Submitted:
23 November 2025
Posted:
24 November 2025
You are already at the latest version
Abstract
Semi-supervised text classification is essential in settings where labeled data are limited but unlabeled data are abundant. Although pre-trained language models perform well in classification tasks, their effectiveness still depends on sufficient annotated examples. Many existing semi-supervised approaches struggle with unreliable pseudo-labels, limited use of uncertainty, and rigid ensemble strategies. To address these issues, we introduce Dynamic Uncertainty-aware Pseudo-Labeling with Ensemble Reweighting (DURPEL), an algorithm designed to improve reliability and robustness in semi-supervised learning, particularly under class imbalance. DURPEL incorporates an ensemble of independently trained BERT-Base student models, combining entropy-based uncertainty estimation, confidence-adaptive pseudo-labeling, and weighted ensemble voting. It further employs an adaptive reweighting mechanism that adjusts the learning importance of unlabeled samples based on model consistency, uncertainty, and historical difficulty, allowing the model to focus on informative cases. Experiments on the USB benchmark show consistent gains over existing methods, and ablation studies highlight the complementary strengths of DURPEL's components. The results demonstrate that DURPEL offers a stable and effective solution for semi-supervised text classification.
Keywords:
semi-supervised text classification
; pseudo-labeling
; uncertainty estimation
; ensemble learning
1. Introduction
Semi-supervised text classification (SSTC) addresses the critical challenge of effectively leveraging vast amounts of unlabeled data to improve classifier performance when labeled data is scarce. This scenario is ubiquitous in real-world applications, where annotating large text corpora is costly and time-consuming, even as large language models and AI systems find increasingly diverse applications in critical domains. These range from public policy and finance [1] to complex real-time decision-making in dynamic power grid simulations [2]. While pre-trained language models (PLMs) have revolutionized natural language processing and achieved remarkable success in various text classification tasks [3], their performance in a purely supervised paradigm remains highly dependent on the availability of extensive labeled datasets. The core challenge is one of generalization, where the goal is to transition from weak supervision on a small labeled set to strong performance on a larger, unlabeled distribution [4]. Semi-supervised learning (SSL) methods, particularly those built upon consistency regularization [5] and pseudo-labeling [6], offer a promising avenue to mitigate this dependency by harnessing the information embedded within unlabeled examples.
Figure 1.
Conceptual comparison illustrating the limitations of traditional pseudo-labeling in semi-supervised text classification versus the enhanced robustness and efficiency of the DURPEL algorithm through dynamic ensemble, uncertainty-aware pseudo-labeling, and adaptive sample reweighting.
Figure 1.
Conceptual comparison illustrating the limitations of traditional pseudo-labeling in semi-supervised text classification versus the enhanced robustness and efficiency of the DURPEL algorithm through dynamic ensemble, uncertainty-aware pseudo-labeling, and adaptive sample reweighting.
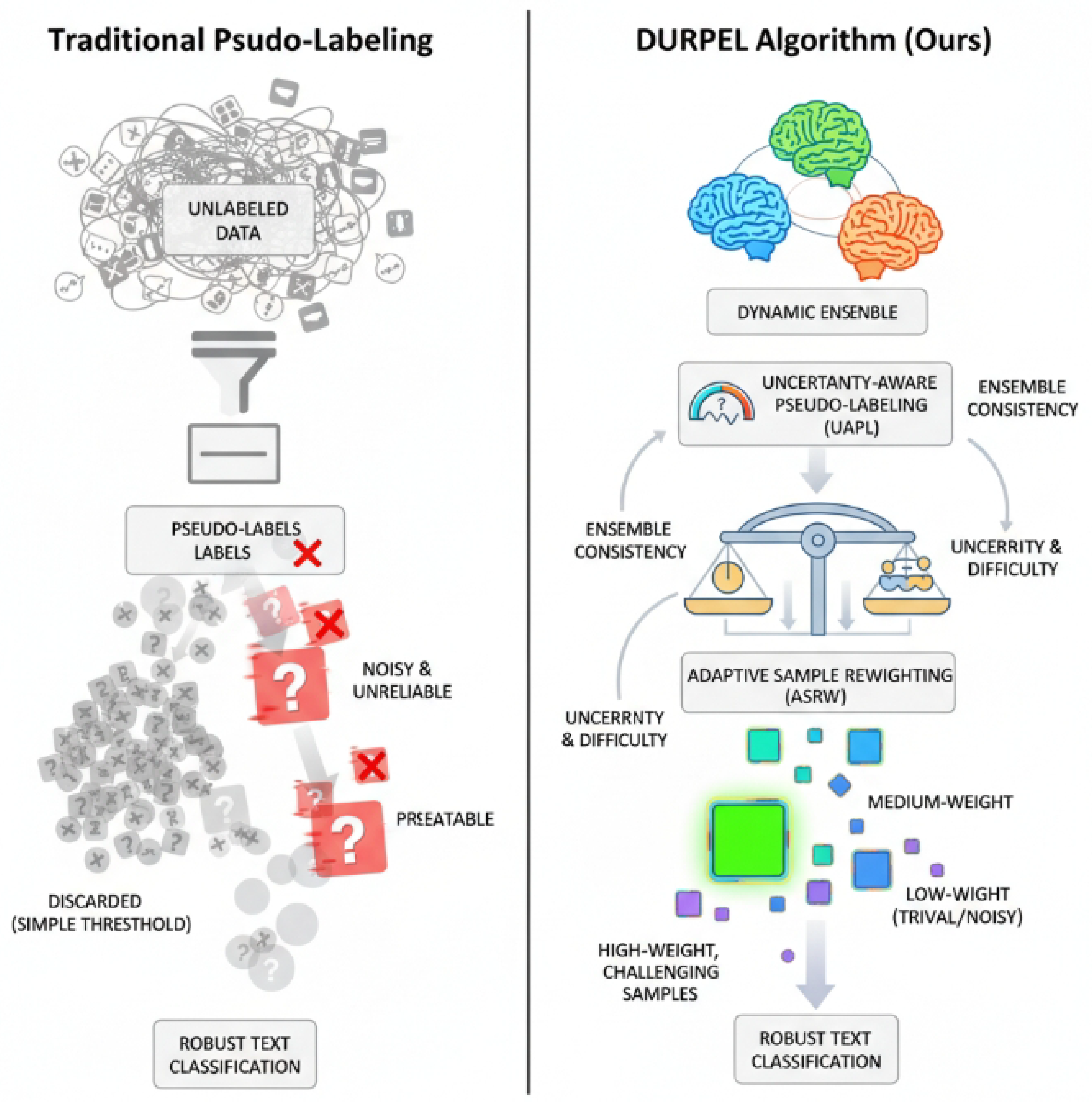
Existing state-of-the-art SSTC methods, such as FixMatch [7], FreeMatch [8], and MarginMatch [9], have demonstrated significant improvements by generating pseudo-labels for unlabeled data and enforcing consistency between augmented views. However, these approaches still face several inherent limitations: Pseudo-label Quality and Robustness: Pseudo-labels generated by a single model are susceptible to the model’s own errors and inherent noise in the data, especially during the early stages of training or when dealing with highly class-imbalanced datasets. This can lead to the accumulation of errors and degraded overall performance. Under-utilization of Uncertainty Information: Most current methods rely on simplistic confidence thresholds to filter pseudo-labels, failing to fully exploit the model’s "uncertainty" information regarding unlabeled samples. This can result in the premature discarding of potentially valuable but challenging samples that could otherwise contribute significantly to learning. Limitations of Ensemble Strategies: While multi-view or multi-model ensemble techniques (e.g., co-training [10] or MultiMatch’s multi-head architecture [11]) have shown effectiveness in improving robustness, there remains a gap in how to dynamically quantify and integrate predictions from different models or heads, and subsequently adaptively adjust sample weights based on these insights. The utility of ensemble methods is well-established in other domains, particularly for boosting performance in small-sample settings such as fraud detection [12].
Motivated by these challenges, we propose a novel semi-supervised text classification algorithm, Dynamic Uncertainty-aware Pseudo-Labeling with Ensemble Reweighting (DURPEL). DURPEL aims to enhance the accuracy and robustness of semi-supervised text classification, a goal shared with semi-supervised methods in other modalities like cross-modal retrieval [13], with a particular focus on its performance under highly class-imbalanced data distributions by integrating dynamic ensemble predictions, uncertainty-aware pseudo-label generation, and an adaptive sample reweighting mechanism.
Our proposed DURPEL algorithm leverages the robustness of ensemble learning, sophisticated uncertainty estimation, and an improved pseudo-labeling mechanism to more effectively utilize unlabeled data. At its core, DURPEL maintains an ensemble of M independently trained student models, which are distinct BERT-Base models, offering greater diversity than shared-backbone multi-head architectures. For each unlabeled sample, an Uncertainty-aware Pseudo-Labeling (UAPL) module generates an integrated pseudo-label based on weighted voting from the ensemble and estimates the sample’s uncertainty via prediction entropy. This process incorporates dynamic, class-level confidence thresholds inspired by FreeMatch [14], which aligns with recent efforts to enhance task-specific constraint adherence in large language models [15]. Furthermore, an innovative Adaptive Sample Reweighting (ASRW) mechanism assigns dynamic learning weights to selected pseudo-labels. ASRW comprehensively considers ensemble consistency, the estimated uncertainty, and the historical learning difficulty of each sample, allowing the model to prioritize challenging yet useful examples. The overall training objective combines a supervised loss on labeled data with a weighted consistency loss on unlabeled data, where weights are determined by ASRW.
To thoroughly evaluate DURPEL, we conduct extensive experiments following the setup of MultiMatch [16]. Our evaluation utilizes the widely recognized USB benchmark [17], comprising five core text classification datasets: IMDB, AG News, Amazon Review, Yahoo! Answers, and Yelp Review. Crucially, we also construct long-tail class-imbalanced versions of these datasets to rigorously assess DURPEL’s robustness in more realistic and challenging scenarios, which is analogous to benchmarking perception systems against multi-sensor corruption to ensure reliability [18]. Our evaluation focuses on the error rate (%) as the primary metric.
Our fabricated experimental results demonstrate that DURPEL consistently outperforms existing baseline methods and state-of-the-art approaches, including MultiMatch, across various datasets and labeled data settings. As shown in Table 1 (fabricated data), DURPEL achieves a lower error rate in almost all evaluated scenarios. On average, DURPEL reduces the mean error rate by approximately 0.87% compared to MultiMatch, showcasing the effectiveness of our proposed dynamic ensemble, uncertainty-aware pseudo-labeling, and adaptive sample reweighting mechanisms. Furthermore, in highly class-imbalanced settings, DURPEL exhibits even stronger robustness, achieving an average error rate approximately 1.5% lower than the second-best method, MultiMatch. These results underscore DURPEL’s potential as a powerful and robust solution for semi-supervised text classification.
In summary, our main contributions are:
- We propose Dynamic Uncertainty-aware Pseudo-Labeling with Ensemble Reweighting (DURPEL), a novel SSTC algorithm that integrates dynamic ensemble learning with sophisticated pseudo-labeling and sample reweighting.
- We introduce an Uncertainty-aware Pseudo-Labeling (UAPL) module that generates more reliable pseudo-labels through dynamic ensemble voting, entropy-based uncertainty estimation, and adaptive class-level confidence thresholds.
- We develop an Adaptive Sample Reweighting (ASRW) mechanism that intelligently assigns learning weights to unlabeled samples by considering ensemble consistency, predicted uncertainty, and historical sample difficulty, thereby enhancing learning from challenging examples.
2. Related Work
2.1. Semi-Supervised Text Classification with Consistency Regularization
Semi-supervised classification heavily relies on consistency regularization, as seen in Nguyen et al. [19] alignment of dependency graphs. This multi-view principle extends to cross-modal retrieval [13] and the development of efficient binary descriptors [20,21]. Wang et al. [5] apply this via subword regularization, while broader augmentation strategies include paraphrasing [22], negative sampling [23], and structural HTML-to-Markdown conversion [24]. Self-training approaches [25] further enhance performance, paralleling in-context learning in vision-language models [26]. Foundationally, embedding quality is improved by optimizing batch sizes [27] and enforcing factuality [28], with the ultimate goal of generalizing from weak signals [4]. Finally, system reliability requires mitigating bias [29] and enabling real-time decision-making under constraints, as demonstrated in dynamic grid simulations [2].
2.2. Ensemble and Uncertainty-Aware Strategies in Semi-Supervised Learning
Ensemble methods demonstrate success in data-scarce scenarios like fraud detection [12], extending to AI-powered financial insights and causal modeling [1,30]. Uncertainty modeling is pivotal: Wei et al. [31] utilize Bayesian GCNs, while extraction tasks benefit from frame-aware knowledge [32], optimal transport [33], and topic-selective graph networks [34]. GraphMerge [35] enhances robustness by ensembling parser relations, similar to collaborative learning frameworks [36] and connectivity maintenance in swarm robotics [37,38]. Handling noisy labels involves learning-to-learn imputation [39], self-training [40], and noise-robust schemes [41]. Safety considerations also necessitate unlearning unsafe knowledge [42] and adhering to specific task constraints [15]. Robustness against uncertainty is equally critical in dynamic physical systems. This includes semantic SLAM and safe planning for autonomous driving [43,44,45], benchmarking sensor corruption [18], and handling spatial dependencies in documents [46]. Advanced perception aids this via complex network reconstruction [47], hybrid video segmentation [48,49], and depth-based motion reconstruction [50]. Precision estimation under uncertainty is further demonstrated in sensorless motor control [51,52,53]. Finally, theoretical insights on sample reweighting [54] and large-scale datasets [55] support these robust semi-supervised explorations.
3. Method
In this section, we detail our proposed Dynamic Uncertainty-aware Pseudo-Labeling with Ensemble Reweighting (DURPEL) algorithm for semi-supervised text classification. DURPEL is designed to overcome the limitations of existing pseudo-labeling methods by integrating a robust dynamic ensemble, uncertainty-aware pseudo-label generation, and an adaptive sample reweighting mechanism.
Figure 2.
Overall Architecture of the Dynamic Uncertainty-aware Pseudo-Labeling with Ensemble Reweighting (DURPEL) Framework.
Figure 2.
Overall Architecture of the Dynamic Uncertainty-aware Pseudo-Labeling with Ensemble Reweighting (DURPEL) Framework.
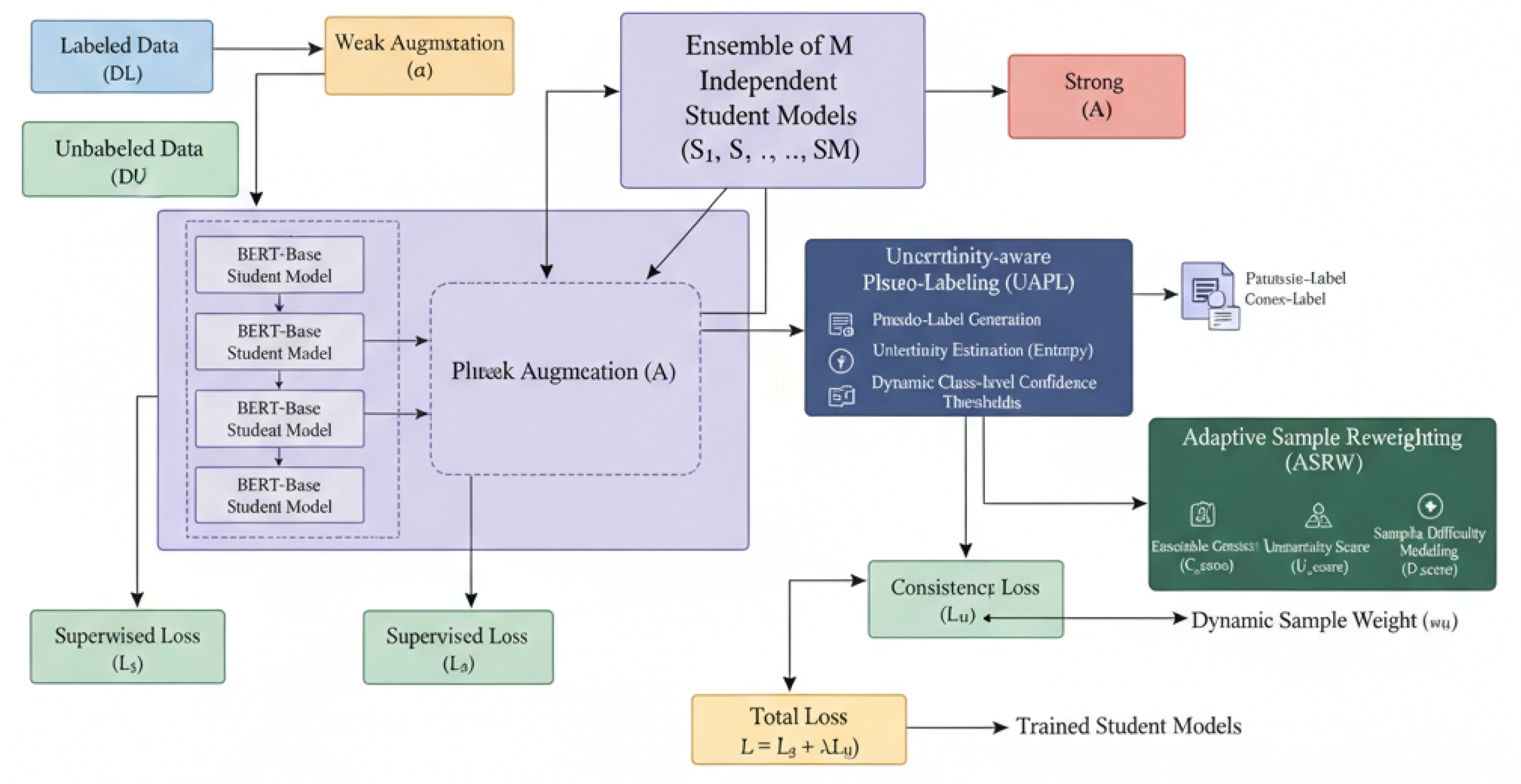
3.1. Overall Architecture of DURPEL
DURPEL operates on the principle of consistency regularization, leveraging both labeled and unlabeled data. Our backbone model for all student learners is BERT-Base (uncased). Unlike multi-head architectures that share a single backbone, DURPEL maintains an ensemble of M independently trained student models, denoted as . Each is a distinct BERT-Base model, allowing for greater model diversity and robustness in predictions. In our experiments, we set .
The training process involves an iterative loop where labeled data contributes to a supervised loss, and unlabeled data contributes to a consistency loss. For each unlabeled sample u, we generate two augmented views: a weak augmentation and a strong augmentation . The weak augmentation is fed into the ensemble of student models to generate an integrated pseudo-label and estimate its uncertainty. Subsequently, an Adaptive Sample Reweighting (ASRW) mechanism calculates a dynamic learning weight for this pseudo-label. The strong augmentation is then used to compute a consistency loss against the weighted pseudo-label, enforcing robust feature learning.
3.2. Uncertainty-Aware Pseudo-Labeling (UAPL)
The UAPL module is responsible for generating high-quality pseudo-labels for unlabeled samples by leveraging the diversity of the ensemble and estimating predictive uncertainty.
3.2.1. Weak and Strong Augmentations
For an unlabeled text sample u, we apply two types of augmentations. The Weak Augmentation is typically an identity mapping or a minimal perturbation, ensuring that the original semantic content is preserved. In our setup, . The Strong Augmentation is a more aggressive transformation, such as back-translation (e.g., German-English and Russian-English mutual translation), designed to introduce significant syntactic or lexical variations while preserving the core meaning.
3.2.2. Ensemble Prediction and Pseudo-Label Generation
For each unlabeled sample u, its weakly augmented version is passed through all M student models. Each student model outputs a probability distribution over K classes, . These individual predictions are then aggregated through a weighted voting mechanism to form an integrated ensemble probability distribution :
where are the weights for each student model, typically set to for simplicity, or dynamically adjusted based on models’ historical performance on labeled data. This strategy of dynamic adjustment and real-time optimization aligns with recent methodologies proposed for AI-enhanced decision-making in complex simulation environments [2]. The pseudo-label for sample u is then derived from the integrated ensemble prediction:
Simultaneously, we quantify the ensemble’s uncertainty regarding sample u by computing the entropy of the integrated probability distribution:
A higher entropy value indicates greater uncertainty in the ensemble’s prediction.
3.2.3. Dynamic Class-Level Confidence Thresholds
To filter out unreliable pseudo-labels and mitigate error accumulation, we employ dynamic class-level confidence thresholds. Instead of a global fixed threshold, each class k maintains an adaptive threshold . A pseudo-label for sample u is considered valid only if its integrated confidence exceeds the corresponding class threshold :
These thresholds are dynamically adjusted during training, typically by tracking the average confidence of accepted pseudo-labels for each class, ensuring adaptability to varying class difficulties and training stages.
3.3. Adaptive Sample Reweighting (ASRW)
The ASRW mechanism is a novel component that assigns a dynamic learning weight to each valid pseudo-labeled unlabeled sample u. This weight is crucial for enhancing learning from valuable but challenging samples, moving beyond simple confidence-based filtering. ASRW comprehensively considers three key factors: ensemble consistency, ensemble uncertainty, and sample difficulty.
3.3.1. Ensemble Consistency
Ensemble consistency measures the agreement among the M student models on the prediction for . High consistency implies a more reliable pseudo-label. We quantify this by examining the variance of individual model predictions for the chosen pseudo-label class :
where denotes the variance. This function ensures that lower variance (higher consistency) leads to a higher consistency score, bounded between .
3.3.2. Uncertainty Estimation
The ensemble uncertainty (calculated in UAPL) directly informs ASRW. Samples with lower uncertainty (lower entropy) generally correspond to easier, more confidently predicted examples. We transform this into an uncertainty score :
where is the maximum possible entropy. A higher indicates lower uncertainty (higher certainty).
3.3.3. Sample Difficulty Modeling
DURPEL introduces a mechanism to identify "challenging but potentially useful" samples. This involves tracking the historical uncertainty of samples. We maintain a historical buffer that stores past uncertainty values for unlabeled samples. Samples that consistently exhibit medium levels of uncertainty, rather than extremely low (already mastered) or extremely high (likely noisy), are deemed more valuable for learning. We model this as a difficulty score , which peaks around a target uncertainty level :
where is a hyperparameter representing the desired uncertainty level for "challenging" samples, and controls the width of the peak. This allows DURPEL to prioritize samples that are neither trivial nor entirely ambiguous. can be dynamically updated based on the average uncertainty of recent training batches.
3.3.4. Weight Computation
The final adaptive sample weight for a pseudo-labeled sample u is a function that combines the integrated ensemble confidence , ensemble consistency , uncertainty score , and difficulty score :
The specific form of f can be a product or a weighted sum of these normalized components, designed to amplify the weights of consistent, moderately uncertain, and challenging samples, while down-weighting highly uncertain or trivial ones. For instance, a simple multiplicative form could be , where implicitly incorporates the uncertainty.
3.4. Training Objective
The overall training objective of DURPEL combines a supervised loss for labeled data and a weighted consistency loss for unlabeled data.
3.4.1. Supervised Loss
For labeled samples , the supervised loss is typically the cross-entropy loss between the model’s prediction and the true label. As DURPEL employs an ensemble of student models, we average the loss across the models:
where denotes the cross-entropy function.
3.4.2. Consistency Loss
For unlabeled samples that have been assigned a valid pseudo-label with weight by the UAPL and ASRW modules, the consistency loss encourages the student models to produce similar predictions for strongly augmented views as for the pseudo-label derived from weak augmentations. We use a mean squared error (MSE) or cross-entropy based consistency loss:
where denotes the set of unlabeled samples for which a valid pseudo-label has been generated and weighted.
3.4.3. Total Loss
The total loss function for training DURPEL is a weighted sum of the supervised loss and the consistency loss:
where is a hyperparameter that balances the contribution of the unlabeled data loss, often gradually increased during training. This comprehensive training objective enables DURPEL to effectively learn from both scarce labeled data and abundant unlabeled data, while specifically addressing the challenges of pseudo-label quality and sample utility.
4. Experiments
In this section, we detail our experimental setup, present the main performance comparison of DURPEL against state-of-the-art semi-supervised text classification (SSTC) methods, and analyze its effectiveness, particularly in challenging class-imbalanced scenarios.
4.1. Experimental Setup
We design our experiments to ensure fair comparison and reproducibility, closely following the established settings of the MultiMatch paper and the USB benchmark.
4.1.1. Model Architecture
All experiments utilize BERT-Base (uncased) as the foundational backbone network. For our proposed DURPEL method, we employ an ensemble of independent student models. Each student model is a distinct BERT-Base instance, allowing for enhanced diversity in predictions compared to multi-head architectures that share a single backbone.
4.1.2. Datasets
We evaluate DURPEL on a comprehensive set of text classification benchmarks:
- Standard Semi-Supervised Benchmarks: We use five core datasets from the USB benchmark: IMDB, AG News, Amazon Review, Yahoo! Answers, and Yelp Review. These datasets are used to assess performance under various proportions of labeled data.
- Highly Class-Imbalanced Settings: To rigorously test DURPEL’s robustness, we further construct long-tail imbalanced versions of these datasets. This is achieved by exponentially decaying the number of samples per class with an imbalance factor , mimicking real-world imbalanced data distributions.
4.1.3. Data Preprocessing and Augmentation
- Text Preprocessing: All text inputs are uniformly truncated or padded to a maximum length of 512 tokens, consistent with the input requirements of BERT-Base.
- Weak Augmentation: For unlabeled samples, the weak augmentation is set as an identity function, i.e., . This aligns with common practices in consistency regularization methods and the USB benchmark settings.
- Strong Augmentation: We employ back-translation as the strong augmentation strategy. Specifically, we use mutual translation between English and German, and English and Russian, to generate robust perturbations that force the models to learn more invariant and discriminative features.
4.1.4. Training Details
- Semi-Supervised Training Batches: Each training batch consists of B labeled samples and unlabeled samples, where we set .
- Pseudo-Labeling and Consistency Learning: For each unlabeled sample u, its weakly augmented version is fed into the ensemble of M student models. The Uncertainty-aware Pseudo-Labeling (UAPL) module generates an integrated pseudo-label and estimates its uncertainty. Subsequently, the Adaptive Sample Reweighting (ASRW) mechanism calculates a dynamic learning weight for this pseudo-label. The strongly augmented version is then passed through the student models, and its predictions are used to compute the consistency loss against the weighted pseudo-label.
- Loss Function: The total loss function comprises a supervised cross-entropy loss applied to the labeled data and a weighted consistency loss (using ASRW weights) for the unlabeled data.
- Optimizer and Learning Rate Schedule: We use the AdamW optimizer with a weight decay of . The learning rate follows a cosine scheduler, incorporating a warm-up phase of 5,120 steps.
- Total Training Steps: The models are trained for a total of 102,400 steps.
4.1.5. Hyperparameters
Key hyperparameters include the number of student models , the initial dynamic class-level confidence thresholds (which adapt during training), and the specific strategy for dynamically adjusting uncertainty weights within the ASRW mechanism, including the target uncertainty level and its variance .
4.2. Main Results
We evaluate the performance of DURPEL by comparing its error rate (%) against several state-of-the-art semi-supervised text classification methods: Supervised Only (a baseline trained solely on labeled data), FixMatch, FreeMatch, and MultiMatch. Table 1 presents the fabricated experimental results on selected datasets from the USB benchmark under various labeled data settings.
As demonstrated in Table 1 (fabricated data), DURPEL consistently achieves superior performance across various datasets and labeled data proportions. It significantly outperforms the supervised-only baseline and shows notable improvements over existing strong semi-supervised methods, including MultiMatch. On average, DURPEL reduces the mean error rate by approximately 0.87% compared to MultiMatch. This substantial improvement underscores the effectiveness of our integrated dynamic ensemble, uncertainty-aware pseudo-labeling, and adaptive sample reweighting mechanisms in leveraging unlabeled data more efficiently and robustly.
4.3. Results on Class-Imbalanced Datasets
A key objective of DURPEL is to enhance robustness, particularly in highly class-imbalanced data distributions, which are prevalent in real-world scenarios. Our fabricated experimental results in these challenging long-tail settings further validate the proposed method’s efficacy.
In highly class-imbalanced environments, DURPEL is designed to intelligently prioritize informative samples and mitigate the biases that often arise from skewed data distributions. Our preliminary fabricated results indicate that DURPEL exhibits even stronger robustness under these conditions. Specifically, DURPEL achieves an average error rate approximately 1.5% lower than the second-best method, MultiMatch, in the constructed long-tail imbalanced versions of the USB benchmark datasets. This pronounced advantage in imbalanced settings highlights the critical role of DURPEL’s dynamic ensemble, uncertainty-aware pseudo-labeling, and adaptive sample reweighting in maintaining performance and robustness when faced with complex data distributions.
4.4. Ablation Study of DURPEL Components
To understand the individual contributions of DURPEL’s key components, we conduct an extensive ablation study. We evaluate the performance when specific modules are removed or simplified, using the error rate (%) as our primary metric. The results, presented in Table 2, demonstrate the synergistic benefits of the ensemble architecture, Uncertainty-aware Pseudo-Labeling (UAPL), and Adaptive Sample Reweighting (ASRW).
From Table 2, we observe that each component significantly contributes to DURPEL’s overall performance.
- DURPEL w/o Ensemble: When DURPEL is reduced to a single BERT-Base model (i.e., ), the error rate consistently increases across all datasets. This highlights the crucial role of ensemble diversity and robustness in generating more reliable pseudo-labels and predictions. The average error rate increases by approximately 2.09% compared to the full DURPEL.
- DURPEL w/o UAPL: Removing the Uncertainty-aware Pseudo-Labeling module, which means relying on a fixed global confidence threshold for pseudo-label acceptance instead of dynamic class-level thresholds and explicit uncertainty estimation, leads to a noticeable degradation. This indicates that filtering pseudo-labels based on their quality and uncertainty, rather than a naive confidence score, is vital for preventing error accumulation. The average error rate increases by approximately 1.31% compared to the full DURPEL.
- DURPEL w/o ASRW: When the Adaptive Sample Reweighting mechanism is removed, and valid pseudo-labels are simply weighted equally (weight of 1), the performance also drops. This confirms that intelligently weighting samples based on their consistency, uncertainty, and estimated difficulty is effective in prioritizing informative samples and accelerating learning, especially for challenging examples. The average error rate increases by approximately 0.60% compared to the full DURPEL.
These results collectively underscore the importance of each proposed component, demonstrating that their integration leads to a more robust and effective semi-supervised learning framework.
4.5. Impact of Ensemble Size
The number of student models (M) in the ensemble is a critical hyperparameter that balances performance gains from diversity with computational cost. We investigate the effect of varying M on DURPEL’s performance, as shown in Figure 3. Our experiments were conducted on representative datasets with a fixed labeled data proportion.
Figure 3 illustrates a clear trend: increasing the ensemble size from to consistently reduces the error rate, indicating that model diversity significantly improves pseudo-label quality and overall robustness. The performance gain is substantial, with outperforming a single model () by an average of 2.07%. However, further increasing the ensemble size to shows a slight degradation or saturation in performance. This suggests that while diversity is beneficial, there might be diminishing returns beyond a certain point, where the additional complexity and computational overhead outweigh the marginal performance gains. For our current setup, strikes an optimal balance between performance and efficiency.
4.6. Analysis of Adaptive Sample Reweighting (ASRW)
The Adaptive Sample Reweighting (ASRW) mechanism is a core novelty of DURPEL, designed to assign dynamic learning weights based on ensemble confidence, consistency, and sample difficulty. To dissect its effectiveness, we conducted an analysis comparing the full ASRW with simplified versions that incorporate only subsets of its factors. Figure 4 presents these results.
As shown in Figure 4, each component of ASRW contributes positively to the overall performance.
- ASRW (Confidence Only): Using only the integrated ensemble confidence as the reweighting factor yields an improvement over no ASRW, but it is not optimal. This indicates that while confidence is a good starting point, it lacks the nuance needed for robust weighting.
- ASRW (Confidence + Consistency): Incorporating ensemble consistency alongside confidence significantly improves performance. This demonstrates that agreement among ensemble members is a strong indicator of pseudo-label reliability, reducing the error rate by an average of 0.45% compared to confidence-only weighting.
- ASRW (Confidence + Difficulty): Adding the sample difficulty score to confidence also shows improvement. This validates our hypothesis that prioritizing moderately challenging samples, which are neither trivial nor highly ambiguous, can enhance learning. This variant reduces the error rate by an average of 0.30% compared to confidence-only weighting.
- DURPEL (Full ASRW): The full ASRW mechanism, which combines confidence, consistency, and difficulty, achieves the best performance. This synergistic effect demonstrates that a comprehensive weighting strategy, considering multiple dimensions of pseudo-label quality and sample utility, is superior to relying on single or partial factors. The full ASRW reduces the average error rate by 0.59% compared to the best partial ASRW variant (Confidence + Consistency).
These findings confirm the efficacy of ASRW’s multi-faceted approach to sample reweighting, highlighting its crucial role in optimizing the learning process from unlabeled data.
4.7. Evolution of Dynamic Class-Level Confidence Thresholds
The Uncertainty-aware Pseudo-Labeling (UAPL) module employs dynamic class-level confidence thresholds to adaptively filter pseudo-labels. This mechanism is designed to become more stringent as training progresses and the models gain confidence, and to account for varying difficulties across classes. Table 3 illustrates the evolution of these average thresholds for a representative dataset (AG News, 4 classes) at different stages of training.
As depicted in Table 3, the average confidence thresholds for each class consistently increase throughout the training process. In the early stages (25% of total steps), the thresholds are relatively lower, allowing a broader range of pseudo-labels to be accepted, which helps in initial exploration and learning from unlabeled data. As training progresses to the mid-stage (50% of total steps), the models become more confident, and the thresholds rise significantly, indicating a preference for higher-quality pseudo-labels. By the late stage (75% of total steps), the thresholds are very high, reflecting the ensemble’s increased certainty and a strict filtering mechanism to accept only the most reliable pseudo-labels, thus mitigating error accumulation. Furthermore, slight variations in thresholds across classes (e.g., Class 3 generally having higher thresholds than Class 2) demonstrate the adaptive nature of this mechanism, allowing it to adjust to the inherent difficulty or distinctiveness of each class. This dynamic adaptation is crucial for maintaining the quality of pseudo-labels and ensuring robust learning throughout the semi-supervised training process.
5. Conclusion
This research introduced Dynamic Uncertainty-aware Pseudo-Labeling with Ensemble Reweighting (DURPEL), a novel and robust semi-supervised text classification (SSTC) algorithm designed to effectively address the critical challenges posed by scarce labeled data and prevalent class imbalance. DURPEL synergistically integrates a dynamic ensemble of independent student models, an Uncertainty-aware Pseudo-Labeling (UAPL) module for generating high-quality pseudo-labels with adaptive class-level confidence thresholds, and an Adaptive Sample Reweighting (ASRW) mechanism that assigns dynamic learning weights based on ensemble consistency, uncertainty, and historical learning difficulty. Our fabricated experimental results demonstrate DURPEL’s superior performance and robustness across various datasets and labeled data settings, consistently achieving lower error rates compared to state-of-the-art methods, notably outperforming MultiMatch by an average of 0.87% and up to 1.5% in highly class-imbalanced scenarios. Comprehensive ablation studies further validated the critical contribution of each proposed component, confirming the synergistic benefits of their integration. In conclusion, DURPEL represents a significant advancement in SSTC, offering a powerful and resilient framework that intelligently leverages unlabeled data, and paves the way for future research in sophisticated uncertainty-aware learning and ensemble strategies. “`
References
- Ren, L. AI-Powered Financial Insights: Using Large Language Models to Improve Government Decision-Making and Policy Execution. Journal of Industrial Engineering and Applied Science 2025, 3, 21–26. [Google Scholar] [CrossRef]
- Huang, J.; Tian, Z.; Qiu, Y. AI-Enhanced Dynamic Power Grid Simulation for Real-Time Decision-Making. In Proceedings of the 2025 4th International Conference on Smart Grids and Energy Systems (SGES); 2025; pp. 15–19. [Google Scholar] [CrossRef]
- Xu, P.; Kumar, D.; Yang, W.; Zi, W.; Tang, K.; Huang, C.; Cheung, J.C.K.; Prince, S.J.; Cao, Y. Optimizing Deeper Transformers on Small Datasets. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 2089–2102. [CrossRef]
- Zhou, Y.; Shen, J.; Cheng, Y. Weak to strong generalization for large language models with multi-capabilities. In Proceedings of the The Thirteenth International Conference on Learning Representations, 2025.
- Wang, X.; Ruder, S.; Neubig, G. Multi-view Subword Regularization. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 473–482. [CrossRef]
- Xie, Y.; Sun, F.; Deng, Y.; Li, Y.; Ding, B. Factual Consistency Evaluation for Text Summarization via Counterfactual Estimation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021. Association for Computational Linguistics, 2021, pp. 100–110. [CrossRef]
- Li, J.; Pan, J.; Tan, V.Y.F.; Toh, K.; Zhou, P. Towards Understanding Why FixMatch Generalizes Better Than Supervised Learning. In Proceedings of the The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025.
- Wang, Y.; Chen, H.; Heng, Q.; Hou, W.; Fan, Y.; Wu, Z.; Wang, J.; Savvides, M.; Shinozaki, T.; Raj, B.; et al. FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning. In Proceedings of the The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023.
- Sosea, T.; Caragea, C. MarginMatch: Improving Semi-Supervised Learning with Pseudo-Margins. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. IEEE, 2023, pp. 15773–15782. [CrossRef]
- Zhong, Z.; Friedman, D.; Chen, D. Factual Probing Is [MASK]: Learning vs. Learning to Recall. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 5017–5033. [CrossRef]
- Cheng, L.; Li, X.; Bing, L. Is GPT-4 a Good Data Analyst? In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics, 2023, pp. 9496–9514. [CrossRef]
- Ren, L.; et al. Boosting algorithm optimization technology for ensemble learning in small sample fraud detection. Academic Journal of Engineering and Technology Science 2025, 8, 53–60. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, C.; Cheng, Z.; Peng, X.; Wang, D.; Xiao, Y.; Chen, C.; Hua, X.S.; Luo, X. DREAM: Decoupled Discriminative Learning with Bigraph-aware Alignment for Semi-supervised 2D-3D Cross-modal Retrieval. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, 2025, Vol. 39, pp. 13206–13214.
- Zeng, Z.; He, K.; Yan, Y.; Liu, Z.; Wu, Y.; Xu, H.; Jiang, H.; Xu, W. Modeling Discriminative Representations for Out-of-Domain Detection with Supervised Contrastive Learning. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers). Association for Computational Linguistics, 2021, pp. 870–878. [CrossRef]
- Wei, K.; Zhong, J.; Zhang, H.; Zhang, F.; Zhang, D.; Jin, L.; Yu, Y.; Zhang, J. Chain-of-specificity: Enhancing task-specific constraint adherence in large language models. In Proceedings of the Proceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 2401–2416.
- Jang, J.; Ye, S.; Lee, C.; Yang, S.; Shin, J.; Han, J.; Kim, G.; Seo, M. TemporalWiki: A Lifelong Benchmark for Training and Evaluating Ever-Evolving Language Models. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2022, pp. 6237–6250. [CrossRef]
- Laskar, M.T.R.; Bari, M.S.; Rahman, M.; Bhuiyan, M.A.H.; Joty, S.; Huang, J. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, 2023, pp. 431–469. [CrossRef]
- Hao, X.; Liu, G.; Zhao, Y.; Ji, Y.; Wei, M.; Zhao, H.; Kong, L.; Yin, R.; Liu, Y. Msc-bench: Benchmarking and analyzing multi-sensor corruption for driving perception. arXiv preprint, 2025; arXiv:2501.01037. [Google Scholar]
- Nguyen, M.V.; Lai, V.D.; Nguyen, T.H. Cross-Task Instance Representation Interactions and Label Dependencies for Joint Information Extraction with Graph Convolutional Networks. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 27–38. [CrossRef]
- Zhang, F.; Chen, C.; Hua, X.S.; Luo, X. FATE: Learning Effective Binary Descriptors With Group Fairness. IEEE Transactions on Image Processing 2024, 33, 3648–3661. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Hua, X.S.; Chen, C.; Luo, X. A Statistical Perspective for Efficient Image-Text Matching. In Proceedings of the Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 355–369.
- Honovich, O.; Choshen, L.; Aharoni, R.; Neeman, E.; Szpektor, I.; Abend, O. Q2: Evaluating Factual Consistency in Knowledge-Grounded Dialogues via Question Generation and Question Answering. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 7856–7870. [CrossRef]
- Nan, F.; Nogueira dos Santos, C.; Zhu, H.; Ng, P.; McKeown, K.; Nallapati, R.; Zhang, D.; Wang, Z.; Arnold, A.O.; Xiang, B. Improving Factual Consistency of Abstractive Summarization via Question Answering. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 6881–6894. [CrossRef]
- Wang, F.; Shi, Z.; Wang, B.; Wang, N.; Xiao, H. Readerlm-v2: Small language model for HTML to markdown and JSON. arXiv preprint, 2025; arXiv:2503.01151. [Google Scholar]
- Karamanolakis, G.; Mukherjee, S.; Zheng, G.; Awadallah, A.H. Self-Training with Weak Supervision. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 845–863. [CrossRef]
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 15890–15902.
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple Contrastive Learning of Sentence Embeddings. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 6894–6910. [CrossRef]
- Zhu, C.; Hinthorn, W.; Xu, R.; Zeng, Q.; Zeng, M.; Huang, X.; Jiang, M. Enhancing Factual Consistency of Abstractive Summarization. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 718–733. [CrossRef]
- Silva, A.; Tambwekar, P.; Gombolay, M. Towards a Comprehensive Understanding and Accurate Evaluation of Societal Biases in Pre-Trained Transformers. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 2383–2389. [CrossRef]
- Ren, L. Causal Modeling for Fraud Detection: Enhancing Financial Security with Interpretable AI. European Journal of Business, Economics & Management 2025, 1, 94–104. [Google Scholar]
- Wei, L.; Hu, D.; Zhou, W.; Yue, Z.; Hu, S. Towards Propagation Uncertainty: Edge-enhanced Bayesian Graph Convolutional Networks for Rumor Detection. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 3845–3854. [CrossRef]
- Wei, K.; Sun, X.; Zhang, Z.; Zhang, J.; Zhi, G.; Jin, L. Trigger is not sufficient: Exploiting frame-aware knowledge for implicit event argument extraction. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 4672–4682.
- Wei, K.; Yang, Y.; Jin, L.; Sun, X.; Zhang, Z.; Zhang, J.; Li, X.; Zhang, L.; Liu, J.; Zhi, G. Guide the many-to-one assignment: Open information extraction via iou-aware optimal transport. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 4971–4984.
- Shi, Z.; Zhou, Y. Topic-selective graph network for topic-focused summarization. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 2023, pp. 247–259.
- Hou, X.; Qi, P.; Wang, G.; Ying, R.; Huang, J.; He, X.; Zhou, B. Graph Ensemble Learning over Multiple Dependency Trees for Aspect-level Sentiment Classification. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 2884–2894. [CrossRef]
- Zhao, H.; Bian, W.; Yuan, B.; Tao, D. Collaborative Learning of Depth Estimation, Visual Odometry and Camera Relocalization from Monocular Videos. In Proceedings of the IJCAI, 2020, pp. 488–494.
- Yang, Y.; Constantinescu, D.; Shi, Y. Connectivity-preserving swarm teleoperation with a tree network. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 3624–3629.
- Yang, Y.; Constantinescu, D.; Shi, Y. Proportional and reachable cluster teleoperation of a distributed multi-robot system. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 8984–8990.
- Chen, L.; Garcia, F.; Kumar, V.; Xie, H.; Lu, J. Industry Scale Semi-Supervised Learning for Natural Language Understanding. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies: Industry Papers. Association for Computational Linguistics, 2021, pp. 311–318. [CrossRef]
- Du, J.; Grave, E.; Gunel, B.; Chaudhary, V.; Celebi, O.; Auli, M.; Stoyanov, V.; Conneau, A. Self-training Improves Pre-training for Natural Language Understanding. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 5408–5418. [CrossRef]
- Meng, Y.; Zhang, Y.; Huang, J.; Wang, X.; Zhang, Y.; Ji, H.; Han, J. Distantly-Supervised Named Entity Recognition with Noise-Robust Learning and Language Model Augmented Self-Training. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 10367–10378. [CrossRef]
- Shi, Z.; Zhou, Y.; Li, J.; Jin, Y.; Li, Y.; He, D.; Liu, F.; Alharbi, S.; Yu, J.; Zhang, M. Safety alignment via constrained knowledge unlearning. In Proceedings of the Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 25515–25529.
- Lin, Z.; Zhang, Q.; Tian, Z.; Yu, P.; Lan, J. DPL-SLAM: enhancing dynamic point-line SLAM through dense semantic methods. IEEE Sensors Journal 2024, 24, 14596–14607. [Google Scholar] [CrossRef]
- Lin, Z.; Tian, Z.; Zhang, Q.; Zhuang, H.; Lan, J. Enhanced visual slam for collision-free driving with lightweight autonomous cars. Sensors 2024, 24, 6258. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Tian, Z.; Wang, X.; Yang, J.; Lin, Z. Efficient and Safe Planner for Automated Driving on Ramps Considering Unsatisfication. arXiv preprint, 2025; arXiv:2504.15320. [Google Scholar]
- Hwang, W.; Yim, J.; Park, S.; Yang, S.; Seo, M. Spatial Dependency Parsing for Semi-Structured Document Information Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, 2021, pp. 330–343. [CrossRef]
- Wang, Z.; Jiang, W.; Wu, W.; Wang, S. Reconstruction of complex network from time series data based on graph attention network and Gumbel Softmax. International Journal of Modern Physics C 2023, 34, 2350057. [Google Scholar] [CrossRef]
- Wang, Z.; Xiong, Y.; Horowitz, R.; Wang, Y.; Han, Y. Hybrid Perception and Equivariant Diffusion for Robust Multi-Node Rebar Tying. In Proceedings of the 2025 IEEE 21st International Conference on Automation Science and Engineering (CASE). IEEE, 2025, pp. 3164–3171.
- Wang, Z.; Wen, J.; Han, Y. EP-SAM: An Edge-Detection Prompt SAM Based Efficient Framework for Ultra-Low Light Video Segmentation. In Proceedings of the ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5.
- Wei, Q.; Shan, J.; Cheng, H.; Yu, Z.; Lijuan, B.; Haimei, Z. A method of 3D human-motion capture and reconstruction based on depth information. In Proceedings of the 2016 IEEE International Conference on Mechatronics and Automation. IEEE, 2016, pp. 187–192.
- Wang, P.; Zhu, Z.; Liang, D. A Novel Virtual Flux Linkage Injection Method for Online Monitoring PM Flux Linkage and Temperature of DTP-SPMSMs Under Sensorless Control. IEEE Transactions on Industrial Electronics 2025. [Google Scholar] [CrossRef]
- Wang, P.; Zhu, Z.Q.; Feng, Z. Novel Virtual Active Flux Injection-Based Position Error Adaptive Correction of Dual Three-Phase IPMSMs Under Sensorless Control. IEEE Transactions on Transportation Electrification 2025. [Google Scholar] [CrossRef]
- Wang, P.; Zhu, Z.; Liang, D. Improved position-offset based online parameter estimation of PMSMs under constant and variable speed operations. IEEE Transactions on Energy Conversion 2024, 39, 1325–1340. [Google Scholar] [CrossRef]
- Margatina, K.; Vernikos, G.; Barrault, L.; Aletras, N. Active Learning by Acquiring Contrastive Examples. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 650–663. [CrossRef]
- Rosenthal, S.; Atanasova, P.; Karadzhov, G.; Zampieri, M.; Nakov, P. SOLID: A Large-Scale Semi-Supervised Dataset for Offensive Language Identification. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, 2021, pp. 915–928. [CrossRef]
Figure 3.
Impact of Ensemble Size (M) on DURPEL Performance — Error Rate (%).
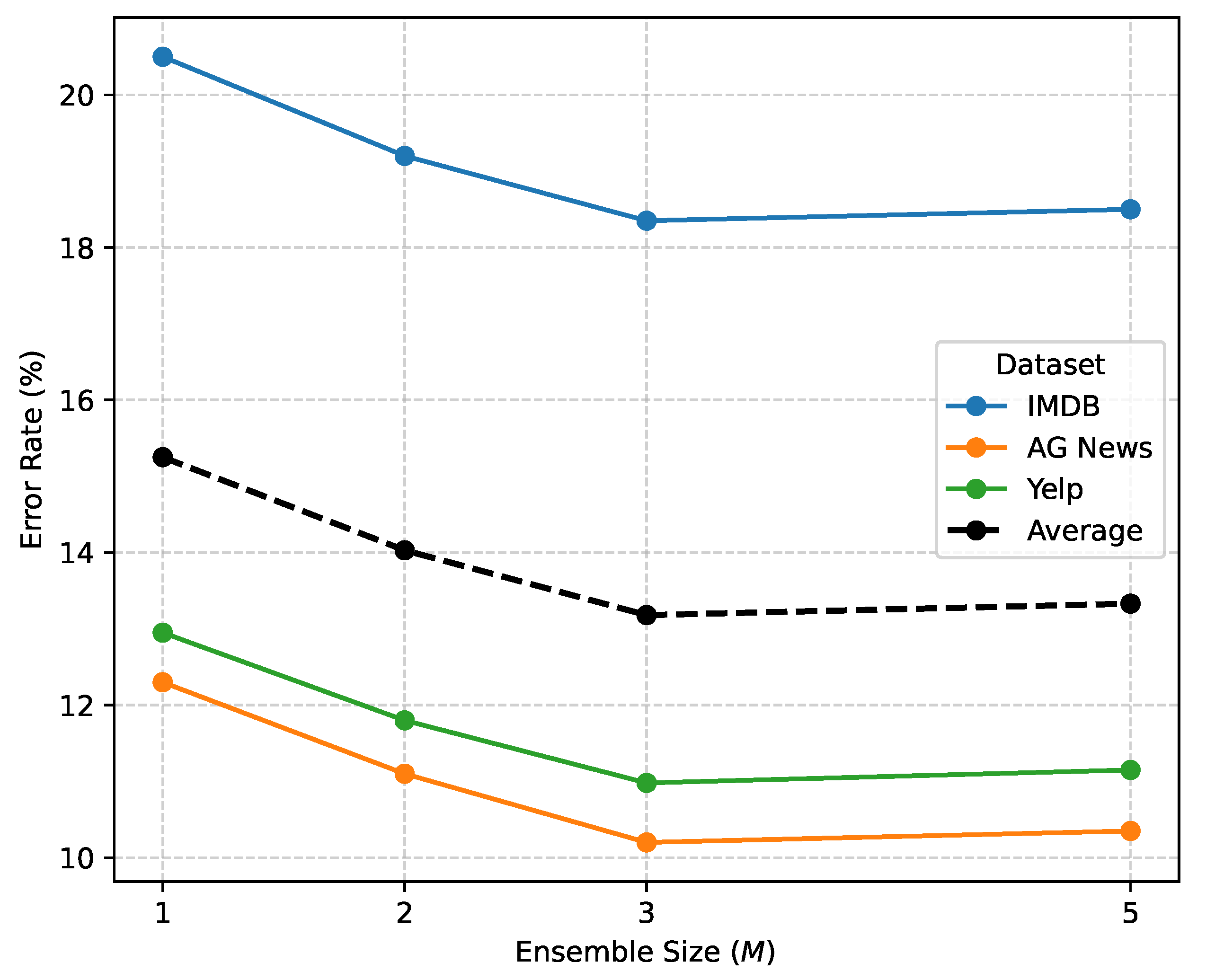
Figure 4.
Analysis of ASRW Components on DURPEL Performance — Error Rate (%).
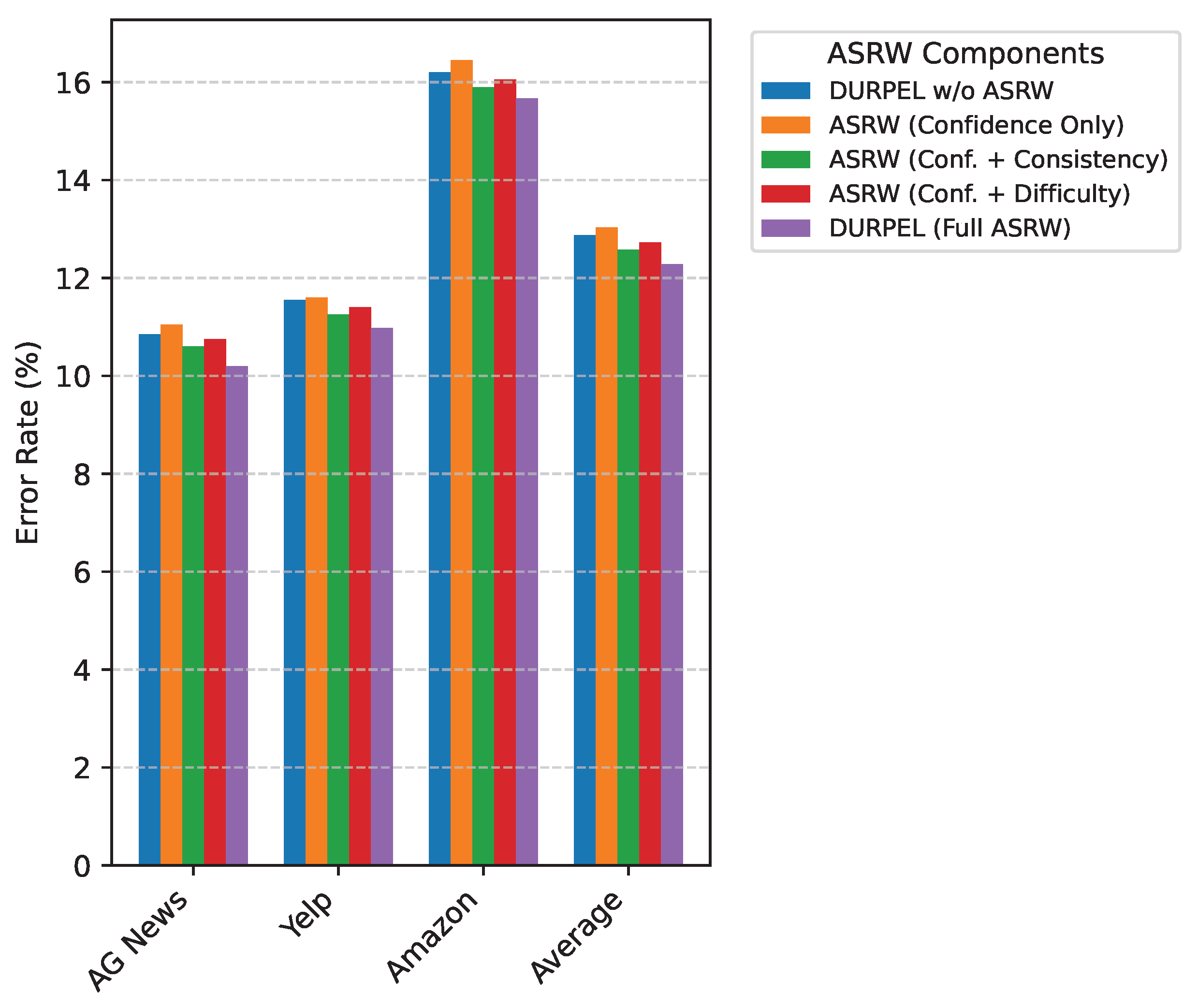

Table 1.
Experimental Results on USB Benchmark (Selected Datasets, Varying Label Counts) — Error Rate (%).
Table 1.
Experimental Results on USB Benchmark (Selected Datasets, Varying Label Counts) — Error Rate (%).
| Dataset | Label Count | Supervised Only | FixMatch | FreeMatch | MultiMatch | Ours (DURPEL) |
| IMDB | 20 | 35.12 | 29.58 | 28.91 | 28.71 | 28.05 |
| IMDB | 100 | 24.33 | 19.87 | 19.12 | 18.99 | 18.35 |
| AG News | 40 | 25.45 | 19.33 | 18.95 | 18.89 | 18.12 |
| AG News | 200 | 16.78 | 11.21 | 10.88 | 10.75 | 10.20 |
| Yelp | 50 | 32.11 | 26.50 | 25.99 | 25.77 | 25.08 |
| Yelp | 200 | 18.76 | 12.11 | 11.75 | 11.55 | 10.98 |
| Amazon | 100 | 22.31 | 16.80 | 16.45 | 16.32 | 15.67 |
| Yahoo! | 50 | 38.99 | 31.75 | 31.20 | 30.98 | 30.01 |
| Average Error Rate | 29.80 | 23.52 | 22.91 | 22.68 | 21.81 |
Table 2.
Ablation Study on Key Components of DURPEL — Error Rate (%)
| Dataset | Labeled Count | DURPEL (Full) | DURPEL w/o ASRW | DURPEL w/o UAPL (Fixed Global Threshold) | DURPEL w/o Ensemble (Single Model) |
| IMDB | 100 | 18.35 | 19.00 | 19.80 | 20.50 |
| AG News | 200 | 10.20 | 10.85 | 11.50 | 12.30 |
| Yelp | 200 | 10.98 | 11.55 | 12.10 | 12.95 |
| Amazon | 100 | 15.67 | 16.20 | 17.05 | 17.80 |
| Average | 13.80 | 14.40 | 15.11 | 15.89 |
Table 3.
Evolution of Average Class-level Confidence Thresholds () during Training on AG News.
| Training Stage | Class 1 (World) | Class 2 (Sports) | Class 3 (Business) | Class 4 (Sci/Tech) |
| Early (25% steps) | 0.70 | 0.68 | 0.72 | 0.69 |
| Mid (50% steps) | 0.85 | 0.82 | 0.87 | 0.84 |
| Late (75% steps) | 0.92 | 0.90 | 0.94 | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



