Submitted:
25 July 2025
Posted:
25 July 2025
You are already at the latest version
Abstract
To address the issue of severe noise caused by reduced radiation dose in low-dose medical CT images, which leads to significant image quality degradation, this paper proposes a denoising algorithm for low-dose CT images based on residual attention mechanisms and adaptive feature fusion. The proposed method utilizes a fully convolutional neural network to complete the denoising task. Within the network architecture, a residual attention mechanism and selective internal core feature fusion module are introduced to filter noise information, extract effective features, and adaptively integrate image characteristics. This approach avoids detail loss during reconstruction and improves image quality, making the denoised image perceptually closer to the original image. Both qualitative and quantitative experiments demonstrate that the proposed method effectively suppresses noise and restores more detailed textures in low-dose CT images. Compared with conventional methods, the proposed algorithm improves peak signal-to-noise ratio by 14.94%, enhances structural similarity by 4.68%, and reduces root mean square error by 40.11%, meeting the diagnostic requirements of medical imaging.
Keywords:
low-dose CT
; fully convolutional neural network
; noise
; attention mechanism
; feature fusion
1. Introduction
Low-Dose Computed Tomography (LDCT) imaging, due to reduced X-ray exposure, offers the potential to lessen radiation, thus attracting significant attention. However, compared with Normal-Dose Computed Tomography (NDCT), LDCT images often suffer from severe noise and artifacts in clinical applications, severely impacting diagnostic accuracy [1]. Therefore, how to suppress noise in LDCT images while preserving original structural details and features is an important research direction [2].
Traditional LDCT denoising methods mainly fall into two categories[3]: image-domain and projection-domain based approaches. Projection-domain methods perform statistical estimation before image reconstruction, filtering noise in the projection data and then completing the inverse reconstruction. While these approaches can suppress noise in projections, they may blur important structural information during image formation.
In contrast, image-domain methods directly denoise CT images after reconstruction. These are more flexible and efficient but are often limited by the difficulty in distinguishing noise from subtle anatomical structures. Recent deep learning approaches, particularly convolutional neural networks (CNNs) and generative adversarial networks (GANs), have shown great promise in LDCT denoising. Chen et al. [4] proposed RED-CNN for LDCT image denoising using an encoder-decoder CNN framework, reducing differences between LDCT and NDCT images while preserving details and reducing artifacts. Wolterink et al. [5] used GANs to enhance LDCT images, achieving noise suppression with improved realism.
Yang et al. [6] proposed a knowledge-guided GAN model that preserves detailed structures and effectively reduces noise. However, existing models still face challenges in extracting comprehensive contextual features, such as top-down information, leading to suboptimal denoising.
To address this, this paper proposes a method that integrates a Residual Attention Module (RAM) and a Selective Kernel Feature Fusion (SKFF) module based on a fully convolutional neural network. The model adaptively fuses spatial contextual features to extract noise-robust representations. By leveraging multi-scale context and enhancing top-down semantic guidance, the method effectively suppresses noise while preserving structural fidelity, leading to improved LDCT image quality and visual perception.
2. Related Work
Deep learning-based denoising methods have advanced significantly, especially in medical imaging domains like LDCT. One core direction is enhancing segmentation and structural preservation using multi-scale fusion and attention mechanisms. Adaptive transformer attention combined with hierarchical feature modeling has proven effective in spine 3D segmentation, showing how multi-resolution fusion can retain critical spatial structures in volumetric data [7]. Similarly, cross-scale attention networks for skin disease detection demonstrate that layered features and fusion schemes are essential for high-precision medical image analysis [8]. The integration of multi-scale attention and spatial integration modules further enhances segmentation accuracy and robustness, particularly in complex imaging environments [9].
Boundary-aware semantic segmentation introduces spatial priors into CNN architectures, helping to delineate object borders clearly in noisy or low-contrast images—a principle vital to preserving anatomical detail in LDCT denoising [10]. Context-aware rule mining using dynamic transformer-based models brings the advantage of high adaptability in feature space, where learned attention maps align with critical medical regions for improved inference [11]. In similar architectural domains, structured memory integration has shown how language-inspired transformers can dynamically weight spatial or channel features for robust contextual understanding [12].
Instruction encoding and multi-task learning strategies extend these insights by allowing a single model to adapt to diverse tasks with reduced computational overhead. Such architectures introduce dynamic gradient coordination, helpful in aligning different feature hierarchies during denoising [13]. Clinical natural language processing frameworks utilizing attention-based deep learning techniques have revealed the utility of attention maps in multi-disease diagnosis, aligning well with attention-guided denoising in LDCT [14].
In the area of model adaptation, low-rank fine-tuning techniques have emerged to enable few-shot learning across complex domains. Dynamic and low-rank adaptation strategies not only compress the model but also guide efficient learning with minimal supervision, particularly valuable in medical applications with limited data [15]. Low-Rank Adaptation (LoRA) has further enhanced model specialization by introducing task-aware modulation, which can be analogously applied to channel-wise fusion in image denoising [16]. Transformer-based few-shot classification models using dual loss mechanisms offer robustness to noise and label sparsity—conditions also prevalent in LDCT denoising scenarios [17].
Task scheduling and control optimization via reinforcement learning (RL) have long been used to adapt to dynamic environments. Scheduling strategies using Double Deep Q-Networks (DQN) have shown strong potential in balancing efficiency and accuracy in decision systems—a dynamic analogous to optimizing multi-stage denoising pipelines [18]. Autonomous microservice resource management systems using RL offer insight into how agents can self-organize around noisy inputs and maximize utility, which correlates with adaptive kernel fusion in CT image enhancement [19]. LSTM-based micro-module scheduling emphasizes the predictive modeling of workloads, aligning with feature prediction and adaptive context regulation in deep medical imaging models [20].
Collaborative RL frameworks for cloud scaling have proposed task-sensitive reward functions, a mechanism that resonates with learning adaptive feature maps for CT restoration based on noise sensitivity [21]. Diffusion models, which are increasingly applied in generative tasks like UI generation, have proven effective in preserving global coherence while allowing local variation—this mirrors the balance needed between noise suppression and edge preservation in medical CT [22]. Hybrid diffusion-transformer models are also particularly adept at managing sparse high-dimensional data, which can be mapped to the high-resolution, low-signal characteristics of LDCT images [23].
Knowledge-informed policy structures for multi-agent collaboration reveal how domain priors can be integrated into deep networks for better alignment with task goals. These insights can enhance adaptive modules that prioritize anatomical relevance during denoising [24]. Named entity recognition and boundary detection in social text using BiLSTM-CRF and social features indicate the importance of edge-aware modeling in noisy or ambiguous inputs, directly relevant to enhancing the delineation of organ boundaries in CT [25]. Finally, boundary-specific modeling and edge fusion strategies are essential for CT denoising pipelines, where both structural continuity and detail fidelity must be simultaneously optimized [26].
Beyond structural modeling, anomaly detection and contrastive learning have become essential tools in distributed environments. Federated contrastive learning has shown exceptional capabilities in identifying behavioral anomalies across distributed systems, which mirrors the challenges faced in detecting subtle anomalies or lesions in LDCT images [27]. Probabilistic modeling using Mixture Density Networks (MDNs) further enhances robustness in anomaly detection by accounting for multimodal data distributions—this can be adopted in modeling complex noise patterns across anatomical regions [28].
Edge computing and model compression strategies, such as MobileNet-based deployments, contribute to real-time inference and resource-efficient imaging—especially useful when deploying LDCT denoising algorithms in clinical edge devices [29]. Diffusion transformers, trained on sparse and high-dimensional feature maps, have shown promise in structuring latent representations, supporting fusion-based denoising pipelines that rely on spatial and frequency-domain information [30].
Memory modeling and structured knowledge integration enhance language systems by embedding semantic continuity into long-context reasoning, a design philosophy translatable to multi-layer feature fusion in medical vision [31]. Reinforcement learning-controlled subspace sampling introduces intelligent control over feature representations—similar to channel reweighting and region-specific attention in denoising models [32]. For text generation under low-resource conditions, transfer learning techniques have emphasized the importance of preserving key context features with limited supervision, analogous to model generalization in LDCT scenarios with scarce training data [33].
Contrastive learning methods in recommender systems demonstrate how data augmentation and representation disentanglement can lead to more resilient embeddings, concepts that support robustness under diverse CT imaging protocols [34]. In a similar line, entity boundary detection using BiLSTM-CRF architectures emphasizes local dependency modeling and sequence coherence—tools that are beneficial for edge and contour preservation in low-dose image restoration [35].
Policy-structured language models for multi-agent systems also serve as a reference for developing structured decision layers in complex vision tasks. These models handle inter-agent information exchange, similar to how adaptive feature modules in a denoising network manage multiple streams of visual information [36]. Reinforcement learning-based IoT scheduling, driven by Deep Q-Networks, shows adaptive behavior under temporal constraints, which is conceptually aligned with frame-wise and patch-wise inference regulation in real-time CT image processing [37].
Graph-based spectral decomposition has been leveraged for coordinating parameter updates across complex models, enabling fine-grained learning control that can be extended to channel-wise fusion optimization [38]. Joint graph convolution and sequence modeling support large-scale spatiotemporal data integration—principles also needed in multi-slice CT data fusion for 3D denoising tasks [39].
In sequential recommendation systems, convolutional user modeling and time-aware features demonstrate that integrating temporal signals enhances inference accuracy. This idea parallels how incorporating acquisition-specific priors improves denoising quality in CT imaging [40]. Transformer architectures guided by dual-loss strategies provide resilience against task drift and noise—key considerations when processing LDCT images with variable exposure [41]. Gesture recognition via DeepSORT visual tracking highlights motion consistency and spatial alignment, which inspire smooth feature transitions in spatial attention mechanisms for denoising [42].
Meta-learned task representations have enabled transferable scheduling and forecasting models in dynamic environments. Such capabilities inform multi-task learning strategies that allow a denoising network to adapt to varying scan regions or noise intensities [43]. Bootstrapped structural prompting in pretrained models facilitates analogical reasoning, which could aid the development of structure-aware CT image reconstruction models [44]. Elastic scaling frameworks, driven by meta-learning in cloud environments, have proposed adaptation strategies that can be mapped to layer-wise denoising refinement in LDCT models [45]. Finally, accurate lesion segmentation using spatial attention and multi-scale features highlights the continued importance of preserving both global structure and localized detail in clinical imaging tasks [46]. Recent developments have also focused on improving knowledge consistency and proactive control in large-scale systems, offering valuable analogies for denoising pipelines. Time-series learning frameworks for proactive fault prediction have introduced mechanisms for capturing evolving patterns in sequential data, which can inspire patch-wise and temporal-aware CT image enhancement strategies [47]. Semantic intent modeling using capsule networks provides structured feature representation, beneficial for distinguishing complex textures and subtle anomalies in noisy CT scans [48].
Internal adaptation techniques in large language models (LLMs), such as consistency-constrained dynamic routing, aim to maintain coherence across layers—this concept can enhance stability in deep denoising networks as well [49]. Reinforcement learning for microservice resource management introduces policy feedback loops and continuous optimization, which aligns with adaptive parameter tuning strategies in LDCT models [50]. Multi-head attention applied to microservice access pattern modeling reveals how attention-based architectures can learn hierarchical dependencies, similar to spatial-context relationships in CT image volumes [51].
Lastly, robust root cause detection in cloud systems using structural encoding and multi-modal attention emphasizes causal modeling and fault localization—approaches that can be translated into spatial reasoning and structural anomaly detection in low-dose CT image recovery [52].
3. Proposed Method
This paper proposes a denoising network based on a Residual Attention-Denoising Network with Adaptive Feature Fusion (RAFDN) for LDCT images, with output as denoised images. The structure of the RAFDN model and the design of the main RAM and SKFF modules are described below.
3.1. RAFDN Architecture
The overall architecture of RAFDN is shown in Figure 1a, which mainly includes a convolution, a convolution, five denoising modules (DM), and two feature extraction modules (FEM). The input LDCT image is first preprocessed into a image patch. Since the input LDCT image has high resolution, a convolution is first applied to perform directional feature extraction and reduce the number of parameters. Then, five DMs are used for progressive noise suppression, followed by two FEMs for deep feature extraction and fusion using the SKFF module, as shown in Figure 1b,c.
Finally, a convolution is used to fuse the features and obtain the denoised output. The denoising process aims to minimize the pixel-wise differences between the predicted image and the ground truth. The Mean Absolute Error (MAE) is used as the loss function, defined as:
where denotes the ground truth CT image, denotes the predicted output, and m is the total number of pixels in the image.
3.2. RAM Structure
The RAM module can be divided into two parts: the feature extraction part and the attention mechanism part, as illustrated in Figure 2. During feature extraction, residual blocks are stacked to extract deeper features and suppress noise. Then, the spatial attention mechanism adaptively enhances features in more informative regions.
After fusing the features extracted from multiple branches, they are passed through a sigmoid activation to generate an attention map, which is multiplied with the input features for enhancement. This enables the network to better focus on noise-suppressed regions.
3.3. SKFF Structure
Conventional feature fusion often directly connects feature maps or adds them element-wise. However, such methods may limit the network’s representation ability. In this paper, a Selective Kernel Feature Fusion (SKFF) module is introduced, as shown in Figure 3, to improve adaptability.
Specifically, the SKFF module performs global average pooling on the two feature maps to obtain vectors, followed by a convolution and non-linear mapping using ReLU. Then, a Softmax function is used to normalize the weights and compute channel-wise fusion coefficients, which are finally multiplied with the respective features and added for adaptive fusion.
4. Experimental Analysis and Results
4.1. Experimental Data and Environment Settings
The experiments used the 2016 NIH-AAPM-Mayo Clinic LDCT Grand Challenge publicly available dataset for training and validation. The dataset consists of 2,378 image slices from 30 patients. These images include low-dose CT (1/4 dose) and corresponding normal-dose images. Data from 10 patients were selected as the test set, and 211 image slices were selected from 5 patients for validation. The remaining 217 image slices were used for model training. To enhance network learning, image patches of were cropped with different rotation angles (, , ) and vertical flipping for data augmentation.
All models were implemented in Pytorch 1.7 and run on an Intel i5-11400F 2.60GHz CPU and NVIDIA GeForce GTX 3060 12GB GPU. The code environment was Pycharm2020.2. Adam optimizer was adopted with the initial learning rate , momentum parameters , , and learning rate decay every 20 epochs. The input image size was , cropped into patches, and batch size was 4. The model was trained for 80 epochs, with each epoch containing 3,600 steps, totaling 3,000 image slices.
4.2. Experimental Results
The Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Root Mean Square Error (RMSE) were adopted to evaluate image quality. Higher PSNR and SSIM indicate better reconstruction, while lower RMSE indicates lower noise and better results.
4.2.1. Ablation Study
This section discusses in detail the impact of each algorithm module and conducts corresponding ablation experiments. The experiments were conducted under a consistent experimental environment and parameter settings. Based on this, different algorithm modules were added in succession to verify their impact on LDCT denoising results.
To avoid randomness, each experiment was repeated ten times. Evaluation metrics included PSNR, SSIM, and RMSE. To validate the effectiveness of the proposed modules, the baseline model was constructed using the proposed RAM convolution as a replacement, and the feature fusion part was implemented without the SKFF module (instead using direct feature addition). The average results on the test set are recorded in Table 1.
From the metrics, adding SKFF and RAM modules progressively improved image quality. Compared to the baseline, our method improved PSNR by 2.85%, SSIM by 1.02%, and reduced RMSE by 10.00%. In particular, the RAM module contributed significantly, as the early-stage feature extraction and final image reconstruction were better preserved.
Figure 4 visually illustrates the effect. From the images, it can be seen that the LDCT image with 1/4 dose contains large noise. As more modules are added, the denoised image becomes progressively clearer and retains more detail, demonstrating an upward trend across evaluation indicators.
4.2.2. Comparison with Other Methods
To further validate the superiority of the proposed method, comparisons were conducted against advanced methods, including REDCNN, EDCNN, and CTformer. These methods were applied to both low-dose and normal-dose CT images. Table 2 reports the average denoising results on the test set across all image quality metrics.
Compared with LDCT, our method improves PSNR by 14.94%, SSIM by 4.68%, and reduces RMSE by 40.11%. Compared with other methods, our approach still achieved the highest scores: PSNR, SSIM, and RMSE reached dB, , and respectively. All metrics demonstrate superiority.
From the denoising results in terms of visual quality and structural preservation, our method better retains anatomical details. Figure 5 illustrates the visual effect comparison. For instance, CTformer and EDCNN both effectively suppress noise, but tend to blur edge details. REDCNN shows weaker performance in noise suppression and detail preservation. As shown in Figure 5f, our method outperforms the others in retaining edge features and presents better contrast and perceptual quality.
5. Conclusions
This study focuses on the denoising task of LDCT images and proposes a deep learning model, RAFDN. The model is based on a fully convolutional network and integrates RAM and SKFF modules. Compared with mainstream LDCT denoising methods, it achieves higher PSNR and SSIM, lower RMSE, and better visual performance.
Future research will further optimize the model by focusing on the structural characteristics of LDCT images, aiming to enhance the quality of LDCT images and assist clinicians in more accurate diagnosis.
References
- Hsieh J. Adaptive streak artifact reduction in computed tomography resulting from excessive X-ray photon noise. Med Phys, 1998, 25(11): 2139–2147. [CrossRef]
- Wang J, Li T, Lu H, et al. Penalized weighted least-squares approach to sinogram noise reduction and image reconstruction for low-dose X-ray computed tomography. IEEE Trans Med Imaging, 2006, 25(10): 1272–1283. [CrossRef]
- Brenner DJ, Hall EJ. Computed tomography—an increasing source of radiation exposure. N Engl J Med, 2007, 357(22): 2277–2284.
- Chen H, Zhang Y, Kalra MK, et al. Low-dose CT with a residual encoder–decoder convolutional neural network. IEEE Trans Med Imaging, 2017, 36(12): 2524–2535. [CrossRef]
- Wolterink JM, Leiner T, Viergever MA, et al. Generative adversarial networks for noise reduction in low-dose CT. IEEE Trans Med Imaging, 2017, 36(12): 2536–2545. [CrossRef]
- Yang Q, Yan P, Zhang Y, et al. Low-dose CT image denoising using a generative adversarial network with Wasserstein distance and perceptual loss. IEEE Trans Med Imaging, 2018, 37(6): 1348–1357. [CrossRef]
- Xiang Y, He Q, Xu T, Hao R, Hu J, Zhang H. Adaptive Transformer Attention and Multi-Scale Fusion for Spine 3D Segmentation. In: Proc 2025 5th Int Conf on Artificial Intelligence and Industrial Technology Applications (AIITA), 2025, pp. 2009–2013. IEEE.
- Xu T, Xiang Y, Du J, Zhang H. Cross-Scale Attention and Multi-Layer Feature Fusion YOLOv8 for Skin Disease Target Detection in Medical Images. J Comput Technol Softw, 2025, 4(2).
- Wu Y, Lin Y, Xu T, Meng X, Liu H, Kang T. Multi-Scale Feature Integration and Spatial Attention for Accurate Lesion Segmentation. 2025.
- An T, Huang W, Xu D, He Q, Hu J, Lou Y. A deep learning framework for boundary-aware semantic segmentation. In: Proc 2025 5th Int Conf on Artificial Intelligence and Industrial Technology Applications (AIITA), 2025, pp. 886–890. IEEE.
- Liu J, Zhang Y, Sheng Y, Lou Y, Wang H, Yang B. Context-Aware Rule Mining Using a Dynamic Transformer-Based Framework. In: Proc 2025 8th Int Conf on Advanced Algorithms and Control Engineering (ICAACE), 2025, pp. 2047–2052. IEEE.
- Peng Y. Structured Knowledge Integration and Memory Modeling in Large Language Systems. Trans Comput Sci Methods, 2024, 4(10).
- Zhang W, Xu Z, Tian Y, Wu Y, Wang M, Meng X. Unified Instruction Encoding and Gradient Coordination for Multi-Task Language Models. 2025.
- Xu T, Deng X, Meng X, Yang H, Wu Y. Clinical NLP with Attention-Based Deep Learning for Multi-Disease Prediction. arXiv preprint, arXiv:2507.01437, 2025.
- Cai G, Kai A, Guo F. Dynamic and Low-Rank Fine-Tuning of Large Language Models for Robust Few-Shot Learning. Trans Comput Sci Methods, 2025, 5(4).
- Peng Y, Wang Y, Fang Z, Zhu L, Deng Y, Duan Y. Revisiting LoRA: A Smarter Low-Rank Approach for Efficient Model Adaptation. In: Proc 2025 5th Int Conf on Artificial Intelligence and Industrial Technology Applications (AIITA), 2025, pp. 1248–1252. IEEE.
- Han X, Sun Y, Huang W, Zheng H, Du J. Towards Robust Few-Shot Text Classification Using Transformer Architectures and Dual Loss Strategies. arXiv preprint, arXiv:2505.06145, 2025.
- Sun X, Duan Y, Deng Y, Guo F, Cai G, Peng Y. Dynamic operating system scheduling using double DQN: A reinforcement learning approach to task optimization. In: Proc 2025 8th Int Conf on Advanced Algorithms and Control Engineering (ICAACE), 2025, pp. 1492–1497. IEEE.
- Zou Y, Qi N, Deng Y, Xue Z, Gong M, Zhang W. Autonomous Resource Management in Microservice Systems via Reinforcement Learning. arXiv preprint, arXiv:2507.12879, 2025.
- Zhan J. Elastic Scheduling of Micro-Modules in Edge Computing Based on LSTM Prediction. J Comput Technol Softw, 2025, 4(2).
- Fang B, Gao D. Collaborative Multi-Agent Reinforcement Learning Approach for Elastic Cloud Resource Scaling. arXiv preprint, arXiv:2507.00550, 2025.
- Duan Y, Yang L, Zhang T, Song Z, Shao F. Automated UI Interface Generation via Diffusion Models: Enhancing Personalization and Efficiency. In: Proc 2025 4th Int Symp on Computer Applications and Information Technology (ISCAIT), 2025, pp. 780–783. IEEE.
- Cui W, Liang A. Diffusion-transformer framework for deep mining of high-dimensional sparse data. J Comput Technol Softw, 2025, 4(4).
- Ma Y, Cai G, Guo F, Fang Z, Wang X. Knowledge-Informed Policy Structuring for Multi-Agent Collaboration Using Language Models. J Comput Sci Softw Appl, 2025, 5(5).
- Zhao Y, Zhang W, Cheng Y, Xu Z, Tian Y, Wei Z. Entity Boundary Detection in Social Texts Using BiLSTM-CRF with Integrated Social Features. 2025.
- Peng S, Zhang X, Zhou L, Wang P. YOLO-CBD: Classroom Behavior Detection Method Based on Behavior Feature Extraction and Aggregation. Sensors, 2025, 25(10): 3073. [CrossRef]
- Jiang N, Zhu W, Han X, Huang W, Sun Y. Joint Graph Convolution and Sequential Modeling for Scalable Network Traffic Estimation. arXiv preprint, arXiv:2505.07674, 2025.
- Zhang H, Ma Y, Wang S, Liu G, Zhu B. Graph-Based Spectral Decomposition for Parameter Coordination in Language Model Fine-Tuning. arXiv preprint, arXiv:2504.19583, 2025.
- Wang Y, Zhu W, Quan X, Wang H, Liu C, Wu Q. Time-Series Learning for Proactive Fault Prediction in Distributed Systems with Deep Neural Structures. arXiv preprint, arXiv:2505.20705, 2025.
- Wang S, Zhuang Y, Zhang R, Song Z. Capsule Network-Based Semantic Intent Modeling for Human-Computer Interaction. arXiv preprint, arXiv:2507.00540, 2025.
- Wu Q. Internal Knowledge Adaptation in LLMs with Consistency-Constrained Dynamic Routing. Trans Comput Sci Methods, 2024, 4(5).
- He Q, Liu C, Zhan J, Huang W, Hao R. State-Aware IoT Scheduling Using Deep Q-Networks and Edge-Based Coordination. arXiv preprint, arXiv:2504.15577, 2025.
- Gong M. Modeling Microservice Access Patterns with Multi-Head Attention and Service Semantics. J Comput Technol Softw, 2025, 4(6).
- Ren Y. Deep Learning for Root Cause Detection in Distributed Systems with Structural Encoding and Multi-modal Attention. J Comput Technol Softw, 2024, 3(5).
- Wang H. Causal Discriminative Modeling for Robust Cloud Service Fault Detection. J Comput Technol Softw, 2024, 3(7).
- Meng R, Wang H, Sun Y, Wu Q, Lian L, Zhang R. Behavioral Anomaly Detection in Distributed Systems via Federated Contrastive Learning. arXiv preprint, arXiv:2506.19246, 2025.
- Dai L, Zhu W, Quan X, Meng R, Chai S, Wang Y. Deep Probabilistic Modeling of User Behavior for Anomaly Detection via Mixture Density Networks. arXiv preprint, arXiv:2505.08220, 2025.
- Zhan J. MobileNet Compression and Edge Computing Strategy for Low-Latency Monitoring. J Comput Sci Softw Appl, 2024, 4(4).
- Pan R. Deep Regression Approach to Predicting Transmission Time Under Dynamic Network Conditions. J Comput Technol Softw, 2024, 3(8).
- Yang T. Transferable Load Forecasting and Scheduling via Meta-Learned Task Representations. J Comput Technol Softw, 2024, 3(8).
- Xing Y. Bootstrapped structural prompting for analogical reasoning in pretrained language models. Trans Comput Sci Methods, 2024, 4(11).
- Tang T. A meta-learning framework for cross-service elastic scaling in cloud environments. J Comput Technol Softw, 2024, 3(8).
- Lou Y, Liu J, Sheng Y, Wang J, Zhang Y, Ren Y. Addressing Class Imbalance with Probabilistic Graphical Models and Variational Inference. In: Proc 2025 5th Int Conf on Artificial Intelligence and Industrial Technology Applications (AIITA), 2025, pp. 1238–1242. IEEE.
- Deng Y. Transfer Methods for Large Language Models in Low-Resource Text Generation Tasks. J Comput Sci Softw Appl, 2024, 4(6).
- Wei M, Xin H, Qi Y, Xing Y, Ren Y, Yang T. Analyzing data augmentation techniques for contrastive learning in recommender models. 2025.
- Wang X. Medical Entity-Driven Analysis of Insurance Claims Using a Multimodal Transformer Model. J Comput Technol Softw, 2025, 4(3).
- Zhang T, Shao F, Zhang R, Zhuang Y, Yang L. DeepSORT-Driven Visual Tracking Approach for Gesture Recognition in Interactive Systems. arXiv preprint, arXiv:2505.07110, 2025.
- Xing Y, Wang Y, Zhu L. Sequential Recommendation via Time-Aware and Multi-Channel Convolutional User Modeling. Trans Comput Sci Methods, 2025, 5(5).
- Wang X, Liu G, Zhu B, He J, Zheng H, Zhang H. Pre-trained Language Models and Few-shot Learning for Medical Entity Extraction. In: Proc 2025 5th Int Conf on Artificial Intelligence and Industrial Technology Applications (AIITA), 2025, pp. 1243–1247. IEEE.
- Peng Y. Semantic Context Modeling for Fine-Grained Access Control Using Large Language Models. J Comput Technol Softw, 2025, 3(7).
- Lou Y. Capsule Network-Based AI Model for Structured Data Mining with Adaptive Feature Representation. Trans Comput Sci Methods, 2024, 4(9).
- Zhu L, Guo F, Cai G, Ma Y. Structured preference modeling for reinforcement learning-based fine-tuning of large models. J Comput Technol Softw, 2025, 4(4).
Figure 1.
Framework of the overall model.
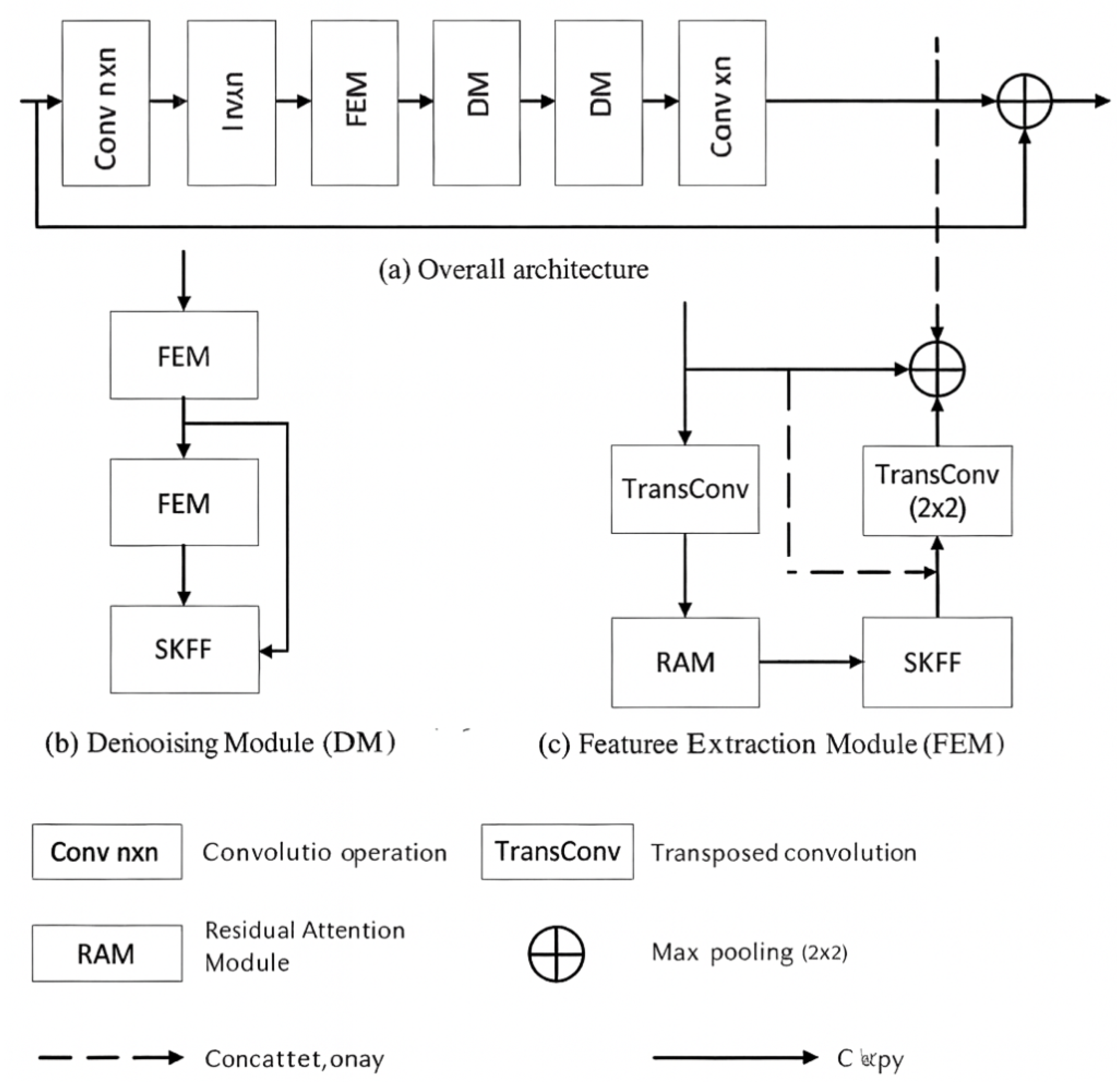
Figure 2.
Residual attention module structure.
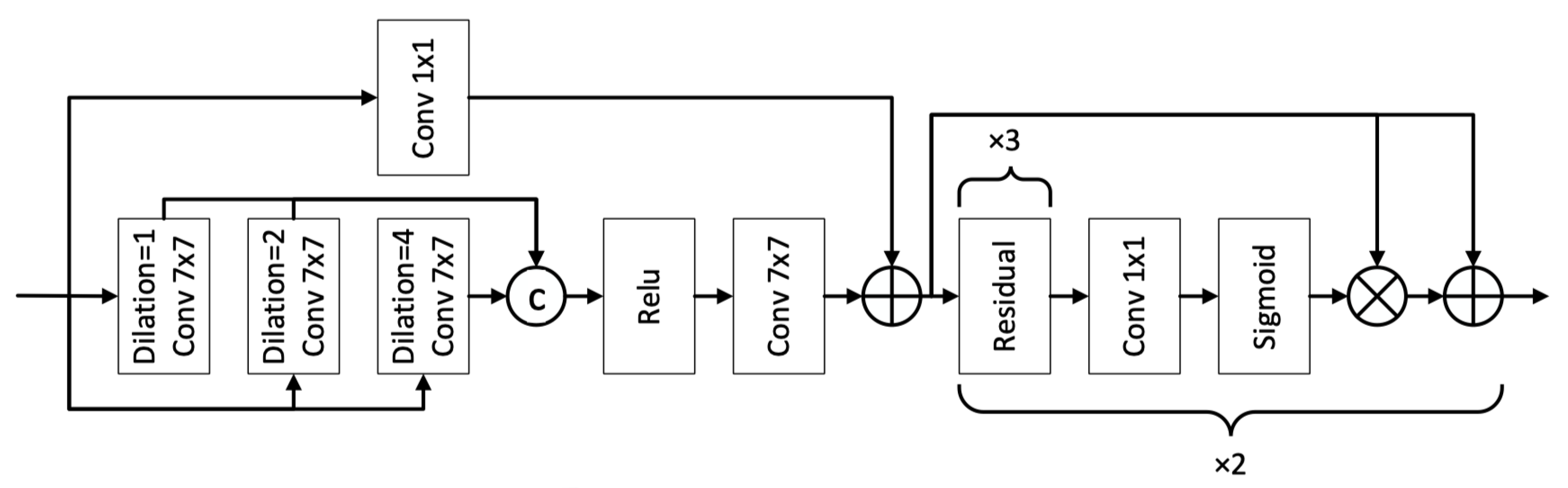
Figure 3.
elective kernel feature fusion module structure.
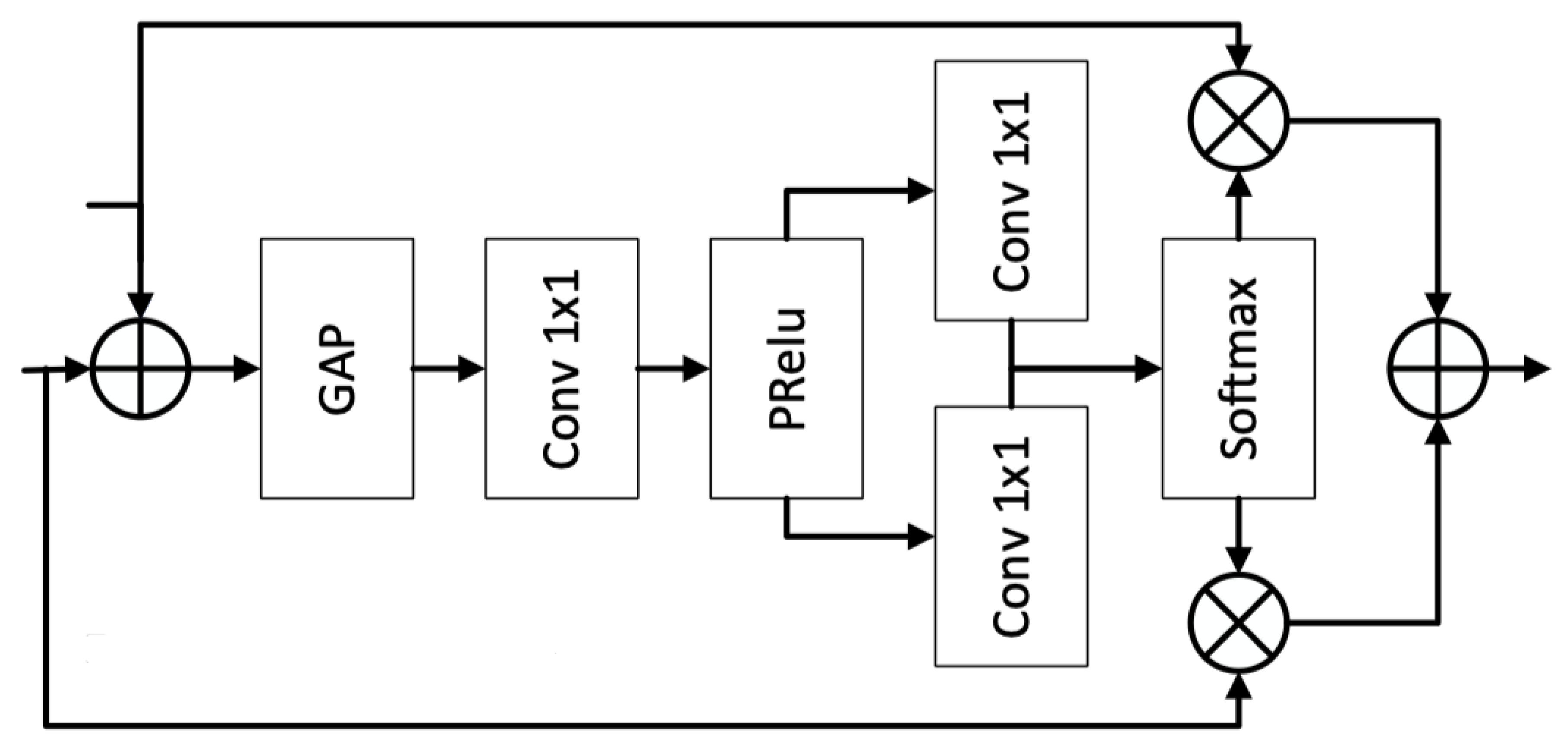
Figure 4.
Visual comparison of denoised images from ablation experiments.
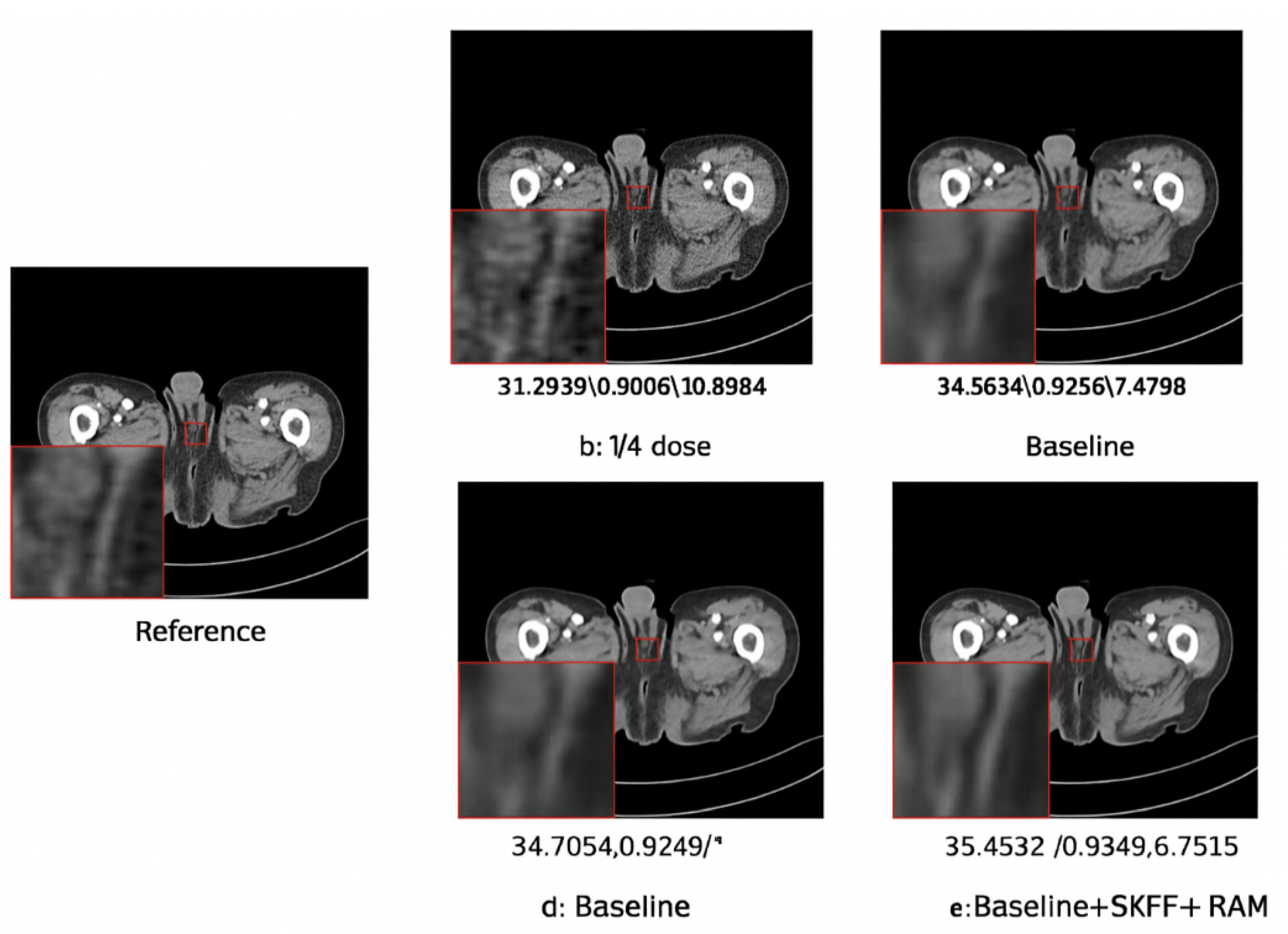
Figure 5.
Visual comparison with advanced algorithms
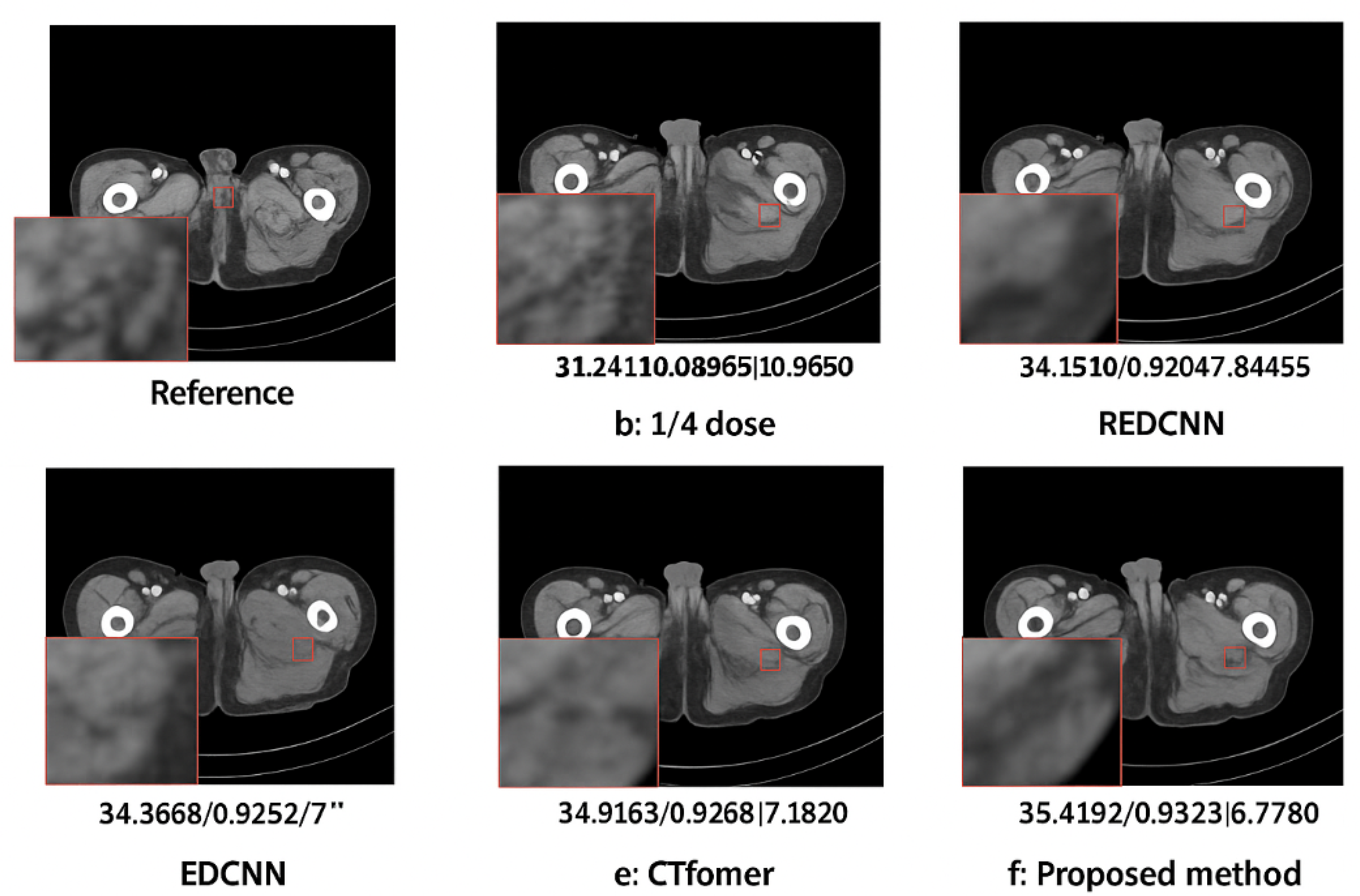

Table 1.
Effect of each algorithm module on image denoising
| Metric | Baseline | Baseline + SKFF | Baseline + SKFF + RAM |
|---|---|---|---|
| PSNR (dB) | |||
| SSIM | |||
| RMSE |
Table 2.
Comparison with advanced algorithms.
| Method | PSNR (dB) | SSIM | RMSE |
|---|---|---|---|
| LDCT | 29.248 ± 2.110 | 0.875 ± 0.036 | 14.241 ± 3.952 |
| REDCNN | 32.329 ± 1.833 | 0.905 ± 0.028 | 9.863 ± 2.044 |
| EDCNN | 32.308 ± 2.139 | 0.907 ± 0.031 | 9.964 ± 2.543 |
| CTformer | 33.080 ± 1.868 | 0.911 ± 0.030 | 9.071 ± 2.054 |
| Proposed Method | 33.618 ± 1.881 | 0.916 ± 0.029 | 8.528 ± 1.938 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



