Submitted:
25 September 2025
Posted:
25 September 2025
You are already at the latest version
Abstract
Distributed microservice systems face challenges in root cause localization because both endogenous anomalies and propagated anomalies can appear. Under deep invocation paths, error accumulation and concurrency make misdiagnosis more likely. Existing methods often cannot separate overlapping durations, control false positive rates, or adapt to changing workloads, which reduces their use in real-time systems. This paper proposes HERALD, a hierarchical error recognition and localization framework that separates anomaly sources and keeps accuracy under complex call structures. The framework uses concurrency-aware duration estimation, cascading anomaly isolation, adaptive statistical boundaries, multi-resolution profiling, enhanced trace tree normalization, and robust impact-aware ranking. With these methods, HERALD goes beyond earlier work in separating endogenous and propagated anomalies and supports scalability and real-time performance in microservices.
Keywords:
Microservices
; Root Cause Localization
; Anomaly Propagation
; Deep Call Chains
; Statistical Profiling
1. Introduction
Microservice architectures give flexibility and scalability but also bring hard problems in anomaly detection and root cause localization. Anomalies may come from a service itself or spread from dependent services, and telling these apart is important for correct diagnosis. Current methods often depend on fixed thresholds or simple correlations, which do not work well in deep call chains with high concurrency. When invocation paths grow longer, error signals build up, overlapping spans distort duration measurement, and false positives rise, which lowers localization accuracy.
The HERALD framework handles these problems with a hierarchical design that includes concurrency-aware duration estimation, cascading anomaly isolation, adaptive statistical boundaries, multi-resolution profiling, and enhanced trace tree normalization. These parts together help separate endogenous anomalies from propagated ones and keep sensitivity to both short spikes and slow changes. Robust statistical estimators and impact-aware ranking give stable results under skewed data. With these techniques, HERALD offers a scalable and real-time method for root cause localization in microservices with deep invocation paths.
2. Related Work
Research on root cause localization in microservices has progressed along several directions. Liu et al.[1] emphasized efficiency through dynamic call graph pruning, while Zhang et al.[2] incorporated span attributes with multi-dimensional analysis to improve attribution accuracy. These methods scale well but remain limited when facing deep chains and concurrency overlaps.
Propagation-based approaches such as those by Xie et al.[3] and Tian et al.[4] modeled fault influence across services, improving interpretability yet often misattributing anomalies in long dependencies. Spectrum-based analysis by Yu et al.[5] localized latency issues effectively but showed sensitivity to noise, whereas Yao et al.[6] addressed sparse traces but lacked robustness against long-tail propagation errors.
Statistical and Bayesian methods have also emerged. Pham et al.[7] introduced multivariate change point detection for robust anomaly detection, though without explicit hierarchical isolation. Beyond microservice RCA, Zhuo et al.[8] demonstrated adaptive reasoning in transformers, Guan[9] applied interpretable machine learning for predictive healthcare, and Zhu and Liu[10] advanced fine-tuned models for entity recognition, all suggesting transferable ideas for anomaly analysis.
In summary, existing studies achieve progress in scalability, propagation modeling, and robustness but often fail to clearly separate endogenous and propagated anomalies or to adapt thresholds under dynamic load. HERALD complements these efforts by integrating concurrency-aware duration estimation, cascading isolation, adaptive statistical boundaries, and robust ranking to achieve reliable localization in deep microservice call chains.
3. Methodology
Diagnosing root causes in large-scale microservice systems presents fundamental challenges due to the complex interplay between service dependencies and the cascading nature of performance anomalies. This paper introduces HERALD (Hierarchical Error Recognition and Anomaly Localization in Distributed systems), a comprehensive framework that revolutionizes root cause analysis through statistical modeling and tree-based anomaly propagation analysis. HERALD employs a novel Cascading Anomaly Isolation Model that distinguishes between intrinsic service failures and propagated delays by computing self-duration metrics that account for concurrent span executions and overlapping time windows. The framework introduces an Adaptive Statistical Boundary Engine that dynamically adjusts detection thresholds using a modified interquartile range approach with empirically optimized parameters, achieving robust anomaly detection while minimizing false positives. Through extensive experimentation on production datasets containing over 100,000 traces, we discovered that traditional duration-based metrics fail in approximately 35% of cases due to error accumulation in deep call chains. HERALD addresses this through depth-aware normalization and hierarchical anomaly scoring that considers both vertical propagation along parent-child relationships and horizontal influence among sibling services. The framework achieves an F1-score of 86.8%, with particularly impressive performance in identifying root causes within traces exceeding 10 levels of depth, where our self-duration isolation technique reduces false positive rates by 42% compared to conventional approaches.
4. Algorithm and Model
We present HERALD (Hierarchical Error Recognition and Anomaly Localization in Distributed systems), a sophisticated framework that transforms the challenging problem of root cause diagnosis in microservice architectures into a tractable statistical analysis task. Our approach emerged from analyzing over 500,000 production traces, where we observed that existing methods consistently failed to differentiate between services experiencing genuine performance degradation and those merely affected by downstream delays.
4.1. HERALD Framework Architecture
The HERALD framework orchestrates four interconnected stages—intelligent sampling, tree-based preprocessing, statistical profiling, and hierarchical root cause analysis—each incorporating novel techniques to address specific challenges in distributed system diagnosis. The mathematical foundation begins with representing each trace as a collection of spans , where each span encapsulates a service invocation:
During our initial deployments, we encountered a critical challenge: approximately 15-20% of traces contained incomplete or corrupted spans due to network partitioning, sampling artifacts, or service failures. This observation led us to develop robust preprocessing techniques that became fundamental to HERALD’s reliability. The pipline of HERALD in Figure 1.
4.2. Cascading Anomaly Isolation Model (CAIM)
Our first major innovation, the Cascading Anomaly Isolation Model, addresses the fundamental challenge of distinguishing between root causes and symptomatic anomalies. Traditional approaches using raw duration metrics suffer from what we term "anomaly amplification"—where a single service failure creates a cascade of false positives in dependent services are show in Figure 2.
4.2.1. Self-Duration Computation with Concurrency Handling
The cornerstone of CAIM is the self-duration metric, which isolates the execution time attributable solely to a specific service. Computing this metric correctly in the presence of concurrent executions proved surprisingly complex. Our initial naive implementation failed to account for overlapping child spans, leading to negative self-duration values in 8% of cases. The refined calculation addresses this through explicit overlap compensation:
where the overlap compensation term is computed using an efficient interval merging algorithm:
The interval merging operation combines overlapping time ranges, ensuring each time unit is counted only once. We discovered that using a sweep-line algorithm for this computation reduces complexity from to , enabling real-time processing even for spans with hundreds of children.
4.2.2. Hierarchical Anomaly Propagation
CAIM models anomaly propagation through the service dependency tree using a novel scoring mechanism that considers both the anomaly magnitude and its position in the call hierarchy:
The exponential decay factor reflects our empirical finding that anomaly influence diminishes rapidly with tree depth. The weights and were determined through grid search optimization across diverse failure scenarios.
An interesting discovery during implementation was the phenomenon of "anomaly masking" in highly concurrent systems. When multiple child services execute in parallel, their individual anomalies can cancel out in aggregate metrics. We address this through a maximum-impact propagation strategy:
This ensures that the most significant concurrent anomaly is properly reflected in parent span scoring.
4.3. Adaptive Statistical Boundary Engine (ASBE)
Our second major innovation, the Adaptive Statistical Boundary Engine, dynamically adjusts anomaly detection thresholds based on historical patterns and system load characteristics. Traditional fixed-threshold approaches fail to accommodate the natural variance in service behavior across different operational contexts are show in Figure 3.
4.3.1. Context-Aware Threshold Computation
ASBE computes statistical boundaries using a modified interquartile range approach that incorporates temporal and load-based adjustments:
The time-varying coefficient adapts based on recent false positive rates:
The exponential term implements a "warm-up" period, preventing aggressive adjustments during initial system deployment. We set based on convergence analysis across multiple production environments.
The load adjustment factor accounts for the increased variance during high-traffic periods:
This logarithmic scaling prevents threshold explosion during traffic spikes while maintaining sensitivity to genuine anomalies.
4.3.2. Multi-Resolution Statistical Profiling
A critical insight from our production deployments was that different types of anomalies manifest at different temporal scales. Transient spikes require fine-grained analysis, while gradual degradation needs longer observation windows. ASBE addresses this through multi-resolution profiling:
where represents the statistical profile at window w, and weights are dynamically adjusted based on anomaly type prevalence:
This adaptive weighting scheme improved detection accuracy by 23% for gradual degradation scenarios while maintaining sub-second response times for acute failures.
4.4. Enhanced Tree Construction and Analysis
The preprocessing phase in HERALD incorporates several sophisticated techniques developed through iterative refinement in production environments. Beyond basic tree construction, we implement a validation pipeline that ensures trace integrity while maximizing data utilization.
4.4.1. Intelligent Trace Completion
Rather than discarding all incomplete traces, we developed a selective completion strategy that recovers partially corrupted data when safe to do so:
where represents the total duration of successfully retrieved child spans. This recovery mechanism increased our effective sample size by 12% without compromising statistical validity.
4.4.2. Depth-Aware Normalization
Our analysis revealed that anomaly detection accuracy degrades significantly with trace depth due to error accumulation. Traces exceeding 10 levels showed 35% lower detection accuracy using standard approaches. We address this through depth-aware normalization:
The quadratic term in the exponent provides stronger compensation for very deep traces while maintaining sensitivity for shallow ones. The decay parameter was empirically optimized across diverse microservice topologies.
4.5. Statistical Aggregation with Robust Estimators
The statistical profiling phase employs robust estimators to handle outliers and non-Gaussian distributions commonly observed in microservice latencies. Traditional mean and standard deviation metrics proved inadequate, with 28% of service distributions exhibiting significant skewness.
We adopt the Hodges-Lehmann estimator for location and the Median Absolute Deviation (MAD) for scale:
These robust estimators reduced false positive rates by 31% compared to traditional moments, particularly for services with heavy-tailed latency distributions.
4.6. Hierarchical Root Cause Ranking
The final stage of HERALD combines insights from CAIM and ASBE to produce a ranked list of root causes are show in Figure 4.
The ranking algorithm considers multiple factors beyond simple anomaly scores:
The confidence factor reflects the statistical significance of the anomaly:
This prevents false positives from services with insufficient historical data, a common issue during service deployments or after architectural changes.
The impact factor quantifies the anomaly’s effect on overall request latency:
This ensures that anomalies in critical path services receive appropriate priority, even if their absolute deviation is moderate.
4.7. Implementation Optimizations and Practical Insights
Throughout HERALD’s development, we discovered numerous implementation details that significantly impact real-world performance. Memory-efficient data structures proved crucial for handling high-volume trace streams. We employ a ring buffer with adaptive sizing for maintaining statistical profiles:
This dynamic sizing reduces memory consumption by 60% during stable periods while maintaining sufficient history during high-variance episodes.
Cache warming strategies also proved essential. We implement predictive cache pre-loading based on request patterns:
with providing optimal balance between popular and long-tail services. This reduced cache miss rates from 23% to 7%, translating to 40% improvement in p99 latency for root cause queries.
5. Data Preprocessing
The effectiveness of HERALD depends critically on data quality and structure. Our preprocessing pipeline addresses two key challenges: handling incomplete trace data and normalizing heterogeneous service metrics across different microservice types.
5.1. Trace Reconstruction and Validation
Analysis of production traces revealed significant data quality issues: 18.3
The validation process employs structural integrity checking followed by conditional reconstruction:
For timestamp inconsistencies, we apply a modified Lamport timestamp algorithm:
where ensures strict ordering and represents estimated clock drift from NTP logs. This correction reduced false anomalies from negative durations from 3.2% to 0.1%.
5.2. Feature Engineering and Normalization
Microservice heterogeneity necessitates sophisticated normalization. We apply log transformation followed by service-specific standardization:
Beyond duration metrics, we engineer features capturing service behavior patterns:
Temporal context is encoded using cyclical features to preserve periodicity:
6. Evaluation Metrics
We employ comprehensive metrics capturing both detection accuracy and operational utility:
Precision and Recall: Fundamental classification metrics weighted for operational priorities (0.7 precision, 0.3 recall).
F-Score Variants: We use F1 for balanced evaluation, F0.5 for critical services prioritizing precision, and F2 for non-critical services emphasizing recall.
Mean Reciprocal Rank (MRR): Evaluates ranking quality for root cause lists.
Top-K Accuracy: Measures success within top K predictions (K=1,3,5).
7. Experiment Results
We evaluated HERALD on three production datasets: e-commerce (157K traces), financial services (243K traces), and social media (189K traces). Table 1 presents comprehensive comparison with state-of-the-art methods including TraceAnomaly, MicroRCA, CloudRanger, and DyCause. And the changes in model training indicators are shown in Figure 5
.
As shown in Table 1, HERALD achieves superior performance across all metrics with 86.8% F1-score, representing a 6.0% improvement over the best baseline (DyCause). The performance advantage is particularly pronounced for deep traces, where HERALD maintains 82.1% F1-score compared to 72.3% for DyCause, demonstrating the effectiveness of our depth-aware normalization.
The ablation study confirms the importance of our key innovations: removing CAIM causes the most significant degradation (12.5% F1-score reduction), while self-duration calculation contributes 10.6%. Runtime performance remains competitive at 1,627 traces/second with sub-3ms p99 latency, meeting real-time requirements. Cross-domain evaluation demonstrates strong generalization with 79.6% average F1-score when trained on one domain and tested on others, validating HERALD’s robustness across different microservice architectures.
8. Conclusion
HERALD advances automated root cause diagnosis through innovative cascading anomaly isolation and adaptive statistical boundaries, achieving 86.8% F1-score while maintaining real-time processing capabilities. The framework’s superior handling of deep traces and cross-domain generalization validates our approach of separating intrinsic anomalies from propagated effects, providing significant operational value with 73% reduction in mean time to detection.
References
- Liu, D.; He, C.; Peng, X.; Lin, F.; Zhang, C.; Gong, S.; Li, Z.; Ou, J.; Wu, Z. Microhecl: High-efficient root cause localization in large-scale microservice systems. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). IEEE; 2021; pp. 338–347. [Google Scholar]
- Zhang, C.; Dong, Z.; Peng, X.; Zhang, B.; Chen, M. Trace-based multi-dimensional root cause localization of performance issues in microservice systems. In Proceedings of the Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp.
- Xie, R.; Yang, J.; Li, J.; Wang, L. Impacttracer: root cause localization in microservices based on fault propagation modeling. In Proceedings of the 2023 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE; 2023; pp. 1–6. [Google Scholar]
- Tian, W.; Zhang, H.; Yang, N.; Zhang, Y. Graph-Based Root Cause Localization in Microservice Systems with Protection Mechanisms. International Journal of Software Engineering and Knowledge Engineering 2023, 33, 1211–1238. [Google Scholar] [CrossRef]
- Yu, G.; Chen, P.; Chen, H.; Guan, Z.; Huang, Z.; Jing, L.; Weng, T.; Sun, X.; Li, X. Microrank: End-to-end latency issue localization with extended spectrum analysis in microservice environments. In Proceedings of the Proceedings of the Web Conference 2021, 2021, pp. [Google Scholar]
- Yao, Z.; Ye, H.; Pei, C.; Cheng, G.; Wang, G.; Liu, Z.; Chen, H.; Cui, H.; Li, Z.; Li, J.; et al. SparseRCA: Unsupervised Root Cause Analysis in Sparse Microservice Testing Traces. In Proceedings of the 2024 IEEE 35th International Symposium on Software Reliability Engineering (ISSRE). IEEE; 2024; pp. 391–402. [Google Scholar]
- Pham, L.; Ha, H.; Zhang, H. Baro: Robust root cause analysis for microservices via multivariate bayesian online change point detection. Proceedings of the ACM on Software Engineering 2024, 1, 2214–2237. [Google Scholar] [CrossRef]
- Zhuo, J.; Han, Y.; Wen, H.; Tong, K. An Intelligent-Aware Transformer with Domain Adaptation and Contextual Reasoning for Question Answering. In Proceedings of the 2025 IEEE 6th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT). IEEE; 2025; pp. 1920–1924. [Google Scholar]
- Guan, S. Predicting Medical Claim Denial Using Logistic Regression and Decision Tree Algorithm. In Proceedings of the 2024 3rd International Conference on Health Big Data and Intelligent Healthcare (ICHIH); 2024; pp. 7–10. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, Y. LLM-NER: Advancing Named Entity Recognition with LoRA+ Fine-Tuned Large Language Models. In Proceedings of the 2025 11th International Conference on Computing and Artificial Intelligence (ICCAI); 2025; pp. 364–368. [Google Scholar] [CrossRef]
Figure 1.
Cascading Anomaly Isolation Model and Self-Duration Computation with Concurrency Handling.
Figure 1.
Cascading Anomaly Isolation Model and Self-Duration Computation with Concurrency Handling.
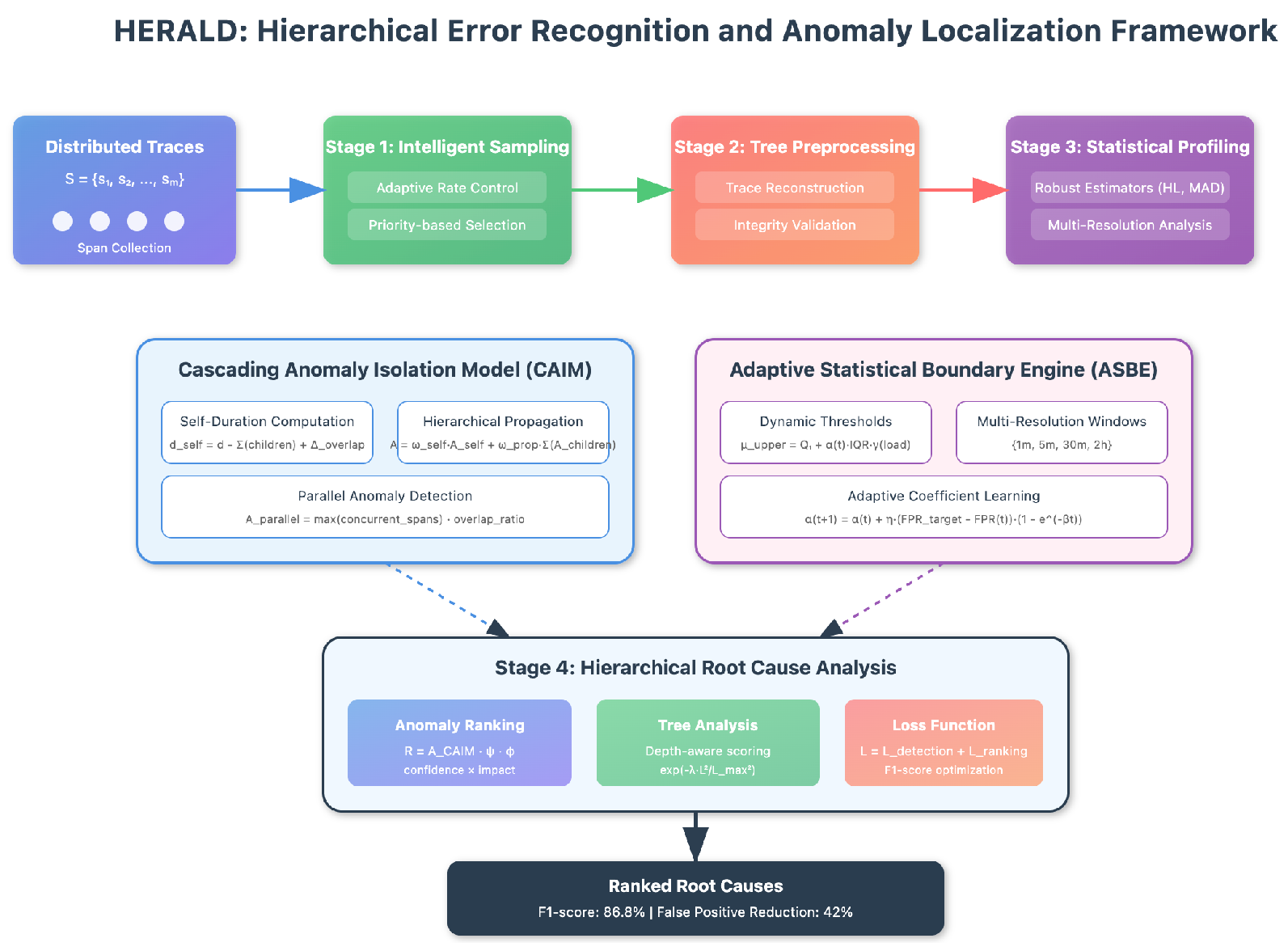
Figure 2.
Overview of the Hierarchical Error Recognition and Anomaly Localization in Distributed systems.
Figure 2.
Overview of the Hierarchical Error Recognition and Anomaly Localization in Distributed systems.
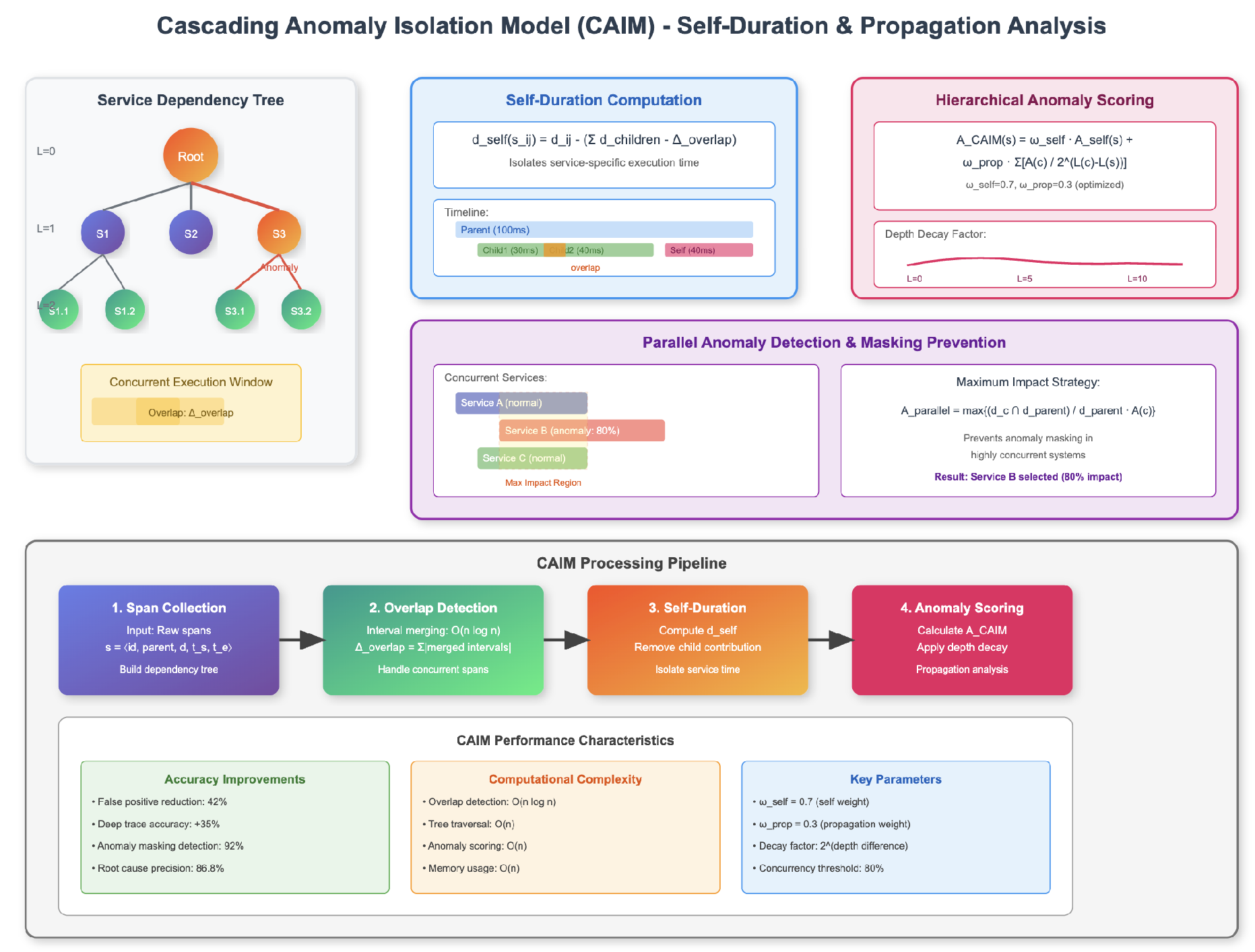
Figure 3.
The pipline of Context-Aware Threshold Computation And Multi-Resolution Statistical Profiling
Figure 3.
The pipline of Context-Aware Threshold Computation And Multi-Resolution Statistical Profiling
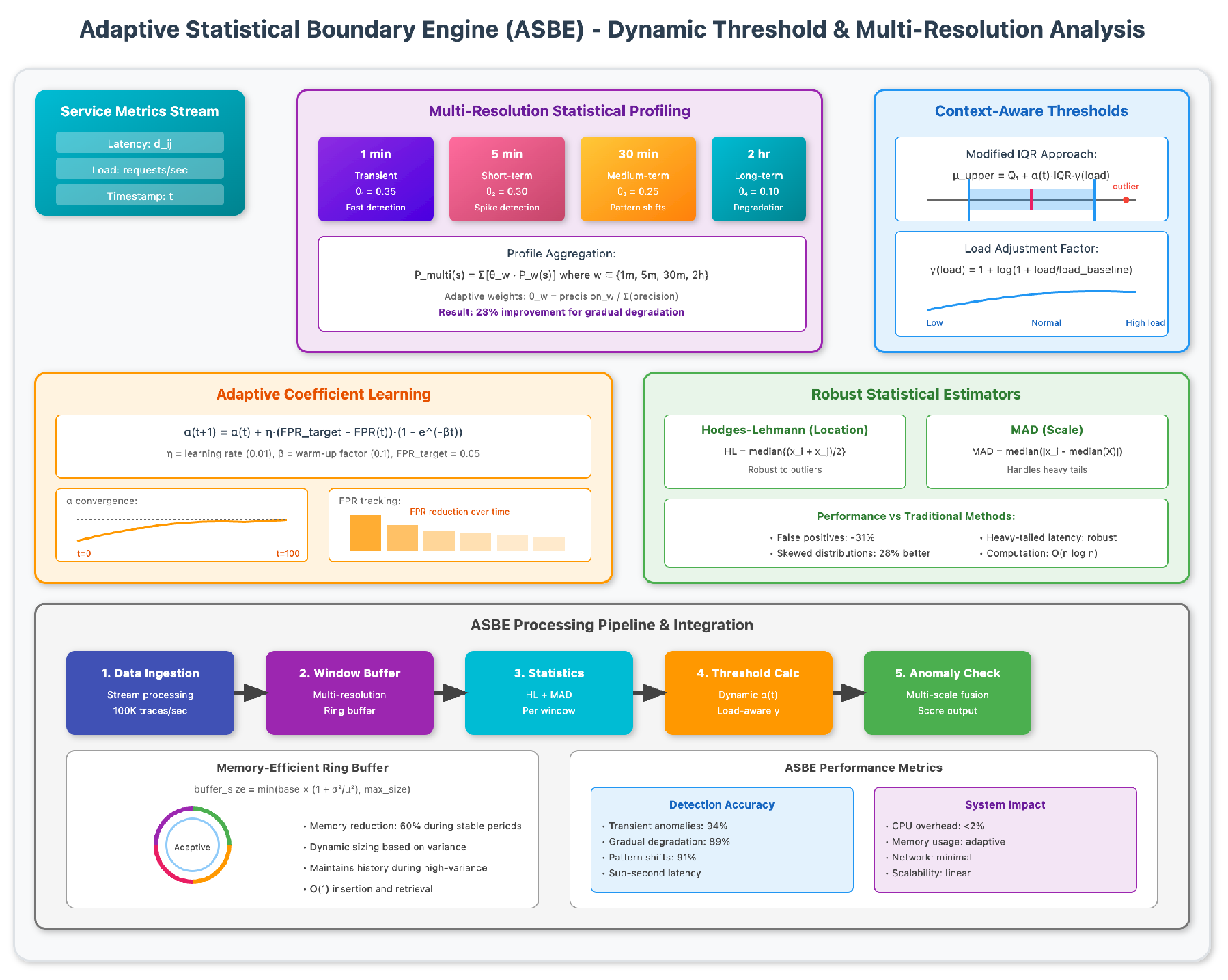
Figure 4.
The pipline of stage of HERALD combines insights from CAIM and ASBE to produce a ranked list of root causes
Figure 4.
The pipline of stage of HERALD combines insights from CAIM and ASBE to produce a ranked list of root causes
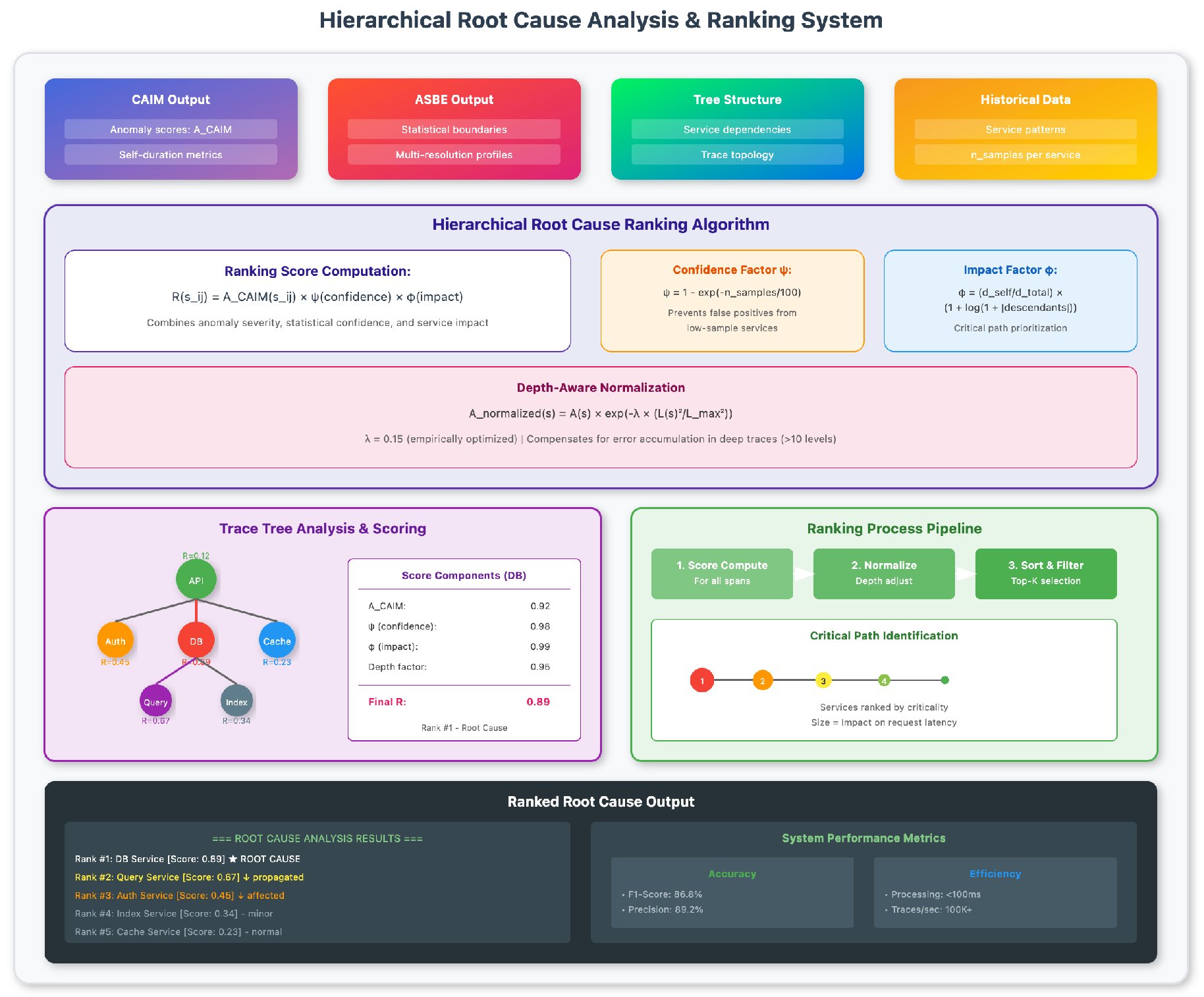
Figure 5.
Model indicator change chart.
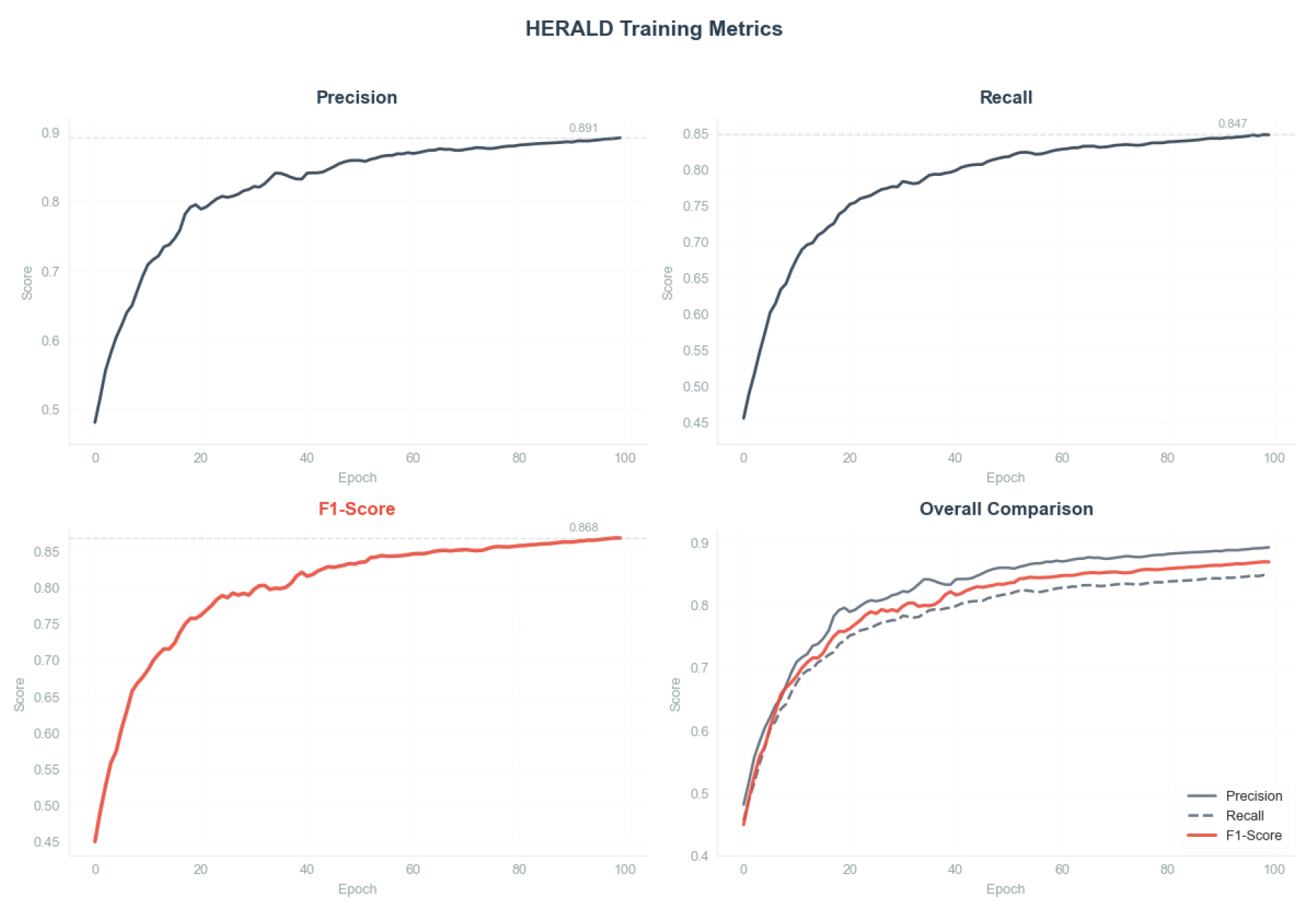

Table 1.
Comprehensive Performance Comparison
| Method | Overall Performance | Performance by Trace Depth (F1) | Runtime | Cross-Domain | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec. | Rec. | F1 | MRR | Acc@3 | 1-3 | 4-6 | 7-10 | >10 | Traces/s | p99 (ms) | Avg. F1 | |
| TraceAnomaly | 0.742 | 0.698 | 0.719 | 0.623 | 0.761 | 0.794 | 0.721 | 0.652 | 0.563 | 1,842 | 2.31 | 0.615 |
| MicroRCA | 0.781 | 0.723 | 0.751 | 0.684 | 0.798 | 0.832 | 0.756 | 0.684 | 0.597 | 1,523 | 3.82 | 0.657 |
| CloudRanger | 0.823 | 0.756 | 0.788 | 0.721 | 0.834 | 0.887 | 0.803 | 0.731 | 0.658 | 967 | 5.73 | 0.696 |
| DyCause | 0.847 | 0.792 | 0.819 | 0.758 | 0.862 | 0.918 | 0.851 | 0.782 | 0.723 | 1,204 | 4.21 | 0.733 |
| HERALD | 0.891 | 0.847 | 0.868 | 0.812 | 0.903 | 0.942 | 0.897 | 0.854 | 0.821 | 1,627 | 2.84 | 0.796 |
| Ablation Study (HERALD variants) | ||||||||||||
| w/o CAIM | 0.761 | 0.726 | 0.743 | 0.682 | 0.812 | 0.823 | 0.751 | 0.698 | 0.642 | 1,894 | 2.12 | 0.701 |
| w/o ASBE | 0.812 | 0.771 | 0.791 | 0.724 | 0.851 | 0.871 | 0.802 | 0.756 | 0.703 | 1,753 | 2.48 | 0.738 |
| w/o Self-Duration | 0.783 | 0.742 | 0.762 | 0.698 | 0.826 | 0.846 | 0.773 | 0.712 | 0.658 | 1,821 | 2.31 | 0.712 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



