
Submitted:
15 June 2025
Posted:
16 June 2025
You are already at the latest version
Abstract
Accurate and timely 3D vegetation structure information is essential for ecological modeling and land management. However, these needs often cannot be met with existing airborne LiDAR surveys, whose broad-area coverage comes with trade-offs in point density and update frequency. To address these limitations, this study introduces a deep learning framework built on attention mechanisms, the fundamental building block of modern large language models. The framework upsamples sparse (<22pt/m2) airborne LiDAR point clouds by fusing them with stacks of multi-temporal optical (NAIP) and L-band quad-polarized Synthetic Aperture Radar (UAVSAR) imagery. Utilizing a novel Local-Global Point Attention Block (LG-PAB), our model directly enhances 3D point cloud density and accuracy in vegetated landscapes by learning structure directly from the point cloud itself. Results in fire-prone Southern California foothill and montane ecosystems demonstrate that fusing both optical and radar imagery reduces reconstruction error (measured by Chamfer distance) compared to using LiDAR alone or with a single image modality. Notably, the fused model substantially mitigates errors arising from vegetation changes over time, particularly in areas of canopy loss, thereby increasing the utility of historical LiDAR archives. This research presents a novel approach for direct 3D point cloud enhancement, moving beyond traditional raster-based methods and offering a pathway to more accurate and up-to-date vegetation structure assessments.
Keywords:
LiDAR upsampling
; point cloud enhancement
; multi-modal fusion
; deep learning
; attention mechanism
; SAR
; optical imagery
; vegetation structure
; transformers
1. Introduction
Accurate three-dimensional (3D) vegetation structure information at submeter spatial scales now plays a key role in applications ranging from wildfire risk modeling [1] to biodiversity and habitat assessment [2,3]. The way vegetation is arranged—its height, density, and continuity—directly influences both fire hazard and fire behavior, and impacts how species use the landscape. Fuels, as opposed to topography and weather, are the only element of the fire behavior triangle that land managers can directly manipulate [4], making structural data vital for strategic interventions. Simultaneously, vegetation structure governs microclimate, resource availability, and landscape connectivity, making it a cornerstone of ecological monitoring and conservation planning [5,6,7]. Airborne light detection and ranging (LiDAR) has emerged as a premier tool for capturing this structural complexity, enabling detailed, landscape-scale mapping of vegetation structure that was previously unattainable with passive optical imagery [2,8,9].
National mapping programs such as the U.S. Geological Survey’s 3D Elevation Program (3DEP) now collect LiDAR data over large areas, but these surveys have important limitations. Typical 3DEP acquisitions are performed at modest point densities (on the order of 0.520pts/) [10] and with much of the national LiDAR baseline acquired over an extended period (e.g., roughly 2015-2023), a significant portion of this data is now several years old, a situation exacerbated by the lack of a guaranteed or universal update timeline [11]. Consequently, the available point clouds often reflect conditions from several years prior and are relatively sparse compared to those obtained from other platforms (e.g., uncrewed aerial vehicles, or UAVs, see Figure 1).
Critical changes in vegetation structure, such as disturbance-driven loss or ongoing vegetation growth, may go undetected between LiDAR acquisition cycles. This sparsity and temporal gap limit the utility of national LiDAR datasets for applications that require up-to-date, high-resolution 3D information.
Given the limitations of national LiDAR in spatial and temporal resolution, one promising avenue is to enrich these sparse datasets using co-registered imagery from other remote sensing platforms that offer more frequent updates. Sub-meter resolution aerial imagery—such as orthophotos from the National Agriculture Imagery Program (NAIP) [12]—provides fine detail on canopy textures, gaps, and vegetation color, typically acquired at 2 year intervals. Complementing this, L-band synthetic aperture radar known for its sensitivity to vegetation structure [13], can provide valuable multi-temporal data through repeat acquisitions. NASA’s UAVSAR [14], for example, conducts roughly bi-annual L-band campaigns to monitor movement along the San Andreas fault in California, and the upcoming NISAR satellite mission will offer global L-band SAR at a 12-day revisit rate [15]. Fusing such temporally rich optical and radar imagery with existing LiDAR has the potential to produce a denser 3D point cloud reflecting more current vegetation conditions—a challenge well-suited to data-driven approaches such as deep learning. In particular, attention-based models offer a powerful way to integrate these diverse inputs by modeling their spatial and semantic relationships.
Attention mechanisms, first introduced for language translation by [16], enable a model to dynamically determine which parts of the input data are most relevant to each other, a capability crucial for understanding complex scenes. For example, in point clouds of vegetated landscapes, a point on a tree’s leaf can learn, through self-attention, to connect more strongly with its own trunk or branches than with foliage from an adjacent, albeit closer, tree. This ability to discern intrinsic structural relationships could be particularly effective in natural vegetation, as its fractal and self-similar nature provides consistent patterns for self-attention to model across different scales [17,18]. When fusing data, cross-attention extends this by allowing features from one modality, such as a LiDAR point, to selectively query information from another modality, like relevant shadow patterns or canopy gaps identified in NAIP imagery or radar data. These powerful attention operations are the fundamental building block of the influential Transformer architecture [19], which serves as the foundation for nearly all large language model architectures in use today. Building on that success, Transformers were adapted for vision tasks [20] and are now increasingly used across many remote sensing tasks [21]. While these advancements showcase their broad utility, their specific application and optimal adaptation for enhancing sparse airborne LiDAR in complex vegetated landscapes present unique challenges and open questions.
Consequently, key knowledge gaps remain. First, most prior work on data-driven LiDAR enhancement has focused on enhancing point-cloud-derived metrics in raster form (e.g. canopy height [22,23], above-ground biomass [24], elevation [25], and other fuel/vegetation metrics [26,27]) rather than directly enhancing the point cloud itself. Although one recent study successfully upsampled mobile laser scanner point clouds in a forested environment using terrestrial LiDAR as the reference dataset [28], both sensors differ substantially from airborne systems in scale and occlusion behavior. Second, existing deep learning frameworks for point cloud upsampling have primarily been developed and tested on synthetic shapes or man-made objects, and their efficacy on the complex, irregular structures of natural vegetation is not well understood. Third, we found no studies that have attempted to leverage optical or radar imagery for enhancing point clouds in vegetated landscapes. Fourth, we found no studies that have analyzed model performance when the LiDAR input is temporally misaligned with the reference dataset, confounding performance metrics with real-world landscape changes. Deep models are typically trained and evaluated on static scenes, often using an artificially down-sampled point cloud as the input. Thus, it remains unknown how upsampling errors behave in areas where substantial canopy growth or loss has occurred since the original LiDAR survey, or whether multi-modal inputs can mitigate errors stemming from such changes.
1.1. Background and Related Work
1.1.1. Point Cloud Upsampling with Deep Learning
In computer vision and graphics, a range of neural frameworks have been proposed to densify sparse point clouds. PU-Net [29] pioneered the task with multi-layer perceptron (MLP) feature extraction and a point-set expansion module, achieving good fidelity on synthetic computer-designed (CAD) objects. PU-GCN (Point Upsampling-Graph Convolution Network) later built upon this by replacing the expansion MLP with a graph-convolution upsampling unit called NodeShuffle and paired it with a GCN feature extractor [30]. Recently, PU-Transformer introduced the first transformer-based upsampler to exploit both local and long-range relations [31]. While these methods deliver state-of-the-art results on synthetic shapes and man-made objects, their behavior on the irregular geometry of vegetation—and in LiDAR-derived point clouds more broadly—remains largely untested.
1.1.2. Upsampling in Vegetated Landscapes
Upsampling LiDAR data from forests and other natural vegetation introduces unique challenges. In natural vegetation, aerial LiDAR point clouds exhibit uneven densities—upper vegetation layers are well sampled due to their proximity to the sensor, while lower vegetation layers and the ground experience significantly reduced returns, introducing complexity that differs from man-made environments. Zhang and Filin [32] highlighted that most existing research had focused on upsampling point clouds of man-made objects, with little attention to natural scenes. They found that standard 3D interpolation or naïve point densification often leads to over-smoothed results in forests, since such methods ignore fine local variations in structure. To address this, Zhang and Filin proposed a graph convolutional network with a global attention mechanism that exploits vegetation’s self-similar geometric patterns for superior vegetated landscape upsampling. Nevertheless, that work relied solely on the geometric information in the LiDAR point cloud, without incorporating external imagery or multi-modal data.
1.2. Utilizing Cross-Attention for Multi-Modal Fusion
Cross-attention mechanisms have proven valuable for multi-modal data fusion in remote sensing, though their application has largely centered on integrating various 2D raster datasets [33,34,35,36]. In remote sensing, the primary method for fusing 3D LiDAR data with imagery involves rasterizing the LiDAR information, most often by integrating digital surface models (DSMs) with hyperspectral data [37,38,39]. Consequently, the direct fusion of individual LiDAR point features with imagery using cross-attention represents a largely unexplored area in remote sensing research. Conversely, the broader computer vision community actively develops and utilizes such direct point-to-image cross-attention techniques for enhancing detailed 3D scene perception [40,41,42].
1.2.1. Attention-Based Multi-Modal Upsampling
Building on these advances, we introduce an upsampling model that leverages attention mechanisms to capture both local and global context while fusing LiDAR with optical and radar inputs. Transformer-based architectures have recently shown promise in 3D point cloud tasks by modeling long-range dependencies in point sets. Our network adopts a Local-Global Point Attention block structure inspired by this paradigm. At the local scale, a multi-head variant of a point transformer architecture developed by Zhao et al. [43] applies self-attention within each point’s neighborhood to learn fine-grained spatial details. This “multi-head” approach enables the model to learn multiple, distinct feature representations in parallel; for instance, one head may learn to model fine-scale canopy texture while another captures broader branch-level geometry. At the global scale, we incorporate a position-aware multi-head attention mechanism over the entire point cloud to ensure structural coherence. To maintain computational efficiency, we implement this global attention with a FlashAttention [44] algorithm, allowing exact multi-head attention across thousands of points in a memory-efficient manner. By combining local and global attention pathways, the model preserves small-scale features (e.g., individual tree crown shapes) while enforcing consistency in larger-scale patterns (e.g., stand-level canopy height gradients). This architecture extends prior point upsampling networks but is uniquely tailored to handle multi-modal inputs and the complexities of natural scenes.
The primary scientific contribution of our study is not merely a new network architecture, but rather the exploration of a fused-modality approach to LiDAR point cloud upsampling. In contrast to previous methods that input only sparse LiDAR points, we evaluate how incorporating additional imagery (optical NAIP and L-band SAR) can improve the reconstruction of vegetation structure. We also explicitly examine the temporal dimension by testing models in areas with known canopy growth or loss since the original LiDAR acquisition, an aspect largely overlooked in prior research.
1.3. Research Questions
-
RQ1: To what extent does incorporating individual imagery modalities, (a) high-resolution optical imagery or (b) L-band Synthetic Aperture Radar (SAR) imagery, lower the point-cloud reconstruction error (measured by the Chamfer distance) compared to a baseline upsampling model that uses only the initial sparse LiDAR as input?
- -
- Hypothesis: Both modalities will reduce reconstruction error, but optical imagery will yield superior results.
- -
- Reasoning: The finer ground sampling distance of optical imagery provides high-resolution texture essential for fine-scale detail. While L-band SAR is sensitive to volumetric structure, its coarser resolution is a limitation.
-
RQ2: Does simultaneously fusing high-resolution optical and L-band SAR imagery yield additional reconstruction accuracy gains beyond the best single-modality model, indicating complementary rather than redundant information?
- -
- Hypothesis: The fused optical and SAR model will achieve the lowest reconstruction error, outperforming both single-sensor models.
- -
- Reasoning: Each sensor captures a different aspect of vegetation structure. The model’s attention-based fusion is expected to leverage optical texture to define canopy boundaries and SAR backscatter to reconstruct internal volume.
-
RQ3: How does reconstruction error change with net canopy-height gains and losses since the initial airborne LiDAR survey, and do the optical, SAR, and fused models mitigate these errors more effectively than a baseline upsampling model that uses only the initial sparse LiDAR as input?
- -
- Hypothesis: Errors will scale with canopy change and be greater for losses than gains. Model performance will stratify accordingly: the fused model will best mitigate these errors, followed by single-modality models, with the baseline performing poorest, though it may capture some uniform growth.
- -
- Reasoning: The predicted error asymmetry stems from the different nature of vegetation dynamics. Growth is often an incremental extrapolation of existing structure, whereas disturbance-driven loss (e.g., fire, treefall) can be abrupt and total. This creates a complete information void for removed canopy in the legacy LiDAR, a more significant reconstruction challenge than modeling gradual growth.
2. Materials and Methods
The core challenge addressed by this research is the enhancement of sparse and outdated national airborne LiDAR datasets. To train and validate supervised upsampling models, we collected dense UAV LiDAR as a benchmark of actual vegetation structure. The sections below describe the study areas where this data was collected, the multi-modal input data sources, and steps taken to ensure spatial alignment and consistency across all modalities.
2.1. Study Area
The study area (Figure 2) consists of two separate sites in Southern California, USA. The first study area includes parts of the 24-square-kilometer Sedgwick Reserve, managed by the University of California, Santa Barbara, and the adjacent 11.5 square kilometer Midland School property. Both sit within the San Rafael Mountain foothills of Santa Barbara County (Figure 3).
The area spans elevations from 287 to 852 meters and supports a mosaic of vegetation types with varying canopy architectures, including coastal sage scrub, native grasslands, chaparral (shrublands), coast live and blue oak woodlands, valley oak savanna, riparian habitats, and gray pine forests. UAV LiDAR was collected on four sites (totaling about 71 hectares) within the study area (Table 1). Given their similar terrain and vegetation, two sites were used for training, while the two smallest were withheld for independent model evaluation.
The second study area (Figure 4) comprises 197 hectares within and adjacent to the Volcan Mountain Wilderness Preserve in the Peninsular Range of Southern California. The reserve is managed by San Diego County and the Volcan Mountain Foundation and ranges in elevation from about 1220 meters to over 1675 meters. It hosts diverse plant communities, including oak woodlands, chaparral, mixed conifer forests, and grasslands. To ensure robust model evaluation across this ecological gradient, roughly 30 percent of the area (58 hectares) was reserved for testing and validation (Table 1). The three holdout zones (Figure 4) used for model evaluation were selected to reflect the site’s vegetation diversity: the northernmost area includes chaparral that replaced forest following wildfires in 2003 and 2005; the central zone contains dense mixed-conifer and riparian vegetation interspersed with oak woodlands and chaparral; and the southernmost zone is predominantly semi-continuous oak canopy.
2.2. The Data
All remote-sensing assets were co-registered within a common tiling framework covering both study sites. First, the UAV-LiDAR acquisition footprints were tessellated into 10 m × 10 m analysis tiles with 15% overlap, yielding an initial set of 9,800 tiles at Sedgwick–Midland and 26,557 tiles at Volcan Mountain. Each tile served as the spatial key for assembling a four-layer data stack (Table 2)
By standardizing on overlapping 10 m patches, we guarantee that each training example draws from the same footprint across sensors—ensuring the model learns consistent, co-registered features from LiDAR, SAR, and imagery.
2.2.1. UAV LiDAR Data
Sedgwick and Midland Sites - Between June and October 2023, UAV LiDAR data were collected by San Diego State Geography Department Staff on the Sedgwick and Midland School Sites using a DJI Matrice 300 drone equipped with a TrueView 515 LiDAR. The drone was flown at an altitude of approximately 60 meters above ground level, achieving a point density of around 300 points per square meter.
Volcan Mountain Site - On October 25, 2024, the same Geography Department staff conducted flights using a DJI Matrice 350 drone equipped with a TrueView 540 LIDAR system. This newer drone and sensor was flown at a higher altitude of approximately 110 meters above ground level, and still achieved a point density of over 600 points per square meter.
2.2.2. Crewed Airborne LiDAR
The available crewed airborne LiDAR (C-ALS) data includes two separate 3DEP datasets. The Sedgwick 3DEP dataset, collected in 2018, has a point density of 22 pts/m2. The C-ALS data for the Volcan Mountain site was collected between October 2015 and November 2016 and has a point density of 6.3 pts/m2 [45]. Both datasets were obtained from Microsoft’s Planetary Computer [46,47]
2.2.3. Synthetic Aperture Radar (SAR)
Fully polarimetric L-band imagery (23.84 cm wavelength) from NASA’s UAVSAR system was obtained with the Alaska Satellite Facility’s asf_search Python API [48]. The UAVSAR flights were conducted from a Gulfstream-III platform with bidirectional acquisitions from opposite look directions at an average altitude of 12,495 meters, providing multi-perspective radar coverage of the landscape at 6.17-meter ground resolution. The specific campaigns and acquisition details for each study site are summarized in Table 3. For every 10 m × 10 m 3DEP tile we extracted a co-centered 20 m × 20 m UAVSAR chip to accommodate layover and shadow extent, then bilinearly resampled each chip to 5 m GSD before fusion with NAIP imagery and LiDAR.
2.2.4. High-Resolution Aerial Imagery
We ingested NAIP imagery through the Microsoft Planetary Computer STAC API [47] for survey years 2014–2022. NAIP provides four-band (Red, Green, Blue, Near-Infrared) orthoimagery of the conterminous United States, collected at peak green-up on a two- to three-year cycle. Prior to the 2016 flight season, data were delivered at 1 m ground-sample distance (GSD); since 2016 the native resolution has been 60 cm. A complete timeline of these acquisitions and their resolutions is provided in Table 3. For every 10 m × 10 m 3DEP tile we extracted a 20 m × 20 m NAIP chip centered on the same point to accommodate viewing-geometry variance and to capture neighboring shadows. All NAIP scenes were then resampled to a common 50 cm grid.
2.3. Data Cleaning and Preprocessing
To reduce computational load and give the upsampling network a uniform-density target, we downsampled the UAV LiDAR for every tile with an adaptive anisotropic voxel grid. Each cloud was first voxelized at a 4 cm × 4 cm × 2 cm resolution; if more than 50,000 points remained, the horizontal voxel edge was incrementally enlarged (keeping the vertical edge at 50% of that value) and the filter reapplied until the count fell below the limit. The resulting point sets preserve fine vertical structure while standardizing horizontal density. The dataset was partitioned into training, validation, and test sets using reference polygons to ensure the holdout sets captured the full environmental gradients found in the training data. We enforced quality constraints by requiring a UAV-to-3DEP point ratio above 2.0, and a minimum of 16,000 UAV LiDAR points and 200 3DEP points per tile.
2.4. Data Augmentation
To increase the model’s robustness and prevent overfitting, we expanded the training dataset from 24,000 to 40,000 tiles via data augmentation[49,50]. First, we preferentially selected source tiles for this process, prioritizing those with high structural complexity (z-variance) and large vegetation changes. Each selected source tile was then used to generate a new, augmented sample by applying a random combination of transformations. These included geometric operations (rotations and reflections) applied to all data layers, and point cloud-specific perturbations (random point removal and jittering) applied only to the input LiDAR data.
2.5. Model Architecture
Our multimodal upsampling framework transforms a sparse 3DEP point cloud, plus co-registered NAIP and UAVSAR image chips, into a denser 3-D point cloud (Figure 5). The network is built around the Local–Global Point Attention Block (LG-PAB; §2.6), which provides permutation-invariant feature learning, optional feature-guided upsampling, and long-range geometric context. Five macro–components are arranged in a feed-forward sequence: (1) point feature extraction, (2) imagery encoding, (3) cross-attention fusion, (4) feature expansion and refinement, and (5) point decoding.
Notation Conventions
Throughout this section, we use the following notation for tensor dimensions:
- Counts: (number of input points), (current points in LG-PAB), (upsampled points), (number of image patches, default 16), (temporal stack length), (maximum look angles, ).
- Dimensions: (coordinate dimension), (attribute dimension), (point feature dimension), (input point feature dimension), (output point feature dimension), (token dimension).
- Channels: (NAIP channels), (UAVSAR channels).
- Image dimensions: (NAIP height/width), (UAVSAR patch region height/width).
- Other: (upsampling ratio, default 2), (k-nearest neighbors).
For tensors, we use the notation TensorSymbol: (dim1, dim2, ..., dimk) to describe their dimensions.
Given an input cloud with points and attributes , the network outputs with points where (typically ).
An overview is:
- LG-PAB Extractor local–global point features ;
- Imagery Encoders NAIP and UAVSAR patch embeddings ;
- Cross-Attention Fusion enriched point features ;
- LG-PAB Expansion & Refinement upsampled features and coordinates ;
- MLP Decoder residual offsets and final coordinates .
2.6. The Local–Global Point Attention Block (LG-PAB)
Figure 6 presents a flow-chart of the Local–Global Point Attention Block, the fundamental unit used three times in our architecture (extraction, expansion, and refinement stages). Each LG-PAB converts an input tuple consisting of point features and 3-D coordinates into refined (and optionally upsampled) features and positions. The block proceeds through the stages that appear in the diagram:
- Local Attention Block A Multi-Head Point Transformer operates on a -nearest-neighbour graph () to capture fine-scale geometry. Its output passes through a two-layer Feed-Forward Network (FFN) with GELU activation, producing an intermediate tensor . When the upsampling ratio this step already delivers the final per-point features.
- Feature-Guided Upsampling (optional) If (expansion stage) the intermediate tensor is reshaped to , effectively cloning each feature vector times. A small Position-Generator MLP then predicts a 3-D offset for every clone, yielding new coordinates . The features are flattened back to .
- Global Attention Block To impose long-range coherence, the upsampled (or original) features are processed by Position-Aware Global Flash Attention. Coordinates are first embedded by a two-layer MLP, concatenated to the features, and fed to a four-head FlashAttention layer that attends across all points in the tile. A second FFN refines the attended features, after which residual connections and LayerNorm complete the block.
2.7. Imagery Encoders
Optical (NAIP) and radar (UAVSAR) image chips are processed by a shared five-stage encoder (with modality specific weights) that converts each image stack into a fixed set of patch tokens. The encoder stages—illustrated in Figure 7—are:
- Patch Tokenization. A two-layer Conv–GELU–Conv stem with stride-1 followed by average pooling (stride=) extracts features on a grid. This design mirrors Shifted Patch Tokenization, which adds local texture bias to Vision Transformers (ViTs) and improves sample efficiency on small datasets [51]. The patches are flattened to and normalized via LayerNorm.
- 2-D Positional Encoding. Normalized patch centers are embedded via a two-layer MLP and added to the tokens: .
- Transformer Encoder Block. A 4-head self-attention layer is paired with LayerScale (), a learnable scalar that stabilizes deep transformers [52]. The accompanying MLP includes a depth-wise 1-D convolution, following the ConViT approach to introduce a soft convolutional inductive bias [53]. The block outputs .
- Temporal GRU–Attention Head. For inputs with temporal length , a bidirectional Gated Recurrent Unit (GRU) with attention pooling aggregates tokens into patch descriptors .
UAVSAR Look Angle Mean Pooling
- UAVSAR. Input with . After stage 3, we average features across available look angles to produce before temporal processing. Otherwise, the pipeline matches NAIP.
Both encoders output token matrices and that are normalized and concatenated before fusion.
2.8. End-to-End Upsampling Pipeline
1) Local–Global Feature Extraction.
The sparse 3DEP cloud—concatenated with intensity, return number, and number or returns (6 attributes total)—is processed by the first Local–Global Point Attention Block (§Section 2.6). The output is a set of point features that encode both neighborhood morphology and tile-level context.
2) Imagery Encoders.
Co-registered NAIP and UAVSAR chips are independently tokenized and fed to lightweight Transformer encoders ( patches, embed dim ). The optical encoder (RGB+NIR) outputs patch embeddings , whereas the radar encoder (L-band polarimetry) outputs . When multiple acquisition dates exist, per-modality tokens are fused temporally via a shared GRU–attention head.
3) Cross-Attention Fusion.
Point features act as queries and image patches as keys/values in a four-head cross-attention block. Scaled dot-product scores are masked for patches whose centroid is more than 8 meters from the query point. The fused representation augments every point with spectral texture and volumetric back-scatter cues, improving discrimination of canopy surfaces versus gaps.
4) Feature-Guided Upsampling.
A second LG-PAB with ratio expands and predicts offsets that generate candidate coordinates. This stage doubles point density while maintaining local topology.
5) Feature Refinement.
A third LG-PAB (ratio ) re-computes local and global attention on the enlarged cloud, ironing out artifacts introduced during expansion and propagating context across newly formed neighborhoods.
6) Coordinate Decoding.
Finally, a four-layer MLP () regresses residual offsets that are added to the upsampled positions, producing the higher-resolution prediction .
2.9. Training Protocol and Analysis
To systematically evaluate our research questions, we established a rigorous training and analysis protocol. The full dataset, comprising tiles from both study areas, was partitioned into training, validation, and testing subsets. The training set consists of 24,000 original tiles, which was expanded to 40,000 through the data augmentation process described previously. A separate set of 3,792 tiles was reserved for validation during training, and a final hold-out set of 5,688 tiles was used for testing and performance evaluation (Table 4).
To isolate the impact of each data modality, we trained four distinct model variants (Table 5). A baseline model was trained using only the sparse 3DEP LiDAR input. Two single-modality models were trained by fusing the LiDAR with either NAIP optical imagery or UAVSAR radar data. Finally, a fully fused model was trained using all three data sources simultaneously.
All model variants were trained using an identical architecture, set of hyperparameters, and training protocol to ensure a fair comparison. Key model configuration parameters, including feature dimensions and attention head counts, are provided in Table 6. The models were trained for 100 epochs on four NVIDIA L40 GPUs using the ScheduleFreeAdamW optimizer [54] and a density-aware Chamfer distance loss function (Eq. 9 in [55]). Further details on the training protocol and hardware are listed in Table 7.
We evaluated our research questions using non-parametric statistical tests to account for non-normality in the error distribution. For RQ1 and RQ2, we used Wilcoxon signed-rank tests to compare reconstruction error (measured by Chamfer distance) between models, with median percentage change and rank-biserial correlation as effect size measures. For RQ3, we used Spearman rank correlations to analyze the relationship between reconstruction error and absolute canopy height change across all models. We further split the dataset into canopy gains (N=2423) and losses (N=3264) to examine potential asymmetries in error patterns. Fisher r-to-z transformations were used to statistically compare correlation coefficients between models. All significance values are reported at =0.05, with bold values indicating statistically significant results.
3. Results
A summary of the reconstruction performance, measured by Chamfer distance (CD), across all models is presented in Table 8. The 3DEP LiDAR-only baseline model provided a substantial improvement over using the raw, sparse input data, reducing the median error by over 60% and tightening the error distribution (Figure 8 and Figure 9). When comparing the performance across all models (Figure 10), the fused model consistently achieved the lowest median error and smallest interquartile range, indicating the most robust performance. To address our first research question (RQ1) on the impact of individual modalities, we compared the error distributions of the single-modality models against the baseline (Table 9).
Both high-resolution optical imagery (NAIP) and L-band SAR imagery significantly reduced reconstruction error compared to the LiDAR-only baseline, with optical imagery providing slightly larger improvements (0.5% vs 0.3%). While statistically significant, the modest effect sizes (0.088 and 0.062 respectively) suggests that single-modality improvements over the baseline upsampling approach are limited in magnitude or may be concentrated in a limited number of tiles. Next, to evaluate our second research question (RQ2), we assessed whether fusing both imagery types yielded additional benefits over the best single-modality model (Table 9).
The fusion of both optical and SAR imagery yielded additional reconstruction accuracy gains (0.7% median reduction) beyond using NAIP alone, with a stronger effect size (0.133) than either individual modality achieved in RQ1. This statistically significant improvement supports our hypothesis that the two modalities contain complementary information that can be effectively combined through attention-based fusion. The results demonstrate that multi-modality approaches can leverage different sensing capabilities to achieve superior point cloud reconstruction (Figure 11).
Finally, to evaluate our third research question (RQ3) on the impact of vegetation change, we correlated model error with the magnitude of canopy height changes between the legacy 3DEP and recent UAV LiDAR surveys. Table 10 shows the overall Spearman rank correlations. To investigate this relationship further, we split the dataset into areas of net canopy gain and net canopy loss, with the results of this extended analysis presented in Table 11.
All models showed strong correlations with absolute canopy height change, confirming that reconstruction error systematically increases with vegetation structure changes since the original LiDAR collection. The baseline model exhibited the strongest correlation with canopy change (), while the fused model showed the weakest (), with this difference being statistically significant (, ). Importantly, the extended analysis revealed this pattern was driven primarily by canopy losses, where the baseline model performed significantly worse than all other models, particularly the fusion approach (, ), while for canopy gains, all models performed similarly without statistically significant differences. These findings partially support our hypothesis that advanced models better mitigate error from canopy changes, but specifically for canopy removal scenarios where legacy LiDAR contains no information about the removed vegetation (Figure 12 and Figure 13).
4. Discussion
This study demonstrates the significant potential of attention-based deep learning models to enhance sparse and outdated airborne LiDAR point clouds by fusing them with more frequently acquired optical (NAIP) and Synthetic Aperture Radar (UAVSAR) imagery. Our findings directly address the critical need for up-to-date, high-resolution 3D vegetation structure information in applications like wildfire risk modeling and ecological monitoring.
The core success of our approach lies in the effective fusion of multi-modal data. As hypothesized (RQ1), both NAIP optical imagery and L-band UAVSAR imagery, when individually integrated, improved point cloud reconstruction accuracy compared to a baseline model relying solely on sparse LiDAR. NAIP, with its finer spatial resolution, offered a slightly greater enhancement, likely due to its ability to delineate canopy edges and small gaps with high fidelity. However, the true advancement was observed when these modalities were combined (RQ2). The fused model, leveraging both NAIP’s textural detail and UAVSAR’s structural sensitivity, outperformed single-modality enhancements. This confirms our hypothesis that these sensors provide complementary, rather than redundant, information, and that the cross-attention mechanisms within our architecture can effectively identify and leverage these synergistic relationships. This synergy is particularly valuable for capturing the complex, heterogeneous nature of vegetation.
Our investigation into temporal dynamics (RQ3) revealed that all models, including the baseline, exhibited increased reconstruction error in areas with substantial canopy change since the initial LiDAR survey. This is expected, as the input LiDAR reflects a past state. However, the fused model demonstrated the most robust performance, showing a significantly weaker correlation between error and the magnitude of canopy change, especially in areas of canopy loss. This is a crucial finding: by incorporating more recent imagery, particularly the optical data that clearly depicts vegetation absence, the model can more effectively correct for outdated LiDAR information. The baseline model, lacking this current-state information, struggled most in loss scenarios. Even in areas of canopy growth, while not as pronounced as with loss, the image-informed models offered an advantage by providing cues about new or denser vegetation that the original sparse LiDAR could not capture. This capacity to "update" historical LiDAR datasets significantly enhances their utility for long-term monitoring and management, especially in landscapes prone to rapid changes from disturbances or growth.
The developed Local-Global Point Attention Block (LG-PAB) proved to be a robust architectural component. Its ability to capture both fine-grained local details through neighborhood-level self-attention and broader structural coherence via global attention across the entire point patch is central to its success. This hierarchical attention is well-suited to the fractal-like patterns often observed in natural vegetation.
Despite these promising results, some limitations exist. The improvements, while statistically significant, were modest in terms of percentage change in Chamfer distance. This suggests that while fusion helps, there might be inherent limits to upsampling very sparse LiDAR or that the current metrics may not fully capture all aspects of structural improvement relevant to ecological applications. Furthermore, our study was conducted in Southern California’s Mediterranean ecosystems; model performance and the relative contributions of optical versus radar data might vary in different biomes with distinct vegetation structures and phenology.
Beyond the primary 2x upsampling task, we also conducted a preliminary investigation into the model’s potential for higher-ratio densification (8x). This exploratory model was scaled up significantly, with larger feature dimensions (512 point, 192 image), more local attention heads for extraction and expansion (16), and a total of 125M parameters. With our hardware, this increased model size necessitated reducing the batch size to one per GPU. The results (Figure 14) show that the architecture can indeed produce highly dense outputs that qualitatively approach the reference data. The appendix provides further qualitative examples from both the standard 2x and experimental 8x models, illustrating their performance across different vegetation change scenarios (Figure 15, Figure 16 and Figure 17).
A recommended area for future research involves adapting the validated multi-modal feature extraction pipeline for direct prediction of key vegetation structure rasters, such as Canopy Height Models (CHM), canopy cover, Above-Ground Biomass (AGB), and fuel types. Such an adaptation would entail replacing the current point cloud generation head with task-specific regression or classification heads, potentially broadening the practical applicability of this work. Integrating geometric priors, like Digital Surface Models (DSMs) and Digital Terrain Models (DTMs), into the loss function also represents a valuable direction. This could not only enforce greater structural realism but also enable the calculation of reconstruction error at various canopy strata, offering deeper insights into model performance. Furthermore, fine-tuning emerging foundation-model vision transformers, such as the Clay model [56], as shared encoders for NAIP and UAVSAR imagery, warrants exploration to leverage large-scale pretraining for enhanced feature representation. Complementary investigations could include a thorough evaluation of the UAVSAR encoder, particularly optimizing multi-look fusion beyond simple averaging and assessing resampling impacts, alongside ablation studies on the LG-PAB and imagery encoders to pinpoint key architectural contributions and guide further optimization. Future architectural research could also explore simplifying the Local-Global Point Attention Block into a pure Point Attention Block by replacing the k-NN local attention with a global attention module. For greater scalability, this could be paired with a latent attention strategy [57] to bypass the quadratic complexity inherent to self-attention.
5. Conclusions
This research successfully demonstrates that attention-based deep learning, leveraging our novel Local-Global Point Attention Block, can significantly enhance sparse airborne LiDAR point clouds in vegetated landscapes through the fusion of more recent optical and radar imagery. We have shown that while individual imagery modalities provide benefits, their combined use yields superior reconstruction accuracy, particularly in mitigating errors arising from vegetation changes over time. Specifically, high-resolution optical imagery (NAIP) proved slightly more effective as a standalone ancillary dataset than L-band SAR within our framework, but the fusion of both offered the best performance, validating the complementary nature of these sensors. A key contribution is the model’s ability to substantially reduce reconstruction degradation in areas of vegetation loss, thereby increasing the utility of historical LiDAR archives. This study presents a novel approach to direct 3D point cloud upsampling using multi-modal fusion in complex natural environments, moving beyond prevalent raster-based enhancement techniques and paving the way for more accurate and timely assessments of vegetation structure.
Author Contributions
Conceptualization, M.M. and D.S.; methodology, M.M.; software, M.M.; validation, M.M.; formal analysis, M.M.; investigation, M.M. and D.S.; resources, D.S. and J.F.; data curation, M.M.; writing—original draft preparation, M.M.; writing—review and editing, D.S. and J.F.; visualization, M.M.; supervision, D.S. and J.F.; project administration, D.S. and J.F.; funding acquisition, D.S. and J.F. All authors have read and agreed to the published version of the manuscript.
Funding
Funding for the research was provided by California Climate Action Matching Grants University of California Office of the President grant (#R02CM708) to M. Jennings, SDSU (PI) and JF. DS gratefully acknowledges funding from the NASA FireSense program (Grant # 80NSSC24K0145), the NASA FireSense Implementation Team (Grants #80NSSC24K1320),the NASA Land-Cover/Land Use Change program (Grant #NNH21ZDA001N-LCLUC), the EMIT Science and Applications Team program (Grant #80NSSC24K0861), the NASA Remote Sensing of Water Quality program (Grant #80NSSC22K0907), the NASA Applications-Oriented Augmentations for Research and Analysis Program (Grant #80NSSC23K1460), the NASA Commercial Smallsat Data Analysis Program (Grant #80NSSC24K0052), the USDA NIFA Sustainable Agroecosystems program (Grant #2022-67019-36397), the USDA AFRI Rapid Response to Extreme Weather Events Across Food and Agricultural Systems program (Grant #2023-68016-40683), the California Climate Action Seed Award Program, and the NSF Signals in the Soil program (Award #2226649).
Data Availability Statement
All Python code used for data collection, preprocessing, model training, and analysis is publicly available on GitHub at https://github.com/mmarks13/geoai_veg_map. The 3DEP airborne LiDAR and NAIP optical imagery used as model inputs were sourced via Microsoft’s Planetary Computer (https://planetarycomputer.microsoft.com/) using the provided code. The UAVSAR radar imagery was sourced via the Alaska Satellite Facility (https://search.asf.alaska.edu/) using the provided code. The UAV LiDAR point clouds used as reference data for model training and evaluation are being made available through OpenTopography (https://opentopography.org/); specific DOIs will be provided upon acceptance or can be requested from the authors. The exact data stacks (input features and reference point clouds) used for model training and evaluation are available from the corresponding author upon reasonable request.
Acknowledgments
The authors wish to express their sincere gratitude to Lloyd L. ("Pete") Coulter (Center for Earth Systems Analysis Research, Department of Geography, SDSU) for his skillful piloting and management of all UAV LiDAR data acquisition campaigns; this data was foundational to the research presented. Separately, during the preparation of this manuscript, generative AI models (including Google’s Gemini, Anthropic’s Claude, and OpenAI’s ChatGPT) were utilized to assist with language refinement, conceptual brainstorming, generating preliminary code structures, and code debugging. The authors have reviewed and edited all AI-generated suggestions and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results
Abbreviations
The following abbreviations are used in this manuscript:
| 3DEP | 3D Elevation Program |
| C-ALS | Crewed Airborne LiDAR |
| CAD | Computer-Aided Design |
| CD | Chamfer Distance |
| DSM | Digital Surface Model |
| FFN | Feed-Forward Network |
| GSD | Ground-Sample Distance |
| GRU | Gated Recurrent Unit |
| LG-PAB | Local-Global Point Attention Block |
| LiDAR | Light Detection and Ranging |
| MLP | Multi-Layer Perceptron |
| NAIP | National Agriculture Imagery Program |
| RQ1 | Research Question 1 |
| SAR | Synthetic Aperture Radar |
| UAV | Unmanned Aerial Vehicle |
| UAVSAR | Uninhabited Aerial Vehicle Synthetic Aperture Radar |
| USGS | U.S. Geological Survey |
| ViT | Vision Transformer |
References
- Martin-Ducup, O.; Dupuy, J.L.; Soma, M.; Guerra-Hernandez, J.; Marino, E.; Fernandes, P.M.; Just, A.; Corbera, J.; Toutchkov, M.; Sorribas, C.; et al. Unlocking the potential of Airborne LiDAR for direct assessment of fuel bulk density and load distributions for wildfire hazard mapping. Agricultural and Forest Meteorology 0 citations (Semantic Scholar/DOI) [2025-05-01]. 2025, 362, 110341. [Google Scholar] [CrossRef]
- Merrick, M.J.; Koprowski, J.L.; Wilcox, C. Into the Third Dimension: Benefits of Incorporating LiDAR Data in Wildlife Habitat Models. In Proceedings of the Merging Science and Management in a Rapidly Changing World: Biodiversity and Management of the Madrean Archipelago III. U.S. Dept. of Agriculture, Forest Service, Rocky Mountain Research Station, 2013, USDA Forest Service Proceedings RMRS-P-67, pp. 389–395.
- Moudrỳ, V.; Cord, A.F.; Gábor, L.; Laurin, G.V.; Barták, V.; Gdulová, K.; Malavasi, M.; Rocchini, D.; Stereńczak, K.; Prošek, J.; et al. Vegetation structure derived from airborne laser scanning to assess species distribution and habitat suitability: The way forward. Diversity and Distributions 2023, 29, 39–50. [Google Scholar] [CrossRef]
- Agee, J.K. The Influence of Forest Structure on Fire Behavior 1996. pp. pp. 52–68.
- Guo, X.; Coops, N.C.; Gergel, S.E.; Bater, C.W.; Nielsen, S.E.; Stadt, J.J.; Drever, M. Integrating airborne lidar and satellite imagery to model habitat connectivity dynamics for spatial conservation prioritization. Landscape ecology 2018, 33, 491–511. [Google Scholar] [CrossRef]
- Mahata, A.; Panda, R.M.; Dash, P.; Naik, A.; Naik, A.K.; Palita, S.K. Microclimate and vegetation structure significantly affect butterfly assemblages in a tropical dry forest. Climate 2023, 11, 220. [Google Scholar] [CrossRef]
- Ustin, S.L.; Middleton, E.M. Current and near-term advances in Earth observation for ecological applications. Ecological Processes 2021, 10, 1. [Google Scholar] [CrossRef]
- Belov, M.; Belov, A.; Gorodnichev, V.; Alkov, S. Capabilities analysis of lidar and passive optical methods for remote vegetation monitoring. In Proceedings of the Journal of Physics: Conference Series. IOP Publishing, 2019, Vol. 1399, p. 055024.
- Guo, Q.; Su, Y.; Hu, T.; Guan, H.; Jin, S.; Zhang, J.; Zhao, X.; Xu, K.; Wei, D.; Kelly, M.; et al. Lidar boosts 3D ecological observations and modelings: A review and perspective. IEEE Geoscience and Remote Sensing Magazine 2020, 9, 232–257. [Google Scholar] [CrossRef]
- Wu, Z.; Dye, D.; Stoker, J.; Vogel, J.; Velasco, M.; Middleton, B. Evaluating LiDAR point densities for effective estimation of aboveground biomass. International Journal of Advanced Remote Sensing and GIS 2016, 5, 1483–1499. [Google Scholar] [CrossRef]
- USGS. What is 3DEP? | U.S. Geological Survey, 2019.
- USDA. National Agriculture Imagery Program - NAIP Hub Site, 2024.
- Wang, C.; Song, C.; Schroeder, T.A.; Woodcock, C.E.; Pavelsky, T.M.; Han, Q.; Yao, F. Interpretable Multi-Sensor Fusion of Optical and SAR Data for GEDI-Based Canopy Height Mapping in Southeastern North Carolina. Remote Sensing 2025, 17, 1536. [Google Scholar] [CrossRef]
- Rosen, P.A.; Hensley, S.; Wheeler, K.; Sadowy, G.; Miller, T.; Shaffer, S.; Muellerschoen, R.; Jones, C.; Zebker, H.; Madsen, S. UAVSAR: A new NASA airborne SAR system for science and technology research. In Proceedings of the 2006 IEEE conference on radar. IEEE, 2006, pp. 8–pp.
- Kellogg, K.; Hoffman, P.; Standley, S.; Shaffer, S.; Rosen, P.; Edelstein, W.; Dunn, C.; Baker, C.; Barela, P.; Shen, Y.; et al. NASA-ISRO synthetic aperture radar (NISAR) mission. In Proceedings of the 2020 IEEE aerospace conference. IEEE, 2020, pp. 1–21.
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, arXiv:1409.0473 2014.
- Scheuring, I.; Riedi, R.H. Application of multifractals to the analysis of vegetation pattern. Journal of Vegetation Science 1994, 5, 489–496. [Google Scholar] [CrossRef]
- Yang, H.; Chen, W.; Qian, T.; Shen, D.; Wang, J. The extraction of vegetation points from LiDAR using 3D fractal dimension analyses. Remote Sensing 2015, 7, 10815–10831. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, .; Polosukhin, I. Attention is all you need. Advances in neural information processing systems 2017, 30.
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, arXiv:2010.11929 2020.
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.S.; Khan, F.S. Transformers in remote sensing: A survey. Remote Sensing 2023, 15, 1860. [Google Scholar] [CrossRef]
- Wilkes, P.; Jones, S.D.; Suarez, L.; Mellor, A.; Woodgate, W.; Soto-Berelov, M.; Haywood, A.; Skidmore, A.K. Mapping Forest Canopy Height Across Large Areas by Upscaling ALS Estimates with Freely Available Satellite Data 2015. 7, 12563–12587. 46 citations (Semantic Scholar/DOI) [2024-10-27] Number: 9 Publisher: Multidisciplinary Digital Publishing Institute. [CrossRef]
- Wagner, F.H.; Roberts, S.; Ritz, A.L.; Carter, G.; Dalagnol, R.; Favrichon, S.; Hirye, M.C.M.; Brandt, M.; Ciais, P.; Saatchi, S. Sub-meter tree height mapping of California using aerial images and LiDAR-informed U-Net model 2024. 305, 114099. [CrossRef]
- Shendryk, Y. Fusing GEDI with earth observation data for large area aboveground biomass mapping. International Journal of Applied Earth Observation and Geoinformation 2022, 115, 103108. [Google Scholar] [CrossRef]
- Li, Z.; Zhu, X.; Yao, S.; Yue, Y.; García-Fernández, Á.F.; Lim, E.G.; Levers, A. A large scale Digital Elevation Model super-resolution Transformer. International Journal of Applied Earth Observation and Geoinformation 2023, 124, 103496. [Google Scholar] [CrossRef]
- Taneja, R.; Wallace, L.; Hillman, S.; Reinke, K.; Hilton, J.; Jones, S.; Hally, B. Up-scaling fuel hazard metrics derived from terrestrial laser scanning using a machine learning model. Remote Sensing 2023, 15, 1273. [Google Scholar] [CrossRef]
- Gazzea, M.; Solheim, A.; Arghandeh, R. High-resolution mapping of forest structure from integrated SAR and optical images using an enhanced U-net method. Science of Remote Sensing 2023, 8, 100093. [Google Scholar] [CrossRef]
- Remijnse, T. Upsampling LiDAR Point Clouds of Forest Environments using Deep Learning 2024.
- Yu, L.; Li, X.; Fu, C.W.; Cohen-Or, D.; Heng, P.A. Pu-net: Point cloud upsampling network. In Proceedings of the Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2790–2799.
- Qian, G.; Abualshour, A.; Li, G.; Thabet, A.; Ghanem, B. Pu-gcn: Point cloud upsampling using graph convolutional networks. In Proceedings of the Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 11683–11692.
- Qiu, S.; Anwar, S.; Barnes, N. Pu-transformer: Point cloud upsampling transformer. In Proceedings of the Proceedings of the Asian conference on computer vision, 2022, pp. 2475–2493.
- Zhang, T.; Filin, S. Deep-Learning-Based Point Cloud Upsampling of Natural Entities and Scenes. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 2022, 43, 321–327. [Google Scholar] [CrossRef]
- Yan, W.; Cao, L.; Yan, P.; Zhu, C.; Wang, M. Remote sensing image change detection based on swin transformer and cross-attention mechanism. Earth Science Informatics 2025, 18, 106. [Google Scholar] [CrossRef]
- Ma, X.; Zhang, X.; Pun, M.O. A crossmodal multiscale fusion network for semantic segmentation of remote sensing data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 2022, 15, 3463–3474. [Google Scholar] [CrossRef]
- Qingyun, F.; Zhaokui, W. Cross-modality attentive feature fusion for object detection in multispectral remote sensing imagery. Pattern Recognition 2022, 130, 108786. [Google Scholar] [CrossRef]
- Li, K.; Xue, Y.; Zhao, J.; Li, H.; Zhang, S. A cross-attention integrated shifted window transformer for remote sensing image scene recognition with limited data. Journal of Applied Remote Sensing 2024, 18, 036506–036506. [Google Scholar] [CrossRef]
- Yu, W.; Huang, F. DMSCA: deep multiscale cross-modal attention network for hyperspectral and light detection and ranging data fusion and joint classification. Journal of Applied Remote Sensing 2024, 18, 036505–036505. [Google Scholar] [CrossRef]
- Li, Z.; Liu, R.; Sun, L.; Zheng, Y. Multi-Feature Cross Attention-Induced Transformer Network for Hyperspectral and LiDAR Data Classification. Remote Sensing 2024, 16, 2775. [Google Scholar] [CrossRef]
- Yang, J.X.; Zhou, J.; Wang, J.; Tian, H.; Liew, A.W.C. LiDAR-guided cross-attention fusion for hyperspectral band selection and image classification. IEEE Transactions on Geoscience and Remote Sensing 2024, 62, 1–15. [Google Scholar] [CrossRef]
- Zhu, W.; Wang, H.; Hou, H.; Yu, W. CAMS: A Cross Attention Based Multi-Scale LiDAR-Camera Fusion Framework for 3D Object Detection. In Proceedings of the International Conference on Guidance, Navigation and Control. Springer; 2024; pp. 533–542. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the Computer vision–ECCV 2020: 16th European conference, Glasgow, UK, August 23–28, 2020, proceedings, part XXVII 16. Springer, 2020, pp. 720–736.
- Wu, H.; Miao, Y.; Fu, R. Point cloud completion using multiscale feature fusion and cross-regional attention. Image and Vision Computing 2021, 111, 104193. [Google Scholar] [CrossRef]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 16259–16268.
- Dao, T.; Fu, D.; Ermon, S.; Rudra, A.; Ré, C. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems 2022, 35, 16344–16359. [Google Scholar]
- USGS. USGS 3DEP - CA SanDiego 2015 C17 1, 2016. Accessed: 2024-10-15.
- U.S. Geological Survey, 3D Elevation Program. USGS 3DEP Lidar Point Cloud (COPC). Published: Microsoft Planetary Computer.
- Microsoft. Microsoft Planetary Computer, 2025.
- Alaska Satellite Facility. ASF search Python API, 2024.
- Zhu, Q.; Fan, L.; Weng, N. Advancements in point cloud data augmentation for deep learning: A survey. Pattern Recognition 2024, p. 110532.
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. Journal of big data 2019, 6, 1–48. [Google Scholar] [CrossRef]
- Lee, S.H.; Lee, S.; Song, B.C. Vision Transformer for Small-Size Datasets: SPT + LSA. arXiv preprint arXiv:2112.13492, arXiv:2112.13492 2021.
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going Deeper with Image Transformers. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 32–42.
- d’Ascoli, S.; Touvron, H.; Leavitt, M.L.; Morcos, A.S.; Biroli, G.; Sagun, L. ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases. In Proceedings of the Proceedings of the 38th International Conference on Machine Learning (ICML), 2021, Vol. 139, pp. 2286–2296.
- Defazio, A.; Yang, X.A.; Mehta, H.; Mishchenko, K.; Khaled, A.; Cutkosky, A. The Road Less Scheduled, 2024, [2405.15682 [cs]]. 44 citations (Semantic Scholar/arXiv) [2025-05-08] 44 citations (Semantic Scholar/DOI) [2025-05-08]. [CrossRef]
- Wu, T.; Pan, L.; Zhang, J.; Wang, T.; Liu, Z.; Lin, D. Density-aware Chamfer Distance as a Comprehensive Metric for Point Cloud Completion, 2021, [2111.12702 [cs]]. 2025. [Google Scholar] [CrossRef]
- Clay Foundation Team. Clay Foundation Model: An open-source AI foundation model for Earth observation. https://github.com/Clay-foundation/model, 2024. Software version 1.5 (commit ), Apache-2.0 license.
- Liu, A.; Feng, B.; Wang, B.; Wang, B.; Liu, B.; Zhao, C.; Dengr, C.; Ruan, C.; Dai, D.; Guo, D.; et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. arXiv preprint arXiv:2405.04434, arXiv:2405.04434 2024.
Figure 1.
Comparison of point clouds with 10 m × 10 m footprints from USGS 3DEP aerial LiDAR (2015–2018, orange) and UAV LiDAR (2023–2024, green) over the same locations. UAV LiDAR captures significantly greater structural detail, especially in fine-scale canopy features. The bottom-left example shows clear canopy loss between surveys due to recent disturbance. The top-left shows clear growth
Figure 1.
Comparison of point clouds with 10 m × 10 m footprints from USGS 3DEP aerial LiDAR (2015–2018, orange) and UAV LiDAR (2023–2024, green) over the same locations. UAV LiDAR captures significantly greater structural detail, especially in fine-scale canopy features. The bottom-left example shows clear canopy loss between surveys due to recent disturbance. The top-left shows clear growth
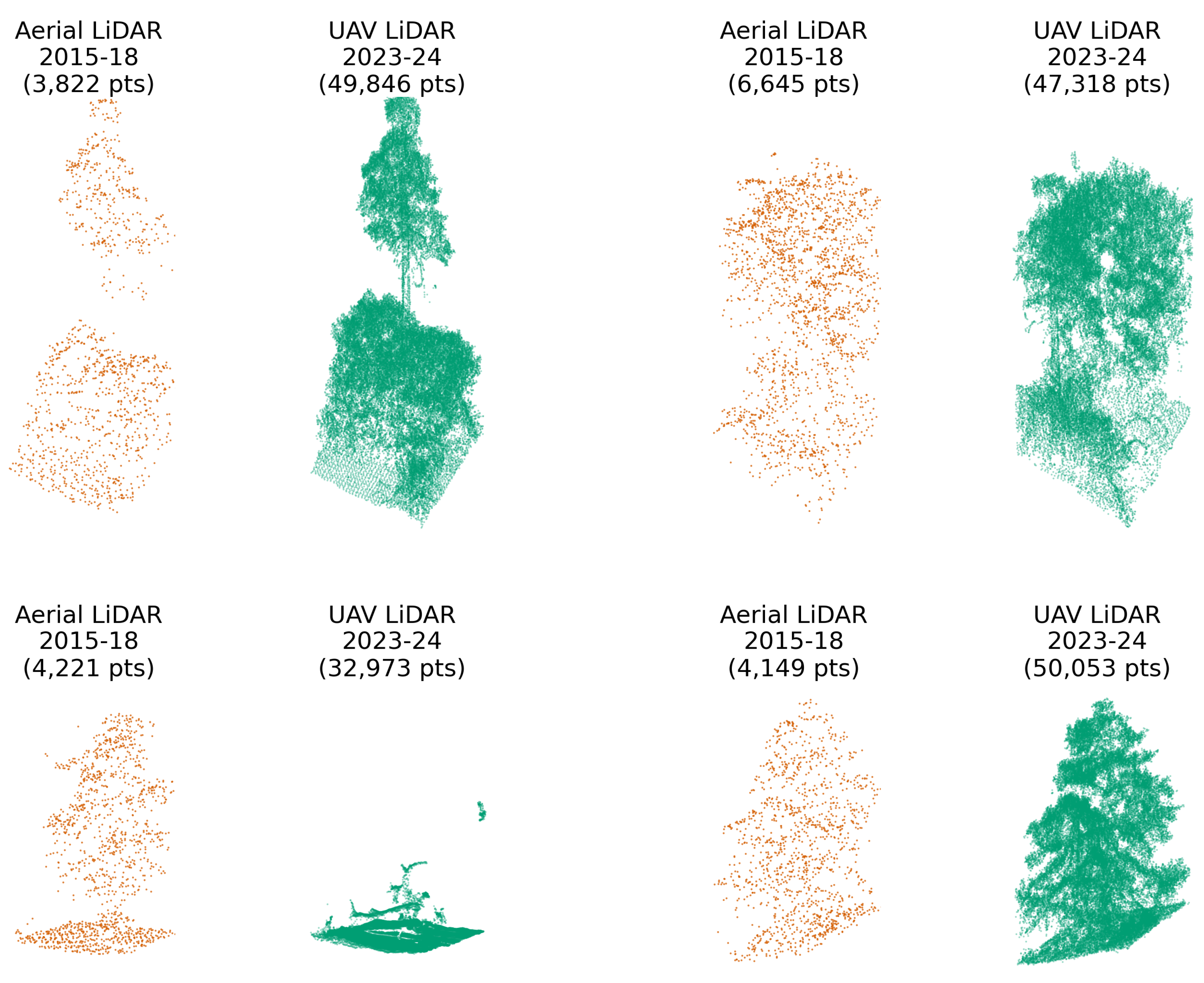
Figure 2.
Locations of the Southern California UAV LiDAR surveys—Sedgwick Reserve–Midland School in the Santa Ynez Valley and Volcan Mountain Wilderness Preserve in the Peninsular Range.
Figure 2.
Locations of the Southern California UAV LiDAR surveys—Sedgwick Reserve–Midland School in the Santa Ynez Valley and Volcan Mountain Wilderness Preserve in the Peninsular Range.
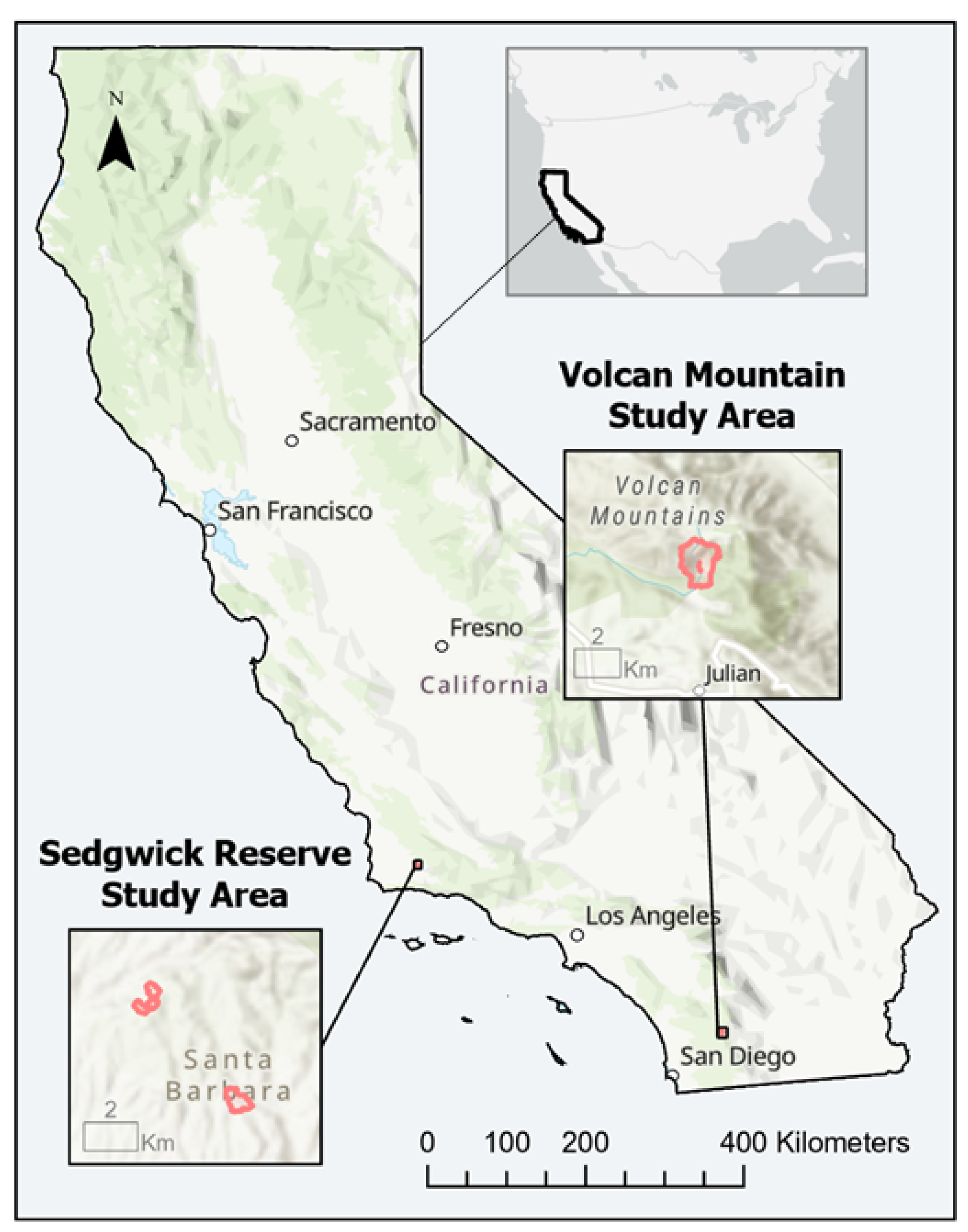
Figure 3.
The first study area combines parts of the Sedgwick Reserve and Midland School property in the San Rafael Mountain foothills, Santa Barbara County. It features diverse vegetation such as oak woodlands, chaparral, grasslands, and coastal sage scrub. Within this area, four UAV LiDAR sites were surveyed, covering a total of 70 hectares.
Figure 3.
The first study area combines parts of the Sedgwick Reserve and Midland School property in the San Rafael Mountain foothills, Santa Barbara County. It features diverse vegetation such as oak woodlands, chaparral, grasslands, and coastal sage scrub. Within this area, four UAV LiDAR sites were surveyed, covering a total of 70 hectares.
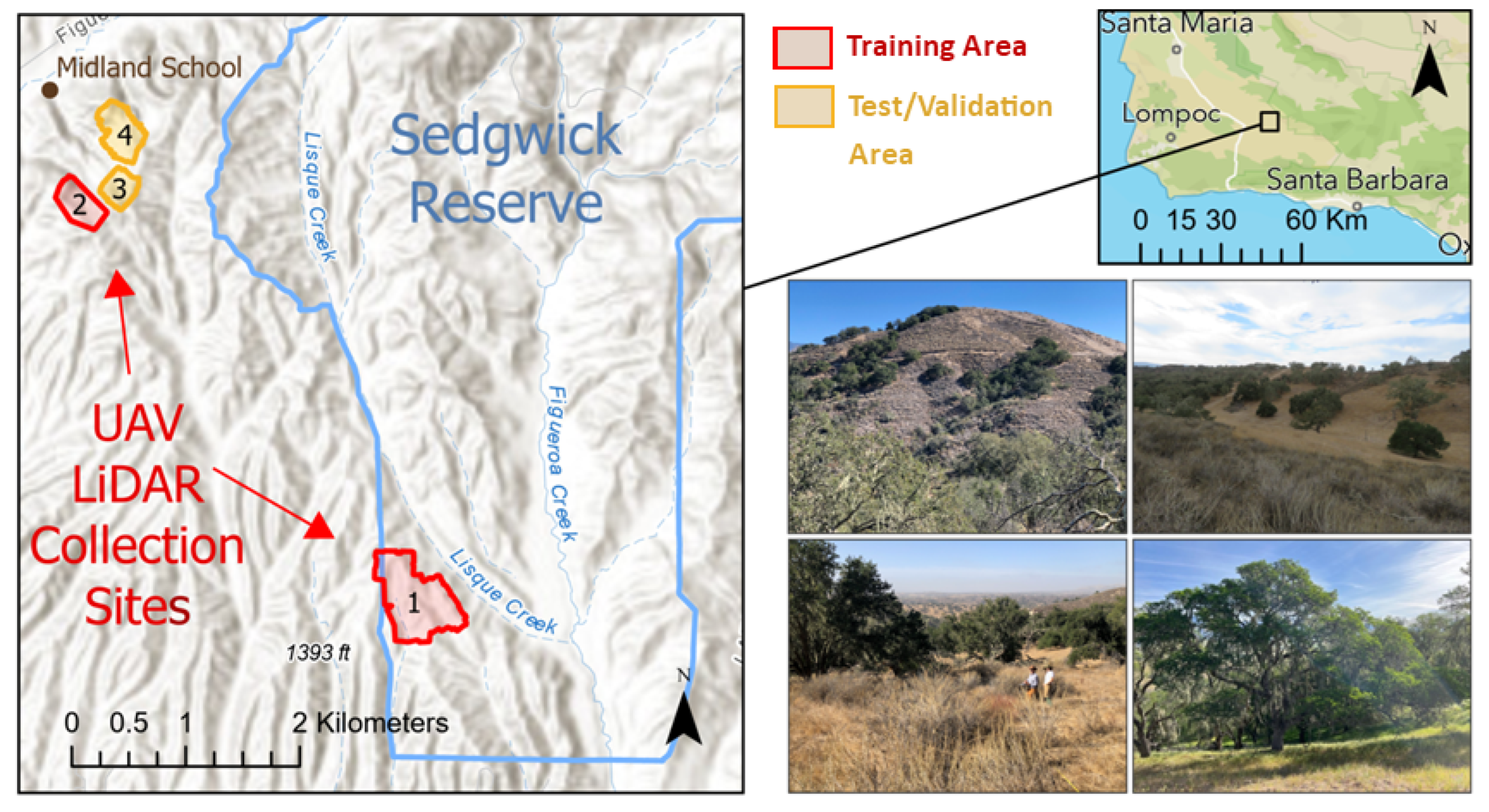
Figure 4.
Volcan Mountain study area (197 hectares) in the Peninsular Range of Southern California, encompassing diverse vegetation types across an elevation range of 1220 to 1675 meters. Thirty percent of the site (58 hectares) was set aside for testing/validation in three zones: post-fire chaparral in the north, mixed conifer and riparian vegetation with oak and chaparral in the center, and oak woodland with semi-continuous canopy in the south.
Figure 4.
Volcan Mountain study area (197 hectares) in the Peninsular Range of Southern California, encompassing diverse vegetation types across an elevation range of 1220 to 1675 meters. Thirty percent of the site (58 hectares) was set aside for testing/validation in three zones: post-fire chaparral in the north, mixed conifer and riparian vegetation with oak and chaparral in the center, and oak woodland with semi-continuous canopy in the south.
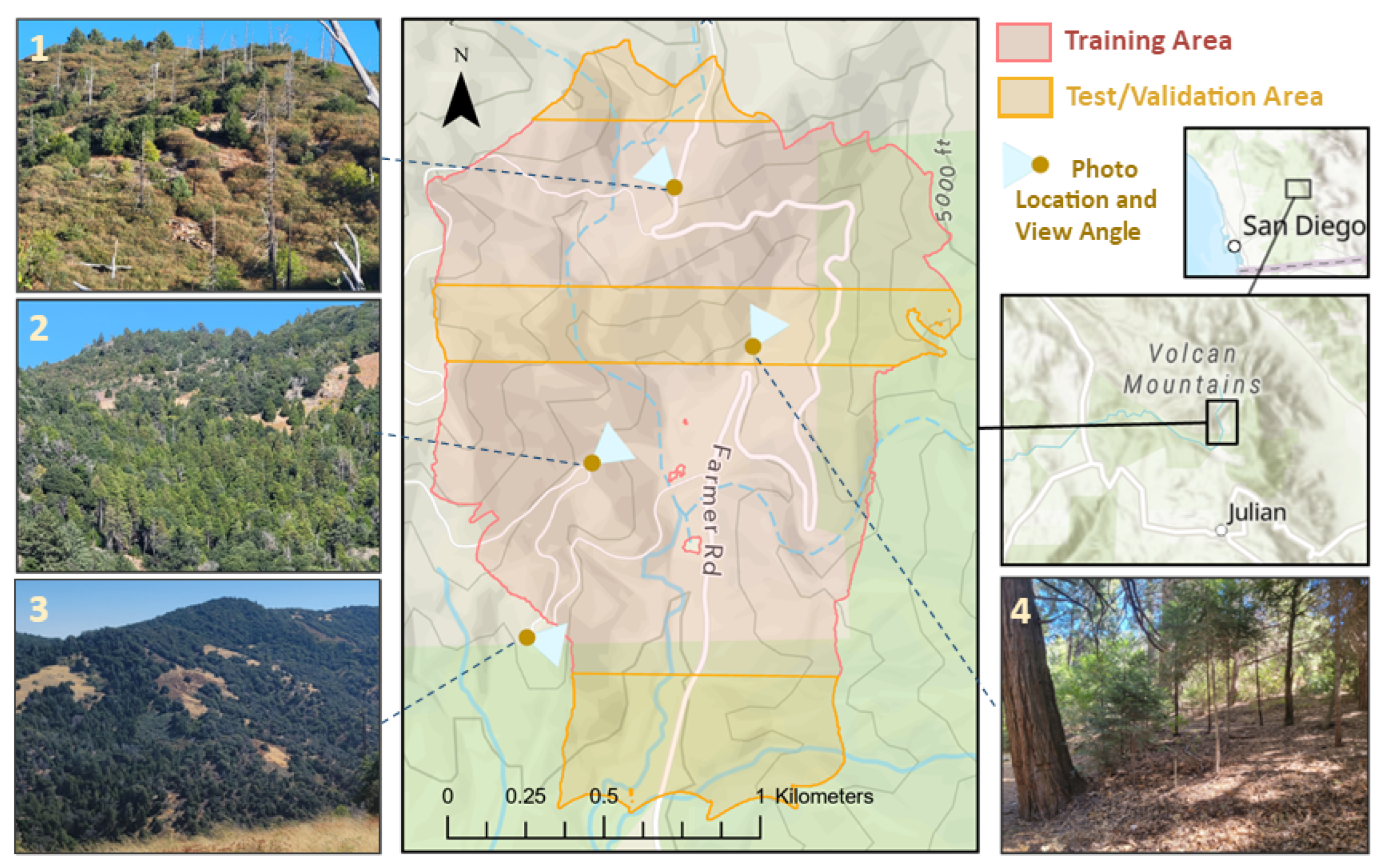
Figure 5.
The overall multimodal upsampling architecture. Key components include Local–Global Point Attention Blocks, modality-specific imagery encoders for processing optical (NAIP) and radar (UAVSAR) data, and a cross-attention fusion module for combining imagery and LiDAR features.
Figure 5.
The overall multimodal upsampling architecture. Key components include Local–Global Point Attention Blocks, modality-specific imagery encoders for processing optical (NAIP) and radar (UAVSAR) data, and a cross-attention fusion module for combining imagery and LiDAR features.
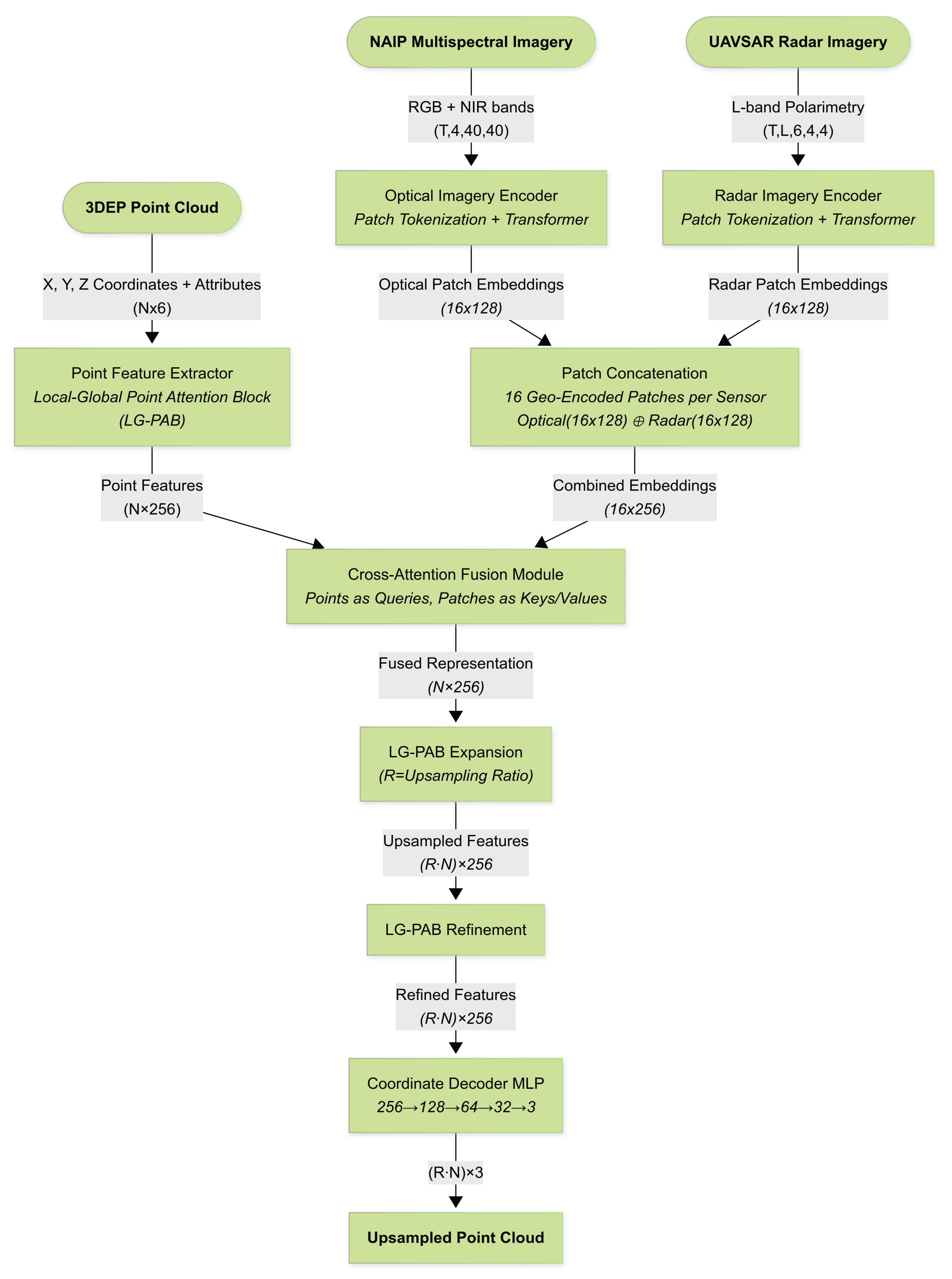
Figure 6.
Flowchart of the Local–Global Point Attention Block (LG-PAB), the core computational unit used across the feature extraction, expansion, and refinement stages. The block applies local attention via a multi-head Point Transformer, optional upsampling with learned position offsets, and global multi-head Flash Attention for broader spatial context. A feed-forward MLP follows both the local and global attention blocks.
Figure 6.
Flowchart of the Local–Global Point Attention Block (LG-PAB), the core computational unit used across the feature extraction, expansion, and refinement stages. The block applies local attention via a multi-head Point Transformer, optional upsampling with learned position offsets, and global multi-head Flash Attention for broader spatial context. A feed-forward MLP follows both the local and global attention blocks.
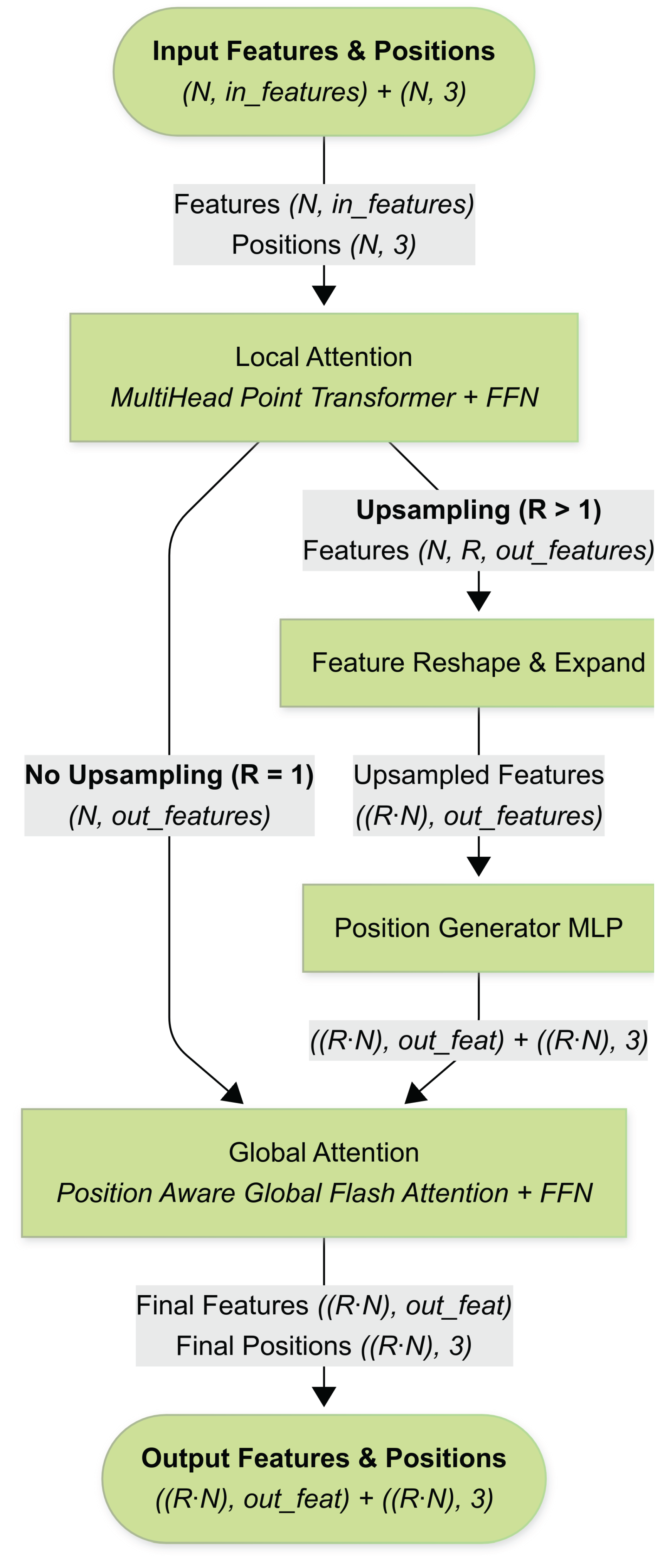
Figure 7.
Architecture diagram of the imagery encoders. Image stacks from NAIP (optical) and UAVSAR (radar) pass sequentially through Patch Tokenization, Transformer Encoder blocks for spatial context modeling, and a Temporal GRU-Attention Head for temporal aggregation.
Figure 7.
Architecture diagram of the imagery encoders. Image stacks from NAIP (optical) and UAVSAR (radar) pass sequentially through Patch Tokenization, Transformer Encoder blocks for spatial context modeling, and a Temporal GRU-Attention Head for temporal aggregation.
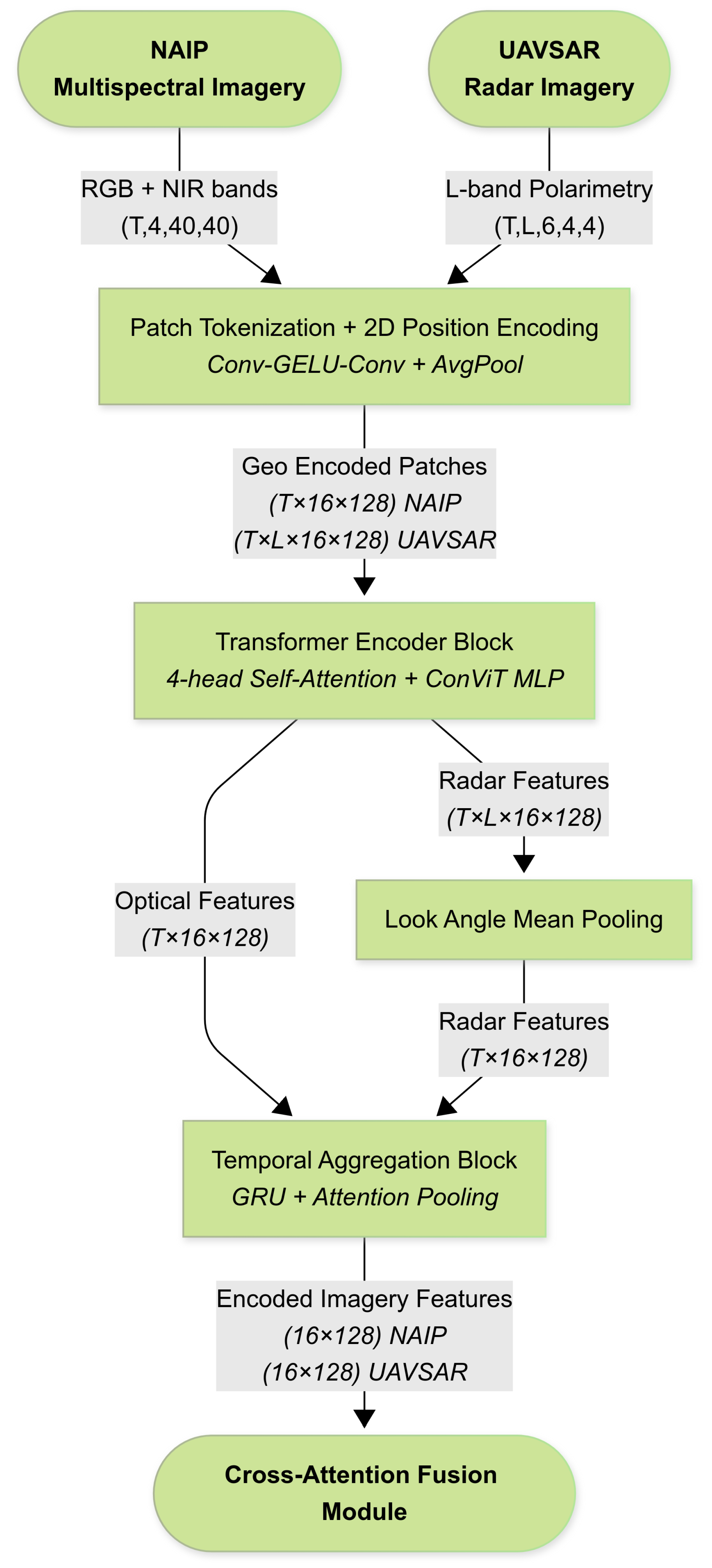
Figure 8.
Distribution of Chamfer distance reconstruction errors comparing raw input data to 3DEP LiDAR-only baseline model. Horizontal boxplots show median (red line), interquartile range (colored boxes), and 10th-90th percentile whiskers. The baseline model demonstrates substantial improvement, reducing median error from 0.858 m to 0.340 m with a significantly tighter distribution. Outliers beyond the 90th percentile are excluded for clarity.
Figure 8.
Distribution of Chamfer distance reconstruction errors comparing raw input data to 3DEP LiDAR-only baseline model. Horizontal boxplots show median (red line), interquartile range (colored boxes), and 10th-90th percentile whiskers. The baseline model demonstrates substantial improvement, reducing median error from 0.858 m to 0.340 m with a significantly tighter distribution. Outliers beyond the 90th percentile are excluded for clarity.
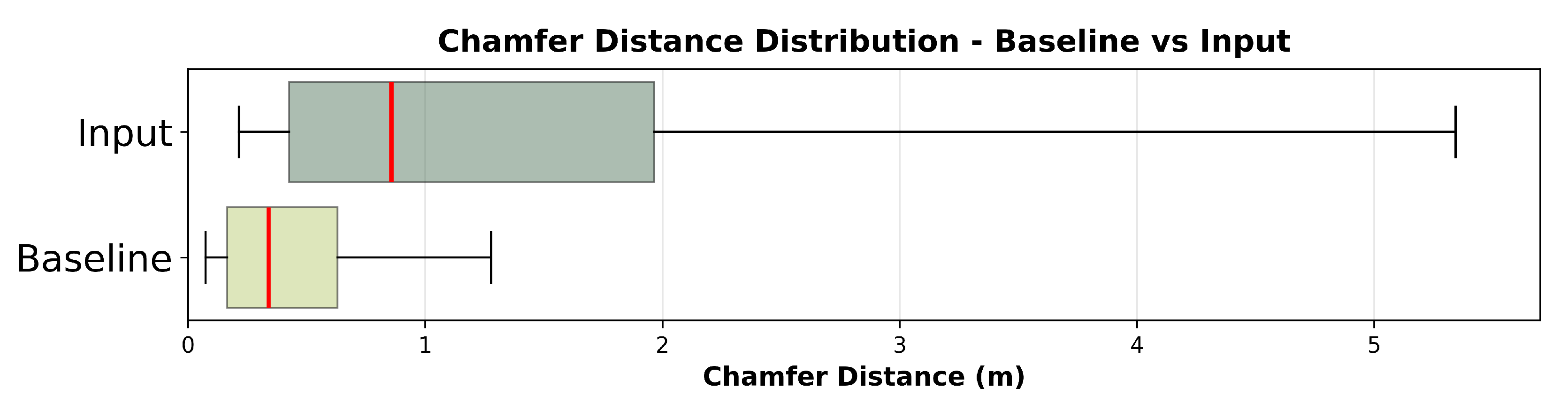
Figure 9.
A comparison of baseline (3DEP LiDAR only) model output vs input
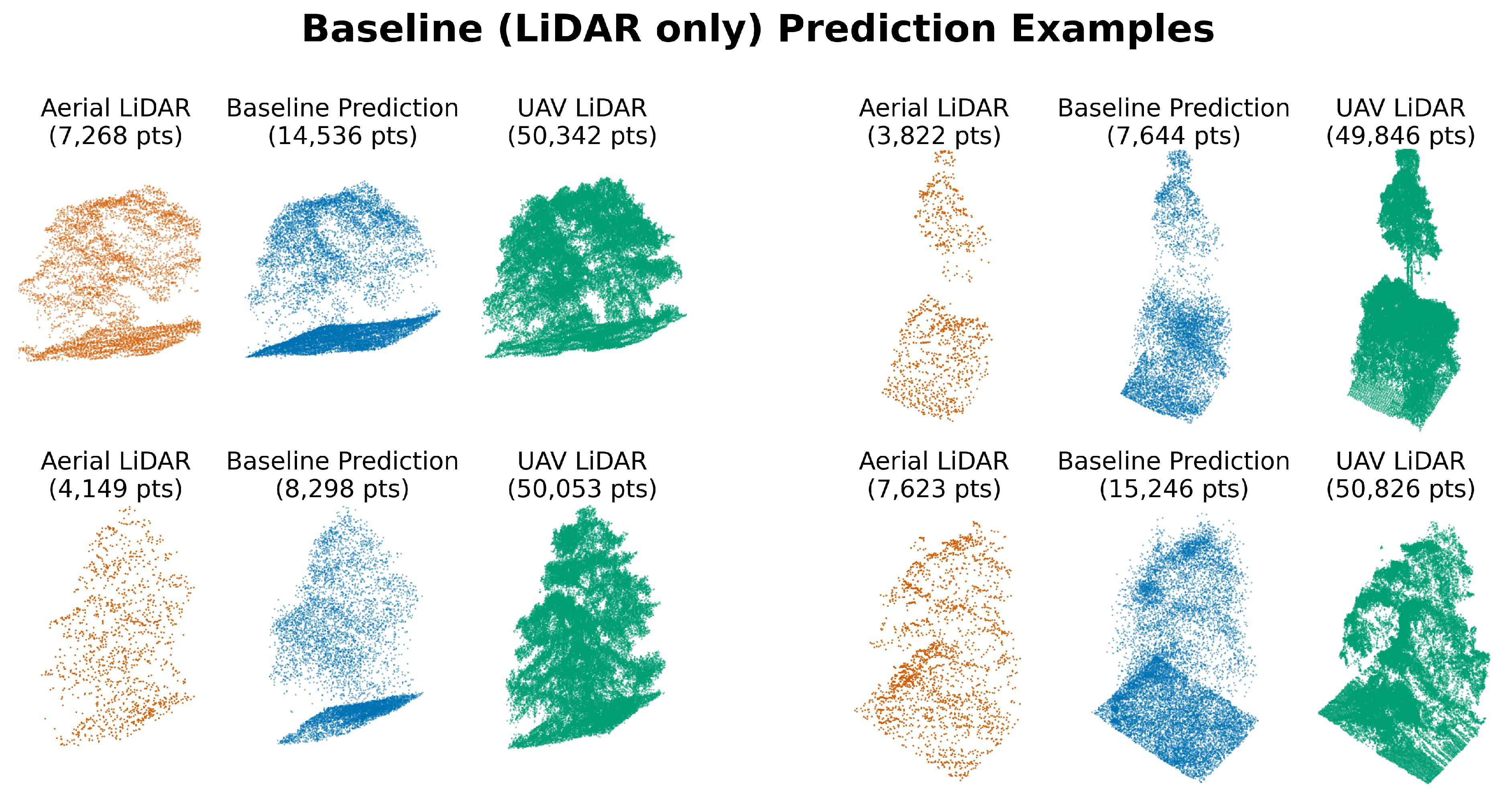
Figure 10.
Distribution of Chamfer distance reconstruction errors across point cloud upsampling models. Horizontal boxplots show median (red line), interquartile range (colored boxes), and 10th-90th percentile whiskers for models trained with different input modalities. All models demonstrate substantial improvement over the LiDAR-only baseline, with the fused model achieving the lowest median error (0.298 m) and tightest distribution. Outliers beyond the 90th percentile are excluded for clarity.
Figure 10.
Distribution of Chamfer distance reconstruction errors across point cloud upsampling models. Horizontal boxplots show median (red line), interquartile range (colored boxes), and 10th-90th percentile whiskers for models trained with different input modalities. All models demonstrate substantial improvement over the LiDAR-only baseline, with the fused model achieving the lowest median error (0.298 m) and tightest distribution. Outliers beyond the 90th percentile are excluded for clarity.
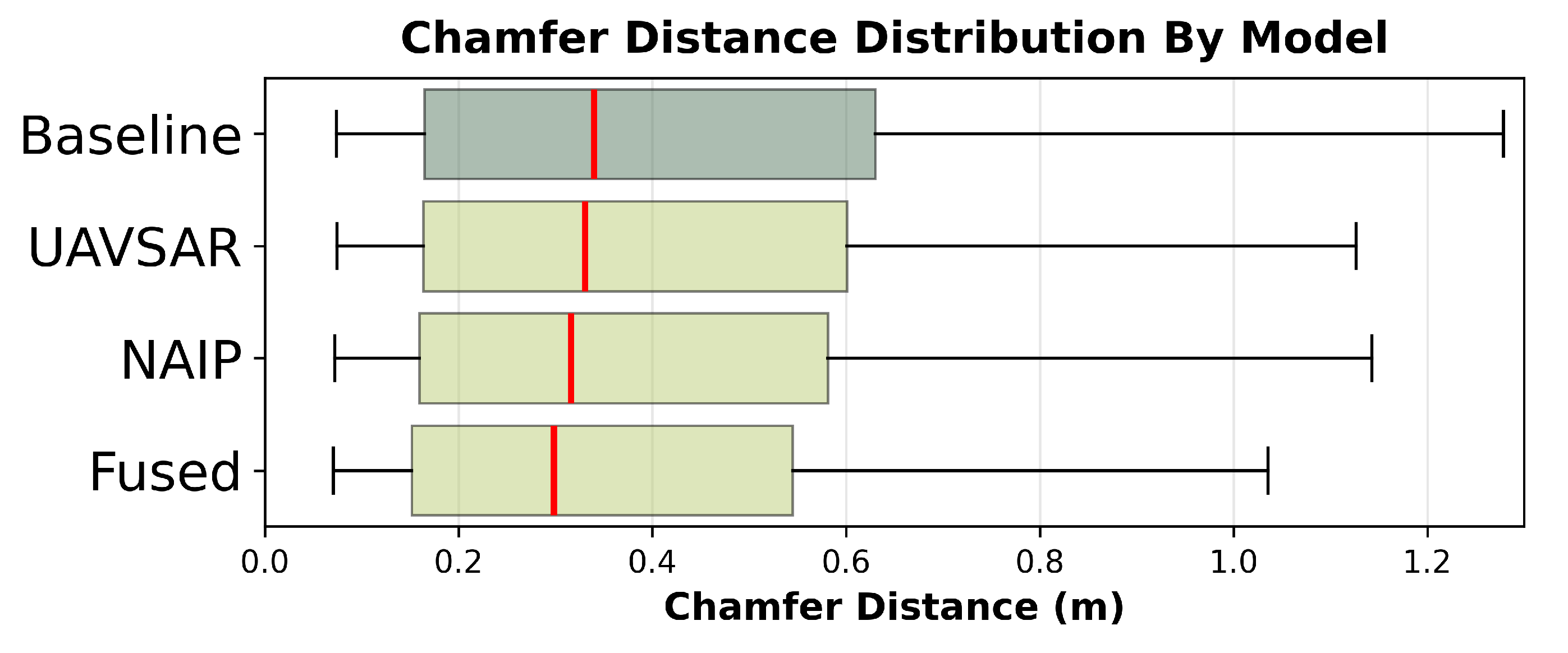
Figure 11.
Example tile where no major vegetation change occurred between the 3DEP aerial LiDAR (2015–2018) and UAV LiDAR (2023–2024). The optical+SAR fusion model more accurately recovers fine-scale canopy structure compared to the LiDAR-only model, producing a point cloud that more closely matches the UAV LiDAR reference (lower Chamfer Distance).
Figure 11.
Example tile where no major vegetation change occurred between the 3DEP aerial LiDAR (2015–2018) and UAV LiDAR (2023–2024). The optical+SAR fusion model more accurately recovers fine-scale canopy structure compared to the LiDAR-only model, producing a point cloud that more closely matches the UAV LiDAR reference (lower Chamfer Distance).
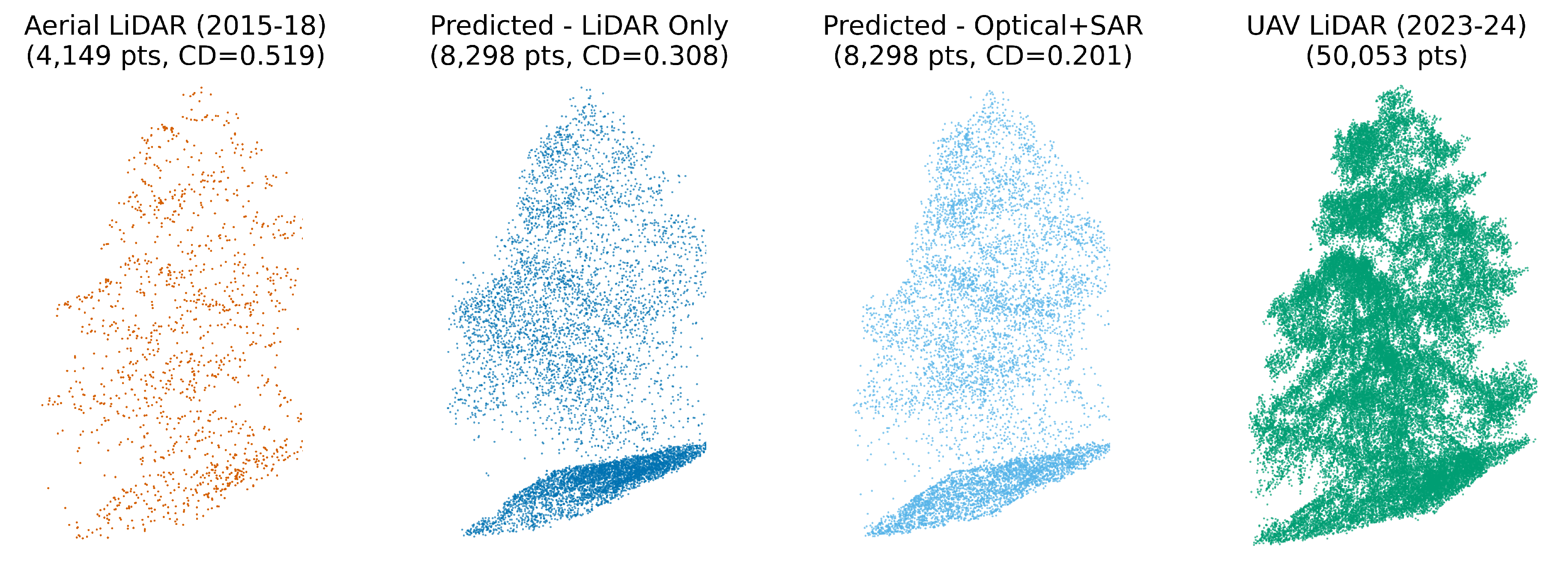
Figure 12.
Example tile illustrating vegetation structure change between legacy aerial LiDAR (2015–2018) and recent UAV LiDAR (2023–2024). The optical+SAR fusion model accurately reconstructs the canopy loss visible in the UAV LiDAR reference, whereas the LiDAR-only model retains outdated structure from the earlier survey. This highlights the value of multi-modal imagery in correcting legacy LiDAR and detecting structural change.
Figure 12.
Example tile illustrating vegetation structure change between legacy aerial LiDAR (2015–2018) and recent UAV LiDAR (2023–2024). The optical+SAR fusion model accurately reconstructs the canopy loss visible in the UAV LiDAR reference, whereas the LiDAR-only model retains outdated structure from the earlier survey. This highlights the value of multi-modal imagery in correcting legacy LiDAR and detecting structural change.
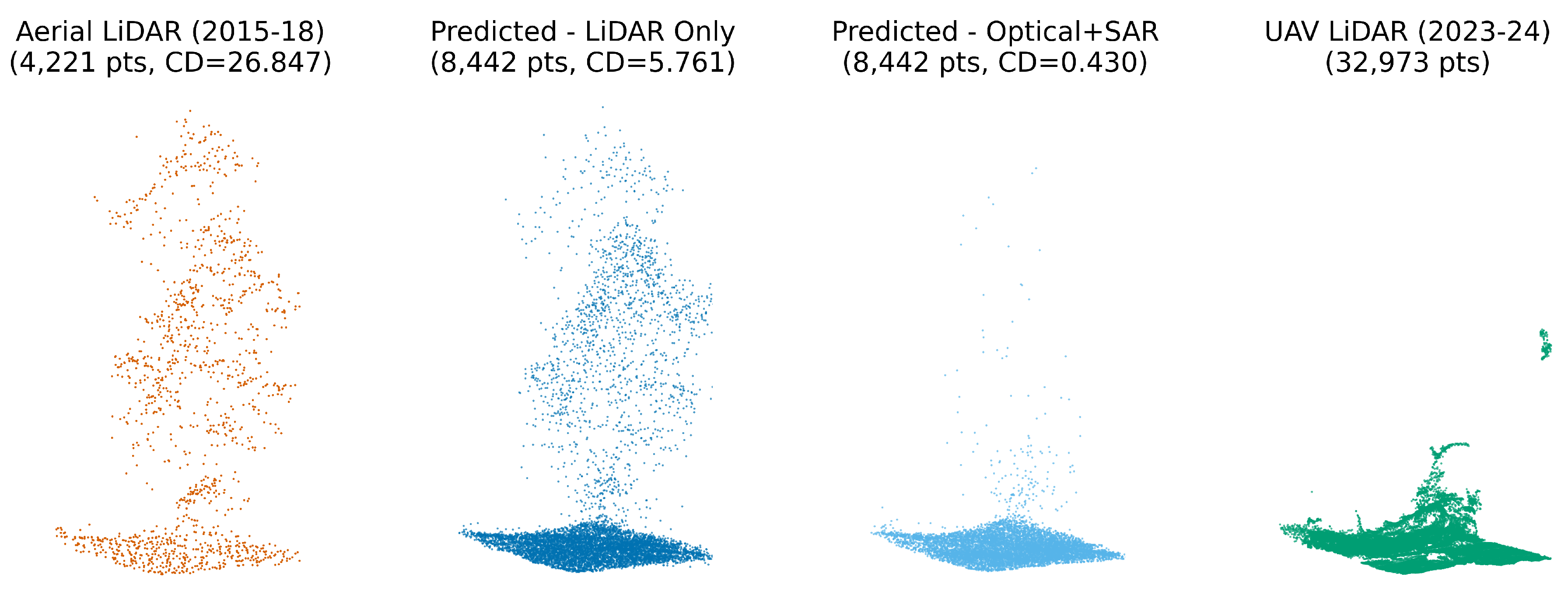
Figure 13.
Relationship between point cloud reconstruction error (Chamfer distance) and net canopy height change since the original LiDAR survey. Scatter points show individual sample tiles (N=5,687) with LOWESS trend lines for each model; outliers above the 99.5th percentile for both error and height change metrics were excluded for visualization clarity. Negative values represent canopy losses while positive values represent gains. The baseline model (blue) shows substantially higher error rates for large canopy losses compared to models incorporating additional remote sensing data (NAIP optical, UAVSAR radar, and fused approaches), while all models perform similarly for canopy gains.
Figure 13.
Relationship between point cloud reconstruction error (Chamfer distance) and net canopy height change since the original LiDAR survey. Scatter points show individual sample tiles (N=5,687) with LOWESS trend lines for each model; outliers above the 99.5th percentile for both error and height change metrics were excluded for visualization clarity. Negative values represent canopy losses while positive values represent gains. The baseline model (blue) shows substantially higher error rates for large canopy losses compared to models incorporating additional remote sensing data (NAIP optical, UAVSAR radar, and fused approaches), while all models perform similarly for canopy gains.
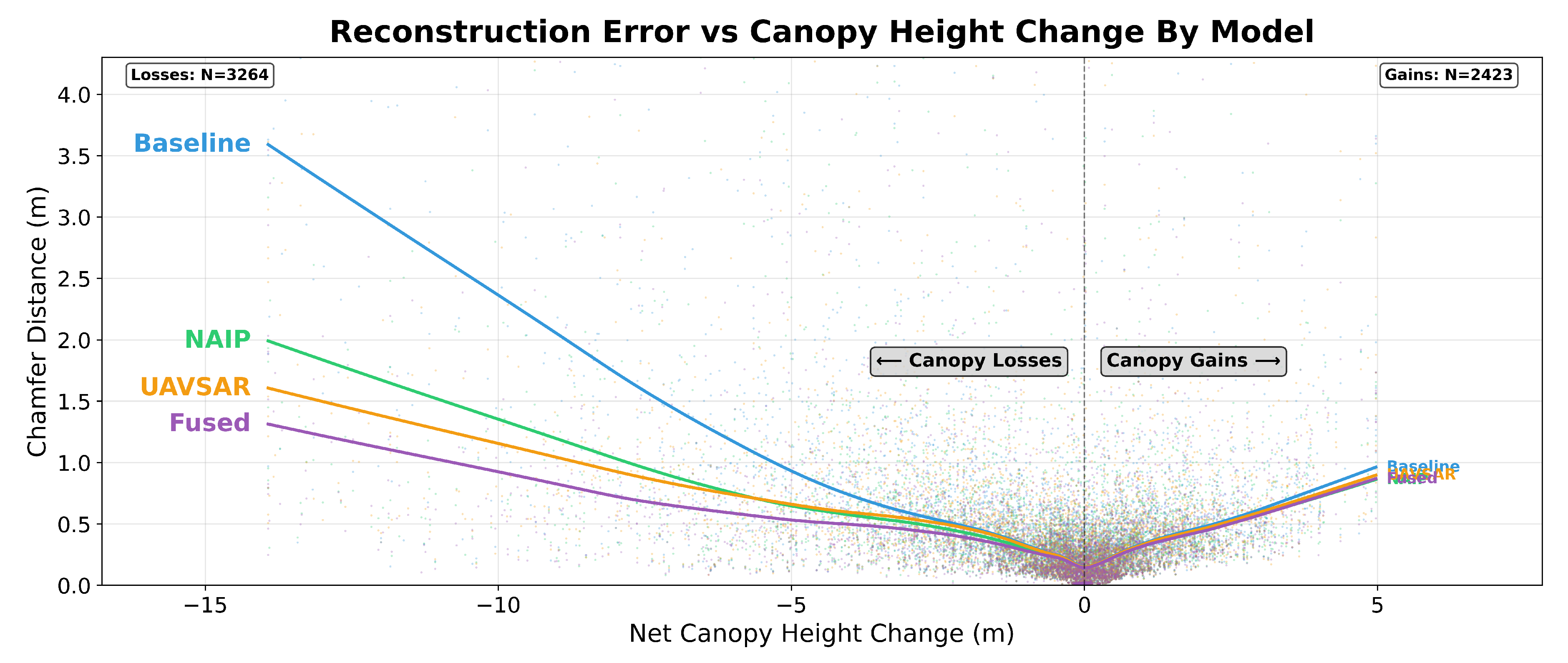
Figure 14.
Comparison of the standard 2x upsampling model (optical+SAR, 6.8 million parameters) output versus a preliminary high-density 8x model (optical+SAR, 125 million parameters)
Figure 14.
Comparison of the standard 2x upsampling model (optical+SAR, 6.8 million parameters) output versus a preliminary high-density 8x model (optical+SAR, 125 million parameters)
Figure 15.
Example of vegetation growth reconstruction (using the experimental 8x upsampling model for better visual clarity). The model successfully infers new canopy structure (center) that is absent in the input 3DEP LiDAR but present in the recent UAV LiDAR reference.
Figure 15.
Example of vegetation growth reconstruction (using the experimental 8x upsampling model for better visual clarity). The model successfully infers new canopy structure (center) that is absent in the input 3DEP LiDAR but present in the recent UAV LiDAR reference.

Figure 16.
A second example of vegetation growth reconstruction with the 8x model.
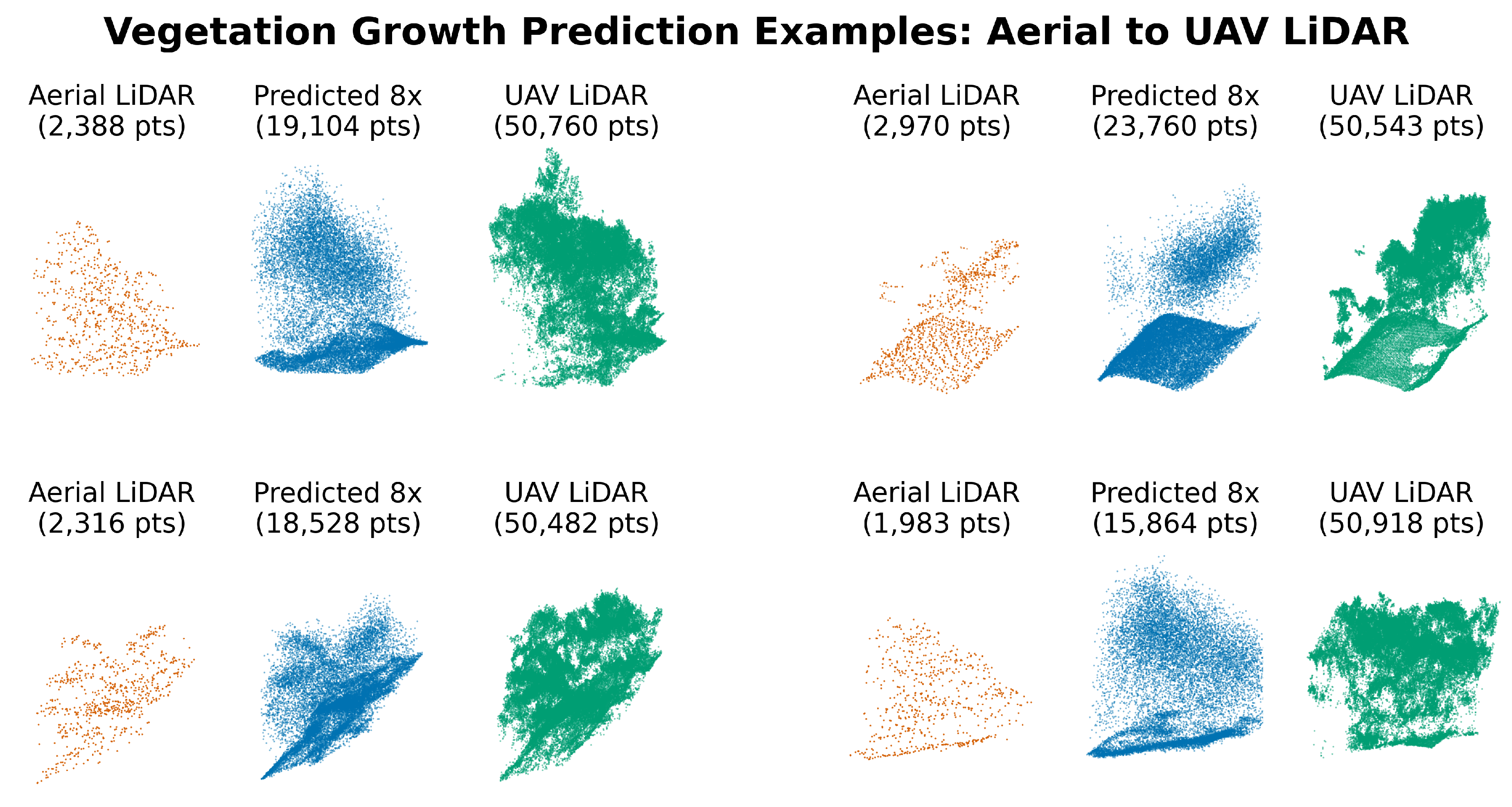
Figure 17.
Example of the standard 2x fusion model correctly identifying vegetation loss. The model removes vegetation present in the outdated input LiDAR (left) to match the state shown in the recent UAV LiDAR reference (right), highlighting the value of multi-modal fusion for change detection.
Figure 17.
Example of the standard 2x fusion model correctly identifying vegetation loss. The model removes vegetation present in the outdated input LiDAR (left) to match the state shown in the recent UAV LiDAR reference (right), highlighting the value of multi-modal fusion for change detection.


Table 1.
UAV LiDAR sites used as ground truth for model development
| Site | Hectares | Location | Collection Date | Model Use |
|---|---|---|---|---|
| 1 | 38 | Sedgwick Reserve | 30 Jun 2023 | Training |
| 2 | 12 | Midland School | 23 Oct 2023 | Training |
| 3 | 9 | Midland School | 23 Oct 2023 | Test/Validation |
| 4 | 11 | Midland School | 28 Sep 2023 | Test/Validation |
| 5 | 197 | Volcan Mountain | 25 Oct 2024 | 70% Training 30% Test/Validation |
Table 2.
Summary of remote sensing datasets used in the data stack.
| Data Source | Role in Study | Details | Revisit Rate |
|---|---|---|---|
| UAV LiDAR | Reference Data | >300 pts/m2Acquired: 2023–2024 | N/A |
| 3DEP Airborne LiDAR | Sparse Input | Sedgwick: ∼22 pts/m2 (2018) Volcan: ∼6 pts/m2 (2015–16) | N/A |
| UAVSAR (L-band) | Ancillary Input | 6.17 m GSD Coverage: 2014–2024 | ∼2-3 years |
| NAIP (Optical) | Ancillary Input | 0.6–1 m GSD Coverage: 2014–2022 | ∼2 years |
Table 3.
Timeline of NAIP and UAVSAR acquisitions for both study sites.
| Volcan Mountain | Sedgwick Reserve | |||
|---|---|---|---|---|
| Year | NAIP (GSD) | UAVSAR (# Looks) | NAIP (GSD) | UAVSAR (# Looks) |
| 2014 | May (1 m) | Jun (3), Oct (2) | Jun (1 m) | Jun (8) |
| 2016 | Apr (60 cm) | — | Jun (60 cm) | Apr (6) |
| 2018 | Aug (60 cm) | Oct (2) | Jul (60 cm) | — |
| 2020 | Apr (60 cm) | — | May (60 cm) | — |
| 2021 | — | Nov (2) | — | — |
| 2022 | Apr (60 cm) | — | May (60 cm) | — |
| 2023 | — | — | — | Sep (6)a |
| 2024 | — | — | — | Oct (2) |
| aPart of the NASA FireSense initiative. | ||||
Table 4.
Dataset preparation
| Subset | Tiles |
|---|---|
| Training | 24 000 original + 16 000 augmented = 40 000 |
| Validation | 3 792 |
| Test | 5 688 |
Table 5.
Model variants evaluated
| Variant | Active encoders | Cross-attention on | Parameters |
|---|---|---|---|
| Baseline | LiDAR only | None | 4.7M |
| + NAIP | LiDAR, optical | NAIP tokens | 5.9M |
| + UAVSAR | LiDAR, radar | UAVSAR tokens | 5.8M |
| Fused | LiDAR, optical, radar | Concatenated token | 6.8M |
Table 6.
Model-configuration parameters
| Parameter | Value | Notes |
|---|---|---|
| Core geometry | ||
| Point-feature dimension | 256 | — |
| KNN neighbours (k) | 16 | Used in local attention graph |
| Upsampling ratio () | 2 | Doubles point density per LG-PAB expansion |
| Point-attention dropout | 0.02 | Dropout inside global attention heads |
| Attention-head counts | ||
| Extractor — local / global | 8 / 4 | Extra local heads help expand feature set |
| Expansion — local / global | 8 / 4 | Extra local heads aid point upsampling |
| Refinement — local / global | 4 / 4 | — |
| Imagery encoders | ||
| Image-token dimension | 128 | Patch embeddings for NAIP & UAVSAR encoders |
| Cross-modality fusion | ||
| Fusion heads | 4 | — |
| Fusion dropout | 0.02 | — |
| Positional-encoding dimension | 36 | — |
Table 7.
Training protocol and hardware
| Setting | Value |
|---|---|
| Hardware | 4 × NVIDIA L40 (48 GB) GPUs under PyTorch DDP |
| Optimizer | ScheduleFreeAdamW [54]; base LR , weight-decay , ; no external LR schedule |
| Loss function | Density-aware Chamfer distance (Eq. 9 in [55]), |
| Batch size | 15 tiles per GPU |
| Epochs | 100 |
| Gradient clip | |
| Training time | ≈ 7 h per model variant |
| Model selection | Epoch with lowest validation loss |
Table 8.
Descriptive Statistics for Chamfer Distance Across All Model Variants (see Table 5)
Table 8.
Descriptive Statistics for Chamfer Distance Across All Model Variants (see Table 5)
| Model | Mean CD (m) | Median CD (m) | Std Dev (m) | IQR (m) |
|---|---|---|---|---|
| Input | 2.568 | 0.858 | 6.852 | 1.540 |
| Baseline | 1.043 | 0.340 | 5.717 | 0.465 |
| NAIP | 0.993 | 0.316 | 5.542 | 0.421 |
| UAVSAR | 0.924 | 0.331 | 5.505 | 0.437 |
| Fused | 0.965 | 0.298 | 5.753 | 0.393 |
Table 9.
RQ1 & RQ2: Impact of Single and Fused Modalities on Reconstruction Error
| Comparison | Median Change (%) | Effect Size |
|---|---|---|
| RQ1: Single Modality vs. Baseline | ||
| NAIP vs Baseline | 0.5 (p<0.001) | 0.088 |
| UAVSAR vs Baseline | 0.3 (p<0.001) | 0.062 |
| RQ2: Fused Modality vs. Best Single Modality | ||
| Fused vs NAIP | 0.7 (p<0.001) | 0.133 |
Table 10.
RQ3: Correlation Between Reconstruction Error and Canopy Height Change
| Model | Spearman | p-value |
|---|---|---|
| Baseline | 0.650 | p<0.001 |
| NAIP | 0.612 | p<0.001 |
| UAVSAR | 0.628 | p<0.001 |
| Fused | 0.582 | p<0.001 |
| Baseline vs NAIP (z) | 3.377 | p<0.001 |
| Baseline vs UAVSAR (z) | 1.999 | p=0.046 |
| Baseline vs Fused (z) | 5.868 | p<0.001 |
Table 11.
RQ3 Extended: Correlation Between Reconstruction Error and Canopy Height Changes (Gains vs. Losses)
Table 11.
RQ3 Extended: Correlation Between Reconstruction Error and Canopy Height Changes (Gains vs. Losses)
| Model | Canopy Gains (N=2423) | Canopy Losses (N=3264) | ||
|---|---|---|---|---|
| Spearman | p-value | Spearman | p-value | |
| Baseline | 0.601 | p<0.001 | 0.671 | p<0.001 |
| Naip | 0.586 | p<0.001 | 0.621 | p<0.001 |
| Uavsar | 0.597 | p<0.001 | 0.637 | p<0.001 |
| Fused | 0.587 | p<0.001 | 0.580 | p<0.001 |
| Baseline vs Naip (z) | 0.825 | p=0.409 | 3.440 | p<0.001 |
| Baseline vs Uavsar (z) | 0.233 | p=0.816 | 2.406 | p=0.016 |
| Baseline vs Fused (z) | 0.768 | p=0.442 | 6.074 | p<0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



