Submitted:
16 October 2025
Posted:
17 October 2025
You are already at the latest version
Abstract
This paper addresses the complexity and high-risk nature of fraud detection in financial transaction data by proposing a discrimination method based on an improved Mamba architecture. The study first performs data cleaning, normalization, and embedding to reduce scale differences across multimodal features, and employs temporal encoding and positional embedding to strengthen sequence representation. A dynamic state updating and selective state space mechanism is then introduced to capture long-term dependencies and global contextual features, thereby enhancing the model's discrimination ability in complex transaction environments. Furthermore, context interaction and weighted aggregation modules are designed to integrate hidden states across time steps into a global representation, providing more robust inputs for final classification. Experiments, including baseline comparisons, sequence length sensitivity, and noise robustness tests, demonstrate that the proposed method outperforms multiple mainstream architectures in Accuracy, F1-score, AUC, and Precision, while showing greater stability in handling data imbalance and adversarial perturbations. Overall, the study confirms the effectiveness and applicability of the improved Mamba architecture for financial fraud detection and provides technical support for building secure and trustworthy risk control systems.
Keywords:
financial fraud detection
; sequence modeling
; dynamic state update
; robustness
1. Introduction
In the context of the highly digitalized and networked global financial system, financial fraud has gradually evolved into a complex and dynamic form of risk. With the spread of electronic payments, internet finance, and blockchain technology, financial activities have become increasingly convenient[1,2]. However, fraud methods have also become more diverse, intelligent, and concealed. From credit card theft to virtual account money laundering, from fraudulent transactions to cross-border scams, the impact of financial fraud extends beyond individual economic losses. It also poses long-term threats to the stability of financial markets and the trust system of society. In recent years, the frequency and scale of financial fraud have increased significantly. The potential losses have shown exponential growth, forcing financial institutions and regulators to seek more forward-looking technological measures for prevention and control[3].
Traditional financial fraud detection methods are often based on rule matching and statistical modeling. These approaches can identify typical abnormal behaviors to some extent, but they are insufficient in complex and evolving transaction environments. Their limitations include poor adaptability to new fraud scenarios, heavy reliance on specific features, and a lack of dynamic learning ability. As fraud evolves rapidly and becomes more hidden, static rules or shallow models alone are often ineffective. Financial data is also characterized by high dimensionality, sequential dependence, and non-stationarity. This means fraud detection must process large volumes of multimodal information and deliver rapid risk judgments in real time. The challenge lies in maintaining a high detection rate while reducing false alarms and in achieving a deeper understanding of complex fraud patterns. This remains a core problem in the field of financial technology[4].
The rapid development of artificial intelligence has injected new momentum into financial fraud detection. Deep learning models, with strong abilities in representation learning and nonlinear modeling, are widely applied in anomaly detection and risk prediction [5,6,7,8]. Yet limitations in sequential modeling remain. Deep neural networks struggle with long-term dependencies, global context awareness, and the extraction of complex sequential features. New architectures have recently been introduced to address these shortcomings by improving information flow [9,10,11,12]. These models provide potential breakthroughs for financial fraud detection. Their ability to capture long-range dependencies in transaction sequences, while remaining robust in non-stationary environments, is crucial[13,14,15]. This is particularly valuable for identifying subtle anomalies within large-scale financial transaction data.
Research on financial fraud detection goes beyond reducing economic losses. It also safeguards the health and stability of the financial ecosystem. If fraudulent behavior is not effectively contained, systemic risks may arise, affecting market liquidity and investor confidence. At the same time, regulators are raising expectations for the risk management capabilities of financial institutions. They emphasize technological innovation as a means to strengthen prevention and control. An efficient and reliable fraud detection system can provide individuals and enterprises with safer financial services while enhancing compliance and transparency across the industry. Advanced models also allow institutions to respond quickly to emerging fraud methods, enabling proactive warning rather than passive response. This strategic shift strengthens the overall resilience of the financial system[16].
Overall, research on fraud detection using improved architectures holds significant academic and practical value. It expands the application of artificial intelligence in financial security and drives deeper exploration of sequential modeling methods. At the same time, it provides more accurate and efficient support for financial risk control, contributing to a robust and trustworthy financial environment. In the accelerating process of global financial integration and digitalization, such research is not only about technological progress but also about reinforcing the social trust foundation of the financial system. Continuous optimization and innovation of model architectures will promote the development of intelligent, real-time, and interpretable fraud detection and play an essential role in the future of financial technology.
2. Related Work
Recent advances in financial fraud detection have leveraged deep sequential models to capture the dynamic and complex nature of transactional data. Pioneering work employing LSTM architectures has demonstrated the value of sequence modeling in identifying temporal patterns associated with fraudulent behavior, setting a strong baseline for subsequent approaches [17]. Building upon this, unsupervised temporal encoding methods have enabled more flexible and robust pattern extraction from financial time series, addressing challenges related to data sparsity and evolving transaction structures [18]. The introduction of deep attention mechanisms has further enhanced the capacity for systemic risk forecasting, allowing models to selectively focus on salient features in long, high-dimensional financial sequences [19]. Additionally, approaches that integrate structured text factors and dynamic time windows into forecasting frameworks have improved the adaptability of models to changing market conditions [20].
Beyond sequential modeling, the incorporation of graph neural networks (GNNs) has opened new avenues for capturing relational dependencies in financial systems. GNN frameworks have proven effective for credit risk identification in enterprise networks by modeling the structural complexities of inter-organizational relationships [21]. Federated graph neural networks extend this paradigm to heterogeneous graphs, supporting collaborative modeling with privacy guarantees and structural consistency across institutions [22]. Moreover, multi-task learning techniques that fuse cross-domain financial data enable the joint learning of macroeconomic indicators and market signals, thereby improving the generalization ability of fraud detection systems [23].
The robustness and interpretability of fraud detection models have also been strengthened by the integration of causal representation learning and structural optimization techniques. Target-oriented causal modeling frameworks support robust cross-market prediction, enhancing the ability to detect subtle fraud patterns even under distribution shifts [24]. Advances in efficient large language model adaptation—such as joint structural pruning and parameter sharing—contribute to scalable and efficient fraud detection, particularly in resource-constrained settings [25]. Finally, hierarchical semantic-structural encoding and compliance risk detection methodologies have been proposed to ensure that detection models align with regulatory requirements and maintain transparency in high-stakes financial environments [26].
Together, these methodological advances in sequential modeling, graph-based representation, causal learning, and structural optimization provide a comprehensive technical foundation for the improved Mamba architecture proposed in this study, supporting both the accuracy and robustness required for next-generation financial fraud detection systems.
3. Proposed Approach
In this study, the overall framework, centered around an improved sequence modeling architecture, leverages feature learning to address the high dimensionality and temporal nature of financial transaction data. First, the raw transaction data is represented as a sequence tensor containing multimodal features such as amounts, time intervals, and account attributes. This is then mapped into a unified representation space through normalization and embedding mechanisms.
To ensure that features of different dimensions can remain relevant in high-dimensional space, we use an embedding function to transform the input into a latent vector , which can be expressed as:
Where represents the original input features at time step t, and d represents the embedding dimension. This step effectively alleviates the scale inconsistency problem between multimodal features and provides a foundation for subsequent time series modeling. The model architecture is shown in Figure 1.
To better model long-term dependencies in financial transaction sequences, this paper introduces a dynamic state update mechanism into the improved Mamba architecture. Unlike traditional sequence models that rely solely on fixed recursive updates, we use a state transition function to dynamically control the implicit state:
Here, represents the hidden state at time step t, and T is an update operator with nonlinear mapping capabilities. This approach allows the model to simultaneously capture local transaction features and global contextual dependencies, thereby improving its ability to characterize complex financial fraud.
After sequence modeling is complete, we further designed a contextual interaction mechanism to enhance the model's discriminability. Specifically, while maintaining temporal dependencies, we use a weighted aggregation function to combine the states of each time step to form a global representation of the entire transaction sequence:
Finally, to complete the classification of fraud and non-fraud, we use a combination of linear mapping and normalization functions to project the global representation z into the category space and output the result in the form of a probability distribution. The classifier can be expressed as:
Here, and are trainable weights and bias parameters, respectively, and represents the probability distribution of belonging to different categories y given an input x. This design ensures that the model can clearly distinguish between financial fraud and legitimate transactions while maintaining high representational power.
4. Performance Evaluation
- A.
- Dataset
The dataset used in this study is the IEEE-CIS Fraud Detection Dataset. It was collected and organized from public sources and is widely applied in research on financial risk and fraud detection. The dataset covers real online payment and transfer records. It contains a large number of transaction samples with rich feature dimensions. These include transaction time, transaction amount, payment method, device type, and network environment. Each record is labeled to indicate whether the transaction is fraudulent. This composition effectively reflects the high-dimensional, multimodal, and complex sequential characteristics of financial transactions.
Some fields in the dataset are anonymized features, such as the V-series and C-series variables, which represent behavioral patterns that cannot be directly disclosed. The presence of these anonymized features increases the research challenge. It also requires models to have strong feature extraction and generalization capabilities. In addition, the dataset provides identifiers such as transaction ID and user ID. These identifiers support sequential modeling of user behavior, which helps to capture potential fraud chains.
The dataset is large in scale and shows an imbalanced class distribution. This reflects the fact that fraudulent transactions are relatively rare in real scenarios. Such an imbalance brings challenges to model training but makes the research setting closer to practical industry requirements. Studies based on this dataset can evaluate the applicability of methods in large-scale and complex environments with class imbalance. They also provide useful references for future deployment in real financial services.
- B.
- Experimental Results
This paper first conducts a comparative experiment, and the experimental results are shown in Table 1.
From the overall results, the method based on the improved Mamba architecture achieved the best performance across all four evaluation metrics. Compared with traditional methods such as LSTM and CNN, both accuracy and F1-score improved significantly. This indicates that the improved model can capture the complex features of financial transaction data more comprehensively. It ensures coverage of detection while effectively reducing missed cases. These results highlight the importance of structural optimization when handling high-dimensional and multimodal financial data, especially in fraud scenarios with strong temporal dependencies and rapidly changing patterns.
Further comparisons show that LSTM-Transformer and ConvNext perform better than plain LSTM or CNN. This suggests that the combination of deep structures and attention mechanisms enhances the ability to model global dependencies. However, these models still show slightly lower performance in AUC and Precision compared with the improved Mamba architecture. This reveals their limitations in capturing long sequential dependencies and dynamic pattern changes. In contrast, the dynamic state updating and efficient sequence modeling of the improved Mamba allow a better balance between global information and local details. As a result, it maintains a high recall rate while reducing false alarms.
The comparison of Precision also reflects the value of the improved Mamba architecture. In financial fraud detection, a high false alarm rate leads to many normal transactions being blocked, which harms system stability and user experience. The results show that the improved method achieves higher Precision than other models. This means it can filter out irrelevant noise while ensuring recall. The outcome improves the reliability of predictions. For financial risk control, this is practically meaningful as it helps balance security and efficiency.
Finally, from the perspective of AUC, the improved Mamba architecture not only enhances overall classification performance but also improves stability under different thresholds. A higher AUC indicates stronger discriminative ability between positive and negative samples. It also shows robust performance in data environments with imbalanced distributions. This demonstrates that the proposed mechanism is not only innovative in theory but also valuable in practice. It provides solid technical support for building efficient and trustworthy financial fraud detection systems.
This paper also gives the results of sequence length sensitivity experiments, which are shown in Figure 2.
From the experimental results, it can be observed that overall performance improves gradually as the sequence length increases. With shorter sequences, the model does not capture transaction behaviors sufficiently, leading to relatively low accuracy and F1-score. When the sequence length reaches a certain range, the model can better exploit long-term dependencies and hidden patterns, resulting in significant performance gains. This shows that the improved Mamba architecture has strong advantages in handling long-sequence financial transaction data.
For the AUC metric, the curve rises with longer sequences and reaches its peak at medium to long lengths. This indicates that the model's ability to distinguish fraudulent from normal transactions becomes stronger under different thresholds. It also demonstrates better robustness and generalization. When the sequence is too short, the decision boundary is unclear, which easily causes misclassification. As the input information becomes richer, the discriminative power of the model is effectively released.
The Precision results also highlight the importance of sequence length. As the sequence length increases, Precision steadily improves and remains at a high level. This shows that the model can better suppress false alarms when dealing with long sequences. In financial fraud detection, improvement in Precision is especially critical. It directly reduces the probability of normal transactions being blocked by mistake, which enhances the usability and user experience of financial systems.
Overall, all four metrics show a stable upward trend as the sequence length grows from 16 to 256, and they reach optimal levels within this range. Although some metrics fluctuate slightly at a length of 512, the overall performance remains high. This demonstrates that the improved Mamba architecture maintains good stability and adaptability in long-sequence settings. It further verifies the effectiveness of the architecture for large-scale financial transaction data and provides methodological support for building reliable financial fraud detection systems.
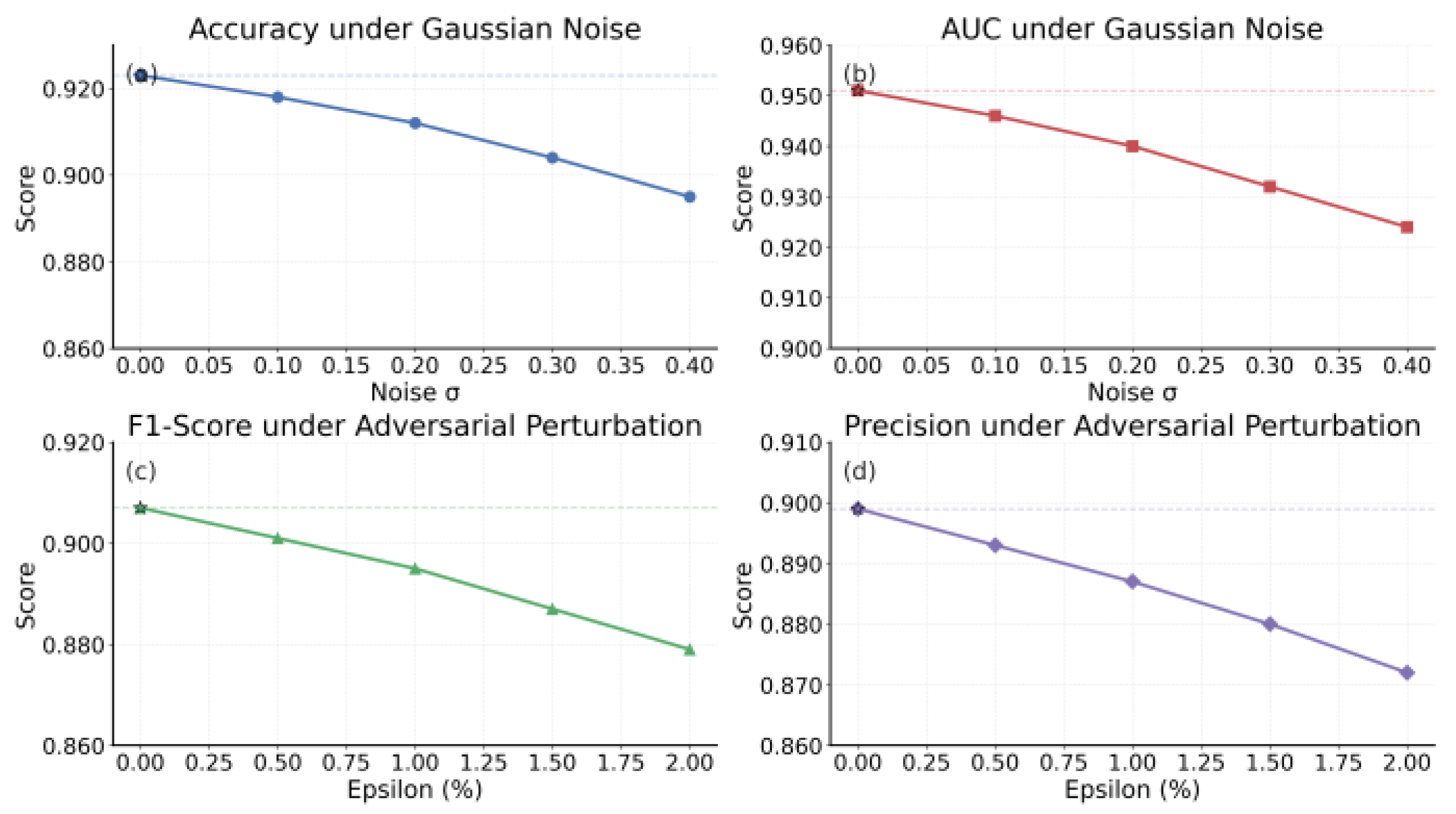
This paper also presents a robustness evaluation of noise injection and adversarial perturbations, and the experimental results are shown in Figure 3.
From the experimental results, it can be observed that overall performance declines as noise intensity increases. Accuracy and AUC remain high under low noise, indicating that the improved Mamba architecture can resist random disturbances to some extent. However, as noise levels grow, the performance curves drop significantly. This suggests that excessive noise weakens the stability of feature representation. The phenomenon is consistent with the characteristics of high-dimensional financial data, showing that stronger robustness mechanisms are still needed in extreme noisy environments.
In the AUC results, the decline is slower compared with the Accuracy. This indicates that even in high-noise scenarios, the model still distinguishes fraudulent and normal transactions relatively well, demonstrating a certain level of generalization. This is especially important in financial fraud detection. The stability of AUC directly reflects the reliability of the model across different thresholds and confirms that the improved architecture retains strong discriminative potential when facing random disturbances.
In the adversarial perturbation experiments, as epsilon increases, both F1-score and Precision show a downward trend. The decline in F1-score indicates that the balance between recall and accuracy is disrupted. The decrease in Precision means that the false alarm rate increases under adversarial attacks. For financial fraud detection, this implies that in adversarial settings, the model is more likely to misclassify normal transactions as fraudulent. Such errors negatively affect user experience and the smoothness of business operations.
Overall, although performance decreases under high noise and strong adversarial perturbations, the improved Mamba architecture maintains high performance under low to moderate interference. This demonstrates good robustness. Such a property is crucial in real financial scenarios, where transaction data often contains noise, instability, or even malicious attacks. The results further confirm the effectiveness and applicability of the architecture in complex environments, providing solid support for building secure and reliable financial fraud detection systems.
6. Conclusion
This study conducted a systematic exploration of financial fraud detection based on the improved Mamba architecture. By constructing efficient sequence modeling and dynamic state updating mechanisms, the model achieved excellent performance across multiple metrics. It effectively handled the complexity and temporal characteristics of financial transaction data. The results show that the method not only improves the ability to identify fraud patterns but also reduces false alarms and enhances stability. This advantage provides new insights for financial risk control systems, making it possible to maintain high accuracy and robustness in large and dynamic transaction networks.
From the experimental performance, the improved Mamba architecture is particularly strong in long-sequence modeling and under noisy disturbances. It demonstrates robustness and adaptability in complex scenarios. Compared with traditional methods, it shows clearer advantages in distinguishing fraud from normal transactions. It also maintains stable performance when dealing with imbalanced data and high-dimensional features. These characteristics meet the urgent needs of the financial industry for risk control and confirm the application potential of sequence modeling architectures in financial security.
The significance of this study goes beyond academic model improvement. It also contributes to the practical implementation of financial technology. Efficient fraud detection systems help financial institutions reduce economic losses and enhance user trust. They also provide regulators with forward-looking technical support. At the same time, the feature modeling and robustness enhancement mechanisms demonstrated in this method can serve as references for other high-risk domains. These include insurance claim review, e-commerce fraud prevention, and cybersecurity defense. This broadens the application value and social impact of the research.
Future research may extend in three directions. First, integrating richer multimodal data, such as text, logs, and graph-structured information, to improve the comprehensiveness of fraud detection. Second, exploring lightweight and low-latency implementations to enable efficient deployment in real-time transaction systems. Third, strengthening adversarial defense and interpretability research to ensure security when facing complex attacks, while providing transparent and reliable decision support for practitioners. With continued progress in these directions, the proposed method is expected to exert a broader and deeper impact across multiple application domains.
References
- D. Vallarino, "Detecting financial fraud with hybrid deep learning: A mix-of-experts approach to sequential and anomalous patterns," arXiv preprint arXiv:2504.03750, 2025.
- G. Zioviris, K. Kolomvatsos and G. Stamoulis, "An intelligent sequential fraud detection model based on deep learning," The Journal of Supercomputing, vol. 80, no. 10, pp. 14824-14847, 2024. [CrossRef]
- Y. Chen, C. Zhao, Y. Xu, et al., "Year-over-year developments in financial fraud detection via deep learning: A systematic literature review," arXiv preprint arXiv:2502.00201, 2025.
- S. S. Sulaiman, I. Nadher and S. M. Hameed, "Credit card fraud detection using improved deep learning models," Computers, Materials & Continua, vol. 78, no. 1, 2024. [CrossRef]
- W. Zhu, "Fast adaptation pipeline for LLMs through structured gradient approximation," Journal of Computer Technology and Software, vol. 3, no. 6, 2024.
- W. Xu, J. Zheng, J. Lin, M. Han and J. Du, "Unified representation learning for multi-intent diversity and behavioral uncertainty in recommender systems," arXiv preprint arXiv:2509.04694, 2025.
- Y. Wang, "Structured compression of large language models with sensitivity-aware pruning mechanisms," Journal of Computer Technology and Software, vol. 3, no. 9, 2024.
- W. Cui, "Unsupervised contrastive learning for anomaly detection in heterogeneous backend system," Transactions on Computational and Scientific Methods, vol. 4, no. 7, 2024.
- Y. T. Lei, C. Q. Ma, Y. S. Ren, et al., "A distributed deep neural network model for credit card fraud detection," Finance Research Letters, vol. 58, 104547, 2023. [CrossRef]
- X. Hu, Y. Kang, G. Yao, T. Kang, M. Wang and H. Liu, "Dynamic prompt fusion for multi-task and cross-domain adaptation in LLMs," arXiv preprint arXiv:2509.18113, 2025.
- R. Zhang, "Privacy-oriented text generation in LLMs via selective fine-tuning and semantic attention masks," Journal of Computer Technology and Software, vol. 4, no. 8, 2025.
- M. Gong, Y. Deng, N. Qi, Y. Zou, Z. Xue and Y. Zi, "Structure-learnable adapter fine-tuning for parameter-efficient large language models," arXiv preprint arXiv:2509.03057, 2025.
- Q. Sha, "Hybrid deep learning for financial volatility forecasting: An LSTM-CNN-Transformer model," Transactions on Computational and Scientific Methods, vol. 4, no. 11, 2024.
- R. Hao, X. Hu, J. Zheng, C. Peng and J. Lin, "Fusion of local and global context in large language models for text classification," 2025.
- R. Zhang, L. Lian, Z. Qi and G. Liu, "Semantic and structural analysis of implicit biases in large language models: An interpretable approach," arXiv preprint arXiv:2508.06155, 2025.
- M. Ahmed, A. N. Mahmood and M. R. Islam, "A survey of anomaly detection techniques in financial domain," Future Generation Computer Systems, vol. 55, pp. 278-288, 2016. [CrossRef]
- Y. Alghofaili, A. Albattah and M. A. Rassam, "A financial fraud detection model based on LSTM deep learning technique," Journal of Applied Security Research, vol. 15, no. 4, pp. 498-516, 2020. [CrossRef]
- Q. Xu, "Unsupervised temporal encoding for stock price prediction through dual-phase learning," 2025.
- Q. R. Xu, W. Xu, X. Su, K. Ma, W. Sun and Y. Qin, "Enhancing systemic risk forecasting with deep attention models in financial time series," 2025.
- X. Su, "Forecasting asset returns with structured text factors and dynamic time windows," Transactions on Computational and Scientific Methods, vol. 4, no. 6, 2024.
- Y. Lin, "Graph neural network framework for default risk identification in enterprise credit relationship networks," Transactions on Computational and Scientific Methods, vol. 4, no. 4, 2024.
- H. Yang, M. Wang, L. Dai, Y. Wu and J. Du, "Federated graph neural networks for heterogeneous graphs with data privacy and structural consistency," 2025.
- Y. Lin and P. Xue, "Multi-task learning for macroeconomic forecasting based on cross-domain data fusion," Journal of Computer Technology and Software, vol. 4, no. 6, 2025.
- Y. Wang, Q. Sha, H. Feng and Q. Bao, "Target-oriented causal representation learning for robust cross-market return prediction," Journal of Computer Science and Software Applications, vol. 5, no. 5, 2025.
- R. Wang, Y. Chen, M. Liu, G. Liu, B. Zhu and W. Zhang, "Efficient large language model fine-tuning with joint structural pruning and parameter sharing," 2025.
- Y. Qin, "Hierarchical semantic-structural encoding for compliance risk detection with LLMs," Transactions on Computational and Scientific Methods, vol. 4, no. 6, 2024.
- T. Pervin, S. Akter, S. Afrin, et al., "A hybrid CNN-LSTM approach for detecting anomalous bank transactions: Enhancing financial fraud detection accuracy," The American Journal of Management and Economics Innovations, vol. 7, no. 04, pp. 116-123, 2025. [CrossRef]
- C. Yu, Y. Xu, J. Cao, et al., "Credit card fraud detection using advanced transformer model," Proceedings of the 2024 IEEE International Conference on Metaverse Computing, Networking, and Applications (MetaCom), IEEE, pp. 343-350, 2024.
- B. Qu, Z. Wang, M. Gu, et al., "Multi-task CNN behavioral embedding model for transaction fraud detection," Proceedings of the 2024 IEEE International Conference on Data Mining Workshops (ICDMW), IEEE, pp. 286-292, 2024.
- Z. Liu, H. Mao, C. Y. Wu, et al., "A convnet for the 2020s," Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11976-11986, 2022. [CrossRef]
- T. Huang, J. Huang, C. Dong, et al., "SAMamba: Structure-aware Mamba for Ethereum fraud detection," IEEE Transactions on Information Forensics and Security, 2025. [CrossRef]
Figure 1.
Overall model architecture diagram.
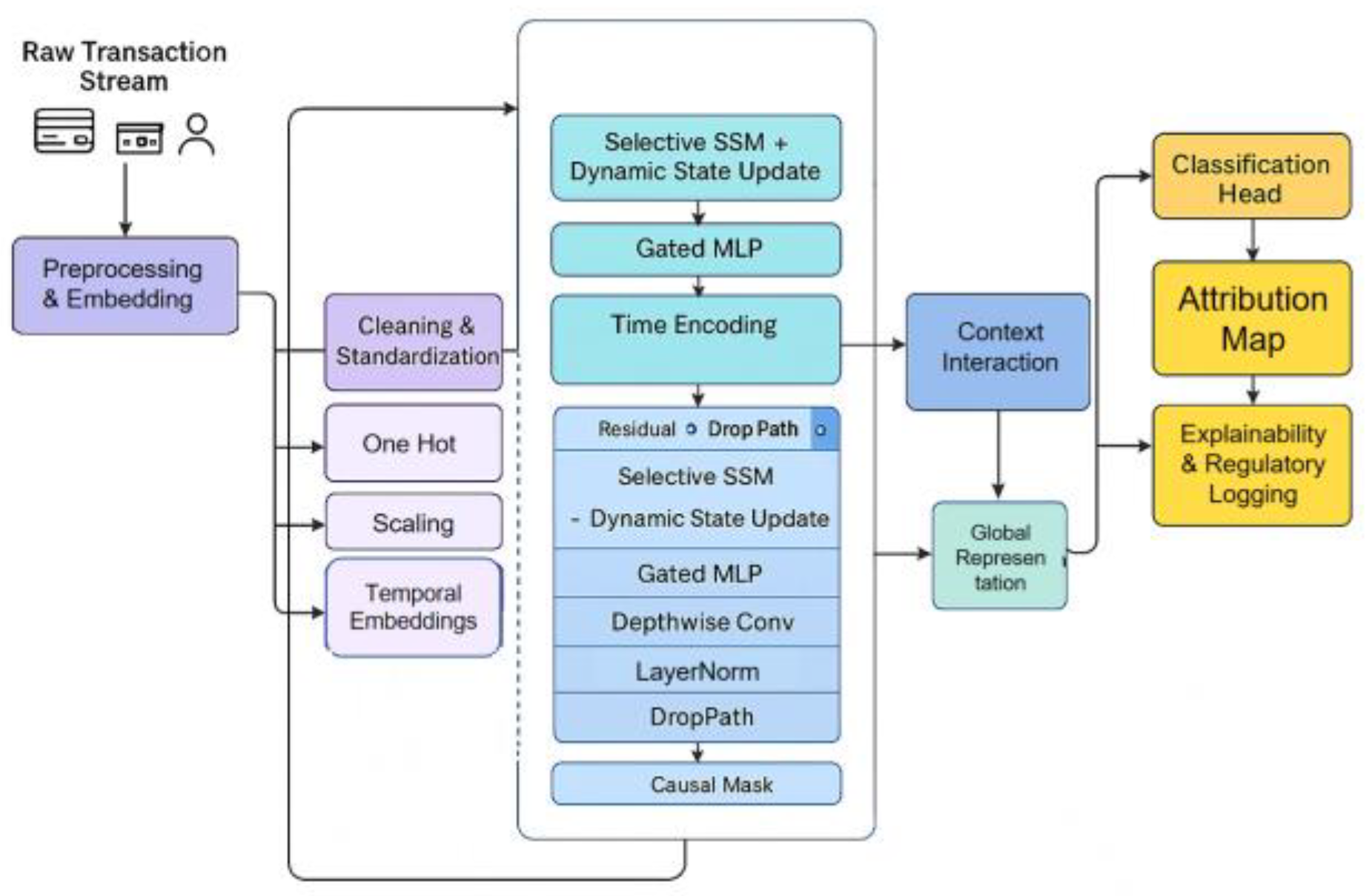
Figure 2.
Results of sequence length sensitivity experiments.
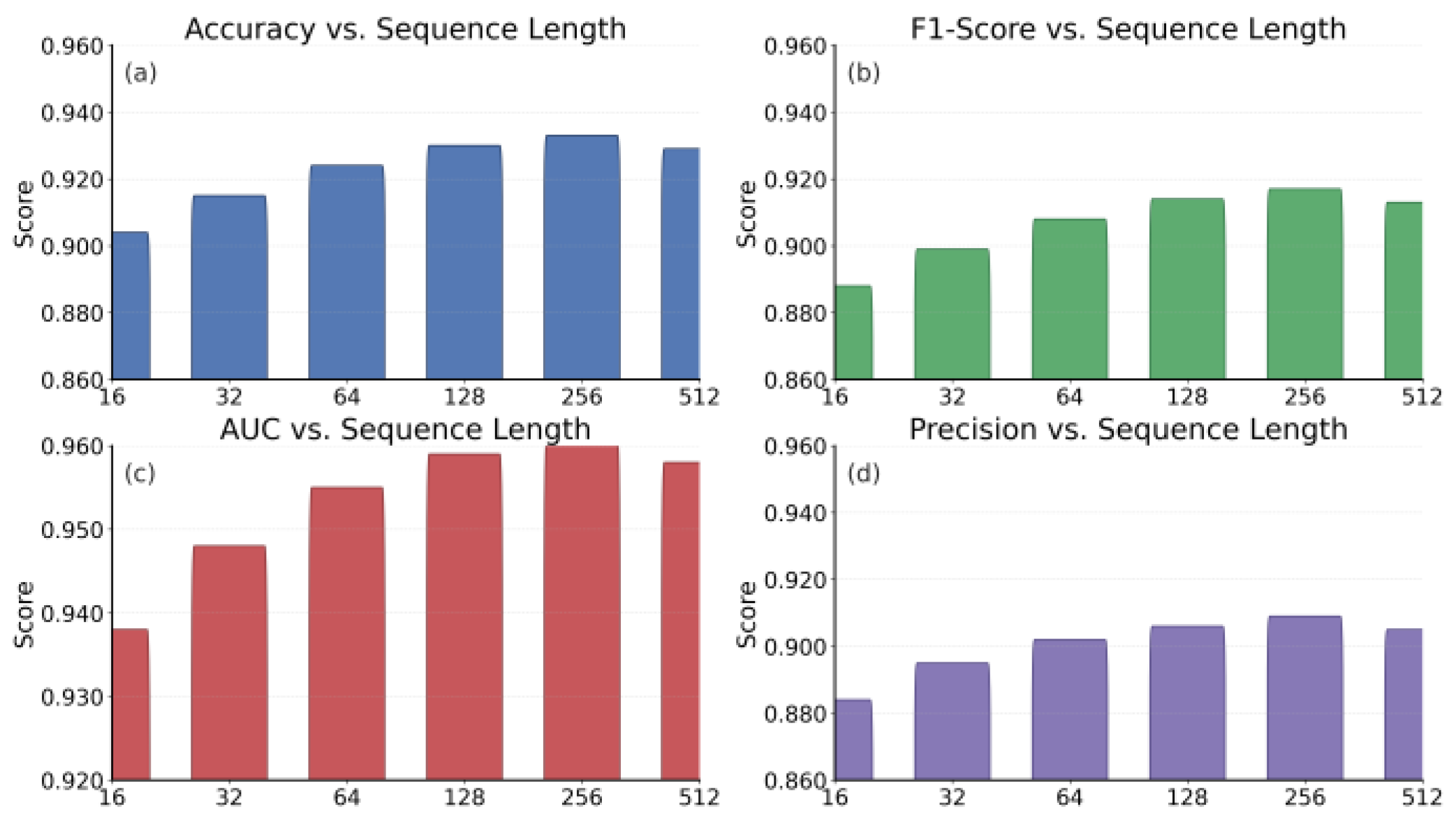
Figure 3.
Noise injection and adversarial perturbation robustness evaluation.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



