Submitted:
02 June 2025
Posted:
03 June 2025
You are already at the latest version
Abstract
The last few years have seen an increase in the amount of data collected in Structural Health Monitoring (SHM) systems. This can be attributed to the availability of cheap sensors and means of data transmission. However, this increase in data presents a challenge in meaningful analysis. Recently, practitioners and researchers have turned to deep learning methods for analysis of such data. Deep learning has already proven to be effective at analysing complex, highly dimensional datasets and this suits well with SHM data streams. The common data type in SHM is time series and mostly comes from vibration based SHM. Unlike static data, time series usually depict temporal dependencies and contextual variations. Further to this, time series are usually noisy and contain missing values. These attributes make the analysis of time series more complex. In deep learning, time series analysis is tackled using specialized architectures such as recurrent neural networks or through careful feature engineering. Considering these issues, it is important to understand the deep intricacies of these models for their effective application and development of new robust models.So far, different reviews have been conducted to provide a state of the art status of deep learning in SHM. However, it is clear that most of the reviews are usually application-centric and rarely consider a deep technical discussion of deep learning analysis for time series. Again, issues to do with uncertainty quantification and data augmentation are rarely discussed from a theoretical standpoint. This review seeks to tackle these issues and provide a deep theoretical review of time series, typical applications, and challenges. The goal is basically to provide the necessary background for researchers and practitioners in SHM to develop new models and to effectively apply the existing models to time series problems.
Keywords:
Time series
; Deep learning
; Structural Health Monitoring
1. Introduction
Many civil infrastructures are in a poor state [1,2,3]. This is mainly due to poor maintenance practices as well as exposure of the infrastructure to harsh environmental conditions [4]. Besides these, structural deterioration has been associated with misuse of infrastructure [5]. Regardless of the cause, structures in such a state usually pose risk to life, property and economic performance. Talking of negative impacts of structural deterioration, South Africa is a good example. To put this into context, South Africa loses almost 50% of the water pumped into its piped networks to leakages, among other factors [6]. This is in part due to deteriorating infrastructure which is rarely maintained. Problems related to deteriorating infrastructure are also encountered in South Africa’s power sector and transportation system [2]. The issue of deteriorating structures is further highlighted in South Africa’s Infrastructure Development scenarios for 2050 [7]. While the problem of deteriorating infrastructure is worse in the developing world, similar challenges are also observed in developed countries. A recent report by MakeUK indicates that approximately 54% of manufacturers in the United Kingdom perceive a decrease in road infrastructure quality over the last decade [8]. These statistics are a clear indication that interventions have to be taken to ensure serviceability of the existing infrastructure. Considering the economic value of civil infrastructure, their exposure to harsh environmental influences, and progressive material deterioration, conventional inspection and maintenance practices, which often rely on manual and periodic interventions, are insufficient to ensure structural integrity and long-term serviceability. As such, there is a need for continuous monitoring to enable early detection of deterioration and timely maintenance decisions [9,10].
Structure Health Monitoring (SHM) appears to be a promising solution to the issues discussed. The field of SHM was developed in the 1990s and has since matured over the years [11]. These days, SHM is extensively studied and applied to civil infrastructure. The aim of SHM is to enable damage identification, localisation, quantification and prognosis. This is accomplished through instrumentation, whereby sensors are deployed to collect data from a structure, followed by data analysis. Fundamentally, SHM is guided by 7 Axioms [12]. Of particular interest to this review is Axiom IV(a), which states that sensors cannot measure damage as such feature extraction is necessary to convert sensor data to damage information. In this regard, statistical and deep learning methods are used.
SHM methods are usually classified into two main categories: global and local [13]. Global methods typically involve acquisition of data across a full structure. The data is then processed to assess damage. Vibration based SHM methods fall under this category. Global methods can be used to detect, locate, and quantify damage on a structure. On the other hand, local methods focus on a particular area of a structure. In most cases, the location is known a priori and the goal is to assess the level of damage. Some methods under non-destructive evaluation are in this category. Considering the wide availability of cheap sensors, some modern SHM systems are hugely global and a common characteristic of such methods is that the generated data is time series. It is therefore important that time series analysis is well understood.
Traditionally, time series analysis uses methods such as Auto Regressive Moving Average(ARMA), AutoRegressive Moving Average with eXogenous excitation (ARMAX), and state space models (SSMs), among others [6]. This is so because time series data exhibit correlations and dependencies which are otherwise absent in static data. Despite the successes of these methods on SHM systems, current data scale in SHM makes them inefficient in some cases. These traditional methods require assumptions which do not fit reality. As is the case with real world systems, noise and missing data are a common issue. Furthermore, modern SHM systems generate huge amounts of highly dimensional data and traditional methods have always found it difficult to analyse such data due to a phenomenon called the curse of dimensionality.
Recently, researchers have turned to deep learning to resolve these issues. Deep learning has proven to work extremely well in high dimensional spaces. With regards to time series, deep learning methods designed for sequential modeling have proven to be effective [14]. However, despite this, the application of deep learning to time series in SHM proves to be an outstanding issues for a number of reasons. Firstly, despite the generation of huge amounts of data by SHM systems, most of this data is inconsistent, contain significant amount of noise and is unlabeled. Secondly, in the real world, the accuracy of models is significantly poor which among other issues is due to domain shift. This is the case because structures are exposed to extremely harsh environments whose nuances might have not been captured in the model. A highlight on these issues is also the lack of integration of existing knowledge in developed models. Another issue with deep learning models is their high computational costs which hinders their development and deployment [15]. Deep learning models are known to be computationally demanding due to the enormous matrix operations which are performed during training and inference. A fourth and less commonly considered reality are regulatory restrictions. The advent of tools like ChatGPT has brought this issue to light [16]. As for structural systems, which by the end of the day can impact life and economies, their deployment is trivial. This is a serious issue as classical deep learning is inherently deterministic and black-box, in which case no rationale is provided for the decision made by the system.
The aim of this paper is therefore to provide a mathematically grounded review of deep learning for time series in an attempt to address the current challenges and scepticisms. The review provides a discussion of neural network architectures which are common in time series, generative deep learning models, and uncertainty quantification in deep learning.To ensure the review is self-contained, we include derivations of key results where appropriate.Although the first part of this review tackles deep learning in general, the primary target audience of this review are SHM practitioners and researchers. Thus, the review provides a discussion of deep learning for time series in SHM, including challenges.
The remainder of the paper is structured as follows: It begins with the discussion of the related works in Section 2. To provide context, Section 3 provides the background to deep learning. This is followed by a discussion of foundational architectures in Section 4 and generative models in Section 5. A review of uncertainty quantification in deep learning is provided in Section 6 .The final discussion in this review deals with applications in Section 7, state of DL in SHM in Section 8 and a concluding synthesis in Section 9
2. Related Works
In recent years, deep learning (DL) has gained significant traction in structural health monitoring (SHM) due to its ability to model complex, high-dimensional, and often nonlinear data [17,18]. Since 2020, several review studies have emerged to synthesize the expanding range of DL applications in SHM. This section analyzes 24 key publications that collectively reflect the current state of research, with a focus on methodological trends and persistent research gaps.
Several reviews have aimed to map the application of DL in SHM. Jia and Li [19], for example, presented a taxonomy based on data types, emphasizing the prevalence of vibration- and vision-based methods. However, their review lacked systematic coverage of sequential modeling or generative approaches. Similarly, Afshar et al. [20] emphasized the predictive power of neural networks for the prediction of structural responses, but provided minimal theoretical grounding.
A focused subset of the current literature addresses vibration-based SHM. Notable among these are works by Spencer et al. [17], Toh and Park [21], Azimi et al. [22], Indhu et al. [23], Wang et al. [24] and Avci et al. [25]. While insightful regarding modal data, these reviews largely overlooked temporal models such as recurrent neural networks (RNNs), temporal convolutional neural networks (TCNNs), and long short-term memory networks (LSTMs), resulting in an application-centric rather than theory-driven perspective.
In vision-based SHM, studies by Hamishebahar et al. [26], Chowdhury and Kaiser [27], Gomez-Cabrera and Escamilla-Ambrosio [28], Sony et al. [29] and Deng et al. [30] reviewed CNN-based methods for surface crack detection, defect classification , among others. Though these works offered comprehensive discussions of image-based SHM and relevant architectures, they paid little attention to temporal modeling, hybrid strategies, or generalization beyond specific materials. Chowdhury and Kaiser [27], for example, focused solely on concrete structures.
A few studies have attempted a more integrative approach. Khan et al. [31] explored hybrid methods combining DL with physics-based models, identifying avenues for methodological convergence, but their review lacked coverage of generative models and uncertainty quantification. Zhang et al. [32] focused on DL-based imputation techniques for incomplete SHM data, though without a rigorous theoretical foundation for the models used.
Despite the rising interest in generative models, only Luleci and Catbas [33] and Luleci et al. [34] have examined their use in SHM, and both lacked mathematical depth. Other reviews by Spencer et al. [17], Cha et al. [35], Abedi et al. [36], Zhang et al. [37], Tapeh and Naser [38] and Xu et al. [39] have made notable contributions, yet often remained narrowly application-focused and did not thoroughly address the theoretical principles underlying DL models.
Collectively, several limitations emerge across the current reviews. Most reviews remain confined to either vision-based or vibration-based SHM, with little integration of multimodal approaches or comparative learning paradigms. While CNNs are extensively covered, sequential models such as LSTMs, gated recurrent units (GRUs), and attention-based architectures receive insufficient attention, despite their common usage in SHM.This analysis finds no prior review dedicated exclusively to these models. Generative models are rarely discussed in depth, and theoretical treatments of uncertainty quantification are largely absent.
CNNs continue to dominate existing literature, while key areas such as uncertainty quantification and generative modeling are rarely covered, and when they are, theoretical treatment is minimal. This review addresses these gaps by providing a unified synthesis of deep learning methods, grounded in theory and explicitly tied to SHM applications. While some theory-focused or theory-practice-focused reviews exist, such as those on RNNs [14], generative models [40], time series [41,42,43], and uncertainty quantification [44,45],this work stands out by offering an integrated perspective across multiple DL paradigms. To the best of our knowledge, it is the first to do so.
3. Background
3.1. Time Series
Since Structural Health Monitoring (SHM) involves continuous monitoring of structures, a significant portion of the generated data is time series [46]. This data may include accelerometers, strain gauges, displacement transducers, and piezoelectric elements that capture the structural response to operational and environmental loading [47] . SHM data is often multivariate, noisy and might contain missing values. As such, modeling this data requires taking these issues into consideration.
Formally, a time series can be represented as where denotes the number of dimensions and L represents the length of the time series [42].
Time series are grouped into two major categories, i.e. univariate and multivariate. In a univariate time series, D=1. A typical example would be water level in a dam. For a multivariate time series, D> 1, and thus additional variables are considered. The presence of multiple variables introduces complexity as they may exhibit correlations which need to be taken into account during analysis. In the dam context, water levels are most likely influenced by daily temperature fluctuations and seasonal variations in rainfall.
Time series models typically serve four key purposes, namely; classification [48], forecasting[49], anomaly detection [50,51], and data imputation [52]. In an SHM system, classification involves assigning labels to time series data based on patterns identified in structural behaviour. A common classification task might be the categorization of the state of a structure based on inspection records. On the other hand, forecasting deals with the prediction of future values based on historical trends. In most cases, forecasting deals with continuous values and provides a quantitative outlook on how a system is likely to evolve over time. Anomaly detection (Figure 1) plays a crucial role in identifying deviations from normal behaviour that may indicate a number of issues such as structural damage, shock events e.g. an earthquake, sensor malfunction or simply false alarms. This is important to ensure that events are correctly detected and an appropriate action is taken. Most importantly, anomaly detection can help save a structure and life of its users or occupants.Finally, data imputation focuses on estimating and filling in missing values to ensure the integrity of a dataset. In real-world scenarios, measurements are often incomplete due to factors such as sensor malfunctions, transmission errors, or the high cost of continuous data collection. For robust analysis, it is important to ensure that the missing data is reconstructed with reasonable accuracy. Imputation directly impacts the results of other time series analysis discussed before. Thus, imputation supports the development of robust predictive models and enhances the reliability of decision-making.
3.1.1. Components of a Time Series
Time series data can be decomposed into four primary components, namely: trend, seasonality, cyclic variations, and irregular fluctuations [53].To begin with, the trend represents long-term changes that are often observable as a gradual shift in the system’s behaviour. In structural systems, a trend may manifest as a slow change in the natural frequency of vibrations due to material aging or increasing stress. Such changes could shift the structural dynamics and thus affect structural response to external loads.
On the other hand, seasonality refers to repetitive patterns that happen at fixed time intervals. In a structure, this could appear as periodic vibrations caused by factors, such as daily traffic patterns or seasonal wind fluctuations.
However, not all oscillations are strictly periodic. The cyclic component captures long-term, non-periodic fluctuations. For example, temperature changes over the year can cause materials to expand and contract, altering the vibrational characteristics of a structure over an extended period. This type of fluctuation, while repetitive, does not follow a fixed schedule, making it distinct from seasonal patterns, yet it still reflects periodic behaviour over the long run.
Lastly, irregular fluctuations, represent random, unpredictable disturbances in a time series. In a signal, irregular fluctuations remain after the seasonal, cyclic, and trend components have been removed. Generally, this component is associated with random noise and and cannot be easily explained.
All in all, time series models typically assume an additive or multiplicative approach to capture the interactions between these components.
3.1.2. Methods of Time Series Analysis
Different methods for time series analysis can be categorised into time domain and frequency-domain [54,55]. Time domain methods consider raw signals relative to the time variable and tend to be useful for forecasting and understanding trends, seasonal patterns, and autocorrelations within the data.However, there are cases where it is important to transform the raw data into the frequency domain to capture other important features. This is done using tools such as such as the Fourier Transform [56] or Wavelet Transform [57]. Frequency-domain analysis is effective at detecting cyclical or periodic patterns, and thus provides insights into the dominant frequencies that influence the behavior of the time series.
3.2. Deep Learning
3.2.1. A Brief History
The foundations of modern neural networks date back to the McCulloch-Pitts model [58] which laid the conceptual groundwork for viewing computation in terms of interconnected logical units. Building on this idea, the perceptron was introduced by Rosenblatt Rosenblatt [59] in the late 1950s. Following that, the development of neural networks had several successes and winters. Despite several challenges, which among others include lack of funding, several researchers persisted on neural network research. The progression of research in this area is in part linked to the the works of Werbos [60], Fukushima [61], Hopfield [62], Rumelhart et al. [63], LeCun et al. [64], Hochreiter and Schmidhuber [65], Bengio et al. [66], Hinton et al. [67] and Glorot and Bengio [68]. Although much progress was made in 1980s, late 1990s and early 2000s, it was not until 2012 that a breakthrough in image classification was achieved using a neural network model [69]. The major reasons for this advancement include data availability, improvements in computational hardware and software, and novel research in machine learning algorithms [70]. Unlike traditional machine learning approaches, neural networks have been empirically shown to perform extremely well on large, highly-dimensional datasets. This is linked to the problem of curse of dimensionality in high dimensional spaces [71,72]. Besides data availability, and hardware and software innovations, he successes of deep learning are attributed to the ability of neural networks to learn a broad class of functions with arbitrary precision. Several results have proven this in the context of multi layer perceptrons [73,74]. The goal of this section is to dissect the inner workings of the neural network model and establish the fundamental principles necessary for their understanding.
3.2.2. Artificial Neuron
A neuron is the basic computational block of an artificial neural network. A conceptual model of a neuron is provided in Figure 2.
Clause 3.4.9 of ISO/IEC 22989:2022 [75] defines a neuron as a primitive processing element which takes one or more input values and produces an output value by combining the input values and applying an activation function, i.e.
The use of an activation function in a neural network is to learn non-linearity in the target function. With a few exceptions, commonly used activation functions are non-linear. An activation function is required to be continuous or piecewise differentiable in order to facilitate the update of network weights, which are usually learned through backpropagation [76]. The choice of an activation function is typically guided by empirical performance, with ReLU [77] being the most commonly used due to its effectiveness in practice. Typical examples of activation functions are shown in Table 1.For a comprehensive treatment of activation functions, the works by Kunc and Kléma [78], Dubey et al. [79] can be consulted.
3.3. Artificial Neural Network
To compose a neural network, a group of neurons is organized into layers. Neurons in one layer are connected to those in the next layer through weights. To build a deep neural network, several layers are arranged in a particular organization called an architecture. While the traditional architectures sequentially stack layers one after the other, it is also common to have architectures with recurrent loops [80] and skip connections [81] which are introduced to solve issues with sequential data and efficient learning in very deep layered networks. For most practical applications, deep architectures are preferred due to their ability to learn rich and expressive feature representations [82].
3.3.1. Learning in Neural Networks
The goal of a neural network is to learn a mapping where D and Q represent the dimensions of the input and output spaces, respectively. The network is designed to handle inputs of arbitrary dimensionality and approximate complex functions. To measure if the network has accurately learned an optimal mapping, its performance is evaluated using a loss function, also known as an objective function, which measures the discrepancy between the neural network’s prediction and the actual target . This is achieved by minimization of the objective function,
Loss functions differ based on the task at hand. Generally, there are three foundational approaches to machine learning, i.e. supervised learning, unsupervised learning, and reinforcement learning [83]. The discussions in this review will only consider the first two.
In a supervised learning setting, the model is trained to predict an output given an input . The data is labelled prior to training where each input is set to predict a given output, i.e., with being the size of the dataset. In this setup, the loss function is designed in such a way that the predicted outputs closely match the target labels . For regression tasks, the mean squared error is a commonly used metric
For classification tasks, a commonly used loss function is the cross-entropy loss, given by
Cross entropy has its origins in information theory.In ML it is used to measure the deviation of the predicted distribution to the true distribution. The goal is to achieve a low cross entropy, where the predicted probability is close to the true label. In the case where the target output has only two labels, the binary cross entropy is used. For multiple classes, the categorical cross entropy is more appropriate.
It is possible to derive the above loss functions using a probabilistic framework where learning is considered an attempt at modeling the probability distributions over the target variables. With such a framework in place, loss functions for regression are formulated considering a continuous probability distribution while those for a classification task consider a discrete distribution [84]. However, it has to be noted that discrete distributions can also be used to formulate loss functions for regression problems.
In unsupervised learning, the goal is to learn patterns from the data which are then used to cluster, reduce data dimensionality, or generate new data samples. Thus, the objective function for unsupervised learning is crafted with these tasks in mind. These are tackled in detail when discussing generative models.
3.3.2. Regularization
The parameter space is highly multidimensional, encompassing various possible parameter sets. This complexity makes learning challenging, as the learning process must identify parameters that generalize well to unseen data. To address this, a regularization term, , can be incorporated into the loss function, helping steer the learning process toward reasonable parameters
Model regularization is a way of restricting the model parameters and helps avoid overfitting [85]. With overfitting, the network learns the training data so well but fails to generalize to unseen data during inference. Common explicit regularization terms are the , , and elastic net[86]. The regularization term is given by, , where is the regularization parameter, and represents the model weights. In practice, regularization produces sparse models [87]. Due to this property, is effective at feature selection and dimensionality reduction in high-dimensional datasets with correlated features. In contrast, regularization, expressed as, , imposes a large penalty on large weights, encouraging the model to select smaller weights. With regularization, most weights are close to zero. In other settings, the best of the two approaches are combined to produce the elastic net. This creates a more flexible regularization scheme. Besides these explicit regularization techniques, neural networks employ other approaches such as early stopping [88], batch normalization [89], and mixup [90]. The discussion of these approaches is outside the scope of this review.
3.3.3. Update of Network Parameters
During training, neural networks are initialized with weights, which get updated over multiple iterations. The initial weights can be categorized as weak or strong. Strong initial weights impose stricter assumptions compared to their weak counterparts.In this light, various weight initialization techniques exist, including Xavier [68], He [91], LeCun [92], and Orthogonal [93,94].
Typically, weights are updated using the following expression
Here, evaluates the sensitivity of the objective function to changes in the parameters.This expression is computed using backpropagation, a specialized case of automatic differentiation [95]. Backpropagation applies the chain rule to compute this term. Following this, parameter updates can occur after a full pass over the dataset (batch gradient descent) or over a smaller subset of data points (mini-batch or stochastic gradient descent(SGD)). Among these two approaches, SGD is preferred as it is more efficient and scalable.
The learning rate governs the step size toward the optimal solution, i.e, . Convergence of the model is hugely dependent on the choice of the learning rate. A small learning rate may lead to slow convergence, while a large learning rate risks overshooting minima or diverging altogether. This is so because the objective function encountered in real world problems is a highly complex, non-convex function characterized by multiple local minima and saddle points.
Despite its use, the basic update rule is somewhat naïve in the sense that the update strength remains constant, regardless of the model’s position in the learning trajectory. To overcome this limitation, a momentum term can be introduced to the update rule. Momentum helps accelerate updates in consistent directions and suppresses oscillations in directions with fluctuating gradients. The modified update rule is given by
Here, is the velocity term, is the momentum coefficient (typically around 0.9). This formulation effectively averages gradients over time, enhancing movement in stable directions while dampening updates in volatile regions. However, one issue with traditional momentum is the potential to overshoot minima. A refined version known as Nesterov Accelerated Gradient (NAG) anticipates the future position of parameters by calculating the gradient at a lookahead point,
This subtle change improves convergence in practice and reduces the risk of overshooting. Rosebrock [96] likens Nesterov momentum to a child rolling down a hill who decelerates early upon seeing a brick fence at the bottom. Besides these two approaches, other more advanced optimization algorithms such as Adagrad [97], RMSProp [98], and Adam [99] have also been proposed to further address the challenges in training deep networks.
4. Foundational Architectures
This section introduces the commonly used architectures for time series analysis. Generative models have been reserved for the next section. The aim is to maintain the natural flow of the discussion, since the architectures covered in this section can serve as the backbone for either generative or discriminative models. Our discussion begins with multilayer perceptrons as they are extensively covered in deep learning literature.
4.1. Multilayer Perceptrons
A multilayer perceptron (MLP) is a feedforward neural network whose architecture is defined by an input layer, one or more hidden layers, and an output layer. A typical compact representation of an MLP with an added observation error is shown in Figure 3.
MLPs have found success in modeling highly complex functions for both classification [101,102] and forecasting tasks [103]. Unlike RNNs, as will be seen later, MLPs do not have an inherent memory mechanism to handle sequential data. In order to process such data, the problem is transformed into a supervised learning problem by creating a lagged version of the data. This approach is called the sliding window approach, where to predict the value at time , the input consists of a fixed-size window of past observations, typically represented as , and this works for both univariate and multivariate time series.
In addition to the sliding window technique, features inherent to time series can be manually engineered and incorporated into model training. Furthermore, network architectures can be designed to autonomously extract essential features from sequential data. For instance, frequency-domain features can be integrated into the model. While several approaches exist, the focus here is on a novel architecture known as the Fourier Analysis Network (FAN) [104]. FANs activate a certain subset of the neurons in a layer using cosine and sine functions, while the remaining neurons are activated using standard functions such as ReLU. Compared to traditional multilayer perceptrons (MLPs), FANs offer the advantage of reduced trainable parameters and, consequently, lower computational complexity due to their design. In principle, FANs are simply performing a Fourier series analysis, as seen by the compact representation of the layer operation,i.e.
which is structurally equivalent to
where corresponds to the constant term , and represent the learned amplitudes analogous to and , respectively, and plays the role of the frequency-modulated phase .
Beyond feature engineering and activation design, recent research has demonstrated that carefully structured MLP architectures can achieve competitive performance on time series forecasting tasks. NBEATS [105] introduced a purely MLP-based approach by stacking fully connected layers into forecast and backcast modules. This enables the network to model trend and seasonality components directly from the data without the need for recurrent or convolutional operations. Building on this idea,N-HiTS [106] extended the architecture by introducing hierarchical interpolation strategies that effectively capture multi-scale temporal patterns. N-HiTS was proven to improve accuracy with almost 20% over Transformer architectures for time series. Similarly, TSMixer [107] employ stacked MLPs to separately mix temporal and feature dimensions. This work was inspired by earlier vision models which showed that simple linear projections over time and features can match or surpass more complex sequential models. The last architecture in our discussion is gMLP [108]. This architecture incorporates spatial gating mechanisms into MLP layers to allow the network to model interactions across time steps more effectively without explicit recurrence.
4.2. Recurrent Neural Networks
Over the last 30 years, recurrent neural networks (RNNs) have been the standard deep neural architecture for time series. RNNs are inherently designed to remember past information using memory cells. Thus, RNNs could also be termed memory or stateful networks due to their ability to remember the past. Different variations of RNNs have so far been developed and the following sections tackle these in detail.
4.2.1. Simple RNNs
Simple RNNs use RNN cells which are stacked together to create an RNN. An RNN cell accepts two inputs at each time step; the previous hidden state, which encodes previous information, and the input at the current time step.
Figure 4.
A representation of a simple Recurrent Neural Network cell (a) and a single-layered unrolled Recurrent Neural Network (b).
Figure 4.
A representation of a simple Recurrent Neural Network cell (a) and a single-layered unrolled Recurrent Neural Network (b).
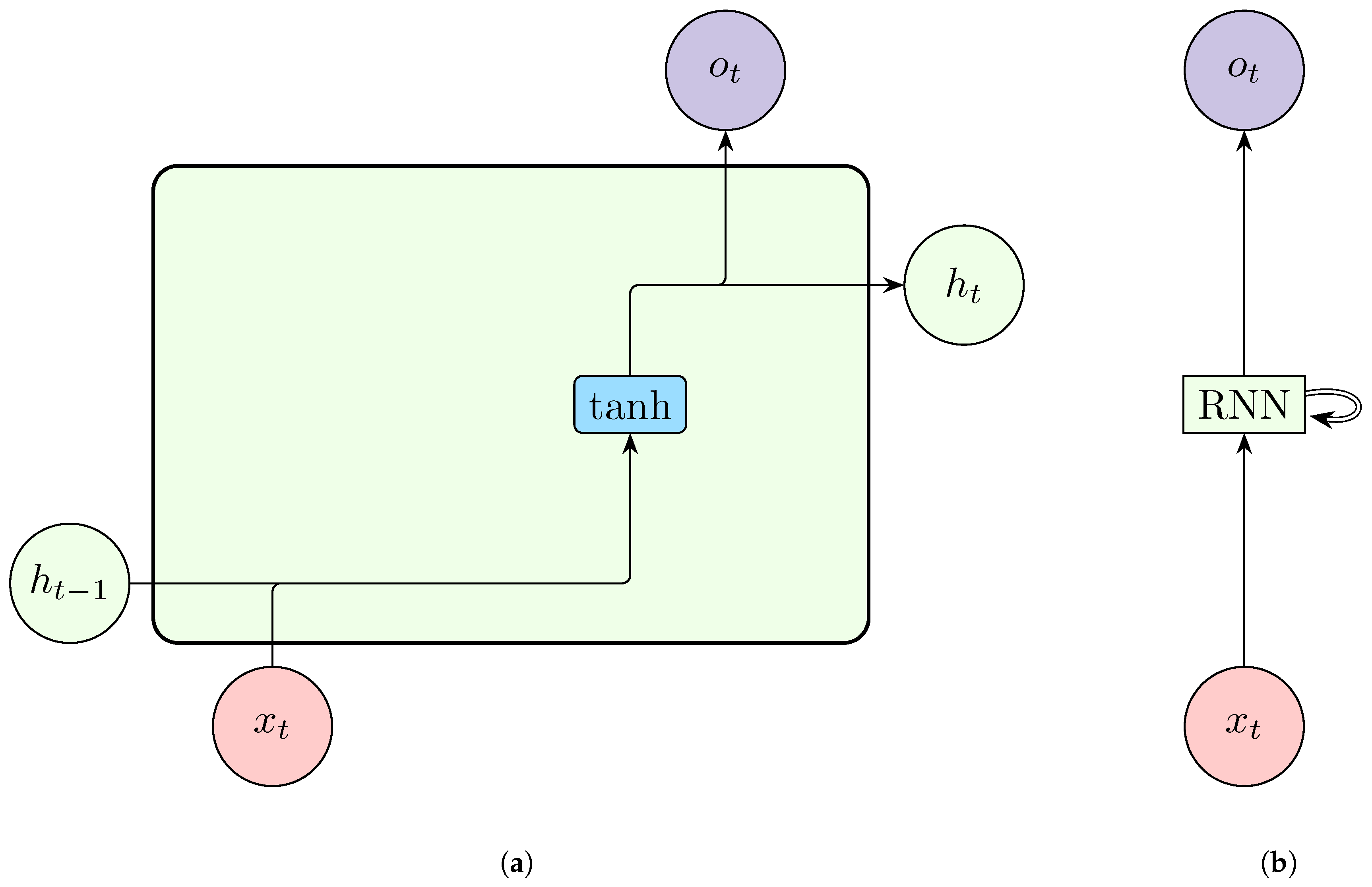
4.2.2. Deep RNN
The typical RNN discussed so far only considers a single layer. However, as indicated earlier, neural networks perform better with depth. Just as MLPs, this is possible with RNNs. Multiple RNN layers are stacked on top of each other as shown in Figure 5 to compose a Deep RNN. Cells in the top layers get input from the previous cell of the same layer as well as from the bottom layer.
4.2.3. Bidirectional RNN
To help address issues like missing values, RNNs use an innovative architecture called bidirectional recurrent neural network(BiRNN). This architecture was proposed by Schuster and Paliwal [111]. BiRNN combines two RNNs oriented in different directions with each RNN treated separately, i.e., for the forward RNN and for the backward RNN. The outputs of these networks are concatenated, i.e., , to produce the final output.
Figure 6.
Architecture of a Bidirectional Recurrent Neural Network (rolled(a) and unrolled(b)). Adapted from Vuong [110].
Figure 6.
Architecture of a Bidirectional Recurrent Neural Network (rolled(a) and unrolled(b)). Adapted from Vuong [110].
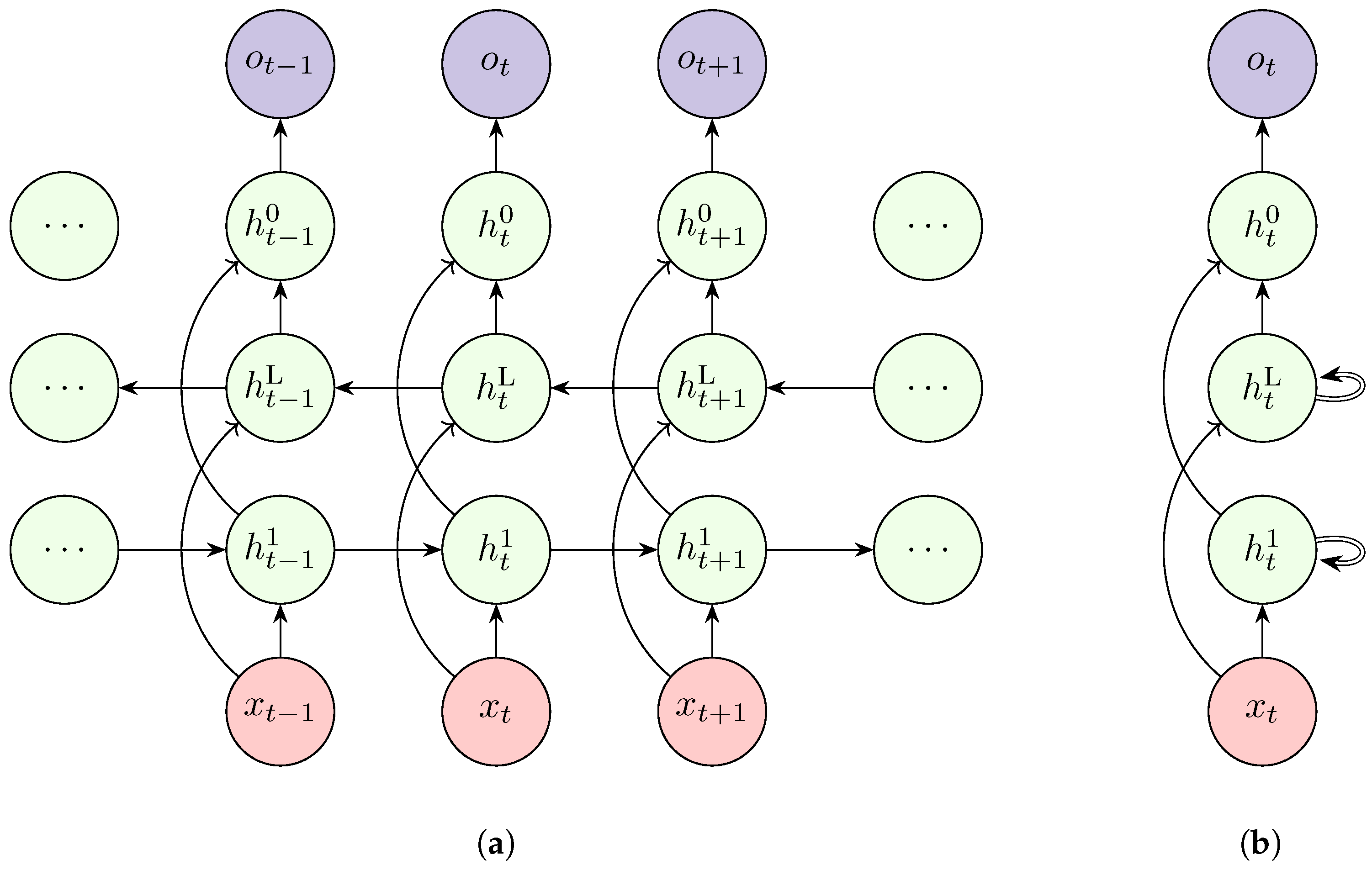
4.3. Comparisons of Standards RNNs
The three architectures of RNNs discussed thus far have some similarities and differencies. Simple RNNs offer a lightweight structure capable of modeling short-term dependencies; however, their effectiveness diminishes on long sequences due to vanishing gradients [112] and limited memory capacity . On the other hand, deep RNNs are able to learn hierarchical temporal features and tend to perform better than simple RNNs. Despite improving model accuracy, the added depth adds a layer of complexity and there is always a tradeoff between accuracy and model generalization. Thus, careful regularization and initialization are needed in deep RNNs to mitigate training instability. BiRNN’s introduce a layer of complexity with their dual encoding feature. This architecture is useful in applications such as anomaly detection, classification or data imputation tasks where the entire sequence is available a priori . However, bidirectionality is inherently noncausal and thus unsuitable for real-time forecasting, where future observations are not accessible. Despite these differences, all RNNs share a common advantage, weight sharing. Weight sharing reduces the number of trainable parameters in RNNs and thus reducing the computational costs

Table 2.
Comparison of Simple RNN, DRNN, and BiRNN in Time Series Modeling.
| Aspect | Simple RNN | Deep RNN | Bidirectional RNN |
|---|---|---|---|
| Temporal direction | Forward only | Forward only | Both |
| Long-term memory | Poor | Improved | Strong (non-causal) |
| Depth and abstraction | Shallow | Hierarchical | Context-rich |
| Suitability for forecasting | Online / short horizon | Long horizon forecasting | Not suitable for real-time use |
| Computation and training | Efficient, stable | Expensive, harder to train | High overhead |
| Best use case | Basic time series tasks | Multiscale or nonlinear time series | Offline classification or anomaly detection |
4.4. Shortfalls of RNNs
There are two main problems with the discussed RNN architectures. Firstly, RNNs are trained through a process called backpropagation through time (BPTT), which involves going back in time n steps to compute the derivative of the loss. Thus, the gradient of the loss function involves repeated multiplication of the Jacobian matrix of the hidden state transition,
If the largest eigenvalue of this matrix is less than 1, gradients tend to vanish. On the other hand, if is greater than 1, gradients grow exponentially, leading to the exploding gradient problem (unstable training) [14,113].
There are different ways to resolve these issues including gradient clipping, proper weight initialization, and use of gating mechanisms (LSTMs and GRUs). This issue is also tackled via training technique called teacher forcing, where ground truth at t is fed as input to the cell at [70].
A second shortfall of RNNs, which is also common to their advanced variants, is their lack of parallelizability, as they process data sequentially. This can significantly slow down training times. Attempts to resolve this have led to the development of advanced architectures such as transformers and parallelizable RNNs.
4.5. Long Short-Term Memory
To handle long and short sequences effectively without issues such as exploding or vanishing gradients, Long Short-Term Memory(LSTM) networks were introduced [65]. LSTM neural networks use a cleverly designed cell (LSTM cell) instead of the simple RNN cell. These gates are depicted in Figure 7.
The input to the forget gate is the previous hidden state and current input
acts as a mask for the cell memory since a sigmoid function squashes all outputs into values between 0 and 1. Zero entries erase irrelevant previous memory contents at a specific memory location.
To update the cell memory, an LSTM uses the following equations,
The input gate controls how much new information, which is represented by the candidate memory , should be stored in the cell state . It decides what proportion of the candidate memory will be added to the current memory, effectively controlling the flow of information into the cell state. The candidate memory represents a potential new memory value that could be added to the cell state. Its value is computed based on the current input and previous hidden state, capturing the new information to be incorporated into the cell state. The input gate modulates this candidate memory and determines how much of it should influence the memory update.
The current hidden state is then calculated based on the updated memory. A copy of the current memory is passed through a tanh activation function to normalize it between -1 and 1. This result is then multiplied by , which is computed as
The current hidden state, given by
along with the current cell memory , are passed to the next LSTM cell.
4.6. Other LSTM Variants
Different variations of the LSTM cell exist. The focus here is on the peephole LSTM [115] and xLSTM [116] The peephole LSTM extends the standard LSTM architecture by adding connections from the internal cell state to the input, forget, and output gates. The main benefit of this approach is improved gradient flow, which aids in mitigating the vanishing gradient problem. In contrast, xLSTM approaches a similar problem by incorporating additional gates for finer control over information retentions. The architecture also includes an exponential gating mechanism in which exponential activation functions are used in the input and forget gates to better manage data flow
4.7. Gated Recurrent Unit
The Gated Recurrent Unit(GRU) [117] was designed to simplify the LSTM while maintaining comparable accuracy. The GRU removes the need for a separate memory cell and reduces the number of gates to two; the reset gate and the update gate .
Figure 8.
Internal structure of a Gated Recurrent Unit(GRU) [114].
Figure 8.
Internal structure of a Gated Recurrent Unit(GRU) [114].
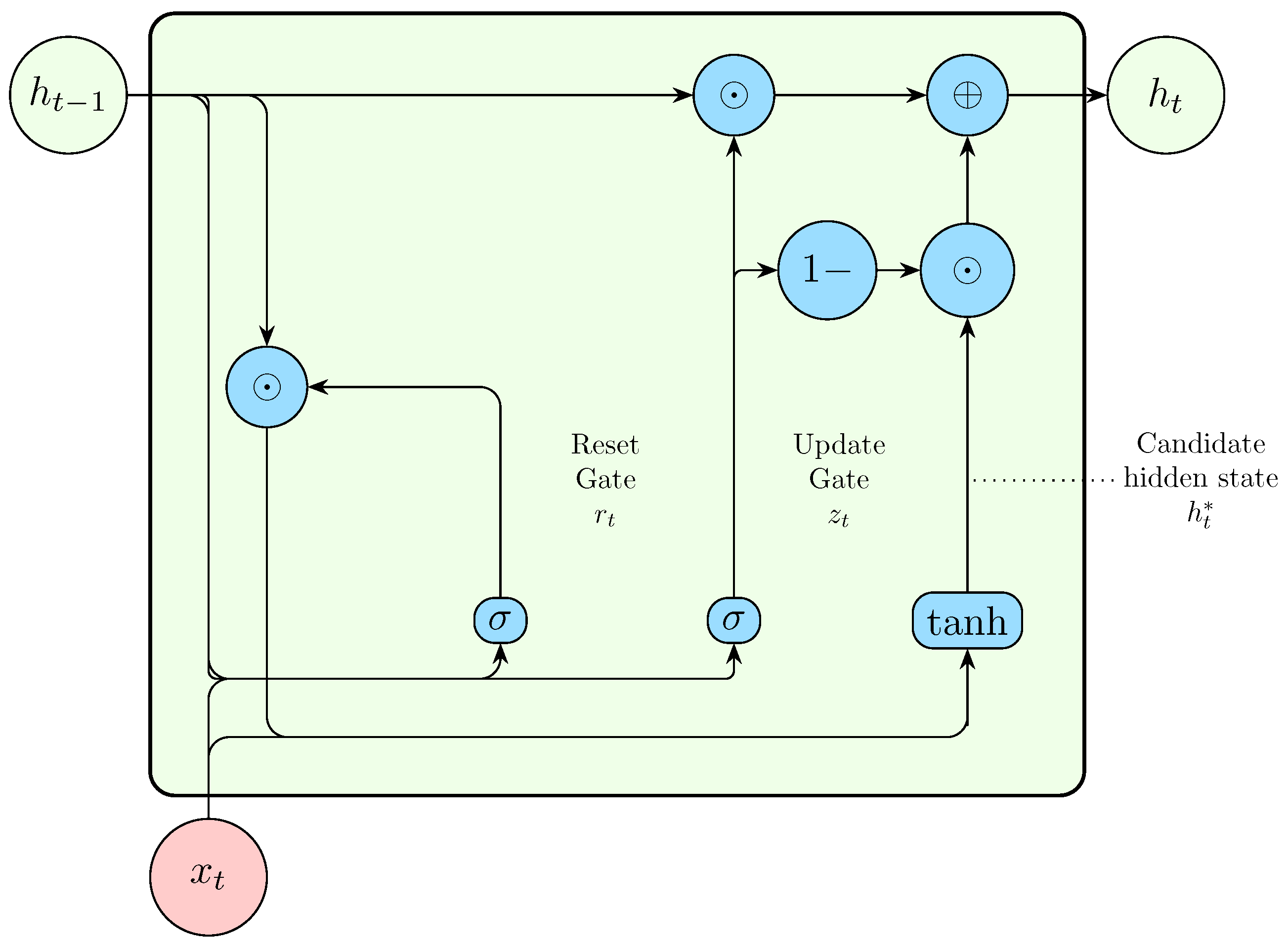
The reset gate controls how much of the previous hidden state should be considered irrelevant for the current time step. The input to the reset gate is the current input and the previous hidden state
After applying the logistic sigmoid activation, determines how much of the previous hidden state should be reset. Next, the candidate current hidden state is calculated by multiplying the reset gate output with the previous hidden state , and then adding the current input
The update gate determines the balance between the previous hidden state and the candidate current hidden state. A value of 0 completely ignores the previous hidden state and only considers the current input. Conversely, a value of 1 completely ignores the current input and only considers the previous hidden state. The update gate is computed as
Finally, the current hidden state is calculated as a linear interpolation between the previous hidden state and the candidate hidden state based on the value of ,
4.8. Comparison Between LSTM and GRU
Both the LSTM and GRU were designed to solve the issue of vanishing gradients and enable long term modeling. The subtle difference between the two architectures is mostly in the cell complexity, where the number of gates in the GRU is reduced to two. While both models perform well on many sequence modeling tasks, GRUs often generalize comparably to LSTMs with less computational cost, making them a preferred choice in scenarios with limited resources or smaller datasets. However, in tasks that require modeling more intricate temporal dynamics, LSTMs may offer better performance due to their more expressive gating mechanisms. For more expressive modeling, in practice, it is also common to use deep or bidirectional RNNs with the LSTM or the GRU as the central computing mechanism.
4.9. Transformer Models
Transformers [118] were introduced to address the limitations of recurrent neural networks (RNNs). The issues referred to here are long-term memory and parallelization. Tranformers rely on self-attention to capture contextual dependencies across input sequences. Mathematically, self-attention is defined as
where , , and represent the query, key, and value matrices, respectively, and d denotes the dimensionality of the key vectors. To ensure causality, which is a key issue in time series, masking is used to prevent information from future time steps from influencing the current prediction.
Original transformer models were designed for machine translation tasks. However, over the past few years, transformers have been adapted to time series analysis due to their ability to capture long-range dependencies and enable parallel computation. Notable variants include Temporal Fusion Transformer (TFT) [119], Informer [120], Autoformer [121], FEDformer [122], and PatchTST [123].
4.10. Mamba
Mamba [124] is a recent architecture for efficient and expressive sequence modeling. This architecture was developed to overcome the quadratic complexity of self-attention in Transformers. It builds on discrete-time state space models (SSMs), represented by
Unlike classical SSMs, Mamba introduces input-dependent parameters , , and a dynamic step size , enabling selective compression of relevant information and improved adaptability. To extend memory and enable parallelization, Mamba uses structured initialization, (HIgh-order Polynomial Projection Operator) [125] for and a hardware-aware parallel scan algorithm.
4.11. Convolutional Neural Networks
Convolutional neural networks (CNNs) are among the most popular architectures and have significantly influenced the modern era of deep learning. CNNs were initially developed to handle grid-like data such as images. However, researchers have found CNNs to perform well on sequential data, such as time series. It has to be noted that time series can be considered one-dimensional grid data [109]. The fundamental operation in a CNN is the convolution. Mathematically, for the one dimensional discrete case, this is defined as,
where G is the input signal, H is the filter or kernel, ★ denotes convolution operator, i is the output index, m is the summation index, is the value of G at m, and is the flipped and shifted version of H.
Convolutions can also be multidimensional. For 2D convolutions, the operation becomes,
As can be seen, a typical convolution operation involves flipping the function H (kernel).However, in CNNs, it is uncommon to flip function H before applying it, so the operation is more accurately described as cross correlation[126]. Despite this, the term convolution is still commonly used. The purpose of CNNs is to learn a set of functions H, also known as filters or kernels. These filters are typically small tensors (e.g., 1x1, 3x3, 5x5, or 7x7). For multi-dimensional inputs, the filters are extended accordingly. Unlike MLPs, CNNs rely on local connections and share the same filter across the entire input to create the output feature map. Multiple filters can be used in one layer, and their outputs are concatenated to form a complete feature representation. The dimensions of the feature map are dependent on the number of kernels, padding, stride, dilation, pooling, and upsampling. Since the same filter is reused across the input, CNNs are able to learn spatial relationships invariant to transformations. Additionally, CNNs require fewer parameters compared to fully connected networks, making them well-suited for high-dimensional data. Unlike RNNs, CNNs are parallelizable.
4.11.1. 1D CNN
The most basic CNNs used for time series are 1D CNNs [127]. This involves sliding the filter along the sequence length from the beginning. Notably, 1D CNNs can be used for multivariate time series modeling as well, provided that the filter width matches the width of the sequence. Despite their effectiveness, 1D CNNs suffer from future data leakage, violating causality.
4.11.2. Causal CNN
To overcome the issue of future data leakage in 1D CNNs, causal convolutions are used. Mathematically, causal convolution is written as,
Causal convolutions only use past data to make predictions. To handle long sequences, dilated convolutions, introduced by Yu and Koltun [128] are used to increase the receptive field with fewer layers,
This generalization allows flexible dilation without modifying the filter. The standard convolution is a special case where .
4.12. Graph Neural Networks
In several practical applications, time series emerge within networked structures such as road networks, water distribution systems, and railway infrastructures. In such settings, the data exhibit dependencies that are both spatial and temporal in nature. To capture these dependencies accurately requires their explicit modeling. Graph Neural Networks(GNNs) are a natural architecture for this as they provide a more flexible way to model such dependencies. Graph Neural Networks that take into account the aspect of time are called dynamic. In this section, we will firstly discuss the fundamentals of GNNs and will then consider how they fit in time series analysis.
Typically, the input to a GNN is a graph, e.g. a protein structure, social network, transportation network, etc. A graph is defined by a set of nodes , a set of edges , and associated mappings that describe the relationships between nodes. Mathematically, a graph is represented either through an adjacency list or adjacency matrix (A). The latter is widely used in Graph Neural Network applications. Each element in A indicates the existence or absence of an edge between a pair of nodes, i.e., if there is an edge from node i to node j, and otherwise. The specific structure of A depends on the type of graph. Graphs can have single or multiple edges between a pair of nodes. It is also possible to have edges which start and terminate on the same node (self-loops). Further categorisation of a graph depends on edge- directionality and edge-weight. Thus, graphs can be classified as directed or undirected as well as weighted or unweighted. A special case which will be our focus are undirected graphs without self-loops or multiple edges. The analysis of such graphs is simple since the adjacency matrix is symmetric.
Node ordering in a graph is arbitrary as such different formulations of the adjacency matrix are possible [84]. For this reason, a permutation matrix P is used to ensure that the output of the GNN remains invariant to the ordering of nodes. This is achieved through permutation-invariant embeddings and a transformed adjacency matrix .
In general, the goals of a GNN span a variety of tasks, including node classification [129], link prediction [130], graph classification [131], and graph generation [132] . A GNN aims to map the input node or edge features into an embedding space that offers a rich representation for further modeling [133]. These node or edge features are continuously updated by aggregating information from neighbouring nodes or edges through a process known as message passing,
where is a non-linear activation function, is the learnable weight matrix at layer t, AGG is a neighborhood aggregation function such as mean or sum, and denotes the set of neighbors of node v.
Message passing in a Graph Neural Network (GNN) occurs iteratively over several iterations. After a specified number of iterations t, each node encodes information about all other nodes in the graph. The number of iterations is considered optimal to ensure that the GNN has a sufficiently large receptive field while preventing oversmoothing; a scenario where all embeddings become indistinguishable [134]. The basic approach assumes all nodes and edges are of equal importance; however, more advanced methods have been developed to account for varying levels of importance.
4.12.1. Temporal Modeling in GNN
To make predictions, a GNN typically utilizes the final embedding layer. For temporal modeling, it is possible to integrate a GNN with other network architectures, where the final embedding layer is passed as input to subsequent neural network blocks. This approach is commonly used in temporal GNNs [135], where the final embedding is fed into another network block, such as an RNN or CNN. This allows the network to capture both spatial patterns using the GNN and temporal features using the RNN or CNN.
GNNs can also be used for data which is not spatial by nature. This is possible by first transforming the data into a graph structure. The approach seems to work quite well with time series. Liang et al. [136] employed this technique to impute missing values in traffic datasets. For a comprehensive overview of GNN applications in time series tasks, refer to Jin et al. [137].
4.13. Physics-Informed Neural Networks
Traditionally, the approach to training neural networks has been heavily data-centric. However, this approach may have drawbacks, such as noisy data that deviates from actual physical reality.To resolve this, researchers have been experimenting with the idea of incorporating the physics of a problem into a model. Enforcing physics into a model is a well studied field of machine learning under the umbrella of Scientific Machine Learning (SciML). Several studies have so far shown that models in scientific settings perform better on unseen data when the physics of the phenomenon being studied is considered [138] . Although SciML has been achieved through different techniques, our consideration in this review are Physics Informed Neural Networks (PINNs) [139] . PINNs are a household name in SciML hence their discussion. PINNs enforce physics through a physics regularization term which is added to the loss function. This is achieved through the problem’s differential equation and its associated conditions.
Consider the general form of a partial differential equation,
where represents a differential operator, is the solution to the PDE, and denotes the forcing term. The solution to this PDE must satisfy both initial and boundary conditions. Specifically, the initial condition is,
where is the initial time, and describes the initial state of the system. The boundary condition is expressed as,
where prescribes the behavior of the solution on the boundary of the spatial domain . Here, the spatial variable x spans the domain , and the temporal variable t lies within the interval .
The first step in a PINN is to calculate the residual of the PDE as follows,
Residuals are also calculated for initial and boundary conditions, and the total residual is termed the physics loss. Minimizing this loss across the domain and over the specified time interval is crucial for validating the accuracy and consistency of the solution under the given initial and boundary conditions. This ensures that the proposed solution adheres to both the dynamics described by the PDE and the constraints imposed by the initial and boundary conditions. However, in practice, exact satisfaction is rarely achievable; hence, PINNs do not perfectly satisfy the governing physics [140,141].
PINNs are usually trained by minimizing the following composite loss function,with each term adequately weighted,
where,
is the Initial Condition Weight, is the Boundary Condition Weight, is the Physics Weight, and is the Data Weight, all balancing their respective influences in the PIN model.
PINNs have been successfully applied to time series problems, such as the estimation of cuffless blood pressure [142]. A recent application of PINNs by Park et al. [143] involved weather data forecasting, where an RNN served as the backbone network and the harmonic oscillator equation was used to enforce physical constraints (see Figure 9).
Due to the nature of the harmonic motion solutions, the neural PDE component effectively modeled the seasonal component of the time series. This approach bears some similarity to the Fourier Analysis Network described earlier.
4.13.1. Issues with PINNs
Similar to other neural architectures, PINNs have shortfalls. A major shortfall lies in the training instability and difficulty in balancing the contributions of data loss and physics loss, especially when dealing with stiff PDEs or multi-scale phenomena [144]. This imbalance often leads to poor convergence or solutions that satisfy the data but violate the governing equations, or vice versa. Moreover, PINNs typically rely on automatic differentiation to compute residuals, which can be computationally intensive . Another notable challenge is the difficulty PINNs face in enforcing complex boundary conditions, especially in domains with discontinuities or sharp gradients [145]. A detailed investigation into the failure modes of PINNs and strategies to address them is provided by Krishnapriyan et al. [140].
5. Generative Modeling
In practical applications, there are scenarios where it is essential to model the input data itself. In such cases, a different class of models, generative models, may be more appropriate. Generative models learn the joint probability distribution and can use this distribution to generate new data points that resemble the training data. The aim of this section is to introduce various classes of generative models that are commonly employed for tasks such as data imputation and synthetic data generation in time series applications.
5.1. Autoencoders
The goal of an autoencoder is to learn a low-dimensional latent space of the data, and then to reconstruct the original data from this compressed space. An authoencoder achieves this using an encoder , for compression, and , for reconstruction. Learning is done by minimizing the reconstruction loss, which is given by
Exact reconstruction is not possible because the latent space has a lower dimension than the input and output. However, this architectural design is necessary to encourage the autoencoder to learn useful features required for reconstruction.Different researchers have successfuly applied autoencoders to data denoising [146], data imputation [147], anomaly detection [148], and more. Despite its wide usage in literature, the standard autoencoder cannot perform meaningful data interpolation, and this arises from the discrete nature of the learned latent space [149]. Among other approaches, this limitation is addressed by variational autoencoders.
5.2. Variational Autoencoders
Unlike traditional autoencoders, variational autoencoders (VAEs) [150] adopt a probabilistic framework to learn a more structured latent space.
Figure 10.
Architecture of a Variational Autoencoder (VAE). The input x is passed through an encoder network to predict the variational parameters: and , which parameterize a Gaussian variational distribution . A latent variable is sampled from this distribution using the reparameterization trick: , where . This sample is then fed into the decoder , to predict the data x. Adapted from Prince [84].
Figure 10.
Architecture of a Variational Autoencoder (VAE). The input x is passed through an encoder network to predict the variational parameters: and , which parameterize a Gaussian variational distribution . A latent variable is sampled from this distribution using the reparameterization trick: , where . This sample is then fed into the decoder , to predict the data x. Adapted from Prince [84].
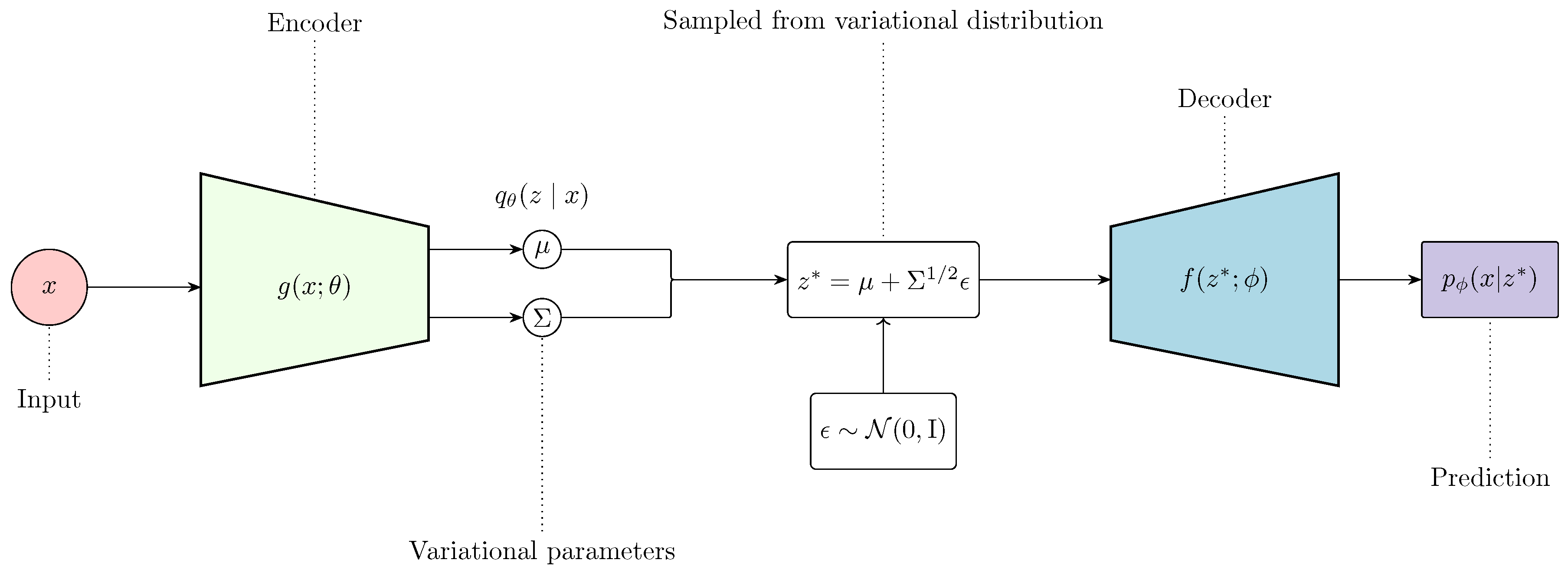
First, the input is mapped to a latent space z using an encoder , where . Since is generally intractable due to the intractability of the marginal likelihood , VAEs introduce a more tractable approximate posterior . Then, to reconstruct the data from the latent space, a decoder is used.
VAEs are trained by maximizing the marginal likelihood over the reconstructed sample, , which is obtained by marginalizing over the latent space,
This integral is generally intractable and is typically simplified to provide tractable proxy objectives. By introducing a variational distribution , we can apply Jensen’s inequality to get lower bound of the log marginal likelihood,
This gives rise to the evidence lower bound (ELBO),
Intuitively, the first part of this expression represents the reconstruction term, which encourages the decoder to accurately reconstruct the input data. The second term encourages the variational distribution to be as close as possible to the prior. It is common not to sample directly from , but rather to use a reparameterization trick (Equation 41),
This allows the expectation over to be rewritten as an expectation over a fixed noise distribution . Expression (40) can therefore be rewritten as a reparameterized objective
According to Gundersen [151], without the reparameterization trick, backproping would not compute an estimate of the derivative of the ELBO and would thus give no guarantee that sampling large numbers of z will help converge to the right estimate of the gradient. The gradient of the ELBO is computed with respect and via
5.3. Generative Adversarial Network
A Generative Adversarial Network (GAN) [126] aims at generating realistic data similar to real-world data present during training by fooling another network into believing that the generated samples are real. This is achieved by simultaneously training two networks: a generator G and a discriminator D.
Figure 11.
Schematic of a Generative Adversarial Network (GAN) training loop. A latent variable z is sampled and transformed by the generator to produce samples. These, along with real data , are evaluated by the discriminator , which outputs the probability of each sample being real. The discriminator is updated to better distinguish real from generated, while the generator updates its parameters to fool the discriminator.Adapted from Calin [155].
Figure 11.
Schematic of a Generative Adversarial Network (GAN) training loop. A latent variable z is sampled and transformed by the generator to produce samples. These, along with real data , are evaluated by the discriminator , which outputs the probability of each sample being real. The discriminator is updated to better distinguish real from generated, while the generator updates its parameters to fool the discriminator.Adapted from Calin [155].
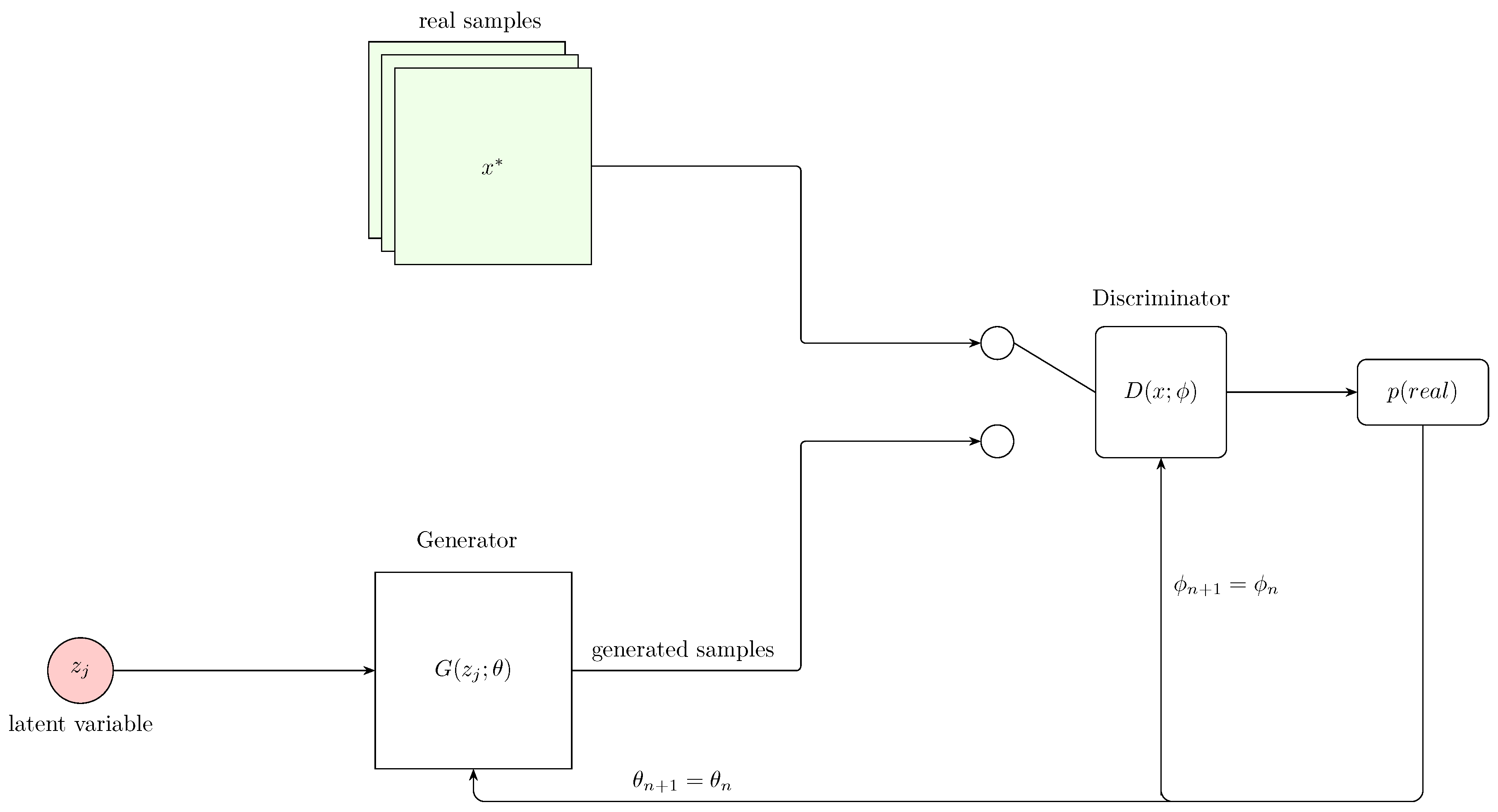
The generator creates samples from a latent variable . The objective of the generator is to produce data that is indistinguishable from real data. Mathematically, this is equivalent to minimizing the following expression with respect to ,
Technically, if samples are assigned a higher probability, i.e., if the discriminator classifies them as being real, the above expression approaches zero. However, if generated data is classified correctly, i.e., a low probability is assigned to generated data, the expression tends to infinity. This means that the generator loss can only be reduced if the discriminator incorrectly classifies generated data, in which case the generator achieves a minimum loss.
As already highlighted, the discriminator is responsible for classifying data as being real or generated(binary classifier). The input to the discriminator is either a generated or real sample, and it returns a probability that is higher when a sample is real (i.e., close to 1). The objective of the discriminator is usually to maximize the following expression with respect to
Despite the fact that the underlying principle behind GANs is conceptually straightforward, they are difficult to train in practice. A major challenge is mode collapse, where the generator ignores the variability in the latent space and produces limited or nearly identical output [84,156]. To address this issue, several techniques have been proposed. They include feature matching and mini-batch discrimination [157], unrolled GANs [158], Wasserstein GANs (WGAN) [159], spectral normalization [160], and gradient penalty methods (e.g., WGAN-GP) [161].
Although GANs were initially developed for image data, they have since been extended to handle sequential data such as time series data. Notable adaptations in this space include TimeGAN [162], SeriesGAN [163]; FinGAN [164] to name a few. For a detailed survey of GAN applications in time series, the works of Brophy et al. [165] and Zhang et al. [166] can be consulted.
5.4. Normalizing Flows
Instead of implicitly modeling the data distribution like GANs, normalizing flows explicitly model the probability distribution over the data [84]. Normalizing flows transform a simple distribution over a latent variable into a more complex distribution using differentiable and bijective transformations (see Figure 12).
The transformation function is usually parameterized by a neural network. Transformations are required to be differentiable and bijective so as to ensure a smooth transition between the latent and data space while enabling efficient learning via gradient-based methods. Several techniques have been developed to design transformations with these desired properties. Among them are coupling flows [168,169], neural ODEs [170], and autoregressive flows [171].
Since the data distribution is defined through a transformation, its density is determined using the change of variables formula,
where .
The objective is then to maximize the likelihood of the data under this model, i.e.,
Recent studies have applied normalizing flows to capture complex temporal dependencies and uncertainty in time series. Dai and Chen [172] proposed a graph-augmented normalizing flow (GANF) using Bayesian networks to model inter-series causality.Flow based modeling has also been combined with temporal and attribute-wise attention for high-dimensional, label-scarce data [173]. In forecasting, Rasul et al. [174] integrated autoregressive models with conditional flows to enhance extrapolation and capture temporal correlations. Fan et al. [175] proposed a decoupled formulation called instance normalization flow (IN-Flow), which addresses distribution shifts via an invertible transformation network.
5.5. Diffusion Models
Diffusion models (DM) [176] are trained by sequentially adding noise to a data sample over multiple time steps and then attempting to remove this noise. The noise is added according to a Markovian process
with its associated distribution,
is a hyperparameter which determines how quickly the noise gets blended. This hyperparameter can be fixed across all time steps or it can vary according to a predefined schedule. While single-step updates are possible for adjacent time steps by applying Equation 48, it is usually helpful to be able to move directly from to in a single step as well. This is important especially in the reverse process when denoising. The expression required to do this can be derived by generalizing Equation 48 over multiple time steps and is expressed as,
Derivation of this expression takes advantage of the properties of sums of Gaussian random variables. On the other hand, during the reverse process, the transition process is modelled as,
with an associated transition probability . is the noise predicted by the neural network, which is parameterized by . The goal is to learn a mapping that makes and as close as possible, which leads to the following loss function,
In other words, the model tries to predict the amount of noise that was added to the data sample during the forward (diffusion) process.
The discussion thus far has primarily focused on denoising diffusion probabilistic models (DDPMs), often considering the unconditional generation setting where the data distribution is modeled without auxiliary information. However, general DMs are also capable of conditional generation, where the data distribution is modeled given some conditioning variable such as class labels or other contextual attributes. DMs have been proposed for forecasting [177,178,179], classification [180,181], anomaly detection [182,183] , imputation [184,185], and generation [186,187]. A comprehensive review of the use of diffusion models in time series has been conducted by Lin et al. [188], covering key models, methodologies, and applications across forecasting, imputation, and generation tasks. More recently, Yang et al. [189] provided an extensive survey encompassing both time series and spatio-temporal applications of diffusion models, categorizing existing approaches based on task type and model structure.
5.6. Autoregressive Models
Given a sequence, , the joint probability distribution can be factorized using the chain rule of probability,
where .
This is called an Autoregressive model (ARM) and it allows for the exact computation of the likelihood [190]. To capture complex dependencies within the data, each conditional distribution in equation 53 is parameterized by a neural network [191]. Tomczak [192] provides good cases for ARMs. Generally, the conditional distribution can be modeled as it is, but in practice, it is usually computationally expensive as the sequence length increases. An alternative approach employs the first-order Markov assumption to simplify the conditional distribution at time t.Thus, the conditional distribution at time step t depends only on the immediate previous time step , i.e.
An ARM is trained by maximizing the likelihood of the observed data. This is also equivalent to minimizing the negative log-likelihood (NLL) given by
Once trained, data generation follows an ancestral sampling procedure, where values are sequentially sampled based on the learned conditionals.
5.7. Energy-Based Models
Energy-Based Models (EBMs) offer a general framework for modeling probability densities by associating scalar energy values to configurations of the input space.EBMs have their origins in statistical physics.The underlying assumption is that observed, high-probability data should correspond to low-energy states, while implausible or unlikely configurations should be mapped to regions of higher energy.
Formally, the model defines an unnormalized density over via a Boltzmann distribution,
Here, is a learned energy function, typically parameterized by a deep neural network, and is the partition function that ensures the density integrates to one. However, this normalization term is generally intractable in high dimensions, rendering exact likelihood evaluation and sampling computationally prohibitive. The parameters of the energy function are found through maximum likelihood estimation, which results in the following objective function,
with the gradient given by,
The first term is readily computable using observed data, while the second requires samples from the model distribution, which is itself defined implicitly by the energy function. Consequently, much of the complexity in training EBMs arises from the need to draw samples from a model whose normalization is unknown. Markov Chain Monte Carlo (MCMC) methods, such as Langevin dynamics, are commonly used for this purpose [190].
Popular examples of EBMs in literature include Boltzmann Machines [193] and Hopfield Networks [62]. Similar to the other generative models, EBMs have also been applied to time series analysis. Brakel et al. [194] outlined the training strategy for training EBMs for data imputation.Yan et al. [195] proposed ScoreGrad, which a is multivariate probabilistic time series forecasting framework based on continuous energy-based generative models and has been found to achieve state of the art results on a number of datasets.
5.8. Summary of Generative Models
Table 3 presents a comparative summary of the generative models discussed.
6. Uncertainty Quantification
SHM data can be limited or noisy. Noise can emanate from different sources such measurement errors and environmental variability. Limited data might be due to sensor malfunction, missing data, and intermittent data collection due to huge costs associated with the process. Considering these factors, uncertainty quantification is critical to SHM for effective decision making. Uncertainties are generally classified as aleatoric and epistemic [83,196]. Aleatoric uncertainty is associated with inherent randomness and cannot be reduced. According to Wikipedia, epistemic uncertainty is associated with things which one could in principle know but does not know [197]. Thus, once knowledge is available, epistemic uncertainty can be reduced. Epistemic uncertainty is further grouped into two major categories: homoscedastic, meaning it is constant across all observations, or heteroscedastic, meaning it varies with covariates. While homoscedastic uncertainty is relatively straightforward to handle, heteroscedasticity introduces additional complexity into modeling tasks. If these uncertainties are not properly accounted for, model predictions are usually unreliable can may potentially lead to suboptimal decision-making.The goal of this section is therefore to discuss how uncertainties are handled in deep learning. We do this from a Bayesian context.
6.1. Bayesian Inference
In many practical scenarios, prior knowledge plays a critical role in shaping our understanding of a problem. However, conventional deterministic modeling approaches typically disregard this prior information. A significant limitation of such methods is their reliance on large volumes of data to achieve good performance. In reality, data is often limited, incomplete, or corrupted by noise. In the late 1980s and early 1990s, Denker et al. [198], Tishby et al. [199], Denker and LeCun [200], Buntine and Weigend [201], MacKay [202], Neal [203] and Neal [204] proposed the bayesian framework as an alternative learning method. This approach provides a way to incorporate prior knowledge into a model as well estimate uncertainties associated with its outputs. The central idea that governs this philosophy is Bayes’ rule. Mathematically, Bayes’ rule is expressed as
where is the posterior, is the likelihood, is the prior, and the evidence term is given by,
To make predictions for a new data point in a supervised mode, the posterior predictive distribution is used,
With regards to this expression, Murphy [205] writes, "the posterior is our internal belief state about the world and the way to test if our beliefs are justified is to use them to predict objectively observable quantities."
Despite the simplicity of Bayes’ rule, the posterior distribution is often analytically intractable in real-world applications. For deep neural neural networks, the parameter vector may contain millions or even billions of parameters. For this reason, Bayesian methods were historically not favored for training deep models. However, this has changed with the development of efficient approximation techniques. Common methods for parameter estimation are discussed in the following sections.
6.1.1. Analytical Methods (Conjugacy)
For certain combinations of the prior and likelihood, the posterior can be computed analytically. In this case, the posterior distribution is of the same functional form as the prior, and the likelihood-prior pair is known as a conjugate pair [83].Besides providing a closed form solution for the posterior distribution, conjugacy enables sequential learning where the posterior at t becomes the prior at . Some of the conjugate pairs include Gaussian-Gamma, Gaussian-Inverse-Chi-Squared, Gaussian-Inverse-Gamma, and Gaussian-Inverse-Wishart [206].
6.1.2. Maximum Likelihood Estimation
Although not Bayesian, Maximum Likelihood Estimation (MLE) is widely used to estimate model parameters. The goal of MLE is to find the set of parameters that maximizes the likelihood of the data,
Equation 61 considers that the data is identically and independently distributed (i.i.d.). For large datasets, the computation of the likelihood can result in numerical instability. Large values of of result in overflow, while small values result in underflow. It is important to note that is a likelihood function, not a probability, and therefore can take values greater than 1.
To improve numerical stability and make the expression amenable to optimization, the log-likelihood is considered instead. Applying the properties of logarithms, the log-likelihood function is given by,
The above equation is a non-convex function and would otherwise benefit from readily available convex optimization algorithms by considering the negative log likelihood. This, in theory, is possible by taking the negative of the function. Thus, it is common to encounter negative log-likelihood in optimization problems
Maximization of the log-likelihood is similar to the minimization of the negative log-likelihood, and thus to find the optimal parameters,
A key limitation of MLE is its tendency to overfit, which can be mitigated using priors, leading us to Maximum A Posteriori estimation.
6.1.3. Maximum A Posteriori (MAP)
Bayes’ rule can be rewritten, omitting the marginal likelihood (which is constant w.r.t. ) as,
With this expression , it is possible to maximize the unnormalized posterior directly, i.e.,
Taking the log for numerical stability,
The second term serves as a regularization term, and this form is structurally similar to penalized optimization.
6.1.4. Laplace Approximation
The Laplace approximation is a technique used to approximate a posterior distribution with a multivariate Gaussian centered at the maximum a posteriori (MAP) estimate or, in some cases, the maximum likelihood estimate (MLE). It provides a way to account for uncertainty in the maximum likelihood or maximum a posteriori parameter estmates. Given a model with parameters , and a log-posterior function , the Laplace approximation takes the following form,
where is the MAP estimate given by equation 67 and the covariance matrix is approximated by the inverse of the negative Hessian of the log-posterior evaluated at ,
This approach captures the local curvature of the posterior distribution around the mode, thereby providing a second-order approximation of the distribution [83]. However, computing the full Hessian matrix is often computationally expensive, especially in high-dimensional parameter spaces. As a result, various approximations and low-rank techniques have been proposed to reduce this burden.
6.1.5. Expectation Maximization
The procedures for MLE and MAP discussed so far assume that the dataset is complete and that all variables associated with the model are fully observed and known. However, in many practical applications, models often involve partial data or incorporate latent variables that are not directly observable. In such scenarios, the complete log-likelihood must account for these hidden variables, necessitating marginalization over them to obtain the observed data likelihood. Our derivation of the E-M algorithm is based on the work of Gao [207].
Formally, let represent the observed dataset, the corresponding latent variables, and the parameters of the model. The complete-data log-likelihood is given by
However, since the latent variables Z are unobserved, the quantity of interest becomes the marginal log-likelihood
where the integral is taken over all possible configurations of the latent variables. In models containing a large number of latent variables, this integral typically becomes intractable, either due to high dimensionality or the complexity of the joint distribution .
To address this intractability, an arbitrary probability density function over the latent variables is introduced. By doing so, the marginal log-likelihood can be rewritten as
This re-expression enables the application of Jensen’s inequality, exploiting the concavity of the logarithm function to derive a lower bound. Specifically, Jensen’s inequality yields
which leads to
Defining the functional,
where denotes the entropy of , the above inequality can be compactly written as,
serves as a surrogate objective function that can be maximized in place of the intractable marginal log-likelihood.
Expectation-Maximization (EM) algorithm is a classical procedure for maximizing the marginal likelihood by iteratively optimizing the lower bound . EM algorithm proceeds in two alternating steps, referred to as the Expectation step (E-step) and the Maximization step (M-step).
In the E-step, given the current estimate of the model parameters , the function is set to the posterior distribution of the latent variables conditioned on the observed data and the current parameters,
Under this choice, the lower bound becomes tight, satisfying
thus removing the looseness introduced by Jensen’s inequality. The E-step therefore consists of computing the expected complete log-likelihood,
Following the E-step, the M-step seeks to update the model parameters by maximizing this expected complete log-likelihood
6.1.6. Monte Carlo Integration
Bayesian inference often requires evaluating integrals like the marginal likelihood, , which is equivalent to an expectation, . This can be approximated by sampling,
where is the number of samples.Monte Carlo integration is useful in high-dimensional spaces where analytical solutions are infeasible. The accuracy improves with more samples.
6.1.7. Importance Sampling
The typical monte carlo assumes that all samples are equally likely, which may not hold for heavily-tailed distributions such as the Gaussian. In such cases, a more effective technique is needed to assign higher weights to high-probability points and lower weights to low-probability points in order to provide accurate estimates of integrals. This can be achieved by modifying the marginal likelihood integral as follows,
with being a simple distribution from which samples can be drawn efficiently. This transformation allows for reweighting samples according to the ratio . The integral is now written as an expectation with respect to
We approximate this expectation using Monte Carlo sampling. Drawing for , the marginal likelihood is estimated as
6.1.8. Variational Inference
Variational Inference (VI) is a method for approximating complex probability distributions in cases where exact computation is intractable. The goal is to approximate a posterior distribution with a simpler variational distribution .Such a variational distribution is considered close to the posterior distribution. Closeness is usually achieved by minimization of the Kullback-Leibler (KL) divergence between the variational distribution and the true posterior,
Minimizing this divergence is equivalent to maximizing the Evidence Lower Bound (ELBO), given by,
The ELBO essentially transforms a bayesian inference problem into an optimization problem and can thus be optimized using gradient-based methods, allowing efficient approximation of the posterior by . While VI is typically faster than sampling-based methods, it is not guaranteed to converge to the true posterior.
6.1.9. Markov Chain Monte Carlo
Markov Chain Monte Carlo (MCMC) methods use a Markov chain to generate samples from an unknown posterior distribution. The chain satisfies the Markov property, where the next state depends only on the current state,
A large number of samples are generated using the chain, which is designed so that its stationary distribution is the target posterior. Perturbations are added iteratively (as in a random walk), and new states are accepted with a certain probability. The stationary distribution satisfies,
If the chain is ergodic, this stationary distribution is unique and reachable from any initial distribution.
Metropolis-Hastings Algorithm
The Metropolis-Hastings (MH) algorithm is an MCMC approach that generates samples from a proposal (or transition) distribution , with acceptance based on a probability criterion. The MH algorithm was first proposed in 1950, and used a symmetric proposal distribution in its initial form. By symmetric, we mean that the probability of moving to state i is equal to the probability of returning to the starting state. This symmetric form is expressed as
Hastings [208] improved upon the algorithm by incorporating asymmetric proposal distributions.
The MH algorithm uses the following criteria to move to new states: if the proposed sample is greater than the previous sample, the new sample is accepted. And if the proposed sample is less than the current sample, the new sample is accepted with an acceptance probability
This recursive process continues until the chain reaches a stationary distribution. One drawback of the MH algorithm is that random sampling can result in slow convergence and correlated samples. The subsequent method, Hamiltonian Monte Carlo (HMC), addresses this issue by incorporating gradient information to enhance sampling efficiency.
Hamiltonian Monte Carlo (HMC)
The Hamiltonian Monte Carlo (HMC) is a sampling-based parameter estimation approach that uses a systematic approach to sampling. To enable faster and efficient exploration of the target distribution, HMC leverages its gradient information. HMC employs Hamiltonian mechanics, incorporating both position q and momentum p. The core principle is to simulate the trajectory of a particle moving through a potential energy landscape defined by the target distribution.
In HMC, the potential energy is related to the target distribution . The kinetic energy and Hamiltonian are expressed as,
where M is the mass matrix. The Hamiltonian governs the dynamics of the system via Hamilton’s equations,
To approximate these dynamics, HMC uses the leapfrog integrator. The updates for momentum and position are,
Finally, the acceptance probability for the proposed state is calculated as,
More extensive treatments of HMC and its variations can be found in Marwala et al. [209]
6.2. Bayesian Neural Networks
6.2.1. Overview
Within a Bayesian context, model parameters are treated as distributions rather than point estimates [210]. The objective of a Bayesian Neural Network(BNN) is to learn these distributions. To this end, different methods have been developed to quantify uncertainty in neural networks. The discussions in this section will focus on 4 methods and the rationale for this choice is simplicity and similarity of each approach to the classic backpropagation. The first approach is discussed mainly because it has been extensively applied to SHM and can easily be scaled.
6.2.2. Tractable Approximate Gaussian Inference
The Tractable Approximate Gaussian Inference (TAGI) [211] is a probabilistic method that allows for the analytical inference of model parameters without relying on backpropagation. TAGI achieves this through a two-step process: propagation of the model uncertainty using moment functions and local linearization of the activation function. Parameters are then updated using a modified Rauch–Tung–Striebel (RTS) algorithm [211,212]. TAGI makes some assumptions about network parameters, layers, and units within layers. Parameters and units within a layer are considered i.i.d. and normally distributed. TAGI also uses the inherent conditional independence between hidden layers, i.e. .
Consider a neural network with an observation model described by
Mathematically, the i-th hidden state of the -th layer can be written as
where is the hidden state of the -th layer, is the weight from the k-th neuron in layer j to the i-th neuron in layer , is the activation of the k-th neuron in layer j, and is the bias term for the i-th neuron in layer .
To propagate uncertainty, TAGI uses the Gaussian Multiplicative Approximation (GMA) given by the following equations
While the sum of Gaussian variables remains Gaussian, the same is not generally true for their product. Equation 97 poses this challenge, as it involves the product of two random variables, i.e., and .
However, under the GMA and with a sufficiently large number of hidden units, the resulting distribution can be shown to converge to a Gaussian, .
Thus, TAGI is theoretically capable of approximating the moments of the hidden states. It is important to note that, although the propagation of information from the input layer to the output layer utilizes nonlinear activation functions, TAGI employs a locally linearized version of this transformation for the hidden state inputs. This linearization facilitates operations involving Gaussian random variables since a linear transformation of a Gaussian random variable results in another Gaussian random variable. TAGI achieves this by locally linearizing the nonlinear activation function about using a first-order Taylor approximation. It is crucial to emphasize that this local linearization does not imply the use of a linear activation function. Instead, for each input covariate , the linearization is performed at different , thereby preserving the nonlinear relationship between the inputs and the outputs .
Since TAGI assumes that the model parameters and hidden states are independent, it is computationally efficient, operating with a complexity of , where is the number of hidden units per layer, and scales linearly with hidden layers . So far, numerous enhancements have been made since the original implementation of TAGI. For instance, Deka et al. [213] extended TAGI to account for heteroscedastic uncertainty (Figure 13).
6.2.3. Learned Observation Noise in TAGI
Instead of treating as a fixed term, it is now learned from the data using the following equations,
Figure 13.
A compact representation of the network in Figure 3 coupled with a directed acyclic graph (DAG) for the estimation of the variance parameter [100].
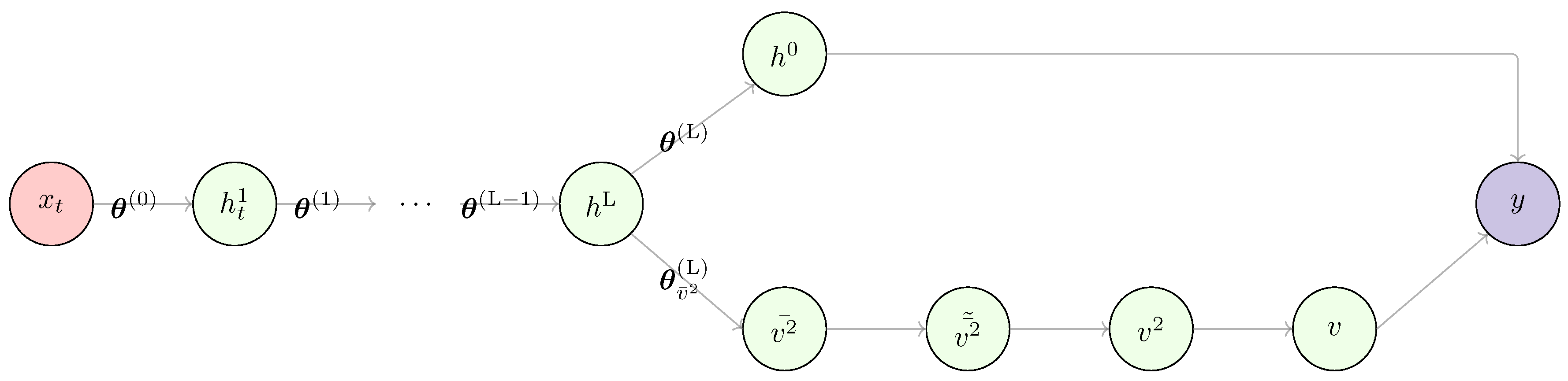
6.2.4. Further TAGI Extensions
TAGI has also been successfully extended to address problems involving sequential data, particularly in time series modeling. Recently, Vuong et al. [214] developed the theory for modeling uncertainty in LSTMs and Gated Recurrent Units (GRUs) using TAGI as the foundational learning algorithm.
6.2.5. Monte Carlo Dropout
Dropout [215] is a method to mitigate overfitting in neural networks. During model training, dropout randomly freezing a subset of nodes (typically 50%) by setting their values to zero. The overall effect of this is that the network is less dependent on any individual weight. Once the model is trained, dropout is no longer applied.
Monte Carlo (MC) [216] dropout reinterprets dropout as a method for performing approximate Bayesian inference. A similar dropout procedure is applied during inference, and multiple forward passes are performed on the same input. This repeated stochastic sampling allows estimation of the predictive uncertainty by treating each forward pass as a sample from the posterior predictive distribution.
In principle, the final output of an MC dropout is considered an ensemble of outputs from different stochastic realizations of the network.
MC dropout is attractive due to its simplicity in implementation. However, it is computationally expensive during inference, as multiple forward passes must be performed. Additionally, the uncertainty estimates produced by MC dropout are often poorly calibrated.
6.2.6. Bayes by Backpropagation
As already highlighted, the goal of a BNN is to learn distributions of the network weights. The posterior distribution of these weights, , is generally intractable since neural networks contain a huge number of weights. This renders the marginal likelihood intractable as well. As already discussed, the standard variational approach employs a more tractable distribution to approximate ; with the Gaussian distribution being a common choice. As is always the case in VI, the goal is to make as close as possible to . This is achieved through minimization of the Kullback-Leibler divergence. We won’t discuss the full details of the derivation of the loss function used in Bayes by backprop as it can be easily derived using same principles used in Section 5.2 and Section 6.1.8. Bayes by backprop [217] uses a similar technique to VAE (reparamaterization trick) to express the gradient of an expectation as an expectation of the gradient. This allows us to compute gradients based on the reparameterization parameters and use standard backpropagation to update the network weights.
6.2.7. Probabilistic Backpropagation
Due to its reliance on sampling during both training and inference, the Bayes by backprop is not scalable. An alternative, scalable approach is the probabilistic backpropagation (PBP) [218], which was developed by researchers at Havard. PBP models each weight as a univariate Gaussian. These weights are learned via forward and backward passes through the network, just like in classic backpropagation. During the forward pass, input is propagated through the network. However, since the weights are random, activations at each layer are also random, though this time more complex and intractable. PBP approximates these intractable distributions with tractable Gaussians using moment matching. At the end of the forward pass, PBP uses the marginal probability of the target variable to measure performance and the gradient of this expression is computed with respect to the means and variances of the approximate distributions. The gradient is then propagated back to update the means and variances of the weights. Unlike classic backpropagation, PBP uses Assumed Density Filtering (ADF) for the parameter updates. ADF is a principled sequential way of minimizing the Kullback-Leibler divergence and is useful in PBP considering that we are building the posterior sequentially from more tractable distributions.
7. Applications
Deep learning for time series have been employed in various applications within SHM. We conducted a systematic literature search to identify studies on deep learning for time series analysis in SHM. The following search querry was used to retrieve articles from the scopus database:
(TITLE-ABS-KEY ("deep learning" OR "neural network" OR "variational autoencoder" OR "VAE" OR "recurrent neural network" OR "RNN" OR "long short-term memory" OR "LSTM" OR "gated recurrent unit" OR "GRU" OR "convolutional neural network" OR "CNN" OR "temporal convolutional network" OR "TCNN" OR "diffusion model" OR "normalizing flow" OR "physics-informed neural network" OR "PINN" OR "Bayesian neural network" OR "BNN" OR "multilayer perceptron" OR "MLP" OR "transformer") AND TITLE-ABS-KEY ("time series*" OR "temporal" OR "forecast*" OR "causal*") AND TITLE-ABS-KEY ("structural health monitoring" OR "SHM")) AND PUBYEAR > 2019 AND PUBYEAR < 2025 AND (LIMIT-TO(SRCTYPE, "j")) AND (LIMIT-TO(PUBSTAGE, "final")) AND (LIMIT-TO(SUBJAREA, "ENGI") OR LIMIT-TO(SUBJAREA, "MULT") OR LIMIT-TO(SUBJAREA, "ENVI") OR LIMIT-TO(SUBJAREA, "EART")) AND (LIMIT-TO(DOCTYPE, "ar")) AND (LIMIT-TO(LANGUAGE, "English"))
Figure 14 summarizes the entire process, from the initial database search, through exclusion of irrelevant studies, to the identification of articles included in the final review.The exclusion criteria were: (a) articles that do not address time series in SHM for civil infrastructure; (b) articles not written in English; and (c) articles published before 2020 or in 2025.
Based on the identified studies, the applications were categorized into five thematic areas: damage assessment, structural response prediction, structural load prediction, data reconstruction, and anomaly detection. Each of these areas is explored in greater detail in the following sections.
7.1. Damage Assessment
Damage assessment includes the detection, localization, and quantification of structural deterioration. A wide range of approaches have been proposed to address this challenge. A hierarchical CNN-GRU framework was developed to exploit both spatial and temporal information for structural damage detection in bridge datasets [219]. Recognizing the importance of feature extraction, another study proposed a channel-spatial-temporal attention network to refine sample-specific features across multiple dimensions [220]. Offshore jacket platforms have also been a subject of interest, where a CNN-BiLSTM-Attention model, optimized via particle swarm optimization, demonstrated more than 95% accuracy in damage detection [221].
In vibration-based damage diagnosis, several studies have focused on improving attention mechanisms and deep feature learning. A multi-head self-attention LSTM autoencoder was introduced for unsupervised diagnosis and quantification of damage in ambient vibration data [222]. The Transformer architecture was leveraged for post-disaster damage state classification using seismic data [223], and a custom 1DCNN-BiLSTM model with an Inception module was used to detect minor changes in RC beams [224].
Additional studies emphasized the localization of structural damage using various techniques. A time-varying damage index was proposed in conjunction with a 1D-CNN to enhance Lamb wave-based localization [225], while an autoencoder-based unsupervised model enabled accurate damage localization using raw acceleration data [226]. Localization has also been explored using acoustic emissions and arrival time distributions via LSTM and Bayesian methods [227], and through Transformer-based learning of multivariate vibration signals for submerged offshore wind turbine structures [228]. Damage classification using CNN and time-frequency analysis has been achieved through continuous wavelet transform representations of acceleration data [229], and Trident, a ConvLSTM3D model, achieved high-resolution damage identification in bridges [230]. Further work addressed unsupervised real-time detection using statistical modeling [231], sensor signal fusion via a 1D-CNN-LSTM hybrid [232], and the integration of Burg Autoregressive features with stacked autoencoders [233]. Multiclass damage detection and classification have also been explored. A 1D CNN method using windowed time series was validated for a full-scale bridge [234], while another study introduced a CNN model with synchrosqueezing transform to detect damage in the Z24 bridge [235]. Others investigated transformer-based models [236], metaheuristic optimization [237], and GAN-based signal augmentation [238]. Stochastic configuration networks [239] and hybrid CNN-RNN methods [240] have further enriched this task.
7.2. Structural Response Prediction
Predicting structural responses such as displacement, strain, stress, and vibration is fundamental in SHM. Deep time series have shown exceptional ability in capturing nonlinear temporal patterns, making them well-suited for this task. Seismic and environmental responses have been a primary focus. A Dung Beetle Optimization-enhanced BiLSTM model, integrated with discrete wavelet transforms, was used for seismic response prediction in slope reinforcement structures [241]. A dual-stage attention LSTM (DALSTM) encoder-decoder model was used for displacement forecasting in arch dams [242]. Another study used STL-extra-trees-LSTM modeling for a similar task [243].
Tunnel and bridge response prediction has also received extensive attention. LSTM-based approaches have been adopted for modeling stress and strain during shield tunneling [244], deflection predictions under vehicle and thermal loads [245,246] , and buffeting response forecasting in a bridge under aerodynamic effects [247]. An ensemble RNN with short-sequence LSTMs has been proposed for high-frequency health monitoring [248], while LSTM and CNN hybrid models have been introduced for rail track systems [249] and long-span bridge deck wind-induced lateral displacement responses [250]. Temperature-induced structural responses have been modeled in numerous studies. These include CNN-based prediction of long-term strain using weather data [251,252], a neural network based on hydrostatic-temperature-time (HTT) for predicting concrete dam displacement [253,254], and HTT enhancements via the DeepLift framework for dams in extreme climates [255]. BiLSTM models have also been used to map temperature fields to strain distributions [256]. Multi-factor response models have been implemented using attention-enhanced BiLSTM frameworks [257] and transformer-based architectures for long-term structural state forecasting and strain prediction [258,259]. Physics-informed models such as Phy-Seisformer [260] and simplified rheological neural networks [261] further emphasize integration with engineering principles. The use of CNNs for spatiotemporal deformation modeling of arch dams[262], and structural performance modeling of underwater tunnels via GC-GRU [263] demonstrate the breadth of this thematic area. Studies have also addressed low-cost strain prediction techniques [264], FEM-integrated RNN approaches for high-rise buildings [265], and global-partial BiLSTM models correlating cable tension and bridge deflection [266].
7.3. Structural Load Prediction
Load-related studies have focused on temperature prediction using ANN and LSTM models. For example, environmental data from the Shanghai Tower was used to predict curtain wall temperature fields using ANN models [10], while a similar deep learning model was used for the Jinping-I arch dam [267]. LSTM models have also been developed for bridge temperature forecasting using meteorological big data [268].
7.4. Data Reconstruction
Data loss is a persistent challenge in SHM, and many studies have focused on reconstructing missing sensor data through advanced deep learning models. BiLSTM and encoder-decoder models with attention mechanisms have been central to this effort. BiLSTM was used to reconstruct acceleration responses in a long span cable-stayed bridge [275] and impute missing dam sensor data using attention and transfer learning [276]. Hybrid models that combined CNN with BiGRU or GRU were developed for strain recovery [277], accelerometer data restoration [278], and recovery of multi-modal heterogeneous signals [279].
GAN-based architectures have also played a key role. A BiLSTM-GAN model was used for bidirectional data imputation [280], while another study applied GANs to restore missing strain data on a concrete bridge [281]. Data augmentation via GANs was also explored for AE signal enhancement [238] , while other studies reconstructed vibration responses for bridge damage detection using ED-DCNNs and attention modules [282].
Additional frameworks used AOA-TCN [283], EMD-LSTM [284], ESMD-PE-BiGRU [285], SSA-optimized BiLSTM [286], and Kriging-based interpolation [287]. External feedback was integrated in an RNN-based approach for response recovery [288]. Meanwhile, CycleGAN [289] and domain adaptation strategies were used for synthetic-to-real transformations, improving model generalizability.
7.5. Anomaly Detection
Anomaly detection serves as an early warning mechanism for structural faults, sensor failures, or environmental interferences. Various models have been proposed to distinguish between normal and anomalous behavior.
The Temporal Fusion Transformer was used to detect anomalies in historic buildings through vibrational analysis [290], while time-series attention models and encoder-decoder frameworks were used to flag abnormal seismic responses [291]. Another encoder-decoder framework integrated temperature-driven PCA for anomaly detection in long-span bridges [292].
Other techniques include semi-supervised anomaly detection using MixMatch technique [293], pattern-recognition neural networks for multi-type data detection anomalies [294], and multi-class imbalanced anomaly detection using 1D CNNs [295]. CNNs were also used to detect abnormal temperature patterns by transforming time-series data into Gramian Angular Field images [296].
Physics-informed models, such as Koopman neural ODEs, were developed for anomaly detection alongside structural forecasting [297], while sparse Bayesian ELMs were used for outlier detection in railway track systems [298], and simple ANNs for SHM anomaly detection were explored in the context of IFC-BIM data integration [299].
Table 4.
Deep Learning Applications in Structural Health Monitoring.
| Application | Scope (Specific Papers) | Deep Learning Architectures Used |
|---|---|---|
| Damage Assessment | Damage detection: [300,301,302,303,304,305,306,307,308,309,310,311,312,313]Damage localization: [314,315,316,317,318,319,320]Damage classification: [321,322,323,324]Damage progression prediction: [325] | CNN, GRU, LSTM, BiLSTM, Autoencoder, Transformer, CNN-RNN hybrids |
| Structural Response Prediction | Strain prediction: [326,327]Displacement/Deflection: [328,329,330,331,332,333,334,335]Seismic and vibration: [336,337,338,339,340]Thermal-induced: [341]Tunnel responses: [342,343,344]Mechanical/Stress: [326,334,340,345,346,347]Cable tension: [348] | LSTM, BiLSTM, CNN, GRU, Attention, Transformer-based models |
| Structural Load Prediction | Dynamic load: [349,350] | CNN, Bayesian optimization, Autoencoder, CNN-BiLSTM hybrids |
| Data Reconstruction | Wind: [287,351,352,353]Vibration: [354,355,356]Temperature: [357]Dam monitoring: [358] | CNN, BiLSTM, GAN, Autoencoder, CNN-GRU hybrids, VMD, EMD |
| Anomaly Detection | Sensor faults: [359,360,361,362,363]Outliers: [363,364,365] | CNN, LSTM, BiLSTM, FCN, Transformer, PCA |
| Sensor Placement | Optimized placement: [336,349] | Attention-based RNN, CNN-BiLSTM |
| Data Augmentation/Generation | Synthetic data: [366] | GAN, CycleGAN, CNN, BiLSTM |
| Other SHM Tasks | Traffic classification: [367]Data compression: [368]Structural state ID: [369]Defect diagnosis: [370] | CNN, Autoencoder, Transformer, CNN-RNN hybrids |
8. State of Deep Times Series in Reviewed Literature
We performed a preliminary visual inspection of the literature to identify prevalent modeling trends and challenges.These are presented in the subsequent sections.
8.1. Models
Advanced recurrent neural networks (LSTM and GRU) are among the most commonly used models for sequence-related processing in structural health monitoring (SHM). However, they are often combined with other architectures, such as convolutional neural networks (CNNs), or enhanced with attention mechanisms. To date, the Mamba architecture has not been employed in any of the studies reviewed in this paper.
The reviewed literature was also examined for the application of deep generative models. So far, autoencoders (AEs), generative adversarial networks (GANs), and autoregressive flows have been used. GANs have been applied in data recovery [280,281], as well as data augmentation[238,366].VAEs and AEs have been used in data compression [297,368] and structural response recovery[279]. However, it is evident that normalizing flows, diffusion models, and energy-based models are not reported at all. This observation aligns with Luleci and Catbas [33].
8.2. Challenges
Several studies have highlighted challenges in deep time series modeling for SHM. Common issues include data related challenges, computational complexity,environmental variability, sensor placement and model transferability and generalization.
Data-related challenges prominently feature in SHM studies, especially regarding missing or incomplete data. Numerous researchers have directed efforts toward developing robust data reconstruction and imputation methods for strain data [277,286], acceleration response [275], wind [351,352] and structural temperature data [357], to mention a few. Additionally, limited availability of labeled data and imbalance between damaged and undamaged structural states pose considerable difficulty for supervised learning frameworks, necessitating innovative approaches in few-shot [303] and unsupervised learning [311] paradigms.
The inherent complexity and variability of structural behavior under diverse environmental and operational conditions further complicate modeling. Structural responses often intertwine with environmental factors such as temperature, wind, and humidity, making it challenging to accurately detect and localize damage. Several studies have thus focused on developing methods to distinguish between genuine structural anomalies and normal variations [292,296]. Other studies have made progress at predicting structural responses under nonlinear and extreme conditions [223,334]. Despite the progresses made so far, this area is still an active area of research and might benefit from uncertainty quantification.
Computational limitations also represent a critical constraint. Studies have highlighted the challenge of balancing model complexity with computational efficiency. Studies have highlighted the challenge of balancing model complexity with computational efficiency.Honarjoo et al. [236], Cao et al. [347] provided in-depth computational complexity analysis of models.
Sensor placement emerges as another practical yet challenging dimension. Optimal sensor placement is vital for maximizing monitoring efficiency while minimizing instrumentation costs and complexity. Li et al. [336] took into account the optimization of sensor locations for seismic displacement response of a building.
Issues surrounding model transferability and generalization pose a significant barrier to deploying machine learning models trained on limited experimental or numerical data to real-world structures. Studies have emphasized the necessity of robust domain adaptation and generalization strategies, highlighting methods such as domain adversarial training and physics-informed approaches [289], and out-of-distribution representation learning [321] to overcome these limitations. The capacity to generalize learned models across different structural types, environments, and operational conditions remains a critical research frontier.
9. Conclusions
The initial objective of this review was to provide a mathematically grounded discussion of deep learning models for time series. Reaching this far, we believe such a discussion has been provided. The paper further discussed the application of these models in structural health monitoring of civil structures. Five key thematic were identified, the current status of deep learning was presented, and critical challenges were pinpointed. What is key from the findings of this review is that many studies in SHM rarely quantify uncertainties in their models. The use of domain knowledge to enhance model performance is also limited. These issues might serve as the basis for future research in SHM.
Abbreviations
The following abbreviations are used in this manuscript:
| ANN | Artificial Neural Network |
| AOA | Arithmetic Optimization Algorithm |
| ARIMA | AutoRegressive Integrated Moving Average |
| BIM | Building Information Modeling |
| BRT | Boosted Regression Trees |
| ELM | Extreme Learning Machine |
| ESMD | Extreme-point Symmetric Mode Decomposition |
| FEM | Finite Element Method |
| GC | Geological Conditions |
| gMLP | Gated Multilayer Perceptron |
| HTT | Hydrostatic-Temperature-Time |
| IFC | Industry Foundation Classes |
| LD | Linear Dichroism |
| MAF | Moving Average Filter |
| MLR | Multiple Linear Regression |
| NAR | Nonlinear Autoregressive |
| NARX | Nonlinear Autoregressive with Exogenous Inputs |
| N-BEATS | Neural Basis Expansion Analysis for Time Series Forecasting |
| N-HITS | Neural Hierarchical Interpolation for Time Series |
| ODE | Ordinary Differential Equation |
| PCA | Principal Component Analysis |
| PE | Permutation Entropy |
| RMSE | Root Mean Squared Error |
| SARIMA | Seasonal AutoRegressive Integrated Moving Average |
| SD | Sequence Decomposition |
| STL | Seasonal-Trend Decomposition using Loess |
| TSMixer | Time Series Mixer |
References
- Vivien Foster, Nisan Gorgulu, Stéphane Straub, and Maria Vagliasindi. The impact of infrastructure on development outcomes: A qualitative review of four decades of literature. Policy Research Working Paper 10343, World Bank, March 2023. URL http://documents.worldbank.org/curated/en/099529203062342252/pdf/IDU0e42ae32f0048304f74086d102b6d7a900223.pdf. © World Bank. Licensed under CC BY-NC 3.0 IGO.
- Kevin Wall. Some implications of the condition of south africa’s public sector fixed infrastructure. 31:224–256, Dec. 2024. URL https://journals.ufs.ac.za/index.php/as/article/view/8824. [CrossRef]
- Xolani Thusi and Victor H. Mlambo. The effects of africa’s infrastructure crisis and its root causes. International Journal of Environmental, Sustainability, and Social Science, 4(4):1055–1067, July 2023. URL https://journalkeberlanjutan.keberlanjutanstrategis.com/index.php/ijesss/article/view/671/646. [CrossRef]
- Francesc Pozo, Diego A. Tibaduiza, and Yolanda Vidal. Sensors for structural health monitoring and condition monitoring. Sensors, 21(5), 2021. ISSN 1424-8220. URL https://www.mdpi.com/1424-8220/21/5/1558. [CrossRef]
- David Blockley. Analysis of structural failures. Ice Proceedings, 62:51–74, 01 1977. [CrossRef]
- PSA. South africa’s water crisis and solutions, November 2024. URL https://www.psa.co.za/docs/default-source/psa-documents/psa-opinion/sa-water-crisis.pdf?sfvrsn=873d4a59_2. The Union of Choice.
- iNFRASTRUCTURE South Africa. Infrastructure development scenarios for south africa towards 2050, n.d. URL https://infrastructuresa.org/wp-content/uploads/2023/07/Infrastructure-development-scenarios-for-south-Africa-2050_For-Print_20230705-Final-Document.pdf. Accessed: 14 May, 2025.
- MAKEUK. Infrastructure: Enabling growth by connecting people and places, n.d. URL https://www.makeuk.org/insights/reports/make-uk-latest-deep-dive-into-the-state-of-uk-infrastructure-is-out-now. Accessed: 14 May, 2025.
- G. Zini, M. Betti, and G. Bartoli. A pilot project for the long-term structural health monitoring of historic city gates. Journal of Civil Structural Health Monitoring, 12:537–556, 2022. [CrossRef]
- Mohamed Abdo. Structural Health Monitoring, History, Applications and Future. A Review Book. 01 2014. ISBN 978-1-941926-07-9.
- C. R. Farrar, N. Dervilis, and K. Worden. The past, present and future of structural health monitoring: An overview of three ages. Strain, 61(1):e12495, 2025. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/str.12495. e12495 5547601. [CrossRef]
- Keith Worden, Charles Farrar, Graeme Manson, and Gyuhae Park. The fundamental axioms of structural health monitoring. Proceedings of The Royal Society A: Mathematical, Physical and Engineering Sciences, 463:1639–1664, 04 2007. [CrossRef]
- Unai Ugalde, Javier Anduaga, Oscar Salgado, and Aitzol Iturrospe. Shm method for locating damage with incomplete observations based on substructure’s connectivity analysis. Mechanical Systems and Signal Processing, 200:110519, 2023. ISSN 0888-3270. URL https://www.sciencedirect.com/science/article/pii/S0888327023004272. [CrossRef]
- Ibomoiye Domor Mienye, Theo G. Swart, and George Obaido. Recurrent neural networks: A comprehensive review of architectures, variants, and applications. Information, 15(9), 2024. ISSN 2078-2489. URL https://www.mdpi.com/2078-2489/15/9/517. [CrossRef]
- Neil C Thompson, Kristjan Greenewald, Keeheon Lee, Gabriel F Manso, et al. The computational limits of deep learning. arXiv preprint arXiv:2007.05558, 10, 2020.
- Yang, Luodongni. Research on the legal regulation of generative artificial intelligence—— take chatgpt as an example. SHS Web of Conf., 178:02017, 2023. [CrossRef]
- Billie F. Spencer, Sung-Han Sim, Robin E. Kim, and Hyungchul Yoon. Advances in artificial intelligence for structural health monitoring: A comprehensive review. KSCE Journal of Civil Engineering, 29(3):100203, 2025. ISSN 1226-7988. URL https://www.sciencedirect.com/science/article/pii/S1226798825003186. [CrossRef]
- Fuh-Gwo Yuan, Sakib Zargar, Qiuyi Chen, and Shaohan Wang. Machine learning for structural health monitoring: challenges and opportunities. page 2, 04 2020. [CrossRef]
- Jing Jia and Ying Li. Deep learning for structural health monitoring: Data, algorithms, applications, challenges, and trends. Sensors, 23(21), 2023. ISSN 1424-8220. URL https://www.mdpi.com/1424-8220/23/21/8824. [CrossRef]
- Aref Afshar, Gholamreza Nouri, Shahin Ghazvineh, and Seyed Hossein Hosseini Lavassani. Machine-learning applications in structural response prediction: A review. Practice Periodical on Structural Design and Construction, 29(3):03124002, 2024. URL https://ascelibrary.org/doi/abs/10.1061/PPSCFX.SCENG-1292. [CrossRef]
- Gyungmin Toh and Junhong Park. Review of vibration-based structural health monitoring using deep learning. Applied Sciences, 10:1680, 03 2020. [CrossRef]
- Mohsen Azimi, Armin Dadras, and Gokhan Pekcan. Data-driven structural health monitoring and damage detection through deep learning: State-of-the-art review. Sensors, 20, 05 2020. [CrossRef]
- R. Indhu, G. Sundar, and H. Parveen. A review of machine learning algorithms for vibration-based shm and vision-based shm. pages 418–422, 02 2022. [CrossRef]
- Hao Wang, Baoli Wang, and Caixia Cui. Deep learning methods for vibration-based structural health monitoring: A review. Iranian Journal of Science and Technology, Transactions of Civil Engineering, 48, 12 2023a. [CrossRef]
- Onur Avci, Osama Abdeljaber, Serkan Kiranyaz, Mohammed Hussein, Moncef Gabbouj, and Daniel J. Inman. A review of vibration-based damage detection in civil structures: From traditional methods to machine learning and deep learning applications. Mechanical Systems and Signal Processing, 147:107077, 2021. ISSN 0888-3270. URL https://www.sciencedirect.com/science/article/pii/S0888327020304635. [CrossRef]
- Younes Hamishebahar, Hong Guan, Stephen So, and Jun Jo. A comprehensive review of deep learning-based crack detection approaches. Applied Sciences, 2022. URL https://api.semanticscholar.org/CorpusID:246408379.
- Ayesha Chowdhury and Rashed Kaiser. A comprehensive analysis of the integration of deep learning models in concrete research from a structural health perspective. Construction Materials, 4:72–90, 01 2024. [CrossRef]
- Alain Gomez-Cabrera and Ponciano Jorge Escamilla-Ambrosio. Review of machine-learning techniques applied to structural health monitoring systems for building and bridge structures. Applied Sciences, 12(21), 2022. ISSN 2076-3417. URL https://www.mdpi.com/2076-3417/12/21/10754. [CrossRef]
- Sandeep Sony, Kyle Dunphy, Ayan Sadhu, and Miriam Capretz. A systematic review of convolutional neural network-based structural condition assessment techniques. Engineering Structures, 226:111347, 01 2021. [CrossRef]
- Jianghua Deng, Amardeep Multani, Yiyi Zhou, Ye Lu, and Vincent Lee. Review on computer vision-based crack detection and quantification methodologies for civil structures. Construction and Building Materials, 356:129238, 11 2022. [CrossRef]
- Samir Khan, Takehisa Yairi, Seiji Tsutsumi, and Shinichi Nakasuka. A review of physics-based learning for system health management. Annual Reviews in Control, 57:100932, 2024a. ISSN 1367-5788. URL https://www.sciencedirect.com/science/article/pii/S1367578824000014. [CrossRef]
- Jianwei Zhang, Minshui Huang, Neng Wan, Zhihang Deng, Zhongao He, and Jin Luo. Missing measurement data recovery methods in structural health monitoring: The state, challenges and case study. Measurement, 231:114528, 03 2024a. [CrossRef]
- Furkan Luleci and F. Necati Catbas. A brief introductory review to deep generative models for civil structural health monitoring. AI in Civil Engineering, 2(1):9, 2023. [CrossRef]
- Furkan Luleci, F. Necati Catbas, and Onur Avci. A literature review: Generative adversarial networks for civil structural health monitoring. Frontiers in Built Environment, 8:1027379, 2022. [CrossRef]
- Young-Jin Cha, Rahmat Ali, John Lewis, and Oral Büyüköztürk. Deep learning-based structural health monitoring. Automation in Construction, 161:105328, 2024. ISSN 0926-5805. URL https://www.sciencedirect.com/science/article/pii/S0926580524000645. [CrossRef]
- Mohammad Ali Abedi, Javad Shayanfar, and Khalifa Al-Jabri. Infrastructure damage assessment via machine learning approaches: a systematic review. Asian Journal of Civil Engineering, 24:3823–3852, 2023. URL https://api.semanticscholar.org/CorpusID:259543609.
- Guo-Qing Zhang, Bin Wang, Jun Li, and You-Lin Xu. The application of deep learning in bridge health monitoring: a literature review. Advances in Bridge Engineering, 3, 12 2022a. [CrossRef]
- Amin T. G. Tapeh and M. Z. Naser. Artificial intelligence, machine learning, and deep learning in structural engineering: A scientometrics review of trends and best practices. Archives of Computational Methods in Engineering, 30:115–159, 2023. [CrossRef]
- Donghui Xu, Xiang Xu, Michael C. Forde, and Antonio Caballero. Concrete and steel bridge structural health monitoring—insight into choices for machine learning applications. Construction and Building Materials, 402:132596, 2023a. ISSN 0950-0618. URL https://www.sciencedirect.com/science/article/pii/S0950061823023127. [CrossRef]
- Sam Bond-Taylor, Adam Leach, Yang Long, and Chris G Willcocks. Deep generative modelling: A comparative review of vaes, gans, normalizing flows, energy-based and autoregressive models. IEEE transactions on pattern analysis and machine intelligence, 44(11):7327–7347, 2021.
- John A Miller, Mohammed Aldosari, Farah Saeed, Nasid Habib Barna, Subas Rana, I Budak Arpinar, and Ninghao Liu. A survey of deep learning and foundation models for time series forecasting. arXiv preprint arXiv:2401.13912, 2024.
- Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Yong Liu, Mingsheng Long, and Jianmin Wang. Deep time series models: A comprehensive survey and benchmark. arXiv preprint arXiv:2407.13278, 2024a.
- Pedro Lara-Benítez, Manuel Carranza-García, and José C Riquelme. An experimental review on deep learning architectures for time series forecasting. International journal of neural systems, 31(03):2130001, 2021.
- Moloud Abdar, Farhad Pourpanah, Sadiq Hussain, Dana Rezazadegan, Li Liu, Mohammad Ghavamzadeh, Paul Fieguth, Xiaochun Cao, Abbas Khosravi, U Rajendra Acharya, et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Information fusion, 76:243–297, 2021.
- Jakob Gawlikowski, Carlo R. N. Tassi, Murtaza Ali, Jonghun Lee, Marcel Humt, Jin Feng, Anna Kruspe, Rudolph Triebel, Peter Jung, Ribana Roscher, et al. A survey of uncertainty in deep neural networks. Artificial Intelligence Review, 56(Suppl 1):1513–1589, 2023. [CrossRef]
- Piotr Omenzetter and James Mark William Brownjohn. Application of time series analysis for bridge monitoring. Smart Materials and Structures, 15(1):129, jan 2006. URL https://dx.doi.org/10.1088/0964-1726/15/1/041. [CrossRef]
- D. Inaudi. 11 - structural health monitoring of bridges: general issues and applications. In Vistasp M. Karbhari and Farhad Ansari, editors, Structural Health Monitoring of Civil Infrastructure Systems, Woodhead Publishing Series in Civil and Structural Engineering, pages 339–370. Woodhead Publishing, 2009. ISBN 978-1-84569-392-3. URL https://www.sciencedirect.com/science/article/pii/B9781845693923500116. [CrossRef]
- Navid Mohammadi Foumani, Lynn Miller, Chang Wei Tan, Geoffrey I Webb, Germain Forestier, and Mahsa Salehi. Deep learning for time series classification and extrinsic regression: A current survey. ACM Computing Surveys, 56(9):1–45, 2024.
- F. Mojtahedi, N. Yousefpour, S. Chow, and M. Cassidy. Deep learning for time series forecasting: Review and applications in geotechnics and geosciences. Archives of Computational Methods in Engineering, 02 2025. [CrossRef]
- Zahra Zamanzadeh Darban, Geoffrey I Webb, Shirui Pan, Charu Aggarwal, and Mahsa Salehi. Deep learning for time series anomaly detection: A survey. ACM Computing Surveys, 57(1):1–42, 2024.
- Paul Boniol, Qinghua Liu, Mingyi Huang, Themis Palpanas, and John Paparrizos. Dive into time-series anomaly detection: A decade review. arXiv preprint arXiv:2412.20512, 2024.
- Chenguang Fang and Chen Wang. Time series data imputation: A survey on deep learning approaches. arXiv preprint arXiv:2011.11347, 2020.
- Pankaj Das and Samir Barman. An Overview of Time Series Decomposition and Its Applications, pages 1–15. 02 2025. [CrossRef]
- Zhengnan Li, Yunxiao Qin, Xilong Cheng, and Yuting Tan. Ftmixer: Frequency and time domain representations fusion for time series modeling. arXiv preprint arXiv:2405.15256, 2024a.
- R.H. Shumway and D.S. Stoffer. Time Series Analysis and Its Applications: With R Examples. Springer Texts in Statistics. Springer International Publishing, 2017. ISBN 9783319524528. URL https://books.google.mw/books?id=sfFdDwAAQBAJ.
- Vishwanathan Iyer and Kaushik Roy Chowdhury. Spectral analysis: Time series analysis in frequency domain. The IUP Journal of Applied Economics, VIII:83–101, 01 2009.
- Alexandr Volvach, Galina Kurbasova, and Larisa Volvach. Wavelets in the analysis of local time series of the earth’s surface air. Heliyon, 10(1):e23237, 2024. ISSN 2405-8440. URL https://www.sciencedirect.com/science/article/pii/S2405844023104452. [CrossRef]
- Warren S. McCulloch and Walter Pitts. A logical calculus of the ideas immanent in nervous activity. Bulletin of Mathematical Biophysics, 5:115–133, 1943. [CrossRef]
- Frank Rosenblatt. The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review, 65 6:386–408, 1958. URL https://api.semanticscholar.org/CorpusID:12781225.
- Paul J. Werbos. Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences. PhD thesis, Harvard University, 1974.
- Kunihiko Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36:193–202, 1980. [CrossRef]
- John Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the National Academy of Sciences of the United States of America, 79:2554–8, 05 1982. [CrossRef]
- David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams. Learning representations by back-propagating errors. Nature, 323:533–536, 1986. URL https://api.semanticscholar.org/CorpusID:205001834.
- Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, 1989. [CrossRef]
- Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
- Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. A neural probabilistic language model. Journal of machine learning research, (Feb):1137–1155, 2003.
- Geoffrey Hinton, Simon Osindero, and Yee-Whye Teh. A fast learning algorithm for deep belief nets. Neural Computation, 18:1527–1554, 07 2006. [CrossRef]
- Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010.
- Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60:84 – 90, 2012. URL https://api.semanticscholar.org/CorpusID:195908774.
- Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016. http://www.deeplearningbook.org.
- Laith Alzubaidi, Jinglan Zhang, Amjad J Humaidi, Ayad Al-Dujaili, Ye Duan, Omran Al-Shamma, José Santamaría, Mohammed A Fadhel, Muthana Al-Amidie, and Laith Farhan. Review of deep learning: concepts, cnn architectures, challenges, applications, future directions. Journal of big Data, 8:1–74, 2021.
- Iqbal H Sarker. Deep learning: a comprehensive overview on techniques, taxonomy, applications and research directions. SN computer science, 2(6):420, 2021.
- George Cybenko. Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems, 2(4):303–314, 1989.
- Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators. Neural Networks, 2(5):359–366, 1989. ISSN 0893-6080. URL https://www.sciencedirect.com/science/article/pii/0893608089900208. [CrossRef]
- International Organization for Standardization and International Electrotechnical Commission. ISO/IEC 22989:2022 - Information technology — Artificial intelligence — Artificial intelligence concepts and terminology, 2022. Edition 1.
- Johannes Lederer. Activation functions in artificial neural networks: A systematic overview. arXiv preprint arXiv:2101.09957, 2021.
- Xavier Glorot, Antoine Bordes, and Y. Bengio. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics (AISTATS), volume 15 of Proceedings of Machine Learning Research, pages 315–323. PMLR, 2011.
- Vladimír Kunc and Jiří Kléma. Three decades of activations: A comprehensive survey of 400 activation functions for neural networks. arXiv preprint arXiv:2402.09092, 2024.
- Shiv Ram Dubey, Satish Kumar Singh, and Bidyut Baran Chaudhuri. Activation functions in deep learning: A comprehensive survey and benchmark. Neurocomputing, 503:92–108, 2022.
- Sajid A. Marhon, Christopher J. F. Cameron, and Stefan C. Kremer. Recurrent Neural Networks, pages 29–65. Springer Berlin Heidelberg, Berlin, Heidelberg, 2013. ISBN 978-3-642-36657-4.
- Guoping Xu, Xiaxia Wang, Xinglong Wu, Xuesong Leng, and Yongchao Xu. Development of skip connection in deep neural networks for computer vision and medical image analysis: A survey. arXiv preprint arXiv:2405.01725, 2024a.
- Shiyu Liang and Rayadurgam Srikant. Why deep neural networks for function approximation? arXiv preprint arXiv:1610.04161, 2016.
- J.-A. Goulet. Probabilistic Machine Learning for Civil Engineers. MIT Press, 2020.
- Simon J.D. Prince. Understanding Deep Learning. The MIT Press, 2023. URL http://udlbook.com.
- Christopher M. Bishop and Hugh Bishop. Deep Learning: Foundations and Concepts. Springer, 2023. ISBN 978-3-031-45468-4. URL https://link.springer.com/book/10.1007/978-3-031-45468-4. [CrossRef]
- Zari Farhadi, Hossein Bevrani, and Mohammad Reza Feizi Derakhshi. Combining regularization and dropout techniques for deep convolutional neural network. pages 335–339, 10 2022. [CrossRef]
- T Hastie. The elements of statistical learning: Data mining, inference, and prediction, 2009.
- Lutz Prechelt. Early Stopping — But When?, pages 53–67. Springer Berlin Heidelberg, Berlin, Heidelberg, 2012. ISBN 978-3-642-35289-8.
- Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. pmlr, 2015.
- Hongyi Zhang, Moustapha Cisse, Yann N Dauphin, and David Lopez-Paz. mixup: Beyond empirical risk minimization. arXiv preprint arXiv:1710.09412, 2017.
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE international conference on computer vision, pages 1026–1034, 2015.
- Yann Lecun, Leon Bottou, Genevieve Orr, and Klaus-Robert Müller. Efficient backprop. 08 2000.
- Wei Hu, Lechao Xiao, and Jeffrey Pennington. Provable benefit of orthogonal initialization in optimizing deep linear networks. arXiv preprint arXiv:2001.05992, 2020.
- Andrew M Saxe, James L McClelland, and Surya Ganguli. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv preprint arXiv:1312.6120, 2013.
- Marc Peter Deisenroth, A Aldo Faisal, and Cheng Soon Ong. Mathematics for machine learning. Cambridge University Press, 2020.
- A. Rosebrock. Deep Learning for Computer Vision with Python: Starter Bundle. PyImageSearch, 2017. URL https://books.google.mw/books?id=9Ul-tgEACAAJ.
- John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(61):2121–2159, 2011. URL http://jmlr.org/papers/v12/duchi11a.html.
- Geoffrey Hinton, Nitish Srivastava, Kevin Swersky, and Timothy Tieleman. Neural networks for machine learning, lecture 6e: Rmsprop: Divide the gradient by a running average of its recent magnitude. https://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf, 2012. Lecture slides.
- Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Bhargob Deka, Luong Ha Nguyen, and James-A. Goulet. Analytically tractable heteroscedastic uncertainty quantification in bayesian neural networks for regression tasks. Neurocomputing, 572:127183, 2024a. ISSN 0925-2312. URL https://www.sciencedirect.com/science/article/pii/S0925231223013061. [CrossRef]
- Ankit Belwal, S. Senthilkumar, Intekhab Alam, and Feon Jaison. Exploring multi-layer perceptrons for time series classification in networks. In Amit Kumar, Vinit Kumar Gunjan, Sabrina Senatore, and Yu-Chen Hu, editors, Proceedings of the 5th International Conference on Data Science, Machine Learning and Applications; Volume 2, pages 663–668, Singapore, 2025. Springer Nature Singapore. ISBN 978-981-97-8043-3.
- Zhiguang Wang, Weizhong Yan, and Tim Oates. Time series classification from scratch with deep neural networks: A strong baseline. In 2017 International joint conference on neural networks (IJCNN), pages 1578–1585. IEEE, 2017.
- Ana Lazcano, Miguel A. Jaramillo-Morán, and Julio E. Sandubete. Back to basics: The power of the multilayer perceptron in financial time series forecasting. Mathematics, 12(12), 2024. ISSN 2227-7390. URL https://www.mdpi.com/2227-7390/12/12/1920. [CrossRef]
- Yihong Dong, Ge Li, Yongding Tao, Xue Jiang, Kechi Zhang, Jia Li, Jinliang Deng, Jing Su, Jun Zhang, and Jingjing Xu. Fan: Fourier analysis networks. arXiv preprint arXiv:2410.02675, 2024.
- Boris N Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-beats: Neural basis expansion analysis for interpretable time series forecasting. arXiv preprint arXiv:1905.10437, 2019.
- Cristian Challu, Kin G Olivares, Boris N Oreshkin, Federico Garza Ramirez, Max Mergenthaler Canseco, and Artur Dubrawski. Nhits: Neural hierarchical interpolation for time series forecasting. In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 6989–6997, 2023.
- Si-An Chen, Chun-Liang Li, Nate Yoder, Sercan O Arik, and Tomas Pfister. Tsmixer: An all-mlp architecture for time series forecasting. arXiv preprint arXiv:2303.06053, 2023a.
- Hanxiao Liu, Zihang Dai, David So, and Quoc V Le. Pay attention to mlps. Advances in neural information processing systems, 34:9204–9215, 2021.
- Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veličković. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv preprint arXiv:2104.13478, 2021.
- Van-Dai Vuong. Analytically Tractable Bayesian Recurrent Neural Networks with Structural Health Monitoring Applications. Ph.d. thesis, Polytechnique Montréal, Département de génie civil, géologique et des mines, March 2024. URL https://publications.polymtl.ca/57728/. Thèse présentée en vue de l’obtention du diplôme de Philosophiæ Doctor en génie civil.
- Mike Schuster and Kuldip Paliwal. Bidirectional recurrent neural networks. Signal Processing, IEEE Transactions on, 45:2673 – 2681, 12 1997. [CrossRef]
- Y. Bengio, P. Simard, and P. Frasconi. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2):157–166, 1994. [CrossRef]
- Simone Scardapane. Alice’s adventures in a differentiable wonderland–volume i, a tour of the land. arXiv preprint arXiv:2404.17625, 2024.
- Aston Zhang, Zachary C Lipton, Mu Li, and Alexander J Smola. Dive into deep learning. arXiv preprint arXiv:2106.11342, 2021a.
- Felix A. Gers, Nicol N. Schraudolph, and Jürgen Schmidhuber. Learning precise timing with lstm recurrent networks. Journal of Machine Learning Research, 3:115–143, 2002. URL http://jmlr.csail.mit.edu/papers/volume3/gers02a/gers02a.pdf. [CrossRef]
- Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. xlstm: Extended long short-term memory. arXiv preprint arXiv:2405.04517, 2024.
- Kyunghyun Cho, Bart Van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- Bryan Lim, Sercan Ö Arık, Nicolas Loeff, and Tomas Pfister. Temporal fusion transformers for interpretable multi-horizon time series forecasting. International Journal of Forecasting, 37(4):1748–1764, 2021.
- Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 11106–11115, 2021.
- Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Advances in neural information processing systems, 34:22419–22430, 2021.
- Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In International conference on machine learning, pages 27268–27286. PMLR, 2022.
- Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. arXiv preprint arXiv:2211.14730, 2022.
- Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023.
- Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher Ré. Hippo: Recurrent memory with optimal polynomial projections. Advances in neural information processing systems, 33:1474–1487, 2020.
- Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
- Serkan Kiranyaz, Onur Avci, Osama Abdeljaber, Turker Ince, Moncef Gabbouj, and Daniel J. Inman. 1d convolutional neural networks and applications: A survey. Mechanical Systems and Signal Processing, 151:107398, 2021. ISSN 0888-3270. URL https://www.sciencedirect.com/science/article/pii/S0888327020307846. [CrossRef]
- Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015.
- Yuhang Zhang, Yaoqun Xu, and Yu Zhang. A graph neural network node classification application model with enhanced node association. Applied Sciences, 13(12), 2023. ISSN 2076-3417. URL https://www.mdpi.com/2076-3417/13/12/7150. [CrossRef]
- Muhan Zhang and Yixin Chen. Link prediction based on graph neural networks. Advances in neural information processing systems, 31, 2018.
- Xingyu Liu, Juan Chen, and Quan Wen. A survey on graph classification and link prediction based on gnn. arXiv preprint arXiv:2307.00865, 2023.
- Renjie Liao, Yujia Li, Yang Song, Shenlong Wang, Will Hamilton, David K Duvenaud, Raquel Urtasun, and Richard Zemel. Efficient graph generation with graph recurrent attention networks. Advances in neural information processing systems, 32, 2019.
- William L. Hamilton. Graph representation learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 14(3):1–159, 2020.
- T Konstantin Rusch, Michael M Bronstein, and Siddhartha Mishra. A survey on oversmoothing in graph neural networks. arXiv preprint arXiv:2303.10993, 2023.
- Ling Zhao, Yujiao Song, Chao Zhang, Yu Liu, Pu Wang, Tao Lin, Min Deng, and Haifeng Li. T-gcn: A temporal graph convolutional network for traffic prediction. IEEE Transactions on Intelligent Transportation Systems, 21(9):3848–3858, 2020. [CrossRef]
- Yuebing Liang, Zhan Zhao, and Lijun Sun. Memory-augmented dynamic graph convolution networks for traffic data imputation with diverse missing patterns. Transportation Research Part C: Emerging Technologies, 143:103826, 10 2022. [CrossRef]
- Ming Jin, Huan Yee Koh, Qingsong Wen, Daniele Zambon, Cesare Alippi, Geoffrey I Webb, Irwin King, and Shirui Pan. A survey on graph neural networks for time series: Forecasting, classification, imputation, and anomaly detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
- Zhongkai Hao, Songming Liu, Yichi Zhang, Chengyang Ying, Yao Feng, Hang Su, and Jun Zhu. Physics-informed machine learning: A survey on problems, methods and applications. arXiv preprint arXiv:2211.08064, 2022.
- Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational physics, 378:686–707, 2019.
- Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks. Advances in neural information processing systems, 34:26548–26560, 2021.
- Nathan Doumèche, Gérard Biau, and Claire Boyer. Convergence and error analysis of pinns. arXiv preprint arXiv:2305.01240, 2023.
- K. Sel, A. Mohammadi, R. I. Pettigrew, et al. Physics-informed neural networks for modeling physiological time series for cuffless blood pressure estimation. npj Digital Medicine, 6:110, 2023. [CrossRef]
- Keon Vin Park, Jisu Kim, and Jaemin Seo. Pint: Physics-informed neural time series models with applications to long-term inference on weatherbench 2m-temperature data. arXiv preprint arXiv:2502.04018, 2025.
- Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks. SIAM Journal on Scientific Computing, 43(5):A3055–A3081, 2021.
- Jassem Abbasi, Ameya D Jagtap, Ben Moseley, Aksel Hiorth, and Pål stebø Andersen. Challenges and advancements in modeling shock fronts with physics-informed neural networks: A review and benchmarking study. arXiv preprint arXiv:2503.17379, 2025.
- Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, Yoshua Bengio, and Pierre-Antoine Manzagol. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Research, 11(110):3371–3408, 2010. URL http://jmlr.org/papers/v11/vincent10a.html.
- Ricardo Cardoso Pereira, Miriam Seoane Santos, Pedro Pereira Rodrigues, and Pedro Henriques Abreu. Reviewing autoencoders for missing data imputation: Technical trends, applications and outcomes. Journal of Artificial Intelligence Research, 69:1255–1285, 2020.
- Chunyong Yin, Sun Zhang, Jin Wang, and Neal N Xiong. Anomaly detection based on convolutional recurrent autoencoder for iot time series. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52(1):112–122, 2020.
- Alon Oring. Autoencoder image interpolation by shaping the latent space. Master’s thesis, Reichman University (Israel), 2021.
- Diederik P Kingma, Max Welling, et al. Auto-encoding variational bayes, 2013.
- Gregory Gundersen. The reparameterization trick, April 2018. URL https://gregorygundersen.com/blog/2018/04/29/reparameterization/.
- Borui Cai, Shuiqiao Yang, Longxiang Gao, and Yong Xiang. Hybrid variational autoencoder for time series forecasting. Knowledge-Based Systems, 281:111079, 2023.
- Abhyuday Desai, Cynthia Freeman, Zuhui Wang, and Ian Beaver. Timevae: A variational auto-encoder for multivariate time series generation. arXiv preprint arXiv:2111.08095, 2021.
- Julia H Wang, Dexter Tsin, and Tatiana A Engel. Predictive variational autoencoder for learning robust representations of time-series data. ArXiv, pages arXiv–2312, 2023b.
- O. Calin. Deep Learning Architectures: A Mathematical Approach. Springer Series in the Data Sciences. Springer International Publishing, 2020. ISBN 9783030367213. URL https://books.google.mw/books?id=R3vQDwAAQBAJ.
- Youssef Kossale, Mohammed Airaj, and Aziz Darouichi. Mode collapse in generative adversarial networks: An overview. pages 1–6, 10 2022. [CrossRef]
- Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. Advances in neural information processing systems, 29, 2016.
- Luke Metz, Ben Poole, David Pfau, and Jascha Sohl-Dickstein. Unrolled generative adversarial networks. arXiv preprint arXiv:1611.02163, 2016.
- Martin Arjovsky, Soumith Chintala, and Léon Bottou. Wasserstein generative adversarial networks. In International conference on machine learning, pages 214–223. PMLR, 2017.
- Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks. arXiv preprint arXiv:1802.05957, 2018.
- Ishaan Gulrajani, Faruk Ahmed, Martin Arjovsky, Vincent Dumoulin, and Aaron C Courville. Improved training of wasserstein gans. Advances in neural information processing systems, 30, 2017.
- Jinsung Yoon, Daniel Jarrett, and Mihaela van der Schaar. Time-series generative adversarial networks. In Advances in Neural Information Processing Systems, volume 32, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/c9efe5f26cd17ba6216bbe2a7d26d490-Abstract.html.
- MohammadReza EskandariNasab, Shah Muhammad Hamdi, and Soukaina Filali Boubrahimi. Seriesgan: Time series generation via adversarial and autoregressive learning. In 2024 IEEE International Conference on Big Data (BigData), pages 860–869. IEEE, 2024.
- Milena Vuletić, Felix Prenzel, and Mihai Cucuringu and. Fin-gan: forecasting and classifying financial time series via generative adversarial networks. Quantitative Finance, 24(2):175–199, 2024. [CrossRef]
- Eoin Brophy, Zhengwei Wang, Qi She, and Tomás Ward. Generative adversarial networks in time series: A systematic literature review. 55(10), 2023. ISSN 0360-0300. [CrossRef]
- Dongrui Zhang, Meng Ma, and Liang Xia. A comprehensive review on gans for time-series signals. Neural Computing and Applications, 34:3551–3571, 2022b. [CrossRef]
- Janosh Riebesell and Stefan Bringuier. Collection of scientific diagrams, 2020. URL https://github.com/janosh/diagrams. 10.5281/zenodo.7486911 - https://github.com/janosh/diagrams.
- Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real nvp. arXiv preprint arXiv:1605.08803, 2016.
- Laurent Dinh, David Krueger, and Yoshua Bengio. Nice: Non-linear independent components estimation. arXiv preprint arXiv:1410.8516, 2014.
- Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. Advances in neural information processing systems, 31, 2018.
- George Papamakarios, Theo Pavlakou, and Iain Murray. Masked autoregressive flow for density estimation. Advances in neural information processing systems, 30, 2017.
- Enyan Dai and Jie Chen. Graph-augmented normalizing flows for anomaly detection of multiple time series. arXiv preprint arXiv:2202.07857, 2022.
- Siwei Guan, Zhiwei He, Shenhui Ma, and Mingyu Gao. Conditional normalizing flow for multivariate time series anomaly detection. ISA Transactions, 143:231–243, 2023. ISSN 0019-0578. URL https://www.sciencedirect.com/science/article/pii/S0019057823004020. [CrossRef]
- Kashif Rasul, Abdul-Saboor Sheikh, Ingmar Schuster, Urs Bergmann, and Roland Vollgraf. Multivariate probabilistic time series forecasting via conditioned normalizing flows. arXiv preprint arXiv:2002.06103, 2020.
- Wei Fan, Shun Zheng, Pengyang Wang, Rui Xie, Jiang Bian, and Yanjie Fu. Addressing distribution shift in time series forecasting with instance normalization flows. arXiv preprint arXiv:2401.16777, 2024.
- Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- Kashif Rasul, Calvin Seward, Ingmar Schuster, and Roland Vollgraf. Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting. In International conference on machine learning, pages 8857–8868. PMLR, 2021.
- Kai Shu, Le Wu, Yuchang Zhao, Aiping Liu, Ruobing Qian, and Xun Chen. Data augmentation for seizure prediction with generative diffusion model. IEEE Transactions on Cognitive and Developmental Systems, 2024.
- Kehua Chen, Guangbo Li, Hewen Li, Yuqi Wang, Wenzhe Wang, Qingyi Liu, and Hongcheng Wang. Quantifying uncertainty: Air quality forecasting based on dynamic spatial-temporal denoising diffusion probabilistic model. Environmental Research, 249:118438, 2024a. ISSN 0013-9351. URL https://www.sciencedirect.com/science/article/pii/S0013935124003426. [CrossRef]
- Xizewen Han, Huangjie Zheng, and Mingyuan Zhou. Card: Classification and regression diffusion models. Advances in Neural Information Processing Systems, 35:18100–18115, 2022.
- Si Zuo, Vitor Fortes Rey, Sungho Suh, Stephan Sigg, and Paul Lukowicz. Unsupervised statistical feature-guided diffusion model for sensor-based human activity recognition. arXiv preprint arXiv:2306.05285, 2023.
- Yuhang Chen, Chaoyun Zhang, Minghua Ma, Yudong Liu, Ruomeng Ding, Bowen Li, Shilin He, Saravan Rajmohan, Qingwei Lin, and Dongmei Zhang. Imdiffusion: Imputed diffusion models for multivariate time series anomaly detection. arXiv preprint arXiv:2307.00754, 2023b.
- Xuan Liu, Jinglong Chen, Jingsong Xie, and Yuanhong Chang. Generating hsr bogie vibration signals via pulse voltage-guided conditional diffusion model. IEEE Transactions on Intelligent Transportation Systems, 2024a.
- Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. Csdi: Conditional score-based diffusion models for probabilistic time series imputation. Advances in neural information processing systems, 34:24804–24816, 2021.
- Xu Wang, Hongbo Zhang, Pengkun Wang, Yudong Zhang, Binwu Wang, Zhengyang Zhou, and Yang Wang. An observed value consistent diffusion model for imputing missing values in multivariate time series. pages 2409–2418, 08 2023c. [CrossRef]
- Sai Shankar Narasimhan, Shubhankar Agarwal, Oguzhan Akcin, Sujay Sanghavi, and Sandeep Chinchali. Time weaver: A conditional time series generation model. arXiv preprint arXiv:2403.02682, 2024.
- Guoxuan Chi, Zheng Yang, Chenshu Wu, Jingao Xu, Yuchong Gao, Yunhao Liu, and Tony Xiao Han. Rf-diffusion: Radio signal generation via time-frequency diffusion. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, pages 77–92, 2024.
- Ling Lin, Ziyang Li, Ruijie Li, et al. Diffusion models for time-series applications: a survey. Frontiers of Information Technology & Electronic Engineering, 25:19–41, 2024. [CrossRef]
- Yiyuan Yang, Ming Jin, Haomin Wen, Chaoli Zhang, Yuxuan Liang, Lintao Ma, Yi Wang, Chenghao Liu, Bin Yang, Zenglin Xu, et al. A survey on diffusion models for time series and spatio-temporal data. arXiv preprint arXiv:2404.18886, 2024.
- Abdul Fatir Ansari. Deep Generative Modeling for Images and Time Series. PhD thesis, National University of Singapore, 2022. URL https://scholarbank.nus.edu.sg/handle/10635/231424.
- Kevin P. Murphy. Probabilistic Machine Learning: Advanced Topics. MIT Press, 2023. URL http://probml.github.io/book2.
- Jakub M. Tomczak. Deep Generative Modeling. Springer Cham, 2 edition, 2024. ISBN 978-3-031-64087-2. [CrossRef]
- G. E. Hinton and T. J. Sejnowski. Learning and relearning in Boltzmann machines, page 282–317. MIT Press, Cambridge, MA, USA, 1986. ISBN 026268053X.
- Philémon Brakel, Dirk Stroobandt, and Benjamin Schrauwen. Training energy-based models for time-series imputation. Journal of Machine Learning Research, 14(48):2771–2797, 2013. URL http://jmlr.org/papers/v14/brakel13a.html.
- Tijin Yan, Hongwei Zhang, Tong Zhou, Yufeng Zhan, and Yuanqing Xia. Scoregrad: Multivariate probabilistic time series forecasting with continuous energy-based generative models. arXiv preprint arXiv:2106.10121, 2021.
- Kevin P. Murphy. Probabilistic Machine Learning: An introduction. MIT Press, 2022. URL probml.ai.
- Wikipedia. Uncertainty quantification. URL https://en.wikipedia.org/wiki/Uncertainty_quantification.
- John Denker, Daniel Schwartz, Ben Wittner, Sara Solla, Richard Howard, Larry Jackel, and John Hopfield. Large automatic learning, rule extraction, and generalization. Complex Systems, 1, 01 1987.
- Naftali Tishby, Esther Levin, and Sara A. Solla. Consistent inference of probabilities in layered networks: Predictions and generalizations. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), pages 403–409. IEEE, 1989. [CrossRef]
- John Denker and Yann LeCun. Transforming neural-net output levels to probability distributions. In R.P. Lippmann, J. Moody, and D. Touretzky, editors, Advances in Neural Information Processing Systems, volume 3. Morgan-Kaufmann, 1990. URL https://proceedings.neurips.cc/paper_files/paper/1990/file/7eacb532570ff6858afd2723755ff790-Paper.pdf.
- Wray L. Buntine and Andreas S. Weigend. Bayesian back-propagation. Complex Syst., 5, 1991. URL https://api.semanticscholar.org/CorpusID:14814125.
- David J. C. MacKay. A practical bayesian framework for backpropagation networks. Neural Computation, 4(3):448–472, 1992. [CrossRef]
- Radford M. Neal. Bayesian learning via stochastic dynamics. In C. L. Giles, S. J. Hanson, and J. D. Cowan, editors, Advances in Neural Information Processing Systems 5, pages 475–482, San Mateo, CA, USA, 1992. Morgan Kaufmann.
- Radford M. Neal. Bayesian Learning for Neural Networks. Ph.D. thesis, University of Toronto, Toronto, Canada, March 1995. URL http://www.cs.toronto.edu/pub/radford/thesis.pdf. Supervised by Geoffrey Hinton.
- KP Murphy. Machine Learning–A probabilistic Perspective. The MIT Press, 2012.
- Kevin P. Murphy. Conjugate bayesian analysis of the gaussian distribution. Technical report, University of British Columbia, 2007. URL https://www.cs.ubc.ca/~murphyk/Papers/bayesGauss.pdf. Technical Report.
- Teng Gao. How to derive an em algorithm from scratch: From theory to implementation, November 2022. URL https://teng-gao.github.io/blog/2022/ems/.
- W. K. Hastings. Monte Carlo sampling methods using Markov chains and their applications. Biometrika, 57(1):97–109, 04 1970. ISSN 0006-3444. [CrossRef]
- Tshilidzi Marwala, Wilson Tsakane Mongwe, and Rendani Mbuvha. 1 - introduction to hamiltonian monte carlo. In Tshilidzi Marwala, Wilson Tsakane Mongwe, and Rendani Mbuvha, editors, Hamiltonian Monte Carlo Methods in Machine Learning, pages 1–29. Academic Press, 2023. ISBN 978-0-443-19035-3. URL https://www.sciencedirect.com/science/article/pii/B9780443190353000136. [CrossRef]
- Jerry Qinghui Yu, Elliot Creager, David Duvenaud, and Jesse Bettencourt. Bayesian neural networks. https://www.cs.toronto.edu/~duvenaud/distill_bayes_net/public/. Tutorial hosted by the University of Toronto.
- James-A Goulet, Luong Ha Nguyen, and Saeid Amiri. Tractable approximate gaussian inference for bayesian neural networks. Journal of Machine Learning Research, 22(251):1–23, 2021.
- H. E. RAUCH, F. TUNG, and C. T. STRIEBEL. Maximum likelihood estimates of linear dynamic systems. AIAA Journal, 3(8):1445–1450, 1965. [CrossRef]
- Bhargob Deka, Luong Ha Nguyen, and James-A. Goulet. Analytically tractable heteroscedastic uncertainty quantification in bayesian neural networks for regression tasks. Neurocomputing, 572:127183, 2024b. ISSN 0925-2312. URL https://www.sciencedirect.com/science/article/pii/S0925231223013061. [CrossRef]
- Van-Dai Vuong, Luong-Ha Nguyen, and James-A Goulet. Coupling lstm neural networks and state-space models through analytically tractable inference. International Journal of Forecasting, 2024.
- Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1):1929–1958, 2014.
- Yarin Gal. Uncertainty in Deep Learning. PhD thesis, University of Cambridge, 2016.
- Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight uncertainty in neural network. In International conference on machine learning, pages 1613–1622. PMLR, 2015.
- José Miguel Hernández-Lobato and Ryan Adams. Probabilistic backpropagation for scalable learning of bayesian neural networks. In International conference on machine learning, pages 1861–1869. PMLR, 2015.
- Jianxi Yang, Likai Zhang, Cen Chen, Yangfan Li, Ren Li, Guiping Wang, Shixin Jiang, and Zeng Zeng. A hierarchical deep convolutional neural network and gated recurrent unit framework for structural damage detection. Information Sciences, 540:117 – 130, 2020. ISSN 00200255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85087336888&doi=10.1016%2fj.ins.2020.05.090&partnerID=40&md5=b2102b845c722bf8e8d602963f453ebd. Cited by: 86; All Open Access, Green Open Access. [CrossRef]
- Shiyun Liao, Huijun Liu, Jianxi Yang, and Yongxin Ge. A channel-spatial-temporal attention-based network for vibration-based damage detection. Information Sciences, 606:213 – 229, 2022. ISSN 00200255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85130546561&doi=10.1016%2fj.ins.2022.05.042&partnerID=40&md5=46fb813cf20534474fdc69b33fdf5ca8. Cited by: 20. [CrossRef]
- Mengmeng Wang, Atilla Incecik, Zhe Tian, Mingyang Zhang, Pentti Kujala, Munish Gupta, Grzegorz Krolczyk, and Zhixiong Li. Structural health monitoring on offshore jacket platforms using a novel ensemble deep learning model. Ocean Engineering, 301, 2024b. ISSN 00298018. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85188522962&doi=10.1016%2fj.oceaneng.2024.117510&partnerID=40&md5=9f5d9802cde5907ca007c87f9cab43a0. Cited by: 9; All Open Access, Hybrid Gold Open Access. [CrossRef]
- Shayan Ghazimoghadam and S.A.A. Hosseinzadeh. A novel unsupervised deep learning approach for vibration-based damage diagnosis using a multi-head self-attention lstm autoencoder. Measurement: Journal of the International Measurement Confederation, 229, 2024. ISSN 02632241. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85186333772&doi=10.1016%2fj.measurement.2024.114410&partnerID=40&md5=966ef02ea702616e5f949ccc0d08312a. Cited by: 16. [CrossRef]
- Youjun Chen, Zeyang Sun, Ruiyang Zhang, Liuzhen Yao, and Gang Wu. Attention mechanism based neural networks for structural post-earthquake damage state prediction and rapid fragility analysis. Computers and Structures, 281, 2023c. ISSN 00457949. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85151284192&doi=10.1016%2fj.compstruc.2023.107038&partnerID=40&md5=b0a0289c594866ab6e76a3fbf1c720a7. Cited by: 20. [CrossRef]
- Xize Chen, Junfeng Jia, Jie Yang, Yulei Bai, and Xiuli Du. A vibration-based 1dcnn-bilstm model for structural state recognition of rc beams. Mechanical Systems and Signal Processing, 203, 2023d. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85172307004&doi=10.1016%2fj.ymssp.2023.110715&partnerID=40&md5=421567b512cb85018074752daefd7cec. Cited by: 16. [CrossRef]
- Shengyuan Zhang, Chun Min Li, and Wenjing Ye. Damage localization in plate-like structures using time-varying feature and one-dimensional convolutional neural network. Mechanical Systems and Signal Processing, 147, 2021b. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85089401038&doi=10.1016%2fj.ymssp.2020.107107&partnerID=40&md5=96394d57fe5cd19ed3433ea21c3f292a. Cited by: 124. [CrossRef]
- Niklas Römgens, Abderrahim Abbassi, Clemens Jonscher, Tanja Grießmann, and Raimund Rolfes. On using autoencoders with non-standardized time series data for damage localization. Engineering Structures, 303, 2024. ISSN 01410296. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85183452721&doi=10.1016%2fj.engstruct.2024.117570&partnerID=40&md5=83cc731790a71b164666887010310595. Cited by: 7; All Open Access, Green Open Access, Hybrid Gold Open Access. [CrossRef]
- Yunwoo Lee, Jae Hyuk Lee, Jin-Seop Kim, and Hyungchul Yoon. A hybrid approach of long short-term memory and machine learning with acoustic emission sensors for structural damage localization. IEEE Sensors Journal, 24(23):39529 – 39539, 2024. ISSN 1530437X. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85207375113&doi=10.1109%2fJSEN.2024.3481411&partnerID=40&md5=f69bf25511b139e5aef96e2f35ec0164. Cited by: 0. [CrossRef]
- Héctor Triviño, Cisne Feijóo, Hugo Lugmania, Yolanda Vidal, and Christian Tutivén. Damage detection and localization at the jacket support of an offshore wind turbine using transformer models. Structural Control and Health Monitoring, 2023, 2023. ISSN 15452255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85181956987&doi=10.1155%2f2023%2f6646599&partnerID=40&md5=1ecd78b8e10dfac5801778a780595311. Cited by: 2; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Maziar Jamshidi and Mamdouh El-Badry. Structural damage severity classification from time-frequency acceleration data using convolutional neural networks. Structures, 54:236 – 253, 2023. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85159782832&doi=10.1016%2fj.istruc.2023.05.009&partnerID=40&md5=f1bc2961882bcd8b26d29ed6faae42c5. Cited by: 23. [CrossRef]
- Seyedomid Sajedi and Xiao Liang. Trident: A deep learning framework for high-resolution bridge vibration monitoring. Applied Sciences (Switzerland), 12(21), 2022. ISSN 20763417. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85141862362&doi=10.3390%2fapp122110999&partnerID=40&md5=89531592bf421c4f69805901e9c50ad4. Cited by: 3; All Open Access, Gold Open Access. [CrossRef]
- Sheng Shi, Dongsheng Du, Oya Mercan, Erol Kalkan, and Shuguang Wang. A novel unsupervised real-time damage detection method for structural health monitoring using machine learning. Structural Control and Health Monitoring, 29(10), 2022. ISSN 15452255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85134644674&doi=10.1002%2fstc.3042&partnerID=40&md5=f7cf5ecbe495949a7578874184333e6e. Cited by: 21; All Open Access, Gold Open Access. [CrossRef]
- Hung V. Dang, Hoa Tran-Ngoc, Tung V. Nguyen, T. Bui-Tien, Guido De Roeck, and Huan X. Nguyen. Data-driven structural health monitoring using feature fusion and hybrid deep learning. IEEE Transactions on Automation Science and Engineering, 18(4):2087 – 2103, 2021a. ISSN 15455955. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85116927576&doi=10.1109%2fTASE.2020.3034401&partnerID=40&md5=92827fdc3ee437fa9b47fc878d29e345. Cited by: 87. [CrossRef]
- Viet-Linh Tran. A new framework for damage detection of steel frames using burg autoregressive and stacked autoencoder-based deep neural network. Innovative Infrastructure Solutions, 7(5), 2022. ISSN 23644176. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85135052762&doi=10.1007%2fs41062-022-00888-8&partnerID=40&md5=0a35f9580e3abfa6de7dc4fdc12ed142. Cited by: 4. [CrossRef]
- Sandeep Sony, Sunanda Gamage, Ayan Sadhu, and Jagath Samarabandu. Multiclass damage identification in a full-scale bridge using optimally tuned one-dimensional convolutional neural network. Journal of Computing in Civil Engineering, 36(2), 2022. ISSN 08873801. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85121045985&doi=10.1061%2f%28ASCE%29CP.1943-5487.0001003&partnerID=40&md5=2e71d47d22c9cea3de1dc5e8704b1123. Cited by: 41; All Open Access, Green Open Access. [CrossRef]
- Pasquale Santaniello and Paolo Russo. Bridge damage identification using deep neural networks on time–frequency signals representation. Sensors, 23(13), 2023. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85164843936&doi=10.3390%2fs23136152&partnerID=40&md5=cdbdaee768621f62db562e7e063695d7. Cited by: 12; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Ahmad Honarjoo, Ehsan Darvishan, Hassan Rezazadeh, and Amir Homayoon Kosarieh. Sigbert: vibration-based steel frame structural damage detection through fine-tuning bert. International Journal of Structural Integrity, 15(5):851 – 872, 2024. ISSN 17579864. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85203529524&doi=10.1108%2fIJSI-04-2024-0065&partnerID=40&md5=d6d62f82e44ff60a193f9f294740f897. Cited by: 1. [CrossRef]
- Thanh Bui-Tien, Thanh Nguyen-Chi, Thang Le-Xuan, and Hoa Tran-Ngoc. Enhancing bridge damage assessment: Adaptive cell and deep learning approaches in time-series analysis. Construction and Building Materials, 439, 2024. ISSN 09500618. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85198016865&doi=10.1016%2fj.conbuildmat.2024.137240&partnerID=40&md5=72c636e4d310e969cba5b3d24b9a8667. Cited by: 3. [CrossRef]
- Wei Fu, Ruohua Zhou, and Ziye Guo. Concrete acoustic emission signal augmentation method based on generative adversarial networks. Measurement: Journal of the International Measurement Confederation, 231, 2024. ISSN 02632241. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85189758383&doi=10.1016%2fj.measurement.2024.114574&partnerID=40&md5=6dfeb866187dc476798d4762f98095bd. Cited by: 5. [CrossRef]
- Yuanming Lu, Di Wang, Die Liu, and Xianyi Yang. A lightweight and efficient method of structural damage detection using stochastic configuration network. Sensors (Basel, Switzerland), 23(22), 2023a. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85177761636&doi=10.3390%2fs23229146&partnerID=40&md5=63e120ead4d155685de24da12b447ad8. Cited by: 3; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Dung Bui-Ngoc, Hieu Nguyen-Tran, Lan Nguyen-Ngoc, Hoa Tran-Ngoc, Thanh Bui-Tien, and Hung Tran-Viet. Damage detection in structural health monitoring using hybrid convolution neural network and recurrent neural network. Frattura ed Integrita Strutturale, 16(59):461 – 470, 2022. ISSN 19718993. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85122427041&doi=10.3221%2fIGF-ESIS.59.30&partnerID=40&md5=69de50235c69a70bf64b812d698bd3fe. Cited by: 29; All Open Access, Gold Open Access. [CrossRef]
- Meng Wu, Xi Xu, Xu Han, and Xiuli Du. Seismic performance prediction of a slope-pile-anchor coupled reinforcement system using recurrent neural networks. Engineering Geology, 338, 2024a. ISSN 00137952. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85198010885&doi=10.1016%2fj.enggeo.2024.107623&partnerID=40&md5=89675afe14586f4197878005cf1023de. Cited by: 3. [CrossRef]
- Ben Huang, Fei Kang, Junjie Li, and Feng Wang. Displacement prediction model for high arch dams using long short-term memory based encoder-decoder with dual-stage attention considering measured dam temperature. Engineering Structures, 280, 2023. ISSN 01410296. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85147189901&doi=10.1016%2fj.engstruct.2023.115686&partnerID=40&md5=a8e071ccad3b633bc922098ada15f0d2. Cited by: 55. [CrossRef]
- Yangtao Li, Tengfei Bao, Jian Gong, Xiaosong Shu, and Kang Zhang. The prediction of dam displacement time series using stl, extra-trees, and stacked lstm neural network. IEEE Access, 8:94440 – 94452, 2020. ISSN 21693536. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85086041637&doi=10.1109%2fACCESS.2020.2995592&partnerID=40&md5=c7e10a14d614e7d9bbedcb7fdcc10703. Cited by: 95; All Open Access, Gold Open Access. [CrossRef]
- Xiao-Wei Ye, Si-Yuan Ma, Zhi-Xiong Liu, Yan-Bo Chen, Ci-Rong Lu, Yue-Jun Song, Xiao-Jun Li, and Li-An Zhao. Lstm-based deformation forecasting for additional stress estimation of existing tunnel structure induced by adjacent shield tunneling. Tunnelling and Underground Space Technology, 146, 2024. ISSN 08867798. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85185410299&doi=10.1016%2fj.tust.2024.105664&partnerID=40&md5=83284916443a02dbd9dbba27ac44ba55. Cited by: 9. [CrossRef]
- Xiang Xu, Donghui Xu, Antonio Caballero, Yuan Ren, Qiao Huang, Weijie Chang, and Michael C. Forde. Vehicle-induced deflection prediction using long short-term memory networks. Structures, 54:596 – 606, 2023b. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85160007801&doi=10.1016%2fj.istruc.2023.04.025&partnerID=40&md5=3ff05605d831828601945402f11c37dc. Cited by: 6. [CrossRef]
- Xinhui Xiao, Zepeng Wang, Haiping Zhang, Yuan Luo, Fanghuai Chen, Yang Deng, Naiwei Lu, and Ying Chen. A novel method of bridge deflection prediction using probabilistic deep learning and measured data. Sensors, 24(21), 2024. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85208608421&doi=10.3390%2fs24216863&partnerID=40&md5=cd14ea55ef52a14971295d8b88997df7. Cited by: 0; All Open Access, Gold Open Access. [CrossRef]
- Shanwu Li, Suchao Li, Shujin Laima, and Hui Li. Data-driven modeling of bridge buffeting in the time domain using long short-term memory network based on structural health monitoring. Structural Control and Health Monitoring, 28(8), 2021a. ISSN 15452255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85105098495&doi=10.1002%2fstc.2772&partnerID=40&md5=ae98db2834c7ca4df8ec2d6211ae4435. Cited by: 49; All Open Access, Gold Open Access. [CrossRef]
- Vahid Barzegar, Simon Laflamme, Chao Hu, and Jacob Dodson. Ensemble of recurrent neural networks with long short-term memory cells for high-rate structural health monitoring. Mechanical Systems and Signal Processing, 164, 2022. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85110418960&doi=10.1016%2fj.ymssp.2021.108201&partnerID=40&md5=b556cf1807fa1b271f2a3ab0617e8a05. Cited by: 32; All Open Access, Bronze Open Access, Green Open Access. [CrossRef]
- Zhuoran Ma and Liang Gao. Predicting mechanical state of high-speed railway elevated station track system using a hybrid prediction model. KSCE Journal of Civil Engineering, 25(7):2474 – 2486, 2021. ISSN 12267988. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85104151877&doi=10.1007%2fs12205-021-1307-z&partnerID=40&md5=94fef56fc082ca229817637d8ae8cc6c. Cited by: 8. [CrossRef]
- Zhi-wei Wang, Xiao-fan Lu, Wen-ming Zhang, Vasileios C. Fragkoulis, Yu-feng Zhang, and Michael Beer. Deep learning-based prediction of wind-induced lateral displacement response of suspension bridge decks for structural health monitoring. Journal of Wind Engineering and Industrial Aerodynamics, 247, 2024c. ISSN 01676105. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85186503997&doi=10.1016%2fj.jweia.2024.105679&partnerID=40&md5=e656f6fa1ff803c0c3deb78f2330759e. Cited by: 7. [CrossRef]
- Byung Kwan Oh, Hyo Seon Park, and Branko Glisic. Prediction of long-term strain in concrete structure using convolutional neural networks, air temperature and time stamp of measurements. Automation in Construction, 126, 2021. ISSN 09265805. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85102361606&doi=10.1016%2fj.autcon.2021.103665&partnerID=40&md5=63ddaaed8bef178f90384975fef90f29. Cited by: 35. [CrossRef]
- Hyo Seon Park, Taehoon Hong, Dong-Eun Lee, Byung Kwan Oh, and Branko Glisic. Long-term structural response prediction models for concrete structures using weather data, fiber-optic sensing, and convolutional neural network. Expert Systems with Applications, 201, 2022. ISSN 09574174. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85129466337&doi=10.1016%2fj.eswa.2022.117152&partnerID=40&md5=562f83bb03ba42994b49f2842e90e20e. Cited by: 12. [CrossRef]
- Xin Yu, Junjie Li, and Fei Kang. Ssa optimized back propagation neural network model for dam displacement monitoring based on long-term temperature data. European Journal of Environmental and Civil Engineering, 27(4):1617 – 1643, 2023. ISSN 19648189. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85132829800&doi=10.1080%2f19648189.2022.2090445&partnerID=40&md5=77ab2ff14ccb19d442702a2eb86354b2. Cited by: 3. [CrossRef]
- Dongyang Yuan, Chongshi Gu, Bowen Wei, Xiangnan Qin, and Hao Gu. Displacement behavior interpretation and prediction model of concrete gravity dams located in cold area. Structural Health Monitoring, 22(4):2384 – 2401, 2023. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85139059161&doi=10.1177%2f14759217221122368&partnerID=40&md5=212eea9ff439b170d677762de067751a. Cited by: 17. [CrossRef]
- Zhiyao Lu, Guantao Zhou, Yong Ding, and Denghua Li. Prediction and analysis of response behavior of concrete face rockfill dam in cold region. Structures, 70, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85208686199&doi=10.1016%2fj.istruc.2024.107732&partnerID=40&md5=26beed20f3b3bd75cd6ae9aab684af97. Cited by: 0. [CrossRef]
- Han-Wei Zhao, You-Liang Ding, Ai-Qun Li, Bin Chen, and Kun-Peng Wang. Digital modeling approach of distributional mapping from structural temperature field to temperature-induced strain field for bridges. Journal of Civil Structural Health Monitoring, 13(1):251 – 267, 2023. ISSN 21905452. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85140052808&doi=10.1007%2fs13349-022-00635-8&partnerID=40&md5=cfa45ece3e937a6c15a58997c2ce4560. Cited by: 31. [CrossRef]
- Kang Yang, Youliang Ding, Fangfang Geng, Huachen Jiang, and Zhengbo Zou. A multi-sensor mapping bi-lstm model of bridge monitoring data based on spatial-temporal attention mechanism. Measurement: Journal of the International Measurement Confederation, 217, 2023. ISSN 02632241. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85160021665&doi=10.1016%2fj.measurement.2023.113053&partnerID=40&md5=19d810669ea2789762e340919f1f5ed0. Cited by: 13. [CrossRef]
- Jihao Ma and Jingpei Dan. Long-term structural state trend forecasting based on an fft–informer model. Applied Sciences (Switzerland), 13(4), 2023. ISSN 20763417. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85149304527&doi=10.3390%2fapp13042553&partnerID=40&md5=298ad1467151b12da3e71e052f7bf9ff. Cited by: 8; All Open Access, Gold Open Access. [CrossRef]
- Ziqi Li, Dongsheng Li, and Tianshu Sun. A transformer-based bridge structural response prediction framework. Sensors, 22(8), 2022a. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85128351219&doi=10.3390%2fs22083100&partnerID=40&md5=d6ed2af86959a95c80e10c454d7f2a13. Cited by: 3; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Ying Zhou, Shiqiao Meng, Yujie Lou, and Qingzhao Kong. Physics-informed deep learning-based real-time structural response prediction method. Engineering, 35:140 – 157, 2024a. ISSN 20958099. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85190104653&doi=10.1016%2fj.eng.2023.08.011&partnerID=40&md5=0c12dc2dd566d17fac1d9e0f687865c5. Cited by: 15; All Open Access, Gold Open Access. [CrossRef]
- Mauricio Pereira and Branko Glisic. Physics-informed data-driven prediction of 2d normal strain field in concrete structures. Sensors, 22(19), 2022a. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85139948522&doi=10.3390%2fs22197190&partnerID=40&md5=eb048466249eb9371d8a6f8cf394669b. Cited by: 7; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Jianwen Pan, Wenju Liu, Changwei Liu, and Jinting Wang. Convolutional neural network-based spatiotemporal prediction for deformation behavior of arch dams. Expert Systems with Applications, 232, 2023. ISSN 09574174. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85163800056&doi=10.1016%2fj.eswa.2023.120835&partnerID=40&md5=91056ae3d6e27f0c62f719fe2fcfb580. Cited by: 25. [CrossRef]
- Xuyan Tan, Weizhong Chen, Jianping Yang, Bowen Du, and Tao Zou. Prediction for segment strain and opening of underwater shield tunnel using deep learning method. Transportation Geotechnics, 39, 2023a. ISSN 22143912. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85146095944&doi=10.1016%2fj.trgeo.2023.100928&partnerID=40&md5=ea05e1e6b47326d5f91584188b582643. Cited by: 11. [CrossRef]
- Hyo Seon Park, Jung Hwan An, Young Jun Park, and Byung Kwan Oh. Convolutional neural network-based safety evaluation method for structures with dynamic responses. Expert Systems with Applications, 158, 2020. ISSN 09574174. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85086798436&doi=10.1016%2fj.eswa.2020.113634&partnerID=40&md5=a25a5fcaadaef426237a1b3d4dddcd11. Cited by: 29. [CrossRef]
- Abbas Ghaffari, Yaser Shahbazi, Mohsen Mokhtari Kashavar, Mohammad Fotouhi, and Siamak Pedrammehr. Advanced predictive structural health monitoring in high-rise buildings using recurrent neural networks. Buildings, 14(10), 2024. ISSN 20755309. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85207362946&doi=10.3390%2fbuildings14103261&partnerID=40&md5=42f46e81441492bca44b28300e706c83. Cited by: 1; All Open Access, Gold Open Access. [CrossRef]
- Yadi Tian, Yang Xu, Dongyu Zhang, and Hui Li. Relationship modeling between vehicle-induced girder vertical deflection and cable tension by bilstm using field monitoring data of a cable-stayed bridge. Structural Control and Health Monitoring, 28(2), 2021. ISSN 15452255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85096791711&doi=10.1002%2fstc.2667&partnerID=40&md5=828d4d020fbe1f3920cbf8f9e33dcfb8. Cited by: 43; All Open Access, Gold Open Access. [CrossRef]
- Shaowei Wang, Bingao Chai, Yi Liu, and Hao Gu. A causal prediction model for the measured temperature field of high arch dams with dual simulation of lag influencing mechanism. Structures, 58, 2023d. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85177191358&doi=10.1016%2fj.istruc.2023.105568&partnerID=40&md5=b54e61bd56b3945634cba61e25d48ad8. Cited by: 6. [CrossRef]
- Linren Zhou, Taojun Wang, and Yumeng Chen. Bridge temperature prediction method based on long short-term memory neural networks and shared meteorological data. Advances in Structural Engineering, 27(8):1349 – 1360, 2024b. ISSN 13694332. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85190839205&doi=10.1177%2f13694332241247918&partnerID=40&md5=51a82b816df22025e6418961af6dc12c. Cited by: 2. [CrossRef]
- Jersson X. Leon-Medina, Ricardo Cesar Gomez Vargas, Camilo Gutierrez-Osorio, Daniel Alfonso Garavito Jimenez, Diego Alexander Velandia Cardenas, Julián Esteban Salomón Torres, Jaiber Camacho-Olarte, Bernardo Rueda, Whilmar Vargas, Jorge Sofrony Esmeral, Felipe Restrepo-Calle, Diego Alexander Tibaduiza Burgos, and Cesar Pedraza Bonilla. Deep learning for the prediction of temperature time series in the lining of an electric arc furnace for structural health monitoring at cerro matoso (cmsa) †. Engineering Proceedings, 2(1), 2020. ISSN 26734591. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85117088545&doi=10.3390%2fecsa-7-08246&partnerID=40&md5=941a04d04e70865bcc016ebdf9e1de96. Cited by: 8; All Open Access, Hybrid Gold Open Access. [CrossRef]
- Jersson X. Leon-Medina, Jaiber Camacho, Camilo Gutierrez-Osorio, Julián Esteban Salomón, Bernardo Rueda, Whilmar Vargas, Jorge Sofrony, Felipe Restrepo-Calle, Cesar Pedraza, and Diego Tibaduiza. Temperature prediction using multivariate time series deep learning in the lining of an electric arc furnace for ferronickel production. Sensors, 21(20), 2021. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85117096620&doi=10.3390%2fs21206894&partnerID=40&md5=4302a2369d25f0c8a415650c6c21cddc. Cited by: 19; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Diego F. Godoy-Rojas, Jersson X. Leon-Medina, Bernardo Rueda, Whilmar Vargas, Juan Romero, Cesar Pedraza, Francesc Pozo, and Diego A. Tibaduiza. Attention-based deep recurrent neural network to forecast the temperature behavior of an electric arc furnace side-wall. Sensors, 22(4), 2022. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85124362038&doi=10.3390%2fs22041418&partnerID=40&md5=d5c7ad8b7a7cd6c376089005fe887d05. Cited by: 11; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Qiushuang Lin and Chunxiang Li. Simplified-boost reinforced model-based complex wind signal forecasting. Advances in Civil Engineering, 2020, 2020. ISSN 16878086. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85093088278&doi=10.1155%2f2020%2f9564287&partnerID=40&md5=c4bccf8e0834adfb9be792c02b4db2ed. Cited by: 0; All Open Access, Gold Open Access. [CrossRef]
- Yang Ding, Xiao-Wei Ye, and Yong Guo. A multistep direct and indirect strategy for predicting wind direction based on the emd-lstm model. Structural Control and Health Monitoring, 2023, 2023. ISSN 15452255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85162208617&doi=10.1155%2f2023%2f4950487&partnerID=40&md5=8d8da4a0224d823bb0559998fce79eb4. Cited by: 43; All Open Access, Gold Open Access. [CrossRef]
- Jae-Yeong Lim, Sejin Kim, Ho-Kyung Kim, and Young-Kuk Kim. Long short-term memory (lstm)-based wind speed prediction during a typhoon for bridge traffic control. Journal of Wind Engineering and Industrial Aerodynamics, 220, 2022. ISSN 01676105. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85120429348&doi=10.1016%2fj.jweia.2021.104788&partnerID=40&md5=20023df00a50422a085103280ca8b102. Cited by: 41. [CrossRef]
- Yonghui Lu, Liqun Tang, Chengbin Chen, Licheng Zhou, Zejia Liu, Yiping Liu, Zhenyu Jiang, and Bao Yang. Reconstruction of structural long-term acceleration response based on bilstm networks. Engineering Structures, 285, 2023b. ISSN 01410296. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85151370560&doi=10.1016%2fj.engstruct.2023.116000&partnerID=40&md5=7c08ecc01e7b750fe1057457dbb2648d. Cited by: 46. [CrossRef]
- Yangtao Li, Tengfei Bao, Hao Chen, Kang Zhang, Xiaosong Shu, Zexun Chen, and Yuhan Hu. A large-scale sensor missing data imputation framework for dams using deep learning and transfer learning strategy. Measurement: Journal of the International Measurement Confederation, 178, 2021b. ISSN 02632241. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85105695016&doi=10.1016%2fj.measurement.2021.109377&partnerID=40&md5=5712580af1f429a5461a6572929dca1b. Cited by: 65. [CrossRef]
- Chengbin Chen, Liqun Tang, Yonghui Lu, Yong Wang, Zejia Liu, Yiping Liu, Licheng Zhou, Zhenyu Jiang, and Bao Yang. Reconstruction of long-term strain data for structural health monitoring with a hybrid deep-learning and autoregressive model considering thermal effects. Engineering Structures, 285, 2023e. ISSN 01410296. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85151710954&doi=10.1016%2fj.engstruct.2023.116063&partnerID=40&md5=0d0a0e1a4885240af0d6999064a4d1a4. Cited by: 22. [CrossRef]
- Nguyen Thi Cam Nhung, Hoang Nguyen Bui, and Tran Quang Minh. Enhancing recovery of structural health monitoring data using cnn combined with gru. Infrastructures, 9(11), 2024. ISSN 24123811. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85210353081&doi=10.3390%2finfrastructures9110205&partnerID=40&md5=af62f5906ec4deae3b3096980149c724. Cited by: 0. [CrossRef]
- Bowen Du, Liyu Wu, Leilei Sun, Fei Xu, and Linchao Li. Heterogeneous structural responses recovery based on multi-modal deep learning. Structural Health Monitoring, 22(2):799 – 813, 2023. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85131104622&doi=10.1177%2f14759217221094499&partnerID=40&md5=469a8c2c42822dbf8016be442477d849. Cited by: 12. [CrossRef]
- Thanh Bui Tien, Tuyen Vu Quang, Lan Nguyen Ngoc, and Hoa Tran Ngoc. Time series data recovery in shm of large-scale bridges: Leveraging gan and bi-lstm networks. Structures, 63, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85190163062&doi=10.1016%2fj.istruc.2024.106368&partnerID=40&md5=f00574682eacb7259f25778e5269ae08. Cited by: 5. [CrossRef]
- Huachen Jiang, Chunfeng Wan, Kang Yang, Youliang Ding, and Songtao Xue. Continuous missing data imputation with incomplete dataset by generative adversarial networks–based unsupervised learning for long-term bridge health monitoring. Structural Health Monitoring, 21(3):1093 – 1109, 2022. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85107283245&doi=10.1177%2f14759217211021942&partnerID=40&md5=1985af9004526d08e63bd6719e702499. Cited by: 76. [CrossRef]
- Jiaqi Shi, Hongmei Shi, Jianbo Li, and Zujun Yu. Train-induced vibration response reconstruction for bridge damage detection with a deep learning methodology. Structures, 64, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85192185155&doi=10.1016%2fj.istruc.2024.106496&partnerID=40&md5=bd812ca636355e1709b299802436489e. Cited by: 8. [CrossRef]
- Guang Qu, Mingming Song, Gongfeng Xin, Zhiqiang Shang, and Limin Sun. Time-convolutional network with joint time-frequency domain loss based on arithmetic optimization algorithm for dynamic response reconstruction. Engineering Structures, 321, 2024. ISSN 01410296. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85204468392&doi=10.1016%2fj.engstruct.2024.119001&partnerID=40&md5=e24b703b0eff4633baf59fb96a9382f9. Cited by: 2. [CrossRef]
- Linchao Li, Haijun Zhou, Hanlin Liu, Chaodong Zhang, and Junhui Liu. A hybrid method coupling empirical mode decomposition and a long short-term memory network to predict missing measured signal data of shm systems. Structural Health Monitoring, 20(4):1778 – 1793, 2021c. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85087443550&doi=10.1177%2f1475921720932813&partnerID=40&md5=e42908e450f8bf48bd4de0827a9a4005. Cited by: 62. [CrossRef]
- Jintao Song, Zhaodi Yang, and Xinru Li. Missing data imputation model for dam health monitoring based on mode decomposition and deep learning. Journal of Civil Structural Health Monitoring, 14:1–14, 03 2024a. [CrossRef]
- Songlin Zhu, Jijun Miao, Wei Chen, Caiwei Liu, Chengliang Weng, and Yichun Luo. Reconstructing missing data using a bi-lstm model based on vmd and ssa for structural health monitoring. Buildings, 14(1), 2024. ISSN 20755309. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85183320112&doi=10.3390%2fbuildings14010251&partnerID=40&md5=9803a872ac2212107150dbe11cf1e7d8. Cited by: 3; All Open Access, Gold Open Access. [CrossRef]
- Qiushuang Lin and Chunxiang Li. Nonstationary wind speed data reconstruction based on secondary correction of statistical characteristics. Structural Control and Health Monitoring, 28(9), 2021. ISSN 15452255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85105640831&doi=10.1002%2fstc.2783&partnerID=40&md5=17bca11977ae8b8706a9d50fce284d74. Cited by: 9. [CrossRef]
- Yoon-Soo Shin and Junhee Kim. Sensor data reconstruction for dynamic responses of structures using external feedback of recurrent neural network. Sensors, 23(5), 2023. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85149496739&doi=10.3390%2fs23052737&partnerID=40&md5=ee918a3303785f82388f956f1d57b194. Cited by: 12; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Liangfu Ge and Ayan Sadhu. Domain adaptation for structural health monitoring via physics-informed and self-attention-enhanced generative adversarial learning. Mechanical Systems and Signal Processing, 211, 2024. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85185394028&doi=10.1016%2fj.ymssp.2024.111236&partnerID=40&md5=96dcc8ae2204f979ba6b9fe6a31aee26. Cited by: 8; All Open Access, Hybrid Gold Open Access. [CrossRef]
- Fabrizio Falchi, Maria Girardi, Gianmarco Gurioli, Nicola Messina, Cristina Padovani, and Daniele Pellegrini. Deep learning and structural health monitoring: Temporal fusion transformers for anomaly detection in masonry towers. Mechanical Systems and Signal Processing, 215, 2024. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85189940916&doi=10.1016%2fj.ymssp.2024.111382&partnerID=40&md5=16f9b36ef8d32816bb9a96ab636b1018. Cited by: 5; All Open Access, Hybrid Gold Open Access. [CrossRef]
- Teng Li, Yuxin Pan, Kaitai Tong, Carlos E. Ventura, and Clarence W. De Silva. Attention-based sequence-to-sequence learning for online structural response forecasting under seismic excitation. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 52(4):2184 – 2200, 2022b. ISSN 21682216. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85099727735&doi=10.1109%2fTSMC.2020.3048696&partnerID=40&md5=608ac21b1ac8b8343a4fc0fa162f5926. Cited by: 30. [CrossRef]
- Chengbin Chen, Liqun Tang, Qingkai Xiao, Licheng Zhou, Hao Wang, Zejia Liu, Chenxi Xing, Yiping Liu, Jinming Chen, Zhenyu Jiang, and Bao Yang. Unsupervised anomaly detection for long-span bridges combining response forecasting by deep learning with td-mpca. Structures, 54:1815 – 1830, 2023f. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85161664908&doi=10.1016%2fj.istruc.2023.06.033&partnerID=40&md5=3a6fab290fdaae3140b9caa027226e4c. Cited by: 10. [CrossRef]
- Xiaoyou Wang, Yao Du, Xiaoqing Zhou, and Yong Xia. Data anomaly detection through semisupervised learning aided by customised data augmentation techniques. Structural Control and Health Monitoring, 2023, 2023e. ISSN 15452255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85167674359&doi=10.1155%2f2023%2f2430011&partnerID=40&md5=b483282bc6f547adbb28cc79a81a0838. Cited by: 3; All Open Access, Gold Open Access. [CrossRef]
- Ke Gao, Zhi-Dan Chen, Shun Weng, Hong-Ping Zhu, and Li-Ying Wu. Detection of multi-type data anomaly for structural health monitoring using pattern recognition neural network. Smart Structures and Systems, 29(1):129 – 140, 2022. ISSN 17381584. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85129174700&doi=10.12989%2fsss.2022.29.1.129&partnerID=40&md5=ae829cbc89b57487a612c137f94cd963. Cited by: 19. [CrossRef]
- Soon-Young Kim and Mukhriddin Mukhiddinov. Data anomaly detection for structural health monitoring based on a convolutional neural network. Sensors (Basel, Switzerland), 23(20), 2023. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85175276902&doi=10.3390%2fs23208525&partnerID=40&md5=12a09064bf62254f97649d949aa29a65. Cited by: 8; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Xiaoyu Gong, Xiaodong Song, Guangqi Li, Wen Xiong, and C.S. Cai. Deep learning based anomaly identification of temperature effects in bridge structural health monitoring data. Structures, 69, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85205815285&doi=10.1016%2fj.istruc.2024.107478&partnerID=40&md5=a0a7728c93fdd8a44476cb89883f3de9. Cited by: 1. [CrossRef]
- Zhao Chen, Hao Sun, and Wen Xiong. Forecasting dynamics by an incomplete equation of motion and an auto-encoder koopman operator. Mechanical Systems and Signal Processing, 220, 2024b. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85196279540&doi=10.1016%2fj.ymssp.2024.111599&partnerID=40&md5=45de44b1668c4215bc3ceee83544e418. Cited by: 0. [CrossRef]
- Qi Li, Jingze Gao, James L. Beck, Chao Lin, Yong Huang, and Hui Li. Probabilistic outlier detection for robust regression modeling of structural response for high-speed railway track monitoring. Structural Health Monitoring, 23(2):1280 – 1296, 2024b. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85164572005&doi=10.1177%2f14759217231184584&partnerID=40&md5=cfea5a92ff52972258b4fd11f44f5582. Cited by: 8. [CrossRef]
- Tae Ho Kwon, Sang Ho Park, Sang I. Park, and Sang-Ho Lee. Building information modeling-based bridge health monitoring for anomaly detection under complex loading conditions using artificial neural networks. Journal of Civil Structural Health Monitoring, 11(5):1301 – 1319, 2021. ISSN 21905452. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85111853342&doi=10.1007%2fs13349-021-00508-6&partnerID=40&md5=39546f3d125bd5f7e131ce9f6d8a3432. Cited by: 27. [CrossRef]
- Mohsen Mousavi and Amir H. Gandomi. Prediction error of johansen cointegration residuals for structural health monitoring. Mechanical Systems and Signal Processing, 160, 2021. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85103690203&doi=10.1016%2fj.ymssp.2021.107847&partnerID=40&md5=3c63df8e471b7375be9e5e6a6f21c42e. Cited by: 39; All Open Access, Green Open Access. [CrossRef]
- Viet-Hung Dang and Hoang-Anh Pham. Vibration-based building health monitoring using spatio-temporal learning model. Engineering Applications of Artificial Intelligence, 126, 2023. ISSN 09521976. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85167454488&doi=10.1016%2fj.engappai.2023.106858&partnerID=40&md5=5813be2d2048506d39ecf8717effe025. Cited by: 7. [CrossRef]
- Thang Le-Xuan, Thanh Bui-Tien, and Hoa Tran-Ngoc. A novel approach model design for signal data using 1dcnn combing with lstm and resnet for damaged detection problem. Structures, 59, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85181052540&doi=10.1016%2fj.istruc.2023.105784&partnerID=40&md5=d07920ca67da166bd5d16737eac65bd8. Cited by: 17. [CrossRef]
- Jianyang Luo, Fangyi Zheng, and Shuli Sun. A few-shot learning method for vibration-based damage detection in civil structures. Structures, 61, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85184804943&doi=10.1016%2fj.istruc.2024.106026&partnerID=40&md5=8a4454e96e510d12a6e98dafa3ceeccd. Cited by: 4. [CrossRef]
- Hoa Tran-Ngoc, Quyet Nguyen-Huu, Thanh Nguyen-Chi, and Thanh Bui-Tien. Enhancing damage detection in truss bridges through structural stiffness reduction using 1dcnn, bilstm, and data augmentation techniques. Structures, 68, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85201097335&doi=10.1016%2fj.istruc.2024.107035&partnerID=40&md5=eee7ae8fb19176e7381a1b6a2ed79533. Cited by: 1. [CrossRef]
- Pengming Zhan, Xianrong Qin, Qing Zhang, and Yuantao Sun. A novel structural damage detection method via multisensor spatial-temporal graph-based features and deep graph convolutional network. IEEE Transactions on Instrumentation and Measurement, 72, 2023. ISSN 00189456. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85147300618&doi=10.1109%2fTIM.2023.3238048&partnerID=40&md5=34799fc557461adf38b6fef98162dc35. Cited by: 12. [CrossRef]
- Ali Dabbous, Riccardo Berta, Matteo Fresta, Hadi Ballout, Luca Lazzaroni, and Francesco Bellotti. Bringing intelligence to the edge for structural health monitoring: The case study of the z24 bridge. IEEE Open Journal of the Industrial Electronics Society, 5:781 – 794, 2024. ISSN 26441284. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85199496894&doi=10.1109%2fOJIES.2024.3434341&partnerID=40&md5=c46062891b595c2ee3da9367db4c83ec. Cited by: 3; All Open Access, Gold Open Access. [CrossRef]
- Hung V. Dang, Mohsin Raza, Tung V. Nguyen, T. Bui-Tien, and Huan X. Nguyen. Deep learning-based detection of structural damage using time-series data. Structure and Infrastructure Engineering, 17(11):1474 – 1493, 2021b. ISSN 15732479. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85090240654&doi=10.1080%2f15732479.2020.1815225&partnerID=40&md5=43cca8527c7d9d0849e1f69e55b34b03. Cited by: 64; All Open Access, Green Open Access. [CrossRef]
- Zhiming Zhang, Jin Yan, Liangding Li, Hong Pan, and Chuanzhi Dong. Condition assessment of stay cables through enhanced time series classification using a deep learning approach. Smart Structures and Systems, 29(1):105 – 116, 2022c. ISSN 17381584. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85129132180&doi=10.12989%2fsss.2022.29.1.105&partnerID=40&md5=f1f17572e5dd15af370ad10fa6409119. Cited by: 5. [CrossRef]
- Younes Nouri, Farzad Shahabian, Hashem Shariatmadar, and Alireza Entezami. Structural damage detection in the wooden bridge using the fourier decomposition, time series modeling and machine learning methods. Journal of Soft Computing in Civil Engineering, 8(2):83 – 101, 2024. ISSN 25882872. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85180854728&doi=10.22115%2fSCCE.2023.401971.1669&partnerID=40&md5=3f8ada360827273dfd32ce5e503d2df1. Cited by: 8. [CrossRef]
- Islam M. Mantawy and Mohamed O. Mantawy. Convolutional neural network based structural health monitoring for rocking bridge system by encoding time-series into images. Structural Control and Health Monitoring, 29(3), 2022. ISSN 15452255. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85119880826&doi=10.1002%2fstc.2897&partnerID=40&md5=fa3f6bb8ffdc09a3234b7eb103ec2e1d. Cited by: 27; All Open Access, Gold Open Access. [CrossRef]
- Alireza Entezami, Hassan Sarmadi, and Stefano Mariani. An unsupervised learning approach for early damage detection by time series analysis and deep neural network to deal with output-only (big) data †. Engineering Proceedings, 2(1), 2020. ISSN 26734591. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85101042664&doi=10.3390%2fecsa-7-08281&partnerID=40&md5=fcdd53adf2fef2096f73604ebd399279. Cited by: 14; All Open Access, Green Open Access, Hybrid Gold Open Access. [CrossRef]
- Viet-Linh Tran, Trong-Cuong Vo, and Thi-Quynh Nguyen. One-dimensional convolutional neural network for damage detection of structures using time series data. Asian Journal of Civil Engineering, 25(1):827 – 860, 2024. ISSN 15630854. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85165189878&doi=10.1007%2fs42107-023-00816-w&partnerID=40&md5=5c2e9ec28e877a7a8e4fd18bf8575fc9. Cited by: 9. [CrossRef]
- L.C.S.M. Ozelim, L.P.F. Borges, A.L.B. Cavalcante, E.A.C. Albuquerque, M.S. Diniz, M.S. Góis, K.R.C.B. da Costa, P.F. de Sousa, A.P.D.N. Dantas, R.M. Jorge, G.R. Moreira, M.L. de Barros, and F.R. de Aquino. Structural health monitoring of dams based on acoustic monitoring, deep neural networks, fuzzy logic and a cusum control algorithm. Sensors, 22(7), 2022. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85126757947&doi=10.3390%2fs22072482&partnerID=40&md5=4f81aeb2ed484c55e3af5adcba7bb088. cited By 13. [CrossRef]
- Lingyu Sun, Ruijie Song, Juntao Wei, Yumeng Gao, Chang Peng, Longqing Fan, Mingshun Jiang, and Lei Zhang. Physics-augmented spatial-temporal graph convolutional network for damage localization using ultrasonic guided waves. Mechanical Systems and Signal Processing, 221, 2024. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85198751936&doi=10.1016%2fj.ymssp.2024.111738&partnerID=40&md5=8f07984104c97a0e9938545b8743ddd8. Cited by: 0. [CrossRef]
- F. Parisi, A.M. Mangini, M.P. Fanti, and Jose M. Adam. Automated location of steel truss bridge damage using machine learning and raw strain sensor data. Automation in Construction, 138, 2022. ISSN 09265805. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85128567321&doi=10.1016%2fj.autcon.2022.104249&partnerID=40&md5=644e537ff9090ee29b0ea559e3c6e717. Cited by: 40. [CrossRef]
- Yan Liu, Xiaolin Meng, Liangliang Hu, Yan Bao, and Craig Hancock. Application of response surface-corrected finite element model and bayesian neural networks to predict the dynamic response of forth road bridges under strong winds. Sensors, 24(7), 2024b. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85190071281&doi=10.3390%2fs24072091&partnerID=40&md5=1e3aa9c9e0796d0f91e9696fb5fbfb12. Cited by: 2; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Syed Haider Mehdi Rizvi, Muntazir Abbas, Syed Sajjad Haider Zaidi, Muhammad Tayyab, and Adil Malik. Lstm-based autoencoder with maximal overlap discrete wavelet transforms using lamb wave for anomaly detection in composites. Applied Sciences (Switzerland), 14(7), 2024. ISSN 20763417. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85192530424&doi=10.3390%2fapp14072925&partnerID=40&md5=4b8cb69ba0a59fd0e3455afd3598e963. Cited by: 2; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Shunlong Li, Jin Niu, and Zhonglong Li. Novelty detection of cable-stayed bridges based on cable force correlation exploration using spatiotemporal graph convolutional networks. Structural Health Monitoring, 20(4):2216 – 2228, 2021d. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85101047512&doi=10.1177%2f1475921720988666&partnerID=40&md5=746e141b6e9c3a7e29a360f6e006eeb4. Cited by: 23. [CrossRef]
- Shayan Mazloom, Nima Sa’adati, Amirmohammad Rabbani, and Maryam Bitaraf. A multi-stage sub-structural damage localization approach using multi-label radial basis function neural network and auto-regressive model parameters. Advances in Structural Engineering, 27(12):2133 – 2152, 2024. ISSN 13694332. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85196537979&doi=10.1177%2f13694332241260132&partnerID=40&md5=625e9692196b92e229f8a3e2f41ab1c4. Cited by: 0. [CrossRef]
- Luca Rosafalco, Andrea Manzoni, Stefano Mariani, and Alberto Corigliano. Fully convolutional networks for structural health monitoring through multivariate time series classification. Advanced Modeling and Simulation in Engineering Sciences, 7(1), 2020. ISSN 22137467. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85091462806&doi=10.1186%2fs40323-020-00174-1&partnerID=40&md5=a641ec5f7ffe24eac32e5525c9b6dc35. Cited by: 45; All Open Access, Gold Open Access. [CrossRef]
- Thanh Bui Tien, Tuyen Vu Quang, Lan Nguyen Ngoc, and Hoa Tran Ngoc. Enhancing time series data classification for structural damage detection through out-of-distribution representation learning. Structures, 65, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85196822713&doi=10.1016%2fj.istruc.2024.106766&partnerID=40&md5=d92a3f6a05d62a3d0af53eadee5571fd. Cited by: 2. [CrossRef]
- Fan Deng, Xiaoming Tao, Pengxiang Wei, and Shiyin Wei. A robust deep learning-based damage identification approach for shm considering missing data. Applied Sciences (Switzerland), 13(9), 2023. ISSN 20763417. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85159352261&doi=10.3390%2fapp13095421&partnerID=40&md5=5b217928f2484063c881e3eef7015d4b. Cited by: 9; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Juntao Wu, M. Hesham El Naggar, and Kuihua Wang. A hybrid convolutional and recurrent neural network for multi-sensor pile damage detection with time series. Sensors, 24(4), 2024b. ISSN 14248220. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85185843060&doi=10.3390%2fs24041190&partnerID=40&md5=609d3a825e7049a728f1dd11a789d217. Cited by: 2; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Chengwei Wang, Farhad Ansari, Bo Wu, Shuangjiang Li, Maurizio Morgese, and Jianting Zhou. Lstm approach for condition assessment of suspension bridges based on time-series deflection and temperature data. Advances in Structural Engineering, 25(16):3450 – 3463, 2022a. ISSN 13694332. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85139994413&doi=10.1177%2f13694332221133604&partnerID=40&md5=da7fd4d47b35feae85339d23e646c173. Cited by: 41. [CrossRef]
- Juan Fernández, Juan Chiachío, José Barros, Manuel Chiachío, and Chetan S. Kulkarni. Physics-guided recurrent neural network trained with approximate bayesian computation: A case study on structural response prognostics. Reliability Engineering and System Safety, 243, 2024a. ISSN 09518320. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85181142960&doi=10.1016%2fj.ress.2023.109822&partnerID=40&md5=bb948e331ffa8c47fd4d9cf517bd2dbd. Cited by: 16; All Open Access, Hybrid Gold Open Access. [CrossRef]
- Alessandro Menghini, Bowen Meng, John Leander, and Carlo Andrea Castiglioni. Estimating bridge stress histories at remote locations from vibration sparse monitoring. Engineering Structures, 318, 2024. ISSN 01410296. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85200573612&doi=10.1016%2fj.engstruct.2024.118720&partnerID=40&md5=5f7c69aaa68a4dc3b7a42cf538892714. Cited by: 1. [CrossRef]
- Songjune Lee, Seungjin Kang, and Gwang-Se Lee. Predictions for bending strain at the tower bottom of offshore wind turbine based on the lstm model. Energies, 16(13), 2023. ISSN 19961073. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85164959375&doi=10.3390%2fen16134922&partnerID=40&md5=1b79d94a8dc03c3f4c993e309a8670a6. Cited by: 3; All Open Access, Gold Open Access. [CrossRef]
- Hanwen Ju, Huaiyuan Shi, Weicheng Shen, and Yang Deng. An accurate and low-cost vehicle-induced deflection prediction framework for long-span bridges using deep learning and monitoring data. Engineering Structures, 310, 2024. ISSN 01410296. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85192207269&doi=10.1016%2fj.engstruct.2024.118094&partnerID=40&md5=57aa664e613f0f0c2422fa30110b4863. Cited by: 10. [CrossRef]
- Mao Li, Sen Wang, Tao Liu, Xiaoqin Liu, and Chang Liu. Rotating box multi-objective visual tracking algorithm for vibration displacement measurement of large-span flexible bridges. Mechanical Systems and Signal Processing, 200, 2023. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85167437998&doi=10.1016%2fj.ymssp.2023.110595&partnerID=40&md5=f699b590ebab7dd44ba0fd62f8c0426e. Cited by: 14. [CrossRef]
- Minshui Huang, Jianwei Zhang, Junliang Hu, Zhongtao Ye, Zhihang Deng, and Neng Wan. Nonlinear modeling of temperature-induced bearing displacement of long-span single-pier rigid frame bridge based on dcnn-lstm. Case Studies in Thermal Engineering, 53, 2024a. ISSN 2214157X. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85180376106&doi=10.1016%2fj.csite.2023.103897&partnerID=40&md5=5c941cf5b3432126849698f02ba38e5c. Cited by: 52. [CrossRef]
- Jiayue Xue and Ge Ou. Predicting wind-induced structural response with lstm in transmission tower-line system. Smart Structures and Systems, 28(3):391 – 405, 2021. ISSN 17381584. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85114484545&doi=10.12989%2fsss.2021.28.3.391&partnerID=40&md5=84b09664d3b0cd46311e7bfc8a08ced5. Cited by: 17. [CrossRef]
- Ehsan Forootan, Saeed Farzaneh, Kowsar Naderi, and Jens Peter Cederholm. Analyzing gnss measurements to detect and predict bridge movements using the kalman filter (kf) and neural network (nn) techniques. Geomatics, 1(1):65 – 80, 2021. ISSN 26737418. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85118549971&doi=10.3390%2fgeomatics1010006&partnerID=40&md5=1795366643f0b5a4b4e4e966bae82c2a. Cited by: 5; All Open Access, Gold Open Access, Green Open Access. [CrossRef]
- Y. Li, T. Bao, Z. Gao, X. Shu, K. Zhang, L. Xie, and Z. Zhang. A new dam structural response estimation paradigm powered by deep learning and transfer learning techniques. Structural Health Monitoring, 21(3):770–787, 2022c. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85105736631&doi=10.1177%2f14759217211009780&partnerID=40&md5=b238faa35c0fafc81603f603ec43b821. cited By 77. [CrossRef]
- Naijian Gu, Wenhua Wu, Kun Liu, and Xinglin Guo. Predictive modeling of nonlinear system responses using the residual improvement deep learning algorithm (ridla). Acta Mechanica, 235(12):7301 – 7315, 2024. ISSN 00015970. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85205040909&doi=10.1007%2fs00707-024-04095-7&partnerID=40&md5=105b89265e91f1fe66f6fda2d3f7dcc3. Cited by: 0. [CrossRef]
- Manya Wang, Youliang Ding, and Hanwei Zhao. Digital prediction model of temperature-induced deflection for cable-stayed bridges based on learning of response-only data. Journal of Civil Structural Health Monitoring, 12(3):629 – 645, 2022b. ISSN 21905452. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85127556073&doi=10.1007%2fs13349-022-00570-8&partnerID=40&md5=28eca296bb7d105ce69d914f6805885f. Cited by: 12. [CrossRef]
- Teng Li, Yuxin Pan, Kaitai Tong, Carlos E. Ventura, and Clarence W. de Silva. A multi-scale attention neural network for sensor location selection and nonlinear structural seismic response prediction. Computers and Structures, 248, 2021e. ISSN 00457949. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85102316553&doi=10.1016%2fj.compstruc.2021.106507&partnerID=40&md5=0d8a17c5a2451d7740febd2d8e966c94. Cited by: 40. [CrossRef]
- Yuchen Liao, Rong Lin, Ruiyang Zhang, and Gang Wu. Attention-based lstm (attlstm) neural network for seismic response modeling of bridges. Computers and Structures, 275, 2023. ISSN 00457949. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85140320186&doi=10.1016%2fj.compstruc.2022.106915&partnerID=40&md5=e60f7d366c065213a0e49e19ff7d1c07. Cited by: 57. [CrossRef]
- Sunjoong Kim and Taeyong Kim. Machine-learning-based prediction of vortex-induced vibration in long-span bridges using limited information. Engineering Structures, 266, 2022. ISSN 01410296. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85133275139&doi=10.1016%2fj.engstruct.2022.114551&partnerID=40&md5=853aca2f84776db7e18794bcc59a345e. Cited by: 24. [CrossRef]
- Omid Bahrami, Wentao Wang, Rui Hou, and Jerome P. Lynch. A sequence-to-sequence model for joint bridge response forecasting. Mechanical Systems and Signal Processing, 203, 2023. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85169796024&doi=10.1016%2fj.ymssp.2023.110690&partnerID=40&md5=1152bad28feec7bfe4f1908f96e4eeec. Cited by: 3; All Open Access, Bronze Open Access. [CrossRef]
- Hyo Seon Park, Sang Hoon Yoo, Da Yo Yun, and Byung Kwan Oh. Investigation on employment of time and frequency domain data for predicting nonlinear seismic responses of structures. Structures, 61, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85184658115&doi=10.1016%2fj.istruc.2024.105996&partnerID=40&md5=f9461dfb5c129f85002ecf12a01f23a5. Cited by: 3; All Open Access, Hybrid Gold Open Access. [CrossRef]
- S. Mariani, A. Kalantari, R. Kromanis, and A. Marzani. Data-driven modeling of long temperature time-series to capture the thermal behavior of bridges for shm purposes. Mechanical Systems and Signal Processing, 206, 2024. ISSN 08883270. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85176500787&doi=10.1016%2fj.ymssp.2023.110934&partnerID=40&md5=ca92d5fe59afcf013146ef0563fc8c84. Cited by: 12; All Open Access, Green Open Access, Hybrid Gold Open Access. [CrossRef]
- Xuyan Tan, Weizhong Chen, Xianjun Tan, Tao Zou, and Bowen Du. Prediction for the future mechanical behavior of underwater shield tunnel fusing deep learning algorithm on shm data. Tunnelling and Underground Space Technology, 125, 2022a. ISSN 08867798. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85129167918&doi=10.1016%2fj.tust.2022.104504&partnerID=40&md5=f7e10291c67456030598570ea7ea6d1f. Cited by: 21. [CrossRef]
- Xuyan Tan, Weizhong Chen, Tao Zou, Jianping Yang, and Bowen Du. Real-time prediction of mechanical behaviors of underwater shield tunnel structure using machine learning method based on structural health monitoring data. Journal of Rock Mechanics and Geotechnical Engineering, 15(4):886 – 895, 2023b. ISSN 16747755. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85136553786&doi=10.1016%2fj.jrmge.2022.06.015&partnerID=40&md5=914481419b48940ec566e47686f4c369. Cited by: 32; All Open Access, Gold Open Access. [CrossRef]
- Xuyan Tan, Weizhong Chen, Jianping Yang, and Xianjun Tan. Temporal–spatial coupled model for multi-prediction of tunnel structure: using deep attention-based temporal convolutional network. Journal of Civil Structural Health Monitoring, 12(3):675 – 687, 2022b. ISSN 21905452. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85129139546&doi=10.1007%2fs13349-022-00574-4&partnerID=40&md5=aaa85f40405bc2c05c727b1419ed04a2. Cited by: 6. [CrossRef]
- Mauricio Pereira and Branko Glisic. A hybrid approach for prediction of long-term behavior of concrete structures. Journal of Civil Structural Health Monitoring, 12(4):891 – 911, 2022b. ISSN 21905452. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85131424067&doi=10.1007%2fs13349-022-00582-4&partnerID=40&md5=3e2a8e195664713b9165151bfcb339c0. Cited by: 6. [CrossRef]
- Thanh Q. Nguyen. A data-driven approach to structural health monitoring of bridge structures based on the discrete model and fft-deep learning. Journal of Vibration Engineering and Technologies, 9(8):1959 – 1981, 2021. ISSN 25233920. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85112865867&doi=10.1007%2fs42417-021-00343-5&partnerID=40&md5=8c5e6d7479afbe8621d9766954dfffa8. Cited by: 23. [CrossRef]
- Wenhan Cao, Zhiping Wen, Yanming Feng, Shuai Zhang, and Huaizhi Su. A multi-point joint prediction model for high-arch dam deformation considering spatial and temporal correlation. Water (Switzerland), 16(10), 2024. ISSN 20734441. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85194430280&doi=10.3390%2fw16101388&partnerID=40&md5=98f8814260ab390e18672066817215e6. Cited by: 7; All Open Access, Gold Open Access. [CrossRef]
- Qianen Xu, Qingfei Gao, and Yang Liu. A method for suspenders tension identification of bridges based on the spatio-temporal correlation between the girder strain and suspenders tension. Computer-Aided Civil and Infrastructure Engineering, 39(11):1641 – 1658, 2024b. ISSN 10939687. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85183920984&doi=10.1111%2fmice.13165&partnerID=40&md5=e3fc503b8934547f477f99800344c266. Cited by: 2; All Open Access, Hybrid Gold Open Access. [CrossRef]
- Tao Chen, Liang Guo, Andongzhe Duan, Hongli Gao, Tingting Feng, and Yichen He. A feature learning-based method for impact load reconstruction and localization of the plate-rib assembled structure. Structural Health Monitoring, 21(4):1590 – 1607, 2022. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85112369348&doi=10.1177%2f14759217211038065&partnerID=40&md5=930d0b126ec7e80b753f5411779da2a2. Cited by: 25. [CrossRef]
- Luca Rosafalco, Andrea Manzoni, Alberto Corigliano, and Stefano Mariani. A time series autoencoder for load identification via dimensionality reduction of sensor recordings †. Engineering Proceedings, 2(1), 2021. ISSN 26734591. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85127156222&doi=10.3390%2fecsa-7-08255&partnerID=40&md5=109fd0b3b50c7b999f31fb322742c6e1. Cited by: 3; All Open Access, Green Open Access, Hybrid Gold Open Access. [CrossRef]
- Jia-Xing Huang, Qiu-Sheng Li, and Xu-Liang Han. Reconstruction of missing wind data based on limited wind pressure measurements and machine learning. Physics of Fluids, 36(7), 2024b. ISSN 10706631. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85199436650&doi=10.1063%2f5.0220410&partnerID=40&md5=40250302ed90ded6285e313f8fe79478. Cited by: 0. [CrossRef]
- Zhi-wei Wang, An-dong Li, Wen-ming Zhang, and Yu-feng Zhang. Long-term missing wind data recovery using free access databases and deep learning for bridge health monitoring. Journal of Wind Engineering and Industrial Aerodynamics, 230, 2022c. ISSN 01676105. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85139356377&doi=10.1016%2fj.jweia.2022.105201&partnerID=40&md5=71ab88966f681c06e1fe3e038a19df01. Cited by: 19. [CrossRef]
- Jia-Xing Huang, Qiu-Sheng Li, and Xu-Liang Han. Recovery of missing field measured wind pressures on a supertall building based on correlation analysis and machine learning. Journal of Wind Engineering and Industrial Aerodynamics, 231, 2022. ISSN 01676105. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85141493389&doi=10.1016%2fj.jweia.2022.105237&partnerID=40&md5=800043f45aad4f8ce36794896a03f3d5. Cited by: 16. [CrossRef]
- Zifeng Wang and Zhenrui Peng. Structural acceleration response reconstruction based on bilstm network and multi-head attention mechanism. Structures, 64, 2024. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85194080470&doi=10.1016%2fj.istruc.2024.106602&partnerID=40&md5=cb9f79da6cb4d8611c2eaa0bcc1a5352. Cited by: 7. [CrossRef]
- Yang Deng, Hanwen Ju, Yuhang Li, Yungang Hu, and Aiqun Li. Abnormal data recovery of structural health monitoring for ancient city wall using deep learning neural network. International Journal of Architectural Heritage, 18(3):389 – 407, 2024. ISSN 15583058. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85144045374&doi=10.1080%2f15583058.2022.2153234&partnerID=40&md5=e3a6576ff94613d545bf7ef375f4583b. Cited by: 8. [CrossRef]
- Changshun Hao, Baodong Liu, Yan Li, Yi Zhuo, and Yongpeng Ma. A data recovery method for extra-long-span railway bridge health monitoring based on tvfemd and cnn-gru. Measurement Science and Technology, 35(8), 2024. ISSN 09570233. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85194726321&doi=10.1088%2f1361-6501%2fad4c84&partnerID=40&md5=50289022e9f0504645f11e375602e97f. Cited by: 5. [CrossRef]
- Hao Liu, You-Liang Ding, Han-Wei Zhao, Man-Ya Wang, and Fang-Fang Geng. Deep learning-based recovery method for missing structural temperature data using lstm network. Structural Monitoring and Maintenance, 7(2):109 – 124, 2020. ISSN 22886605. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85087913786&doi=10.12989%2fsmm.2020.7.2.109&partnerID=40&md5=dcc055e7512e439dafdd11d73b83835f. Cited by: 28. [CrossRef]
- Jintao Song, Zhaodi Yang, and Xinru Li. Missing data imputation model for dam health monitoring based on mode decomposition and deep learning. Journal of Civil Structural Health Monitoring, 14(5):1111 – 1124, 2024b. ISSN 21905452. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85186614892&doi=10.1007%2fs13349-024-00776-y&partnerID=40&md5=262e6e9c581157bc48694775e129b8a0. Cited by: 9. [CrossRef]
- Huachen Jiang, Ensheng Ge, Chunfeng Wan, Shu Li, Ser Tong Quek, Kang Yang, Youliang Ding, and Songtao Xue. Data anomaly detection with automatic feature selection and deep learning. Structures, 57, 2023. ISSN 23520124. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85168407602&doi=10.1016%2fj.istruc.2023.105082&partnerID=40&md5=30e3a6234994f99964badb38f8e8135b. Cited by: 4. [CrossRef]
- Hanlin Liu and Linchao Li. Anomaly detection of high-frequency sensing data in transportation infrastructure monitoring system based on fine-tuned model. IEEE Sensors Journal, 23(8):8630 – 8638, 2023. ISSN 1530437X. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85151337895&doi=10.1109%2fJSEN.2023.3254506&partnerID=40&md5=c88a5948451d9ae92c8efbc400e2ade7. Cited by: 12. [CrossRef]
- Hyesook Son, Yun Jang, Seung-Eock Kim, Dongjoo Kim, and Jong-Woong Park. Deep learning-based anomaly detection to classify inaccurate data and damaged condition of a cable-stayed bridge. IEEE Access, 9:124549 – 124559, 2021. ISSN 21693536. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85112595847&doi=10.1109%2fACCESS.2021.3100419&partnerID=40&md5=6c6a3bb2f5aa722184f777bc7a561e4b. Cited by: 24; All Open Access, Gold Open Access. [CrossRef]
- Imdad Ullah Khan, Seunghoo Jeong, and Sung-Han Sim. Investigation of issues in data anomaly detection using deep-learning- and rule-based classifications for long-term vibration measurements. Applied Sciences (Switzerland), 14(13), 2024b. ISSN 20763417. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85198489585&doi=10.3390%2fapp14135476&partnerID=40&md5=96a44be4c52aaed00674d07881bb9778. Cited by: 3; All Open Access, Gold Open Access. [CrossRef]
- Mengchen Zhao, Ayan Sadhu, and Miriam Capretz. Multiclass anomaly detection in imbalanced structural health monitoring data using convolutional neural network. Journal of Infrastructure Preservation and Resilience, 3(1), 2022. ISSN 26622521. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85159345683&doi=10.1186%2fs43065-022-00055-4&partnerID=40&md5=81d3da29526dd3a02bc16baa3ec45b8c. Cited by: 10; All Open Access, Gold Open Access. [CrossRef]
- Changwei Liu, Jianwen Pan, and Jinting Wang. An lstm-based anomaly detection model for the deformation of concrete dams. Structural Health Monitoring, 23(3):1914 – 1925, 2024c. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85173919203&doi=10.1177%2f14759217231199569&partnerID=40&md5=c4da31d45fbd4858c1cffc9fc6ac6fd1. Cited by: 10. [CrossRef]
- Nicolas Manzini, André Orcesi, Christian Thom, Marc-Antoine Brossault, Serge Botton, Miguel Ortiz, and John Dumoulin. Machine learning models applied to a gnss sensor network for automated bridge anomaly detection. Journal of Structural Engineering (United States), 148(11), 2022. ISSN 07339445. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85137109652&doi=10.1061%2f%28ASCE%29ST.1943-541X.0003469&partnerID=40&md5=c10ad1c3a811048d1923ec347dc67dd1. Cited by: 4. [CrossRef]
- Chong Zhang, Ke Lei, Xin Shi, Yang Wang, Ting Wang, Xin Wang, Lihu Zhou, Chuanhui Zhang, and Xingjie Zeng. A reliable virtual sensing architecture with zero additional deployment costs for shm systems. IEEE Sensors Journal, 24(22):38527 – 38539, 2024b. ISSN 1530437X. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85206990035&doi=10.1109%2fJSEN.2024.3474678&partnerID=40&md5=61dd7107446296c854328c8b090bdc55. Cited by: 1. [CrossRef]
- Matthias Arnold and Sina Keller. Machine learning and signal processing for bridge traffic classification with radar displacement time-series data. Infrastructures, 9(3), 2024. ISSN 24123811. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85188915365&doi=10.3390%2finfrastructures9030037&partnerID=40&md5=e588db5f3a4b0e0addb9d3d7f8021266. Cited by: 3; All Open Access, Gold Open Access. [CrossRef]
- Ge Liang, Zhenglin Ji, Qunhong Zhong, Yong Huang, and Kun Han. Vector quantized variational autoencoder-based compressive sampling method for time series in structural health monitoring. Sustainability (Switzerland), 15(20), 2023. ISSN 20711050. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85192929659&doi=10.3390%2fsu152014868&partnerID=40&md5=215f8320a4be1658d05421ad3fa87d32. Cited by: 2; All Open Access, Gold Open Access. [CrossRef]
- Viet-Hung Dang and Truong-Thang Nguyen. Robust vibration output-only structural health monitoring framework based on multi-modal feature fusion and self-learning. Periodica Polytechnica Civil Engineering, 67(2):416 – 430, 2023. ISSN 05536626. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85152926294&doi=10.3311%2fPPci.21756&partnerID=40&md5=9fe77a186c983b61ef2a602574f06077. Cited by: 4; All Open Access, Gold Open Access. [CrossRef]
- Thanh Q. Nguyen and Hoang B. Nguyen. Structural health monitoring of bridge spans using moment cumulative functions of power spectral density (mcf-psd) and deep learning. Bridge Structures, 17(1-2):15 – 39, 2021. ISSN 15732487. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85107968923&doi=10.3233%2fBRS-210183&partnerID=40&md5=28930731d6b4ce1aec049c849e3748d7. Cited by: 7. [CrossRef]
- Juan Fernández, Juan Chiachío, José Barros, Manuel Chiachío, and Chetan S. Kulkarni. Physics-guided recurrent neural network trained with approximate bayesian computation: A case study on structural response prognostics. Reliability Engineering ‘&’ System Safety, 243:109822, 2024b. ISSN 0951-8320. URL https://www.sciencedirect.com/science/article/pii/S0951832023007366. [CrossRef]
- Nandar Hlaing, Pablo G. Morato, Francisco de Nolasco Santos, Wout Weijtjens, Christof Devriendt, and Philippe Rigo. Farm-wide virtual load monitoring for offshore wind structures via bayesian neural networks. Structural Health Monitoring, 23(3):1641 – 1663, 2024. ISSN 14759217. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85170850420&doi=10.1177%2f14759217231186048&partnerID=40&md5=7caab62d1e3978fb57509dbbcca490ec. Cited by: 4; All Open Access, Green Open Access. [CrossRef]
- Mauricio Pereira and Branko Glisic. Detection and quantification of temperature sensor drift using probabilistic neural networks. Expert Systems with Applications, 213, 2023. ISSN 09574174. URL https://www.scopus.com/inward/record.uri?eid=2-s2.0-85139188167&doi=10.1016%2fj.eswa.2022.118884&partnerID=40&md5=5e022251c70e3ab037fbf7c3b8512f76. Cited by: 24; All Open Access, Hybrid Gold Open Access. [CrossRef]
Figure 1.
Depiction of a cable stayed bridge equipped with a sensor.The plot shows an anomaly detected from the sensor data.
Figure 1.
Depiction of a cable stayed bridge equipped with a sensor.The plot shows an anomaly detected from the sensor data.
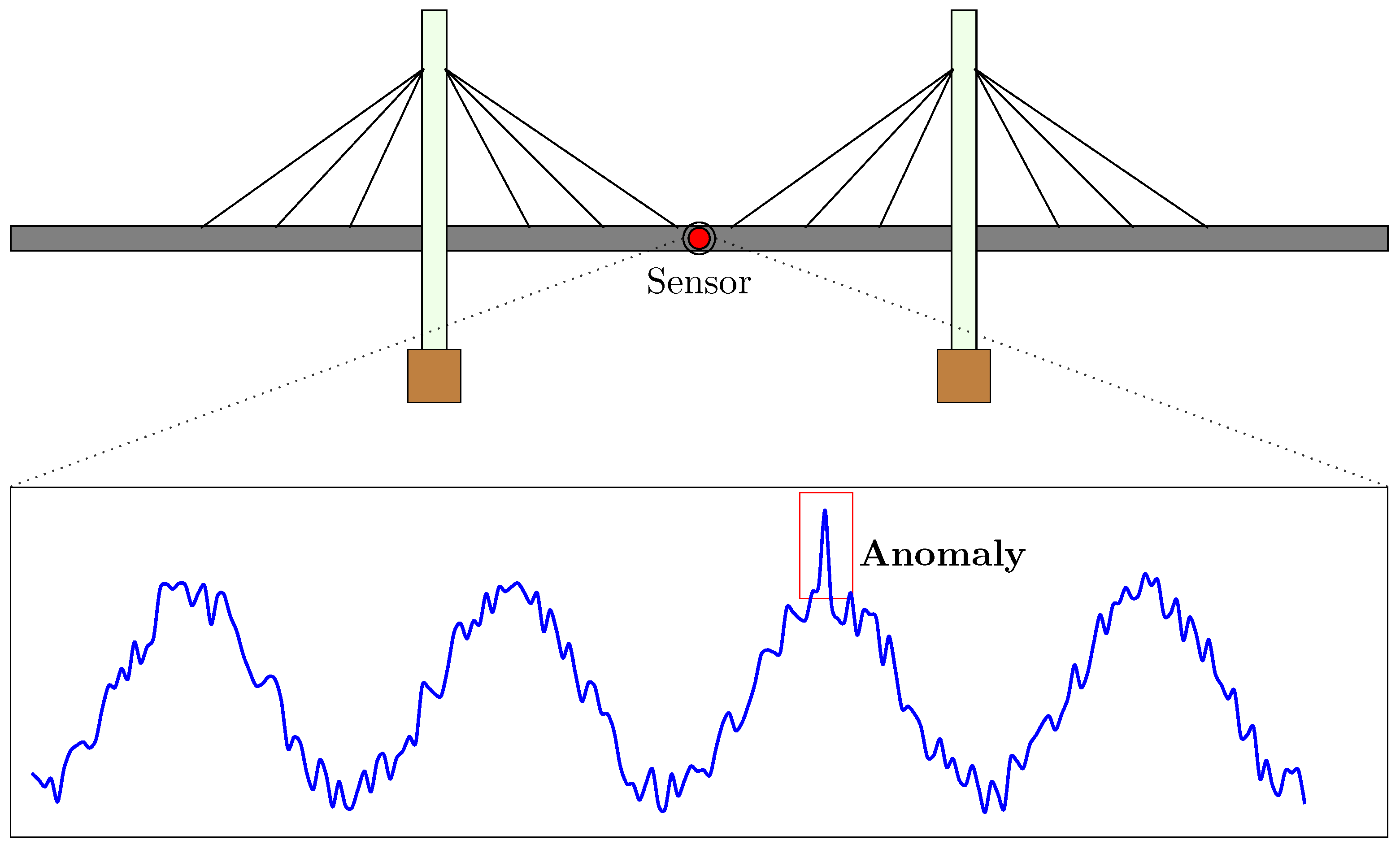
Figure 2.
A schematic representation of of a perceptron model. A weighted sum of the inputs () is passed through an activation function () to get the output ().
Figure 2.
A schematic representation of of a perceptron model. A weighted sum of the inputs () is passed through an activation function () to get the output ().
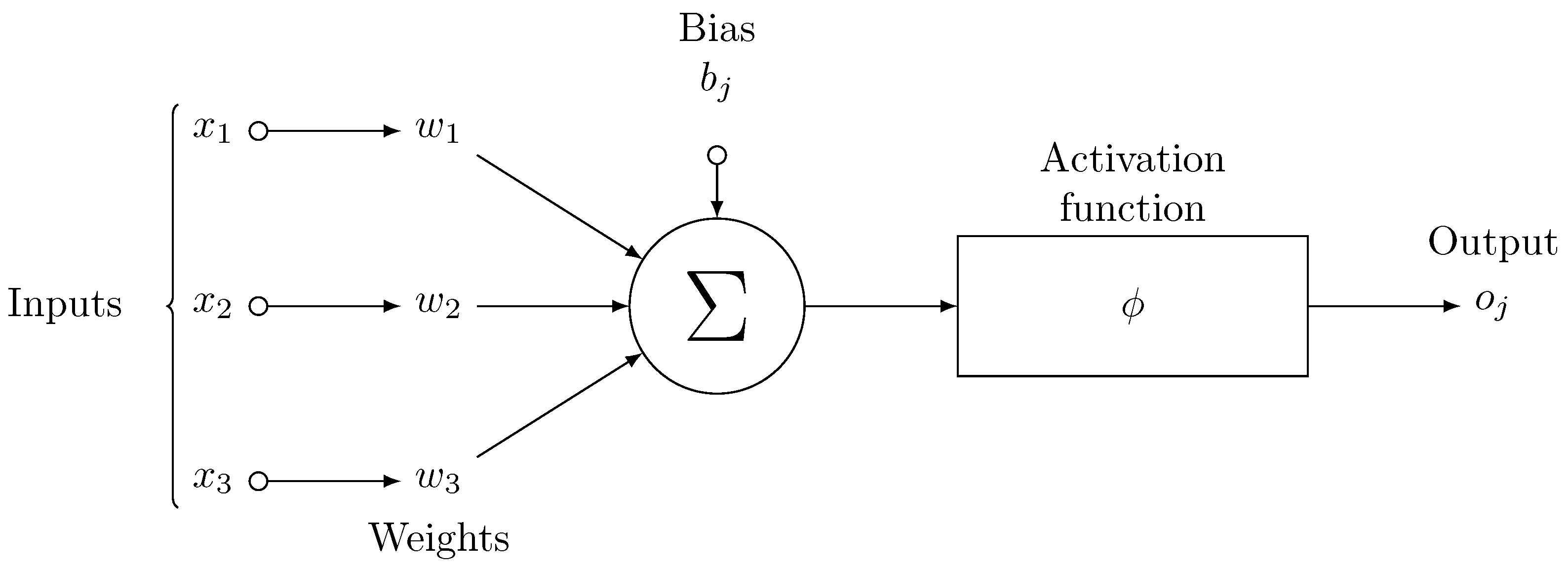
Figure 3.
A compact representation of a Feedforward Neural Network (FFNN). For simplicity, we assume , and the observation model is given by , where . The network consists of hidden layers, each containing hidden units. For any layer , the parameters between layers j and are denoted by . Adopted from Deka et al. [100].
Figure 3.
A compact representation of a Feedforward Neural Network (FFNN). For simplicity, we assume , and the observation model is given by , where . The network consists of hidden layers, each containing hidden units. For any layer , the parameters between layers j and are denoted by . Adopted from Deka et al. [100].
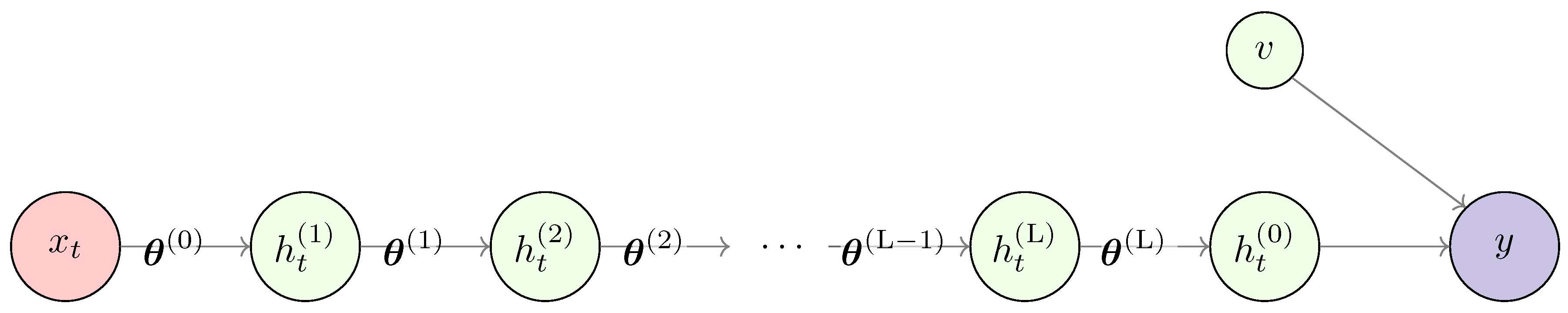
Figure 5.
Representations a rolled(a) and unrolled (b) 2-layer Deep Recurrent Neural Network (DRNN).Adapted from Vuong [110].
Figure 5.
Representations a rolled(a) and unrolled (b) 2-layer Deep Recurrent Neural Network (DRNN).Adapted from Vuong [110].
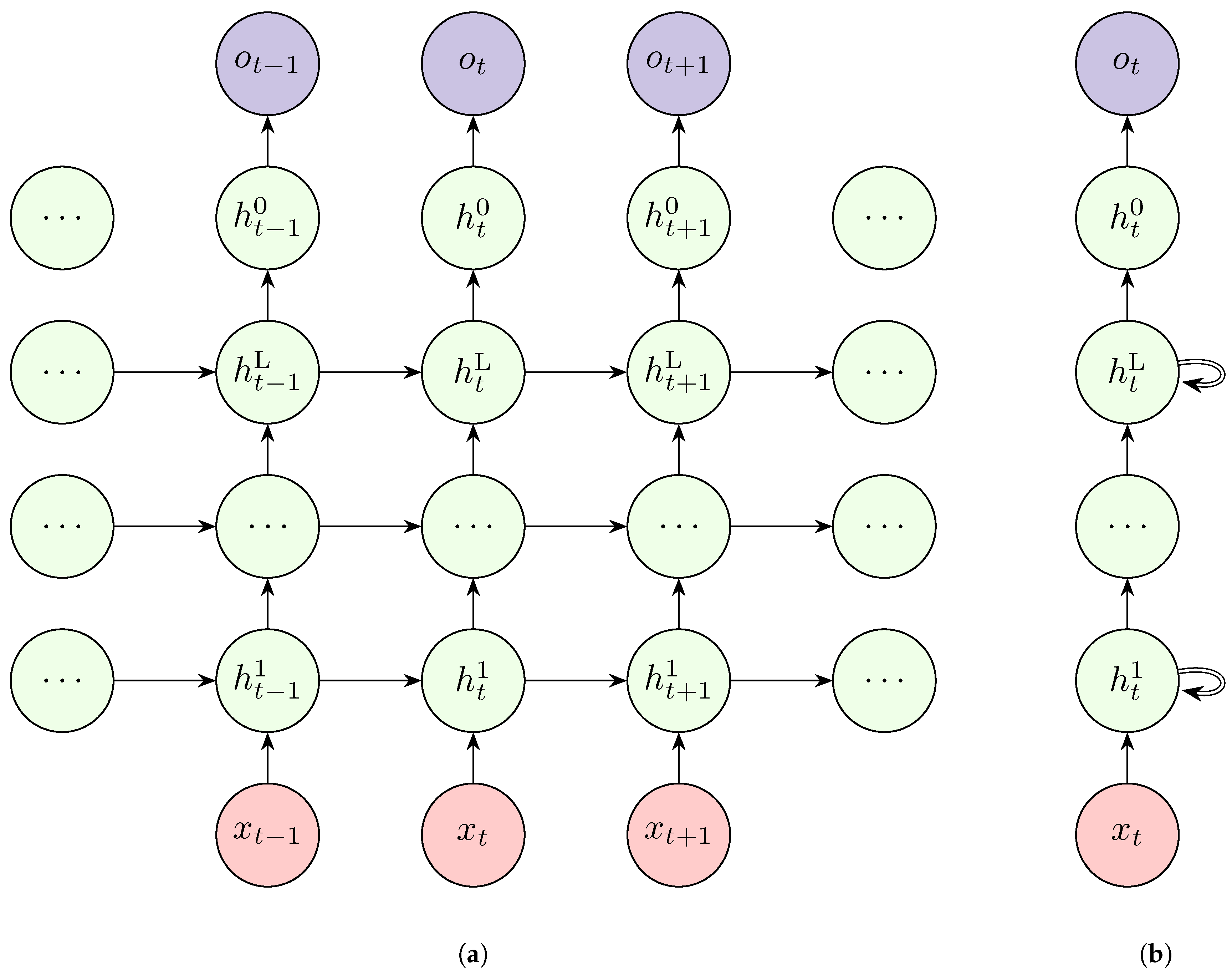
Figure 7.
Internal structure of a Long-Short Term Memory (LSTM) cell [114].
Figure 7.
Internal structure of a Long-Short Term Memory (LSTM) cell [114].
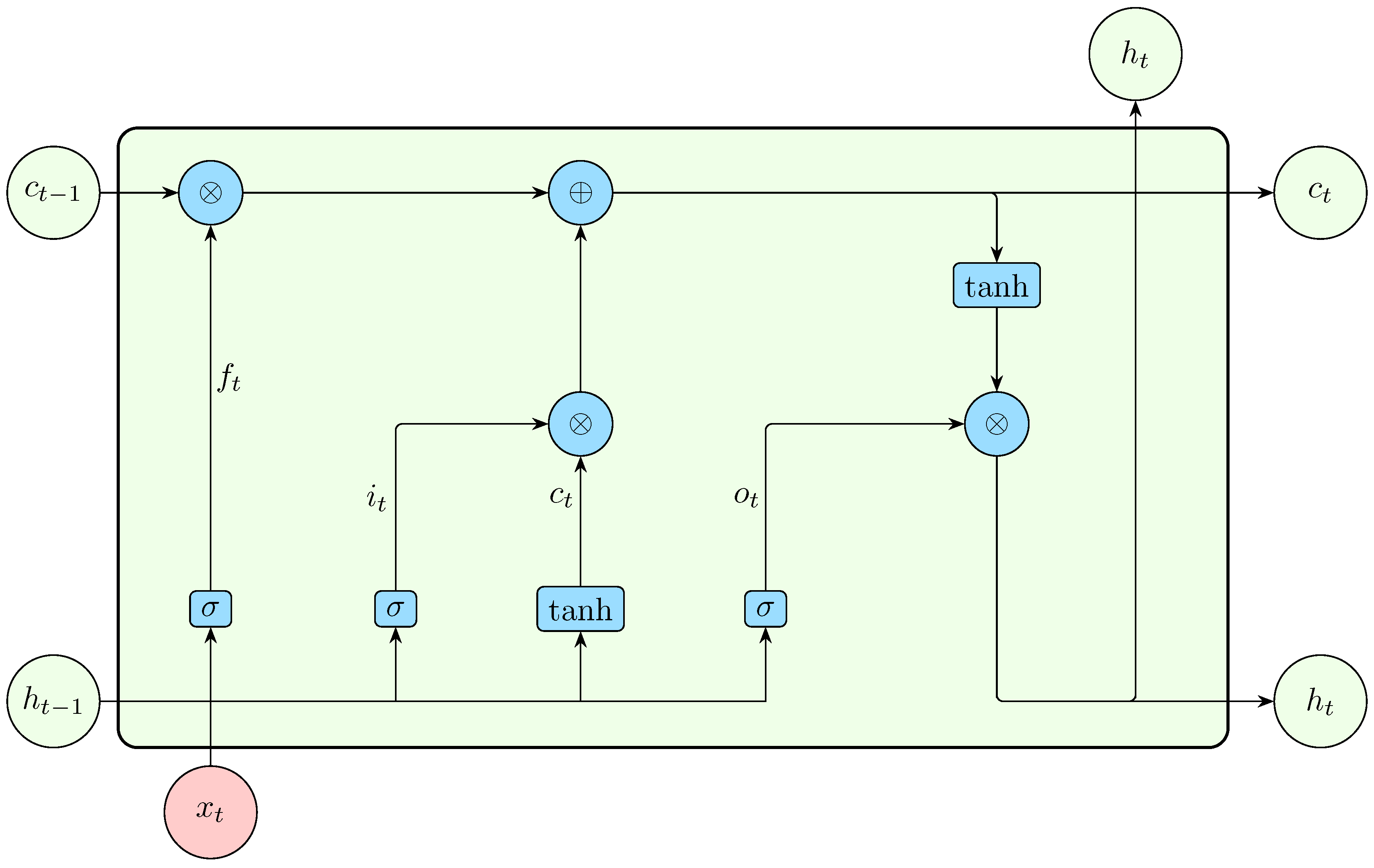
Figure 9.
Structure of physics neural time series model utilizing physics knowledge based on Simple harmonic oscillator [143].
Figure 9.
Structure of physics neural time series model utilizing physics knowledge based on Simple harmonic oscillator [143].
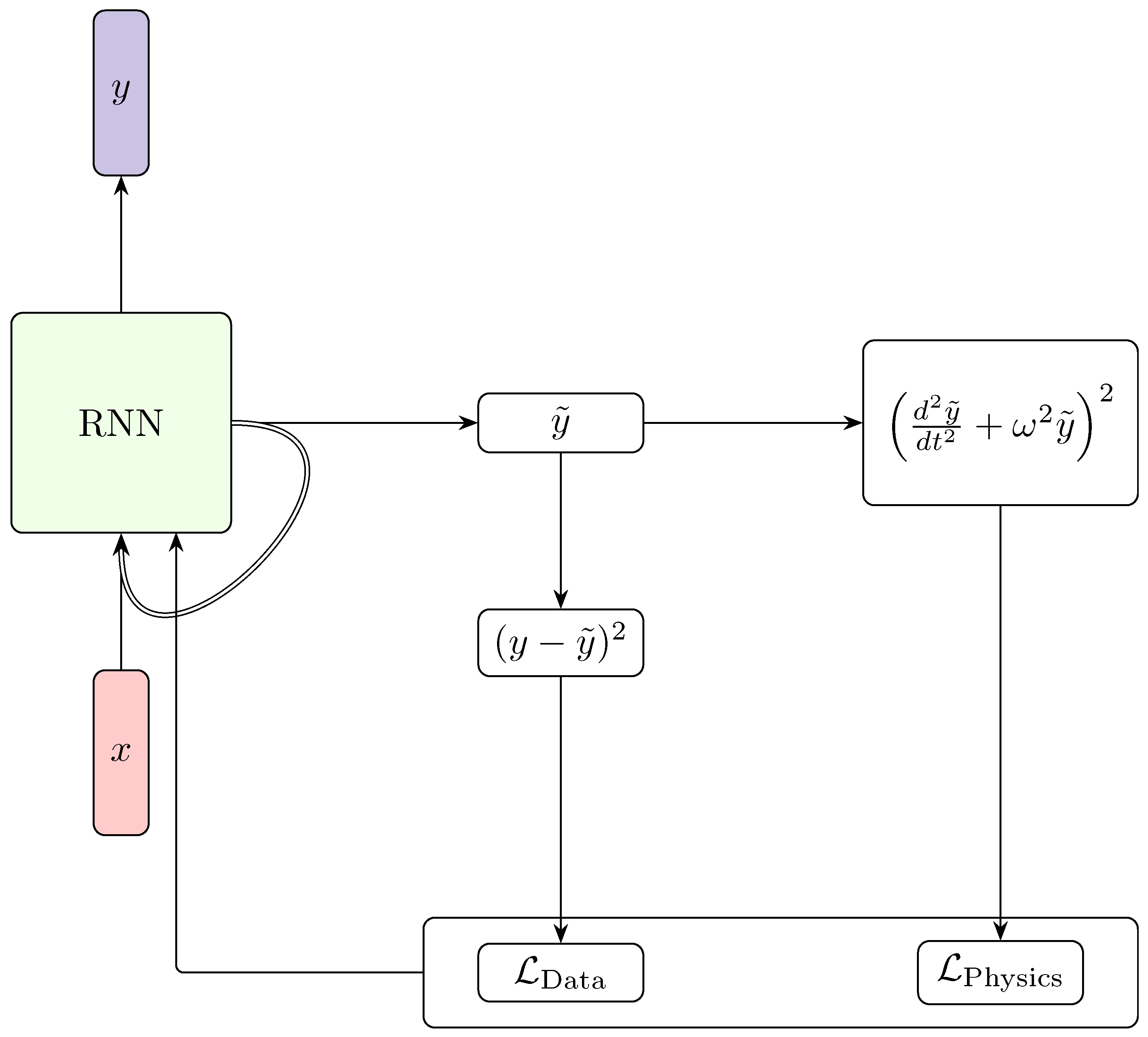
Figure 12.
Illustration of a normalizing flow transformation, adapted from Riebesell and Bringuier [167]. A simple base distribution is progressively mapped into a more complex target distribution through a sequence of invertible transformations. The process is fully reversible, allowing for inference in both forward and backward directions.
Figure 12.
Illustration of a normalizing flow transformation, adapted from Riebesell and Bringuier [167]. A simple base distribution is progressively mapped into a more complex target distribution through a sequence of invertible transformations. The process is fully reversible, allowing for inference in both forward and backward directions.
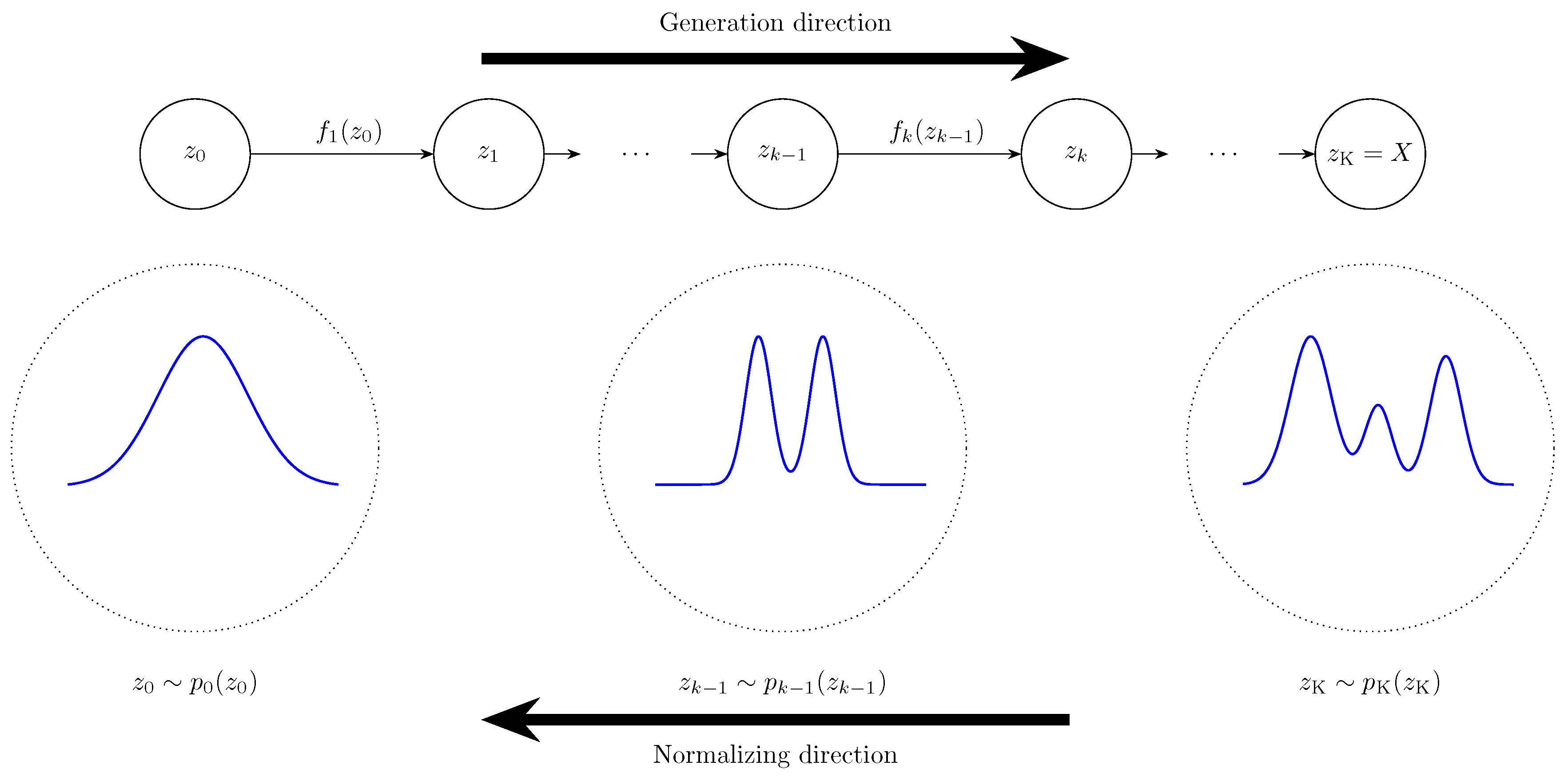
Figure 14.
PRISMA model.
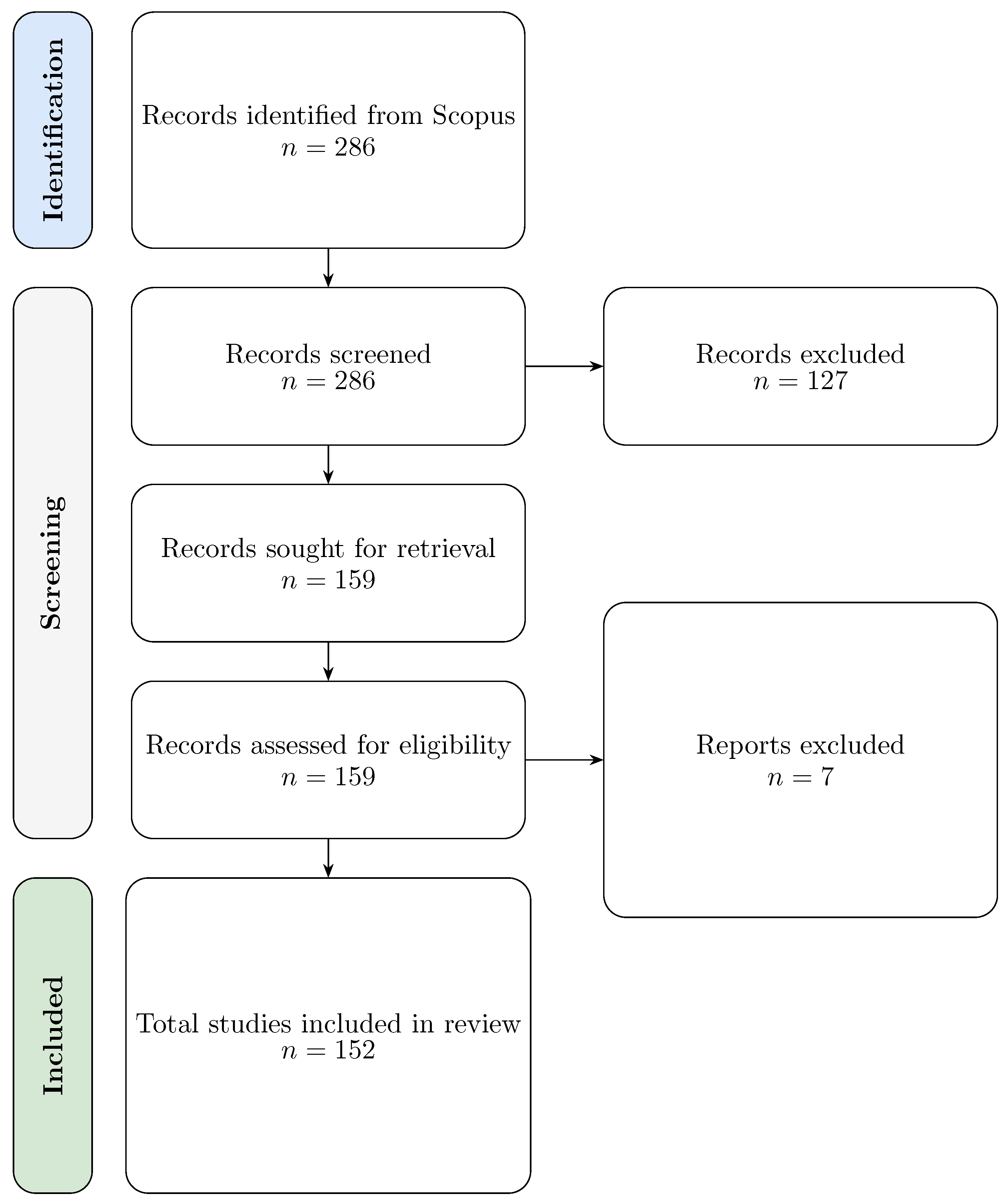
Table 1.
Common activation functions with expressions, ranges, and plots.
| Name | Expression | Range | Plot |
|---|---|---|---|
| Sigmoid | 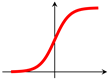 |
||
| Tanh | 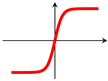 |
||
| ReLU | 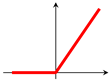 |
||
| Leaky ReLU | 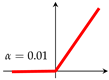 |
||
| ELU | 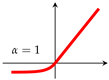 |
||
| Softplus | 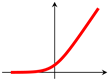 |
||
| Swish |  |
||
| GELU |  |
Table 3.
Comparison of Generative Models for Time Series across Structural and Functional Characteristics.
Table 3.
Comparison of Generative Models for Time Series across Structural and Functional Characteristics.
| Aspect | AE | VAE | GAN | Normalizing Flows | Diffusion Models | Autoregressive Models | Energy-Based Models |
|---|---|---|---|---|---|---|---|
| Generative Nature | Deterministic decoder | Probabilistic decoder via latent sampling | Adversarial generator-discriminator | Invertible transformation of base distribution | Gradual denoising from noise | Step-wise prediction of sequence | Energy function defines density score |
| Latent Space | Yes (fixed) | Yes (stochastic) | Often implicit | Explicit and invertible | No explicit latent space | Typically absent | Optional |
| Training Objective | MSE reconstruction | ELBO = Rec. + KL | Minimax (adversarial) | Maximum likelihood | Score-matching or ELBO variant | MLE with teacher forcing | Contrastive divergence |
| Likelihood Estimate | No | Approximate lower bound | No | Exact | Approximate (sampling) | Exact (autoregressive) | Intractable |
| Sampling Efficiency | Fast (1 pass) | Fast (1 pass) | Fast (1 pass) | Fast (invertible map) | Slow (multi-step denoising) | Fast (step-by-step) | Slow (requires MCMC) |
| Time Series Suitability | Weak (static) | Moderate with encoder/decoder | Requires temporal adaptation (e.g. RNN-GAN) | Challenging for long sequences | Promising (e.g. TimeGrad, DiffWave) | Excellent (causal modeling) | Limited or theoretical |
| Uncertainty Modeling | No | Yes | No | Limited | Yes | Limited | Yes |
| Mode Collapse Risk | Low | Low | High | Low | Low | N/A | Medium |
| Interpretability | Moderate | Moderate | Low | Moderate to high | Moderate | High | Low to moderate |
| Use in Anomaly Detection | Reconstruction error | Posterior deviation | Discriminator confidence | Log-likelihood score | Score deviation | Forecast residual | Energy score |
| Example Models | LSTM-AE, TCN-AE | VRNN, Temporal VAE | TimeGAN, C-RNN-GAN | RealNVP, MAF, Glow | TimeGrad, DiffWave | WaveNet, TransformerXL, GPT | Score-based EBMs, CPC |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



