Submitted:
22 October 2025
Posted:
23 October 2025
You are already at the latest version
Abstract
The aging global population is experiencing a rising prevalence of age-related hearing loss. Conventional hearing aids often fail in noisy environments, leading to user dissatisfaction. Recent advancements in deep learning, particularly in automatic speech recognition (ASR) and smart filter, highlight the potential for a new generation of hearing aids. This paper explores the transformative potential of evolving deep learning architectures to address the critical limitation of noise suppression. We review the progression of models specifically for auditory processing: from Deep Neural Networks (DNNs) for basic noise reduction, to Convolutional Neural Networks (CNNs) which analyse spectral features in audio spectrograms. Recurrent Neural Networks (RNNs) and sequence-to-sequence (seq2seq) models and transformer models which is a improved version of the Seq2Seq that further improved the handling of temporal speech patterns. We conclude that integrating these sophisticated models into next-generation hearing aids is essential for dramatically improving speech intelligibility in complex settings. This technological evolution promises to enhance the quality of life for the aging population by reducing hearing effort and promoting social engagement.
Keywords:
deep learning
Introduction
The world is undergoing a profound demographic shift, marked by a rapidly increasing aging population. This trend brings to the forefront a significant public health challenge: age-related hearing loss or presbycusis [5,6]. Recognized by the World Health Organization (WHO) as a leading cause of years lived with disability among older adults, hearing impairment is far more than a simple inconvenience; it is a critical factor contributing to social isolation, cognitive decline, depression, and increased healthcare costs. In response, entities from national governments to global bodies are exploring avenues for governmental aid and subsidy programs to make hearing assistance more accessible. However, the effectiveness of this aid is contingent on the technology it supports [7,8].
While conventional hearing aids, even when subsidized, provide essential amplification, they often fall short in the complex listening environments of daily life. They struggle with the "cocktail party problem" the brain's innate, but often age-compromised, ability to separate a target speaker from a background of competing noise. This technological limitation means that without smarter solutions, even widely accessible hearing aids fail to fully reintegrate individuals into social and professional life, undermining the public health investments made by organizations like the WHO[9,10]. Today, we will be looking into different types of deep learning AI that are commonly used as smart filters and for speech recognition in modern auditory applications. These sophisticated neural network architectures represent a logical progression, with each generation building upon the last to deliver more powerful and nuanced solutions for processing sound [11].
Smart Filter
A deep learning encoder also known as smart filter is fundamentally a data compression and feature extraction engine that progressively transforms high dimensional, raw input data such as an image, a sentence, or an audio clip into a compact, dense, and informative representation known as a latent code or embedding. It operates through a series of hierarchical layers, where each layer applies non-linear transformations to learn and extract features at increasing levels of abstraction. For instance, in an image, early layers might detect simple edges and textures, while deeper layers assemble these into complex shapes and entire objects. The core objective of the encoder is to distil the most salient and discriminative patterns from the input, discarding irrelevant noise and redundancy, thereby creating a meaningful summary that is optimally structured for a downstream task, such as classification by a subsequent decoder network or a standalone predictor [12].Some of the commonly used unified encoder comprising CNN, RNN, and DNN components works synergistically to transform noisy audio into an intelligible signal.
The Convolutional Neural Network (CNN), which acts as Spatial Feature Extractor. It analyses the input Mel-spectrogram as a visual image, using its hierarchical layers of filters to detect and amplify critical acoustic patterns: lower layers identify fundamental elements like harmonic structures and noise-like fricatives, while deeper layers synthesize these into complex constructs such as specific phonemes and syllables, effectively building a robust spectral representation of the audio [13,14].
A Recurrent Neural Network (RNN), or its advanced variants like LSTM and GRU, acts as an encoder by processing sequential data one element at a time and building a representation that encapsulates the temporal context of the entire sequence. Its power lies in its internal "hidden state," which is updated at each time step and serves as a memory of all previous inputs. When processing an audio sequence that is normally extracted from the CNN or raw waveform and then the RNN encoder integrates information from the past into the present. This allows it to understand dependencies over time, such as how the pronunciation of a vowel is influenced by the preceding consonant, or how a word's meaning is shaped by the words that came before it. The encoding is often taken as the final hidden state of the RNN after processing the entire sequence, which functions as a fixed size "summary vector" containing the contextual essence of the input [15].
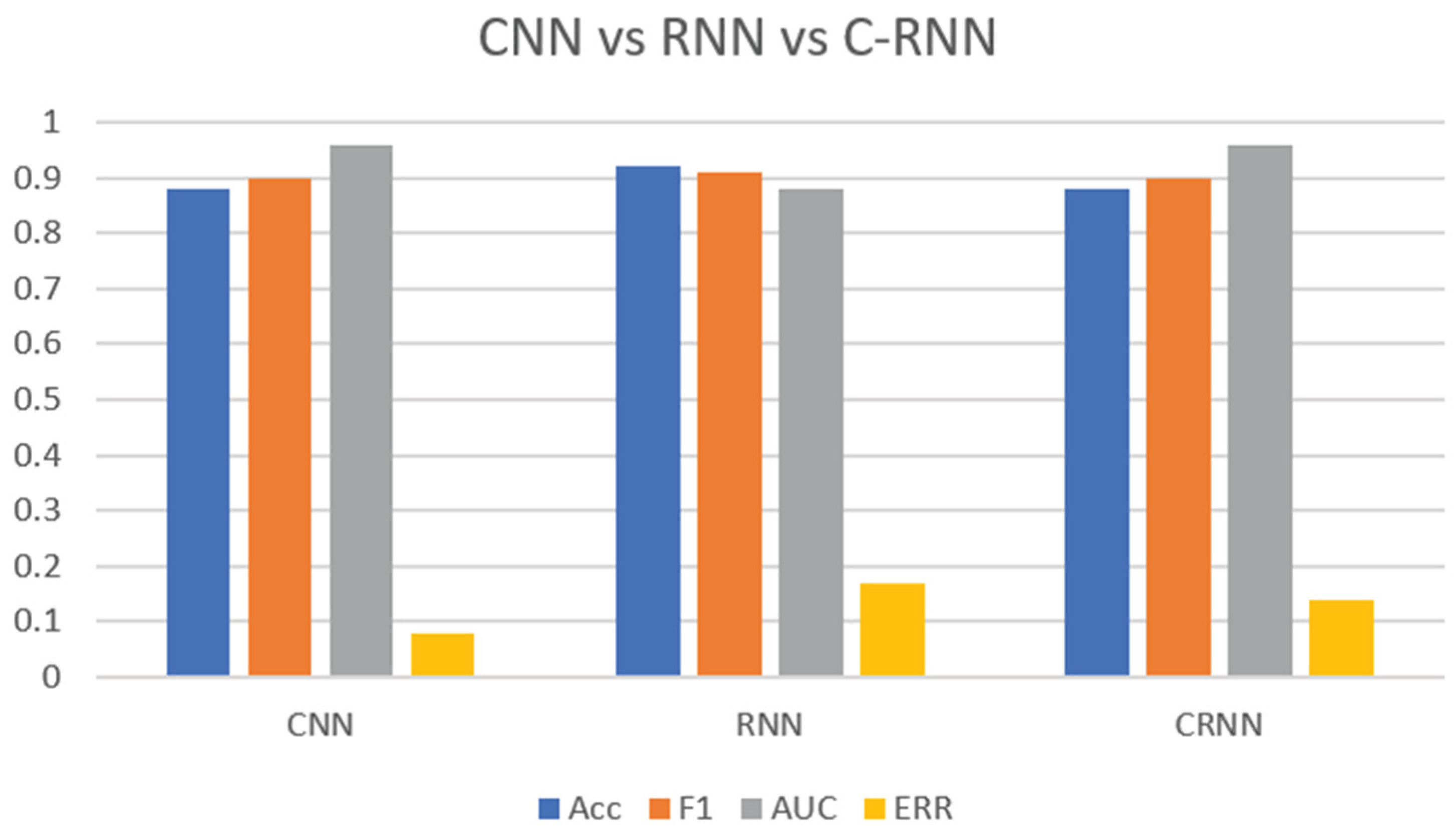
By comparing both CNN and RNN we can see from Figure 1 below which shows that with the same spectrogram that was made up of Short Time Fourier Transform & Linear Filter we can see that CNN have a accuracy of 0.88 , F1 score of 0.90 and AUC of 0.96 and ERR of 0.08. while RNN have a higher accuracy of 0.92 , a higher F1 score of 0.91 but a lower AUC of 0.88 and a a higher ERR of 0.17. which shows that both CNN and RNN have their pros and cons. So by combing both of them to C-RNN we can see that overall it improved with the accuracy of 0.88 , F1 score of 0.9 AUC of 0.96 and ERR of 0.14. which we can see that its not the best but overall it balanced out the pro and con of both neural networks [16].
The output from the RNN is a rich, context-aware representation that encapsulates the entire auditory scene. Finally, this representation is fed into a Deep Neural Network (DNN) or Multi-Layer Perceptron (MLP), which functions as the high-level feature compressor and non-linear mapper. The DNN, with its multiple fully connected layers, performs the final stage of abstraction, distilling the most salient information for the task of speech enhancement and learning the complex function to map the encoded features to a target output, such as a time-frequency mask for noise suppression [17,18,19,20].
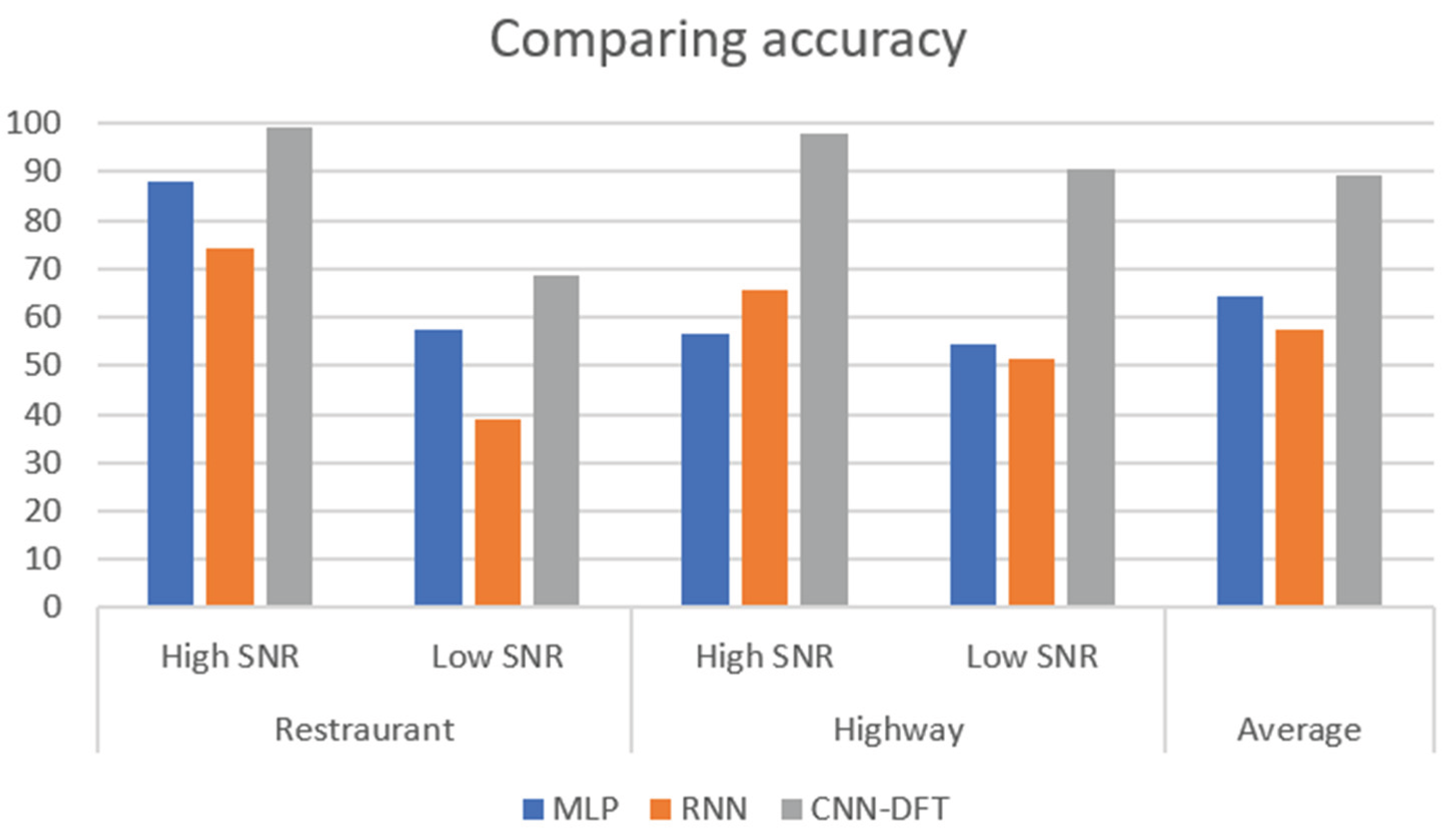
Figure 2 shows a comparison of DNN (MLP) RNN and CNN with discrete Fourier Transform. We can with different signal and noise ratio (SNR) in different environments will cause different a bit variation of the result. We can see that on average CNN with DFT overall have the best average accuracy of 89.13 followed by DNN of average accuracy of 64.14 then RNN of average accuracy of 57.66 however with high SNR value at highway RNN have a higher accuracy of 65.80 while DNN have 56.65 [21].
Overall the CNN, RNN, and DNN collectively form a powerful encoder that performs spectral analysis, temporal modelling, and high-level decision-making to enable clear hearing.
Architecture
There are many types of architectural system used for audio filter and speech recognition however this 3 are more commonly used.
- Seq2Seq (Sequence-to-Sequence)
Seq2Seq is an encoder-decoder architecture designed for transforming one sequence into another, such as language translation or speech enhancement. It works in two distinct, sequential stages. First, an encoder network such as RNN processes the entire input sequence and summarizes it into a fixed-dimensional context vector, which serves as a "thought" or memory of the input. Second, a decoder network uses this context vector to generate the output sequence one element at a time in an autoregressive manner. This means each step of the decoder's output is fed back as its input for the next step, allowing it to build the sequence piece by piece. Its key characteristic is this step-by-step, sequential processing of both understanding and generation [22]. While most of the time Seq2Seq is paired with word token to produce word output and then with additional of speech from the words [23].
- 2.
- Transformer
The Transformer is also an encoder-decoder architecture for sequence transformation, but it fundamentally replaces the sequential core of Seq2Seq with a self-attention mechanism. Instead of processing words one after another, the Transformer encoder and decoder analyse all words in a sequence simultaneously. Self-attention allows the model to weigh the importance of every word in relation to all others, regardless of their position, creating a rich, contextualized understanding in parallel. This eliminates the bottleneck of the single context vector used in traditional Seq2Seq models and allows for much more efficient training on longer sequences. While it can be used in the same encoder-decoder setup as Seq2Seq for translation, its self-attention block is so powerful that it can also be used as a standalone encoder or decoder [24,25]. Transformer system also can be trained to translate different languages [26].
By comparing transformer and Seq2Seq as transformer is a more advanced version of Seq2Seq it have better advantages such as lesser training time. Seq2Seq took 5 days and 10 GPU to train [27] while speech-transformer took 1.2days and 1 GPU [28].
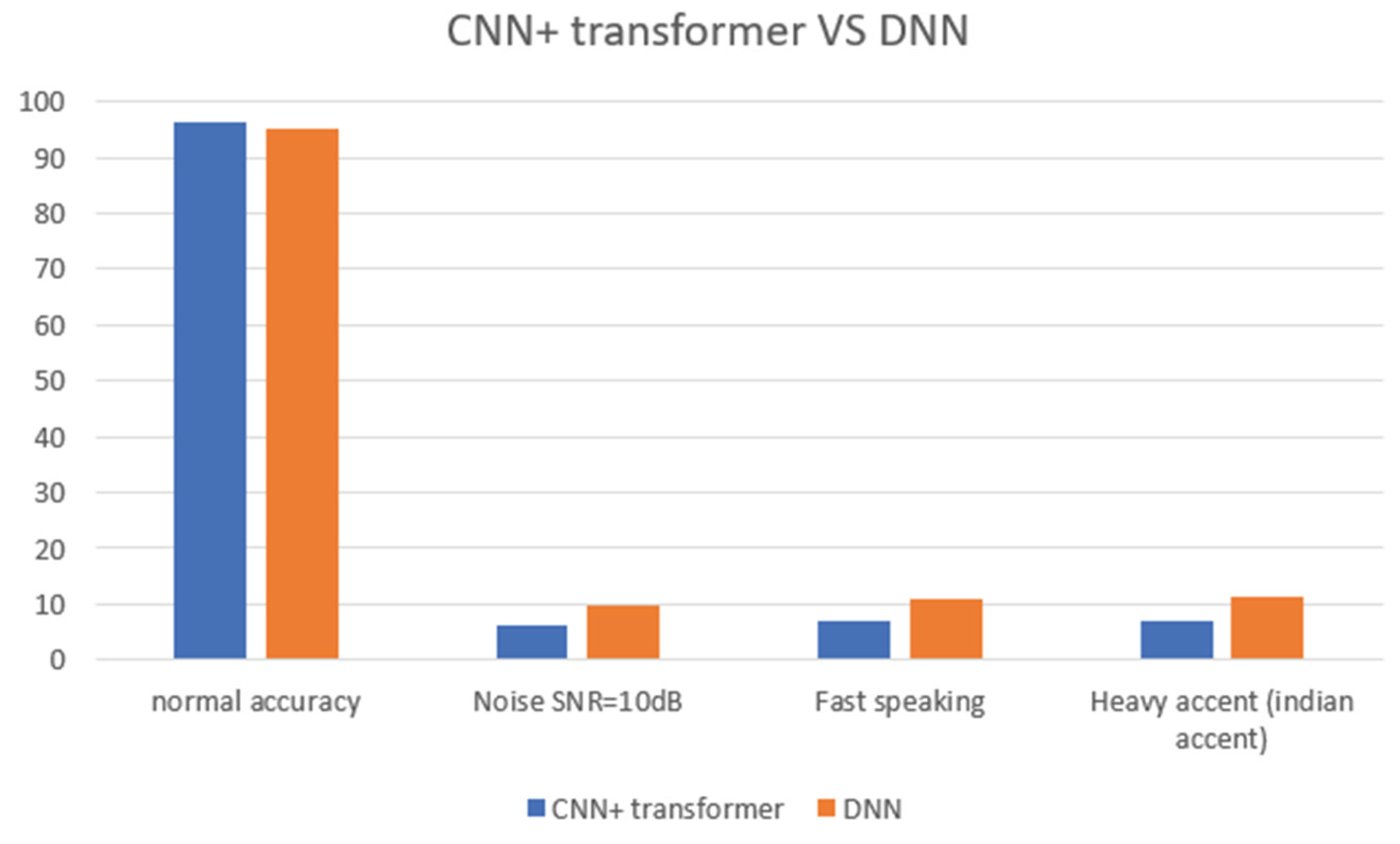
From Figure 3 we can see that in normal room tone CNN+ transformer and DNN have high accuracy of 96.38% and 95.13%. we can see that both of them can perform almost perfectly in normal environments however their performance drop when noise SNR of 10dB , and when the other speaker was speaking too fast or heavy accent. Those few common factor cause the accuracy of CNN+ transformer drop below 10% while DNN have a slightly better accuracy over 10% [30].
- 3.
- GAN (Generative Adversarial Network)
A GAN operates on a completely different principle from Seq2Seq and transformer it is a generative framework for creating new, realistic data, not for transforming sequences. It consists of two separate neural networks locked in a competitive game. The Generator network takes random noise as input and learns to produce synthetic data, such as an image that looks authentic. The Discriminator network acts as a critic, trying to distinguish between real data from the training set and the fake data produced by the Generator. During training, the Generator strives to become better at fooling the Discriminator, while the Discriminator simultaneously improves its ability to detect fakes. This adversarial process drives both networks to improve until the Generator produces highly realistic data [31,32,33,34].
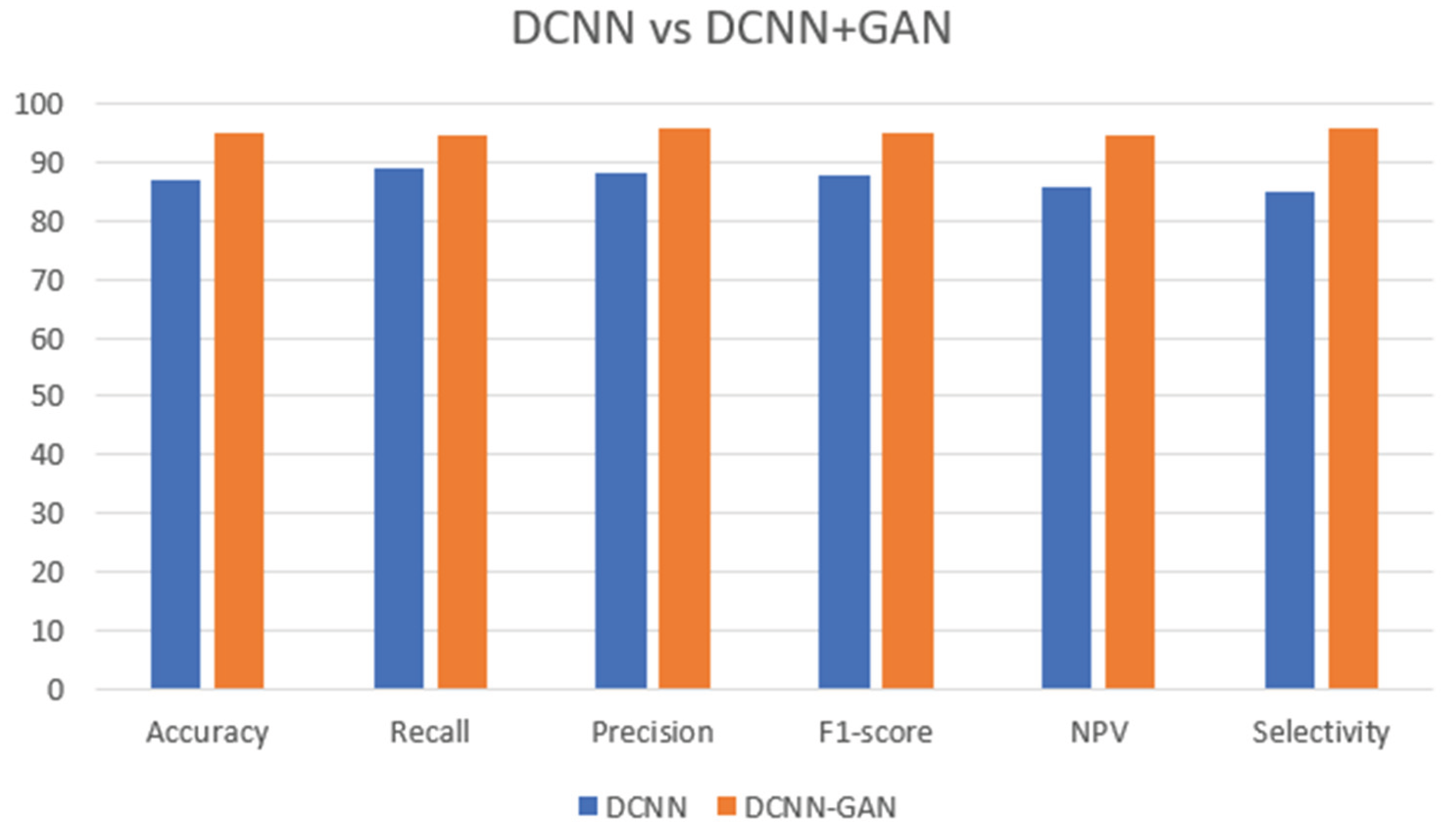
Figure 4.
We can see that DCNN and DCNN added with GAN we can see that together with GAN it have a better accuracy of 95.2% and a recall of 94.8% Precision of 95.7% and F1-score of 95% and Negative Predictive Value (NPV) and the selectivity of 95.7% while only with DCNN it only have a accuracy of 87.1% and Recall of 88.9% Precision 88.2% and F1-score of 87.9% NPV of 85.6% selectivity 84.8% which we can see that after adding the GAN system over performance have improved [35]
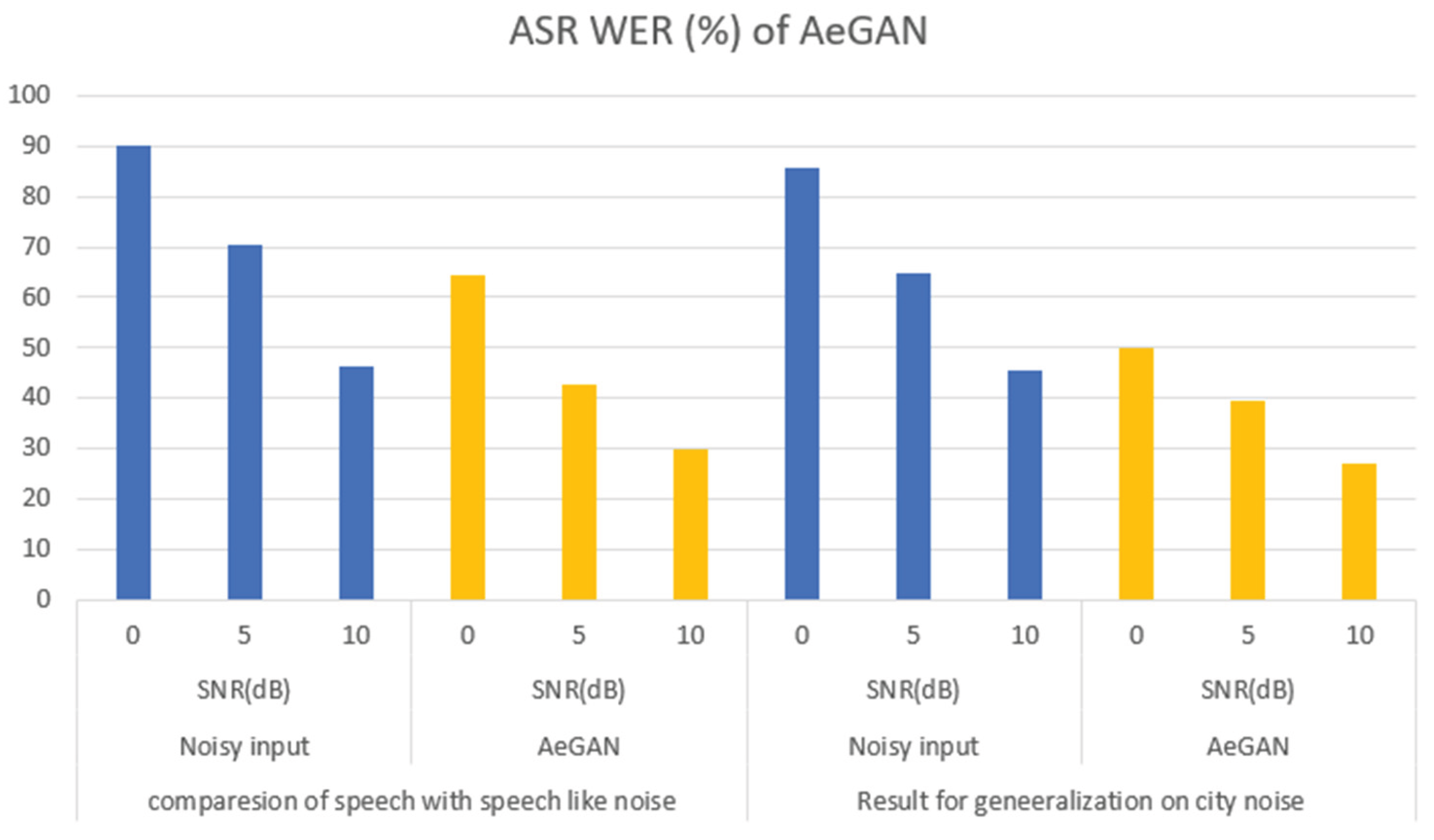
There are also other improved version of GAN such as autoencoders(Ae) GAN. From Figure 5 we can see that AeGan have improved the ASR WER (%) from the noisy input when comparing speech with speech like noise of 0 dB from 90% to 64.6% and 5 dB 70.4% to 42.9% and 10 dB of 46.3% to 29.7% which shows that in noisy environments it can still recognises to a certain extent of the sound input. While in city noise we can see that from 0 dB 85.6% to 50.1% , 5 dB 64.7% to 39.4% and 10 dB 64.7% to 27.1% which shows that in noisy environments such as traffic noise or etc it can recognises the speech [36] and other type of architecture to improve the speech enhancement [37,38].
How Does This Help the Elderly
As technological advancements continue to enhance smartphone capabilities, artificial intelligence presents a transformative opportunity to support the aging population. For instance, an elderly individual with hearing impairment could use their phone as a powerful, AI-driven assistant. By implementing a sophisticated Generative Adversarial Network (GAN), the phone can act as a smart hearing aid [39,40]. This system performs real-time speech enhancement, intelligibly separating voices from background noise. The effectiveness of such a model is demonstrated by high scores in standardized metrics specifically, a strong CBAK score, confirming minimal intrusive background noise, and a high CSIG score, indicating clear and undistorted speech. Furthermore, for moments when audio alone is insufficient, a Seq2Seq model could provide live transcription, converting spoken dialogue into accurate text on the screen. This powerful combination of AI technologies empowers the elderly to engage in conversations with greater confidence and independence, significantly improving their daily standard of living.
Conclusion and Future Outlook
In conclusion, the rapid evolution of deep learning systems and mobile hardware is paving the way for a transformative future in elderly care. By integrating sophisticated AI assistants directly onto smartphones, we can create a powerful and accessible support system. This technological synergy will be crucial for assisting with daily needs, such as through advanced assisting hearing aids that can filter noise and enhance speech clarity and help them to prevent scam calls [16]. Ultimately, leveraging the mobile phone for such practical AI assistance has the profound potential to significantly uplift the standard of living for the elderly, promoting greater independence, safety, and engagement with the world around them.
References
- P. Wang, X. Lu, H. Sun and W. Lv, "Application of speech recognition technology in IoT smart home," 2019 IEEE 3rd Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Chongqing, China, 2019, pp. 1264-1267. [CrossRef]
- Kok, C.L.; Siek, L. Designing a Twin Frequency Control DC-DC Buck Converter Using Accurate Load Current Sensing Technique. Electronics 2024, 13, 45. [CrossRef]
- M. Vacher, N. Guirand, J. -F. Serignat, A. Fleury and N. Noury, "Speech recognition in a smart home: Some experiments for telemonitoring," 2009 Proceedings of the 5-th Conference on Speech Technology and Human-Computer Dialogue, Constanta, Romania, 2009, pp. 1-10. [CrossRef]
- M. Krishnaveni, P. Subashini, J. Gracy and M. Manjutha, "An Optimal Speech Recognition Module for Patient's Voice Monitoring System in Smart Healthcare Applications," 2018 Renewable Energies, Power Systems & Green Inclusive Economy (REPS-GIE), Casablanca, Morocco, 2018, pp. 1-6. [CrossRef]
- D'Haese PSC, Van Rompaey V, De Bodt M, Van de Heyning P. Severe Hearing Loss in the Aging Population Poses a Global Public Health Challenge. How Can We Better Realize the Benefits of Cochlear Implantation to Mitigate This Crisis? Front Public Health. 2019 Aug 16;7:227. [CrossRef]
- Easwar V, Hou S, Zhang VW. Parent-Reported Ease of Listening in Preschool-Aged Children With Bilateral and Unilateral Hearing Loss. Ear Hear. 2024 Nov-Dec 01;45(6):1600-1612. Epub 2024 Aug 9. PMID: 39118218. [CrossRef]
- Wells TS, Rush SR, Nickels LD, Wu L, Bhattarai GR, Yeh CS. Limited Health Literacy and Hearing Loss Among Older Adults. Health Lit Res Pract. 2020 Jun 4;4(2):e129-e137. [CrossRef]
- Thai A, Khan SI, Choi J, Ma Y, Megwalu UC. Associations of Hearing Loss Severity and Hearing Aid Use With Hospitalization Among Older US Adults. JAMA Otolaryngol Head Neck Surg. 2022 Nov 1;148(11):1005-1012. [CrossRef]
- D'Haese PSC, Van Rompaey V, De Bodt M, Van de Heyning P. Severe Hearing Loss in the Aging Population Poses a Global Public Health Challenge. How Can We Better Realize the Benefits of Cochlear Implantation to Mitigate This Crisis? Front Public Health. 2019 Aug 16;7:227. [CrossRef]
- World Health Organisation Deafness and hearing loss. https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss.
- C. L. Kok, X. Li, L. Siek, D. Zhu and J. J. Kong, "A switched capacitor deadtime controller for DC-DC buck converter," 2015 IEEE International Symposium on Circuits and Systems (ISCAS), Lisbon, Portugal, 2015, pp. 217-220. [CrossRef]
- H. H. Hussein, O. Karan, S. Kurnaz and A. K. Turkben, "Speech Recognition of High Impact Model Using Deep Learning Technique: A Review," 2025 7th International Congress on Human-Computer Interaction, Optimization and Robotic Applications (ICHORA), Ankara, Turkiye, 2025, pp. 1-10. [CrossRef]
- S. Pushparani, K. S. Rekha, V. M. Sivagami, R. Usharani and M. Jothi, "Exploring the Effectiveness of Deep Learning in Audio Compression and Restoration," 2024 International Conference on Trends in Quantum Computing and Emerging Business Technologies, Pune, India, 2024, pp. 1-5. [CrossRef]
- S. Wan, "Research on Speech Separation and Recognition Algorithm Based on Deep Learning," 2021 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 2021, pp. 722-725. [CrossRef]
- L. Pham, P. Lam, T. Nguyen, H. Nguyen and A. Schindler, "Deepfake Audio Detection Using Spectrogram-based Feature and Ensemble of Deep Learning Models," 2024 IEEE 5th International Symposium on the Internet of Sounds (IS2), Erlangen, Germany, 2024, pp. 1-5. [CrossRef]
- P. Wang, "Research and Design of Smart Home Speech Recognition System Based on Deep Learning," 2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL), Chongqing, China, 2020, pp. 218-221. [CrossRef]
- D. Stankevicius and P. Treigys, "Investigation of Machine Learning Methods for Colour Audio Noise Suppression," 2023 18th Iberian Conference on Information Systems and Technologies (CISTI), Aveiro, Portugal, 2023, pp. 1-6. [CrossRef]
- S. M, R. Biradar and P. V. Joshi, "Implementation of an Active Noise Cancellation Technique using Deep Learning," 2022 International Conference on Inventive Computation Technologies (ICICT), Nepal, 2022, pp. 249-253. [CrossRef]
- P. Wang, "Research and Design of Smart Home Speech Recognition System Based on Deep Learning," 2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL), Chongqing, China, 2020, pp. 218-221. [CrossRef]
- S. Mihalache, I. -A. Ivanov and D. Burileanu, "Deep Neural Networks for Voice Activity Detection," 2021 44th International Conference on Telecommunications and Signal Processing (TSP), Brno, Czech Republic, 2021, pp. 191-194. [CrossRef]
- D. Ma, Y. Choi, F. Li, C. Xie, K. Kobayashi and T. Toda, "Robust Sequence-to-sequence Voice Conversion for Electrolaryngeal Speech Enhancement in Noisy and Reverberant Conditions," 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 2024, pp. 1-4. [CrossRef]
- Dzmitry Bahdanau, Jan Chorowski, Dmitriy Serdyuk, Philemon Brakel, and Yoshua Bengio, “End-to-end attention-based large vocabulary speech recognition,” in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on. IEEE,2016, pp. 4945–4949.
- U. Bayraktar, H. Kilimci, H. H. Kilinc and Z. H. Kilimci, "Assessing Audio-Based Transformer Models for Speech Emotion Recognition," 2023 7th International Symposium on Innovative Approaches in Smart Technologies (ISAS), Istanbul, Turkiye, 2023, pp. 1-7. [CrossRef]
- Q. Kong, Y. Xu, W. Wang and M. D. Plumbley, "Sound Event Detection of Weakly Labelled Data With CNN-Transformer and Automatic Threshold Optimization," in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2450-2460, 2020. [CrossRef]
- M. Karafiát, M. Janda, J. Černocký and L. Burget, "Region dependent linear transforms in multilingual speech recognition," 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 2012, pp. 4885-4888. [CrossRef]
- Yu Zhang, William Chan, and Navdeep Jaitly, “Very deep convolutional networks for end-to-end speech recognition,” in Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEEInternational Conference on. IEEE, 2017, pp. 4845–4849.
- L. Dong, S. Xu and B. Xu, "Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition," 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 2018, pp. 5884-5888. [CrossRef]
- M. Karafiát, M. Janda, J. Černocký and L. Burget, "Region dependent linear transforms in multilingual speech recognition," 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 2012, pp. 4885-4888. [CrossRef]
- D. Jiang and X. Yu, "Research on Speech Recognition Model Optimization and Real-Time Speech Interaction System Based on Deep Learning," 2025 IEEE 5th International Conference on Power, Electronics and Computer Applications (ICPECA), Shenyang, China, 2025, pp. 281-285. [CrossRef]
- S. Pushparani, K. S. Rekha, V. M. Sivagami, R. Usharani and M. Jothi, "Exploring the Effectiveness of Deep Learning in Audio Compression and Restoration," 2024 International Conference on Trends in Quantum Computing and Emerging Business Technologies, Pune, India, 2024, pp. 1-5. [CrossRef]
- M. Costante, M. Matassoni and A. Brutti, "Using Seq2seq voice conversion with pre-trained representations for audio anonymization: experimental insights," 2022 IEEE International Smart Cities Conference (ISC2), Pafos, Cyprus, 2022, pp. 1-7. [CrossRef]
- B. Lohani, C. K. Gautam, P. K. Kushwaha and A. Gupta, "Deep Learning Approaches for Enhanced Audio Quality Through Noise Reduction," 2024 International Conference on Communication, Computer Sciences and Engineering (IC3SE), Gautam Buddha Nagar, India, 2024, pp. 447-453. [CrossRef]
- Sania Gul, Muhammad Salman Khan. "A survey of audio enhancement algorithms for music, speech, and voice applications", 2023.
- N. Kure and S. B. Dhonde, "Dysarthric Speech Data Augmentation using Generative Adversarial Networks," 2025 6th International Conference for Emerging Technology (INCET), BELGAUM, India, 2025, pp. 1-5. [CrossRef]
- S. Abdulatif, K. Armanious, K. Guirguis, J. T. Sajeev and B. Yang, "AeGAN: Time-Frequency Speech Denoising via Generative Adversarial Networks," 2020 28th European Signal Processing Conference (EUSIPCO), Amsterdam, Netherlands, 2021, pp. 451-455. [CrossRef]
- S. Ye, T. Jiang, S. Qin, W. Zou and C. Deng, "Speech Enhancement Based on A New Architecture of Wasserstein Generative Adversarial Networks," 2018 11th International Symposium on Chinese Spoken Language Processing (ISCSLP), Taipei, Taiwan, 2018, pp. 399-403. [CrossRef]
- S. Pascual, A. Bonafonte, and J. Serrà, “SEGAN: Speech enhancement generative adversarial network,” in Interspeech, 2017, pp.3642–3646.
- K. Patel and I. M. S. Panahi, "Compression Fitting of Hearing Aids and Implementation," 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 2020, pp. 968-971. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



