
Submitted:
16 July 2025
Posted:
17 July 2025
You are already at the latest version
Abstract
This study proposes a conceptual framework to redefine the role of business analysts (BAs) in machine learning (ML)-driven digital transformation initiatives, focusing on the public sector. Through a fictional scenario, the study extends the 4S model — Strategist, Synthesizer, Facilitator, and Spokesperson — to illustrate how BAs can guide organizations in adopting and integrating ML technologies effectively.Unlike traditional views that see BAs mainly as technical mediators, this framework positions them as strategic actors who bridge organizational goals and advanced analytics capabilities, facilitate cross-functional collaboration, and support ethical and effective ML deployment.Rather than presenting empirical results, this conceptual paper synthesizes existing literature to offer a unified perspective on the evolving BA role. The proposed framework aligns with the "Digital Transformation: Strategies and Technologies," "e‑Government," and "AI and Machine Learning" tracks, offering both theoretical contributions and practical implications for practitioners and policymakers.
Keywords:
crowdfunding
; machine learning
; classification
; prediction
1. Introduction
Crowdfunding has evolved into a revolutionary funding method that enables entrepreneurs, along with small businesses, to obtain funding directly from public support through digital crowdfunding networks. The internet-based gathering of numerous small financial deposits from crowds represents crowdfunding, which operates without conventional financial institutions and supports multiple funding structures from sponsorship to lending and equity fundraising [1]. People across the world increasingly choose reward-based crowdfunding platforms through Kickstarter because of their easy accessibility combined with their entrepreneurial benefits[2]. The quick development and growing attraction of crowdfunding face persistent operational challenges that make its processes hard to predict. A significant number of crowdfunding projects miss their funding goals because of information disparities among donors and insufficient social networks and poor marketing efforts, and substandard project demonstrations [3].
Research focusing on crowdfunding success prediction shows increasing importance because it determines the understanding of effective campaigns. The success of crowdfunding initiatives depends on social networks, together with campaign quality and presentation style, and human capital attributes of project creators [3,4].
Recent literature adopts machine learning (ML) methods for dealing with the challenges of success prediction. The programming system of ML enables the detection of challenging hidden patterns of interaction beyond standard linear predictions, which traditional regression algorithms cannot identify [2]. Ensemble methods and neural networks, along with deep learning architectures, use large-scale campaign data to analyze complex relationships between campaign features, thereby improving success predictions [3,5].
The value of crowdfunding platforms grew more significant during economic difficulties, especially during the COVID-19 pandemic. Crowdfunding plays an essential role in maintaining the sustainability of small and medium enterprises (SMEs) in emerging markets, including Indonesia and Malaysia, together with Turkey, since these countries face limited access to conventional capital resources [1].
The online crowdfunding method enables businesses along with entrepreneurs, and individuals to obtain backing from various funding sources through digital channels. The funding method has become popular because it is easily accessible and efficient, and friendly toward innovation. Some of the numerous crowdfunding campaigns fail to meet their funding targets because their success remains very hard to predict. Sophisticated predictive models are required to analyze campaign content along with social network engagement and funding target success because these elements create complexity in crowdfunding outcomes.
The crowdfunding platforms Kickstarter, Indiegogo, and GoFundMe establish bases for multiple successful campaign launches, though many initiatives fall short of their financial objectives. According to [4] reward structure, backer engagement, and campaign updates, together with linguistic sentiment, play a key role in influencing funding performance. Market conditions, together with economic aspects, play an essential role in campaign funding outcomes, while investor behavior patterns become particularly noticeable during financial turmoil [6]. Emerging markets have found crowdfunding to serve as a valuable funding option that provides relief from economic limitations for their businesses [7].
Machine learning (ML) is now extensively employed by organizations to improve their crowdfunding success predictions because of growing demands to use data-driven decision-making strategies. The analysis of extensive datasets through ML models reveals behavioral patterns and helps evaluate contributors’ actions while enabling optimization of fundraising strategies. The statistical methods that exist today have their benefits, yet they cannot recognize the complex non-linear patterns that drive crowdfunding since these patterns lie hidden in their dynamics. The predictive power of ML techniques is superior compared to traditional models because it employs decision trees and support vector machines (SVM), and deep learning architectures, including recurrent neural networks (RNN) and transformers (BERT) [8].
The field of crowdfunding has been enhanced by Multiple research teams who examined three distinct ML applications involving campaign description sentiment evaluation with feature extraction optimization, and automated fraud discoveries [9,10] . The research field lacks comprehensive studies that evaluate how various ML approaches perform regarding crowdfunding success prediction. The evaluation process of ML models delivers essential information about funding strategy optimization to both campaign developers and platform administrators, and investors through performance-driven suggestions.
An analytical examination of different ML techniques used for crowdfunding success forecasting represents the core purpose of this research. The research explores both traditional ML classifiers and ensemble models, and deep learning techniques for their ability to predict campaign success. This investigation undertakes an evaluation of the interpretability aspects for these models while it addresses questions regarding AI-driven decision-making, trust, and transparency. The analysis benefits existing research about AI systems in financial technology (FinTech) and crowdfunding analytics through its use of large datasets with strict evaluation criteria.
Section 2 of this paper begins with a review of related research about crowdfunding success forecasts before discussing essential research approaches and results. The comparative framework of this study includes an examination of the dataset alongside the selection criteria of features and implementation strategies of ML models in Section 3. The paper continues with its results and analysis section before exploring implications and future research directions in the subsequent parts. Finally, Section 4 concludes the study.
This study addresses the gap in localized machine learning applications by evaluating 24 ML algorithms on a real-world dataset of crowdfunding campaigns from Turkey. While the dataset is country-specific, the methodology draws from internationally validated models and evaluation metrics. This hybrid approach enables both context-specific insights and broader methodological relevance, contributing to the literature on crowdfunding analytics and entrepreneurial finance in emerging markets.
1.1. Research Questions
The study explores various research questions in Turkish crowdfunding analytics and financial technology that it intends to answer:
- What machine learning algorithms show the most successful accuracy when predicting Turkish crowdfunding campaign results?
- What performance metrics reveal about the outcome of ensemble models against traditional and deep learning classifiers when measuring accuracy along with precision, recall, and F1-score?
- The analysis explores which features create the most impact on crowdfunding success prediction within Turkish crowdfunding campaigns and their influence on model’s predictive outcome.
- Does the development of a decision support system through machine learning provide enough effectiveness to help Turkish crowdfunding platforms in their campaign success forecasting efforts?
- The impact of unsuccessful campaign rates on model assessment results needs evaluation, and there are proven methods to minimize these adverse effects.
1.2. Contributions
The research delivers important point-based contributions to both crowdfunding analytics research and financial technology development:
- The research implements a complete examination of 24 machine learning prediction algorithms used for crowdfunding campaign success, which incorporates traditional classifiers alongside ensemble techniques and deep learning architectures.
- The authors apply their developed models to 1628 Turkish crowdfunding campaigns for a first-hand assessment of machine learning effectiveness in this space.
- The research determines which campaign determining factors drive success most effectively in Turkish crowdfunding through analysis of social engagement metrics, campaign acceptability levels and funding requirements.
- The paper introduces a decision support framework that unites SVM and CatBoost and Gradient Boosting with confidence interval mechanisms for operational readiness.
- The research delivers essential knowledge about model interpretability in addition to handling imbalanced data and improving performance, which benefits academic research and practical applications in FinTech.
2. Literature Review
To provide a comprehensive understanding of the existing research on crowdfunding in Turkey, a systematic literature review was conducted using the SCOPUS database. The initial query, TITLE-ABS-KEY (crowdfunding), retrieved a broad range of studies discussing various aspects of crowdfunding. To focus specifically on research related to Turkey, the search was refined by applying an affiliation country filter: TITLE-ABS-KEY (crowdfunding) AND (LIMIT-TO (AFFILCOUNTRY, “Turkey”)). This refinement ensured that only studies affiliated with institutions in Turkey were considered. Figure 1 and Figure 2 show documents by year and documents by type, respectively. Further filtering to include only conference papers and journal articles resulted in a final dataset of 37 relevant publications. These selected studies serve as the foundation for analyzing the current academic discourse on crowdfunding within the Turkish context. Figure 3 shows the documents by subject area that were included in the literature review section.
Scientists have extensively researched crowdfunding throughout the finance and entrepreneurship domains. The success of crowdfunding depends on four specific elements those elements are campaign duration, funding goal, social media engagement, and project description quality. Numerous studies show that analyzing text content helps forecast campaign success because backers’ perceptions emerge from descriptions and status updates [8].
The research investigates how social and economic influences affect crowdfunding, along with other variables. Crowdfunding platforms specifically designed for Qatar include supportive mentorship programs that tackle regional challenges to entrepreneurship [7]. Investigations into sustainability-based crowdfunding have produced results related to renewable energy financing in addition to environmental funding systems [11]. Researchers have conducted studies on debt-based crowdfunding in specific domains, such as wearable technology, where in [12] introduced this financing model as a possible solution. The examination of social capital led to discoveries about crowdfunding platforms, which demonstrate that strong social networks combined with innovation performance drive successful fund solicitations [13].
Due to recent innovations in ML, the precision of crowdfunding success prediction models has experienced considerable improvement. Researchers have used three supervised learning methods, which include support vector machines (SVM), decision trees, and gradient boosting machines (GBM) for forecasting campaign success [8]. BERT-type transformer systems show an exceptional ability to evaluate crowdfunding texts and forecast campaign outcomes according to [8]. Research about NLP focuses on how it extracts features by studying sentiment and linguistic characteristics in campaign advertising materials. ML models working with sentiment analysis systems identify previously hidden patterns in text-based data to deliver better predictions, according to research findings [9]. Hybrid deep learning systems, along with traditional classifiers, constitute proposed models for enhancing both interpretability and overall performance. Blockchains represent an approved solution for making crowdfunding decisions more transparent [14]. The implementation of AI-powered personalization methods is suggested for both improved campaign visibility as well as supporter engagement in creative crowdfunding [15]. Research on feature selection in crowdfunding makes use of machine learning methods to discover which variables influence project success the most [10].
The assessment of different ML models for crowdfunding success prediction exists as an individual study, but overall comparative analysis remains limited. Research has performed side-by-side tests comparing traditional ML approaches with deep learning models to demonstrate their different advantages and disadvantages regarding interpretation and prediction accuracy [8]. There is still a lack in the number of studies to examine standardized metrics across numerous ML algorithms within the same evaluation framework. The research intends to address this gap in knowledge by executing a systematic evaluation of different ML models for crowdfunding success prediction. Studies about ML implementation for Islamic finance crowdfunding in the Middle East [16] demonstrate the necessity for localized ML strategies. The research investigates Islamic fintech functions for next-generation funding through Shariah-compliant modes like agricultural crowdfunding based on Islam [17].
The advances in ML-based crowdfunding prediction have not solved all existing challenges. The application of ML in crowdfunding platforms needs further development through research on understandable algorithms and combined modeling strategies, and streaming prediction systems.
The research expands previous work by executing a thorough review of various ML algorithms and evaluating their capability to forecast crowdfunding outcomes. A dataset consisting of Turkish crowdfunding campaigns enables the delivery of practical recommendations for creators and investors while also assisting platform administrators.
A word cloud analysis operation examined primary research subjects through extracted keywords found in selected articles. Figure 4 demonstrates that crowdfunding stands as the dominant keyword, followed by finance and investment, which then leads to innovation then success followed by blockchain. The current studies about crowdfunding concentrate their attention on financial concepts alongside investment operations with blockchain technology and innovation development.
The terms “machine learning”, along with “artificial intelligence” and “predictive modeling”, have minimal occurrence throughout the studied articles. The literature shows scarce investigation of machine learning-based success prediction for crowdfunding despite numerous studies in various settings and the Turkish market.
The research project analyzes Machine Learning methods for forecasting crowdfunding success in Turkey because there is little existing information on this topic. The systematic application of machine learning techniques within this research will lead to fresh perspectives about crowdfunding data-driven decision-making, thus achieving better predictions while developing stronger campaign success approaches.
Table 1 demonstrates how modern crowdfunding prediction and financial modeling research depend on diverse machine-learning techniques that improve forecasting precision. The authors of [18] developed borrower behavior predictions in peer-to-peer lending through Evolving Connectionist System (ECoS) and Neural Networks, which produced an exceptional Mean Absolute Percentage Error (MAPE) result. The research of[8] compared Kickstarter campaign predictions between BERT, FastText, LSTM, and Gradient Boosting Machines (GBM), with BERT combined with LSTM obtaining the highest accuracy, as it demonstrated the strengths of NLP-based models in crowdfunding analytics.
The research of [19] analyzed 3,985 Kickstarter campaigns to show how stretch goals and transparent communication practices result in better crowdfunding outcomes. [20] created autonomous reward-based funding through Ethereum-based smart contracts to show how DeFi mechanisms improve financing security and automation during crowdfunding activities.

Table 1.
Articles included in the literature review.
| Article | Domain | Dataset | Methods & Techniques |
|---|---|---|---|
| [18] | Finance | P2P lending data from Indonesia’ s Financial Services Authority (OJK) | Evolving Connectionist System (ECoS), Neural Networks |
| [8] | Prediction /text mining | Kickstarter campaign blurbs | BERT, FastText, LSTM, Gradient Boosting Machine (GBM) |
| [21] | Finance | Conceptual analysis of sustainability metaphors from literature and policy documents | Qualitative content analysis, theoretical framework on environmental metaphors |
| [19] | Finance | 3,985 campaigns from Kickstarter | Empirical analysis, statistical regression |
| [20] | Crypto currency | Ethereum blockchain-based deployment and testing dataset | Smart contract implementation using Solidity, Ethereum blockchain testing, decentralized voting and funding mechanisms |
| [22] | Finance | Equity-based crowdfunding platforms | General survey model, document analysis |
| [23] | Renewable Energy | Microgrid project investments data | q-rung orthopair fuzzy sets (q-ROFSs), Multi-Stepwise Weight Assessment Ratio Analysis (M-SWARA), DEMATEL |
| [24] | Finance & Investment | Prosper Marketplace peer-to-peer lending data, Lottery jackpot data | Natural experiments, statistical analysis |
| [25] | Real estate | Case studies of real estate tokenization projects, legal frameworks, and blockchain implementations | Legal analysis, blockchain security token offering (STO) framework, smart contract evaluation |
| [9] | Crowdfunding & Alternative Finance | Kickstarter, Metacritic, Steamspy | Regression analysis |
| [7] | Islamic Finance | Stakeholder interviews in Qatar | Case study, qualitative analysis |
| [26] | Economy | Hand-collected reward-based crowdfunding data from Turkey (2013–2020) | Binary logistic regression, ordinary least squares (OLS) model |
| [11] | Energy | Renewable energy projects in Turkey | Comparative financial analysis, policy review |
| [27] | Management | Qualitative in-depth interviews and quantitative survey data from 360 entrepreneurs in Turkey | Mixed-method research (qualitative interviews + quantitative survey analysis) |
| [14] | Blockchain | Marine ranching projects data | Multi-level programming, backward induction method |
| [16] | Islamic Finance | 319 papers published in IMEFM from 2008-2019 | Bibliometric analysis, citation mapping |
| [28] | High Education Finance | Survey data from Turkish universities and alumni | Content analysis, data triangulation, behavioral economics model |
| [15] | Crowdfunding Success Factors | Crowdfunding projects from Turkey and the US | Signaling Theory, Social Network Theory, logistic regression |
| [29] | Finance | Public and private sector finance reports, biodiversity investment case studies | Review of biodiversity finance methodologies, investment gap analysis, global finance strategies |
| [6] | Crowdfunding | Case studies of five BIOFIN crowdfunding campaigns in marine and coastal protected areas (Belize, Costa Rica, Ecuador, Philippines, Thailand) | Comparative analysis of crowdfunding campaigns, economic impact assessment, review of finance strategies |
| [17] | Islamic Finance | Conceptual analysis of Islamic crowdfunding models, financial system comparison, regulatory challenges | Theoretical framework analysis, comparative study of Islamic vs. conventional crowdfunding, examination of Islamic P2P models |
| [30] | Turism | 49 ICOs from tourism industry (2017-2021) | Logistic regression analysis |
| [31] | Clustering, Text mining | 7059 publications on crowdsourcing (2006—2019) | Scientometric analysis, text mining |
| [32] | Digital Platforms | Analysis of major online platforms (Uber, Airbnb, WeWork, Kickstarter) | Economic impact assessment, policy review |
| [13] | Economy | Survey data from emerging markets | Quantitative modeling, mediation analysis |
| [33] | Islamic Finance | Islamic fintech case studies | Comparative analysis, case study approach |
| [34] | Agriculture, Islamic Finance | Afghanistan agricultural finance sector | Triangulation approach (library research, interviews, document review) |
| [35] | Text mining, Clustering | 8021 crowdfunding projects (2009—2018) | Text mining, clustering, natural language processing (NLP) |
| [10] | ML, Feature selection | Crowdfunding projects from Fongogo (Turkey) | Feature selection (Pearson correlation, chi-square, Recursive Feature Elimination) |
| [36] | Clean Energy | Fintech-based clean energy investment projects | Pythagorean fuzzy DEMATEL, TOPSIS, VIKOR |
| [37] | Media | Interviews with Turkish documentary producers | Ethnographic research, narrative analysis |
| [12] | Wearable Technology | Case studies of wearable technology crowdfunding projects | Debt financing model analysis, incentive problem identification |
| [38] | Health | Philanthropy-based crowdfunding initiatives | Qualitative analysis, case studies |
| [39] | ML, prediction | Crowdfunding data from Turkish platforms (Fongogo, Fonbulucu, Crowdfon, Arıkovanı, Ideanest, Buluşum) | Machine learning (Random Forest, Decision Trees, SVM), web scraping |
| [40] | Management | Exploratory research on existing digital platforms and collaboration mechanisms | Conceptual framework development, exploratory research, innovation ecosystem analysis |
| [41] | Crowdfunding awareness | Survey data from university students in Istanbul | Quantitative research, logit regression models |
These research findings establish machine learning approaches with NLP text analysis and smart contract implementations on blockchain to function as essential framework elements for crowdfunding security enhancement and success estimation. The research landscape currently shows a significant absence of studies on Turkey’s crowdfunding environment and its application of machine learning for predictive analyses. This research will analyze the performance of machine learning models for crowdfunding success prediction in the Turkish market to fulfill the current research limitation in this area.
The examined research articles illustrate the complete classification of crowdfunding studies, which extends through financial exploration and prediction modeling and blockchain applications, as well as empirical campaign examination. The field of crowdfunding research has evolved in complexity, which is why some studies examine conceptual models alongside statistical models, while others focus on improving crowdfunded success estimation through machine learning techniques. Executive management has turned its focus to blockchain and decentralized finance (DeFi) as they introduce safe automatic systems that reshape crowdfunding mechanisms. Predictive modeling together with campaign optimization has brought progress to crowdfunding practices, but these advancements exclude substantial Turkish market applications of machine learning methods. The study aims to fill the current knowledge gap by analyzing machine learning algorithms for crowdfunding success prediction in Turkey to create useful information that assists researchers and practitioners in the field.
3. Materials and Methods
This section presents background details on the key components of the dataset used, a description and overview of various machine learning algorithms, performance evaluation metrics, and the proposed approach.
3.1. Data Description
This study employs the Turkish Crowdfunding Startups dataset, published by the UCI Machine Learning Repository on July 2, 2024 [10]. The dataset consists of 1,628 crowdfunding campaigns launched in Turkey and includes 38 features capturing the financial, temporal, categorical, and textual characteristics of each campaign. Feature types span real, categorical, and integer values, and the dataset contains no missing data, making it suitable for direct use in machine-learning workflows.
Key features include Project Title and Description (textual fields), Target Amount and Raised, Amount (numeric, monetary values), Campaign Duration (in days), Number of Backers, Funding Type (reward-based, donation, equity, etc.), Project Category (e.g., technology, arts, health), Location, Launch Date and Deadline. The dependent variable for classification tasks is defined as campaign success, which we derive by setting a binary label: 1 (Successful) if and 0 (Unsuccessful) otherwise. Figure 5 shows a snapshot of the dataset, while Figure 6 shows the data description.
Data Preprocessing
Text cleaning and tokenization for project descriptions and titles, including removal of stop words and punctuation. One-hot encoding of categorical features such as funding type and project category. Min-max normalization of numerical features like raised amount and campaign duration to ensure model convergence. Date features were transformed to numeric values, such as the day of the week and campaign month. Synthetic features such as funding ratio (raised_amount / target_amount) and average funding per backer were engineered to improve model performance.
The dataset’s diversity in feature types and its relevance to real-world Turkish entrepreneurial activity provide a robust foundation for building and comparing machine learning models for crowdfunding success prediction.
The correlation coefficients of feature graphs help to visualize which features are highly correlated, which features are independent of each other, and potential multicollinearity in the dataset. A high correlation between two features means that one feature can be used interchangeably with the other, so these cases can be taken into account when training the model. Having highly correlated features is undesirable as it may cause the model to overfit. The correlation graph of the data used in this study is shown in Figure 7.
In machine learning, feature importance is a concept used to determine how effective each feature is in a model’s predictions. The feature importance graph allows you to visualize the contribution of each feature to the performance of the model. In this study, the feature importance values of the model using Random Forest Classifier are shown in Figure 8.
The heatmap illustration demonstrates how the crowdfunding dataset features maintain several robust relationships with each other. “sm_sayisi” (network of social media platforms) demonstrates a high correlation relationship with both “sosyal_medya” (social media presence) and “sm_takipci” (social media followers) with a correlation coefficient value of 0.82. The presence of a high correlation between these features indicates they provide redundant information on how widely campaigns spread through social channels. A correlation value of 0.74 exists between “toplanan_tutar” (collected amount) and “destek_oranı” (support rate) showing that successful funding relies heavily on total contributions. The number of project supporters called “destekci_sayisi” demonstrates a 0.41 correlation strength with actual collected donations known as “toplanan_tutar” that underscores the essential rank of supporter engagement. The success status variable named “basari_durumu” demonstrates a moderate 0.24 level of beneficial relationship with the “destek_oranı” response rate making it important for outcome prediction. The discovered relationships enable researchers to determine significant features among inputs and reduce pointless training components.
From Figure 8, we can see that the most important features that can affect the success of any crowdfunding campaign are support rate, collected amount, number of supporters, video length, updates, and target amount. A translation of attribute names from Turkish to English is declared in Table 2.
The selected dataset is imbalanced; 77% of the instances belong to the Successful class and 23% belong to the Unsuccessful class. The distribution of the two classes is shown in Figure 9.
3.2. Machine Learning Methods
The machine learning methods used in this study, their description, parameters, advantages, and disadvantages are given in Table 3.
A decision support system has been programmed in a Python environment using the most widely used algorithms in the literature and the widely used algorithms in MLLib, Sklearn, etc. libraries. Different parameters of these models have been determined experimentally in the working environment. It has been developed using Python 3 on Windows 11 operating system with an Intel i7 and 64 GB RAM hardware.
In this study, the key metrics used to evaluate the effectiveness and performance of machine learning algorithms include confusion matrix, accuracy, precision, recall, F1 score, and confidence interval. These metrics are critical to measuring and improving the success of algorithms.
Confusion Matrix: The confusion matrix is a matrix that shows in detail how accurately and inaccurately the model predicts the true and predicted classes in classification problems. This matrix contains four different terms: true positive, false positive, true negative and false negative. In our study, the confusion matrices for the Gradient Boost and Ada Boost methods which demonstrated the highest performance, are provided in Figure 10.
Accuracy: Accuracy is a metric that expresses the ratio of correct predictions of a classification model to the total number of predictions. In simple terms, it is the percentage of correct predictions. The accuracy performance of a model is measured by the following equation (1).
Precision: Precision is a metric that indicates how many of the samples predicted to be positive by a classification model are actually positive. This helps to assess how often false positive predictions are made. For example, in the application of a machine learning model that predicts a disease, precision is used to answer the question “How many of those predicted to be patients are actually patients? The precision metric of a model is measured by the following equation (2).
Recall (Sensitivity): Sensitivity is an important metric for evaluating the performance of classification models and measuring the impact of false negative predictions. In other words, sensitivity is a metric that measures how accurately a classification model detects true positives. It shows how many of the true positives are not missed. Sensitivity is also referred to as “recall” or “true positive rate (TPR)”. The sensitivity metric of a model is measured by the following equation (3).
F1 Score: The F1 score is an important metric used to evaluate the performance of a classification model and to measure the balance between precision and recall. The F1 score is the harmonic mean of the precision and recall metrics of a classification model. This metric provides a balance between false positives and false negatives in the model. By considering both precision and recall as shown in equation (4), the F1 score provides a comprehensive assessment of the model’s performance.
Confidence Interval: This represents the range of possible values for a measurement, typically accuracy. It can be used to determine that the performance of the model is within a certain range. This interval includes the values at which the measurement is found at a given confidence level (e.g., measured at a 1.000–0.882 confidence level with SVM in this study). The confidence interval provides flexibility in estimating the exact value of a measurement and can help assess whether the model’s performance is within a certain range. Mathematically, a confidence interval for a measurement can be expressed as equation (5).
Confidence Interval = [Lower Bound, Upper Bound]
4. Experimental Results
The dataset was split into training and testing sets randomly for machine learning, using the train_test_split function of the Python environment. The conventional split operation involves using 70% of the data for training and 30% for testing.
As a result of numerous experimental studies, 24 different methods were tested for the proposed model, and accuracy metrics ranging from 8% to 99.4% were observed, as shown in Figure 11. Among these performances, Gaussian Mixture showed a very low and insufficient performance, while others, such as Gradient Boosting, Ada Boosting, and Cat Boost, showed a significantly higher performance. The main objective of this research involved enhancing the performance of machine learning models that already demonstrated robust predictions instead of working on less accurate models. We set the purpose to select and optimize the most accurate predictive model, which will serve as part of an operational decision support tool for crowdfunding platforms. The research team devoted extra effort towards bettering the Support Vector Machine’s (SVM) performance because this algorithm showed top-level results across measurement criteria. SVM model enhancement was developed by refining its effectiveness, although Gradient Boosting alongside AdaBoost and CatBoost consistently reached an accuracy at 99.4%. The study focused its strategic direction on deploying practical solutions while giving less attention to the comprehensive optimization of less promising models.
While the lowest performance was 8% for Gaussian Mixture, the highest accuracy was 99.4% for Gradient Boosting and Ada Boosting methods. Examining these performances, it is clear that machine learning algorithms can be used as decision support systems for crowdfunding success prediction, with some models showing high accuracy prediction capability. Due to their high predictive accuracies, the use of Gradient Boosting, Ada methods, and Cat Boost is recommended for the most effective prediction of crowdfunding success prediction.
Results with other performance metrics are given in Table 4. In Table 4, accuracy, confusion matrices, precision, recall, F1-score, and confidence interval information have been provided for all models.
All performance metrics indicate that the SVM algorithm is the best-performing method, while the lowest values are observed for the MLP method. It is evident that the algorithms may not be able to adequately perform the learning process and select decision boundaries appropriately based on the type of problem and classification capability. Therefore, one of the necessary steps recommended is to increase the training data. The Gaussian Mixture model is removed from the performance table because it expects 3 classes of output and is removed from Table 4.
5. Conclusions and Discussion
The purpose of this study entailed evaluating artificial intelligence algorithms developed from crowdfunding campaigns conducted throughout Turkey during 2011-2021, which amounted to 1,628 entries. Standard evaluation metrics determined the assessment outcomes of different machine learning models, which worked on training-test divided data.
Twenty-four machine learning algorithms were included in the testing phase. The accuracy scores varied between 8.6% for Gaussian Mixture and 99.4% for Gradient Boosting, as well as Ada and Cat Boost models. The predictive abilities of MLP and Gaussian Process were insufficient, but Random Forest, together with CatBoost and SVM, demonstrated consistently high-performance ratings. Gradient Boosting produced the same accuracy score of 99.4% as AdaBoost. Tree-based ensemble methods prove to be highly effective for predicting crowdfunding success based on the obtained experimental outcomes.
The study concentrated on maximizing the performance of superior models and assessing their effectiveness while disregarding the enhancement of inadequate methods. The team focused on selecting the most dependable algorithm, which will become part of an actual crowdfunding platform decision support system in the future. Both SVM and Gradient Boosting demonstrated outstanding results that make them suitable for practical FinTech deployments.
Predictive information generated through machine learning systems helps developers and platform staff create superior funding plans and distribute marketing budgets more effectively. Among the predictive elements modelled by these approaches are support rate metrics alongside funding goal achievements and social media involvement, and project description extent.
The proposed research findings can establish foundational input for future studies about crowdfunding success prediction.
Author Contributions
The author solely conceived the idea, developed the methodology, conducted the analysis, and wrote the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
The dataset used in this study is publicly available at the UCI Machine Learning Repository: https://archive.ics.uci.edu/dataset/1025/turkish+crowdfunding+startups.
Conflicts of Interest
The Author Declares That There Are No Competing Interests.
References
- [1] A. Marina, S. Imam Wahjono, S.-F. Fam, and I. Rasulong, “Crowdfunding to Finance SMEs: New Model After Pandemic Disease,” Sustainability Science and Resources, vol. 5, pp. 1–19, 2023. [CrossRef]
- [2] R. Elitzur, N. Katz, P. Muttath, and D. Soberman, “The power of machine learning methods to predict crowdfunding success: Accounting for complex relationships efficiently,” Journal of Business Venturing Design, vol. 3, p. 100022, Dec. 2024. [CrossRef]
- [3] J. Y. Yeh and C. H. Chen, “A machine learning approach to predict the success of crowdfunding fintech project,” Journal of Enterprise Information Management, vol. 35, no. 6, pp. 1678–1696, 2022. [CrossRef]
- [4] E. Mollick, “The dynamics of crowdfunding: An exploratory study,” J Bus Ventur, vol. 29, no. 1, pp. 1–16, 2014. [CrossRef]
- [5] M. S. Oduro, H. Yu, and H. Huang, “Predicting the Entrepreneurial Success of Crowdfunding Campaigns Using Model-Based Machine Learning Methods,” International Journal of Crowd Science, vol. 6, no. 1, pp. 7–16, 2022. [CrossRef]
- [6] A. Seidl, T. Cumming, M. Arlaud, C. Crossett, and O. van den Heuvel, “Investing in the wealth of nature through biodiversity and ecosystem service finance solutions,” Ecosyst Serv, vol. 66, no. November 2023, p. 101601, 2024. [CrossRef]
- [7] A. Al-Mulla, I. Ari, and M. Koç, “Sustainable financing for entrepreneurs: Case study in designing a crowdfunding platform tailored for Qatar,” Digital Business, vol. 2, no. 2, p. 100032, 2022. [CrossRef]
- [8] H. Gunduz, “Comparative analysis of BERT and FastText representations on crowdfunding campaign success prediction,” PeerJ Comput Sci, vol. 10, 2024. [CrossRef]
- [9] O. Aygoren and S. Koch, “Community support or funding amount: Actual contribution of reward-based crowdfunding to market success of video game projects on kickstarter,” Sustainability (Switzerland), vol. 13, no. 16, 2021. [CrossRef]
- [10] M. Kilinc and C. Aydin, “Feature selection for Turkish Crowdfunding projects with using filtering and wrapping methods,” Electron Commer Res Appl, vol. 62, no. June, p. 101340, 2023. [CrossRef]
- [11] S. M. Altunkaya and M. Özcan, “Yenilenebilir Enerji Yatırımlarının Finansmanında Kullanılabilecek Yeni Nesil Finansman Mekanizmaları,” no. November 2020, pp. 35–43, 2021.
- [12] F. Tanrisever and K. A. Wismans-Voorbraak, “Crowdfunding for financing wearable technologies,” Proceedings of the Annual Hawaii International Conference on System Sciences, vol. 2016-March, pp. 1800–1807, 2016. [CrossRef]
- [13] Z. Yousaf, O. Shakaki, N. Isac, A. Cretu, and A. Hrebenciuc, “Towards Crowdfunding Performance through Crowdfunding Digital Platforms: Investigation of Social Capital and Innovation Performance in Emerging Economies,” Sustainability (Switzerland), vol. 14, no. 15, 2022. [CrossRef]
- [14] X. Wan, Z. Teng, Q. Li, and M. Deveci, “Blockchain technology empowers the crowdfunding decision-making of marine ranching,” Expert Syst Appl, vol. 221, no. December 2022, p. 119685, 2023. [CrossRef]
- [15] B. Akyildiz, S. Metin-Camgöz, and K. B. Atici, “An Investigation on Factors Affecting Crowdfunding Project Success,” Sosyoekonomi, vol. 29, no. 50, pp. 521–545, 2021. [CrossRef]
- [16] M. Özdemir and M. Selçuk, “A bibliometric analysis of the International Journal of Islamic and Middle Eastern Finance and Management,” International Journal of Islamic and Middle Eastern Finance and Management, vol. 14, no. 4, pp. 767–791, 2021. [CrossRef]
- [17] B. Saiti, M. H. Musito, and E. Yucel, “Islamic Crowdfunding: Fundamentals, Developments and Challenges,” Islamic Quarterly, vol. 62, no. 3, pp. 469–485, 2018.
- [18] Al-Khowarizmi, M. J. Watts, S. Efendi, and A. A. Kamil, “Financial technology forecasting using an evolving connectionist system for lenders and borrowers: ecosystem behavior,” IAES International Journal of Artificial Intelligence, vol. 13, no. 2, pp. 2386–2394, 2024. [CrossRef]
- [19] B. Yasar, I. Sevilay Yılmaz, N. Hatipoğlu, and A. Salih, “Stretching the success in reward-based crowdfunding,” J Bus Res, vol. 152, no. July, pp. 205–220, 2022. [CrossRef]
- [20] A. Alimoglu and C. Ozturan, “Design of a smart contract based autonomous organization for sustainable software,” Proceedings—13th IEEE International Conference on eScience, eScience 2017, pp. 471–476, 2017. [CrossRef]
- [21] A. Napari, R. Ozcan, and A. U. I. Khan, “the Language of Sustainability: Exploring the Implications of Metaphors on Environmental Action and Finance,” Appl Ecol Environ Res, vol. 21, no. 5, pp. 4653–4675, 2023. [CrossRef]
- [22] V. Altundal, “Can equity-based crowdfunding be a fast and effective financing model for early-stage startups?,” Journal of the International Council for Small Business, vol. 5, no. 3, pp. 304–329, 2024. [CrossRef]
- [23] X. Wu, H. Dinçer, and S. Yüksel, “Analysis of crowdfunding platforms for microgrid project investors via a q-rung orthopair fuzzy hybrid decision-making approach,” Financial Innovation, vol. 8, no. 1, 2022. [CrossRef]
- [24] T. Demir, A. Mohammadi, and K. Shafi, “Crowdfunding as gambling: Evidence from repeated natural experiments,” Journal of Corporate Finance, vol. 77, no. August 2019, p. 101905, 2022. [CrossRef]
- [25] G. Avci and Y. O. Erzurumlu, “Blockchain tokenization of real estate investment: a security token offering procedure and legal design proposal,” Journal of Property Research, vol. 40, no. 2, pp. 188–207, 2023. [CrossRef]
- [26] O. Ekici and Y. Aytürk, “The role of consumer confidence and inflation in crowdfunding success,” International Journal of Entrepreneurial Venturing, vol. 15, no. 4, pp. 295–316, 2023.
- [27] M. Demiray, S. Burnaz, and D. Li, “Effects of Institutions on Entrepreneurs’ Trust and Engagement in Crowdfunding,” Journal of Electronic Commerce Research, vol. 22, no. 2, pp. 95–109, 2021.
- [28] S. Son-Turan, “Reforming higher education finance in Turkey: The alumni-crowdfunded student debt fund ‘a-CSDF’ model,” Egitim ve Bilim, vol. 41, no. 184, pp. 267–289, 2016. [CrossRef]
- [29] A. Seidl et al., “Crowdfunding marine and coastal protected areas: Reducing the revenue gap and financial vulnerabilities revealed by COVID-19,” Ocean Coast Manag, vol. 242, no. June, p. 106726, 2023. [CrossRef]
- [30] E. Bulut, “Blockchain-based entrepreneurial finance: success determinants of tourism initial coin offerings,” Current Issues in Tourism, vol. 25, no. 11, pp. 1767–1781, 2022. [CrossRef]
- [31] S. Ozcan, D. Boye, J. Arsenyan, and P. Trott, “A Scientometric Exploration of Crowdsourcing: Research Clusters and Applications,” IEEE Trans Eng Manag, vol. 69, no. 6, pp. 3023–3037, 2022. [CrossRef]
- [32] Y.-J. Chen et al., “Innovative Online Platforms: Research Opportunities,” SSRN Electronic Journal, pp. 1–31, 2018. [CrossRef]
- [33] Y. Demirdöğen, “New Resources For Islamıc Fınance: Islamıc Fıntech,” Hitit Theology Journal, vol. 20, no. 3, pp. 29–56, 2021. [CrossRef]
- [34] B. Saiti, M. Afghan, and N. H. Noordin, “Financing agricultural activities in Afghanistan: a proposed salam-based crowdfunding structure,” ISRA International Journal of Islamic Finance, vol. 10, no. 1, pp. 52–61, 2018. [CrossRef]
- [35] D. Boye, S. Ozcan, and O. Fajana, “Text Mining Approach for Identifying Product Ideas and Trends Based on Crowdfunding Projects,” IEEE Trans Eng Manag, vol. 71, pp. 7112–7127, 2024. [CrossRef]
- [36] Y. Meng, H. Wu, W. Zhao, W. Chen, H. Dinçer, and S. Yüksel, “A hybrid heterogeneous Pythagorean fuzzy group decision modelling for crowdfunding development process pathways of fintech-based clean energy investment projects,” Financial Innovation, vol. 7, no. 1, 2021. [CrossRef]
- [37] S. Koçer, “Social business in online financing: Crowdfunding narratives of independent documentary producers in Turkey,” New Media Soc, vol. 17, no. 2, pp. 231–248, 2015. [CrossRef]
- [38] V. Özdemir, J. Faris, and S. Srivastava, “Crowdfunding 2.0: the next-generation philanthropy,” EMBO Rep, vol. 16, no. 3, pp. 267–271, 2015. [CrossRef]
- [39] M. Kilinc, C. Aydin, and C. Tarhan, “CFTest: Web Based Business Intelligence Application That Measures Crowdfunding Success,” Proceedings—2022 Innovations in Intelligent Systems and Applications Conference, ASYU 2022, pp. 1–5, 2022. [CrossRef]
- [40] A. Çubukcu, T. Ulusoy, and E. Y. Boz, “Crowdfunding and Open Innovation Together: A Conceptual framework of a hybrid crowd innovation model,” International Journal of Innovation and Technology Management, vol. 17, no. 08, p. 2150003, 2020.
- [41] İ. Sirma, O. Ekici, and Y. Aytürk, “Crowdfunding Awareness in Turkey,” Procedia Comput Sci, vol. 158, pp. 490–497, 2019. [CrossRef]
Figure 1.
References by year.
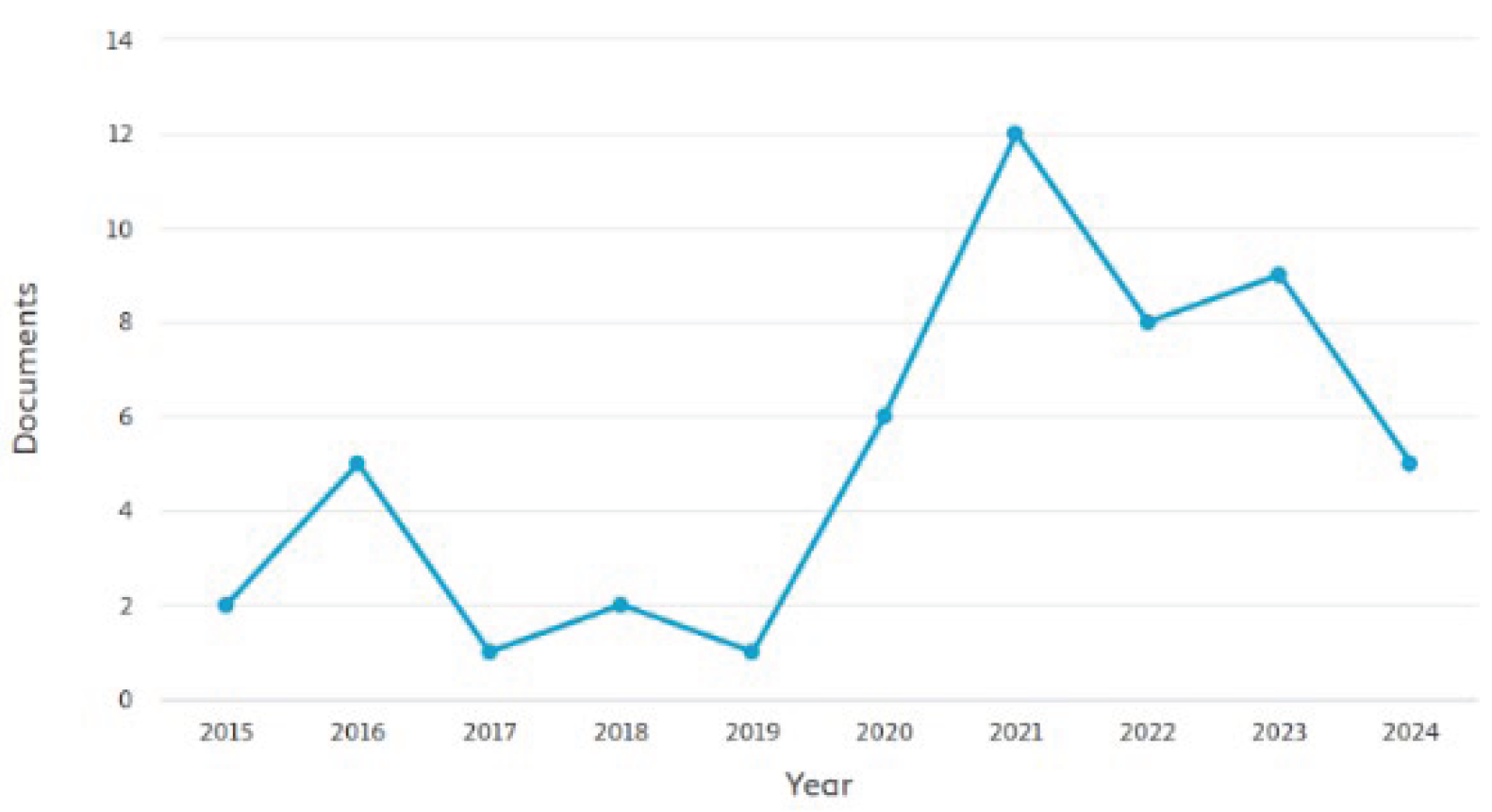
Figure 2.
References by type.
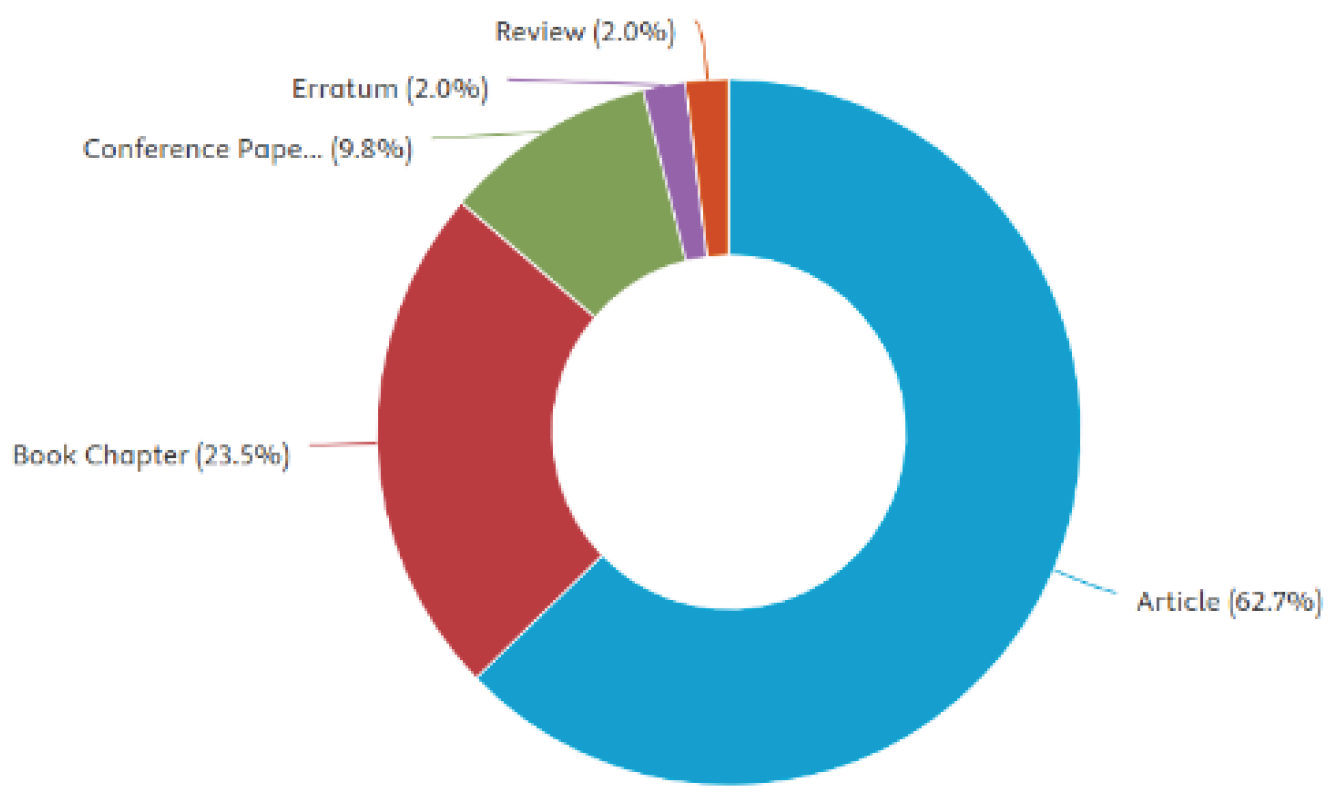
Figure 3.
References by subject area.
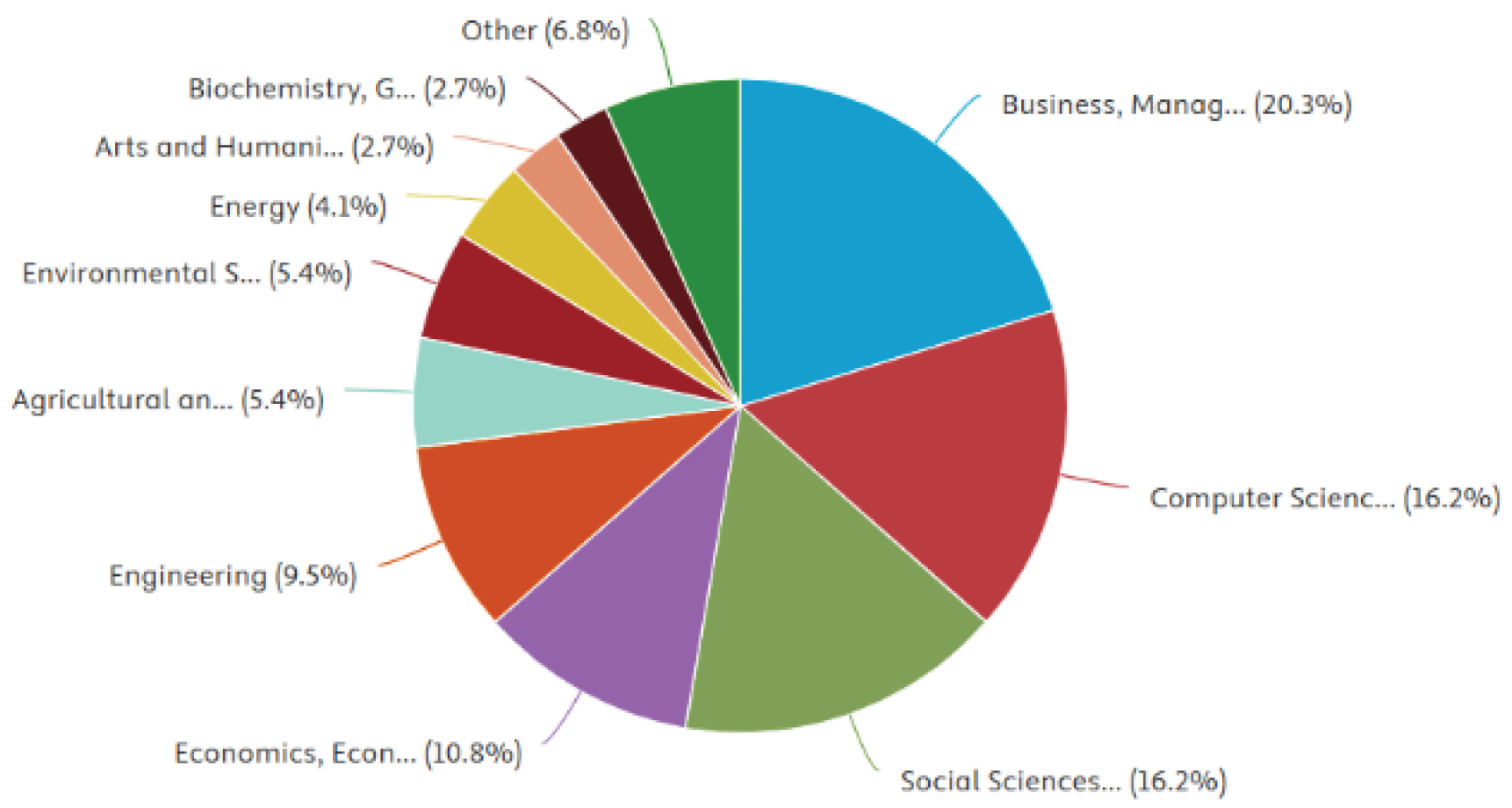
Figure 4.
Word cloud analysis for the articles under study.
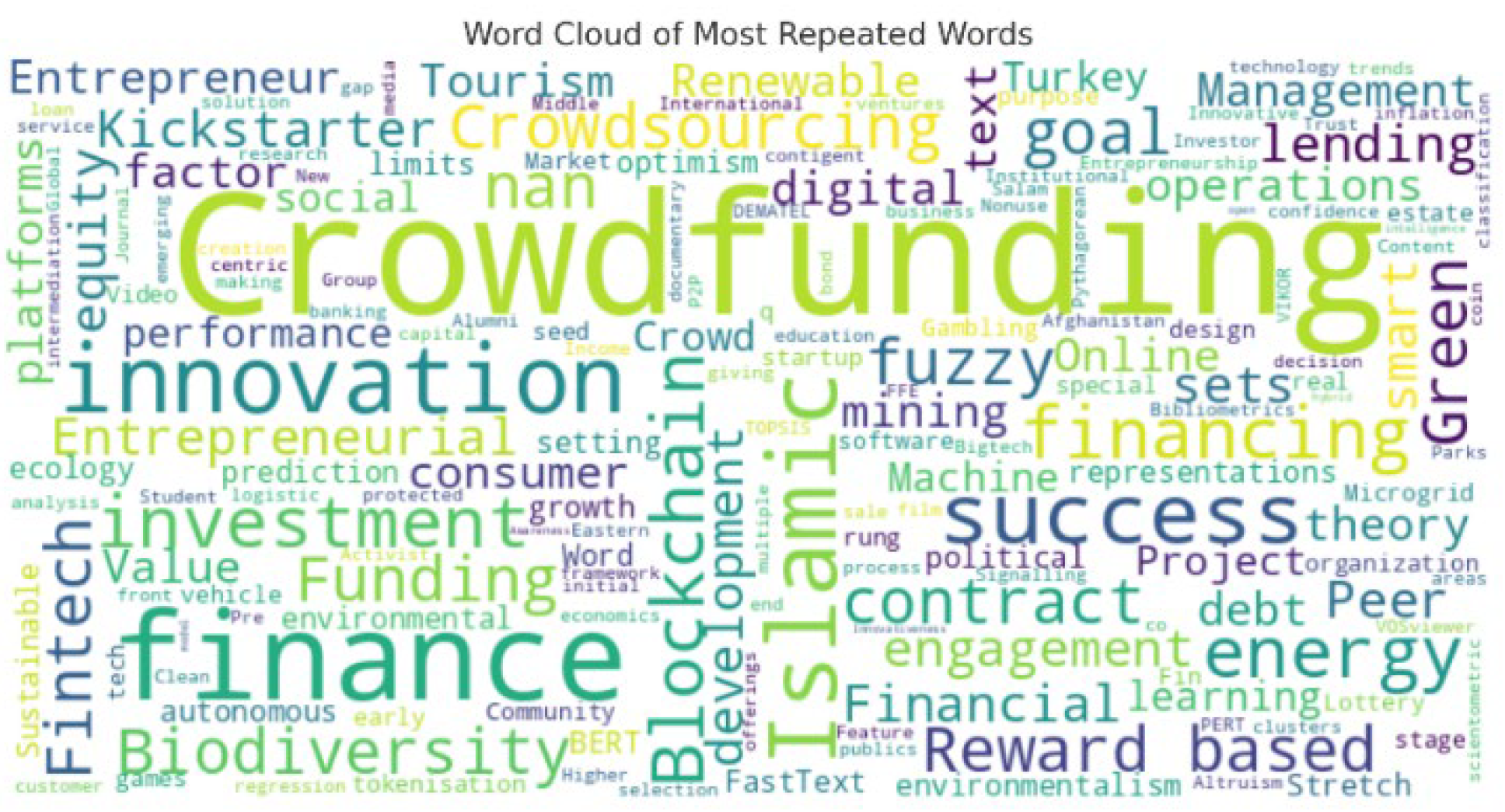
Figure 5.
Dataset of crowdfunding features.
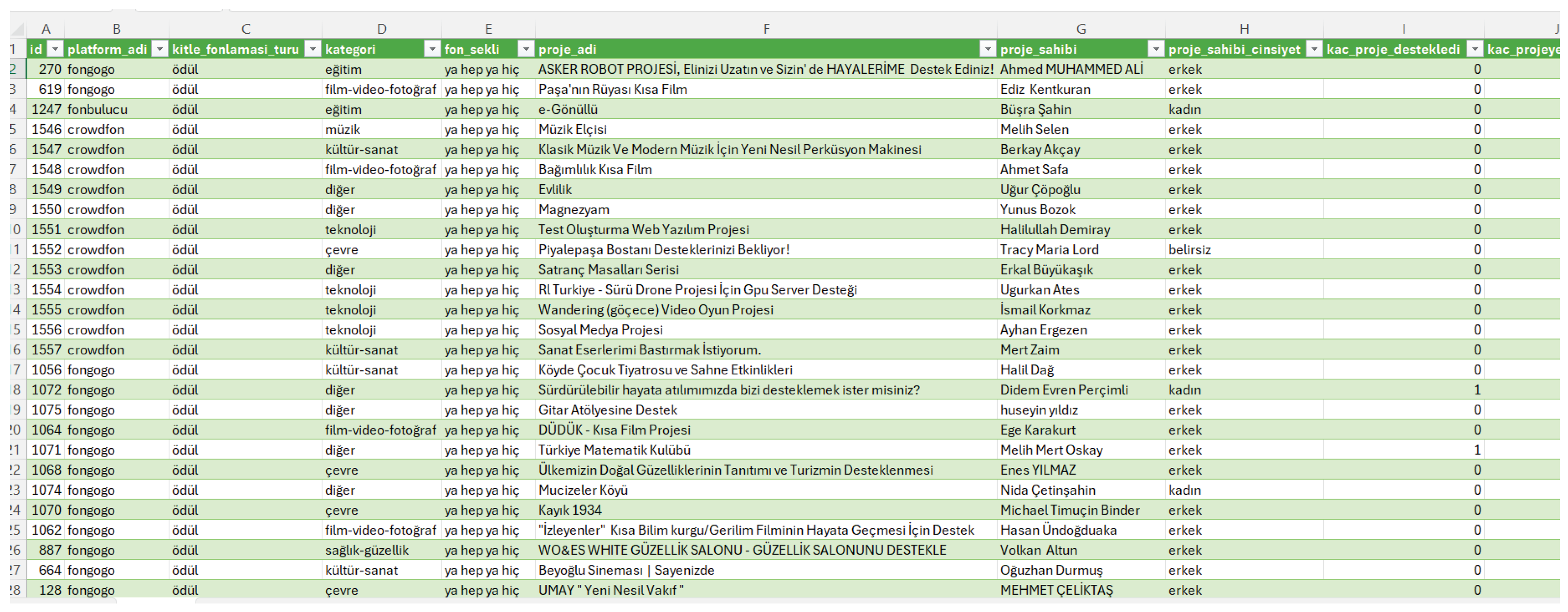
Figure 6.
Dataset description.
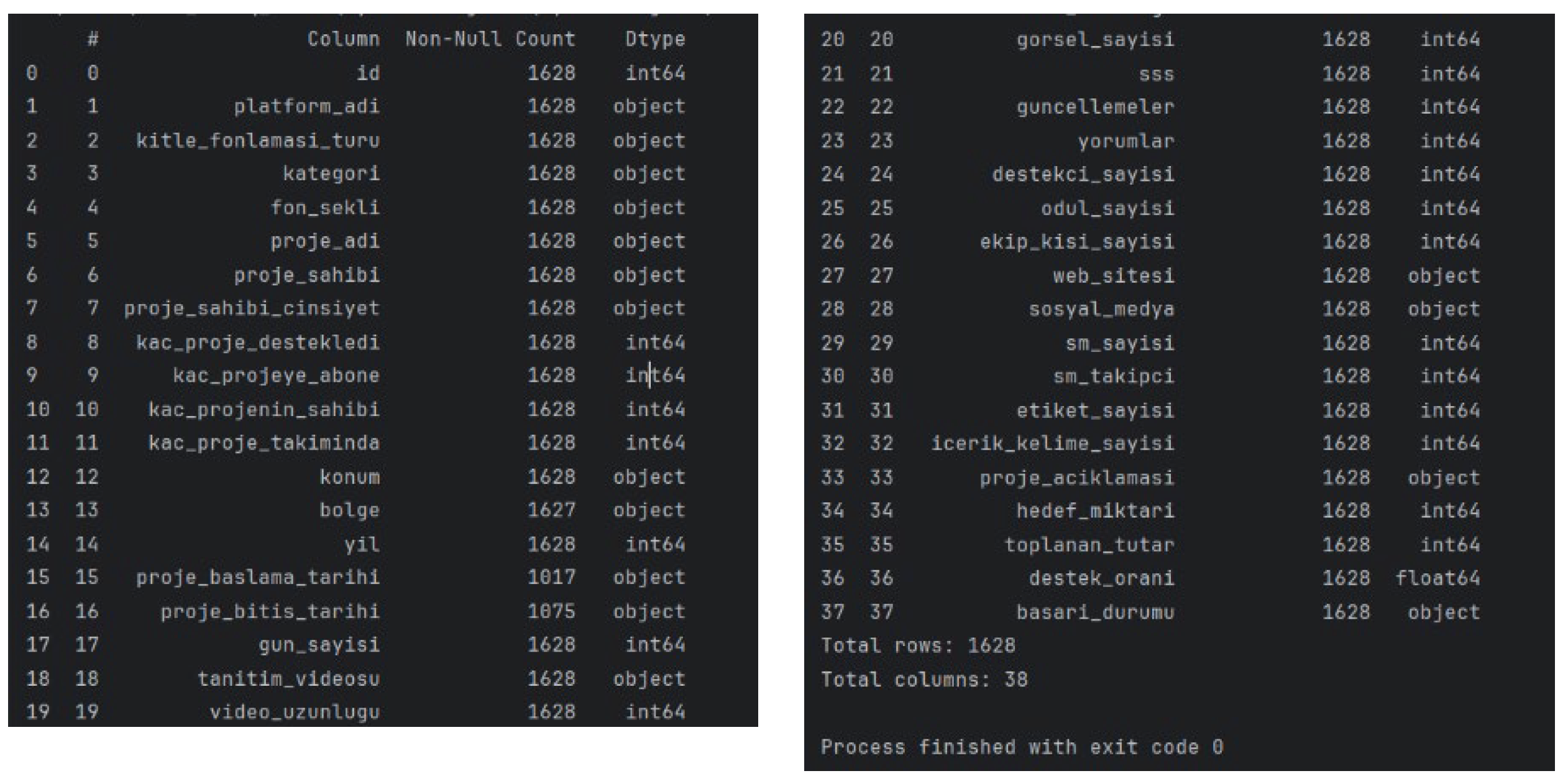
Figure 7.
Features’ correlation coefficients.
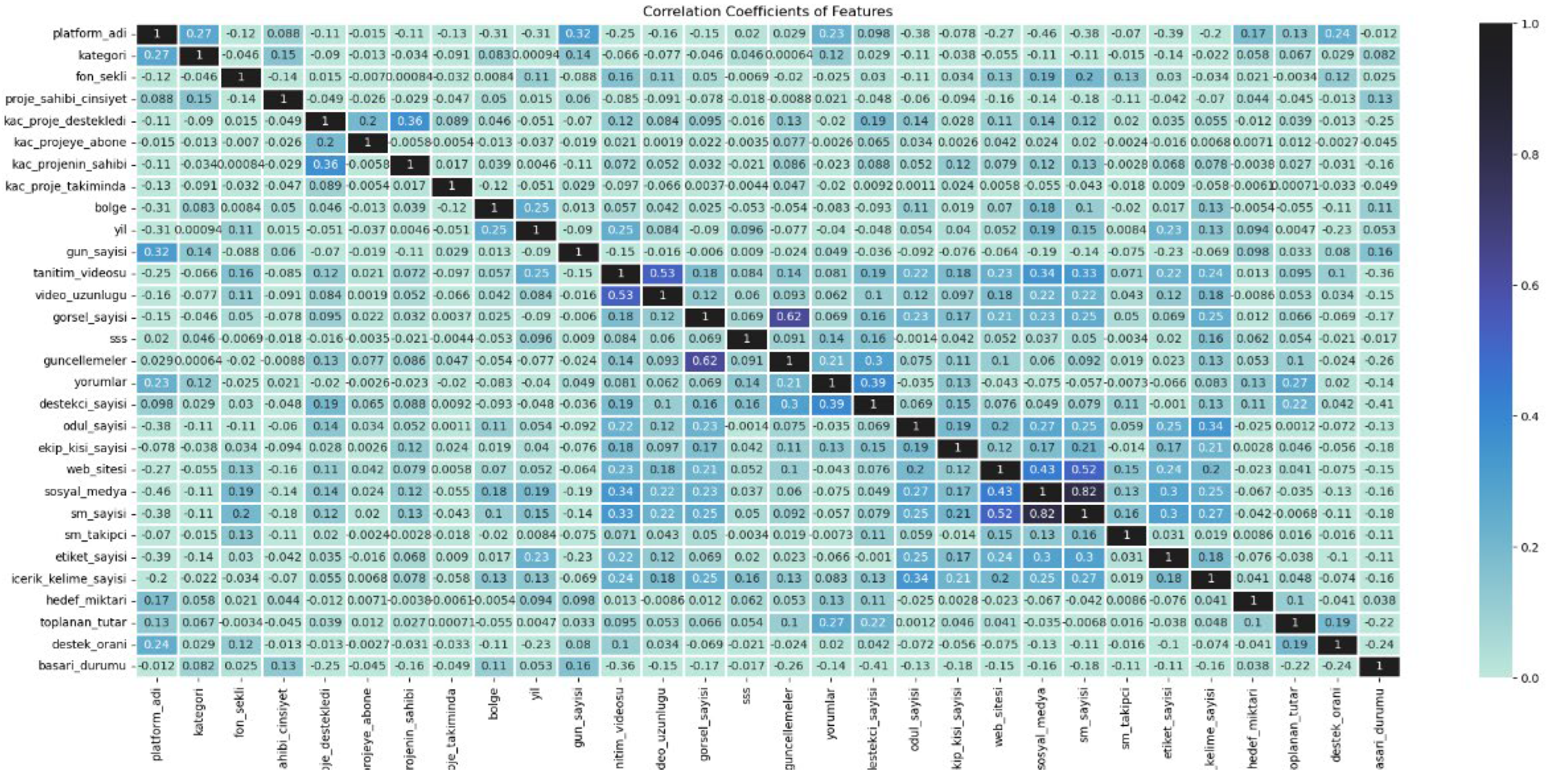
Figure 8.
Random forest classifier feature importance.
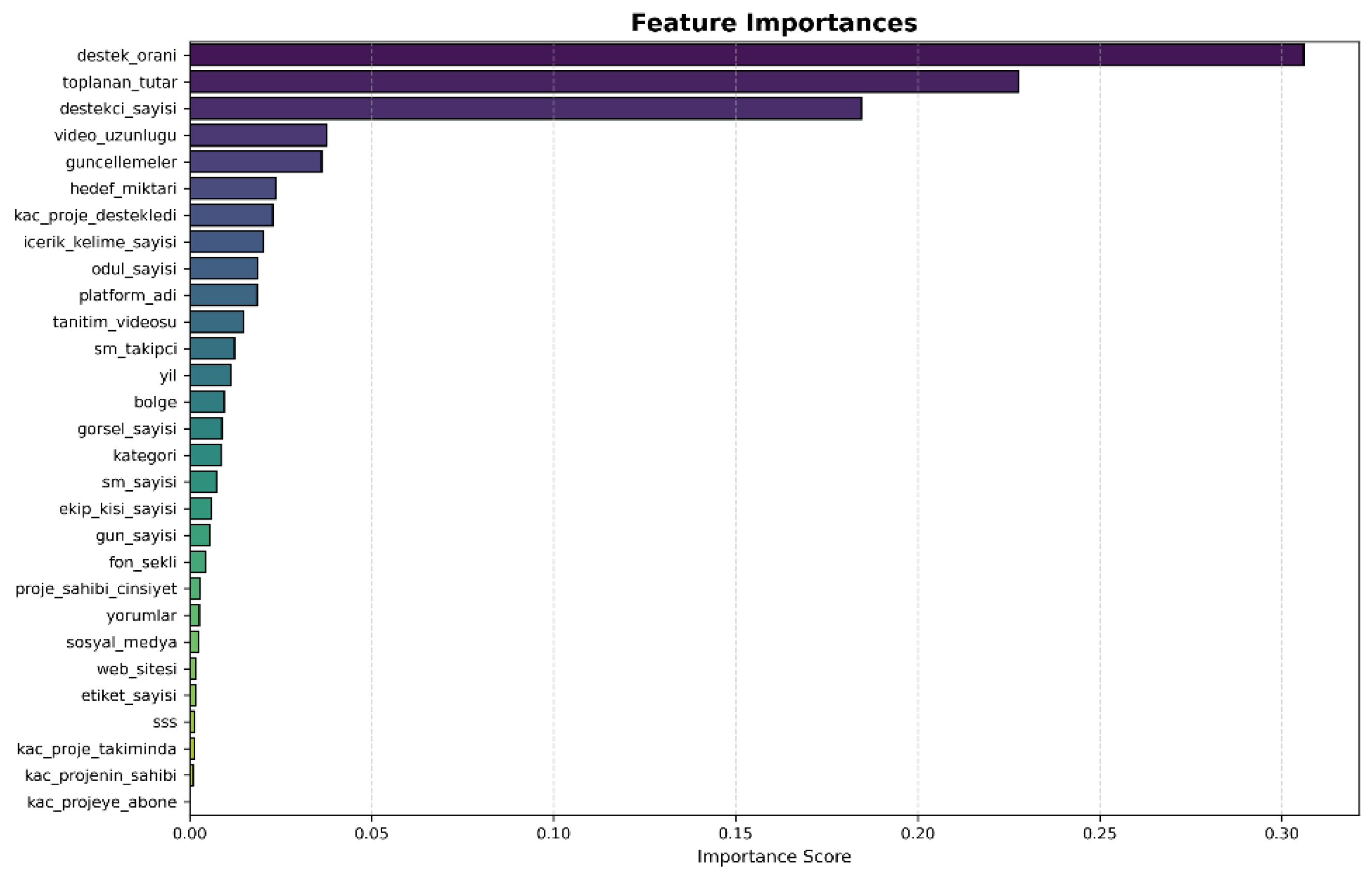
Figure 9.
Distribution of data classes.
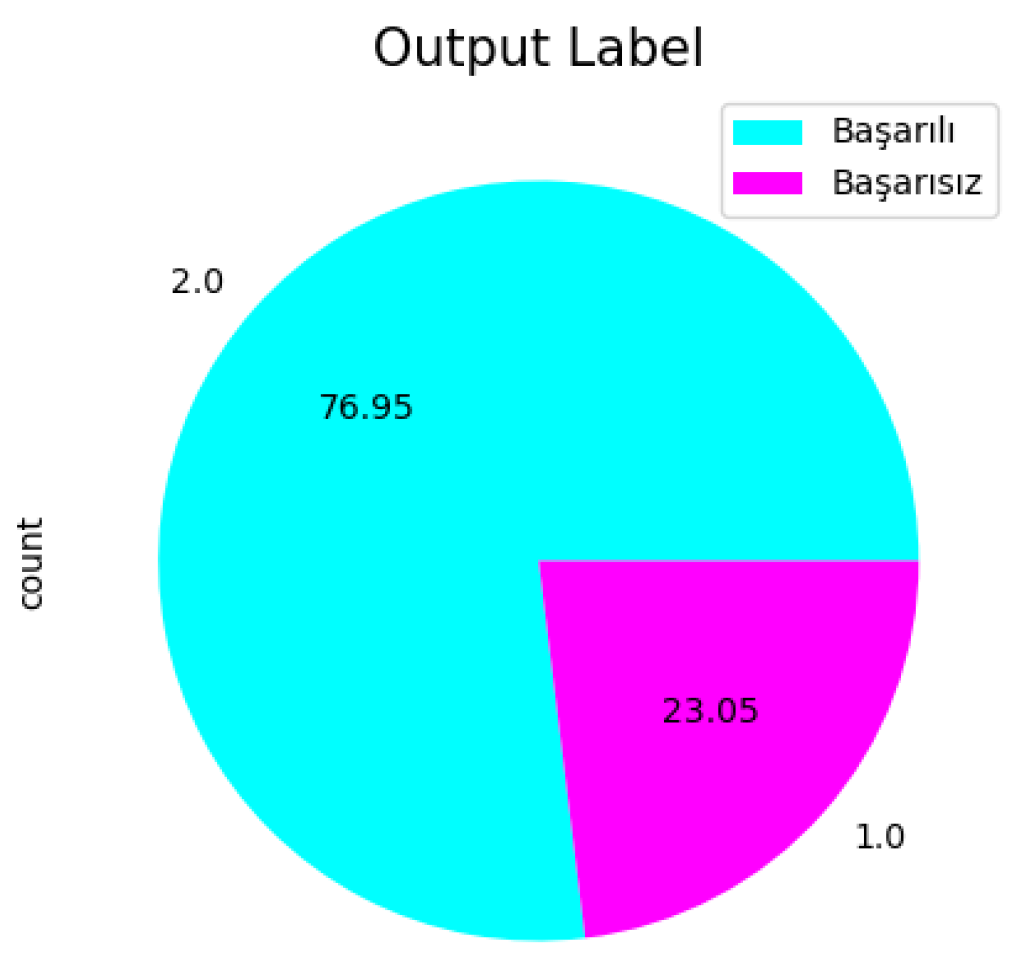
Figure 10.
Confusion matrix of Ada Boost and Gradient Boost algorithms.
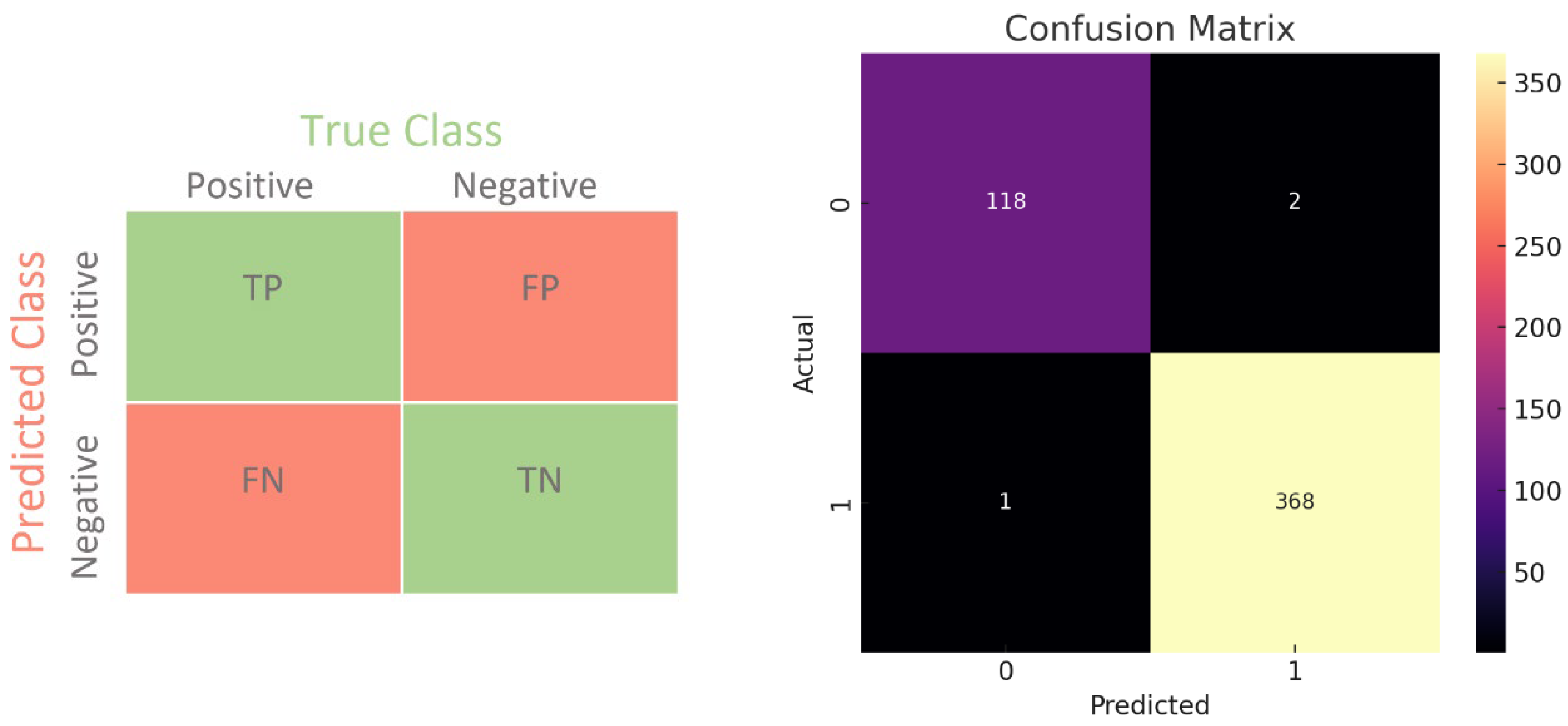
Figure 11.
Accuracy Performance of ML models.
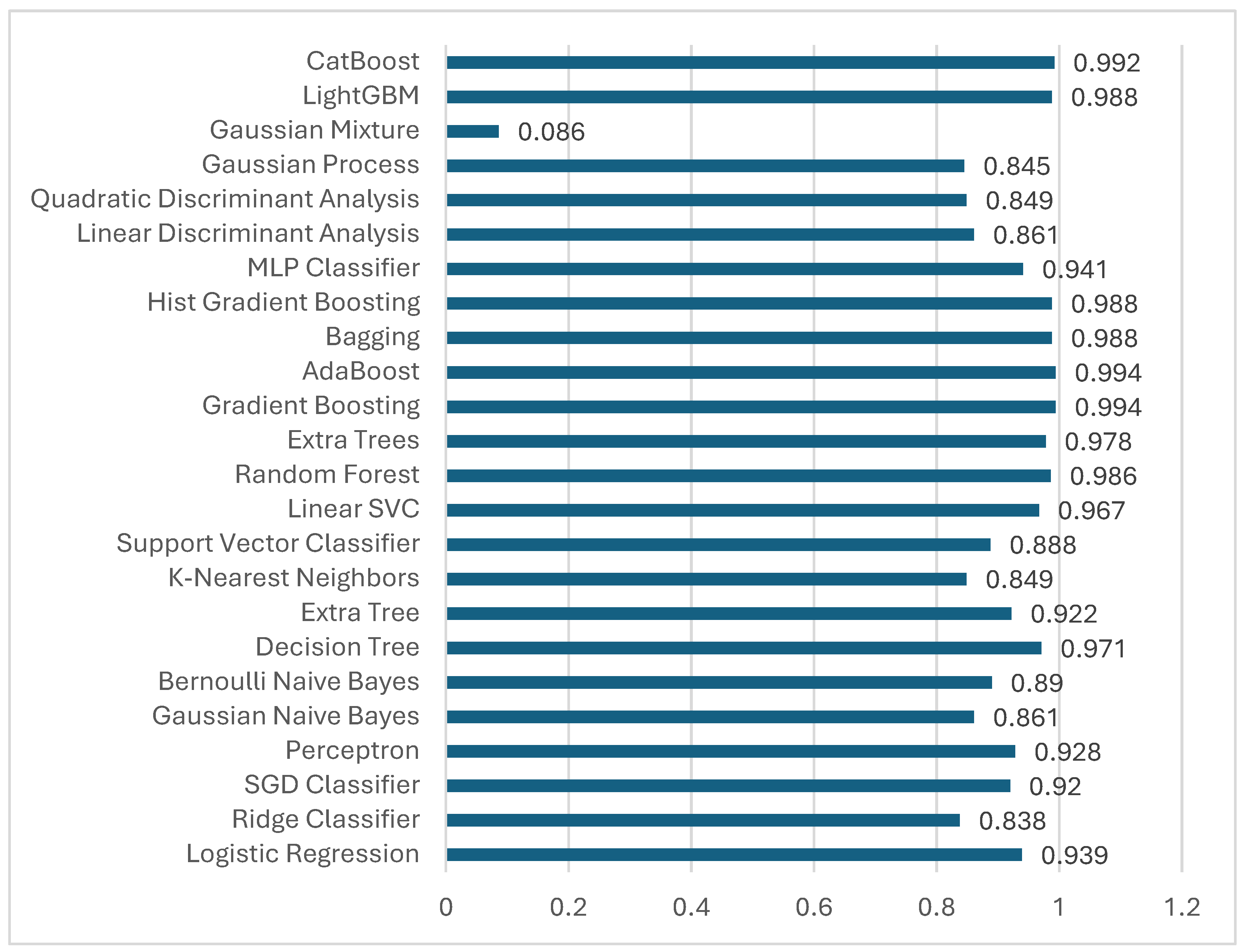
Table 2.
Translation of features.
| Turkish Feature Name | English Translation |
|---|---|
| destek_oranı | support rate |
| toplanan_tutar | collected amount |
| destekci_sayısı | number of supporters |
| video_uzunlugu | video length |
| guncellemeler | updates |
| hedef_miktari | target amount |
| kac_proje_destekledi | how many projects supported |
| icerik_kelime_sayısı | content word count |
| odul_sayısı | number of rewards |
| platform_adi | platform name |
| tanıtım_videosu | promotional video |
| sm_takipçi | social media followers |
| yıl | year |
| bolge | region |
| gorsel_sayısı | number of visuals |
| kategori | category |
| sm_sayısı | number of social media platforms |
| ekip_kisi_sayısı | number of team members |
| gun_sayısı | number of days |
| fon_sekli | funding type |
Table 3.
Machine learning techniques used in the study.
| ID | Method | Description | Parameters | Advantages | Disadvantages |
|---|---|---|---|---|---|
| 1 | Logistic Regression (LR) | A linear model is used for classification problems. | Regularization term, solver | Simple, interpretable, and fast. | Limited in handling complexity. |
| 2 | Ridge Classifier (RIDGE) | Applies L2 regularization to logistic regression for robustness. | Regularization strength (alpha), solver type | Reduces overfitting, handles multicollinearity | May underperform when features are not correlated |
| 3 | SGD Classifier (SGD) | Stochastic Gradient Descent-based linear classifier for large-scale and sparse data. | Learning rate, penalty, loss function | Efficient for large datasets, supports many loss functions | Sensitive to feature scaling and parameter tuning |
| 4 | Perceptron (PER) | A simple linear binary classifier that updates weights based on misclassified samples. | Number of iterations, learning rate | Fast and easy to implement | Cannot solve non-linear problems |
| 5 | Gaussian Naive Bayes (GNB) | Probability-based classification using Bayes’ theorem, assuming independence between features. | Few default parameters | Simple, fast, and often successful in tasks like text classification. | The independence assumption may not hold in the real world. |
| 6 | Bernoulli Naive Bayes (BNB) | Naive Bayes variant designed for binary/Boolean features. | Alpha (smoothing), binarize threshold | Works well with text classification, especially binary features | Assumes binary input, the independence assumption |
| 7 | Decision Tree (TREE) | Used for classification/regression via tree structure. | Tree depth, min sample split | Easy to understand, minimal data preprocessing | Prone to overfitting |
| 8 | Extra Tree (EXTRA) | Similar to Random Forest, it selects split points more randomly. | Number of trees, feature selection | Resistant to overfitting, low variance | Complex internal structure |
| 9 | K-Nearest Neighbors (K-NN) | Classifies by using the class labels of nearest neighbors. | Number of neighbors (K) | Simple and effective | Computationally expensive for large datasets |
| 10 | Support Vector Classifier (SVC) | Tries to find the best separating hyperplane between two classes. | Kernel type, C (error tolerance) | Effective in high-dimensional data | Long training time for large datasets |
| 11 | Linear SVC (LSVC) | A linear version of SVM using liblinear. | Regularization parameter (C), loss, penalty | Faster than kernel SVMs | Does not support non-linear decision boundaries |
| 12 | Random Forest (FOREST) | Classifies by combining many decision trees. | Number of trees, feature selection | Strong generalization, resistant to overfitting | Complex internal structure |
| 13 | Extra Trees (EXTREME) | Ensemble of randomized decision trees. | Number of trees, max features | Faster than Random Forest, less variance | Less interpretable, more randomness |
| 14 | Gradient Boosting (GRADIENT) | Combines weak learners (often trees) to create a strong model. | Learning rate, number of trees | High generalization ability | May require more training time and tuning |
| 15 | AdaBoost (ADA) | Combines weak classifiers by focusing on misclassified examples. | Type of weak learner, learning rate | Resistant to overfitting, high generalization | Sensitive to tuning |
| 16 | Bagging (BGC) | Improves performance by training on different subsamples. | Base learner type, sampling strategy | Resistant to overfitting, low variance | Depends on base learner type |
| 17 | Hist Gradient Boosting (HGB) | Histogram-based gradient boosting for scalable learning. | Learning rate, max bins, iterations | Faster training, high accuracy | Requires preprocessing for categorical data |
| 18 | MLP Classifier (MLP) | Artificial neural network with multiple layers that update weights during learning. | Number of layers, hidden neurons | Learns complex relationships, good for large datasets | Long training time, risk of overfitting |
| 19 | Linear Discriminant Analysis (LDA) | Finds axes that best express class differences. | Few default parameters | Provides dimensionality reduction, emphasizes differences | Assumes equal covariances |
| 20 | Quadratic Discriminant Analysis (QDA) | Allows different covariance matrices for each class. | Few default parameters | Better with distinct class covariances | Sensitive to outliers, overfits on small data |
| 21 | Gaussian Process (GP) | Defines a distribution over functions, used for non-parametric modeling. | Kernel, alpha | Provides uncertainty estimates | Computationally expensive |
| 22 | Gaussian Mixture (GM) | Assumes data is from a mixture of Gaussians; used in clustering. | Number of components, covariance type | Model’s complex distributions | Sensitive to initialization and local optima |
| 23 | LightGBM (LGBM) | Gradient boosting framework optimized for speed and efficiency. | Learning rate, number of leaves, max depth | Very fast, supports categorical features | May overfit on small datasets |
| 24 | CatBoost (CAT) | Gradient boosting library optimized for categorical features. | Depth, learning rate, iterations | Handles categorical data natively | Slower than LightGBM |
Table 4.
Performance metrics for all AI models.
| Model | CONFUSION MATRIX | ACCURACY | PRECISION | RECALL | F1 | CONFIDENCE-Min | CONFIDENCE-Max |
|---|---|---|---|---|---|---|---|
| Logistic Regression | [100 20] [ 10 359] |
0.939 | 0.938 | 0.939 | 0.938 | 1 | 0.862 |
| Ridge Classifier | [ 49 71] [ 8 361] |
0.838 | 0.842 | 0.838 | 0.816 | 0.919 | 0.758 |
| SGD Classifier | [100 20] [ 19 350] |
0.92 | 0.92 | 0.92 | 0.92 | 0.996 | 0.845 |
| Perceptron | [ 96 24] [ 11 358] |
0.928 | 0.927 | 0.928 | 0.927 | 1 | 0.852 |
| Gaussian Naive Bayes | [ 62 58] [ 10 359] |
0.861 | 0.861 | 0.861 | 0.848 | 0.941 | 0.781 |
| Bernoulli Naive Bayes | [ 93 27] [ 27 342] |
0.89 | 0.89 | 0.89 | 0.89 | 0.965 | 0.814 |
| Decision Tree | [107 13] [ 1 368] |
0.971 | 0.972 | 0.971 | 0.971 | 1 | 0.895 |
| Extra Tree | [104 16] [ 22 347] |
0.922 | 0.924 | 0.922 | 0.923 | 0.997 | 0.847 |
| K-Nearest Neighbors | [ 64 56] [ 18 351] |
0.849 | 0.842 | 0.849 | 0.838 | 0.927 | 0.77 |
| Support Vector Classifier | [ 73 47] [ 8 361] |
0.888 | 0.889 | 0.888 | 0.879 | 0.966 | 0.809 |
| Linear SVC | [111 9] [ 7 362] |
0.967 | 0.967 | 0.967 | 0.967 | 1 | 0.892 |
| Random Forest | [115 5] [ 2 367] |
0.986 | 0.986 | 0.986 | 0.986 | 1 | 0.91 |
| Extra Trees | [112 8] [ 3 366] |
0.978 | 0.977 | 0.978 | 0.977 | 1 | 0.902 |
| Gradient Boosting | [118 2] [ 1 368] |
0.994 | 0.994 | 0.994 | 0.994 | 1 | 0.918 |
| AdaBoost | [118 2] [ 1 368] |
0.994 | 0.994 | 0.994 | 0.994 | 1 | 0.918 |
| Bagging | [116 4] [ 2 367] |
0.988 | 0.988 | 0.988 | 0.988 | 1 | 0.912 |
| Hist Gradient Boosting | [115 5] [ 1 368] |
0.988 | 0.988 | 0.988 | 0.988 | 1 | 0.912 |
| MLP Classifier | [101 19] [ 10 359] |
0.941 | 0.94 | 0.941 | 0.94 | 1 | 0.865 |
| Linear Discriminant Analysis | [ 60 60] [ 8 361] |
0.861 | 0.864 | 0.861 | 0.846 | 0.941 | 0.781 |
| Quadratic Discriminant Analysis | [ 55 65] [ 9 360] |
0.849 | 0.85 | 0.849 | 0.831 | 0.929 | 0.768 |
| Gaussian Process | [ 68 52] [ 24 345] |
0.845 | 0.837 | 0.845 | 0.837 | 0.922 | 0.767 |
| LightGBM | [115 5] [ 1 368] |
0.988 | 0.988 | 0.988 | 0.988 | 1 | 0.912 |
| CatBoost | [118 2] [ 2 367] |
0.992 | 0.992 | 0.992 | 0.992 | 1 | 0.916 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



