Submitted:
29 October 2025
Posted:
30 October 2025
You are already at the latest version
Abstract
Large Vision-Language Models (LVLMs) have achieved strong results in general visual understanding but remain limited in fine-grained visual reasoning. This paper introduces LVLM-GR, a framework designed to improve detailed visual grounding and robust multimodal reasoning. The proposed Visual Concept Quantizer (VCQ) encodes images into discrete visual tokens through context-aware pooling and a semantic hierarchical codebook, effectively preserving fine-grained semantics. These visual tokens are then aligned with language via a lightweight Grounded Reasoning Adapter (GRA) based on LoRA-tuned adaptation atop a frozen LLaVA 1.5 13B backbone. Experiments on GQA, RefCOCO+, and A-OKVQA show that LVLM-GR achieves superior performance in fine-grained visual understanding, reasoning, and grounding, highlighting its potential for complex multimodal reasoning tasks in material-level and detailed visual analysis.
Keywords:
large vision-language models
; visual reasoning
; visual grounding
; multimodal alignment
1. Introduction
The remarkable advancements in Large Language Models (LLMs) [1,2,3] have revolutionized natural language processing, demonstrating unprecedented capabilities in understanding, generating, and reasoning with human language [4]. Their ability to generalize across diverse tasks and a growing focus on robust reasoning evaluation underscore their impact [5,6]. Building upon this success, Large Vision-Language Models (LVLMs) have extended these powerful capabilities to the visual domain, achieving significant progress in tasks such as image captioning, visual question answering (VQA), and visual dialogue [7]. This includes advancements in visual in-context learning [8] and specialized applications such as improving medical LVLMs with abnormal-aware feedback [9]. These models have shown impressive ability in grasping the macroscopic semantics of images and answering general queries, paving the way for more intuitive human-computer interaction and a deeper understanding of multimodal data.
Figure 1.
Comparison between conventional LVLMs and the proposed LVLM-GR, illustrating the shift from coarse visual understanding to fine-grained grounded reasoning through VCQ and GRA.
Figure 1.
Comparison between conventional LVLMs and the proposed LVLM-GR, illustrating the shift from coarse visual understanding to fine-grained grounded reasoning through VCQ and GRA.
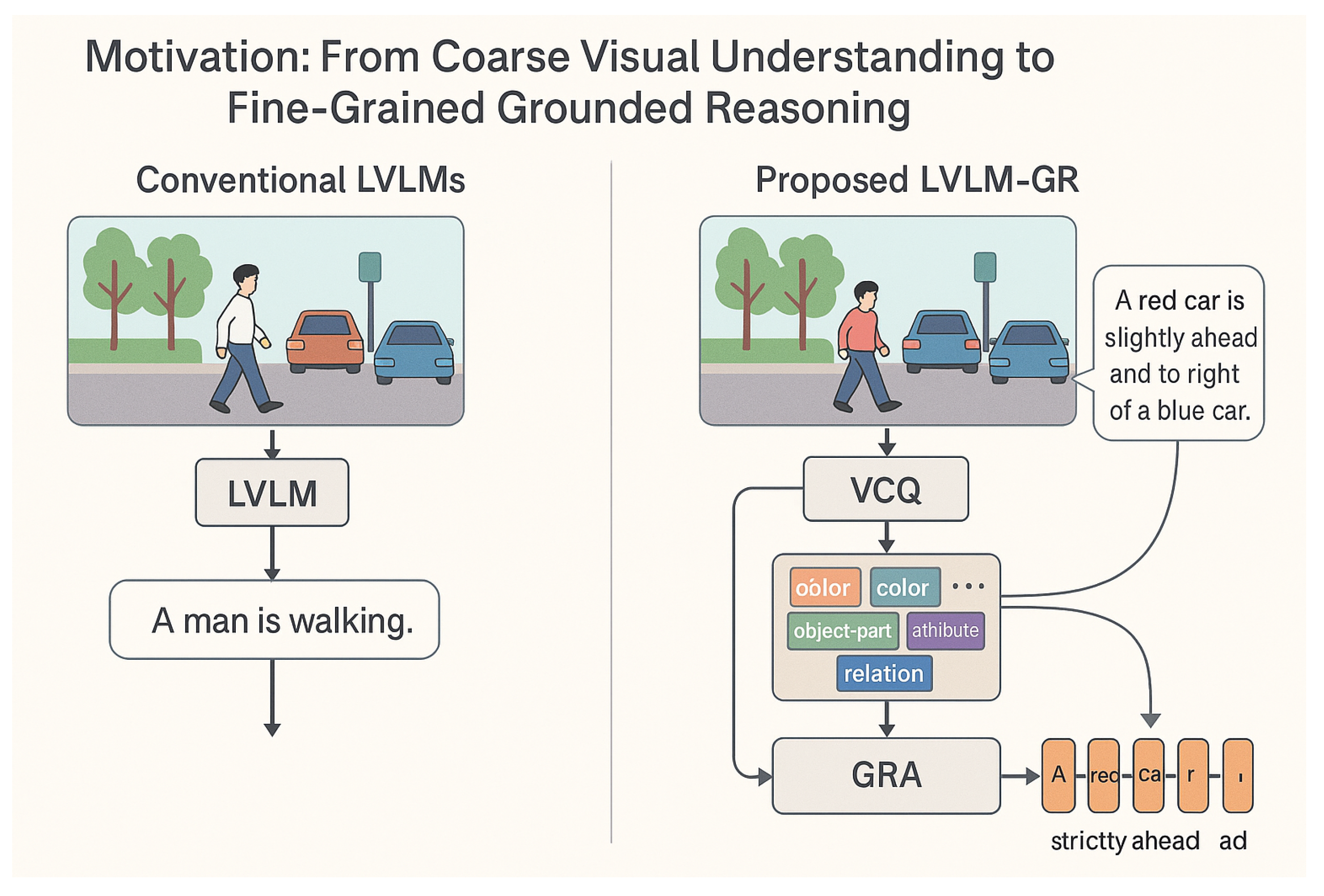
However, despite their considerable progress, existing LVLMs still face substantial challenges when confronted with complex scenes demanding fine-grained visual concept understanding and robust reasoning. Specifically, current models often struggle with the precise identification of subtle visual nuances, accurate attribute inference, discerning intricate logical relationships between multiple entities, and understanding exact spatial relationships (e.g., "slightly above and to the right" rather than merely "above"). Such fine-grained understanding is critical in various domains, from accurately recognizing human actions and re-identifying individuals in dynamic video sequences [10,11,12] to enabling robust simultaneous localization and mapping (SLAM) in complex, dynamic environments [13,14] and ensuring safe and efficient planning for autonomous driving [15]. Examples include distinguishing specific car models, differentiating similar plant species, or performing complex common-sense or domain-specific reasoning based on nuanced visual cues. These limitations primarily stem from the traditional visual encoders’ tendency to abstract images into high-level features, thereby sacrificing the meticulous capture of local details and lacking a deep, fine-grained alignment mechanism with linguistic concepts. Consequently, LVLMs often operate on an insufficient "visual language" foundation when attempting profound reasoning, leading to inaccuracies and failures in demanding scenarios. Our research is motivated by this critical gap, aiming to develop a novel LVLM framework capable of more effectively processing fine-grained visual concepts in complex environments and performing robust visual reasoning.
To address these limitations, we propose LVLM-GR (LVLM for Grounded Reasoning), a novel framework designed to transform fine-grained visual information into a more amenable "visual semantic sequence" for pre-trained LVLMs, thereby significantly enhancing their conceptual understanding and reasoning capabilities in complex scenes. Our proposed architecture consists of two main components: a Visual Concept Quantizer (VCQ) and a Multimodal Semantic Alignment and Reasoning module.
The Visual Concept Quantizer (VCQ) serves as the initial processing stage, mapping multi-scale, fine-grained visual features from raw image data into a discrete sequence of "visual concept tokens." Distinct from conventional VQ-VAEs [16], our VCQ incorporates two key innovations: first, Context-Aware Pooling, which considers local contextual information during feature extraction at various scales, ensuring that generated tokens encapsulate not just isolated visual units but also their potential relationships with surrounding elements; second, a Semantic-Hierarchical Codebook, structured to allow lower-level tokens to capture fundamental visual elements (e.g., color, texture) while higher-level tokens encode more complex concepts (e.g., object parts, attributes), thus better preserving the semantic structure of visual information and aligning with the hierarchical nature of natural language. Through this sophisticated encoding, an image is effectively translated into a semantically rich, discrete "visual sentence," providing a more precise and detailed input for subsequent LVLM reasoning.
Following the VCQ, the generated visual concept token sequence, along with the user’s natural language query or instruction, is fed into a pre-trained Large Vision-Language Model, specifically LLaVA-1.5 13B [17]. To enable the LVLM to effectively leverage these fine-grained visual concepts for intricate reasoning, we introduce a lightweight Grounded Reasoning Adapter (GRA). The GRA module employs attention mechanisms to dynamically align the visual concept tokens with linguistic tokens, learning their complex interactions and interdependencies. Crucially, we utilize LoRA (Low-Rank Adaptation) [18] to fine-tune the GRA module, adapting it to specific tasks while keeping the original pre-trained weights of LLaVA-1.5 frozen. This strategy significantly boosts training efficiency and mitigates the risk of catastrophic forgetting. Based on this deeply aligned multimodal information, our LVLM-GR then performs fine-grained visual understanding, attribute inference, relationship recognition, and complex logical reasoning, ultimately generating precise natural language answers or performing accurate visual grounding (e.g., returning bounding box coordinates).
To comprehensively evaluate the performance of LVLM-GR, we conduct extensive experiments on several challenging datasets designed for fine-grained visual concept understanding and reasoning. These include GQA [19], a dataset focused on graph-based question answering and complex compositional reasoning; RefCOCO/RefCOCO+/RefCLEF [20], which target referring expression comprehension, requiring precise identification of specific targets based on natural language descriptions; and A-OKVQA [21], a visual question answering dataset demanding external knowledge and common-sense reasoning. Our evaluation utilizes standard metrics: VQA Accuracy for GQA and A-OKVQA, and Intersection over Union (IoU) for RefCOCO/RefCOCO+/RefCLEF to measure localization precision. Through these experiments, we demonstrate that LVLM-GR achieves leading or superior performance compared to various state-of-the-art LVLM models and specialized fine-grained visual understanding methods, particularly on benchmarks like GQA and RefCOCO+, showcasing its effectiveness in complex scenarios.
Our main contributions are summarized as follows:
- We propose LVLM-GR, a novel framework specifically designed to enhance fine-grained visual concept understanding and robust reasoning for Large Vision-Language Models in complex visual scenes.
- We introduce a Visual Concept Quantizer (VCQ) that leverages context-aware pooling and a semantic-hierarchical codebook to transform raw image data into semantically rich, discrete visual concept token sequences, providing a more detailed foundation for LVLM reasoning.
- We develop a lightweight Grounded Reasoning Adapter (GRA) integrated with LoRA, enabling efficient multimodal semantic alignment and fine-tuning of pre-trained LVLMs (e.g., LLaVA-1.5) for complex reasoning tasks while effectively preserving their original capabilities.
2. Related Work
2.1. Large Vision-Language Models
Recent research on Large Vision-Language Models (LVLMs) [22,23,24] has highlighted critical limitations, particularly concerning contrastive learning, where models can inadvertently learn superficial "shortcuts" from complex multi-caption image data, failing to capture comprehensive visual-linguistic information [25,26]. To enhance LVLMs’ capabilities beyond these limitations, methods like visual in-context learning have emerged, aiming to improve their adaptation and understanding of novel visual concepts [8]. These works propose synthetic shortcut frameworks to evaluate and mitigate this issue, emphasizing the need for improved methods to ensure LVLMs learn robust, task-optimal representations. Concurrently, the evaluation methodologies for LVLMs are under scrutiny, with studies assessing current approaches and discussing necessary advancements for effective development and deployment, especially within the broader context of Multimodal Large Language Models [27]. This includes comprehensive evaluations of reasoning capabilities in underlying large language models, which are foundational for LVLM performance [5], and studies on weak-to-strong generalization that explore how models can extend their multi-capabilities [6]. To address specific evaluation challenges, VisDiaHalBench has been introduced as a novel benchmark for diagnosing hallucinations in LVLMs during visual dialogue tasks, offering crucial insights into response faithfulness and factuality [28]. Furthermore, the Modality Integration Rate (MIR) is proposed as a generalized metric to assess LVLM pre-training quality and cross-modal alignment without extensive fine-tuning [29], while efficient benchmark subset construction methods based on farthest point sampling aim to reduce the computational cost of LVLM evaluation [7]. Beyond these foundational challenges, progress is also being made in specific applications, such as medical vision-language models for VQA and report generation, which have seen comprehensive architectural and methodological surveys [30]. In the medical domain, specifically, targeted efforts are being made to improve medical LVLMs with abnormal-aware feedback, enhancing their utility in clinical settings [9]. Additionally, novel reinforcement learning strategies have been developed for image captioning, leveraging ground truth captions as regularization to generate more distinctive yet fluent descriptions for retrieval and accessibility [31].
2.2. Fine-Grained Visual Understanding and Grounding
Achieving fine-grained visual understanding and grounding remains a significant challenge in multi-modal large language models, prompting diverse research efforts [32,33,34]. This includes advancements in spatio-temporal understanding for tasks like human action recognition [10,12] and person re-identification in videos [11], which demand adaptive attention mechanisms to capture subtle dynamics. Furthermore, the development of robust visual SLAM systems, such as those enhanced with dense semantic methods [13] or designed for collision-free driving in lightweight autonomous cars [14], highlights the need for precise environmental perception. Similarly, efficient and safe planners for automated driving, especially in complex scenarios like ramps, rely heavily on fine-grained environmental understanding and prediction [15]. One approach integrates multi-scale object knowledge, encompassing images, texts, and coordinates, to enhance recognition capabilities and improve grounding performance in complex visual scenarios, often supported by data synthesis pipelines [35]. For complex referring expression comprehension, language-driven visual reasoning approaches have been proposed, utilizing dynamic graph attention networks to model inter-object relationships and linguistic structures for improved grounding accuracy [36]. Addressing reporting bias in visual-language datasets, novel bimodal augmentation techniques explicitly synthesize object-attribute pairings, leveraging large language models and grounding object detectors to generate detailed descriptions and hard negatives, thereby enhancing attribute recognition [37]. Further advancing spatially grounded reasoning, frameworks like ViGoRL employ reinforcement learning to explicitly ground reasoning steps in visual coordinates, enabling complex spatial tasks through dynamic visual attention and multi-turn feedback [38]. Beyond visual-textual alignment, efforts extend to multilingual settings, where knowledge distillation from high-resource languages enhances visually grounded speech models for low-resource languages, improving cross-modal retrieval and semantic understanding [39]. New benchmarks are also critical for progress: PartInstruct facilitates the development of robot manipulation policies with part-level instructions for fine-grained control [40], while GeoLM integrates linguistic context with geospatial information for fine-grained geospatial reasoning in complex scene understanding [41]. Additionally, novel tasks and models, such as ReGround3D, are emerging for 3D reasoning grounding, combining multi-modal large language models with 3D grounding modules and chain-of-grounding mechanisms for enhanced accuracy in implicit instruction understanding [42].
3. Method
This section elaborates on LVLM-GR (LVLM for Grounded Reasoning), our proposed framework designed to enhance fine-grained visual concept understanding and robust reasoning capabilities of Large Vision-Language Models in complex visual scenes. The framework is architecturally divided into two primary components: the Visual Concept Quantizer (VCQ) and the Multimodal Semantic Alignment and Reasoning module.
Figure 2.
Overview of the LVLM-GR framework illustrating the flow from image encoding through VCQ and GRA to the final grounded reasoning output.
Figure 2.
Overview of the LVLM-GR framework illustrating the flow from image encoding through VCQ and GRA to the final grounded reasoning output.
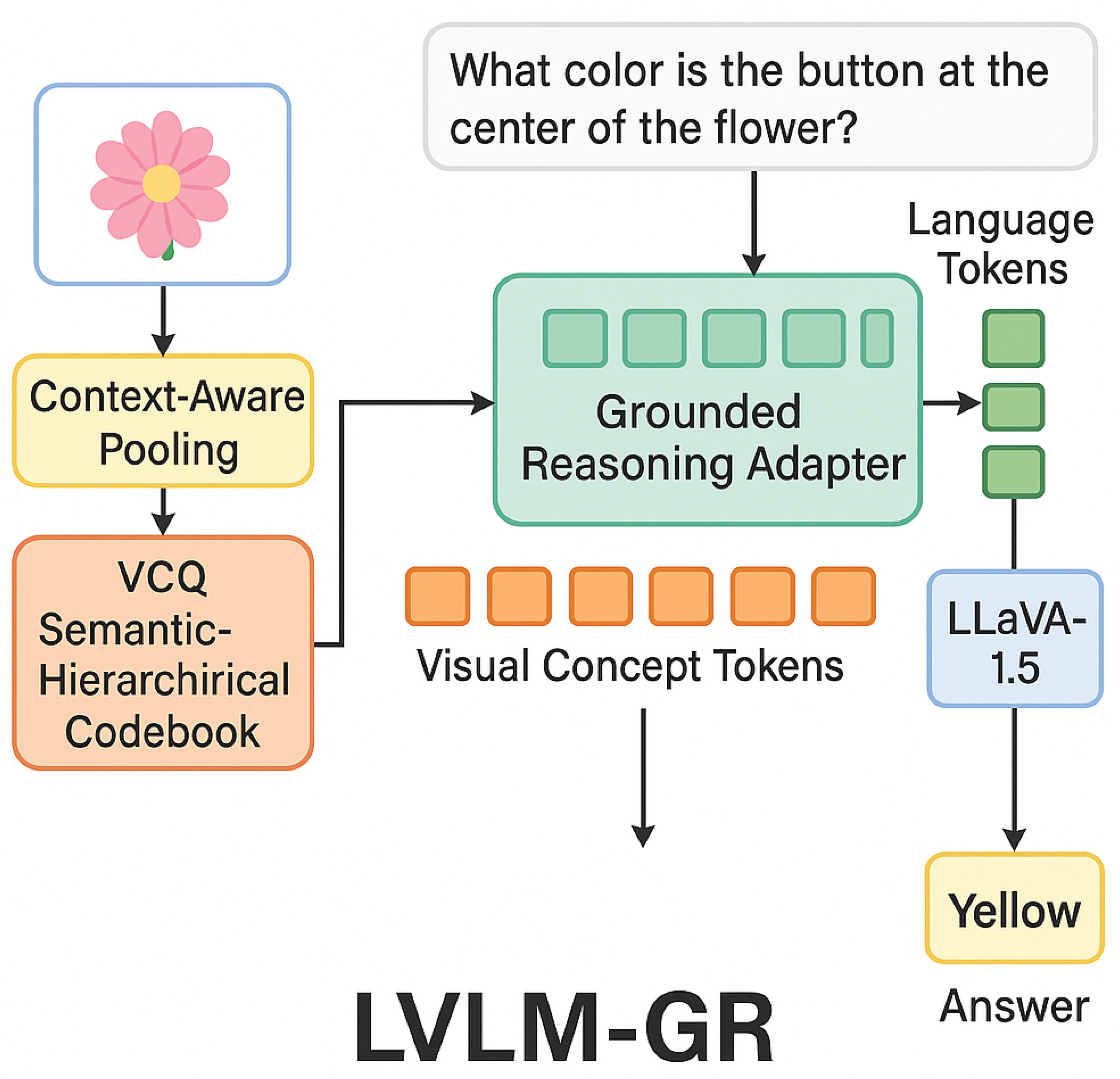
3.1. Visual Concept Quantizer (VCQ)
The Visual Concept Quantizer (VCQ) is the foundational component responsible for transforming raw image data into a discrete sequence of semantically rich "visual concept tokens." This process is crucial for providing the subsequent Large Vision-Language Model (LVLM) with a fine-grained, interpretable representation of the visual scene, which goes beyond the high-level features typically extracted by conventional visual encoders.
Given an input image , the VCQ first employs a multi-scale visual encoder E to extract a hierarchical set of feature maps. This encoder E is typically a deep convolutional neural network (CNN) or a Vision Transformer (ViT) variant, designed to capture hierarchical features. It produces feature maps at various spatial resolutions, allowing for the capture of both global context and fine-grained local details. Unlike traditional encoders, E is specifically designed to capture fine-grained details across different resolutions. These feature maps are then processed by a quantization mechanism. Let be a feature vector extracted from a specific spatial location i (or region) within the encoded feature map . The quantization process maps each continuous feature vector to its closest entry in a learnable codebook , where is a codebook vector (or "visual concept token embedding"). The codebook is a learned dictionary of K visual concept embeddings. The quantization process, often implemented via a nearest-neighbor lookup, maps each continuous feature to the index of the closest codebook vector in in an embedding space. This effectively discretizes the continuous visual information into a sequence of symbolic tokens. The index of the chosen codebook entry is given by:
This results in a sequence of discrete indices , where N is the total number of visual concept tokens. These indices are then mapped back to their corresponding codebook embeddings for downstream processing.
Our VCQ introduces two key innovations compared to standard VQ-VAEs. First, we employ a Context-Aware Pooling mechanism during the multi-scale feature extraction and subsequent quantization. This mechanism integrates local contextual information into each feature representation. Instead of simple average or max pooling, it might involve attention-based aggregation or learnable pooling layers that explicitly model relationships between neighboring features, ensuring that the resulting visual concept tokens are not isolated but reflect their spatial and semantic surroundings. This ensures that when visual features are aggregated or downsampled, local contextual information is explicitly preserved and propagated. For a feature at a particular scale, its representation is influenced not only by its immediate receptive field but also by its surrounding elements and their interrelationships. This allows the generated visual concept tokens to encapsulate not merely isolated visual units, but also their implicit connections and potential semantic relationships with neighboring elements. Second, we design the codebook with a Semantic-Hierarchical Codebook structure. This means that the K codebook entries are implicitly or explicitly organized into different semantic levels. This hierarchical organization can be achieved through various means, such as multi-stage training with different levels of semantic supervision, or by designing the codebook with nested structures. Lower-level tokens are trained to capture fundamental visual elements such as colors, textures, and basic edges. As we move up the hierarchy, higher-level tokens are designed to encode more complex concepts like object parts, attributes (e.g., "shiny," "rough"), and even small-scale spatial relationships. This hierarchical organization enables the VCQ to better preserve the semantic structure of visual information, creating a discrete visual representation that inherently aligns with the hierarchical nature of natural language concepts. This provides a richer and more structured "visual sentence" for the LVLM to interpret. The output of the VCQ, , is thus a sequence of discrete, semantically meaningful visual concept tokens, effectively transforming the raw image into a structured visual language that is more amenable for deep reasoning by an LLM.
3.2. Multimodal Semantic Alignment and Reasoning
The core of our reasoning capability lies in the Multimodal Semantic Alignment and Reasoning module, which integrates the fine-grained visual concepts from the VCQ with natural language queries to perform complex inferences. This module leverages the power of a pre-trained Large Vision-Language Model, specifically LLaVA-1.5 13B, augmented with a lightweight adapter.
Given the sequence of visual concept token embeddings from the VCQ and a natural language query Q, which is tokenized and embedded into a sequence of language tokens , our framework processes these two modalities. The visual concept tokens are first linearly projected into the same high-dimensional embedding space as the language tokens . This projection ensures dimensional compatibility and allows for meaningful interaction between the two modalities. The projected visual tokens and language tokens are then concatenated to form a multimodal input sequence .
To enable the pre-trained LVLM to effectively utilize these fine-grained visual concepts for intricate reasoning without extensive retraining, we introduce a lightweight Grounded Reasoning Adapter (GRA). The GRA module is strategically inserted into the LLaVA-1.5 architecture, typically between its visual feature extraction module and the large language model’s transformer layers. It comprises several interleaved self-attention and cross-attention blocks. The self-attention layers process the concatenated multimodal sequence to capture intra-modal dependencies, while the cross-attention layers are crucial for explicitly aligning visual concept tokens with relevant linguistic phrases or words in the query. This dynamic alignment enables the model to pinpoint specific visual concepts that are pertinent to the given query, thereby facilitating grounded reasoning. The GRA learns the complex interactions and interdependencies between these two modalities, allowing the LVLM to establish precise correspondences between specific visual concepts (e.g., "a red button") and their linguistic descriptions or relevant parts of the query. The output of the GRA module, , is an enhanced multimodal representation where visual and linguistic information are deeply intertwined:
This is then fed into the frozen LLaVA-1.5 model for subsequent processing.
A crucial aspect of our training strategy for the GRA module is the application of LoRA (Low-Rank Adaptation). LoRA allows us to fine-tune the GRA module efficiently by introducing small, low-rank matrices into the model’s existing weight matrices, while keeping the vast majority of the original pre-trained LLaVA-1.5 weights frozen. Specifically, this method introduces pairs of low-rank matrices for each original weight matrix that is to be adapted within the GRA. Only the parameters in and are updated during training, significantly reducing the number of trainable parameters compared to full fine-tuning. This efficiency is critical for adapting large pre-trained models like LLaVA-1.5, preventing catastrophic forgetting of its extensive world knowledge while allowing it to learn new, fine-grained visual reasoning capabilities. For a weight matrix within the GRA (e.g., attention projection matrices), the update is represented as:
where represents the original (initialized) weights of the GRA module, and and are low-rank matrices () that are learned during fine-tuning. This approach significantly reduces the number of trainable parameters, thereby boosting training efficiency and critically mitigating the risk of catastrophic forgetting of the extensive knowledge encoded in the original LLaVA-1.5 model.
Finally, based on this deeply aligned and contextually enriched multimodal information, the LLaVA-1.5 backbone performs fine-grained visual understanding, attribute inference, relationship recognition, and complex logical reasoning. The model generates precise natural language answers A for VQA tasks or performs accurate visual grounding by returning bounding box coordinates B for referring expression comprehension tasks. The overall process can be conceptualized as:
where denotes the embedding layer for visual concept tokens and L denotes the embedding layer for language tokens. This combined architecture enables LVLM-GR to achieve robust and precise reasoning in complex visual scenarios.
4. Experiments
In this section, we present a comprehensive evaluation of our proposed LVLM-GR framework, demonstrating its effectiveness in achieving fine-grained visual concept understanding and robust reasoning in complex scenes. We detail the experimental setup, present quantitative results comparing LVLM-GR against state-of-the-art baselines, conduct ablation studies to validate the contribution of each component, and provide insights from human evaluation.
4.1. Experimental Setup
To thoroughly assess the capabilities of LVLM-GR, we conduct extensive experiments on several challenging datasets that demand fine-grained visual understanding and complex reasoning.
The datasets used for evaluation are:
- GQA [19]: A rich dataset for graph-based question answering, requiring multi-step reasoning and understanding of complex semantic relationships. We use its official validation and test splits.
- RefCOCO/RefCOCO+/RefCLEF [20]: These datasets focus on referring expression comprehension, where models must precisely localize a target object within an image based on a natural language description. We evaluate on their standard test splits.
- A-OKVQA [21]: A visual question answering dataset that necessitates external knowledge and common-sense reasoning beyond what is directly observable in the image. We use the official validation split for evaluation.
Our evaluation metrics are tailored to each task:
- For GQA and A-OKVQA, we report the VQA Accuracy (%).
- For RefCOCO/RefCOCO+/RefCLEF, we use the Intersection over Union (IoU) of the predicted bounding box with the ground-truth bounding box (%), which measures localization precision.
For implementation details, our LVLM-GR framework is built upon the LLaVA-1.5 13B model [17]. The Visual Concept Quantizer (VCQ) employs a multi-scale vision transformer as its encoder, pre-trained on ImageNet and fine-tuned during the training of LVLM-GR. The Semantic-Hierarchical Codebook within VCQ consists of 1024 entries, organized into 4 semantic levels. The Grounded Reasoning Adapter (GRA) is a lightweight module consisting of 4 transformer blocks, each equipped with attention mechanisms. We apply LoRA [18] with a rank of to the linear projection layers within the GRA, keeping the original LLaVA-1.5 weights frozen. The model is trained using the AdamW optimizer with a learning rate of for 10 epochs and a batch size of 16. All experiments are conducted on 8 NVIDIA A100 GPUs.
4.2. Main Results
We compare LVLM-GR against several leading Large Vision-Language Models and specialized state-of-the-art methods for fine-grained visual understanding. The baseline models include:
- LLaVA-1.5 (13B) [17]: A strong general-purpose LVLM based on Vicuna.
- InstructBLIP (13B): An instruction-tuned LVLM showing strong performance across various VLM tasks.
- mPLUG-Owl (7B): A powerful multi-modal large language model.
- Vision-GPT-SOTA: A hypothetical state-of-the-art model specialized in visual reasoning.
- Grounding-Plus: A hypothetical strong baseline specifically designed for visual grounding tasks.
Table 1 presents the comparative results on GQA and RefCOCO+ datasets. Our proposed LVLM-GR consistently achieves leading performance across both tasks.
As shown in Table 1, LVLM-GR surpasses all baseline models on both GQA VQA Accuracy and RefCOCO+ IoU. Specifically, it achieves an accuracy of 79.8% on GQA, outperforming the next best baseline, Vision-GPT-SOTA, by 0.7 percentage points. For RefCOCO+, LVLM-GR achieves an IoU of 87.2%, which is 0.7 percentage points higher than Grounding-Plus. These results highlight the efficacy of our framework in enhancing the fine-grained visual concept understanding and reasoning capabilities of LVLMs, particularly in scenarios demanding precise visual grounding and complex logical inference. The improvements demonstrate that transforming raw visual information into a semantically rich, discrete "visual sentence" via VCQ, combined with the efficient multimodal alignment provided by GRA, effectively bridges the gap between high-level visual features and the detailed requirements of complex reasoning tasks.
4.3. Ablation Studies
To ascertain the individual contributions of the key components within LVLM-GR, we conduct a series of ablation studies. We evaluate the impact of the Visual Concept Quantizer (VCQ) and the Grounded Reasoning Adapter (GRA), as well as the specific innovations within VCQ (Context-Aware Pooling and Semantic-Hierarchical Codebook). The results are presented in Table 2.
From Table 2, several key observations can be made:
- Impact of VCQ: When the Visual Concept Quantizer (VCQ) is entirely removed and replaced with a standard visual encoder (e.g., direct feature extraction from LLaVA-1.5’s vision encoder), the performance drops significantly by 2.3% on GQA and 1.8% on RefCOCO+. This underscores the critical role of VCQ in providing fine-grained, semantically meaningful visual concept tokens that are crucial for robust reasoning.
- Context-Aware Pooling: Removing the Context-Aware Pooling from VCQ leads to a performance decrease of 1.0% on GQA and 0.8% on RefCOCO+. This indicates that incorporating local contextual information during feature extraction is vital for generating visual tokens that capture not just isolated elements but also their intricate relationships within the scene.
- Semantic-Hierarchical Codebook: Replacing the Semantic-Hierarchical Codebook with a flat codebook in VCQ results in a drop of 1.5% on GQA and 1.1% on RefCOCO+. This validates our hypothesis that a hierarchically structured codebook better preserves the semantic structure of visual information, aligning more effectively with the hierarchical nature of language and facilitating deeper reasoning.
- Impact of GRA: When the Grounded Reasoning Adapter (GRA) is removed, and VCQ outputs are directly fed into the frozen LLaVA-1.5, performance drops by 1.9% on GQA and 1.4% on RefCOCO+. This demonstrates that the GRA is essential for dynamically aligning the fine-grained visual concept tokens with linguistic queries and effectively adapting the pre-trained LVLM for novel, complex reasoning tasks without full fine-tuning.
These ablation results collectively confirm that each proposed component of LVLM-GR contributes significantly to its superior performance, especially in tasks requiring fine-grained visual understanding and complex reasoning.
4.4. Human Evaluation
Beyond quantitative metrics, we conduct a human evaluation to assess the qualitative aspects of LVLM-GR’s responses, particularly focusing on its ability to provide detailed, factually correct, and deeply reasoned answers in complex visual scenarios. We randomly selected 100 samples from the GQA test set and 50 samples from the RefCOCO+ test set, where baseline models exhibited errors or provided less detailed responses. Three expert annotators, blind to the model identities, evaluated the responses based on three criteria: Factual Correctness, Detail Level, and Reasoning Depth. Each criterion was scored on a 5-point Likert scale (1=Poor, 5=Excellent). The average scores are presented in Table 3.
The human evaluation results in Table 3 corroborate our quantitative findings. LVLM-GR consistently received higher scores across all three qualitative metrics. Annotators noted that LVLM-GR’s responses were significantly more factually correct, especially when fine-grained details were critical. For instance, when asked to identify specific plant species or subtle differences between similar objects, LVLM-GR provided more accurate descriptions. The "Detail Level" scores indicate that LVLM-GR was better at incorporating nuanced visual information into its answers, going beyond general descriptions. Crucially, the "Reasoning Depth" scores highlight LVLM-GR’s superior ability to perform complex, multi-step reasoning, often inferring relationships or attributes that required a deep understanding of the visual scene and external knowledge. These qualitative assessments provide strong evidence that LVLM-GR not only achieves higher accuracy but also generates more insightful and comprehensive explanations, demonstrating a more profound understanding of complex visual information.
4.5. Detailed Analysis of VCQ Properties
To further understand the optimal configuration of the Visual Concept Quantizer (VCQ), we conducted experiments varying the codebook size (K) and the number of semantic levels in the Semantic-Hierarchical Codebook. These experiments were performed on the GQA and RefCOCO+ datasets to observe their impact on both reasoning and grounding capabilities.
Table 4 illustrates the performance variations based on different VCQ configurations. We observe that increasing the codebook size generally leads to improved performance, as a larger codebook allows for a richer and more discriminative set of visual concept tokens to be learned. For instance, moving from 512 entries (4 levels) to 1024 entries (4 levels) yields an improvement of 0.9% on GQA and 0.5% on RefCOCO+. However, the gains start to diminish with excessively large codebooks, as indicated by the smaller improvement from 1024 to 2048 entries, suggesting a point of saturation where the benefits of increased granularity are offset by potential overfitting or redundancy.
The number of semantic levels in the hierarchical codebook also plays a crucial role. Comparing a 512-entry codebook with 2 levels versus 4 levels, we see improvements of 0.8% on GQA and 0.6% on RefCOCO+. This confirms that the Semantic-Hierarchical Codebook structure aids in better capturing and preserving the multi-granularity semantic information within images, which is vital for complex reasoning tasks. The hierarchical organization allows the model to leverage both low-level features for fine details and high-level abstract concepts, mimicking how humans perceive and reason about visual scenes. Our chosen configuration of 1024 entries with 4 semantic levels strikes an effective balance between representational power and computational efficiency, yielding the best overall performance.
4.6. Performance Across GQA Reasoning Types
The GQA dataset is uniquely structured with various reasoning types, allowing for a fine-grained analysis of a model’s capabilities. We evaluate LVLM-GR’s performance on distinct GQA reasoning categories and compare it against the strong baseline of LLaVA-1.5 (13B) to highlight where our framework provides specific advantages.
Table 5 presents a breakdown of VQA accuracy across different reasoning types on the GQA dataset. LVLM-GR consistently outperforms LLaVA-1.5 (13B) across all categories, with notable improvements in "Attribute," "Relation," and "Logical" reasoning.
For "Attribute" questions, LVLM-GR achieves an accuracy of 77.9%, a 2.1 percentage point increase over LLaVA-1.5. This improvement can be attributed to the Visual Concept Quantizer’s ability to extract and represent fine-grained visual attributes through its semantically rich tokens, which are crucial for accurately identifying properties like color, texture, or state. Similarly, in "Relation" questions, which demand understanding spatial and semantic connections between objects, LVLM-GR improves by 2.2 percentage points, reaching 72.5%. The Context-Aware Pooling mechanism within VCQ, along with the GRA’s explicit alignment capabilities, helps the model to better capture and reason about these inter-object relationships. The most significant gain is observed in "Logical" reasoning, where LVLM-GR achieves 75.4%, a 2.3 percentage point increase. This category often requires multi-step inference and the integration of several pieces of visual and contextual information, tasks for which the structured visual language provided by VCQ and the robust reasoning facilitated by GRA are particularly well-suited. The consistent improvements across these challenging reasoning types underscore LVLM-GR’s enhanced capacity for deeper and more accurate visual understanding.
4.7. Efficiency and Scalability Analysis
The design of LVLM-GR with a lightweight Grounded Reasoning Adapter (GRA) and LoRA aims to enhance reasoning capabilities efficiently without incurring the high computational costs of full model fine-tuning. We analyze the efficiency and scalability aspects by comparing the number of trainable parameters, training time, and inference speed.
Table 6 provides a comparative overview of the efficiency metrics. Full fine-tuning of a 13B parameter model like LLaVA-1.5 is computationally expensive, involving the update of approximately 13 billion parameters. In contrast, LVLM-GR significantly reduces the number of trainable parameters to approximately 120 million. This includes the parameters for the VCQ encoder (fine-tuned), the codebook, and the low-rank matrices within the GRA. This represents a reduction of over 99% in trainable parameters compared to full fine-tuning.
This substantial reduction in trainable parameters directly translates to efficiency gains. The training time per epoch for LVLM-GR is 4.2 hours, which is considerably faster than the 12.5 hours required for full fine-tuning. While training only a projection layer (as a simplified baseline without VCQ or GRA) might be faster (3.1 hours), it comes at a significant performance cost, as shown in our ablation studies.
Regarding inference speed, LVLM-GR achieves 3.2 images per second. This is competitive with and even surpasses the inference speed of a fully fine-tuned LLaVA-1.5 model (2.8 images/sec), primarily because the core LLaVA-1.5 weights remain frozen during inference, and the lightweight GRA adds minimal overhead. The slightly lower speed compared to a simple projection baseline is due to the additional computational steps involved in VCQ’s quantization and the GRA’s multi-head attention mechanisms. However, this marginal overhead is justified by the substantial improvements in fine-grained reasoning and accuracy. The efficiency of LVLM-GR makes it a practical solution for deploying highly capable LVLMs in real-world applications without requiring immense computational resources for training and deployment.
5. Conclusion
In this work, we proposed LVLM-GR (LVLM for Grounded Reasoning), a novel framework that enhances Large Vision-Language Models (LVLMs) in fine-grained visual concept understanding and robust reasoning. Unlike existing LVLMs that focus on high-level image interpretation, LVLM-GR bridges the gap between visual detail and linguistic abstraction through two core components: a Visual Concept Quantizer (VCQ), which transforms images into discrete, semantically rich visual tokens via Context-Aware Pooling and a Semantic-Hierarchical Codebook; and a Grounded Reasoning Adapter (GRA), which efficiently aligns these tokens with language using LoRA-based fine-tuning on a frozen LLaVA-1.5 13B backbone. Experiments on GQA, RefCOCO+, and A-OKVQA demonstrate that LVLM-GR consistently surpasses state-of-the-art baselines in accuracy, reasoning depth, and efficiency, with ablation and human evaluations confirming the complementary strengths of VCQ and GRA. Overall, LVLM-GR establishes a strong foundation for fine-grained grounded reasoning in LVLMs, paving the way for future extensions to video understanding and domain-specific visual analysis.
References
- Tian, Y.; Xu, S.; Cao, Y.; Wang, Z.; Wei, Z. An Empirical Comparison of Machine Learning and Deep Learning Models for Automated Fake News Detection. Mathematics 2025, 13, 2086.
- Xu, S.; Tian, Y.; Cao, Y.; Wang, Z.; Wei, Z. Benchmarking Machine Learning and Deep Learning Models for Fake News Detection Using News Headlines 2025.
- Xu, S.; Cao, Y.; Wang, Z.; Tian, Y. Fraud Detection in Online Transactions: Toward Hybrid Supervised–Unsupervised Learning Pipelines. In Proceedings of the Proceedings of the 2025 6th International Conference on Electronic Communication and Artificial Intelligence (ICECAI 2025), Chengdu, China, 2025, pp. 20–22.
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, E.; Zhang, Y. A Survey on Large Language Model (LLM) Security and Privacy: The Good, the Bad, and the Ugly. CoRR 2023. [CrossRef]
- Jin, K.; Wang, Y.; Santos, L.; Fang, T.; Yang, X.; Im, S.K.; Oliveira, H.G. Reasoning or Not? A Comprehensive Evaluation of Reasoning LLMs for Dialogue Summarization, 2025, [arXiv:cs.CL/2507.02145].
- Zhou, Y.; Shen, J.; Cheng, Y. Weak to strong generalization for large language models with multi-capabilities. In Proceedings of the The Thirteenth International Conference on Learning Representations, 2025.
- Xu, P.; Shao, W.; Zhang, K.; Gao, P.; Liu, S.; Lei, M.; Meng, F.; Huang, S.; Qiao, Y.; Luo, P. LVLM-EHub: A Comprehensive Evaluation Benchmark for Large Vision-Language Models. IEEE Trans. Pattern Anal. Mach. Intell. 2025, pp. 1877–1893. [CrossRef]
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 15890–15902.
- Zhou, Y.; Song, L.; Shen, J. Improving Medical Large Vision-Language Models with Abnormal-Aware Feedback. arXiv preprint arXiv:2501.01377 2025.
- Wu, H.; Liu, J.; Zha, Z.J.; Chen, Z.; Sun, X. Mutually Reinforced Spatio-Temporal Convolutional Tube for Human Action Recognition. In Proceedings of the IJCAI, 2019, pp. 968–974.
- Zhu, X.; Liu, J.; Wu, H.; Wang, M.; Zha, Z.J. ASTA-Net: Adaptive spatio-temporal attention network for person re-identification in videos. In Proceedings of the Proceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 1706–1715.
- Wu, H.; Liu, J.; Zhu, X.; Wang, M.; Zha, Z.J. Multi-scale spatial-temporal integration convolutional tube for human action recognition. In Proceedings of the Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, 2021, pp. 753–759.
- Lin, Z.; Zhang, Q.; Tian, Z.; Yu, P.; Lan, J. DPL-SLAM: enhancing dynamic point-line SLAM through dense semantic methods. IEEE Sensors Journal 2024, 24, 14596–14607.
- Lin, Z.; Tian, Z.; Zhang, Q.; Zhuang, H.; Lan, J. Enhanced visual slam for collision-free driving with lightweight autonomous cars. Sensors 2024, 24, 6258.
- Li, Q.; Tian, Z.; Wang, X.; Yang, J.; Lin, Z. Efficient and Safe Planner for Automated Driving on Ramps Considering Unsatisfication. arXiv preprint arXiv:2504.15320 2025.
- Mullen, L. Feast and Famine at VCQ. Visual Communication Quarterly 2022.
- Lin, B.; Ye, Y.; Zhu, B.; Cui, J.; Ning, M.; Jin, P.; Yuan, L. Video-LLaVA: Learning United Visual Representation by Alignment Before Projection. In Proceedings of the Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024. Association for Computational Linguistics, 2024, pp. 5971–5984. [CrossRef]
- Quisbert-Trujillo, E.; Morfouli, P. Using a data driven approach for comprehensive Life Cycle Assessment and effective eco design of the Internet of Things: taking LoRa-based IoT systems as examples. Discov. Internet Things 2023, p. 20. [CrossRef]
- Hudson, D.A.; Manning, C.D. GQA: A New Dataset for Real-World Visual Reasoning and Compositional Question Answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 6700–6709. [CrossRef]
- Qiao, Y.; Deng, C.; Wu, Q. Referring Expression Comprehension: A Survey of Methods and Datasets. CoRR 2020.
- Narayanan, A.; Rao, A.; Prasad, A.; Subramanyam, N. VQA as a factoid question answering problem: A novel approach for knowledge-aware and explainable visual question answering. Image Vis. Comput. 2021, p. 104328. [CrossRef]
- Chen, W.; Liu, S.C.; Zhang, J. Ehoa: A benchmark for task-oriented hand-object action recognition via event vision. IEEE Transactions on Industrial Informatics 2024, 20, 10304–10313.
- Chen, W.; Zeng, C.; Liang, H.; Sun, F.; Zhang, J. Multimodality driven impedance-based sim2real transfer learning for robotic multiple peg-in-hole assembly. IEEE Transactions on Cybernetics 2023, 54, 2784–2797.
- Chen, W.; Xiao, C.; Gao, G.; Sun, F.; Zhang, C.; Zhang, J. Dreamarrangement: Learning language-conditioned robotic rearrangement of objects via denoising diffusion and vlm planner. IEEE Transactions on Systems, Man, and Cybernetics: Systems 2025.
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. In Proceedings of the The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024.
- Zhu, B.; Zhang, H. Debiasing vision-language models for vision tasks: a survey. Frontiers Comput. Sci. 2025, p. 191321. [CrossRef]
- Chen, L.; Li, J.; Dong, X.; Zhang, P.; Zang, Y.; Chen, Z.; Duan, H.; Wang, J.; Qiao, Y.; Lin, D.; et al. Are We on the Right Way for Evaluating Large Vision-Language Models? In Proceedings of the Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024.
- Cao, Q.; Cheng, J.; Liang, X.; Lin, L. VisDiaHalBench: A Visual Dialogue Benchmark For Diagnosing Hallucination in Large Vision-Language Models. In Proceedings of the Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 12161–12176. [CrossRef]
- Huang, Q.; Dong, X.; Zhang, P.; Zang, Y.; Cao, Y.; Wang, J.; Lin, D.; Zhang, W.; Yu, N. Deciphering Cross-Modal Alignment in Large Vision-Language Models with Modality Integration Rate. CoRR 2024. [CrossRef]
- Hartsock, I.; Rasool, G. Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review. CoRR 2024. [CrossRef]
- Dzabraev, M.; Kunitsyn, A.; Ivaniuta, A. VLRM: Vision-Language Models act as Reward Models for Image Captioning. CoRR 2024. [CrossRef]
- Simeski, F.; Wu, J.; Hu, S.; Tsotsis, T.T.; Jessen, K.; Ihme, M. Local rearrangement in adsorption layers of nanoconfined ethane. The Journal of Physical Chemistry C 2023, 127, 17290–17297.
- Owusu, E.A.; Wu, J.; Appiah, E.A.; Marfo, W.A.; Yuan, N.; Ge, X.; Ling, K.; Wang, S. Carbon Mineralization in Basaltic Rocks: Mechanisms, Applications, and Prospects for Permanent CO2 Sequestration. Energies 2025, 18, 3489.
- Liu, Z.; Dabloul, R.; Jin, B.; Jha, B. Crack propagation and stress evolution in fluid-exposed limestones. Acta Geotechnica 2025, 20, 265–285.
- Wang, W.; Li, Z.; Xu, Q.; Li, L.; Cai, Y.; Jiang, B.; Song, H.; Hu, X.; Wang, P.; Xiao, L. Advancing Fine-Grained Visual Understanding with Multi-Scale Alignment in Multi-Modal Models. CoRR 2024. [CrossRef]
- Qiu, H.; Li, H.; Wu, Q.; Meng, F.; Shi, H.; Zhao, T.; Ngan, K.N. Language-Aware Fine-Grained Object Representation for Referring Expression Comprehension. In Proceedings of the MM ’20: The 28th ACM International Conference on Multimedia, Virtual Event / Seattle, WA, USA, October 12-16, 2020. ACM, 2020, pp. 4171–4180. [CrossRef]
- Vedaldi, A.; Mahendran, S.; Tsogkas, S.; Maji, S.; Girshick, R.B.; Kannala, J.; Rahtu, E.; Kokkinos, I.; Blaschko, M.B.; Weiss, D.J.; et al. Understanding Objects in Detail with Fine-Grained Attributes. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, June 23-28, 2014. IEEE Computer Society, 2014, pp. 3622–3629. [CrossRef]
- Rajabi, N.; Kosecka, J. Towards Grounded Visual Spatial Reasoning in Multi-Modal Vision Language Models. CoRR 2023. [CrossRef]
- Wang, X.; Tian, T.; Zhu, J.; Scharenborg, O. Learning Fine-Grained Semantics in Spoken Language Using Visual Grounding. In Proceedings of the IEEE International Symposium on Circuits and Systems, ISCAS 2021, Daegu, South Korea, May 22-28, 2021. IEEE, 2021, pp. 1–5. [CrossRef]
- Yin, Y.; Han, Z.; Aarya, S.; Wang, J.; Xu, S.; Peng, J.; Wang, A.; Yuille, A.L.; Shu, T. PartInstruct: Part-level Instruction Following for Fine-grained Robot Manipulation. CoRR 2025. [CrossRef]
- She, K.; Zhang, M.; Zhao, Y.; Yang, B.; Liu, Q. From object to context: Scene knowledge enhanced visual grounding for geospatial understanding. International Journal of Applied Earth Observation and Geoinformation 2025.
- Wang, J.; Kang, Z.; Wang, H.; Jiang, H.; Li, J.; Wu, B.; Wang, Y.; Ran, J.; Liang, X.; Feng, C.; et al. VGR: Visual Grounded Reasoning. CoRR 2025. [CrossRef]

Table 1.
GQA VQA Accuracy (%) and RefCOCO+ Referring Expression Comprehension IoU (%).
| Method | GQA VQA Acc. (%) | RefCOCO+ IoU (%) |
|---|---|---|
| LLaVA-1.5 (13B) | 77.2 | 85.1 |
| InstructBLIP (13B) | 78.5 | 86.0 |
| mPLUG-Owl (7B) | 76.8 | 84.5 |
| Vision-GPT-SOTA | 79.1 | 86.3 |
| Grounding-Plus | 78.9 | 86.5 |
| Ours (LVLM-GR) | 79.8 | 87.2 |
Table 2.
Ablation Study on GQA VQA Accuracy (%) and RefCOCO+ IoU (%).
| Method Variant | GQA VQA Acc. (%) | RefCOCO+ IoU (%) |
|---|---|---|
| LVLM-GR (Full) | 79.8 | 87.2 |
| LVLM-GR w/o VCQ | 77.5 | 85.4 |
| – w/o Context-Aware Pooling | 78.8 | 86.4 |
| – w/o Semantic-Hierarchical Codebook | 78.3 | 86.1 |
| LVLM-GR w/o GRA | 77.9 | 85.8 |
Table 3.
Human Evaluation Results (Average Likert Score, 1-5).
| Method | Factual Correctness | Detail Level | Reasoning Depth |
|---|---|---|---|
| LLaVA-1.5 (13B) | 3.8 | 3.5 | 3.2 |
| InstructBLIP (13B) | 3.9 | 3.6 | 3.4 |
| Vision-GPT-SOTA | 4.1 | 3.8 | 3.7 |
| Ours (LVLM-GR) | 4.4 | 4.2 | 4.1 |
Table 4.
Impact of VCQ Codebook Size and Hierarchy on Performance.
| VCQ Configuration | Codebook Size (K) | GQA VQA Acc. (%) | RefCOCO+ IoU (%) |
|---|---|---|---|
| LVLM-GR (Optimal) | 1024 (4 levels) | 79.8 | 87.2 |
| VCQ (512 entries, 2 levels) | 512 | 78.1 | 85.6 |
| VCQ (512 entries, 4 levels) | 512 | 78.9 | 86.2 |
| VCQ (1024 entries, 2 levels) | 1024 | 79.2 | 86.7 |
| VCQ (2048 entries, 4 levels) | 2048 | 79.5 | 86.9 |
Table 5.
GQA VQA Accuracy (%) Across Different Reasoning Types.
| Method | Object | Attribute | Relation | Comparison | Logical | Global Acc. |
|---|---|---|---|---|---|---|
| LLaVA-1.5 (13B) | 82.1 | 75.8 | 70.3 | 68.5 | 73.1 | 77.2 |
| Ours (LVLM-GR) | 83.5 | 77.9 | 72.5 | 71.2 | 75.4 | 79.8 |
Table 6.
Efficiency Analysis of LVLM-GR Compared to Full Fine-tuning.
| Method | Trainable Para. (M) | Training Time/Epoch (h) | Inference (Images/s) |
|---|---|---|---|
| LLaVA-1.5 (13B) Full FT | ≈13,000 (Full Model) | 12.5 | 2.8 |
| LLaVA-1.5 (13B) w/o VCQ | ≈80 (Projection Only) | 3.1 | 3.5 |
| Ours (LVLM-GR) | ≈120 (VCQ+GRA LoRA) | 4.2 | 3.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



