
Submitted:
19 June 2025
Posted:
19 June 2025
You are already at the latest version
Abstract
This paper presents a novel Retrieval-AugmentedGeneration (RAG) framework tailored for complex questionanswering tasks, addressing challenges in multi-hop reasoningand contextual understanding across lengthy documents. Builtupon LLaMA 3, the framework integrates a dense retrievalmodule with advanced context fusion and multi-hop reasoningmechanisms, enabling more accurate and coherent responsegeneration. A joint optimization strategy combining retrievallikelihood and generation cross-entropy improves the model’srobustness and adaptability. Experimental results show that theproposed system outperforms existing retrieval-augmented andgenerative baselines, confirming its effectiveness in deliveringprecise, contextually grounded answers.
Keywords:
retrieval-augmented generation
; financial QA
; multi-hop reasoning
; LLaMA 3
; context fusion
1. Introduction
Understanding complex question answering (QA) tasks requires deep comprehension of documents containing numbers, legal texts, and intricate language. Large language models (LLMs) often struggle to effectively retrieve and reason over dispersed pieces of information. Retrieval-Augmented Generation (RAG), which integrates retrieval and generation, has shown promising results. However, many existing RAG models still face limitations in multi-hop reasoning and context fusion, which are crucial for tasks involving linked reports, statements, and structured content. Recent advances have addressed these challenges in part—for instance, Dai et al.[1] employed contrastive augmentation to strengthen retrieval, Wang et al.[2] introduced an attention-based architecture for improved context comprehension.
In this study, we propose a multi-module RAG framework built on LLaMA 3 with enhanced retrieval and reasoning capabilities. The system incorporates a query-document embedding module that generates high-dimensional representations and retrieves relevant content from a vector database. To overcome single-hop limitations, we introduce a multi-hop reasoning module that incrementally aggregates context across documents via attention mechanisms. A joint optimization strategy combining retrieval likelihood and generation cross-entropy further improves both retrieval precision and generation quality. Overall, the framework demonstrates improved performance in answering complex queries requiring deep contextual understanding.
Beyond improving general document QA, our methodology also supports high-stakes domains—fraud investigation, regulatory compliance and risk analysis—by enabling accurate multi-document retrieval and reasoning over lengthy, cross-referenced records (e.g., suspicious activity reports, customer disclosures and transaction logs). This capability facilitates automated early fraud detection, streamlined compliance workflows and enhanced transparency in financial operations—key priorities for institutions and regulators. Building on these findings, FinLLaMA-RAG holds significant potential in tax compliance and strategy through two key applications. First, it can empower individual taxpayers and small businesses by serving as a virtual tax assistant. Leveraging its multi-hop retrieval and reasoning, the system can dynamically retrieve relevant sections of tax code and official publications and fuse context (e.g. income type, filing status) to provide personalized, legally accurate guidance on deductions, credits, and filing requirements—helping users maximize benefits and avoid errors that often lead to inquiries or penalties.
2. Related Work
Choi et al.[3] made FinDER, a dataset for financial QA and RAG tests, to solve the lack of good financial data. Kim et al.[4] improved retrieval for financial QA by adding a multi-stage optimization that raises document relevance, but their work focuses more on retrieval than text generation. Chen et al.[5] created a coarse-to-fine 3D reconstruction system with transformers. While it works in vision tasks, it shows how attention can help in text retrieval too. Guan et al.[6] used machine learning to predict breast cancer with network analysis, giving ideas about modeling complex links, though in a medical setting. Luo, Wang, and Guo [7] introduce Gemini-GraphQA, a graph question answering framework that integrates the Gemini large language model with a graph neural network encoder, a graph solver network to translate natural language into executable graph code, and a retrieval-augmented generation module—enhanced by an execution correctness loss—to ensure syntactic and functional accuracy, achieving state-of-the-art performance on diverse graph reasoning tasks.
Chen et al.[8] made FinTextQA, a dataset for long-form financial QA, which helps with large-context understanding but does not add new RAG methods. Sarmah et al.[9] proposed HybridRAG, which mixes knowledge graphs with vector retrieval to improve information extraction, but its multi-hop part is still simple. Iaroshev et al.[10] tested RAG systems on financial reports and showed that challenges remain in dealing with detailed domain language and links between documents.Yu [11] introduces DynaSched-Net, a dual-network framework that combines a Deep Q-Network–based reinforcement learning scheduler with a hybrid LSTM-Transformer workload predictor—optimized via a joint loss function and stabilized by experience replay and target network updates—to enable real-time adaptive cloud resource scheduling that outperforms traditional FCFS and RR methods. Their results also pointed out that current systems often fail when financial questions need reasoning over multiple sections, which shows a need for better ways to combine retrieved data into a full answer.
Lin et al.[12] propose a vector-weighted average algorithm–optimized kernel Extreme Learning Machine for national tax revenue ratio prediction, achieving R² values of 0.995 (training) and 0.994 (test) with RMSEs of 0.185 and 0.177, respectively, demonstrating excellent generalization and stability for tax forecasting. In many cases, the retrieved documents are relevant but the generated answers miss key context, which limits the system’s real use. This makes it clear that a better model should focus on both improving retrieval precision and making sure the generation part fully uses all the retrieved information. Guo and Yu [13] propose PrivacyPreserveNet, a novel multilevel privacy-preserving framework for multimodal large language models that integrates differential privacy-enhanced pretraining, privacy-aware gradient clipping, and noise-injected attention mechanisms to safeguard sensitive text, image, and audio data without sacrificing task performance.
3. Methodology
In this section, we introduce FinLLaMA-RAG, an advanced Retrieval-Augmented Generation (RAG) model designed for document analysis. Leveraging the LLaMA 3 model, FinLLaMA-RAG integrates a multi-hop reasoning module to traverse complex data, enhancing the accuracy and relevance of generated responses. The system employs a contextual fusion layer to aggregate information from multiple document chunks, facilitating comprehensive understanding. A novel loss function balances retrieval accuracy and generation quality, optimizing both components simultaneously. Experimental evaluations demonstrate that FinLLaMA-RAG outperforms existing models in handling intricate queries, offering a robust solution for document analysis. The pipeline of our approach is shown in Fig. Figure 1.
3.1. Query Embedding Module
The input query q is transformed into a dense vector representation using a pre-trained LLaMA 3 model:
This embedding captures the semantic meaning of the query, facilitating efficient retrieval of relevant document chunks.
3.2. Document Retrieval Module
Utilizing the query embedding , the system retrieves the top-k most relevant document chunks from a vector database. The relevance of each chunk is assessed using cosine similarity:
where is the embedding of chunk .
3.3. Contextual Fusion Layer
To enhance the representation of the retrieved chunks, a contextual fusion layer aggregates the embeddings:
with attention weights
3.4. Multi-Hop Reasoning Module
The multi-hop reasoning module performs iterative updates over the aggregated representation:
for . The pipeline of this module is shown in Figure 2.
3.5. Generation Module
The final representation is passed to the LLaMA 3-based generation module, which produces the response r to the input query q:
3.6. Loss Function
The training objective combines retrieval accuracy and generation quality. The retrieval loss is
and the generation loss is
The total loss is a weighted sum:
where and are hyperparameters. Training loss curves are shown in Fig. Figure 3.
3.7. Integration of Large-Scale Document Embeddings
One key innovation of FinLLaMA-RAG is the integration of large-scale pre-trained models like LLaMA 3 with efficient document retrieval and re-ranking mechanisms. By embedding both the query and chunks into high-dimensional vectors and applying similarity-based retrieval, the model can efficiently handle vast collections of documents. Combining retrieval-augmented information with the generative capabilities of LLaMA 3 enables more accurate, contextually relevant responses. FinLLaMA-RAG can streamline international tax strategy for multinational corporations. By parsing and comparing complex regulations—such as bilateral treaties and global tax frameworks—it can rapidly benchmark transfer-pricing policies across jurisdictions. This reduces research time, enhances accuracy of intercompany pricing, and generates an audit-ready trail of citations, supporting both corporate documentation and regulatory oversight to minimize costly disputes.
3.8. Multi-Hop Reasoning Across Hierarchical Data
Another innovation is the use of the multi-hop reasoning module, which enables iterative reasoning across multiple document sections. This approach allows for a more comprehensive understanding of information, as the model can reason over interconnected sections to extract insights. This is especially crucial in analysis scenarios where a question may require synthesizing information from several document parts. As shown in Fig. Figure 4, the left panel visualizes the embedding space via PCA, and the right panel compares initial retrieval scores with re-ranked scores.
3.9. Data Preprocessing
Raw documents are cleaned by
The cleaned text is tokenized into IDs:
Embeddings are generated and indexed for retrieval:
4. Evaluation Metrics
The model performance is evaluated using several key metrics:
4.1. nDCG@10
nDCG@10 evaluates the ranking of the top-10 retrieved documents. It is calculated as:
4.2. BLEU
BLEU measures the overlap of n-grams between the predicted and reference responses. It is computed as:
4.3. ROUGE-L
ROUGE-L measures the longest common subsequence (LCS) between predicted and reference responses:
4.4. F1 Score
The F1 score is calculated as:
5. Experiment Results
6. Conclusions
In this paper, we introduced FinLLaMA-RAG, a novel Retrieval-Augmented Generation model for document analysis. Building on its strengths in complex financial QA, FinLLaMA-RAG also extends naturally into tax compliance and strategy—whether as a virtual tax assistant for individuals and SMEs or as a corporate tool for international transfer-pricing analysis. The model combines advanced retrieval techniques with a powerful generation model and multi-hop reasoning.
References
- Dai, W.; Jiang, Y.; Liu, Y.; Chen, J.; Sun, X.; Tao, J. CAB-KWS: Contrastive Augmentation: An Unsupervised Learning Approach for Keyword Spotting in Speech Technology. In Proceedings of the International Conference on Pattern Recognition. Springer, 2025, pp. 98–112.
- Wang, E. Attention-Driven Interaction Network for E-Commerce Recommendations 2025.
- Choi, C.; Kwon, J.; Ha, J.; Choi, H.; Kim, C.; Lee, Y.; Sohn, J.y.; Lopez-Lira, A. FinDER: Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation. arXiv preprint arXiv:2504.15800 2025.
- Kim, S.; Song, H.; Seo, H.; Kim, H. Optimizing Retrieval Strategies for Financial Question Answering Documents in Retrieval-Augmented Generation Systems. arXiv preprint arXiv:2503.15191 2025.
- Chen, X. Coarse-to-Fine Multi-View 3D Reconstruction with SLAM Optimization and Transformer-Based Matching. In Proceedings of the 2024 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML). IEEE, 2024, pp. 855–859.
- Guan, S. Breast Cancer Risk Prediction: A Machine Learning Study Using Network Analysis. In Proceedings of the 2025 IEEE 15th Annual Computing and Communication Workshop and Conference (CCWC). IEEE, 2025, pp. 00448–00452.
- Luo, X.; Wang, E.; Guo, Y. Gemini-GraphQA: Integrating Language Models and Graph Encoders for Executable Graph Reasoning 2025.
- Chen, J.; Zhou, P.; Hua, Y.; Loh, Y.; Chen, K.; Li, Z.; Zhu, B.; Liang, J. Fintextqa: A dataset for long-form financial question answering. arXiv preprint arXiv:2405.09980 2024.
- Sarmah, B.; Mehta, D.; Hall, B.; Rao, R.; Patel, S.; Pasquali, S. Hybridrag: Integrating knowledge graphs and vector retrieval augmented generation for efficient information extraction. In Proceedings of the Proceedings of the 5th ACM International Conference on AI in Finance, 2024, pp. 608–616.
- Iaroshev, I.; Pillai, R.; Vaglietti, L.; Hanne, T. Evaluating Retrieval-Augmented Generation Models for Financial Report Question and Answering. Applied Sciences (2076-3417) 2024, 14.
- Yu, Y. Towards Intelligent Cloud Scheduling: DynaSched-Net with Reinforcement Learning and Predictive Modeling 2025.
- Lin, Z. Tax share analysis and prediction of kernel extreme Learning machine optimized by vector weighted average algorithm. In Proceedings of the Proceedings of the International Conference on Economic Management and Green Development (ICEMGD), UK, 2025. [CrossRef]
- Guo, Y.; Yu, Y. PrivacyPreserveNet: A Multilevel Privacy-Preserving Framework for Multimodal LLMs via Gradient Clipping and Attention Noise 2025.
Figure 1.
The FinLLaMA-RAG base on LLaMA 3 using multi-hop reasoning module.
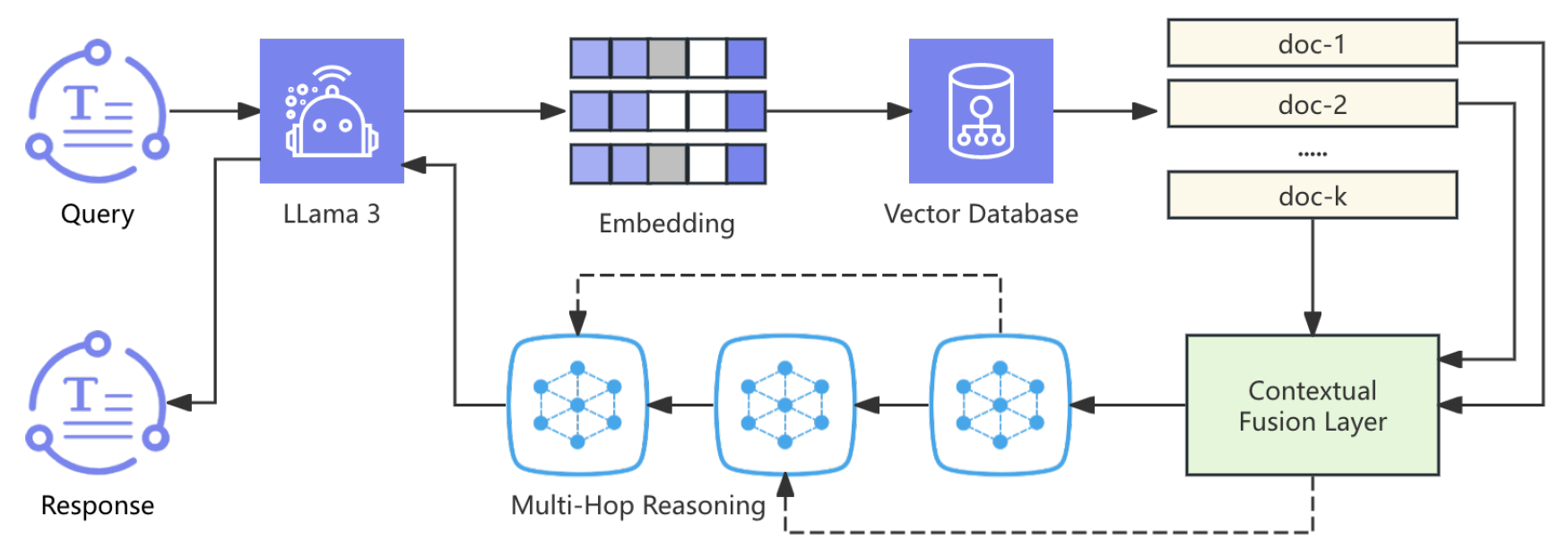
Figure 3.
Training loss components over epochs: retrieval loss, generation loss, and total loss.
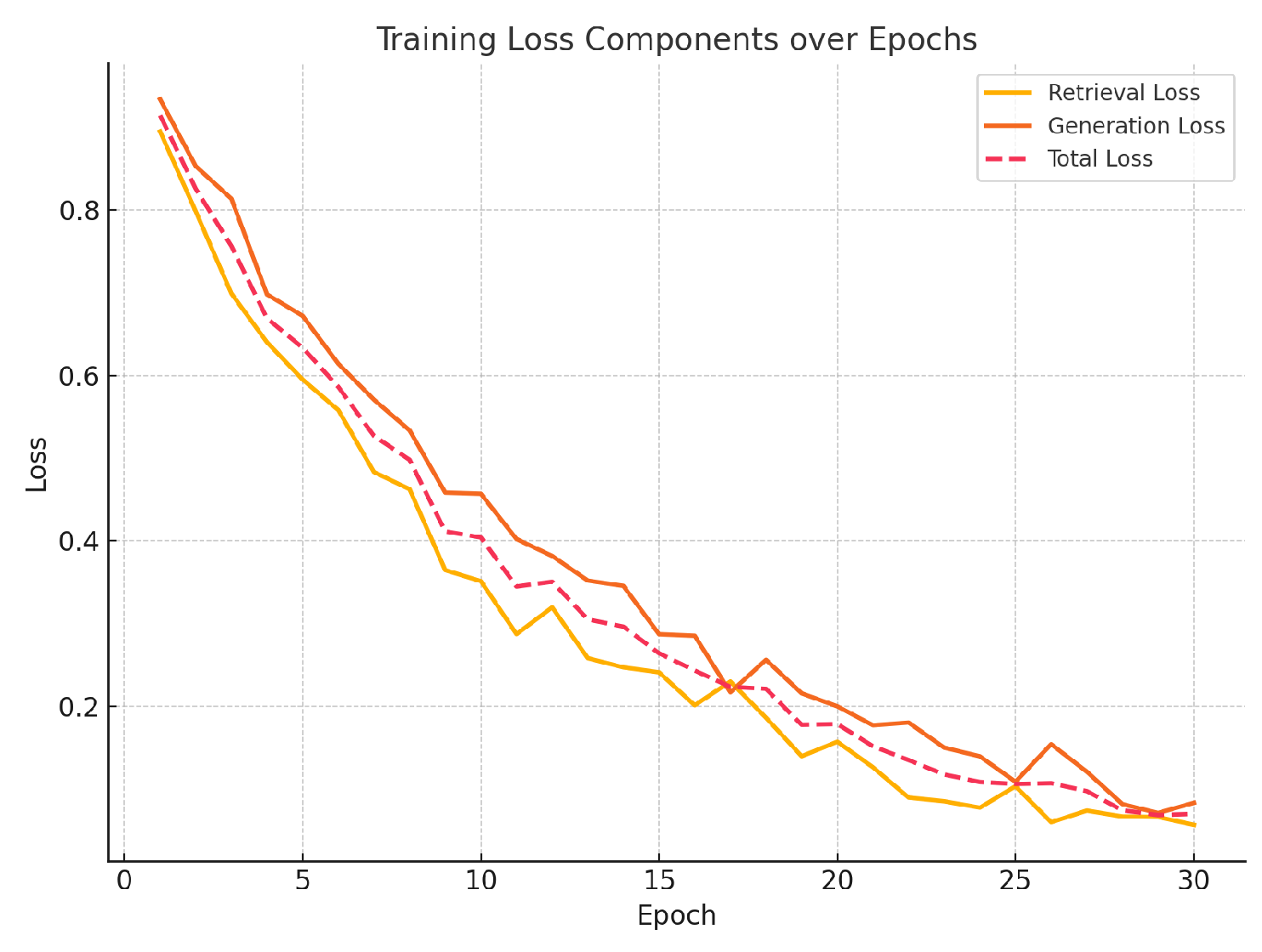
Figure 4.
(Left) Visualization of query and document embeddings in 2D via PCA. (Right) Comparison of initial retrieval scores and re-ranked scores across top-k documents.
Figure 4.
(Left) Visualization of query and document embeddings in 2D via PCA. (Right) Comparison of initial retrieval scores and re-ranked scores across top-k documents.
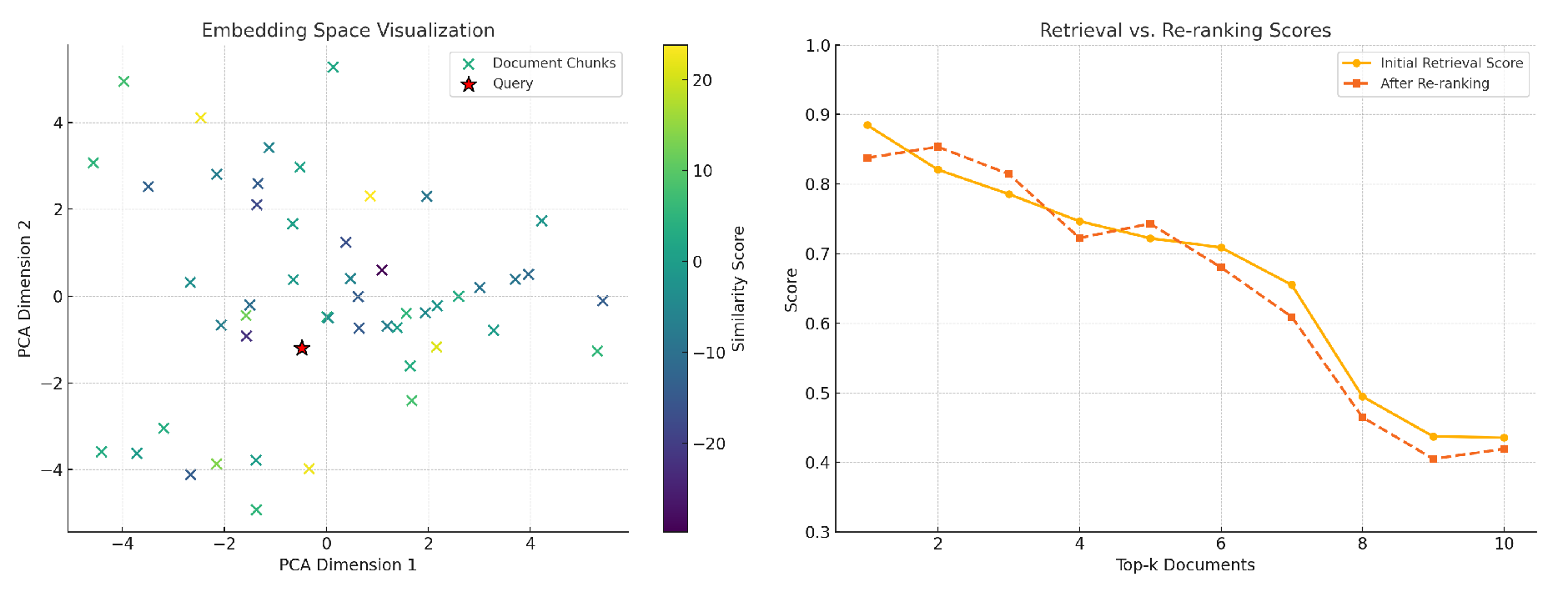
Figure 5.
Changes in model training indicators over time.
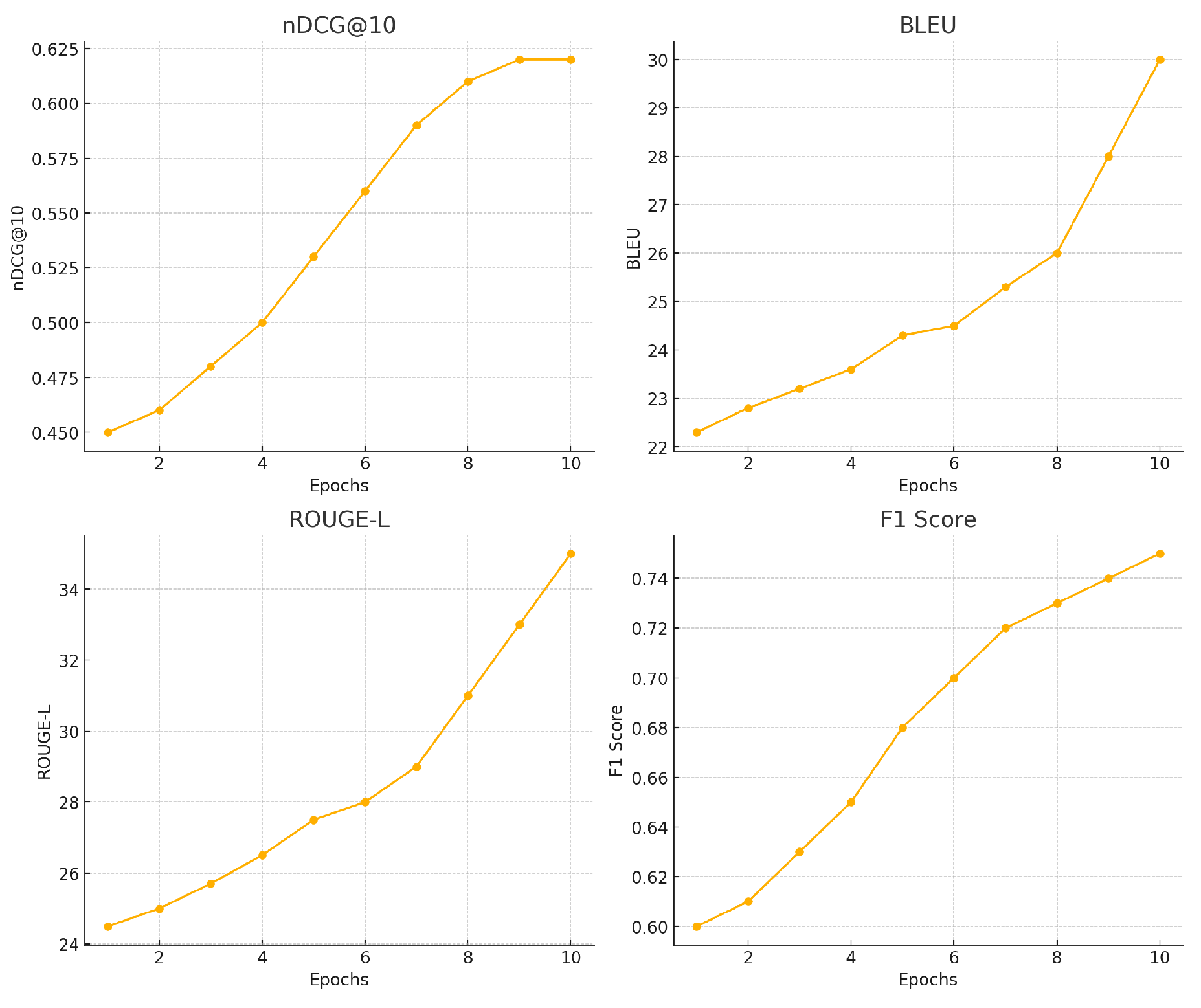

Table 1.
Full Model Evaluation Results.
| Model | FinDER (nDCG@10) | FinQABench (BLEU) | FinanceBench (ROUGE-L) | TATQA (F1) | FinQA (F1) |
|---|---|---|---|---|---|
| BERT-based Retriever | 0.45 | 22.3 | 24.5 | 0.60 | 0.63 |
| Traditional RAG | 0.49 | 23.5 | 26.3 | 0.62 | 0.67 |
| FinBERT | 0.52 | 24.7 | 28.0 | 0.64 | 0.70 |
| GPT-3 | 0.56 | 26.3 | 29.2 | 0.66 | 0.72 |
| FinLLaMA-RAG | 0.62 | 30.5 | 35.2 | 0.75 | 0.78 |
| Retrieval-Only Model | – | – | – | – | – |
| Generation-Only Model | – | – | – | – | – |
Table 2.
Ablation Study Results.
| Model | nDCG@10 | BLEU | ROUGE-L | F1 |
|---|---|---|---|---|
| BERT-based Retriever | – | – | – | – |
| Traditional RAG | – | – | – | – |
| FinBERT | – | – | – | – |
| GPT-3 | – | – | – | – |
| FinLLaMA-RAG | 0.62 | 30.5 | 35.2 | 0.75 |
| Retrieval-Only Model | 0.45 | 18.2 | 22.5 | 0.60 |
| Generation-Only Model | 0.48 | 19.1 | 24.1 | 0.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



