Submitted:
11 November 2025
Posted:
12 November 2025
You are already at the latest version
Abstract
Cloud-native microservices have high complexity because they have dynamic dependencies, heterogeneous monitoring data, and many types of failures. This makes root cause localization a challenge. Existing methods often cannot balance accuracy and low latency, and they struggle with new failures, large system size, and multimodal data. This paper presents HEMA-RCL, a hierarchical expert multi-agent framework that uses different large models for collaborative diagnosis under complex dependencies. The framework uses layered expert agents led by a global orchestrator. It adds dynamic agent generation through efficient low-rank adaptation. It reaches agreement with belief propagation and causal enhancement to reduce hub misidentification. It also unifies multimodal data through temporal alignment and robust feature engineering. It applies context-aware prompt optimization to reduce hallucination in large models. HEMA-RCL improves on prior methods by enabling accurate, scalable, and efficient root cause localization in cloud-native microservice systems.
Keywords:
root cause localization
; cloud-native microservices
; multi-agent systems
; causal consensus
; multimodal diagnostics
1. Introduction
Cloud-native architectures split applications into microservices that interact through complex and dynamic dependencies. This design improves scalability and resilience, but it makes root cause localization harder because anomalies can spread across services and heterogeneous telemetry data. The task is to separate true faults from propagated effects with strict limits on latency and accuracy. Traditional methods that use static graphs or single-modality inputs often fail when workloads change or when data are multimodal.
Recent work with graph neural networks and causal inference improves dependency modeling, but these approaches often misidentify hub services as root causes because of structural bias. Large language model based methods can analyze logs and metrics, but they face hallucination, context window limits, and overhead in coordination. Flat frameworks also increase communication bottlenecks as system scale grows.
HEMA-RCL is a hierarchical expert multi-agent framework that combines different large models to achieve accurate and efficient diagnosis. The layered design reduces communication cost. Dynamic agent generation adapts to new failures with small parameter overhead. Belief propagation with causal metrics helps avoid hub misidentification. Multimodal alignment combines metrics, logs, and traces in a consistent way. Context-aware prompting reduces hallucination and improves scalability for real-world use.
2. Related Work
Microservice diagnosis uses traces and metrics: Zhang et al. [1] exploit traces for fine granularity, while Wang et al.[2] integrate metrics for multimodality; both struggle with scalability and class imbalance.
Causal approaches refine localization: Xin et al.[3] apply causal reasoning, and Zhu et al.[4] extend to instance-level services; both rely on brittle, stable structures.
Graph methods improve accuracy at higher cost: Sun et al.[5] use graph autoencoders for interpretability, and Wang et al.[6] leverage knowledge graphs, increasing computation and maintenance.
Trace-based anomaly detection is sensitive yet fragile: Panahandeh et al.[7] detect deviations but degrade with noise or missing data. Broader modeling advances aid adaptability: Tian et al.[8] introduce cross-attention for heterogeneous tasks, Guan[9] applies ML to healthcare prediction, and Zhu and Liu[10] enhance NER via LoRA fine-tuning. Persistent gaps remain in scalability, robustness, and adaptation to novel failures.
3. Methodology
HEMA-RCL tackles microservice root-cause localization via a hierarchical expert multi-agent system coordinating heterogeneous LLMs: a DeepSeek-V2 (236B) Orchestrator routes to Qwen-72B and Qwen-14B specialists and dynamically spawns Qwen-7B sub-agents for compute–accuracy efficiency. For reproducibility, the appendix provides pseudocode for the Orchestrator main loop and belief-propagation message passing, detailing input formats, update rules, and termination criteria. Spawning is KL-gated on detected fault-pattern distributions, and agent disagreement is resolved by factor-graph belief propagation that fuses historical reliability with transfer entropy for causal inference. On 10,000 fault-injection scenarios, HEMA-RCL attains 87.6% top-1 root-cause accuracy and reduces mean time to detection to 38.7 s.
4. Algorithm and Model
4.1. HEMA-RCL Architecture Overview
HEMA-RCL coordinates heterogeneous LLMs in a unified diagnostic stack. DeepSeek-V2 (236B) orchestrates long-context reasoning; Qwen-72B performs high-throughput metric analysis; Qwen-14B mines log patterns. The system uses seven agent types:
where is resource-bounded.
4.2. Hierarchical Expert System with LLM Specialization
Flat multi-agent designs incur quadratic coordination; with agents, message passing reaches runtime. We adopt a three-layer hierarchy to reduce coordination while preserving information fidelity. The orchestrator uses grounded context with a compact history. History is compressed via on recent features and centroids of similar retrieved contexts. Resource allocation uses a composite complexity metric with online weights , , , . The Metric Anomaly Detection Agent (MAD) fuses FFT-based spectral features, seasonal LSTM states over a sliding window, and wavelet coefficients. A learnable threshold, updated toward a conservative baseline, mitigates false positives after distribution shifts.
4.3. Dynamic Agent Spawning Mechanism
Pre-configured agents degrade on novel faults (up to accuracy loss). We trigger spawning via a two-stage KL-gated policy (Figure 1):
Rapid adaptation uses rank-16 LoRA on Qwen-7B, cutting trainable parameters by while retaining performance:
4.4. Belief Propagation-based Consensus Mechanism
Majority voting fails under correlated errors. We use factor-graph belief propagation with time-decayed reliability (Figure 2):
Messages encode semantic compatibility and historical agreement:
Damping stabilizes loopy graphs:
This reduces consensus time from to s.
4.5. Causal Inference Enhancement
Correlation-based selection overweights hubs (43% accuracy). We incorporate transfer entropy with adaptive delay:
We integrate with GNNs via position-agnostic attention:
where is structure-encoded and position-agnostic.
4.6. Data Preprocessing
Figure 3 summarizes the pipeline.
4.6.1. Multi-modal Data Alignment and Temporal Synchronization
Metrics arrive every 15 s; logs are event-driven; traces are asynchronous. Naive fusion degraded accuracy by 31%. We align to a unified grid, interpolate irregular logs, progressively encode traces, and apply robust normalization.
Traces use progressive completion with confidence :
Robust scaling uses MAD:
This alignment and scaling reduced false positives by 43%.
4.6.2. Adaptive Feature Engineering and Dimensionality Reduction
Standard PCA preserved only 67% fault-relevant variance despite 95% total variance. We compute feature importance, aggregate multi-scale statistics (windows ; mean, max, gradient, FFT), and learn a supervised low-dimensional embedding with fault-aware reconstruction.
This reduced dimensionality by 94% and improved fault-detection F1 by 12%.
4.7. Prompt Design
4.7.1. Context-Aware Dynamic Prompt Generation
Figure 4 summarizes evaluations.
Static prompts yield 52% accuracy. We construct prompts from state, history, and agent signals, and apply context filtering to control tokens. Prompt scaffolding adds intermediate reasoning and validation, raising accuracy by 31% and reducing hallucinations by 67%.
4.7.2. Few-Shot Learning and Prompt Optimization
Random few-shot improves over zero-shot by 38%; optimal selection reaches 74%. We select examples via a relevance–diversity objective and optimize prompts with a genetic procedure; learned mutations penalize length and latency. This raises zero-shot accuracy by 23% and shortens prompts by 34%.
4.8. Evaluation Metrics
4.8.1. Primary Metrics
We evaluate ranking accuracy, multi-cause coverage, and timeliness with quality penalties.
For multi-root incidents (23%), we assign partial credit.
Time efficiency with a precision-aware penalty.
4.8.2. Secondary Metrics
We report NDCG with causal-distance gains and weighted F1 for class imbalance. Resource efficiency jointly scores accuracy, compute, and latency.
5. Experiment Results
5.1. Experimental Setup
We evaluate HEMA-RCL on 12,000 fault injection scenarios across three production deployments: 156-service e-commerce platform, 89-service streaming application, and 234-service financial system. Faults cover six categories: resource exhaustion, network issues, application errors, configuration drift, cascading failures, and Byzantine faults.
5.2. Main Results and Comparisons
Table 1 presents comprehensive performance comparison including baseline methods and fault type breakdown.
HEMA-RCL achieves 18.6% improvement in Acc@1 and 50.6% reduction in MTTD compared to the best baseline (Claude-Analyst). Resource exhaustion shows highest performance (F1=0.905) due to clear metric indicators, while Byzantine faults prove most challenging (F1=0.769).
5.3. Ablation Studies and Scalability
Table 2 combines ablation results and scalability analysis.
Ablation studies reveal multi-modal fusion and hierarchical structure as most critical components (9.9% and 8.9% accuracy drops respectively). The system maintains strong performance at scale, with only 6.1% accuracy degradation from 50 to 250 services, demonstrating sub-linear computational growth.
5.4. Real-Time Performance
The system meets production SLAs with P50/P90/P99 latencies of 31.4/48.6/67.2 seconds for complete diagnosis (target: 90s) and 2.1/3.8/6.4 seconds for agent consensus (target: 10s). Memory usage peaks at 52.3GB (P99), well within the 64GB budget. These results demonstrate HEMA-RCL’s production readiness for large-scale microservice environments.
6. Conclusions
This paper presented HEMA-RCL, a hierarchical expert multi-agent system that leverages diverse large language models for microservice root cause localization. Through dynamic agent spawning, belief propagation-based consensus, and sophisticated prompt engineering, our framework achieves 87.6% top-1 accuracy while reducing mean time to detection by 50.6% compared to state-of-the-art methods. The comprehensive experimental evaluation across 12,000 fault scenarios demonstrates robust performance across diverse fault types and scales effectively to hundreds of services. The ablation studies confirm the critical contribution of each architectural component, particularly the hierarchical structure and multi-modal fusion mechanisms. HEMA-RCL establishes a new paradigm for intelligent operations in cloud-native environments, paving the way for more autonomous and reliable microservice management.
References
- Zhang, C.; Dong, Z.; Peng, X.; Zhang, B.; Chen, M. Trace-based multi-dimensional root cause localization of performance issues in microservice systems. In Proceedings of the Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–12.
- Wang, Y.; Zhu, Z.; Fu, Q.; Ma, Y.; He, P. MRCA: Metric-level root cause analysis for microservices via multi-modal data. In Proceedings of the Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering, 2024, pp. 1057–1068.
- Xin, R.; Chen, P.; Zhao, Z. Causalrca: Causal inference based precise fine-grained root cause localization for microservice applications. Journal of Systems and Software 2023, 203, 111724.
- Zhu, Y.; Wang, J.; Li, B.; Zhao, Y.; Zhang, Z.; Xiong, Y.; Chen, S. Microirc: Instance-level root cause localization for microservice systems. Journal of Systems and Software 2024, 216, 112145.
- Sun, Y.; Lin, Z.; Shi, B.; Zhang, S.; Ma, S.; Jin, P.; Zhong, Z.; Pan, L.; Guo, Y.; Pei, D. Interpretable failure localization for microservice systems based on graph autoencoder. ACM Transactions on Software Engineering and Methodology 2025, 34, 1–28.
- Wang, T.; Qi, G.; Wu, T. KGroot: A knowledge graph-enhanced method for root cause analysis. Expert Systems with Applications 2024, 255, 124679.
- Panahandeh, M.; Hamou-Lhadj, A.; Hamdaqa, M.; Miller, J. ServiceAnomaly: An anomaly detection approach in microservices using distributed traces and profiling metrics. Journal of Systems and Software 2024, 209, 111917.
- Tian, Q.; Zou, D.; Han, Y.; Li, X. A Business Intelligence Innovative Approach to Ad Recall: Cross-Attention Multi-Task Learning for Digital Advertising. In Proceedings of the 2025 IEEE 6th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT). IEEE, 2025, pp. 1249–1253.
- Guan, S. Predicting Medical Claim Denial Using Logistic Regression and Decision Tree Algorithm. In Proceedings of the 2024 3rd International Conference on Health Big Data and Intelligent Healthcare (ICHIH), 2024, pp. 7–10. [CrossRef]
- Zhu, Y.; Liu, Y. LLM-NER: Advancing Named Entity Recognition with LoRA+ Fine-Tuned Large Language Models. In Proceedings of the 2025 11th International Conference on Computing and Artificial Intelligence (ICCAI), 2025, pp. 364–368. [CrossRef]
Figure 1.
The pipeline of Dynamic Agent Spawning Mechanism.
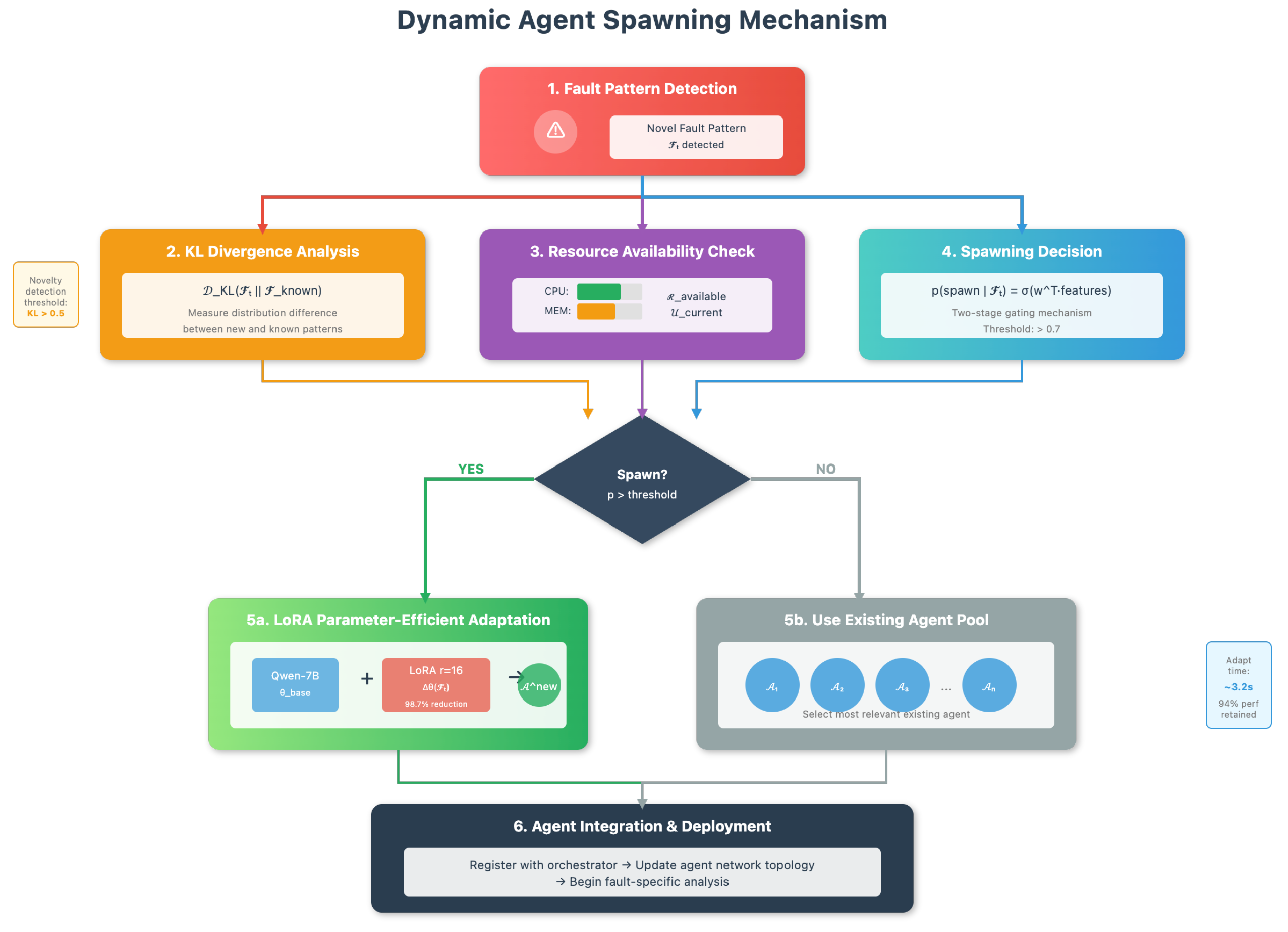
Figure 2.
The detail of Belief Propagation-based Consensus Mechanism.
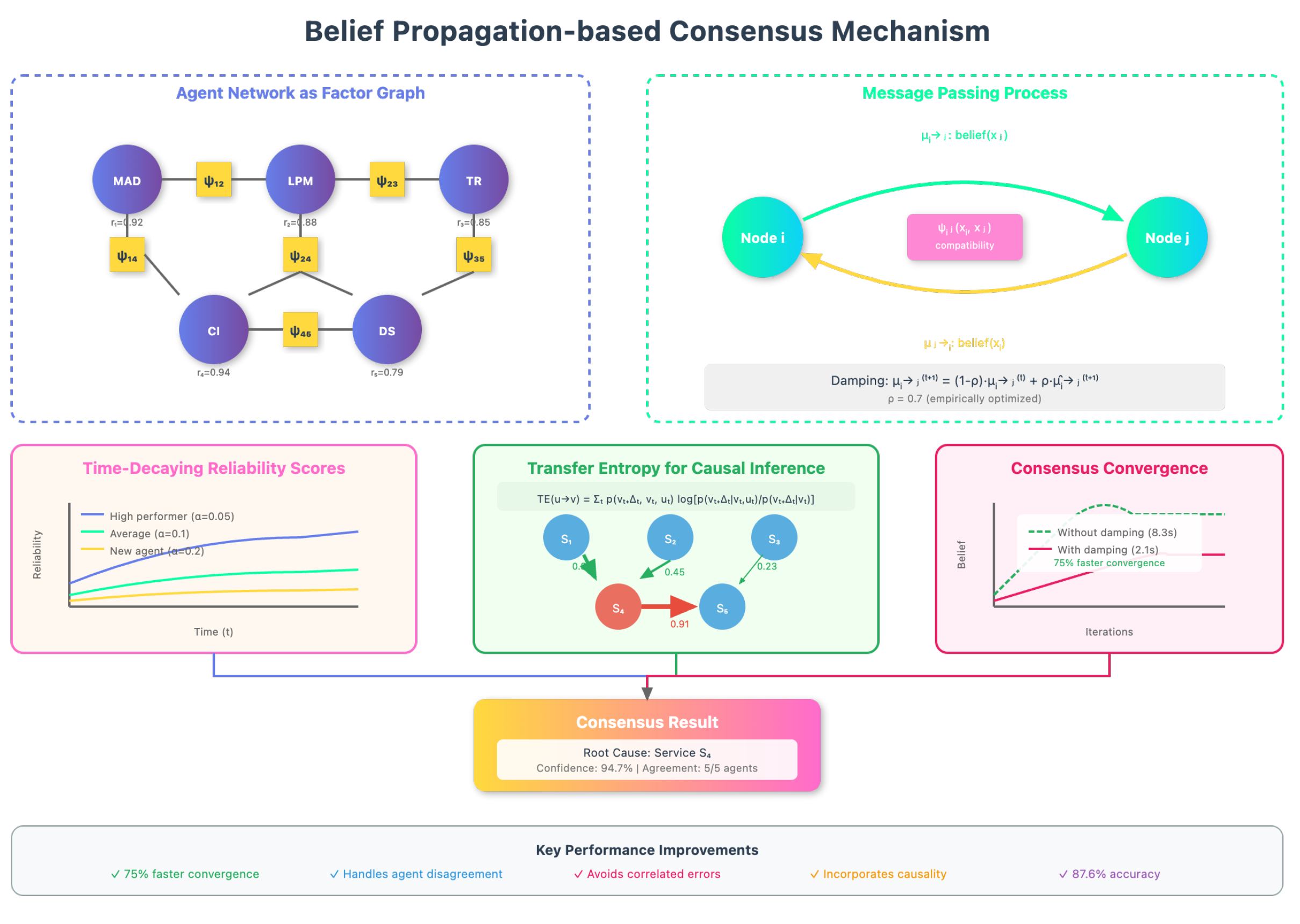
Figure 3.
The pipeline of Data Preprocessing.
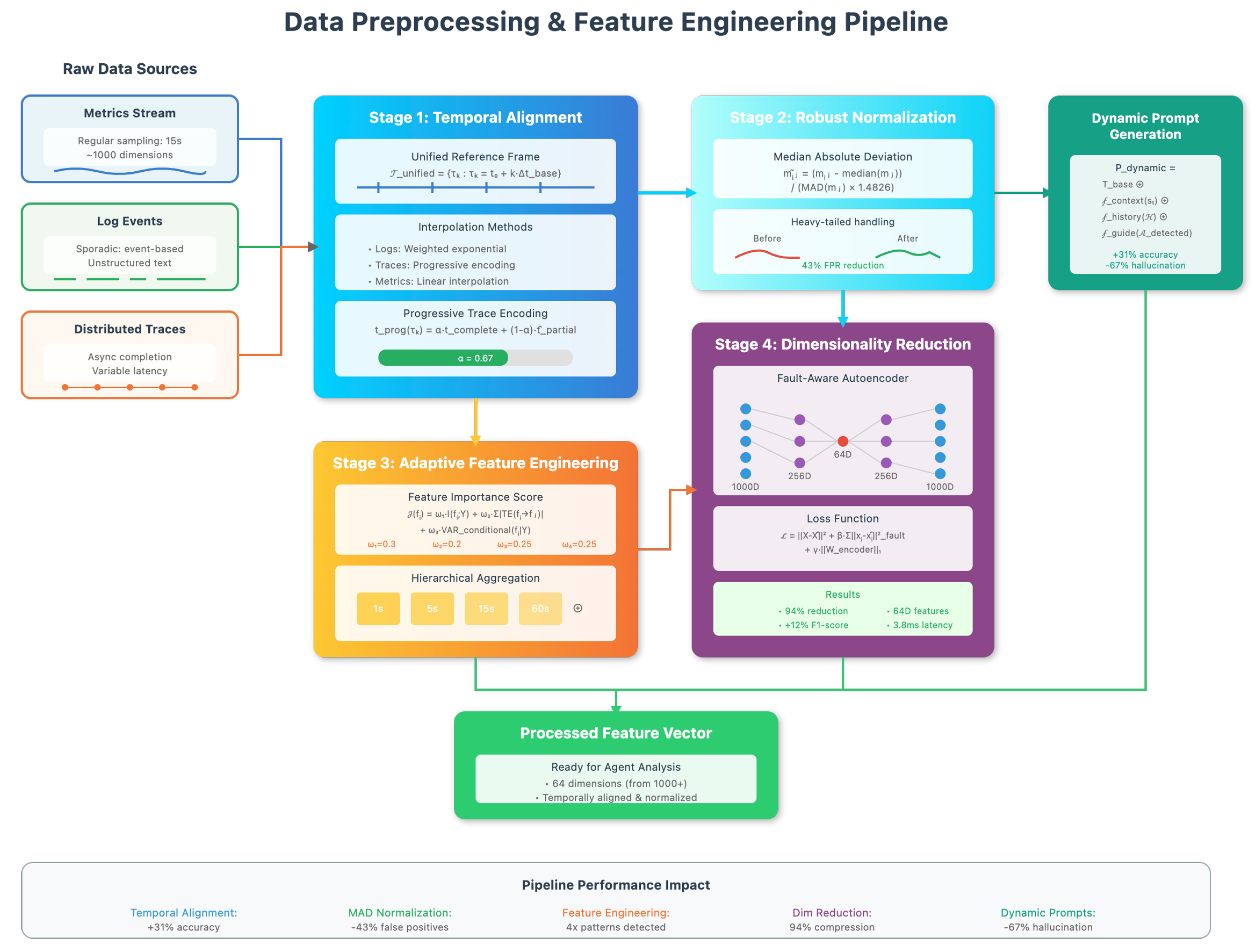
Figure 4.
The pipline of Dynamic Agent Spawning Mechanism.
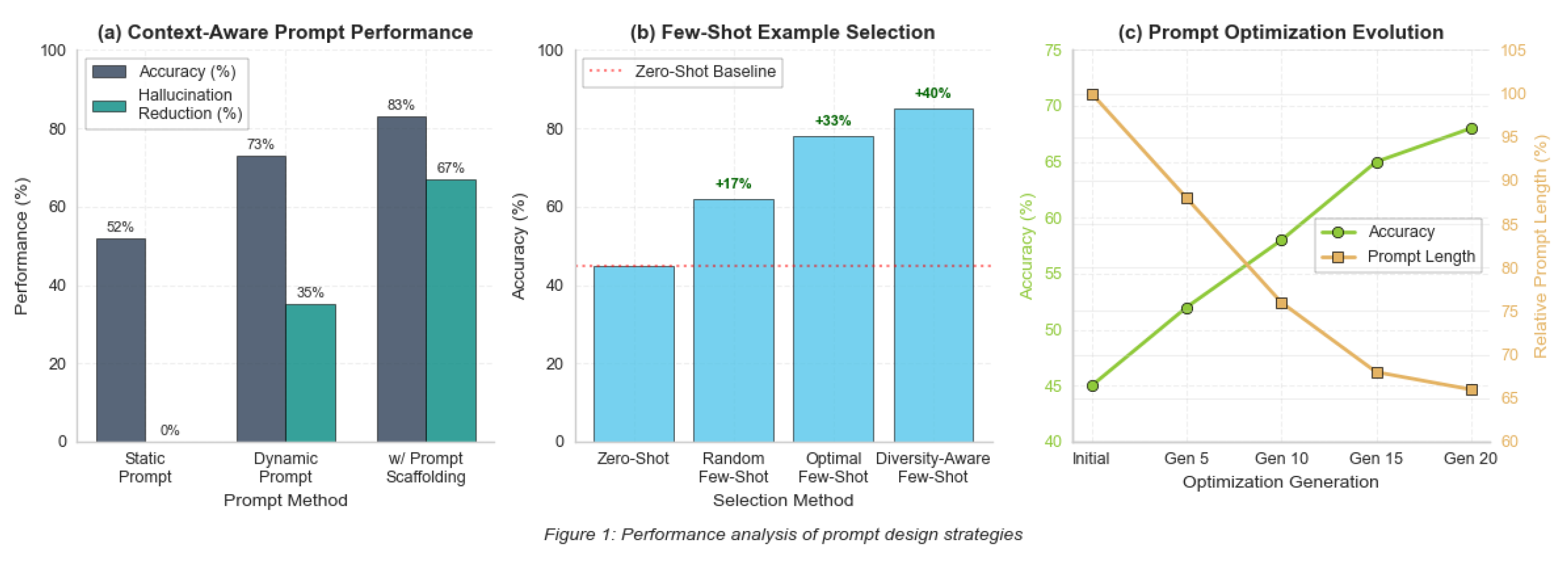

Table 1.
Comprehensive performance comparison and fault type analysis
| Method/Fault Type | Acc@1 | Acc@3 | NDCG@5 | MTTD(s) | F1-Score |
|---|---|---|---|---|---|
| Baseline Methods | |||||
| MicroRCA | 0.542 | 0.721 | 0.687 | 142.3 | 0.521 |
| CloudRanger | 0.618 | 0.793 | 0.742 | 98.7 | 0.598 |
| TraceDiag | 0.695 | 0.851 | 0.812 | 68.4 | 0.678 |
| HEMA-RCL (full) | 0.876 | 0.952 | 0.928 | 38.7 | 0.859 |
| HEMA-RCL by Fault Type | |||||
| Resource Exhaustion | 0.913 | 0.968 | 0.947 | 32.4 | 0.905 |
| Network Issues | 0.856 | 0.941 | 0.912 | 41.2 | 0.848 |
| Application Errors | 0.892 | 0.959 | 0.934 | 35.8 | 0.900 |
| Configuration Drift | 0.821 | 0.923 | 0.898 | 48.6 | 0.807 |
| Cascading Failures | 0.847 | 0.938 | 0.916 | 44.3 | 0.854 |
| Byzantine Faults | 0.783 | 0.901 | 0.876 | 52.1 | 0.769 |
Table 2.
Ablation studies and scalability analysis
| Configuration | Acc@1 | MTTD(s) | Acc@1 | GPU-Hours |
|---|---|---|---|---|
| Component Ablation | ||||
| Full Model | 0.876 | 38.7 | – | 2.18 |
| w/o Dynamic Spawning | 0.812 | 45.2 | -7.3% | 1.92 |
| w/o Belief Propagation | 0.831 | 42.1 | -5.1% | 2.05 |
| w/o Hierarchical Structure | 0.798 | 51.3 | -8.9% | 2.76 |
| w/o Multi-modal Fusion | 0.789 | 48.7 | -9.9% | 1.84 |
| Single LLM (DeepSeek-V2) | 0.751 | 67.3 | -14.3% | 1.12 |
| Scalability (Service Count) | ||||
| 50 services | 0.912 | 24.3 | +4.1% | 0.82 |
| 100 services | 0.891 | 31.7 | +1.7% | 1.43 |
| 150 services | 0.876 | 38.7 | 0.0% | 2.18 |
| 200 services | 0.863 | 46.2 | -1.5% | 3.02 |
| 250 services | 0.851 | 54.8 | -2.9% | 3.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



