Submitted:
22 September 2025
Posted:
23 September 2025
You are already at the latest version
Abstract
We discuss Markov
edge processes $\{Y_e; e \in E\}$ defined on edges of a directed
acyclic graph $(V, E)$ with the consistency property:
$$
{\mathrm P}_{E'}(Y_e; e \in E') = {\mathrm P}_E(Y_e; e \in E')
$$
for a large class of subgraphs $(V',E')$ of $(V,E)$ obtained
through a mesh dismantling algorithm.
The probability distribution ${\mathrm P}_E$ of such edge process is a discrete version of consistent polygonal Markov graphs studied in \cite{arakDS1993, arakDS1989}. The class of Markov edge processes is related to the class of Bayesian networks and may be of interest to causal inference and decision theory.
On regular $\nu$-dimensional lattices, consistent Markov edge processes have similar properties to
Pickard random fields on ${\mathbb Z}^2$, representing a far-reaching
extension of the latter class. A particular case of binary consistent edge process on ${\mathbb Z}^3$ was disclosed by Arak in a private communication.
We prove that symmetric
binary Pickard model generates Arak model on ${\mathbb Z}^2$ as
a contour model.
Keywords:
directed acyclic graph
; Markov edge process
; clique distribution
; consistency criterion
; mesh dismantling algorithm
; Bayesian network
; Pickard random field
; regular lattice
; Arak model
; evolution of particle system
; broken line process
; contour edge process
1. Introduction
Bayesian network is a probabilistic graphical model that represents a set of variables and their conditional dependencies via a directed acyclic graph [Wikipedia]. Bayesian network is a fundamental concept in learning and artificial intelligence, see [20,21,25]. Formally, a Bayesian network is a random field indexed by sites of a directed acyclic graph (DAG) whose probability distribution writes as a product over of conditional probabilities of given its parent variables , where is the set of parents of v.
Bayesian network is a special case of Markov random field on (generally undirected) graph . Markov random fields include nearest-neighbor Gibbs random fields and play an important role in many applied sciences including statistical physics and image analysis [4,13,17,18].
As noted in [5,10,23] and elsewhere, manipulating marginals (e.g., computing the mean or the covariance function) of a Gibbs random field is generally very hard when V is large. A class of Markov random fields on which avoids this difficulty was proposed by Pickard [22,23] (the main idea of their construction belongs to Verhagen [30], see [22]). Pickard and related unilateral random fields have been found useful applications in image analysis, coding, information theory, crystallography, and other scientific areas, not least because they allow for efficient simulation procedures [5,7,10,11,14]
Pickard model (rigorously defined in sec.2) is a family of Bayesian networks on rectangular graphs enjoying the important (Kolmogorov) consistency property: for any rectangles we have that
where is the distribution of and is the restriction of marginal of on . Property (1.1) implies that Pickard model extends to a stationary random field on whose marginals coincide with and form Markov chains on each horizontal or vertical line.
Arak et al [1,2] introduced a class of polygonal Markov graphs and random fields indexed by continuous argument satisfying a similar consistency property: for any bounded convex domains the restriction of to coincides in distribution with . The above models allow a Gibbs representation but are constructed via equilibrium evolution of a one-dimensional particle system with random piece-wise constant Markov velocities, with birth, death and branching. Particles move independently and interact only at collisions. Similarity between polygonal and Pickard models was noted in [28]. Several papers [15,16,29] used polygonal graphs in landscape modeling and random tesselation problems.
The present paper discusses a far-reaching extension of polygonal graphs and Pickard model, satisfying a consistency property similar to (1.1) but not directly related to lattices or rectangles. The original idea of the construction (communicated to the author by Taivo Arak in 1992) referred to a particle evolution on the three-dimensional lattice . In this paper, the above Arak model is extended to any dimension and discussed in sec.5 in detail. It is a special case of a Markov edge process with probability distribution introduced in sec.2 and defined on edges of a directed acyclic graph (DAG) as the product over of the conditional clique probabilities , somewhat similarly to Bayesian network, albeit the conditional probabilities refer to collection of `out-going’ clique variables and not to a single `child’ as in a Bayesian network. Markov random fields indexed by edges discussed in the literature [13,17,18] are usually defined on undirected graphs through Gibbs representation and experience a similar difficulty of computing their marginal distributions as Gibbsian site models. On the other hand, `directed’ Markov edge processes might be useful in causal analysis where edges of DAG represent `decisions’ and can be interpreted as (random) `cost’ of `decision’ .
The main result of this work is Theorem 2, providing sufficient conditions for consistency
of a family of Markov edge processes defined on DAGs with the partial order given by The sufficient conditions for (1.2) are expressed in terms of clique distributions and essentially reduce to marginal independence of incoming and outgoing clique variables (i.e., collections and ), see (3.16), (3.17).
The class of DAGs satisfying (1.2) is of special interest. In Theorem 2, is the class of all sub-DAGs obtained from a given DAG by a mesh dismantling algorithm (MDA). The above algorithm starts by erasing any edge that leads to a sink or comes from a source , and proceeds in the same way and in arbitrary order, see Definition 4. The class contains several interesting classes of `one-dimensional’ and `multi-dimensional’ sub-DAGs on which the restriction in (1.2) is identified as a Markov chain or a sequence of independent r.v.s (Corollary 2).
Section 4 discusses consistent Markov edge process on `rectangular’ sub-graphs of endowed with nearest-neighbor edges directed in the lexicographic order. We discuss properties of such edge processes and present several examples of generic clique distributions with particular attention to the binary case (referred to as Arak model). In dimension we provide a detailed description of Arak model in terms of a particle system moving along edges of . Finally, section 5 establishes a relation between Pickard and Arak models, the latter model identified in Theorem 3 as a contour model of the former model under an additional symmetry assumption.
We expect that the present work can be extended in several directions. Similarly to [5,10] and some other related studies, the discussion is limited to discrete probability distributions, albeit continuous distributions (e.g., Gaussian edge processes) are of interest. A major challenge is the application of Markov edge processes to causal analysis and Bayesian inference, bearing in mind the extensive research in the case of Bayesian networks [20,21]. Consistent Markov edge processes on regular lattices may be of interest to pattern recognition and information theory. Some open problems are mentioned in Remark 7.
2. Bayesian Networks and Pickard Random Fields
Let be a given DAG. A directed edge from to is denoted . With any vertex we can associate three sets of edges
representing the incoming edges, outgoing edges, and all edges incident to v. A vertex is called a source (respectively, a sink) if (respectively, ). The partial order (reachability relation) on G means that there is a directed path on this DAG from to . We write if The above partial order carries over to edges of G, namely, Following [21], the set of vertices is called the parents of v, whereas is called the family of v.
Definition 1.
Let be a given DAG. A family distribution at is any discrete probability distribution , that is, a sequence of positive numbers summing up to 1:
The set of all family distributions at is denoted by .
For , the conditional probability of given parent configuration writes as
with if and if .
Definition 2.
A Bayesian network on a DAG corresponding to a given set of family distributions is a random process indexed by vertices (sites) of G and such that for any configuration
We remark that the terminology `family distribution’ is not commonplace, whereas the definition of Bayesian network varies in the literature [3,20,21], being equivalent to (2.3) under the positivity condition Actually, the conditional (family) distributions in (2.3) are most intuitive and used instead of . A Bayesian network satisfies several Markov conditions [21], particularly, the ordered Markov condition:
In the rest of this subsection, is a directed subgraph of the infinite DAG with lexicographic partial order :
and edge set
The class of `rectangular’ subDAGs with
will be denoted . Given two `rectangular’ DAGs we write if . For generic family in Figure 1, right, the family distribution is is indexed by the elements of the table
and written as the joint distribution of four r.v.s with . Marginal distributions of these r.v.s are designated by the corresponding subsets of the table (2.6), e.g., is the distribution of r.v. A. The conditional distributions of these r.v.s are denoted as in (2.2), viz., is the conditional distribution of B given a value of A.
Definition 3.
We call Pickard model a Bayesian network on DAG with family distribution independent of and satisfying the following conditions:
(stationarity), and
(conditional independence).
In Pickard model, the family of consists of 4 points, see Figure 1, except when v belongs to the left lower boundary of rectangle V in (2.5) and , for it consists of the single point: . Accordingly, the family distributions are marginals of the generic distribution in Definition 3. We note that Pickard model (also called Pickard random field) is defined in [5,10,14,23] in somewhat different ways, which are equivalent to Definition 3.
Theorem 1.
[23] The family of Pickard models on DAGs and corresponding to the same generic family distribution ϕ in (2.7)-(2.8) is consistent; in other words, for any we have that
Remark 1.
The consistency property in (2.9) implies that for in (2.5), and any the restriction of Pickard model on the horizontal interval is a Markov chain
with initial distribution and transition probabilities . Indeed, is the set of vertices of and the corresponding `one-dimensional’ Pickard model on is defined by (2.10). In a similar way, the restriction of Pickard model on a vertical interval is a Markov chain
with initial distribution and transition probabilities .
[23, Thm.3] extend Markov chain identifications in (2.10) and (2.11) to any non-increasing undirected path in V. This fact and the discussion in sec.3 suggest that Pickard model and the consistency property in (2.9) can be extended to non-rectangular index sets .
Remark 2.
In the binary case or the distribution is completely determined by probabilities
In terms of (2.12), conditions (2.7)-(2.8) translate to
see [23, p666]. The special cases , correspond to degenerated Pickard model, the latter implying and , respectively, and leading to a random field which takes constant values on each horizontal (respectively, vertical) line in . Hence, a binary Pickard model can be parametrized by 7 parameters
as in the non-degenerated case can be found from :
The parameters in (2.14) satisfy natural constraints resulting from their definition as probabilities, particularly, .
3. Markov Edge Process: General Properties and Consistency
It is convenient to allow G to have isolated vertices, which of course can be removed w.l.g., our interest primarily being focused on edges. The directed line graph of DAG is defined as the graph whose set of vertices is is the same as that of undirected line graph and the set of (directed) edges is
Note is acyclic, hence a DAG.
Given a DAG we denote the class of all non-empty sub-DAGs (subgraphs) with .
Definition 4.
A transformation is said a top mesh dismantling algorithm (top MDA) if it erases an edge leading to a sink ; in other words, if with
Similarly, a transformation is said a bottom mesh dismantling algorithm (bottom MDA) if it erases an edge starting from a source , in other words, if with
We denote the classes of DAGs containing G and the subDAGs which can be obtained from G by succesively applying top MDA, bottom MDA, or both types of MDA in an arbitrary order:
Note that the above transformations may lead to a subDAG containing isolated vertices which can be removed from w.l.g.
Definition 5.
A subDAG is said:
(i) interval DAG if
for some ;
(ii) chain DAG if , for some
(iii) source-to-sink DAG if any edge connects a source of to a sink of .
The corresponding classes of subDAGs in Definition 5 (i)-(iii) will be denoted by and .
Proposition 1.
For any DAG we have that
Proof. The proof of each inclusion in (3.3) proceeds by induction on the number of edges of G. Clearly, the proposition holds for . Assume it holds for , we will show that it holds for The induction step for the three relation in (3.3) is proved as follows.
(i) Fix and be as in (3.2). Let be the set of sinks of G. If is a sink and (or ) then belongs to by definition of the last class. If is a sink and , we can dismantle an edge and the remaining graph in (3.1) has edges and contains , so that the inductive assumption applies, proving .
Next, let . Then there is a path in G from to at least one of these sinks. If , we apply top MDA to and see that in (3.1) has the number of edges and contains the interval graph in (3.2), so that the inductive assumption applies to and consequently to G as well, as before, proving the induction step in case (i).
(ii) Let be a chain between and , since belongs to by definition. Let be the set of sinks of G. If is a sink and then G contains an edge which does not belong to . Then, by removing e from G by top MDA we see that in (3.1) contains the chain viz., , and therefore by the inductive assumption. If is a sink and , we remove from G any edge leading to and arrive at the same conclusion. If is not a sink, we remove any edge leading to a sink and apply the inductive assumption to the remaining graph having edges. This proves the induction step in case (ii).
(iii) Let , where are the sets of sources and sinks of , respectively. Let be the sets of sources and sinks of . If , i.e., G is a source-to-sink DAG, we can remove from it a edge and the remaining graph in (3.1) contains and satisfies the inductive assumption. If G is not a source-to-sink DAG, it contains a sink or a source In the first case, there is which can be removed from G and the remaining graph contains and satisfies the inductive assumption. The second case follows from the first one by DAG reversion. This proves the induction step in case (iii), hence the proposition. □
An edge process on DAG is a family of discrete r.v.s indexed by edges of G. It is identified with a (discrete) probability distribution
Definition 6.
Let be a given DAG. A clique distribution at is any discrete probability distribution , that is, a family of positive numbers summing up to 1:
The set of all clique distributions at is denoted by .
Given , the conditional probabilities of out-configuration given in-configuration write as
with and for for .
Definition 7.
A Markov edge process on a DAG corresponding to a given family of clique distributions is a random process indexed by edges of G and such that for any configuration
An edge process on a DAG can be viewed as a site process on the line graph of , with
Corollary 1.
A Markov edge process in (3.4) is a Bayesian network on the line DAG if
Condition (3.5) can be rephrased as the statement that outgoing’ variables are conditionally independent given `ingoing’ variables , for each node . Analogously, in (3.6) is a Bayesian network on the reversed line graph under a symmetric condition that `ingoing’ variables are conditionally independent given `outgoing’ variables , for each node .
Definition 8.
Let be a DAG and be a family of subDAGs of G. A family of edge processes is said consistent if
Given edge process in (3.4), we define its restriction on a subDAG as
In general, is not a Markov edge process on , as shown in the following example.
Example 1.
Let Then and
The subDAG is composed of two edges going from different sources 1 and 2 to the same sink 3. By definition, a Markov edge process on corresponds to independent , viz.,
It is easy to see that the two probabilities in (3.8) and (3.9) are generally different (however, they are equal if is a product distribution and , in which case and
In Example 1, the restriction to is a Markov edge process with . The following proposition shows that a similar fact holds in a general case for subgraphs obtained from G by applying top MDA.
Proposition 2.
Let be a Markov edge process on DAG . Then for any , the restriction is a Markov edge process on with clique distribution given by
which is the restriction of clique distributions to (sub-clique)
Proof. It suffices to prove the proposition for a one-step top MDA, or in (3.1). Let , , . From the definitions in (3.4) and (3.10),
Example 2. Markov chain. Let be a chain from 0 to n. The classes and consist respectively of all chains from 0 to , from to n, and from i to j ( A Markov edge process on the above graph is a Markov chain with probability distribution
where is a (discrete) univariate and are bivariate probability distributions; are conditional or transitional probabilities. It is clear that the restriction on is a Markov chain with ; in other words, it satisfies Proposition 2 and (3.10). However, the restriction to or is a Markov chain with initial distribution
which is generally different from . We conclude that Proposition 2 ((3.10) in particular) fail for subDAGs of G obtained by bottom MDA. On the other hand, hold for the above provided the ’s satisfy the additional compatibility condition:
Proposition 3.
Let be a Markov edge process on DAG in (3.4). Then for any edge
and
with satisfying .
Proof. Relation (3.11) follows from
and the definition in (3.4), since the products cancel in the numerator and the denominator of (3.13).
Consider (3.12). We use Propositions 1 and 2 according to which the interval DAGs belong to . The `intermediate’ DAG constructed from by adding the single edge , viz., also belongs to since it can be attained from by dismantling all edges with the exception of . Note . Therefore, by Proposition 2, where is a Markov edge process on with clique distributions
The expression in (3.12) follows from (3.14) and (3.11) with E replaced by , by noting that is a sink in , hence whereas . □
Remark 3.
Note that in the conditional probability on the r.h.s. of (3.11) are nearest neighbors of e in the line graph (DAG)
Theorem 2.
Let be a given DAG and a Markov edge process in (3.4) with clique distributions satisfying the compatibility condition
and two marginal independence conditions:
and
Then the family of Markov edge process with clique distributions given in (3.10) is consistent, viz.,
Remark 4. (i) Conditions (3.16) and (3.17) do not imply mutual independence of the in- and out- clique variables and under .
(ii) Conditions (3.16) and (3.17) automatically are satisfied if (Markov chain).
(iii) Conditions (3.16) and (3.17) are symmetric w.r.t. DAG reversion (all directions reversed)
(iv) In the binary case (), the value can be interpreted as the presence of `particle’ and as its absence on edge . `Particles’ `move’ on DAG in the direction of arrows. `Particles’ `collide’, `annihilate’, or `branch’ at nodes , with probabilities determined by clique distribution . See sec.4 for a detailed description of particle evolution for Arak model on .
Proof of Theorem 2. it suffices to prove (3.18) for 1-step MDA:
which remove a single edge coming from a source , and a single edge going to a sink , respectively. Moreover, it suffices to consider only. The proof for follows from Proposition 2 and does not require (3.15)-(3.17). (It also follows from by DAG reversion.) Then, by marginal independence of and ,
From the definition of in (3.10) we have that and therefore
leading to
and proving (3.18) for defined above, or the statement of the theorem for 1-step MDA . □
Corollary 2.
Let be a Markov edge process on DAG satisfying the conditions of Theorem 2. Then:
(i) The restriction of on a chain DAG is a Markov chain, viz.,
where
(ii) The restriction of on a source-to-sink DAG is a sequence of independent r.v.s, viz.,
where is the set of sources of , is the set of edges coming from a source and ending into a sink of ,
Proof. (i) By Proposition 1, belongs to so that Theorem 2 applies with in (3.10) given by (3.14), resulting in (3.19).
(ii) By Proposition 1, belongs to so that Theorem 2 applies with in (3.10) given by
(the second equality holds by (3.16)), resulting in (3.20). □
Remark 5.
A natural generalization of chain and source-to-sink DAGs is a source-chain-sink DAG with the property that any sink is reachable from a source by a single chain (directed path). We conjecture that for a source-chain-sink DAG , the restriction of in Theorem 2 is a product of independent Markov chains on disjoint directed paths of , in agreement with the representations (3.19) and (3.20) of Corollary 2.
Gibbsian representation of Markov edge process. Gibbsian representation is fundamental in the study of Markov random fields [4,17]. Gibbsian representation of Pickard random fields was discussed in [5,10,22,30]. The following Corollary 3 provides Gibbsian representation of consistent Markov edge process in Theorem 2. Accordingly, the set of vertices of DAG is written as , where the boundary consists of sinks and sources of G, and the interior of the remaining sites.
Corollary 3.
Let be a Markov edge process on DAG satisfying the conditions of Theorem 2 and the positivity condition . Then
where the inner and boundary potentials are given by
Formula (3.21) follows by writing (3.4) as and rearranging terms in the exponent using (3.15)-(3.17). Note (3.21) is invariant w.r.t. graph reversal (direction of all edges reversed). Formally, the inner potentials in (3.22) do not depend on the orientation of G, raising the question of the necessity of conditions (3.16)-(3.17) in Theorem 2. An interesting perspective seems the study of Markov evolution of Markov edge process on DAG with invariant Gibbs distribution in (3.21).
4. Consistent Markov Edge Process on and Arak Model
Let be infinite DAG whose vertices are points of regular lattice and whose edges are pairs directed in the lexicographic order: if and only if . We write if . A -dimensional hyperplane
can be identified with , for any fixed .
Let denote the class of all finite `rectangular’ subgraphs of , viz., if for some and We denote
the class of all subgraphs of formed by intersection with a -dimensional hyperplane can be identified with an element of . Particularly, for and any ,
the subgraph can be identified with a chain
of length . Similarly, for any ,
the subgraph of is a planar `rectangular’ graph belonging to .
Proposition 4.
Let . Any subgraph can be obtained by applying MDA to G.
We designate `outgoing’ and `incoming’ clique variables (see Figure 1). Let be a generic clique distribution of random vector on incident edges of . We use the notation .
The compatibility and consistency relations in Theorem 1 write as follows: For any
and
Let be the class of all discrete probability distributions on satisfying (4.6)-(4.7).
Corollary 4.
Let be a (consistent) Markov edge process on DAG with clique distribution . The restriction
of on any -dimensional hyperplane in (4.1) is a consistent Markov edge process on DAG with generic clique distribution . Particularly, the restriction
of to a 1-dimensional hyperplane in ... is a reversible Markov chain with probability distribution
where and are the conditional probabilities.
Example 3.
Broken line process. Let and take integer values and have a joint distribution
, where is a parameter. Note that for
the last equality is valid for , too. Therefore, in (4.11) is a probability distribution on with (marginals) and written as the product of the geometric distribution with parameter . We see that (4.11) belongs to and satisfies (4.6) -(4.7) of Corollary 4. The corresponding edge process called the discrete broken line process was studied in Rollo et al [24] and Sidoravicius et al [26] in connection with planar Bernoulli first passage percolation (edge variables are interpreted as random passage times between neighboring sites). The discrete broken line process can be described as an evolution of particles moving (horizontally or vertically) with constant velocity until collision with another particle and dying upon collision, with independent immigration of pairs of particles. An interesting and challenging open problem is the extension of the broken line process to higher dimensions, particularly, to or .
Definition 9.
We call Arak model a binary Markov edge process on a DAG with clique distribution .
We also use the same terminology for the restriction of Arak model on a subDAG , and speak about Arak model on since extends to infinite DAG ; the extension is a stationary binary random field whose restriction coincides with . Note that when , the clique distribution is determined by probabilities
Particularly, for the compatibility and consistency relations in (4.6)-(4.7) read as
The resulting consistent Markov edge process on depends on parameters. In the lattice isotropic case it depends on 9 parameters satisfying 2 consistency equations: , resulting in a 7-parameter isotropic binary edge process communicated to the author by Arak
Denote unit vectors in , - edges parallel to vectors The following corollary is a consequence of Corollary 1 and the formula for transition probabilities of binary Markov chain in Feller [8][Ch.16.2].
Corollary 5.
Covariance function of Arak model. Let be Arak model on DAG Then for any ,
where are as in (4.12).
Remark 6.
The conditional probabilities in Corollary 2 (3.5) for Arak model can be expressed through in (4.12). Particularly, Arak model in dimension is a Bayesian network on the line graph of if
In the two-dimensional case Arak model on DAG is determined by clique distribution of in Figure 1 (b) with probabilities satisfying four conditions:
The resulting edge process depends on 11 = (15 -4) parameters. In the lattice isotropic case, we have 5 parameters satisfying a single condition and leading to a 4-parameter consistent isotropic binary Markov edge process on . Some special cases of parameters in (4.15) are discussed in Examples
Evolution of particle system. Below, we describe the binary edge process in Remark 2 on DAG in terms of particle system evolution. The description becomes somewhat simpler by embedding G into , where
where are boundary sites (sources or sinks belonging of the extended graph ) as shown in Figure 2. The edge process is obtained from as
The presence of a particle on edge (in the sense explained in sec.2) is identified with . A particle moving on a horizontal (respectively, vertical) edge is termed horizontal (respectively, vertical). The evolution of particles is described by the following rules:
- (p0)
- Particles enter the boundary edges and independently of each other with respective probabilities and .
- (p1)
-
Particles move along directed edges of independently of each other until collision with another moving particle. A vertical particle entering an empty site , either
- (i)
- leaves v as a vertical particle with probability ; or
- (ii)
- changes the direction at v to horizontal with probability or
- (iii)
- branches at v into two particles moving into different directions, with probability ;, or
- (iv)
- dies at v, with probability .
Similarly, a horizontal particle entering an empty site exhibits transformations as in (i)-(iv) with respective probabilities , and . - (p2)
-
Two (horizontal and vertical) particles entering , either
- (i)
- both die with probability or
- (ii)
- the horizontal one survives and the vertical one dies with probability . or
- (iii)
- the vertical one survives and the horizontal one dies with probability . or
- (iv)
- both particles survive with probability .
- (p3)
-
At an empty site (no particle enters v), either
- (i)
- a single horizontal particle is born with probability or
- (ii)
- a single vertical particle is born with probability or
- (iii)
- no particles are born, with probability . or
- (iii)
- two (horizontal and vertical particles) are born with probability .
The above list provides a complete description of particle transformations or transition probabilities of the edge process in terms of parameters
Example 4. are independent r.v.s, . Accordingly, take independent values on edges of a ’rectangular’ graph , with generally different probabilities and for horizontal and vertical edges. In terms of the particle evolution, this means the `outgoing’ particles at each site being independent and independent of the `incoming’ ones.
Example 5.
, implying and for any horizontal shift of . The corresponding edge process in this case takes constant values on each horizontal line of the rectangle V. Similarly, case leads to taking constant values on each vertical line of V.
Example 6.
, meaning that none of the four binary edge variables can be different from the remaining three. This implies or
and or
The resulting 4-parameter model is determined by . In the isotropic case we have two parameters since This case does not allow for death, birth or branching of a single particle; particles move independently till collision with another moving particle, upon which both colliding particles die or cross each other with probabilities defined in (p1)-(p3) above.
5. Contour Edge Process Induced by Pickard Model
Consider a binary site model on rectangular graph
Let be the shifted lattice, and be the rectangular graph with For any horizontal or vertical edge we designate
the edge of which `perpendicularly crosses e at the middle’ and is defined formally by
A Boolean function takes two values 0 or 1. The class of such Boolean functions has elements.
Definition 10.
Let be two Boolean functions. A contour edge process induced by a binary site model on in (5.1) and corresponding to is a binary edge process on defined by
Probably, the most natural contour process occurs in the case of Boolean functions
visualized by `drawing an edge’ across neighboring `occupied’ and `empty’ sites in the site process. The introduced `edges’ form `contours’ between connected components of the random set . Contour edge processes are usually defined for site models on undirected lattices and are well-known in statistical physics [27] (e.g., the Ising model), where they represent boundaries between `spins’ and are very helpful in rigorous study of phase transitions. In our paper, a contour process is viewed as a bridge between binary site and edge processes on DAG in (5.1), particularly, between Pickard and Arak models. Even in this special case, our results are limited to the Boolean functions in (5.4), raising many open questions for future work. Some of these questions are mentioned at the end of the paper.
Theorem 3.
The contour edge process in (5.3)-(5.4) induced by a non-degenerate Pickard model coincides with Arak model on if and only if is symmetric w.r.t. . The last condition is equivalent to
Moreover, coincides with Arak model in Example 6 with
Proof.Necessity. Let in (5.3)-(5.4) agree with Arak model. Accordingly, the generic clique distribution is determined by generic family distribution as
see Figure 3. From (2.13) we find that
The two first equations in (4.15) are satisfied by (5.8). Let us show that (5.8) imply the last two equations in (4.15), viz., Using (2.8), (5.8) and the same notation as in (2.15) we see that is equivalent to equation
that factorizes as Hence, since are excluded by non-degeneracy of .
Let us show the necessity of the two other conditions in (5.5). Let be a rectangle as in Figure 3, and be the corresponding edge process, where are as in ... and
The last fact implies that and are conditionally independent given . Particularly,
and
From and (2.13) we find that
and
Hence, (5.9) for leads to , or
Next, consider (5.10). We have
Hence, (5.10) for writes as yielding and
Equations (5.11) and (5.12) prove (5.5).
Finally, let us show that (5.5) implies symmetry of family distribution and Pickard model . Indeed, is equivalent to equality of moment functions:
Relation implies the coincidence of moment functions up to order 2: so that (5.13) reduces to
Relation follows from (2.13), whereas the remaining three relations in (5.14) use (2.13) and (5.5).
It remains to show the symmetry of Pickard model . Write for configuration of the transformed Pickard model . Then by the definition of Bayesian network in (2.3),
where provided have the symmetry property. The latter property is valid for our family distribution , implying and ending the proof of the necessity part of Theorem 3.
Sufficiency. As shown above, the symmetry implies (5.5) and (4.15) for the distribution of the quadruple in (5.7). We need to show that in (5.3)-(5.4) is a Markov edge process with clique distribution following Definition 7.
Let be the left bottom point of V in (5.1) and
be the set of all configurations of the contour model. It is clear that any uniquely determines in (5.16) up to the symmetry transformation: there exist two and only two configurations satisfying (5.16). Then, by the definition of Pickard model, and the symmetry of
where
for and having a 4-point family as in Figure 1, right. From the definitions in (5.7) we see that
This and (5.18) yield
where are out-edges and in-edges of . An analogous relation to (5.19) holds for whereas for we have , cancelling with factor 2 on the r.h.s. of (5.17). The above argument leads to the desired expression
of the contour model as the Arak model with clique distribution given by the distribution of in (5.7).
Let us show that the latter model coincides with Example 6 and its parameters satisfy (5.6), (4.16). and (4.17). Indeed, (5.7) imply hence (4.16) since follow from the 2nd equation in (5.5). Finally, (5.6) is a consequence of (2.15). Theorem 3 is proved. □
Remark 7. (i) The Boolean functions in (5.4) are invariant under symmetry . This fact seems to be related to the symmetry of Pickard model in Theorem 3. It is of interest to extend Theorem 3 to non-symmetric Boolean functions, in an attempt to completely clarify the relation between Pickard and Arak models in dimension 2.
(ii) A contour model in dimension is usually formed by drawing a -dimensional plaquette perpendicularly to the edge between neighboring sites of a site model X in [12,27]. It is possible that a natural extension of the Pickard model in higher dimensions is a plaquette model (i.e., a random field indexed by plaquettes rather than sites in ), which satisfies a similar consistency property as in (2.9) and is related to the Arak model in . Plaquette models may be a useful and realistic alternative to site models in crystallography [6].
Acknowledgments
This work was inspired by collaboration and personal communication with Taivo Arak (1946-2007). I also thank Mindaugas Bloznelis for his interest and encouragement.
References
- Arak, T., Clifford, P. and Surgailis, D. (1993) Point-based polygonal models for random graphs. Adv. Appl. Prob. 25, 348–372.
- Arak, T. and Surgailis, D. (1989) Markov fields with polygonal realizations. Probab. Th. Rel. Fields 80, 543–579.
- Ben-Gal, I. (2007) Bayesian networks. In: Ruggeri F., Faltin F. and Kenett R., Encyclopedia of Statistics in Quality and Reliability, 1–6, Wiley.
- Besag, J. (1974) Spatial interaction and the statistical analysis of lattice systems (with Discussion). J. Royal Statist. Soc. B, 36, 192–236,.
- Champagnat, F., Idier, J. and Goussard, Y. (1998) Stationary Markov random fields on a finite rectangular lattice. IEEE Trans. Inf. Th. 44, 2901 - 2916.
- Enting, I.G. (1977) Crystal growth models and Ising models: disorder points. J. Phys. C. Solid State Phys. 10, 1379–1388.
- Davidson, J., Talukder, A. and Cressie, N. (1994) Texture analysis using partially ordered Markov models. In: Image Processing, 1994. Proceedings. ICIP-94., IEEE International Conference (pp. 402-406). IEEE Computer Soc Press.
- Feller, W. (1950) An Introduction to Probability Theory and Its Applications, vol. 1. Wiley, New York.
- Forchhammer, S. and Justesen, J. (2009) Block Pickard models for two-dimensional constraints. IEEE Trans. Inf. Th. 55, 4626–4634.
- Goutsias, J. (1989) Mutually compatible Gibbs random fields. IEEE Trans. Inform. Theory 35, 1233–1249.
- Gray, A.J., Kay, J.W. and Titterington, D.M. (1994) An empirical study of the simulation of various models used for images. IEEE Trans. Pattern Anal. Machine Intel. 16, 507–513.
- Grimmet, G. (2006) The Random Cluster Model. Springer, New York.
- Grimmet, G. (2018) Probability on Graphs, 2nd edition. Cambridge Univ. Press.
- Justesen, J. (2005) Fields from Markov chains. IEEE Trans. Inf. Th. 51, 4358–4362.
- Kahn, J. (2015) How many T-tessellations on k lines? Existence of associated Gibbs measures on bounded convex domains. Random Struct. Alg. 47, 561–587.
- Kiêu, K., Adamczyk-Chauvat, K., Monod, H. and Stoica, R. (2013) A completely random T-tessellation model and Gibbsian extensions. Spat. Statist. 6, 118–138.
- Kindermann, R. and Snell, J.L. (1980) Markov Random Fields and Their Applications. Contemporary Mathematics, v.1. American Math. Soc.
- Lauritzen, S. (1996) Graphical Models. Oxford Univ. Press.
- Lauritzen, S., Dawid, A.P., Larsen, B. and Leimer, H. (1990) Independence properties of directed Markov fields. Networks 20, 491–505.
- Neapolitan R.E. (2004) Learning Bayesian networks. Prentice Hall, N.Y.
- Pearl, J. (2000) Causality: models, reasoning, and inference. Cambridge University Press, N.Y.
- Pickard, D.K. (1977) A curious binary lattice process. J. Appl. Probab. 14, 717–731.
- Pickard, D.K. (1980) Unilateral Markov fields. Adv. Appl. Probab. 12, 655–671.
- Rollo, L.T., Sidoravicius, V., Surgailis, D. and Vares, M.E. (2010) The discrete and continuum broken line process. Markov Process. Rel. Fields 16, 79–116.
- Russell, S.J. and Norvig, P. (2003) Artificial Intelligence: A Modern Approach (2nd ed.), : Prentice Hall. N.Y.
- Sidoravicius, V., Surgailis, D. and Vares, M.E. (1999) Poisson broken lines’ process and its application to Bernoulli first passage percolation. Acta Appl. Math. 58, 311–325.
- Sinai, Ya.G. (1982) Theory of Phase Transitions: Rigorous Results. Pergamon Press, Oxford.
- Surgailis, D. (1991) The thermodynamic limit of polygonal models. Acta Appl. Math. 22, 77–102.
- Thäle, C. (2011) Arak-Clifford-Surgailis tesselations. Basic properties and variance of the total edge length. J. Statist. Phys. 144, 1329–1339.
- Verhagen, A.M.V. (1977) A three parameter isotropic distribution of atoms and the hard-core square lattice gas. J. Chem. Phys. 67, 5060–5065.
Figure 1.
Left: rectangular DAG in (2.5), right: generic family
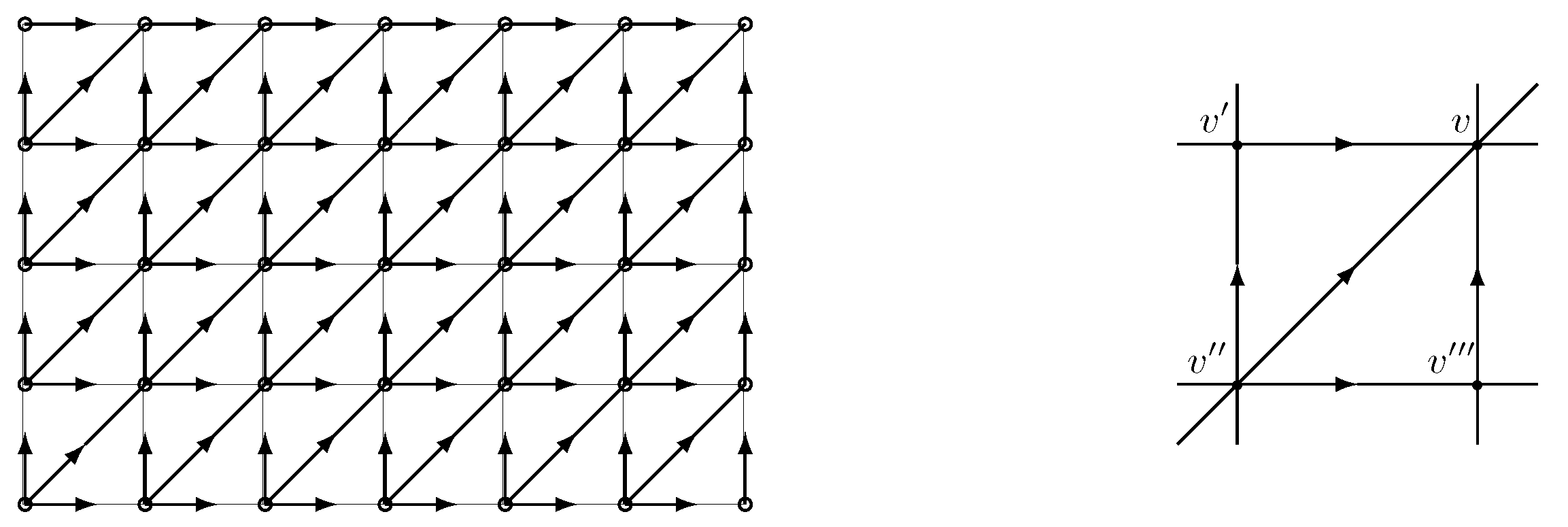
Figure 2.
Generic clique variables of Markov edge process on ,
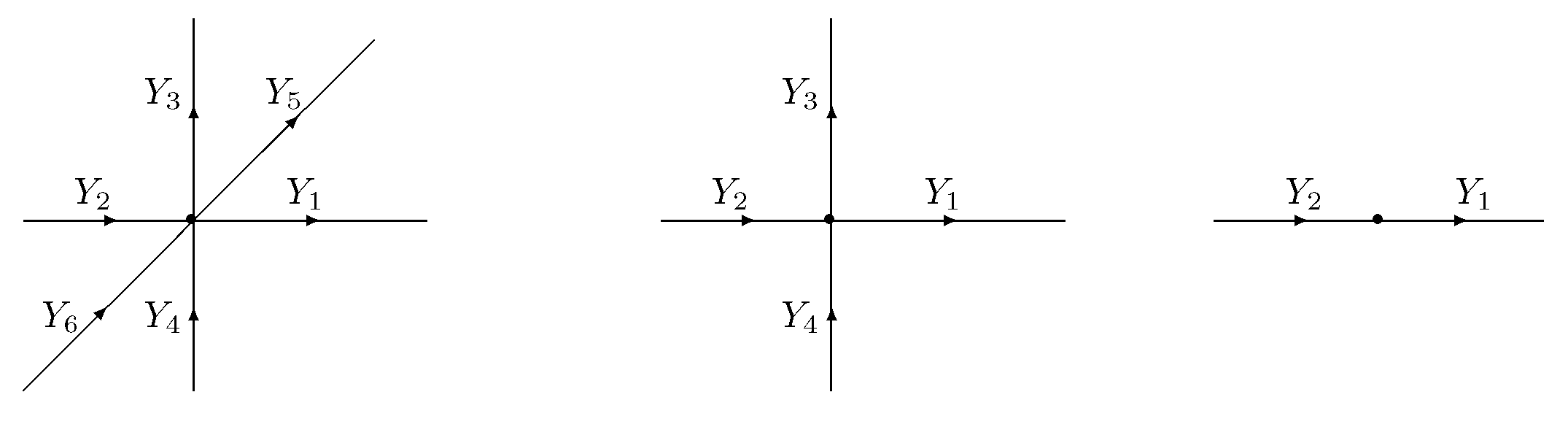
Figure 3.
Contour edge variables in Theorem 3
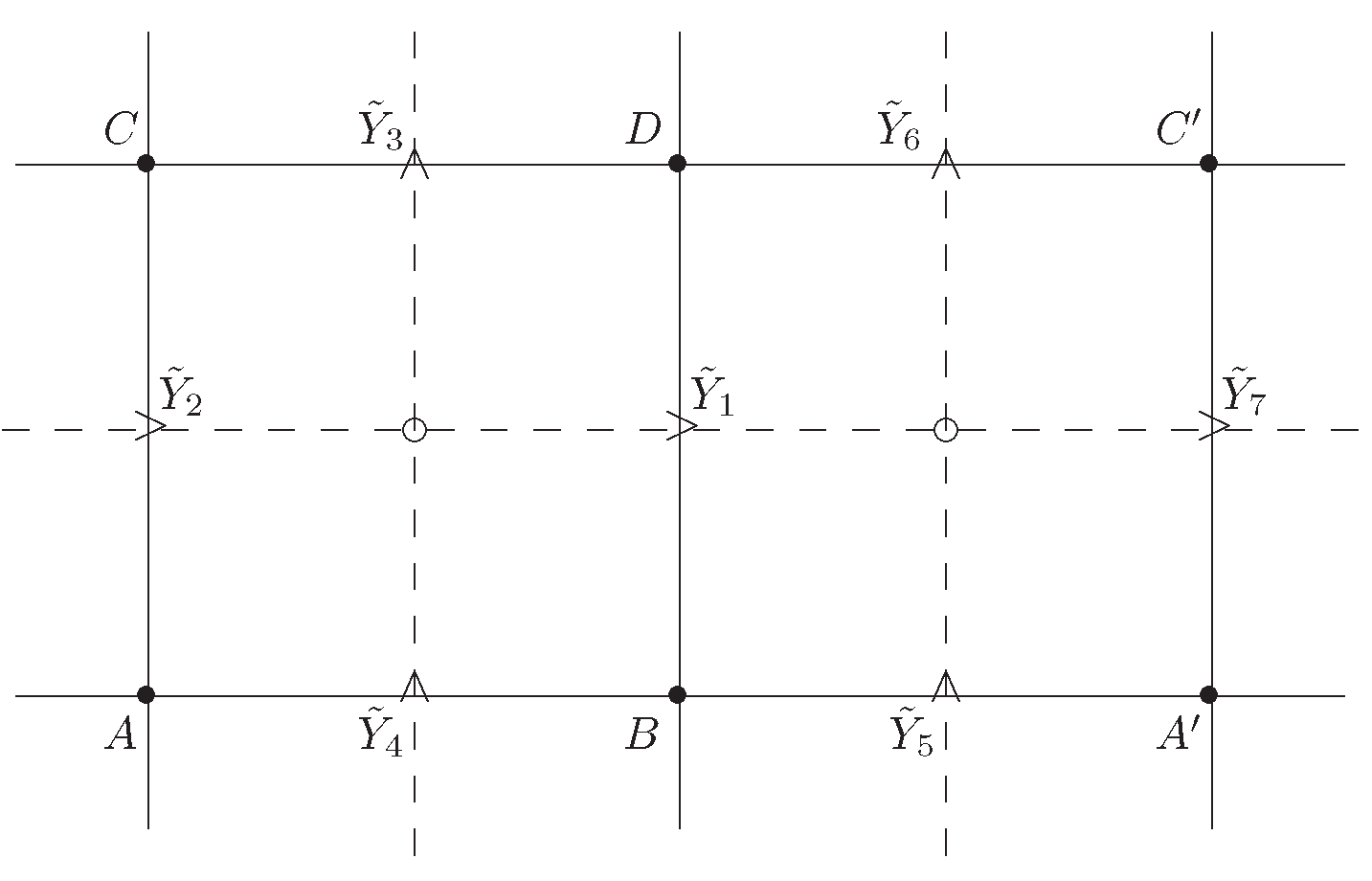
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



