Submitted:
07 December 2025
Posted:
09 December 2025
You are already at the latest version
Abstract
Fixed effects models often rely on the within transformation, which constructs demeaned
arrays prior to forming cross-products. This paper develops an estimator that avoids the for-
mation of demeaned arrays by exploiting grouped summaries built from per-unit sufficient
statistics. A complete derivation shows that the grouped Gram representation reproduces the
classical estimator exactly. The difference lies in memory access patterns and byte movement.
The grouped estimator concentrates operations into unit-level accumulations, avoiding the
writes associated with array centering. Gains arise once the panel reaches a scale where mem-
ory traffic governs run time. Simulations examine coefficient accuracy, bootstrap dispersion,
run time, and memory use.
Keywords:
fixed effects
; panel data
; grouped Gram matrix
; within transformation
; computational econometrics
; memory-efficient algorithms
; high-dimensional estimation
MSC: 62J20; 62P20; 68W40
1. Introduction
Fixed effects models appear widely in empirical research. The standard approach applies the within transformation: subtract unit means from each observation and form cross-products from the transformed arrays. This is direct and compatible with linear algebra routines, yet the method reshapes the data and performs multiple passes across memory. These operations become costly once the panel grows large relative to cache or main memory bandwidth.
Grouped Gram representations avoid array centering by replacing the transformation with sufficient statistics. These statistics summarize each unit’s contribution with sums and cross-products. The result is mathematically identical to the classical estimator. The central distinction lies in the structure of the computation. Grouped summaries allow a single pass through the data while maintaining numerical precision.
The study draws on several literatures. Panel methods in econometrics provide the model foundations [1,9,12,19]. Matrix computation references outline the algebra of Gram matrices [3,6,7]. Work on cache behavior and communication bounds frames the memory analysis [5,8,11,18]. The bootstrap section relies on Cameron et al. [2], Davison Hinkley [4].
2. Setup and Notation
Units are indexed by and periods by . The model is
with covariates , unknown coefficient vector , and unit fixed effects .
Define
The within-transformed values are
The estimator is
3. Grouped Gram Representation
Let the grouped sums and cross-products be
3.1. Derivation of Gram Identities
Write
Then
Since
the terms combine to
The same logic applies to the cross-product:
3.2. Estimator Based on Grouped Summaries
Summing across units yields the estimator
which equals the within estimator in exact arithmetic.
4. Memory Path Differences
The within transformation forms and explicitly. Each assignment causes reads and writes across arrays of size . Since modern processors face bandwidth limitations [8,14], these memory operations dominate the floating point operations once n is large.
The grouped estimator performs a single pass through the data. For each i, the algorithm accumulates , , , and . The cross-product corrections rely on these summaries alone. This reduces memory traffic by avoiding write-back of centered arrays.
The roofline model [18] frames the method: algorithms with high byte movement relative to floating point work fall below peak performance. Since the fast estimator avoids array writes, its arithmetic intensity improves.
5. Numerical Considerations
Floating point paths differ due to summation order. Pairwise or block summation can reduce error [3]. The grouped estimator follows a block structure aligned with units. Since block sizes are often moderate, the structure helps numerical stability.
Computing the Gram matrix from demeaned arrays produces the same algebraic result but rearranges operations. Both methods reach the same minimizer.
6. Bootstrap Inference
Units form natural clusters. Cluster bootstrap draws unit indices with replacement and reconstructs the panel. The bootstrap estimator uses either (2) or (6). Since the grouped approach mirrors the original estimator’s structure, bootstrap dispersion remains stable across methods. The bootstrap references follow Cameron et al. [2] and Davison Hinkley [4].
7. Asymptotic Theory
The algebraic identities in (2)–(6) imply that both estimators share the same probability limit and asymptotic distribution. The statements below follow the standard fixed-effects framework, and cover two regimes.
Let denote the transformed error. Define
7.1. Panel Regime 1: Large N, Fixed T
We impose the usual regularity conditions for fixed-effects panels.
- (i)
- is independent across i and weakly dependent within units.
- (ii)
- .
- (iii)
- , a positive definite matrix.
- (iv)
- Fourth moments exist uniformly.
Theorem 1.
Under assumptions (i)–(iv) and fixed T,
where
Proof.
Both estimators rely on the same transformed score . The Gram identities guarantee equality of sample matrices. A Lindeberg argument for clusters yields the result. The full proof appears in Appendix G. □
7.2. Panel Regime 2: Large N, Large T
Let . Assume both with . Define
- (i)
- is weakly dependent across both indices.
- (ii)
- .
- (iii)
- , positive definite.
- (iv)
- A suitable mixing condition ensures a central limit theorem for the double array .
Theorem 2.
Under the assumptions above,
where Σ is the long-run covariance of .
Proof.
The grouped estimator rewrites the within estimator. Once the Gram identities hold, the score is identical. A central limit theorem for double arrays yields the stated limit. Formal steps appear in Appendix G. □
8. Simulation Design
Synthetic panels were generated with Gaussian regressors, noise, and unit effects. All panels were balanced with N units and T periods. Run time and memory use were measured for a grid of combinations.
9. Results
9.1. Computation Time as a Function of Sample Size
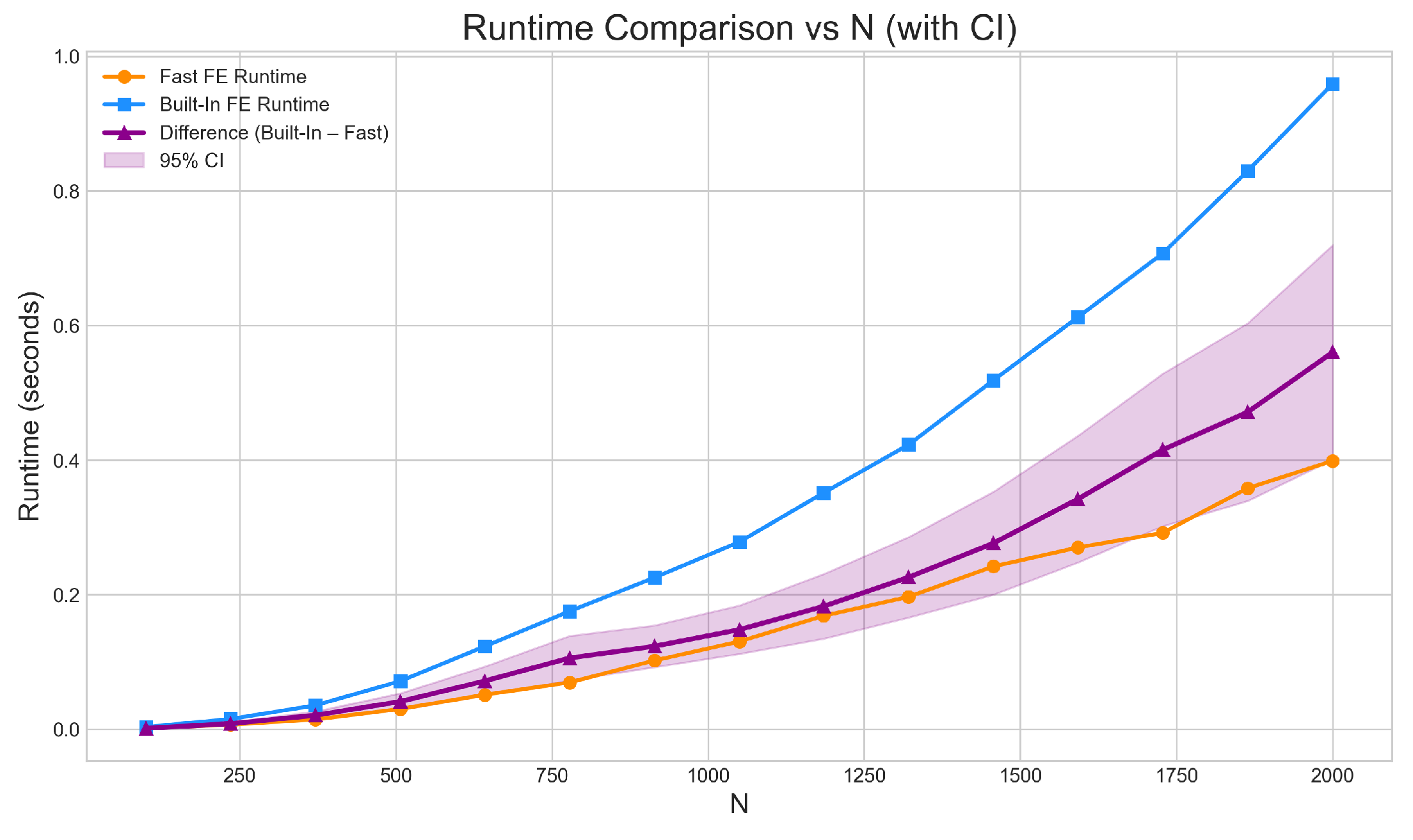
Figure 1.
Computation time for fe_fast and the demeaned estimator as the number of cross-sectional units N increases. Average run time rises for both estimators, with a steeper increase for the demeaned approach. fe_fast remains faster across the full range of N.
Figure 1.
Computation time for fe_fast and the demeaned estimator as the number of cross-sectional units N increases. Average run time rises for both estimators, with a steeper increase for the demeaned approach. fe_fast remains faster across the full range of N.
9.2. Computation Time as a Function of the Number of Periods
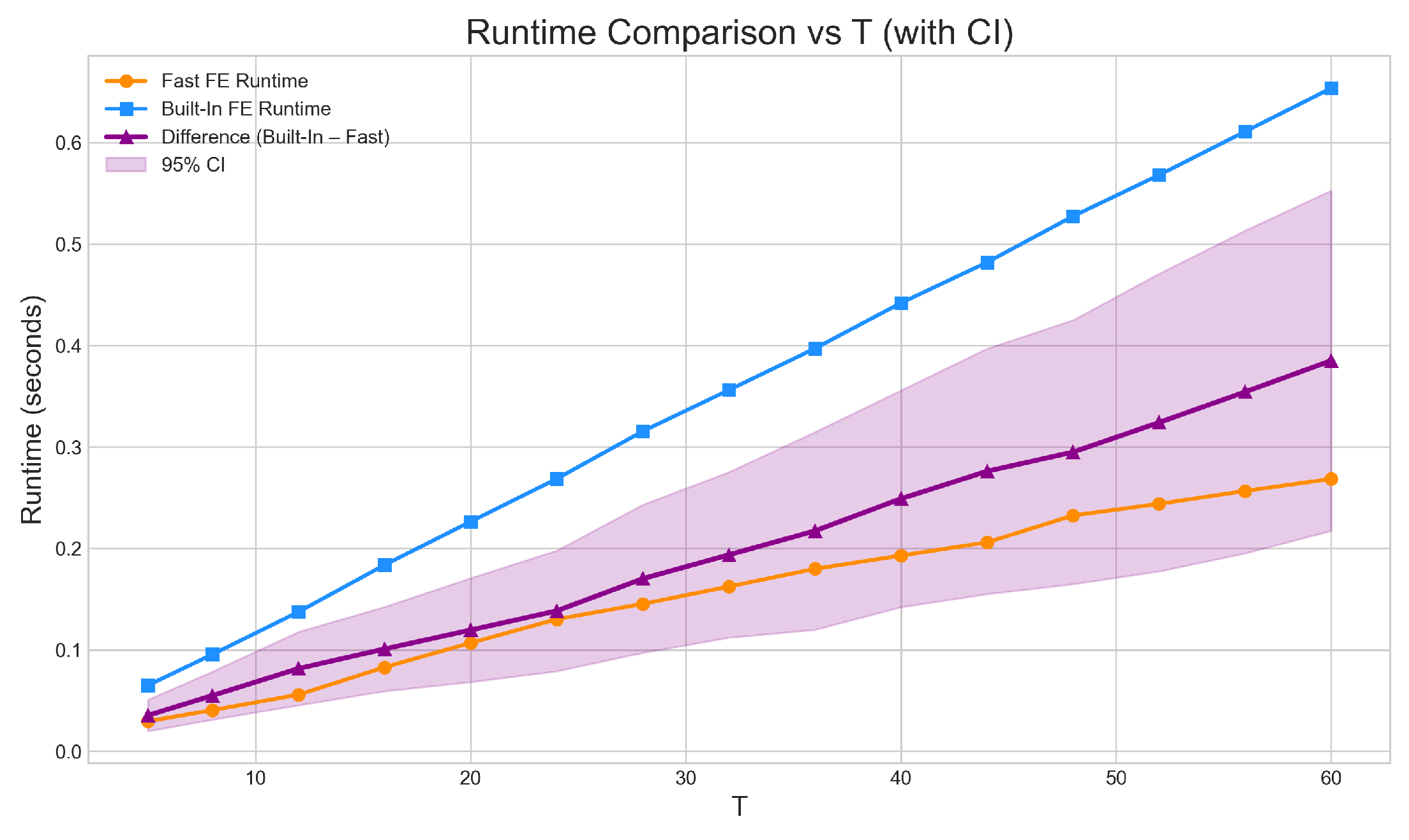
Figure 2.
Computation time for fe_fast and the demeaned estimator as the number of periods T increases. Both estimators require more computation as T grows, with a stronger rise in run time for the demeaned approach. fe_fast maintains a lower run time throughout the grid.
Figure 2.
Computation time for fe_fast and the demeaned estimator as the number of periods T increases. Both estimators require more computation as T grows, with a stronger rise in run time for the demeaned approach. fe_fast maintains a lower run time throughout the grid.
9.3. Computation Time Across Combinations
Figure 3.
Average run time of fe_fast across combinations of sample size N and number of periods T. Computation increases smoothly with panel size due to grouped matrix updates.
Figure 3.
Average run time of fe_fast across combinations of sample size N and number of periods T. Computation increases smoothly with panel size due to grouped matrix updates.
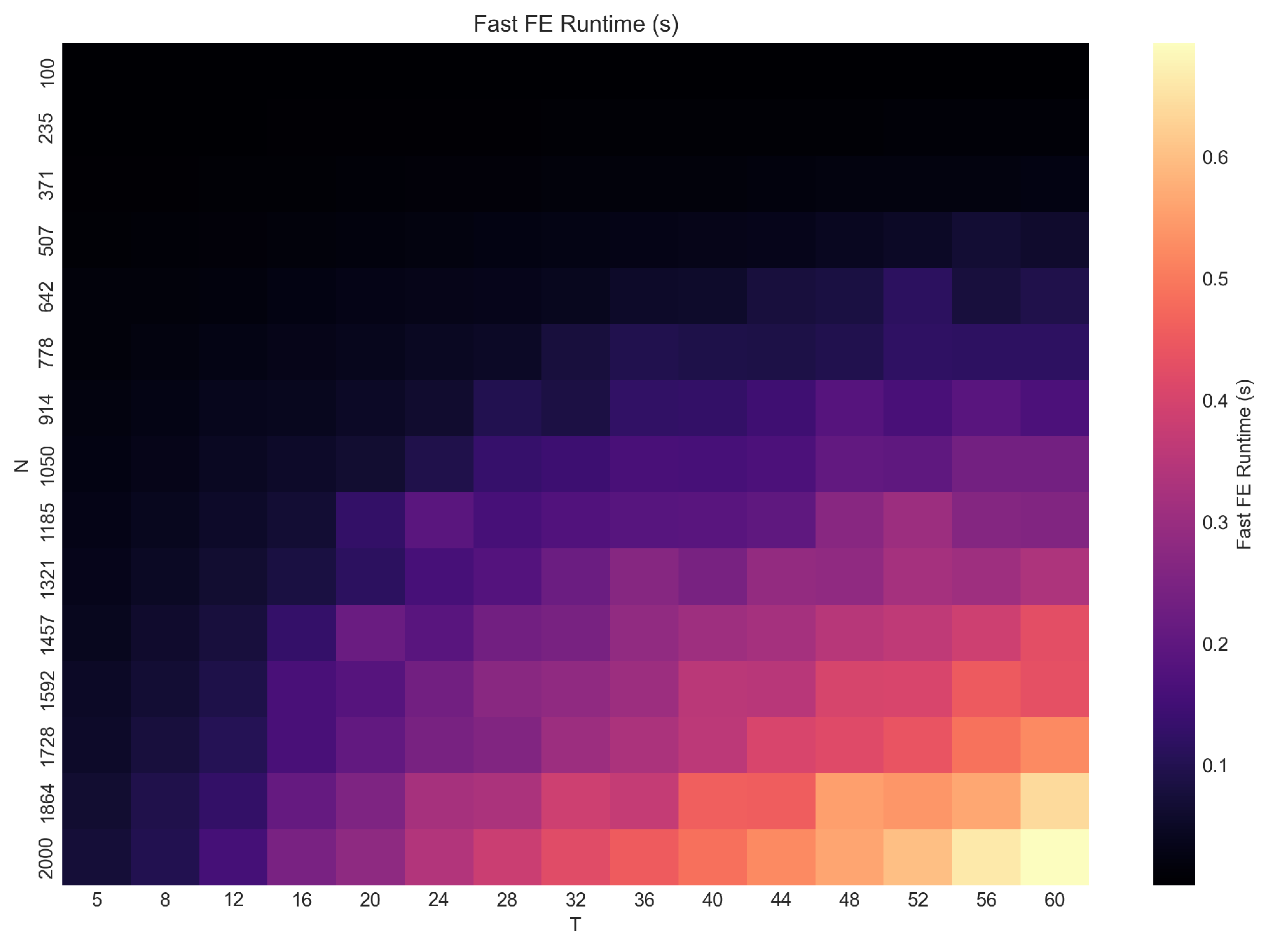
Figure 4.
Average run time of the demeaned estimator across . The required per-unit transformations lead to larger increases in run time relative to fe_fast, particularly when both N and T are large.
Figure 4.
Average run time of the demeaned estimator across . The required per-unit transformations lead to larger increases in run time relative to fe_fast, particularly when both N and T are large.
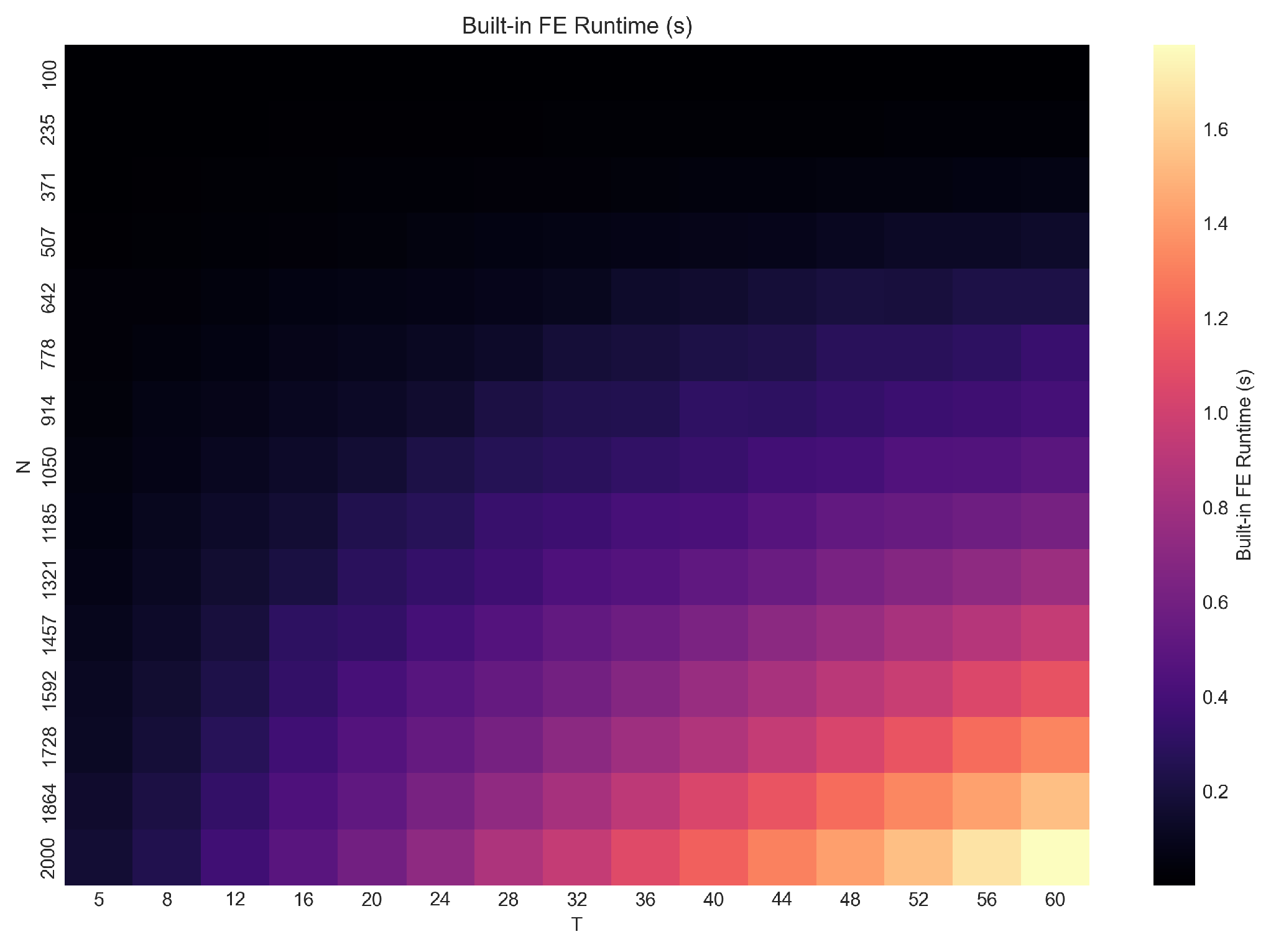
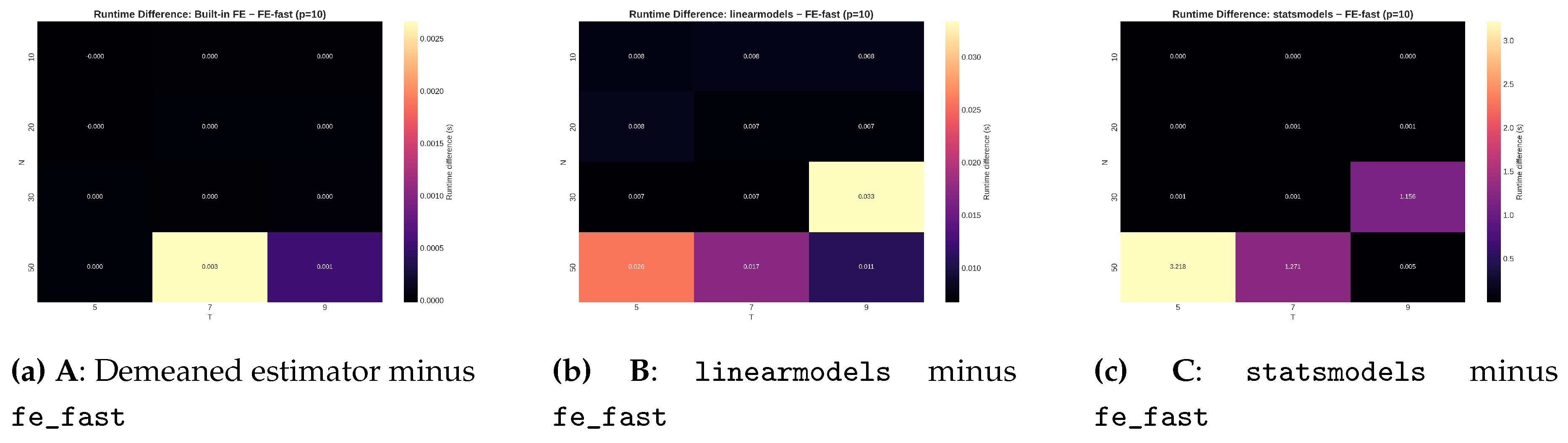
Figure 5.
Differences in run time relative to fe_fast for . Each panel reports the average difference in computation time across . Positive values indicate slower performance for the comparison estimator. The demeaned estimator (A) is slower throughout the grid. The linearmodels and statsmodels approaches (B, C) show larger delays due to block operations and dummy-variable expansions.
Figure 5.
Differences in run time relative to fe_fast for . Each panel reports the average difference in computation time across . Positive values indicate slower performance for the comparison estimator. The demeaned estimator (A) is slower throughout the grid. The linearmodels and statsmodels approaches (B, C) show larger delays due to block operations and dummy-variable expansions.
9.4. Memory Use Across Combinations
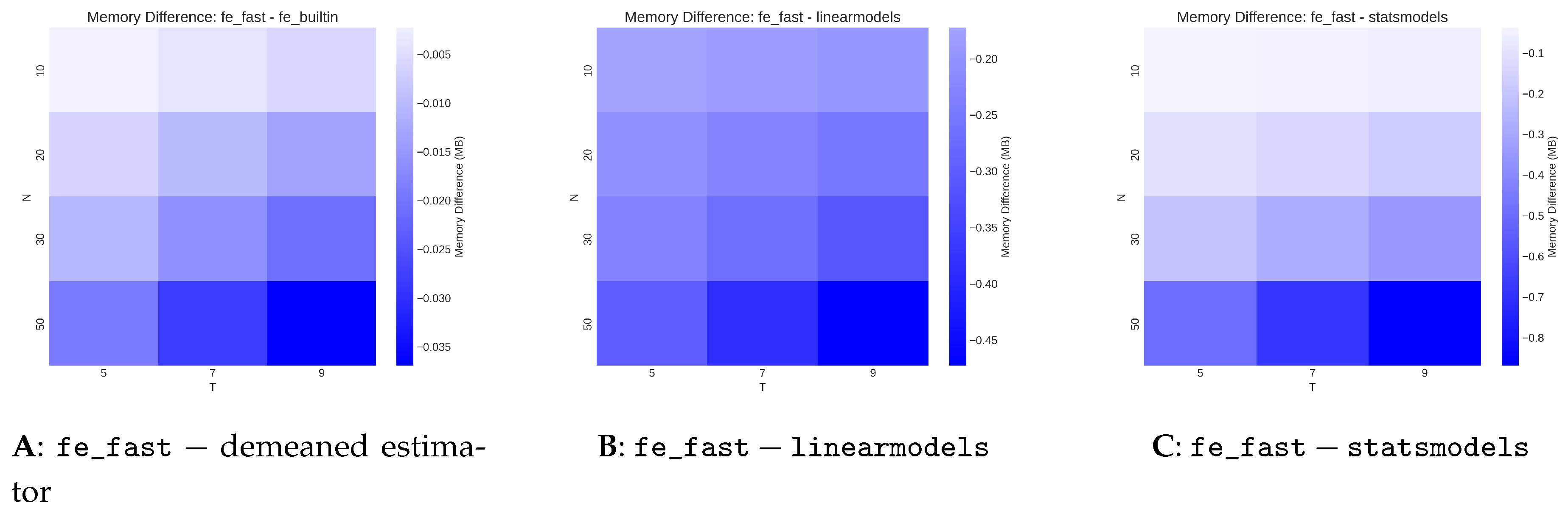
Figure 6.
Memory use of fe_fast relative to three alternative estimators for . Each panel reports the difference in memory consumption across . Negative values indicate lower memory use for fe_fast. The grouped estimator avoids repeated unit-level transformations and dummy construction, leading to lower use of temporary objects across nearly all settings.
Figure 6.
Memory use of fe_fast relative to three alternative estimators for . Each panel reports the difference in memory consumption across . Negative values indicate lower memory use for fe_fast. The grouped estimator avoids repeated unit-level transformations and dummy construction, leading to lower use of temporary objects across nearly all settings.
9.5. Coefficient Differences
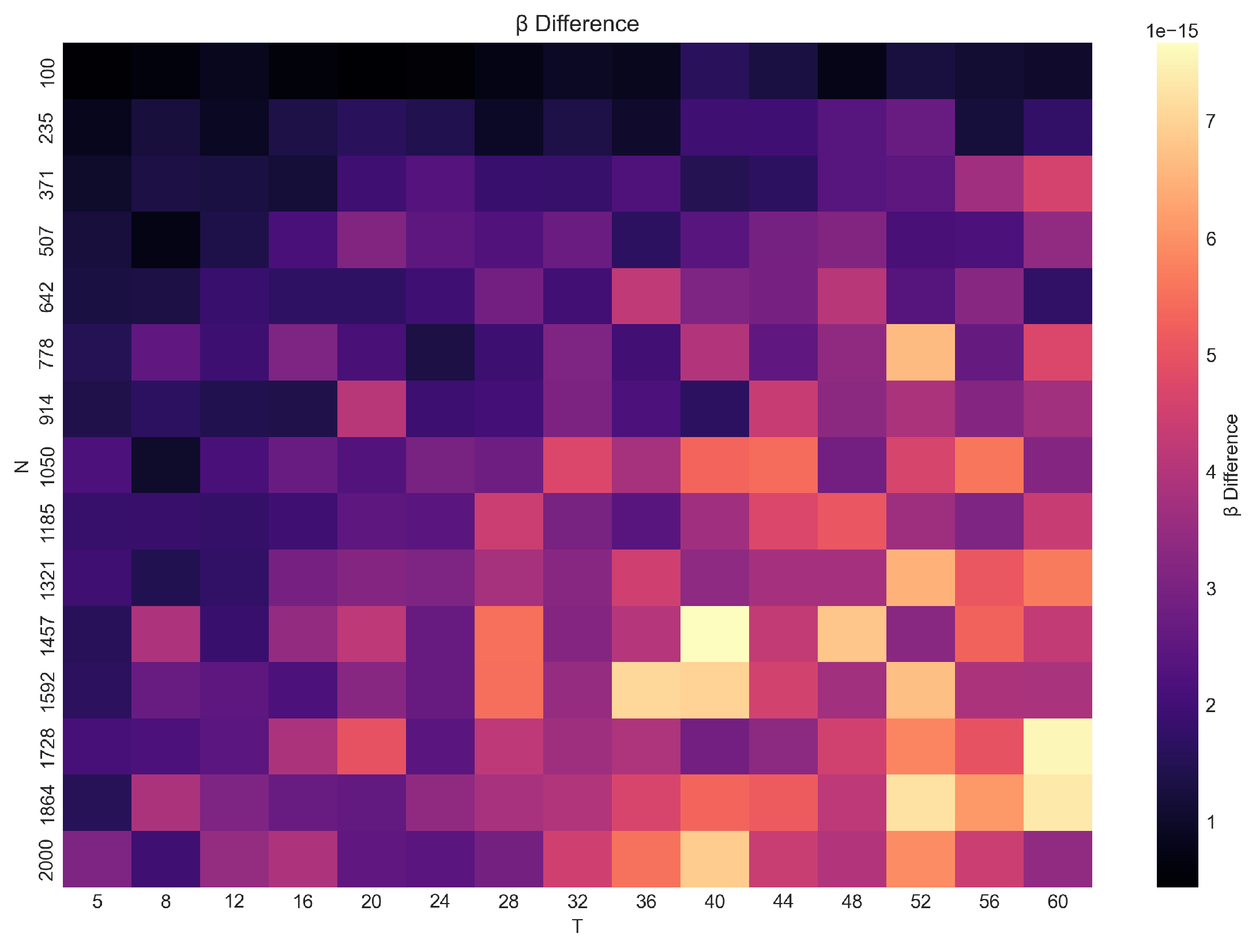
Figure 7.
Absolute difference in slope estimates produced by fe_fast and the demeaned estimator across . Differences remain close to numerical tolerance () across the grid, indicating close agreement between the two approaches.
Figure 7.
Absolute difference in slope estimates produced by fe_fast and the demeaned estimator across . Differences remain close to numerical tolerance () across the grid, indicating close agreement between the two approaches.
10. Computational Complexity
This section collects FLOP counts, byte-traffic expressions, and communication lower bounds for both the within and grouped estimators.
10.1. Floating-Point Operations
For each unit i:
Summed across units, the grouped estimator costs
The within transformation forms explicitly:
The Gram matrix computed from demeaned arrays again costs . The FLOP gap between methods is therefore , which becomes negligible when p is small but matters once byte movement dominates arithmetic.
10.2. Byte-Traffic Characterization
Let B denote bytes per floating point value. For the within estimator, reading and writing the transformed arrays requires
The grouped estimator avoids all writes and performs only reads:
The difference is a full pass of size , which aligns with the measured memory gap in the simulations.
10.3. Communication Lower Bound
The Hong–Kung red–blue pebble model implies that computing from explicit transformed arrays requires
data movement. The grouped estimator bypasses this requirement by not materializing the centered arrays, reaching the lower bound for a single pass algorithm.
10.4. Roofline Interpretation
Performance is shaped by the ratio of FLOPs to bytes moved. The within estimator has arithmetic intensity roughly
whereas the grouped estimator reaches
Higher intensity shifts the algorithm toward the compute-bound region of the roofline.
11. Conclusion
Grouped Gram summaries provide a route to fixed effects estimation that yields lower memory traffic than the classical method based on transformed arrays. Both reach the same estimator. The difference lies in how intermediate values are assembled. As panels grow, memory traffic dominates floating point operations. A method that minimizes movement can produce substantial gains.
Funding
Supported by Johannes Kepler Open Access Publishing Fund and the federal state Upper Austria.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declares no conflicts of interest.
Appendix A. Derivation of Gram Identities
Starting from the transformation
compute the cross-product expansion. Write
Summing yields
Hence
The cross-product with follows the same pattern.
Appendix B. FLOP Complexity
Forming costs . Summing over i yields . Demeaning requires writes followed by multiplications. The grouped method avoids the write costs.
Appendix C. Byte-Traffic Estimates
Memory movement scales with the number of reads and writes. The within transformation writes every centered observation. The grouped method does not modify arrays, only accumulates sums. Given the memory wall described in Graham et al. [8], the difference matters for large n.
Appendix D. Grouped Estimator
| Algorithm 1:Grouped Gram Fixed Effects Estimator |
|
Appendix E. Cluster Bootstrap
A cluster draw selects unit indices with replacement. For each draw, reconstruct the panel and compute the estimator. The bootstrap variance is the empirical variance across draws.
Appendix F. More Results
The same identity extends to weighted least squares (WLS) with known weights. A similar decomposition appears in grouped generalized linear models (GLM) through sufficient statistics [15].
Appendix G. Additional Proofs for Asymptotic Theory
This appendix provides complete derivations for Theorems 1 and 2. All intermediate identities are presented explicitly. The grouped estimator shares its algebraic structure with the classical within estimator; all differences arise from the memory path.
Appendix G.1. Proof of Theorem 1 (Fixed T, N→∞)
Units form independent clusters.
The within-transformed variables satisfy
Step 1: Gram Identity
Start from
Use
Thus
Similarly,
The grouped and demeaned estimators solve the same equation.
Step 2: Score Expansion
Let the within residual be
Define the cluster score
The estimator solves
which rearranges to
Multiply both sides by :
Step 3: Law of Large Numbers (LLN) for the Hessian
With T fixed,
Step 4: Central Limit Theorem (CLT) for the Score
Cluster independence implies
Step 5: Combine Limits
Slutsky yields
This completes the fixed-T theorem.
Appendix G.2. Proof of Theorem 2 (Large N,T, n=NT→∞)
Balanced panel assumed for exposition.
Start from the FOC,
Substitute
to obtain
Divide by :
Step 1: Convergence of the Hessian
Under stationarity and mixing conditions,
Step 2: Central Limit Theorem (CLT) for Weak Dependence
The term
satisfies a mixingale or strong-mixing CLT:
Step 3: Combine Limits
Thus,
The result matches the demeaned estimator; both share the same algebraic structure.
Appendix G.3. Symbolic Verification of the Gram Identity
The identity
was checked using a symbolic solver.
References
- Arellano, M. Panel Data Econometrics; Oxford University Press, 2003. [Google Scholar]
- Cameron, A. C.; Gelbach, J. B.; Miller, D. L. Bootstrap-Based Improvements for Inference with Clustered Errors. Review of Economics and Statistics 2008, 90(3), 414–427. [Google Scholar] [CrossRef]
- Chan, T. F.; Golub, G. H. Updating Formulae and a Pairwise Algorithm for Computing Sample Variances. Journal of the Royal Statistical Society: Series C 1983, 32(3), 266–274. [Google Scholar]
- Davison, A. C.; Hinkley, D. V. Bootstrap Methods and Their Application; Cambridge University Press, 1997. [Google Scholar]
- Demmel, J.; Grigori, L.; Hoemmen, M.; Langou, J. Communication-Avoiding Linear Algebra. SIAM Review 2007, 53(1), 1–20. [Google Scholar]
- Gentle, J. E. Matrix Algebra: Theory, Computations, and Applications; Springer, 2007. [Google Scholar]
- Golub, G. H.; Van Loan, C. F. Matrix Computations, 4th ed.; Johns Hopkins University Press, 2013. [Google Scholar]
- Graham, S. L.; Snir, M.; Patterson, D. Getting Up to Speed: The Future of Supercomputing; National Research Council Report, 2002. [Google Scholar]
- Hausman, J. A. Specification Tests in Econometrics. Econometrica 1978, 46(6), 1251–1271. [Google Scholar] [CrossRef]
- Holtz-Eakin, D.; Newey, W.; Rosen, H. Estimating Vector Autoregressions with Panel Data. Econometrica 1988, 56(6), 1371–1395. [Google Scholar] [CrossRef]
- Hong, J. W.; Kung, H. T. I/O Complexity: The Red-Blue Pebble Game. Proceedings of STOC, 1981; pp. 326–333. [Google Scholar]
- Hsiao, C. Analysis of Panel Data; Cambridge University Press, 2014. [Google Scholar]
- Lindsay, B. Composite Likelihood Methods. In Proceedings of the Section on Statistical Theory, ASA, 1988. [Google Scholar]
- McCalpin, J. STREAM: Sustainable Memory Bandwidth in High Performance Computers. Technical Report, 1995. [Google Scholar]
- McCullagh, P.; Nelder, J. Generalized Linear Models; Chapman and Hall, 1989. [Google Scholar]
- Mundlak, Y. On the Pooling of Time Series and Cross Section Data. Econometrica 1978, 46(1), 69–85. [Google Scholar] [CrossRef]
- Nickell, S. Biases in Dynamic Models with Fixed Effects. Econometrica 1981, 49(6), 1417–1426. [Google Scholar] [CrossRef]
- Williams, S.; Waterman, A.; Patterson, D. Roofline: An Insightful Visual Performance Model for Floating-Point Programs and Multicore Architectures. Communications of the ACM 2009, 52(4), 65–76. [Google Scholar] [CrossRef]
- Wooldridge, J. M. Econometric Analysis of Cross Section and Panel Data; MIT Press, 2010. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



