Submitted:
03 July 2025
Posted:
03 July 2025
You are already at the latest version
Abstract
Purpose: Traditional inspection of railway turnout rutting machines, crucial for track switching safety, suffers from fragmented mechanical/electrical data, environmental limitations, and inadequate modeling of signal-state relationships. Existing intelligent algorithms lack visual characterization of mechanical deformation. This study aims to overcome these limitations and data scarcity to advance intelligent rail maintenance. Methods: We constructed the TurnoutSegmentation dataset with 2,360 high-definition, EN 50129-compliant trackside images. It features standardized pixel-level annotations of key components [Switch rail, Stock rail, Tie Rod (Switch Machine Rod), and Switch Machine] and is divided into training, validation, and test sets. Imaging incorporated dynamic light compensation for all-weather HDR, with pre-processing including grayscale equalization, ROI extraction, and geometric correction. Comparative experiments used the UNet architecture, evaluating segmentation performance. Results: The UNet++ model, optimized via deep supervision, achieved a rutting equipment segmentation accuracy of 0.8306 mIoU. This enables automated defect detection through precise part segmentation and establishes a baseline for cross-domain analyses like track condition assessment and predictive maintenance. Conclusion: This study breaks the bottleneck of data scarcity and algorithm generalization for turnout monitoring. The methodology promotes intelligent rail maintenance system development and is extendable to other industrial inspection scenarios requiring fine-grained analysis. The standardized dataset ensures reproducibility and supports vision-based infrastructure monitoring research. (Code: https://github.com/louzongzhi/Segment, Dataset: https: //doi.org/10.57760/sciencedb.22706).
Keywords:
railway turnout
; semantic segmentation
; automated defect detection
; predictive maintenance
1. Background & Summary
Railway turnouts, acting as the "throat" of rail transit networks, are indispensable for directing train movements, with their reliability directly impacting transportation safety and efficiency. According to China State Railway Group statistics, turnout-related faults account for 18.7% of annual train delays nationwide, with component wear and close-fitting failures contributing to over 60% of incidents. In high-speed rail scenarios, dynamic loads exceeding 50kN and high-frequency vibrations (10–50Hz) generated by trains moving at speeds over 300 km/h accelerate contact fatigue on switch rails, increasing wear rates by 30% compared to conventional lines. Traditional manual inspections exhibit a 25% miss rate under complex conditions, failing to meet the "zero-fault" operation requirements for high-speed railways.
Current detection technologies face three critical limitations:
- Scarcity of high-quality annotated datasets: While datasets like RailSem19 [1] offer semantic annotations for track scenes, they only cover macro-level categories (e.g., tracks, signals), lacking fine-grained annotations for turnout components. Similarly, CrackTree [2] focuses on rail surface defect detection but excludes structural information specific to turnouts. Existing public datasets remain deficient in pixel-level annotations for functional turnout components, hindering models from capturing key features such as switch rail close-fitting surface deformations [3] and rod connection statuses.
- Inadequate robustness in complex environments: Real-world scenarios involve dynamic challenges like lighting variations (e.g., tunnel reflections) and transient occlusions (e.g., component blockages during train passage), which significantly degrade detection accuracy. Most existing methods rely on laboratory-trained data, exhibiting limited generalization in operational environments. Robust algorithm development therefore requires standardized datasets incorporating multi-environmental variables.
To address these bottlenecks,we introduce TurnoutSegmentation, the first publicly available dataset for semantic segmentation of turnout components. Comprising a total of 2,360 high-resolution (1280×1280 pixels) railway turnout images. Each image has been pixel-level annotated (see Figure 1), defining four key turnout components: Switch rail, Stock rail, Tie Rod (Switch Machine Rod), and Switch Machine. The annotation files are stored in PNG format, compatible with mainstream semantic segmentation frameworks.
- Switch Rail: Movable track component enabling direction changes, with annotations focusing on critical regions (close-fitting surfaces, rail head profiles);
- Stock Rail: Fixed track component, emphasizing the gauge maintenance area interacting with the switch rail;
- Tie Rod (Switch Machine Rod): Transmission component connecting switch rails to point machines, with precise boundary delineation of connection nodes (pins, bolts);
- Switch Machine: Electromechanical device driving switch rail movement, including detailed contours of moving parts (gear sets, locking rods), adhering to the annotation standards of TB/T 2478-2020 Railway Turnout Conversion Equipment.
Potential applications of TurnoutSegmentation encompass but are not restricted to: (1) Automated identification of turnout component conditions to facilitate fault localization (e.g., detecting switch rail close-fitting defects); (2) Cross-domain adaptation research to validate model transfer performance from controlled laboratory settings to operational field environments.
2. Methods
2.1. Dataset Acquisition
The imaging system was developed compliant with ISO 14839-3:2018(track geometry measurement) and UIC 719-R(rail component testing standards), utilizing a 4K industrial camera (Sony IMX415 sensor, 8.3 MP resolution at 60 fps) with 5-50 mm optical zoom to achieve 0.05 mm/pixel spatial resolution(see Table 1).This configuration enables quantitative detection of micro-scale defects (e.g., switch rail gaps ≥4 mm) under dynamic conditions. To suppress vibration artifacts during high-speed train operations (≤160 km/h), a three-axis active stabilization platform was designed based on a carbon fiber bracket and PID-controlled gimbal, achieving ±0.05° angular compensation and limiting motion blur to 1.2 pixels. Equipment installation adhered to GB/T 50308-2017 safety protocols, maintaining a 3.5 m offset from the track centerline to avoid clearance zone violations.
To mitigate vibration interference during high-speed train passage, The anti-vibration system was engineered based on a three-axis gimbal architecture with a PID-controlled active stabilization algorithm (angular compensation ±0.05°), coupled with a carbon fiber base (tensile resistance ≤500 N) to limit motion blur to 1.2 pixels at 160 km/h train speeds. Installation strictly adhered to GB/T 50308-2017 safety standards, maintaining a 3.5 m offset from the track centerline to prevent clearance zone intrusion. For multi-angle data capture, three synchronized cameras (1.2 m spacing, 15° depression angle) were deployed with dynamic ISO (100–3200) and exposure control (1/800–1/2000 s), ensuring consistent imaging under variable illumination (200–1000 Lux).
Data collection was conducted at a railway hub in China, covering an 8-kilometer track section with ambient temperatures ranging from 10°C to 38°C. A combined strategy of equal-interval time sampling and key frame extraction was employed in post-processing to select representative turnout status images from recorded videos. To ensure data diversity, a three-camera synchronous acquisition system (with a spacing of 1.2 m and a depression angle of 15°) was deployed to eliminate single-view occlusion issues. The system adapted to all-weather lighting variations (200–1000 Lux) through dynamic adjustments of ISO (100–3200) and exposure time (1/800 s–1/2000 s). In strict compliance with Article 388 of the Railway Technical Management Regulations, our team established a 300-meter early-warning zone equipped with infrared sensors and dedicated safety officers, enabling real-time monitoring of approaching train signals and automatic power-off protection.
2.2. Dataset Processing
A combined strategy of equal-interval time sampling and key frame extraction was employed in post-processing to select representative turnout status images from recorded videos. To ensure data diversity, a three-camera synchronous acquisition system (with a spacing of 1.2 m and a depression angle of 15°) was deployed to eliminate single-view occlusion issues. The system adapted to all-weather lighting variations (200–1000 Lux) through dynamic adjustments of ISO (100–3200) and exposure time (1/800 s–1/2000 s). In strict compliance with Article 388 of the Railway Technical Management Regulations, our team established a 300-meter early-warning zone equipped with infrared sensors and dedicated safety officers, enabling real-time monitoring of approaching train signals and automatic power-off protectionA combined approach of equal-interval time sampling and key frame extraction was employed to select 2,360 representative turnout status images from raw videos. The preprocessing pipeline included three core steps:
- Images were uniformly resized to 1280×1280 pixels using a bicubic interpolation algorithm to standardize spatial dimensions;
- Illumination normalization was performed via CLAHE (contrast-limited adaptive histogram equalization), dynamically adjusting brightness and contrast to mitigate variations caused by all-weather conditions—effectively normalizing low-contrast overcast scenes and high-reflectance sunny environments alike;
- A non-local mean denoising algorithm was applied to eliminate motion blur induced by passing trains, enhancing edge clarity through adaptive pixel similarity weighting.
This systematic processing chain significantly improved image quality: CLAHE [4,5] normalized illumination inconsistencies across diverse lighting scenarios (200–1000 Lux), ensuring uniform visual features for both low-contrast overcast and high-glare sunny conditions; the denoising algorithm selectively reduced blur while preserving fine-grained details of turnout components (e.g., switch rail contact surfaces). The resultant images exhibit consistent brightness, optimized contrast, and minimized noise, providing an ideal foundation for subsequent analytical tasks.
2.3. Dataset Labelling
Data annotation, as a core component of dataset construction, directly impacts the training efficacy of subsequent deep learning models [6] through its accuracy and consistency. In this study, a rigorous hierarchical annotation system was developed (as shown in Figure 2), guided by senior engineers from railway maintenance divisions to ensure professional rigor.
First, the Labelme annotation tool was employed for pixel-level detailed annotation of four core turnout components: switch machines, rod connection systems, switch rail assemblies, and stock rail structures. Our team strictly adhered to the pre-established Turnout Component Annotation Specification:
- For components with clear contours (e.g., switch machines), boundaries were precisely outlined using polygonal tools;
- For complex structural regions such as rod connection systems, a hierarchical annotation strategy was adopted to avoid:
Labeling ambiguities between overlapping components.
Prior to annotation, all team members underwent standardized training to master a unified color-coding system:
- Blue: Switch Machine
- Yellow: Tie Rod (Switch Machine Rod)
- Purple: Switch Rail
- Green: Stock Rail
This operational standardization ensured consistency in annotation logic across the labeling process, minimizing inter-operator variability and establishing a robust foundation for subsequent model training.
To ensure comprehensive control over annotation quality, this study established a three-tier quality verification system via the CVAT platform, with the detailed workflow illustrated in Figure 3.
Primary verification is conducted by junior annotators through mutual inspection, where annotators work in pairs to check the integrity of annotation boundaries and the accuracy of categories according to the annotation specifications, with a focus on identifying missing labels for components in occluded scenarios. Secondary verification is carried out by senior engineers from the railway maintenance section, who leverage their extensive field experience to professionally verify the annotation results of complex switch scenes, setting a tolerance threshold for pixel-level errors ≤ 2px to ensure that the coverage rate of key components meets standards.
At the level of dataset partitioning, the study divide the training set, validation set, and test set. This ratio is established based on statistical analysis of the diversity of switch scenes [7], ensuring that the training set fully covers a variety of scenarios including normal operating conditions, worn parts, and uneven lighting, while the validation and test sets retain similar scene distribution characteristics. Stratified random sampling is used during the partitioning process to avoid data leakage issues, providing a fair baseline data for model training and evaluation.
3. Data Records
The TurnoutSegmentation dataset comprises 2,360 meticulously labeled images, each with a high resolution of 1280×1280 pixels. This dataset’s scale and diversity serve as a crucial foundation for advancing intelligent maintenance [8] and diagnostic systems in railway switch machinery. To facilitate robust model development, the dataset is partitioned into three distinct subsets: a training set (1,611 images), a validation set (690 images), and a test set (59 images). This thoughtful division accounts for the balance and representativeness of samples across training, validation, and testing phases, ensuring a reliable framework for both machine learning and rigorous performance evaluation.
The dataset’s directory architecture is illustrated in Figure 4, featuring three core components:
- Hierarchical Storage Structure: Three primary modules are established under the root directory: JPEGImages (stores source *.jpg images), SegmentationClass (contains *.png annotation files), and label_mapping.txt (defines semantic mappings). Both JPEGImages and SegmentationClass directories incorporate subdirectories categorizing standard data into three distinct partitions: train, val, and test;
- Anti-bias Naming Strategy: All files employ cryptographically secure UUID-generated 8-bit hash prefixes, guaranteeing precise image-annotation file matching while neutralizing potential influences of filename sequencing on model training;
- Semantic Encoding Framework: The label_mapping.txt utilizes an ID: Class format to define a five-tier classification system (0: [background], 1: [Switch Machine], 2: [Switch Rail], 3: [Stock Rail], 4: [Tie_Rail]). Single-channel PNG annotation files directly map pixel grayscale values to semantic spaces, enabling pixel-perfect interpretation through this comprehensive encoding protocol.
4. Technical Validation
4.1. Evaluation
To comprehensively validate the dataset’s validity and annotation quality, this study constructs a systematic multi-dimensional evaluation framework. This framework encompasses three core dimensions: data availability verification, model performance validation, and cross-dataset comparative analysis, ensuring comprehensive assessment of dataset reliability and applicability through multi-perspective evaluations. All experiments are conducted based on the RTX 4060 GPU, and the algorithm deployment is implemented through the torch framework.
Establishing a semantic segmentation benchmark model based on the UNet architecture, the dataset is divided into a training set (1611 frames), a validation set (690 frames), and a test set (59 frames), with the training configuration shown in Table 2.
In this section, the average intersection ratio, boundary F1 score are chosen as the evaluation metrics of the model. Specifically, the average intersection and merger ratio measures the segmentation accuracy of the model by calculating the intersection and merger ratio of the predicted region to the real label for each category and averaging the intersection and merger ratios for all categories. The Boundary F1 score is used to assess the quality of the segmentation boundaries and is calculated by calculating the precision and recall between the predicted boundary and the true boundary and then taking their reconciled average.
4.2. Modelling Assessment
We select four representative segmentation models of the UNet family, which were proposed between 2015 and 2023, and have continued to drive the technological evolution in the field of image segmentation.
U-Net [9] adopts a symmetric encoder-decoder architecture, splicing and fusing shallow detailed features with deep semantic information through jump connections, and has demonstrated excellent boundary recognition capability in medical image segmentation. It shows excellent boundary recognition ability in medical image segmentation, but its shallow network depth limits semantic modelling of complex scenes.U-Net++ [10] introduces nested jump connections and depth supervision mechanism based on the original structure, and improves the segmentation accuracy of multiscale targets through dense multilayer feature fusion, which is especially suitable for fine medical tasks such as liver tumour segmentation, but the network complexity U-Net3+ [11] further proposes a full-scale jump connection and category guidance module, aggregates multiscale features of encoder and decoder across hierarchical levels, and combines channel attention to dynamically optimise the feature weights in key regions, which significantly enhances the segmentation robustness of fuzzy edges and small targets in remote sensing imagery, but a large number of model parameters may need to rely on U-NetV2 [12] optimises feature integration through semantic and detail fusion module (SDI) and improved jump connection design, dynamically fuses multi-scale semantic and local detail features using Hadamard product, and combines with depth-separable convolution to achieve lightweight, which improves the edge accuracy in medical tasks such as skin lesion segmentation, and supports real-time reasoning above 30 FPS.
At the same time, it supports real-time inference above 30 FPS, which is suitable for resource-constrained scenarios such as mobile endoscopic video analysis. To ensure the fairness of the experiments, none of the above four models were trained using pre-trained models for migration.
4.3. Quantitative Analysis
To benchmark the performance of mainstream segmentation models on the TurnoutSegmentation dataset, we conducted a comprehensive evaluation using four widely adopted architectures: UNet, UNet++, UNet3+, and UNetv2. Quantitative results (Table 3) reveal significant disparities in component-specific segmentation accuracy and boundary detection capabilities across models, particularly for critical turnout components: Point Machine, Switch Rail, Stock Rail, and Tie Rod.
-
Key ObservationsUNet: Achieved moderate performance on Point Machine (IoU: 0.8781; boundary F1: 0.8423) and Switch Rail (IoU: 0.7915; boundary F1: 0.7836), but exhibited limitations on Stock Rail (IoU: 0.7048) and Tie Rod (boundary F1: 0.6807), yielding a global mIoU of 0.7736.UNet++: Outperformed all models with superior IoU and boundary F1 scores across components, notably excelling in Point Machine (IoU: 0.9503; boundary F1: 0.9201) and Switch Rail (IoU: 0.8112; boundary F1: 0.8048). Despite achieving the highest mIoU (0.8306), its boundary detection for Tie Rod remained suboptimal (boundary F1: 0.7142), highlighting challenges in segmenting slender structures.UNet3+: Demonstrated comparable performance to UNet (mIoU: 0.7731) but showed degraded boundary precision for Tie Rod (boundary F1: 0.6794), suggesting sensitivity to structural complexity.UNetv2: Delivered marginal improvements over UNet (mIoU: 0.7738) but struggled with boundary delineation in Stock Rail (boundary F1: 0.7015) and Tie Rod (boundary F1: 0.6857).
-
Critical InsightsThe superior performance of UNet++ underscores the effectiveness of nested skip connections in capturing multi-scale features for railway infrastructure.All models exhibited degraded performance on Tie Rod segmentation (boundary F1 max 0.72), emphasizing the need for specialized architectures to address elongated and occluded components.The mIoU gap between UNet++ (0.8306) and other models (max 0.7738) highlights the importance of hierarchical feature fusion in complex railway environments.
As shown in the table above, different UNet models exhibit distinct differences in IoU and boundary F1 scores across various components. These visualization results provide an intuitive foundation for an in - depth analysis of the models’performance on different components. The detailed analysis is as follows:
The task of segmenting railway networks needs to take into account both overall segmentation accuracy and the precision of boundary detection. Given the shape characteristics of different components in railway networks (such as the regular geometric shape of Switch Machine, the complex branching structure of Switch Rail, the linear distribution of Stock Rail, and the slender structure of Switch Rod), a multi-task learning framework [13] can be designed to separately optimize IoU and boundary f1, balancing overall segmentation accuracy with the precision of boundary detection. For slender structures (like Switch Rod), attention mechanisms (such as attention gating or channel attention) can be introduced to enhance the model’s perception of slender targets, thereby improving the accuracy of boundary detection. For components that perform poorly (such as Stock Rail and Switch Rod), data augmentation techniques (such as rotation, scaling, and noise addition) can be used to increase sample diversity. Additionally, transfer learning can be combined to migrate the feature extraction capabilities of pre-trained models to the railway network segmentation task enhancing the model’s generalization ability. Drawing on UNet++’s multi-scale feature fusion strategy, the model structure can be further optimized to enhance segmentation capabilities for targets of different scales, for example, by introducing deeper feature fusion modules on the basis of UNet to improve segmentation accuracy for complex structures (such as Switch Rail). For components with lower boundary f1 (such as Switch Rod), specialized boundary detection modules (such as edge-enhanced convolutions or boundary-aware loss functions) can be designed to improve the model’s ability to recognize boundaries of slender targets.
In summary, by introducing strategies such as multitask learning frameworks, attention mechanisms, data augmentation, and model structure optimization, the performance of models on various components can be significantly enhanced, especially in the segmentation of slender structures and complex branched structures. These improvement strategies not only enhance the performance of existing models but also provide more efficient and accurate solutions for future railway network segmentation tasks.
5. Code Availability
The source codes are at https://github.com/louzongzhi/Segment, and the The source dataset is at https://doi.org/10.57760/sciencedb.22706.
Author Contributions
Zongzhi Lou: Conceptualization, Methodology, Software, Validation, Writing Original Draft, Writing - Review & Editing, Visualization. Liyao Xiao: Data Curation, Writing - Review & Editing; Yantao Shao: Resources, Investigation. Tian Guo: Data Curation; Zhixiang Huang: Data Curation. Haofeng Liu: Data Curation. Jianyong Zhang: Data Curation. Jiale Chen: Data Curation. Jiahui Ma: Data Curation. Yan Zhang: Supervision, Resources, Investigation.
Acknowledgments
This work was supported by the 2023 China University Industry University Research Innovation Fund - New Generation Information Technology Innovation Project (Grant No. 2023IT252) and the National Natural Science Foundation of China (Grant No. 62302155).
Conflicts of Interest
The author declares that there is no competitive interest.
References
- Zendel, O.; Murschitz, M.; Zeilinger, M.; Steininger, D.; Abbasi, S.; Beleznai, C. RailSem19: A Dataset for Semantic Rail Scene Understanding. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2019, pp. 1221–1229. [CrossRef]
- Zou, Q.; Cao, Y.; Li, Q.; Mao, Q.; Wang, S. CrackTree: Automatic crack detection from pavement images. Pattern Recognition Letters 2012, 33, 227–238. [CrossRef]
- fengweidong.; zhangjiwei.; xujianjian.; liuyuansheng.; fanjianjun. single turnout for coal mine roadway.
- Sepasian, M.; Balachandran, W.; Mares, C. Image enhancement for fingerprint minutiae-based algorithms using CLAHE, standard deviation analysis and sliding neighborhood. In Proceedings of the Proceedings of the World congress on Engineering and Computer Science, 2008, pp. 22–24.
- Setiawan, A.W.; Mengko, T.R.; Santoso, O.S.; Suksmono, A.B. Color retinal image enhancement using CLAHE. In Proceedings of the International conference on ICT for smart society. IEEE, 2013, pp. 1–3.
- Qian, Z.; MI, G.; Zhu, Y.; lifeI, W. research on deep learning model for high speed railway freight station location. Journal of Railways 2024, 46, 36–45.
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015; Navab, N.; Hornegger, J.; Wells, W.M.; Frangi, A.F., Eds., Cham, 2015; pp. 234–241.
- Yiming, O.; Jian, D.; Jianhua, L.; Huaguo, L.; Zhengfeng, H.; Gaoming, D. A Fine-Grained Fault-Tolerant Design of Crossbar Based on Path Diversity in Network-on-Chip. Journal of Computer-Aided Design & Computer Graphics 2017, 29, 180–188,210.
- Wang, X.; Wang, Y.; Zhou, J.; Liu, J.; Gao, Y.; Wang, Y.; Zheng, J. An unsupervised learning method based on U-Net++ for low-light image enhancement. Signal, Image and Video Processing 2025, 19, 282.
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Transactions on Medical Imaging 2020, 39, 1856–1867. [CrossRef]
- Xinyue, M.; Huifeng, W.; Jiale, Z.; Zhen, G.; Bingyong, Y. Semantic Segmentation of Phased Array Ultrasound Images Based on Improved U-Net3+. Journal of East China University of Science and Technology 2025, 51, 242–249. [CrossRef]
- Peng, Y.; Sonka, M.; Chen, D.Z. U-Net v2: Rethinking the Skip Connections of U-Net for Medical Image Segmentation, 2024, [arXiv:eess.IV/2311.17791].
- Lian, L.; Cao, Z.; Qin, Y.; Gao, Y.; Bai, J.; Yu, H.; Jia, L. Densely Multiscale Fusion Network for Lightweight and Accurate Semantic Segmentation of Railway Scenes. IEEE Transactions on Instrumentation and Measurement 2024, 73, 1–11. [CrossRef]
Figure 1.
Sample of the Dataset.
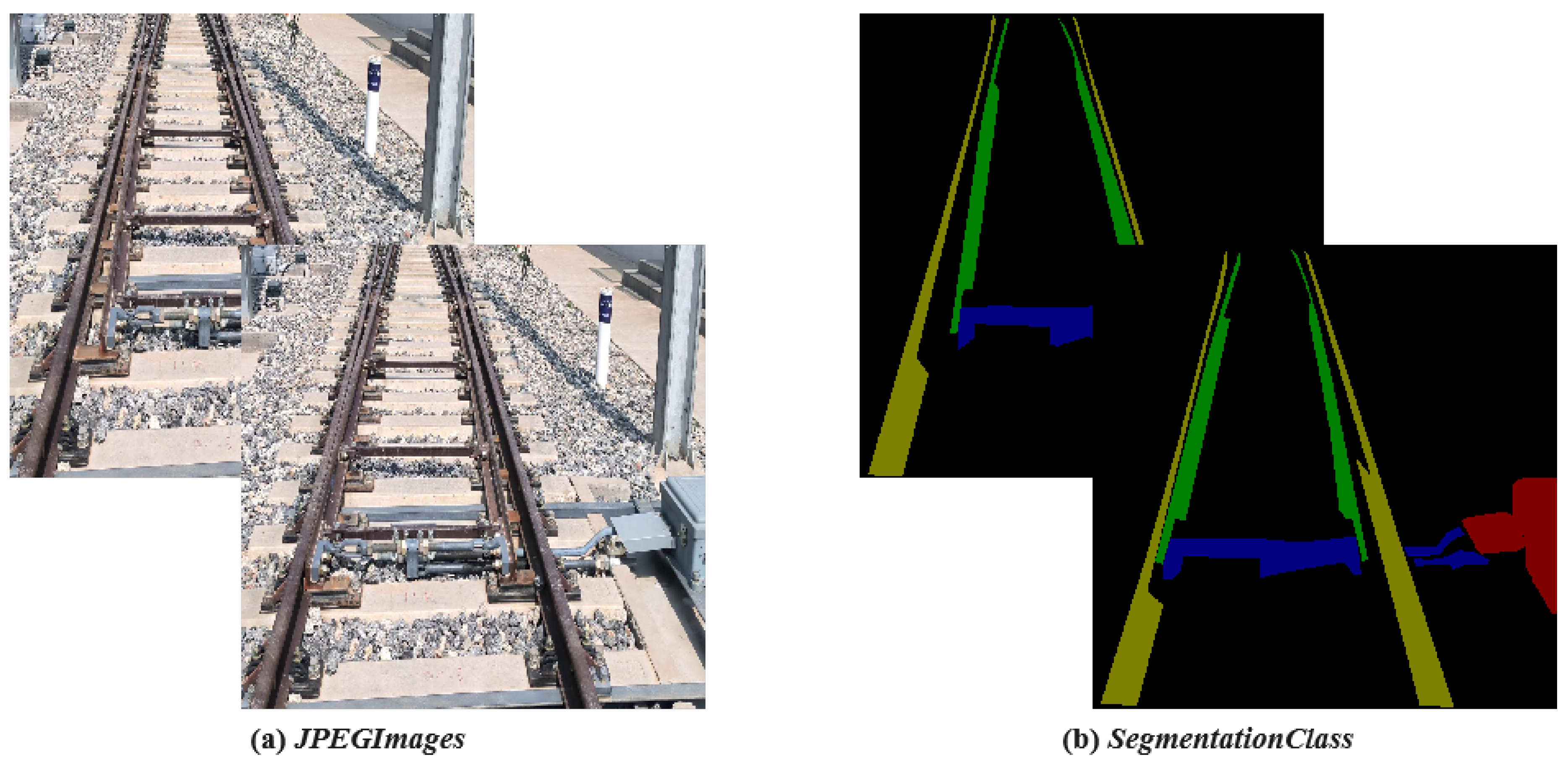
Figure 2.
Hierarchical Data Annotation System for Turnout Components.

Figure 3.
Schematic Diagram of the Three-Tier Quality Verification Workflow.
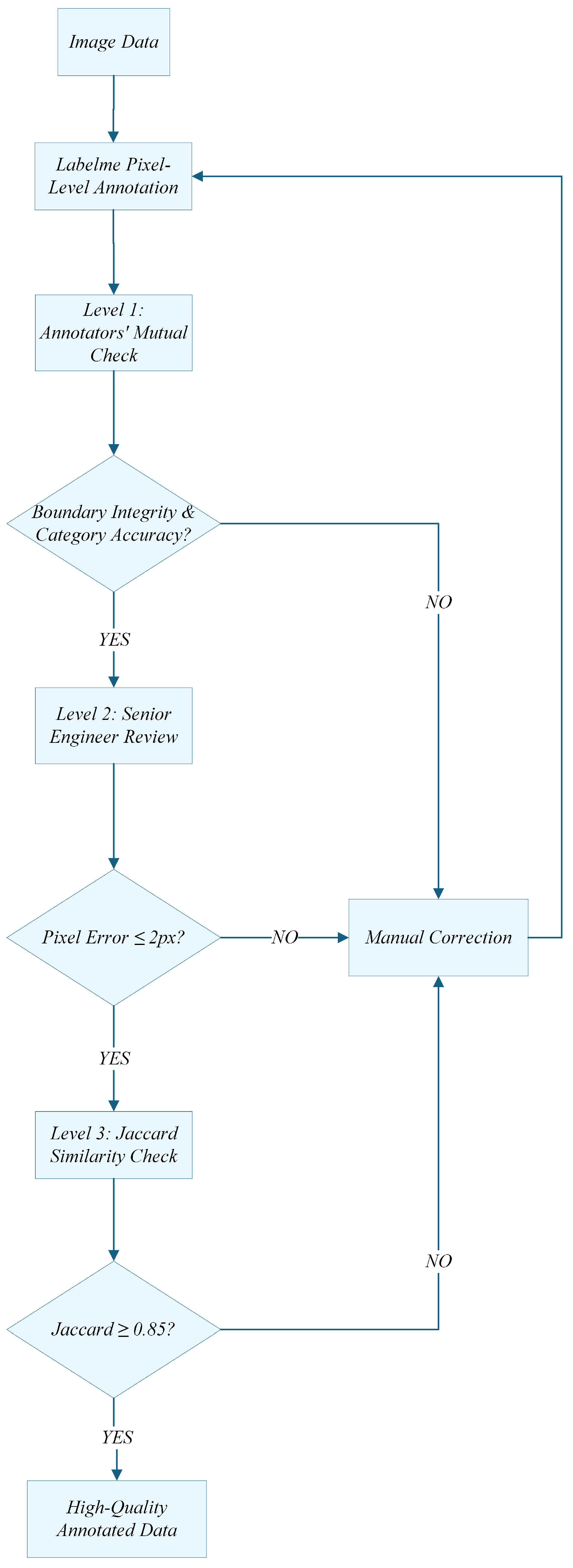
Figure 4.
The Directory Structure of the Dataset.
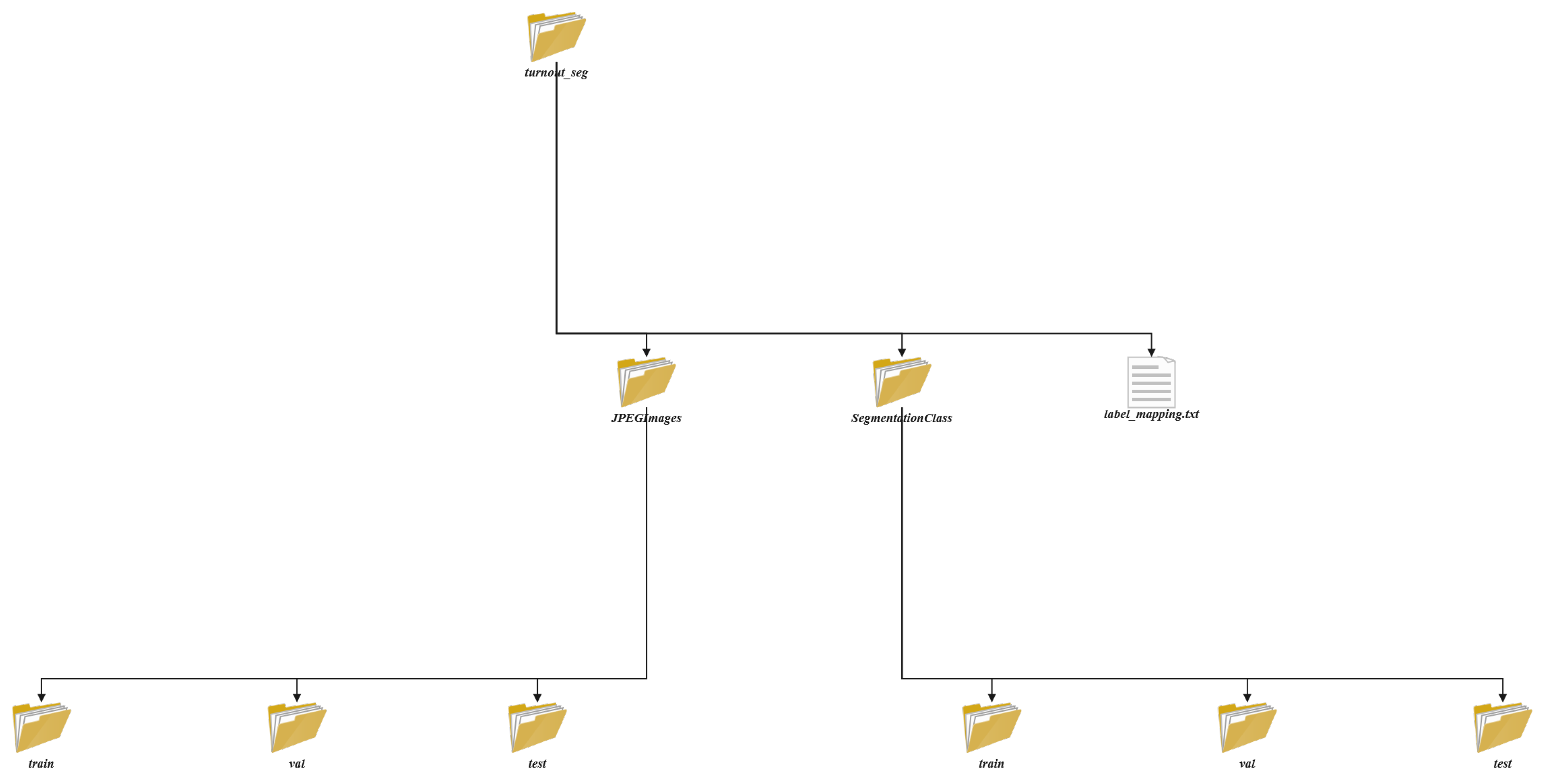

Table 1.
Key Parameters of the Imaging Equipment.
| Parameter | Details |
| Camera Type | 4K industrial camera with manual optical zoom (focal length 5–50 mm, 10× zoom) |
| Resolution | 3840×2160 pixels (8.3-megapixel) |
| Image Sensor | Sony IMX415 (1/2.8-inch) |
| Interface | USB 3.0 + HDMI v1.4 (dual-port synchronous output) |
| Exposure Control | Dynamic ISO adjustment (100–3200), exposure time 1/80 s–1/200 s |
Table 2.
Training Configuration.
| Model Parameters | Value |
| epochs | 1e5 |
| patience | 20 |
| batch size | 32 |
| learning rate | 1e-5 |
| scale | 0.5 |
Table 3.
Quantitative Analysis Results of Different Segmentation Models on Turnout Components.
| models | Switch Machine | Switch Rail | Stock Rail | Switch Rod | mIoU | ||||
| IoU | boundary f1 | IoU | boundary f1 | IoU | boundary f1 | IoU | boundary f1 | ||
| UNet | 0.8788 | 0.7379 | 0.7597 | 0.7428 | 0.6886 | 0.7167 | 0.7672 | 0.6807 | 0.7736 |
| UNet++ | 0.9503 | 0.8008 | 0.8112 | 0.7837 | 0.7424 | 0.7615 | 0.8186 | 0.7142 | 0.8306 |
| UNet3+ | 0.878 | 0.7345 | 0.7509 | 0.7365 | 0.6932 | 0.7187 | 0.7703 | 0.6794 | 0.7731 |
| UNetv2 | 0.8769 | 0.7227 | 0.7594 | 0.7398 | 0.6919 | 0.7158 | 0.7668 | 0.6857 | 0.7738 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



