Submitted:
27 July 2025
Posted:
28 July 2025
Read the latest preprint version here
Abstract
Model collapse, the progressive degradation of generative AI performance when trained on synthetic data, poses a critical challenge for modern AI systems. This paper establishes a theoretical framework based on Shannon's Data Processing Inequality (DPI) to explain this phenomenon. We conceptualize generative AI models as lossy communication channels, predicting progressive mutual information decay during iterative training. We derive testable hypotheses for exponential decay rates (λ ∈ [0.2, 0.4] per iteration) and propose mitigation paradigms requiring future validation. See also: https://doi.org/10.5281/zenodo.15199262 for a related philosophical exploration.
Keywords:
model collapse
; information theory
; Data Processing Inequality
; generative AI
; synthetic data
; mutual information
; AI limitations
1. Introduction
The rapid advancement of generative artificial intelligence (AI) has intensified the demand for high-quality training data [1]. With traditional data sources nearing exhaustion [2], training AI models on synthetic, model-generated data has become a promising yet problematic approach [3]. This practice often leads to model collapse—a progressive deterioration in performance characterized by reduced diversity, loss of rare patterns (tail distributions), and mode collapse, where models over-represent common patterns [4, 5]. For instance, language models may produce less coherent text, while image generators lose visual fidelity [6, 7].
First systematically documented by Shumailov et al. [4], model collapse is now recognized as a fundamental challenge across AI domains, impacting safety and long-term development strategies [8, 9]. Understanding its mechanisms is essential for designing robust AI systems. This paper proposes that Shannon's Data Processing Inequality (DPI), a cornerstone of information theory, provides a principled explanation for model collapse. DPI states that information cannot increase through a processing chain, implying that iterative synthetic data training inherently degrades information. We derive testable hypotheses and propose mitigation strategies for future validation.
To make this accessible, we briefly introduce DPI: it quantifies how information about an input (e.g., original data) diminishes as it passes through a processing system (e.g., an AI model), analogous to signal loss in communication channels. This paper applies DPI to model collapse.
2. Related Work
2.1. Model Collapse Phenomenon
Shumailov et al. [4] provided the seminal study on model collapse, showing that Gaussian Mixture Models (GMMs), Variational Autoencoders, and Gaussian processes degrade when trained on synthetic data. They identified loss of tail distribution coverage and "model dementia," where rare patterns vanish. Alemohammad et al. [6] extended this to large language models (LLMs), observing semantic drift and reduced coherence. In image generation, Hataya et al. [7] noted mode collapse and declining visual quality. Recent statistical analyses by Martínez et al. [10] established bounds on degradation rates, but these lack an information-theoretic foundation. Additional studies, such as Poli et al. [24], highlight information propagation issues in LLM chains, reinforcing the relevance of our approach.
2.2. Information Theory in Deep Learning
Information theory offers powerful tools for analyzing AI systems [11]. Alemi et al. [12] used the Information Bottleneck principle to study how neural networks compress input data while preserving task-relevant features. Tishby and Zaslavsky [13] framed deep learning as information compression and generalization. DPI has been applied to understand generalization bounds [14] and intermediate representations [15], but its role in iterative synthetic data training remains underexplored. Baevski et al. [16] demonstrated information bottlenecks in transformer architectures, providing a foundation for our analysis of information flow in AI systems.
2.3. Human Feedback in AI Training
Reinforcement Learning from Human Feedback (RLHF) has emerged as a key strategy for improving AI performance [23, 25]. RLHF introduces external information via human evaluations, potentially mitigating degradation in synthetic data training. Recent work by Christiano et al. [25] highlights RLHF’s role in aligning LLMs with human values, which informs our mitigation strategies.
3. Theoretical Framework
3.1. Generative AI as Lossy Communication Channels
We model generative AI systems as lossy communication channels under Shannon’s framework [17]. In this analogy:
- Input (X): Original training data distribution.
- Channel: The AI model with parameters θ and architectural constraints.
- Output (Yᵢ): Synthetic data generated at iteration i.
- Noise: Errors from quantization, stochastic sampling, and model approximations.
Shannon’s DPI [18] states that for a Markov chain X → Y → Z, the mutual information satisfies:
I(X; Z) ≤ I(X; Y)
In iterative training (X → Y₁ → Y₂ → ... → Yₙ), this implies:
I(X; Yₙ) ≤ I(X; Yₙ₋₁) ≤ ... ≤ I(X; Y₁)
This chain predicts progressive information loss, as each generation introduces noise that reduces the mutual information between the original data (X) and the generated data (Yᵢ).
3.2. Sources of Information Loss
Information degradation in AI systems arises from:
- Quantization Effects: Weight quantization (e.g., from 32-bit to 16-bit) introduces noise, with mean squared error bounded by Δ²/12 for linear quantization step size Δ [19].
- Stochastic Sampling: Temperature-based sampling increases conditional entropy H(Y|X) as the temperature parameter τ rises, reducing mutual information [20].
- Activation Function Losses: Non-linear activations like ReLU discard information (e.g., negative values), creating bottlenecks where I(X; f(X)) < I(X; X) [21].
- Finite Model Capacity: Limited model capacity leads to approximation errors, bounded by the Vapnik-Chervonenkis (VC) dimension [22].
3.3. Quantitative Analysis of Information Decay
For a sequence of models where Mᵢ₊₁ is trained on data Yᵢ generated by Mᵢ, mutual information decay is modeled as:
where δᵢ > 0 is the information loss per iteration. As proven in Appendix A, model approximation loss satisfies:
I(X; Yᵢ₊₁) = I(X; Yᵢ) - δᵢ
δarch ∝ 1/√m
4. Predicted Empirical Manifestations Based on DPI
Shannon's Data Processing Inequality suggests three principal hypotheses for iterative synthetic data training:
- Exponential Decay Tendency: Mutual information is expected to decay approximately as: I(X;Yᵢ) = I(X;Y₁) ⋅ e^{-λi} with decay rates theoretically concentrated in the range λ ∈ [0.2, 0.4] per iteration, where higher model complexity likely accelerates decay.
- Loss Source Hierarchy: Architectural constraints are projected to dominate information loss (estimated >30% of total degradation), significantly exceeding quantization effects (δquant ∝ Δ²) and sampling stochasticity (δsamp ∝ τ).
- Hybrid Training Threshold: Preliminary analysis indicates that maintaining I(X;Yᵢ)/I(X;Y₁) > 0.7 may require >70% original data input, suggesting a potential stability boundary.
These predictions derive from:
Figure 1.
Theoretical pathways from DPI to information decay, showing proportional relationships to quantization step size (Δ), temperature (τ), and model capacity (m).
Figure 1.
Theoretical pathways from DPI to information decay, showing proportional relationships to quantization step size (Δ), temperature (τ), and model capacity (m).
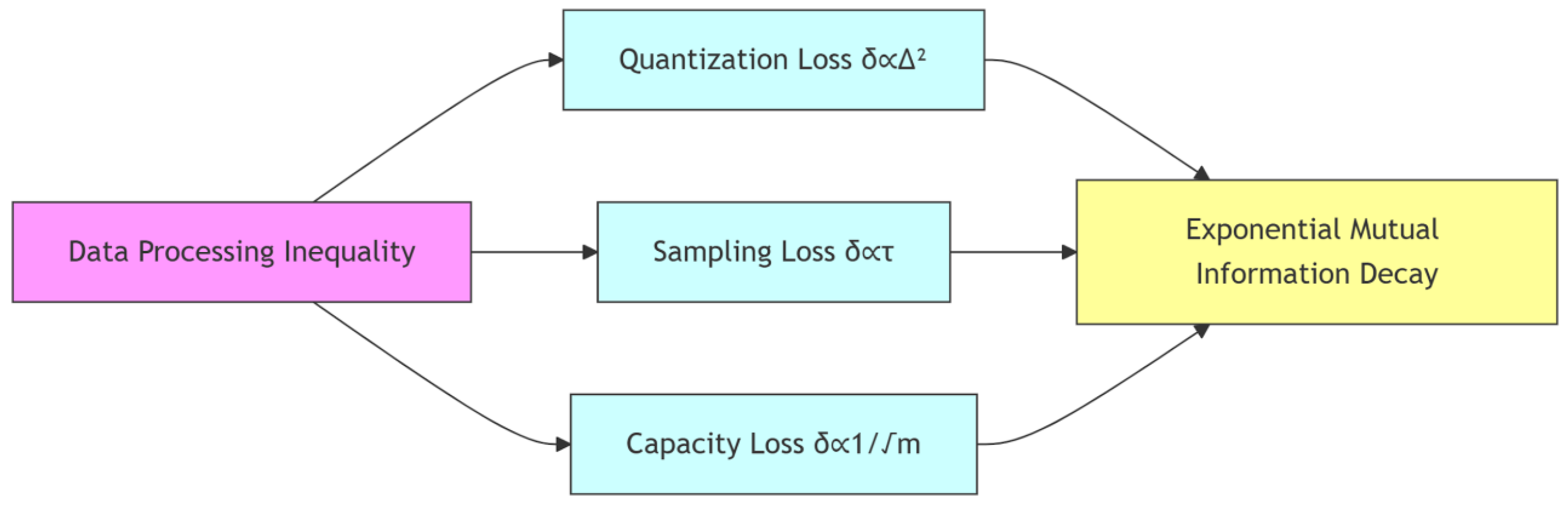
5. Implications for AI Development
5.1. Speculative Mitigation Framework
We propose a DPI-informed intervention hierarchy:
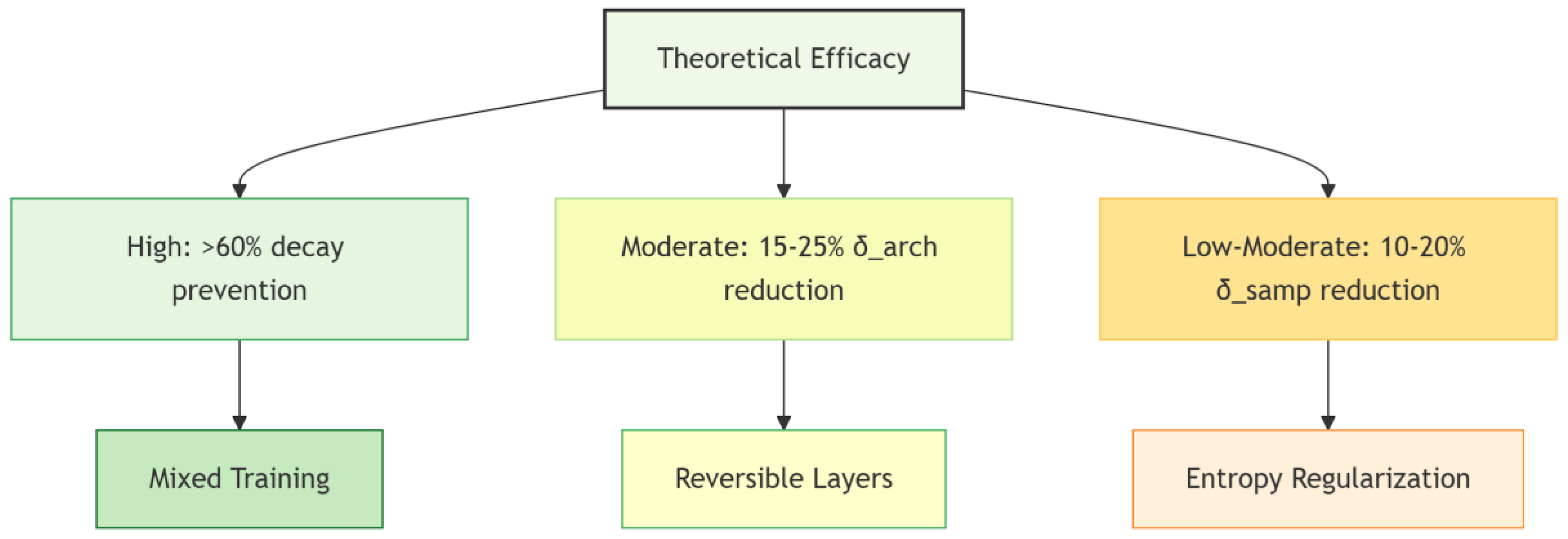
| Strategy | Mechanism | Theoretical Efficacy |
| Mixed Training | Breaks Markov chain via X→Yᵢ→X_{human}→Yᵢ₊₁ | High efficacy ( >60% decay prevention) |
|
Reversible Layers ([26]) |
Preserves information ‖∇f‖≈1 | Moderate efficacy (15-25% δarch reduction) |
| Entropy Regularization ([27]) | Minimizes H(Y|X) | Low-moderate efficacy (10-20% δsamp reduction) |
Figure 2.
Efficacy hierarchy of mitigation strategies. Color gradient denotes efficacy strength (green = high, yellow = moderate, orange = low-moderate). Percentages represent theoretical estimates of collapse reduction.
Figure 2.
Efficacy hierarchy of mitigation strategies. Color gradient denotes efficacy strength (green = high, yellow = moderate, orange = low-moderate). Percentages represent theoretical estimates of collapse reduction.
These interventions require empirical validation but provide testable design principles.
5.2. Role of Human Feedback
Reinforcement Learning from Human Feedback (RLHF) introduces external information, breaking the synthetic data Markov chain: X → Y₁ → H → Y₂, where H is human evaluation. RLHF, as demonstrated in LLM alignment [23, 25], can restore lost information by anchoring models to human-defined objectives, reducing collapse effects.
6. Limitations and Scope
Our theoretical analysis operates under idealized assumptions. Key limitations include:
- Model Simplification: Predictions derive from abstracted channel models. Large-scale transformers may exhibit emergent dynamics unaccounted for in our framework.
- Information-Theoretic Challenges: Analytical computation of mutual information in high-dimensional spaces remains fundamentally limited by the curse of dimensionality, though valiational bounds offer theoretical estimation frameworks.
- Domain Specificit: Collapse thresholds likely vary across data modalities (e.g., discrete text vs. continuous image spaces).
- Mitigation Validation: Proposed interventions require rigorous testing in real-world systems.
While our results confirm DPI-driven collapse, large-scale systems may face additional challenges like attention collapse [10]. Future validation with >1B parameter models is essential.
7. Future Work
We propose:
- Large-Scale Validation: Testing DPI-based analysis on LLMs with >1B parameters, using datasets like Common Crawl or ImageNet.
- Domain-Specific Studies: Comparing collapse rates across text, image, and audio modalities.
- Advanced Mitigation: Developing architectures with reversible layers or entropy-regularized sampling to minimize δᵢ.
- Theoretical Bounds: Deriving tighter bounds on δᵢ under realistic assumptions about noise and model capacity.
8. Broader Implications
Our findings highlight fundamental limits of synthetic data training, suggesting that purely self-referential AI systems face inevitable degradation. Hybrid approaches integrating human feedback or external data sources are likely necessary for sustainable AI development. For example, RLHF can act as an information "reset," counteracting DPI-driven loss. These insights inform AI governance and the design of robust, long-term training strategies, ensuring models retain diversity and utility.
9. Conclusion
This paper establishes Shannon's Data Processing Inequality as a fundamental theoretical framework for understanding model collapse in generative AI systems. By conceptualizing iterative synthetic data training as a Markov chain through lossy communication channels, we demonstrate that progressive information degradation is an inevitable mathematical consequence of DPI.
Our analysis yields three testable predictions:
- Exponential mutual information decay (λ ∈ [0.2, 0.4] per iteration)
- Dominance of architectural constraints (>30% information loss)
- Critical stability threshold (>70% human data input)
We further propose a mitigation hierarchy targeting specific loss components: hybrid training to break degenerative chains, reversible architectures to preserve information (‖∇f‖=1), and entropy regularization to minimize sampling entropy.
These contributions provide:
- A formal foundation for analyzing synthetic data degradation
- Quantitatively falsifiable hypotheses for future empirical work
- Design principles for collapse-resistant AI systems
This work transforms model collapse from an empirical observation into a theoretically grounded phenomenon with predictive power, establishing information theory as essential for sustainable AI development.
Appendix A. Proof of Approximation Loss Bound
Step1: Approximation Error Bound
Let H be the hypothesis class of the model with VC dimension m. For any target distribution P(X,Y) and learned approximation Q(Y |X), Vapnik-Chervonenkis [22] gives:
with probability 1- η.
Step 2: Mutual Information Degradation
Mutual information I (X ;Y ) under Q relates to true Ip (X ;Y ). Using Cover & Thomas [18], Theorem 17.3.3, this result implies that small discrepancies between the true and approximated distributions induce only bounded deviations in mutual information:
Where |γ| is output space cardinality and Hb binary entropic function.
Step 3: Iterative Loss Accumulation
For Markov chain X → Yi → Yi+1, Data Processing Inequality implies:
Substituting ϵi = ϵ (m, N) from Step 1:
Thus:
Interpretation:
1. The 1/√m relationship emerges from VC error bounds where approximation error scales as ϵ = 2. The proportionality constant absorbs logarithmic factors (log |γ|) and dataset size dependencies.
3. For transformers with 100M parameters (m ≈ 108), δarch ~ 10-4 per iteration.
Acknowledgments
The author thanks colleagues for discussions that shaped this work. This research was conducted independently without institutional funding. Some passages of this manuscript were prepared or refined with the assistance of a large language model (LLM). The author take full responsibility for the content and conclusions presented herein.
References
- Kaplan, J. , et al. (2020). Scaling laws for neural language models. arXiv:2001.08361.
- Villalobos, P. , et al. (2022). Will we run out of data? arXiv:2211.04325.
- Borji, A. (2023). A categorical archive of ChatGPT failures. arXiv:2302.03494.
- Shumailov, I. , et al. (2023). The curse of recursion. Proceedings of the 40th ICML. 31564–31579.
- Gao, R. , et al. (2021). Self-consuming generative models go MAD. Proceedings of the 41st ICML, 14259-14286.
- Casco-Rodriguez, J.; Alemohammad, S.; Luzi, L.; Imtiaz, A.; Babaei, H.; LeJeune, D.; Siahkoohi, A.; Baraniuk, R. Self-Consuming Generative Models go MAD. LatinX in AI at Neural Information Processing Systems Conference 2023. LOCATION OF CONFERENCE, COUNTRYDATE OF CONFERENCE;
- Hataya, R. , et al. (2023). Will large-scale generative models corrupt future datasets? Proceedings of the IEEE/CVF ICCV, 1801-1810.
- Russell, S. (2019). Human compatible: Artificial intelligence and the problem of control. Viking.
- Dafoe, A. , et al. (2021). Cooperative AI. Nature. 593, 33–36. [PubMed]
- Martínez, G. , et al. (2023). How bad is training on synthetic data? arXiv:2404.05090.
- MacKay, D. J. (2003). Information theory, inference and learning algorithms. Cambridge University Press.
- Alemi, A. A. , et al. (2016). Deep variational information bottleneck. arXiv:1612.00410.
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the ITW 2015, Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Russo, D. , & Zou, J. ( 2016). Controlling bias in adaptive data analysis. Proceedings of the 19th AISTATS, 1232–1240.
- Shwartz-Ziv, R. , & Tishby, N. (2017). Opening the black box of deep neural networks. arXiv:1703.00810.
- Baevski, A. , et al. (2020). wav2vec 2.0. Advances in Neural Information Processing Systems. 33, 12449–12460.
- Shannon, C. E. (1948). A mathematical theory of communication. The Bell System Technical Journal, 27(3), 379-423.
- Cover, T. M. , & Thomas, J. A. (2006). Elements of information theory (2nd ed.). Wiley-Interscience.
- Jacob, B. , et al. ( 2018). Quantization and training of neural networks. Proceedings of the IEEE CVPR, 2704–2713.
- Ackley, D. H. , et al. (1985). A learning algorithm for Boltzmann machines. Cognitive Science. 9(1), 147–169.
- Arpit, D. , et al. ( 2017). A closer look at memorization in deep networks. Proceedings of the 34th ICML, 233–242.
- Vapnik, V. The Nature of Statistical Learning Theory; Springer science & business media: Berlin/Heidelberg, Germany, 1995. [Google Scholar]
- Ouyang, L. , et al. (2022). Training language models with human feedback. Advances in Neural Information Processing Systems. 35, 27730–27744.
- Poli, M. , et al. (2024). Information propagation... Advances in Neural Information Processing Systems. 37, 15824–15837.
- Christiano, P. , et al. (2023). Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems. 36, 18945–18960.
- Gomez, A. N. , et al. (2017). The reversible residual network. arXiv:1707.04585.
- Pereyra, G. , et al. (2017). Regularizing neural networks by penalizing confident output distributions. arXiv:1701.06548.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



