Submitted:
10 September 2025
Posted:
11 September 2025
You are already at the latest version
Abstract
The patient problem list is a key component of an electronic health record (EHR), and must be accurate and accessible for all professionals involved in patient care. Unfortu-nately, such a list is mostly found as an unstructured text format, is not easily sharable across digital health systems, and lacks semantic interoperability.
Natural Language Processing (NLP) techniques are widely used for clinical concept ex-traction, particularly for English text. However, in the Canadian context, clinical notes in a patient problem list can also be found in French. This research presents a framework based on Fast Healthcare Interoperability Resource (FHIR) consisting of an NLP clinical pipeline and a rule-based approach to convert the textual patient problem list, including notes regarding allergies, to an FHIR model. The proposed approach considers concept modifiers to map to the International Patient Summary (IPS) FHIR model element.
The main contributions of this research include the early detection of FHIR resources from unstructured data written in the French language, and the design of a rule-based algo-rithm to identify and map extracted data to the appropriate FHIR resource attributes using an annotator. A primary evaluation of the Resource tag which uses the rule-based method demonstrates the feasibility of the proposed model to facilitate semantic interoperability. The assessment was conducted using the French FRASIMED Corpora.
Keywords:
EHR
; HL7
; FHIR
; interoperability
; semantic
; terminology
; NLP
; IPS
; ML
; SNOMED CT
; rule-based
1. Introduction
The introduction should briefly place the study in a broad context and highlight why it is important. It should define the purpose of the work and its significance. The current state of the research field should be carefully reviewed and key publications cited. Please highlight controversial and diverging hypotheses when necessary. Finally, briefly mention the main aim of the work and highlight the principal conclusions. As far as possible, please keep the introduction comprehensible to scientists outside your particular field of research. References should be numbered in order of appearance and indicated by a numeral or numerals in square brackets—e.g., [1] or [2,3], or [4,5,6]. See the end of the document for further details on references.
The patient problem list is a key component of the patient health record, identified as required in the International Patient Summary (IPS) [2]. It must be accurate and accessible to all those involved in patient care. However, a patient problem list is often available mainly in an unstructured format, for example, clinical notes and pathology reports, etc. Such a list is typically difficult to share because it is unstructured.
Electronic health record (EHR) systems contain patient clinical information in various formats, including unstructured formats, which impede semantic interoperability. Facilitating the semantic interoperability of healthcare data, not only for primary care but also for secondary use (e.g., clinical analysis and medical research) using Natural Language Processing (NLP) techniques and Machine Learning (ML) algorithms have gained popularity for dealing with unstructured data [1]. NLP techniques and tools are mostly available in the English language. However, in the Canadian context, and specifically in the province of Quebec, clinical notes can be written in either English or French. Since NLP techniques are language-specific and there is a need to convert clinical problems written in French into a standard-based model, the focus of this study is scenarios in French.
The IPS profile has been adopted by the International Organization for Standardization (ISO), Health Level Seven (HL7) and the Integrating the Healthcare Enterprise (IHE) initiative to facilitate semantic interoperability based on clinical data normalization [2]. The IPS dataset is minimal and non-exhaustive; it is a brief summary, but still clinically relevant, and is composed of FHIR resources classified into three categories: required, recommended, and optional [3]. The FHIR IPS specification describes the FHIR implementation of the IPS. It is an implementation guide defining how to create an IPS document using the FHIR standard. From an FHIR implementation perspective, the “Condition resource” is used to store information related to the patient problem list, the diagnosis or other clinical concepts[4]. The patient problem list also includes information about allergies that need to be clearly identified and stored in the “Allergy Intolerance resource”.
This research experiments an FHIR-based framework consisting of an NLP clinical pipeline as well as a rule-based approach to convert a patient problem list written in French, including allergies, to an FHIR model. The proposed framework aims to transform the French unstructured text of the clinical problem list to an FHIR-based model using the IPS specification. The proposed approach considers concept modifiers while mapping to the IPS FHIR model elements. The feasibility of the proposed approach is evaluated using the FRASIMED dataset, an annotated corpus for clinical cases in French [5]:
The remainder of this paper is structured as follows: Section 2 describes related works; Section 3 presents the research methodology, including research challenges, and the proposed approach; Section 4 considers the results that address the research challenges; and finally, Section 5 presents the discussion followed by the conclusion regarding future work.
2. Related Work
A number of medication information extraction studies have proposed frameworks to transform unstructured clinical text into FHIR models using artificial intelligence natural language processing (NLP) pipeline composed of two main steps: 1) extracting concepts using different NLP techniques, 2) mapping the resulting concepts to a health domain ontology (e.g., UMLS, SNOMED CT) to ensure a shared understanding and enable data exchange where the meaning is preserved.
Durango et al. [6] presented different methods for automatically extracting valuable information using NLP techniques, most of which were applied to English texts. The most common open-source NLP tools highlighted in another survey [7] are: 1) MetaMap, 2) MetaMap Lite, 3) Clinical Text Analysis and Knowledge Extraction System (cTAKES), and 4) Open Biomedical Annotator (OBA). Lee et al. [8] proposes the Biodirectional Encoder Representations from Transformers for Biomedical Text Mining (BIoBERT), a pre-trained language representation model to extract valuable information from unstructured biomedical text.
NLP tools developed for the Unstructured Information Management Architecture (UIMA) architecture are widely used [9]. Their extraction process is based on several clinical NLP tools such as cTAKES and MedXN. In another study specific to medication data [10], NLP-based mapping rules were used to convert unstructured data to an FHIR model, and the proposed model was applied to the FHIR resource “MedicationStatement”.
A more general framework proposed by Hong et al. [11], referred to as NLP2FHIR, is an FHIR-based clinical data normalization pipeline mainly comprised of an NLP pipeline with mapping and normalization rules that includes a module for integrating structured data. The NLP2FHIR clinical data normalization pipeline was used and extended by Liu et al. [12]. It includes a use-case scenario from an obesity database that applies deep learning models for text classification of NLP2FHIR outputs for analytics.
To customize NLP pipelines, Soysal et al. [13] present an NLP toolkit named Clinical Language Annotation, Modeling, and Processing (CLAMP) that enables non-NLP expert users to customize their NLP pipelines via a graphical user interface. Wang et al. [14] used the CLAMP toolkit with UMLS to automatically extract opioid information from free text and map it to FHIR.
Peterson et al. [15] converted free text to FHIR using NLP models, namely Bidirectional Encoder Representations from Transformers (BERT) and UMLS, to map extracted concepts into FHIR models. A neural network classification model allows for mapping the concept to the corresponding element in the “Condition resource”, which includes the patient problem list.
In another study, Peterson and Liu [16] converted unstructured problem descriptions into SNOMED CT expressions using a deep learning method for relation identification between concepts and problem phrases. The concept extraction process from UMLS was performed using the MetaMap tool, a named-entity recognition tool developed by the National Library of Medicine (NLM).
Published results have shown that patient problem lists require extraction along with their context. For instance, Wu et al. [17] proposed an open-source semantic search tool to extract concepts from UMLS, including contextualized mentions (e.g., negation, temporality, and experiencer). The retrieval process is based on the NLP pipeline, which focuses on annotating the UMLS concepts in clinical notes.
SNOMED CT and related SNOMED tools [7] are widely used in English to facilitate semantic interoperability, mainly with rule-based approaches. Studies dealing with other languages, including French, remain limited. Most studies mapping to terminology use UMLS; however, there is no easy solution for aligning unstructured text with SNOMED CT. The study by Gaudet-Blavignac et al. [7] highlighted the target language, which is mainly English, while the other languages mentioned are Swedish, Czech, and Chinese. In the literature, the reported mapping methods are mainly rule-based (70%), manual (14%), hybrid (11%), and machine learning (5%) [7].
Almost all NLP techniques for the clinical field are applied to text written in English. Since NLP techniques are dependent on language, there is still research to be done for other languages, such as French. A recent survey of NLP techniques available in languages other than English for extraction and name entity recognition purposes confirmed the absence of a French pre-trained medical model [18]. Although French is an important language in UMLS, only 4% of all available concepts are linked to at least one label term in French. In the literature, one strategy to address this issue is to first perform a translation to English to then find a corresponding concept [18].
From this related work, we can see that no framework has addressed the semantic interoperability of a patient problem list using FHIR format for unstructured text in French. The survey in [18] also confirmed that there is a lack of annotated datasets and models for languages other than English, including French.
3. Research Methodology
3.1. Problem Statement
The research motivation of this study is to improve the data sharing of the existing free-text patient problem list written in French using standards that ensure a common understanding (i.e., semantics) between systems involved (i.e., allowing better interoperability). This research focuses on converting the patient problem list and detecting allergies/intolerances from French unstructured text to an FHIR model.
This study proposes an FHIR-based framework in the Canadian context to address the challenges listed in Table 1.
3.2. Method
The system architecture of the proposed framework consists of two stages (Figure 1):
- Identification of the section and resource tags – executed only once (Stage1),
- Data processing – executed for every clinical note file (Stage 2).
- Stage 1: Tag Identification
Clinical notes are typically split into sections such as “diagnosis” or “physical exam”. Knowing the section from which the concept is extracted is an important semantic indicator. Therefore, section recognition is a fundamental step in NLP pipelines for unstructured data [19], [20]. Furthermore, since allergies also belong to the list of clinical problems (same section) and may be stored in different FHIR resources (Condition vs. Allergy Intolerance), we seek a way to recognize it by using the Allergy Resource Tag. Stage 1 involves four steps:
- Identification of sections related to the patient problem list and diagnosis: The list of section tags in [20] with 6773 items was used as the starting point to identify and extract section candidates that may contain information related to the patient problem list and diagnosis. The resulting list is then optimized by eliminating duplicates and semantic matching using a pivot term. For example, principal diagnosis, secondary diagnosis are replaced by diagnosis (Figure 2).
- Classification to categories: The final French tag list includes three main categories: tags related to allergies (50 elements), diagnosis (106 elements) and other conditions (156 elements)
- Stage 2: Data processing
Stage 2 comprises four steps: data preparation, NLP pipelines, mapping to SNOMED, and FHIR model creation (Figure 3).
-
Step1: Data preparationData sources of clinical notes in English or French were converted into text format when required [27]. Next, the list of section tags related to patient problem lists is used to extract the sections where possible.
- 2.
-
Step 2: NLP pipelinesMedSpacy is an NLP toolkit designed for processing clinical and biomedical texts [28] [29]. It is integrated within the SpaCy platform, an open-source NLP library for Python [30].Language detection: MedSpacy includes tools for language and section detection. Both tools are useful because the clinical notes are written in either English or French. This step is essential because the models are language-dependent and the study investigated French textual data.Resource Tag detection: This step is implemented with MedSpacy where the module seeks to detect more context of the concept to determine whether it is related to an Allergy or intolerance, as well as any diagnosis, based on the established resource tags list.
- 3.
-
Step 3: Mapping to SNOMED
- 4.
-
Step 4: FHIR model creationThe data output from step 3 is aggregated to construct the FHIR model. To achieve this, we used the following rule-based method that was designed to map the extracted concepts to their corresponding IPS FHIR elements (Figure 3).This rule-based method for mapping NLP output to FHIR model elements consists of:
- four rules related to context modifiers (experiencer, negation, temporality, and certainty) and
- two additional rules related to Resource tags identification (allergy, diagnosis).
There are three alternatives for each concept in terms of FHIR resources:
- Experiencer = Non Patient: Experiencer context means that the indicated problem is for the patient or their family member. In this scenario, the FHIR resource used was FamliyMemberHistory. In this study, the focus was on the patient’s clinical problems.
- Experiencer = Patient and Allergy Tag Presence: when an Allergy tag is detected, the concept is mainly for an allergy. Therefore, the FHIR resource to be used is AllergyIntolerance. The Negation context was then used to confirm whether the patient had an allergy.
-
Experiencer = Patient and No Allergy Tag detected: The current patient problem is not related to an allergy, so the FHIR resource to be used is Condition. Next, the Negation context is used to confirm the decision rule following these alternatives:
- Negation = Yes (Concept is negated): If it is the only concept for a condition, then the patient has no known conditions and the corresponding SNOMED CT code will be added. Otherwise, the process continues with the next concept.
-
Negation = No. The next step is to add the corresponding SNOMED CT code and mapping to the corresponding FHIR Condition element following these three rules:
- ○
- Temporality confirms whether the identified problem is still active The value of the ClinicalStatus element of the Condition resource is active or inactive if temporality is Recent or Historical, respectively.
- ○
- Certainty enables us to determine whether an identified problem is confirmed or only a hypothesis. In the first case, the VerificationStatus element value is confirmed; otherwise, it is unconfirmed.
- ○
- The diagnosis section tag enables the identification of the condition category element. The possible values are Encounter-diagnosis or Problem-List-Item.
3.3. Evaluation
The assessment involves the Resource tag detection as well as the rule-based approach:
Resource Tag detection: The performance of the implemented module was evaluated in terms of accuracy (Equation 1), recall (Equation 2), precision (Equation 3), and F1 score (Equation 4).
Equation 1: Accuracy calculation formula
Equation 2: Recall calculation formula
Equation 3: Precision calculation formula
Equation 4: F1 Score calculation formula
Where TP= true positive, TN= true negative, FP= false positive, and FN= false negative
- -
- The rulebased approach results were manually validated by testing all possible cases because the dataset did not cover all scenarios of the context modifiers.
- -
- The result of the overall process is then viewed in IPS viewer
4. Results
This study used the FRASIMED dataset [5], a French-annotated corpus with 2051 clinical cases. FRASIMED comprises two types of corpora with their corresponding annotated files:
- a)
- CANTEMIST-FRASIMED: The patient summary is organized into sections for medical history, physical examination, diagnosis, treatment, etc.
- b)
- DISTEMIST-FRASIMED: the summary is a text with no headers.
A sample of 50 randomly selected clinical notes was used to evaluate the proposed approach (25 files from each FRAMISED corpora).
-
Step1: Data preparation:
- -
- Conversion to text format: the file format is text type.
- -
-
Sections extraction:
- a)
- CANTEMIST-FRASIMED Corpus: Based on the Resource and section tag list, the sections related to the patient problem list were extracted (see Table 2 for the list of section titles available in this corpus and their corresponding categories).
- b)
- DISTEMIST-FRASIMED Corpus: This step is not applicable to this corpus because there are no headers.
- 2.
-
Step 2: NLP pipelines
- -
- Language detection: The purpose of this step is to select either the French or English model to be use based as the text file language. This study focuses on French text cases.
- -
- Concepts and context extraction: Figure 4 is an example of the SIFR output for a clinical text that contains the results of context modifiers for each detected concept.
Figure 5 presents an example of the output of our Resource tag module for French clinical text. Resource information is highlighted in different colors, and a label is displayed for the corresponding category.
The “Allergy resource” tag was evaluated for the French dataset using the sample of 50 randomly selected clinical notes. The evaluation results in terms of accuracy (from 0.947 to 1), recall (1), precision (from 0.8888 to 1) and F1 score (from 0.9411 to 1) are shown in Table 3.
The results obtained demonstrate the feasibility of detecting information related to the Allergy resource tag from the patient problem list.
- 3.
-
Step 3: Mapping to SNOMEDThe Shrimp tool was used to find the SNOMED CT code for the extracted concepts related to the problem list.
- 4.
-
Step 4: FHIR model creationBefore delving deeper into the use cases, it is important to provide a quick overview of the FHIR specifications used.
- -
- Most of the tools used in this study were an implementation of version 4 of FHIR [36].
- -
- The HAPI FHIR server, an implementation of the FHIR specifications in JAVA, was used to test the proposed FHIR model [37].
- -
- The details of the specification profile describing the FHIR resources and their format are based on the IPS implementation guide [38].
- -
Table 4 describes an example of the concept “Carcinome Canalaire” (Figure 4) (Negation= Affirmed, Experiencer= Patient, Temporality= Recent, Certainty= Certain).
Limitations
The performance of this framework depends on the NLP output using the annotator, especially for context modifiers. There are still issues regarding abbreviations that are not necessarily detected. Although NLP techniques provide promising results, there are still some limitations, as the clinical notes may include abbreviations, syntax, and grammatical errors that may have a negative impact on the quality of results.
Another important limitation is related to the absence of a gold-standard testset for evaluating the full conversion of the patient problem list/condition, including allergies, from unstructured data to well-known terminologies, such as SNOMED CT.
5. Discussion and Conclusions
Several studies on clinical data have been devoted to patient summaries, particularly on how to extract and structure valuable information from clinical notes using NLP tools.
This paper presented a method for converting an unformatted patient problem list into a formal model using the IPS profile that can be shared around the globe, satisfying semantic interoperability using SNOMED CT as terminology.
Overall, the framework described in this paper demonstrated the feasibility of converting the patient problem list from French free text to an FHIR-based model using a hybrid system of NLP and a rule-based technique. The proposed approach considers the challenges of context modifiers (negation, experiencer, temporality, and certainty). Two main FHIR resources were used in this study: Condition and Allergy Intolerance.
The primary contributions are the implementation of the module responsible for the early detection of possible FHIR resource presence (Resource Tag) from unstructured data in the French language, followed by the design of a rule-based algorithm to identify and map the extracted data to the appropriate FHIR resource attributes using an annotator.
Although this study focused on the patient problem list, the approach can be applied to other resources as well as the EHR, which contain a minimum amount of structured and semi-structured data.
Conclusion
This research addressed the possibility to convert an unstructured patient problem list into an FHIR model, considering their context modifiers (negation, experiencer, temporality, and certainty). The research focused on French language texts because there is a significant demand for semantic interoperability in Canada and other French countries around the world.
This paper presented a proposed FHIR-based framework consisting of using an NLP clinical pipeline as well as a rule-based approach to convert the patient problem list, including allergies, to an FHIR model. The proposed approach considers concept modifiers while mapping to the IPS FHIR model elements. The feasibility of the proposed approach is evaluated using the FRASIMED dataset.
Although the approach was limited to the patient problem list in the French language, ongoing work is underway on interoperability of many other resources, such as immunization, to cover the maximum information available on the clinical patient profile.
Future work will also include the automatization of current manual steps, such as using the terminology server API instead of a manual process. This allows easier system-to-system access.
Finally, the proposed framework considered the Canadian context of bilingual clinical notes. This will be useful for other countries with similar national contexts, particularly in Europe and Africa, where both English and French are widely used.
Author Contributions
Fouzia Amar: Conceptualization, Methodology, Formal analysis, software, Data curation, Writing - original draft, Writing - review & editing, Visualization. Alain April: Writing – review & editing. Alain Abran: Writing – review & editing.
Abbreviations
The following abbreviations are used in this manuscript:
| API | Application Programming Interface |
| BERT | Bidirectional Encoder Representations from Transformers |
| BioBERT | Bidirectional Encoder Representations from Transformers for Biomedical Text Mining |
| CEN | European Commitee for Standardization |
| CDA | Clinical Document Architecture |
| CLAMP | Clinical Language Annotation, Modeling, and Processing |
| cTAKES | Clinical Text Analysis and Knowledge Extraction System |
| eHN | European eHealth Network |
| EHR | Electronic Health Record |
| FHIR | Fast Healthcare Interoperability Resource |
| G7 | Group of Seven Summits: Annual meeting of leaders from seven of the world’s largest advanced economies |
| GDHP | Global Digital Health Partnership |
| HL7 | Health Level Seven |
| IHE | Integrated Healthcare Exchange |
| IPS | International Patient Summary |
| ISO | International Organization for Standardization |
| PS-CA | Canadian Patient Summary |
| MedXN | Medication eXtraction and Normalization |
| MedSpacy | SpaCy-based library of core components targeting medical text |
| ML | Machine Learning |
| NLM | National Library of Medicine |
| NLP | Natural Language Processing |
| ONC | Office of the National Coordinator |
| SIFR | Ontology-based annotation web service to process biomedical text in French |
| SNOMED CT | Systematized Nomenclature of Medicine - Clinical Terms |
| UIMA | Unstructured Information Management Architecture |
| UMLS | Unified Medical language System |
References
- Amar, F.; April, A.; Abran, A. Electronic Health Record and Semantic Issues Using Fast Healthcare Interoperability Resources: Systematic Mapping Review. J Med Internet Res 2024, 26, e45209. [Google Scholar] [CrossRef] [PubMed]
- International Patient Summary. Date of access: 2025. https://international-patient-summary.net/ips-links-to-standards-and-specifications/.
- FHIR IPS Resources. Date of access: 2025. https://hl7.org/fhir/uv/ips/.
- IPS- Condition Resource. Date of access: 2025. https://build.fhir.org/ig/HL7/fhir-ips/StructureDefinition-Condition-uv-ips.html.
- Zaghir, J.; Bjelogrlic, M.; Goldman, J.P.; Aananou, S.; Gaudet-Blavignac, C.; Lovis, C. FRASIMED: a Clinical French Annotated Resource Produced through Crosslingual BERT-Based Annotation Projection. Published online 2023.
- Durango, M.C.; Torres-Silva, E.A.; Orozco-Duque, A. Named Entity Recognition in Electronic Health Records: A Methodological Review. Healthc Inform Res. 2023, 29, 286–300. [Google Scholar] [CrossRef] [PubMed]
- Gaudet-Blavignac, C.; Foufi, V.; Bjelogrlic, M.; Lovis, C. Use of the Systematized Nomenclature of Medicine Clinical Terms (SNOMED CT) for Processing Free Text in Health Care: Systematic Scoping Review. J Med Internet Res. 2021, 23, e24594. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Yoon, W.; Kim, S.; et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining. Wren J, ed. Bioinformatics. 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Hong, N.; Wen, A.; Stone, D.J.; et al. Developing a FHIR-based EHR phenotyping framework: A case study for identification of patients with obesity and multiple comorbidities from discharge summaries. Journal of Biomedical Informatics. 2019, 99, 103310. [Google Scholar] [CrossRef] [PubMed]
- Hong, N.; Wen, A.; Shen, F.; et al. Integrating Structured and Unstructured EHR Data Using an FHIR-based Type System: A Case Study with Medication Data. Proceedings of AMIA Joint Summits on Translational Science. 2018, 2017. [Google Scholar]
- Hong, N.; Wen, A.; Shen, F.; et al. Developing a scalable FHIR-based clinical data normalization pipeline for standardizing and integrating unstructured and structured electronic health record data. JAMIA Open. 2019, 2, 570–579. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Luo, Y.; Stone, D.; et al. Integration of NLP2FHIR Representation with Deep Learning Models for EHR Phenotyping: A Pilot Study on Obesity Datasets. Published online 2021.
- Soysal, E.; Wang, J.; Jiang, M.; et al. CLAMP – a toolkit for efficiently building customized clinical natural language processing pipelines. Journal of the American Medical Informatics Association. 2018, 25, 331–336. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Mathews, W.C.; Pham, H.A.; Xu, H.; Zhang, Y. Opioid2FHIR: A system for extracting FHIR-compatible opioid prescriptions from clinical text. In: 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE; 2020:1748-1751. [CrossRef]
- Peterson, K.J.; Jiang, G.; Liu, H. A corpus-driven standardization framework for encoding clinical problems with HL7 FHIR. Journal of Biomedical Informatics. 2020, 110, 103541. [Google Scholar] [CrossRef] [PubMed]
- Peterson, K.J.; Liu, H. Automating the Transformation of Free-Text Clinical Problems into SNOMED CT Expressions. Published online 2020.
- Wu, H.; Toti, G.; Morley, K.I.; et al. SemEHR: A general-purpose semantic search system to surface semantic data from clinical notes for tailored care, trial recruitment, and clinical research. Journal of the American Medical Informatics Association. 2018, 25. [Google Scholar] [CrossRef] [PubMed]
- Shaitarova, A.; Zaghir, J.; Lavelli, A.; Krauthammer, M.; Rinaldi, F. Exploring the Latest Highlights in Medical Natural Language Processing across Multiple Languages: A Survey. Yearb Med Inform. 2023, 32, 230–243. [Google Scholar] [CrossRef] [PubMed]
- Denny, J.C.; Spickard, A.; Johnson, K.B.; Peterson, N.B.; Peterson, J.F.; Miller, R.A. Evaluation of a Method to Identify and Categorize Section Headers in Clinical Documents. Journal of the American Medical Informatics Association. 2009, 16, 806–815. [Google Scholar] [CrossRef] [PubMed]
- Pomares-Quimbaya, A.; Kreuzthaler, M.; Schulz, S. Current approaches to identify sections within clinical narratives from electronic health records: a systematic review. BMC Med Res Methodol. 2019, 19, 155. [Google Scholar] [CrossRef] [PubMed]
- Deepl translator. Date of access: 2025. https://www.deepl.com/en/translator.
- French English Medical Dictionary. Date of access: 2025. https://dictionary.reverso.net/medical-french-english/.
- ChatGPT. Date of access: 2025. https://chatgpt.com/.
- Feng, S.Y.; Gangal, V.; Wei, J.; et al. A Survey of Data Augmentation Approaches for NLP. Published online December 1, 2021. [CrossRef]
- Bayer, M.; Kaufhold, M.A.; Reuter, C. A Survey on Data Augmentation for Text Classification. ACM Comput Surv. 2023, 55, 1–39. [Google Scholar] [CrossRef]
- Li, B.; Hou, Y.; Che, W. Data augmentation approaches in natural language processing: A survey. AI Open. 2022, 3, 71–90. [Google Scholar] [CrossRef]
- File Convertor PDF to Text. Date of access: 2025. https://www.freeconvert.com/pdf-to-text.
- MedSpacy githib. Date of access: 2025. https://github.com/medspacy/medspacy/blob/master/README.md.
- Eyre, H.; Chapman, A.B.; Peterson, K.S.; et al. Launching into clinical space with medspaCy: a new clinical text processing toolkit in Python.
- Spacy. Date of access: 2025. https://spacy.io/.
- Clinical French Annotator. Date of access: 2025. https://bioportal.lirmm.fr/annotator.
- Tchechmedjiev, A.; Abdaoui, A.; Emonet, V.; Zevio, S.; Jonquet, C. SIFR annotator: ontology-based semantic annotation of French biomedical text and clinical notes. BMC Bioinformatics. 2018, 19, 405. [Google Scholar] [CrossRef] [PubMed]
- Mirzapour, M.; Abdaoui, A.; Tchechmedjiev, A.; Digan, W.; Bringay, S.; Jonquet, C. French FastContext: A publicly accessible system for detecting negation, temporality and experiencer in French clinical notes. Journal of Biomedical Informatics. 2021, 117, 103733. [Google Scholar] [CrossRef] [PubMed]
- Canada Health Infoway. Canada Infoway healthcare terminology server. Date of access: 2025. https://infocentral.infoway-inforoute.ca/en/tools/standards-tools/terminology-server.
- Shrimp Tool. Date of access: 2025. https://ontoserver.csiro.au/shrimp/.
- H7 FHIR V4. Date of access: 2025. https://hl7.org/fhir/R4/resourcelist.html.
- HAPI FHIR. Date of access: 2025. https://hapi.fhir.org/.
- IPS Implementation Guide. Date of access: 2025. https://build.fhir.org/ig/HL7/fhir-ips/OperationDefinition-summary.html.
- IPS Viewer. Date of access: 2025. https://www.ipsviewer.com/classic.
Figure 1.
The framework for converting unstructured clinical problem data using FHIR.
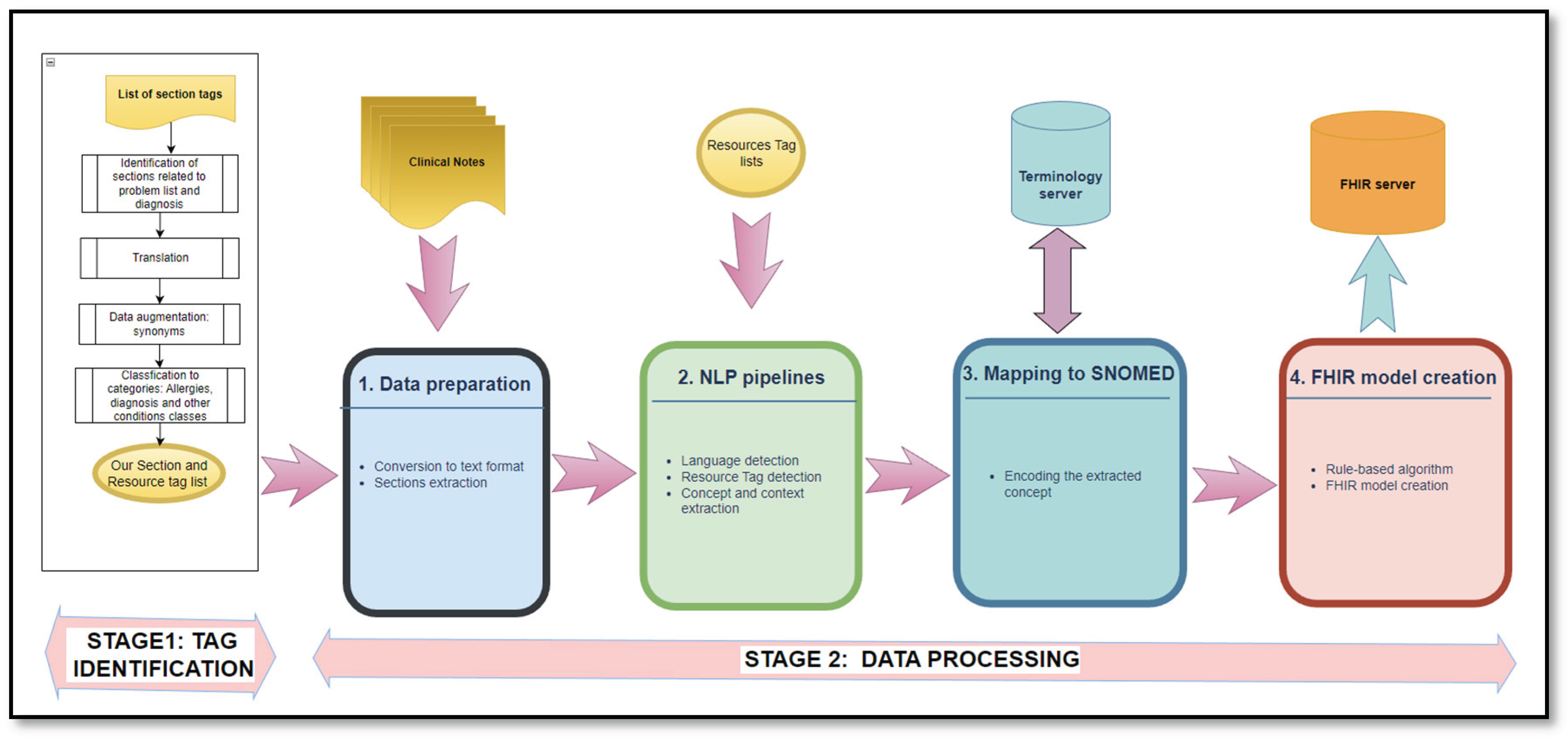
Figure 2.
Example of section and resource tags optimization.
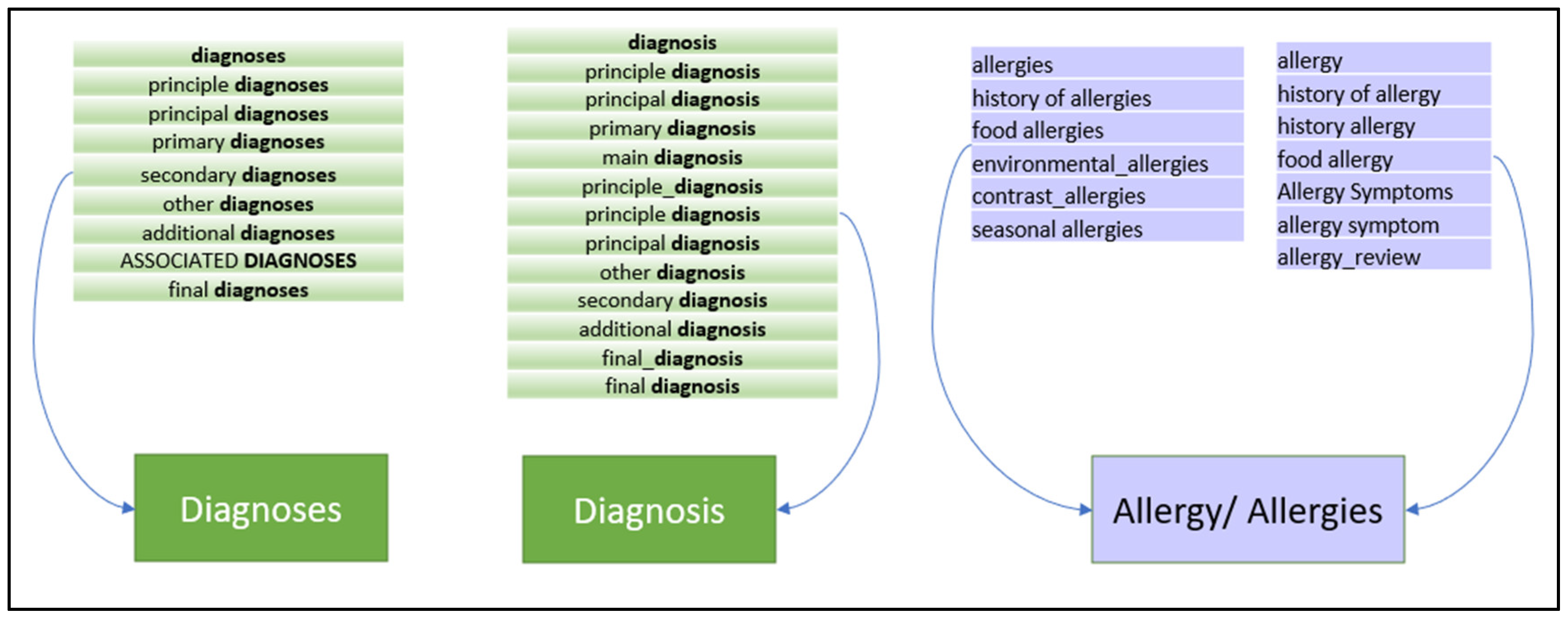
Figure 3.
Rule-based method for mapping NLP output to FHIR model elements.
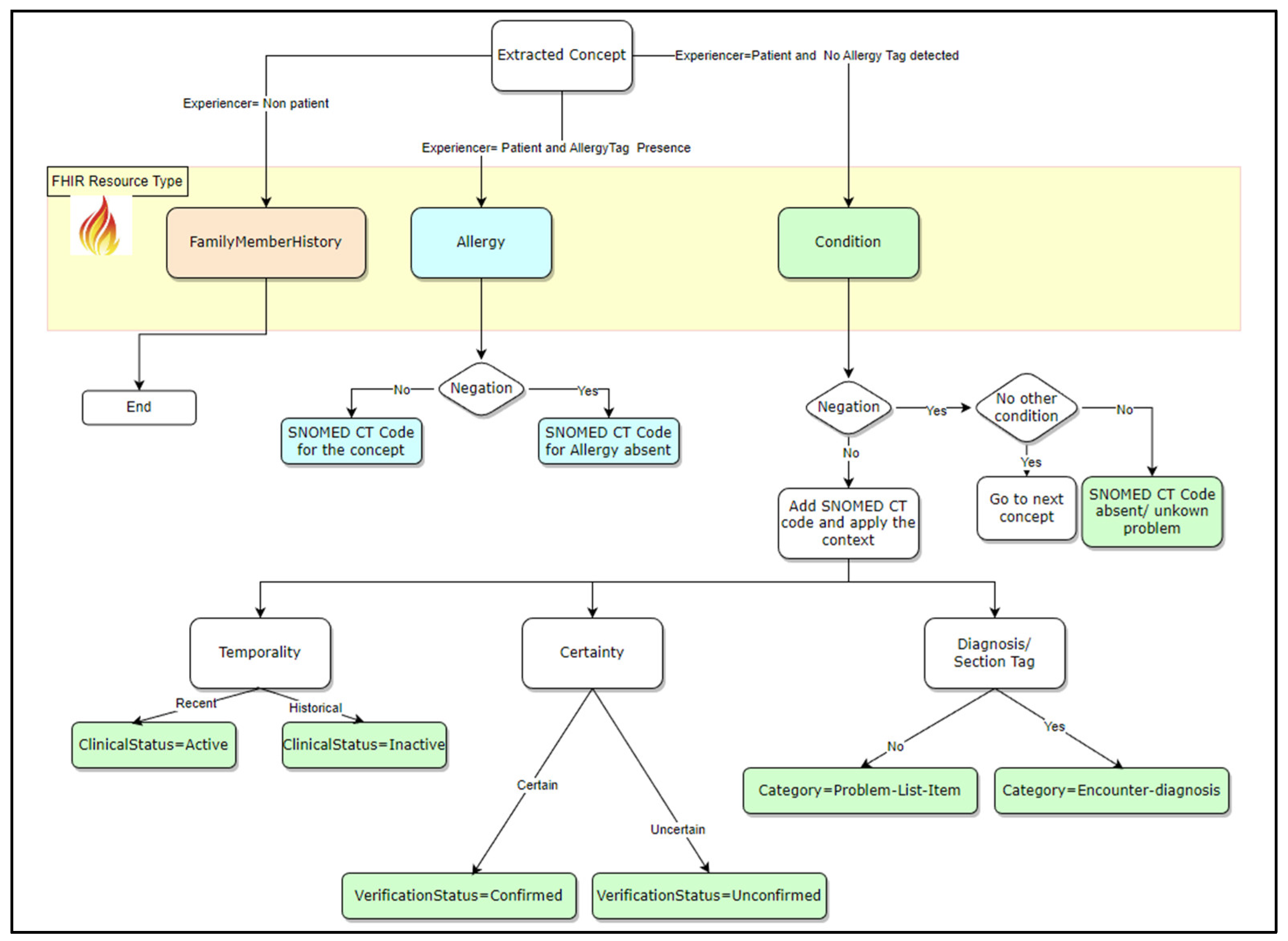
Figure 4.
An example of the extracted concepts with their context using SIFR.
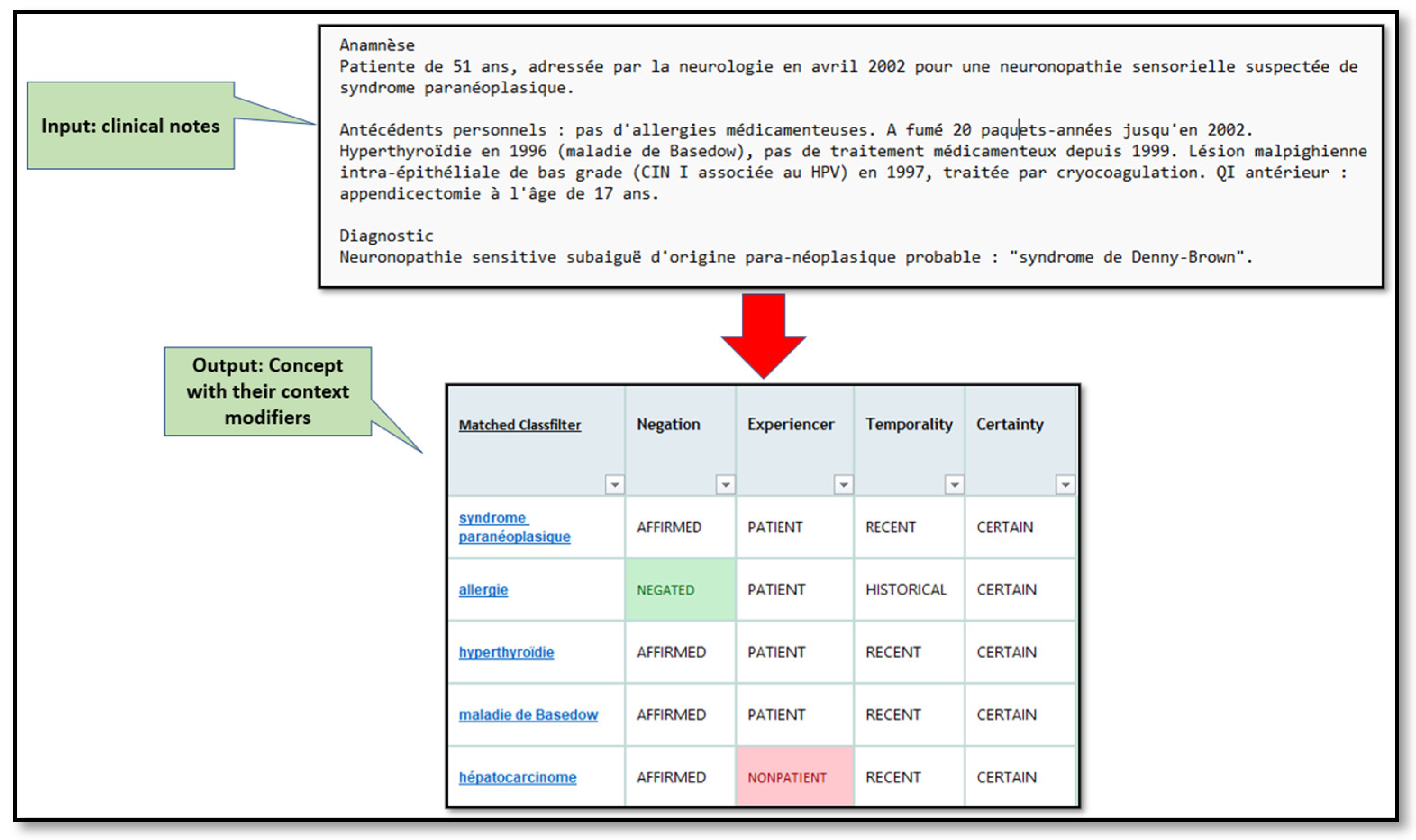
Figure 5.
An example of Resource Tag detection.
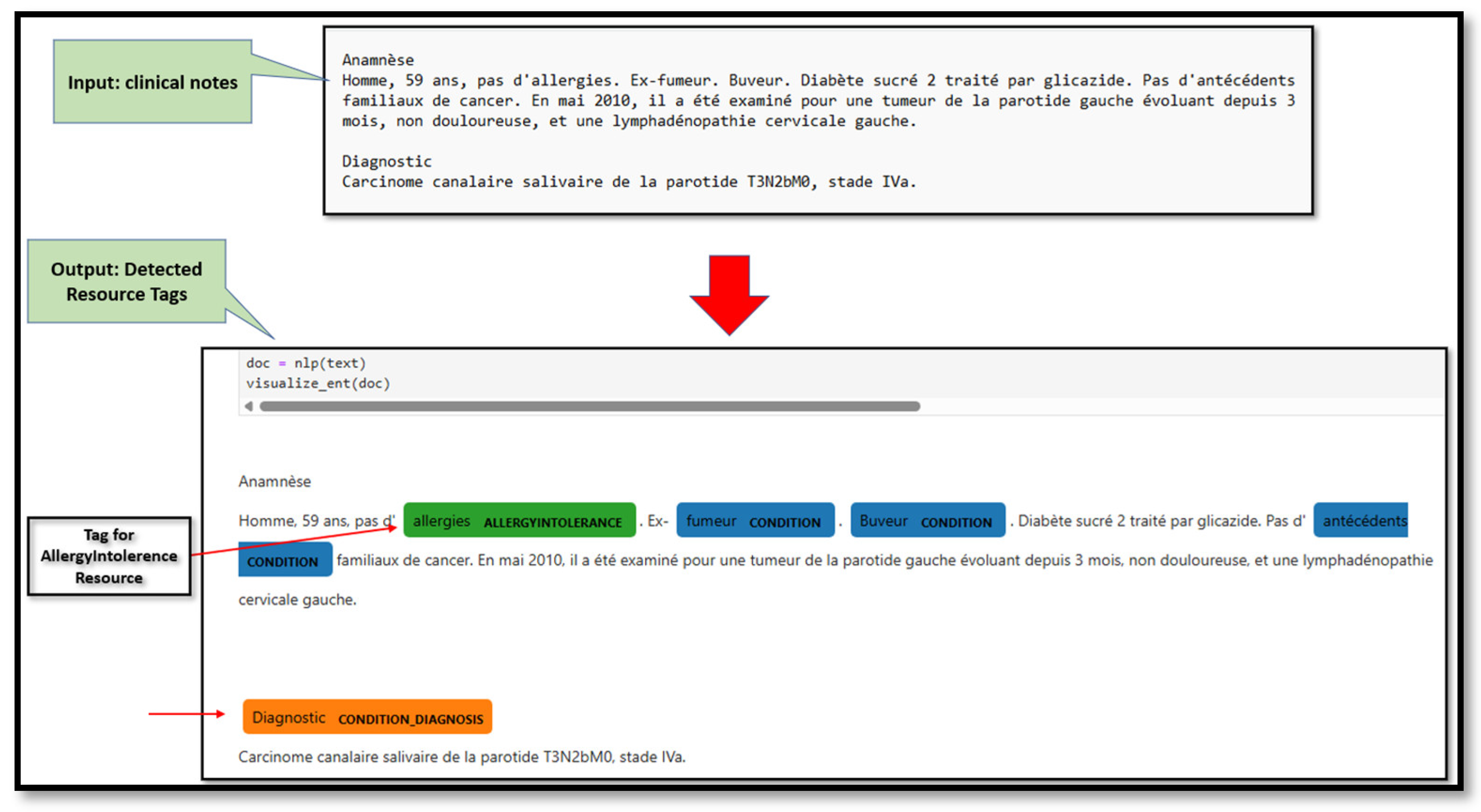
Figure 6.
An example of IPS creation using the Rule-based approach.
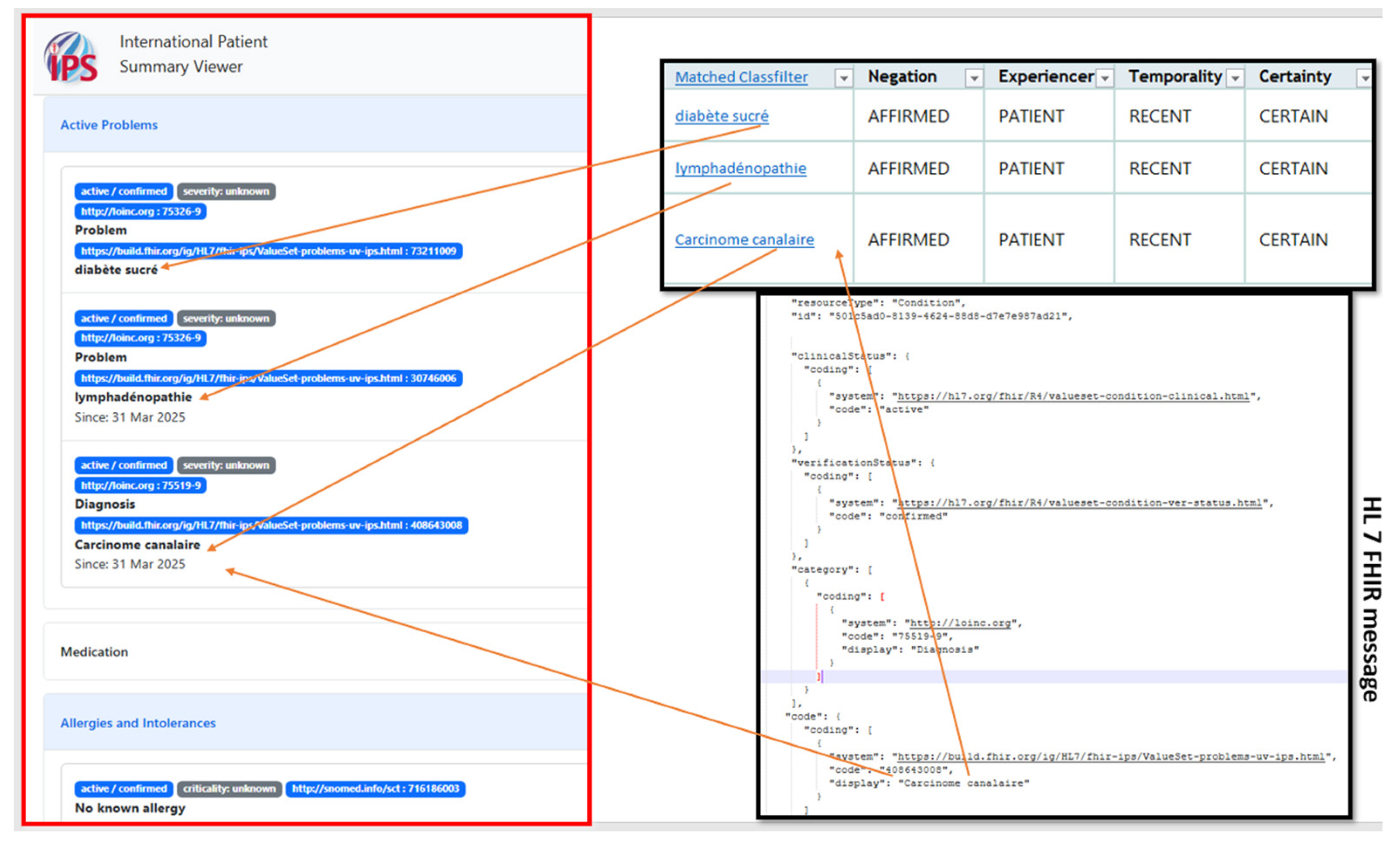

Table 1.
Research challenges.
| ID | Category | Challenge description |
|---|---|---|
| 1. | Data format | |
| 1.1 | Information related to the patient problem list is mainly in unstructured format. | |
| 1.2 | Most reports are in PDF file format. | |
| 2. | Language | |
| 2.1 | Clinical notes in Canada, and other French countries, are either in English or French. | |
| 2.2 | NLP models and techniques are language dependent. Selecting the appropriate NLP pipeline requires prior identification of the language used. | |
| 2.3 | Most NLP tools are for English text. There is a major need in other languages, including French which is largely used in Quebec, for the interoperability of the patient problem list. | |
| 3. | Context and modifiers | |
| 3.1 | The patient problem list may be related to an allergy/intolerance, a diagnosis or other types of related clinical conditions. It is important to distinguish between these items to ensure correct mapping to FHIR elements. | |
| 3.2 | The proposed framework needs to consider that the extracted condition may be in a negation context. | |
| 3.3 | Extracted condition may be related to the patient or their family members. | |
| 3.4 | Extracted condition may be confirmed or only an hypothesis. | |
| 3.5 | Extracted condition may be active or resolved (historical). | |
| 4. | Standard/ guidelines | |
| 4.1 | Must use a standard (e.g., SNOMED CT) to ensure semantic interoperability or common understanding and interpretability. | |
| 5. | Condition type | |
| The patient problem list may be related to an allergy or other type of health conditions. Need to distinguish allergies from the rest of condition types. |
Table 2.
Section selection for the patient problem list in the CANTEMIST_FRAMISED corpus.
| Section title (original list) | Selected/ Unselected | Tag category |
|---|---|---|
| Anamnèse | Selected | Other condition |
| Examen physique | Unselected | - |
| Examens complémentaires | Unselected | - |
| Tests complémentaires | Unselected | - |
| Diagnostic | Selected | Diagnosis |
| DIAGNOSTIC PRINCIPAL | Selected | Diagnosis |
| HISTOIRE DE LA FAMILLE | Selected | Other condition |
| MALADIE ACTUELLE | Selected | Diagnosis |
| CONTEXTE PERSONNEL | Selected | Other condition |
| Antécédents | Selected | Other condition |
| Antécédents oncologiques | Selected | Other condition |
| Traitement | Unselected | - |
| Évolution | Unselected | - |
| L’évolution | Unselected | - |
| Développements | Unselected | - |
Table 3.
Performance evaluation of Allergy resource tag on the two FRASIMED files (N=50).
| FRAMISED Dataset files | Language | Accuracy | Recall | Precision | F1 Score |
|---|---|---|---|---|---|
| CANTEMIST-FRASIMED | French | 1 | 1 | 1 | 1 |
| DISTEMIST-FRASIMED | French | 0.947 | 1 | 0.8888 | 0.9411 |
Table 4.
An example of the Rule-Based validation.
| Step | Input | Decision logic | Output |
|---|---|---|---|
| 1 | Experiencer=Patient and no associated allergy tag | The concept is related to the patient and no flag that it is an allergy | Use the Condition Resource |
| 2 | Negation | “Affirmed” means there is no negation | Three contexts to verify |
| 3 | Temporality | Apply rule for Recent | ClinicalStatus=Active |
| 4 | Certainty | Apply rule for value= Certain | VerificationStatus=Confirmed |
| 5 | Diagnostic Section Tag | Concept included in Diagnosis section | Category=Encounter-diagnosis |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



