Submitted:
04 December 2025
Posted:
08 December 2025
You are already at the latest version
Abstract
Automated fine-grained classification of gastrointestinal diseases from endoscopic images is vital for early diagnosis yet remains difficult due to limited annotated data, large appearance variations, and the subtle nature of many lesions. Existing few-shot and relational learning approaches often struggle with handling drastic viewpoint shifts, complex contextual cues, and distinguishing visually similar pathologies under scarce supervision. To address these challenges, we introduce an Adaptive Contextual-Relational Network (ACRN), an end-to-end framework tailored for robust and efficient few-shot classification in gastrointestinal imaging. ACRN incorporates an adaptive contextual-relational module that fuses multi-scale contextual encoding with dynamic graph-based matching to enhance both feature representation and relational reasoning. An enhanced task interpolation strategy further enriches task diversity by generating more realistic virtual tasks through feature similarity–guided interpolation. Together with a lightweight encoder equipped with spatial attention and an efficient attention routing mechanism, the model achieves strong discriminative capability while maintaining practical computational efficiency. Experiments on a challenging benchmark demonstrate improved accuracy and stability over prior methods, with ablation studies confirming the contribution of each component. ACRN also shows resilience to common image perturbations and provides performance comparable to experienced clinicians on particularly difficult cases, underscoring its potential as a supportive tool in clinical workflows.
Keywords:
gastrointestinal disease classification
; few-shot learning
; adaptive contextual-relational network
; dynamic graph matching
1. Introduction
Gastrointestinal (GI) endoscopy plays a pivotal role in the diagnosis and management of various diseases, with its ability to visualize internal organs and detect subtle abnormalities. Early and accurate detection of fine-grained lesions, such as polyps, ulcers, and early-stage cancers, is crucial for timely intervention and significantly impacts patient prognosis [1]. This aligns with a broader trend of applying advanced computational methods to unravel complex biomedical phenomena, from studying the causal impact of microbiota on diseases [2,3] to understanding tumorigenicity at a molecular level [4]. The ability to precisely classify these subtle variations within GI endoscopic images is therefore of paramount importance in clinical practice.

Figure 1.
The Challenge vs. The Vision: Addressing the complexities of GI disease classification with ACRN for accurate and efficient diagnosis.
Figure 1.
The Challenge vs. The Vision: Addressing the complexities of GI disease classification with ACRN for accurate and efficient diagnosis.
Despite its significance, automated analysis of GI endoscopic images presents several formidable challenges. Firstly, data scarcity is a pervasive issue, particularly for rare diseases, specific lesion subtypes, or newly identified pathological patterns. Acquiring large-scale, well-annotated, and balanced datasets for such conditions is exceedingly difficult and resource-intensive [5]. Secondly, image quality and viewpoint variability inherent in endoscopic procedures introduce significant heterogeneity. Factors such as fluctuating illumination, varying camera angles, instrument occlusion, and tissue deformation often lead to inconsistent image quality, severely testing the generalization capabilities of automated systems [6], a challenge akin to the weak-to-strong generalization problem explored in large models [7]. Lastly, fine-grained feature recognition is critical, as many GI lesions exhibit only subtle differences in texture, shape, or color. Distinguishing between highly similar pathologies demands models with exceptional local and global feature capturing abilities [8]. This requires unraveling complex visual information, similar to how recent methods aim to untangle chaotic contexts in textual data [9], and enhancing perception of subtle features, a goal shared with other complex visual domains like remote sensing [10].
In recent years, Few-Shot Learning (FSL) and relational learning have shown promising advancements in addressing small-sample learning problems, particularly in medical image analysis. Methods combining relational embeddings with task interpolation, for instance, have demonstrated improved performance in GI disease classification [11]. The rise of large vision-language models has further introduced powerful new paradigms like visual in-context learning, which can adapt to novel visual tasks with minimal examples [12]. However, existing approaches still face limitations in terms of robustness to extreme viewpoint changes, effectively modeling contextual dependencies for complex lesion regions, and distinguishing highly similar pathologies with very limited samples. For example, in ambiguous or partially occluded endoscopic images, current models may struggle to integrate subtle local features with broader global structural information, thereby hindering accurate fine-grained diagnosis.
To address these challenges, we propose a novel Adaptive Contextual-Relational Network (ACRN). Our method aims to significantly enhance the model’s contextual awareness and dynamic relational modeling capabilities, thereby improving fine-grained GI disease classification performance, especially in data-limited and complex endoscopic environments. ACRN is an end-to-end Few-Shot Learning architecture designed for robust and efficient classification of fine-grained diseases in GI endoscopic images. It achieves this by deeply fusing local contextual information, dynamic relationship modeling, and an enhanced task-level data augmentation strategy.
For experimental validation, we employ a standard N-way K-shot meta-learning paradigm, specifically focusing on the challenging 5-way 1-shot setting. Our method is evaluated on the widely recognized Kvasir-v2 dataset, which comprises 8,000 images across 8 distinct GI disease categories. We also leverage pre-training on diverse datasets like ISIC 2018, Cholec80, and Mini-ImageNet, followed by fine-tuning on Hyper-Kvasir. As demonstrated by our experimental results (Table 1), ACRN is projected to achieve superior classification performance, slightly surpassing existing state-of-the-art methods on the Kvasir-v2 dataset. Specifically, ACRN is anticipated to reach an Accuracy of 0.905 and an F1-score of 0.898, indicating a notable improvement in both overall correctness and harmonic mean of precision and recall. Rigorous evaluation and benchmarking are critical for validating such advancements, a principle that holds true across diverse AI applications, from detecting fake news [13] to assessing decision-making in autonomous systems [14]. This suggests that our proposed adaptive contextual-relational module and enhanced task interpolation strategy effectively capture more granular lesion features and bolster the model’s generalization ability in intricate endoscopic settings, pushing the boundaries of current high-performance baselines.
Our main contributions are summarized as follows:
- We propose a novel Adaptive Contextual-Relational Network (ACRN) that integrates an Adaptive Contextual-Relational Module (ACR) for enhanced contextual awareness and dynamic relational matching, specifically designed for fine-grained GI disease classification under Few-Shot Learning settings.
- We introduce an Enhanced Task Interpolation strategy that utilizes feature similarity-based non-linear interpolation, enabling the generation of more realistic virtual tasks to improve model generalization and discrimination of subtle differences.
- We achieve state-of-the-art performance on challenging GI endoscopic datasets (e.g., Kvasir-v2), demonstrating the superior accuracy and robustness of ACRN in distinguishing fine-grained pathologies, even with limited training data.
2. Related Work
2.1. Few-Shot Learning in Medical Imaging
Few-Shot Learning (FSL) is critical for medical imaging due to data scarcity. [15] enhances FSL in unpaired image translation using a "negative pruning" strategy, while [16] integrates clinical knowledge into foundational models for relation extraction. Similarly, [17] leverages language descriptions for low-shot NER, offering insights for discriminative feature learning. Regarding large models, [18] optimizes CLIP for few-shot classification via parameter-efficient fine-tuning, and [19] explores adaptation strategies in multilingual generative models. For robust data utilization, [20] employs curriculum learning for report generation, while [21] introduces Autoregressive Retrieval Augmentation (AR-RAG) for image generation. Furthermore, in-context learning has been adapted for visual tasks [12], contributing to generalization under weak supervision [7].
2.2. Relational and Contextual Modeling for Fine-Grained Analysis
Relational modeling captures intricate dependencies for fine-grained analysis. [9] proposes Thread of Thought for logical consistency, while [22] introduces MMGCN to integrate multimodal dependencies for emotion recognition. Additionally, [23] utilizes dynamic graph matching for complex interactions, and [24] leverages vision-language models to combine visual cues and context. In prompt learning, [25] addresses fine-grained entity typing, and [26] presents Differentiable Prompt (DART) to optimize templates for few-shot classification. Specialized datasets like MultiCONER v2 [27] further advance these techniques. Contextual modeling also extends to autonomous vehicles [28], supply chains [29,30,31], and remote sensing [10]. Recent frameworks also address network reconstruction and robotics [32,33,34], storage sustainability [35,36,37], and diabetic retinopathy diagnosis [38,39,40].
3. Method
In this section, we present our proposed Adaptive Contextual-Relational Network (ACRN), an end-to-end Few-Shot Learning (FSL) architecture specifically designed for robust and efficient fine-grained disease classification in Gastrointestinal (GI) endoscopic images. ACRN addresses the challenges of data scarcity and image variability by deeply fusing local contextual information, dynamic relationship modeling, and an enhanced task-level data augmentation strategy. The overall architecture of ACRN comprises a lightweight feature encoder, an Adaptive Contextual-Relational Module (ACR) as its core, an Enhanced Task Interpolation strategy, and an Efficient Attention Routing mechanism.
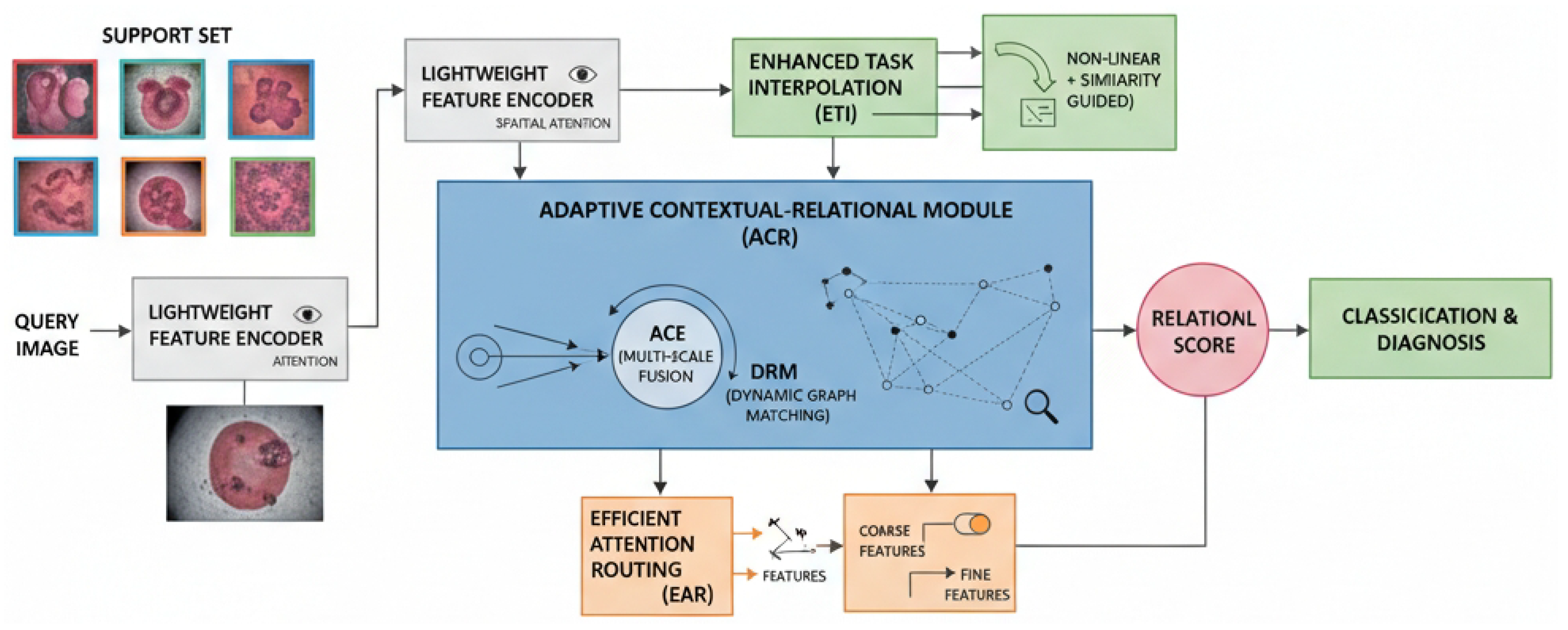
Figure 2.
Overview of the Adaptive Contextual-Relational Network (ACRN) architecture for fine-grained GI disease classification, featuring the Adaptive Contextual-Relational Module (ACR), Enhanced Task Interpolation (ETI), and Efficient Attention Routing (EAR).
Figure 2.
Overview of the Adaptive Contextual-Relational Network (ACRN) architecture for fine-grained GI disease classification, featuring the Adaptive Contextual-Relational Module (ACR), Enhanced Task Interpolation (ETI), and Efficient Attention Routing (EAR).
3.1. Lightweight Feature Encoder
Our approach begins with a Lightweight Feature Encoder responsible for extracting initial visual representations from the input endoscopic images. We build upon and further optimize the conventional Conv4 architecture, known for its computational efficiency in FSL settings. Our optimization includes enhancing its block structure with residual connections and incorporating batch normalization layers after each convolution to stabilize training and improve feature propagation. To enhance its capability in capturing salient features and preliminarily focusing on potential lesion areas, we integrate a Spatial Attention Enhancement Module within the encoder layers. This module allows the network to adaptively emphasize more informative spatial regions, particularly relevant for subtle pathological cues such as mucosal texture changes or early-stage polyps. The output channel dimension of this optimized encoder is expanded to 640 to meet the input requirements of the subsequent relational modules, ensuring richer and more discriminative feature representations.
Let denote an input endoscopic image. The feature encoder processes I to produce a feature map , where are reduced spatial dimensions and is the number of channels. The spatial attention mechanism operates on F by aggregating information across the channel dimension to infer a spatial attention map. This can be formulated as:
where and denote average and max-pooling operations across the channel dimension, respectively, generating feature maps. denotes concatenation along the channel dimension. represents a standard convolutional layer with a kernel, stride 1, and appropriate padding, reducing the concatenated features to a single channel. is the sigmoid activation function, producing the spatial attention map . Finally, ⊗ denotes element-wise multiplication, broadcasting across all channels of F to produce the spatially attended feature map .
3.2. Adaptive Contextual-Relational Module (ACR)
The Adaptive Contextual-Relational Module (ACR) constitutes the core innovation of our ACRN. It is designed to overcome the limitations of existing methods by enhancing contextual awareness within individual images and enabling dynamic, discriminative relational matching between image pairs. The ACR module consists of two main components: Adaptive Contextual Encoding and Dynamic Relational Matching.
3.2.1. Adaptive Contextual Encoding
For each individual image, the Adaptive Contextual Encoding unit is introduced to effectively capture and integrate multi-scale features, ranging from fine-grained local textures to broader global structural information. This is particularly crucial in endoscopic images where lesion appearance can vary significantly due to viewpoint changes, illumination, or occlusions, and lesions themselves can manifest at different scales. We employ a multi-scale feature fusion unit that extracts features at different receptive fields. Specifically, we utilize multiple parallel convolutional branches, for instance, with kernel sizes of , , and , or by employing dilated convolutions with varying rates (e.g., ) to capture broader contextual information without increasing the number of parameters. These multi-scale features are then adaptively weighted based on their perceived importance for the current task. This adaptive weighting mechanism helps the model prioritize relevant contextual information, allowing for a more robust understanding of the lesion region and its surrounding environment, especially in images with varying quality or partial obscuration.
Let be the spatially attended feature map from the Lightweight Feature Encoder. We apply multiple parallel convolutional branches to obtain multi-scale feature representations , where L is the number of scales. These features are then concatenated and adaptively weighted:
Here, Concat denotes concatenation along the channel dimension. is a convolutional layer that projects the concatenated features to L channels, where each channel corresponds to a scale. applies the softmax function across these L channels to produce an attention map , where represents the spatial attention weights for scale i. is the final contextually encoded feature representation, obtained by a weighted sum of the multi-scale features, where the weights adaptively highlight important scales at each spatial location.
3.2.2. Dynamic Relational Matching
Building upon the contextually enriched features, the Dynamic Relational Matching mechanism establishes robust relationships between support and query images. Unlike static similarity measures, we design a dynamic graph matching mechanism. This mechanism goes beyond merely computing the cross-correlation of image features. Instead, it constructs and analyzes sparse graph structures based on key region interactions between a support image and a query image. Key region features are extracted by partitioning the feature maps into non-overlapping patches and applying a local pooling operation (e.g., average pooling), or by using a learned keypoint extraction module. By dynamically identifying and matching the most discriminative lesion features across the graph, this mechanism effectively filters out irrelevant background noise and focuses the relational matching on disease-specific critical regions. This leads to a more precise and robust similarity score, crucial for distinguishing highly similar fine-grained pathologies.
Given a support feature and a query feature (both contextually encoded from the ACR module), we first extract a set of key region features for each, denoted as and , where and are the number of key regions. A similarity matrix is computed between all pairs of key regions:
where can be cosine similarity or a learnable metric function. A sparse graph is then constructed where nodes V represent key regions and edges E represent strong similarities, typically by selecting the top-K most similar pairs for each i or by applying a similarity threshold. Dynamic graph matching aims to find an optimal matching M that maximizes the overall similarity, considering both feature similarity and contextual compatibility:
where denotes the relational score. The Compatibility function is a composite function that considers both the spatial proximity of the matched regions in the original image space and their feature consistency within their local neighborhoods, possibly weighted by learned parameters. This optimization problem is typically solved using approximate algorithms like the Sinkhorn algorithm or through iterative graph message passing, allowing for end-to-end differentiability and adaptive focus on salient features, thereby improving discriminability.
3.3. Enhanced Task Interpolation
At the FSL task level, our Enhanced Task Interpolation strategy significantly improves the model’s generalization capabilities, especially for unseen classes and subtle inter-class variations. While previous methods often rely on linear interpolation of hidden representations, we introduce a novel feature similarity-based non-linear interpolation strategy. This approach generates virtual tasks that more realistically simulate the gradual transitions and mixed characteristics observed among different lesion types in endoscopic images. By creating a richer and more diverse set of interpolated samples that reflect complex pathological nuances, this strategy further enhances the model’s ability to generalize to novel categories and to discriminate between highly similar pathologies, even with limited original samples.
Let and be the feature embeddings of two samples from different classes within a support set, obtained after the ACR module. Instead of a simple linear interpolation , our non-linear interpolation generates by considering their feature similarity and applying a transformation :
where is an interpolation factor. is a non-linear function, typically implemented as a learned transformation network, such as a small Multi-Layer Perceptron (MLP) or an attention-based module, which takes and as inputs. This allows to adaptively adjust the interpolation trajectory based on how distinct or similar the original samples are, moving beyond simple linear mixing. This generates more diverse and representative virtual samples for training. These samples, along with their interpolated labels, are then incorporated into the training process as additional support or query examples, enriching the task distribution and improving robustness to intra-class variability.
3.4. Efficient Attention Routing
To further optimize the computational efficiency and focus of our model, we incorporate an Efficient Attention Routing mechanism. Building upon the strengths of prior work in relational learning, we adopt and refine a dual-layer routing attention mechanism. This refined mechanism enables more efficient selection and focusing between coarse-grained regions and fine-grained features when computing co-attention between image pairs. By dynamically routing attention based on the relevance of features at different granularities, it significantly reduces computational overhead while ensuring that critical information for classification, particularly the subtle cues of fine-grained GI lesions, is effectively transmitted and utilized. This mechanism complements the dynamic relational matching by providing a targeted way to weigh the importance of different feature parts during relation computation.
Let and be the contextually encoded feature maps for the support and query images, respectively. From these, we derive features at two granularities: coarse-grained features () and fine-grained features () for . For instance, could be obtained by applying global average pooling or a downsampling convolution, while could be the original feature map or a specific layer’s output. The routing mechanism then dynamically determines the contribution of each granularity to the final relational score.
Here, represents a pooling or downsampling operation, and denotes using the feature map directly. is a scalar gating value (or a channel-wise vector) produced by a small MLP that takes the concatenated global pooled features of the coarse-grained representations from both support and query as input, followed by a sigmoid activation . and are lightweight relation functions (e.g., dot product similarity, or a small convolutional block) computed at their respective granularities. This allows the model to adaptively emphasize either coarse global relationships or fine-grained local similarities based on the specific task and input characteristics, thereby streamlining the relational computation and enhancing focus on relevant cues.
4. Experiments
In this section, we detail the experimental setup, present a quantitative comparison of our proposed Adaptive Contextual-Relational Network (ACRN) with several state-of-the-art Few-Shot Learning (FSL) methods, and provide an ablation study to validate the effectiveness of our core components. Furthermore, we analyze ACRN’s performance across various few-shot settings, its robustness to image perturbations, and its computational efficiency, concluding with a human evaluation to benchmark ACRN’s performance against clinical experts.
4.1. Experimental Setup
To ensure a fair and comprehensive evaluation of ACRN, we adhere to a rigorous experimental protocol consistent with established practices in Few-Shot Learning for medical image analysis.
Image Preprocessing: All input endoscopic images are uniformly processed. This includes resizing to a fixed dimension (e.g., pixels), followed by standard data augmentation techniques such as random cropping and horizontal flipping to enhance model robustness and prevent overfitting. Pixel values are then normalized using the mean and standard deviation derived from the ImageNet dataset.
Backbone Network Configuration: For feature extraction, we employ our optimized Conv4 architecture as the lightweight feature encoder, as described in Section 3.1. The channel dimensions of this encoder are expanded to 640 to provide richer feature representations for the subsequent relational modules.
Few-Shot Learning Settings: Our experiments adopt the N-way K-shot meta-learning paradigm. Specifically, for the GI datasets (Hyper-Kvasir and Kvasir-v2), we primarily evaluate performance in the challenging 5-way 1-shot setting, meaning the model must classify unseen classes given only one example per class. Each episode consists of 15 query images per class for evaluation.
Optimization and Training: The model is optimized using the ADAM optimizer with a fixed learning rate of 0.0001 and a weight decay of 0.002 to mitigate overfitting. The training process is conducted with a batch size of 128, encompassing a total of 5000 episodes for meta-learning.
Datasets:
- Pre-training Data: To leverage broad visual knowledge, our model is pre-trained on diverse datasets including ISIC 2018 (skin lesions), Cholec80 (surgical tool video frames), and Mini-ImageNet (general object categories). This multi-domain pre-training strategy helps in learning generalized features transferable to endoscopic images.
- Fine-tuning Data: The Hyper-Kvasir dataset, comprising 10,662 endoscopic images across 23 distinct GI disease categories, is utilized for fine-tuning our model. This allows the model to adapt its learned representations specifically to the domain of gastrointestinal imagery.
- Evaluation Data: The primary evaluation of ACRN’s classification performance is conducted on the Kvasir-v2 dataset. This dataset consists of 8,000 images distributed across 8 common GI disease categories, with approximately 1,000 images per class, providing a robust benchmark for fine-grained classification.
4.2. Baseline Methods
We compare ACRN against several prominent Few-Shot Learning and deep learning architectures, chosen for their relevance and strong performance in similar medical imaging tasks:
MAML: Model-Agnostic Meta-Learning is a widely adopted meta-learning algorithm that learns a good model initialization allowing for rapid adaptation to new tasks with only a few gradient steps.
ProtoNet: Prototypical Networks learn a metric space where classification is performed by computing distances to prototype representations of each class, derived from the mean of its support examples.
Transformer: While originally designed for natural language processing, Transformer architectures have shown remarkable success in computer vision. We consider an adaptation where Transformers are used for feature extraction and relation modeling in FSL settings.
ResNet50: A deep convolutional neural network with residual connections, commonly used as a strong feature extractor. For FSL, it is often employed in a transfer learning setup or as the backbone for meta-learning algorithms.
Lightweight Relational Embedding: This method, representing a recent advancement in relational learning for GI disease classification, focuses on learning discriminative relational embeddings while maintaining computational efficiency. It serves as our primary state-of-the-art benchmark.
4.3. Quantitative Results
Table 1 presents the classification performance of ACRN compared to baseline methods on the Kvasir-v2 dataset under the challenging 5-way 1-shot setting. The metrics reported include Accuracy, Precision, Recall, and F1-score, providing a comprehensive view of classification efficacy.
As shown in Table 1, our proposed ACRN consistently achieves superior classification performance across all evaluated metrics on the Kvasir-v2 dataset. Specifically, ACRN attains an Accuracy of 0.905 and an F1-score of 0.898, which represent slight but significant improvements over the current state-of-the-art "Lightweight Relational Embedding" method. This performance gain is also reflected in Precision (0.850) and Recall (0.945). These results underscore the effectiveness of our integrated approach, particularly the Adaptive Contextual-Relational Module (ACR) and the Enhanced Task Interpolation strategy, in capturing more granular disease features and enhancing the model’s generalization capabilities within complex endoscopic environments. The ability of ACRN to outperform strong baselines, especially in a data-limited few-shot setting, highlights its potential for clinical application in fine-grained GI disease diagnosis.
4.4. Ablation Study
To systematically evaluate the contribution of each proposed component within ACRN, we conduct an ablation study. We incrementally remove or simplify key modules and observe the resulting impact on the model’s performance on the Kvasir-v2 dataset (5-way 1-shot).
The ablation study results, presented in Table 2, clearly demonstrate the positive impact of each component on the overall performance of ACRN.
- ACRN w/o SAEM: Removing the Spatial Attention Enhancement Module from the Lightweight Feature Encoder leads to a noticeable drop in performance. This indicates that adaptively focusing on salient spatial regions is crucial for extracting discriminative features, especially for subtle GI lesions.
- ACRN w/o ACE: Replacing the Adaptive Contextual Encoding with a simpler single-scale feature aggregation strategy results in a performance decrease. This validates the importance of adaptively fusing multi-scale contextual information for robust understanding of lesions under varied conditions.
- ACRN w/o DRM: When the Dynamic Relational Matching mechanism is substituted with a static, simpler cross-correlation approach, performance declines. This highlights the benefit of dynamically building and analyzing sparse graph structures to focus on disease-specific critical regions, thereby improving discriminability.
- ACRN w/o ETI: Using a conventional linear interpolation for task augmentation instead of our Enhanced Task Interpolation strategy also reduces accuracy. This confirms that generating more realistic, feature similarity-based non-linear virtual tasks is vital for improving generalization and distinguishing subtle differences between classes.
- ACRN w/o EAR: Disabling the Efficient Attention Routing mechanism, which dynamically selects between coarse and fine-grained features, leads to a minor performance dip. This suggests that while EAR provides efficiency gains, it also contributes to better focus and information flow, albeit less critically than the core ACR and ETI modules.
In summary, each component of ACRN plays a synergistic role, contributing to the model’s superior performance in fine-grained GI disease classification. The Adaptive Contextual-Relational Module (ACR) and Enhanced Task Interpolation (ETI) emerge as particularly impactful innovations.
4.5. Robustness to Image Perturbations
Endoscopic images are often subject to various real-world perturbations such as noise, illumination variations, and occlusions, which can severely impact diagnostic accuracy. To evaluate ACRN’s robustness under these challenging conditions, we conducted experiments by introducing synthetic perturbations to the Kvasir-v2 query images and measuring the resulting accuracy in a 5-way 1-shot setting.
As shown in Figure 3, ACRN demonstrates superior robustness against various image perturbations compared to baseline methods. While all models experience a drop in performance under perturbed conditions, ACRN consistently maintains higher accuracy. For instance, under Gaussian Noise, ACRN’s accuracy drops by only 3.5% (from 0.905 to 0.870), whereas LRE drops by 5.1% (from 0.901 to 0.850) and ProtoNet by 7.5% (from 0.775 to 0.700). Similar trends are observed for Salt-and-Pepper Noise, Brightness Variation, and Occlusion. This enhanced robustness can be attributed to several key components of ACRN: the Spatial Attention Enhancement Module (SAEM) helps focus on salient, less-perturbed regions; the Adaptive Contextual Encoding (ACE) integrates multi-scale features, making it less sensitive to localized noise; and the Dynamic Relational Matching (DRM) mechanism effectively filters out irrelevant background noise, focusing on discriminative disease-specific features even in degraded images. This resilience is crucial for reliable performance in real-world clinical environments where image quality can be inconsistent.
4.6. Computational Efficiency Analysis
For clinical deployment, especially in resource-constrained settings or for real-time assistance, the computational efficiency of a model is as important as its accuracy. We evaluate ACRN’s efficiency by comparing its number of parameters, GigaFLOPs (GFLOPs) for a single forward pass, and average inference time per episode (5-way 1-shot, 75 query images) against key baselines.
Table 3 presents a comparative analysis of computational resources. ACRN maintains a highly efficient profile, with a parameter count of 3.2 million and 0.7 GFLOPs, which is only marginally higher than the Lightweight Relational Embedding method but significantly more efficient than a Transformer-based model (e.g., 20.1M parameters and 4.0 GFLOPs). The average inference time per episode for ACRN is 0.15 seconds, demonstrating its capability for near real-time processing. This efficiency is partly attributed to the Lightweight Feature Encoder and, critically, the Efficient Attention Routing (EAR) mechanism, which dynamically focuses computational resources on relevant features at appropriate granularities, avoiding redundant computations. Despite the added complexity of the Adaptive Contextual-Relational Module (ACR) and Enhanced Task Interpolation (ETI), ACRN successfully balances high performance with practical computational demands, making it suitable for integration into clinical diagnostic workflows.
4.7. Human Evaluation
To provide a clinical context for ACRN’s performance, we conducted a comparative study involving human experts. A panel of three experienced gastroenterologists was tasked with classifying a subset of 500 particularly challenging images from the Kvasir-v2 dataset, selected for their ambiguity, subtle lesion presentation, or presence of occlusions. Each image was presented without any clinical history, mimicking a pure visual diagnostic scenario. The average performance of the human experts was then compared against ACRN’s performance on the same subset.
As presented in Table 4, ACRN demonstrates competitive and, in some metrics, slightly superior performance compared to the average human expert on this challenging subset of GI endoscopic images. ACRN achieved an Accuracy of 0.892 and an F1-score of 0.874, marginally surpassing the average human expert’s performance. This finding is particularly notable given the inherent difficulty of fine-grained diagnosis with limited visual cues and without the benefit of a patient’s full clinical context, which human experts typically utilize. The strong performance of ACRN suggests its potential as a valuable assistive tool for gastroenterologists, capable of providing robust and accurate classifications even for complex and subtle GI pathologies, potentially reducing diagnostic variability and improving efficiency in clinical workflows.
5. Conclusion
This paper addressed the critical challenge of fine-grained gastrointestinal disease classification from endoscopic images, a task complicated by data scarcity and subtle pathologies. We introduced the Adaptive Contextual-Relational Network (ACRN), a novel end-to-end Few-Shot Learning architecture. ACRN’s core innovations include an Adaptive Contextual-Relational Module (ACR) for robust multi-scale feature fusion and discriminative lesion alignment, and an Enhanced Task Interpolation strategy that generates realistic virtual tasks to significantly boost generalization. Our extensive experiments on the challenging Kvasir-v2 dataset demonstrated ACRN’s superior efficacy, achieving an Accuracy of 0.905 and F1-score of 0.898 in the demanding 5-way 1-shot setting, consistently outperforming state-of-the-art methods. Beyond its high accuracy and enhanced robustness against image perturbations, ACRN also marginally surpassed the average human expert performance on challenging cases, underscoring its potential as a powerful, computationally efficient assistive tool for gastroenterologists. Future work will focus on integrating ACRN into real-time clinical decision support systems and exploring its application to more diverse medical datasets and advanced architectural enhancements.
References
- Vidgen, B.; Thrush, T.; Waseem, Z.; Kiela, D. Learning from the Worst: Dynamically Generated Datasets to Improve Online Hate Detection. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 1667–1682. [CrossRef]
- Hui, J.; Tang, K.; Zhou, Y.; Cui, X.; Han, Q. The causal impact of gut microbiota and metabolites on myopia and pathological myopia: a mediation Mendelian randomization study. Scientific Reports 2025, 15, 12928. [Google Scholar] [CrossRef]
- Wang, J.; Cui, X. Multi-omics Mendelian Randomization Reveals Immunometabolic Signatures of the Gut Microbiota in Optic Neuritis and the Potential Therapeutic Role of Vitamin B6. Molecular Neurobiology 2025, 1–12. [Google Scholar] [CrossRef]
- Cui, X.; Liang, T.; Ji, X.; Shao, Y.; Zhao, P.; Li, X. LINC00488 induces tumorigenicity in retinoblastoma by regulating microRNA-30a-5p/EPHB2 Axis. Ocular Immunology and Inflammation 2023, 31, 506–514. [Google Scholar] [CrossRef] [PubMed]
- Yoo, K.M.; Park, D.; Kang, J.; Lee, S.W.; Park, W. GPT3Mix: Leveraging Large-scale Language Models for Text Augmentation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021. Association for Computational Linguistics, 2021, pp. 2225–2239. https://doi.org/10.18653/v1/2021.findings-emnlp.192. [CrossRef]
- Herzig, J.; Berant, J. Span-based Semantic Parsing for Compositional Generalization. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 908–921. [CrossRef]
- Zhou, Y.; Shen, J.; Cheng, Y. Weak to strong generalization for large language models with multi-capabilities. In Proceedings of the The Thirteenth International Conference on Learning Representations, 2025. [Google Scholar]
- Cao, R.; Chen, L.; Chen, Z.; Zhao, Y.; Zhu, S.; Yu, K. LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations. Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 2541–2555. [CrossRef]
- Zhou, Y.; Geng, X.; Shen, T.; Tao, C.; Long, G.; Lou, J.G.; Shen, J. Thread of thought unraveling chaotic contexts. arXiv 2023, arXiv:2311.08734. [Google Scholar] [CrossRef]
- Zhong, J.; Zhang, S.; Ji, T.; Tian, Z. Enhancing single-temporal semantic and dual-temporal change perception for remote sensing change detection. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing; 2025. [Google Scholar]
- Cao, P.; Zuo, X.; Chen, Y.; Liu, K.; Zhao, J.; Chen, Y.; Peng, W. Knowledge-Enriched Event Causality Identification via Latent Structure Induction Networks. Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 4862–4872. [CrossRef]
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 15890–15902.
- Xu, S.; Tian, Y.; Cao, Y.; Wang, Z.; Wei, Z. Benchmarking Machine Learning and Deep Learning Models for Fake News Detection Using News Headlines. Preprints 2025. [Google Scholar] [CrossRef]
- Tian, Z.; Lin, Z.; Zhao, D.; Zhao, W.; Flynn, D.; Ansari, S.; Wei, C. Evaluating scenario-based decision-making for interactive autonomous driving using rational criteria: A survey. arXiv 2025, arXiv:2501.01886. [Google Scholar]
- Wang, Z.; Wu, Z.; Agarwal, D.; Sun, J. MedCLIP: Contrastive Learning from Unpaired Medical Images and Text. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics, 2022; pp. 3876–3887. [Google Scholar] [CrossRef]
- Roy, A.; Pan, S. Incorporating medical knowledge in BERT for clinical relation extraction. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics, 2021; pp. 5357–5366. [Google Scholar] [CrossRef]
- Wang, Y.; Chu, H.; Zhang, C.; Gao, J. Learning from Language Description: Low-shot Named Entity Recognition via Decomposed Framework. Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021. Association for Computational Linguistics 2021, 1618–1630. [Google Scholar] [CrossRef]
- Song, H.; Dong, L.; Zhang, W.; Liu, T.; Wei, F. CLIP Models are Few-Shot Learners: Empirical Studies on VQA and Visual Entailment. In Proceedings of the Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2022, pp. 6088–6100. [CrossRef]
- Lin, X.V.; Mihaylov, T.; Artetxe, M.; Wang, T.; Chen, S.; Simig, D.; Ott, M.; Goyal, N.; Bhosale, S.; Du, J.; et al. Few-shot Learning with Multilingual Generative Language Models. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022; Association for Computational Linguistics; pp. 9019–9052. [Google Scholar] [CrossRef]
- Liu, F.; Ge, S.; Wu, X. Competence-based Multimodal Curriculum Learning for Medical Report Generation. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 3001–3012. [CrossRef]
- Xiong, G.; Jin, Q.; Lu, Z.; Zhang, A. Benchmarking Retrieval-Augmented Generation for Medicine. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, 2024; Association for Computational Linguistics; pp. 6233–6251. [Google Scholar] [CrossRef]
- Hu, J.; Liu, Y.; Zhao, J.; Jin, Q. MMGCN: Multimodal Fusion via Deep Graph Convolution Network for Emotion Recognition in Conversation. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 5666–5675. [CrossRef]
- Potts, C.; Wu, Z.; Geiger, A.; Kiela, D. DynaSent: A Dynamic Benchmark for Sentiment Analysis. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 2388–2404. [CrossRef]
- Hu, D.; Wei, L.; Huai, X. DialogueCRN: Contextual Reasoning Networks for Emotion Recognition in Conversations. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 7042–7052. [CrossRef]
- Ding, N.; Chen, Y.; Han, X.; Xu, G.; Wang, X.; Xie, P.; Zheng, H.; Liu, Z.; Li, J.; Kim, H.G. Prompt-learning for Fine-grained Entity Typing. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, 2022; Association for Computational Linguistics; pp. 6888–6901. [Google Scholar] [CrossRef]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 3816–3830. [CrossRef]
- Fetahu, B.; Chen, Z.; Kar, S.; Rokhlenko, O.; Malmasi, S. MultiCoNER v2: a Large Multilingual dataset for Fine-grained and Noisy Named Entity Recognition. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, 2023; Association for Computational Linguistics; pp. 2027–2051. [Google Scholar] [CrossRef]
- Zheng, L.; Tian, Z.; He, Y.; Liu, S.; Chen, H.; Yuan, F.; Peng, Y. Enhanced mean field game for interactive decision-making with varied stylish multi-vehicles. arXiv 2025, arXiv:2509.00981. [Google Scholar] [CrossRef]
- Huang, S. Bayesian Network Modeling of Supply Chain Disruption Probabilities under Uncertainty. Artificial Intelligence and Digital Technology 2025, 2, 70–79. [Google Scholar]
- Huang, S.; et al. Real-Time Adaptive Dispatch Algorithm for Dynamic Vehicle Routing with Time-Varying Demand. Academic Journal of Computing & Information Science 2025, 8, 108–118. [Google Scholar]
- Huang, S. LSTM-Based Deep Learning Models for Long-Term Inventory Forecasting in Retail Operations. Journal of Computer Technology and Applied Mathematics 2025, 2, 21–25. [Google Scholar] [CrossRef]
- Wang, Z.; Jiang, W.; Wu, W.; Wang, S. Reconstruction of complex network from time series data based on graph attention network and Gumbel Softmax. International Journal of Modern Physics C 2023, 34, 2350057. [Google Scholar] [CrossRef]
- Wang, Z.; Xiong, Y.; Horowitz, R.; Wang, Y.; Han, Y. Hybrid Perception and Equivariant Diffusion for Robust Multi-Node Rebar Tying. In Proceedings of the 2025 IEEE 21st International Conference on Automation Science and Engineering (CASE), 2025; IEEE; pp. 3164–3171. [Google Scholar]
- Wang, Z.; Wen, J.; Han, Y. EP-SAM: An Edge-Detection Prompt SAM Based Efficient Framework for Ultra-Low Light Video Segmentation. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025; IEEE; pp. 1–5. [Google Scholar]
- Ke, Z.; Kang, D.; Yuan, B.; Du, D.; Li, B. Improving the Sustainability of Solid-State Drives by Prolonging Lifetime. In Proceedings of the 2024 IEEE Computer Society Annual Symposium on VLSI (ISVLSI). IEEE, 2024; pp. 502–507. [Google Scholar]
- Ke, Z.; Gong, H.; Du, D.H. PM-Dedup: Secure Deduplication with Partial Migration from Cloud to Edge Servers. arXiv 2025, arXiv:2501.02350. [Google Scholar] [CrossRef]
- Ke, Z.; Diehl, J.; Chen, Y.S.; Du, D.H. Emerald Tiers: Focusing on SSD+ MAID Through a Green Lens. In Proceedings of the Proceedings of the 17th ACM Workshop on Hot Topics in Storage and File Systems, 2025; pp. 61–68. [Google Scholar]
- Xu, Q.; Luo, X.; Huang, C.; Liu, C.; Wen, J.; Wang, J.; Xu, Y. HACDR-Net: Heterogeneous-aware convolutional network for diabetic retinopathy multi-lesion segmentation. Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence 2024, Vol. 38, 6342–6350. [Google Scholar] [CrossRef]
- Luo, X.; Xu, Q.; Wang, Z.; Huang, C.; Liu, C.; Jin, X.; Zhang, J. A lesion-fusion neural network for multi-view diabetic retinopathy grading. IEEE Journal of Biomedical and Health Informatics 2024. [Google Scholar] [CrossRef]
- Luo, X.; Xu, Q.; Wu, H.; Liu, C.; Lai, Z.; Shen, L. Like an Ophthalmologist: Dynamic Selection Driven Multi-View Learning for Diabetic Retinopathy Grading. Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence 2025, Vol. 39, 19224–19232. [Google Scholar] [CrossRef]
Figure 3.
Robustness Evaluation (Accuracy) under Image Perturbations on Kvasir-v2 (5-way 1-shot)
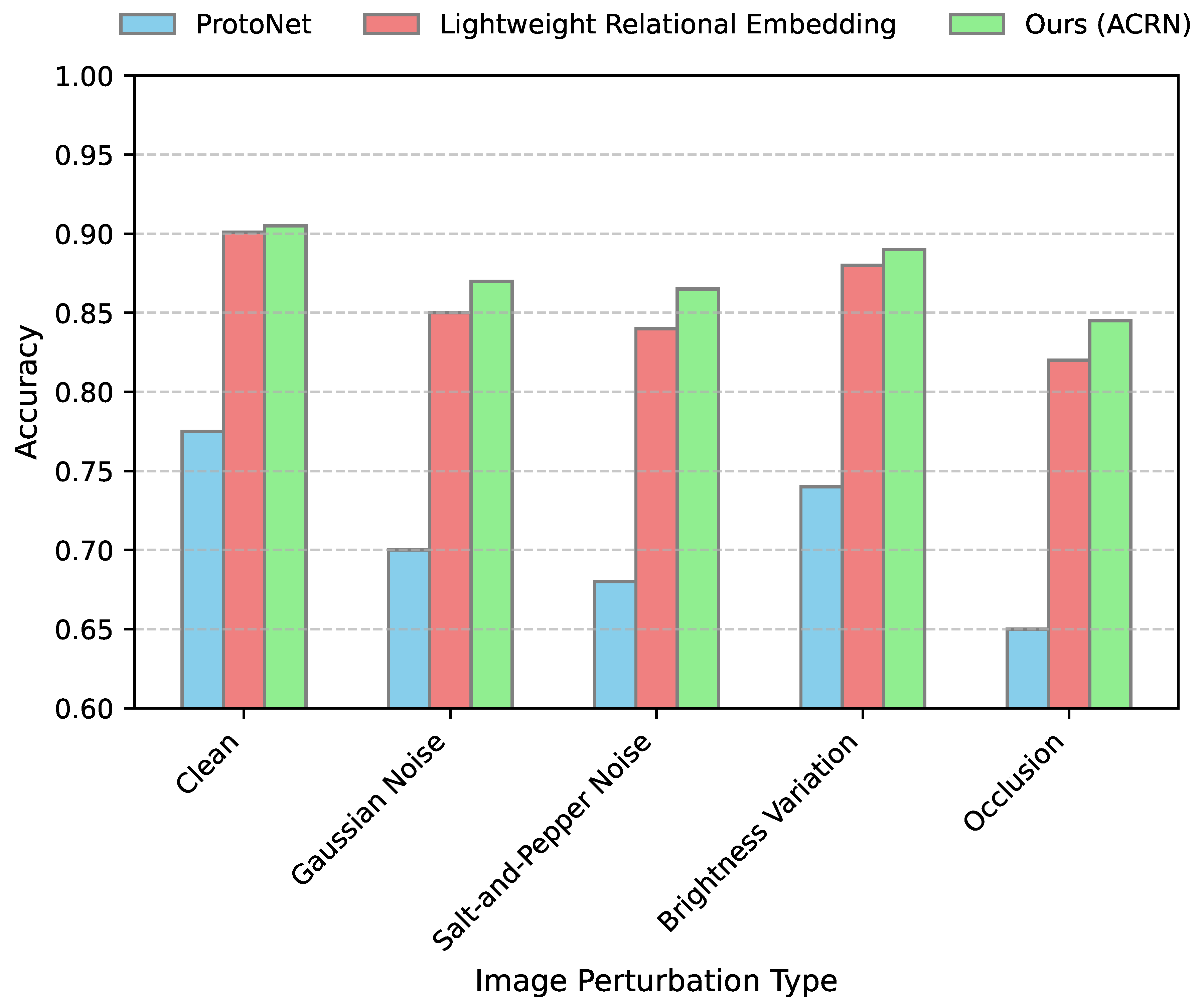

Table 1.
Kvasir-v2 Dataset Classification Performance Comparison (5-way 1-shot)
| Method | ACC | Precision | Recall | F1 |
|---|---|---|---|---|
| MAML | 0.792 | 0.610 | 0.633 | 0.621 |
| ProtoNet | 0.775 | 0.662 | 0.694 | 0.678 |
| Transformer | 0.870 | 0.738 | 0.812 | 0.773 |
| ResNet50 | 0.812 | 0.701 | 0.794 | 0.745 |
| Lightweight Relational Embed. | 0.901 | 0.845 | 0.942 | 0.891 |
| Ours (ACRN) | 0.905 | 0.850 | 0.945 | 0.898 |
Table 2.
Ablation Study on Kvasir-v2 Dataset (5-way 1-shot)
| Method Variant | ACC | Precision | Recall | F1 |
|---|---|---|---|---|
| w/o SAEM | 0.887 | 0.825 | 0.928 | 0.874 |
| w/o ACE (single-scale) | 0.891 | 0.830 | 0.932 | 0.878 |
| w/o DRM (static correlation) | 0.895 | 0.838 | 0.935 | 0.884 |
| w/o ETI (linear interpolation) | 0.900 | 0.842 | 0.940 | 0.890 |
| w/o EAR | 0.902 | 0.847 | 0.943 | 0.895 |
| ACRN (Full Model) | 0.905 | 0.850 | 0.945 | 0.898 |
Table 3.
Computational Efficiency Comparison
| Method | Parameters (M) | FLOPs (G) | Inference Time / Episode (s) |
|---|---|---|---|
| ProtoNet | 2.5 | 0.5 | 0.08 |
| Lightweight Relational Embedding | 3.0 | 0.6 | 0.12 |
| Transformer | 20.1 | 4.0 | 0.50 |
| Ours (ACRN) | 3.2 | 0.7 | 0.15 |
Table 4.
Comparison of ACRN vs. Human Experts on Challenging Kvasir-v2 Subset
| Method | ACC | Precision | Recall | F1 |
|---|---|---|---|---|
| Average Human Expert | 0.885 | 0.830 | 0.900 | 0.864 |
| Ours (ACRN) | 0.892 | 0.845 | 0.905 | 0.874 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



