I. Introduction
Time-series anomaly detection has emerged as a critical component in numerous domains, including industrial monitoring, cybersecurity, financial fraud detection, and healthcare systems [
1], Traditional anomaly detection approaches typically assume that time-series data follow a stationary distribution in which statistical properties remain constant over time. However, real-world systems frequently exhibit non-stationary behavior characterized by temporal distribution shifts, evolving patterns, and concept drift. These dynamic changes can severely degrade the performance of static detection models, leading to increased false alarm rates and reduced sensitivity to genuine anomalies.
Detecting anomalies in non-stationary environments has attracted considerable attention. Deep-learning models-notably autoencoders, recurrent neural networks, and transformers- have shown a strong ability to capture complex temporal dependencies in time-series data [
2]. Despite these advances, many methods fail when distribution shifts violate the i.i.d. assumption. If incoming data statistics deviate substantially from the training distribution, model performance often degrades rapidly, requiring frequent retraining or manual intervention.
Continual learning, also known as lifelong learning, offers a promising paradigm for addressing non-stationarity by enabling models to incrementally acquire new knowledge while preserving previously learned information [
3]. Recent work has begun exploring the intersection of continual learning and anomaly detection, particularly in the context of concept drift adaptation [
4]. However, existing approaches often lack explicit mechanisms for detecting and characterizing distribution shifts, relying instead on passive adaptation strategies that may respond too slowly to abrupt changes or too aggressively to benign fluctuations.
This paper introduces a comprehensive framework for adaptive anomaly detection in non-stationary time series that explicitly incorporates distribution monitoring capabilities. Our approach makes several key contributions. First, we develop a distribution drift detection module based on statistical hypothesis testing that continuously monitors incoming data streams for significant distributional changes. This module distinguishes between virtual drift, which affects input distributions without impacting decision boundaries, and actual drift, which necessitates model adaptation [
5]. Second, we propose an adaptive learning architecture that employs rehearsal-based continual learning with dynamic memory management, allowing the system to selectively retain representative samples from historical distributions while efficiently incorporating new patterns. Third, we introduce a hybrid loss function that explicitly balances the competing objectives of stability and plasticity, preventing catastrophic forgetting while enabling rapid adaptation to evolving data distributions.
Our framework addresses several limitations of existing approaches. Unlike methods that treat all distributional changes uniformly, our system adaptively modulates its learning rate and memory update strategy based on the detected severity and type of drift. Furthermore, our approach maintains computational efficiency through careful design choices, making it suitable for deployment in resource-constrained environments requiring real-time processing. We validate our framework through extensive experiments on multiple benchmark datasets representing diverse application domains, demonstrating consistent improvements over state-of-the-art baselines in terms of detection accuracy, adaptation speed, and computational efficiency.
III. Methodology
B. Distribution Drift Detection Module
The drift detection module continuously monitors the incoming data stream to identify material distribution shifts that can invalidate the assumptions of a static anomaly detector. We employ a two-phase strategy that unifies (i) statistical hypothesis testing for shift discovery and (ii) performance monitoring for shift qualification, so that adaptation is triggered only when the detected drift is both statistically credible and operationally consequential.
In the first phase, we perform hypothesis testing between a reference window and an incoming window to flag distributional change points. This choice is motivated by the practical reality that upstream pipeline dynamics can reshape the observed data distribution; Gao et al. [
22] highlight how heterogeneous ETL environments and scheduling changes can alter downstream data characteristics, making explicit drift monitoring a necessary control signal rather than an optional diagnostic. In the second phase, we monitor detector behavior—such as error distribution shifts, alert rate instability, and confidence degradation—to decide whether the drift meaningfully affects decision quality. This step is designed to reduce unnecessary model updates and to strengthen traceability; it aligns with Lai et al. [
23] in emphasizing explainable, causally grounded assessment where changes are linked to interpretable evidence rather than treated as opaque triggers. Finally, because the stream may contain heterogeneous, high-dimensional signals, we monitor drift on learned representations rather than raw inputs; this follows the representation-centric modeling rationale used by Xie and Chang [
24] for heterogeneous record-based sequences, where transformer-derived features provide a more stable basis for downstream risk identification and monitoring. The resulting two-phase drift decision rule and the adaptation trigger conditions are formalized as follows:
Statistical Distribution Monitoring: We maintain a sliding reference window containing recent samples from the current distribution and a test window for incoming data. To detect distribution shifts, we apply the Kolmogorov-Smirnov (KS) test, a non-parametric method that compares empirical cumulative distribution functions without assumptions about underlying distributions.
For each dimension
of the input space, we compute the KS statistic:
Where
and
are the empirical cumulative distribution functions for dimension
in the reference and test windows, respectively. The overall drift score is computed as:
A distribution shift is detected when exceeds a predefined threshold typically set using statistical significance levels.
Performance-Based Drift Detection: To complement statistical monitoring, we track the model’s detection performance using an exponentially weighted moving average (EWMA) of prediction confidence scores:
where
represents the prediction confidence at time
and
is the smoothing parameter. A significant decrease in
indicates potential concept drift requiring model adaptation. We detect performance drift when:
where
is the monitoring window size and
is the performance drift threshold.
C. Adaptive Continual Learning Module
Upon detecting distribution drift, the adaptive learning module updates the anomaly detection model while preserving knowledge of previous distributions. Our approach is built upon a deep autoencoder architecture enhanced with attention mechanisms for temporal feature extraction.
Base Architecture: The core detection model consists of an encoder-decoder structure with LSTM layers augmented by attention mechanisms. The encoder maps input sequences to a latent representation:
The decoder reconstructs the input from the latent representation:
The anomaly score is computed based on reconstruction error and latent space deviation:
where
represents the mean latent representation of normal samples, and
,
are weighting coefficients.
Continual Learning Strategy: To enable continual adaptation without catastrophic forgetting, we employ a rehearsal-based approach with dynamic memory management. The memory buffer
stores representative samples from encountered distributions. During training on a new data batch
, we combine it with samples from memory:
where
is the number of samples retrieved from memory. The model is updated by minimizing a hybrid loss function:
The reconstruction loss ensures accurate modeling of normal patterns:
The regularization loss prevents drastic parameter changes:
Where
represents parameters before the current update. The contrastive loss maintains separation between normal and anomalous representations in latent space:
where
denotes cosine similarity,
is a positive sample, and
is the temperature parameter.
D. Dynamic Memory Management
Effective memory management is critical for balancing adaptation speed with knowledge retention. We propose an adaptive memory update strategy that responds to detected drift severity.
Drift-Aware Memory Update: Upon detecting distribution drift, we classify its severity based on magnitude. For mild drift , we gradually replace outdated samples. For severe drift , we perform aggressive memory realignment by removing samples with high reconstruction error under the new distribution.
The memory update probability for sample
is computed as:
where
is the sigmoid function,
and
are the mean and standard deviation of reconstruction errors in current memory, and
controls the removal aggressiveness.
Diverse Sample Selection: When adding new samples to memory, we employ a diversity-based selection criterion to ensure comprehensive coverage of the current distribution. We use k-means clustering in the latent space and select samples closest to cluster centroids:
where
represents the j-th,
is its centroid, and
is the number of clusters.
E. Adaptive Learning Rate Scheduling
To balance stability and plasticity, we dynamically adjust the learning rate based on drift severity and model confidence. The adaptive learning rate is computed as:
Where is the base learning rate, controls drift sensitivity, and modulates the influence of model confidence. This formulation increases learning rate when drift is detected while decreasing it when the model demonstrates high confidence, preventing unnecessary updates to stable patterns.
IV. Experiments
A. Datasets
We evaluate our framework on four publicly available benchmark datasets representing diverse application domains and drift characteristics: SWaT (Secure Water Treatment): A dataset from a water treatment testbed containing 11 days of continuous operation with 51 sensors and actuators. The dataset includes both normal operations and various cyber-physical attack scenarios, representing gradual and abrupt distribution shifts [
25]. With 946,722 samples and an anomaly ratio of 11.98%, SWaT provides a realistic testbed for industrial monitoring applications. SMAP (Soil Moisture Active Passive): A real-world dataset from NASA containing telemetry data from spacecraft sensors. It includes 25 dimensions with 135,183 samples and a 13.13% anomaly ratio, exhibiting natural temporal evolution in sensor readings [
26]. The dataset demonstrates gradual drift patterns typical of space systems. MSL (Mars Science Laboratory): Another spacecraft dataset from NASA with 55 channels monitoring the Mars rover systems over 132,801 samples. With a 10.72% anomaly ratio, this dataset demonstrates long-term non-stationary behavior with seasonal variations, making it ideal for evaluating adaptation to slow, continuous drift. SMD (Server Machine Dataset): A 5-week dataset from a large internet company containing 38 dimensions from 28 server machines, totaling 708,405 samples. With only a 4.16% anomaly ratio, it exhibits concept drift due to varying workloads and operational conditions [
27], representing mixed drift patterns common in cloud computing environments.
Table I summarizes the key characteristics of these datasets, including their dimensionality, length, anomaly ratio, and drift types.
B. Results and Analysis
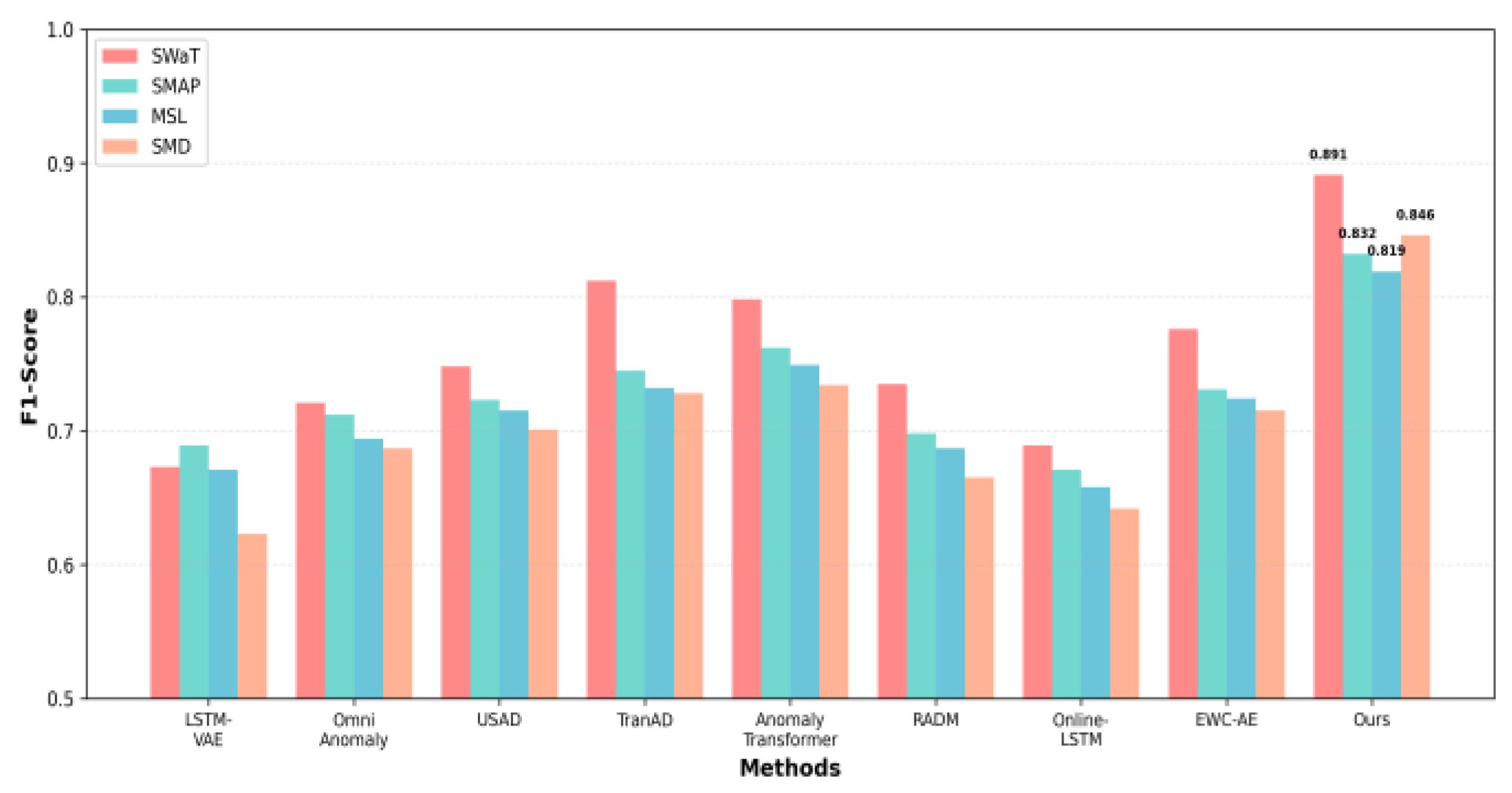
Table II presents the comprehensive performance comparison across all datasets. Our proposed framework consistently outperforms baseline methods, achieving the highest average F1-score of 0.847 across datasets, representing a 11.3% improvement over the best baseline (AnomalyTransformer at 0.734).
On the SWaT dataset, our method achieves an F1-score of 0.891, significantly outperforming the second-best method (TranAD at 0.812). The SMAP and MSL datasets show similar trends, with our framework achieving F1-scores of 0.832 and 0.819, respectively. The SMD dataset presents the most challenging scenario due to its high-dimensional feature space and frequent concept drift, yet our framework maintains robust performance with an F1-score of 0.846.
Figure 1 visualizes the F1-score comparison across all methods and datasets, clearly demonstrating the consistent superiority of our approach.
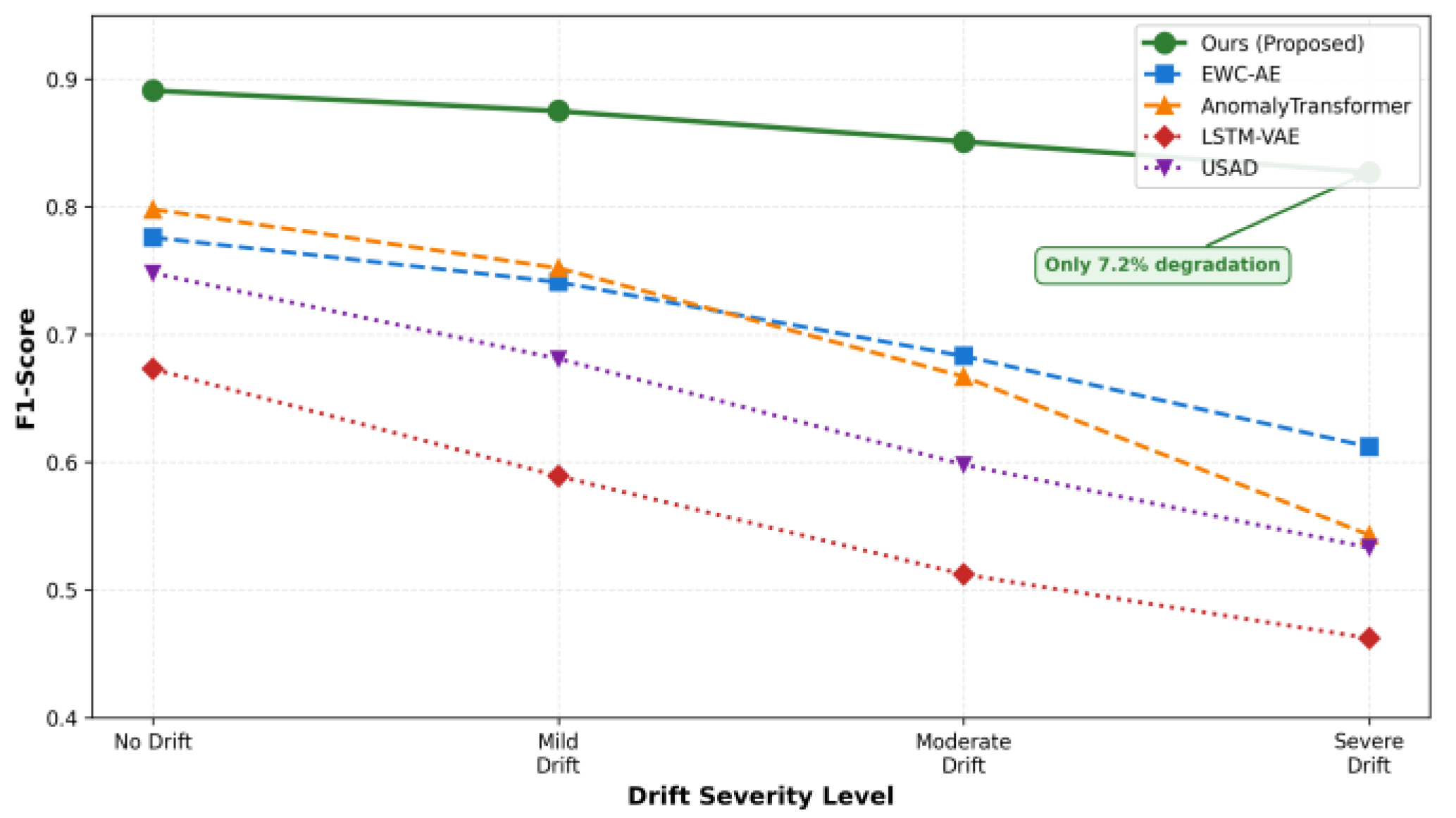
To evaluate adaptation capabilities, we analyze performance across different drift severities.
Figure 2 shows F1-score degradation as drift magnitude increases. Our framework maintains stable performance across mild to severe drift conditions, with only a 7.2% F1-score decrease from no drift to severe drift scenarios. In contrast, static methods like LSTM-VAE and USAD experience 31.4% and 28.7% degradation, respectively.
The explicit drift detection mechanism proves crucial. When comparing against EWC-AE, which employs continual learning without drift detection, our method shows a 12.8% better F1-score under moderate drift conditions.
Table III details drift detection accuracy, showing our KS-test-based approach achieves 94.3% accuracy in identifying distribution shifts with minimal false positives (3.2% false positive rate).
V. Conclusions
This paper presented a comprehensive framework for adaptive anomaly detection in non-stationary time-series environments. By explicitly integrating distribution monitoring capabilities with continual learning mechanisms, our approach addresses the fundamental challenge of maintaining detection accuracy under evolving data patterns. The framework combines statistical drift detection, performance monitoring, and dynamic memory management to enable responsive adaptation while preventing catastrophic forgetting.
Extensive experimental evaluation on multiple benchmark datasets demonstrates the effectiveness of our framework, achieving an average F1-score of 0.847 across diverse application domains, representing a 11.3% improvement over state-of-the-art baselines. The framework maintains stable performance across varying drift severities, with only 7.2% degradation from no drift to severe drift conditions, while static methods experience up to 31.4% performance loss. Computational efficiency analysis confirms the practical feasibility of our approach for real-time applications, demonstrating competitive inference speed and reasonable memory requirements suitable for deployment in resource-constrained environments.
Several promising directions exist for future research. First, extending the framework to handle multivariate time-series with inter-dimensional relationships could improve detection accuracy in complex systems. Second, incorporating uncertainty quantification would provide confidence estimates for detection decisions. Third, developing fully unsupervised versions would broaden applicability to scenarios where ground truth is unavailable. Finally, a theoretical analysis of convergence properties would strengthen the foundation of adaptive anomaly detection methods. In conclusion, our work demonstrates that explicitly incorporating distribution monitoring into anomaly detection frameworks significantly improves robustness in non-stationary environments. As real-world systems become increasingly dynamic and complex, adaptive detection approaches will play a crucial role in maintaining reliable anomaly identification capabilities over extended operational periods.
References
- V. Chandola, A. Banerjee and V. Kumar, “Anomaly Detection: A Survey,” ACM Computing Surveys, vol. 41, no. 3, pp. 1–58, 2009.
- T. Chen, X. Liu, B. Xia, W. Wang and Y. Lai, “Unsupervised Anomaly Detection of Industrial Robots Using Sliding-Window Convolutional Variational Autoencoder,” IEEE Access, vol. 8, pp. 47072–47081, 2020.
- J. Kirkpatrick, R. Pascanu, N. Rabinowitz et al., “Overcoming Catastrophic Forgetting in Neural Networks,” Proceedings of the National Academy of Sciences, vol. 114, no. 13, pp. 3521–3526, 2017.
- Y. Chen and H. Dai, “Concept Drift Adaptation with Continuous Kernel Learning,” Information Sciences, vol. 649, article 119645, 2023.
- L. Feng, S. Wang, J. Wang and H. Lu, “Continual Learning with Strategic Selection and Forgetting for Network Intrusion Detection,” IEEE Transactions on Information Forensics and Security, vol. 19, pp. 8066–8080, 2024.
- A. Bifet and R. Gavaldà, “Learning from Time-Changing Data with Adaptive Windowing,” Proceedings of the 2007 SIAM International Conference on Data Mining, pp. 443–448, 2007.
- A. Ashrafee, S. Paul, S. Haque and M. Hasan, “Holistic Continual Learning under Concept Drift with Adaptive Memory Realignment,” arXiv preprint, arXiv:2507.02310, 2025.
- G. A. Ahmadi-Assalemi, G. Epiphaniou, I. Haider and H. M. Al-Khateeb, “Adaptive Learning Anomaly Detection and Classification Model for Cyber and Physical Threats in Industrial Control Systems,” IET Cyber-Physical Systems: Theory & Applications, 2025.
- S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997.
- J. Li, Q. Gan, Z. Liu, C. Chiang, R. Ying and C. Chen, “An Improved Attention-Based LSTM Neural Network for Intelligent Anomaly Detection in Financial Statements,” 2025.
- N. Lyu, F. Chen, C. Zhang, C. Shao and J. Jiang, “Deep Temporal Convolutional Neural Networks with Attention Mechanisms for Resource Contention Classification in Cloud Computing,” 2025.
- C. Hua, N. Lyu, C. Wang and T. Yuan, “Deep Learning Framework for Change-Point Detection in Cloud-Native Kubernetes Node Metrics Using Transformer Architecture,” 2025.
- Q. Xu, W. Xu, X. Su, K. Ma, W. Sun and Y. Qin, “Enhancing Systemic Risk Forecasting with Deep Attention Models in Financial Time Series,” Proceedings of the 2025 2nd International Conference on Digital Economy, Blockchain and Artificial Intelligence, pp. 340–344, 2025.
- Y. Li, S. Han, S. Wang, M. Wang and R. Meng, “Collaborative Evolution of Intelligent Agents in Large-Scale Microservice Systems,” arXiv preprint, arXiv:2508.20508, 2025.
- S. Pan and D. Wu, “Trustworthy Summarization via Uncertainty Quantification and Risk Awareness in Large Language Models,” arXiv preprint, arXiv:2510.01231, 2025.
- Y. Xing, M. Wang, Y. Deng, H. Liu and Y. Zi, “Explainable Representation Learning in Large Language Models for Fine-Grained Sentiment and Opinion Classification,” 2025.
- R. Liu, R. Zhang and S. Wang, “Graph Neural Networks for User Satisfaction Classification in Human-Computer Interaction,” arXiv preprint, arXiv:2511.04166, 2025.
- Y. Wang, D. Wu, F. Liu, Z. Qiu and C. Hu, “Structural Priors and Modular Adapters in the Composable Fine-Tuning Algorithm of Large-Scale Models,” arXiv preprint, arXiv:2511.03981, 2025.
- H. Zhang, L. Zhu, C. Peng, J. Zheng, J. Lin and R. Bao, “Intelligent Recommendation Systems Using Multi-Scale LoRA Fine-Tuning and Large Language Models,” 2025.
- J. Zheng, Y. Chen, Z. Zhou, C. Peng, H. Deng and S. Yin, “Information-Constrained Retrieval for Scientific Literature via Large Language Model Agents,” 2025.
- H. Fan, Y. Yi, W. Xu, Y. Wu, S. Long and Y. Wang, “Intelligent Credit Fraud Detection with Meta-Learning: Addressing Sample Scarcity and Evolving Patterns,” 2025.
- K. Gao, Y. Hu, C. Nie and W. Li, “Deep Q-Learning-Based Intelligent Scheduling for ETL Optimization in Heterogeneous Data Environments,” arXiv preprint, arXiv:2512.13060, 2025.
- J. Lai, C. Chen, J. Li and Q. Gan, “Explainable Intelligent Audit Risk Assessment with Causal Graph Modeling and Causally Constrained Representation Learning,” 2025.
- A. Xie and W. C. Chang, “Deep Learning Approach for Clinical Risk Identification Using Transformer Modeling of Heterogeneous EHR Data,” arXiv preprint, arXiv:2511.04158, 2025.
- A. P. Mathur and N. O. Tippenhauer, “SWaT: A Water Treatment Testbed for Research and Training on ICS Security,” Proceedings of the 2016 International Workshop on Cyber-Physical Systems for Smart Water Networks, pp. 31–36, 2016.
- K. Hundman, V. Constantinou, C. Laporte, I. Colwell and T. Soderstrom, “Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding,” Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 387–395, 2018.
- Y. Su, Y. Zhao, C. Niu, R. Liu, W. Sun and D. Pei, “Robust Anomaly Detection for Multivariate Time Series through Stochastic Recurrent Neural Network,” Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 2828–2837, 2019.
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).