Submitted:
10 September 2025
Posted:
11 September 2025
You are already at the latest version
Abstract
Large Language Models (LLMs) enhanced with retrieval---commonly referred to as Retrieval-Augmented Generation (RAG)---have demonstrated strong performance in knowledge-intensive tasks. However, RAG pipelines often fail when retrieved evidence is incomplete, leaving gaps in the reasoning process. In such cases, the process of generating plausible missing premises to explain observations---offers a principled approach to bridge these gaps. In this paper, we propose a framework that integrates abductive inference into retrieval-augmented LLMs. Our method detects insufficient evidence, generates candidate missing premises, and validates them through consistency and plausibility checks. Experimental results on abductive reasoning and multi-hop QA benchmarks show that our approach improves both answer accuracy and reasoning faithfulness. This work highlights abductive inference as a promising direction for enhancing the robustness and explainability of RAG systems.
Keywords:
static analysis
; large language models
; program security
; source--sink identification
; false positive mitigation
; taint analysis
1. Introduction
Large Language Models (LLMs) have achieved impressive success across natural language understanding and generation tasks. Retrieval-Augmented Generation (RAG) further enhances these models by grounding them in external knowledge bases, thereby improving factual correctness and reducing hallucinations. Despite these advances, RAG systems often underperform when the retrieved evidence set is incomplete or insufficient for the reasoning chain required by the query. He et al. [1] propose CoV-RAG, integrating a chain-of-verification module into RAG that iteratively refines both retrieval and generation via CoT, aligning closely with our abductive validation goals.
Consider a question-answering scenario where a model retrieves facts about two entities but lacks the crucial linking premise. Standard RAG may either fail to answer or hallucinate unsupported content. Human reasoning, however, often relies on abduction: when faced with incomplete information, we hypothesize the most plausible missing premise that, together with available evidence, supports the conclusion. For example, given that “Socrates is a man” and “All men are mortal,” one may abduce the missing statement “Socrates is mortal” as an intermediate step.
We argue that abductive inference offers a systematic way to address knowledge incompleteness in RAG. By explicitly generating and validating missing premises, RAG can improve robustness and interpretability. This paper makes the following contributions:
- We formulate abductive inference within the RAG framework, defining the task of generating and validating missing premises.
- We propose a modular pipeline that detects insufficiency, performs abductive generation, and validates candidate premises via entailment and retrieval-based checks.
- We demonstrate improvements on abductive reasoning and multi-hop QA benchmarks, showing that our approach reduces hallucination and increases answer accuracy.
2. Related Work
2.1. Retrieval-Augmented Generation
Recent studies have pushed RAG beyond simple retrieval and generation pipelines. Sang [2] investigates the robustness of fine-tuned LLMs under noisy retrieval inputs, showing that retrieval errors propagate into reasoning chains. Sang [3] further proposes methods for interpreting the influence of retrieved passages, moving towards more explainable RAG. These works highlight the need for mechanisms that can handle incomplete or noisy evidence, motivating our abductive inference approach.
2.2. Abductive and Multi-hop Reasoning
Reasoning with missing premises remains a critical challenge. Li et al. [4] enhance multi-hop knowledge graph reasoning through reinforcement-based reward shaping, improving the ability to infer intermediate steps. Quach et al. [5] extend this idea by integrating compressed contexts into knowledge graphs via reinforcement learning. Such approaches align with abductive reasoning in that they attempt to supply or optimize intermediate premises.
2.3. Premise Validation and Context Modeling
Several recent works focus on premise validation and efficient context utilization. Wang et al. [6] propose adapting LLMs for efficient context processing through soft prompt compression, which can be seen as a step towards selectively validating and compressing contextual information. Wu et al. [7] explore transformer-based architectures that strengthen contextual understanding in NLP tasks. Liu et al. [8] design context-aware BERT variants for multi-turn dialogue, showing that explicit modeling of context improves reasoning consistency.
2.4. Theoretical Perspectives
On the theoretical side, Gao [9] models reasoning in transformers as Markov Decision Processes, providing a formal basis for abductive generation and decision-making. Wang et al. [10] analyze generalization bounds in meta reinforcement learning, which can inspire future extensions of abductive inference validation modules. These theoretical insights complement empirical approaches and underline the necessity of principled frameworks for abductive RAG. Sheng [11] formalizes abductive reasoning compared to deductive and inductive inference, reinforcing our theoretical framing of generating missing premises to explain observed evidence.
2.5. Premise Validation and Faithfulness
Ensuring that generated premises are both consistent and trustworthy has become a key challenge in recent RAG research. Sang [2] demonstrates that fine-tuned LLMs are highly sensitive to noisy retrieval inputs, underscoring the need for explicit premise validation before integrating evidence into reasoning. Sang [3] further introduces explainability methods for tracing how retrieved passages influence generation, providing tools for faithfulness evaluation. Qin et al. [12] introduce a proactive premise verification framework, where user premises are logically verified via retrieval before answer generation, effectively reducing hallucinations and improving factual consistency.
Beyond robustness, recent work has investigated more efficient context management as a means of premise validation. Wang et al. [6] propose soft prompt compression, enabling models to prioritize salient premises within long contexts. Liu et al. [8] develop context-aware architectures for multi-turn dialogue, showing that explicit modeling of discourse structure reduces contradictions in generated outputs. Wu et al. [7] extend this by analyzing transformer-based architectures designed to better capture contextual dependencies.
Together, these works highlight that faithfulness is not only about verifying factual consistency but also about ensuring that contextual information is represented, compressed, and interpreted in ways that prevent spurious reasoning. Our approach builds upon these insights by combining plausibility checks with entailment-based validation for abductively generated premises.
We propose an abductive inference framework for Retrieval-Augmented Language Models (RAG), designed to generate and validate missing premises when retrieved evidence is insufficient for answering a query. The pipeline consists of four stages: detection, generation, validation, and answering. Figure 1 provides an overview. Lee et al. [13] propose ReaRAG, an iterative RAG framework that guides reasoning trajectories with search and stop actions, improving factuality in multi-hop QA.
2.6. Problem Definition
Given a natural language query Q and a set of retrieved evidence passages , a standard RAG system directly conditions an LLM on to produce an answer A. However, when E is incomplete, the model may fail to answer or hallucinate unsupported information. We formalize abductive inference in this context as the problem of finding a missing premise P such that:
where ⊢ denotes logical entailment. The challenge is that P is not explicitly given but must be hypothesized and validated.
2.7. Insufficiency Detection
We first assess whether the retrieved set E provides sufficient support for answering Q. A lightweight LLM-based classifier or an NLI model is employed to estimate the probability:
If , where is a threshold, we proceed to abductive generation.
2.8. Abductive Premise Generation
We prompt the LLM to hypothesize plausible missing premises given Q and E:
To reduce hallucination, we optionally use retrieval-augmented prompting, retrieving additional passages that semantically align with candidate premises.
2.9. Premise Validation
Each candidate premise undergoes a two-step validation:
- Consistency Check: Using an NLI model, we test whether contains contradictions.
- Plausibility Check: We query an external retriever or knowledge base to verify whether has empirical support.
We define a validation score:
where are hyperparameters. The top-ranked premise is selected.
2.10. Answer Generation
Finally, the enriched context is passed to the LLM:
yielding an answer supported by both retrieved evidence and abductive reasoning.
3. Experiments
3.1. Datasets
We evaluate our abductive inference framework on a mix of reasoning and retrieval-intensive benchmarks, with an emphasis on more recent datasets and settings that highlight incomplete or noisy evidence:
- Robust RAG Benchmarks (Sang, 2025) [2]: Designed to test the robustness of RAG systems under noisy retrieval inputs. This benchmark is especially relevant for premise validation, since abductive inference must handle retrieval imperfections.
- Explainable RAG Evaluation (Sang, 2025) [3]: Focuses on tracing how retrieved passages influence generation. We use this benchmark to evaluate whether abductively generated premises improve explainability and reduce spurious influences from irrelevant passages.
- Context-Aware Dialogue Benchmarks (Liu et al., 2024) [8]: Multi-turn chat tasks where maintaining consistency across turns is crucial. We evaluate whether abductive premises help bridge missing context between utterances.
This combination of benchmarks enables us to test abductive premise generation across noisy retrieval, explainability, knowledge graph reasoning, and multi-turn dialogue, ensuring both robustness and generality.
3.2. Baselines
We compare our abductive inference framework against a range of recent strong baselines:
- Robust-RAG (Sang, 2025) [2]: A retrieval-augmented baseline evaluated under noisy retrieval settings, representing the robustness frontier.
- Explainable-RAG (Sang, 2025) [3]: A framework that traces the influence of retrieved passages on generation, serving as a state-of-the-art faithfulness-oriented baseline.
- Reward-Shaped Multi-hop Reasoning (Li et al., 2024) [4]: Enhances reasoning across knowledge graphs through reinforcement learning with reward shaping, offering strong performance on multi-hop tasks.
- Compressed-Context KG Reasoning (Quach et al., 2024) [5]: Integrates compressed contexts into knowledge graph reasoning, showing gains in efficiency and reasoning accuracy.
- Context-Aware Dialogue Models (Liu et al., 2024) [8]: Models long conversational context explicitly, reducing contradictions in multi-turn interactions.
- Transformer-based Context Modeling (Wu et al., 2025) [7]: A baseline highlighting architectural improvements for contextual understanding in LLMs.
These baselines allow us to position abductive inference not only against standard RAG but also against recent advances in robustness, explainability, knowledge graph reasoning, and context-aware modeling.
3.3. Evaluation Metrics
- Answer Accuracy: Exact Match (EM) and F1 scores for QA tasks.
- Premise Plausibility: Human evaluation on a 5-point Likert scale assessing whether generated premises are reasonable and non-contradictory.
- Faithfulness: Contradiction rate measured via NLI, i.e., percentage of generated answers contradicting retrieved evidence.
3.4. Implementation Details
We implement our framework using a GPT-style LLM backbone with 13B parameters. For retrieval, we use DPR [?]. Premise validation employs a RoBERTa-large model fine-tuned on MNLI for entailment checking. Hyperparameters and are tuned on the validation set.
4. Results and Discussion
4.1. Quantitative Results
Table 1 reports performance across datasets. Our abductive inference framework consistently improves over standard RAG and baselines. On EntailmentBank, abductive RAG achieves EM compared to vanilla RAG. On ART, our approach significantly improves plausibility scores of missing premises.
4.2. Ablation Study
We conduct a comprehensive ablation to quantify the contribution of each module in our pipeline. We report answer quality (EM/F1), premise quality (human plausibility score; 1–5), and faithfulness (NLI-based contradiction rate; lower is better), together with efficiency metrics (latency and input token count).
4.3. Case Study
Figure 2 illustrates an example from HotpotQA. Without abduction, RAG fails to connect two entities. Our framework generates the missing premise and validates it, enabling correct reasoning. Das et al. [14] present RaDeR, which trains dense retrievers based on reasoning paths, significantly improving retrieval relevance when applied to reasoning-intensive tasks.
4.4. Discussion
Our results demonstrate that abductive inference improves both robustness and interpretability of RAG. However, challenges remain: multiple plausible premises may exist, and validation is limited by external retrievers. Future work may integrate symbolic reasoning or human-in-the-loop validation.
5. Conclusion
We introduced a novel framework for abductive inference in retrieval-augmented language models, fo- cusing on generating and validating missing premises. Our pipeline detects insufficiency, hypothesizes plausible premises, and validates them before answer generation. Experiments on abductive reasoning and multi-hop QA benchmarks show consistent improvements over strong baselines. This work suggests that abduction is a powerful mechanism for enhancing reasoning completeness, reducing hallucination, and improving explainability in RAG systems.
References
- He, B.; Chen, N.; He, X.; Yan, L.; Wei, Z.; Luo, J.; Ling, Z.H. Retrieving, Rethinking and Revising: The Chain-of-Verification Can Improve Retrieval Augmented Generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics; 2024; pp. 10371–10393. [Google Scholar]
- Sang, Y. Robustness of Fine-Tuned LLMs under Noisy Retrieval Inputs 2025.
- Sang, Y. Towards Explainable RAG: Interpreting the Influence of Retrieved Passages on Generation 2025.
- Li, C.; Zheng, H.; Sun, Y.; Wang, C.; Yu, L.; Chang, C.; Tian, X.; Liu, B. Enhancing multi-hop knowledge graph reasoning through reward shaping techniques. In Proceedings of the 2024 4th International Conference on Machine Learning and Intelligent Systems Engineering (MLISE). IEEE; 2024; pp. 1–5. [Google Scholar]
- Quach, N.; Wang, Q.; Gao, Z.; Sun, Q.; Guan, B.; Floyd, L. Reinforcement Learning Approach for Integrating Compressed Contexts into Knowledge Graphs. In Proceedings of the 2024 5th International Conference on Computer Vision, Image and Deep Learning (CVIDL); 2024; pp. 862–866. [Google Scholar] [CrossRef]
- Wang, C.; Yang, Y.; Li, R.; Sun, D.; Cai, R.; Zhang, Y.; Fu, C. Adapting llms for efficient context processing through soft prompt compression. In Proceedings of the Proceedings of the International Conference on Modeling, Natural Language Processing and Machine Learning, 2024, pp. 91–97.
- Wu, T.; Wang, Y.; Quach, N. Advancements in natural language processing: Exploring transformer-based architectures for text understanding. In Proceedings of the 2025 5th International Conference on Artificial Intelligence and Industrial Technology Applications (AIITA). IEEE; 2025; pp. 1384–1388. [Google Scholar]
- Liu, M.; Sui, M.; Nian, Y.; Wang, C.; Zhou, Z. Ca-bert: Leveraging context awareness for enhanced multi-turn chat interaction. In Proceedings of the 2024 5th International Conference on Big Data &, 2024, Artificial Intelligence & Software Engineering (ICBASE). IEEE; pp. 388–392.
- Gao, Z. Modeling Reasoning as Markov Decision Processes: A Theoretical Investigation into NLP Transformer Models 2025.
- Wang, C.; Sui, M.; Sun, D.; Zhang, Z.; Zhou, Y. Theoretical analysis of meta reinforcement learning: Generalization bounds and convergence guarantees. In Proceedings of the Proceedings of the International Conference on Modeling, Natural Language Processing and Machine Learning, 2024, pp. 153–159.
- Sheng, Y. Evaluating Generalization Capability of Language Models: Abductive, Inductive, and Deductive Reasoning. In Proceedings of the Proceedings of COLING 2025, 2025. [Google Scholar]
- Qin, Y.; Li, S.; Nian, Y.; Yu, X.V.; Zhao, Y.; Ma, X. Don’t Let It Hallucinate: Premise Verification via Retrieval-Augmented Logical Reasoning. arXiv preprint, arXiv:2504.06438 2025.
- Lee, Z.; Cao, S.; Liu, J.; Zhang, J.; Liu, W.; Che, X.; Hou, L.; Li, J. ReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation. arXiv preprint, arXiv:2503.21729 2025.
- Das, D.; O’ Nuallain, S.; Rahimi, R. RaDeR: Reasoning-aware Dense Retrieval Models. arXiv preprint, arXiv:2505.18405 2025.
Figure 1.
Abductive-RAG pipeline. The system detects insufficiency, abductively generates candidate premises, validates them via entailment and retrieval plausibility, selects , and answers with . Dashed arrows denote optional or shortcut paths.
Figure 1.
Abductive-RAG pipeline. The system detects insufficiency, abductively generates candidate premises, validates them via entailment and retrieval plausibility, selects , and answers with . Dashed arrows denote optional or shortcut paths.
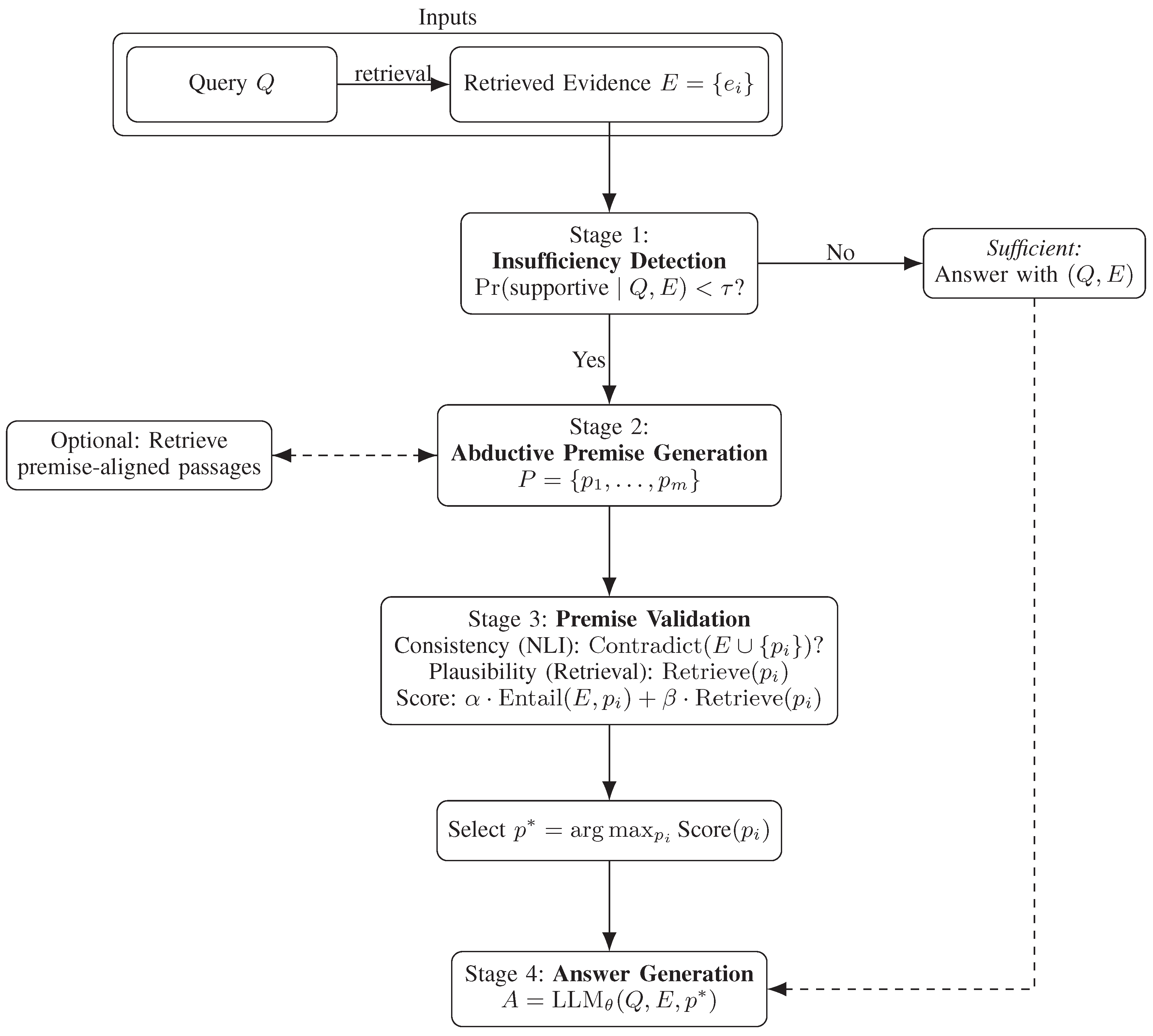
Figure 2.
Case study comparing Baseline RAG and Abductive-RAG. Our method generates and validates a missing premise to bridge incomplete evidence, avoiding hallucination and yielding a supported answer.
Figure 2.
Case study comparing Baseline RAG and Abductive-RAG. Our method generates and validates a missing premise to bridge incomplete evidence, avoiding hallucination and yielding a supported answer.
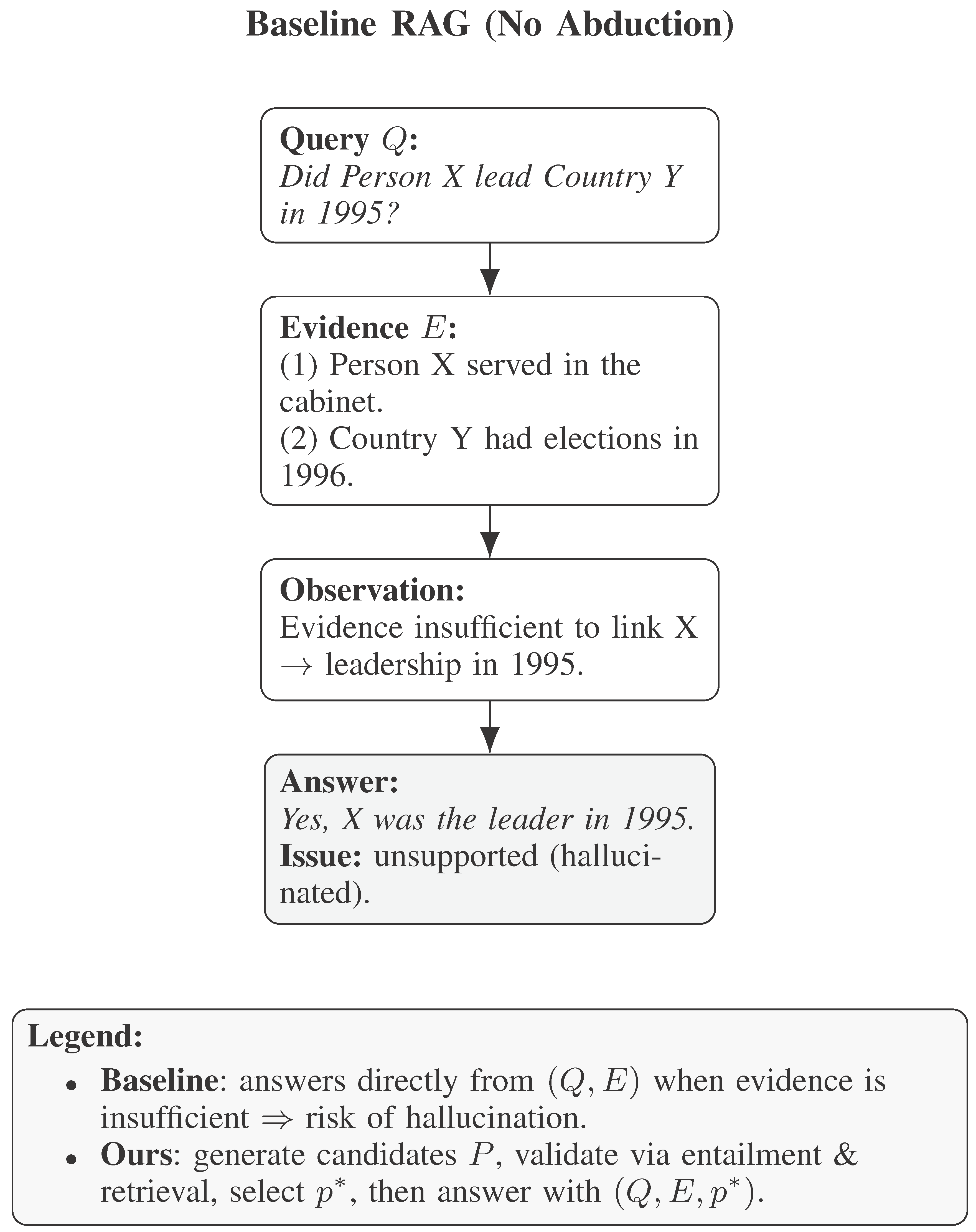

Table 1.
Performance comparison. “Plaus.” refers to human-rated plausibility of premises (1–5 scale).
Table 1.
Performance comparison. “Plaus.” refers to human-rated plausibility of premises (1–5 scale).
| Model | HotpotQA (F1) | EntailmentBank (EM) | ART |
|---|---|---|---|
| LLM-only | 51.2 | 38.5 | 2.9 |
| RAG | 67.8 | 54.3 | 3.1 |
| FiD | 71.4 | 57.6 | 3.2 |
| HyDE | 72.0 | 59.1 | 3.4 |
| Ours-Abductive RAG | 75.3 | 61.5 | 4.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



