
Submitted:
29 December 2025
Posted:
30 December 2025
You are already at the latest version
Abstract
Video synthetic aperture radar (SAR) enables observation of moving targets by leveraging temporal information across successive frames. In particular, dynamic shadows in video SAR image sequences provide critical cues for detecting moving objects whose energy is smeared or Doppler-shifted. To achieve high-resolution imaging at a high frame rate for effective dynamic scene monitoring, video SAR systems typically operate at extremely high frequencies or even in the terahertz band, rather than the microwave band. However, terahertz video SAR suffers from significant signal attenuation due to atmospheric absorption. We present a deep learning framework for high-frame-rate and high-resolution imaging with microwave video SAR system. In this framework, the problem of microwave video SAR imaging is formulated as an image super-resolution reconstruction task for low-resolution yet high-frame-rate image sequences from microwave video SAR. We develop a simple yet effective image super-resolution reconstruction network that is completely built upon convolutional neural networks. The designed network takes a low-resolution image sequence and the corresponding high-resolution image with blurred shadows as input, and then produces a high-resolution image sequence where shadows are clearly visible. Furthermore, the network is trained in a self-supervised manner and thus does not require desired high-resolution image sequences as ground truth, which is appealing to practical applications. Processing results of real data from two different video SAR systems have shown good performance of the proposed approach with convincing generalization ability.
Keywords:
synthetic aperture radar (SAR)
; video SAR
; radar imaging
; deep learning
; image super-resolution reconstruction
1. Introduction
Video synthetic aperture radar (SAR) not only retains the all-weather and all-day remote sensing capability of traditional SAR but also possesses the dynamic perception capability analogous to that of optical sensors, which has received significant research interests recently [1,2]. By extending the original two-dimensional spatial information into the third temporal dimension, video SAR produces high-frame-rate sequential SAR images, enabling continuous observation of the region of interest [3]. These image sequences visually capture dynamic changes, facilitating both intuitive human interpretation and efficient detection and tracking of moving targets.
In SAR imagery, the energy of a moving target often appears defocusing and positional shift, yet a distinct shadow is usually observable near the actual position of the target [4]. As a result, the dynamic shadows in video SAR image sequences can provide valuable information about a moving target’s position, velocity, and other motion parameters. In addition, the target shadow contrast to clutter is independent of the target’s radar cross section (RCS) [5], meaning that dynamic shadows are helpful for the detection of low-RCS moving targets. Shadow-assisted moving target detection and tracking in video SAR has received considerable attention [6,7,8].
Video SAR systems are expected to possess both high frame-rate and high-resolution imaging capabilities. To meet this requirement, a straightforward way is to increase the radar carrier frequency, and thus many video SAR systems typically operate at extremely high frequencies [9] or even in the terahertz band [10,11]. However, these system results in high cost and a very limited operation range due to atmospheric attenuation of signals, which in many cases is not acceptable. To enable long-range imaging, some video SAR systems operate at relatively low frequencies, such as K band, and adopt some alternative approaches to produce high-frame-rate and high-resolution sequential SAR images. The first approach is to increase the speed of radar platform. As platform speed increases, the synthetic aperture time for the desired azimuth resolution decreases, thereby increasing the frame rate. As a side effect, the azimuth Doppler bandwidth expands, which often results in Doppler ambiguity. Moreover, the platform speed cannot be increased indefinitely in many practical applications. The second approach is to use the overlapped aperture imaging technique to improve frame rate. Although this method generates more sequential SAR images, the synthetic aperture time of each frame image is not reduced. Consequently, during the long synthetic aperture time for high-resolution imaging, no-return areas in the SAR scene may quickly be washed out, which leads to moving target shadows are often blurred even fail to form. In other words, this method offers no substantial improvement in dynamic target detection capability. Most recently, a collaborative imaging framework based on distributed radar systems has been proposed for high-frame-rate imaging in common microwave band, where the spatial degrees of freedom are employed to shorten the synthetic time and thus improve the frame rate. However, this approach significantly increases system complexity and cost. Consequently, it is still a challenge for microwave video SAR to improve resolution and frame rate simultaneously.
We propose a deep learning-based super-resolution reconstruction network for microwave video SAR to overcome the contradiction of high-resolution imaging and high-frame-rate imaging. The contributions can be outlined as follows.
- 1.
- To the best of our knowledge, this is the first work to formulate the problem of achieving high-frame-rate and high-resolution imaging as a deep learning-based image super-resolution reconstruction task, pioneering the high-frame-rate microwave video SAR imaging with low system complexity and low cost.
- 2.
- We propose a mathematical model for video SAR image super-resolution reconstruction, which simplifies the reconstruction task as the nonlinear mapping from a low-resolution image sequence to the desired high-resolution sequence with assistance from a shadow-blurred high-resolution image. Building on this model, we design a simple yet effective image super-resolution network that can be trained in a self-supervised manner. Therefore, unavailable high resolution images with unblurred shadows are not required as ground truth for the training.
- 3.
- Experiments on the real video SAR data recorded by two different video SAR systems show that the proposed approach achieves excellent performance of video SAR image reconstruction and good generalization ability on the unseen data during the training.
The paper is organized as follows. Section 2 briefly introduces the related work. Section 3 details the complete framework for video SAR image super-resolution reconstruction, including the presented mathematical model, the designed network and its loss function. Experimental results are presented in Section 4, and Section 5 concludes this paper.
2. Related Work
2.1. Microwave Video SAR Imaging
When operating at the common microwave band, video SAR systems struggle to maintain high azimuth resolution without sacrificing imaging frame rates. To address the issue, the overlapping aperture processing technique was developed to achieve higher frame rates through data reuse. The back projection (BP) algorithm, suitable for arbitrary trajectories and inherently conducive to data reuse, has been successfully applied in video SAR imaging. For instance, Hawley et al. [12] improved imaging efficiency through weighted fusion of sub-apertures based on the BP algorithm, enabling effective data reuse. Meanwhile, Moses et al. [13] introduced a recursive BP algorithm that models the current frame as a linear combination of previous frames and newly acquired back-projection data, significantly improving data reuse efficiency and reducing memory consumption. Similarly, Miller [14] employed circular shift registers for sub-aperture data reuse. Song et al. [15] divided imaging areas into regions of interest and general regions, applying the fast factorized BP algorithm to maintain high resolution in critical areas while sacrificing quality in less important regions to boost computational efficiency. Cheng et al. [16] proposed an improved cartesian factorized BP algorithm, achieving data reuse while avoiding the interpolation required by traditional fast BP algorithms. Overlapping aperture processing reuses partial echo data among adjacent frames, resulting in more video SAR images. However, each frame produced by overlapping or non-overlapping apertures shares an equivalent synthetic aperture length when azimuth resolution remains unchanged, offering no improvement in the shadow quality of moving targets. Recently, research efforts have been paid for the achievement of realistically effective high-frame-rate and high-resolution imaging in the microwave band. Kim et al. [17] proposed a multi-input multi-output-based video SAR imaging technique, where the platform speed is very high for high-frame-rate imaging and then multi-channel joint processing is employed to mitigate Doppler spectrum ambiguities induced by the high platform speed, successfully validating both high-frame-rate and high-resolution imaging through simulations. Nevertheless, the radar platform speed is constrained by multiple real-world factors. Ding et al. [18] proposed a collaborative high-frame-rate imaging framework based on swarm UAV-borne radar systems, where each UAV-borne radar obtains short aperture data in a short time, and then multiple aperture data are fused to achieve the desired azimuth resolution and thus improve the frame rate.
In conclusion, achieving realistic and effective microwave video SAR imaging with low system complexity remains a challenge.
2.2. SAR Image Super-Resolution Based On Deep Learning
Deep neural networks, capable of modeling complex nonlinear mappings through extensive training data, have demonstrated remarkable success in optical image super-resolution reconstruction tasks [19,20,21]. Researchers have extended these deep learning techniques to SAR image super-resolution reconstruction. Building on the FSRCNN [22], a fast optical image super-resolution network, Luo et al. presented the IFSRCNN [23] where the structural similarity index (SSIM) is incorporated into the original loss function to improve the performance and applied it to SAR images. Similarly, Sun et al. [24] employed convolutional neural networks to reconstruct high-resolution images from low-resolution images generated by the conventional BP algorithm. Wei et al. [25] combined alternating direction method of multipliers with deep neural networks to achieve fast super-resolution reconstruction of SAR images. Wang et al. proposed SRGAN [26] to utilize the generative adversarial network for SAR image super-resolution reconstruction, achieving significant breakthroughs in reconstruction accuracy and computational efficiency compared with traditional super-resolution algorithms. Addressing the issue of low spatial resolution in polarimetric SAR images, Shen et al. [27] proposed a polarimetric SAR super-resolution reconstruction framework using residual convolutional neural networks to enhance spatial resolution. Li et al. [28] proposed a novel optical-guided super-resolution reconstruction network (OGSRN) for SAR images with large scaling factors. Guided by the corresponding optical images of SAR images, OGSRN achieved excellent performance in both quantitative evaluation metrics and visual quality.
High-frame-rate and high-resolution imaging of microwave video SAR can be viewed as a low-resolution image sequence super-resolution reconstruction task. Although deep learning methods demonstrate significant potential for high-quality image reconstruction, deep-learning-based super-resolution technology specifically for video SAR has yet to be explored.
3. Methodology
Although microwave video SAR systems enable long-range detection and imaging, achieving high-resolution and high-frame-rate imaging simultaneously remains challenging. Higher resolution demands a more considerable synthetic aperture length. Due to the limited speed of SAR platforms, higher resolution means longer synthetic aperture time, resulting in decreased frame rates. In addition, moving target shadows result from the obstruction of electromagnetic waves by targets on the ground, and thus the target shadow contrast to clutter is associated with the ratio of occlusion time to synthetic aperture time [29]. As the azimuth resolution increases, the synthetic aperture time also increases, but the occlusion time remains unchanged since it depends on the speed of the moving target. As a result, the shadows quality is degraded, adversely affecting subsequent moving target detection and tracking. As shown in Figure 1, moving target shadows often appear blurred in high-resolution SAR imagery while they are visible in low-resolution SAR imagery.
For a microwave video SAR system, high-resolution imaging not only conflicts with high-frame-rate imaging but also leads to blurred shadows of moving targets. In contrast, low-resolution imaging can satisfy the high-frame-rate requirement and produce clearer shadows of moving targets, but it inherently lacks the detailed information necessary for subsequent image interpretation and target identification. To resolve this contradiction, we formulate the challenge of achieving high-frame-rate and high-resolution imaging in microwave video SAR as a super-resolution reconstruction task of the high-frame-rate but low-resolution image sequence.
3.1. Mathematical Model for Super-Resolution Reconstruction
Existing deep learning-based super-resolution reconstruction methods typically model the reconstruction task as a complex nonlinear mapping from low-resolution images to the corresponding high-resolution images, training the network with massive one-to-one correspondence image pairs. However, in the video SAR image super-resolution reconstruction task, high-resolution images with unblurred shadows, which could serve as ground truth for the network training, are unavailable. Furthermore, due to the presence of speckle noise, it is difficult to train the network to learn the complex nonlinear mapping between low-resolution and high-resolution SAR images. Fortunately, in video SAR imaging, moving target shadows are more visible in low-resolution SAR images while the background exhibits higher resolution in high-resolution images. Leveraging this characteristic, our proposed mathematical model formulates video SAR super-resolution reconstruction as a nonlinear mapping from low-resolution image sequences to desired high-resolution sequences with assistance from high-resolution but shadow-blurred images. This can be mathematically expressed as:
where represents the low-resolution image sequence with N frames, denotes the desired high-resolution image sequence with clear shadows of moving targets, and indicates the high-resolution but shadow-blurred image. The nonlinear mapping parameters correspond to the network weights when approximated using a deep neural network.
3.2. Imaging Framework
The proposed framework for high-frame-rate and high-resolution imaging in microwave video SAR is illustrated in Figure 2. In order to meet the requirement of high azimuth resolution, existing video SAR imaging techniques generally divide the raw data into multiple frames of long aperture echoes to obtain high-resolution image sequences. In contrast, as shown in the Figure 2, during the imaging preprocessing of the proposed framework, one frame of long aperture echo is further split into multiple short sub-apertures, producing a high-frame-rate but low-resolution image sequence. Moreover, we use the accelerated fast back-projection (AFBP) algorithm [30] to efficiently generate the low-resolution image sequence and the high-resolution images in the same coordinate. It should be pointed out that the high-resolution image corresponding to the long aperture and the low-resolution image sequence generated by multiple frames of short aperture should share consistent information in the background areas, except for differences in the dynamic areas. This physical relationship establishes the feasibility of the presented mathematical model, wherein the high-resolution image guides the super-resolution reconstruction of the low-resolution sequence, specifically enhancing details in the background area.
Guided by the proposed mathematical model, we design a super-resolution reconstruction network to transform the high-frame-rate but low-resolution image sequence into a high-resolution and high-frame-rate image sequence while preserving clear moving target shadows. Furthermore, to learn the nonlinear mapping effectively, we design a loss function for the network training. The loss function regionally maps the network’s output to the corresponding low-resolution input sequence and the shadow-blurred high-resolution image, enabling self-supervised learning. Finally, the trained network can be directly applied to high-frame-rate, but low-resolution video SAR image sequences unseen in the network training, yielding high-frame-rate and high-resolution image sequences.
3.3. Super-Resolution Reconstruction Network
As illustrated in Figure 3, the designed super-resolution reconstruction network consists of two encoders, a spatiotemporal learning module and a fusion and reconstruction module. The two encoders are the low-resolution image sequence encoder and the high-resolution image encoder, which respectively extract features from the low-resolution image sequence and the shadow-blurred yet high-resolution image. The spatiotemporal learning module learns both spatial dependencies and temporal variations of features from the low-resolution image sequence encoder. The fusion and reconstruction module integrates features from the outputs of the high-resolution image encoder and the spatiotemporal learning module at multiple scales and reconstructs the high-resolution image sequence based on the fused features.
3.3.1. High-Resolution Image Encoder
The encoder takes the high-resolution image with blurred shadows as input to extract features through four convolution blocks, where each block contains a 3×3 convolution, group normalization, and leaky ReLU activation. Group normalization stabilizes training via feature re-scaling, while leaky ReLU preserves gradient flow. Spatial downsampling is triggered every two blocks via stride- convolutions, where channels double at each downsampling stage.
3.3.2. Low-Resolution Image Sequence Encoder
For a low-resolution image sequence of length N as input, the low-resolution image sequence encoder comprises N branches with shared weights for feature extraction. Each branch consists of 4 cascaded convolution blocks, where each block includes a 3×3 convolution, group normalization, and a Leaky ReLU activation function. Spatial downsampling is also triggered every two blocks while channels double at each downsampling stage. To ensure that the spatial dimensions of the output feature maps from the low-resolution image sequence encoder match those of the high-resolution image encoder, the stride of the 2-nd and 4-th convolutional layers is set to .
3.3.3. Spatiotemporal Learning Module
The spatiotemporal learning module employs two stacked gated spatiotemporal attention (gSTA) blocks [31] to enhance the features extracted by the low-resolution image sequence encoder. It should be noted that the features from N frames in the low-resolution image sequence are first concatenated along the channel dimension and then are fed into the spatiotemporal learning module for feature enhancement.
The gSTA block is introduced for its ability to efficiently capture spatiotemporal dependencies while maintaining computational efficiency, offering a critical advantage over traditional recurrent or transformer-based architectures. By leveraging a decomposed large-kernel convolution and a gating mechanism, gSTA block dynamically filters and emphasizes informative spatiotemporal features, suppressing noise and irrelevant details. Internally, each gSTA block consists of three key components: a depth-wise convolution for local receptive fields, a depth-wise dilated convolution for distant connections, and a 1×1 convolution for channel interactions. Furthermore, the gating mechanism splits the features into two streams, applying a sigmoid activation to one stream to generate adaptive attention weights, which are then multiplied element-wise with the other stream to perform feature selection. This architecture enables our module to effectively model both spatial details and temporal evolution in video SAR sequences, crucial for high-quality super-resolution reconstruction. The stacked gSTA blocks further enhance this capability by progressively refining spatiotemporal representations.
3.3.4. Fusion and Reconstruction Module
The proposed fusion and reconstruction module reconstructs the desired high-resolution image sequence by fusing enhanced spatiotemporal features and the spatial features from the high-resolution image with blurred shadows. This module consists of N parallel branches with shared weights, and each branch is built by stacking two sum-difference attention (SDA) blocks and two up-sampling blocks. Two SDA blocks fuse the features at two different scales, where the first SDA block directly integrates the enhanced features from the spatiotemporal learning module and the spatial features from the high-resolution image encoder and another SDA block fuses the up-sampling features with features of the same size from the high-resolution image encoder. Notably, the enhanced spatiotemporal features are first split into N parts along the channel dimension, and each part is then fed into the corresponding branch for fusion and reconstruction.
As shown in Figure 4, we propose the SDA block for efficient feature fusion. Given two feature maps X and Y to be fused, the SDA block performs element-wise addition and subtraction to generate a sum branch and a difference branch, respectively. The sum branch enhances features corresponding to static background regions, while the difference branch captures dynamic variations between the input features. Inspired by the large-kernel attention mechanism [32], both branches are processed by two decomposed large-kernel convolution branches, and then the features from both branches are multiplied element-wise, followed by a sigmoid activation to produce the gated attention map W. Finally, the fused features Z are obtained as follows:
The proposed SDA block offers three key advantages. First, the sum-difference decomposition explicitly models both static and dynamic components of the input features, enabling a more comprehensive feature representation. Second, the decomposed large-kernel convolution retains the benefits of global receptive fields while significantly reducing computational overhead compared to standard large-kernel operations. Third, the gating mechanism provides adaptive feature selection capability. This design is particularly effective for video SAR super-resolution tasks where both spatial details and temporal coherence need to be preserved. The two up-sampling blocks perform spatial up-sampling on fused features, and each block doubles the two-dimensional scale of the input features. Each up-sampling block incorporates a convolution layer with the kernel size of 3×3, followed by group normalization and Leaky ReLU activation. Spatial up-sampling is implemented by a 3×3 convolution layer and a pixel-shuffle layer for efficiency. Finally, the 1×1 convolution layer projects the up-sampling features to the desired video SAR image sequence.
3.4. Loss Function
Existing deep learning-based image super-resolution reconstruction methods generally define the loss function by minimizing the difference between the network’s output and the ground truth. However, for video SAR image super-resolution reconstruction, high-resolution SAR images generated from long synthetic aperture often contain blurred moving target shadows, rendering them unsuitable as ground truth for the training. In contrast, moving target shadows are clearer in low-resolution SAR images. Therefore, we define a loss function that regionally maps the network output to the input low-resolution sequence and the shadow-blurred high-resolution image.
Given the input low-resolution image sequence and the high-resolution image, two-dimensional regions within the output images are classified into background, potential moving-target shadow regions, and uncertain areas. Specifically, since the background regions in both the low-resolution and high-resolution images are highly similar, we perform SAR image similarity analysis [33] between each frame of low-resolution image sequence and the high-resolution image, obtaining N binary mask matrixes where 1 represents background pixels and 0 otherwise. It should be pointed out that before conducting similarity analysis, we should interpolate the low-resolution images to the same size as the high-resolution image. Subsequently, the morphological processing is employed to mitigate the effect of the speckle noise on the identification of background areas. Additionally, by further leveraging the grayscale information of low-resolution image sequence, N binary mask matrixes indicating potential shadow regions are generated, as described below:
where is the i-th frame of the low-resolution image sequence processed by the interpolation and the Lee filter [34], ⊙ represents Hadamard product, is a threshold of shadow intensities, which is empirically set as 0.25.
The loss function is mathematically defined as:
where is a weighting factor balancing reconstruction quality and shadow preservation, which is set as 0.2 in this article. is a small constant (e.g., ). denotes the mean filter with 5×9 kernel size, which can mitigate the effect of the speckle noise. is the i-th frame of the low-resolution image sequence processed by the interpolation. The first term aligns output images to the high-resolution image in the background regions, and the second term ensures shadow consistency with low-resolution inputs, preserving shadow clarity. Pixels in uncertain regions are excluded during training.
4. Experiments
We demonstrate the effectiveness of the proposed approach by using the real video SAR data recorded by two different video SAR systems. The generalization ability of the proposed approach is evaluated and discussed in detail.
4.1. Datasets and Training Strategy
4.1.1. Datasets
We use real video SAR data recorded by two different systems to build the datasets, which include one training set and two test sets. Both video SAR systems operate at W band but with different parameters, as listed in the Table 1. It should be noted that due to the lack of real K-band radar data, only W-band radar data are available and used to equivalently validate the proposed high-frame-rate imaging for microwave video SAR. On the W-band radar data, we perform a four-fold () super-resolution reconstruction to generate images with an ultra-high azimuth resolution of approximately 0.07 cm while maintaining clearly visible shadows of moving targets.
The real video SAR data from radar A contains 1,600,000 pulses and is processed by the AFBP algorithm to generate 800 samples, where each sample consists of one high-resolution image and four low-resolution images. The high-resolution image has a size of 2048×4096 with a resolution of 0.15 m×0.07 m while low-resolution images have a size of 2048×1024 with a resolution of 0.15 m×0.28 m. The first 80 samples form the first testing set and the remaining 720 samples are used to build the training set. The original training set is augmented by cutting and rotating, as is commonly done in deep learning applications, and 60 sets are obtained, yielding a total of 43,200 samples where the high-resolution image has a size of 1024×1024 and low-resolution images have a size of 1024×256.
In addition, the real video SAR data from radar B contains 145000 pulses and is processed to generate 31 samples, where each sample also consists of one high-resolution image and four low-resolution images. The high-resolution image has a size of 2048×4096 with a resolution of 0.17 m×0.08 m while low-resolution images have a size of 2048×1024 with a resolution of 0.17 m×0.32 m. The 31 samples are used for testing only to evaluate the generalization ability of the proposed approach.
4.1.2. Training
The super-resolution reconstruction network is trained by Adam optimizer with a batch size of 1. The learning rate is set to in the 20 epoches. All experiments were conducted on a workstation equipped with an Intel i7-12700KF CPU and an Nvidia GeForce RTX 3090 GPU.
4.2. Evaluation Metrics
To comprehensively evaluate the proposed super-resolution reconstruction network for video SAR imaging, we use two specialized metrics to assess different aspects of reconstruction quality. First, the mask peak signal-to-noise ratio (MPSNR) is employed to quantify the similarity between the reconstruction image and the input high-resolution image specifically in background regions, which can be represented as follows:
where M represents the binary mask matrix with 1 for background pixels and 0 otherwise. In addition, is the maximum pixel value. The mask operation ensures that the evaluation focuses exclusively on static background regions. Additionally, we introduce the average intensity of fast-moving shadow regions to specifically evaluate the preservation of moving target shadows, which is defined as follows:
where denotes the predefined moving target shadow regions. The two metrics provide a rigorous assessment of reconstruction fidelity for both static scenes and dynamic features, offering comprehensive insights into the reconstruction performance.
4.3. Comparison Methods
To validate the effectiveness of the proposed approach, we compared it with the conventional video SAR imaging methods and the state-of-the-art image super-resolution reconstruction methods using deep-learning.The comparative algorithms can be classified as follows.
- Video SAR imaging based on overlapped aperture processing (VSAR-OAP) and low-resolution video SAR imaging (LR-VSAR) are traditional high-frame-rate imaging methods. VSAR-OAP obtains high-frame-rate and high-resolution SAR images by overlapped aperture processing while LR-VSAR achieves high-frame-rate imaging at the expense of azimuth resolution.
- IFSRCNN and SRGAN are supervised learning-based algorithms for SAR image super-resolution reconstruction. IFSRCNN is derived from the fast super-resolution convolutional neural network, adapted and optimized for SAR imagery. SRGAN employs a generative adversarial network (GAN) framework to learn the mapping from low-resolution to high-resolution SAR images.
- ZSR [35] and SRCycleGAN [36] are unsupervised learning-based image super-resolution reconstruction algorithms. ZSR is originally developed for optical images, which leverages the internal self-similarity within an image to train the network. SRcycleGAN employs a cycle-consistent generative adversarial network (CycleGAN) to translate low-resolution SAR images to high-resolution images without requiring paired training data.
4.4. Super-Resolution Imaging Results
The proposed approach is tested on the first test set to validate its effectiveness and practicality. The processing results are compared with those of the above six algorithms, and some representative imaging results obtained by different approaches are shown in Figure 5. As illustrated in Figure 5a, although the overlapping aperture method can obtain both high-frame-rate and high-resolution sequential SAR images, it results in blurred moving target shadows. While low-resolution imaging meets the high-frame-rate requirement, the imaging result shown in Figure 5b suffers from poor quality. As shown in Figure 5c,d, IFSRCNN and SRGAN exhibit limited super-resolution reconstruction performance because speckle noise in SAR imagery hinders the mapping from low-resolution SAR images to high-resolution ones by supervised learning. Similarly, since speckle noise severely degrades the self-similarity of SAR imagery, ZSR produces unsatisfactory super-resolution reconstruction results, as seen in Figure 5e. Although SRCycleGAN generates images of higher quality than ZSR, it still loses fine details, as depicted in Figure 5f. In contrast, as can be observed from the Figure 5g, our algorithm not only shows superior super-resolution reconstruction performance but also preserves clear moving target shadows in the reconstructed images. Furthermore, Table 2 lists the assessment results for all the imaging results on the first test set by different approaches. As revealed by the MPSNR and AISR values listed in the Table, compared to other algorithms, the proposed approach achieves high-quality image super-resolution reconstruction while preserving clear moving target shadows, which effectively resolves the conflict between high-frame-rate imaging and high-resolution imaging in microwave video SAR.
Additionally, the efficiency of the proposed approach is also considered. When running on the GPU, the developed super-resolution reconstruction network takes 0.67s to generate four 2048×4096 high-resolution images, which is acceptable.
4.5. Ablation Study
A series of ablation studies are conducted to assess the individual contributions of the designed loss function and the use of a shadow-blurred high-resolution image as auxiliary inputs for reconstruction. First, we compare the performance of the proposed approach when is respectively set as 0, 0.2, and 0.4. Table 3 summarizes the quantitative comparison of all processing results on the first test set, while Figure 6 shows the processing results on the 32-nd sample from the first test set. Obviously, as the value increases, the shadows in the network output images become clearer, but the overall image quality decreases. Therefore, in this paper, we set the value to 0.2 to achieve a good trade-off between overall image quality and shadow clarity. Notably, when , the second term in the designed loss function is inactive, and thus the network produces high-resolution images with noticeably blurred shadows. It can be concluded that the designed loss function that regionally maps the network output to the input low-resolution sequence and the shadow-blurred high-resolution image is effective.
Additionally, we compare the reconstruction performance of the proposed approach with and without the shadow-blurred high-resolution image as assistance, and Figure 7 shows the processing results on the 48-th sample from the first test set. Moreover, the quantitative results under the two cases are presented in Table 4 for all the processing results on the first test set. It can be seen that incorporating the shadow-blurred high-resolution image into the reconstruction process substantially enhances the reconstruction performance. This confirms the feasibility and effectiveness of our proposed strategy, which leverages the shadow-blurred high-resolution image to assist in the reconstruction task.
4.6. Generalization Ability
The generalization ability of deep learning-based methods depends on a large amount of training samples of different scenarios. However, different from optical images that can be available easily, it is difficult and expensive to obtain numerous video SAR images with sufficient diversity. The challenge to apply deep learning-based methods for video SAR comes from the generalization ability.
To check the generalization ability of the proposed approach, the network trained on the data of the first video SAR dataset is directly applied to another video SAR dataset. The processing results are compared with those obtained by the conventional video SAR imaging methods and four image super-resolution reconstructions using deep-learning methods. Table 5 lists the assessment results measured on all the processing results by different approaches. In addition, some representative results obtained by different approaches are shown in Figure 8. As confirmed by both the quantitative assessment and the visual performance, the proposed approach can achieve satisfactory super-resolution reconstruction performance when applied to unseen video SAR data during the training. Therefore, it can be concluded that the proposed approach has a satisfactory generalization ability, which may be attributed to its self-supervised training strategy.
5. Conclusions
It is challenging for microwave video SAR to achieve simultaneously high-frame-rate and high-resolution, particularly with low system complexity and low cost. This paper formulates the problem as an image super-resolution reconstruction task for low-resolution yet high-frame-rate image sequences, paving a new way for microwave video SAR imaging. We simplify the reconstruction task as the nonlinear mapping from the low-resolution image sequence to the desired high-resolution sequence with the shadow-blurred high-resolution image aided. Furthermore, we design a self-supervised deep neural network to learn the nonlinear mapping for high-quality super-resolution reconstruction. Processing results of real video SAR data have revealed that the proposed approach achieves good performance in image super-resolution reconstruction and moving target shadows preservation. In addition, the proposed approach shows a convincing generalization ability when applied to different video SAR data.
Despite its promising performance, this work serves as a preliminary exploration into the use of super-resolution reconstruction for achieving high-frame-rate and high-resolution video SAR imaging. Avenues for future research include developing more efficient super-resolution reconstruction networks and comprehensively evaluating the effectiveness and practicality of the proposed approach on a large amount of low-frequency video SAR data.
Author Contributions
Conceptualization, X.H.; methodology, X.H. and L.W.; software, X.H. and Y.Z.; validation, X.H. and Y.Z.; formal analysis, X.H. and C.Z.; investigation, X.H. and C.Z.; resources, J.D.; writing—original draft preparation X.H. and L.W.; supervision L.W. and J.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded in part by the National Natural Science Foundation of China under Grant 62171358 and 62401436.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author. The data are not publicly available due to privacy.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Damini, A.; Balaji, B.; Parry, C.; Mantle, V. A VideoSAR mode for the x-band wideband experimental airborne radar. In Proceedings of the SPIE, Algorithms for Synthetic Aperture Radar Imagery XVII, Orlando, FL, USA, 5-9 April 2010; pp. 135–145.
- Wallace, H.B. Development of a video SAR for FMV through clouds. In Proceedings of the SPIE, Algorithms for Synthetic Aperture Radar Imagery XXII, Baltimore, MD, USA, 20-24 April 2015; pp. 64–65.
- Wells, L.; Sorensen, K.; Doerry, A.; Remund, B. Developments in SAR and IFSAR systems and technologies at Sandia National Laboratories. In Proceedings of the 2003 IEEE Aerospace Conference, Big Sky, MT, USA, 8–15 March 2003; pp. 1085–1095.
- Raynal, A.M.; Bickel, D.L.; Doerry, A.W. Stationary and moving target shadow characteristics in synthetic aperture radar. In Proceedings of the SPIE, Algorithms for Synthetic Aperture Radar Imagery XXI, Baltimore, MD, USA, 5–9 May 2014; pp. 413–427.
- Wang, H.; Chen, Z.; Zheng, S. Preliminary Research of Low-RCS Moving Target Detection Based on Ka-Band Video SAR. IEEE Geosci. Remote Sens. Lett. 2017, 14, 811–815.
- Ding, J.; Wen, L.; Zhong, C.; Loffeld, O. Video SAR Moving Target Indication Using Deep Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7194–7204.
- Zhong, C.; Ding, J.; Zhang, Y. Joint Tracking of Moving Target in Single-Channel Video SAR. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–18.
- Tian, X.; Liu, J.; Mallick, M.; Huang, K. Simultaneous detection and tracking of moving-target shadows in ViSAR imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1182–1199.
- Palm, S.; Sommer, R.; Janssen, D.; Tessmann, A.; Stilla, U. Airborne Circular W-Band SAR for Multiple Aspect Urban Site Monitoring. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6996–7016.
- Kim, S.H.; Fan, R.; Dominski, F. ViSAR: A 235 GHz radar for airborne applications. In Proceedings of the 2018 IEEE Radar Conference (RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018; pp. 1549–1554.
- Zuo, F.; Li, J.; Hu, R.; Pi, Y. Unified Coordinate System Algorithm for Terahertz Video-SAR Image Formation. IEEE Trans. Terahertz Sci. Technol. 2018, 8, 725–735.
- Hawley, R.W.; Garber, W.L. Aperture weighting technique for video synthetic aperture radar. In Proceedings of the SPIE, Algorithms for Synthetic Aperture Radar Imagery XVIII, Orlando, FL, USA, 25–29 April 2011; pp. 67–73.
- Moses, R.L.; Ash, J.N. An autoregressive formulation for SAR backprojection imaging. IEEE Trans. Aerosp. Electron. Syst. 2011, 47, 2860–2873.
- Miller, J.; Bishop, E.; Doerry, A. An application of backprojection for video SAR image formation exploiting a subaperature circular shift register. In Proceedings of the SPIE, Algorithms for Synthetic Aperture Radar Imagery XX, Baltimore, MD, USA, 29 April–3 May 2013; pp. 66–79.
- Song, X.; Yu, W. Processing video-SAR data with the fast backprojection method. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2838–2848.
- Cheng, Y.; Ding, J.; Sun, Z.; Zhong, C. Processing of Airborne Video SAR Data Using the Modified Back Projection Algorithm. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13.
- Kim, S.; Yu, J.; Jeon, S.-Y.; Dewantari, A.; Ka, M.-H. Signal processing for a multiple-input, multiple-output (MIMO) video synthetic aperture radar (SAR) with beat frequency division frequency-modulated continuous wave (FMCW). Remote Sens. 2017, 9, 491.
- Ding, J.; Zhang, K.; Huang, X.; Xu, Z. High Frame-Rate Imaging Using Swarm of UAV-Borne Radars. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–12.
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307.
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481.
- Moser, B.B.; Raue, F.; Frolov, S.; Palacio, S.; Hees, J.; Dengel, A. Hitchhiker’s Guide to Super-Resolution: Introduction and Recent Advances. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9862–9882.
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 8–16 October 2016; pp. 391–407.
- Luo, Z.; Yu, J.; Liu, Z. The super-resolution reconstruction of SAR image based on the improved FSRCNN. J. Eng. 2019, 2019, 5975–5978.
- Sun, G.; Zhang, F. Convolutional neural network (CNN)-based fast back projection imaging with noise-resistant capability. IEEE Access 2020, 8, 117080–117085.
- Wei, Y.; Li, Y.; Ding, Z.; Wang, Y.; Zeng, T.; Long, T. SAR parametric super-resolution image reconstruction methods based on ADMM and deep neural network. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10197–10212.
- Wang, L.; Zheng, M.; Du, W.; Wei, M.; Li, L. Super-resolution SAR image reconstruction via generative adversarial network. In Proceedings of the 12th International Symposium on Antennas, Propagation and EM Theory (ISAPE), Hangzhou, China, 3–6 December 2018; pp. 1–4.
- Shen, H.; Lin, L.; Li, J.; Yuan, Q.; Zhao, L. A residual convolutional neural network for polarimetric SAR image super-resolution. ISPRS J. Photogramm. Remote Sens. 2020, 161, 90–108.
- Li, Y.; Zhou, L.; Xu, F.; Chen, S. OGSRN: Optical-guided super-resolution network for SAR image. Chin. J. Aeronaut. 2022, 35, 204–219.
- Yan, S. Review of the development status for ViSAR techniques. Syst. Eng. Electron. 2024, 46, 2650–2666.
- Zhang, L.; Li, H.; Qiao, Z.; Xu, Z. A Fast BP Algorithm With Wavenumber Spectrum Fusion for High-Resolution Spotlight SAR Imaging. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1460–1464.
- Tan, C.; Gao, Z.; Li, S.; Li, S.Z. SimVPv2: Towards Simple yet Powerful Spatiotemporal Predictive Learning. IEEE Trans. Multimed. 2025, 27, 5170–5184.
- Guo, M.H.; Lu, C.Z.; Liu, Z.N.; Cheng, M.M.; Hu, S.M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752.
- Conradsen, K.; Nielsen, A.A.; Schou, J.; Skriver, H. A test statistic in the complex Wishart distribution and its application to change detection in polarimetric SAR data. IEEE Trans. Geosci. Remote Sens. 2003, 41, 4–19.
- Lee, J.S. Speckle analysis and smoothing of synthetic aperture radar images. Comput. Graph. Image Process. 1981, 17, 24–32.
- Shocher, A.; Cohen, N.; Irani, M. “Zero-Shot” Super-Resolution Using Deep Internal Learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3118–3126.
- Zheng, T.; Oda, H.; Hayashi, Y.; Moriya, T.; Nakamura, S.; Mori, M.; Takabatake, H.; Natori, H.; Oda, M.; Mori, K. SR-CycleGAN: super-resolution of clinical CT to micro-CT level with multi-modality super-resolution loss. J. Med. Imaging 2022, 9, 1–28.
Figure 1.
Video SAR images with different azimuth resolution. (a) 0.28 m. (b) 0.14m. (c) 0.07m.

Figure 2.
High-frame-rate and high-resolution imaging framework for microwave video SAR based on deep learning.
Figure 2.
High-frame-rate and high-resolution imaging framework for microwave video SAR based on deep learning.
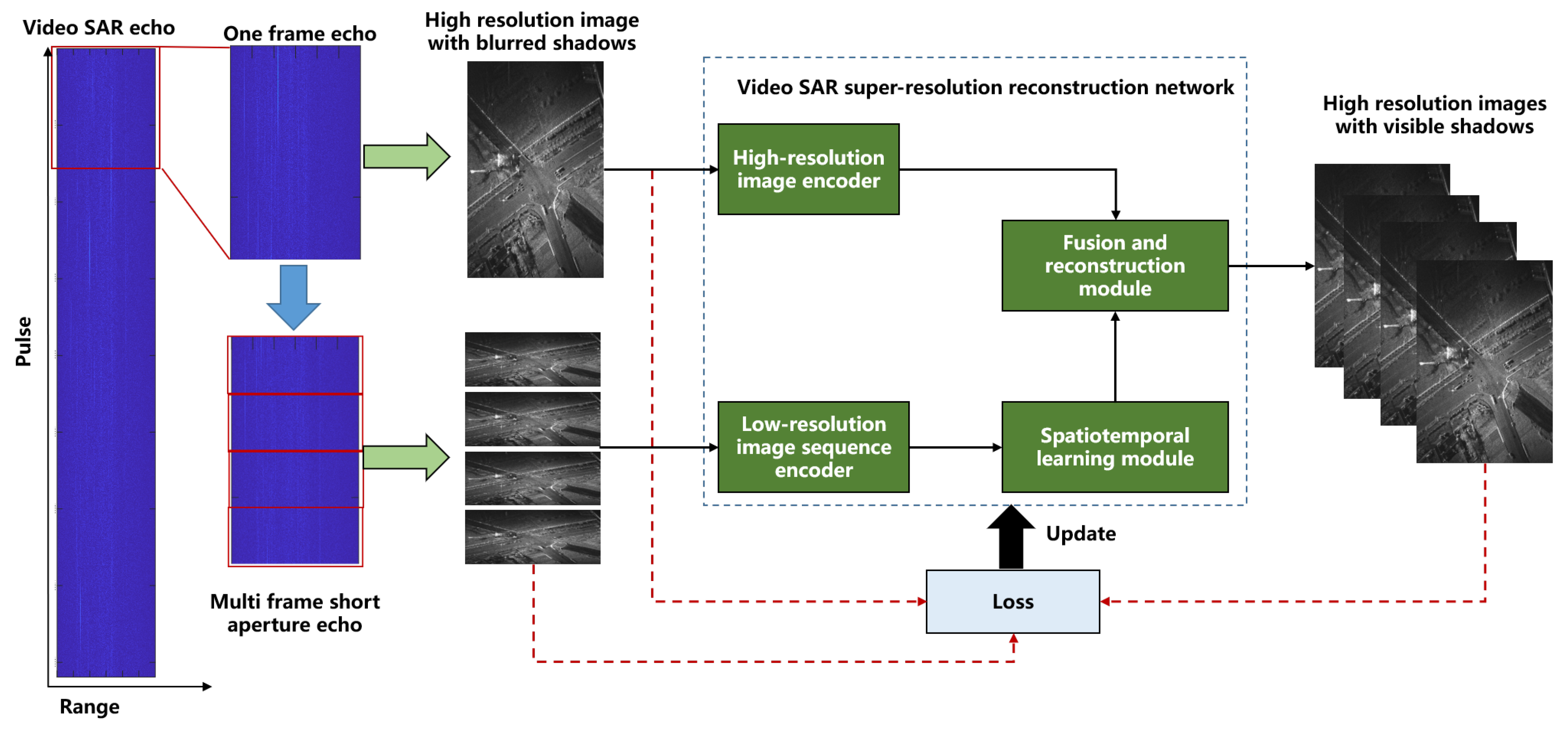
Figure 3.
Architecture of designed super-resolution reconstruction network.
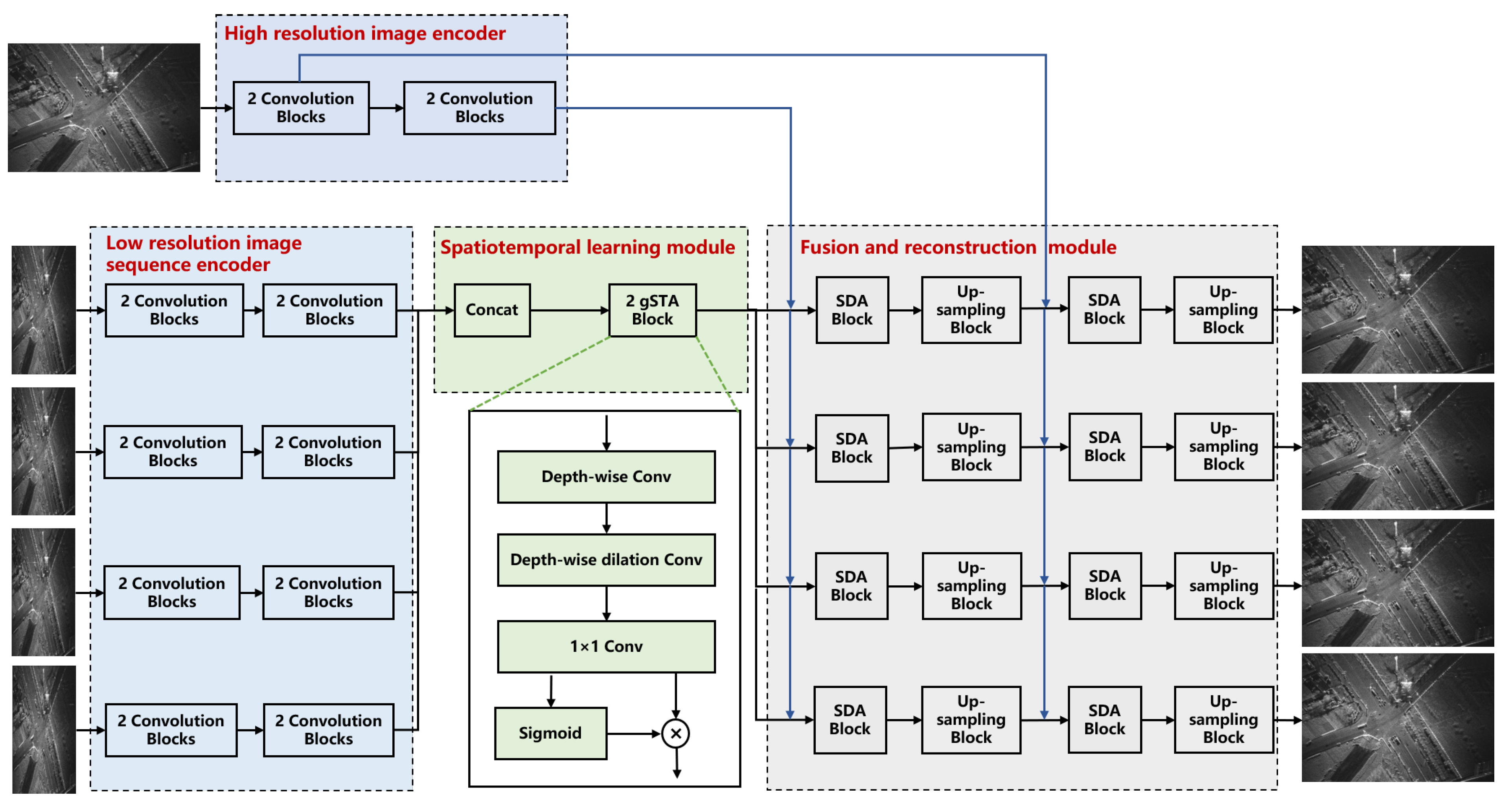
Figure 4.
Illustration of sum and difference attention block.
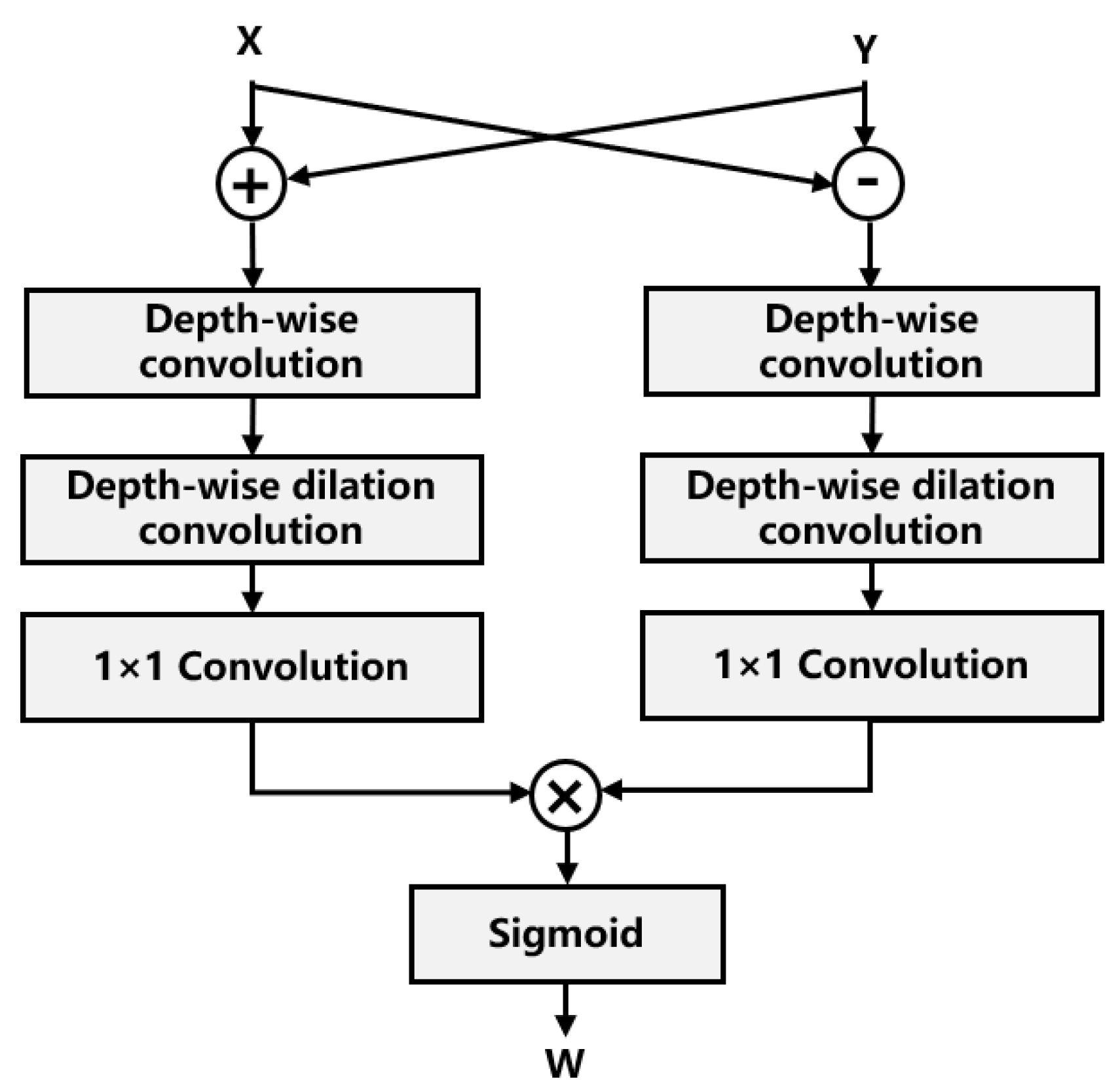
Figure 5.
Processing results by different methods on the 16-th sample from first video SAR data. (a) VSAR-OAP. (b) LR-VSAR. (c) IFSRCNN. (d) SRGAN. (e) ZSR. (f) SRCycleGAN. (g) Proposed approach.
Figure 5.
Processing results by different methods on the 16-th sample from first video SAR data. (a) VSAR-OAP. (b) LR-VSAR. (c) IFSRCNN. (d) SRGAN. (e) ZSR. (f) SRCycleGAN. (g) Proposed approach.

Figure 6.
Representative results of the proposed approach with set to (a) 0, (b) 0.2, and (c) 0.4.

Figure 7.
Representative results of the proposed approach under different cases. (a) Without the shadow-blurred high-resolution image as assistance. (b) With the shadow-blurred high-resolution image as assistance.
Figure 7.
Representative results of the proposed approach under different cases. (a) Without the shadow-blurred high-resolution image as assistance. (b) With the shadow-blurred high-resolution image as assistance.

Figure 8.
Results obtained by different methods on the 16-th sample from another video SAR data. (a) VSAR-OAP. (b) LR-VSAR. (c) IFSRCNN. (d) SRGAN. (e) ZSR. (f) SRCycleGAN. (g) Proposed approach.
Figure 8.
Results obtained by different methods on the 16-th sample from another video SAR data. (a) VSAR-OAP. (b) LR-VSAR. (c) IFSRCNN. (d) SRGAN. (e) ZSR. (f) SRCycleGAN. (g) Proposed approach.


Table 1.
Parameters of two different video SAR systems.
| Parameters | Radar A | Radar B |
|---|---|---|
| Center frequency | 94 GHz | 92.92 GHz |
| Bandwidth | 1000 MHz | 900 MHz |
| Pluse width | 12 | 20 |
| Platform velocity | 46 m/s | 75 m/s |
| Platform height | 1263 m | 2470 m |
| Number of pluse | 1600000 | 145000 |
| Radius of circular flight path | 2400 m | 6650 m |
Table 2.
Assessment of different methods on the first test set.
| Methods | MPSNR | AISR |
|---|---|---|
| VSAR-OAP | - | 0.3317 |
| LR-VSAR | 14.1413 | 0.2002 |
| IFSRCNN | 15.5998 | 0.2302 |
| SRGAN | 15.8566 | 0.2122 |
| ZSR | 12.9469 | 0.2329 |
| SRCycleGAN | 13.6804 | 0.2127 |
| Proposed approach | 48.2291 | 0.2057 |
Table 3.
Influence of parameter on the reconstruction performance.
| MPSNR | AISR | |
|---|---|---|
| 0 | 51.8546 | 0.3416 |
| 0.2 | 48.2291 | 0.2057 |
| 0.4 | 41.6733 | 0.2028 |
Table 4.
Reconstruction performance of the proposed approach with and without the shadow-blurred high-resolution image as assistance.
Table 4.
Reconstruction performance of the proposed approach with and without the shadow-blurred high-resolution image as assistance.
| Cases | MPSNR | AISR |
|---|---|---|
| Without the image as assistance | 16.1459 | 0.2067 |
| With the image as assistance | 48.2291 | 0.2057 |
Table 5.
Assessments by different methods on the second test set.
| Methods | MPSNR | AISR |
|---|---|---|
| VSAR-OAP | - | 0.1542 |
| LR-VSAR | 15.6533 | 0.0967 |
| IFSRCNN | 17.4123 | 0.1505 |
| SRGAN | 17.4828 | 0.1124 |
| ZSR | 13.8451 | 0.1016 |
| SRCycleGAN | 14.7680 | 0.1173 |
| Proposed approach | 44.1817 | 0.0999 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



