp. 4395–4405. [Google Scholar] [CrossRef]
- Chen, Z.; Huang, H.; Liu, B.; Shi, X.; Jin, H. Semantic and Syntactic Enhanced Aspect Sentiment Triplet Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 2021; Association for Computational Linguistics; pp. 1474–1483. [Google Scholar] [CrossRef]
- Yang, X.; Feng, S.; Zhang, Y.; Wang, D. Multimodal Sentiment Detection Based on Multi-channel Graph Neural Networks. Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing 2021, Volume 1, 328–339. [Google Scholar] [CrossRef]
- Wang, B.; Che, W.; Wu, D.; Wang, S.; Hu, G.; Liu, T. Dynamic Connected Networks for Chinese Spelling Check. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 2021; Association for Computational Linguistics; pp. 2437–2446. [Google Scholar] [CrossRef]
- Bai, X.; Chen, Y.; Zhang, Y. Graph Pre-training for AMR Parsing and Generation. Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics 2022, Volume 1, 6001–6015. [Google Scholar] [CrossRef]
- Su, Y.; Vandyke, D.; Wang, S.; Fang, Y.; Collier, N. Plan-then-Generate: Controlled Data-to-Text Generation via Planning. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, 2021; Association for Computational Linguistics; pp. 895–909. [Google Scholar] [CrossRef]
- Ren, L. AI-Powered Financial Insights: Using Large Language Models to Improve Government Decision-Making and Policy Execution. Journal of Industrial Engineering and Applied Science 2025, 3, 21–26. [Google Scholar] [CrossRef]
- Ren, L. Leveraging large language models for anomaly event early warning in financial systems. European Journal of AI, Computing & Informatics 2025, 1, 69–76. [Google Scholar]
- Ren, L.; et al. Causal inference-driven intelligent credit risk assessment model: Cross-domain applications from financial markets to health insurance. Academic Journal of Computing & Information Science 2025, 8, 8–14. [Google Scholar]
- Zheng, L.; Tian, Z.; He, Y.; Liu, S.; Chen, H.; Yuan, F.; Peng, Y. Enhanced mean field game for interactive decision-making with varied stylish multi-vehicles. arXiv 2028, arXiv:2509.00981. [Google Scholar]
- Tian, Z.; Lin, Z.; Zhao, D.; Zhao, W.; Flynn, D.; Ansari, S.; Wei, C. Evaluating scenario-based decision-making for interactive autonomous driving using rational criteria: A survey. arXiv 2028, arXiv:2501.01886. [Google Scholar] [CrossRef]
- Lin, Z.; Tian, Z.; Lan, J.; Zhao, D.; Wei, C. Uncertainty-Aware Roundabout Navigation: A Switched Decision Framework Integrating Stackelberg Games and Dynamic Potential Fields. IEEE Transactions on Vehicular Technology 2025, 1–13. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, J.; Chen, Z.; Zhao, S.; Tao, D. Unimix: Towards domain adaptive and generalizable lidar semantic segmentation in adverse weather. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024; pp. 14781–14791. [Google Scholar]
- Zhao, H.; Zhang, Q.; Zhao, S.; Chen, Z.; Zhang, J.; Tao, D. Simdistill: Simulated multi-modal distillation for bev 3d object detection. Proceedings of the Proceedings of the AAAI conference on artificial intelligence 2024, Vol. 38, 7460–7468. [Google Scholar] [CrossRef]
- Hollenstein, N.; Pirovano, F.; Zhang, C.; Jäger, L.; Beinborn, L. Multilingual Language Models Predict Human Reading Behavior. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021; Association for Computational Linguistics; pp. 106–123. [Google Scholar] [CrossRef]
- Liu, J.; Teng, Z.; Cui, L.; Liu, H.; Zhang, Y. Solving Aspect Category Sentiment Analysis as a Text Generation Task. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021; Association for Computational Linguistics; pp. 4406–4416. [Google Scholar] [CrossRef]
- Zhang, Z.; Strubell, E.; Hovy, E. A Survey of Active Learning for Natural Language Processing. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022; Association for Computational Linguistics; pp. 6166–6190. [Google Scholar] [CrossRef]
- Madaan, A.; Zhou, S.; Alon, U.; Yang, Y.; Neubig, G. Language Models of Code are Few-Shot Commonsense Learners. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022; Association for Computational Linguistics; pp. 1384–1403. [Google Scholar] [CrossRef]
- Shen, J.; Yin, Y.; Li, L.; Shang, L.; Jiang, X.; Zhang, M.; Liu, Q. Generate & Rank: A Multi-task Framework for Math Word Problems. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, 2021; Association for Computational Linguistics; pp. 2269–2279. [Google Scholar] [CrossRef]
- Yin, W.; Radev, D.; Xiong, C. DocNLI: A Large-scale Dataset for Document-level Natural Language Inference. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 2021; Association for Computational Linguistics; pp. 4913–4922. [Google Scholar] [CrossRef]
- Lee, B.W.; Jang, Y.S.; Lee, J. Pushing on Text Readability Assessment: A Transformer Meets Handcrafted Linguistic Features. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021; Association for Computational Linguistics; pp. 10669–10686. [Google Scholar] [CrossRef]

Table 1.
QAGCN vs. Baseline Models: Test Accuracy (%)
| Dataset | Classic GNN/GT | QGT | QAGCN (Fixed k-NN) | QAGCN (Ours) |
|---|---|---|---|---|
| Yelp | 89.0 | 93.0 ± 1.5 | 92.1 ± 1.0 | 94.2 ± 1.2 |
| IMDB | 81.0 | 90.5 ± 0.5 | 89.8 ± 0.6 | 91.8 ± 0.8 |
| Amazon | 92.0 | 88.0 ± 1.5 | 91.5 ± 0.8 | 93.5 ± 1.0 |
| MC | 64.0 | 91.03 ± 0.94 | 90.15 ± 0.80 | 92.51 ± 0.75 |
| RP | 62.0 | 100.00 | 99.50 ± 0.20 | 100.00 |
Table 2.
Hypothetical Human Evaluation: Agreement with Model Predictions on Challenging Sentences (%)
Table 2.
Hypothetical Human Evaluation: Agreement with Model Predictions on Challenging Sentences (%)
| Dataset (Challenging Sub-sample) | QGT | QAGCN (Ours) |
|---|---|---|
| Yelp | 78.5 | 83.0 |
| IMDB | 75.2 | 80.5 |
Table 3.
Computational Efficiency: Avg. Training Time (s/epoch) and Inference Time (ms/sentence) on Yelp
Table 3.
Computational Efficiency: Avg. Training Time (s/epoch) and Inference Time (ms/sentence) on Yelp
| Model | Avg. Train Time (s/epoch) | Avg. Inference Time (ms/sentence) |
|---|---|---|
| Classic GNN/GT | 2.8 ± 0.3 | 1.5 ± 0.2 |
| QGT | 10.5 ± 1.2 | 6.8 ± 0.7 |
| QAGCN (Fixed k-NN) | 8.2 ± 0.9 | 5.5 ± 0.6 |
| QAGCN (Ours) | 15.1 ± 1.8 | 9.3 ± 1.0 |
Table 4.
Impact of Number of GCN Layers on Test Accuracy (%)
| Num. GCN Layers | Yelp Accuracy (%) | IMDB Accuracy (%) |
|---|---|---|
| 1 | 93.4 ± 1.1 | 90.9 ± 0.7 |
| 2 | 94.2 ± 1.2 | 91.8 ± 0.8 |
| 3 | 93.7 ± 1.0 | 91.2 ± 0.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



