Submitted:
18 November 2025
Posted:
19 November 2025
You are already at the latest version
Abstract
Single nucleotide variants (SNVs) are crucial for cancer occurrence and development. SNVs at transcriptomic generally come from genomic variants (g-tSNVs) and RNA editing (e-tSNVs). Types and quantities of e-tSNVs remain a large argument due to relatively poor understanding of RNA editing processes. Herein, we developed TSCS (Transcript SNVs Classifier relied on complementary Sequencings), a machine learning classifier that integrates short-read (MGI) and long-read (PacBio) RNA-seq data to accurately distinguish true transcript SNVs using stringent criteria. Applied to five colorectal cancer cell lines (HCT15, LoVo, SW480, SW620, and HCT116), TSCS demonstrated superior accuracy and sensitivity, especially for low-frequency variants, outperforming established tools (GATK, BCFtools, Longshot, RED_ML). It increased total detected transcript SNVs by 31.83% on average, with g-tSNVs and e-tSNVs exceeding conventional methods by >1-fold and >2-fold, respectively. TSCS achieved mean recall rates of 75.3% for g-tSNVs and 77.2% for e-tSNVs. Notably, For the first time, e-tSNVs were found in relatively large proportion of total transcript SNVs in cancer cell lines, approximately 40%. Of the identified e-tSNVs, 80% were attributed to the known-RNA editing, but the other e-tSNVs did not fall into any known category. Importantly, the e-tSNVs uniquely detected in this study showed distinct patterns in SNV types and genomic locations. Additionally, the transcript SNVs called by TSCS were partially confirmed by experimental approaches, such as Sanger sequencing, RNC-seq and mass spectrometry. This study lays the foundation for surveying and appraising the cancer-related e-tSNVs.
Keywords:
RNA-seq
; SRS
; LRS
; g-tSNV
; e-tSNV
; TSCS
; machine learning
1. Introduction
Cancer is a genomic disorder driven by extensive mutational events [1]. The Cancer Genome Atlas (TCGA) has revealed that approximately 95% of these mutations are single nucleotide variations (SNVs), among which about 91% are nonsynonymous (nsSNVs) that contribute to functional aberrations in cancer cells [2,3,4,5]. Advances in next-generation sequencing (NGS) have led to the identification of millions of nsSNVs, with around 6 million cataloged in the COSMIC database [6]. Concurrently, RNA-seq enables quantitative detection of transcript-level SNVs, which fall into two categories: those originating from genomic mutations (g-tSNVs) and those arising from RNA editing (e-tSNVs) [7]. As e-tSNVs are not genetically inherited and can alter amino acid sequences—potentially distorting protein function—they offer a valuable perspective for investigating cancer mechanisms [8,9,10].
Currently, e-tSNVs are primarily identified by excluding g-tSNVs from total transcript SNVs. Databases such as REDIdb, DARNED, RADAR, and REDIportal compile RNA editing events [11,12,13,14]. A key feature of e-tSNVs is their variant allele frequency (VAF), calculated as the ratio of main variant supporting reads to total reads at a given locus, characterizes the allelic representation of detected variants, which is often low, with adenosine-to-inosine (A-to-I) changes in non-coding regions—especially in 3′UTR Alu repeats—being most common [15]. However, the abundance and diversity of RNA editing events remain controversial [16]. Some studies report widespread editing involving diverse mechanisms [17,18], whereas others highlight high false-positive rates in e-tSNV identification [19,20]. A major challenge lies in accurately detecting e-tSNVs, particularly those with low VAF. Issues such as transcript strand-specificity, splicing complexity, and highly variable expression levels complicate SNV calling in RNA-seq [21,22]. Current transcript SNV callers (e.g., SNVQ[23], SNPiR[21], eSNV-detect[24], MuTect2, and VarScan2[25],) typically employ a two-stage approach: initial calling using genomic tools like GATK[26] or BCFtools[27], followed by transcript-aware filtering. However, this strategy has key limitations. Genomic callers often discard true low-VAF variants due to poor adaptation to RNA expression characteristics. Moreover, inconsistent filtering criteria across tools lead to low reproducibility—especially for e-tSNVs. To address this, specialized tools such as RNAEditor[28], SPRINT[29], REDItools2[30], JACUSA2[31], RDDpred, RED-ML[32], and DeepRed[33,34] incorporate RNA editing features to improve accuracy. However, their reliance on known editing databases limits the discovery of novel events. A robust and comprehensive pipeline for e-tSNV detection is urgently needed.
Accurate e-tSNV identification requires optimized sequencing strategies and analytical methods. Short-read sequencing (e.g., MGI’s DNB-based NGS technology) offers high depth and coverage at low cost but is prone to mismapping and artifacts, particularly for transcript SNVs[35,36,37,38]. Long-read technologies (e.g., PacBio single-molecular real-time sequencing) yield accurate long reads that improve variant detection but suffer from lower depth in transcriptomic applications [39,40]. Combining both sequencing technologies could leverage their respective strengths. Second, current algorithms often apply arbitrary thresholds that overlook transcript-specific attributes. A quality-focused approach—emphasizing sequencing reliability over preset filters—may improve SNV calling. Third, systematic integrated multi-omics profiling and orthogonal technical validation are essential to distinguish g-tSNVs from e-tSNVs and confirm transcript SNVs. All the considerations above prompt the effort to develop a pipeline for clarification of g-tSNVs and e-tSNVs in cancer cell lines.
In this communication, five cell lines of colorectal cancer (CRC), HCT15, LoVo, SW480, SW620, and HCT116, were cultured and performed parallel genomic and transcriptomic sequencing—using both MGI and PacBio technologies. With integration of data advantages from the two sequencings, a BCFtools-based variant calling workflow incorporating machine learning was established to distinguish true SNVs. Predictions were verified via Sanger sequencing, RNC-seq, and mass spectrometry. The systematic investigation to transcript SNVs in different CRC cell lines lays the foundation for overall survey of g-tSNVs and e-tSNVs, and profits discovery of cancer related e-tSNVs.
2. Material and Methods
2.1. Cell Culturing for Cell Lines
Five human colorectal cancer cell lines—HCT15 (ATCC® CCL-225™), LoVo (ATCC® CCL-229™), SW480 (ATCC® CCL-228™), SW620 (ATCC® CCL-227™), and HCT116 (ATCC® CCL-247™)—were obtained from American Type Culture Collection (ATCC, USA). HCT15 was maintained in Roswell Park Memorial Institute 1640 (RPMI-1640) medium, while the others were cultured in Dulbecco’s Modified Eagle’s Medium (DMEM). All media were supplemented with 10% fetal bovine serum and 1% penicillin/streptomycin, and cells were incubated at 37 °C in a 5% CO₂ atmosphere. To ensure robust omics profiling, biological triplicates for each line were established, pooled to minimize culture-specific variation, and subdivided into technical replicates for genomic and transcriptomic sequencing. Independent cell batches were cultivated for all validation studies, including Sanger sequencing of cDNA to verify transcriptional variants, alongside translatomic and proteomic analyses.
2.2. Extraction of Genomic DNAs, RNAs, RNCs and Proteins from Cell Lines
Genomic DNA was extracted from all five cell lines using a phenol-chloroform-isoamyl alcohol protocol. Cell pellets were lysed in TritonX-100/SDS buffer, followed by extraction with glass bead-assisted phenol-chloroform. After centrifugation, the aqueous phase was treated with chloroform-isoamyl alcohol, RNase, and ethanol-precipitated using sodium acetate. DNA was resuspended in TE buffer and stored at –80 °C.
Total RNA was isolated using TRIzol™ Reagent. Cell lysates in TRIzol were chloroform-extracted, and RNA was precipitated with isopropanol, washed with ethanol, and assessed for quality using an Agilent Bioanalyzer 2100.
RNCs were isolated from HCT116 cells using a cycloheximide-based method[41]. Cells were lysed in Triton X-100 buffer, and the supernatant was ultracentrifuged through a sucrose cushion. RNC-associated RNA was extracted with TRIzol and quality-checked via Bioanalyzer.
Proteins were extracted using urea/thiourea lysis buffer. Lysates were sonicated, reduced with DTT, alkylated with iodoacetamide, and digested overnight with trypsin via FASP membrane purification.
2.3. Genomic DNAs Sequencing
Genomic DNA was fragmented using a Covaris E220, and fragments of 200–400 bp were selected with MGIEasy DNA Clean Beads. Library preparation—including end repair, A-tailing, and adapter ligation—was performed using the MGIEasy Universal DNA Library Prep Kit. Adapter-ligated DNA was amplified, circularized with the MGIEasy Circularization Kit, and sequenced on the DNBSEQ-T7 platform (MGI) with 150 bp paired-end reads.
2.4. RNAs and RNCs Sequencing
For MGI sequencing, RNA and RNC samples were reverse-transcribed using SuperScript™ II with oligo(dT) priming. cDNA libraries were constructed with the MGIEasy RNA Library Prep Kit and sequenced on the DNBSEQ-T7 (150 bp PE).
For PacBio sequencing, poly(A) RNA was selected, tailed, and reverse-transcribed using SuperScript™ II Reverse Transcriptase and an RT primer (5’-AAGCAGTGGTATCAACGCAGAGTACNNNNNNNNTTTTTTTTTTTTTTTTTTTTTTTTTTTTTTVN-3’). cDNA was amplified, ligated into SMRTbell templates, and sequenced on the PacBio Sequel II system with SMRT Cell 8M. CCS reads were generated under minimum three full passes and 90% accuracy.
2.5. Proteomics Analyzed by LC-MS/MS
Digested peptides were fractionated using a C18 column under high-pH conditions, redissolved in 0.1% formic acid, and analyzed on a nanoElute UPLC system coupled to a timsTOF Pro2 mass spectrometer. Peptides were eluted with an acetonitrile gradient (2%–80% B) over 60 minutes at 300 nL/min and 50 °C. MS/MS data were acquired in data-dependent acquisition (DDA) mode.
2.6. DNA Sequencing Bioinformatics
Raw DNA sequencing data were filtered with SOAPnuke (v1.5.6) to remove adapters and low-quality reads. Clean reads were aligned to the GRCh38 reference genome using BWA. Post-alignment processing was performed with Picard tools: SortSam, AddOrReplaceReadGroups, MarkDuplicates, and ReorderSam. Variant calling was conducted using GATK (v4.2.2.0) with BaseRecalibrator, ApplyBQSR, and HaplotypeCaller (-ERC GVCF). Subsequent steps included VariantRecalibrator, ApplyVQSR, and hard filtering (AB < 0.2 || MQ0 > 50). Final variants were annotated using ANNOVAR.
2.7. RNA and RNC Sequencing Bioinformatics
MGI-derived RNA and RNC reads were preprocessed with SOAPnuke and aligned to the reference genome via STAR (v2.7.10b) using two-pass mode with transcriptome quantification. GATK (v4.1.7.0) and BCFtools (v1.13) were used for transcript SNV calling, with BCFtools parameters: mpileup -a AD,DP -Ov, followed by call -m -Oz and filtering. RED-ML identified e-tSNVs using dbSNP138, simpleRepeat, and Alu databases. Transcript abundance was estimated with StringTie and normalized by FPKM (≥1 threshold).
PacBio FLNC reads, generated via SMRT Link and lima, were aligned with GMAP. GATK, BCFtools, and Longshot were used for transcript SNV calling; RED-ML was applied for e-tSNV detection.
2.8. Proteomic Bioinformatics
Peptides were identified using MaxQuant (v2.0.1.0) against the UniProtKB/Swiss-Prot database (Oct 2020 release) with trypsin digestion, two missed cleavages allowed, carbamidomethylation (fixed), oxidation and acetylation (variable), and FDR ≤ 0.01. For SAV detection, a custom library including reference and variant sequences was searched similarly. Identification quality was assessed using posterior error probability (PEP).
2.9. Verification of Transcript SNVs Using Sanger Sequencing
Genomic regions containing target SNVs were amplified from DNA and cDNA using primers (Supplementary Table S1). PCR products were gel-purified, cloned into pClone007, and transformed into E. coli. Positive clones were validated by PCR and sequenced (GENEWIZ). Data were analyzed with Sequencing Analysis 5.2 and MEGA6.
2.10. Analysis of SNVs Characteristic
SNV analyses were performed using Python (v3.9.13). Sequencing read depths in exons were estimated from BCFtools-derived genotype likelihoods and RefSeq hg38 annotations. SNV features (VAF, type, genomic region) were extracted from VCF files and ANNOVAR annotations. Mutated peptides were identified via MaxQuant using a custom UniProt-SAV library. Protein isoelectric points (pI) were computed with ProtParam, and functional predictions were conducted using enrichGO in R (v4.2.0).
2.11. Model Construction for Transcription-Dependent SNVs Calling
A SNV library comprising true and false variants from BCFtools calls (MGI and PacBio) was constructed. Data were split into training (80%) and testing sets. Five algorithms—RF, SVM, LR, XGB, and GBDT—were evaluated over 100 iterations. The best-performing model was selected based on AUROC.
2.12. General Data Analysis
The correlations of SNVs VAF between MGI and PacBio were estimated by Spearman’s correlation analysis with the spearmanr module of scipy.stats in Python. All the plots for figure generation were based on matplotlib.pyplot packages in python and ggplot2 package in R.
3. Results
3.1. Discriminator Establishment Towards Transcript SNVs Based on Sequencing Data from MGI and PacBio
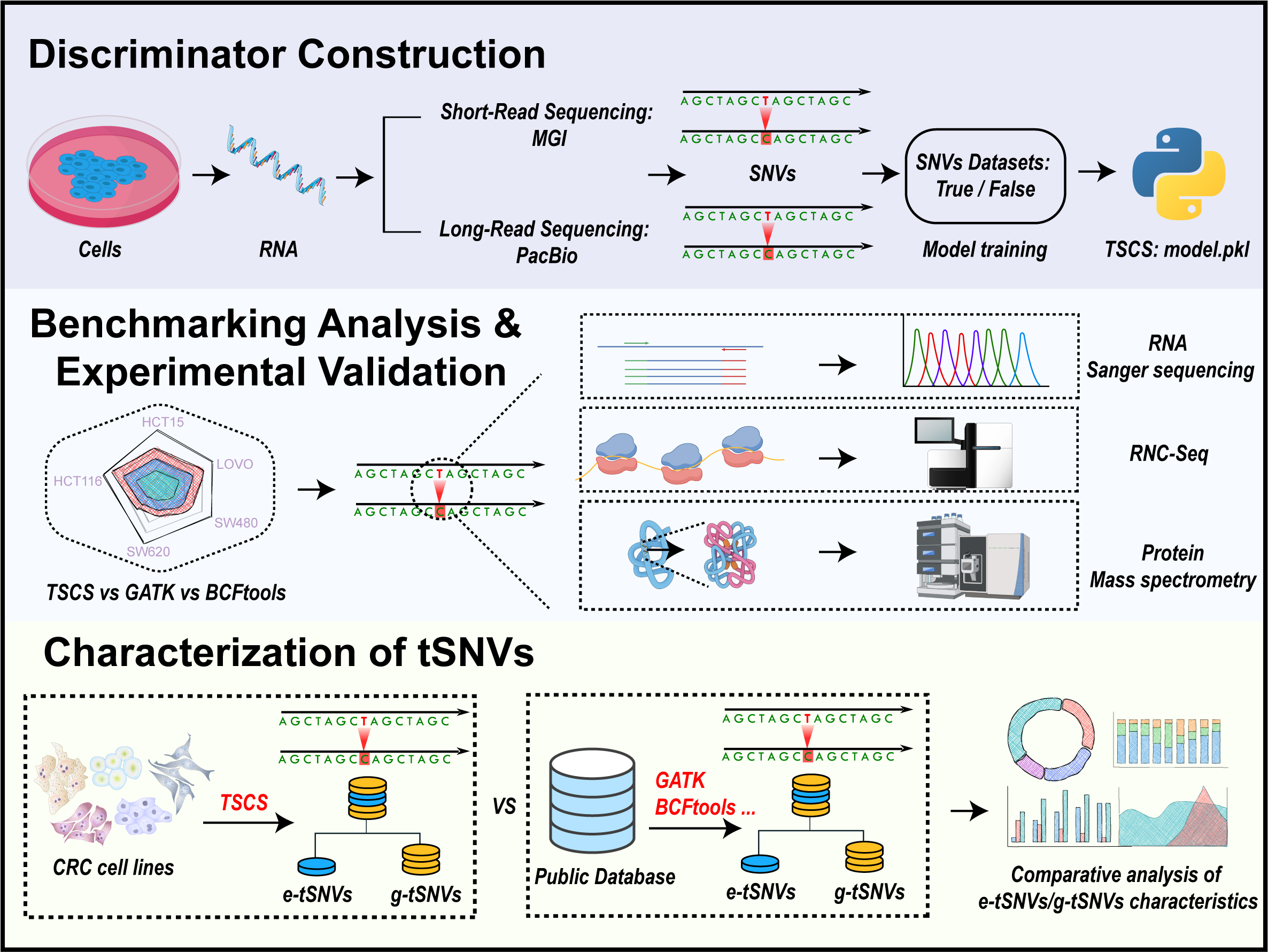
We systematically evaluated the performance of MGI and PacBio platforms in transcriptomic SNV calling across five colorectal cancer cell lines. 1) The identified exons and average of sequencing depth per exon derived from the two sequencing technologies in the same cell line are compared, as exemplified by HCT15 (Figure 1A), MGI identified more exons with high sequencing depth (59%) than PacBio (39%), demonstrating its superior exon coverage. This pattern was uniformly observed in all five cell lines (Figure S1A). 2) Specifically looking at the RNA-seq data coverage in an exon, PacBio exhibits higher densities of the RNA-seq data with complete coverage than these found by MGI as depicted in Figure 1B and Figure S1B, suggesting that PacBio with longer reads can provide high quality data for fully covering entire genes. 3) Relative standard deviation (RSD) of sequencing depth per exon is introduced to describe the uniformity of RNA-seq data in an exon, the higher RSD values the stronger flexibilities of sequencing data within exons. Figure 1C and Figure S1C displays the density distribution of RSD generated from either MGI or PacBio sequencing and indicates that the peak of RSD density curve from PacBio is lower than that from MGI. Thus, the uniformity of PacBio sequencing data is reasoned over that of MGI. And 4) Primary SNV calling with BCFtools consistently yielded a greater number of raw variants from MGI data compared to PacBio across all five cell lines (e.g., HCT15: 22,502,174 vs. 3,503,950; for complete counts see Table S1). The consistency of primary SNVs at a site (CPS) is defined as the ratio of main variant reads divided by total variants reads at a site, and the CPS profiles of MGI and PacBio are presented in Figure 1D and Figure S1D, implicating the average of CPS with 100% consistency in PacBio significantly higher than that in MGI (e.g., HCT15: 96% vs 83%). Even though the total primary SNVs called from PacBio are much less than MGI, the data quality of SNVs calling is highly acceptable in PacBio. Selecting SNVs with read depth ≥5 and 100% consistency yielded 55,083 variants co-detected by both technologies in HCT15, showing strong VAF correlation (Spearman r = 0.89; Figure 1E). The VAF of these co-detected SNVs, 55083 SNVs, are broadly divided 5 groups indicated in Figure 1F. Importantly, 15294 SNVs with lower VAF groups (<0.1) are totally removed by the filtration in BCFtools. This pattern—high concordance among co-detected variants coupled with systematic loss of low-VAF SNVs—was consistently observed across all additional cell lines (Figure S1E, F). It is clear that BCFtools with setting simply transcriptional features as filtration criteria results in mis-calling of the SNVs with low VAF. Collectively, our analyses demonstrate that PacBio (LRS) provides more uniform and complete sequencing data for reliable SNV calling, whereas MGI (SRS) offers greater depth for variant discovery. To ascertain whether these differences were technology-inherent rather than batch-specific, we compared additional SRS and LRS datasets from the same HCT15 cell line generated across independent laboratory batches. As shown in Figure S1G, the disparities in exon coverage, sequence reads distribution, and primary SNV calls between SRS and LRS were substantially greater than those observed between different SRS batches. This confirms that the observed distinctions are systematic attributes of the sequencing technologies. Therefore, we conclude that the complementary strengths of SRS and LRS can be leveraged to enhance alignment accuracy and improve SNV detection performance when integrated.
To leverage the complementary strengths of both sequencing technologies, we developed the Transcript SNVs Classifier based on complementary Sequencings (TSCS) pipeline (Figure 1G), which integrates four technical phases: 1) selection of high-confidence genomic regions from PacBio data (reads ≥10, supporting reads ≥5 per site); 2) matching these regions to MGI-called SNVs to define true (shared) and false (unshared) variants; 3) extraction of discriminative features from VCF files and exon uniformity metrics (Figure S2); and 4) development of a machine learning model for variant classification. Among five algorithms evaluated, Random Forest (RF) demonstrated superior performance (Figure S3) and was selected as the final classifier for TSCS.
The discriminator performance for identification of true SNVs was examined by two approaches. First, using RNA-seq data from five cell lines (HCT15, LoVo, SW480, SW620, and HCT116), we trained a Random Forest model on HCT15-derived true and false SNVs and tested it on the other four cell lines. The model achieved an AUC of 0.91 across all test sets (Figure 1H), demonstrating robust cross-cell-line recognition of true and false SNVs. Second, we trained four independent discriminators on SNVs from LoVo, SW480, SW620 and HCT116 respectively, then applied each to classify HCT15 SNVs. All four discriminators successfully identified HCT15 SNVs with AUC values exceeding 0.99 (Figure 1I), and showed 95-98% overlap in their true SNV predictions, indicating high reproducibility. These results establish that combining MGI and PacBio data to train a discrimination model seem workable as a universal strategy to find out the reliable signals of transcript SNVs, at least in cell lines.
Furthermore, TSCS demonstrated consistent performance across sequencing platforms and experimental batches. Evaluation of PacBio and MGI data from the same cell lines revealed that over 89% of SNVs identified from PacBio were replicated in MGI datasets, with similar concordance rates observed across all cell lines (89-94%, Table S2). To further assess reproducibility, we applied TSCS to replicate SRS datasets from HCT15 generated across different experimental batches. The results showed 85% (50755/59644) concordance in SNV calls within commonly covered regions. These results establish TSCS as a robust method for cross-platform and cross-batch SNV analysis, providing highly reproducible results regardless of sequencing technology or experimental conditions.
3.2. Performance Comparison of Transcript SNVs Callings Among Different Software
To evaluate the performance of transcript SNV calling across different software, we cultured five cell lines (HCT15, HCT116, LoVo, SW480, and SW620) and performed parallel genomic sequencing and RNA-seq. Genomic SNVs were called using GATK, while primary transcript SNVs were identified using GATK and BCFtools for both MGI and PacBio data, with Longshot[42] additionally applied to PacBio data. We focused on comparing transcript SNVs called by TSCS against those from other tools. Following strict filtering based on transcriptional parameters and sequencing data quality, the final SNV sets were categorized into g-tSNVs (overlapping between genomic and transcriptomic data) and e-tSNVs (unique to transcriptomes). For e-tSNV comparison, RED-ML was also implemented.
Figure 2A summarizes the total SNVs identified by GATK, BCFtools, and TSCS across the five cell lines using MGI data. While all three tools yielded SNVs with similar distribution patterns, TSCS consistently detected a greater number of variants, increasing the total yield of transcriptomic SNVs by 31.83% compared to the average of the other methods, , with g-tSNV and e-tSNV counts exceeding those of conventional methods by more than 1-fold and 2-fold, respectively. Comparative analysis of VAF distributions revealed that TSCS recovered a higher proportion of low-VAF SNVs (Figure 2B). Furthermore, Figure S4 highlights a pronounced divergence between e-tSNVs and g-tSNVs: e-tSNVs were predominantly low-frequency (>70% at VAF<0.5; only 4% at VAF=1.0), whereas g-tSNVs showed higher VAF values (40% at VAF=1.0; 26% below 0.5). We defined recognition sensitivity for g-tSNVs (RS:g-tSNVs) as the ratio of transcript g-tSNVs to total genomic SNVs. As shown in Figure 2C, TSCS achieved moderately higher RS:g-tSNVs across all cell lines compared to GATK and BCFtools, with an average recall of 75.3% versus 69.9% for GATK and 65.9% for BCFtools, representing absolute improvements of 4.04 and 8.10 percentage points, respectively. For e-tSNVs, due to the absence of a gold-standard set, we defined a PacBio-validated reference set (read depth ≥100, variant reads ≥30). RS:e-tSNVs was then calculated as the recall rate, i.e., the proportion of e-tSNVs in this reference set that were successfully detected by each tool. TSCS demonstrated substantially higher RS:e-tSNVs than the other tools (Figure 2D), achieving an average e-tSNV recall of 77.20% compared to 14.52% for GATK, 21.38% for BCFtools, and 20.28% for RED_ML, corresponding to absolute improvements of 62.68, 51.37, and 51.89 percentage points, respectively, indicating particularly enhanced sensitivity for e-tSNV detection. Overall, TSCS demonstrates superior capability in identifying both g-tSNVs and e-tSNVs from MGI data, at least in cell line.
Overlap rates of total transcript SNVs, g-tSNVs, and e-tSNVs between GATK and BCFtools were first evaluated across five cell lines, showing 79% agreement for g-tSNVs but only 43% for e-tSNVs (Figure S5A, S5D), indicating poor consistency in e-tSNV calling. In contrast, TSCS overlapped with 99.4% and 99.9% of g-tSNVs called by GATK and BCFtools, respectively, and captured 88.56% and 97.8% of their e-tSNVs (Figure S5B, C, E, F). Notably, among the g-tSNVs and e-tSNVs uniquely identified by GATK or BCFtools, TSCS recovered 96.3% and 99.6% of g-tSNVs, and 72.8% and 94.4% of e-tSNVs, respectively (Figure 2E, 2F), demonstrating its superior comprehensiveness. Furthermore, we assessed whether SNV detection was influenced by transcript abundance. As shown in Figure 2G, both g-tSNVs and e-tSNVs called by TSCS were evenly distributed across transcripts regardless of expression level, indicating that variant calling with TSCS is not affected by transcript abundance.
To evaluate the robustness and generalizability of TSCS, we analyzed CRC tissue RNA-seq data from NCBI SRA (accessions SRP303779 and SRP303082)[43] using the same bioinformatic workflow. Supplementary Figure S6 summarizes transcript SNV detection rates across clinical samples, showing that TSCS identified markedly more high-detection-rate SNVs than GATK or BCFtools in both adjacent and tumor tissues. We further examined SNVs co-detected in over 70% of samples by all three tools across both tissue types. As shown in Figure 2H, TSCS yielded more high-quality transcript SNVs across three VAF ranges compared to the other methods, except at VAF > 0.5 where GATK performed comparably. These results strongly support that TSCS robustly captures more transcript SNVs, particularly at low VAFs, and demonstrate its potential for reliable SNV identification in tissue-derived data.
We further evaluated TSCS on PacBio RNA-seq data from the five cell lines. As summarized in Supplementary Figure S7, TSCS increased the total yield of transcriptomic SNVs by 71.89% compared to the average of other tools. For gSNV detection, it improved the mean recall from 54.56% to 70.69%, representing an absolute gain of 15.77 percentage points over GATK, BCFtools, and Longshot. For tSNV detection, TSCS elevated the average recall from 28.82% to 54.54%, an absolute improvement of 25.72 percentage points compared to GATK, BCFtools, Longshot, and RED_ML. TSCS consistently outperformed existing tools in recognition sensitivity and overlap rates for both g-tSNVs and e-tSNVs, mirroring trends observed in MGI data. Notably, the performance improvement achieved by TSCS was more pronounced on PacBio data than on MGI data, despite the lower number of transcript SNVs typically detected from long-read sequencing.
3.3. Verification of Transcript SNVs and Their Translated Products in Cell Lines
The transcript SNVs by TSCS were further verified through three complementary experimental approaches, Sanger sequencing to confirm the target SNV segments[44], ribosome-nascent chain complex sequencing (RNC-seq) to detect the SNVs on translational track[45,46,47], and mass spectrometric to identify the translated variant peptides[48,49,50,51].
To independently validate transcript SNVs identified by TSCS, we performed Sanger sequencing on mRNA amplicons from 25 randomly selected gene segments across the five colorectal cancer cell lines. The validation confirmed 173, 33, 47, 42, and 50 SNVs in HCT15, LoVo, SW480, SW620, and HCT116, respectively. Among these, 121, 8, 31, 4, and 23 were verified as e-tSNVs. The overall validation rates for TSCS-predicted SNVs reached 40%, 33%, 37%, 45%, and 58% across the respective cell lines. As shown in Figure 3A, the validation rate by Sanger sequencing increased with higher VAF values (based on MGI data). Further analysis of g-tSNVs and e-tSNVs across three VAF categories (Figure 3B) revealed that g-tSNVs showed validation rates proportional to VAF, whereas e-tSNVs were primarily detected in the lower VAF category, with few in higher VAF ranges—consistent with the distribution shown in Figure S4. The overall validation rate was approximately 30% for SNVs with VAF < 0.5, but exceeded 80% for those with higher VAF. These results confirm the accuracy of TSCS-called SNVs and support the presence of both g-tSNVs and e-tSNVs in these cell lines, although lower validation rates for low-VAF variants indicate a need for larger clone numbers to fully verify these events[52].
The translatome, representing actively translating mRNAs bound to ribosomes, was profiled using RNC-seq to assess the translational potential of SNVs identified by TSCS, GATK, and BCFtools in HCT116 cells. As shown in Figure 3C and 3D, TSCS-derived g-tSNVs and e-tSNVs showed identification rates of 43% and 33%, respectively. In comparison, the rates for GATK were 35% and 18%, and for BCFtools 44% and 19%. These results not only confirm the presence of software-predicted SNVs but also unveil significant portion of transcript SNVs on the translational track. Notably, while verification rates for g-tSNVs were comparable across tools, TSCS exhibited markedly higher validation rates for e-tSNVs, consistent with previous observations.
To further validate the translatability of TSCS-called SNVs, we performed peptide mass spectrometry. A total of 10,615, 6,837, 5,195, 4,904, and 6,505 nonsynonymous SNVs were annotated by TSCS in HCT15, LoVo, SW480, SW620, and HCT116, respectively. As shown in Figure 3E, the number of identified peptides correlated with the total SNV count per line (e.g., highest in HCT15), with g-tSNVs yielding higher identification rates than e-tSNVs—consistent with Sanger data (Figure 3B) and reflecting the challenge of detecting low-VAF e-tSNVs by MS[53,54]. Peptide identification rates were comparable across tools (TSCS: 5.5%, GATK: 5.6%, BCFtools: 6.5%; Figure S8). This suggests that the strategy of peptide search upon MS/MS is workable through the peptide libraries containing SNVs generated from different SNVs calling programs. Posterior error probability (PEP)[55] score distributions (Figure 3F) confirmed high-quality matches for both g-tSNVs and e-tSNVs, with peaks near zero indicating confident identifications despite lower e-tSNV abundance.
Hence, the transcript SNVs recognized by TSCS across different cancer cell lines were rigorously verified through three experimental approaches, reinforcing the presence of g-tSNVs and e-tSNVs and leading a clue that significant SNVs are translational and potentially functional.
3.4. Characterization of e-tSNVs in Cancer Cell Lines
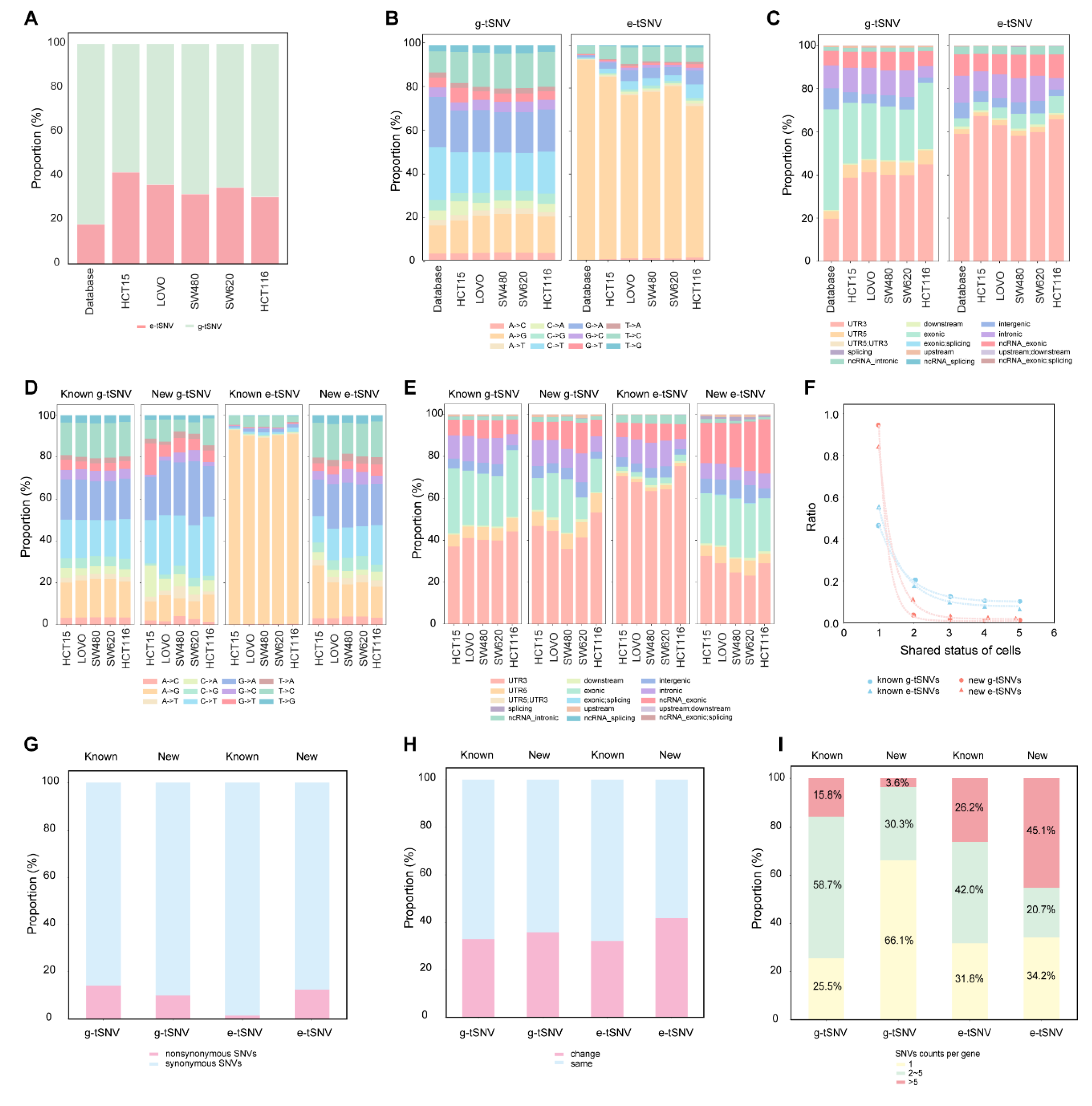
We compiled a non-redundant set of public SNVs by merging g-tSNVs from dbSNP[56] and COSMIC[57] with e-tSNVs from REDIportal and DARNED for comparative analysis. As shown in Figure 4A, e-tSNVs constituted 18% of total SNVs in this public dataset (921841/5147327), whereas TSCS identified a notably higher proportion (30–42%) across the five cell lines (Table S3), indicating that e-tSNVs represent a larger fraction of transcriptomic variation than previously recognized, with stable proportions observed in cancer cells. Analysis of SNV types (Figure 4B) revealed that both public and TSCS g-tSNVs were dominated by C>T, G>A, A>G, and T>C changes. However, while public e-tSNVs were overwhelmingly A-to-I(G) (93%), TSCS-called e-tSNVs included substantial non-A-to-I changes (>20%), consistent with reports of more diverse RNA editing[7,58,59]. Regarding genomic distribution, both public and TSCS-derived SNVs exhibit similar patterns: g-tSNVs show less than 40% localization in 3′UTR, while e-tSNVs are enriched in 3′UTR (>60%; Figure 4C). This trend persists among individual base substitutions: g-tSNVs maintain ∼40% UTR3 localization across all types, whereas among e-tSNVs, A-to-I(G) and T-to-C events are highly enriched in UTR3 (>60%), while other substitutions show less UTR3 preference (<40%; Figure S9).
On average, 92% of g-tSNVs and 80% of e-tSNVs identified in the five cell lines overlapped with public SNV databases and were classified as known variants. The remaining comprised 21,284 new g-tSNVs and 18,173 new e-tSNVs, distributed cell-specifically across HCT15, LoVo, SW480, SW620, and HCT116. Only 316 new g-tSNVs and 503 new e-tSNVs were shared across ≥80% of the cell lines. As shown in Figure 4D, new g-tSNVs closely resembled known g-tSNVs in SNV type profiles, whereas new e-tSNVs exhibited markedly different patterns: while known e-tSNVs were dominated by A-to-I(G) (>90%), new e-tSNVs showed considerable diversity, with A-to-I(G) accounting for less than 20% and numerous other base changes well represented. This result well agrees the deduction from Figure 4B that TSCS improvement in e-tSNVs discovery appears to dig SNV types with more base alterations. Genomic region analysis (Figure 4E) indicated that new g-tSNVs retained distribution patterns similar to known g-tSNVs, but new e-tSNVs diverged significantly from known e-tSNVs—known e-tSNVs were highly enriched in 3′UTR (>60%), whereas new e-tSNVs showed less than 40% in 3′UTR and increased presence in exonic regions. These findings indicate that new g-tSNVs resemble publicly documented variants in both type and genomic distribution, while novel e-tSNVs discovered by TSCS exhibit distinct characteristics from the known e-tSNVs: the new e-tSNVs are distributed relatively larger genomics regions with many different base shifts, potentially beneficial for transcription.
To assess the generalizability of the observed e-tSNV diversity, we extended our analysis to multiple orthogonal datasets representing distinct experimental conditions (Figure S10). This included: (1) RNC-seq-validated SNVs from HCT116, (2) SNV calls from technical replicates of HCT15, and (3) SNVs identified from PacBio long-read data across all five cell lines. Critically, the patterns of SNV types and genomic distributions remained consistent across all these datasets and recapitulated the global profiles obtained from MGI data analyzed by TSCS. These reproducible findings across translational profiling, technical replicates, and alternative sequencing technologies confirm that the observed diversity is non-random, firmly establishes that the expanded diversity of e-tSNVs represents a general biological characteristic rather than a technical artifact.
To assess the specificity of transcript SNVs, overlap ratios of known and new variants were evaluated across the five cell lines (Figure 4F). Unique known g-tSNVs and e-tSNVs (found in only one cell line) accounted for 47% and 55%, respectively, while unique new g-tSNVs and e-tSNVs were substantially higher at 94% and 84%, indicating strong cell-line specificity. Distribution patterns of SNV types and genomic regions for these unique and shared variants were consistent with those in Figure 4D and 4E (Figure S11C, S11D). The evidence of new g-tSNVs and e-tSNVs with specifically cell-dependent, therefore, demonstrates that SNVs calling from TSCS indeed helps discovery of uncommon SNVs signals.
For further understanding of if transcript SNVs lead to changes in amino acids, nonsynonymous analysis of total SNVs among the five cell lines was conducted and resulted in Figure 4G. Generally, the known and new g-tSNVs had comparable rates (14% vs. 10%), whereas known e-tSNVs showed a much lower nonsynonymous rate than new e-tSNVs (1% vs. 13%), aligning with the typological diversity and broader genomic within exons of new e-tSNVs. Based on a seven-category classification of amino acid properties[60], approximately 40% of nonsynonymous SNVs—across both known and new g-tSNVs and e-tSNVs—resulted in property-altering changes (Figure 4H). This proportion remained consistent despite substantial differences in variant numbers between known and new g-tSNVs (15,145 vs. 2,126) and e-tSNVs (755 vs. 2,284), indicating that the nonsynonymous SNVs differences seem irrelevant to the corresponding types of amino acids.
Moreover, looking at the distribution of nonsynonymous SNVs in each gene, the distribution of nonsynonymous SNVs per gene differed between g-tSNVs and e-tSNVs (Figure 4I). New e-tSNVs showed high clustering (45% with >5 SNVs/gene), prompting investigation into potential protein physicochemical effects like pI shift[61,62]. However, theoretical estimates revealed comparable pI changes across all variant types (Figure S11E), indicating clustered occurrences of new e-tSNVs seems without obvious property alterations in the corresponding proteins.
We assessed whether genes harboring new e-tSNVs were functionally enriched. Among 8,967 genes carrying nonsynonymous SNVs, only 294 contained exclusively new e-tSNVs. GO analysis of these 294 genes showed no significant enrichment. Notably, new e-tSNVs were highly prevalent in NBPF family genes, such as NBPF10, NBPF12, NBPF14, NBPF20, and NBPF26 with 41, 19, 25, 20, and 34, respectively, compared to known e-tSNVs in the same genes (8, 1, 0, 2, and 6, respectively). The NBPF genes are believed involvement of cancer and brain development[63,64]. Higher new e-tSNVs in the NBPF genes merit to further study.
4. Discussion
Large evidence has demonstrated that SNVs are not only in genomes but also are generated during transcriptional process, so called RNA editing. How to accurately identify transcription-dependent SNVs, i.e. e-tSNVs, and to clearly distinguish g-tSNVs and e-tSNVs are an argument for long period due to inconsistent parameters across existing tools. Given the incomplete understanding of RNA editing mechanisms, a major challenge has been developing accurate transcript SNV callers that avoid dependence on RNA-editing-specific parameters. To overcome this, we proposed that high-quality RNA-seq data alone could enable reliable SNV detection without relying on RNA editing features. Using integrated SNV calls from parallel MGI and PacBio sequencing as a high-confidence set, we developed TSCS, a random forest-based classifier. As shown in Figure 2C and 2D, TSCS achieved significantly higher recognition sensitivity for transcript SNVs compared to other tools across five cell lines, with particularly pronounced improvement for e-tSNVs over g-tSNVs. The high quality of TSCS-called variants is supported by multiple lines of evidence: most SNVs identified by GATK and BCFtools were also detected by TSCS (Figure 2E, 2F); TSCS-unique SNVs showed similar abundance and detection frequency profiles to consensus variants; and critically, orthogonal validation through Sanger sequencing, RNC-seq, and mass spectrometry confirmed the detectability and authenticity of TSCS-derived SNV signals. Collectively, this evidence supports that TSCS-called transcript SNVs are reasonably acceptable in further the relevant characteristic study and a good replenishment to the previous databases in this frontier.
RNA editing-mediated transcript-dependent SNVs are well established, with adenosine-to-inosine (A-to-I) conversion catalyzed by ADARs representing a canonical type of e-tSNVs[17] that occur in both coding and non-coding regions, some leading to nonsynonymous amino acid changes[19] and being implicated in various cancers, such as glioblastoma, liver cancer, esophageal carcinoma, breast, colorectal and gastric cancer and so on. For instance, A-to-I editing in AZIN1 promotes oncogenic signaling and nuclear translocation in liver cancer[65,66], while A-to-I editing in CDC14B modulates the Skp2/p21/p27 pathway in glioblastoma[67]. Beyond A-to-I, C-to-U editing mediated by APOBEC enzymes can disrupt protein coding by introducing premature stop codons or altering start sites, contributing to tumorigenesis[18,68,69]. Although diverse RNA editing types have been reported—such as 5 in human fibroblasts[70], 9 in brain tissues[71], and up to 12 in B cells and cancer cell lines[58,59]—a comprehensive atlas is still lacking. In this study, TSCS-based analysis of five CRC cell lines revealed that e-tSNVs consistently accounted for approximately 40% of all transcript SNVs, suggesting previously underreported diversity in both type and genomic distribution. Although A-to-I editing remained dominant (~80% of e-tSNVs), a substantial fraction (~20%) comprised other subtypes—including C-to-U, G-to-A, and T-to-C—distributed across 3′UTR, exonic, and ncRNA exonic regions (Figure 4B, 4D, 4E). The reliability of these findings is supported by three lines of evidence: detection criteria were consistent with those for known variants; patterns were reproducible across all five cell lines and in multiple orthogonal datasets representing distinct experimental conditions, suggesting that the observation is not random events; and a subset was validated via orthogonal assays. Of course, it is difficult in theoretical explanation to the new RNA editing events at current. As mentioned above, deamination reaction well explains the conversion of A-to-I and C-to-U, however, which reaction schemes make G-to-A and T-to-C is still a query to be addressed in future. In summary, TSCS represents a significant advance in transcriptomic SNV screening, providing novel insights into RNA editing biology and its superior performance validated in clinical RNA-seq samples, demonstrates robust capability to uncover clinically relevant e-tSNVs that may illuminate previously unrecognized mechanisms in cancer pathogenesis, offering new avenues for understanding functional SNV involvement in tumor development.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org.
Author Contributions
Siqi Liu and Xia Zhang conceived this study and prepared the manuscript. Xia Zhang designed the experiments, analyzed the data, and prepared manuscript. Xia Zhang, Jiawei Liu and Yabin Zhu assisted the data analysis. All authors approved the final version of the manuscript.
Funding
This work was supported by the National Key Research and Development Program of China (2023YFC3402900). We thank the China National Gene Bank for its support.
Data Availability
The RNA-seq data underlying this article are available in CNGB Sequence Archive (CNSA) of China National GeneBank DataBase (CNGBdb) with accession number CNP0006938. The mass spectrometry proteomics data have been deposited to the ProteomeXchange Consortium (https://proteomecentral.proteomexchange.org) via the iProX partner repository with the dataset identifier PXD061293. All the code is available on the GitHub repository at https://github.com/zhangxia-prog/TSCS.
Acknowledgments
We thank Chen Zhang, Yan Ren and Liang Lin for the insightful discussion.
Conflicts of Interest
We have no conflict of interest.
References
- Vogelstein, B.; Papadopoulos, N.; Velculescu, V.E.; Zhou, S.; Diaz, L.A., Jr.; Kinzler, K.W. Cancer genome landscapes. Science 2013, 339, 1546–1558. [Google Scholar] [CrossRef] [PubMed]
- Bailey, M.H.; Tokheim, C.; Porta-Pardo, E.; Sengupta, S.; Bertrand, D.; Weerasinghe, A.; Colaprico, A.; Wendl, M.C.; Kim, J.; Reardon, B.; et al. Comprehensive Characterization of Cancer Driver Genes and Mutations. Cell 2018, 173, 371–385 e318. [Google Scholar] [CrossRef]
- Olivier, M.; Hollstein, M.; Hainaut, P. TP53 mutations in human cancers: origins, consequences, and clinical use. Cold Spring Harb Perspect Biol 2010, 2, a001008. [Google Scholar] [CrossRef]
- Wood, L.D.; Parsons, D.W.; Jones, S.; Lin, J.; Sjoblom, T.; Leary, R.J.; Shen, D.; Boca, S.M.; Barber, T.; Ptak, J.; et al. The genomic landscapes of human breast and colorectal cancers. Science 2007, 318, 1108–1113. [Google Scholar] [CrossRef]
- Martincorena, I.; Raine, K.M.; Gerstung, M.; Dawson, K.J.; Haase, K.; Van Loo, P.; Davies, H.; Stratton, M.R.; Campbell, P.J. Universal Patterns of Selection in Cancer and Somatic Tissues. Cell 2017, 171, 1029–1041 e1021. [Google Scholar] [CrossRef] [PubMed]
- Alexandrov, L.B.; Kim, J.; Haradhvala, N.J.; Huang, M.N.; Tian Ng, A.W.; Wu, Y.; Boot, A.; Covington, K.R.; Gordenin, D.A.; Bergstrom, E.N.; et al. Author Correction: The repertoire of mutational signatures in human cancer. Nature 2023, 614, E41. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Wang, I.X.; Li, Y.; Bruzel, A.; Richards, A.L.; Toung, J.M.; Cheung, V.G. Widespread RNA and DNA sequence differences in the human transcriptome. Science 2011, 333, 53–58. [Google Scholar] [CrossRef]
- Peng, X.; Xu, X.; Wang, Y.; Hawke, D.H.; Yu, S.; Han, L.; Zhou, Z.; Mojumdar, K.; Jeong, K.J.; Labrie, M.; et al. A-to-I RNA Editing Contributes to Proteomic Diversity in Cancer. Cancer Cell 2018, 33, 817–828 e817. [Google Scholar] [CrossRef]
- Ben-Aroya, S.; Levanon, E.Y. A-to-I RNA Editing: An Overlooked Source of Cancer Mutations. Cancer Cell 2018, 33, 789–790. [Google Scholar] [CrossRef]
- Cayir, A. RNA modifications as emerging therapeutic targets. Wiley Interdiscip Rev RNA 2022, 13, e1702. [Google Scholar] [CrossRef]
- Picardi, E.; Regina, T.M.; Brennicke, A.; Quagliariello, C. REDIdb: the RNA editing database. Nucleic Acids Res 2007, 35, D173–D177. [Google Scholar] [CrossRef]
- Kiran, A.; Baranov, P.V. DARNED: a DAtabase of RNa EDiting in humans. Bioinformatics 2010, 26, 1772–1776. [Google Scholar] [CrossRef]
- Ramaswami, G.; Li, J.B. RADAR: a rigorously annotated database of A-to-I RNA editing. Nucleic Acids Res 2014, 42, D109–D113. [Google Scholar] [CrossRef] [PubMed]
- Picardi, E.; D’Erchia, A.M.; Lo Giudice, C.; Pesole, G. REDIportal: a comprehensive database of A-to-I RNA editing events in humans. Nucleic Acids Res 2017, 45, D750–D757. [Google Scholar] [CrossRef] [PubMed]
- Guo, Y.; Yu, H.; Samuels, D.C.; Yue, W.; Ness, S.; Zhao, Y.Y. Single-nucleotide variants in human RNA: RNA editing and beyond. Brief Funct Genomics 2019, 18, 30–39. [Google Scholar] [CrossRef]
- Porath, H.T.; Schaffer, A.A.; Kaniewska, P.; Alon, S.; Eisenberg, E.; Rosenthal, J.; Levanon, E.Y.; Levy, O. A-to-I RNA Editing in the Earliest-Diverging Eumetazoan Phyla. Mol Biol Evol 2017, 34, 1890–1901. [Google Scholar] [CrossRef] [PubMed]
- Nishikura, K. A-to-I editing of coding and non-coding RNAs by ADARs. Nat Rev Mol Cell Biol 2016, 17, 83–96. [Google Scholar] [CrossRef]
- Navaratnam, N.; Sarwar, R. An overview of cytidine deaminases. Int J Hematol 2006, 83, 195–200. [Google Scholar] [CrossRef]
- Bazak, L.; Haviv, A.; Barak, M.; Jacob-Hirsch, J.; Deng, P.; Zhang, R.; Isaacs, F.J.; Rechavi, G.; Li, J.B.; Eisenberg, E.; et al. A-to-I RNA editing occurs at over a hundred million genomic sites, located in a majority of human genes. Genome Res 2014, 24, 365–376. [Google Scholar] [CrossRef]
- Tan, M.H.; Li, Q.; Shanmugam, R.; Piskol, R.; Kohler, J.; Young, A.N.; Liu, K.I.; Zhang, R.; Ramaswami, G.; Ariyoshi, K.; et al. Dynamic landscape and regulation of RNA editing in mammals. Nature 2017, 550, 249–254. [Google Scholar] [CrossRef]
- Piskol, R.; Ramaswami, G.; Li, J.B. Reliable identification of genomic variants from RNA-seq data. Am J Hum Genet 2013, 93, 641–651. [Google Scholar] [CrossRef]
- Castel, S.E.; Levy-Moonshine, A.; Mohammadi, P.; Banks, E.; Lappalainen, T. Tools and best practices for data processing in allelic expression analysis. Genome Biol 2015, 16, 195. [Google Scholar] [CrossRef]
- Duitama, J.; Srivastava, P.K.; Mandoiu, II. Towards accurate detection and genotyping of expressed variants from whole transcriptome sequencing data. BMC Genomics 2012, 13 Suppl 2, S6. [Google Scholar] [CrossRef] [PubMed]
- Tang, X.; Baheti, S.; Shameer, K.; Thompson, K.J.; Wills, Q.; Niu, N.; Holcomb, I.N.; Boutet, S.C.; Ramakrishnan, R.; Kachergus, J.M.; et al. The eSNV-detect: a computational system to identify expressed single nucleotide variants from transcriptome sequencing data. Nucleic Acids Res 2014, 42, e172. [Google Scholar] [CrossRef]
- Koboldt, D.C.; Zhang, Q.; Larson, D.E.; Shen, D.; McLellan, M.D.; Lin, L.; Miller, C.A.; Mardis, E.R.; Ding, L.; Wilson, R.K. VarScan 2: somatic mutation and copy number alteration discovery in cancer by exome sequencing. Genome Res 2012, 22, 568–576. [Google Scholar] [CrossRef] [PubMed]
- Van der Auwera, G.A.; Carneiro, M.O.; Hartl, C.; Poplin, R.; Del Angel, G.; Levy-Moonshine, A.; Jordan, T.; Shakir, K.; Roazen, D.; Thibault, J.; et al. From FastQ data to high confidence variant calls: the Genome Analysis Toolkit best practices pipeline. Curr Protoc Bioinformatics 2013, 43, 11–11 10 11-11 10 33. [Google Scholar] [CrossRef]
- Danecek, P.; Bonfield, J.K.; Liddle, J.; Marshall, J.; Ohan, V.; Pollard, M.O.; Whitwham, A.; Keane, T.; McCarthy, S.A.; Davies, R.M.; et al. Twelve years of SAMtools and BCFtools. Gigascience 2021, 10. [Google Scholar] [CrossRef]
- John, D.; Weirick, T.; Dimmeler, S.; Uchida, S. RNAEditor: easy detection of RNA editing events and the introduction of editing islands. Brief Bioinform 2017, 18, 993–1001. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Lu, Y.; Yan, S.; Xing, Q.; Tian, W. SPRINT: an SNP-free toolkit for identifying RNA editing sites. Bioinformatics 2017, 33, 3538–3548. [Google Scholar] [CrossRef]
- Picardi, E.; Pesole, G. REDItools: high-throughput RNA editing detection made easy. Bioinformatics 2013, 29, 1813–1814. [Google Scholar] [CrossRef]
- Piechotta, M.; Wyler, E.; Ohler, U.; Landthaler, M.; Dieterich, C. JACUSA: site-specific identification of RNA editing events from replicate sequencing data. BMC Bioinformatics 2017, 18, 7. [Google Scholar] [CrossRef]
- Xiong, H.; Liu, D.; Li, Q.; Lei, M.; Xu, L.; Wu, L.; Wang, Z.; Ren, S.; Li, W.; Xia, M.; et al. RED-ML: a novel, effective RNA editing detection method based on machine learning. Gigascience 2017, 6, 1–8. [Google Scholar] [CrossRef]
- Kim, N.; Choi, S.; Kim, S.; Song, M.; Seo, J.H.; Min, S.; Park, J.; Cho, S.R.; Kim, H.H. Deep learning models to predict the editing efficiencies and outcomes of diverse base editors. Nat Biotechnol 2024, 42, 484–497. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, Z.; Liu, F.; Zhao, C.; Ren, C.; An, G.; Mei, C.; Bo, X.; Shu, W. Accurate identification of RNA editing sites from primitive sequence with deep neural networks. Sci Rep 2018, 8, 6005. [Google Scholar] [CrossRef]
- Verma, R.; Sharma, P.C. Next generation sequencing-based emerging trends in molecular biology of gastric cancer. Am J Cancer Res 2018, 8, 207–225. [Google Scholar]
- Engstrom, P.G.; Steijger, T.; Sipos, B.; Grant, G.R.; Kahles, A.; Ratsch, G.; Goldman, N.; Hubbard, T.J.; Harrow, J.; Guigo, R.; et al. Systematic evaluation of spliced alignment programs for RNA-seq data. Nat Methods 2013, 10, 1185–1191. [Google Scholar] [CrossRef] [PubMed]
- Steijger, T.; Abril, J.F.; Engstrom, P.G.; Kokocinski, F.; Consortium, R.; Hubbard, T.J.; Guigo, R.; Harrow, J.; Bertone, P. Assessment of transcript reconstruction methods for RNA-seq. Nat Methods 2013, 10, 1177–1184. [Google Scholar] [CrossRef]
- Conesa, A.; Madrigal, P.; Tarazona, S.; Gomez-Cabrero, D.; Cervera, A.; McPherson, A.; Szczesniak, M.W.; Gaffney, D.J.; Elo, L.L.; Zhang, X.; et al. A survey of best practices for RNA-seq data analysis. Genome Biol 2016, 17, 13. [Google Scholar] [CrossRef] [PubMed]
- Sharon, D.; Tilgner, H.; Grubert, F.; Snyder, M. A single-molecule long-read survey of the human transcriptome. Nat Biotechnol 2013, 31, 1009–1014. [Google Scholar] [CrossRef]
- Rhoads, A.; Au, K.F. PacBio Sequencing and Its Applications. Genomics Proteomics Bioinformatics 2015, 13, 278–289. [Google Scholar] [CrossRef]
- Wang, T.; Cui, Y.; Jin, J.; Guo, J.; Wang, G.; Yin, X.; He, Q.Y.; Zhang, G. Translating mRNAs strongly correlate to proteins in a multivariate manner and their translation ratios are phenotype specific. Nucleic Acids Res 2013, 41, 4743–4754. [Google Scholar] [CrossRef]
- Edge, P.; Bansal, V. Longshot enables accurate variant calling in diploid genomes from single-molecule long read sequencing. Nat Commun 2019, 10, 4660. [Google Scholar] [CrossRef]
- Sun, Q.; Han, Y.; He, J.; Wang, J.; Ma, X.; Ning, Q.; Zhao, Q.; Jin, Q.; Yang, L.; Li, S.; et al. Long-read sequencing reveals the landscape of aberrant alternative splicing and novel therapeutic target in colorectal cancer. Genome Med 2023, 15, 76. [Google Scholar] [CrossRef] [PubMed]
- Sanger, F.; Nicklen, S.; Coulson, A.R. DNA sequencing with chain-terminating inhibitors. Proc Natl Acad Sci U S A 1977, 74, 5463–5467. [Google Scholar] [CrossRef]
- Ingolia, N.T.; Ghaemmaghami, S.; Newman, J.R.; Weissman, J.S. Genome-wide analysis in vivo of translation with nucleotide resolution using ribosome profiling. Science 2009, 324, 218–223. [Google Scholar] [CrossRef] [PubMed]
- Calviello, L.; Mukherjee, N.; Wyler, E.; Zauber, H.; Hirsekorn, A.; Selbach, M.; Landthaler, M.; Obermayer, B.; Ohler, U. Detecting actively translated open reading frames in ribosome profiling data. Nat Methods 2016, 13, 165–170. [Google Scholar] [CrossRef] [PubMed]
- Guttman, M.; Russell, P.; Ingolia, N.T.; Weissman, J.S.; Lander, E.S. Ribosome profiling provides evidence that large noncoding RNAs do not encode proteins. Cell 2013, 154, 240–251. [Google Scholar] [CrossRef]
- Krug, K.; Mertins, P.; Zhang, B.; Hornbeck, P.; Raju, R.; Ahmad, R.; Szucs, M.; Mundt, F.; Forestier, D.; Jane-Valbuena, J.; et al. A Curated Resource for Phosphosite-specific Signature Analysis. Mol Cell Proteomics 2019, 18, 576–593. [Google Scholar] [CrossRef]
- Zhang, B.; Wang, J.; Wang, X.; Zhu, J.; Liu, Q.; Shi, Z.; Chambers, M.C.; Zimmerman, L.J.; Shaddox, K.F.; Kim, S.; et al. Proteogenomic characterization of human colon and rectal cancer. Nature 2014, 513, 382–387. [Google Scholar] [CrossRef]
- Wilhelm, M.; Schlegl, J.; Hahne, H.; Gholami, A.M.; Lieberenz, M.; Savitski, M.M.; Ziegler, E.; Butzmann, L.; Gessulat, S.; Marx, H.; et al. Mass-spectrometry-based draft of the human proteome. Nature 2014, 509, 582–587. [Google Scholar] [CrossRef]
- Vaudel, M.; Verheggen, K.; Csordas, A.; Raeder, H.; Berven, F.S.; Martens, L.; Vizcaino, J.A.; Barsnes, H. Exploring the potential of public proteomics data. Proteomics 2016, 16, 214–225. [Google Scholar] [CrossRef]
- Liu, L.; Li, Y.; Li, S.; Hu, N.; He, Y.; Pong, R.; Lin, D.; Lu, L.; Law, M. Comparison of next-generation sequencing systems. J Biomed Biotechnol 2012, 2012, 251364. [Google Scholar] [CrossRef]
- Bantscheff, M.; Schirle, M.; Sweetman, G.; Rick, J.; Kuster, B. Quantitative mass spectrometry in proteomics: a critical review. Anal Bioanal Chem 2007, 389, 1017–1031. [Google Scholar] [CrossRef] [PubMed]
- Kitteringham, N.R.; Jenkins, R.E.; Lane, C.S.; Elliott, V.L.; Park, B.K. Multiple reaction monitoring for quantitative biomarker analysis in proteomics and metabolomics. J Chromatogr B Analyt Technol Biomed Life Sci 2009, 877, 1229–1239. [Google Scholar] [CrossRef]
- Kall, L.; Storey, J.D.; MacCoss, M.J.; Noble, W.S. Posterior error probabilities and false discovery rates: two sides of the same coin. J Proteome Res 2008, 7, 40–44. [Google Scholar] [CrossRef] [PubMed]
- Sherry, S.T.; Ward, M.H.; Kholodov, M.; Baker, J.; Phan, L.; Smigielski, E.M.; Sirotkin, K. dbSNP: the NCBI database of genetic variation. Nucleic Acids Res 2001, 29, 308–311. [Google Scholar] [CrossRef]
- Tate, J.G.; Bamford, S.; Jubb, H.C.; Sondka, Z.; Beare, D.M.; Bindal, N.; Boutselakis, H.; Cole, C.G.; Creatore, C.; Dawson, E.; et al. COSMIC: the Catalogue Of Somatic Mutations In Cancer. Nucleic Acids Res 2019, 47, D941–D947. [Google Scholar] [CrossRef] [PubMed]
- Ju, Y.S.; Kim, J.I.; Kim, S.; Hong, D.; Park, H.; Shin, J.Y.; Lee, S.; Lee, W.C.; Kim, S.; Yu, S.B.; et al. Extensive genomic and transcriptional diversity identified through massively parallel DNA and RNA sequencing of eighteen Korean individuals. Nat Genet 2011, 43, 745–752. [Google Scholar] [CrossRef]
- Bahn, J.H.; Lee, J.H.; Li, G.; Greer, C.; Peng, G.; Xiao, X. Accurate identification of A-to-I RNA editing in human by transcriptome sequencing. Genome Res 2012, 22, 142–150. [Google Scholar] [CrossRef]
- Taylor, W.R. The classification of amino acid conservation. J Theor Biol 1986, 119, 205–218. [Google Scholar] [CrossRef]
- Kumar, P.; Henikoff, S.; Ng, P.C. Predicting the effects of coding non-synonymous variants on protein function using the SIFT algorithm. Nat Protoc 2009, 4, 1073–1081. [Google Scholar] [CrossRef]
- Yates, A.; Beal, K.; Keenan, S.; McLaren, W.; Pignatelli, M.; Ritchie, G.R.; Ruffier, M.; Taylor, K.; Vullo, A.; Flicek, P. The Ensembl REST API: Ensembl Data for Any Language. Bioinformatics 2015, 31, 143–145. [Google Scholar] [CrossRef]
- Dumas, L.J.; O’Bleness, M.S.; Davis, J.M.; Dickens, C.M.; Anderson, N.; Keeney, J.G.; Jackson, J.; Sikela, M.; Raznahan, A.; Giedd, J.; et al. DUF1220-domain copy number implicated in human brain-size pathology and evolution. Am J Hum Genet 2012, 91, 444–454. [Google Scholar] [CrossRef]
- Kung, C.P.; Maggi, L.B.; Jr Weber, J.D. The Role of RNA Editing in Cancer Development and Metabolic Disorders. Front Endocrinol (Lausanne) 2018, 9, 762. [Google Scholar] [CrossRef]
- Paz-Yaacov, N.; Bazak, L.; Buchumenski, I.; Porath, H.T.; Danan-Gotthold, M.; Knisbacher, B.A.; Eisenberg, E.; Levanon, E.Y. Elevated RNA Editing Activity Is a Major Contributor to Transcriptomic Diversity in Tumors. Cell Rep 2015, 13, 267–276. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Li, Y.; Lin, C.H.; Chan, T.H.; Chow, R.K.; Song, Y.; Liu, M.; Yuan, Y.F.; Fu, L.; Kong, K.L.; et al. Recoding RNA editing of AZIN1 predisposes to hepatocellular carcinoma. Nat Med 2013, 19, 209–216. [Google Scholar] [CrossRef]
- Galeano, F.; Rossetti, C.; Tomaselli, S.; Cifaldi, L.; Lezzerini, M.; Pezzullo, M.; Boldrini, R.; Massimi, L.; Di Rocco, C.M.; Locatelli, F.; et al. ADAR2-editing activity inhibits glioblastoma growth through the modulation of the CDC14B/Skp2/p21/p27 axis. Oncogene 2013, 32, 998–1009. [Google Scholar] [CrossRef]
- Gott, J.M.; Emeson, R.B. Functions and mechanisms of RNA editing. Annu Rev Genet 2000, 34, 499–531. [Google Scholar] [CrossRef] [PubMed]
- Powell, L.M.; Wallis, S.C.; Pease, R.J.; Edwards, Y.H.; Knott, T.J.; Scott, J. A novel form of tissue-specific RNA processing produces apolipoprotein-B48 in intestine. Cell 1987, 50, 831–840. [Google Scholar] [CrossRef] [PubMed]
- Qian, L.; Quadros, E.V.; Regec, A.; Zittoun, J.; Rothenberg, S.P. Congenital transcobalamin II deficiency due to errors in RNA editing. Blood Cells Mol Dis 2002, 28, 134–142, discussion 143-135. [Google Scholar] [CrossRef]
- Silberberg, G.; Lundin, D.; Navon, R.; Ohman, M. Deregulation of the A-to-I RNA editing mechanism in psychiatric disorders. Hum Mol Genet 2012, 21, 311–321. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Construction of workflow to discover transcript SNVs in cancer cell lines. (A) Comparison of the identified exons between two sequencing datasets according to the sequencing depth per exon in HCT15. (B) Comparison of the sequencing coverage per exon between two sequencing datasets in HCT15. (C) RSD distribution of the sequencing depth per exon in the two sequencing datasets in HCT15. (D) Evaluation of data consistency for SNVs identified by two different sequencing approaches in HCT15. (E) Correlation of VAF for the SNVs co-identified by two different sequencing approaches using Spearman correlation analysis in HCT15. (F) Comparison of the SNVs extracted by the two different calling approaches according to the SNVs at different levels of VAF in HCT15. (G) The infrastructure of transcript SNVs callings (TSCS) workflow developed in this study. (H) Based on the TSCS constructed by HCT15 sequencing data, the transcript SNVs in LoVo, SW480, SW620 and HCT116 were predicted. And (I) Based on the TSCS models constructed by LoVo, SW480, SW620 and HCT116 sequencing data, the transcript SNVs in HCT15 were predicted in different discriminators.
Figure 1.
Construction of workflow to discover transcript SNVs in cancer cell lines. (A) Comparison of the identified exons between two sequencing datasets according to the sequencing depth per exon in HCT15. (B) Comparison of the sequencing coverage per exon between two sequencing datasets in HCT15. (C) RSD distribution of the sequencing depth per exon in the two sequencing datasets in HCT15. (D) Evaluation of data consistency for SNVs identified by two different sequencing approaches in HCT15. (E) Correlation of VAF for the SNVs co-identified by two different sequencing approaches using Spearman correlation analysis in HCT15. (F) Comparison of the SNVs extracted by the two different calling approaches according to the SNVs at different levels of VAF in HCT15. (G) The infrastructure of transcript SNVs callings (TSCS) workflow developed in this study. (H) Based on the TSCS constructed by HCT15 sequencing data, the transcript SNVs in LoVo, SW480, SW620 and HCT116 were predicted. And (I) Based on the TSCS models constructed by LoVo, SW480, SW620 and HCT116 sequencing data, the transcript SNVs in HCT15 were predicted in different discriminators.
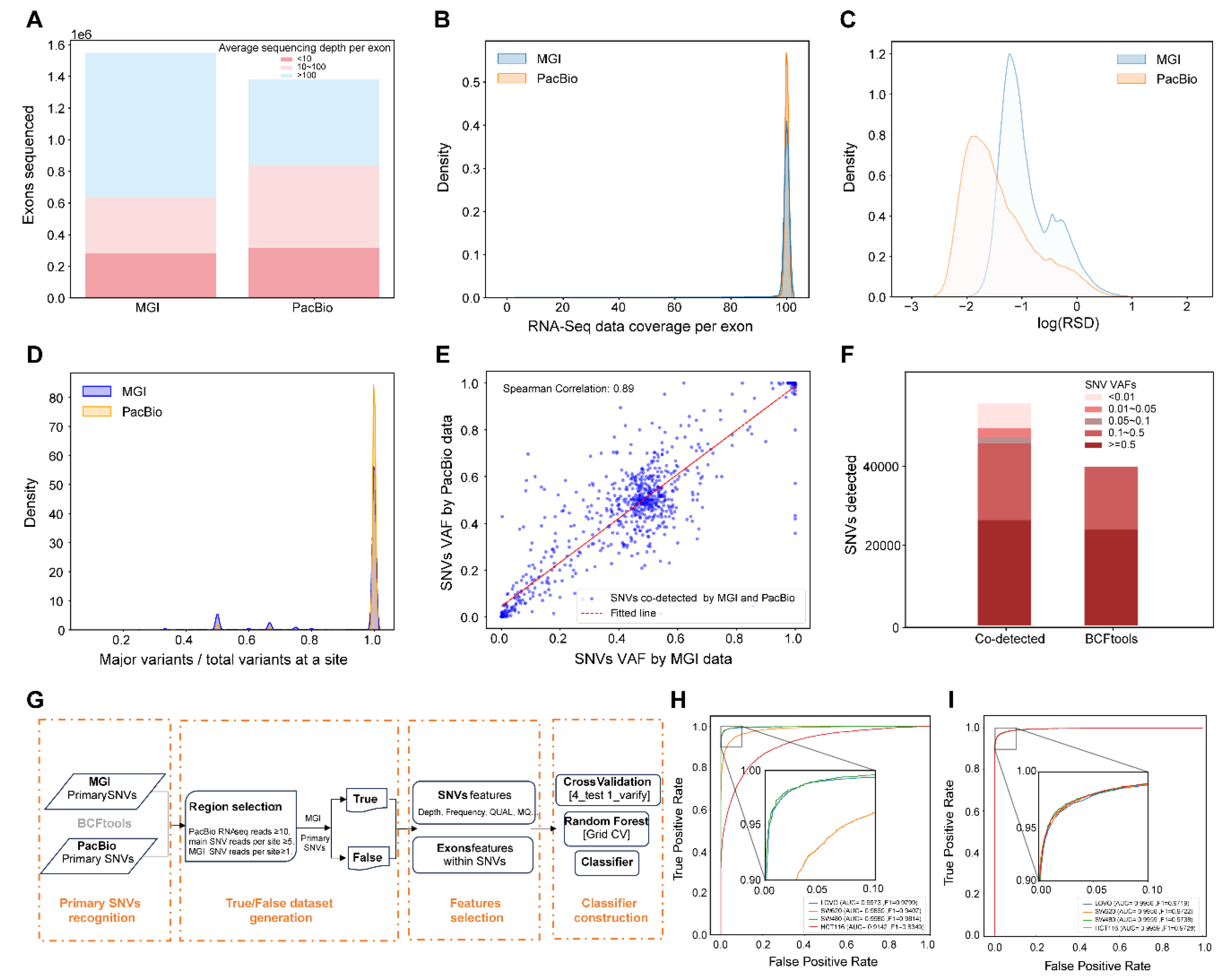
Figure 2.
Comparison of transcript SNVs called from different software based on MGI RNA-seq data. (A) Comparison of SNVs called by GATK, BCFtools, and TSCS in five cell lines. (B) In view of SNVs VAF, comparison of SNVs called by GATK, BCFtools, and TSCS in five cell lines. (C) Radar plot represents comparison of ratios of total transcript g-tSNVs verse total genome SNVs per cell line derived from GATK, BCFtools, and TSCS in five cell lines. (D) Radar plot represents comparison of ratios of the transcript e-tSNVs called by a software matched with experimental e-tSNVs against the total experimental e-tSNVs in five cell lines. (E) Overlap status of total g-tSNVs elicited from GATK and BCFtools against that from TSCS in all the five cell lines. Outer ring represents g-tSNVs overlapped between GATK and BCFtools and inner ring means g-tSNVs overlapped between TSCS and GATK or BCFtools. (F) Overlap status of total e-tSNVs elicited from GATK and BCFtools against that from TSCS in all the five cell lines. (G) Distribution of abundance per transcript and g-tSNVs detected per transcript (left) as well as e-tSNVs detected per transcript (right) from TSCS in HCT15. And (H) Comparation of the SNVs recognized by BCFtools, GATK and TSCS, which are derived from public database and are commonly founded over 70% samples.
Figure 2.
Comparison of transcript SNVs called from different software based on MGI RNA-seq data. (A) Comparison of SNVs called by GATK, BCFtools, and TSCS in five cell lines. (B) In view of SNVs VAF, comparison of SNVs called by GATK, BCFtools, and TSCS in five cell lines. (C) Radar plot represents comparison of ratios of total transcript g-tSNVs verse total genome SNVs per cell line derived from GATK, BCFtools, and TSCS in five cell lines. (D) Radar plot represents comparison of ratios of the transcript e-tSNVs called by a software matched with experimental e-tSNVs against the total experimental e-tSNVs in five cell lines. (E) Overlap status of total g-tSNVs elicited from GATK and BCFtools against that from TSCS in all the five cell lines. Outer ring represents g-tSNVs overlapped between GATK and BCFtools and inner ring means g-tSNVs overlapped between TSCS and GATK or BCFtools. (F) Overlap status of total e-tSNVs elicited from GATK and BCFtools against that from TSCS in all the five cell lines. (G) Distribution of abundance per transcript and g-tSNVs detected per transcript (left) as well as e-tSNVs detected per transcript (right) from TSCS in HCT15. And (H) Comparation of the SNVs recognized by BCFtools, GATK and TSCS, which are derived from public database and are commonly founded over 70% samples.
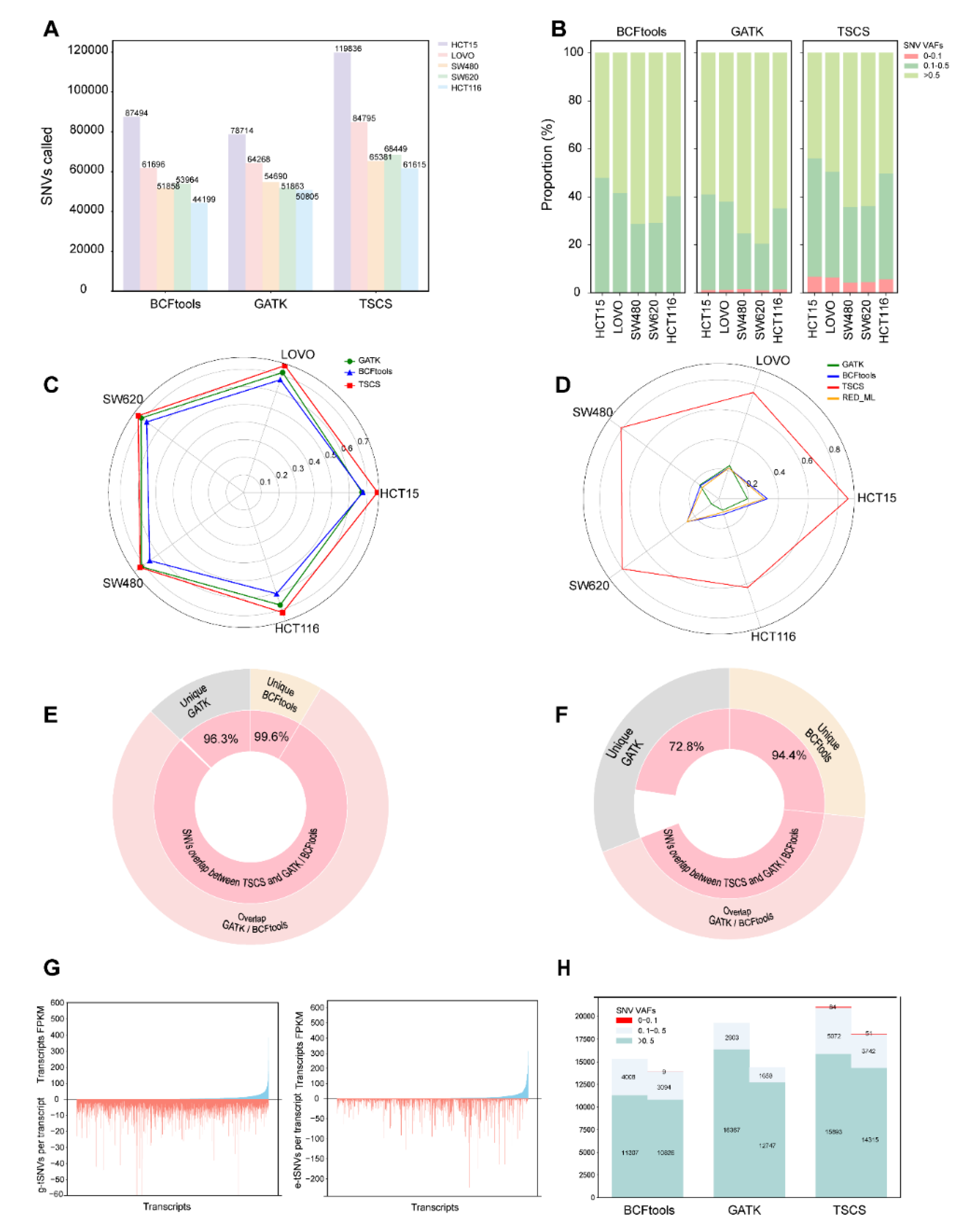
Figure 3.
Verification of transcript SNVs and proteins SAVs by Sanger sequencing, RNC-seq and mass spectrometry in five cell lines. (A) Distribution of the verification rates to transcript SNVs by Sanger sequencing through the SNVs detected by Sanger against that selected from transcript SNVs library in the five cell lines. (B) The g-tSNVs- and e-tSNVs-dependent verification rates by Sanger in the five cell lines. (C) and (D) Verification of g-tSNVs and e-tSNVs in HCT116 (n=3) by RNC-seq. (E) The identified peptides corresponding to SAVs elicited from g-tSNVs and e-tSNVs in the five cell lines. And (F) Distribution of PEP scores for all the peptides identified by LC MS/MS to view of peptide identification quality.
Figure 3.
Verification of transcript SNVs and proteins SAVs by Sanger sequencing, RNC-seq and mass spectrometry in five cell lines. (A) Distribution of the verification rates to transcript SNVs by Sanger sequencing through the SNVs detected by Sanger against that selected from transcript SNVs library in the five cell lines. (B) The g-tSNVs- and e-tSNVs-dependent verification rates by Sanger in the five cell lines. (C) and (D) Verification of g-tSNVs and e-tSNVs in HCT116 (n=3) by RNC-seq. (E) The identified peptides corresponding to SAVs elicited from g-tSNVs and e-tSNVs in the five cell lines. And (F) Distribution of PEP scores for all the peptides identified by LC MS/MS to view of peptide identification quality.
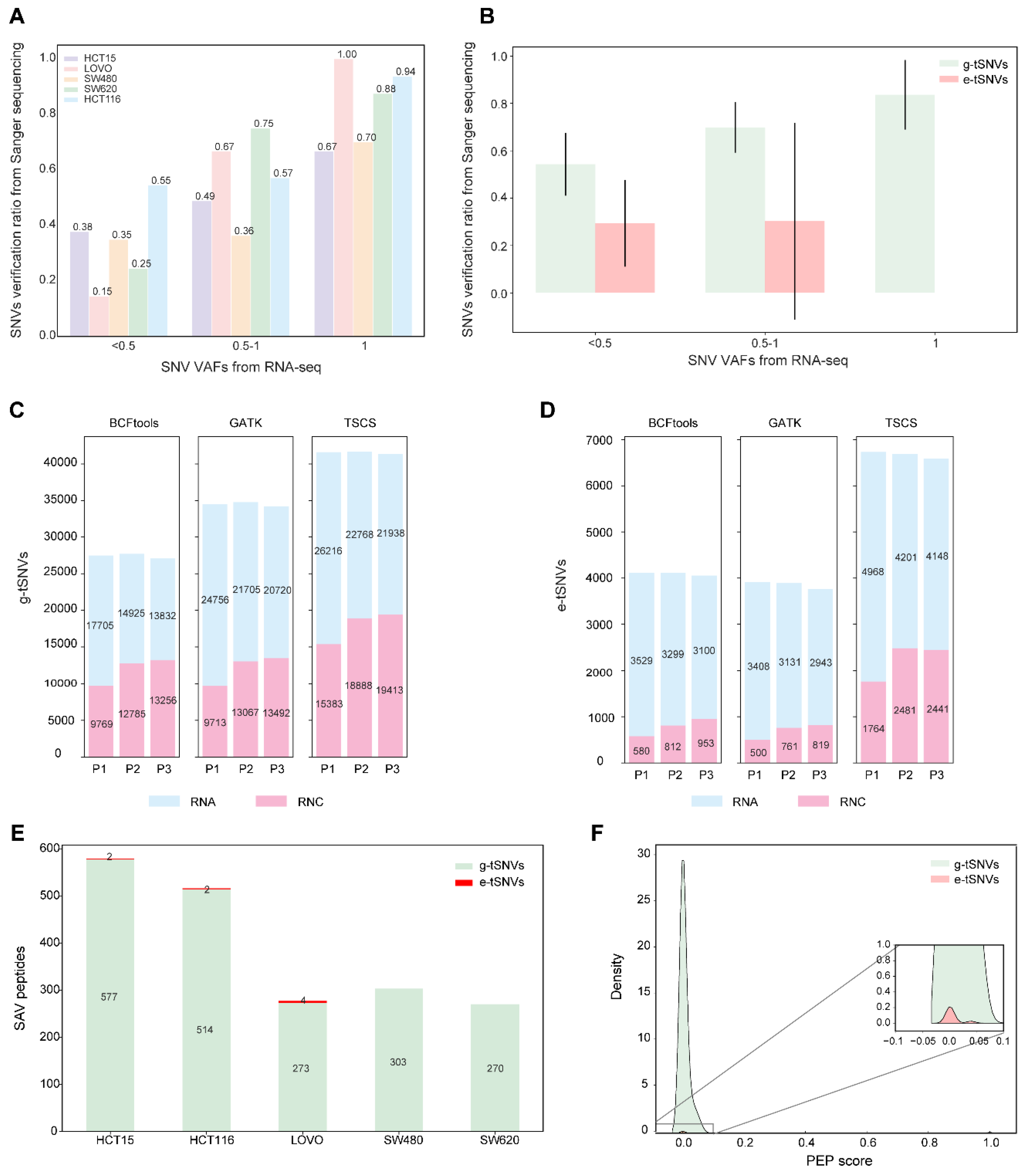
Figure 4.
Characterization of the g-tSNVs and e-tSNVs called by TSCS in the five cell lines. (A) Comparison of the ratios of e-tSNVs versus g-tSNVs in public SNVs database and in the transcript SNVs called by TSCS in the five cell lines. (B) Comparison of the nucleotide-substation dependent SNV types in g-tSNVs and e-tSNVs in public SNVs database and in the transcript SNVs called by TSCS in the five cell lines. (C) Comparison of the genomic regions of g-tSNVs and e-tSNVs in public SNVs database and in the transcript SNVs called by TSCS in the five cell lines. (D) Comparison of the nucleotide-substation dependent SNV types of g-tSNVs and e-tSNVs between the known and new SNVs called by TSCS in the five cell lines. (E) Comparison of SNVs genomic regions between the known and new g-tSNVs and e-tSNVs. (F) The shared status of the known and new for g-tSNVs and e-tSNVs in the five cell lines. (G) Nonsynonymous of the total of known g-tSNVs and e-tSNVs as well as of new g-tSNVs and e-tSNVs in all the cell lines. (H) Assessment of the changes in amino acid properties induced by nonsynonymous g-tSNVs and e-tSNVs, known or new, in all the cell lines. And (I) Distribution of nonsynonymous SNVs per gene for g-tSNVs and e-tSNVs, known or new.
Figure 4.
Characterization of the g-tSNVs and e-tSNVs called by TSCS in the five cell lines. (A) Comparison of the ratios of e-tSNVs versus g-tSNVs in public SNVs database and in the transcript SNVs called by TSCS in the five cell lines. (B) Comparison of the nucleotide-substation dependent SNV types in g-tSNVs and e-tSNVs in public SNVs database and in the transcript SNVs called by TSCS in the five cell lines. (C) Comparison of the genomic regions of g-tSNVs and e-tSNVs in public SNVs database and in the transcript SNVs called by TSCS in the five cell lines. (D) Comparison of the nucleotide-substation dependent SNV types of g-tSNVs and e-tSNVs between the known and new SNVs called by TSCS in the five cell lines. (E) Comparison of SNVs genomic regions between the known and new g-tSNVs and e-tSNVs. (F) The shared status of the known and new for g-tSNVs and e-tSNVs in the five cell lines. (G) Nonsynonymous of the total of known g-tSNVs and e-tSNVs as well as of new g-tSNVs and e-tSNVs in all the cell lines. (H) Assessment of the changes in amino acid properties induced by nonsynonymous g-tSNVs and e-tSNVs, known or new, in all the cell lines. And (I) Distribution of nonsynonymous SNVs per gene for g-tSNVs and e-tSNVs, known or new.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



