Submitted:
13 November 2025
Posted:
14 November 2025
You are already at the latest version
Abstract
AI accelerators, customized to AI workloads, provide cost- effective and high-performance solutions for training and inference. Trainium, an AI accelerator recently developed by Amazon Web Services (AWS), provides an attractive op- tion for LLM training and inference through its heteroge- neous architecture. However, leveraging Trainium architec- ture for high performance can be challenging because of its systolic array architecture and special requirement on data layout. In this paper, we design high-performance ma- trix multiplication (matmul), a critical compute kernel, for LLM inference on Trainium. We introduce a series of tech- niques customized to Trainium based on kernel fusion and novel caching strategies to reduce data movement across the software-managed memory hierarchy, maximize SRAM bandwidth, and avoid expensive matrix transpose. Evalu- ating with nine datasets and four recent LLMs, we show that our system largely outperforms the state-of-the-art mat- mul implemented by AWS on Trainium: at the level of mat- mul kernel, it achieves an average 1.35× speedup (up to 2.22×), which translates to an average 1.66× speedup (up to 2.49×) for end-to-end LLM inference. Our code is released at https://github.com/dinghongsong/NeuronMM.
Keywords:
LLM inference
; kernel fusion
; singular value decomposition
1. Introduction
Large Language Models (LLMs) have achieved remarkable success across a wide range of text-based tasks [49,78]. Yet, the steady growth in their parameter counts and architec- tural complexity makes deployment increasingly prohibitive, particularly in resource-constrained environments. These challenges have driven extensive research into model com- pression [1,13,17,18,23,45,65,82] and efficient hardware design [7,39,44,50,66,67,68,87].
AI accelerators [15,22,43], customized to AI workloads, provide cost-effective and high-performance solutions for training and inference. Trainium is an AI accelerator re- cently developed by Amazon Web Services (AWS). It has been reported that Trainium can deliver 30–40% lower cost while providing performance comparable to GPU-based EC2 instances [2]. Each Trainium2 device (the most advanced Trainium) integrates two NeuronCores, each delivering up to 95 TFLOPS ofFP16/BF16 compute capability, comparable to NVIDIA A100 GPUs at roughly 60% of the cost. Such a cost–effective advantage makes Trainium an attractive plat- form for LLM training and inference [21,25]. Furthermore, Trainium, as a typical systolic-array architecture, features a programmable memory hierarchy (including two types of on- chip SRAMs and off-chip HBM) [9,37,38,40,41,42,51,75,84,85,86,88]. It also provides a rich set of specialized compute engines tailored for various AI operators. Such hardware heterogeneity gives programmers a lot of flexibility to ex- plore for better performance.
However, leveraging Trainium architecture for high per- formance can be challenging. First, as a systolic array ar- chitecture, Trainium must repeatedly go through a load- compute-store cycle to accommodate the small capacity of its on-chip SRAM. This design causes frequent data move- ment across the memory hierarchy, whose overhead can often be larger than the computation time spent in various compute engines in Trainium. In addition, allocating too much data to the on-chip SRAM can lead to implicit “mem- ory spill” to HBM, which stalls the compute engines. On the other hand, underutilizing the on-chip SRAM wastes its high memory bandwidth and lowers the overall system throughput. Second, the programmer must carefully align a tensor’s logical shape with Trainium’s physical memory lay- out. Misalignment often requires tensor transposes, which incur costly data transfers between HBM and on-chip SRAM.
In this paper, we design high-performance matrix multi- plication (matmul), a dominating compute kernel in LLM, for LLM inference on Trainium. We call our system, NeuronMM. Building high-performance matmul for LLM inference on Trainium, we face the challenges discussed above. To reduce data movement overhead, we apply Singular Value Decom- position (SVD) to the weight matrices in LLM. By factoring a large weight matrix into two but retaining the top singular values and their corresponding singular vectors, we obtain a low-rank approximation to the original weight matrix but with smaller matrix size, hence leading to reductions of data movement. To make the application ofSVD aligned with the capacity of on-chip SRAM in Trainium and maximize SRAM utilization, we employ a three-level hierarchical data layout (i.e, tile, block, and strip) and introduce a block-wise SVD.
After applying SVD to the weight matrix W (W ≈ Uv), the large matmul in LLM (XW, where X is input embedding) is transformed to XUv, a sequence of two matmuls. Naively implementing it on Trainium suffers from the overhead of the data movement and data layout transpose. In particu- lar, materializing the intermediate result (the output of the first matmul in the sequence) causes data reloading from HBM because of small SRAM capacity and the necessity of storing the output of the first matmul in HBM [8,12,27,28,29,30,31,32,47,48,60,61,62,69,83]. To avoid this problem, we can fuse the two matmuls in the sequence without the materializa- tion of the intermediate result; this approach recomputes the blocks ofthe intermediate result when needed without storing them in HBM. However, it brings a new I/O over- head of loading sources blocks of X and U to compute each block of the intermediate result, which outweighs the benefit of recomputation. Furthermore, the transpose must happen between the two matmuls in the sequence, leading to extra overhead.
To address the above problem, NeuronMM introduces a new kernel fusion method for Trainium, named TrainiumFu- sion. It is featured with three major techniques. First, Traini- umFusion introduces an SRAM-capacity-aware caching strat- egy to eliminate recomputation penalty. This strategy caches multiple rows ofthe intermediate matrix on the SRAM based on its capacity, and carefully reuses it when generating the output blocks with the corresponding column strips in the source blocks. This method avoids recomputation and fre- quent data movement. Second, TrainiumFusion reduces ma- trix transpose by leveraging the matrix-identify property without impacting the result correctness. Third, Trainium- Fusion computes the matmul sequence by blocks in combi- nation with its caching strategy and DMA-assisted result accumulation in SRAM. We further develop performance modeling to quantify the relationship between the block size and arithmetic intensity (or peak SRAM usage), allowing the programmer to maximize utilization of compute engines while respecting the memory constraint.
We summarize the major contributions as follows.
- We build a high-performance matmul, NeuronMM, for LLM inference on Trainium. NeuronMM is open- sourced and adds a key milestone to the Trainium eco-system
- We introduce a series of techniques customized to Trainium to reduce data movement across the software- managed memory hierarchy, maximize the utilization of SRAM and compute engines, and avoid expensive matrix transpose
- Evaluating with nine datasets and four recent LLMs, we show that NeuronMM largely outperform the state- of–the art matmul implemented by AWS on Trainium: at the level of matmul kernel, NeuronMM achieves an average 1.35× speedup (up to 2.22×), which translates to an average 1.66× speedup (up to 2.49×) for end-to- end LLM inference
2. Background
2.1. SVD for Weight Compression
SVD is a well-established technique for approximating high- dimensional matrices with low-rank representations [16]. Given a weight matrix W, SVD factorizes it into three matri- ces: U, Σ, and v, such that W = U ΣvT . By retaining only the top-k singular values in Σ and their corresponding singular vectors in U and v, one obtains a low-rank approximation W ≈ UKΣ KvKT . This approximation preserves the most infor- mative components of W while substantially reducing the number of parameters to represent W. As a result, SVD is particularly well-suited for compressing the large weight matrices in the linear layers of LLMs, where parameter re- duction directly improves efficiency with tolerable accuracy loss.
Applying SVD involves two steps: matrix factorization and fine-tuning. We perform SVD offline on invariant weight matrices, and the resulting low-rank factors are used dur- ing inference for efficient matmuls. This design specifically targets LLM inference, where weights remain fixed and com- pression directly improves performance. In contrast, LLM training continuously updates weights, making SVD-based factorization impractical. Hence, NeuronMM is optimized specifically for inference.
2.2. AWS Trainium
AWS Trainium is a custom silicon chip designed to accelerate deep learning workloads. It adopts a systolic array–based ar- chitecture with rich hardware heterogeneity. Each Trainium chip integrates two NeuronCores. Each NeuronCore func- tions as an independent heterogeneous compute unit com- posed of a rich set of specialized engines designed for differ- ent operations, such as tensor engine, scalar engine, vector engine, and GPSIMD engine. In addition, Trainium includes DMA engines that can transfer data between HBM and on- chip SRAM in Trainium. Those engines operate in parallel, enabling Trainium to efficiently support diverse deep learn- ing tasks [6]. In addition, we particularly focus on the tensor engine for matmul in the following discussion.
We use Neuron Kernel Interface (NKI) [3], a bare-metal language and compiler for directly programming NeuronDe- vices available on AWS Trainium, in our study.
Tensor engine. It accelerates matmuls by reading input tiles from SBUF (an on-chip SRAM on Trainium) and writing output tiles to PSUM (another on-chip SRAM on Trainium).
The tensor engine is organized as a 128 × 128 systolic ar- ray of processing elements, defining a partition dimension (p = 128), where each partition maps to a memory partition in SBUF or PSUM. To fully exploit parallelism across the 128 processing units, the contraction dimension of a mat- mul must align with the partition dimension, allowing each partition to process a distinct tile of data concurrently.
Each tile-level matmul involves two input matrices, named as the stationary (left-hand side) matrix and moving (right- hand side) matrix (using AWS terms). The tensor engine loads the stationary matrix into its internal storage and streams the moving matrix across it. Due to the hardware’s systolic array design, the stationary matrix must be con- sumed in a transposed layout [6]. For clarity, we denote the low-level instruction nki.isa.nc_matmul [5] as NKIMatmul, which carries out this tile-level operation. Thus, computing the product of AB is formulated as NKIMatmul(stationary = AT , moving = B). The stationary matrix, which remains fixed during the computation, is transposed so that its rows align with the columns of the moving matrix, ensuring both input tiles share the same first dimension which corresponds to the partition dimension in SBUF.
Memory heterogeneity. A NeuronCore is associated with three types of memory (Figure 1): 16 GB off-chip High Bandwidth Memory (HBM), 24 MB on-chip State Buffer (SBUF), and 2 MB on-chip Partial Sum Buffer (PSUM). SBUF serves as the primary on-chip data buffer while PSUM serves as the dedicated accumulation buffer for the tensor engine. Both SBUF and PSUM are two-dimensional, each consisting of 128 partitions. Computation proceeds by loading data from HBM into SBUF, where the data is accessible by all engines. Once the computation is completed, the final results are writ- ten back to HBM. This explicit programming-model shifts responsibility to software: efficient tiling and placement are essential to exploit on-chip locality. Inefficient management instead leads to excessive HBM traffic, longer DMA trans- fers, and tensor engine stalls, directly limiting Trainium’s performance.
Three-level hierarchical data layout. For clarity, given a matrix A ∈ RM ×N, we define a hierarchical three-level data layout, ordered from the finest to coarsest: the Trainium- native tile, the logical block, and the matrix-spanning strip. The tile is the fundamental, hardware-native unit of data processed by a single NKIMatmul instruction. The tensor en- gine imposes strict, hardware-defined maximum dimensions on these tiles, and these constraints differ for the two matrix operands [6]. Specifically, a tile for the stationary matrix cannot exceed dimensions of (128, 128) for its partition and free axes, respectively. In contrast, a tile for the moving ma- trix can have a larger free axis, with its dimensions limited to (128, 512). When a matrix is larger than these hardware limits, it must be divided into multiple tiles for processing.
The block is a higher-level, logical software construct composed of one or more computational tiles. Specifically, a block groups a tM × tN grid of tiles, where tM and tN denote the number of tiles along two dimensions. This forms a block with dimensions (BM, BN ), where BM = tM × TM , BN = tN × TN, and TM, TN is the tile size of Trainium. When a matrix A is partitioned into blocks, we denote the block at the ith row and jth column as A ij. We use lowercase notation to denote individual tiles; for example, akl refers to the tile at the kth row and lth column of A.
The strip is a collection of blocks that span one entire dimension of A. A row strip, corresponding to the ith row of blocks in matrix A, is denoted as Ai∗ . Similarly, a column strip can be denoted as A ∗j. A strip is thus a set of blocks (e.g., Ai∗ = {Ai1, Ai2, . . . }) that form a sub-matrix, such as the one with a shape (BM, N) for a row strip in a matrix with the dimension (M, N).
The block-level multiplication in Trainium repeatedly per- forms the following three steps: (1) loading a pair of tiles from HBM to SBUF (one of the tiles must be transposed), (2) multipling the two tiles, and (3) storing the multiplica- tion result into PSUM. PSUM is used to accumulate the tile- multiplication results from all tiles in the input blocks. We use MatMulBlock(S, m) to denote this block-level matmul, where the stationary matrix S multiplies the moving matrix m on SBUF, and the result is accumulated into PSUM.
Matmultiling on Trainium. PSUM serves as a dedicated landing buffer for the tensor engine, with near-memory ac- cumulation capabilities that enables read-accumulate-write operations at a fine granularity of every 4B memory element. The accumulation mode of PSUM is particularly useful for large matmul, especially when the matrices have a high con- traction dimension (usually the inner dimension in a dot product). For instance, consider a matmul operation where the input tensors have dimensions: x.shape = [128, 512] and y.shape = [512, 512]. As illustrated in Figure 2, the input matrix can be partitioned through tiling, resulting in sliced input tiles [x0, x1, x2, x3] and [y0, y1, y2, y3]. The final out- put is obtained by computing individual partial sums, such as output0 = matmul(x0, y0), followed by the accumulation of these intermediate outputs: output = output0 + ... + output3.
Figure 3 shows that PSUM efficiently supports both intra- tile matmul and inter-tile result accumulation. Specifically, the first tensor-engine instruction writes its output directly into a designated PSUM bank, while subsequent instruc- tions incrementally accumulate their results onto the ex- isting content in the same PSUM bank. With eight PSUM banks allocated per partition, the tensor engine is capable of maintaining up to eight independent matmul accumulation groups concurrently. This architecture not only enhances the flexibility of matmul instruction scheduling on the tensor engine, but also enables overlap between the tensor engine operations and computation on other engines.
3. Motivation
Enabling high-performance matmul on Trainium faces mul- tiple challenges. We discuss them in this section to motivate our work.
3.1. Challenge 1: I/O Bottleneck
As established in Section 2.1, SVD transforms a matmul xw into a three-matrix chain xuv. However, executing this new formulation sequentially on Trainium introduces serious inefficiencies if not co-designed with the architecture.
Executing the SVD-compressed xuv computation with a standard, sequential approach on Trainium results in poor hardware utilization. Figure 4 shows a Neuron Profiler trace of theSVD-compressed up_projection matmulin Deepseek- V3 [49]. For an input length of 4096, with hidden size 7168 and intermediate size 18432, the up_projection matrix ([7168, 18432]) is factorized into two low-rank matrices: u ([7168, 4096]) and v ([4096, 18432]). This transforms the original matmul ([4096, 7168] × [7168, 18432]) into a chain of three multiplications: [4096, 7168] × [7168, 4096] × [4096, 18432]. As highlighted in Figure 4, this decomposition results in frequent idle gaps in Model FLOPs Utilization (MFU) and inefficient use of the on-chip SBUF, indicating that the tensor engine is often stalled waiting for data.
The root cause is the materialization of the intermediate re- sult. Sequential execution of xuv first computes the interme- diate matrix Y = xu, writes it from the fast on-chip SBUF to the slower HBM, and then reloads it into SBUF for the second multiplication O = Yv. This load-compute-store cycle creates a severe I/O bottleneck inherent to Trainium’s systolic-style architecture. Compared to the original up_projection, the SVD-compressed version increases direct memory access (DMA) transfer time by 65% and more than doubles the traf- fic between HBM and SBUF.
| Algorithm 1: Naive kernel fusion for Y = Xuv. |
 |
3.2. Challenge 2: Recomputation
To implement Xuv with minimum data movement, we fuse the two matmuls into a single kernel. We call our approach the naïve fused kernel. Instead of materializing the interme- diate result Y = Xu in HBM, the kernel recomputes Y on the fly for each block of the final output. While this eliminates intermediate HBM writes, it replaces the I/O overhead with a penalty in computation and HBM reads.
Algorithm 1 details our naive fused kernel. The computa- tional penalty arises because the calculation of the interme- diate block Ymp (lines 9–11) is nested inside the main loop over n (lines 5-13). As a result, the kernel redundantly re- computes the same Ymp for every output block omn in a row. The computation of each output block omn can be expressed as the following nested summation:
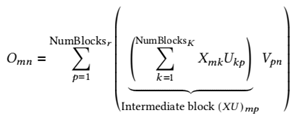
This formula reveals the source of recomputation. The inner summation, which calculates each block of the inter- mediate matrix (Xu)mp, depends only on the row-block index m and the reduction-block index p; it is independent of the output column-block index n. Yet, the naive fused kernel re-calculates this inner sum for every output block in the row strip om,∗ (om,1, . . . , om,NumBlocks N). As a result, the same intermediate blocks are recomputed unnecessarily, incurring a penalty factor of NumBlocksN =「N/B Nl.
This recomputation arises solely from Trainium’s on-chip memory limits. Avoiding recomputation would require set- ting BN = N, producing an entire row-block (BM, N) at once. But for LLM-scale matrices (e.g., N = 16384), such a block cannot fit within the 24 MB SBUF. In practice, we are therefore constrained to choose a much smaller BN (e.g., 512), forcing repeated recomputation. Worse, each recompu- tation triggers additional I/O: source blocks of X and u are repeatedly reloaded from HBM, inflating memory traffic and erasing the benefits of kernel fusion.
We quantify this penalty by benchmarking the naïve fused kernel against the sequential approach using matrix X ([2048, 2048]), u ([2048, 2048]), and v ([(2048,8192]) with a block size of BN = 512. Table 1 reports the results. The naïve fused kernel is more than 11× slower (18.06 ms vs. 1.57 ms). The slowdown stems directly from the recomputation factor 「8192/512l = 16, which causes a 4× increase in FLOPs and a 10.5× increase in HBM traffic due to repeated reloading of X and u. This confirms that for LLM-scale matrices, recom- putation penalties far outweigh the savings from avoiding intermediate I/O.
3.3. Challenge 3: Transpose Overhead
Transpose overhead on Trainium stems from the systolic- array design of its tensor engine, which requires the station- ary matrix in a matmul to be supplied in a transposed layout. This requirement conflicts with the natural data flow of LLMs and introduces two types of overhead: (1) I/O transposes on tensors entering or leaving a kernel, and (2) intermediate transposes on temporary results produced on-chip. Our goal is to eliminate intermediate transposes entirely and minimize the impact ofI/O transposes.
I/O transpose. An I/O transpose occurs when a tensor’s layout expected by an NKI compute API differs from the lay- out stored in HBM which is constrained by the surrounding LLM computation graph. In the Xuv operator, for example, the input activation matrix X must remain in its natural, non-transposed layout to integrate with the LLM data flow. However, for the first matmul Y = Xu, the tensor engine requires the stationary input to be XT. Thus, transposing X is unavoidable, making it an I/O transpose.
Intermediate transpose. An intermediate transpose oc- curs when the output of one NKI kernel must be reshaped before it can be consumed by another kernel due to a layout mismatch. In the sequential execution of xuv, the first mat- mul produces Y = xu, which serves as the stationary input for the second multiplication O = Yv. Because the tensor engine requires YT, a naïve implementation must explicitly transpose Y on chip. This extra step is costly, as it intro- duces additional memory movement and synchronization overhead.
4. Design
Figure 5 provides an overview of NeuronMM, a framework for accelerating LLMs on AWSTrainium. Table 2 summarizes the notations used in this section.
NeuronMM compresses the large weight matrices in MLP layers using block-aligned SVD and restores accuracy through Low-Rank Adaptation (LoRA) [36] fine-tuning. It further pro- vides high-performance NKI kernels, termed TrainiumFu- sion, that execute matmuls on compressed models efficiently by exploiting Trainium’s architectural features.
4.1. Block-Aligned SVD
Leveraging existing work. Following the standard work- flow of post-training LLM compression methods [20,72,80], the weight matrix W is first scaled by a matrix S to cap- ture the influence of input activations. S is derived from a random set of input sentences. Specifically, for each MLP layer in LLMs, we record input activations x using forward hooks, compute the covariance matrix, and apply Cholesky decomposition:
where S is a lower triangular matrix with all positive diag- onal elements. NeuronMM then performs SVD on W S and reconstructs W using S−1.
where W ∈ Rk ×n , u∈ Rk ×r , vr/ ∈ Rr×n and r denotes the
SS⊤ = Cholesky(x⊤x)
W = (WS) · S−1 = (u Σv⊤ ) · S−1 ≈ urΣrvr⊤ · S−1
top-r singular values. The choice of r is crucial for balancing model accuracy and compression ratio.
We define the compression ratio as follows.
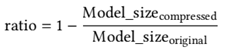 where Model_size compressed and Model_size original denote the model parameter counts with and without compression. This definition follows the existing work on LLM compression [20,46,71,72,80].
where Model_size compressed and Model_size original denote the model parameter counts with and without compression. This definition follows the existing work on LLM compression [20,46,71,72,80].
Block alignment. Unlike prior work, we introduce a block-aligned rank selection strategy that maximizes tensor engine utilization by coupling the compression ratio with the tensor engine’s tile size. The rank r is computed as follows.
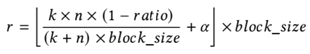 where k and n are the dimensions of W, and block_size is an integer multiple of tile_size. α is a rounding threshold that adjusts the required number of blocks, with α = 0.5 cor- responding to standard rounding. This formulation ensures that the choice of r both satisfies the target compression ratio and aligns with hardware tile boundaries, avoiding intra-block padding and improving utilization ofSBUF and the tensor engine. With r determined, ur, Σr, vr⊤ , and S−1 are consolidated into and .
where k and n are the dimensions of W, and block_size is an integer multiple of tile_size. α is a rounding threshold that adjusts the required number of blocks, with α = 0.5 cor- responding to standard rounding. This formulation ensures that the choice of r both satisfies the target compression ratio and aligns with hardware tile boundaries, avoiding intra-block padding and improving utilization ofSBUF and the tensor engine. With r determined, ur, Σr, vr⊤ , and S−1 are consolidated into and .
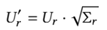
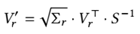
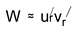
This transformation represents each weight matrix as the product of two low-rank matrices, reducing parameters from kn to r × (k + n).
Although SVD substantially reduces the size of the weight matrix, it inevitably introduces accuracy loss. To recover accuracy, we apply LoRA fine-tuning to the compressed weights, similar to the prior work [46,72]. During fine-tuning, we freeze the compressed weights uand vr/, and fine-tune them with LoRA:
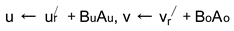 where Au, Bu, Ao, and Bo are the trainable matrices used to adapt the model via LoRA. After fine-tuning, we incorporate the matrices BuAu and BoA o into uand vr/, respectively, to form the final compressed weight matrices u and v.
where Au, Bu, Ao, and Bo are the trainable matrices used to adapt the model via LoRA. After fine-tuning, we incorporate the matrices BuAu and BoA o into uand vr/, respectively, to form the final compressed weight matrices u and v.
4.2. TrainiumFusion
After SVD, we build a Xuv NKI kernel using new kernel fusion techniques in Trainium.
4.2.1. XUV NKI Kernel We introduce three techniques: caching, implicit transposition, and blocking, to overcome the challenges of I/O bottlenecks and recomputation. The main idea is to fuse theXuv chain into a two-stage computa- tion that executes entirely within the on-chip SBUF. First, we compute a strip of the intermediate product, using implicit transposition by reordering the inputs to the NKIMatmul primitive to directly generate its transpose, (Xu)T . This on-chip result is then immediately consumed in the second stage, where it is multiplied with a corresponding strip of v to produce a block of the final output. This fused dataflow avoids intermediate data transfer between HBM and SBUF, eliminates the recomputation penalty, and removes the inter- mediate transpose, as illustrated in Figure 5b. We give more details as follows.
Caching. NeuronMM uses a capacity-aware caching strat- egy to eliminate recomputation penalty. The kernel calcu- lates an entire row strip of the intermediate matrix, (Xu)m* , and caches it in a dedicated buffer within the on-chip SBUF. This cached strip is then efficiently reused for the subse- quent multiplications with all corresponding column strips of the v matrix (v*1, v*2, . . . ) to produce every output block (Om1, Om2, . . . ) to eliminate the recomputation. This on-chip caching is feasible within the SVD-based LLM, because theintermediate strip’s memory usage is manageable. In par- ticular, its shape is (BM, r), where BM is a block size (e.g., 1024) and r is the SVD rank. The resulting buffer size (e.g., 1024 × r × 2 bytes for float16 tensor) fits within the 24MB SBUF, leaving enough space for other necessary data blocks.
Implicit transposition. The low-level NKIMatmul prim- itive computes a matrix product AB using a specific input layout: NKIMatmul(stationary=AT , moving=B), required by the tensor engine. Therefore, the calculation of O = (Xu)v first computes the intermediate matrix Y = Xu. Then the subsequent multiplication, O = Yv, requires YT as its stationary input. This layout mismatch forces an ex- plicit transpose operation overhead on the intermediate matrix Y, which grows linearly with the input sequence length. NeuronMM eliminates this overhead with an im- plicit transpose. We leverage the matrix identity (Xu)T = uTXT, which is equivalent to computing result with the call NKIMatmul(stationary=u , moving=XT). In practice, this is implemented by controlling the order of the inputs to the NKIMatmul primitive. This yields the correctly trans- posed intermediate result YT on chip, completely avoiding the explicit data transpose.
Blocking. We compute Xuv by blocks as shown in Fig- ure 5b. The dataflow is structured around a main outer loop that processes the input matrix X one row strip at a time. Within each iteration of this outer loop, the computation proceeds in two phases within inner loops. First, the kernel computes and caches the entire intermediate strip, 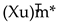 , in SBUF. To do this, its inner loops load corresponding blocks of X and u from HBM. The X block is transposed in transit by the DMA engine, and the blocks are multiplied, with the result
, in SBUF. To do this, its inner loops load corresponding blocks of X and u from HBM. The X block is transposed in transit by the DMA engine, and the blocks are multiplied, with the result 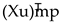 accumulated in PSUM before being stored in the SBUF cache. In the second phase, another set of inner loops iterates through the blocks of matrix V, loading them from HBM and multiplying them with the pre-computed blocks fetched from the cached strip in SBUF. The final re- sult for the output block, Omn, is accumulated in PSUM and then written back to HBM.
accumulated in PSUM before being stored in the SBUF cache. In the second phase, another set of inner loops iterates through the blocks of matrix V, loading them from HBM and multiplying them with the pre-computed blocks fetched from the cached strip in SBUF. The final re- sult for the output block, Omn, is accumulated in PSUM and then written back to HBM.
, in SBUF. To do this, its inner loops load corresponding blocks of X and u from HBM. The X block is transposed in transit by the DMA engine, and the blocks are multiplied, with the result accumulated in PSUM before being stored in the SBUF cache. In the second phase, another set of inner loops iterates through the blocks of matrix V, loading them from HBM and multiplying them with the pre-computed blocks fetched from the cached strip in SBUF. The final re- sult for the output block, Omn, is accumulated in PSUM and then written back to HBM.The block size can impact kernel performance significantly because there is a trade-off between computational efficiency and on-chip memory usage. We model the trade-off with two metrics – Arithmetic Intensity and Peak SBUF Usage. Assume that we have the inputs X ∈ RM ×k , u ∈ Rk ×r and V ∈ Rr ×N in HBM, and S is the size of the data type of inputs. The arithmetic intensity (Equation 10) is defined as the ratio of total FLOPs to HBM traffic. The HBM traffic is composed of initial reads of X, final writes of O, and repeated reads of u and V for each of the M/BM row strips.
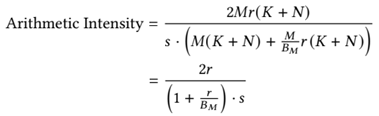
The peakSBUF usage is determined by the maximum mem- ory required across the kernel’s two computational phases: first computing the intermediate strip (Xu)m∗, and second, using that strip to produce the final output blocks. The peak requirement is the maximum of the SBUF footprints in these two phases, formulated as follows.
Peak SBUF Usage = max ((B Mr + BMBk + B kBr), (B Mr + BrBN + BMBN)) · S
= (B Mr + (BM + Br) · max(Bk, BN )) · S
= (B Mr + (BM + Br) · max(Bk, BN )) · S
Equations 10-11 model a trade-off: the arithmetic intensity increases with a larger BM due to better data reuse, while the peak SBUF usage also grows as it must hold larger blocks. Therefore, an optimal block size must be large enough to maximize arithmetic intensity and saturate the tensor en- gine, yet small enough to fit within the 24 MB SBUF capacity to avoid memory spills. As shown in Section 5.3, our experi- mental results validate the two models.
Using Equations 10-11, we determine the optimal block size. By the roofline model, a kernel becomes compute-bound when its arithmetic intensity exceeds a hardware-specific threshold [73]—for a Trainium NeuronCore with bfloat16 data, this threshold is 222 Flops/Byte [59]. Setting the arith- metic intensity (Equation10) to this threshold yields the min- imum block size BM required to saturate the tensor engine. Starting with this BM, the peak SBUF usage model (Equa- tion 11) can then identify block combinations that maximize data reuse within the 24 MB SBUF capacity.
4.2.2 Kernel Input and Output Layout Our XuV NKI kernel must integrate seamlessly into the LLM in a high-level framework like PyTorch or vLLM, where tensors typically maintain a standard, non-transposed layout. This presents a challenge, as Trainium’s systolic array architecture requires the stationary matrix in a multiplication to be transposed. To manage this layout mismatch, our strategy is twofold: we aim to completely eliminate transposes between kernels (intermediate transposes) and minimize the performance impact of unavoidable transposes at the kernel’s boundary (I/O transposes).
Input layout. The unavoidable I/O transpose of the input matrix X can be addressed in two ways. One option is to load data at full DMA bandwidth and perform the transpose on the tensor engine, but this wastes valuable compute cycles. The alternative is to let the DMA engine transpose data on- the-fly, which lowers effective DMA bandwidth but frees the tensor engine for matmul. We adopt the latter approach: the DMA engine handles transposes, while the tensor engine remains dedicated to computation. This strategy overlaps communication with computation, as the DMA engine can load and transpose the next tile while the tensor engine processes the current one.
Output layout. The kernel’s output layout is chosen to eliminate downstream transpose operations, depending on the output’s consumer. If the output is to be consumed by another NKI kernel that requires a transposed, stationary ma- trix, we produce OT directly. If the output is passed back to the high-level model, which expects a standard tensor layout, we produce the non-transposed output O. By swapping the order of the stationary and moving matrices in NKIMatmul, we can produce either O or OT with no performance over- head.
4.2.3 MLP NKI Kernel We introduce a specialized NKI kernel for SVD-compressed MLP layers, which extends the XuV kernel design to a multi-stage operation.
The computation in an MLP layer, such as one using SwiGLU, involves three matmuls. First, two parallel linear transformations—a “gate” projection and an "up" projection— are applied to the input tensor X. The gate’s output is passed through a SiLU activation function and then combined with the up-projection’s output via an element-wise multiplica- tion. This intermediate result is then passed through a “down” projection to produce the MLP layer’s output.
Our implementation (Algorithm 3) maps the MLP com- putation onto two NKI kernels (lines 6-7) derived from the XUV kernel. The first stage, UpGateProjection kernel (Al- gorithm 2) extends the XUV kernel to compute the “gate” and “up” projections in parallel (lines 6-20). It then uses Trainium’s Scalar and Vector Engines to perform SiLU(gate)⊙ up on-chip SBUF and writes the transposed result to HBM (line 21). The second stage, DownProjection, uses the XUV kernel that accepts a pre-transposed input and produces a standard-layout output. This stage seamlessly consumes the transposed output from the first stage without intermediate transpose, and writes the final result to HBM in the standard layout required by subsequent LLM layers.
4.3. Discussions
Focus on MLP in LLM. A typical transformer layer in LLM consists of the attention and MLP, both of which employ matmul. We apply NeuronMM to MLP because of the follow- ing two reasons. First, the parameters in MLP account for the majority of parameters in LLM. For example, in Llama-3.1-8B, the parameters in MLP takes 70% of the overall parameters. Hence, working on MLP can bring larger reduction in in- ference time and LLM size. Second, applying NeuronMM to attention and MLP, we find big loss in LLM accuracy, even though we go through rigorous fine-tuning process to restore accuracy. Hence, we apply NeuronMM to MLP alone.
| Algorithm 2: MLP up-projection kernel |
 |
| Algorithm 3: SVD-compressed MLP layer |
 |
5. Evaluation
5.1. Experimental Setup
Implementation. We develop NeuronMM on top of Neu- ronX Distributed Inference library [57] and implement MLP kernels based on NKI [58]. We evaluate NeuronMM on an trn1 .2xlarge instance of Amazon Elastic Compute Cloud (Amazon EC2) equipped with AWS Trainium accelerators, running the Deep Learning Amazon Machine Images (AMI) Neuron (Ubuntu 22.04). We use a single NeuronCore with 16GB HBM on a Trainium chip for evaluation, because using more than one core for inference based on tensor/pipeline/ data parallelism is not fully supported in NKI yet.
Models and datasets. We test LLMs that fit entirely into the HBM and are currently supported by NeuronX Distributed In- ference library, including Llama-3.2-1B, Llama-3.2-3B, Qwen3- 1.7B, and Qwen3-4B. We evaluate NeuronMM with nine datasets, covering three language modeling datasets (WikiText- 2 [54], PTB [53], and C4 [63]) and six common sense reason- ing datasets (OpenBookQA [55], WinoGrande [64], PIQA [11], HellaSwag [81], ARC-e, and ARC-c [14]). For fine-tuning with LoRA, we use the yahma/alpaca-cleaned [77].
5.2. Evaluation of XUV Kernel
We compare NeuronMM against two baselines: NKIXW and NKI XUV. Both baselines use the state-of-the-art matmul kernel implemented by AWS official [5]. NKIXW computes the standard matmul without SVD, while NKIXUV executes matmuls using the low-rank factors U and V derived from the SVD ofW, without TrainiumFusion optimization in Neu- ronMM. We evaluate our kernel with matrices X ∈ RM ×8192 , W ∈ R8192×16384 , U ∈ R8192×4096, and V ∈ R4096×16384, where U, V denotes the low-rank approximation derived from the SVD of W. We vary the first dimension M ofX from 1024 to 32768 to simulate different sequence lengths. For this evaluation, we assume that the kernel’s output is to be con- sumed as the stationary matrix in a subsequent kernel com- putation. Therefore, to eliminate intermediate transpose, the kernel is configured to compute the transposed output, OT = (XUV)T .
Figure 6 reports execution time and HBM-SBUF memory traffic, while Table 3 summarizes the average performance metrics for each kernel across the range of sequence lengths. As shown in Table 3, NeuronMM sustains the highest tensor engine active time and MFU, meaning that most cycles in the tensor engine are devoted to useful matmul operations. This high utilization directly translates into the lowest ex- ecution time, as shown in Figure 6. Compared to the NKI XW baseline, NeuronMM delivers an average 2.09× speedup, reaching 2.22× (84.15 ms vs. 186.60 ms) at sequence length 32K, driven by 4.78× reduction in HBM-SBUF memory traffic. NeuronMM also outperforms NKIXUV baseline, achieving a 1.35× speedup with over 2.6× less memory traffic on average.
Breakdown Analysis. The performance gains of our approach stem from an algorithm–hardware co-design that combines the algorithmic efficiency of SVD with a fused kernel tailored to Trainium. We study the contributions of SVD and TrainiumFusion separately.
We first measure the speedup from SVD alone by compar- ing NKIXW to NKIXUV. SVD yields an average speedup of 1.54×. This gain results from SVD’s algorithmic advantage; by factorizing W into two low-rank matrices, SVD reduces both computation and memory traffic. On average, total FLOPs drop by 26% (2.96 to 2.18 TFLOPs) and HBM–SBUF traffic decreases by 34% (9.93 to 6.52 GB).
We then compare NeuronMM to NKIXUV to isolate the effect of TrainiumFusion. NeuronMM achieves an average speedup of 1.36× by exploiting Trainium’s architecture in two ways. First, it avoids materializing the intermediate ma- trix in HBM, cutting the average memory traffic by 2.64× (6.52 to 2.47 GB). Second, it eliminates intermediate trans- poses, reducing the average transpose-related FLOPs by 3.5× (78.92 to 22.55 GFLOPs). These optimizations raise the ten- sor engine MFU to 85%, compared to 65% for the sequential kernel.
Together, SVD’s algorithmic savings and TrainiumFusion’s hardware co-design deliver an average speedup of 2.10× over the original NKI XW baseline. This demonstrates that the SVD alone is insufficient and co-designing with accelerator architecture is essential to fully realize performance gains.
5.3. Impact of Block Size on Kernel Performance
To empirically validate the trade-off model proposed in Sec- tion 4.2.1, we benchmark the NeuronMM kernel with vary- ing block sizes, BM . The experiment uses bfloat16 matri- ces derived from an SVD-compressed DeepSeek-V3 MLP layer [49]. We fix the input sequence length at 4096, yielding X ∈ R4096×7168 , U ∈ R7168×4096, and V ∈ R4096×18432 .
The results in Table 4 align with our model’s predictions in Section 4.2.1: latency decreases initially and then rises as BM grows. When BM increases from 128 to 1024, latency drops sharply because arithmetic intensity rises, saturating the tensor engine and making the kernel compute-bound. For BM ≥ 1024, however, performance degrades as the memory footprint exceeds the SBUF capacity. This is evidenced by non-zero spill_reload_bytes. These spills stall execution and reduce arithmetic intensity.
These findings confirm that kernel performance hinges on selecting a block size that balances arithmetic intensity against on-chip memory limits. The optimal BM fully uti- lizes the tensor engine without triggering SBUF spills, high- lighting block-size tuning as a critical design parameter for Trainium kernels.
5.4. Evaluation of MLP Kernel
We integrate NeuronMM into the MLP layer of LLMs and evaluate its perplexity, accuracy and speedup on end-to-end inference. For language modeling tasks (Wiki2, PTB, and C4), we report perplexity (PPL), which measures the model’s uncertainty in predicting the next token, with lower values indicating better predictions. For common-sense reasoning tasks (the other six tasks), we report task accuracy.
To assess the trade-off between inference speed and ac- curacy degradation, we adopt the Speedup Degradation Ra- tio Y [33]:
 where Avgfull and Avgmethod denote the average accuracy of the full model and the performance-optimization method, respectively. A lower Y reflects greater efficiency, capturing how well a method retains accuracy for each unit of speedup.
where Avgfull and Avgmethod denote the average accuracy of the full model and the performance-optimization method, respectively. A lower Y reflects greater efficiency, capturing how well a method retains accuracy for each unit of speedup.
5.4.1 Impact of Compression Ratio We evaluate Llama- 3.2-1B under compression ratios from 0.05 to 0.5 on the WikiText-2 language modeling task and the ARC Easy com- monsense reasoning benchmark. As shown in Figure7, higher compression ratios reduce the number of model parameters but lead to increased perplexity and decreased accuracy. This demonstrates the fundamental trade-off between model size and predictive performance. The model degradation is ac- ceptable under mild compression. However, as the compres- sion ratio increases performance drops sharply. In particular, between 0.4 and 0.5, PPL surges from 38.87 to 51.29, and ac- curacy drops from 46% to 40%, indicating that compression has significantly harm the model’s capabilities. To ensure that the accuracy degradation stays within an acceptable range [46,70,71,72,80], we adopt compression ratios of 0.1 and 0.2 for the end-to-end evaluation (Sections 5.4.3 and 5.4.4).
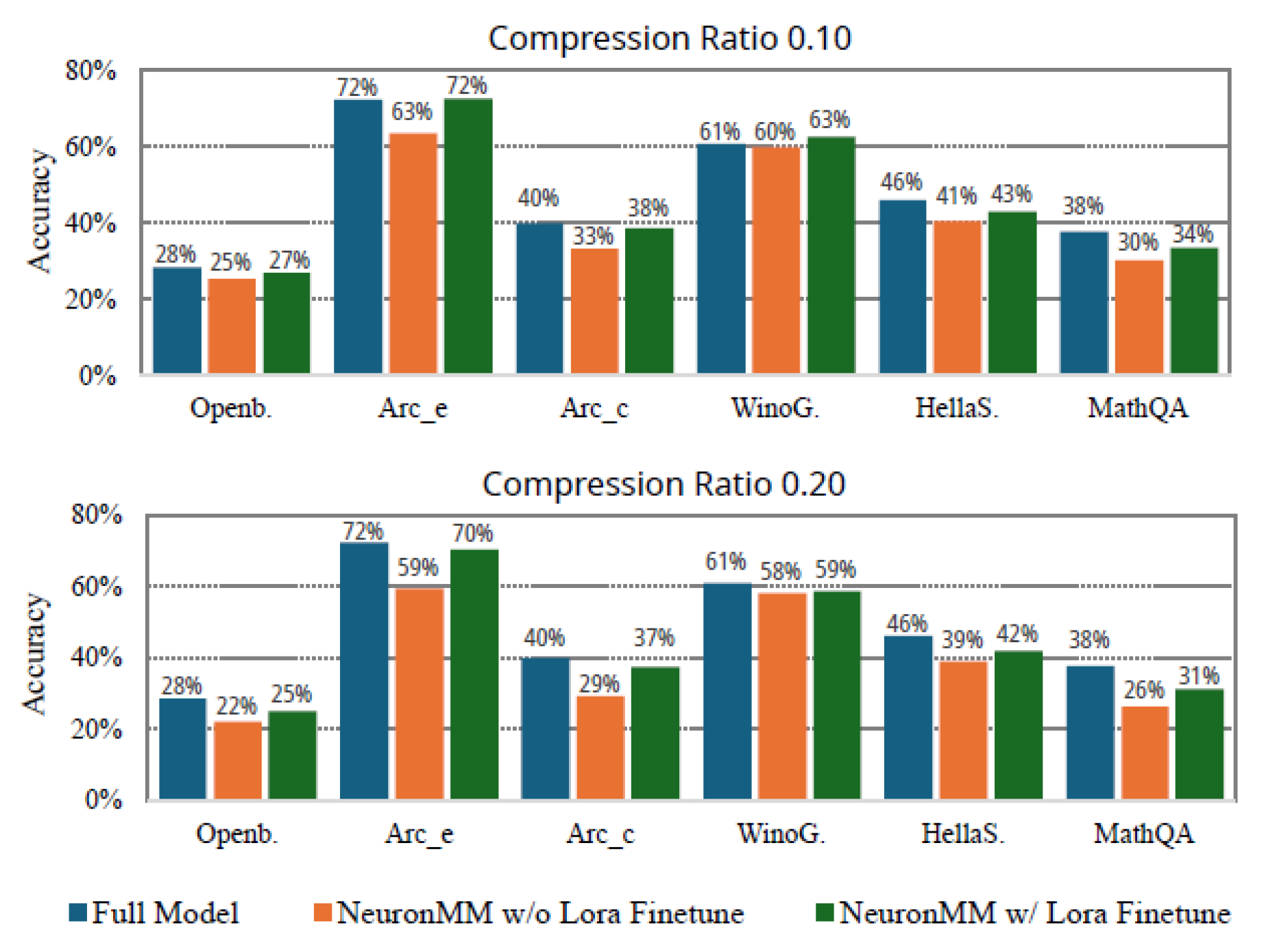
5.4.2 Impact of LoRA Fine-Tuning Figure 8 presents the accuracy of Qwen-3-1.7B under compression ratios of 0.1 and 0.2 across six commonsense reasoning benchmarks. We can observe that while compression reduces accuracy, LoRA fine-tuning effectively restores it, keeping degradation negligible at these low ratios.
5.4.3 Impact of Different LLMs To demonstrate the gen- erability of NeuronMM across various LLMs, we evaluate it on four LLMs (Llama-3.2-1B, Llama-3.2-3B, Qwen3-1.7B, and Qwen3-4B) across 9 datasets. We report mean accu- racy (mAcc) and average end-to-end speedup, with results summarized in Table 5. Across all LLMs evaluated, the SVD- compressed models retain accuracy largely comparable to the original, with mAcc drop ≤ 0.10 in every case, a level of loss generally considered acceptable [46,70,71,72,80].
Figure 7.
Model degradation with increasing compression ratios.
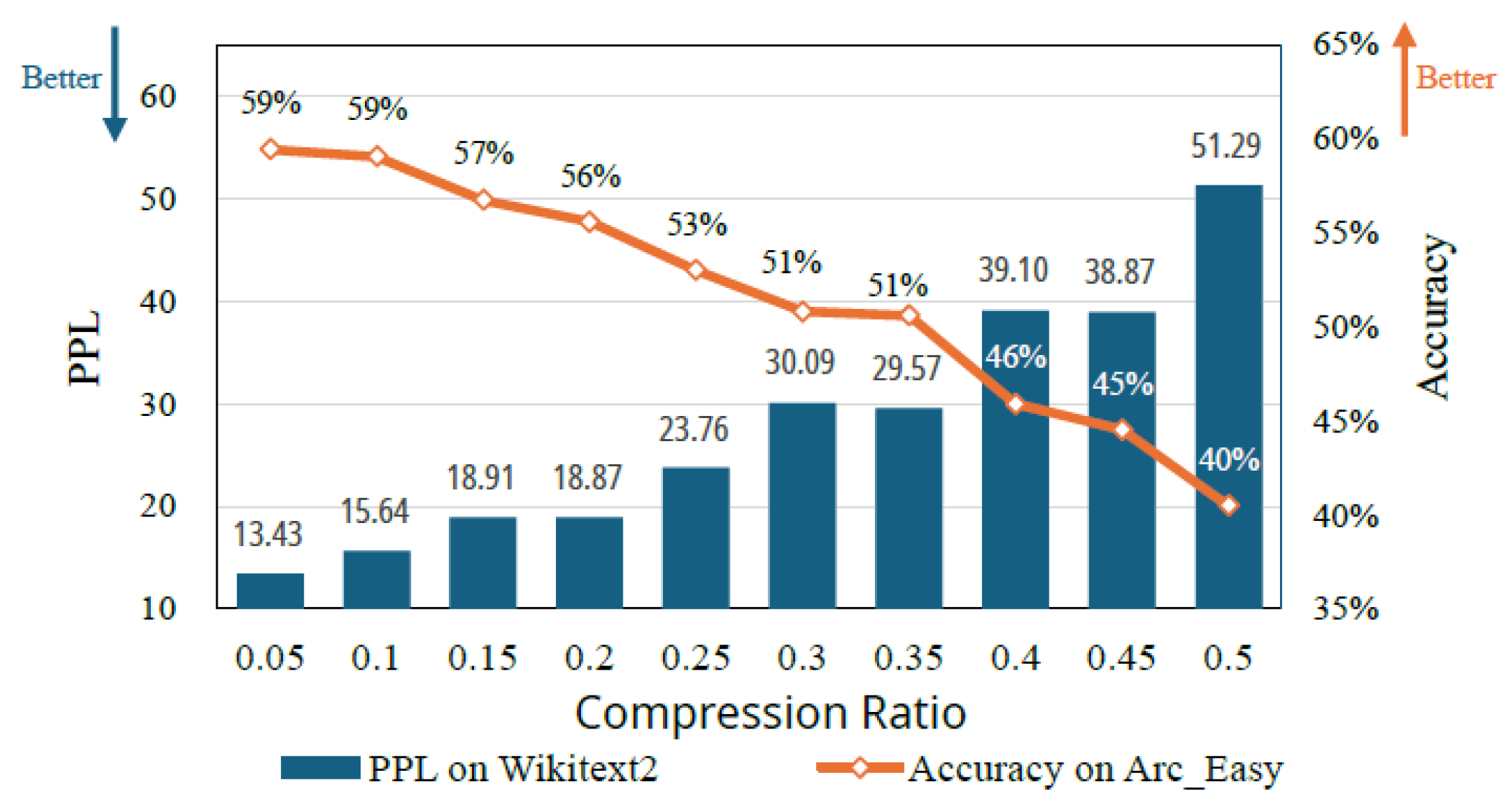
Figure 8.
Accuracy degradation and recovery of Qwen-3- 1.7B under different compression ratios on six common-sense reasoning datasets.
Figure 8.
Accuracy degradation and recovery of Qwen-3- 1.7B under different compression ratios on six common-sense reasoning datasets.
Meanwhile, NeuronMM achieves significant end-to-end inference speedup (1.21×–2.49×), while Y remains low — ranging from 3.24% to 25.27% (shown in Table 5), with the most values below 10% — indicating a favorable trade-off be- tween speedup and accuracy. For example, on Qwen-3-1.7B, NeuronMM enables 1.74× faster inference with only a 0.03 mean accuracy drop compared to standard LLM inference.
5.4.4 Impact on Inference TTFT and TPOT We show how NeuronMM can be applied to LLM to reduce their Time to First Token (TTFT) and Time Per Output Token (TPOT), thereby improving inference speed. As a concrete example, we take Llama 3.2-1B and apply NeuronMM to evaluate its effectiveness. We set the batch size to 1, and input sequence length (ISL) and output sequence length (OSL) to 1024, yield- ing a total sequence length of 2048. The compression ratio is set from 0.05 to 0.2. Table 7 shows that as the compression ratio increases from 0 to 0.2, end-to-end latency is signifi- cantly reduced, resulting in 1.86× speedup (from 41.22s to 22.14s), while the throughput nearly doubles from 49.69 to 92.52 tokens/s. Both TTFT and TPOT also show consider- able improvements, dropping from 82.22ms to 61.20ms and from 39.65ms to 20.41ms, respectively. These results stem both from block-aligned SVD decomposition of the weights (as shown in Table 2 under a compression ratio of 0.2) and from the efficient TrainiumFusion implementation, which together achieve faster response times and higher processing speeds on Trainium.

Table 5.
Evaluation of NeuronMM across four LLMs and nine datasets under compression ratios of 0.1 and 0.2.
Table 5.
Evaluation of NeuronMM across four LLMs and nine datasets under compression ratios of 0.1 and 0.2.
| Model | Compr Ratio | PPL (↓) | Accuracy (↑) | mAcc (↑) | Avg. Speedup (↑) | γ (↓) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Wiki2 | PTB | C4 | Openb. | ARC_e | ARC_c | WinoG. | HellaS. | MathQA | |||||
| Llama-3.2-1B | 0 | 9.75 | 15.4 | 13.83 | 0.26 | 0.66 | 0.31 | 0.61 | 0.48 | 0.29 | 0.43 | 1.00× | - |
| 0.1 | 15.64 | 22.8 | 22.72 | 0.2 | 0.59 | 0.28 | 0.55 | 0.41 | 0.26 | 0.38 | 1.21× | 25.27% | |
| 0.2 | 18.87 | 27.24 | 26.71 | 0.18 | 0.56 | 0.26 | 0.54 | 0.39 | 0.25 | 0.36 | 1.63× | 11.24% | |
| Llama-3.2-3B | 0 | 7.82 | 11.78 | 11.29 | 0.31 | 0.74 | 0.42 | 0.7 | 0.55 | 0.35 | 0.51 | 1.00× | - |
| 0.1 | 11.58 | 15.61 | 17.11 | 0.24 | 0.65 | 0.34 | 0.64 | 0.47 | 0.28 | 0.44 | 1.88× | 8.66% | |
| 0.2 | 15.13 | 18.69 | 20.8 | 0.23 | 0.62 | 0.29 | 0.6 | 0.43 | 0.27 | 0.41 | 2.49× | 7.20% | |
| Qwen-3-1.7B | 0 | 16.68 | 28.88 | 22.8 | 0.28 | 0.72 | 0.4 | 0.61 | 0.46 | 0.38 | 0.47 | 1.00× | - |
| 0.1 | 15.43 | 25 | 20.13 | 0.27 | 0.72 | 0.39 | 0.62 | 0.43 | 0.34 | 0.46 | 1.41× | 3.24% | |
| 0.2 | 17.05 | 26.97 | 22.14 | 0.25 | 0.7 | 0.37 | 0.58 | 0.42 | 0.31 | 0.44 | 1.74× | 4.72% | |
| Qwen-3-4B | 0 | 9.75 | 15.4 | 13.83 | 0.29 | 0.8 | 0.51 | 0.66 | 0.52 | 0.47 | 0.54 | 1.00× | - |
| 0.1 | 12.18 | 18.98 | 19.05 | 0.31 | 0.78 | 0.47 | 0.66 | 0.5 | 0.42 | 0.52 | 1.28× | 6.93% | |
| 0.2 | 14.05 | 21.09 | 21.38 | 0.3 | 0.75 | 0.43 | 0.64 | 0.48 | 0.37 | 0.49 | 1.67× | 7.41% | |
Table 6.
Module sizes of Llama-3.2-1B with and without SVD compression at compression ratio of 0.2.
| Without SVD | Compression Ratio 0.2 | ||
|---|---|---|---|
| Module | Size | Module | Size |
| up_proj gate_proj down_proj |
[2048, 8192] [2048, 8192] [8192, 2048] |
up_u_proj up_v_proj gate_u_proj gate_v_proj down_u_proj down_v_proj |
[2048, 1280] [1280, 8192] [2048, 1280] [1280, 8192] [8192, 1280] [1280, 2048] |
Table 7.
Performance of Llama-3.2-1B under different com- pression ratios with batch size= 1, ISL = 1024, OSL = 1024. Ratio means compression ratio.
Table 7.
Performance of Llama-3.2-1B under different com- pression ratios with batch size= 1, ISL = 1024, OSL = 1024. Ratio means compression ratio.
| Ratio | E2E Latency (s) | Throughput | TTFT (ms) | TPOT (ms) |
|---|---|---|---|---|
| 0 | 41.22 | 49.69 | 82.22 | 39.65 |
| 0.05 | 33.76 | 60.67 | 74.18 | 32.38 |
| 0.10 | 30.45 | 67.25 | 71.41 | 29.15 |
| 0.15 | 24.90 | 82.25 | 63.07 | 23.74 |
| 0.20 | 22.14 | 92.52 | 61.20 | 20.41 |
6. Related Work
SVD and LLM. LLM can have billions of parameters, mak- ing inference on resource-constrained hardware challenging.
Various model compression techniques have been proposed to reduce their latency and memory footprint [4,19,23,24,26,34,52,56,74,79]. Recent works have explored various SVD-based approaches for model compression. For exam- ple, FWSVD [35] introduces a weighted low-rank factoriza- tion scheme, while ASVD [80] develops an activation-aware SVD technique that exploits layer-wise activation patterns to enhance compression effectiveness. SVD-LLM [71,72] further incorporates truncation-aware data whitening and layer-specific parameter updates, assigning unique ratios to individual weights. In contrast, Dobi-SVD [70] establishes a bijection mapping, allowing the model to automatically learn the best truncation points among layers. However, those works do not consider the characteristics of accelera- tor hardware and the additional matmul overhead introduced by SVD (e.g., memory spilling) as NeuronMM.
Performance optimization on Trainium. Recent stud- ies [10,76] have demonstrated that AWS Trainium is promis- ing to accelerate generative AI workloads. HLAT [21] demon- strates that, through a series of system-level optimizations and training strategies, Trainium can reduce training costs to 60% of those on p4d GPU instances while maintaining comparable model quality to GPU-based baselines. Com- plementing this, a study [25] details NeuronX Distributed Training (NxDT), quantifies scaling and efficiency against contemporary GPU baselines, and elucidates runtime and compiler support critical for stable large-cluster operation.
While most existing work leverages Trainium primarily for large-scale pretraining, very few studies investigate its use for inference. Inference workloads on Trainium often involve substantial data movement between off-chip and on-chip memory, which can become a significant perfor- mance bottleneck. This motivates our work, which focuses on mitigating these data movement costs to unlock the full inference potential of Trainium.
7. Conclusions
We present NeuronMM, a high-performance matmul for LLM inference on Trainium. NeuronMM is a combination ofSVD compression and architecture-specific optimization for high performance. NeuronMM can serve as a foundation for many AI inference workloads and maximize the perfor- mance benefit of Trainium. Our evaluation demonstrates that NeuronMM consistently accelerates LLM inference across nine datasets and four recent LLMs, achieving an average 1.35× speedup (up to 2.22×) at the matmul kernel level and an average 1.66× speedup (up to 2.49×) for end-to-end LLM inference.
References
- Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In The Twelfth International Conference on Learning Representations, 2024.
- Amazon Web Services. Aws trainium, 2023. Accessed: 2025-09-23.
- Amazon Web Services. Aws neuron introduces neuron kernel interface (nki), nxd training, and jax support for training, 2024. Accessed: 2025- 09-23.
- Saleh Ashkboos, Maximilian L. Croci, Marcelo Gennari do Nascimento, Torsten Hoefler, and James Hensman. SliceGPT: Compress large lan- guage models by deleting rows and columns. In The Twelfth Interna- tional Conference on Learning Representations, 2024.
- AWS Neuron SDK Documentation. NKI Matrix multiplication, 2025. Accessed: 2025-09-13.
- AWS Neuron SDK Documentation. Trainium and Inferentia2 Architec- ture, 2025. Accessed: 2025-07-28.
- Yueyin Bai, Hao Zhou, Keqing Zhao, Jianli Chen, Jun Yu, and Kun Wang. Transformer-opu: An fpga-based overlay processor for trans- former networks. In 2023 IEEE 31st Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), pages 221–221. IEEE, 2023.
- Steven Bart, Zepeng Wu, YE Rachmad, Yuze Hao, Lan Duo, and X. Zhang. Frontier ai safety confidence evaluate. Cambridge Open Engage, 2025.
- Jiang Bian, Helai Huang, Qianyuan Yu, and Rui Zhou. Search-to- crash: Generating safety-critical scenarios from in-depth crash data for testing autonomous vehicles. Energy, page 137174, 2025.
- Yahav Biran and Imry Kissos. Adaptive orchestration for large-scale inference on heterogeneous accelerator systems balancing cost, per- formance, and resilience, 2025.
- Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Pro- ceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
- Jie Chen, Ziyi Li, Lu Li, Jialing Wang, Wenyan Qi, Chong-Yu Xu, and Jong-Suk Kim. Evaluation of multi-satellite precipitation datasets and their error propagation in hydrological modeling in a monsoon-prone region. Remote Sensing, 12(21):3550, 2020.
- Zeming Chen, Qiyue Gao, Antoine Bosselut, Ashish Sabharwal, and Kyle Richardson. Disco: Distilling counterfactuals with large language models. arXiv, 2022; arXiv:2212.10534.
- Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sab- harwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv, 2018; arXiv:1803.05457.
- Joel Coburn, Chunqiang Tang, Sameer Abu Asal, Neeraj Agrawal, Raviteja Chinta, Harish Dixit, Brian Dodds, Saritha Dwarakapuram, Amin Firoozshahian, Cao Gao, et al. Meta’s second generation ai chip: Model-chip co-design and productionization experiences. In Proceedings of the 52nd Annual International Symposium on Computer Architecture, pages 1689–1702, 2025.
- James W Demmel. Applied numerical linear algebra. SIAM, 1997.
- Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in neural information processing systems, 35:30318–30332, 2022.
- Tim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettlemoyer. 8-bit optimizers via block-wise quantization. arXiv, 2021; arXiv:2110.02861.
- Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms, 2023.
- Xuan Ding, Rui Sun, Yunjian Zhang, Xiu Yan, Yueqi Zhou, Kaihao Huang, Suzhong Fu, Chuanlong Xie, and Yao Zhu. Dipsvd: Dual- importance protected svd for efficient llm compression. arXiv, 2025; arXiv:2506.20353.
- Haozheng Fan, Hao Zhou, Guangtai Huang, Parameswaran Raman, Xinwei Fu, Gaurav Gupta, Dhananjay Ram, Yida Wang, and Jun Huan. Hlat: High-quality large language model pre-trained on aws trainium. In 2024 IEEE International Conference on Big Data (BigData), pages 2100–2109. IEEE, 2024.
- Amin Firoozshahian, Joel Coburn, Roman Levenstein, Rakesh Nat- toji, Ashwin Kamath, Olivia Wu, Gurdeepak Grewal, Harish Aepala, Bhasker Jakka, Bob Dreyer, et al. Mtia: First generation silicon target- ing meta’s recommendation systems. In Proceedings of the 50th Annual International Symposium on Computer Architecture, pages 1–13, 2023.
- Elias Frantar and Dan Alistarh. Sparsegpt: Massive language models can be accurately pruned in one-shot. In International conference on machine learning, pages 10323–10337. PMLR, 2023.
- Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Optq: Accurate quantization for generative pre-trained transformers. In International Conference on Learning Representations, 2023.
- Xinwei Fu, Zhen Zhang, Haozheng Fan, Guangtai Huang, Moham- mad El-Shabani, Randy Huang, Rahul Solanki, Fei Wu, Ron Diamant, and Yida Wang. Distributed training of large language models on aws trainium. In Proceedings of the 2024 ACM Symposium on Cloud Computing, pages 961–976, 2024.
- Song Guo, Jiahang Xu, Li Lyna Zhang, and Mao Yang. Compresso: Structured pruning with collaborative prompting learns compact large language models, 2023.
- Yuze Hao. Comment on’predictions of groundwater pfas occurrence at drinking water supply depths in the united states’ by andrea k. tokranov et al., science 386, 748-755 (2024). Science, 386:748–755, 2024.
- Yuze Hao. Accelerated photocatalytic c–c coupling via interpretable deep learning: Single-crystal perovskite catalyst design using first- principles calculations. In AI for Accelerated Materials Design-ICLR 2025, 2025.
- Yuze Hao, Lan Duo, and Jinlu He. Autonomous materials synthesis laboratories: Integrating artificial intelligence with advanced robotics for accelerated discovery. ChemRxiv, 2025.
- Yuze Hao and Yueqi Wang. Quasi liquid layer-pressure asymmetrical model for the motion of of a curling rock on ice surface. arXiv, 2023; arXiv:2302.11348.
- Yuze Hao and Yueqi Wang. Unveiling anomalous curling stone tra- jectories: A multi-modal deep learning approach to friction dynamics and the quasi-liquid layer, 2025.
- Yuze Hao, X Yan, Lan Duo, H Hu, and J He. Diffusion models for 3d molecular and crystal structure generation: Advancing materials discovery through equivariance, multi-property design, and synthe- sizability. 2025.
- Shwai He, Guoheng Sun, Zheyu Shen, and Ang Li. What mat- ters in transformers? not all attention is needed. arXiv, 2024; arXiv:2406.15786.
- Lu Hou, Zhiqi Huang, Lifeng Shang, XinJiang, Xiao Chen, and Qun Liu. Dynabert: dynamic bert with adaptive width and depth. NIPS ’20, Red Hook, NY, USA, 2020. Curran Associates Inc.
- Yen-Chang Hsu, Ting Hua, Sungen Chang, Qian Lou, Yilin Shen, and Hongxia Jin. Language model compression with weighted low-rank factorization. arXiv, 2022; arXiv:2207.00112.
- Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adap- tation of large language models. ICLR, 1(2):3, 2022.
- Xinyue Huang, Ziqi Lin, Fang Sun, Wenchao Zhang, Kejian Tong, and Yunbo Liu. Enhancing document-level question answering via multi-hop retrieval-augmented generation with llama 3, 2025.
- Xinyue Huang, Chen Zhao, Xiang Li, Chengwei Feng, and Wuyang Zhang. Gam-cot transformer: Hierarchical attention networks for anomaly detection in blockchain transactions. INNO-PRESS: Journal of Emerging Applied AI, 1(3), 2025.
- Yuhao Ji, Chao Fang, and Zhongfeng Wang. Beta: Binarized energy- efficient transformer accelerator at the edge. In 2024 IEEE International Symposium on Circuits and Systems (ISCAS), pages 1–5. IEEE, 2024.
- XinyuJia, Weinan Hou, Shi-Ze Cao, Wang-Ji Yan, and Costas Papadim- itriou. Analytical hierarchical bayesian modeling framework for model updating and uncertainty propagation utilizing frequency response function data. Computer Methods in Applied Mechanics and Engineering, 447:118341, 2025.
- Xinyu Jia and Costas Papadimitriou. Data features-based bayesian learning for time-domain model updating and robust predictions in structural dynamics. Mechanical Systems and Signal Processing, 224:112197, 2025.
- XinyuJia, Omid Sedehi, Costas Papadimitriou, Lambros S Katafygiotis, and Babak Moaveni. Nonlinear model updating through a hierar- chical bayesian modeling framework. Computer Methods in Applied Mechanics and Engineering, 392:114646, 2022.
- Norm Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian Towles, et al. Tpu v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings. In Proceedings of the 50th annual international symposium on computer architecture, pages 1–14, 2023.
- Norman PJouppi, Doe Hyun Yoon, George Kurian, Sheng Li, Nishant Patil, James Laudon, Cliff Young, and David Patterson. A domain- specific supercomputer for training deep neural networks. Communi- cations of the ACM, 63(7):67–78, 2020.
- Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, and Yejin Choi. Symbolic chain-of-thought distillation: Small models can also" think" step-by-step. arXiv, 2023; arXiv:2306.14050.
- Zhiteng Li, Mingyuan Xia, Jingyuan Zhang, Zheng Hui, Linghe Kong, Yulun Zhang, and Xiaokang Yang. Adasvd: Adaptive singular value de- composition for large language models. arXiv, 2025; arXiv:2502.01403.
- Ziyi Li, Kaiyu Guan, Wang Zhou, Bin Peng, Zhenong Jin, Jinyun Tang, Robert F Grant, Emerson D Nafziger, Andrew J Margenot, Lowell E Gentry, et al. Assessing the impacts of pre-growing-season weather conditions on soil nitrogen dynamics and corn productivity in the us midwest. Field Crops Research, 284:108563, 2022.
- Ziyi Li, Kaiyu Guan, Wang Zhou, Bin Peng, Emerson D Nafziger, Robert F Grant, Zhenong Jin, Jinyun Tang, Andrew J Margenot, DoKy- oungLee, et al. Comparing continuous-corn and soybean-corn rotation cropping systems in the us central midwest: Trade-offs among crop yield, nutrient losses, and change in soil organic carbon. Agriculture, Ecosystems & Environment, 393:109739, 2025.
- Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv, 2024; arXiv:2412.19437.
- Shiwei Liu, Chen Mu, Hao Jiang, Yunzhengmao Wang, Jinshan Zhang, Feng Lin, Keji Zhou, Qi Liu, and Chixiao Chen. Hardsea: Hybrid analog- reram clustering and digital-sram in-memory computing accelerator for dynamic sparse self-attention in transformer. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 32(2):269–282, 2023.
- Xichang Liu, Helai Huang, Jiang Bian, Rui Zhou, Zhiyuan Wei, and Hanchu Zhou. Generating intersection pre-crash trajectories for au- tonomous driving safety testing using transformer time-series gen- erative adversarial networks. Engineering Applications of Artificial Intelligence, 160:111995, 2025.
- Xinyin Ma, Gongfan Fang, and Xinchao Wang. Llm-pruner: On the structural pruning of large language models, 2023.
- MaryAnn Marcinkiewicz. Building a large annotated corpus of english: The penn treebank. Using Large Corpora, 273:31, 1994.
- Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv, 2016; arXiv:1609.07843.
- Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv, 2018; arXiv:1809.02789.
- Roy Miles, Adrian Lopez Rodriguez, and Krystian Mikolajczyk. Infor- mation theoretic representation distillation, 2022.
- AWS Neuron. neuronx-distributed-inference, 2025. Accessed: 2025- 09-24.
- Neuron Kernel Interface. Neuron kernel interface. https://awsdocs- neuron.readthedocs-hosted.com/en/latest/general/nki/index.html, 2025. Accessed: August 1, 2025.
- Neuron Kernel Interface. Neuron kernel interface mm. https://awsdocs-neuron.readthedocs-hosted.com/en/latest/general/ nki/tutorials/matrix_multiplication.html, 2025. Accessed: August 1, 2025.
- Jiaming Pei, Jinhai Li, Zhenyu Song, Maryam Mohamed Al Dabel, Mohammed JF Alenazi, Sun Zhang, and Ali Kashif Bashir. Neuro-vae- symbolic dynamic traffic management. IEEE Transactions on Intelligent Transportation Systems, 2025.
- Jiaming Pei, Wenxuan Liu, Jinhai Li, Lukun Wang, and Chao Liu. A review of federated learning methods in heterogeneous scenarios. IEEE Transactions on Consumer Electronics, 70(3):5983–5999, 2024.
- Jiaming Pei, Marwan Omar, Maryam Mohamed AlDabel, Shahid Mum- taz, and Wei Liu. Federated few-shot learning with intelligent trans- portation cross-regional adaptation. IEEE Transactions on Intelligent Transportation Systems, 2025.
- Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020.
- Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- Victor Sanh, Thomas Wolf, and Alexander Rush. Movement pruning: Adaptive sparsity by fine-tuning. Advances in neural information processing systems, 33:20378–20389, 2020.
- Shikhar Tuli and Niraj K Jha. Acceltran: A sparsity-aware accelera- tor for dynamic inference with transformers. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 42(11):4038– 4051, 2023.
- Georgios Tzanos, Christoforos Kachris, and Dimitrios Soudris. Hard- ware acceleration of transformer networks using fpgas. In 2022 Panhel- lenic Conference on Electronics & Telecommunications (PACET), pages 1–5. IEEE, 2022.
- Zhongwei Wan, Xin Wang, Che Liu, Samiul Alam, Yu Zheng, Jiachen Liu, Zhongnan Qu, Shen Yan, Yi Zhu, Quanlu Zhang, et al. Efficient large language models: A survey. arXiv, 2023; arXiv:2312.03863.
- Lukun Wang, Xiaoqing Xu, and Jiaming Pei. Communication-efficient federated learning via dynamic sparsity: An adaptive pruning ratio based on weight importance. IEEE Transactions on Cognitive Commu- nications and Networking, 2025.
- Qinsi Wang, Jinghan Ke, Masayoshi Tomizuka, Yiran Chen, Kurt Keutzer, and Chenfeng Xu. Dobi-svd: Differentiable svd for llm com- pression and some new perspectives. arXiv, 2025; arXiv:2502.02723.
- Xin Wang, Samiul Alam, Zhongwei Wan, Hui Shen, and Mi Zhang. Svd-llm v2: Optimizing singular value truncation for large language model compression. arXiv, 2025; arXiv:2503.12340.
- Xin Wang, Yu Zheng, Zhongwei Wan, and Mi Zhang. SVD-LLM: Truncation-aware singular value decomposition for large language model compression. In The Thirteenth International Conference on Learning Representations, 2025.
- Samuel Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architectures. Communications of the ACM, 52(4):65–76, 2009.
- Xiaoxia Wu, Cheng Li, Reza Yazdani Aminabadi, Zhewei Yao, and Yuxiong He. Understanding int4 quantization for transformer models: Latency speedup, composability, and failure cases, 2023.
- ShuoXu, Yuchen ***, Zhongyan Wang, andYexin Tian. Fraud detection in online transactions: Toward hybrid supervised–unsupervised learn- ing pipelines. In Proceedings of the 2025 6th International Conference on Electronic Communication and Artificial Intelligence (ICECAI 2025), Chengdu, China, pages 20–22, 2025.
- Tengfei Xue, Xuefeng Li, Roman Smirnov, Tahir Azim, Arash Sadrieh, and Babak Pahlavan. Ninjallm: Fast, scalable and cost-effective rag using amazon sagemaker and aws trainium and inferentia2, 2024.
- Yahma. Alpaca cleaned dataset. https://huggingface.co/datasets/ yahma/alpaca-cleaned, 2023. Accessed: 2025-07-28.
- An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv, 2025; arXiv:2505.09388.
- Shuo Yang, Sujay Sanghavi, Holakou Rahmanian,Jan Bakus, and S. V. N. Vishwanathan. Toward understanding privileged features distillation in learning-to-rank, 2022.
- Zhihang Yuan, Yuzhang Shang, Yue Song, Qiang Wu, Yan Yan, and Guangyu Sun. Asvd: Activation-aware singular value decom- position for compressing large language models. arXiv preprint arXiv:2312.05821, 2023.
- Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- Minjia Zhang and Yuxiong He. Accelerating training of transformer- based language models with progressive layer dropping. Advances in neural information processing systems, 33:14011–14023, 2020.
- Kaiyang Zhong, Yifan Wang, Jiaming Pei, Shimeng Tang, and Zonglin Han. Super efficiency sbm-dea and neural network for performance evaluation. Information Processing & Management, 58(6):102728, 2021.
- Rui Zhou, Weihua Gui, Helai Huang, Xichang Liu, Zhiyuan Wei, and Jiang Bian. Diffcrash: Leveraging denoising diffusion probabilistic models to expand high-risk testing scenarios using in-depth crash data. Expert Systems with Applications, page 128140, 2025.
- Rui Zhou, Helai Huang, Guoqing Zhang, Hanchu Zhou, and Jiang Bian. Crash-based safety testing of autonomous vehicles: Insights from generating safety-critical scenarios based on in-depth crash data. IEEE Transactions on Intelligent Transportation Systems, 2025.
- Rui Zhou, Guoqing Zhang, Helai Huang, Zhiyuan Wei, Hanchu Zhou, Jieling Jin, Fangrong Chang, and Jiguang Chen. How would au- tonomous vehicles behave in real-world crash scenarios? Accident Analysis & Prevention, 202:107572, 2024.
- Xunyu Zhu, Jian Li, Yong Liu, Can Ma, and Weiping Wang. A survey on model compression for large language models. Transactions of the Association for Computational Linguistics, 12:1556–1577, 2024.
- J Zhuang, G Li, H Xu, J Xu, and R Tian. Text-to-city controllable 3d urban block generation with latent diffusion model. In Proceedings of the 29th International Conference of the Association for Computer-Aided Architectural Design Research in Asia (CAADRIA), Singapore, pages 20–26, 2024.
Figure 1.
NeuronCore memory hierarchy on Trainium with bandwidth and memory size.
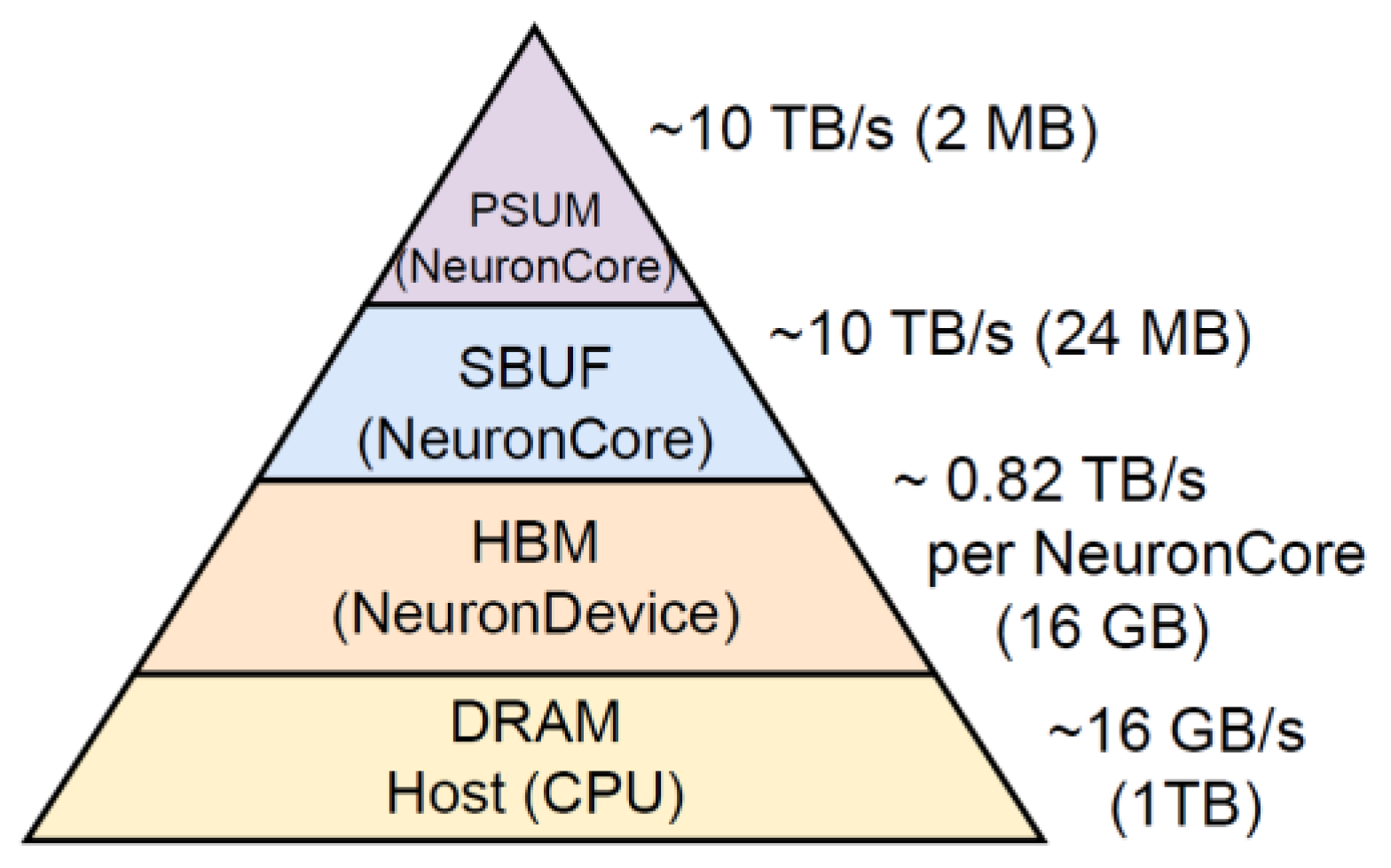
Figure 2.
Matmul tiling on Trainium (mathematical view).
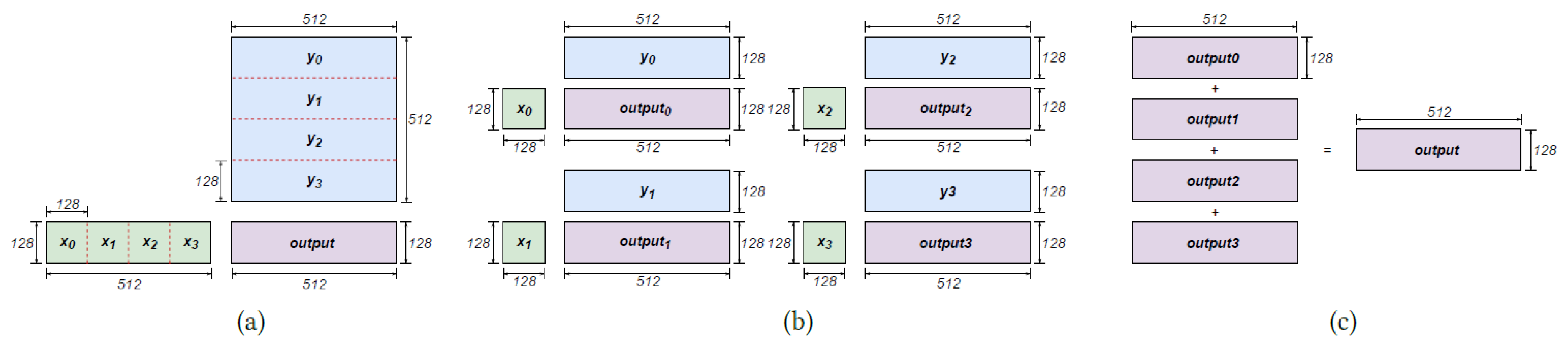
Figure 3.
Matmul tiling on Trainium (hardware view).

Figure 4.
The Neuron Profiler view of up_projection mat- mul in Deepseek-V3 with SVD-compression. Directly com- puting on the SVD-compressed weight matrices sequentially leads to low SBUF and PSUM utilization and reduced Model Float Utilization (MFU). Frequent idle periods in the MFU indicate that the tensor engine is underutilized while waiting for data transfers and data preparation to complete.
Figure 4.
The Neuron Profiler view of up_projection mat- mul in Deepseek-V3 with SVD-compression. Directly com- puting on the SVD-compressed weight matrices sequentially leads to low SBUF and PSUM utilization and reduced Model Float Utilization (MFU). Frequent idle periods in the MFU indicate that the tensor engine is underutilized while waiting for data transfers and data preparation to complete.
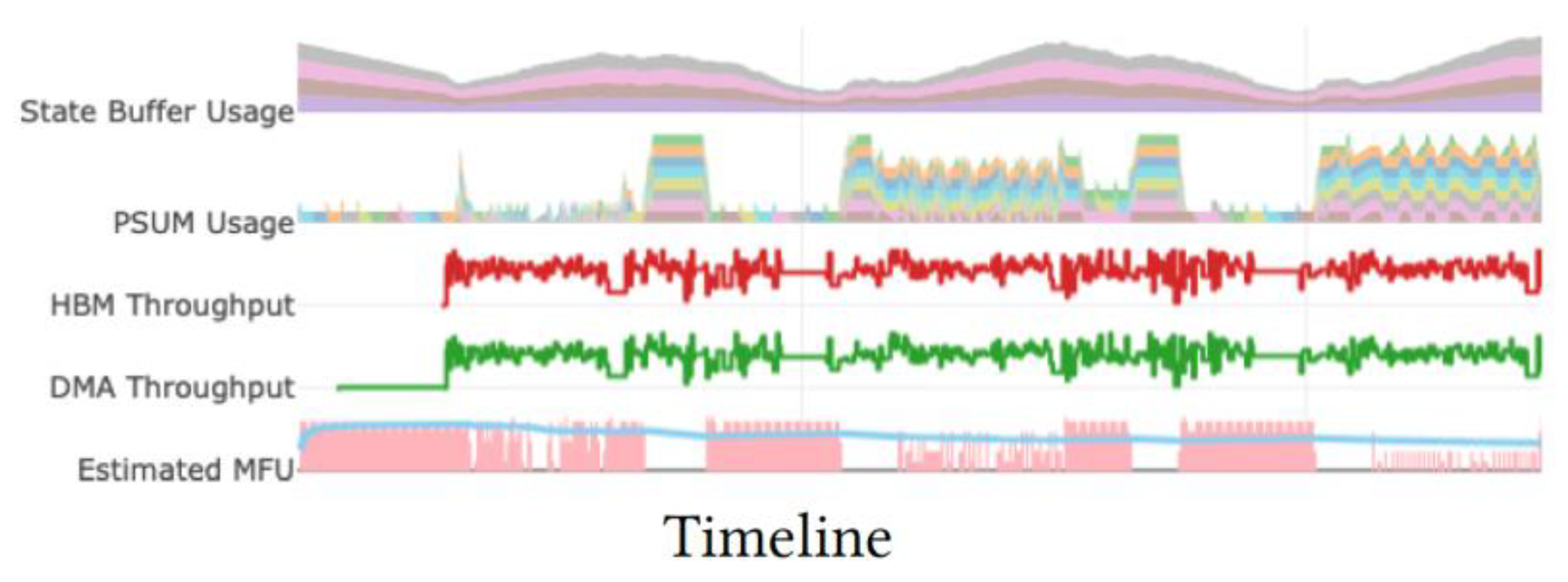
Figure 5.
The overview of NeuronMM. (a) Block-aligned SVD. The weight parameters of the attention layers remain unchanged, while only the large matrices W in the MLP layers are compressed using SVD. (b) TrainiumFusion. The weight W is decomposed into u and v, and the original matmul XW turns into Xuv. The kernel leverages caching, implicit transposition, and blocking to enable efficient matmul, thereby reducing data movement between off-chip HBM and on-chip SRAM (SBUF and PSUM).
Figure 5.
The overview of NeuronMM. (a) Block-aligned SVD. The weight parameters of the attention layers remain unchanged, while only the large matrices W in the MLP layers are compressed using SVD. (b) TrainiumFusion. The weight W is decomposed into u and v, and the original matmul XW turns into Xuv. The kernel leverages caching, implicit transposition, and blocking to enable efficient matmul, thereby reducing data movement between off-chip HBM and on-chip SRAM (SBUF and PSUM).
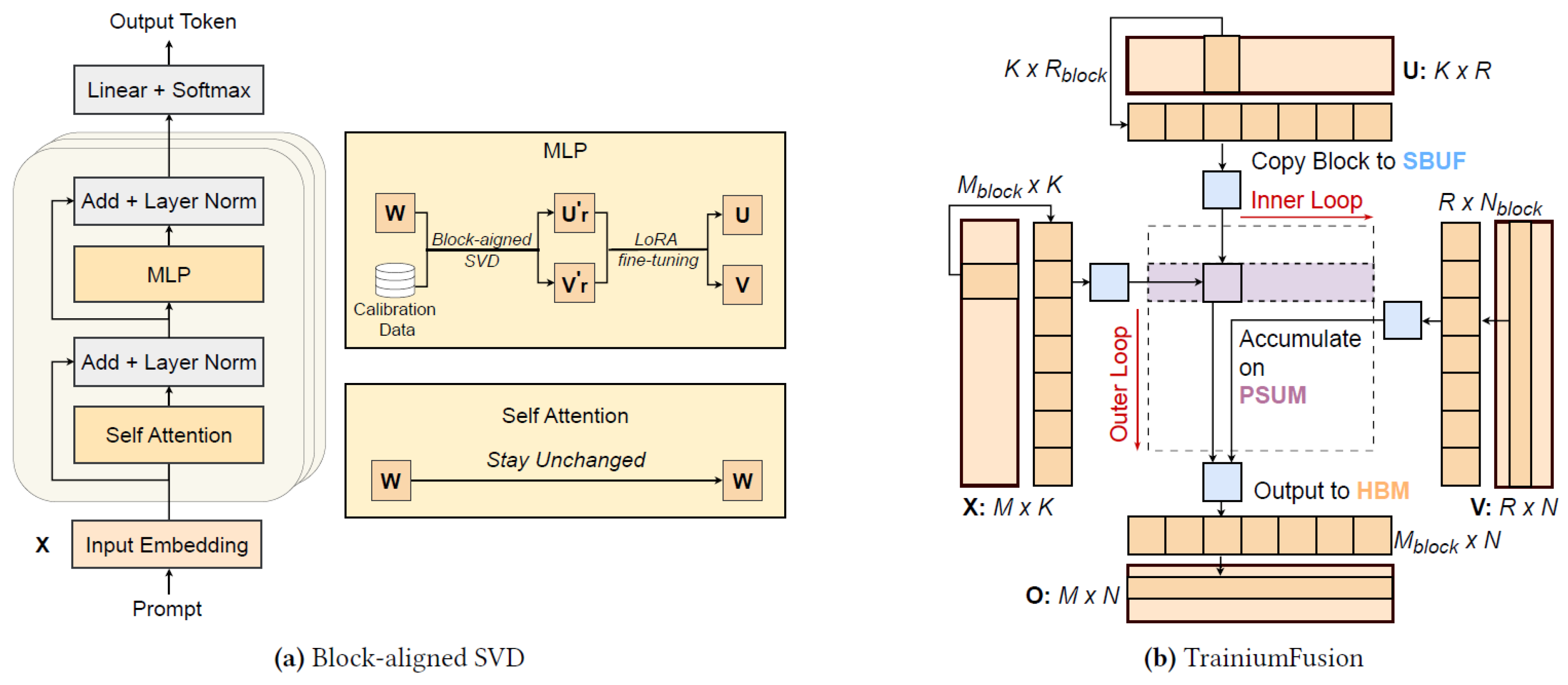
Figure 6.
Execution time and HBM-SBUF memory traffic of different matmul implementations across input sequence lengths.
Figure 6.
Execution time and HBM-SBUF memory traffic of different matmul implementations across input sequence lengths.
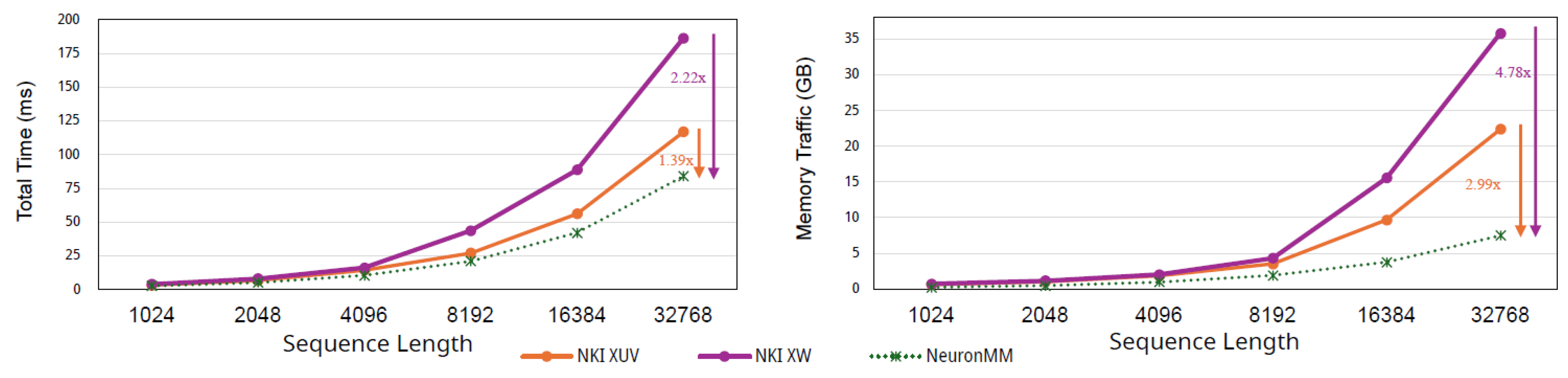
Table 1.
Evaluation of the sequential matmul and naïve kernel fusion for matmul.
| Metric | Sequential Matmul | Naive Kernel fusion |
|---|---|---|
| Total Time (ms) | 1.57 | 18.06 |
| Model FLOPs (GFLOPs) | 85.90 | 343.60 |
| Memory Footprint (MB) | 298.66 | 3140.42 |
Table 2.
Notations.
| Notation | Description |
|---|---|
| Matrix Operations & Dimensions | |
| W ≈ UV X ∈ RM ×k U ∈ Rk ×r , V ∈ Rr ×N M K, N r |
The weight matrix W is approximated by the product of two low-rank matrices. The input activation matrix. The low-rank matrices from SVD. The input sequence length. The hidden size and intermediate size in MLP layer of LLMs. The rank of the SVD-decomposed matrices. |
| Data Layout Hierarchy | |
| BM, Bk, Br, BN TM, TN Aij Ai∗ A ∗j |
The sizes of a block along dimensions. The sizes of a tile along dimensions. The block at the i-th row and j-th column of matrix A. The row strip composed of all blocks in the i-th row of matrix A. The column strip composed of all blocks in the j-th column of matrix A. |
Table 3.
Average performance across the sequence lengths 1K to 32K. The best performance is shown in bold, and the second best is shown underlined.
Table 3.
Average performance across the sequence lengths 1K to 32K. The best performance is shown in bold, and the second best is shown underlined.
| NKI XW | NKI XUV | NeuronMM | |
|---|---|---|---|
| Latency (ms) | 57.89 | 37.47 | 27.63 |
| Memory Traffic (GB) | 9.93 | 6.52 | 2.47 |
| Tensor Engine Active Time (%) | 78.52 | 81.28 | 99.21 |
| MFU (%) | 64.09 | 65.24 | 85.20 |
| FLOPs (TFLOPS) | 2.96 | 2.18 | 2.18 |
| Transpose FLOPs (GFLOPS) | 68.01 | 78.92 | 22.55 |
Table 4.
Performance under different block size BM .
| BM | 128 | 256 | 512 | 1024 | 2048 | 4096 |
|---|---|---|---|---|---|---|
| Total Time (ms) | 31.25 | 16.02 | 11.02 | 10.99 | 11.07 | 12.50 |
| Arithmetic Intensity (flops/byte) | 124.12 | 240.94 | 455.10 | 819.17 | 1280.50 | 512.95 |
| SBUF Usage (%) | 19.54 | 51.69 | 80.07 | 90.05 | 96.35 | 98.96 |
| Spill Reload (MB) | 0 | 0 | 0 | 0 | 29.19 | 931.00 |
| Spill Save (MB) | 0 | 0 | 0 | 0 | 10.53 | 266.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



