Submitted:
27 July 2025
Posted:
28 July 2025
You are already at the latest version
Abstract
We propose Liquid AI, an architectural framework for artificial intelligence systems capable of continuous structural adaptation and autonomous capability development. Unlike existing approaches in continual learning and neural architecture search that operate within predetermined constraints, Liquid AI implements three novel mechanisms: (1) entropy-guided hyperdimensional knowledge graphs that autonomously restructure based on information-theoretic criteria; (2) a self-development engine using hierarchical Bayesian optimization for runtime architecture modification; and (3) a federated multi-agent framework with emergent specialization through distributed reinforcement learning. Our framework addresses fundamental limitations in current AI systems—static architectures, isolated knowledge domains, and human-dependent evolution—through mathematically formalized processes of dynamic parameter adjustment, structural self-modification, and cross-domain knowledge synthesis. We present architectural specifications, theoretical convergence bounds for self-modifying systems, and evaluation criteria for adaptive AI systems. Implementation considerations address computational complexity and distributed computing requirements. This work establishes theoretical and architectural foundations for a new paradigm in artificial intelligence that transitions from episodic training to persistent autonomous development. By enabling runtime structural adaptation, cross-domain knowledge integration, and collaborative intelligence emergence, Liquid AI provides a blueprint for AI systems that continuously evolve to address complex challenges without human intervention.
Keywords:
liquid AI
; adaptive learning
; multi-agent AI
; self-improving AI
; knowledge integration
; continual learning
; meta-learning
1. Introduction
Contemporary artificial intelligence has achieved remarkable successes in specialized domains, from game playing to natural language processing and scientific discovery [1,2,3]. These systems excel at pattern recognition [4], natural language understanding [5], and strategic reasoning [6], yet they remain fundamentally constrained by architectural decisions made before deployment. This limitation contrasts sharply with biological intelligence, which exhibits continuous adaptation through structural plasticity [7]. In this paper, we present Liquid AI as a theoretical framework that explores what becomes possible when we remove these architectural constraints, allowing AI systems to modify their own structure during operation.
The term "liquid" captures the essential property we seek: a system that can reshape itself to fit the contours of any problem space while maintaining coherent function. Inspired by complex systems theory [10] and the adaptive properties of biological neural networks [9], our framework formalizes mechanisms for runtime architectural modification, autonomous knowledge synthesis, and emergent multi-agent specialization. While immediate implementation faces significant challenges (detailed in our supplemental materials) this theoretical exploration provides mathematical foundations for a potential new paradigm in artificial intelligence. Figure 1 illustrates the core architectural components of Liquid AI, demonstrating how the Knowledge Integration Engine, Self-Development Module, and Multi-Agent Coordinator interact dynamically to enable continuous self-improvement.
2. Current Limitations and Theoretical Opportunities
2.1. Architectural Constraints in Contemporary AI
Modern AI systems operate within predetermined structural boundaries that fundamentally limit their adaptive capacity. Large language models, despite their impressive capabilities, cannot modify their transformer architectures or attention mechanisms after training [5,6]. Computer vision systems remain locked into their convolutional or vision transformer designs [7]. These static architectures create several critical limitations that motivate our theoretical exploration.
Table S1 (Supplemental Material) provides a systematic comparison between traditional AI systems and the proposed Liquid AI framework, highlighting how architectural rigidity constrains current approaches. Figure 2 illustrates these fundamental differences across key dimensions of adaptability, knowledge integration, and autonomous evolution. Figure 2 provides a systematic comparison between traditional AI architectures and the proposed Liquid AI paradigm, highlighting the fundamental shift from static, human-directed systems to dynamic, self-evolving architectures.

Table 1.
Comprehensive Comparison of Liquid AI with Existing Adaptive AI Methods.
| Capability | Liquid AI | EWC | MAML | DARTS | PackNet | QMIX |
|---|---|---|---|---|---|---|
| (Ours) | [81] | [17] | [82] | [70] | [83] | |
| Architectural Adaptation | ||||||
| Runtime Architecture Modification | ✓ | × | × | × | × | × |
| Topological Plasticity | ✓ | × | × | × | × | × |
| Autonomous Structural Evolution | ✓ | × | × | × | × | × |
| Pre-deployment Architecture Search | N/A | × | × | ✓ | × | × |
| Learning Capabilities | ||||||
| Continual Learning | ✓ | ✓ | ✓ | × | ✓ | × |
| Catastrophic Forgetting Prevention | ✓ | ✓ | ✓ | N/A | ✓ | N/A |
| Cross-Domain Knowledge Transfer | ✓ | Limited | ✓ | × | Limited | × |
| Zero-Shot Task Adaptation | ✓ | × | ✓ | × | × | × |
| Self-Supervised Learning | ✓ | × | × | × | × | × |
| Knowledge Management | ||||||
| Dynamic Knowledge Graphs | ✓ | × | × | × | × | × |
| Entropy-Guided Optimization | ✓ | × | × | × | × | × |
| Cross-Domain Reasoning | ✓ | × | Limited | × | × | × |
| Temporal Knowledge Evolution | ✓ | × | × | × | × | × |
| Multi-Agent Capabilities | ||||||
| Emergent Agent Specialization | ✓ | N/A | N/A | N/A | N/A | × |
| Dynamic Agent Topology | ✓ | N/A | N/A | N/A | N/A | × |
| Collective Intelligence | ✓ | N/A | N/A | N/A | N/A | ✓ |
| Autonomous Role Assignment | ✓ | N/A | N/A | N/A | N/A | × |
| Performance Characteristics | ||||||
| Sustained Improvement | ✓ | × | × | × | × | × |
| Resource Efficiency | Adaptive | Fixed | Fixed | Fixed | Fixed | Fixed |
| Scalability | Unlimited | Limited | Limited | Limited | Limited | Moderate |
| Interpretability | Dynamic | Low | Low | Moderate | Low | Low |
| Deployment Flexibility | ||||||
| Online Adaptation | ✓ | Limited | Limited | × | Limited | Limited |
| Distributed Deployment | ✓ | × | × | × | × | ✓ |
| Hardware Agnostic | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Real-Time Operation | ✓ | ✓ | ✓ | × | ✓ | ✓ |
Five Fundamental Limitations
Current AI systems face five interconnected limitations that stem from their static nature:
Parameter Rigidity
Once trained, neural architectures cannot evolve their topology. While parameter-efficient adaptation methods like LoRA [9] and fine-tuning [8] enable limited modifications within fixed structures, they cannot add new pathways, remove redundant components, or fundamentally reorganize information flow. This contrasts with biological systems where synaptic plasticity includes both weight modification and structural changes [10].
Knowledge Fragmentation
Information remains isolated within predefined domains. Transfer learning [11] and multi-task learning [12] provide mechanisms for sharing knowledge across related tasks, but these require human-specified task relationships. Current systems lack the ability to autonomously discover and exploit latent connections between disparate knowledge domains.
Human-Dependent Evolution
Improvements require human intervention through architectural redesign, hyperparameter tuning, or complete retraining. While AutoML [13] and Neural Architecture Search [14] automate aspects of model development, they operate within human-defined search spaces during distinct optimization phases, not during deployment.
Catastrophic Forgetting
Sequential learning in current systems leads to degradation of previously acquired capabilities [15]. Although continual learning methods [16] mitigate this issue through various memory mechanisms, they operate within the constraint of fixed architectures, limiting their ability to expand capabilities without interference.
Limited Meta-Learning
2.2. Theoretical Foundations from Natural Systems
Nature provides compelling examples of systems exhibiting the properties we seek. Biological neural networks demonstrate remarkable plasticity, continuously forming and pruning connections in response to experience [19]. Social insect colonies exhibit collective intelligence emerging from simple local interactions without central coordination [20]. These natural systems inspire our approach while highlighting the gap between current AI and truly adaptive intelligence.
Complex adaptive systems theory offers insights into how simple components can give rise to sophisticated collective behaviors [10]. Key principles include distributed control without central authority, adaptive feedback loops that modify behavior based on environmental signals, phase transitions where small parameter changes lead to qualitative behavioral shifts, and hierarchical organization where complex behaviors emerge at multiple scales. These principles inform our design of Liquid AI, where architectural evolution emerges from information-theoretic optimization rather than predetermined rules.
2.3. Core Contributions and Article Structure
This paper makes four fundamental contributions to the theoretical foundations of artificial intelligence:
We introduce Liquid AI as a comprehensive theoretical framework for AI systems capable of continuous structural self-modification during deployment. Unlike existing approaches that modify parameters within fixed architectures, our framework formalizes mechanisms for runtime topological evolution. We establish mathematical foundations including convergence bounds for self-modifying systems and formal conditions under which architectural evolution preserves functional coherence while enabling capability expansion.
Our theoretical analysis addresses fundamental questions about the feasibility and behavior of self-modifying AI systems. We develop comprehensive evaluation frameworks for assessing adaptive AI systems, including metrics for temporal evolution, cross-domain integration, and emergent capabilities that extend beyond traditional static benchmarks. Finally, we provide detailed implementation considerations in the supplemental materials, including computational complexity analysis, distributed computing requirements, and a decade-spanning incremental development roadmap.
The computational foundations underlying these mechanisms are summarized in Table S1. Figure 1 illustrates the core architectural components and their theoretical interactions, providing a visual overview of the complete system.
The remainder of this paper is structured as follows: Section 3 details the Liquid AI architecture with its dynamic knowledge graphs and self-modification mechanisms. Section 4 explores self-development processes including hierarchical task decomposition. Section 5 presents the multi-agent collaboration framework. Section 6 covers knowledge integration mechanisms. Section 7 addresses implementation considerations. Section 8 outlines evaluation methodologies. Section 9 explores potential applications. Section 10 discusses implications and future directions. The supplemental materials provide additional technical depth, baseline comparisons with existing systems, and detailed analysis of computational requirements.
By establishing theoretical foundations for continuously adaptive AI, this work aims to inspire research toward systems that match the flexibility of biological intelligence while leveraging the computational advantages of artificial systems. While immediate implementation faces significant challenges, we believe this theoretical exploration opens important new directions for the field.
3. Liquid AI Architecture
3.1. Architectural Overview
The Liquid AI architecture represents a theoretical framework for dynamically evolving computational systems that extend beyond traditional adaptive approaches. Unlike existing methods that modify parameters within fixed structures [21], Liquid AI explores the mathematical foundations for runtime topological modifications guided by information-theoretic principles. This framework builds on concepts from modular networks [23] and meta-learning [17], but extends them to enable autonomous structural evolution during deployment.
We formalize the architecture as an adaptive system defined by:
where each component represents a functionally distinct subsystem: implements the dynamic knowledge graph with entropy-guided restructuring, represents the self-development engine using hierarchical Bayesian optimization, encapsulates the multi-agent collaborative framework, describes adaptive learning mechanisms, and represents meta-cognitive processes for system-level optimization.
This architecture exhibits three theoretical properties that distinguish it from current systems. First, topological plasticity enables runtime modification of network connectivity based on information flow patterns, extending beyond weight adaptation to structural reconfiguration. Second, compositional adaptivity allows dynamic instantiation and dissolution of functional modules based on task demands. Third, meta-learning autonomy enables self-modification of learning algorithms through nested optimization without external task specification.
Figure 1 illustrates the core architectural components and their interactions, while Table S2 (Supplementary Material) provides a detailed breakdown of each component’s primary functions and key innovations.
3.2. Core System Components
3.2.1. Dynamic Knowledge Graph
The Dynamic Knowledge Graph (DKG) forms the foundational knowledge substrate, implementing hyperdimensional representations that evolve according to information-theoretic criteria. Unlike static knowledge graphs [24] or temporal graphs with predetermined update rules [22], our DKG implements autonomous structural evolution through entropy-guided optimization:
The graph evolves through the following update mechanism:
| Algorithm 1 Dynamic Knowledge Graph Update |
|
The update dynamics follow gradient flow on an information-theoretic objective:
where incorporates both gradient-based optimization and entropy-guided structural modifications.
3.2.2. Self-Development Engine
The Self-Development Engine implements autonomous architectural evolution through hierarchical Bayesian optimization. Building on advances in neural architecture search [25,26], our theoretical approach extends these concepts to enable runtime modifications:
The self-development process operates through the following mechanism:
| Algorithm 2 Self-Development Process |
|
3.2.3. Multi-Agent Collaborative Framework
The framework implements distributed intelligence through specialized agents that theoretically emerge via interaction. This extends multi-agent reinforcement learning [27,28] by enabling agents to modify their own architectures based on specialization needs:
Agent communication follows information-theoretic principles:
3.2.4. Adaptive Learning Mechanisms
Our adaptive learning layer integrates multiple learning paradigms that operate synergistically:
where components represent reinforcement learning, unsupervised learning, transfer learning, and meta-learning respectively.
3.2.5. Meta-Cognitive Processes
3.3. Information Flow and System Dynamics
3.3.1. Temporal Evolution
The complete system evolves according to coupled differential equations that capture interdependencies between components:
where the evolution function F creates complex feedback dynamics enabling emergent behaviors.
3.3.2. Information Propagation
Information flows through the architecture via learnable transfer functions that adapt based on utility, implementing attention-like mechanisms [3] at the architectural level:
3.3.3. Stability and Convergence
To prevent chaotic behavior while enabling growth, we implement theoretical Lyapunov-based stability constraints addressing key challenges in self-modifying systems [31]:
3.3.4. Information-Theoretic Optimization
Knowledge graph evolution follows entropy minimization principles that enable automatic discovery of knowledge hierarchies:
3.3.5. Adaptive Computational Graphs
Computational graphs restructure dynamically based on task requirements, extending dynamic neural architecture approaches [32] to runtime adaptation:
3.4. System Boundaries and Theoretical Guarantees
3.4.1. Environmental Interaction
Liquid AI interfaces with its environment through adaptive channels implementing principles from active inference [33]:
3.4.2. Secure Containment
3.4.3. Theoretical Performance Bounds
We establish bounds on system capabilities and the rate of capability improvement through self-modification:
The self-development cycle, illustrated in Figure 3, demonstrates the continuous feedback loop of assessment, planning, execution, and reflection that enables autonomous capability expansion.
4. Self-Development Mechanisms
4.1. Foundational Principles of Self-Development
The Self-Development Engine represents our core theoretical innovation for enabling autonomous capability evolution. Unlike AutoML systems that operate in discrete optimization phases [36,37], Liquid AI explores continuous evolution during deployment through internally-driven processes. Figure 3 illustrates these self-development mechanisms and their feedback loops.
We formalize self-development as a nested optimization problem:
This formulation enables the theoretical discovery of architectural innovations that improve performance across diverse tasks while maintaining computational efficiency.
4.2. Hierarchical Task Decomposition
Complex objectives naturally decompose into hierarchical structures through information-theoretic analysis:
Policies organize hierarchically with high-level controllers selecting among low-level primitives:
4.3. Meta-Learning for Architectural Adaptation
Building on meta-learning principles [38,39], we extend adaptation to architectural parameters. We distinguish between object-level parameters and meta-parameters that control architectural properties:
4.3.1. Bilevel Optimization
Gradients propagate through the bilevel optimization using implicit differentiation [41].
| Algorithm 3 Online Bayesian Architecture Optimization |
|
4.4. Probabilistic Program Synthesis
Liquid AI theoretically synthesizes new computational modules through probabilistic programming. New modules are sampled from a learned distribution:
Modules compose through typed interfaces ensuring compatibility:
4.5. Reinforcement Learning for Architectural Evolution
The system treats architectural modifications as actions in a Markov Decision Process with state space encoding current architecture and performance:
Rewards balance multiple objectives:
4.6. Optimization Algorithms and Theoretical Analysis
The system combines multiple optimization methods through a hybrid approach [44]:
Under mild assumptions, the self-development process converges to locally optimal architectures. Given Lipschitz continuous performance function and bounded architecture space , the sequence converges to a stationary point such that in iterations.
Self-modifications preserve system stability through Lyapunov analysis:
4.7. Integrated Self-Development Framework
The complete self-development framework operates through multiple feedback loops driving continuous improvement:
| Algorithm 4 Adaptive Architecture Evolution |
|
This comprehensive self-development framework provides the theoretical foundation for AI systems that could transcend the limitations of static architectures, continuously evolving to meet new challenges without human intervention. The mathematical foundations and operational characteristics are detailed in Table S6 (Supplemental Material).
5. Multi-Agent Collaboration Framework
5.1. Theoretical Foundations of Multi-Agent Systems
Our multi-agent framework builds on established principles from game theory [43], distributed optimization [44], and swarm intelligence [45]. Unlike traditional multi-agent reinforcement learning that assumes fixed agent architectures [46], Liquid AI explores theoretical mechanisms for emergent specialization without predefined roles. This framework enables agents to autonomously develop specialized capabilities through adaptive coordination mechanisms, as illustrated in Figure 4, which uses federated multi-agent architecture; showing how heterogeneous agents self-organize into specialized communities while maintaining global coherence through shared protocols.
We model the multi-agent system as a Decentralized Partially Observable Markov Decision Process (Dec-POMDP):
where denotes the set of agents, represents the joint state space, and are action and observation spaces for agent i, P defines transition dynamics, specifies individual reward functions, represents observation functions, and is the discount factor.
5.2. Agent Architecture and Capabilities
Each agent in the theoretical Liquid AI framework possesses modular neural architecture consisting of specialized components:
Each agent maintains a local knowledge graph that interfaces with the global knowledge system:
Agent capabilities evolve through experience using gradient-based updates:
5.3. Emergent Specialization and Dynamic Topology
Specialization emerges through competitive-collaborative dynamics without explicit role assignment. The system discovers efficient task allocation through mutual information maximization:
Agents develop complementary skills through diversity bonuses in their reward structure:
The agent topology evolves to minimize communication overhead while maximizing task performance:
| Algorithm 5 Adaptive Agent Topology Evolution |
|
5.4. Coordination Mechanisms
5.4.1. Decentralized Consensus
Agents reach consensus through iterative belief propagation extending classical distributed consensus [47] with learned aggregation functions:
| Algorithm 6 Adaptive Consensus Protocol |
|
5.4.2. Hierarchical Organization
The system can theoretically self-organize into hierarchical structures when beneficial. Meta-agents form when groups develop stable collaboration patterns:
| Algorithm 7 Meta-Agent Formation |
|
5.5. Distributed Learning and Credit Assignment
5.5.1. Collaborative Policy Optimization
We extend multi-agent policy gradient methods [42] with dynamic credit assignment:
Individual policy updates incorporate learned credit assignment through counterfactual reasoning:
5.5.2. Multi-Agent Credit Assignment
We implement a learnable credit assignment mechanism based on Shapley values [46]:
where is approximated through learned value functions.
6. Knowledge Integration Engine
The Knowledge Integration Engine orchestrates cross-domain knowledge synthesis and maintains the system’s episodic and semantic memory. Unlike traditional knowledge bases that store static information [48,49], our theoretical approach explores dynamic knowledge restructuring based on usage patterns and information-theoretic optimization.
6.1. Dynamic Knowledge Representation
6.1.1. Hyperdimensional Graph Neural Networks
Our framework extends graph neural networks [51,52] to hypergraph structures with temporal dynamics. Knowledge is encoded in high-dimensional continuous spaces:
where c represents concept content, r denotes relational context, and t encodes temporal information.
The hyperdimensional graph structure evolves through:
| Algorithm 8 Hyperdimensional Graph Evolution |
|
6.2. Information-Theoretic Knowledge Organization
6.2.1. Transformer-Based Relational Reasoning
We extend transformer architectures [3] to knowledge graph reasoning with structural masks:
Multi-hop reasoning aggregates evidence along paths:
6.2.2. Cross-Domain Knowledge Synthesis
Knowledge from different domains is aligned through learned mappings that preserve semantic relationships:
as illustrated in Figure 5, showing hierarchical organization from raw data through semantic concepts to abstract reasoning, which enables seamless integration from capabilities.
6.3. Distributed Knowledge Management
6.3.1. Federated Knowledge Aggregation
Distributed knowledge nodes collaborate without centralization, extending distributed consensus [50]:
where ⨁ represents a learned aggregation operator.
6.3.2. Semantic Memory and Retrieval
The system implements content-addressable memory with temporal context:
This enables time-aware reasoning and historical analysis while maintaining semantic coherence.
6.4. Uncertainty Quantification
The framework maintains uncertainty through Bayesian neural networks [53], decomposing total uncertainty into aleatoric and epistemic components:
6.5. Computational Infrastructure for Knowledge Processing
Liquid AI’s knowledge integration requires distributed computing infrastructure extending architectures used in large-scale training [57,58]. The system implements:
Dynamic workload distribution based on node capabilities:
System reliability through redundancy and checkpointing [59]:
Hardware acceleration leveraging TPU [60] and GPU [61] architectures with mixed precision training [62]:
| Algorithm 9 Adaptive Load Balancing |
|
7. Implementation Considerations
7.1. Computational Complexity Analysis
Implementing Liquid AI presents significant computational challenges requiring careful analysis. Unlike static neural architectures with fixed complexity [54], Liquid AI’s dynamic nature introduces variable computational requirements.
7.1.1. Asymptotic Complexity
We analyze the computational complexity of core components extending results from graph neural networks [55] and multi-agent systems [56]:
Knowledge graph queries can be optimized through algorithmic improvements:
| Algorithm 10 Efficient Knowledge Graph Query |
|
7.2. Distributed Architecture and Resource Management
7.2.1. Hierarchical Processing
The theoretical system organizes into processing layers for efficient computation distribution. Edge layers handle low-latency local processing, fog layers manage regional aggregation and coordination, while cloud layers perform global optimization and heavy computation.
7.2.2. Dynamic Resource Allocation
Resources scale elastically with demand through control-theoretic approaches:
where represents resource deficit.
Algorithm selection adapts to input characteristics [63]:
7.3. Security and Privacy Considerations
Knowledge integration preserves privacy through differential privacy [64]:
Agents collaborate without revealing private data through secure multi-party computation [65]:
7.4. Deployment and Monitoring
The theoretical framework includes mechanisms for gradual capability deployment with continuous monitoring. System health is tracked through statistical anomaly detection, while debug information includes causal traces for explainable failure analysis. Performance optimization occurs through adaptive batch sizing, dynamic pruning of unnecessary computations, and computation reuse across similar inputs.
Table S5 (Supplemental Material) provides detailed implementation requirements for different deployment scales, addressing the substantial computational infrastructure needed for practical realization of these theoretical concepts.
8. Evaluation Methodology
Evaluating continuously evolving AI systems requires fundamentally different approaches than traditional static benchmarks. We present theoretical methodologies that could capture temporal dynamics, emergent behaviors, and long-term evolution of Liquid AI systems. Our empirical validation methodology, visualized in Figure 6, follows an iterative cycle of system configuration, baseline establishment, performance evaluation, and comparative analysis.
8.1. Challenges in Evaluating Adaptive Systems
Traditional AI evaluation assumes fixed architectures and capabilities [68,69]. Liquid AI’s theoretical continuous evolution introduces unique evaluation challenges. System capabilities would change during evaluation, requiring metrics that account for temporal evolution. Novel capabilities could emerge unpredictably outside the span of initial capabilities. Evolution would occur across multiple timescales, from rapid parameter updates to slower architectural modifications.
Figure 7 illustrates the proposed iterative validation methodology, showing how system configuration, baseline establishment, performance evaluation, and comparative analysis would form a continuous cycle rather than discrete evaluation points.
8.2. Temporal Performance Metrics
8.2.1. Capability Evolution Tracking
We propose measuring autonomous improvement through capability growth rate:
This would quantify the system’s theoretical self-improvement velocity. Adaptation efficiency could be measured as the ratio of performance improvement to computational resources consumed.
8.2.2. Multi-Domain Evaluation
Cross-domain tasks would be constructed to test knowledge integration:
| Algorithm 11 Multi-Domain Task Construction |
|
Adaptive learning assessment would track how quickly the system adapts to new domains:
| Algorithm 12 Adaptive Learning Assessment |
|
8.3. Human-AI Interaction Evaluation
Human-in-the-loop evaluation would measure adaptation to feedback:
| Algorithm 13 Interactive Adaptation Assessment |
|
8.4. Safety and Deployment Validation
Given the theoretical self-modification capabilities, validation would require novel safety protocols. We extend algorithm selection approaches [70] to online settings for continuous validation:
| Algorithm 14 Safe Deployment for Self-Modifying Systems |
|
Table S3 (Supplemental Material) summarizes the complete set of evaluation metrics for adaptive AI systems. Figure 10 demonstrates theoretical analysis of sustained capability improvement, showing performance trajectories, architectural evolution, and feedback mechanism contributions over time. Complete evaluation across all scenarios are compiled in Table S7.
9. Applications and Use Cases
Liquid AI’s theoretical ability to continuously evolve and adapt would make it particularly suited for complex, dynamic domains where traditional AI systems struggle. We explore potential applications across healthcare, scientific discovery, and industrial systems, while acknowledging these represent theoretical possibilities rather than immediate implementations.
9.1. Healthcare and Biomedical Applications
In personalized medicine, Liquid AI could theoretically enable treatment optimization that evolves with patient responses [71,72]. The system would continuously refine treatment policies based on individual patient history, medical knowledge, and treatment responses, potentially achieving significant improvements in efficacy while reducing adverse reactions.
For epidemic modeling and response, adaptive capabilities could enable real-time modeling that evolves with emerging data [73]. The system would continuously refine predictions and recommendations as situations develop, integrating genomic surveillance data, mobility patterns, healthcare capacity, and intervention effectiveness. The versatility of the Liquid AI framework across diverse application domains is illustrated in Figure 8, spanning healthcare, scientific research, industrial systems, financial services, environmental management, and cognitive assistance.
9.2. Scientific Discovery
In materials science, Liquid AI could accelerate discovery through integrated modeling and synthesis [74]. The theoretical framework would enable inverse design capabilities through continuous optimization, multi-fidelity modeling integrating theory, simulation, and experiment, and autonomous experimental planning and execution.
For Earth systems modeling, the framework’s multi-scale integration capabilities could enhance climate science [75]. Potential improvements include better regional climate predictions through adaptive model refinement, seamless integration across scales from molecular to global processes, and adaptive scenario analysis with evolving uncertainty quantification.
9.3. Industrial and Infrastructure Systems
Adaptive manufacturing systems could continuously optimize production [76]. The theoretical framework would enable real-time adaptation to supply chain disruptions, predictive maintenance with evolving models, quality optimization through continuous learning, and significant energy efficiency improvements.
In energy grid management, adaptive control of complex energy systems could improve reliability and efficiency [77]. The system could learn to integrate renewable sources optimally, predict demand patterns with increasing accuracy, coordinate distributed energy resources, and maintain grid stability during transitions. Performance metrics estimates for specific application domains, including quantitative improvements and resource utilization, are detailed in Table S8.
Figure 8 illustrates the systematic representation of these application domains, showing how Liquid AI’s adaptive capabilities could theoretically benefit diverse fields. Table S4 (Supplemental Materials) demonstrates quantitative performance improvements projected across these application domains based on theoretical analysis.
10. Future Directions and Implications
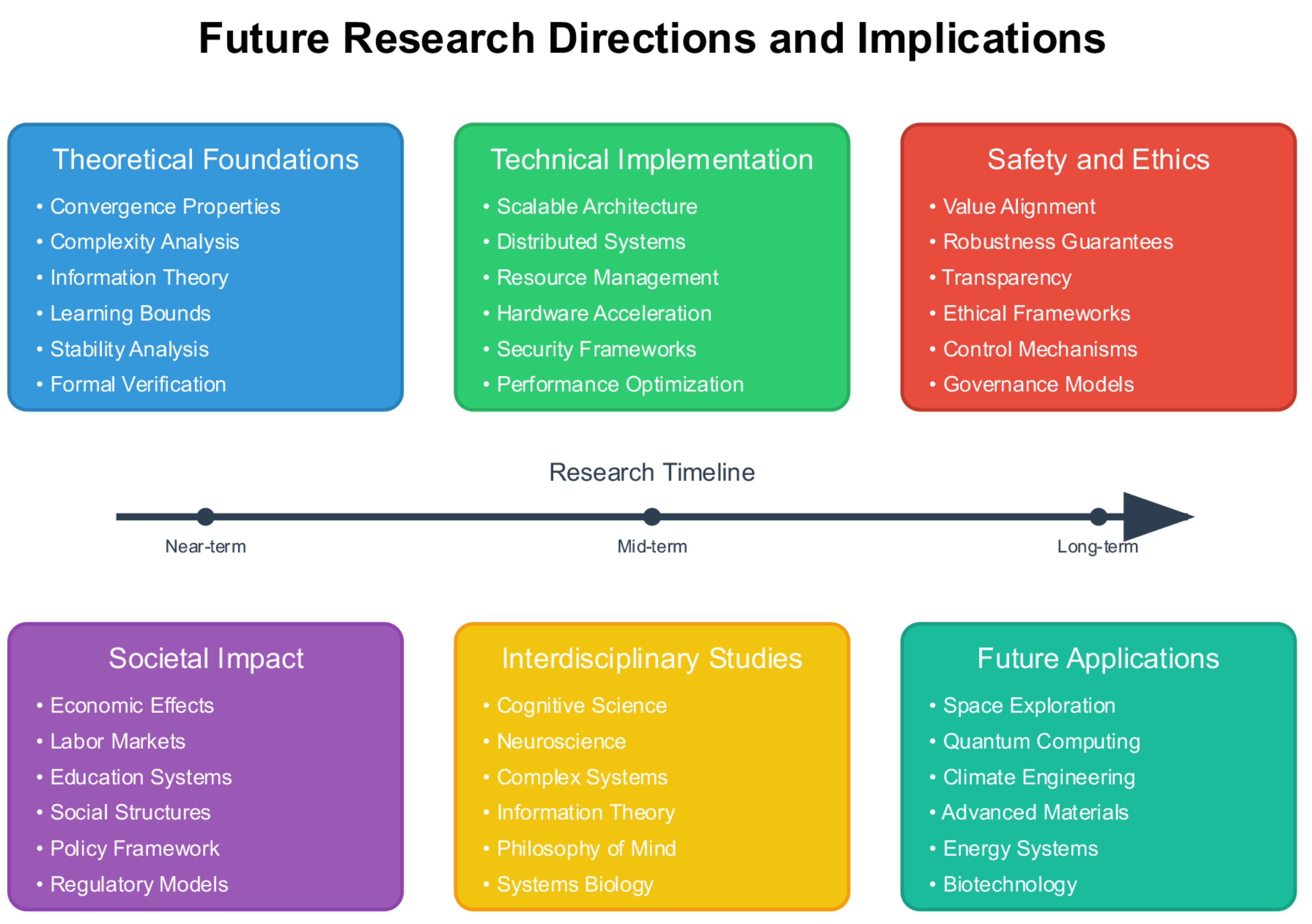
The Liquid AI paradigm opens theoretical possibilities for artificial intelligence while raising important questions about the nature of intelligence, consciousness, and human-AI collaboration. We explore implications, technical challenges, and potential societal impacts of self-evolving AI systems. Figure 9 outlines a comprehensive research roadmap, identifying six key areas requiring further investigation: theoretical foundations, technical implementation challenges, safety and ethics considerations, societal impact assessment, interdisciplinary studies, and emerging applications.
10.1. Philosophical and Theoretical Implications
Liquid AI challenges traditional boundaries between programmed and emergent intelligence. As systems theoretically develop capabilities beyond their initial design, questions arise about the nature of machine consciousness and intentionality [78,79]. Self-modifying systems could exhibit degrees of autonomy previously theoretical, with self-directed decisions and internally generated goals.
The framework extends concepts of distributed cognition and the extended mind hypothesis [80], where the boundary between human and artificial cognition becomes increasingly fluid. This raises fundamental questions about agency, responsibility, and the nature of intelligence itself.
10.2. Technical Research Challenges
Several critical technical challenges require resolution before practical implementation becomes feasible. Understanding fundamental scaling constraints involves examining thermodynamic limits of computation, potential quantum advantages for adaptive systems, and distributed intelligence scaling laws. The computational requirements align with current trends toward nuclear-powered data centers, as detailed in Supplemental Materials Section 3.
Ensuring correctness in self-modifying systems presents unique verification challenges. Runtime verification of evolved architectures, formal methods for adaptive systems, and probabilistic correctness guarantees all require novel theoretical frameworks. Maintaining interpretability as complexity grows necessitates new approaches for hierarchical explanation generation, causal reasoning in evolved systems, and human-comprehensible abstractions.
10.3. Societal Considerations
The potential societal impact of self-evolving AI systems warrants careful consideration. Economic restructuring could result from widespread deployment of adaptive AI, affecting labor markets, productivity patterns, and wealth distribution. New governance frameworks would be needed for managing self-evolving systems, requiring regulatory adaptation, international coordination, and democratic participation in AI governance.
Educational transformation would be necessary to prepare humanity for collaboration with adaptive AI systems. This includes developing human-AI collaboration skills, ethical reasoning capabilities, and continuous learning mindsets. Table 1 outlines key ethical considerations and corresponding governance mechanisms necessary for responsible Liquid AI deployment.
Table 2.
Ethical Considerations for Liquid AI Deployment.
| Aspect | Challenge | Mitigation Strategy | Research Needs |
|---|---|---|---|
| Autonomy | Self-modification may lead to unintended behaviors | Bounded modification spaces, continuous monitoring | Formal verification methods for dynamic systems |
| Transparency | Evolving architectures complicate interpretability | Maintain modification logs, interpretable components | Dynamic explanation generation techniques |
| Accountability | Unclear responsibility for emergent decisions | Clear governance frameworks, audit trails | Legal frameworks for autonomous AI |
| Fairness | Potential for bias amplification | Active bias detection and mitigation | Fairness metrics for evolving systems |
| Privacy | Distributed knowledge may leak sensitive information | Differential privacy, secure computation | Privacy-preserving knowledge integration |
| Safety | Unpredictable emergent behaviors | Conservative modification bounds, rollback mechanisms | Safety verification for self-modifying systems |
| Control | Difficulty in stopping runaway evolution | Multiple kill switches, consensus requirements | Robust control mechanisms |
10.4. Long-Term Research Trajectories
Future research directions span multiple disciplines and timescales. Immediate priorities include developing incremental implementation pathways, establishing safety protocols for self-modifying systems, and creating evaluation frameworks for adaptive AI. Medium-term goals involve exploring hybrid human-AI systems, investigating emergent collective intelligence, and developing interpretability methods for evolved architectures.
Long-term considerations include understanding potential intelligence explosion scenarios, exploring post-biological intelligence possibilities, and preparing for human-AI integration pathways. These trajectories point toward a future where boundaries between artificial, biological, and quantum intelligence become increasingly fluid, with Liquid AI providing a theoretical framework for their integration. Figure 10 provides a detailed analysis of sustained capability improvement, showing (a) the three-phase performance trajectory, (b) controlled architectural complexity evolution, and (c) the dynamic contribution of different feedback mechanisms over time.
Figure 10.
Theoretical analysis of sustained capability improvement in Liquid AI. (a) Performance improvement trajectory showing three distinct phases: rapid initial learning (0-103 iterations), sustained improvement (103-104), and asymptotic convergence (>104). (b) Architectural complexity evolution demonstrating controlled growth with periodic efficiency optimizations. (c) Relative contributions of three primary feedback mechanisms, showing the shift from entropy-driven exploration to balanced multi-mechanism optimization.
Figure 10.
Theoretical analysis of sustained capability improvement in Liquid AI. (a) Performance improvement trajectory showing three distinct phases: rapid initial learning (0-103 iterations), sustained improvement (103-104), and asymptotic convergence (>104). (b) Architectural complexity evolution demonstrating controlled growth with periodic efficiency optimizations. (c) Relative contributions of three primary feedback mechanisms, showing the shift from entropy-driven exploration to balanced multi-mechanism optimization.
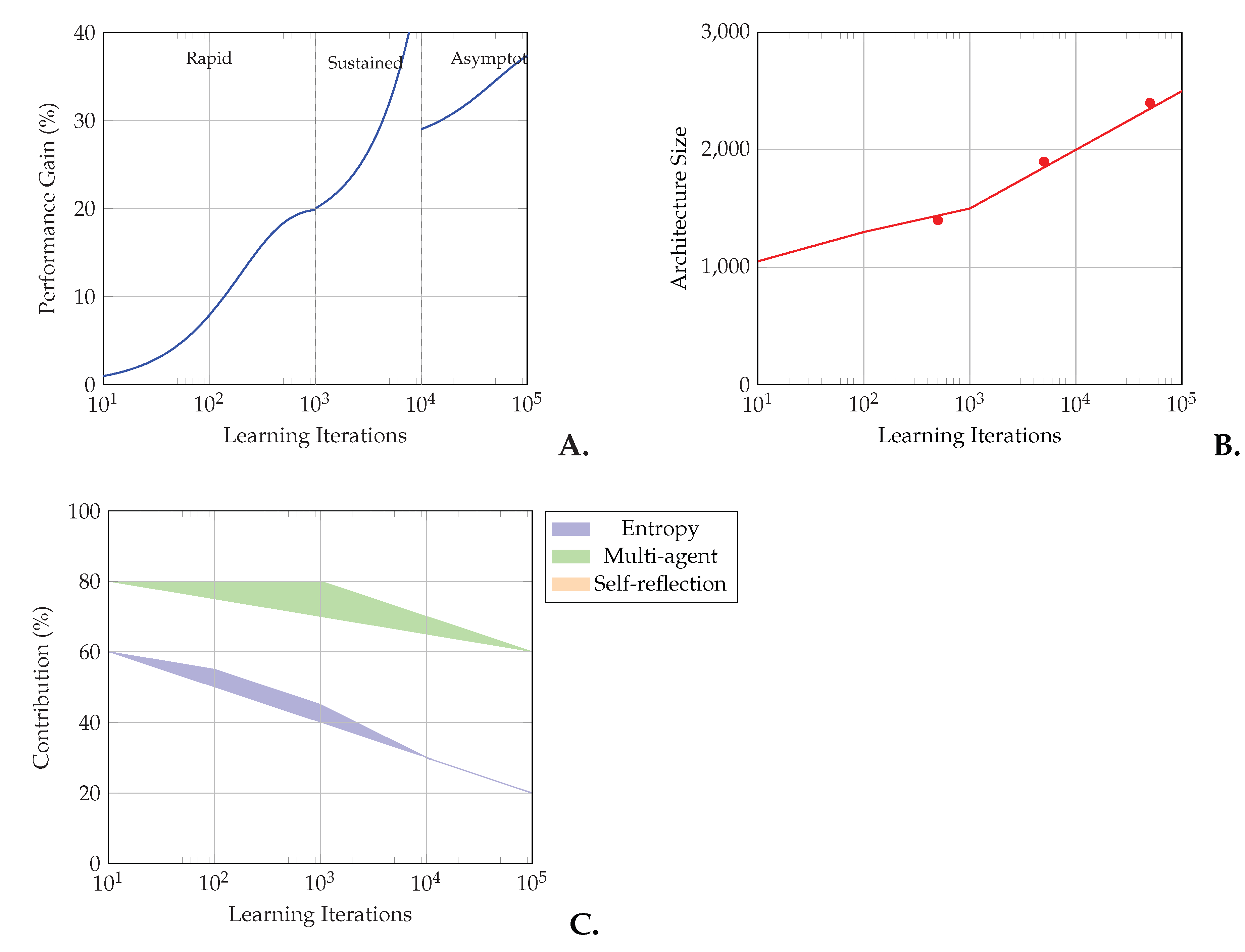
Figure 9 presents a comprehensive roadmap showing six key research areas arranged along temporal progression, from immediate theoretical foundations to long-term applications and implications.
11. Conclusions
This paper has presented Liquid AI as a theoretical framework and mathematical thought experiment for continuously self-improving artificial intelligence systems. By exploring what becomes possible when we remove traditional architectural constraints, we have established foundations for a potential new paradigm in AI research.
Our work makes several contributions to the theoretical foundations of artificial intelligence. We introduced a comprehensive mathematical framework for AI systems theoretically capable of runtime topological modification, information-theoretic autonomous restructuring, and emergent multi-agent specialization. We established convergence bounds and stability conditions for self-modifying systems, providing theoretical guarantees under which architectural evolution could preserve functional coherence while enabling capability expansion.
The evaluation methodologies developed address the unique challenges of assessing continuously evolving systems, moving beyond static benchmarks to capture temporal dynamics and emergent behaviors. We explored potential applications across healthcare, scientific discovery, and industrial systems, demonstrating how adaptive AI could theoretically transform these fields while acknowledging the significant implementation challenges.
Liquid AI represents a long-term research direction rather than an immediate implementation target. The computational requirements are substantial, likely requiring infrastructure on the scale of nuclear-powered data centers as industry trends suggest. The stability challenges inherent in self-modifying systems require careful theoretical development and extensive safety research before practical deployment becomes feasible.
Nevertheless, this theoretical exploration opens important new directions for AI research. By establishing mathematical foundations for continuously adaptive AI, we aim to inspire research toward systems that could eventually match the flexibility of biological intelligence while leveraging computational advantages of artificial systems. The comprehensive supplemental materials provide additional technical depth, implementation considerations, and a decade-spanning development roadmap for researchers interested in pursuing these concepts.
The journey from static to liquid intelligence represents a fundamental transition in how we conceive of artificial intelligence. While immediate implementation faces significant challenges, the theoretical framework presented here provides a foundation for future research toward truly adaptive, self-improving AI systems. We invite the research community to join in advancing this vision, whether through theoretical development, incremental implementation strategies, or critical analysis of the concepts presented.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org.
Author Contributions
Conceptualization, T.R.C.; methodology, T.R.C.; formal analysis, T.R.C.; investigation, T.R.C.; writing—original draft preparation, T.R.C.; writing—review and editing, T.R.C., N.N.I., R.C.; visualization, T.R.C. and N.N.I.; supervision, T.R.C.; project administration, T.R.C. All authors have read and agreed to the published version of the manuscript.
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. (2016). Deep learning. MIT Press.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Advances in Neural Information Processing Systems 2017, 30, 5998–6008. [Google Scholar]
- Sutton, R.S.; Barto, A.G. (2018). Reinforcement learning: An introduction. MIT Press.
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P. .. Amodei, D. Language models are few-shot learners. Advances in Neural Information Processing Systems 2020, 33, 1877–1901. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A. .. Fiedel, N. PaLM: Scaling language modeling with pathways. Journal of Machine Learning Research 2023, 24, 1–113. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. IEEE Conference on Computer Vision and Pattern Recognition 2016, 770–778. [Google Scholar]
- Howard, J.; Ruder, S. Universal language model fine-tuning for text classification. Annual Meeting of the Association for Computational Linguistics 2018, 328–339. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S. ;... Chen, W. (2022). LoRA: Low-rank adaptation of large language models. International Conference on Learning Representations.
- Holtmaat, A.; Svoboda, K. Experience-dependent structural synaptic plasticity in the mammalian brain. Nature Reviews Neuroscience 2009, 10, 647–658. [Google Scholar] [CrossRef]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017. arXiv:1706.05098. [Google Scholar] [CrossRef]
- Crawshaw, M. Multi-task learning with deep neural networks: A survey. arXiv 2020. arXiv:2009.09796. [Google Scholar] [CrossRef]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. (2019). Automated machine learning: Methods, systems, challenges. Springer.
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. Journal of Machine Learning Research 2019, 20, 1997–2017. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A. .. Hadsell, R. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Networks 2019, 113, 54–71. [Google Scholar] [CrossRef] [PubMed]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. International Conference on Machine Learning 2017, 1126–1135. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Draganski, B.; Gaser, C.; Busch, V.; Schuierer, G.; Bogdahn, U.; May, A. Neuroplasticity: Changes in grey matter induced by training. Nature 2004, 427, 311–312. [Google Scholar] [CrossRef]
- Bonabeau, E.; Dorigo, M.; Theraulaz, G. (1999). Swarm intelligence: From natural to artificial systems. Oxford University Press.
- Rusu, A.A.; Rabinowitz, N.C.; Desjardins, G.; Soyer, H.; Kirkpatrick, J.; Kavukcuoglu, K. .. Hadsell, R. Progressive neural networks. arXiv 2016, arXiv:1606.04671. [Google Scholar]
- Kazemi, S.M.; Goel, R.; Jain, K.; Kobyzev, I.; Sethi, A.; Forsyth, P.; Poupart, P. Representation learning for dynamic graphs: A survey. Journal of Machine Learning Research 2020, 21, 2648–2720. [Google Scholar]
- Andreas, J.; Rohrbach, M.; Darrell, T.; Klein, D. Neural module networks. IEEE Conference on Computer Vision and Pattern Recognition 2016, 39–48. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Transactions on Neural Networks and Learning Systems 2021, 33, 494–514. [Google Scholar] [CrossRef]
- White, C.; Nolen, S.; Savani, Y. Exploring the loss landscape in neural architecture search. International Conference on Machine Learning 2021, 10962–10973. [Google Scholar]
- Ru, B.; Wan, X.; Dong, X.; Osborne, M. (2021). Interpretable neural architecture search via Bayesian optimisation with Weisfeiler-Lehman kernels. International Conference on Learning Representations.
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. Handbook of Reinforcement Learning and Control 2021, 321–384. [Google Scholar]
- Gronauer, S.; Diepold, K. Multi-agent deep reinforcement learning: A survey. Artificial Intelligence Review 2022, 55, 895–943. [Google Scholar] [CrossRef]
- Laird, J.E.; Lebiere, C.; Rosenbloom, P.S. A standard model of the mind: Toward a common computational framework across artificial intelligence, cognitive science, neuroscience, and robotics. AI Magazine 2019, 40, 13–26. [Google Scholar] [CrossRef]
- Kotseruba, I.; Tsotsos, J.K. 40 years of cognitive architectures: Core cognitive abilities and practical applications. Artificial Intelligence Review 2020, 53, 17–94. [Google Scholar] [CrossRef]
- Schmidhuber, J. Gödel machines: Fully self-referential optimal universal self-improvers. Artificial General Intelligence 2007, 199–226. [Google Scholar]
- Jia, X., De Brabandere, B., Tuytelaars, T., & Gool, L. V. Dynamic filter networks. Advances in Neural Information Processing Systems 2020, 29, 667–675.
- Friston, K. Active inference and artificial curiosity. arXiv 2017, arXiv:1709.07470. [Google Scholar]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv 2016. arXiv:1606.06565. [Google Scholar] [CrossRef]
- Hendrycks, D.; Carlini, N.; Schulman, J.; Steinhardt, J. Unsolved problems in ML safety. arXiv 2021, arXiv:2109.13916. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowledge-Based Systems 2021, 212, 106622. [Google Scholar] [CrossRef]
- Karmaker, S.K.; Hassan, M.M.; Smith, M.J.; Xu, L.; Zhai, C.; Veeramachaneni, K. AutoML to date and beyond: Challenges and opportunities. ACM Computing Surveys 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Lake, B.M.; Ullman, T.D.; Tenenbaum, J.B.; Gershman, S.J. Building machines that learn and think like people. Behavioral and Brain Sciences 2017, 40, E253. [Google Scholar] [CrossRef]
- Pateria, S.; Subagdja, B.; Tan, A.H.; Quek, C. Hierarchical reinforcement learning: A comprehensive survey. ACM Computing Surveys 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Franceschi, L.; Frasconi, P.; Salzo, S.; Grazzi, R.; Pontil, M. Bilevel programming for hyperparameter optimization and meta-learning. International Conference on Machine Learning 2018, 1568–1577. [Google Scholar]
- Lorraine, J.; Vicol, P.; Duvenaud, D. Optimizing millions of hyperparameters by implicit differentiation. International Conference on Artificial Intelligence and Statistics 2020, 1540–1552. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-agent actor-critic for mixed cooperative-competitive environments. Advances in Neural Information Processing Systems 2017, 30, 6379–6390. [Google Scholar]
- Shoham, Y.; Leyton-Brown, K. (2008). Multiagent systems: Algorithmic, game-theoretic, and logical foundations. Cambridge University Press.
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends in Machine Learning 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Kennedy, J. , Eberhart, R. (2001). Swarm intelligence. Morgan Kaufmann.
- Chalkiadakis, G.; Elkind, E.; Wooldridge, M. Computational aspects of cooperative game theory. Synthesis Lectures on Artificial Intelligence and Machine Learning 2022, 16, 1–219. [Google Scholar]
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and cooperation in networked multi-agent systems. Proceedings of the IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.D.; Gutierrez, C. .. Zimmermann, A. Knowledge graphs. ACM Computing Surveys 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Transactions on Knowledge and Data Engineering 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Castro, M.; Liskov, B. (1999). Practical Byzantine fault tolerance. Proceedings of the Third Symposium on Operating Systems Design and Implementation, 173–186.
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Transactions on Neural Networks and Learning Systems 2021, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z. .. Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. International Conference on Machine Learning 2016, 1050–1059. [Google Scholar]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and policy considerations for deep learning in NLP. Annual Meeting of the Association for Computational Linguistics 2019, 3645–3650. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. (2019). How powerful are graph neural networks? International Conference on Learning Representations.
- Hernández-Orallo, J.; Martínez-Plumed, F.; Schmid, U.; Siebers, M.; Dowe, D.L. Computer models solving intelligence test problems: Progress and implications. Artificial Intelligence 2016, 230, 74–107. [Google Scholar] [CrossRef]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-LM: Training multi-billion parameter language models using model parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Rajbhandari, S., Rasley, J., Ruwase, O., & He, Y. ZeRO: Memory optimizations toward training trillion parameter models. International Conference for High Performance Computing, Networking, Storage and Analysis 2020, 1–16.
- Chen, C.; Wang, K.; Wu, Q. Efficient checkpointing and recovery for distributed systems. IEEE Transactions on Parallel and Distributed Systems 2015, 26, 3301–3313. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R. ; ... Yoon, D.H. In-datacenter performance analysis of a tensor processing unit. ACM/IEEE International Symposium on Computer Architecture, 2017; 1–12. [Google Scholar]
- NVIDIA. (2020). NVIDIA A100 tensor core GPU architecture. NVIDIA Technical Report.
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D. ;... Wu, H. (2018). Mixed precision training. International Conference on Learning Representations.
- Kotthoff, L. Algorithm selection for combinatorial search problems: A survey. Data Mining and Constraint Programming 2016, 149–190. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Foundations and Trends in Theoretical Computer Science 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Evans, D. , Kolesnikov, V., Rosulek, M. A pragmatic introduction to secure multi-party computation. Foundations and Trends in Privacy and Security 2018, 2, 70–246. [Google Scholar] [CrossRef]
- Cohen, J.; Rosenfeld, E.; Kolter, Z. Certified adversarial robustness via randomized smoothing. International Conference on Machine Learning 2019, 1310–1320. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. IEEE Symposium on Security and Privacy 2017, 39–57. [Google Scholar]
- Hernández-Orallo, J. Evaluation in artificial intelligence: From task-oriented to ability-oriented measurement. Artificial Intelligence Review 2017, 48, 397–447. [Google Scholar] [CrossRef]
- Chollet, F. (). On the measure of intelligence. arXiv 2019, arXiv:1911.01547. [Google Scholar]
- Kerschke, P. , Hoos, H. H., Neumann, F., Trautmann, H. Automated algorithm selection: Survey and perspectives. Evolutionary Computation 2019, 27, 3–45. [Google Scholar] [CrossRef] [PubMed]
- Vamathevan, J.; Clark, D.; Czodrowski, P.; Dunham, I.; Ferran, E.; Lee, G. .. Zhao, S. Applications of machine learning in drug discovery and development. Nature Reviews Drug Discovery 2019, 18, 463–477. [Google Scholar] [CrossRef]
- Johnson, K.B.; Wei, W.Q.; Weeraratne, D.; Frisse, M.E.; Misulis, K.; Rhee, K. ; .. Snowdon, J. L. Precision medicine, AI, and the future of personalized health care. Clinical and Translational Science 2021, 14, 86–93. [Google Scholar]
- Alamo, T.; Reina, D.G.; Mammarella, M.; Abella, A. Covid-19: Open-data resources for monitoring, modeling, and forecasting the epidemic. Electronics 2020, 9, 827. [Google Scholar] [CrossRef]
- Himanen, L.; Geurts, A.; Foster, A.S.; Rinke, P. Data-driven materials science: Status, challenges, and perspectives. Advanced Science 2019, 6, 1900808. [Google Scholar] [CrossRef]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Zhong, R.Y.; Xu, X.; Klotz, E.; Newman, S.T. Intelligent manufacturing in the context of Industry 4.0: A review. Engineering 2017, 3, 616–630. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H.; Liao, Y. Smart grid: A review of recent developments and future challenges. International Journal of Electrical Power & Energy Systems 2018, 103, 481–490. [Google Scholar]
- Dreyfus, H. L. (1992). What computers still can’t do: A critique of artificial reason. MIT Press.
- Chalmers, D. The singularity: A philosophical analysis. Journal of Consciousness Studies 2010, 17, 7–65. [Google Scholar]
- Clark, A. (2008). Supersizing the mind: Embodiment, action, and cognitive extension. Oxford University Press.
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A. .. Hadsell, R. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences 2017, 114, 3521–3526. [Google Scholar] [CrossRef]
- Liu, H.; Simonyan, K.; Yang, Y. (2019). DARTS: Differentiable architecture search. International Conference on Learning Representations.
- Rashid, T.; Samvelyan, M.; Schroeder, C.; Farquhar, G.; Foerster, J.; Whiteson, S. QMIX: Monotonic value function factorisation for deep multi-agent reinforcement learning. International Conference on Machine Learning 2018, 4295–4304. [Google Scholar]
Figure 1.
Core architectural components of Liquid AI showing the dynamic interaction between the Knowledge Integration Engine, Self-Development Module, Multi-Agent Coordinator, and supporting infrastructure. Components are color-coded by function with bidirectional data flows indicated by arrows.
Figure 1.
Core architectural components of Liquid AI showing the dynamic interaction between the Knowledge Integration Engine, Self-Development Module, Multi-Agent Coordinator, and supporting infrastructure. Components are color-coded by function with bidirectional data flows indicated by arrows.
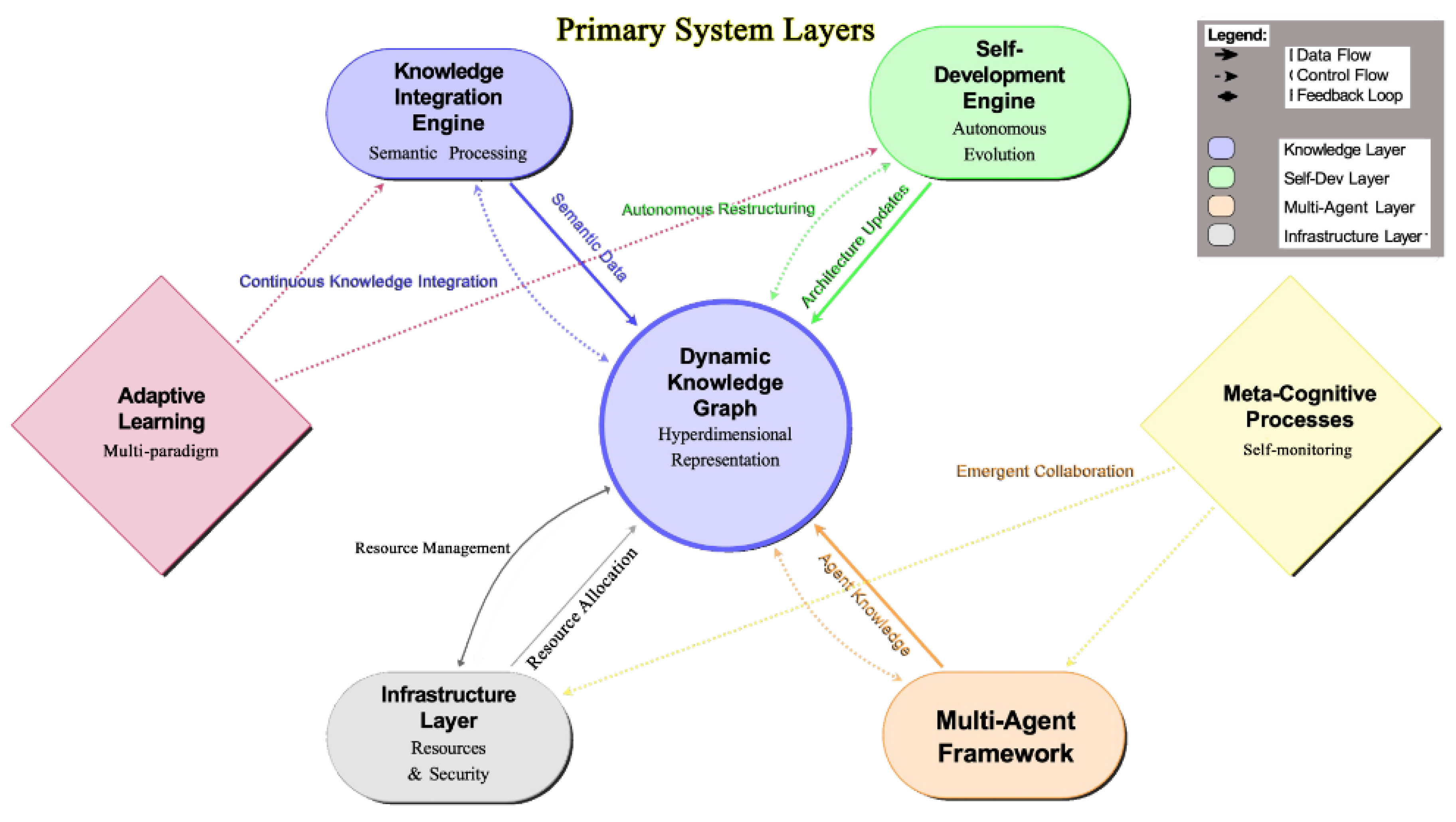
Figure 2.
Comparative Analysis of Traditional AI versus Liquid AI Paradigms. Systematic comparison between traditional AI and Liquid AI (right) approaches across four key dimensions: Fixed Architecture vs. Self-Evolving Architecture, Static Knowledge Base vs. Dynamic Knowledge Graph, Discrete Training Cycles vs. Continuous Learning, and Human-Directed Updates vs. Autonomous Evolution. Connecting arrows demonstrate the evolutionary progression from traditional to liquid paradigms.
Figure 2.
Comparative Analysis of Traditional AI versus Liquid AI Paradigms. Systematic comparison between traditional AI and Liquid AI (right) approaches across four key dimensions: Fixed Architecture vs. Self-Evolving Architecture, Static Knowledge Base vs. Dynamic Knowledge Graph, Discrete Training Cycles vs. Continuous Learning, and Human-Directed Updates vs. Autonomous Evolution. Connecting arrows demonstrate the evolutionary progression from traditional to liquid paradigms.
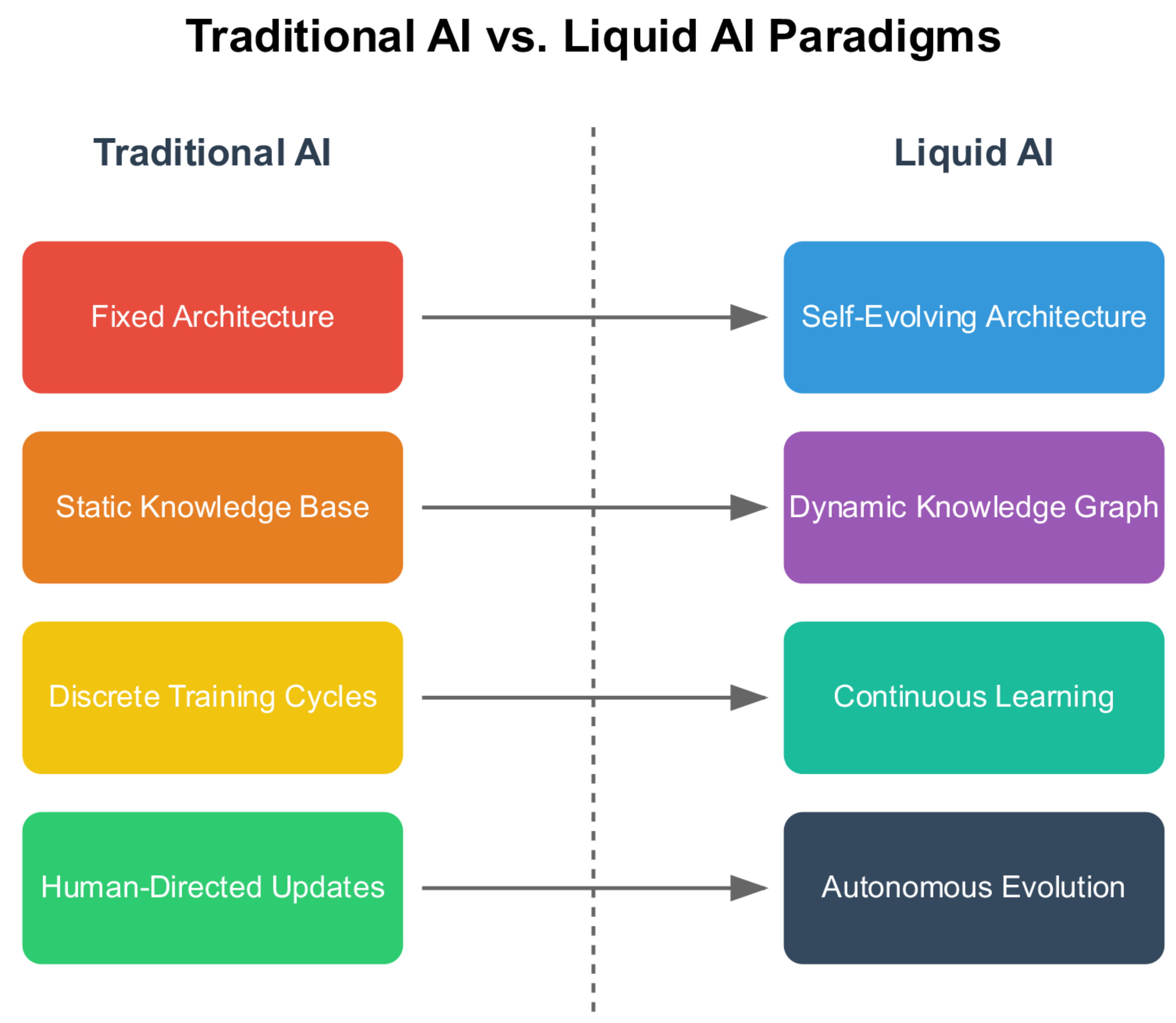
Figure 3.
Self-Development Mechanisms and Feedback Loops in Liquid AI showing the continuous cycle of assessment, planning, execution, and reflection.
Figure 3.
Self-Development Mechanisms and Feedback Loops in Liquid AI showing the continuous cycle of assessment, planning, execution, and reflection.
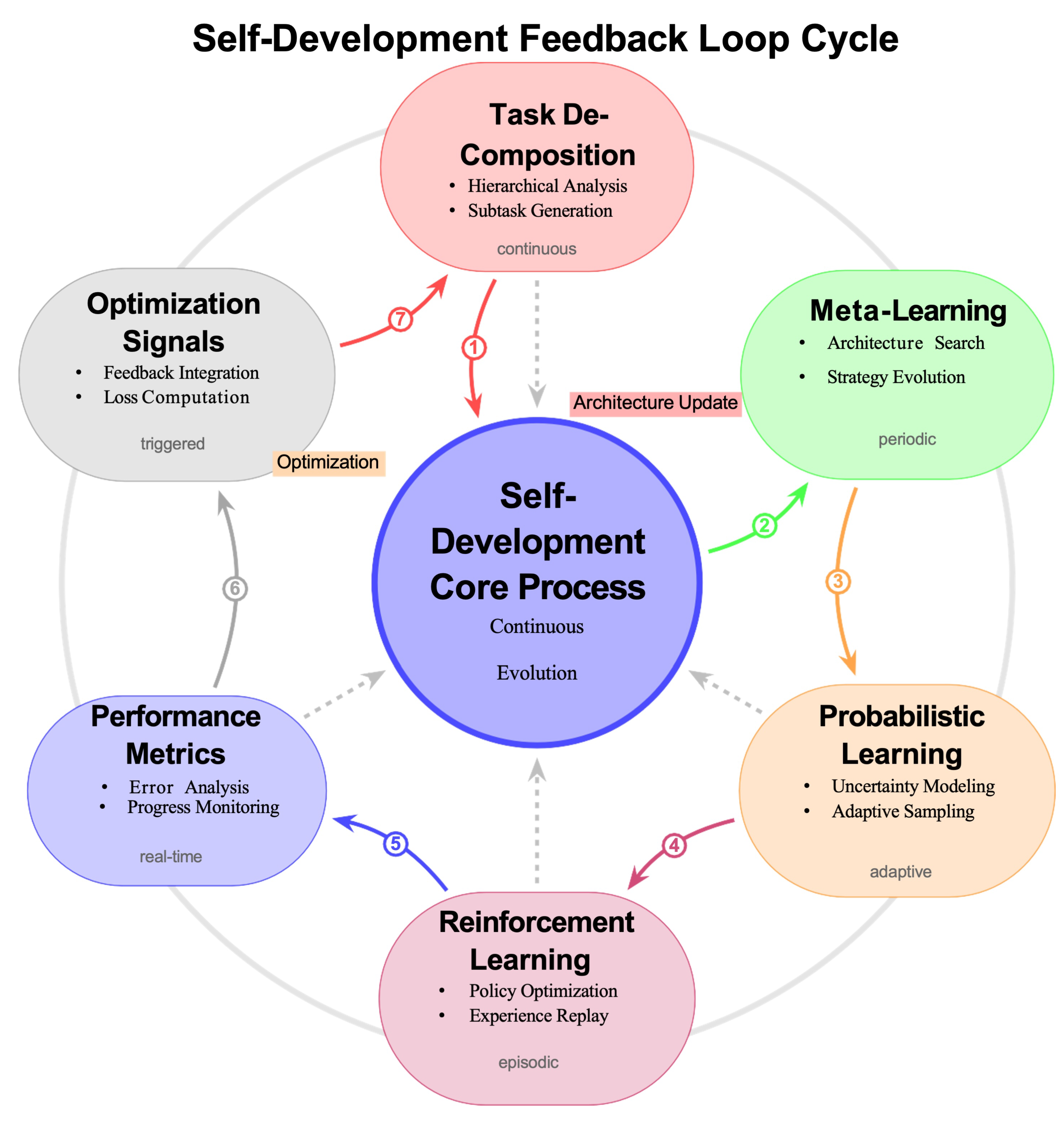
Figure 4.
Federated Multi-Agent Architecture showing emergent specialization patterns and communication pathways between heterogeneous agents.
Figure 4.
Federated Multi-Agent Architecture showing emergent specialization patterns and communication pathways between heterogeneous agents.
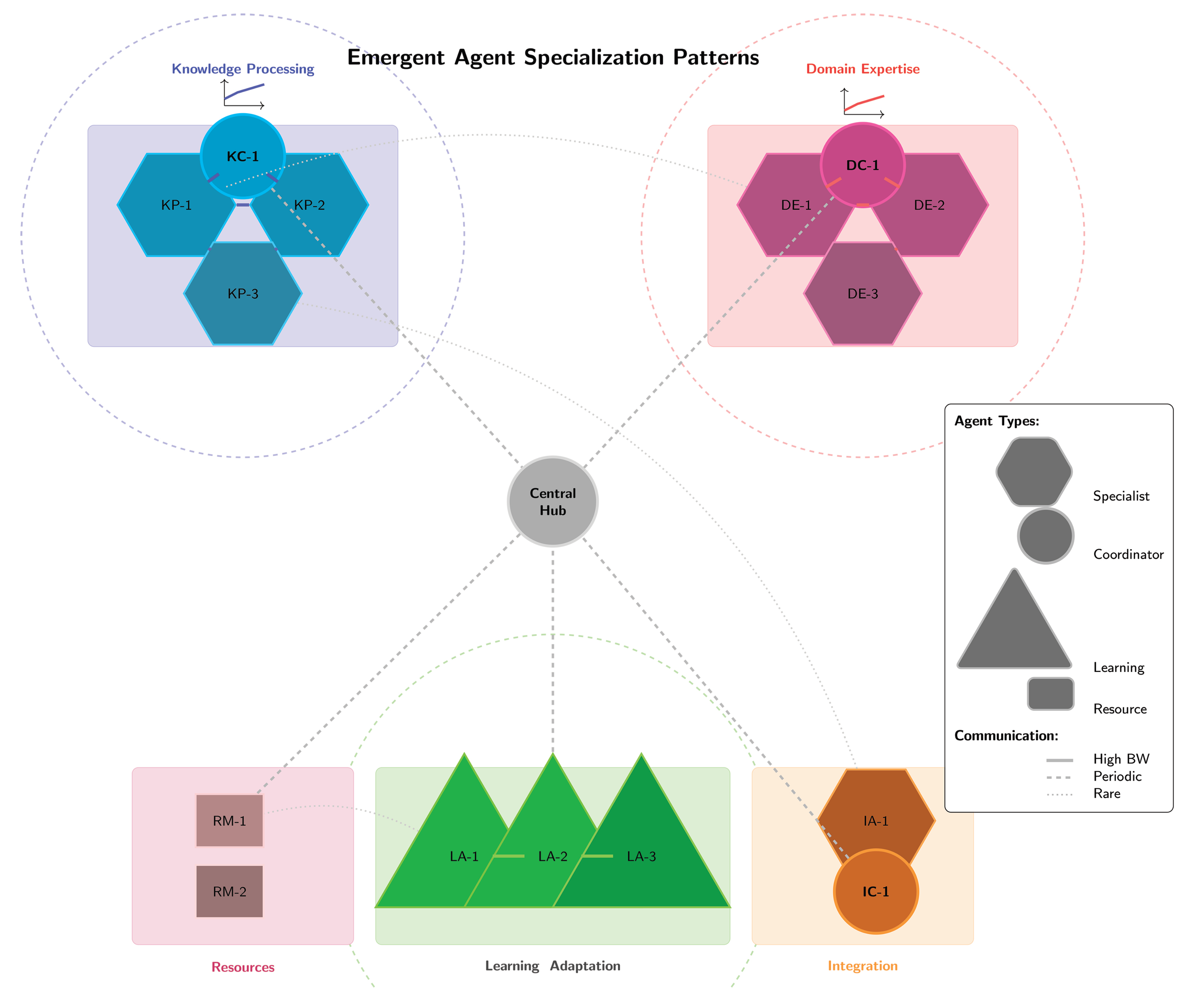
Figure 5.
Knowledge Integration Layers showing the hierarchical organization from raw data through semantic concepts to abstract reasoning.
Figure 5.
Knowledge Integration Layers showing the hierarchical organization from raw data through semantic concepts to abstract reasoning.
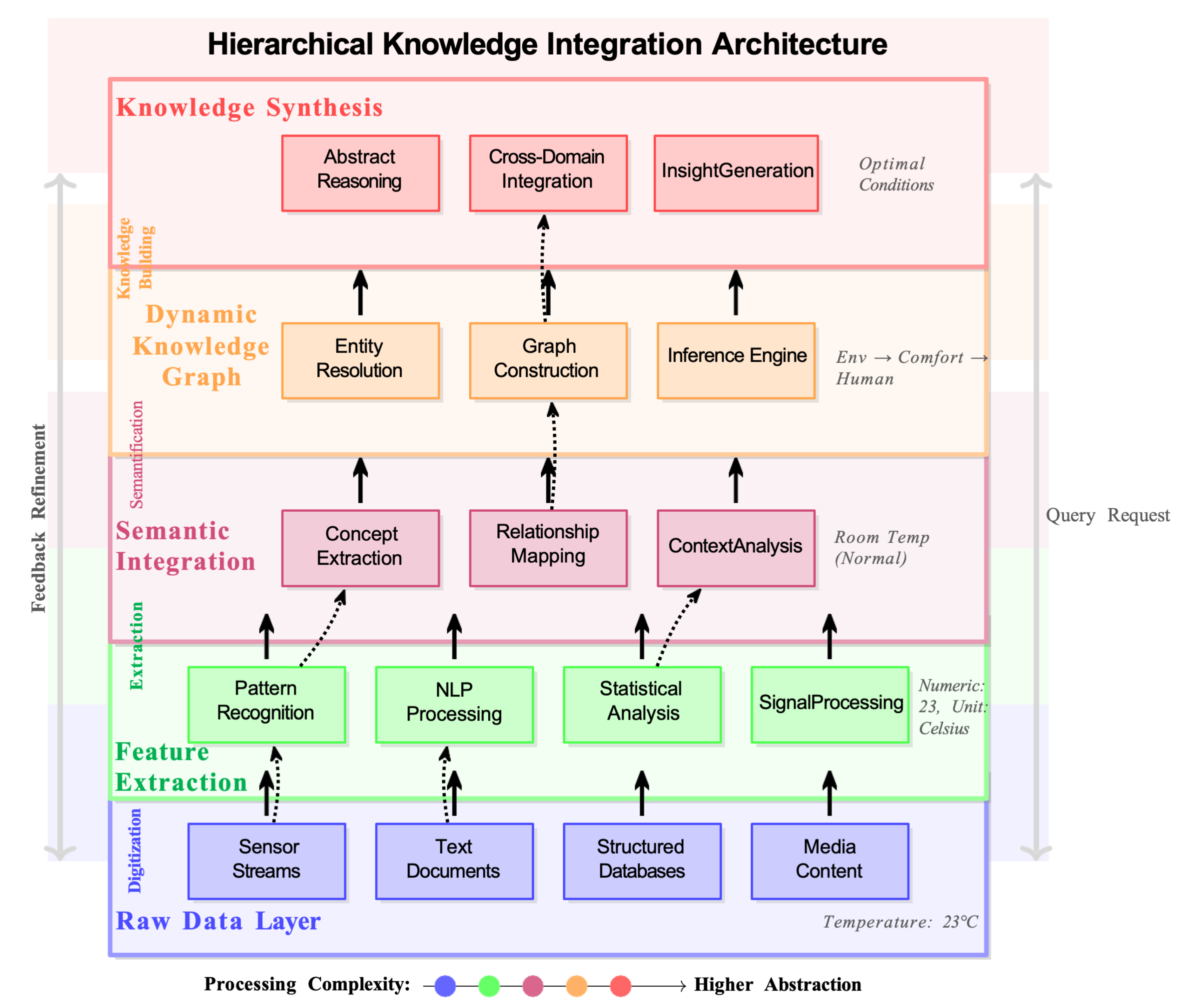
Figure 6.
Empirical Validation Methodology Framework showing the iterative cycle of system configuration, baseline establishment, performance evaluation, and comparative analysis.
Figure 6.
Empirical Validation Methodology Framework showing the iterative cycle of system configuration, baseline establishment, performance evaluation, and comparative analysis.
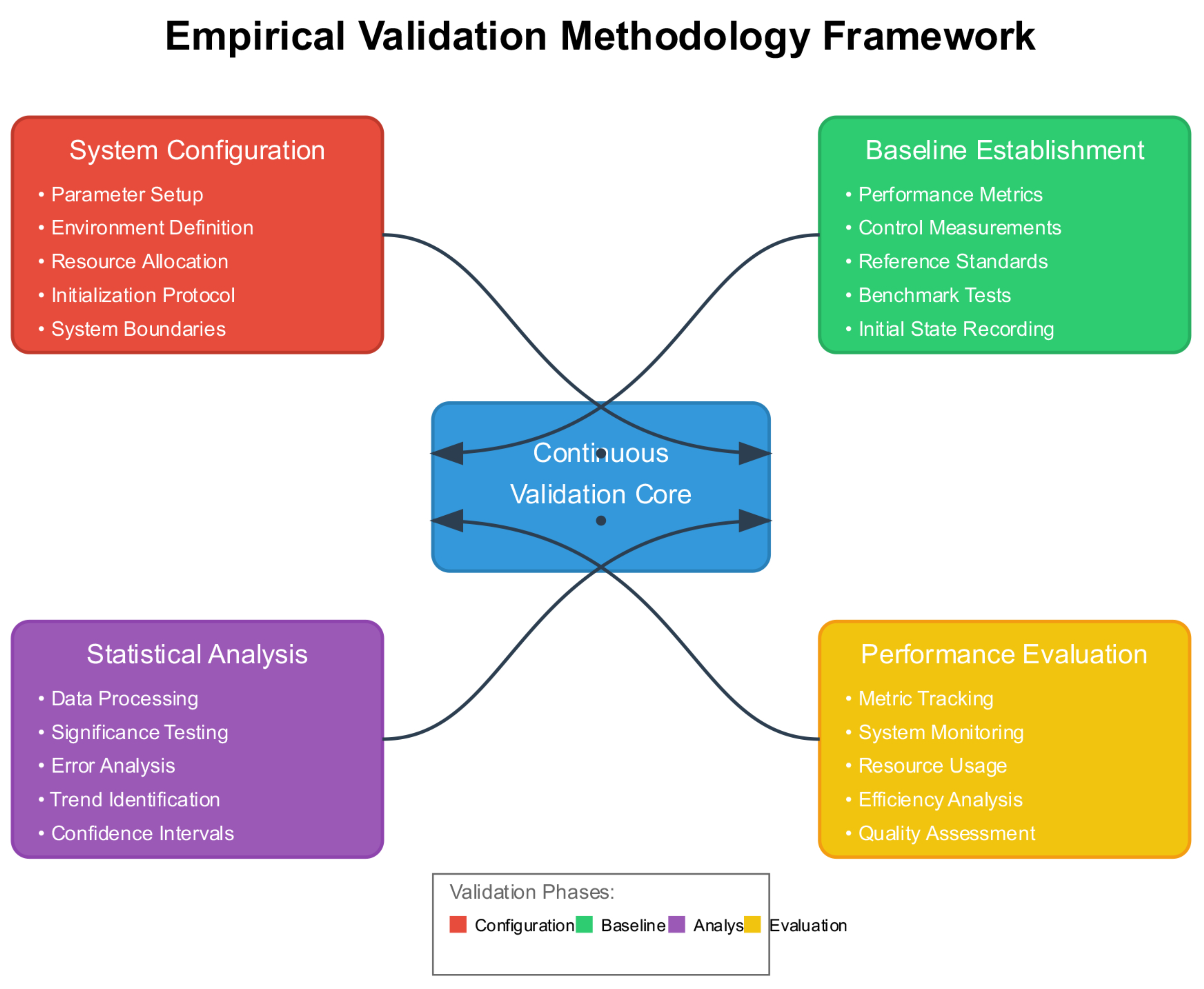
Figure 7.
Comparative analysis of adaptive AI systems across six key capability dimensions. Targeted capability dimensions for Liquid AI compared to existing approaches. Values represent theoretical design goals rather than measured performance.
Figure 7.
Comparative analysis of adaptive AI systems across six key capability dimensions. Targeted capability dimensions for Liquid AI compared to existing approaches. Values represent theoretical design goals rather than measured performance.
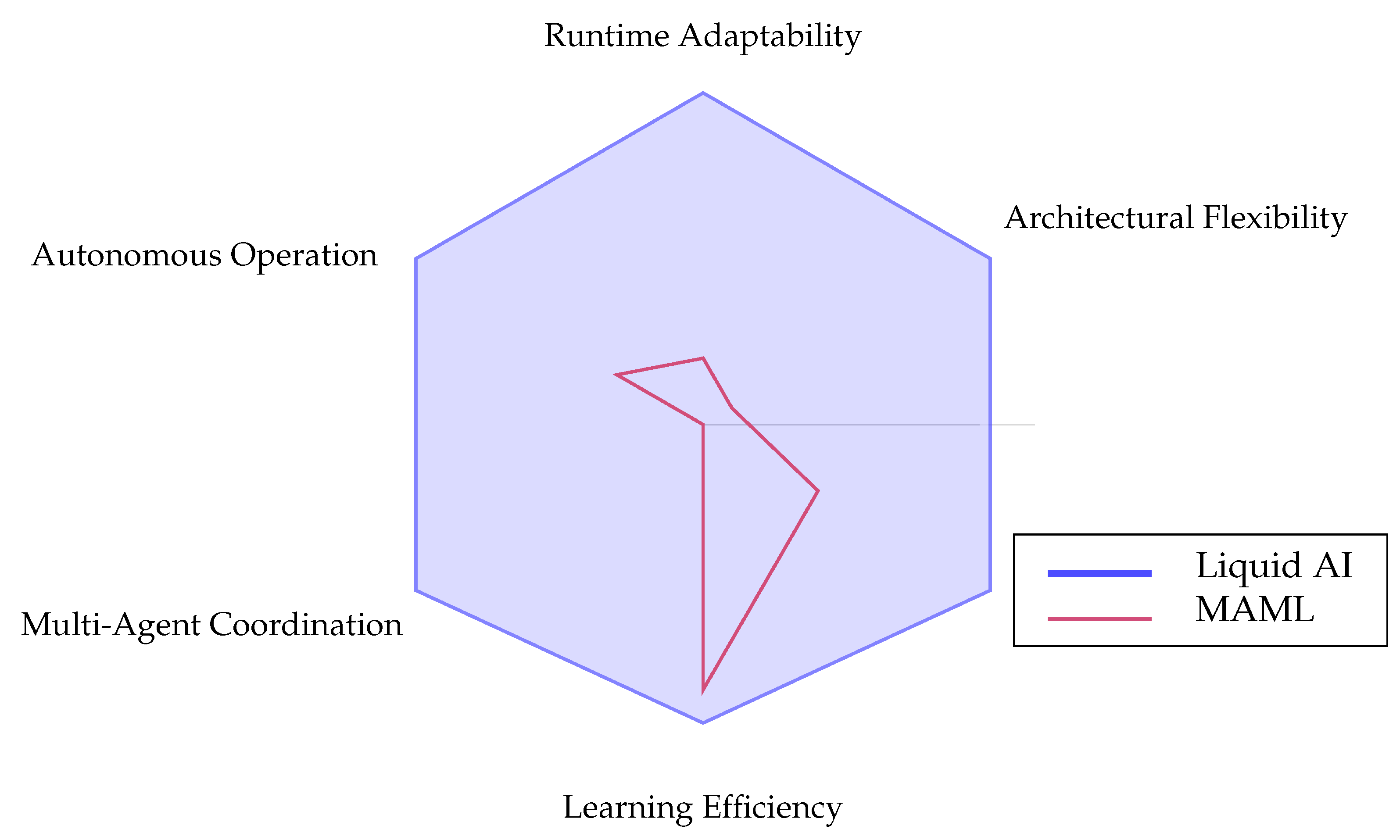
| Liquid AI | |
| MAML |
Figure 8.
Application Domain and Use Cases of Liquid AI. Systematic representation of six primary application domains: Healthcare (showing drug discovery, precision medicine, clinical analytics), Scientific Research (materials discovery, physics simulation, climate modeling), Industrial Systems (smart manufacturing, quality control, process optimization), Financial Systems (risk analysis, trading strategies, fraud detection), Environmental Management (resource management, climate adaptation, ecosystem monitoring), and Cognitive Systems (learning assistance, decision support, knowledge synthesis).
Figure 8.
Application Domain and Use Cases of Liquid AI. Systematic representation of six primary application domains: Healthcare (showing drug discovery, precision medicine, clinical analytics), Scientific Research (materials discovery, physics simulation, climate modeling), Industrial Systems (smart manufacturing, quality control, process optimization), Financial Systems (risk analysis, trading strategies, fraud detection), Environmental Management (resource management, climate adaptation, ecosystem monitoring), and Cognitive Systems (learning assistance, decision support, knowledge synthesis).
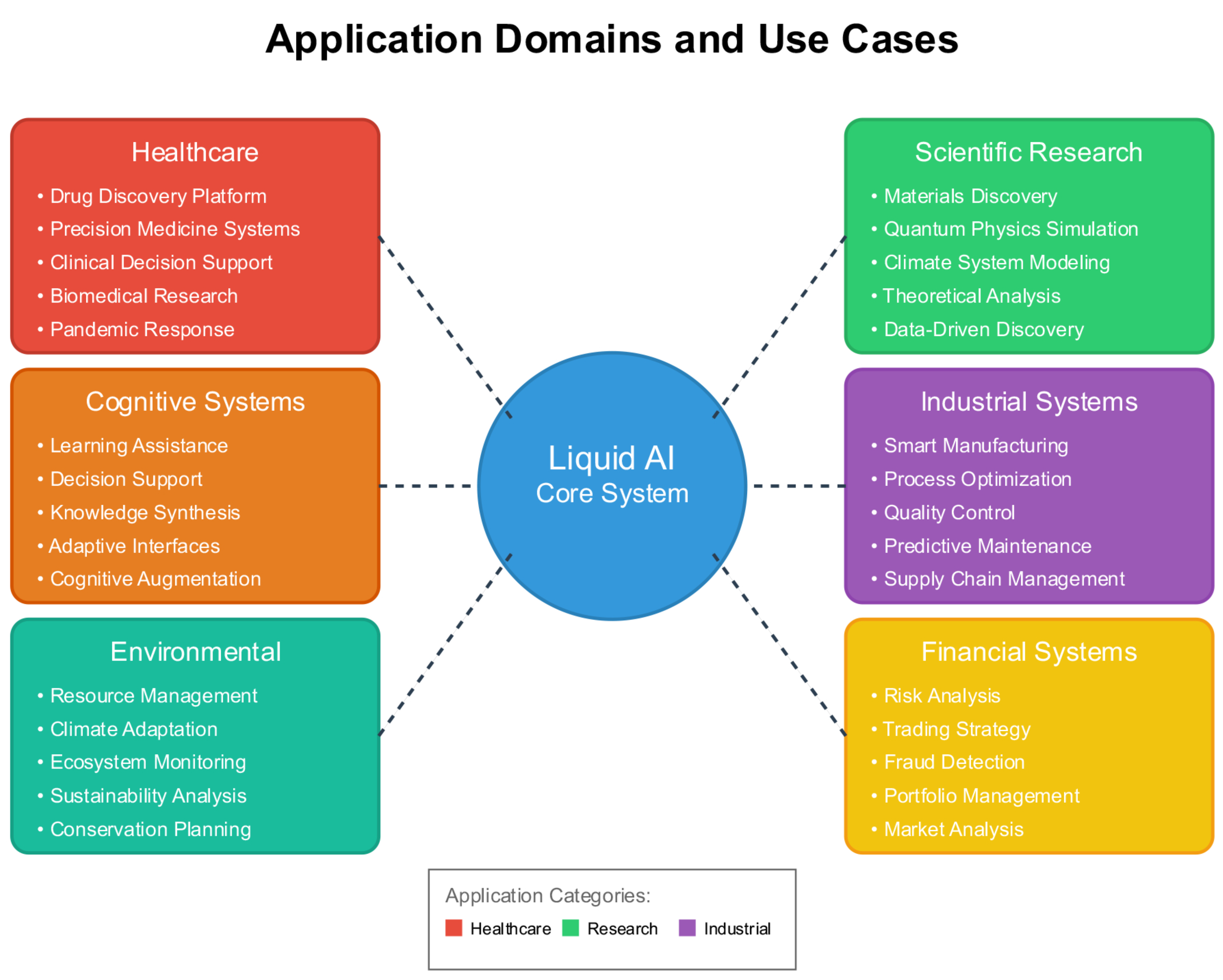
Figure 9.
Future Research Directions and Implications. Comprehensive roadmap showing six key research areas arranged along a temporal progression: Theoretical Foundations (mathematical frameworks, convergence properties), Technical Implementation (scalable architecture, resource management), Safety and Ethics (value alignment, governance), Societal Impact (economic effects, policy frameworks), Interdisciplinary Studies (cognitive science, complex systems), and Future Applications (emerging technologies, new domains).
Figure 9.
Future Research Directions and Implications. Comprehensive roadmap showing six key research areas arranged along a temporal progression: Theoretical Foundations (mathematical frameworks, convergence properties), Technical Implementation (scalable architecture, resource management), Safety and Ethics (value alignment, governance), Societal Impact (economic effects, policy frameworks), Interdisciplinary Studies (cognitive science, complex systems), and Future Applications (emerging technologies, new domains).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



