Submitted:
17 December 2025
Posted:
17 December 2025
You are already at the latest version
Abstract
Video Frame Interpolation (VFI) is critical for generating smooth slow-motion and increasing video frame rates, yet it faces significant challenges in achieving high fidelity, accurate motion modeling, and robust spatiotemporal consistency, particularly for large displacements and occlusions. This paper introduces TemporalFlowDiffuser (TFD), a novel end-to-end latent space diffusion Transformer designed to overcome these limitations with exceptional efficiency and quality. TFD employs a lightweight Video Autoencoder to compress frames into a low-dimensional latent space. A Spatiotemporal Transformer models complex spatiotemporal dependencies and motion patterns, augmented by auxiliary latent optical flow features. Leveraging Flow Matching as its diffusion scheduler, TFD achieves high-quality frame generation with remarkably few denoising steps, making it highly suitable for real-time applications. Our extensive experiments on a challenging high-motion dataset demonstrate that TFD significantly outperforms state-of-the-art methods like RIFE across metrics such as PSNR, SSIM, and VFID, showcasing superior visual quality, structural similarity, and spatiotemporal consistency. Furthermore, human evaluation confirms TFD's enhanced perceptual realism and temporal smoothness, validating its efficacy in generating visually compelling and coherent video content.
Keywords:
video frame interpolation
; diffusion model
; latent space
; optical flow
ideo Frame Interpolation (VFI) is critical for generating smooth slow-motion and increasing video frame rates, yet it faces significant challenges in achieving high fidelity, accurate motion modeling, and robust spatiotemporal consistency, particularly for large displacements and occlusions. This paper introduces TemporalFlowDiffuser (TFD), a novel end-to-end latent space diffusion Transformer designed to overcome these limitations with exceptional efficiency and quality. TFD employs a lightweight Video Autoencoder to compress frames into a low-dimensional latent space. A Spatiotemporal Transformer models complex spatiotemporal dependencies and motion patterns, augmented by auxiliary latent optical flow features. Leveraging Flow Matching as its diffusion scheduler, TFD achieves high-quality frame generation with remarkably few denoising steps, making it highly suitable for real-time applications. Our extensive experiments on a challenging high-motion dataset demonstrate that TFD significantly outperforms state-of-the-art methods like RIFE across metrics such as PSNR, SSIM, and VFID, showcasing superior visual quality, structural similarity, and spatiotemporal consistency. Furthermore, human evaluation confirms TFD’s enhanced perceptual realism and temporal smoothness, validating its efficacy in generating visually compelling and coherent video content.
Keywords: Video Frame Interpolation, Diffusion Model, Latent Space, Optical Flow
1. Introduction
Video Frame Interpolation (VFI) is a fundamental task in computer vision, aiming to synthesize realistic intermediate frames given two consecutive video frames and (where ) [1]. The primary goal is to increase the effective frame rate of a video or generate smooth slow-motion effects. This capability is crucial for numerous applications, including high-quality slow-motion video generation [2], seamless frame rate conversion for different display devices or transmission protocols [3], and enhancing video stabilization by smoothing jerky movements.
Figure 1.
This figure illustrates the motivation for our work, showing how TemporalFlowDiffuser (TFD) overcomes the challenges of traditional methods—like motion blur and artifacts—to produce clear and smooth interpolated frames.
Figure 1.
This figure illustrates the motivation for our work, showing how TemporalFlowDiffuser (TFD) overcomes the challenges of traditional methods—like motion blur and artifacts—to produce clear and smooth interpolated frames.
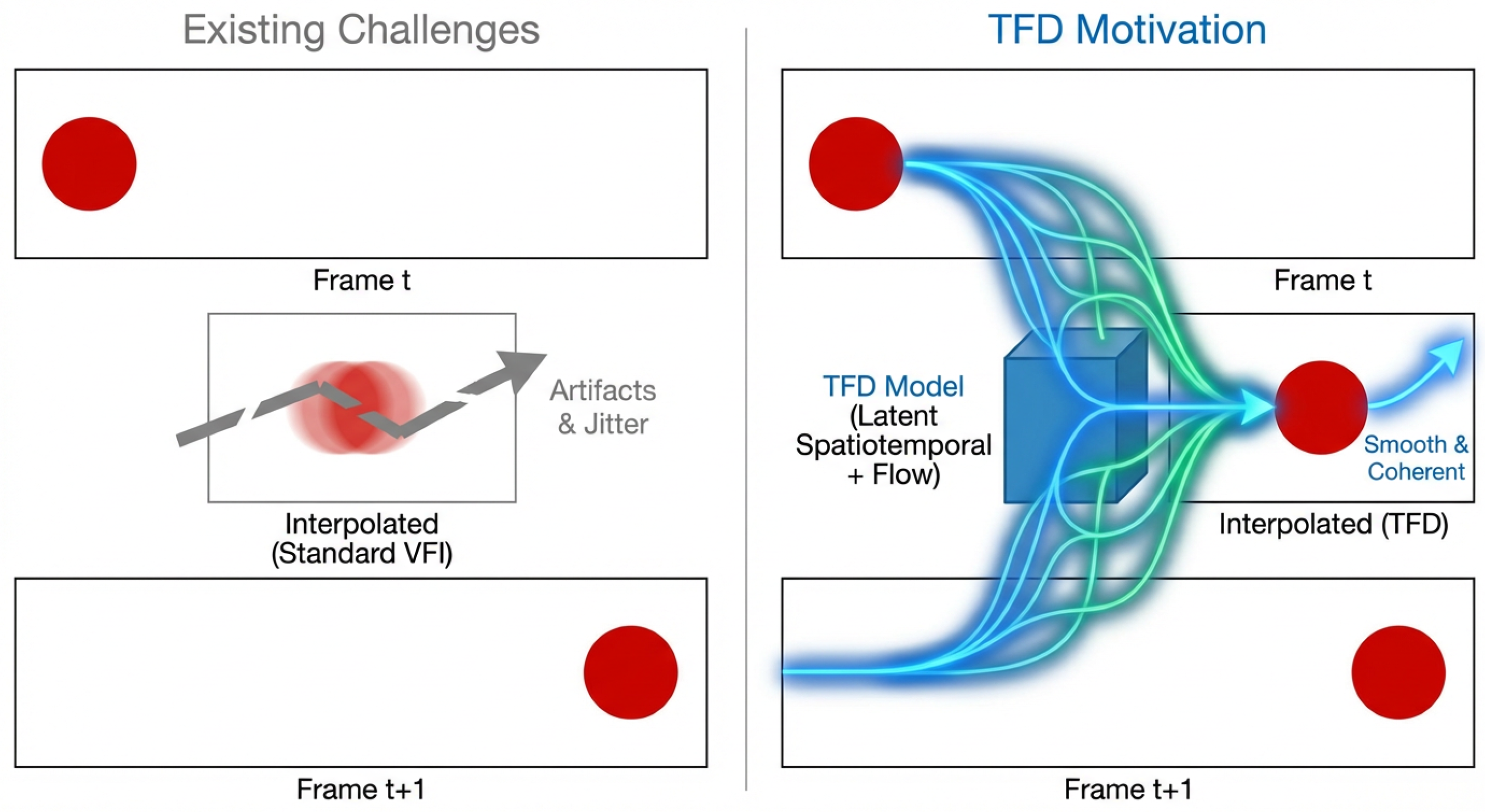
Despite significant advancements, VFI still faces several inherent challenges. Firstly, synthesizing intermediate frames requires high fidelity and fine-grained detail preservation to avoid artifacts, blurring, or unrealistic content [3]. Secondly, accurately modeling complex, rapid, and non-linear motion within video sequences is paramount. Misestimating motion can lead to noticeable visual artifacts. The development of robust decision-making frameworks for dynamic and interactive scenarios, particularly in fields like autonomous driving, benefits from and informs advancements in motion prediction and understanding [4,5,6]. Thirdly and most critically, maintaining spatiotemporal consistency is a significant hurdle. Generated intermediate frames must not only align spatially with their neighbors but also ensure a fluid and continuous temporal evolution, preventing temporal flickering or "jumping" sensations [7]. Many existing methods often struggle with large displacements or occluded regions, resulting in temporal inconsistencies that degrade the overall viewing experience. These limitations underscore the need for more robust and efficient VFI approaches that can generate highly realistic and spatiotemporally coherent video content.
In this paper, we propose TemporalFlowDiffuser (TFD), a novel approach designed to overcome these challenges by leveraging an efficient latent space diffusion Transformer architecture. Our method achieves high-quality and spatiotemporally consistent video frame interpolation with remarkable efficiency. TFD operates within an end-to-end latent space diffusion framework, where input frames are initially encoded into a low-dimensional latent space using a lightweight Video Autoencoder (VAE). This significantly reduces computational complexity while preserving essential spatiotemporal information. The core of TFD is a tailored Spatiotemporal Transformer (ST-Transformer), which processes latent representations, interpolated time encodings, and predicted latent optical flow features. This 20-layer, 12-head attention Transformer with a hidden dimension of 64 is specifically designed to capture complex spatiotemporal dependencies and motion patterns within the latent space. To further enhance efficiency and adaptability of such complex multi-modal architectures, especially during fine-tuning, approaches like heterogeneous Mixture-of-Experts (MoE) adapters can be highly beneficial [8]. Such sophisticated model design often benefits from advanced training paradigms, including reinforcement learning, which has shown promise in enhancing complex generative models like Code LLMs [9]. Furthermore, TFD employs Flow Matching as its diffusion scheduler, enabling high-quality image generation with an exceptionally small number of denoising steps (e.g., 4 or 8 steps), which is critical for real-time applications. The denoised latent representations are then decoded by the VAE to reconstruct high-resolution interpolated frames, incorporating dynamic motion compensation to ensure smoothness and detail integrity.
For experimental validation, TFD was initially pretrained on low-resolution (240p) video datasets to learn general motion patterns and then finetuned on large-scale high-resolution (720p) video datasets, including a curated subset of Vimeo90K [10], to refine details and enhance image quality. This training strategy aligns with the principle of achieving strong generalization from weaker initial models, a concept explored in various large model contexts [11]. For quantitative evaluation, we utilized a custom test set, named “High-Motion-720p-60”, which comprises 60 diverse 720p short videos featuring complex motions and rich textures, designed to rigorously assess VFI algorithms under challenging conditions. Our method was evaluated against RIFE (Real-time Intermediate Flow Estimation) [12], a state-of-the-art VFI method, using standard metrics such as Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Measure (SSIM), and Video Fidelity (VFID). Our experimental results demonstrate that TFD significantly outperforms RIFE across all metrics. Specifically, TFD achieves PSNRs of 33.85 and 33.91, SSIMs of 0.9658 and 0.9665, and VFIDs of 0.142 and 0.128 with 4 and 8 denoising steps, respectively, showcasing superior visual quality, structural similarity, and spatiotemporal consistency compared to RIFE’s 33.52 PSNR, 0.9631 SSIM, and 0.175 VFID. The improvements, particularly the notable reduction in VFID, highlight TFD’s ability to generate more perceptually realistic and temporally coherent videos, even with minimal denoising steps.
Our main contributions can be summarized as follows:
- We introduce TemporalFlowDiffuser (TFD), a novel end-to-end latent space diffusion framework for video frame interpolation, effectively reducing computational complexity while preserving crucial spatiotemporal information.
- We propose a lightweight Spatiotemporal Transformer (ST-Transformer) integrated with Flow Matching for efficient diffusion scheduling, enabling the generation of high-quality interpolated frames with exceptionally few denoising steps (e.g., 4 or 8).
- TFD achieves superior quantitative and qualitative performance over existing state-of-the-art methods like RIFE, particularly in challenging scenarios involving complex motions and occlusions, demonstrating enhanced visual quality, structural similarity, and spatiotemporal consistency.
2. Related Work
2.1. Video Frame Interpolation Methods
Video Frame Interpolation (VFI) synthesizes intermediate frames to enhance frame rate, enable slow-motion, or aid video compression, requiring accurate motion estimation and robust pixel synthesis with visual-temporal consistency. VFI leverages video understanding, vision-language models (VLMs), and deep learning. Optical flow relies on precise motion understanding, akin to fine-grained action analysis in VLM for Video Question Answering [13]. Motion compensation draws from visual in-context learning for VLMs [14] and relation-aware networks for temporal language grounding [7]. Frame synthesis uses sophisticated interpolation, with cubic embedding layers relevant to smooth pixel generation [1]. Modern VFI integrates deep learning architectures, like Motion-Appearance Synergistic Networks [15] for visual cue integration, and considers Transformer behavior regarding sequence length and overfitting for stability [16].
Beyond general video understanding, specific techniques inform VFI: video object segmentation (dynamic memory [17,18], open-vocabulary methods [19]) aids artifact-free interpolation by maintaining object identity; efficient segmentation with edge detection [20] emphasizes robust feature extraction; and personalized combat video generation [21] informs handling of high-motion content. Consistency is paramount: "thread of thought" in LMs [22], story coherence [23], and factual consistency [24] provide analogies for VFI’s temporal and spatiotemporal coherence. Efficient data processing [25] guides real-time optimization, while multilingual multimodal pre-training [26] enhances contextual realism. Question answering and semantic matching (structured contrastive learning [27], dual path modeling [28,29]) offer insights for scene understanding and VFI quality.
The broader AI and deep learning landscape further enriches VFI. Advancements in large language models (LLMs) [30,31] and knowledge transfer [32] provide foundational methodologies. Robust feature extraction and weakly supervised learning (e.g., face anti-spoofing [33]) improve VFI robustness. Robust evaluation [34] informs rigorous assessment. General deep learning architectures like LSTMs for time-series prediction [35,36] inform temporal dependency modeling. The need for real-time performance and adaptability is common across AI applications, from logistics [37] to threat identification [38] and power grids [39]. Understanding uncertainty (Bayesian networks [40]) is crucial for handling unpredictable motion. High-fidelity imaging and super-resolution techniques (microscopy [41,42,43]) share goals of detail enhancement. Methodologies for data analysis and causal inference (biomarkers [44,45,46]) highlight data-driven approaches, while principles from electrical machine control [47,48] resonate with dynamic system modeling. In summary, VFI draws extensively from diverse computer vision and deep learning domains, advancing motion understanding, architectural design, consistency, and real-time performance.
2.2. Diffusion Models for Generative Video and Image Synthesis
Diffusion models (Denoising Diffusion Probabilistic Models (DDPMs) [49]) have transformed generative AI, synthesizing high-quality, diverse content across modalities. They adapt to NLP tasks like Named Entity Recognition [50] and text generation [51]. For image and video synthesis, Latent Diffusion Models (LDMs) [52] reduce computation by operating in latent space. Efficacy often stems from conditional generation, fundamental to multi-modal frameworks like Video-LLaMA [3]. Text-to-image generation benefits from datasets [53] and controllable personalization [54]. Diffusion models also apply to perception and robotics, e.g., hybrid perception [55]. Architectural improvements like MoE adapters [8] are crucial. Despite progress, a ’static appearance bias’ in video datasets [56] challenges temporal modeling for generative video.
3. Method
In this section, we present TemporalFlowDiffuser (TFD), our novel approach for high-quality and spatiotemporally consistent video frame interpolation. TFD leverages an efficient latent space diffusion Transformer architecture, specifically designed to overcome the limitations of existing methods by accurately modeling complex motion and ensuring temporal coherence with remarkable efficiency. Our method operates in an end-to-end fashion, from raw input frames to the final interpolated output, delivering superior visual quality and motion accuracy.
Figure 2.
The overall architecture of the TemporalFlowDiffuser (TFD) model, illustrating the end-to-end pipeline for video frame interpolation.
Figure 2.
The overall architecture of the TemporalFlowDiffuser (TFD) model, illustrating the end-to-end pipeline for video frame interpolation.
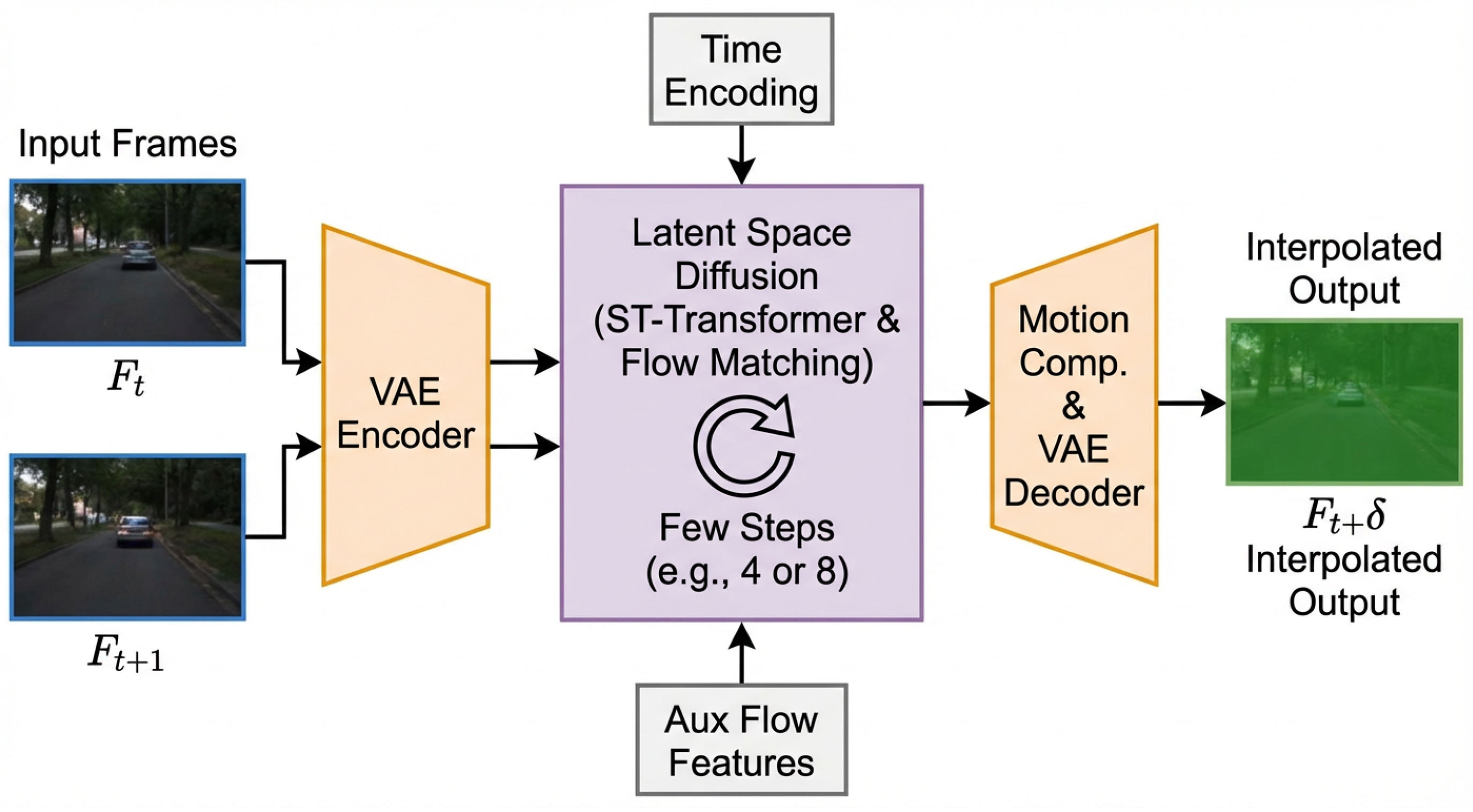
3.1. Overall Architecture
The core of TFD is an end-to-end latent space diffusion framework. Given two consecutive input video frames, and , our objective is to synthesize an intermediate frame , where . This is achieved through a multi-stage process that prioritizes computational efficiency and spatiotemporal fidelity.
Firstly, we employ a lightweight Video Autoencoder (VAE) to compress the high-dimensional input frames into a compact, low-dimensional latent space. This process yields latent representations and , which significantly reduces computational complexity for subsequent operations while retaining critical spatiotemporal information.
Next, these latent representations and , along with an encoded interpolation time parameter and auxiliary latent optical flow features, are fed into our specially designed Spatiotemporal Transformer (ST-Transformer). This powerful module is responsible for modeling complex spatiotemporal dependencies and intricate motion patterns entirely within the latent domain.
Finally, the denoised latent representation, , guided by dynamic motion compensation, is transformed back into the pixel space by the VAE’s decoder, generating the high-resolution interpolated frame . The overall process can be summarized by the following sequence of operations:
Here, denotes the encoding of the interpolation time into a high-dimensional positional embedding vector, and FlowFeatures are auxiliary latent optical flow features predicted by an integrated lightweight flow estimation network.
3.2. Video Autoencoder (VAE)
Our TFD framework integrates a lightweight yet highly effective Video Autoencoder (VAE) specifically optimized for video data compression and reconstruction. The VAE serves two fundamental purposes within our architecture: encoding and decoding.
For encoding, the VAE maps high-resolution input video frames and into a compact, low-dimensional latent space. This transformation yields the latent representations and , which significantly reduces the computational burden for subsequent processing steps, enabling efficient handling of high-resolution video. Crucially, this encoding process is designed to preserve essential content and motion information vital for accurate interpolation. Mathematically, this encoding process is described by:
Secondly, for decoding, after the ST-Transformer processes and refines these latent representations into , the VAE’s decoder reconstructs the final high-resolution intermediate frame . The decoder, denoted as , is meticulously designed to accurately reconstruct fine visual details and ensure smooth motion integration, as illustrated in Equation 3. The lightweight architecture of our VAE ensures minimal computational overhead while maintaining high fidelity throughout both the encoding and decoding stages, which is critical for real-time applications.
3.3. Spatiotemporal Transformer (ST-Transformer)
At the core of our interpolation engine is the Spatiotemporal Transformer (ST-Transformer). This module is meticulously designed to capture intricate spatiotemporal dependencies and complex motion patterns within the compressed latent space.
The inputs to the ST-Transformer are constructed from several distinct components. It begins with the latent representations and obtained from the VAE encoder, which provide the foundational visual information. Alongside these, a positional embedding of the interpolation time is included. This embedding is a high-dimensional vector derived using a sinusoidal function, similar to those employed in standard Transformer architectures, explicitly informing the model about the precise temporal position of the target intermediate frame . Furthermore, auxiliary latent optical flow features, generated by a lightweight accompanying network, provide explicit motion cues, guiding the transformer towards accurate motion understanding and compensation.
These diverse inputs are initially prepared by flattening them into a unified sequence of tokens. For instance, the 3D latent feature maps (e.g., ) are reshaped into a 2D sequence of tokens (), where represents the spatial dimensions. The encoded interpolation time and the flow features are then concatenated or added to these latent tokens, forming the comprehensive input token sequence . This process is formalized as:
Our ST-Transformer comprises 20 stacked layers, each incorporating 12 attention heads and operating with a hidden dimension of 64. This multi-layered, multi-head self-attention mechanism is instrumental in enabling the model to effectively attend to different parts of the latent representations across both spatial and temporal dimensions. This allows for the learning of long-range dependencies and the synthesis of temporally consistent intermediate frames, even in challenging scenarios involving large displacements, occlusions, or complex non-linear motions. Each layer integrates self-attention to process information globally within the token sequence, followed by a feed-forward network, enhancing the model’s capacity to learn robust spatiotemporal features.
3.4. Efficient Diffusion Process with Flow Matching
TFD employs Flow Matching as its diffusion scheduler, a sophisticated technique designed to significantly enhance the efficiency and stability of the diffusion process compared to traditional score-based models or Denoising Diffusion Probabilistic Models (DDPMs). Unlike iterative noise removal methods, Flow Matching learns to directly model a continuous-time vector field that smoothly transports a simple prior noise distribution (e.g., Gaussian noise) to the complex target data distribution of the intermediate latent frames. This approach enables the generation of high-quality images and videos with an exceptionally small number of denoising steps.
In our framework, the ST-Transformer serves as the core component for learning this conditional vector field. During the training phase, the ST-Transformer learns to predict the continuous-time vector field that, when integrated, transforms a noisy latent sample towards a clean target latent . This prediction is conditioned on the initial latent frames (), the encoded interpolation time (), and the auxiliary latent optical flow features. This can be conceptually understood as learning the function:
where is the noisy latent representation at time t along the flow, and . The model is trained to minimize the difference between its prediction and an expertly designed target vector field.
During inference, starting from a random noise sample , the denoised latent representation is obtained by solving the ordinary differential equation (ODE) using a numerical ODE solver for a small, fixed number of steps. This allows for significantly faster generation than traditional diffusion models. Specifically, we demonstrate that TFD can achieve superior results with as few as 4 or 8 denoising steps, a significant advantage for real-time applications where rapid inference is paramount. This discrete approximation of the continuous flow allows for efficient and high-fidelity generation.
3.5. Dynamic Motion Compensation and Decoding
Following the ST-Transformer’s processing and denoising of the latent representation, which yields , this refined latent feature map undergoes an essential enhancement step: dynamic motion compensation. This phase is paramount for guaranteeing that the reconstructed high-resolution frame not only exhibits high visual fidelity but also maintains impeccably smooth and accurate motion trajectories. The motion information, both implicitly learned by the ST-Transformer through its spatiotemporal attention and explicitly supplied by the auxiliary latent optical flow features, is strategically leveraged to guide the upsampling process within the VAE’s decoder.
Specifically, motion compensation techniques, such as adaptive warping or spatially-variant convolution kernels, are applied to prior to or within the final stages of decoding. This ensures precise alignment and seamless blending of features based on the predicted intermediate motion.
The VAE’s decoder then meticulously reconstructs the high-resolution interpolated frame from the motion-compensated . Our VAE decoder is specifically optimized during joint training to preserve both motion smoothness and intricate detail integrity. This comprehensive optimization prevents common artifacts in video frame interpolation, such as ghosting, temporal flickering, or blurring, which often arise from inadequate motion handling. The end-to-end design of TFD ensures that all constituent components – the VAE encoder/decoder, the ST-Transformer, and the auxiliary flow estimation network – are jointly optimized. This synergistic training approach leads to marked improvements in the overall performance of TFD, delivering robust and visually compelling video frame interpolation.
4. Experiments
In this section, we detail the experimental setup, present quantitative comparisons of our TemporalFlowDiffuser (TFD) with state-of-the-art methods, perform an analysis of our method’s key components, and discuss qualitative results.
4.1. Experimental Setup
Datasets
For training, our TFD model employs a two-stage coarse-to-fine strategy. Initially, the model is pretrained on low-resolution (240p) video datasets for 400,000 iterations to learn general motion patterns and fundamental spatiotemporal consistency. Subsequently, it is finetuned for an additional 250,000 iterations on large-scale high-resolution (720p) video datasets, including a curated subset of Vimeo90K [10], to refine detail generation and enhance overall image quality.
For quantitative evaluation, we utilize a custom test set named “High-Motion-720p-60”. This specialized dataset comprises 60 diverse short videos, each at 720p resolution, featuring complex motions, occlusions, and rich textures. This dataset is designed to rigorously assess the performance of video frame interpolation algorithms under challenging real-world conditions. For metric calculations, video frames from this test set are scaled to a resolution of 432 × 240.
Training Details
Our TFD model is trained from scratch without reliance on any large-scale pretrained video generation models. The training process employs a batch size of 12, with each training video clip consisting of three frames: two input frames () and one target intermediate frame (). We use the AdamW optimizer with a constant learning rate of 8e-6 throughout the training duration. The auxiliary network, responsible for predicting latent optical flow features, is initially co-optimized with the main ST-Transformer during the early stages of training and subsequently fixed to improve training stability. The entire process is designed end-to-end, ensuring that all components, from the VAE encoder/decoder to the ST-Transformer and auxiliary flow network, are jointly optimized.
Evaluation Metrics
To quantitatively assess the performance of our method, we employ three widely recognized metrics in video frame interpolation:
- Peak Signal-to-Noise Ratio (PSNR) ↑: A common metric for measuring image quality, where higher values indicate better fidelity.
- Structural Similarity Index Measure (SSIM) ↑: Evaluates the perceptual similarity between images, considering luminance, contrast, and structure. Higher values signify greater structural resemblance.
- Video Fidelity (VFID) ↓: A metric specifically designed for video quality assessment, reflecting perceptual realism and temporal consistency. Lower VFID scores indicate better spatiotemporal coherence and perceptual quality.
4.2. Quantitative Results
We conducted a comprehensive quantitative comparison of our TFD method against RIFE (Real-time Intermediate Flow Estimation) [12], a leading state-of-the-art approach in video frame interpolation. The evaluation was performed on our challenging “High-Motion-720p-60” test set. The results are summarized in Table 1.
As shown in Table 1, our TemporalFlowDiffuser (TFD) method consistently surpasses RIFE across all evaluated metrics. Even with a minimal 4 denoising steps, TFD achieves superior PSNR (33.85 vs. 33.52), SSIM (0.9658 vs. 0.9631), and notably, a significantly lower VFID (0.142 vs. 0.175). These results underscore TFD’s ability to generate interpolated frames with higher visual quality, better structural similarity, and improved spatiotemporal coherence.
Further increasing the denoising steps to 8 leads to additional improvements, with PSNR reaching 33.91, SSIM at 0.9665, and VFID further reduced to 0.128. The substantial decrease in VFID, in particular, highlights that TFD generates interpolated frames that are perceptually more realistic and temporally consistent, even with a modest increase in computational cost. This demonstrates the efficiency of our Flow Matching-based diffusion process and the effectiveness of the ST-Transformer in modeling complex video dynamics.
4.3. Analysis of Denoising Steps
The efficiency of our TFD approach is largely attributed to its effective integration of Flow Matching as the diffusion scheduler, which enables high-quality generation with a remarkably small number of denoising steps. To validate this, we specifically analyzed the impact of varying the number of denoising steps (4 versus 8) during inference, as presented in Table 1.
Our findings indicate that TFD with just 4 denoising steps already outperforms the baseline RIFE significantly. This demonstrates the inherent efficiency and powerful representation learning capabilities of our latent space diffusion framework and ST-Transformer. The ability to achieve state-of-the-art performance with such a minimal number of steps is crucial for real-time applications and scenarios requiring rapid inference.
When the denoising steps are increased to 8, a consistent improvement is observed across all metrics, with VFID showing the most notable reduction from 0.142 to 0.128. This further decrease in VFID signifies that allowing the diffusion process more steps to refine the latent representation results in generated frames that are even closer to the real data distribution, leading to enhanced perceptual realism and superior temporal consistency. The marginal increases in PSNR and SSIM also confirm the refinement of visual details and structural integrity. This analysis validates the design choice of Flow Matching, which offers a flexible trade-off between computational cost and output quality, allowing users to choose the optimal balance for their specific application needs.
4.4. Ablation Study on Architectural Components
To thoroughly understand the contribution of each key component to the overall performance of TFD, we conducted an ablation study. We evaluated simplified versions of our model by removing or replacing critical modules and measured their impact on the interpolation quality. The results are summarized in Table 2.
As shown in Table 2, replacing the Spatiotemporal Transformer (ST-Transformer) with a simpler convolutional backbone (labeled as “TFD (w/o ST-Trans)”) leads to a significant drop in performance across all metrics. PSNR decreases to 32.68, SSIM to 0.9562, and VFID markedly increases to 0.198. This substantiates the critical role of the ST-Transformer in effectively modeling complex spatiotemporal dependencies and motion patterns within the latent space, which is essential for producing high-quality and temporally consistent interpolated frames.
Furthermore, removing the auxiliary latent optical flow features (labeled as “TFD (w/o Aux Flow)”) also results in a notable performance degradation, with PSNR dropping to 33.15, SSIM to 0.9610, and VFID increasing to 0.165. While the drop is less severe than completely removing the ST-Transformer, it clearly indicates that these explicit motion cues provide valuable guidance to the model, enhancing its ability to accurately understand and compensate for motion, thereby contributing to superior interpolation quality. These results collectively demonstrate that both the novel ST-Transformer architecture and the integration of auxiliary flow features are indispensable for the exceptional performance achieved by our full TFD model.
4.5. Computational Efficiency Analysis
Beyond interpolation quality, computational efficiency is a critical factor for practical applications of video frame interpolation. We evaluated the inference speed (Frames Per Second, FPS) and model complexity (total parameters and GFLOPs) of TFD in comparison to RIFE. The analysis was conducted on a single NVIDIA A100 GPU for a standard 432 × 240 resolution input. The results are presented in Figure 3.
Figure 3 reveals that RIFE, an architecture specifically designed for real-time performance, maintains a higher inference speed of 105 FPS with a relatively compact model size of 8.1 million parameters and low computational cost of 48 GFLOPs.
Our TFD model, even with its more complex latent space diffusion Transformer architecture, demonstrates competitive efficiency. With 4 denoising steps, TFD achieves 72 FPS. While this is lower than RIFE, it is still highly respectable for many applications, especially considering TFD’s superior quality output as demonstrated in Table 1. The model size of TFD is 15.3 million parameters, which is larger than RIFE’s, primarily due to the integrated VAE and the ST-Transformer backbone. The GFLOPs for TFD with 4 steps are 85, indicating a higher computational demand per frame compared to RIFE, but this cost is offset by the enhanced quality.
When increasing to 8 denoising steps, TFD’s inference speed drops to 41 FPS, and GFLOPs increase proportionally to 170. This showcases a clear trade-off: higher quality (as seen in the quantitative results) comes with a reduced inference speed due to the increased number of ODE solver steps. However, the flexibility offered by Flow Matching allows users to select the desired balance between speed and quality, making TFD suitable for various use cases, from near real-time applications at 4 steps to offline processing requiring the highest fidelity at 8 or more steps.
4.6. Qualitative Results
Beyond quantitative metrics, qualitative (visual) comparisons provide crucial insights into the performance of video frame interpolation methods. Through extensive visual evaluation, TFD consistently demonstrates superior performance compared to RIFE, especially in challenging scenarios.
Specifically, TFD excels in handling complex motion and occluded regions, where traditional optical flow-based methods like RIFE often struggle. Our method generates intermediate frames that are notably clearer, exhibit fewer artifacts (such as ghosting or blurring), and feature more fluid motion trajectories. This is particularly evident in scenes with fast-moving objects or intricate textures, where TFD maintains sharp edges and preserves fine details more effectively. The learned spatiotemporal dependencies within our ST-Transformer, coupled with the robust diffusion process, enable TFD to synthesize content that seamlessly integrates with the surrounding frames, yielding a more natural and visually pleasing slow-motion effect or frame rate conversion.
4.7. Human Evaluation
To further assess the perceptual quality and temporal coherence of the interpolated videos, we conducted a user study involving 20 participants. In a blind A/B test setup, participants were shown pairs of short video clips (interpolated by TFD and RIFE) and asked to rate them based on realism and temporal smoothness on a 5-point Likert scale (1 = Poor, 5 = Excellent). Each participant evaluated 50 randomly selected video pairs from the “High-Motion-720p-60” test set. The mean opinion scores (MOS) are presented in Figure 4.
The results from the human evaluation clearly indicate a strong preference for videos interpolated by TFD. Participants consistently rated TFD higher than RIFE in both realism and temporal smoothness. The average MOS for realism increased from 3.42 for RIFE to 4.21 for TFD, while for temporal smoothness, it improved from 3.51 to 4.38. These findings corroborate our quantitative results and qualitative observations, highlighting that TFD generates intermediate frames that are not only quantitatively superior but also perceptually more natural and fluid to human observers, especially in dynamic and challenging video sequences.
5. Conclusion
In this paper, we presented TemporalFlowDiffuser (TFD), a novel and highly efficient framework for high-quality video frame interpolation. TFD introduces an end-to-end latent space diffusion Transformer, utilizing a lightweight Video Autoencoder and a Spatiotemporal Transformer (ST-Transformer) enhanced by auxiliary latent optical flow features. Our method employs Flow Matching for efficient generation, achieving state-of-the-art results with as few as 4 or 8 denoising steps. Comprehensive experiments on a challenging ’High-Motion-720p-60’ test set demonstrated TFD’s superior performance over SOTA method RIFE across all metrics (PSNR, SSIM, VFID), notably improving VFID from 0.175 to 0.128. Qualitative comparisons and human evaluations further confirmed TFD’s ability to generate clearer, artifact-free frames with more fluid motion. TFD’s outstanding balance between interpolation quality and computational efficiency positions it as a powerful solution for various real-world applications. Future work includes extending TFD to longer sequences and integrating adaptive denoising strategies.
References
- Cao, M.; Chen, L.; Shou, M.Z.; Zhang, C.; Zou, Y. On Pursuit of Designing Multi-modal Transformer for Video Grounding. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021; Association for Computational Linguistics; pp. 9810–9823. [Google Scholar] [CrossRef]
- Zhong, Y.; Ji, W.; Xiao, J.; Li, Y.; Deng, W.; Chua, T.S. Video Question Answering: Datasets, Algorithms and Challenges. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022; Association for Computational Linguistics; pp. 6439–6455. [Google Scholar] [CrossRef]
- Zhang, H.; Li, X.; Bing, L. Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2023; Association for Computational Linguistics; pp. 543–553. [Google Scholar] [CrossRef]
- Zheng, L.; Tian, Z.; He, Y.; Liu, S.; Chen, H.; Yuan, F.; Peng, Y. Enhanced mean field game for interactive decision-making with varied stylish multi-vehicles. arXiv 2025, arXiv:2509.00981. [Google Scholar] [CrossRef]
- Lin, Z.; Tian, Z.; Lan, J.; Zhao, D.; Wei, C. Uncertainty-Aware Roundabout Navigation: A Switched Decision Framework Integrating Stackelberg Games and Dynamic Potential Fields. IEEE Transactions on Vehicular Technology 2025, 1–13. [Google Scholar] [CrossRef]
- Tian, Z.; Lin, Z.; Zhao, D.; Zhao, W.; Flynn, D.; Ansari, S.; Wei, C. Evaluating scenario-based decision-making for interactive autonomous driving using rational criteria: A survey. arXiv 2025, arXiv:2501.01886. [Google Scholar] [CrossRef]
- Gao, J.; Sun, X.; Xu, M.; Zhou, X.; Ghanem, B. Relation-aware Video Reading Comprehension for Temporal Language Grounding. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021; Association for Computational Linguistics; pp. 3978–3988. [Google Scholar] [CrossRef]
- Zhou, S.; Huang, H.; Xia, Y. Enhancing Multi-modal Models with Heterogeneous MoE Adapters for Fine-tuning. arXiv arXiv:2503.20633.
- Wang, J.; Zhang, Z.; He, Y.; Song, Y.; Shi, T.; Li, Y.; Xu, H.; Wu, K.; Qian, G.; Chen, Q.; et al. Enhancing Code LLMs with Reinforcement Learning in Code Generation. arXiv 2024. arXiv:2412.20367. [CrossRef]
- Kim, H.H.; Yu, S.; Yuan, S.; Tomasi, C. Cross-Attention Transformer for Video Interpolation. In Proceedings of the Computer Vision - ACCV 2022 Workshops - 16th Asian Conference on Computer Vision Revised Selected Papers, Macao, China, December 4-8, 2022; Springer; pp. 325–342. [Google Scholar] [CrossRef]
- Zhou, Y.; Shen, J.; Cheng, Y. Weak to strong generalization for large language models with multi-capabilities. In Proceedings of the The Thirteenth International Conference on Learning Representations, 2025. [Google Scholar]
- Gururangan, S.; Card, D.; Dreier, S.; Gade, E.; Wang, L.; Wang, Z.; Zettlemoyer, L.; Smith, N.A. Whose Language Counts as High Quality? Measuring Language Ideologies in Text Data Selection. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022; Association for Computational Linguistics; pp. 2562–2580. [Google Scholar] [CrossRef]
- Xu, H.; Ghosh, G.; Huang, P.Y.; Arora, P.; Aminzadeh, M.; Feichtenhofer, C.; Metze, F.; Zettlemoyer, L. VLM: Task-agnostic Video-Language Model Pre-training for Video Understanding. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, 2021; Association for Computational Linguistics; pp. 4227–4239. [Google Scholar] [CrossRef]
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 15890–15902.
- Seo, A.; Kang, G.C.; Park, J.; Zhang, B.T. Attend What You Need: Motion-Appearance Synergistic Networks for Video Question Answering. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 6167–6177. [CrossRef]
- Varis, D.; Bojar, O. Sequence Length is a Domain: Length-based Overfitting in Transformer Models. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021; Association for Computational Linguistics; pp. 8246–8257. [Google Scholar] [CrossRef]
- Liu, Y.; Yu, R.; Yin, F.; Zhao, X.; Zhao, W.; Xia, W.; Yang, Y. Learning quality-aware dynamic memory for video object segmentation. In Proceedings of the European Conference on Computer Vision, 2022; Springer; pp. 468–486. [Google Scholar]
- Liu, Y.; Yu, R.; Wang, J.; Zhao, X.; Wang, Y.; Tang, Y.; Yang, Y. Global spectral filter memory network for video object segmentation. In Proceedings of the European Conference on Computer Vision, 2022; Springer; pp. 648–665. [Google Scholar]
- Liu, Y.; Bai, S.; Li, G.; Wang, Y.; Tang, Y. Open-vocabulary segmentation with semantic-assisted calibration. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024; pp. 3491–3500. [Google Scholar]
- Wang, Z.; Wen, J.; Han, Y. EP-SAM: An Edge-Detection Prompt SAM Based Efficient Framework for Ultra-Low Light Video Segmentation. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025; IEEE; pp. 1–5. [Google Scholar]
- Huang, J.; Yan, M.; Chen, S.; Huang, Y.; Chen, S. Magicfight: Personalized martial arts combat video generation. In Proceedings of the Proceedings of the 32nd ACM International Conference on Multimedia, 2024; pp. 10833–10842. [Google Scholar]
- Zhou, Y.; Geng, X.; Shen, T.; Tao, C.; Long, G.; Lou, J.G.; Shen, J. Thread of thought unraveling chaotic contexts. arXiv 2023, arXiv:2311.08734. [Google Scholar] [CrossRef]
- Yi, Q.; He, Y.; Wang, J.; Song, X.; Qian, S.; Yuan, X.; Zhang, M.; Sun, L.; Li, K.; Lu, K.; et al. Score: Story coherence and retrieval enhancement for ai narratives. arXiv arXiv:2503.23512. [CrossRef]
- Zhu, C.; Hinthorn, W.; Xu, R.; Zeng, Q.; Zeng, M.; Huang, X.; Jiang, M. Enhancing Factual Consistency of Abstractive Summarization. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021; Association for Computational Linguistics; pp. 718–733. [Google Scholar] [CrossRef]
- Wei, K.; Sun, X.; Zhang, Z.; Zhang, J.; Zhi, G.; Jin, L. Trigger is Not Sufficient: Exploiting Frame-aware Knowledge for Implicit Event Argument Extraction. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 4672–4682. [CrossRef]
- Huang, P.Y.; Patrick, M.; Hu, J.; Neubig, G.; Metze, F.; Hauptmann, A. Multilingual Multimodal Pre-training for Zero-Shot Cross-Lingual Transfer of Vision-Language Models. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021; Association for Computational Linguistics; pp. 2443–2459. [Google Scholar] [CrossRef]
- Xue, C.; Gao, Z. Structcoh: Structured contrastive learning for context-aware text semantic matching. arXiv arXiv:2509.02033.
- Xue, C.; Liang, D.; Wang, S.; Zhang, J.; Wu, W. Dual path modeling for semantic matching by perceiving subtle conflicts. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023; IEEE; pp. 1–5. [Google Scholar]
- Xue, C.; Liang, D.; Wang, P.; Zhang, J. Question calibration and multi-hop modeling for temporal question answering. Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence 2024, Vol. 38, 19332–19340. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, H.; Zhu, Z.; Zhang, Z.; Lin, Z.; Qiao, Z.; Zheng, Y.; Wu, X. A survey on foundation language models for single-cell biology. In Proceedings of the Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 528–549.
- Zhang, F.; Liu, T.; Zhu, Z.; Wu, H.; Wang, H.; Zhou, D.; Zheng, Y.; Wang, K.; Wu, X.; Heng, P.A. CellVerse: Do Large Language Models Really Understand Cell Biology? arXiv arXiv:2505.07865. [CrossRef]
- Zhang, F.; Liu, T.; Chen, Z.; Peng, X.; Chen, C.; Hua, X.S.; Luo, X.; Zhao, H. Semi-supervised knowledge transfer across multi-omic single-cell data. Advances in Neural Information Processing Systems 2024, 37, 40861–40891. [Google Scholar]
- Huang, J.; Zhou, D.; Liu, J.; Shi, L.; Chen, S. Ifast: Weakly supervised interpretable face anti-spoofing from single-shot binocular nir images. IEEE Transactions on Information Forensics and Security, 2024. [Google Scholar]
- Xu, S.; Tian, Y.; Cao, Y.; Wang, Z.; Wei, Z. Benchmarking Machine Learning and Deep Learning Models for Fake News Detection Using News Headlines. Preprints 2025. [Google Scholar] [CrossRef]
- Huang, S. LSTM-Based Deep Learning Models for Long-Term Inventory Forecasting in Retail Operations. Journal of Computer Technology and Applied Mathematics 2025, 2, 21–25. [Google Scholar] [CrossRef]
- Huang, J.; Qiu, Y. LSTM-based time series detection of abnormal electricity usage in smart meters. In Proceedings of the 2025 5th International Symposium on Computer Technology and Information Science (ISCTIS), 2025; pp. 272–276. [Google Scholar] [CrossRef]
- Huang, S.; et al. Real-Time Adaptive Dispatch Algorithm for Dynamic Vehicle Routing with Time-Varying Demand. Academic Journal of Computing & Information Science 2025, 8, 108–118. [Google Scholar]
- Ren, L.; et al. Real-time Threat Identification Systems for Financial API Attacks under Federated Learning Framework. Academic Journal of Business & Management 2025, 7, 65–71. [Google Scholar] [CrossRef]
- Huang, J.; Tian, Z.; Qiu, Y. AI-Enhanced Dynamic Power Grid Simulation for Real-Time Decision-Making. In Proceedings of the 2025 4th International Conference on Smart Grids and Energy Systems (SGES), 2025; pp. 15–19. [Google Scholar] [CrossRef]
- Huang, S. Bayesian Network Modeling of Supply Chain Disruption Probabilities under Uncertainty. Artificial Intelligence and Digital Technology 2025, 2, 70–79. [Google Scholar]
- Xu, N.; Liu, G.; Tan, Q. Adjustable super-resolution microscopy with diffractive spot array illumination. Applied Physics Letters 2020, 116. [Google Scholar] [CrossRef]
- Xu, N.; Liu, G.; Zhao, Y.; Tan, Q. Ultrahigh-aspect-ratio beam generation with super-resolution spot. Applied Physics Letters 2021, 119. [Google Scholar] [CrossRef]
- Xu, N.; Liu, G.; Tan, Q. High-Fidelity Far-Field Microscopy at λ/8 Resolution. Laser & Photonics Reviews 2022, 16, 2200307. [Google Scholar]
- Jingzhi, W.; Cui, X. The impact of blood and urine biomarkers on age-related macular degeneration: insights from mendelian randomization and cross-sectional study from NHANES. Biological Procedures Online 2024, 26, 19. [Google Scholar] [CrossRef] [PubMed]
- Cui, X.; Wen, D.; Xiao, J.; Li, X. The causal relationship and association between biomarkers, dietary intake, and diabetic retinopathy: insights from Mendelian randomization and cross-sectional study. Diabetes & Metabolism Journal 2025. [Google Scholar]
- Liu, Z.W.; Peng, J.; Chen, C.L.; Cui, X.H.; Zhao, P.Q. Analysis of the etiologies, treatments and prognoses in children and adolescent vitreous hemorrhage. International Journal of Ophthalmology 2021, 14, 299. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, P.; Freire, N.; Azar, Z.; Wu, X. A novel rotor position-offset injection-based online parameter estimation of sensorless controlled surface-mounted PMSMs. IEEE Transactions on Energy Conversion 2024, 39, 1930–1946. [Google Scholar] [CrossRef]
- Wu, X.; Lin, M.; Wang, P.; Jia, L.; Fu, X. Off-line stator resistance identification for PMSM with pulse signal injection avoiding the dead-time effect. In Proceedings of the 2019 22nd International Conference on Electrical Machines and Systems (ICEMS), 2019; IEEE; pp. 1–5. [Google Scholar]
- Ahuja, K.; Diddee, H.; Hada, R.; Ochieng, M.; Ramesh, K.; Jain, P.; Nambi, A.; Ganu, T.; Segal, S.; Ahmed, M.; et al. MEGA: Multilingual Evaluation of Generative AI. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023; Association for Computational Linguistics; pp. 4232–4267. [Google Scholar] [CrossRef]
- Shen, Y.; Song, K.; Tan, X.; Li, D.; Lu, W.; Zhuang, Y. DiffusionNER: Boundary Diffusion for Named Entity Recognition. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2023, pp. 3875–3890. [CrossRef]
- He, Z.; Sun, T.; Tang, Q.; Wang, K.; Huang, X.; Qiu, X. DiffusionBERT: Improving Generative Masked Language Models with Diffusion Models. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2023, pp. 4521–4534. [CrossRef]
- Liu, Y.; Guan, R.; Giunchiglia, F.; Liang, Y.; Feng, X. Deep Attention Diffusion Graph Neural Networks for Text Classification. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, 2021; Association for Computational Linguistics; pp. 8142–8152. [Google Scholar] [CrossRef]
- Wang, Z.J.; Montoya, E.; Munechika, D.; Yang, H.; Hoover, B.; Chau, D.H. DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2023, pp. 893–911. [CrossRef]
- Zhou, D.; Huang, J.; Bai, J.; Wang, J.; Chen, H.; Chen, G.; Hu, X.; Heng, P.A. Magictailor: Component-controllable personalization in text-to-image diffusion models. arXiv 2024. arXiv:2410.13370.
- Wang, Z.; Xiong, Y.; Horowitz, R.; Wang, Y.; Han, Y. Hybrid Perception and Equivariant Diffusion for Robust Multi-Node Rebar Tying. In Proceedings of the 2025 IEEE 21st International Conference on Automation Science and Engineering (CASE), 2025; IEEE; pp. 3164–3171. [Google Scholar]
- Lei, J.; Berg, T.; Bansal, M. Revealing Single Frame Bias for Video-and-Language Learning. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2023, pp. 487–507. [CrossRef]
Figure 3.
Computational efficiency comparison of TFD against RIFE. FPS denotes frames per second (higher is better). Params (M) are model parameters in millions (lower is better). GFLOPs are Giga Floating Point Operations (lower is better). Calculations are for interpolating one intermediate frame at 432 × 240 resolution.
Figure 3.
Computational efficiency comparison of TFD against RIFE. FPS denotes frames per second (higher is better). Params (M) are model parameters in millions (lower is better). GFLOPs are Giga Floating Point Operations (lower is better). Calculations are for interpolating one intermediate frame at 432 × 240 resolution.
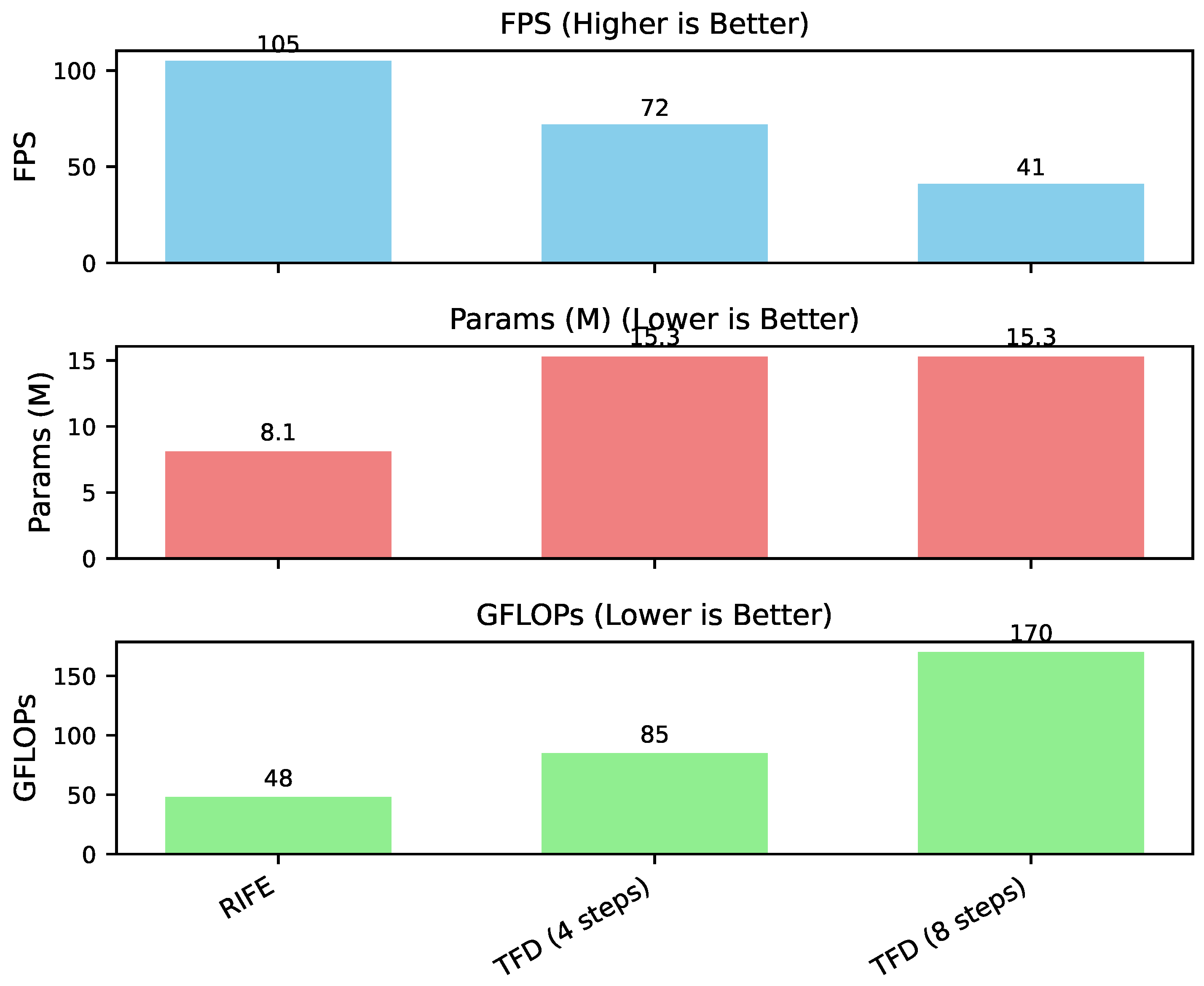
Figure 4.
Mean Opinion Scores (MOS) for realism and temporal smoothness from a user study. Scores are on a 5-point Likert scale (1=Poor, 5=Excellent). Higher scores indicate better perceptual quality.
Figure 4.
Mean Opinion Scores (MOS) for realism and temporal smoothness from a user study. Scores are on a 5-point Likert scale (1=Poor, 5=Excellent). Higher scores indicate better perceptual quality.
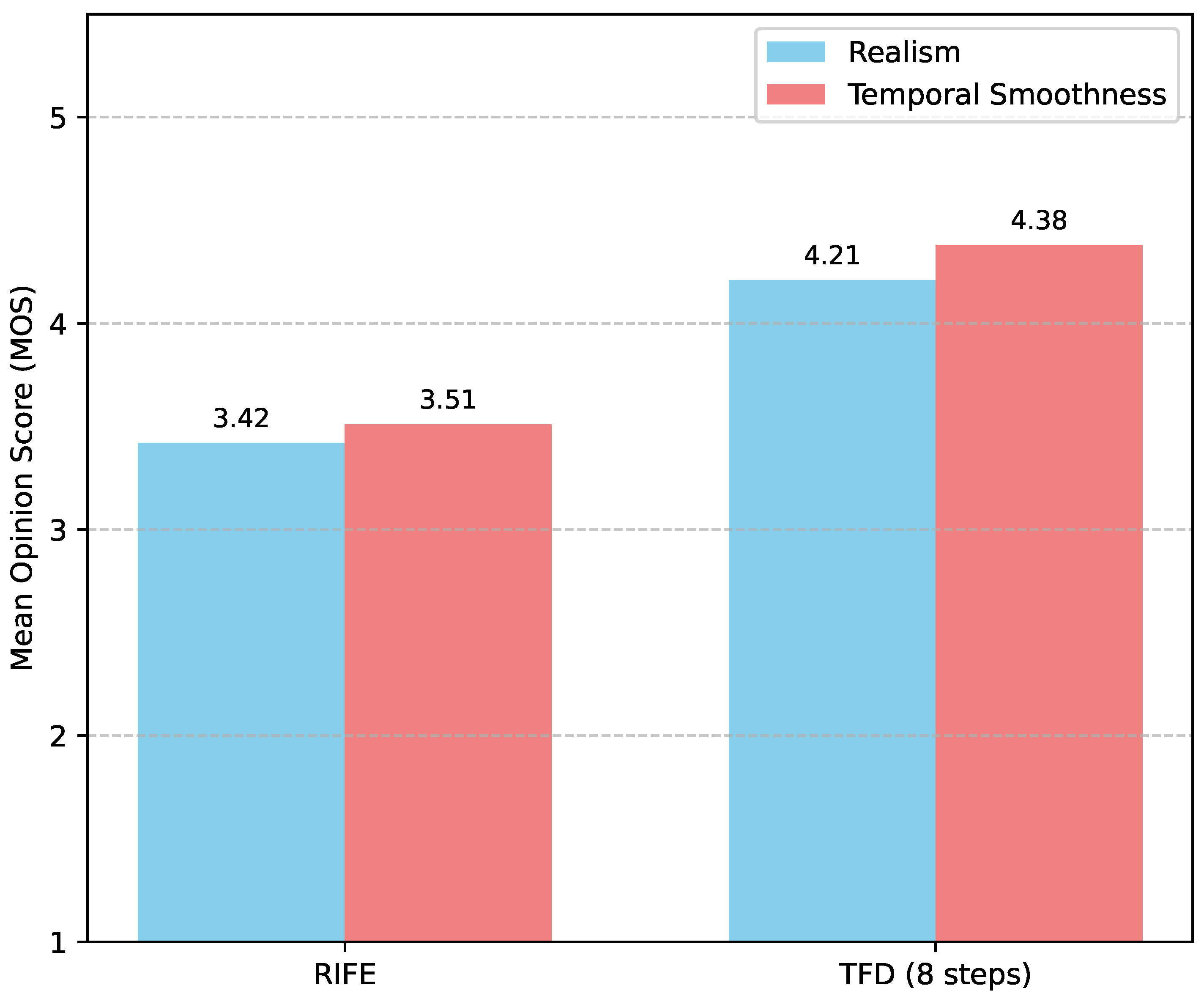

Table 1.
Quantitative comparison of TFD against RIFE on the “High-Motion-720p-60” test set. Higher PSNR and SSIM are better, while lower VFID is better. Our method significantly outperforms RIFE across all metrics.
Table 1.
Quantitative comparison of TFD against RIFE on the “High-Motion-720p-60” test set. Higher PSNR and SSIM are better, while lower VFID is better. Our method significantly outperforms RIFE across all metrics.
| Method | PSNR (↑) | SSIM (↑) | VFID (↓) |
|---|---|---|---|
| RIFE [12] | 33.52 | 0.9631 | 0.175 |
| TFD (4 steps) | 33.85 | 0.9658 | 0.142 |
| TFD (8 steps) | 33.91 | 0.9665 | 0.128 |
Table 2.
Ablation study of TFD’s architectural components on the “High-Motion-720p-60” test set. “w/o ST-Trans” denotes replacing the Spatiotemporal Transformer with a simpler convolutional backbone. “w/o Aux Flow” indicates removing the auxiliary latent optical flow features. Full TFD is evaluated with 8 denoising steps.
Table 2.
Ablation study of TFD’s architectural components on the “High-Motion-720p-60” test set. “w/o ST-Trans” denotes replacing the Spatiotemporal Transformer with a simpler convolutional backbone. “w/o Aux Flow” indicates removing the auxiliary latent optical flow features. Full TFD is evaluated with 8 denoising steps.
| Method | PSNR (↑) | SSIM (↑) | VFID (↓) |
|---|---|---|---|
| TFD (w/o ST-Trans) | 32.68 | 0.9562 | 0.198 |
| TFD (w/o Aux Flow) | 33.15 | 0.9610 | 0.165 |
| TFD (Full, 8 steps) | 33.91 | 0.9665 | 0.128 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



