
Submitted:
29 May 2025
Posted:
29 May 2025
You are already at the latest version
Abstract
This paper presents the Multimodal Language-Image Fusion Network (MLIF-Net), a new architecture to distinguish AI-generated images from real ones. MLIF-Net combines Vision Transformer (ViT) and Large Language Models (LLMs) to build a multimodal feature fusion network that improves AI-generated content detection accuracy. The model uses a Cross-Attention Mechanism to combine visual and semantic features and a Multiscale Contextual Reasoning Layer to capture both global and local image features. An Adaptive Loss Function improves the consistency and robustness of feature extraction. Experimental results show that MLIF-Net outperforms existing models in accuracy, recall, and Average Precision (AP). This approach can lead to more accurate detection of AI-generated content and may have applications in other generative content tasks.
Keywords:
multimodal fusion
; cross-attention mechanism
; vision transformer
; AI-generated content detection
; adaptive loss function
1. Introduction
Artificial intelligence (AI) is growing fast. Generative models, especially in image synthesis, are improving quickly. Techniques like GANs (Generative Adversarial Networks) create realistic AI-generated images. These advances are impressive. But they also make it harder to tell real images from fake ones. This causes problems in misinformation, media, security, and trust.
To fix this, researchers study machine learning-based detection methods. Hybrid models, for example, improve prediction accuracy for complex datasets [1]. Some recent studies focus on temporal modeling. Jin’s work [2] shows that attention-based temporal convolutional networks help make strong predictions. But these methods mainly work with time-series data. They do not explore multimodal fusion. Other models like BERT and cross-modal transformers show the power of large-scale pretrained models. They capture contextual and semantic information well [3,4]. But current models still have trouble combining visual and semantic features. This combination is important for detecting AI-generated images.
This paper presents the Multimodal Language-Image Fusion Network (MLIF-Net). It combines Vision Transformers (ViTs) and Large Language Models (LLMs). The network uses cross-attention to fuse features and multiscale contextual reasoning to extract both global and local details. An adaptive loss function helps make feature extraction more stable. Experiments show better accuracy, recall, and average precision than existing methods.
2. Related Work
In AI-generated image detection, previous research has mainly focused on feature extraction methods, model architectures, and multimodal learning. Early approaches used convolutional neural networks (CNNs) to detect artifacts and anomalies in AI-generated images. While CNNs were effective in some cases, they struggled to capture the semantic relationships between features[5].
With transformer advancements, researchers leveraged them for cross-modal tasks. Radford et al. [6] introduced CLIP, employing contrastive learning on image-text pairs for better multimodal representation.
A few studies, such as those by Jin[7] and Dai[8], have examined adaptive learning techniques in AI-driven prediction models. These works emphasize the importance of robust loss functions and adaptive mechanisms to improve model performance under different conditions. Our work extends these ideas by using an adaptive loss function designed for multimodal feature extraction.
Despite these advances, current methods either fail to generalize across diverse datasets or do not effectively integrate multimodal information. MLIF-Net addresses these issues by using a cross-attention mechanism to combine visual and semantic features and a multiscale contextual reasoning layer to ensure thorough feature extraction.
3. Methodology
With the rise of generative models, distinguishing real from AI-generated images has become challenging. This section presents Multimodal Language-Image Fusion Network (MLIF-Net), leveraging large language models (LLMs) and vision transformers (ViTs) for detection. MLIF-Net integrates high-level semantics from LLMs with fine-grained visual features from ViTs, enhancing its ability to discern subtle differences.
The architecture employs cross-attention fusion for visual-semantic alignment and a multiscale reasoning layer to capture both local and global image details. An adaptive loss function optimizes feature extraction while preserving semantic consistency. Experimental results demonstrate MLIF-Net’s superiority over conventional image classifiers, achieving state-of-the-art accuracy in AI image detection. Figure 1 illustrates the framework.
3.1. Model Overview
MLIF-Net consists of four parts: image encoder, LLM-based semantic encoder, feature fusion layer, and multimodal reasoning layer. These components enhance image understanding by capturing both fine spatial details and high-level semantics.
3.2. Image Encoder with Vision Transformer
The image encoder employs a Vision Transformer (ViT). It divides the input image into patches and applies self-attention to extract spatial and contextual features:
where is the input image, and represents patch-wise features. ViT uses self-attention layers to form a global feature representation. The self-attention MLP in ViT is shown in Figure 2.
3.3. Semantic Encoder based on LLMs
The model extracts image semantics using a Large Language Model (LLM). Trained on extensive text data, the LLM processes image captions to generate feature representations:
where is the image caption, and is the learned feature representation, capturing objects, scenes, and context.
3.4. Multimodal Feature Fusion Layer
Visual and semantic features are fused using a cross-attention mechanism:
CrossAttention integrates visual and semantic tokens, forming a unified representation:
Here, are query, key, and value matrices from visual and semantic features, and d is the dimensionality. The result encodes fused multimodal information.
3.5. Multiscale Contextual Reasoning Layer
The model processes information at different levels using a multiscale contextual reasoning layer. This enhances fusion by capturing both local and global features:
This layer refines fused features by integrating information from multiple scales. The output improves contextual understanding for better decision-making.
3.6. Final Decision Layer
The model classifies images using a softmax classifier on multimodal features:
Here, W is the weight matrix, and b is the bias. The output represents the probability of the image being real or AI-generated.
3.7. Adaptive Loss Function with Multi-Loss Components
MLIF-Net is trained with an adaptive loss function combining multiple components to enhance visual and semantic learning. The total loss is:
where: - is the cross-entropy loss:
- is the regularization term:
- enforces semantic coherence:
Here, are hyperparameters controlling each loss component’s contribution.
3.8. Model Output
The final model output is a classification score indicating whether the image is real or AI-generated:
where is the predicted probability vector, and the decision is made based on the class with the highest probability.
4. Data Preprocessing
This section outlines preprocessing steps for preparing image and text data in MLIF-Net. The pipeline standardizes and augments images while tokenizing and embedding captions for compatibility with the network. Figure 3 illustrates image preprocessing (left), data augmentation (middle), and image-text alignment via cross-attention (right).
4.1. Image Preprocessing
Images are resized to pixels and normalized to :
where is the input image. Augmentation applies random flipping, rotation (), and color jittering (brightness, contrast, saturation up to ):
where is the augmentation function, enhancing generalization.
4.2. Textual Data Preprocessing
Captions are tokenized using the BERT tokenizer. Each caption is split into tokens , then mapped to embeddings:
where . Sequences are padded to 32 tokens:
The padded embeddings are input to the LLM for semantic extraction.
4.3. Fusion Preparation
After preprocessing, images and captions are fused. Vision Transformer (ViT) extracts visual features, while BERT embeddings provide semantic features. Cross-attention aligns these modalities during training, forming a unified multimodal representation for classification.
5. Evaluation Metrics
5.1. Accuracy
Accuracy quantifies overall prediction correctness, computed as:
where , , , and denote true positives, true negatives, false positives, and false negatives, respectively.
5.2. Precision
Precision is the proportion of true positive predictions among all positive predictions (both real and AI-generated images). It is calculated as:
5.3. Recall
Recall measures the ability of the model to correctly identify the positive class (e.g., AI-generated images). It is given by:
5.4. Average Precision (AP)
AP represents the weighted average of precision across recall levels, assessing performance across thresholds:
where and are computed at each threshold.
6. Experiment Results
MLIF-Net is compared with ViT-GAN, ResNet-50-CNN, CLIP, and Xception-V2. Table 1 shows MLIF-Net achieves the highest accuracy, precision, recall, and average precision (AP).
7. Conclusions
In this paper, we introduced the Multimodal Language-Image Fusion Network (MLIF-Net) for detecting AI-generated images. The model leverages the strengths of both visual and semantic modalities by combining Vision Transformers with a large language model-based encoder. Our extensive experimental results demonstrate that MLIF-Net outperforms several benchmark models, including ViT-GAN, ResNet-50-CNN, CLIP, and Xception-V2, achieving the highest accuracy, precision, recall, and average precision. Ablation studies further reveal the essential role of multimodal fusion, multiscale reasoning, and the LLM encoder in contributing to the model’s effectiveness. This work opens new opportunities for the application of multimodal fusion techniques in AI detection tasks and other multimodal learning problems.
References
- Lu, J.; Long, Y.; Li, X.; Shen, Y.; Wang, X. Hybrid Model Integration of LightGBM, DeepFM, and DIN for Enhanced Purchase Prediction on the Elo Dataset. In Proceedings of the 2024 IEEE 7th International Conference on Information Systems and Computer Aided Education (ICISCAE). IEEE, 2024, pp. 16–20. [CrossRef]
- Jin, T. Attention-Based Temporal Convolutional Networks and Reinforcement Learning for Supply Chain Delay Prediction and Inventory Optimization. Preprints 2025. [CrossRef]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Proceedings of naacL-HLT. Minneapolis, Minnesota, 2019, Vol. 1.
- Li, S. Leveraging Large Language Models in a Retriever-Reader Framework for Solving STEM Multiple-Choice Questions. In Proceedings of the 2024 4th International Conference on Electronic Information Engineering and Computer Science (EIECS). IEEE, 2024, pp. 658–661.
- Huang, B.; Carley, K.M. Syntax-aware aspect level sentiment classification with graph attention networks. arXiv preprint arXiv:1909.02606, arXiv:1909.02606 2019.
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- Jin, T. Integrated Machine Learning for Enhanced Supply Chain Risk Prediction 2025.
- Dai, W.; Jiang, Y.; Liu, Y.; Chen, J.; Sun, X.; Tao, J. CAB-KWS: Contrastive Augmentation: An Unsupervised Learning Approach for Keyword Spotting in Speech Technology. In Proceedings of the International Conference on Pattern Recognition. Springer, 2025, pp. 98–112. [CrossRef]
Figure 1.
Multimodal Language-Image Fusion Network.
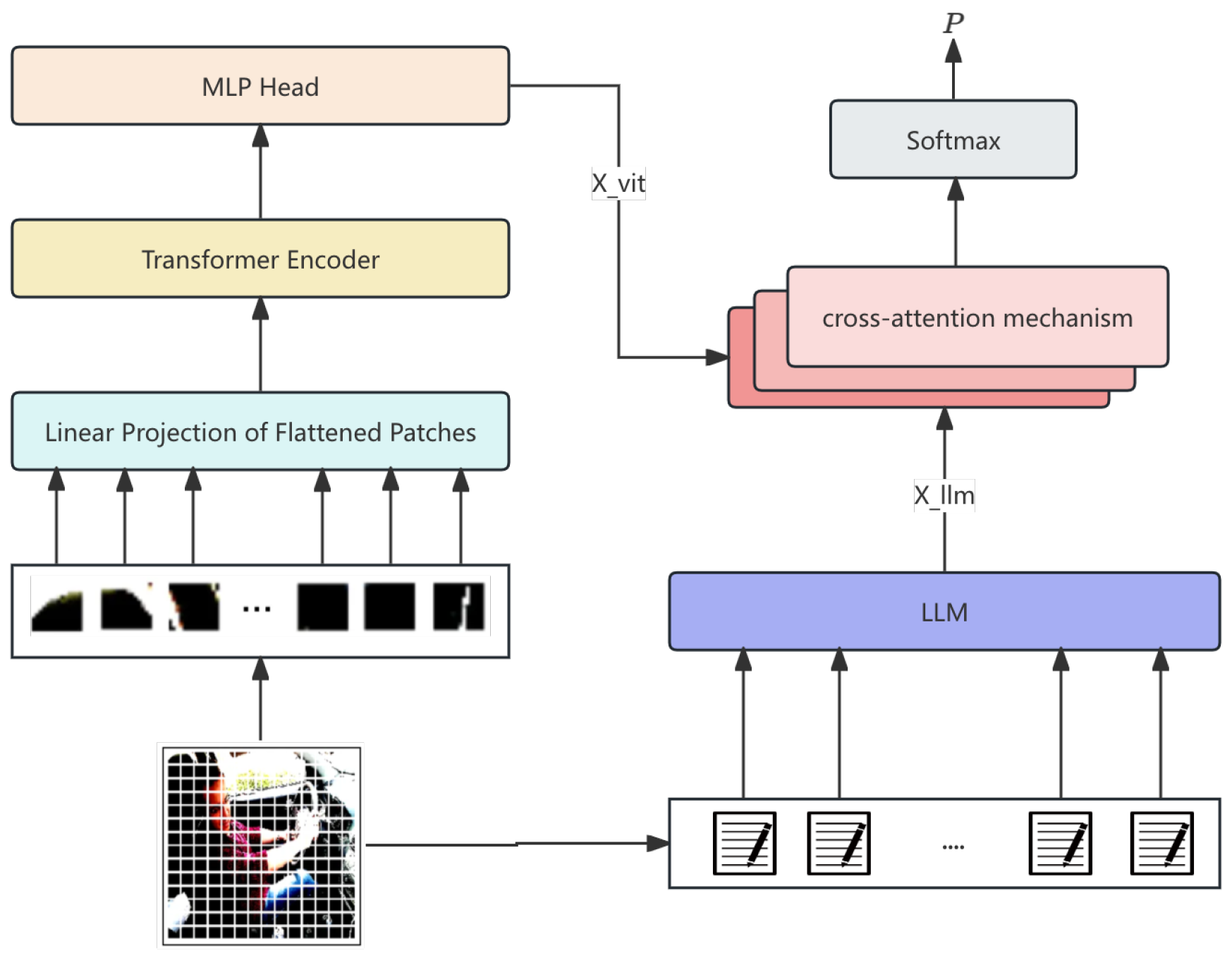
Figure 2.
Self-attention mechanism in ViT.
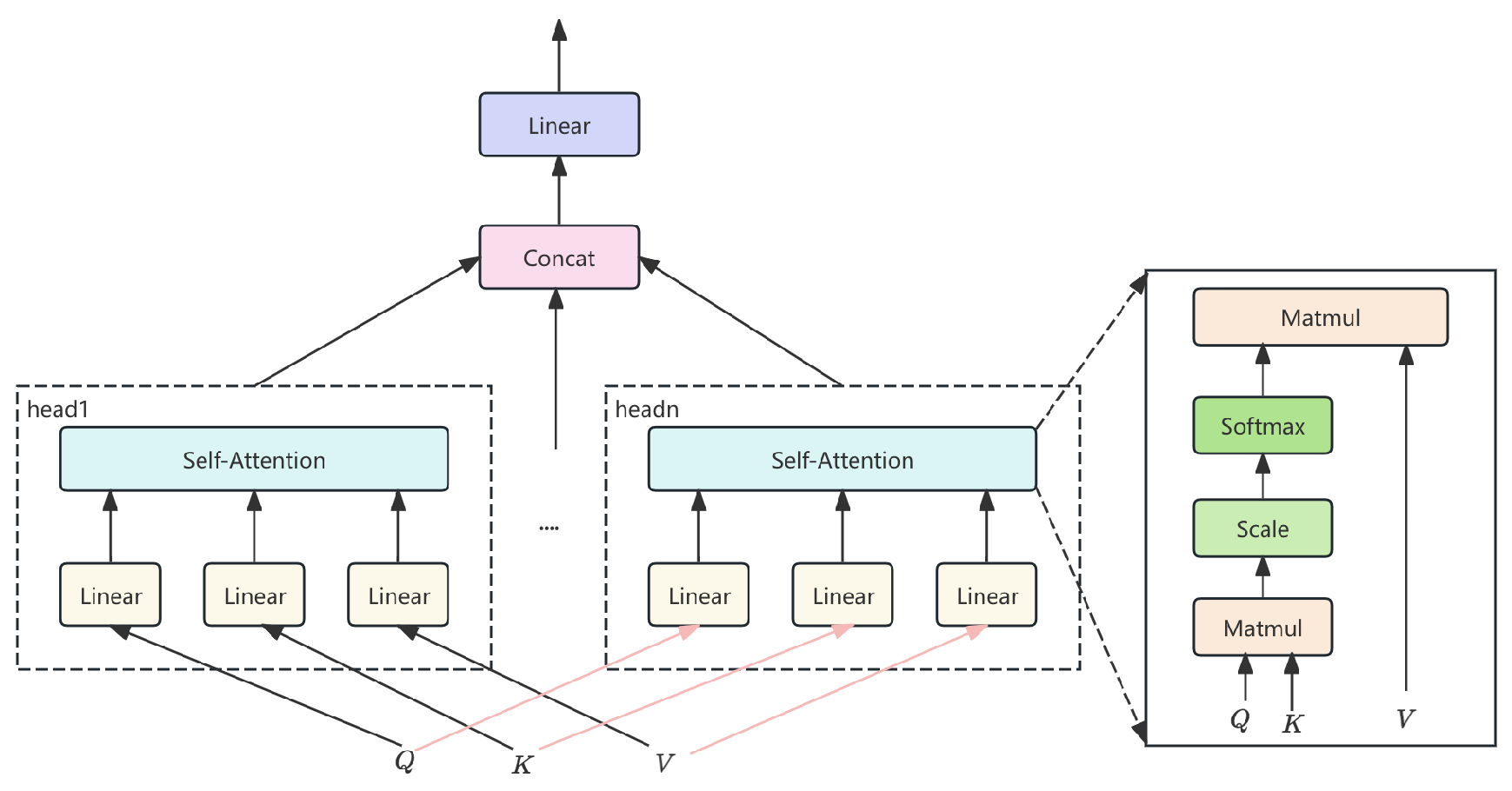
Figure 3.
Examples of data preprocessing.

Figure 4.
Model indicator change chart.
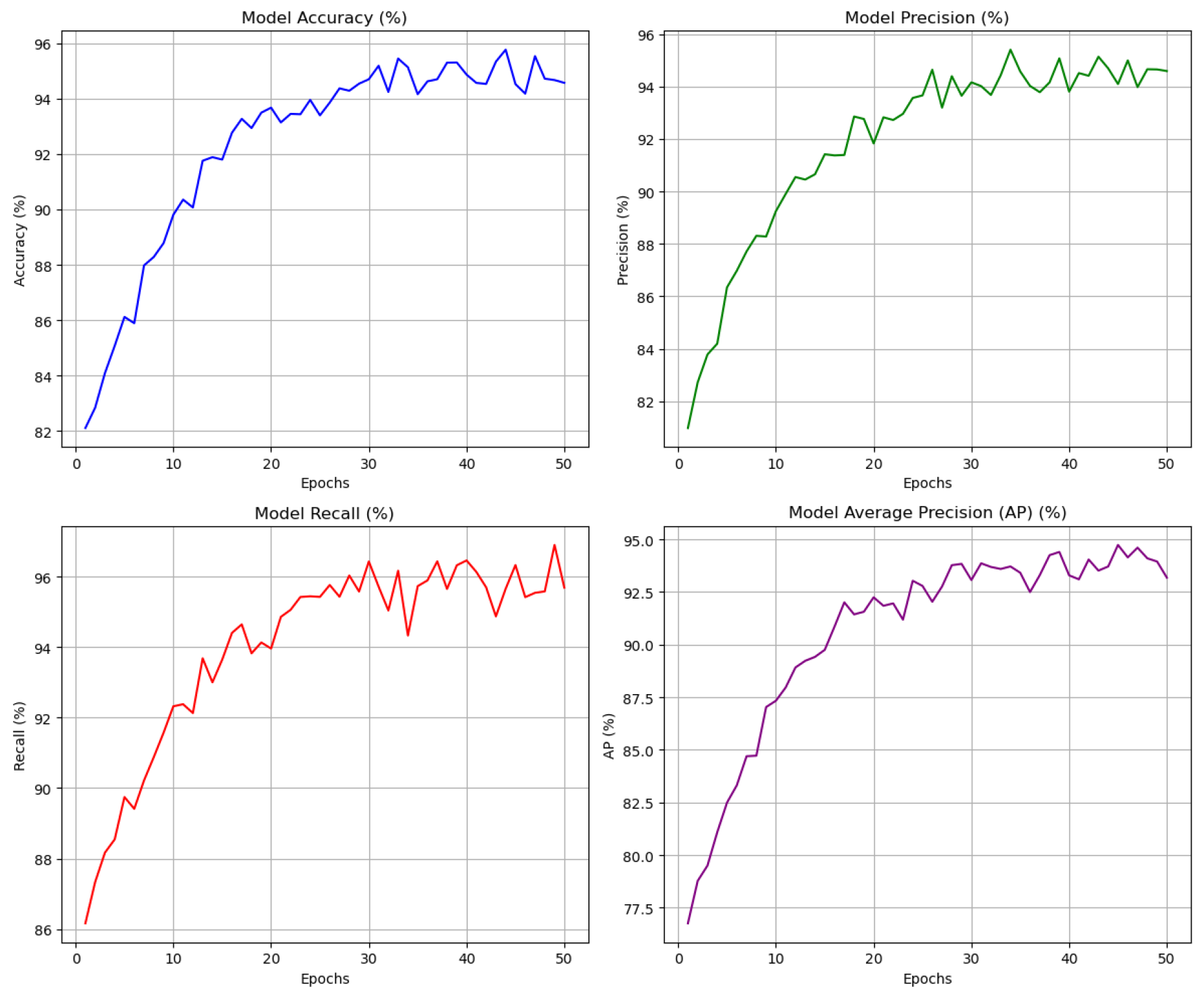

Table 1.
Comparison of Model Performance on COCO and FakeImage Datasets
| Model | Accuracy (%) | Precision (%) | Recall (%) | AP (%) |
|---|---|---|---|---|
| MLIF-Net | 95.3 | 94.7 | 96.1 | 94.2 |
| ViT-GAN | 91.4 | 89.5 | 92.3 | 90.5 |
| ResNet-50-CNN | 85.6 | 83.2 | 87.0 | 84.8 |
| CLIP | 92.0 | 90.1 | 93.3 | 91.5 |
| Xception-V2 | 89.5 | 88.0 | 90.7 | 88.9 |
Table 2.
Ablation Study Results
| Model Variant | Accuracy (%) | Precision (%) | Recall (%) | AP (%) |
|---|---|---|---|---|
| MLIF-Net | 95.3 | 94.7 | 96.1 | 94.2 |
| Without Fusion | 89.7 | 88.1 | 91.2 | 88.3 |
| Without Multiscale Reasoning | 93.1 | 92.6 | 93.5 | 92.0 |
| Without LLM Encoder | 90.8 | 89.2 | 92.1 | 89.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



