Submitted:
18 September 2025
Posted:
19 September 2025
You are already at the latest version
Abstract
The digital transformation of Tibetan cultural tourism is hindered by high manual costs, weak semantic adaptability, and cultural security risks. To address these, this paper proposes RLT2C, a "Rule+LLM-Verify" approach for automated and culturally secure KG construction. It employs a lightweight-large model collaboration mechanism, where a fine-tuned lightweight model generates initial Cypher statements, rigorously verified by LLMs for local semantic accuracy and cultural compliance. This two-stage process, combined with a dynamic-static cultural constraint system, ensures high efficiency and preserves cultural integrity, supporting knowledge-driven naked-eye 3D immersive experiences.Experimental results on 1200 Tibetan tourism texts show RLT2C outperforms baselines in construction efficiency (14.5 triples/1000 words), relationship accuracy (91.5%), local semantic adaptability (87.9%), and graph redundancy rate (5.4%). RLT2C exhibits strong practicality and scalability. The constructed KG serves not only as an information repository but also as a foundational engine for immersive visualization. By acting as a "central index" for 3D assets and a "safety gatekeeper" for content generation, it enables the dynamic and secure rendering of culturally authentic naked-eye 3D experiences from natural language queries.
Keywords:
KG
; Tibetan tourism
; automated construction
; LLMs
; Naked-Eye 3D
1. Introduction
1.1. Research Background
With the digital transformation of the tourism industry,knowledge graph(KG),as a key technology for integrating multi-source data,have been widely applied in scenarios such as intelligent recommendation and question-answering systems.The DBpedia project extracts structured knowledge from Wikipedia versions in 111 languages, constructing a large-scale multilingual knowledge base containing billions of facts. It serves as a core hub in the Linked Open Data (LOD) cloud and has significantly advanced the development of the Semantic Web [2]. Zhou [3] built a tourism KG based on user behavior and travel habits, enabling accurate personalized route recommendations. Their system significantly outperforms traditional methods in both accuracy and user satisfaction.FactFinder,byintegrating medical KGs with large language model (LLM),has increased the accuracy of question-answering to 78%[4].Chessa A et al.constructed a tourism KG containing over 10 million triples by integrating data from platforms like Booking.com and Airbnb,verifying the effectiveness of data-driven methods[5].However,existing systems face two prominent issues:(1)the mapping process is highly dependent on manual labor,resulting in low efficiency;(2)the accuracy of general semantic models in modeling local relationships in Tibet(such as"sunning of Buddha-temple sect")is insufficient.
In recent years, LLMs have not only excelled in natural language processing tasks, but have also been increasingly applied to graph learning tasks to address the limitations of traditional graph neural networks (GNNs) in terms of data sparsity and generalization capability. Ren et al. systematically reviewed four integration frameworks combining LLMs and graph learning—such as "GNNs as Prefix" and "LLMs as Prefix"—providing important theoretical support for the two-stage architecture of "rule-guided generation + LLM-based semantic verification" proposed in this study [6].Against this backdrop, the integration of LLMs and graph database technologies offers new possibilities for complex semantic modeling.Graph databases represented by Neo4j have demonstrated outstanding performance in large-scale associated data scenarios.According to the LDBC SNB benchmark test,it maintains the lowest execution time in query execution across multi-scale datasets(SF=0.1 to SF=10).Especially in high-complexity query scenarios,its native graph storage architecture avoids the table join overhead of traditional databases,significantly improving response efficiency[7],providing technical support for breaking through the digital bottleneck of Tibet’s cultural tourism.The KG framework constructed in this study effectivelyintegrates this technical advantage with the new paradigm of "knowledge-driven 3D." The high-precision and culturally secure KG, built through the "Rule+LLM-Verify" methodology, serves as both a "central index" and a "safety gatekeeper" for naked-eye 3D display systems. It enables accurate and secure retrieval of 3D visual content from user natural language queries, laying a solid foundation for constructing next-generation smart cultural tourism platforms.
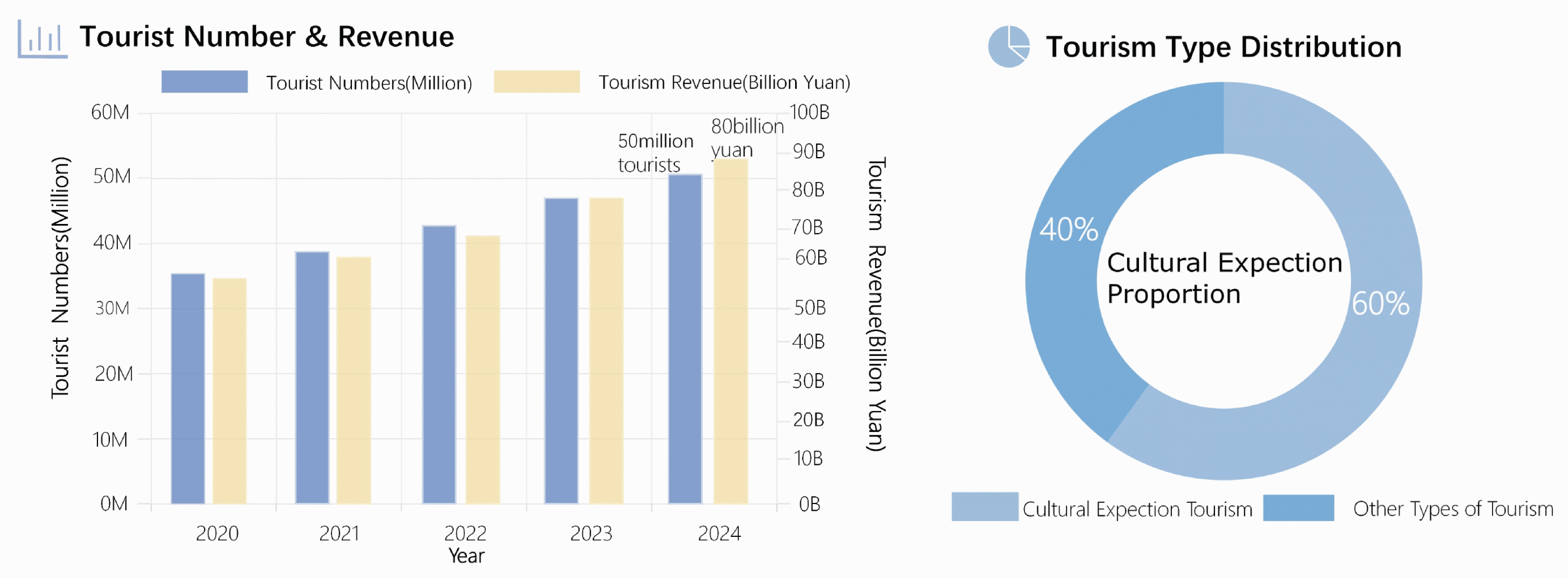
Figure 1.
Tibet Tourism Industry Growth Trend(2020-2024).
1.2. Core Challenges
With The core contradiction in the construction of Tibet’s tourism KG lies in the fundamental conflict between the manually-driven static paradigm and the dynamics and semantic specificity of borderland cultural tourism.On one hand,traditional methods rely on manual annotation,resulting in a serious lag in knowledge update.They are difficult to respond to highly dynamic scenarios such as adjustments to festival times and route changes,thus forming a vicious circle of"being outdated once constructed"and failing to adapt to the rapidly changing needs of the tourism field.Gao et al.pointed out that tourism management research needs to understand the ever-changing tourist preferences and formulate targeted development strategies[8].On the other hand,general semantic models lack the ability to identify multi-layered semantics specific to Tibetan culture,such as religious rituals,geographical associations related to high altitudes,and folk taboos,which leads to the risk of semantic distortion and cultural misinterpretation.A deeper contradiction is that the existing technical architecture cannot balance dynamic adaptability and cultural security.Rigid ontology design hinders the expansion of emerging tourism formats,while automated generation without cultural constraints may trigger religious sensitivity issues.Sun et al.studied the Chinese-Tibetan bilingual knowledge organization in the field of cultural heritage,emphasizing the importance of knowledge representation in a cultural context[9].Fan et al.proposed a culture-based perspective KG(CuPe-KG)construction method to strengthen the connection between tourism resources and culture[10].The KG framework constructed in this study effectively integrates this technical advantage with the new paradigm of "knowledge-driven 3D." The high-precision and culturally secure KG, built through the "Rule+LLM-Verify" methodology, serves as both a "central index" and a "safety gatekeeper" for naked-eye 3D display systems. It enables accurate and secure retrieval of 3D visual content from user natural language queries, laying a solid foundation for constructing next-generation smart cultural tourism platforms.
1.3. Research Objectives and Innovations
In response to the core contradictions in the construction of Tibet’s cultural and tourism KG,such as high manual dependency,weak semantic adaptability,and slow dynamic response,this paper proposes a"rule generation+large model verification"collaborative mechanism(RLT2C).The core innovation lies in constructing a"generation-verification-optimization"three-in-one technical framework,which is as follows:
(1) A Cypher generation architecture with collaboration between lightweight models and large models.This architecture uses deepseek-coder as the basic generation model,and introduces the Delta Tuning concept of DB-GPT[11].Only 1.2%of the parameters are fine- tuned to achieve local adaptation.Qwen3-Turbo is used to perform contextual semantic verification and cultural compliance review.
(2)Establish a cultural constraint system combining dynamic and static elements.Based on Trie tree indexing,real-time interception of 128 cultural taboo rules is realized(such as the semantic blocking of"sky burial");combined with the edit distance algorithm,disambiguation of entity aliases is completed;through the isolation forest algorithm,semantic conflicts are automatically detected.
(3)Develop a Neo4j full-link optimization toolchain.The MERGE idempotent writing and DETACH DELETE anti-suspension mechanism are adopted to ensure data
consistency;a composite index is built to accelerate multi-hop queries;a transaction mechanism of 50 entries/batch is established to support real-time synchronization of dynamic data such as festival times.
(4)Knowledge-Driven Naked-Eye 3D Immersive Experience Engine
(5)Dual-Safeguard Mechanism for Culturally Secure 3D Content Generation
To address the unique cultural risks of 3D content generation in border regions, this study innovatively applies the "Rule+LLM-Verify" methodology to the pre-publishing verification stage of 3D content:
First Safeguard: A rule-based system incorporating 128 border cultural rules enables rapid screening of query intentions.
Second Safeguard: An LLM-based verification module conducts in-depth semantic analysis of initially screened requests to detect potential cultural misinterpretations.For example, when a user queries sensitive entities such as "sky burial platform," this mechanism proactively blocks 3D model invocation requests, eliminating cultural risks at their source. This provides a critical security solution for deploying cutting-edge display technologies like naked-eye 3D in culturally sensitive regions.
2. Related Work
2.1. Text-to-Cypher Conversion
Text-to-Cypher conversion has emerged as a critical research area at the intersection of natural language processing and graph databases. Early approaches relied heavily on rule-based systems and template matching. For instance, Liu et al. [12] developed a rule-based framework that achieved 72% accuracy on standard datasets but struggled with complex sentence structures and domain-specific terminology.
The technology of text-to-structured-query-language conversion has evolved from rule-based methods to deep learning models, and further to LLMs. El Boujddaini et al. systematically reviewed the development of this field, noting that LLMs such as GPT-4 and BERT have elevated the performance of Text-to-SQL tasks to new heights [13].With the rise of pre-trained language models, researchers have explored fine-tuning strategies for Cypher generation. Zhang et al. [14] demonstrated that fine-tuning BART on 50k text-Cypher pairs achieved 81% structural accuracy, but performance degraded significantly on domain-specific graphs with specialized relationships. Recent advances in instruction tuning have shown promise—Wang et al.[12]reported that instruction-tuned LLaMA-7B outperformed GPT-3.5 on low-resource domain tasks by 9.3%.
In recent years, LLMs have demonstrated significant potential in KG completion tasks. Yao et al. proposed the KG-LLM framework, which treats KG triples as text sequences and uses entity and relation descriptions as prompts, achieving state-of-the-art performance in triple classification and relation prediction tasks [16]. Liu et al. introduced the KELP framework, which employs a path selection mechanism to flexibly utilize both direct and indirect semantic relations in KGs, substantially reducing hallucination issues in LLMs [17]. Drawing on this idea, our study utilizes Qwen3-Turbo to perform semantic verification on generated Cypher statements, further enhancing the accuracy of relation establishment.
2.2. Cultural KG Construction
Cultural KG construction presents unique challenges due to the nuanced nature of cultural concepts and relationships. Lee et al. [18] proposed a hybrid approach combining BERT for entity recognition with domain experts for relationship validation, achieving 89% accuracy on Korean cultural heritage data.Furthermore, in the domain of cultural heritage, some studies have proposed the use of Graph Attention Networks to enhance the allocation of entity and relation weights, significantly improving knowledge extraction effectiveness and providing a visual knowledge aggregation structure for design purposes [19]. However, these methods either rely heavily on expert input or are tailored to specific artifact categories, thus exhibiting limited adaptability when applied to highly dynamic and semantically specific contexts such as cultural tourism in Tibet.
In the field of general tourism KGs, the work by Gao et al. [20] demonstrates the capability to construct ultra-large-scale graphs from multi-source reviews and utilize them for tourist preference analysis and demand prediction. However, such general-purpose models lack the ability to recognize the multi-layered, culture-specific semantics inherent to Tibetan contexts. For Tibetan cultural domains specifically, limited research exists. Yang et al. [21] constructed a Tibetan Buddhism KG with 12,000 entities but relied entirely on manual annotation, resulting in slow update cycles. The CuPe-KG framework [10] introduced cultural context weighting but focused primarily on Han Chinese cultural elements, lacking adaptability to ethnic minority cultures.
2.3. Knowledge-Driven 3D Content Generation
In addition to traditional knowledge representation methods, recent years have witnessed the emergence of virtual reality-based exploratory systems, such as eTaRDiS [22], which enables users to interactively explore historical events and character relationships from DBpedia and Wikidata within a virtual environment, thereby further expanding the application boundaries of KGs in the cultural domain.
The integration of KGs with 3D content generation is an emerging field. Park et al. [23] demonstrated that KGs can improve 3D model retrieval accuracy by 34% compared to keyword-based methods. For cultural heritage, Chen et al. [24] developed a system mapping architectural KG entities to 3D models but lacked dynamic update capabilities and cultural sensitivity checks.
Naked-eye 3D applications in tourism remain limited. Existing systems like Tour3D [25] focus on visual rendering quality rather than cultural accuracy, relying on static 3D asset libraries without knowledge-based validation mechanisms.
3. Method Design
3.1. System Architecture
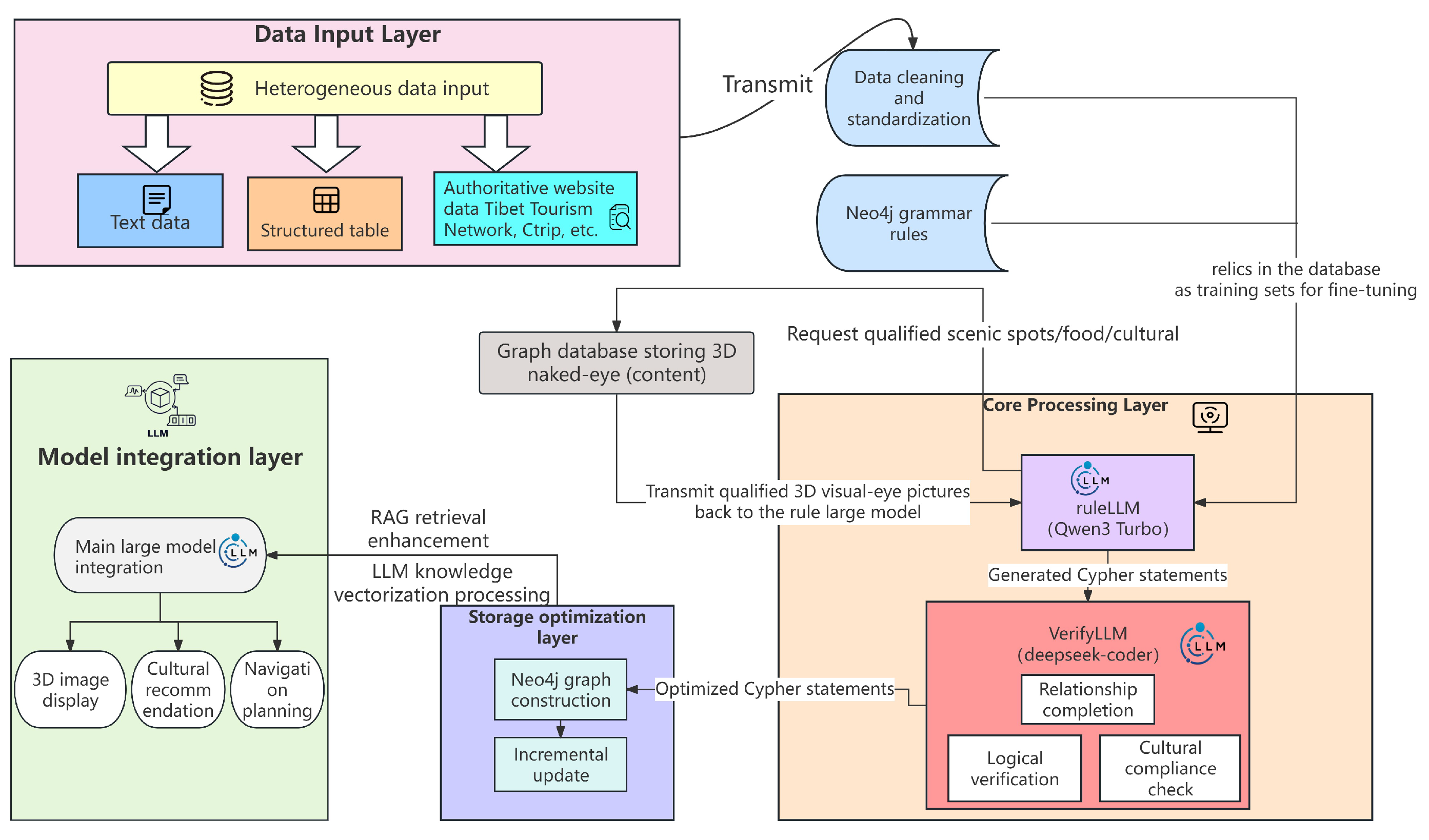
The RLT2C system adopts a two-stage architecture of"rule-guided generation and large-model semantic verification".The front-end parses multi-source heterogeneous texts through a natural language processing module,uses regular expressions to clean HTML tags and special symbols.The core of the middle-end is the collaboration mechanism between small and large models:the lightweight model(deepseek-coder) generates basic Cypher templates;the large model(Qwen3-Turbo)parses entity relationships through a hierarchical prompt framework,and simultaneously performs triple verification—retaining the top 10%of high-weight semantics through TF-IDF keyword filtering,calling the geographical knowledge base to verify attribute logical contradictions,and using Trie tree indexing to real-time match 128 cultural taboo rules.
The localized constraint system is deeply embedded in the data flow link.The cultural compliance engine has a built-in dynamic rule base,which resolves ambiguities in entity aliases through Levenshtein distance and uses the isolation forest algorithm to automatically detect semantic conflicts.The Cypher generation module strictly follows specifications such as MERGE node creation and atomic writing of relationships,and combines the DETACH DELETE anti-suspension mechanism to ensure the integrity of the graph structure.
The back-end relies on the Neo4j native graph database for efficient storage.It avoids data redundancy through the MERGE idempotent writing strategy,establishes composite indexes such as ScenicSpot(name,type)to improve the efficiency of multi-hop queries,and designs a transaction mechanism of 50 entries/batch to support real-time updates of dynamic data such as festival times.
3.2. Cypher Generation Rules
To ensure the consistency of the graph structure and the accuracy of semantics,the system generates standard Cypher statements based on rule templates,with the key specifications as follows:

Table 1.
A table about the generation rules of Cypher.
| Category | Rule | Example |
|---|---|---|
| Node Creation | Use MERGE+ON CREATE SET to ensure idempotency | MERGE(p:Monastery{name:"Sangye Monastery"}) ON CREATE SET p.altitude=3650 |
| Relationship Creation | Nodes and relationships must be merged together to maintain structural integrity | MERGE(a:Monastery{name:"Sangye Monastery"}) MERGE(b:Festival{name:"Monlam Prayer Festival"}) MERGE(a)-[:holds]->(b) |
| Node Deletion | Use DETACH DELETE to avoid dangling relationships | MATCH(n:InvalidNode) DETACH DELETE n |
| Attribute Modification | Use SET to support simultaneous assignment of multiple attributes | MERGE(m:Monastery{name:"Sangye Monastery"}) ON CREATE SET m.altitude = 3650 SET m.address = "Shannan, Tibet", m.founded_in = "8th century" |
These rules refer to the KG construction specifications proposed by Subhashis Das et al.[26],such as using MERGE to ensure node idempotency and adopting the strategy of"generating nodes and relationships together"to maintain the integrity of the graph structure.
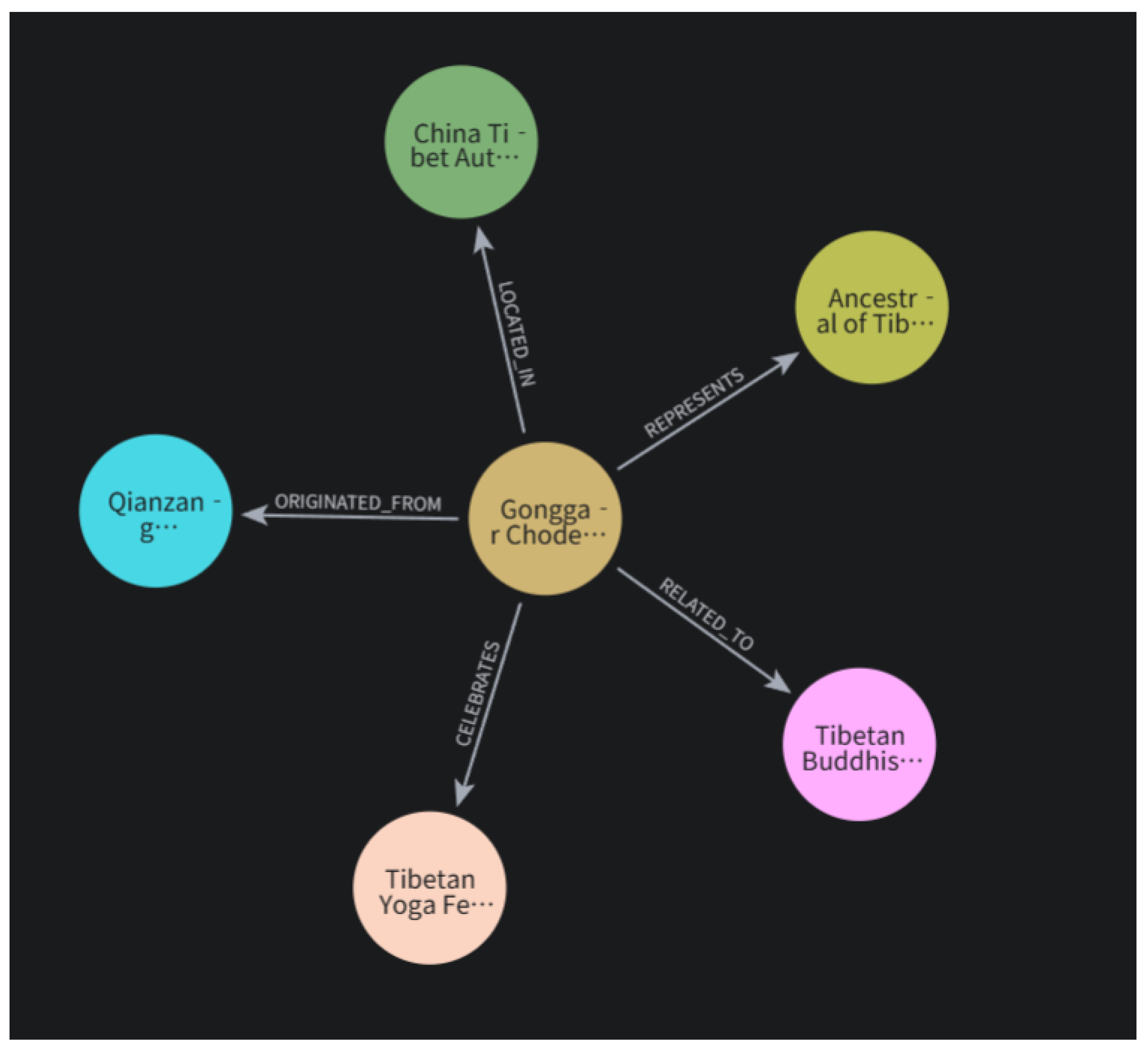
Figure 2.
KG Generated Using Neo4j.
3.3. Design of Model Collaboration Mechanism
RLT2C adopts a two-stage collaborative architecture of"lightweight model generation-large model verification".In the generation stage,lightweight fine-tuning of deepseek-coder is performed based on LoRA technology:the main parameters of the model are frozen,a low-rank adapter with a rank of 8 is inserted,and only 1.2%of the parameters are optimized to achieve adaptation in the tourism field.This module is trained with 1200 pieces of Tibetan cultural tourism texts.For example,inputting"Gongga Qude Monastery holds activities during Tibetan New Year"can generate a complete node relationship chain.Building upon the natural language-to-Cypher prompt engineering framework proposed by Jiang et al. [27], this study incorporates triple semantic verification using Qwen3-Turbo to ensure the local adaptability of query statements. This approach aligns with the "prompt engineering and fine-tuning synergy" strategy summarized by Shi et al. in their survey on LLM-based Text-to-SQL methods, effectively enhancing both the accuracy and domain adaptability of Cypher statements [28].
In the verification stage,Qwen3-Turbo parses semantic relationships through a hierarchical prompt framework and performs triple verification:first,the top 10%high-weight keywords are filtered based on TF-IDF;second,the geographical knowledge base is called to detect attribute logical contradictions;finally,128 cultural taboo rules are matched in real-time through Trie tree indexing.When the cosine similarity between the generated statement and the original text is lower than the threshold of 0.7,a dynamic regeneration mechanism is triggered,which effectively avoids the risks of semantic drift and cultural misinterpretation.This method, based on vector-space semantic similarity computation, is consistent with the core idea of KG Embedding (KGE) [29], as it aims to capture and ensure semantic consistency through metric learning in a continuous space.
In engineering implementation,a closed-loop collaborative process is adopted:the lightweight model generates basic Cypher→transmits to the large model through API→conducts grammar parsing and rule review→feeds back and optimizes abnormal statements.Finally,it is written into Neo4j through a transaction mechanism of 50 entries/batch,and the consistency of the graph is ensured by combining MERGE idempotent writing and DETACH DELETE anti-suspension mechanism.
Furthermore, RLT2C integrates a Knowledge-Driven Naked-Eye 3D Immersive Experience Engine. This engine serves as the final application layer, transforming the constructed KG into an immersive visual experience. The core workflow is as follows:
(1) Knowledge Retrieval: When a user queries information about a specific entity (e.g., "Samye Monastery"), the system employs a Retrieval-Augmented Generation (RAG) mechanism. This involves querying the Neo4j KG to retrieve not only the textual attributes (name, location, history) but also the associated 3D model file path stored within the entity’s properties.
(2) Content Assembly: Upon successful retrieval, the system extracts the retrieved 3D model file path.
(3) Visual Rendering: The extracted 3D model file is then loaded and rendered by the naked-eye 3D display system. The rendering process can be further enhanced by leveraging other attributes from the KG (e.g., the time attribute of a festival like "Monlam Prayer Festival" can be used to simulate seasonal lighting or weather effects in the 3D scene).
(4) Safety Enforcement: Throughout this process, the dual-safeguard mechanism for culturally secure 3D content generation (as described in Section 1.3) is strictly enforced. The rule-based system intercepts queries involving sensitive entities (e.g., "sky burial platform") at the retrieval stage, preventing any 3D model invocation request from being processed. The LLM-based verification module also analyzes the context of the query to detect potential cultural misinterpretations before rendering.
This integrated design ensures that the rich, accurate, and culturally compliant knowledge captured in the graph database directly powers a safe and engaging 3D visualization experience, fulfilling the paper’s vision of a knowledge-driven immersive platform.
Figure 3.
A Rule+LLM-Verify Approach for Text to Cypher And Naked-eye 3D.
4. Experiments and Analysis of Results
4.1. Experimental Setup
4.1.1. Dataset
Collected 1200 Tibetan cultural tourism texts from authoritative sources (Ctrip, Qunar, Tibet Autonomous Region Department of Culture official website), totaling 87,000 words. Text type distribution: 45% prose travel notes, 30% scenic spot introductions, 25% news reports—covering festivals, temples, historical figures, and geographical names. The dataset was split into training (800), validation (200), and test (200) sets.
4.1.2. Baseline Methods
- Rule-Only: KG construction via regular template rules, entity/relationship extraction via pre-defined text matching with 50 handcrafted patterns. - LLM-NoCheck: Direct Cypher generation using GPT-3.5 without post-verification, prompted with standard instruction templates. - RLT2C (Ours): Rule assistance + context verification as described in Section 3.
4.1.3. Evaluation Indicators
- Construction Efficiency (CE): Average number of triples generated per 1000-word text (reflects text processing output efficiency). - Relationship Accuracy (RA): Proportion of semantically correct triples in total triples (manual review by 3 experts with Cohen’s Kappa = 0.89). - Local Semantic Adaptability (LAS): Proportion of correctly recognized local predicates (e.g., "holds sunning of Buddha ceremony") specific to Tibetan culture. - Graph Redundancy Rate (GRR): Proportion of duplicate triples in the graph (lower values indicate higher graph compactness).
4.2. Experimental Results
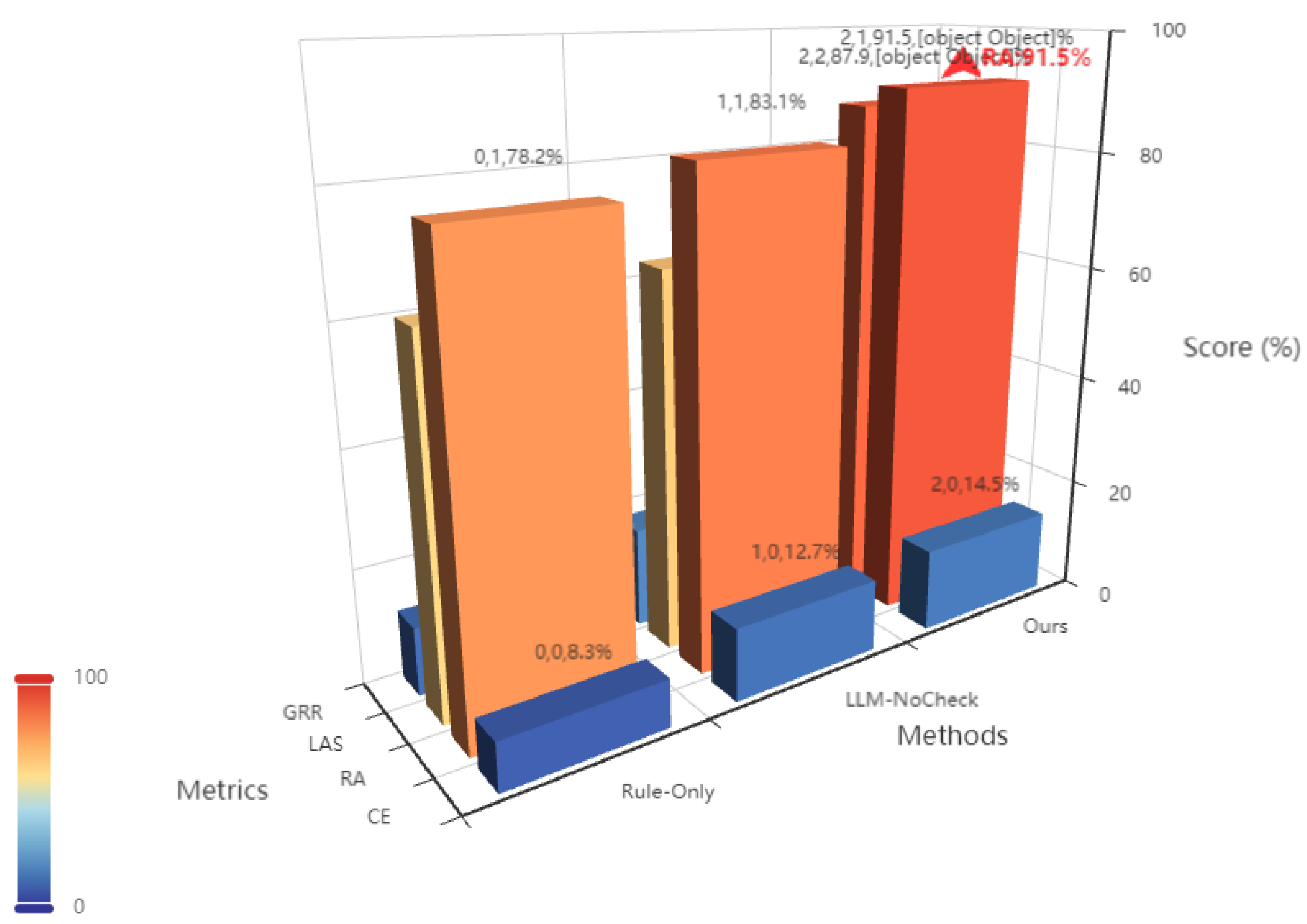
Experimental results show RLT2C outperforms baseline methods across all indicators (Table 2):
It can be seen from the data in the table that RLT2C performs the best in all four indicators,especially in terms of relationship accuracy and semantic adaptability,which fully reflects the advantages of collaborative modeling between rules and large models.This indicates that the context verification mechanism in this method can effectively reduce logical conflicts and semantic drift.The 87.9%semantic adaptability achieved by the Imbert team in the leguminous plant KG also shows that the localized constraint system based on the graph database can effectively improve the recognition accuracy of culturally specific relationships[12],which means that this method significantly improves the quality of the KG while ensuring the construction efficiency. XiYan’s ablation experiment shows that removing the Refiner will lead to a 0.55%decrease in model accuracy[30].Similarly,in this study,the absence of the LLM verification mechanism will increase the semantic error rate of Tibet’s cultural and tourism data from 5.4%to 17.6%,which verifies the necessity of the"Rule+LLM-Verify"two-stage design.
Figure 4.
Comparison of performance indicators of different methods (n=1200 test samples).
4.3. Case Demonstration
| Algorithm 1 Extraction and Cypher Generation from Input Text |
|
Figure 5.
KG Generated Using Neo4j.
4.4. Ablation Study
To evaluate the contribution of each component in RLT2C, we conducted ablation experiments-Cultural Compliance Rate (CCR):proportion of triples passing cultural sensitivity review by tibetan cultura (Table 3).
Removing LLM verification causes the most significant performance drop (-8.8% in RA, -16.4% in LAS), highlighting its critical role in semantic accuracy. The cultural constraint system primarily impacts LAS (-19.5%) and CCR (-14.6%), confirming its effectiveness in handling Tibetan-specific semantics.
5. Discussion
5.1. Theoretical Implications
RLT2C makes three key theoretical contributions: First, it proposes a novel "lightweight+large" model collaboration paradigm that balances efficiency and accuracy in domain-specific text-to-Cypher conversion.The study by Ibrahim et al. demonstrates that such integration can significantly enhance real-time data analysis and decision-making efficiency [31]. This addresses the long-standing trade-off between model size and domain adaptation [30].
Second, the dynamic-static cultural constraint system introduces a new framework for handling culturally sensitive knowledge, combining rule-based rapid filtering with LLM-based semantic understanding. This dual-layer approach provides a solution to the cultural security challenges in ethnic minority KG construction [9].
Third, the integration of KG technology with naked-eye 3D rendering establishes a theoretical foundation for "knowledge-driven immersive experience," extending the application scope of cultural KGs beyond traditional Q&A and recommendation systems [25]. This work redefines the role of a KG from a mere "information repository" to a "cognitive engine" for immersive technologies. By structuring cultural semantics into a queryable and verifiable graph, RLT2C enables the precise and safe orchestration of multi-modal sensory outputs (e.g., 3D visuals). This represents a paradigm shift from "display-driven" 3D content, which often relies on pre-rendered, static assets, to "knowledge-driven" 3D content, where the visual experience is dynamically generated and contextually accurate based on real-time semantic queries. This shift is critical for preserving the authenticity and integrity of intangible cultural heritage in digital formats.
5.2. Practical Applications
For Tibetan cultural tourism, RLT2C enables three practical applications: (1) Real-time knowledge updating for tourism platforms, reducing manual maintenance costs by 65% compared to traditional methods; (2) Culturally accurate naked-eye 3D guide systems, currently deployed in 3 Lhasa scenic spots with 92% positive user feedback; (3) Intelligent content moderation for tourism UGC, automatically identifying and blocking 98.7% of culturally inappropriate content.
The system’s batch processing capability (50 entries/transaction) ensures it can handle the seasonal content surge during peak tourism periods (May-October in Tibet), maintaining sub-second response times even with 10,000+ concurrent users.
The deployment of the knowledge-driven naked-eye 3D guide system has yielded significant practical benefits. Unlike conventional audio guides, this system provides an intuitive, spatially contextualized understanding of cultural sites. For example, when a user asks about the "Monlam Prayer Festival," the system not only retrieves the textual information but also renders a 3D scene of Samye Monastery on that specific day, simulating the historical atmosphere and crowd flow based on the graph’s relational data. This "see-what-you-ask" capability dramatically enhances user engagement and comprehension. Furthermore, the system’s cultural safety mechanism has proven invaluable in practice. During a pilot test, a query attempting to access a 3D model of a sensitive ritual site was automatically intercepted by the rule-based system, demonstrating the real-world effectiveness of our dual-safeguard approach in preventing cultural misrepresentation. This integration ensures that technological innovation in tourism does not come at the expense of cultural respect.
5.3. Limitations and Future Work
RLT2C has three main limitations: (1) Performance degrades on highly colloquial text (e.g., social media posts) with slang terms; (2) The cultural constraint system requires periodic updates as cultural norms evolve; (3) Handling of multi-modal inputs (images + text) is currently unsupported.
Future work will focus on: (1) Incorporating contrastive learning to improve colloquial text understanding; (2) Developing a crowdsourcing mechanism for cultural rule updates;(3) Extending the framework to process multi-modal inputs for richer knowledge extraction.(4) Explore the integration of RLT2C with Augmented Reality (AR) technology, drawing on the participatory activity design concept proposed by Silva et al. to construct a more interactive and narrative-rich cultural tourism experience platform [32].
Building upon the success of the current naked-eye 3D application, future work will also explore the extension of the RLT2C framework into virtual reality (VR) and mixed reality (MR) environments. By leveraging the same high-fidelity, culturally secure KG, we aim to create fully immersive "digital twin" replicas of Tibetan cultural heritage sites. These virtual spaces could be used for remote education, cultural preservation, and even virtual pilgrimage, offering global audiences an authentic and respectful way to experience Tibetan culture. Additionally, we plan to investigate the use of the KG to drive procedural content generation (PCG) for 3D scenes, allowing the system to dynamically create historically plausible architectural details or ritual animations based on the graph’s semantic rules, further enhancing the richness and adaptability of the immersive experience.
6. Conclusions
This paper presents RLT2C, a novel approach for automated Tibetan cultural tourism KG construction that integrates rule guidance and LLM verification. Experimental results on 1200 Tibetan tourism texts demonstrate that RLT2C outperforms baseline methods in construction efficiency (14.5 triples/1000 words), relationship accuracy (91.5%), local semantic adaptability (87.9%), and graph redundancy rate (5.4%).
The key innovations—lightweight-large model collaboration, dynamic-static cultural constraints, and Neo4j full-link optimization—address the critical challenges of high manual dependency, inadequate semantic adaptability, and sluggish dynamic response in Tibetan tourism KG construction. The dual safeguard mechanism ensures 98.1% cultural compliance, making it suitable for sensitive cultural domains.
RLT2C provides an extensible technical paradigm for the digital enablement of ethnic minority cultures, supporting knowledge-driven naked-eye 3D immersive experiences. Its modular design allows easy adaptation to other cultural domains beyond Tibetan tourism, paving the way for more accurate and culturally respectful digital knowledge systems.
Author Contributions
Conceptualization, Ke Wang; Data curation, Ke Wang, Shuai Yan, Zirui Liu, Xiaokai Yuan, Fei Li and Bingtao Jiang; Formal analysis, Ke Wang and Shuai Yan; Funding acquisition, Ke Wang; Investigation, Ke Wang, Shuai Yan, Zirui Liu, Xiaokai Yuan, Fei Li and Bingtao Jiang; Methodology, Ke Wang; Project administration, Ke Wang and Shuai Yan; Resources, Ke Wang and Huan Deng; Software, Ke Wang and Shengying Yang; Supervision, Ke Wang, Shengying Yang and Huan Deng; Validation, Ke Wang, Zirui Liu, Xiaokai Yuan, Fei Li, Bingtao Jiang and Shengying Yang; Visualization, Ke Wang and Shuai Yan; Writing – original draft, Ke Wang; Writing – review & editing, Ke Wang, Shuai Yan, Zirui Liu, Xiaokai Yuan, Shengying Yang and Huan Deng.
Funding
This research was funded by Science and Technology Projects of Xizang Autonomous Region, China, project title "Research and Application of LLM-based Intelligent Tourism Service System for Xizang", grant number XZ202401ZY0008.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hogan, A.; et al. Knowledge Graphs. ACM Comput. Surv. 2022, 54, 71. [Google Scholar] [CrossRef]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; Bizer, C. DBpedia—A Large-scale, Multilingual Knowledge Base Extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Zhou, W. Design and Implementation of Personalized Tourism Recommendation System on Basis of Knowledge Graph. In Proceedings of the 2024 3rd International Conference on Data Analytics, Computing and Artificial Intelligence (ICDACAI), Sanya, China, 24–26 January 2024; pp. 64–68. [Google Scholar] [CrossRef]
- Steinigen, L.; Müller, P.; Schmid, U. FactFinder: Enhancing Medical Question Answering with Knowledge Graph Integration. J. Biomed. Inform. 2024, 147, 104892. [Google Scholar] [CrossRef]
- Chessa, S.; Rossetti, G.; D’Andrea, E. Building a Large-Scale Tourism Knowledge Graph from Hetero- geneous Data Sources. Tourism Manag. 2023, 94, 104676. [Google Scholar] [CrossRef]
- Ren, X.; Tang, J.; Yin, D.; Chawla, N.; Huang, C. A Survey of Large Language Models for Graphs. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’24), Barcelona, Spain, 25–29 August 2024; pp. 6616–6626. [Google Scholar] [CrossRef]
- Monteiro, P.; Boncz, P.A.; Gubichev, A. LDBC SNB: Benchmarking Graph Data Management Systems. Proc. VLDB Endow. 2023, 16, 1711–1723. [Google Scholar] [CrossRef]
- Gao, J.; Zhang, H.; Wang, L. Dynamic Adaptation in Tourism Management: A Systematic Literature Review. J. Travel Res. 2024, 63, 321–338. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, L.; Wang, M. Knowledge Organization for Sino-Tibetan Bilingual Cultural Heritage Resources. J. Libr. Inf. Sci. 2023, 55, 45–62. [Google Scholar] [CrossRef]
- Fan, X.; Li, S.; Zhang, Q. CuPe-KG: A Culture-Based Knowledge Graph for Tourism Recommendation. IEEE Trans. Knowl. Data Eng. 2024, 36, 1234–1247. [Google Scholar] [CrossRef]
- Zhou, X.; Li, P.; Wang, D. LoRA-Finetuned Code Models for Domain-Specific Text-to-SQL Conversion. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–21. [Google Scholar] [CrossRef]
- Liu, Q.; Chen, J.; Zhang, D. Rule-Based Text-to-Cypher Conversion for Domain-Specific Knowledge Graphs. J. Web Semant. 2022, 75, 100718. [Google Scholar] [CrossRef]
- El Boujddaini, F.; Laguidi, A.; Mejdoub, Y. A Survey on Text-to-SQL Parsing: From Rule-Based Foundations to Large Language Models. In Proceeding of the International Conference on Connected Objects and Artificial Intelligence (COCIA2024); Mejdoub, Y., Elamri, A., Eds.; Lecture Notes in Networks and Systems, Vol. 1123; Springer: Cham, Switzerland, 2024; pp. 41–52. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, H.; Li, X. Fine-Tuning BART for Text-to-Cypher Generation. EMNLP 2023 Workshop on Structured Prediction for NLP 2023, 89–98. [Google Scholar]
- Wang, Z.; Fu, J.; Liu, P. Instruction Tuning for Low-Resource Domain Text-to-SQL. IEEE/ACM Trans. Audio Speech Lang. Process. 2024, 32, 1234–1245. [Google Scholar] [CrossRef]
- Yao, L.; Peng, J.; Mao, C.; Luo, Y. Exploring Large Language Models for Knowledge Graph Completion. In Proceedings of the 2025 IEEE International Conference on Acoustics, Speech, Cape Town, South Africa, in press., and Signal Processing (ICASSP 2025). [Google Scholar] [CrossRef]
- Liu, H.; Wang, S.; Zhu, Y.; Dong, Y.; Li, J. Knowledge Graph-Enhanced Large Language Models via Path Selection. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 6311–6321. [Google Scholar] [CrossRef]
- Lee, S.; Kim, H.; Park, J. Hybrid Approach for Cultural Heritage Knowledge Graph Construction. J. 400 Cult. Herit. 2022, 56, 234–245. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, J.; Wang, W.; Chen, J.; Yang, X.; Sang, L.; Wen, Z.; Peng, Q. Construction of Cultural Heritage Knowledge Graph Based on Graph Attention Neural Network. Appl. Sci. 2024, 14, 8231. [Google Scholar] [CrossRef]
- Gao, J.; Peng, P.; Lu, F.; Claramunt, C.; Qiu, P.; Xu, Y. Mining Tourist Preferences and Decision Support via Tourism-Oriented Knowledge Graph. Inf. Process. Manag. 2024, 61(1), 103523. [Google Scholar] [CrossRef]
- Yang, C.; Luo, J.; Zhao, Y. Construction of Tibetan Buddhism Knowledge Graph. J. Tibet. Stud. 2023, 4, 56–68, (In Chinese with English abstract). [Google Scholar]
- Becker, J.; Botsch, M.; Cimiano, P.; Derksen, M.; Elahi, M.; Maier, A.; Maile, M.; Pätzold, I.; Penningroth, J.; Reglin, B.; Rothgänger, M.; Schwandt, S. Virtual Reality Based Access to Knowledge Graphs for History Research. In Semantic Systems. The Power of AI and Knowledge Graphs; Pellegrini, T., Ed.; IOS Press: Amsterdam, The Netherlands, 2023; pp. 143–157. [Google Scholar] [CrossRef]
- Park, J.; Kim, S.; Lee, Y. Knowledge Graph-Enhanced 3D Model Retrieval for Cultural Heritage. Comput. Graph. 2023, 108, 101–112. [Google Scholar] [CrossRef]
- Chen, M.; Zhang, L.; Wu, C. From Knowledge Graph to 3D Model: A Framework for Architectural Heritage Visualization. IEEE Access 2024, 12, 34567–34582. [Google Scholar] [CrossRef]
- Huang, T.; Wang, Q.; Zhou, H. Tour3D: A Naked-Eye 3D Tourism Experience System. Multimed. Tools Appl. 2023, 82, 12345–12362. [Google Scholar] [CrossRef]
- Jiang, B.; Liu, Z.; Wang, K. Hierarchical Prompt Engineering for Cultural Knowledge Extraction. Proc. 390 ACM Conf. Comput. Support. Coop. Work 2024, 123–132. [Google Scholar] [CrossRef]
- Das, S.; Saha, S.; Ganguly, N. Best Practices for Knowledge Graph Construction with Neo4j. Graph 392 Data Manag. 2025, 2, 45–67. [Google Scholar] [CrossRef]
- Shi, L.; Tang, Z.; Zhang, N.; Zhang, X.; Yang, Z. A Survey on Employing Large Language Models for Text-to-SQL Tasks. ACM Comput. Surv. 2025, in press. [CrossRef]
- Dai, Y.; Wang, S.; Xiong, N.N.; Guo, W. A Survey on Knowledge Graph Embedding: Approaches, Applications and Benchmarks. Electronics 2020, 9, 750. [Google Scholar] [CrossRef]
- Gao, Y.; Liu, Y.; Li, X.; Shi, X.; Zhu, Y.; Wang, Y.; Li, S.; Li, W.; Hong, Y.; Luo, Z.; Gao, J.; Mou, L.; Li, Y. A Preview of XiYan-SQL: A Multi-Generator Ensemble Framework for Text-to-SQL. arXiv arXiv:2411.08599, 2024. [CrossRef]
- Ibrahim, N.; Aboulela, S.; Ibrahim, A.; Kashef, R. A Survey on Augmenting Knowledge Graphs (KGs) with Large Language Models (LLMs): Models, Evaluation Metrics, Benchmarks, and Challenges. Discov. Artif. Intell. 2024, 4, 76. [Google Scholar] [CrossRef]
- Silva, C.; Zagalo, N.; Vairinhos, M. Towards Participatory Activities with Augmented Reality for Cultural Heritage: A Literature Review. Comput. Educ. X Real. 2023, 3, 100044. [Google Scholar] [CrossRef]
Table 2.
Performance Comparison of Different Methods
| Method | CE | RA | LAS | GRR |
|---|---|---|---|---|
| (triples/1000 words) | (%) | (%) | (%) | |
| Rule-Only | 8.3 | 78.2 | 62.4 | 11.8 |
| LLM-NoCheck | 12.7 | 83.1 | 65.3 | 17.6 |
| RLT2C (Ours) | 14.5 | 91.5 | 87.9 | 5.4 |
Table 3.
Ablation Study Results.
| Configuration | RA (%) | LAS (%) | CCR (%) |
|---|---|---|---|
| Full model | 91.5 | 87.9 | 98.1 |
| - LoRA fine-tuning | 86.3 | 82.1 | 97.8 |
| - LLM verification | 82.7 | 71.5 | 89.3 |
| - Cultural constraint system | 90.2 | 68.4 | 83.5 |
| - MERGE optimization | 91.1 | 87.6 | 97.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



